Topology Assisted Clustering of Temporal fMRI Brain Networks With Use-Case in Mitigating Non-Neural Multi-Site Variability
AHMEDUR RAHMAN SHOVON, SIDHARTH KUMAR, GOPIKRISHNA DESHPANDE

TL;DR
This paper introduces a topological data analysis-based pipeline to improve the clustering of dynamic fMRI brain networks, reducing variability from non-neural factors and different scanning protocols.
Contribution
The novel contribution is a TDA-based temporal clustering pipeline that enhances robustness in dynamic fMRI analysis across varying sampling rates and multi-site data.
Findings
The TDA pipeline achieved 59% overlap in optimal cluster numbers across different sampling cohorts.
It showed 74–77% pairwise similarity between subjects' cluster solutions.
Validation on the ADHD-200 dataset showed >80% similarity in cluster assignments across sites and protocols.
Abstract
Using temporal analysis of fMRI (functional Magnetic Resonance Imaging) data, we can characterize dynamic changes in brain connectivity over time. However, dynamic temporal analysis of fMRI data is challenging due to the high dimensionality of the datasets. Another fundamental challenge of dynamic temporal analysis of fMRI is the presence of non-neural artifacts that add sources of variation in the data that are not directly related to brain activity. For example, when data are acquired at different scanners at different temporal sampling rates and later analyzed as a single dataset, we have to contend with different number of image snapshots for different subjects. Also, high-frequency scans lead to more fine-grained temporal snapshotting than low-frequency scans. These factors can obscure true neural signals and lead to inconsistent characterization of dynamic brain connectivity…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
