Deep Architectures Fail to Generalize: A Lightweight Alternative for Agricultural Domain Transfer in Hyperspectral Images
Praveen Pankajakshan, Aravind Padmasanan, S. Sundar

TL;DR
This paper introduces a lightweight framework for classifying hyperspectral satellite images in agriculture, which generalizes well even with limited labeled data and new crop types.
Contribution
The novel framework explicitly balances spatial and spectral features for better generalization in open-set agricultural scenarios.
Findings
The framework improves classification accuracy by 7.22–15% over spectral-only models on benchmark datasets.
Incorporating unsupervised learning further boosts accuracy beyond recent state-of-the-art methods.
The method demonstrates transferability to new domains like unseen crop classes and regions without re-training.
Abstract
We present a novel framework for hyperspectral satellite image classification that explicitly balances spatial nearness with spectral similarity. The proposed method is trained on closed-set datasets, and it generalizes well to open-set agricultural scenarios that include both class distribution shifts and presence of novel and absence of known classes. This scenario is reflective of real-world agricultural conditions, where geographic regions, crop types, and seasonal dynamics vary widely and labeled data are scarce and expensive. The input data are projected onto a lower-dimensional spectral manifold, and a pixel-wise classifier generates an initial class probability saliency map. A kernel-based spectral-spatial weighting strategy fuses the spatial-spectral features. The proposed approach improves the classification accuracy by 7.22–15% over spectral-only models on benchmark datasets.…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
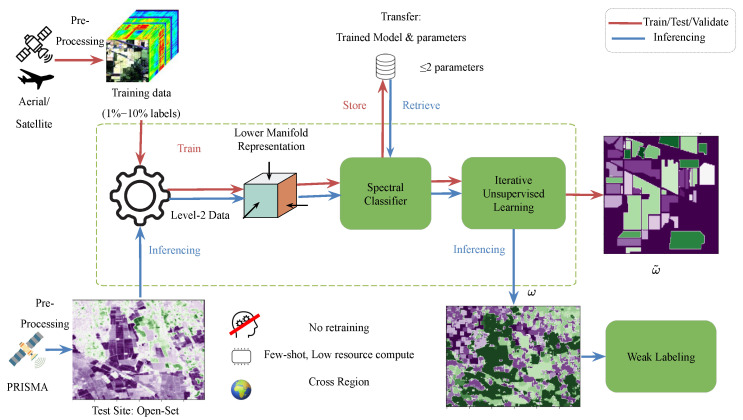 Figure 1
Figure 1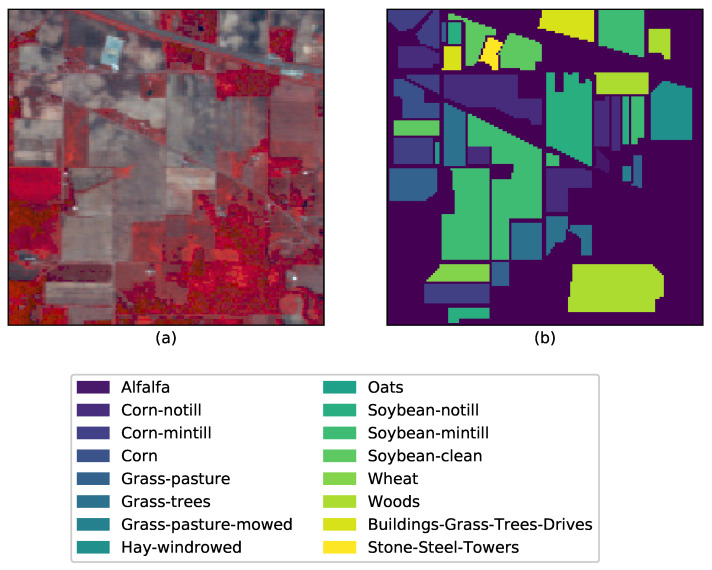 Figure 2
Figure 2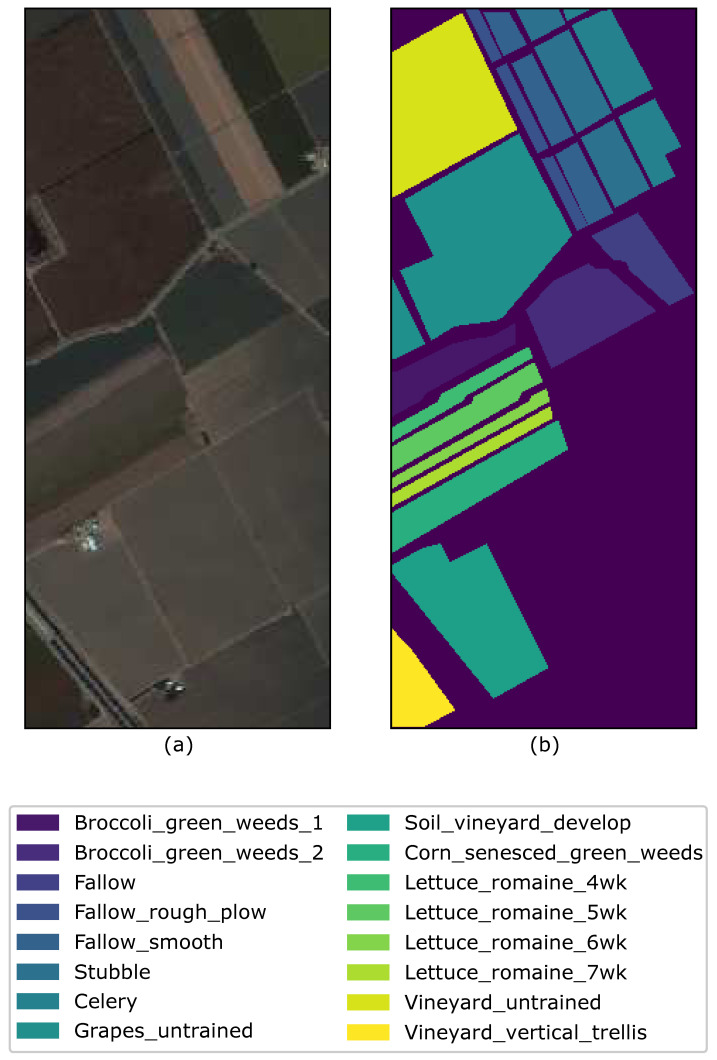 Figure 3
Figure 3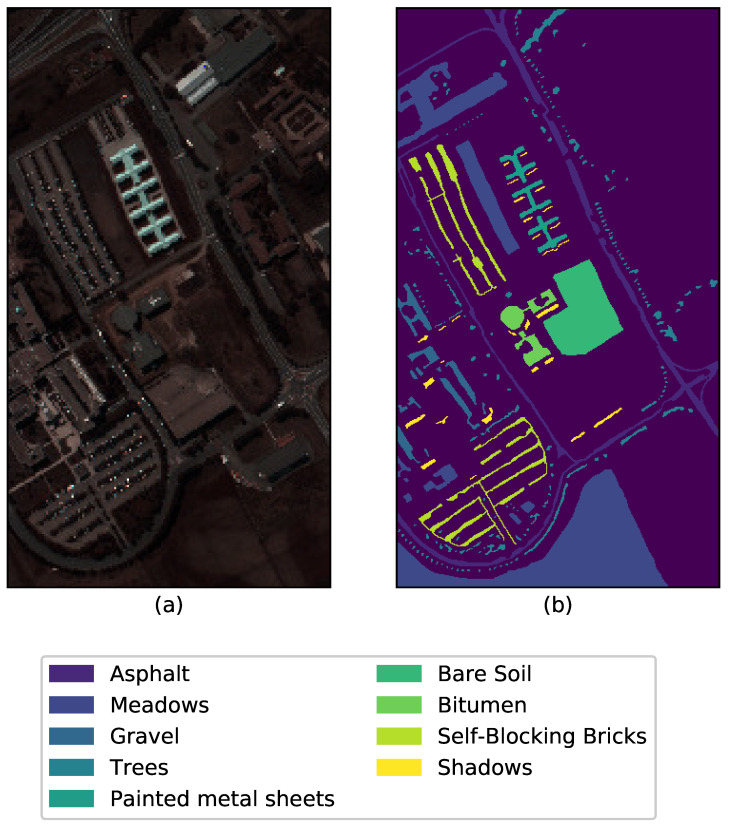 Figure 4
Figure 4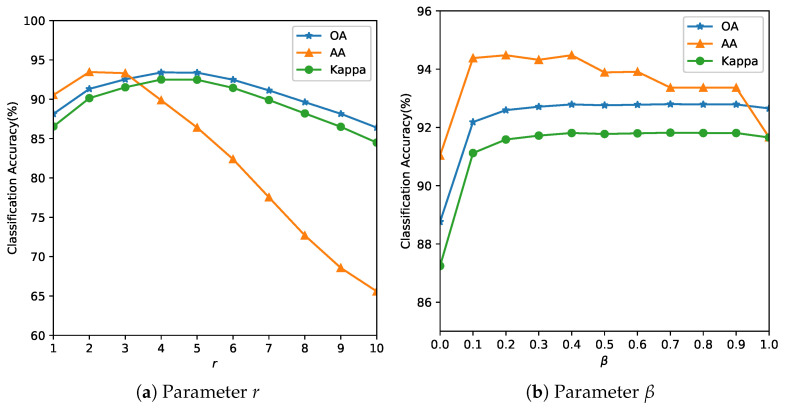 Figure 5
Figure 5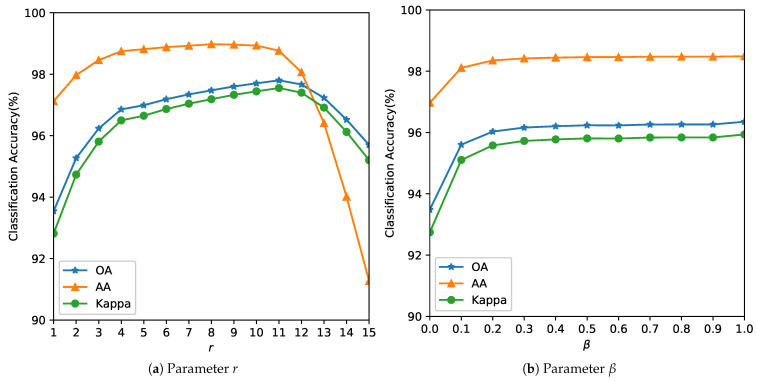 Figure 6
Figure 6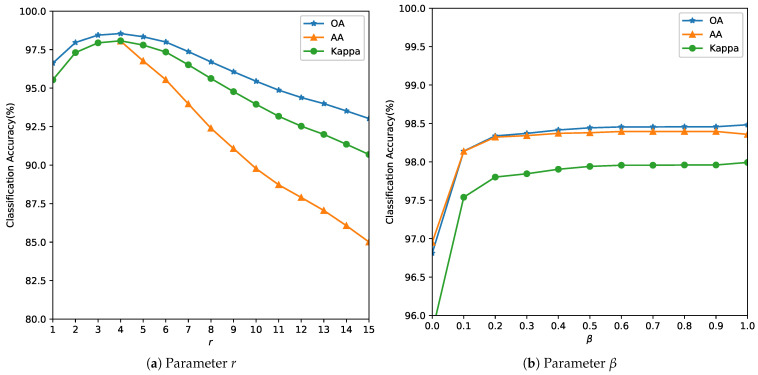 Figure 7
Figure 7 Figure 8
Figure 8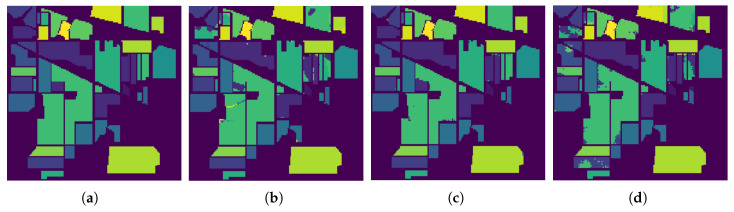 Figure 9
Figure 9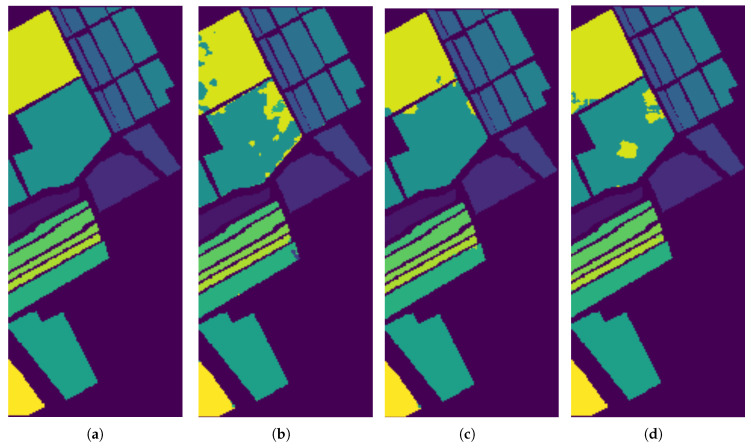 Figure 10
Figure 10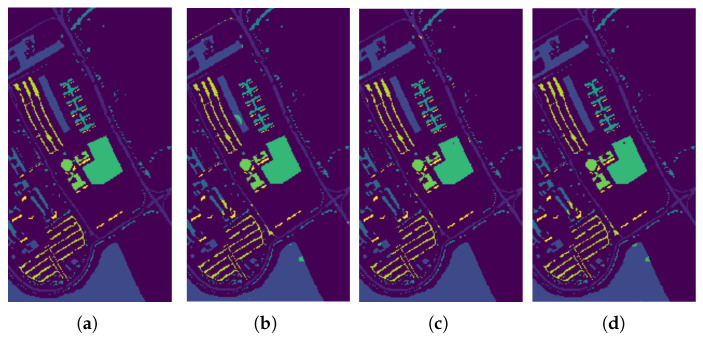 Figure 11
Figure 11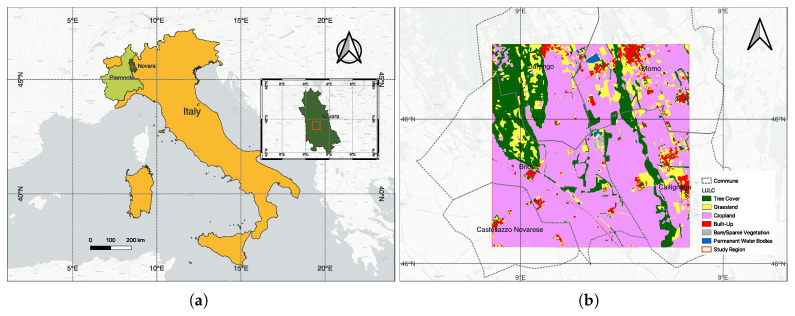 Figure 12
Figure 12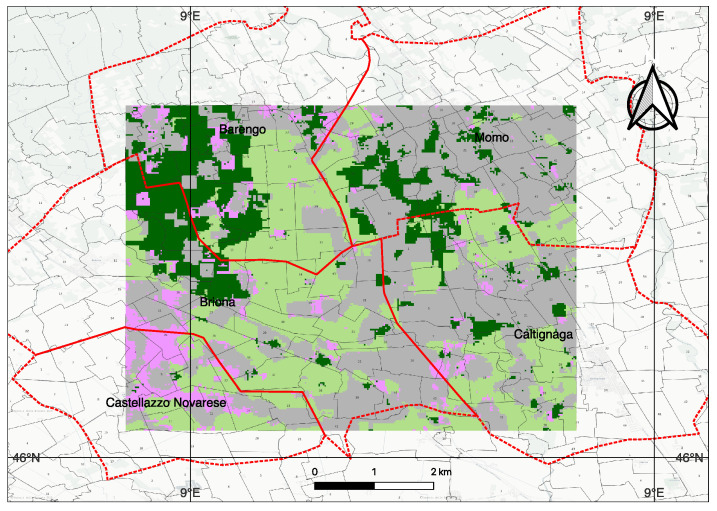 Figure 13
Figure 13 Figure 14
Figure 14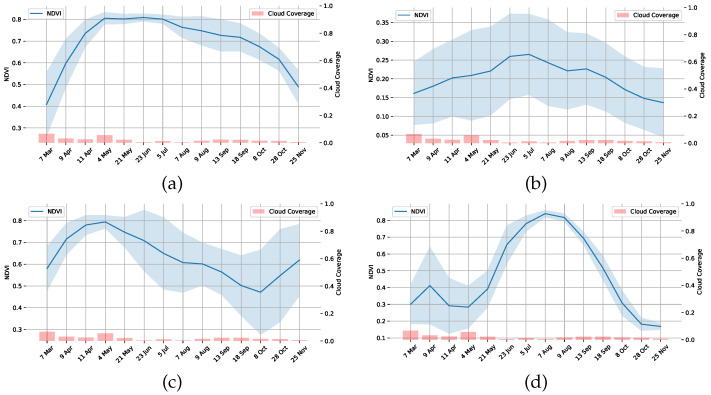 Figure 15
Figure 15 Figure 16
Figure 16- —UrbanKisaan Inc.
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRemote-Sensing Image Classification · Remote Sensing in Agriculture · Advanced Image Fusion Techniques