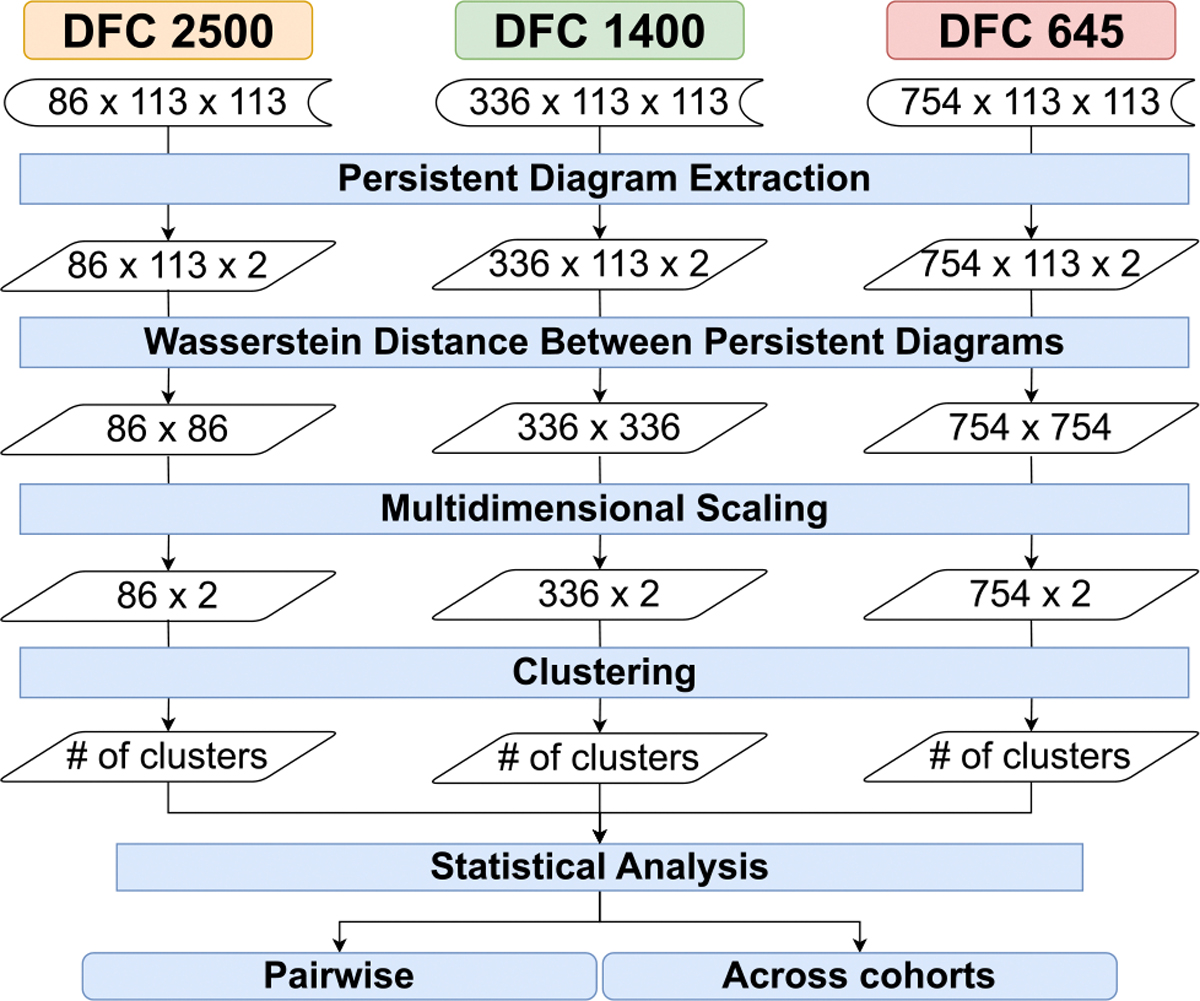 Figure 1
Figure 1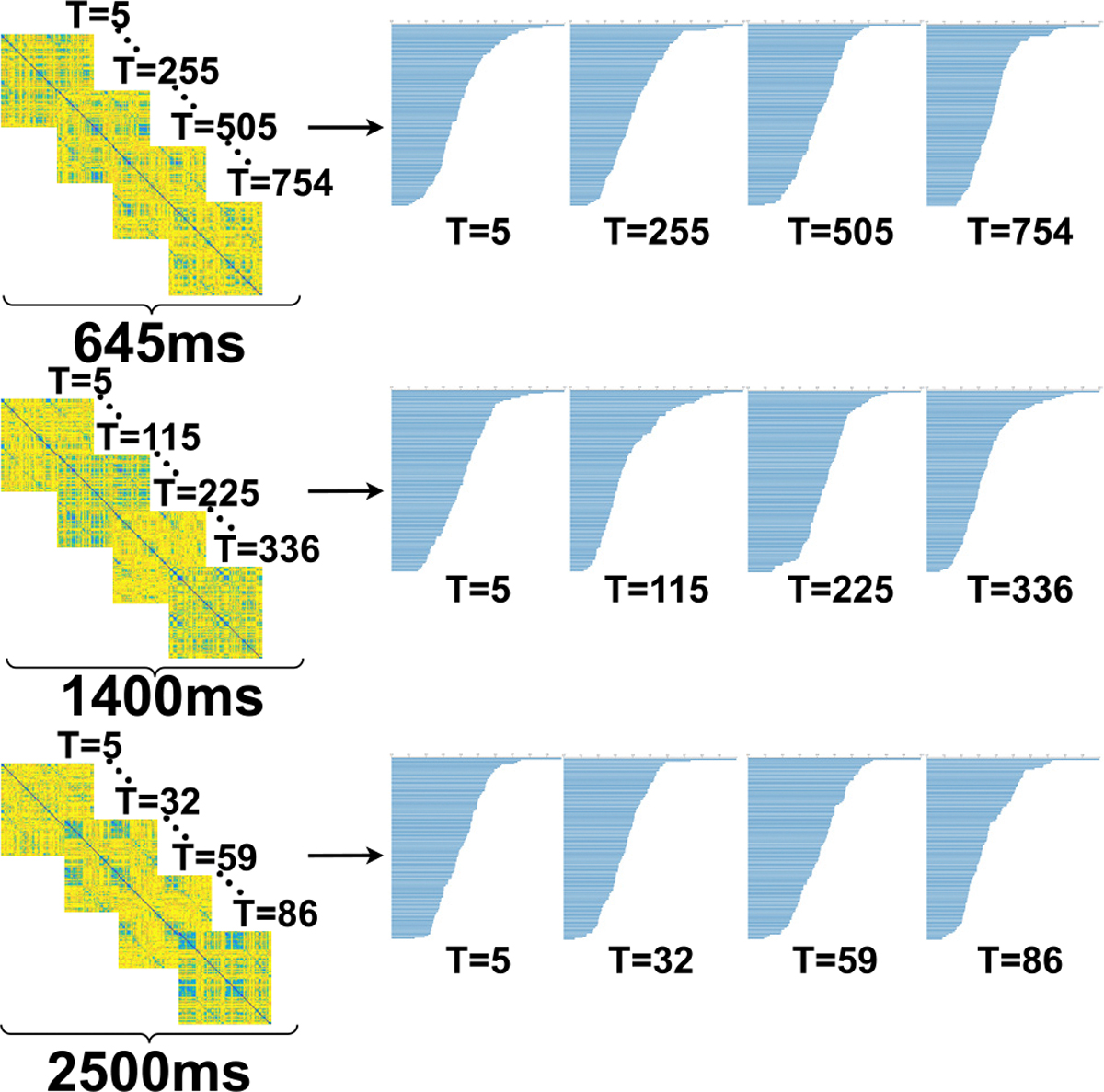 Figure 2
Figure 2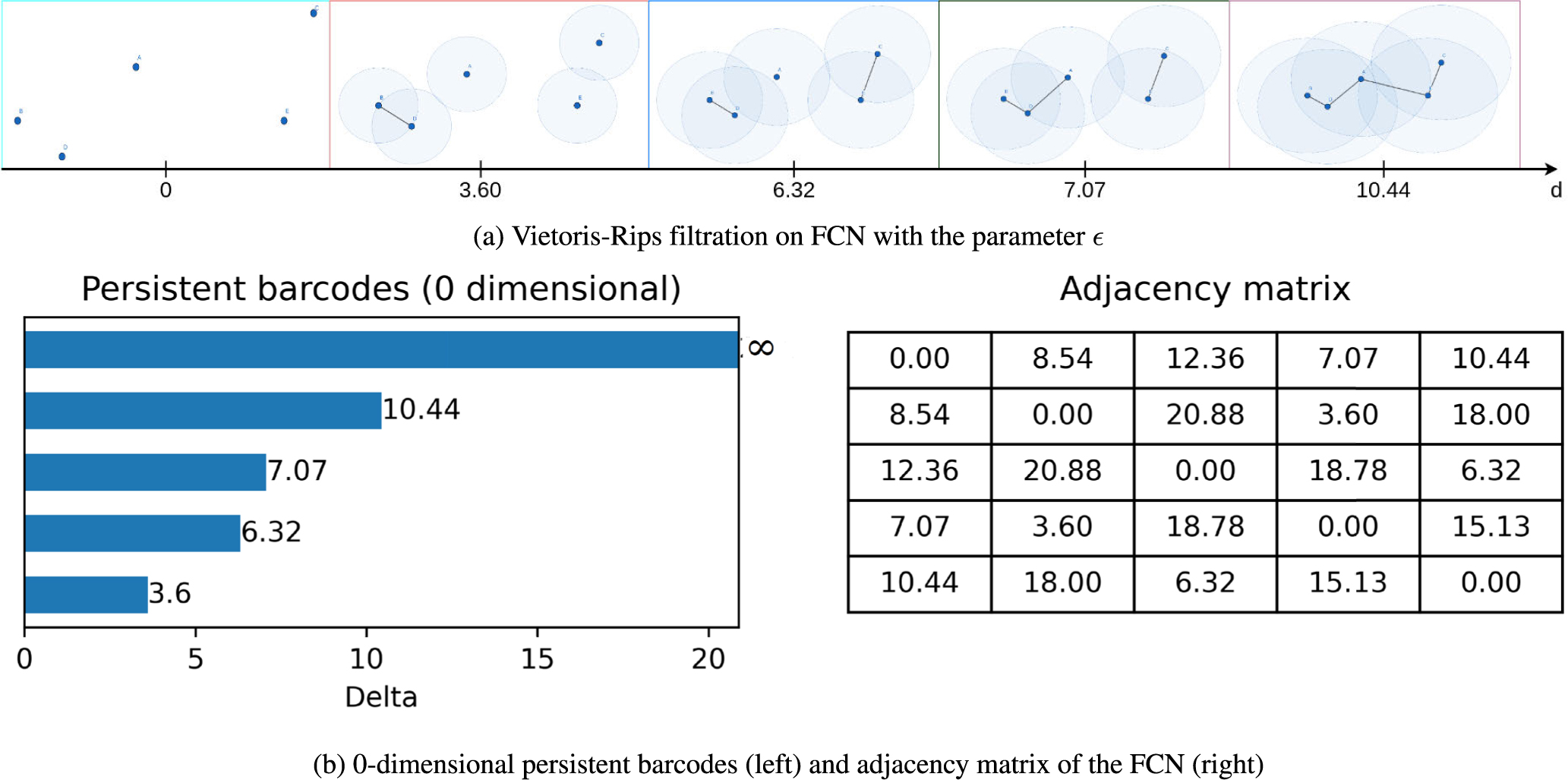 Figure 3
Figure 3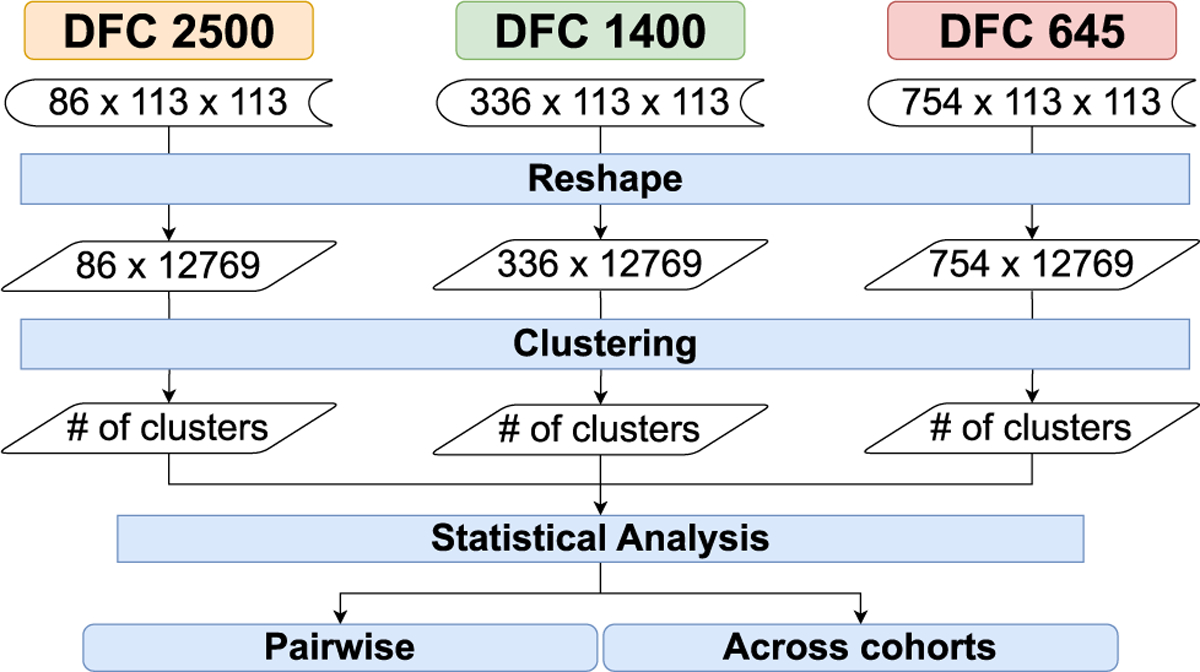 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6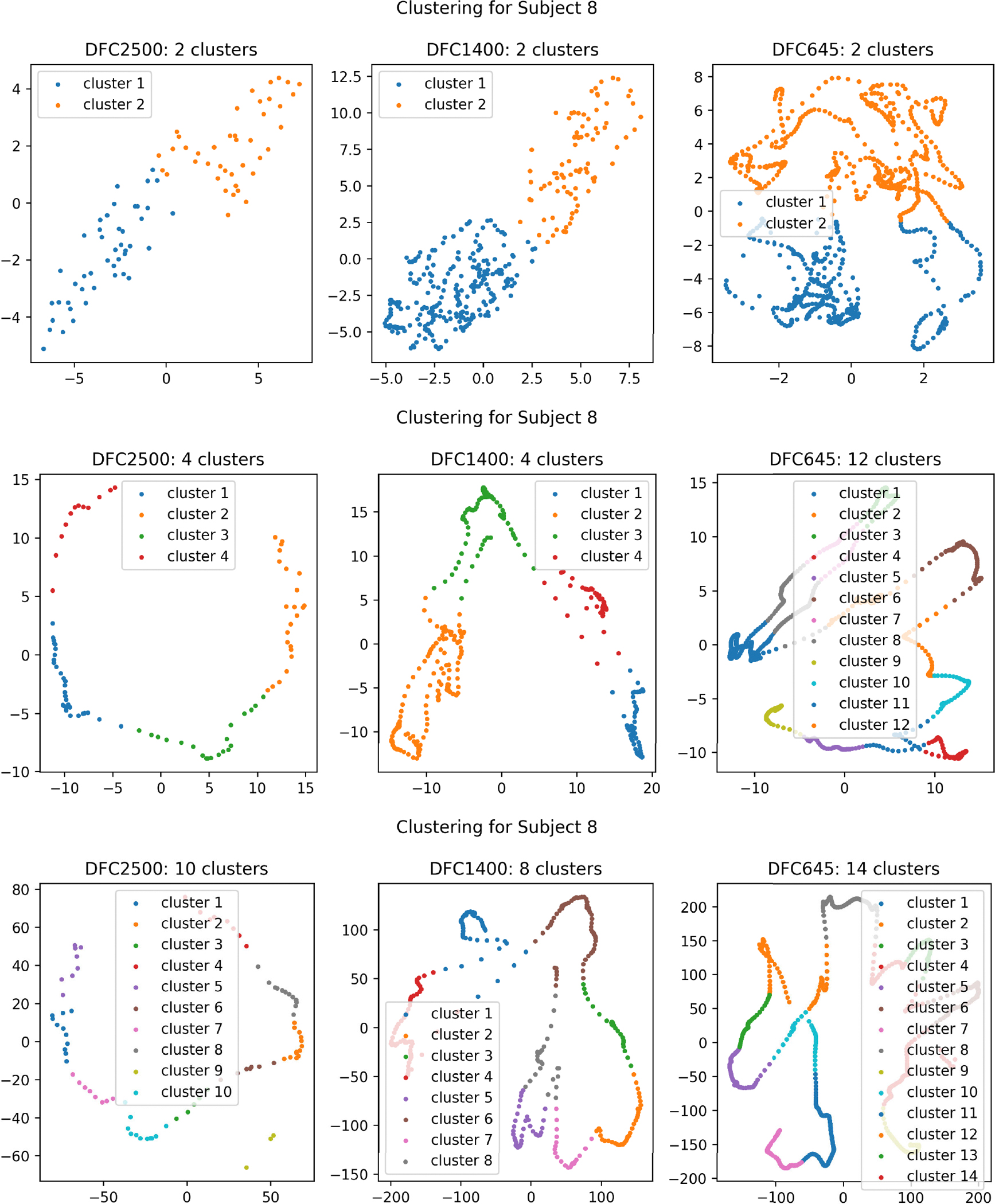 Figure 7
Figure 7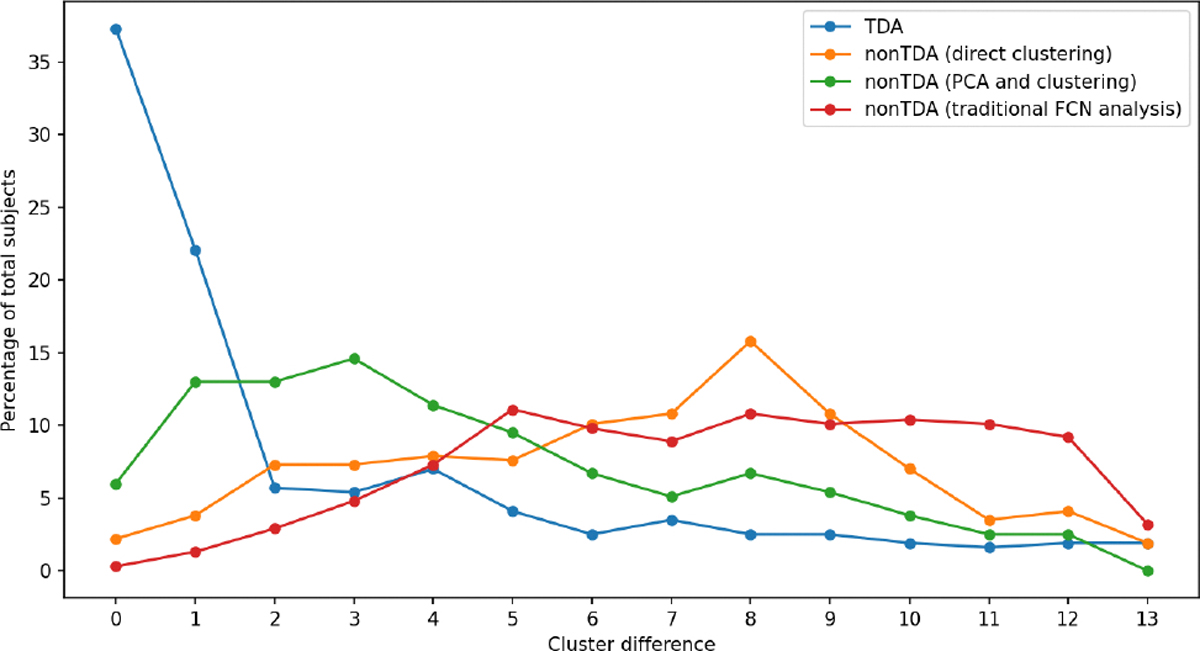 Figure 8
Figure 8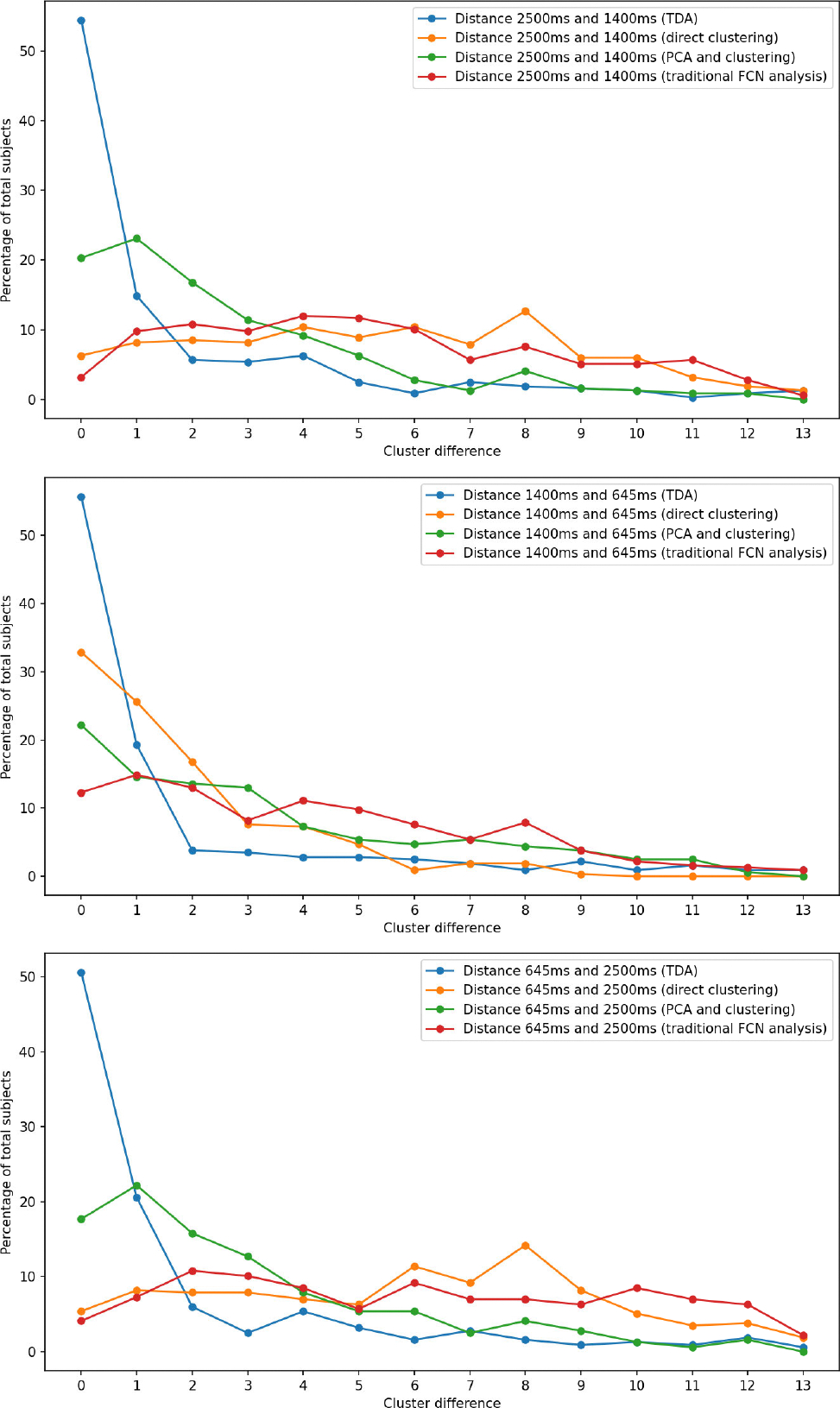 Figure 9
Figure 9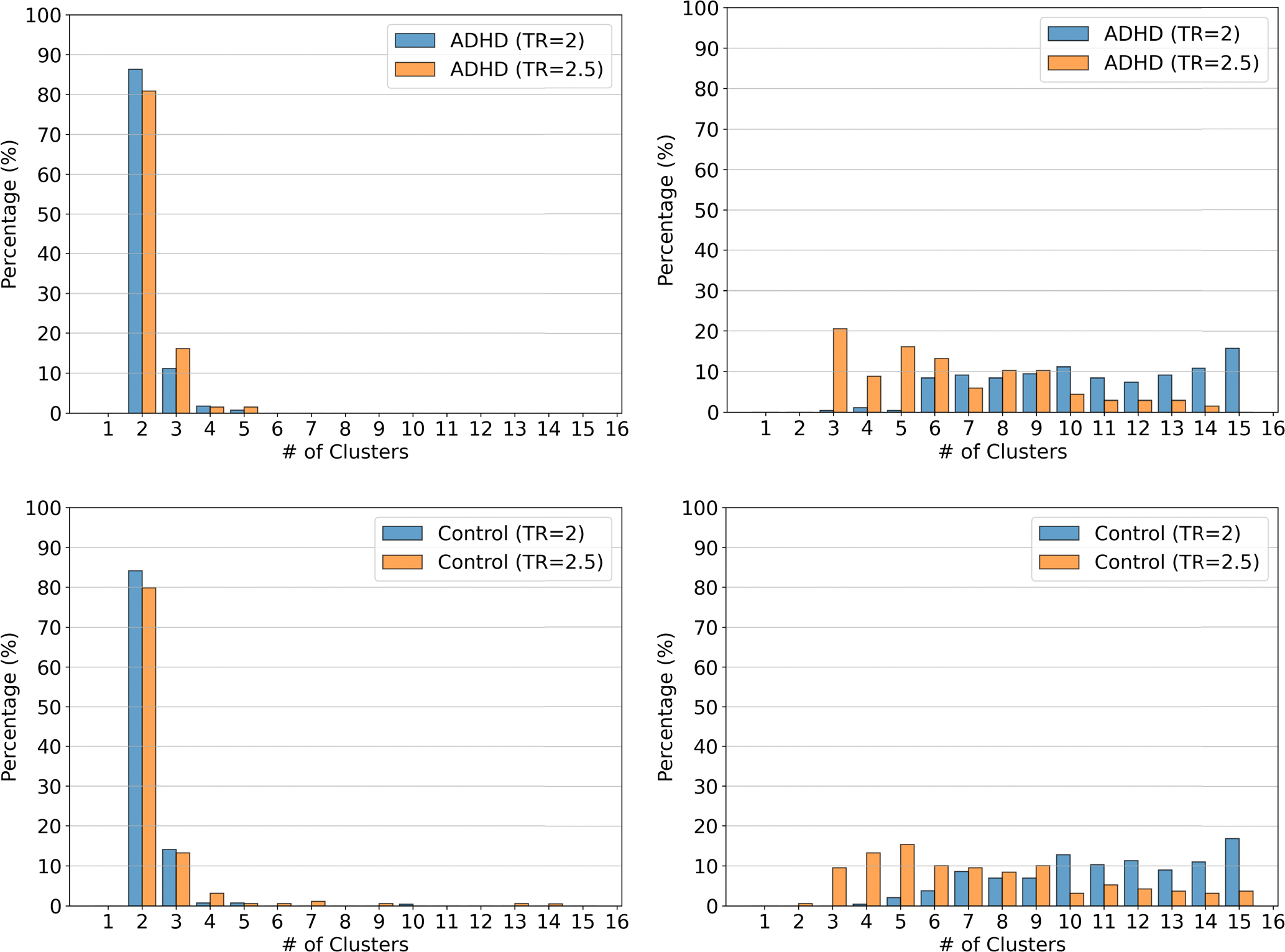 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTopological and Geometric Data Analysis · Functional Brain Connectivity Studies · Cell Image Analysis Techniques
INTRODUCTION
I.
Temporal fMRI (functional Magnetic Resonance Imaging) analysis [1], [2] is a technique used to study brain activity over time, with a focus on capturing changes in neural activity as they unfold during various cognitive tasks or in resting state conditions. Resting-state functional MRI (rs-fMRI), in particular, examines spontaneous fluctuations in brain activity that occur when a subject is at rest and not performing a specific task. This approach aims to identify intrinsic functional connectivity patterns within the brain, which can reveal networks and interactions that are present even in the absence of external stimuli. Temporal resting-state fMRI analysis is crucial for understanding how the brain processes information dynamically and how the interactions between different brain regions change with time, referred to as dynamic functional connectivity (DFC). It has been shown that DFC is very important for characterizing the healthy brain [3], [4], as well as in various brain disorders [5], [6], [7].
Temporal fMRI data typically has a temporal resolution on the order of hundreds of milliseconds to a couple of seconds, with each time point representing a snapshot of brain activity at a particular moment during the scan. DFC calculated from rs-fMRI data sampled at different rates tends to capture underlying dynamics evolving at different scales. Also, rs-fMRI data with higher sampling frequency tends to have more time points compared to that sampled at lower frequency for the same experimental duration. More time points tend to increase the robustness of DFC estimates. Given these factors, DFC calculated from rs-fMRI data sampled at different frequencies are not comparable. This is problematic since different groups tend to have different sampling rates owing to other factors, such as the capabilities of the MRI scanner as well as SNR available for a given field strength and field of view. Given the ever-increasing demands on sample size, pooling data acquired from multiple sites has become a priority, but that seems impractical as data across sites is not acquired using the same sampling frequency. Here, we seek to address this problem. Our reasoning is that a video captured at two different frame rates must convey the same content, even though they might not be of the same quality. Our quest is to devise a method that would capture the underlying content correctly, irrespective of how fast or slow the temporal dynamics are sampled. Obviously, DFC is not doing this job. Instead, we propose to use topological data analysis (TDA), which has been shown to characterize the structure underlying the data, which may be invariant to how the data is acquired [8].
Within the domain of functional brain imaging research, there is a growing trend towards the adoption of topological data analysis (TDA), an algebraic topology-based mathematical approach [9]. More recently, topological data analysis tools such as persistent homology (PH) have been utilized to study complex networks [10] including fMRI network dynamics [11], [12], [13], [14]. The persistence of topological features over a range of spatial scales provides insight into the robustness and stability of network architecture. Persistent homology generates topological barcodes that serve as a quantitative fingerprint for complex networks. Specifically, persistent homology tracks the emergence and disappearance of topological features such as connected components, loops, and higher-dimensional cavities across a range of thresholds applied to the network. Importantly, statistical distances between barcodes, such as the Wasserstein distance(WD) [15], [16], can be computed to quantitatively compare network topologies robustly. Thus, persistent homology barcodes provide a distinctive topological signature and metric for interrogating complex network architecture over the traditional graph-based tools [8]. Recent studies have further extended the use of TDA to unsupervised learning and clustering applications. For example, TDA-based clustering of functional brain networks has been successfully applied to Alzheimer’s disease cohorts, revealing significant associations between functional topology and brain morphometry using Wasserstein distance kernels [17]. In task-based fMRI, TDA pipelines have outperformed traditional vectorization methods in classifying condition-specific activity, highlighting their ability to capture individualized functional profiles [11]. More broadly, TDA-based classifiers have shown promising results across domains like trajectory classification and imbalanced multi-class datasets, underscoring the versatility and power of topological representations in complex data settings [18], [19]. We harness this capability to compare the similarities of temporal dynamics of brain networks extracted from different sampling periods. We develop a TDA-based statistical data processing pipeline targeted for temporal fMRI datasets that preserves the temporal dynamics of rs-fMRI datasets with the ability to mask out the non-neural variability induced by varying temporal sampling rates.
We evaluate the efficacy of our framework using three data cohorts, each of which corresponds to rs-fMRI data acquired for a subject at a different temporal sampling rate. The input to our pipeline comprises functional connectivity networks (FCNs) derived from rs-fMRI data acquired from 316 subjects, scanned at three temporal frequencies: , and . High temporal frequency ( ) corresponds to fine-grained snapshotting, yielding a total of 754 time-steps; medium temporal frequency ( ) scan yields 336 time-steps; and on the other end of the spectrum is low-frequency scans of , which yields 86 time-steps. The total number of adjacency matrices (FCNs) used in our study is therefore 371,616 (= 316 × 754 for for matrices for ). In essence, our statistical pipeline deals with a complex high-dimensional space, the three cohorts are each 4-dimensional spaces, of resolution 113 × 113 × timestep# × subjects#. 113 × 113 corresponds to the spatial resolution of each of the individual FCN (adjacency matrix), capturing the pairwise connectivity strengths among the 113 spatial regions of the brain. The timestep# is respectively 754, 336, and 86 for the three temporal frequencies , and, . subject# is 316. Demonstrating any notion of similarity across such a high-dimensional space is a challenging task, which is further exacerbated by the fact that the resolution across the three spaces varies (along the timestep# dimension). To solve this challenge, we rely on a well-established notion that the resting-state brain typically oscillates between a handful of discrete states. We develop a statistical pipeline that uses persistent homology from TDA to gradually reduce the high-dimensional temporal data to two dimensions – which is then reduced further to a one-dimensional scalar quantity that captures the total number of clusters. The novelty of this paper is twofold: (1) developing a statistical framework based on TDA techniques to effectively reduce the complex high dimensional space into simple 1D space (corresponding to the number of clusters), and (2) demonstrating that the number of temporal clusters of same subjects across the three temporal sampling rates is indeed the same, unlike existing methods.
To further evaluate the performance of our TDA pipeline, we developed three alternative statistical data analysis pipelines that utilize the same datasets. These pipelines represent different approaches to data processing and dimensionality reduction that have been used traditionally, allowing for a comprehensive comparison of our TDA pipeline against other established methods.
Direct time-series clustering pipeline: The first pipeline employs a direct clustering across time, where the original time-series data is reshaped into a suitable format for clustering algorithms. This direct approach bypasses the need for dimensionality reduction, retaining the full temporal dynamics of the data.PCA-Based dimensionality reduction and clustering pipeline: The second pipeline utilizes principal component analysis (PCA) to reduce the dimensionality of the time-series data before applying a clustering algorithm. PCA identifies the principal components, which are linear combinations of the original features that capture the maximum variance in the data. By retaining only the most significant principal components, PCA reduces the dimensionality while preserving the essential information for clustering.Traditional dynamic FCN analysis pipeline with MDS-based dimensionality reduction: The third pipeline adopts a traditional dynamic FCN (dFCN) analysis approach similar to our TDA pipeline with multidimensional scaling (MDS) for dimensionality reduction. This pipeline calculates the pairwise correlation coefficients between all 113 brain regions at every time point, resulting in a temporally varying correlation matrix. MDS is then applied to the correlation matrix to reduce its dimensionality while preserving the underlying connectivity patterns. This approach retains the inter-subject connectivity information, which differs from the aforementioned pipelines.
To determine the appropriate number of clusters for our TDA and the three nonTDA pipelines, we employ the k-means clustering algorithm in conjunction with the silhouette criterion. Since the number of clusters is insufficient to effectively capture the similarities between different temporal sampling periods, we conduct cluster distance comparisons both across the data cohorts ( , and ) and between individual data cohort pairs ( , and ). We further evaluate the efficacy of the TDA pipeline with a real clinical dataset. Detailed descriptions of these pipelines and statistical methods can be found in Section III and Section IV.
Our key contributions include:
Novel TDA pipeline for preserving temporal dynamics: We introduce a novel topological data analysis (TDA) pipeline specifically designed for processing resting state fMRI datasets that preserves the temporal dynamics of functional connectivity networks, enabling more accurate and robust analysis of brain connectivity patterns.Evaluate pipeline accuracy: We evaluate the performance of our TDA pipeline on a resting state fMRI dataset comprising 371,616 adjacency matrices from 316 subjects at three temporal frequencies. To ensure the efficacy of the TDA-based pipeline, we compare it with three alternative approaches: direct time-series clustering, PCA-based dimensionality reduction and clustering, and traditional fully connected network analysis pipeline with MDS-based dimensionality reduction technique.Robustness to non-neural variability: Additionally, we investigate the robustness of the TDA pipeline to variations in data acquisition parameters, specifically examining the impact of temporal sampling rates mitigating the influence of non-neural variability on temporal fMRI datasets.Validation on multi-site ADHD dataset: We further validate our method on the ADHD-200 dataset to test generalizability in a multi-site setting with heterogeneous scanning protocols. The TDA pipeline achieves higher inter-site consistency in cluster structure and better subject-level reproducibility, confirming its applicability to broader clinical and developmental neuroscience settings.Open-source implementation for reproducibility: We open-source the source code, documentation, and data for all components of our work on GitHub (https://github.com/harp-lab/TemporalBrainPH/), ensuring reproducibility and accessibility.
The remainder of this paper proceeds as follows. First, Section II provides background on related work and the progression of topology-based functional connectivity network analysis. Next, Section III introduces our proposed end-to-end topological data analysis pipeline for temporal brain rs-fMRI data, and Section IV describes the nonTDA-based data processing pipelines for comparison. Section V then presents an evaluation of our TDA pipeline by applying it to analyze temporal dynamics in resting-state fMRI datasets. Finally, Section VI offers a discussion of the results and implications, and Section VII concludes with a summary of our contributions and directions for future work.
RELATED WORK
II.
The application of topological data analysis (TDA) in network analysis extends beyond conventional graph theory, harnessing computational topology tools to characterize network or data structure architectures with greater adaptability [20]. TDA-driven technique has also demonstrated encouraging outcomes in modeling transitions among brain states within fMRI datasets [21]. Persistent homology, as an advanced tool of TDA, is being applied to analyze the topological features of data, providing a powerful framework for studying the evolution and persistence of structural patterns across various scales [22], [23], [24], [25]. The use of persistent homology to analyze functional connectivity networks (FCNs) from resting state fMRI data is on the rise [12], [13], [14], [26]. Persistent homology can quantify structural changes in time-varying graphs, providing both topological summaries and visualizations to identify temporal patterns and anomalies [27]. Recently, we demonstrated that FCN metrics are statistically similar across varied sampling periods [8] only for TDA and not for traditional pipelines. This suggests persistent homology provides a robust topological representation of FCNs invariant to acquisition parameters, potentially removing noise in multi-site studies and improving group comparison effect sizes. Multi-site fMRI studies, despite their advantages in increasing sample size and generalizability [28], [29], introduce variability across scanners and protocols that can undermine statistical power and validity. Differences in acquisition parameters and processing methods across sites can lead to non-biological variability in functional connectivity metrics, posing challenges in large-scale fMRI research [30]. Furthermore, multi-site designs can potentially impact the measurement of temporal dynamics in fMRI studies.
The study of temporal variability in rs-fMRI data has gained significant attention in recent years, as it provides valuable insights into the dynamic nature of functional brain networks and their relevance to human cognition [31]. Growing evidence suggests that functional brain networks exhibit temporal variability, reflecting the dynamic interplay between different cognitive states, arousal levels, and external stimuli [32]. One of the widely used techniques for characterizing temporal variability in rs-fMRI data is the sliding-window correlation analysis. This approach involves dividing the time series into overlapping temporal windows and estimating FCNs for each window [32], [33]. By tracking the changes in functional connectivity patterns across these windows, the dynamic nature of brain networks can be captured, and their evolution over time can be investigated. However, this method relies on predefined window lengths and may not fully capture the inherent temporal dynamics of the data. To address these challenges, existing techniques for analyzing FCNs derived from rs-fMRI have largely relied on graph theory to compute metrics like clustering coefficient and node degree [34], [35]. These measures summarize individual weighted networks and enable comparisons between FCNs, either at the level of nodes/links or using whole-network summaries. However, graph-based methods have significant limitations. First, common graph metrics depend heavily on the parcellation scheme used to define network nodes [36]. Second, graph analysis requires binarizing network links based on an arbitrary threshold, discarding valuable weighting information [37]. While weighted graph analysis has been proposed, such measures still vary with network density [10]. Multi-threshold analysis can mitigate this issue but remains constrained by density effects [38].
Principal component analysis (PCA) is another a useful technique for reducing the high dimensionality of rs-fMRI datasets before applying clustering [39]. By transforming the data into a lower dimensional space of uncorrelated principal components, PCA enables more efficient and robust clustering of large-scale rs-fMRI data [40]. Studies have shown PCA preprocessing can remove noise and highlight the most informative spatial and temporal features in rs-fMRI for improved clustering performance [41], [42] compared to direct clustering approaches [43]. Another approach to characterizing temporal variability is through temporal independent component analysis (ICA) [44]. Temporal ICA aims to identify temporally distinct functional modes or networks from the rs-fMRI data, revealing the underlying temporal structure and dynamics of brain activity. The applicability of temporal principal component analysis (PCA) as a preprocessing step for sliding-window spatial independent component analysis (sICA) of rs-fMRI data is evaluated by analyzing the consistency of PCA-retained subspaces across overlapping time windows [45]. While PCA-based dimensionality reduction has proven useful for rs-fMRI clustering, it is limited to capturing linear relationships and may miss critical topological features in complex functional connectivity networks. Advanced network science techniques are needed to overcome these limitations and characterize topology more comprehensively in a manner invariant to connectivity density or regional parcellation. For example, topological data analysis (TDA) provides a powerful framework for analyzing weighted networks across scales using methods like persistent homology. TDA yields topological summaries that are stable to network density variation. Further, TDA can be applied in a resolution-invariant manner using expansive parcellations. By moving beyond graph theory, TDA-based network analysis can uncover robust and informative topological signatures while avoiding common density and parcellation dependencies. More recently, TDA techniques, such as Mapper and persistent homology, have been introduced as promising tools for studying the temporal variability of rs-fMRI data. Mapper offers a low-dimensional representation of the high-dimensional rs-fMRI data while preserving its topological features [21]. This technique can be particularly useful for visualizing and exploring the temporal variability and overall structure of functional connectivity patterns. Persistent homology, on the other hand, captures the evolution and persistence of topological features (e.g., connected components, loops, voids) across different scales or time points, providing a quantitative measure of the stability and dynamics of functional brain networks [8]. Recently, Chung et al. demonstrated the use of a TDA technique that estimates the state spaces of dynamically changing functional brain networks during resting state by clustering based on the Wasserstein distance metric [46] and proposed a dynamic-TDA framework to distinguish topological patterns of gender-specific brain networks [47]. Furthermore, TDA is well-suited for characterizing changes in network topology over time, providing new avenues for investigating temporal dynamics in fMRI connectivity [48], [49].