1. Introduction
Monitoring crop health, distribution, and biophysical traits through advanced hyperspectral remote sensing is a cornerstone for sustainable agricultural systems, enabling precision resource management, adaptation to climate variability, and mitigation of environmental impacts such as greenhouse gas emissions. Accurate mapping and quantification of the biophysical and biochemical traits of agricultural crops, growth seasons, land use, and human activity are crucial for sustainable agriculture and food security. These enable precise resource management, adaptation to climate variability, and mitigation of environmental impacts such as greenhouse gas emissions [1,2]. Regular temporal monitoring throughout the cropping cycle, from sowing to harvest, is essential for timely interventions. Monitoring of farm plot and land use at scale and at different time instances of a growing season, and pre-/post-harvest is very critical. Farmers, support organizations or field scientists/personnel find it difficult to audit or scout fields on a regular basis for monitoring or interventions. This has led to increased reliance on low-altitude flights, satellite-based and UAV-based remote sensing technologies [3,4]. There were many historical developments in imaging spectrometry for applications in agriculture and forestry, since the launch of Landsat 1 [5] in 1972 to the present day high-resolution imagery based on UAV sensors [1]. More recently, UAVs have been equipped with imaging spectrometers to collect high-resolution imagery for applications in agriculture and forest. Hyperspectral Imaging (HSI) [6], with its rich spectral bands, has emerged as a key enabler providing information in both the spatial, and the spectral dimensions. Using field-collected data, machine learning, and high spectral resolution, it is possible to perform crop discrimination [2], determine biotic and abiotic stresses [7,8], monitor health, nutrients [9], cropping patterns, and support the goals of sustainable development [10].
The article [11], provides the recent trends in HSI analysis, while in [12,13], the authors review recent Hyperspectral and Deep Learning methods. Deep learning-based methods [14,15,16,17,18,19] have relatively higher accuracy in comparison to other approaches. Remote sensing plays a crucial role in quantifying crop biophysical parameters and supporting sustainable agricultural practices. HSI provides detailed spectral information that enables discrimination of crop types, health conditions, and stress factors. Despite these advantages, Hyperspectral sensed images in application to agricultural applications is limited by five key challenges:
- the number of spectral components increases the data processing complexity during preparation, training and inference [6],
- high correlation between the individual bands and added redundancy [20],
- difficulty in interpreting the model [21,22] and explainability of the decision making process for trust and scaling,
- limited number of benchmark labeled datasets available after ground truth verification for the different practices followed in sustainable and regenerative agriculture, and
- limited ability of the models to generalize to new regions or new classes or new context where limited or no prior data is available for training.
Although earlier studies extensively addressed spectral redundancy, data dimensionality, and model interpretability, these methods are entirely focused on obtaining high-accuracy classification maps in a very localized or selected study region. Very few works address the last two challenges related to the limited dataset with diverse classes and generalizability of models. Notable among these previous work is [23] where the authors use a three-dimensional convolutional neural network or 3D CNN along with an OpenMax layer (with a Weibull distribution) to reject unknown classes. Unfortunately, in new geographies (test region), often there can be minimal to no overlap between the classes in the training and the test sites or classes. This can especially be the case for agricultural applications. In which case, the classifier can reject all crops of interest. In Ref. [24], the authors designed a framework to enhance the latent spectral and spatial features that can be used to classify the known classes while rejecting the unknown classes. Recent studies on trade-offs have focused mainly on pan-sharpening [25], super-resolution [26], or enhancement [27]. In Ref. [28], a Dynamic Spatial-Spectral Attention Network (DSSAN) is introduced with an adaptive attention mechanism to dynamically recalibrate features. Similarly, in Ref. [29], the authors introduce an attention mechanism as well by separating spatial and spectral as two independent branches, and incorporate modules with convolution, LSTM and attention. There is no doubt that the above and recent approaches demonstrate high accuracies in closed-set benchmark data sets [30] but the parameter space is quite large in addition to being computationally very expensive. For large scale deployment for practical applications (with full training inference class overlap), trust in the performance of these models is less due to overfit to the training data/domain. Most importantly, when operating in new regions, environment, and crops, ‘by design’ they cannot be generalized.