TOPOLOGICAL DATA ANALYSIS BASED TEMPORAL CLUSTERING PIPELINE
III.
In this section, we present our end-to-end topological data analysis-based clustering pipeline targeted for temporal resting state fMRI datasets that preserve the temporal dynamics of the high dimensional brain networks. This pipeline masks out non-neural variability in temporal fMRI datasets and demonstrates similarity across temporal cohorts acquired at different sampling frequencies. Our TDA pipeline integrally relies on persistent homology, which, unlike traditional graph analytic approaches, permits analyzing a range of thresholds to gather connectivity information from FCNs.
Our processing pipeline aims to exploit the commonly known fact that the resting-state brain typically oscillates between a handful of discrete states [50], [51]. This implies that it is potentially possible to group the temporal timesteps into a discrete number of states. This inherently is a data clustering problem. Therefore, at the heart of our data processing pipeline, we have data clustering across time, which is applied to topological features extracted from the rs-fMRI datasets. A schematic representation of our data processing pipeline can be seen in figure 1. Here we can see the inputs are the three temporal cohorts acquired from sampling 316 subjects at three temporal frequencies ( , and ).
MATHEMATICAL FOUNDATIONS AND APPLICATION OF PERSISTENT HOMOLOGY TO RESTING-STATE FMRI
A.
Persistent homology (PH) is an algebraic topology method from Topological Data Analysis (TDA) domain used to study qualitative features of data across multiple scales. It operates on the principle of building simplicial complexes, which are geometric constructs consisting of vertices, edges, triangles, and their higher-dimensional counterparts. These complexes evolve over a range of parameters, providing insights into the topology of the underlying dataset.
Formally, for a given set of points (point cloud) , persistent homology tracks the birth and death of topological features as a parameter varies. At each threshold , a Vietoris-Rips complex is constructed by connecting points if the distance between them is less than or equal to . As grows, simplices (vertices, edges, triangles) appear and merge, reflecting changes in topology. Persistent homology captures these changes as persistent barcodes or persistence diagrams, encoding the lifespan (birth to death intervals) of topological features.
In the context of rs-fMRI, PH provides a robust methodology to analyze FCNs, which represent interactions between brain regions as correlation-based adjacency matrices. Direct analysis of these networks can be challenging due to high dimensionality and inherent noise. Persistent homology addresses these challenges by interpreting each brain region as a vertex, forming Vietoris-Rips complexes based on distances derived from correlations. By varying the threshold , persistent homology captures and quantifies the emergence and merging of connected components, offering robust summaries of complex temporal dynamics.
Our pipeline specifically employs 0-dimensional persistent homology to characterize the evolution of connected components within dynamic FCNs. This approach facilitates robust and interpretable topological signatures suitable for temporal clustering analyses across diverse data acquisition parameters and sampling frequencies.
Our end-to-end TDA pipeline has the following steps:
Generate FCNs from rs-fMRI data: We applied dynamic-windowed Pearson correlation on the fMRI dataset (as used by us before in Jia et al [4]) to generate the dFCNs from data acquired with different acquisition parameters ( , and .) as a data pre-processing step (Section III-B). This provides an FCN at each time point.Create distance matrix from FCNs: The extracted FCNs at each time point are then converted into distance matrices as a weighted graph (Section III-C).Extract persistent barcodes from distance matrix: In this step, we extract persistent diagrams (0-dimensional barcodes) from the distance matrices using persistent homology to identify the topological features from the matrices (Section III-D).Temporal clustering on PD to prove the resiliency of different data acquisition parameters: Finally, we apply temporal clustering on the extracted barcodes to see the similarity between the topological features extracted using different data acquisition parameters (HYPERLINK Section III-E).
FCN GENERATION FROM RS-FMRI DATA
B.
We sourced the structural T1-weighted and rs-fMRI data from the freely accessible Enhanced Nathan Kline Institute Rockland Sample database (NKI-RS) [52]. The MRI data was collected using a 3T Siemens Magnetom Tim Trio scanner. The acquisition parameters for the T1-weighted structural data included: isotropic voxels of 1.0 mm with 176 slices, a repetition time (TR) of 1900 ms, an echo time (TE) of 2.52 ms, and a field of view (FOV) of 250 × 250. Resting state fMRI data was gathered using multiband echo-planar imaging (EPI) [53] from each participant using three distinct acquisition protocols with varying parameters. The first protocol used 3.0 mm isotropic voxels with 40 slices, a TR of 645 ms, a TE of 30 ms, a FOV of 222 × 222 mm, 900 volumes, and a multi-band factor of 4. The second protocol used 2.0 mm isotropic voxels with 64 slices, a TR of 1400 ms, a TE of 30 ms, a FOV of 224 × 224 mm, 404 volumes, and a multi-band factor of 4. The third protocol used 2.0 mm isotropic voxels with 38 slices, a TR of 2500 ms, a TE of 30 ms, a FOV of 216 × 216 mm, 120 volumes, and a multi-band factor of 1. Even though the three datasets from each participant are identified with the corresponding TR, they differ in several other scan parameters, such as the number of volumes, multi-band factor, FOV, and voxel size. The MRI data underwent a standard pre-processing pipeline, which included the removal of the first five volumes, slice time correction, and motion correction. T1-weighted anatomical images were aligned to the mean functional images, which were then spatially registered to a standard MNI152 template. Nuisance variables such as low-frequency drifts, and motion parameters were regressed out. Unwanted physiological fluctuations (signals from white matter and cerebrospinal fluid) were eliminated using aCOMPCor (anatomical component-based noise correction). After excluding subjects that did not pass quality control, we identified 316 subjects with usable data from all three acquisition protocols. We then obtained mean time series from 113 brain regions (using the Yeo parcellation template [54]) for each subject and acquisition protocol. Using Pearson’s correlation, we estimated FCN matrices from these mean time series.
At this stage, we generate one FCN for each timepoint using dynamic-windowed Pearson’s correlation as in our previous work [4]. Briefly, this method uses sliding temporal windows to calculate Pearson’s correlation to be assigned to each time point. The width of the temporal window is dynamically determined by the stationarity of the statistical properties of the time series within the window, determined by the Augmented Dickey-Fuller test. Each FCN is stored as a symmetric adjacency matrix with size 113 × 113, where represents the correlation coefficient between brain nodes and . The dataset consists of three temporal frequencies ( , , and ). There are 316 subjects for each temporal frequency. High temporal frequency ( ) yields a total of 754 time-steps; medium temporal frequency ( ) scan yields 336 time-steps; and on the other end of the spectrum is low-frequency scans of yields 86 time-steps. The total number of adjacency matrices is 371,616(316 × 754) + (316 × 336) + (316 × 86) with a dimension of 113 × 113. Figure 2 (left column) shows an example of the extracted FCNs for subject 32, for the three sampling periods at different time points.
CREATION OF MATRICES FROM FCNS
C.
Usually, topological data analysis uses point cloud data in metric configuration. We confine the weighted networks from fMRI data in distance matrices in our TDA pipeline before applying TDA techniques. Then, we extract persistent barcodes from the distance matrices.
We use popular Pearson’s correlation coefficients to measure the linear correlation between any two data points (nodes) and at time in the fMRI data [55]. However, correlation coefficients do not directly represent distances, which are often required for clustering algorithms or other analyses. Therefore, we transform the correlation coefficients into a distance metric using the following formula:
This transformation ensures that higher positive correlations (closer to 1) are mapped to smaller distances (closer to 0), while lower correlations (closer to 0) or negative correlations are mapped to larger distances. The temporal indexing indicates this is a temporally dynamic dataset, and the correlations and distances are calculated between node pairs at each time point.
EXTRACTION OF PERSISTENT BARCODES FROM DISTANCE MATRICES
D.
Unlike traditional graph analytic approaches, persistent homology permits analyzing a range of thresholds to gather connectivity information from a given FCN. Figure 3 shows an example of using persistent homology to record the changes of topological features over the changes of distances using zero-dimensional barcodes. Vietoris-Rips filtration on the given 5 × 5 FCN is applied to capture the changes in the number of connected components for different parameters of . Using persistent homology, we capture topological features from the distance matrices extracted from the fMRI FCNs. This section overviews topological feature extraction using persistent barcodes and the distance metric we have used. The existing literature contains the details on these topics [24], [56].
EXTRACTION OF TOPOLOGICAL FEATURES USING PERSISTENT HOMOLOGY
Persistent homology can extract topological features from a topological space. The homology of the space can be divided into groups based on the dimensions of the features. A topological space can be divided into homology groups for where represents the homology group. Each homology group denotes the number of n-dimensional holes in the topological space . For example, the homology group shows the number of connected components, homology group shows the number of holes, homology group shows the number of voids in the topological space .
In this paper, we use homology group (0-dimensional) to extract the number of connected components from the rs-fMRI FCNs (at each time point) as topological features. Figure 3 shows a simple example of using persistent homology to extract the topological features from a given FCN. The table at the bottom right in Figure 3(b) represents the adjacency matrix of an FCN with five nodes. Persistent homology captures the changes in topological features over distance thresholds between the nodes. In a point cloud, with nodes, two nodes are marked as connected with an edge if the distance is less than threshold . In this scenario, they form a 1-Simplex. When three nodes are connected with each other for some value of , they form 2-Simplex and so on. For a given , the graph is called a Rips complex represented by . These continuous changes in the value of result in the changes in topological features. Vietoris-Rips filtration captures the increasing value of for which a new Rips-complex, in other words, a new topological feature, is being generated [57]. Figure 3(a) shows the extraction of different topological features in various thresholds of using Vietoris-Rips filtration.
In this example, for each real number where topological features are changed, we consider them important events and store these values of . Here, represents the filtration value used in the persistent homology analysis, which is derived from the adjacency matrix (bottom right table of Figure 3) representing the FCN. As the filtration value increases, topological features (such as connected components) can appear, merge, or disappear in the simplicial complex constructed from the data. For instance, at some time , a topological feature, a component is being created, and at time , it is merged with another component. We keep track of the as and as for each component. The time of the ( of the topological features is visualized as barcodes. The span of time for each feature is called the persistence of that feature. Figure 3(b)(left) shows the barcodes for the given FCN. At , five topological features are born as five independent (connected) components. At , two components are merged; thus, the death of a component is recorded at . Therefore, the persistence of that component is 3.6. Similarly, at , another component is merged with a persistence of 6.32. For 0-dimensional persistence barcodes, this process continues until there is only one connected component. This last component never dies; thus, the persistence of this component is . The 0-dimensional persistence barcodes in Figure 3(b)(left) represent the birth and death of the topological features, which is the changes in the number of connected components of the FCN. Each horizontal bar begins at the birth of a component and ends at the death of each component in the barcodes representation. While higher-order features such as 1-dimensional homology (loops) can in principle be extracted, we restrict our analysis to for two reasons: (i) computational tractability on large, time-varying FCNs, and (ii) prior evidence that connected components provide stable and interpretable topological features for functional brain networks.
FORMATION OF PERSISTENT DIAGRAMS AS SIGNATURES FOR THE FCNS
The 0-dimensional barcodes extracted from the functional connectivity networks (FCNs) represent the evolution of connected components over distance thresholds. In our pipeline, we generate 0-dimensional persistent barcodes for each FCN. Each FCN has 113 vertices that form the finite set of points where the value represents the pairwise distance between the points. We extract 0-dimensional barcodes using persistent homology for all the 371,616 FCNs ((316 × 86) + (316 × 336) + (316 × 754)). Figure 2 displays illustrations of the extracted barcodes at various time points across three different temporal sampling periods ( , and ) for a single subject (subject 32). After this stage, we get timestep# × 113 × 2 as 0-dimensional barcodes for each of the sampling periods.
A persistent barcode can be represented with a persistent diagram without information loss where the birth and death of a component (a topological feature) are represented as a point on the X-axis and Y-axis, respectively. These points on a two-dimensional surface as a persistent diagram can be used for statistical inference to prove that persistent homology is resilient to different data acquisition parameters. By forming the persistent diagrams from the 0-dimensional barcodes of each FCN, we obtain topological signatures that quantify the evolution of connected components over distance thresholds in the functional brain networks. The distance between points in the persistent diagram provides a stability measure, allowing us to compare topological signatures across subjects. Thus, these signatures are used as features for statistical analysis in our experiments.
TEMPORAL CLUSTERING ANALYSIS
E.
The literature shows the usability of earth moving distance, also known as Wasserstein distance (WD), for statistical inference of persistent diagrams [15], [16]. We use WD as a metric to compute the distance between two persistence diagrams extracted from two FCNs. WD represents the minimum value that is computed in the match calculation between the points of two persistent diagrams. The WD value of two similar persistent diagrams is smaller than two dissimilar persistent diagrams. This WD metric assists in proving the hypothesis of similarity between the persistent diagrams extracted from different data acquisition parameters, such as sampling rates.
The temporal clustering analysis is to evaluate our hypothesis of the similarity of the fMRI FCNs obtained from different data acquisition parameters, such as different temporal sampling rates (TR). Our dataset includes three data cohorts: , and . High temporal frequency ( ) has a total of 754 time-steps; medium temporal frequency ( ) scan yields 336 time-steps; and low temporal frequency yields 86 time-steps for each of the subjects. Figure 1 represents the TDA pipeline we develop for the TDA framework. We calculate pairwise WD between the persistent diagrams of the timesteps for all subjects within the same data cohort.
Let,
where
where
The TDA distance matrix for a given subject in cohort is defined as:
In Eq. 1, we compute the pairwise Wasserstein distance between persistence diagrams at times and , which gives a distance matrix for each subject . We have three data cohorts ( , and ) with different timesteps (754, 336, 86). Thus, we get 316 adjacency matrices for each data cohort with size (754 × 754), (336 × 336), and (86 × 86), respectively.
These high-dimensional adjacency matrices are complex and cannot be analyzed by statistical methods. To make it interpretable by the statistical methods and for better visualization, we apply the multidimensional scaling (MDS) technique to reduce the dimensionality of the matrices. After this stage, we get 316 adjacency matrices for each data cohort with sizes (754 × 2), (336 × 2), and (86 × 2).The two-dimensional MDS results are plotted using scatter plots that give an intuition to use clustering to calculate the similarity between the TRs. We apply the k-means clustering technique to the MDS results to get the number of clusters for the reduced-sized matrices. As k-means clustering requires configuring the number of clusters before the cluster computation, we choose using a well-known approach called Silhouette analysis. Using Silhouette analysis, we choose that gives the maximum Silhouette score for the given adjacency matrices between the range from 2 to 16 [58], [59]. After calculating the number of clusters for all three data cohorts, we get the number of clusters for all 316 subjects across these data cohorts. A similar number of clusters for the same subject across three data cohorts will indicate the similarity between the subjects for different data acquisition parameters (different TRs in our case). If we get significant similarity between the TRs, we can conclude the resiliency of persistent homology for dynamic functional connectivity derived from rs-fMRI with different data acquisition parameters.
We use Matlab during the data preprocessing steps and Python for statistical analysis. For the topological data analysis framework, we use Gudhi library [60], [61] to compute the 0-dimensional barcodes from FCNs and to calculate WD distances between the persistent diagrams. We also use scikit-learn library for multidimensional scaling and cluster calculation [58].
NONTDA-BASED DATA PROCESSING PIPELINES FOR RS-FMRI DATASET
IV.
To assess the effectiveness of our TDA pipeline presented in Section III, we implement three alternative nonTDA-based data processing pipelines for comparative analysis. Section IV-A provides a detailed walkthrough of a direct time-series clustering pipeline. In Section IV-B, we show a pipeline that employs Principal Component Analysis (PCA) for dimensionality reduction and clustering. Section IV-C outlines a traditional functional connectivity network (FCN) analysis pipeline tailored for brain network datasets. As the datasets are in mat format, for data preprocessing, we utilize Matlab to process the raw fMRI time series, handle missing values, and construct functional connectivity networks. Python is used for all subsequent analyses, including dimensionality reduction, clustering, and statistical testing. We use scikit-learn library for principal component analysis, multidimensional scaling, and k-means clustering [58].
DIRECT TIME-SERIES CLUSTERING PIPELINE
A.
Our first baseline pipeline is the nonTDA-based direct clustering pipeline. It implements a direct clustering approach on the temporal rs-fMRI datasets without any dimensionality reduction or graph construction steps. As shown in Figure 4 the input of this pipeline is the timestep# × 113 × 113× where 113×113 corresponds to the spatial resolution of each of the individual FCN capturing the pairwise connectivity strengths among the 113 spatial regions of the brain. The timestep# is respectively 86, 336, and 754 for the three temporal frequencies , and, respectively.
Directly clustering multivariate FCNs poses challenges due to the high dimensionality of the data. To mitigate this, we flatten the 113 × 113 matrices into one-dimensional arrays of length 12, 769, resulting in timestep# × 12, 769 sized matrices for each of the subjects for each data cohort prior to clustering. This reshaping transforms the data into a format amenable to traditional clustering algorithms. Similar to the TDA pipeline, we then apply the k-means clustering technique to reshaped matrices. We utilize the silhouette analysis method to determine the optimal number of clusters, denoted as , within the range of 2 to 16, ensuring the selection of the cluster configuration with the highest silhouette score.
After calculating the number of clusters for all three data cohorts, we get the number of clusters for all 316 subjects across these data cohorts. The subsequent step defines the statistical analysis phase, where we perform pairwise and cohort-wide set overlaps of the number of clusters. Similar to the TDA pipeline, the key hypothesis is that robust clustering solutions should exhibit consistency across subjects and sampling rates. To evaluate this, we statistically compare the identified cluster numbers across cohorts using pairwise and group-wise similarity scores. Higher overlaps in the optimal cluster numbers between the three temporal sampling periods and higher pairwise set overlaps will indicate higher similarity scores, thereby affirming the robustness of the direct clustering approach to variability in sampling rates.
PCA-BASED DIMENSIONALITY REDUCTION AND CLUSTERING PIPELINE
B.
After establishing the baseline with the direct clustering approach, we introduce a principal component analysis (PCA)-based dimensionality reduction and clustering pipeline to address the high dimensionality challenges in the temporal FCN datasets. Figure 5 displays PCA-based dimensionality reduction and clustering pipeline. This pipeline incorporates a three-step process involving PCA for dimensionality reduction, k-means clustering, followed by statistical analysis.
Like the prior pipelines, this pipelines takes as input matrices of size timestep# × 113 × 113. where the timestep# values are 86, 336, and 754 for the temporal frequencies , and, , respectively. We flatten the 113 × 113 functional connectivity matrices into one-dimensional arrays of length 12, 769 to reorganize our data into a 2D matrix suitable for PCA, where each row represents a timestep and each column represents an element of the flattened connectivity matrix. After flattening, the input to PCA would indeed be a 2D matrix with dimensions: for , for , and for This reshaping transforms the higher-dimensional tensor data into a 2D matrix format required by PCA to identify the top principal components capturing the most variance in the connectivity patterns across time. Applying PCA on the flattened 12, 769 dimensional data then allows us to reduce the high dimensionality down to the most informative 2 principal components before clustering. In this stage, we apply PCA to reduce the dimensionality of the flattened timestep# × 12, 769 matrices. Specifically, we use PCA to project the data onto a lower-dimensional subspace while retaining as much variance as possible. For each temporal frequency ( ), we reduce the dimensions from 86 × 12769 to 86 × 2 for , 336 × 12769 to 336 × 2 for , and 754 × 12769 to 754 × 2 for . The resulting PCA-transformed matrices, now of size timestep# × 2, capture the most salient features of the original data. This dimensionality reduction facilitates subsequent clustering by focusing on the most informative components while significantly reducing computational complexity.
Following the PCA-based dimensionality reduction, we apply k-means clustering to identify patterns and group subjects based on the reduced feature space. Similar to the direct clustering approach, we leverage silhouette analysis to determine the optimal number of clusters ( ) within the range of 2 to 16 for each temporal frequency that maximizes clustering quality. The resulting cluster assignments provide a compact representation of the original data while capturing meaningful variations across subjects and temporal sampling rates.
To assess the performance of the PCA-based pipeline, we follow a similar statistical analysis phase as in the direct clustering approach. The number of clusters obtained for all subjects across the three temporal frequencies undergoes pairwise and cohort-wide set overlap analysis. This comparison helps evaluate the consistency of clustering solutions across different temporal sampling periods. The hypothesis remains that a robust clustering solution should exhibit coherence in identified clusters across subjects and temporal frequencies. We use pairwise and group-wise similarity scores to statistically compare the optimal cluster numbers. Higher overlaps in cluster assignments between temporal sampling periods and increased pairwise set overlaps indicate greater stability and reliability in the face of variability in sampling rates.