This study presents a novel approach and framework that addresses all of the above five challenges, with a special emphasis on domain generalization (minimal or no overlap with training classes) and low-resource adaptability. We demonstrate transferability and domain generalization for paddy extent mapping. Paddy fields play an essential role in global food security, but are also a significant contributor to greenhouse gas emissions, especially methane. Methane produced under anaerobic growing conditions typical of flooded rice cultivation accounts for approximately of global anthropogenic methane emissions and approximately 9–11% of total agricultural GHG emissions. Therefore, accurate remote sensing of the extent of flooded rice is essential to estimate, monitor, and manage these emissions, thus supporting climate-smart and sustainable rice production systems. This study aims to evaluate whether a weakly supervised minimal parameter spectral–spatial classifier trained on benchmark datasets is transferable to low-label agricultural settings.
1.1. Problem Formulation
Let be the HSI where M and N are the spatial dimensions and D is the number of spectral bands in the image. We define K as the number of distinct classes, with , and by the set of class labels that belong to the set of universal class labels . is transformed into the set of features , where is the total number of pixels. The set of training data pairs, , is randomly chosen from . For our case, we assume that the training examples . The first objective is to build a classifier, s.t. using , where the final class labels are .
1.2. Contributions
The key contributions of this work are as follows:
- A lightweight framework that introduces a tunable balance between spectral similarity and spatial nearness, with minimal computational overhead.
- A weighting mechanism that requires tuning of at most two dataset-specific parameters (C, ) while maintaining four fixed parameters (r, , , ) transferable across domains, enabling operation with only 1–10% labeled data.
- Demonstration of domain generalization capabilities by training on one benchmark dataset (Indian Pines) and successfully inferring on two different datasets (Kennedy Space Center dataset and the Hyperion Botswana dataset) without retraining.
- Extension to real-world agricultural settings (e.g., ASI PRISMA imagery over Italy), showcasing transferability to unseen crops and regions with minimal supervision.
- Comparative performance exceeding or matching state-of-the-art transformer-based models (e.g., MASSFormer 97.92% with 0.5% training samples and ours 97.69% with 1% training samples in Salinas) in terms of accuracy, computational efficiency, and label efficiency.
2. Learning Approach
The proposed learning approach is shown in Figure 1 and has the following main steps:
- Map the analysis-ready data to a lower dimension representation in the space , reducing along the spectral features (either linearly or non-linearly)
- Supervised pixel-wise classification on K classes on the new representation,
- Construct the class probability map based on the pixel-wise classifier and use as initial seed
- Iterative unsupervised learning using trade-off between spatial nearness and spectral similarity measures,
- Ensemble the different model outputs from each iteration based on majority voting
- Final class assignment using weak labeling.
We will discuss the details in the following subsections.
2.1. Class Separability
As the number of spectral bands in the hyperspectral is very high (D), for a spectral classifier such as a SVM, the worst-case computational complexity can be . This is computationally expensive for large features and the additional bands can add redundancy [31].
For class separability, we project the data into another manifold. After exploring many methods in our experiments and validating their performance with respect to the spectral classifier, the PCA [31,32] worked reliably with the least loss of accuracy. This is also consistent with previous work on this subject [33,34]. KPCA and other nonlinear methods gave poor results when the training samples is small or was computationally more expensive without significant contribution to the accuracy.
The data , are orthogonally projected onto a lower-dimensional linear principal subspace , to capture maximum data variance. The principal components are the Eigen vectors of the covariance matrix of and the amount of “explained variance” in each component is proportional to the Eigen value. Let each hyperspectral pixel be projected onto a lower-dimensional spectral manifold :
The explained variances are arranged in descending order of value, and the components are chosen so that the cumulative explained variance ratio is higher than a threshold . We fixed the value of the threshold to be ≥90% as the cumulative explained-variance plateaued beyond.
We observed that PCA alone cannot bring about class separability. For example, in the Indian Pines dataset, the “Corn-notill”, the “Corn-mintil” and “Corn” classes seem to have very similar spectral signatures. This also applied to the classes “Soybean-notill”, “Soybean-mintill”, “Soybean-clean”. Some sustainable and regenerative agriculture farmers practice ‘zero-tillage’ or ‘minimum-tillage’ to reduce mechanical interventions to the soil so as to not disturb the physical structure or the beneficial organisms present in the soil. However, it is difficult to detect the intervention or the absence of intervention practices such as tillage using only a single time-stamp image. Interventions may have occurred before sowing, while the acquired image may have been captured much later in time during the vegetative period or at the time of maturity. When the canopy is dense, the signatures from the soil are minimal, and hence the signatures are mostly from the crops. This explains why these classes might have similar signatures when we study the spatial-spectral features.
2.2. Construction of Initial Classification Probability Map
The initial classification map is obtained from a pixel-wise spectral classifier
with multiclass decision functions, where is identity (linear) or kernel map. For each pixel, we attribute the class probability as
with . The initial probability map for all pixels, is used as an initializer for subsequent steps. It is possible to add a penalizing term to the probability map depending on the deviation from the true labels . There is much prior literature that compares Random Forest (RF) and Support Vector Machine (SVM) for pixel-wise labeling of the images. While the overall accuracy (OA) is comparable, SVM classifiers better spatially associate pixels with similar signatures, resulting in less noisy maps [35,36]. In addition, the number of parameters is lower than that of tree-based approaches. Throughout this text, we will use SVM as the pixel-wise classifier, but it can be replaced by RF or CNN-based classifiers with softmax probabilities. We used the SVM algorithm implemented in the ThunderSVM library [37] that has GPU support. The initialization seed (similar to the unary potentials [38,39]) is constructed from the probability map of the pixel classifier.
2.3. The Model
We model the joint distribution of the probabilities of pixels using the nearness with the spatial neighbors and spectral similarity. For each pixel, i, a neighborhood which belongs to the partition of the possible neighborhood partitions of the image. This neighborhood is defined on the output obtained from the spectral classification map, and the joint probability distribution is constructed by integrating the spatial nearness and the spectral similarity between the pixels. The following are the definitions of nearness and similarities.
2.3.1. Spatial Nearness Kernel
We assume that the pixels , are spatially close. To quantify this idea, we have the spatial proximity kernel as:
where, is the distance -norm between the reference pixel i and the neighborhood set of pixels . The parameter of the Gaussian kernel controls the local spatial connectedness of the pixels. A lower (higher) value of means that the pixels that are closer are only (farther are also) considered spatially similar to the central pixel. This also ensures label compatibility between neighboring pixels.
2.3.2. Spectral Similarity Kernel
We can assume that the spectrum of the reference and neighborhood pixels is similar if they are of the same class. The spectral similarity is defined as follows:
where, is the spectral feature vector of the reference pixel, is the spectral feature of the neighborhood pixels in , and is the parameter that controls the degree of similarity. Due to normalization, the parameters of the kernels and are independent of both the spatial and spectral resolutions, respectively.
2.3.3. Boundary Condition Handling
For pixels, i, at the image boundaries where the full neighborhood extends beyond the image extent, we employ mirror padding:
- Symmetric Padding: The input image is padded to by reflecting the pixel values at the borders. This ensures that every pixel has a complete neighborhood and is better than truncation.
- Small Memory Overhead: For , the padding increases only fractionally the memory footprint and is negligible.
2.3.4. Attention as Generalized Weighting
In recent transformer architectures, self-attention computes pairwise relationships (attention weights) between spatial tokens/pixels, dynamically weighting their influence based on feature similarity. The kernels described in the previous paragraphs (spatial proximity) and (spectral similarity) play similar roles as attention masks that highlight the relative importance of neighboring pixels based on their spatial proximity and spectral relatedness. Many of the vision transformers (e.g., Swin transformers) incorporate a variant of localized self-attention to the spatial windows, and they locally resemble spatial kernels while the spectral similarity kernel promotes semantic consistency.
2.3.5. Unsupervised Learning
We construct the conditional probability distribution of the final classification map ( ), given the initial classification map ( ) and the unsupervised learning parametrized by and . i.e., . Since the adjacency of pixels in the image is a local phenomenon, it might not be necessary to use the entire initial classification map to obtain the final classification label for a pixel. For the reference pixel i, we compute the conditional probability in the neighborhood . This approach reduces computational cost by not using the predictions from pixels far from the reference pixel [40]. Using the definition of conditional probability,
The numerator term in the above equation is the joint distribution of the initial and final classification maps. Since the denominator term is constant over the neighborhood, the numerator is the only component which decides the conditional probability. In Ref. [39], the authors use a mean-field approximation to compute a distribution rather than to compute the exact distribution of Equation (5).
To make the computation of the joint probability tractable, we rather assume conditional independence between the neighborhood (given the reference pixel), and we factorize the distribution based on this assumption. Let us suppose that j and l are the neighborhood pixel locations in , the conditional independence implies that . So, using this condition, the joint probability distribution can be factorized as the following:
where is the potential function between the reference pixel i and the neighborhood pixel , and Z is the partition function given by,
The potential function in Equation (6) can be any positive non-zero functions. Since we are restricted to strictly positive functions, it is convenient to express the potential functions as an exponential:
We assume that is the energy function which is influenced by the unary potentials of the spectral classifier and the neighborhood interactions.
The joint distribution is defined as the product of potentials, and so the total energy is obtained by adding the potentials of the interactions in the spatial and the spectral directions. The potential is defined as (below all the multiplications are element-wise):
where the indicator operator is given by,
is the parameter of the energy function and is the class probability at neighbor pixel j. By combining the spatial and the spectral components together, we can rewrite Equation (9) as:
By replacing by , this could be simplified as:
where: · denotes element-wise multiplication, spectral similarity weights (high for spectrally similar neighbors), spatial proximity weights (high for nearby neighbors), class probabilities from initial SVM, is an indicator function (1 if same class, −1 otherwise), : trade-off parameter controlling spatial closeness vs. spectral similarity. The above is familiarly similar in form to the way that the unary and pairwise potentials are built for the Gibbs’ energy [38]. The difference is that in this case, the output from the spectral classifier interacts with the nearness and similarity kernels non-linearly and is not a spatial-only regularizer. As described earlier, the total energy is the sum of the potentials as
From Equation (11), the parameter gives a trade-off between the spatial nearness metric and the spectral similarity metric. For simplicity herein we refer to as . This parameter is linear in the cost function and can be estimated by minimizing the cost function in . Since the initial classification has good accuracy, we weigh the probability map of the reference pixel with spatial nearness and spectral similarity to reward or penalize the correct and incorrect classification of the initial spectral classifier.
To make a prediction on the reference pixels, we now fix the initial probability map based on the spectral classifier, which implicitly defines the conditional distribution . First, we fix the final classification map to the initial classification map. Then, we take one reference node i at a time and evaluate the total energy for all possible states, keeping all other variables fixed, and set the reference node i to whichever state has the lowest energy. Since the entire inner-loop computation is performed in a small neighborhood, the overall optimization is efficient. After finding the state for a node, we will move to another node and the above steps are repeated. We have a sequence of updates in which every site is visited at least once, and the variables remain unchanged during this time. This inner site-iteration is repeated until the assignment of the class labels is complete for all the sites. The entire methodology is repeated as an outer loop iteration (n) until the total assignment probability of the class labels stabilizes i.e.,
where refers to the probabilities of the class at site i at the iteration and is a convergence threshold that can be very small (say ). This iterative approach has been explored in other prior work as in the ICM [35]. The inner and outer loop iterations ensure that the local and global connectivity of the pixels are maintained. A section of the Python 3.12.12 notebook and the benchmark dataset is made available for reproducibility as a Github (https://github.com/praveenpankaj/mdpi_sensors_hsi/, accessed on 16 October 2025) and newer versions will be uploaded to IEEE CodeOcean [41].
2.4. Ensemble Voting
An ensemble voting algorithm helps in generalizing the model well and avoids overfitting to the training samples [19]. This can decrease the overall accuracies, but ensures the reliability of the classification results. So, the following optional steps are proposed in addition to the above methodology.
Step 1: The features are divided into 4 mutually exclusive and collectively exhaustive subsets using random sampling.Step 2: The proposed model is built on all the subsets individually and the classification map is obtained for every single model.Step 3: The classification maps from Step 2 are stacked and the final classification map is obtained by voting for the majority class.
3. Evaluation
3.1. Benchmark Data for Training and Testing, and Open-Set Data for Inference
We use data from three open-source hyperspectral images, which are the Indian Pines Image [42], the Salinas Image [42], and the University of Pavia Image. These are from different sensor resolutions, sizes, and classes. The Indian Pines’ scene was captured by NASA’s AVIRIS sensor over the test site in North Western Indian, USA [43]. The image has a size with a spatial resolution of 20 m and a total of 224 spectral reflectance bands present within the wavelength range m to m. The scene mainly contains agricultural land, forests, grasslands, and some urban classes. The ground truth is mapped into sixteen classes that are not all mutually exclusive. It is a conventional practice to reduce the number of spectral bands to 200 by removing the bands covering the regions of water absorption e.g., the bands . Figure 2 shows a randomly selected band (band 3) and the ground truth with class labels.