TRADITIONAL DFCN CLUSTERING PIPELINE WITH MDS-BASED DIMENSIONALITY REDUCTION
C.
We develop a traditional dynamic FCN (dFCN) analysis pipeline with similar steps to the aforementioned TDA-based pipeline for the rs-fMRI dataset. The traditional dFCN analysis pipeline is illustrated in Figure 6. Analysis steps include extracting subject-specific DFC (dynamic functional connectivity) matrices, calculating graph metrics, dimensionality reduction via MDS, clustering with k-means, and computing cluster overlaps. Instead of the persistent diagrams or applying any persistent homology methods, we use a correlation coefficient between the timesteps for all three data cohorts.
Let,
where
The distance matrix for a given subject in cohort is defined as:
In Eq. 2, are the dimensions of the adjacency matrices. We compute the Euclidean distance [62] between adjacency matrices at times and , which gives 316 distance matrices of sizes (86 × 86), (336 × 336), and (754 × 754) for the three cohorts respectively. In this stage, we acquire 316 matrices for each of the data cohorts with the size of (86 × 86) for , (336 × 336) for , and (754 × 754) for . Then, we follow a similar pipeline of the TDA framework to keep the comparison uniform. We reduce the dimension of the matrices using two-component multidimensional scaling (MDS) and then calculate the number of clusters ( ) on the reduced matrices using k-means clustering. We also use the maximum Silhouette score to choose the value of within the range from 2 to 16. Finally, this pipeline will also produce the number of clusters of the MDS for every 316 subjects for all three data cohorts. Our hypothesis will be proven right if the TDA pipeline gives a better similarity score than the non-TDA pipelines.
RESULTS
V.
All of the TDA-based and nonTDA-based pipelines start with embedding one FCN for each rs-fMRI scan as an adjacency matrix (section III-B). In this stage, we get 371, 616 adjacency matrices ((316 × 86) + (316 × 336) + (316 × 754)) for three temporal sampling periods ( , and ). Each matrix has a dimension of 113 × 113. In the second stage of the pipelines, we embed the FCN using Pearson’s correlation coefficients and range the values between 0 and 1. In the TDA-based pipeline, the third stage extracts 0-dimensional persistent barcodes from the matrices using persistent homology (Section III-D). In the nonTDA-based pipelines, instead of using persistent homology, we use correlation coefficients between the timesteps for the three temporal sampling periods (TRs) for traditional FCN analysis(Section IV-C). Both the direct clustering and PCA-based dimensionality and clustering pipeline reshape the input matrices from timestep# × 113 × 113 to timestep# × 12,769 where the later one applies PCA based dimensionality reduction before applying clustering. For all of the TDA-based and nonTDA-based pipelines, we continue to the statistical analysis phase, where we compute the cohort-wide and pairwise cluster intersections of the subjects for all data cohorts.
In the TDA-based pipeline, we use the Wasserstein distance metric on the persistent diagrams for all the subjects for all three temporal sampling periods. On the contrary, in the nonTDA-based traditional FCN analysis pipeline, we directly use the correlation coefficient on the extracted FCNs. Adjacency matrices generated after this stage in these pipelines are similar in size for respective temporal sampling periods. For temporal sampling period with 86 timesteps in the TDA-based pipeline, each subject yields adjacency matrix of size (86 × 86) where represents the pairwise Wasserstein distance between timestep and . In the traditional FCN analysis pipeline for the same data cohort, each subject yields adjacency matrix of size (86 × 86) where represents the pairwise norm between timestep and . Similarly, and yield adjacency matrix of size (336 × 336) and (754 × 754), respectively, for each of the subjects during TDA and traditional FCN analysis. This high dimensionality of the matrix size makes it challenging to apply statistical analysis. For this reason, we applied multidimensional scaling (MDS) and reduced the size of the matrices to fit into a two-dimensional surface for all the data cohorts( , , ). Then, we applied clustering on the MDS data using the k-means clustering algorithm with Silhouette analysis to select the number of clusters. Finally, we get the number of clusters for all 316 subjects for both of these pipelines.
For the other two nonTDA-based data processing pipelines, we first reshape the input matrices. In the direct time-series clustering pipeline, we flatten the 113 × 113 matrices into 12, 769-dimensional vectors and calculate the optimal number of clusters for each data cohort directly on this reshaped high-dimensional data. In contrast, for the PCA-based dimensionality reduction and clustering pipeline, we flatten the FCNs and then apply 2-component PCA to reduce the dimensionality down to 2 principal components before clustering. This PCA step mitigates the challenge of directly clustering high-dimensional data. After PCA reduction to 2D, we determine the optimal cluster numbers for each subject on the low-dimensional PCA-reduced data. Both pipelines reshape the data as a preprocessing step, but the PCA pipeline has an additional dimensionality reduction phase prior to clustering.
Figure 7 shows the clustering result for a single subject (subject 8) for all three data cohorts ( ). The top row of the figure represents the plotted clusters using the TDA-based pipeline, and we see that each data cohort here has two clusters. The second row shows the clustering result for same subject using the PCA-based dimensionality reduction and clustering pipeline. While the number of clusters remains consistent for and in this pipeline, there is a notable discrepancy in the number of clusters for . This suggests that the pipeline can not effectively preserve robustness across different data cohorts. The bottom row of the figure shows the plotted clusters for the same subject using the nonTDA-based traditional FCN analysis pipeline, and the number of clusters varies for the data cohorts. As the number of clusters remains unchanged for different temporal sampling periods with similar shape using the TDA-based pipeline and varies largely for the nonTDA-based pipelines, it shows the invariant of the TDA pipeline. We cannot plot the clustering result for direct clustering pipeline due to the elevated size of the data in this clustering analysis (#timestep×12, 769), and the absence of any dimensionality reduction techniques (MDS or PCA) applied on the original data. Thus, this illustration gives an intuition towards our hypothesis of the resiliency of persistent homology-based methods to different data acquisition parameters (temporal sampling periods) in brain rs-fMRI data analysis.
To statistically compare the consistency of identified cluster patterns across subjects for both the TDA-based and nonTDA-based pipelines, we compute two similarity metrics - the cohort-wide and pairwise cluster distances. For the cohort-wide analysis, we calculate the absolute difference in number of clusters between each subject’s optimal solution. This provides a distribution of cluster number distances indicating the spread/variability across subjects. For pairwise analysis, we compute cluster distances between each pair of data cohorts for the same subject. The pairwise distances are aggregated to produce a distribution showing the overall pairwise consistency. Lower cohort-wide and pairwise distances indicate higher similarity and consistency in optimal cluster numbers. This quantifies the robustness of each method to individual variations and its ability to extract connectivity patterns that are generalizable across populations. The metrics provide crucial insights into the stability and reproducibility of the clustering solutions.
COHORT-WIDE CLUSTER DISTANCE COMPARISON
A.
We capture the number of clusters for all 316 subjects for all three data cohorts for all the pipelines. We calculate the distance between the number of clusters for each subject using:
where are the number of clusters for for the data cohorts respectively and abs denotes the absolute difference.
The cohort-wide cluster distance analysis in Figure 8 reveals striking differences between the TDA-based and nonTDA-based pipelines. For the TDA pipeline, the majority of subjects (59%) exhibit a tight cluster number distance of less than or equal to one across cohorts. This indicates TDA identifies highly robust cluster patterns consistent across individuals. In contrast, for the direct clustering pipeline, only 6% of subjects have a cohort-wide distance less than or equal to one. For the PCA-based pipeline, this number rises to 19% of subjects and for the traditional FCN analysis plummets to 2% of subjects. The significantly lower consistency highlights the inability of these nonTDA-based techniques to extract stable brain states generalizable across the population. Unlike the topological approach, these methods are heavily influenced by individual variations. Overall, the cohort-wide analysis affirms the resilience of TDA for rs-fMRI analysis, which is able to mitigate differences in data acquisition parameters.
PAIRWISE CLUSTER DISTANCE COMPARISON
B.
Additionally, we perform a pairwise comparison of the number of clusters for the data cohorts for all of the pipelines. The value of represents the pairwise distance on the number of clusters for for the data cohorts and . Similarly, the value of and represent the pairwise distance on the number of clusters between the data cohorts ( ) and ( ) respectively. This pairwise comparison will help to identify whether there is a closer similarity between the data cohorts in the TDA-based pipeline over the nonTDA-based pipelines. Figure 9 shows the pairwise distance between the data cohorts in the TDA-based pipeline and in the nonTDA-based pipelines. In the TDA pipeline, the pairwise distance between data cohorts and show the highest similarity (78% matching within distance 2). The data cohort pair and has a similarity of 77% within distance two, and data cohort pair and has a similarity of 74% within the same distance. This high similarity between the data cohort pairs proves the efficacy of persistent homology-based techniques on the rs-fMRI data analysis with different temporal sampling periods. In the nonTDA-based direct clustering pipeline, we see the maximum similarity between the data cohorts and with 75% similarity within distance 2. The other data cohort pairs ( and ) has 23% and 21% similarity within the same distance. In the PCA-based dimensionality reduction and clustering pipeline, we see the maximum similarity between the data cohorts and with 60% similarity within distance 2. The other data cohort pairs ( and ) has 50% and 55% similarity within the same distance. In the last nonTDA-based traditional FCN analysis pipeline, we see the maximum similarity between the data cohorts and with 40% similarity within distance 2. The other data cohort pairs ( and ) has 23% and 22% similarity within the same distance. This low similarity between the data cohorts using nonTDA-based pipelines indicates the inefficiency of the nonTDA-based method for analysing rs-fMRI data with different data acquisition parameters.
EVALUATION USING A CLINICAL ADHD DATASET
C.
To validate the robustness of our TDA-based temporal clustering pipeline, we conducted a comparative evaluation against the traditional dynamic functional connectivity network (dFCN) pipeline using the publicly available ADHD-200 dataset [63], [64]. We constructed two cohorts based on the temporal resolution (TR) of the rs-fMRI scans: TR=2s and TR=2.5s. Each cohort comprises ADHD and control subjects. The TR=2s cohort includes 290 control and 285 ADHD subjects, while the TR=2.5s cohort consists of 189 control and 68 ADHD subjects. Figure 10 presents a systematic comparison of clustering consistency between the TDA-based pipeline (left column) and traditional dFCN pipeline (right column) across ADHD and control groups. Each subplot shows the distribution of the number of clusters across all subjects within a group and TR condition. The x-axis denotes the number of clusters (ranging from 1 to 16), and the y-axis indicates the percentage of subjects exhibiting each cluster count.