The Salinas image was captured by NASA’s AVIRIS sensor over the Salinas Valley in California. The image has a size with a spatial resolution of m and has 224 spectral reflectance bands. Similarly to the Indian Pines, there are twenty bands that cover the water absorption bands with band numbers . The Salinas ground truth is designated to sixteen classes that are not all mutually exclusive. The Salinas scene contains vegetables, bare soils, and vineyard fields. Figure 3 shows a randomly chosen band 101 with ground-truth.
The Pavia University scene was acquired as one of the experimental analyses using the ROSIS-03 sensor (or Reflective Optics System Imaging. Spectrometer) during a flight campaign over Pavia in Northern Italy. The ROSIS was jointly developed by Dornier Satellite Systems (DSS, former MBB), GKSS Research Centre (Institute of Hydrophysics) and German Aerospace Center (DLR, Institute of Optoelectronics). The detector chip is a 2-dimensional CCD array. The image has 115 spectral bands of size and with a spatial resolution of m per pixel. It is the general norm to keep only 103 channels from the original 115 by discarding the 12 most noisy channel from the raw data. The ground truth contains nine classes as shown in Figure 4 with a randomly chosen band 41.
The test samples are chosen from the same 3 set of images, and hence this is a closed-set with the class representations in the test being fully represented in the training set.
The open-set data are chosen from a study region in Italy, as described in Section 3.6. The PRISMA sensors acquire VNIR and SWIR products, with a 30 m spatial-resolution, and a panchromatic camera with a 5 m spatial resolution. The hyperspectral camera works in the range of – m with 66 and 173 channels in the VNIR and SWIR, respectively. Due to their low SNR, SWIR bands (2392 nm) and (2495 nm) were not considered. We used the L2D HCO product and the SWIR images with the number of bands being 171 and a size of .
3.2. Performance Metrics
The performance of the proposed model is evaluated using three quality indices, which are the overall accuracy (OA), average accuracy (AA), and the Kappa coefficient. The OA is the percentage of correctly classified pixels, the AA is the mean of the percentage of correctly classified pixels for each class, and the Kappa coefficient gives the percentage of correctly classified pixels corrected by the number of agreements that would be expected purely by chance.
The advantages of the framework are also computational efficiency. In Ref. [29], the authors have made a comparison of the different state-of-the-art algorithms and have highlighted that the SVM with the RBF kernel has the least computational time during training. The computational order for our approach is determined by the pixel classifier viz. , while for CNN it will be for P pixels, L layers and M operations in each layer.
3.3. Analysis of Parameters
The proposed methodology is a mixture of supervised and unsupervised classification because the first stage of the modeling is a supervised spectral classification, and the second stage is an unsupervised approach that uses the spatial nearness and spectral similarity of pixels in the image. The basic objective of the proposed model is to designate each pixel in the image to a class by making use of the least amount of labeled data. So, the entire pixels in the image are split into two sets, viz. training data and testing data s.t. the training data have samples from each class. The labels of the first set are visible to the model and are used to determine the optimum value of parameters of the classifier, and the testing data is left untouched. The parameters of both classifiers are determined independently and the methodology is as follows.
Parameter Selection for PCA: We fixed the PCA parameters, viz. the explained ratio, to for all images, and the optimal number of principal components can be automatically calculated from that threshold. The cumulative explained variance ratio curves reached saturation after the first 30 main principal components. However, during cross-validation (CV), we found that the accuracies of the classifier do not improve after the first 18 of the principal components. For the training data partition, we deliberately used a smaller training fraction than conventional literature splits in order to simulate real-world data-scarce agricultural conditions (see Table 1).Spectral classifier parameter tuning: We used SVM [36] with the RBF kernel as a spectral classifier due to its relatively higher accuracy compared to other classifiers. We observed that spatial adjacency is maintained better by SVM’s pixel-level class label assignment than by using a tree-based classifier. When training, we randomly choose a few pixels from each class label. For training data partition, we deliberately used a smaller training fraction than conventional literature splits in order to simulate real-world data-scarce agricultural conditions:This choice is based on our operational experience:
- ground truth collection requires expensive field campaigns and multiple visits during a growing season,
- the minor crops that are grown in a region during main season could be minimum,
- with changing climatic conditions, for the same region, a different crop might be chosen the next season and re-labeling is required. Our objective is to demonstrate that the proposed method maintains competitive accuracy even under extreme label scarcity ( ), whereas deep models typically require much higher data for stable training.As the number of parameters of the SVM (C and ) is small, these are estimated using an exhaustive grid search algorithm [44,45] within a specified coarse bound using a 5-fold CV. Some authors have estimated that their algorithm gave the best OA when of data was used for training for the Indian Pines, for the Salinas and for the Pavia respectively [46]. In real-world scenarios, ground truth is sparse and expensive. We used smaller training fractions than conventional splits for these benchmark datasets to highlight low-label scenarios. So, we reduce efforts in manual ground truth data collection and annotation, our objective towards model building was to use as few training samples as possible or low-resource conditions. Finer grid search for the parameter is computationally feasible and can be parallelized [44] but at the risk of overfitting to the data.Parameter tuning: The parameter r determines the size of the neighborhood around the reference pixel, the parameters and control the degree of spatial nearness and spectral similarity Gaussian kernel, respectively. The parameter , with , specifies the relative importance between the two terms in Equation (10). It was observed that the parameter r more influences the model and this is estimated first, while and are bounded by r. This is also expected behavior, as the value of the parameter r is linked to spatial resolution. In missions with lower resolution acquisitions, to avoid smoothing, a lower value of r is required. The spatial resolution and the choice of the neighborhood are also closely linked to the type of farm holding size. It is likely that for smaller landholding sizes (<1.58 acres or 6400 m^2^), the performance of the method could be affected. The performance of the model is evaluated with respect to the three quality indexes mentioned in Section 3.2 and the results are summarized in Figure 5, Figure 6 and Figure 7. The parameter r determines the size of the neighborhood around the reference pixel, the parameters and control the degree of spatial nearness and spectral similarity (see Figure 8) Gaussian kernel, respectively.
Table 2 summarizes the optimal parameters required by the algorithm for the analysis in Figure 5, Figure 6 and Figure 7. We found that by fixing the set of parameters to , , , and , for all images, there was a slight loss in the OA but we benefit from not having to fine-tune these parameters in the future. This was also observed in [39] with the smoothness kernel parameter and the weights that did not influence the accuracy of a given dataset. So, the only parameters to estimate are the parameters of the SVM C and to improve accuracies the [47] parameter. We observed that the AA of the algorithm is especially sensitive to C and the degree of dependency is smaller on the other parameters, so we recommend estimating the value of C for each dataset.
3.4. Classification Results and Model Transferability
The performance of the proposed algorithm is shown, for the three data sets, in Table 3, Table 4 and Table 5 and compared with the other methods. The comparison is made with some closely related hyperspectral classification methods such as Edge Preserving Filter (EPF) [48], Image Fusion and Recursive Filtering (IFRF) [46], Random Multi-Graphs (RMG) [49]. EPF generates pixel-wise classification maps and handles these maps by edge-preserving filtering. Then, the class of each pixel is selected on the basis of the maximum probability. The IFRF combines the spatial and spectral information through image fusion and recursive filtering. IFRF does not directly extract the features of the patches and uses two parameters and to extract the spatial features. RMG is a semi-supervised ensemble learning method based on Random Multi-Graphs.
In Figure 9, Figure 10 and Figure 11, we present the classification results of the EPF, IFRF, and our proposed approach for a single run. Experimental results on this dataset show that the spatial consistency is roughly preserved by all these methods and they all significantly outperform the unary spectral classifier.
IFRF and RMG have comparable results and they slightly outperform EPF. In some of the previous work above, noisy channels were removed prior to spectral classification. In this work, the only preprocessing step was the removal of the background pixels that did not have any classification label assigned to them (mixture of classes), and the other step was to normalize the intensities (Min-Max). For the Salinas dataset, when the final classification map is fed back as weak labels, and input as a replacement for the spectral classification map, our accuracy increased to 99.42% which is the highest compared to EPF, IFRF or RMG. We observed the same phenomenon in the Indian Pines, where the accuracy rose to about 97% (from 92.78%) with just one additional run. The accuracy increased to 99.58% for the Indian Pines dataset when the number of training samples was increased. However, the greatest confusion was between the crop classes “Soybean-mintill” and “Corn-notill”. The algorithm is likely to have recognized the corn residue from the previous season as the current season planted soybean due to the minimum tilling agricultural practice. For Indian Pines, Salinas, and Pavia datasets, several new results have set accuracy benchmarks using CNNs and Transformer architectures, respectively. For example, in SSRN [16], the authors used about 25% of the samples for training for Indian Pines and about 11% for Pavia University datasets and reached maximum accuracies of more than 97% and more than 99% for Indian Pines and Pavia University, respectively, by using Batch Normalization and Dropouts. The training time for Indian Pines is longer at 106 minutes and inference is 17.2 s on a MSI GT72S laptop (Micro Star International Co Ltd., Taiwan, China) with Intel Core i7 processor up to 64 GB memory and the GeForce GTX 980M GPU 8/4GB GDDR5. SpectralFormer [50] has demonstrated accuracy > 99% with a combined training and inference time of about 20 s on a server equipped with an Intel Xeon Silver 4210 2.20-GHz CPU and an NVIDIA GeForce RTX 2080Ti GPU with 11 GB of memory. Our accuracy results are comparable and sometimes better than some of these models. The parameter complexity is very high in some of these recent models, low model interpretability, the transferability and open-set classification is not tested, and requires GPUs for deployment. In addition, in our methodology, the number of parameters to estimate are 2 (C and ). Our algorithm does not require high-performance computations or GPUs, and training and inference take less than 21 s for the Indian Pines Dataset, which could be optimized further. The server CPU used is Intel(R) Xeon(R) CPU GHz and GB Memory. Hybrid CNN models, 2D and 3D work very well, but seem to be sensitive to the amount of training data and window size. For example, for the Indian Pines dataset, when the training data is less than , for a window size of 25, hybrid approach produce an AA of . When the window size is decreased to 9, the AA drops to .
The model is designed to enable the transfer of all parameters except C, which requires dataset-specific tuning. This significantly reduces the dependency on the training data and decreases the training time since only one parameter out of six needs to be optimized for new datasets. To understand the transferability of the model, the parameters , were fixed at , , , , and as described in Table 2, and the tests were carried out on the AVIRIS Kennedy Space Center dataset and the Hyperion Botswana dataset. For the Salinas-A dataset, the OA and AA were at . For the Botswana dataset, the true value of C is around the value of 32, and with this value, the AA and for the spectral classifier were and , and increased with the spectral-spatial classifier to and respectively. However, for the KSC image, the true value of C was ≫ 32, and the OA and values increased from and to and respectively. By setting the parameter to a low value, the spectral classifier’s decisions alone can be included, and the performance is closer to the spectral classifier.
3.5. Ablation Studies
To evaluate the contribution of each component in the proposed framework, we performed ablation studies by comparing three variants:
- a pixel-wise classifier based on SVM,
- the SVM classifier followed by CRF-based regularization, and
- the full pipeline integrating weak supervision and iterative unsupervised learning with refinement.
The goal of the ablation experiments is to disentangle the importance of the components in weakly labeled guided iterative learning.
From the ablation studies, it was found that the baseline SVM classifier achieves good separability for certain dominant classes, but suffers from noise and fragmented predictions. Incorporating CRF-based regularization (SVM+CRF) provides spatial consistency and improved accuracies in several classes (e.g., Classes 2, 5, 10, 11, 12), although performance degrades in very small or spectrally ambiguous classes (e.g., Classes 1, 7, 9) leading to an OA of . The complete model also takes advantage of weak labeling and iterative unsupervised learning, producing the most balanced performance across classes and significantly higher overall accuracy .
These results confirmed the following.
Purely pixel-wise classification is insufficient for open-set agricultural scenarios due to high within-class variability and due to minimal/no class overlap with training data.Adding spatial regularization using CRF improves the homogeneity of the predictions, but can also decrease the performance if the initial labeling is wrong. Regularization cannot handle unknown classes.The full model makes use of both spatial proximity and spectral similarity. So, even if the initial mapping is mislabeled, iteratively it is refined. It is also effective in handling unseen or under-represented classes, demonstrating robustness to domain transfer with limited training labels.
Overall, ablation experiments confirmed that each stage contributes incrementally, with the final system offering a practical trade-off between accuracy and generalization.
3.6. Testing on New Region and on Open Set Data
In Computer Vision, Open-Set is the problem of handling images or inputs having ‘unknown’ classes. Some of the classes may be absent in the training dataset, but are present in the test dataset (novel) or vice versa. Traditionally, classifiers assume inherently that the classes present in the training are also present in the test set. In the case of agricultural applications, this is not always the case. Often, the crops that have to be identified are usually novel and specific to the region of interest i.e., . Depending on the agroecological zones (see https://gaez.fao.org/, accessed on 16 October 2025), there can be multiple crops that grow in a particular region during the major and minor seasons. Even if there are the same set of crops, we often find that the genetic variety may be different at the test site than at the training site, which might result in the same crop having a different spectral signature even at the same phenological stages. In addition, the type of sensor may not be the same as the availability of the same satellite modality, and coverage may not be possible at all study locations. Some recent interest has been in the development of methods to overcome the limitations of supervised methodologies in a new region or crop by fine-tuning selected collected ground data points [51]. However, it is difficult to collect sample data points across multiple seasons and multiple crops or land use patterns. There are some recent attempts at unsupervised domain adaptation methodologies [52] and transfer learning techniques, but there are no known frameworks for hyperspectral analysis for agricultural applications. All these prior limitations are motivation factors to create the framework explained in Section 2. To assess the generalizability and transferability of our method, we trained on the benchmark datasets and evaluated it at a new location, which includes multiple types of crops not seen during training i.e., .
The chosen study area is in the Barengo commune, in the province of Novara, in the Italian Piedmont region, located about 80 kilometers from the city of Turin. The cumulative annual rainfall in this region is about 600 mm and the temperatures range between 5–25 °C.