In the TDA-based pipeline (left column), we observe a strong peak at 2 clusters for both ADHD and control subjects across TR=2s and TR=2.5s. This suggests a high degree of consistency in the extracted brain state patterns, with over 80% of subjects in each subgroup consistently showing two clusters. This invariance across different TRs demonstrates the robustness of persistent homology and topological features in summarizing the intrinsic structure of time-varying brain connectivity.
In contrast, the traditional dFCN pipeline (right column) exhibits significant variability in the number of clusters across TRs. For both ADHD and control groups, the cluster distributions are dispersed, with subjects assigned to a wide range of cluster numbers, especially at higher TRs. For instance, in the ADHD group (top right), the cluster counts span from 3 to 15, with no dominant mode. This inconsistency indicates the sensitivity of the dFCN pipeline to changes in temporal resolution and its reduced ability to extract reproducible brain state signatures.
This analysis highlights the advantage of using topological features derived from persistent homology over traditional correlation-based approaches. While dFCN pipelines are prone to capturing noise and suffer from over-fragmentation of temporal brain states, the TDA pipeline produces stable and interpretable cluster structures. These findings support the hypothesis that TDA provides a more reliable abstraction of temporal dynamics in brain connectivity, particularly in clinical neuroimaging datasets with acquisition variability.
COMPUTATIONAL COMPLEXITY ANALYSIS
D.
We now analyze the computational complexity of the TDA-based (Sec. III) and nonTDA-based pipelines (Sec. IV) up to the statistical analysis stage. Since the statistical analysis stage is common across all pipelines, our analysis focuses on the pipeline-specific processing steps prior to statistical testing. The computational trade-offs of the pipelines are summarized in Table 1.
Let denote the number of subjects ( the number of timepoints per subject ( in the largest case), the number of regions of interest ( ), and the number of features in each flattened functional connectivity network (FCN). The number of clusters explored in KMeans is , and the maximum number of KMeans iterations is .
TDA-BASED PIPELINE
In the TDA-based pipeline, each subject and timepoint undergoes persistent homology computation on its FCN, resulting in a total cost of . The computational cost for generating a single persistence barcode is denoted by . For our approach, using the Gudhi library with the Vietoris–Rips complex and max_dimension=1 on ROIs, the time complexity for 0-dimensional persistent homology scales as , which yields approximately 86,800 operations per timepoint. After barcode extraction, each subject requires a pairwise Wasserstein distance matrix between all timepoints ( ), two-dimensional MDS on this matrix ( ), and k-means clustering ( ). The total computational complexity is:
which, for the largest case, evaluates to 20,871 M.
DIRECT CLUSTERING PIPELINE
For direct clustering, all FCNs for a subject are flattened into a ( ) matrix, and k-means clustering is applied in the high-dimensional space. The complexity is:
which evaluates to 13,695,004 M.
PCA-BASED PIPELINE
In the PCA-based pipeline, the ( ) FCN matrix is first reduced to two dimensions using PCA, which has complexity per subject (due to SVD on high-dimensional data), followed by k-means clustering on the reduced matrix. The total computational complexity is:
which for the largest case evaluates to 38,860, 145 M.
TRADITIONAL DFCN CLUSTERING PIPELINE
In the traditional dFCN pipeline, for each subject we compute a pairwise Euclidean distance matrix ( ) between all adjacency matrices at all timepoints, with a cost of . This is followed by the same MDS embedding and k-means clustering as in the TDA-based pipeline. The total computational complexity is:
which, for the largest case, is 2,290, 525 M.
COMPARISON BETWEEN TDA-BASED AND NON-TDA BASED PIPELINES
E.
We extensively evaluated the accuracy and robustness of our TDA pipeline for rs-fMRI analysis on a large-scale healthy control dataset comprising 371,616 adjacency matrices across 316 subjects as well as a clinical ADHD dataset comprising of 832 subjects. Comparisons are made to three alternative approaches - direct clustering, PCA, and traditional FCN analysis.
Table 2 summarizes the systematic comparison between TDA-based and NonTDA-based data processing pipelines in terms of methodology, dimensionality reduction, cluster interpretability, robustness (cohort-wide and pairwise similarities), as well as their advantages and limitations. Clearly, the TDA-based pipeline demonstrates significantly higher robustness, interpretability, and consistency across different temporal data acquisition parameters, albeit with higher computational overhead, when compared to the NonTDA-based methods. The NonTDA-based pipelines vary in their advantages–such as simplicity, computational efficiency, and low computational cost–but generally exhibit reduced robustness, higher noise sensitivity, and lower interpretability. The results demonstrate TDA’s superior ability to extract robust and invariant topological signatures intrinsically linked to resting-state functional architectures. Remarkably, the brain states identified by TDA exhibit high consistency across the three sampling frequencies, affirming resilience to acquisition variations. This also highlights TDA’s efficacy in mitigating non-neural variability and capturing fundamental dynamics as compared to conventional techniques. By applying the persistent homology technique to filter noise and reveal salient connectivity motifs, TDA provides a principled graph-free technique for preserving temporal dynamics of complex rs-fMRI data. These findings establish persistent homology as a powerful approach for analyzing temporal patterns and validating TDA as a promising pipeline for robust discovery of data-driven functional brain states.
DISCUSSION
VI.
MRI scanners around the globe vary in their configurations and field strengths. This variation leads to a certain level of noise in the data collected due to non-neural differences introduced by the diverse scanner setups and data collection parameters. This noise complicates the process of combining data from different scanners into a single, large dataset for unified analysis. Consequently, most fMRI brain network research is localized, limited by the number of subjects that can be scanned at a single location. This limitation reduces the sample size and, therefore, the applicability of the results. One solution is to conduct studies across multiple sites closer to the target population. However, the noise introduced by using different scanners and parameters diminishes the neural effects of interest, thereby reducing the effectiveness of such multi-site efforts.
We addressed these issues in our previous paper [8] in the context of characterizing brain networks using static functional connectivity. However, DFC is critical for understanding how the brain processes information dynamically and how the interactions between different brain regions change with time. It has been shown that DFC is very important for characterizing the healthy brain [3], [4], as well as in various brain disorders [5], [6], [7]. Therefore, it becomes necessary to develop a TDA-based framework for DFC so that investigations of temporal dynamics in the brain are shielded from non-neural variability in the data.
We validated the effectiveness of the proposed Topological Data Analysis (TDA)-based pipeline by contrasting it with the conventional data analysis pipelines outlined in Section IV. In the conventional pipelines, we employed direct time-series clustering, PCA-based dimensionality reduction and clustering, as well as traditional dynamic FCN pipeline with MDS-based dimensionality reduction. The outcomes of this pipeline strongly suggest that these conventional methods fail to establish similarity across dynamic FCNs of the same subjects obtained with different repetition times (TRs) and acquisition parameters.
On the contrary, for the TDA-based metric, we demonstrated both qualitatively and quantitatively that the metric remains statistically consistent across the same subjects, regardless of the sampling period used to acquire resting-state fMRI data. This underscores the usefulness of TDA-based analysis because, theoretically, data collected using different parameters from the same subject should still represent the same brain network dynamics.
CONCLUSION
VII.
In this study, we have demonstrated the effectiveness of Topological Data Analysis (TDA) in uncovering temporal properties within resting-state functional magnetic resonance imaging (rs-fMRI) data. Our research highlights TDA’s robustness in the presence of varying temporal sampling rates, surpassing traditional connectivity analysis methods. Key findings emphasize TDA’s remarkable stability, with 59% of subjects consistently showing clustering results across different temporal sampling periods (2500ms, 1400ms, 645ms), compared to less than 19% using nonTDA-based methods. TDA also reveals strong pairwise similarities between sampling periods, showcasing its ability to capture temporal dynamics. The robustness of the TDA pipeline is further confirmed through evaluation on clinical ADHD datasets, where it achieves high consistency (≥ 80%) in clustering outcomes across different sites and scanning conditions. In conclusion, our study establishes TDA as a valuable tool for revealing temporal nuances in rs-fMRI data, offering a level of robustness unmatched by traditional methods. Through persistent homology, TDA provides a stable, invariant representation of dynamic brain connectivity, promising valuable insights into complex temporal patterns in resting-state fMRI data across diverse acquisition parameters. To promote reproducibility, we have made all our code, scripts, data, and documentation available at https://github.com/harp-lab/TemporalBrainPH.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Menon RS and Kim S-G, “Spatial and temporal limits in cognitive neuroimaging with f MRI,” Trends Cognit. Sci, vol. 3, no. 6, pp. 207–216, Jun. 1999.10354573 10.1016/s 1364-6613(99)01329-7 · doi ↗ · pubmed ↗
- 2Hall DA, Haggard M, Akeroyd MA, Palmer AR, Summerfield AQ, Elliott MR, Gurney E, and Bowtell R, “‘Sparse’ temporal sampling in auditory f MRI,” Human brain mapping, vol. 7, no. 3, pp. 213–223, 1999.10194620 10.1002/(SICI)1097-0193(1999)7:3<213::AID-HBM 5>3.0.CO;2-NPMC 6873323 · doi ↗ · pubmed ↗
- 3Deshpande G and Jia H, “Multi-level clustering of dynamic directional brain network patterns and their behavioral relevance,” Frontiers Neurosci, vol. 13, Feb. 2020, Art. no. 476054.
- 4Jia H, Hu X, and Deshpande G, “Behavioral relevance of the dynamics of the functional brain connectome,” Brain Connectivity, vol. 4, no. 9, pp. 741–759, Nov. 2014.25163490 10.1089/brain.2014.0300 PMC 4238311 · doi ↗ · pubmed ↗
- 5Rangaprakash D, Dretsch MN, Katz JS, Denney TS Jr., and Deshpande G, “Dynamics of segregation and integration in directional brain networks: Illustration in soldiers with PTSD and neurotrauma,” Frontiers Neurosci, vol. 13, Aug. 2019, Art. no. 442861.
- 6Rangaprakash D, Dretsch MN, Venkataraman A, Katz JS, Denney TS, and Deshpande G, “Identifying disease foci from static and dynamic effective connectivity networks: Illustration in soldiers with trauma,” Human Brain Mapping, vol. 39, no. 1, pp. 264–287, Jan. 2018.29058357 10.1002/hbm.23841 PMC 6866312 · doi ↗ · pubmed ↗
- 7Jin C, Jia H, Lanka P, Rangaprakash D, Li L, Liu T, Hu X, and Deshpande G, “Dynamic brain connectivity is a better predictor of PTSD than static connectivity,” Human Brain Mapping, vol. 38, no. 9, pp. 4479–4496, Sep. 2017.28603919 10.1002/hbm.23676 PMC 6866943 · doi ↗ · pubmed ↗
- 8Kumar S, Shovon AR, and Deshpande G, “The robustness of persistent homology of brain networks to data acquisition-related non-neural variability in resting state f MRI,” Human Brain Mapping, vol. 44, no. 13, pp. 4637–4651, Sep. 2023.37449464 10.1002/hbm.26403 PMC 10400795 · doi ↗ · pubmed ↗