Currently, there are no field survey data for the April 2020 acquisition over Piedmont. We emphasize that the PRISMA experiment demonstrates feasibility rather than benchmarking accuracy. We therefore rely on the multi-sensor data to validate the results. We know that the study area comprises a mixture of landcover classes [53] including croplands (mainly paddy), trees, grasslands, urban/built-up areas, bare soil and a permanent water body (see Figure 12b). This is very different from the Indian Pines dataset where the crops are primarily Alfalfa, Corn, Oats, Wheat, and Soybean (Figure 2). The only common land use classes in these two datasets are grasslands/pastures and trees. We chose the Piedmont region in Italy as it is responsible for the production of almost of Italy’s annual total rice production and due to the availability of hyperspectral data from the PRISMA (PRecursore IperSpettrale della Missione Applicativa) [54] (a Hyperspectral/Panchromatic instrument from the ASI-Italian Space Agency). Rice is an important crop for food security and also for sustainability. It is important to map paddy growing regions and monitor them to ensure sustainable production considering the fact that paddy is heavily dependent on water during the different stages and it also produces GHG emissions from Methanogenesis. The mapping of the extent of the rice plot, the quantification of water usage, and emissions can help plan the mitigation steps around the emissions [55]. The PRISMA image was acquired on 25 April 2020, and it is the peak period of transplantation. After land preparation and flooding, paddy transplantation begins in early April and continues until the end of May, while all harvesting is complete by mid-October. Due to climate change, there are recent variations in the beginning and end of the seasons.
In Figure 13, we show the results of the model trained on the Indian Pines datasets but inferred on the PRISMA dataset that was specified above. The groups were ‘weakly labeled’ by subject matter experts (human in the loop), based on information from the Corine land cover [56], the ESA LULC Map [53] and ground validation.
Transplanted rice cultivation requires standing water, which serves as a spectral signature to identify the regions that grow paddy [57]. In Figure 14, we show the output rice growing region identified using the Sentinel-1 VH band as a feature layered on top of the estimated crop-land extents (pink color in Figure 12).
An additional level of verification is by observing the NDVI signatures of each class. We randomly selected a few pixels from each of the following distinct groups: Tree, Urban, Crops, Barren and Flooded Rice, and the NDVI plot is shown in Figure 15. The Figure 15d shows the Copernicus Sentinel-2 multi-spectral satellite-derived vegetation index (NDVI) plot of randomly sampled pixels from the regions classified as Paddy by our approach. The chart shows that the seedling/transplantation from the nursery to the farm plot occurs around the end of April and at the beginning of May, and the vegetative, reproductive, and ripening stages are also clearly visible. As the year of growth and the availability of the data was in 2020, it is difficult to do the ground truth validation, but we verified that the paddy was growing in these plots in 2023. Farmers have traditionally grown paddy in this region for many seasons and will continue to be the main crop in the region. This rice mask is also used as a reference map to validate the results of our classification. In addition to these sources, in the absence of field visit data, we used Street View images to verify selective areas in the regions, which is shown in Figure 16. We also tried the same approach of training a deep learning model with a deep learning model (3D CNN) that uses both spectral and spatial features [58] and then inferred in the Barengo study area, but the model was not transferable and the results were very poor despite the model having a training accuracy of and a validation accuracy of on the Pines dataset (train:test:val split : : ).
3.7. Limitations
There are three current limitations of our proposed approach that warrant discussion:
- Spectral Confusion: The model confuses between spectrally similar crops or same crop with different management practices, and is typical of single temporal snapshot-based analysis. Multi-temporal analysis might resolve this confusion.
- Phenology Sensitivity: The model is sensitivity to the phenological stage and the accuracy is during the maturity stage of the crop, and
- Validation Constraints: The absence of field campaigns for PRISMA dataset means that the methodology depends on proxy validation using multi-sensor cross-validation than actual field campaign data. While we observed that the inter-method agreement was high, having ground-truth field campaigns could also give accuracy statistics.
4. Conclusions and Future Work
We propose a novel lightweight framework for Hyperspectral image-based classification by using a combination of pixel-wise supervised and iterative unsupervised learning methods. The key feature is that the learning method, at least, requires estimation of only one parameter and, for a better accuracy, requires a maximum of two parameters and minimal training samples. Across the different benchmark datasets, our method demonstrated 7.22–15% improvements in the overall accuracy compared to pure spectral classifiers. After convergence, the method achieved the highest accuracy in the Salinas dataset ( ) and remains comparable to other state-of-the-art models for the Indian Pines dataset ( ). It is best suited for sustainable agricultural applications where ground truth is very sparse and with many unseen classes. The model is faster to train, and the trained model parameters are transferable across the different datasets while maintaining the accuracies. Our lightweight framework offers a robust baseline for domain transfer in label-sparsity situations, though it might not be a replacement for deep networks where data are abundant, diverse, or in well-annotated settings. Transformer-based models such as the MASSFormer [50] work well in closed-set scenarios with >10% training data. We aim to extend this framework to diverse HSI datasets and datasets from a broader set of satellite missions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Adão T. Hruška J. Pádua L. Bessa J. Peres E. Morais R. Sousa J. Hyperspectral Imaging: A Review on UAV-Based Sensors, Data Processing and Applications for Agriculture and Forestry Remote Sens.20179111010.3390/rs 9111110 · doi ↗
- 2Thenkabail P.S. Smith R.B. Pauw E.D. Hyperspectral Vegetation Indices and Their Relationships with Agricultural Crop Characteristics Remote Sens. Environ.20007115818210.1016/S 0034-4257(99)00067-X · doi ↗
- 3Weiss M. Jacob F. Duveiller G. Remote sensing for agricultural applications: A meta-review Remote Sens. Environ.202023611140210.1016/j.rse.2019.111402 · doi ↗
- 4del Cerro J. Cruz Ulloa C. Barrientos A. de León Rivas J. Unmanned aerial vehicles in agriculture: A survey Agronomy 20211120310.3390/agronomy 11020203 · doi ↗
- 5Leslie C.R. Serbina L.O. Miller H.M. Landsat and Agriculture—Case Studies on the Uses and Benefits of Landsat Imagery in Agricultural Monitoring and Production Technical Report U.S. Geological Survey Reston, VA, USA 2017
- 6Lu B. Dao P.D. Liu J. He Y. Shang J. Recent advances of hyperspectral imaging technology and applications in agriculture Remote Sens.202012265910.3390/rs 12162659 · doi ↗
- 7Arellano P. Tansey K. Balzter H. Boyd D.S. Detecting the effects of hydrocarbon pollution in the Amazon forest using hyperspectral satellite images Environ. Pollut.201520522523910.1016/j.envpol.2015.05.04126074164 · doi ↗ · pubmed ↗
- 8Apan A. Held A. Phinn S. Markley J. Detecting sugarcane ‘orange rust’ disease using EO-1 Hyperion hyperspectral imagery Int. J. Remote Sens.20042548949810.1080/01431160310001618031 · doi ↗