Adaptive Non-Singular Fast Terminal Sliding Mode Trajectory Tracking Control for Robotic Manipulator with Novel Configuration Based on TD3 Deep Reinforcement Learning and Nonlinear Disturbance Observer
Huaqiang You, Yanjun Liu, Zhenjie Shi, Zekai Wang, Lin Wang, Gang Xue

TL;DR
This paper introduces a new control strategy for robotic manipulators that combines deep reinforcement learning and disturbance observers to improve tracking accuracy and robustness.
Contribution
The novel integration of TD3 deep reinforcement learning with NFTSMC and NDO for enhanced trajectory tracking in robotic manipulators.
Findings
The proposed TD3NDONFT algorithm reduces position tracking errors by up to 19.94% in robotic manipulator joints.
Velocity tracking errors are also reduced, with the highest improvement of 9.10% in one joint.
The algorithm demonstrates strong robustness against sudden disturbances and unknown time-varying disturbances.
Abstract
This work proposes a non-singular fast terminal sliding mode control (NFTSMC) strategy based on the Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm and a nonlinear disturbance observer (NDO) to address the issues of modeling errors, motion disturbances, and transmission friction in robotic manipulators. Firstly, a novel modular serial 5-DOF robotic manipulator configuration is designed, and its kinematic and dynamic models are established. Secondly, a nonlinear disturbance observer is employed to estimate the total disturbance of the system and apply feedforward compensation. Based on boundary layer technology, an improved NFTSMC method is proposed to accelerate the convergence of tracking errors, reduce chattering, and avoid singularity issues inherent in traditional terminal sliding mode control. The stability of the designed control system is proved using Lyapunov…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
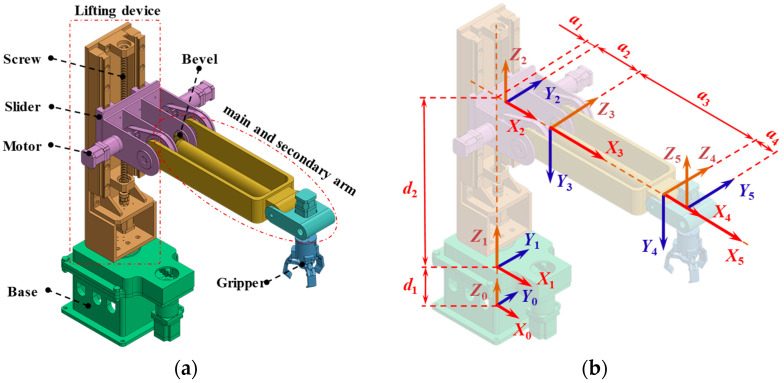 Figure 1
Figure 1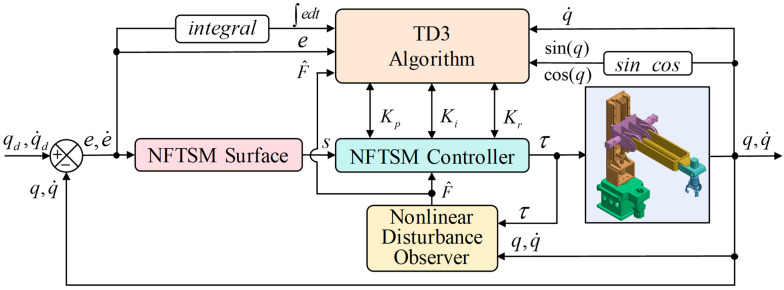 Figure 2
Figure 2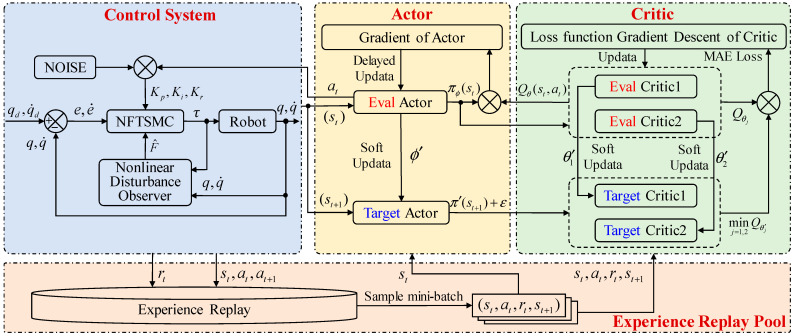 Figure 3
Figure 3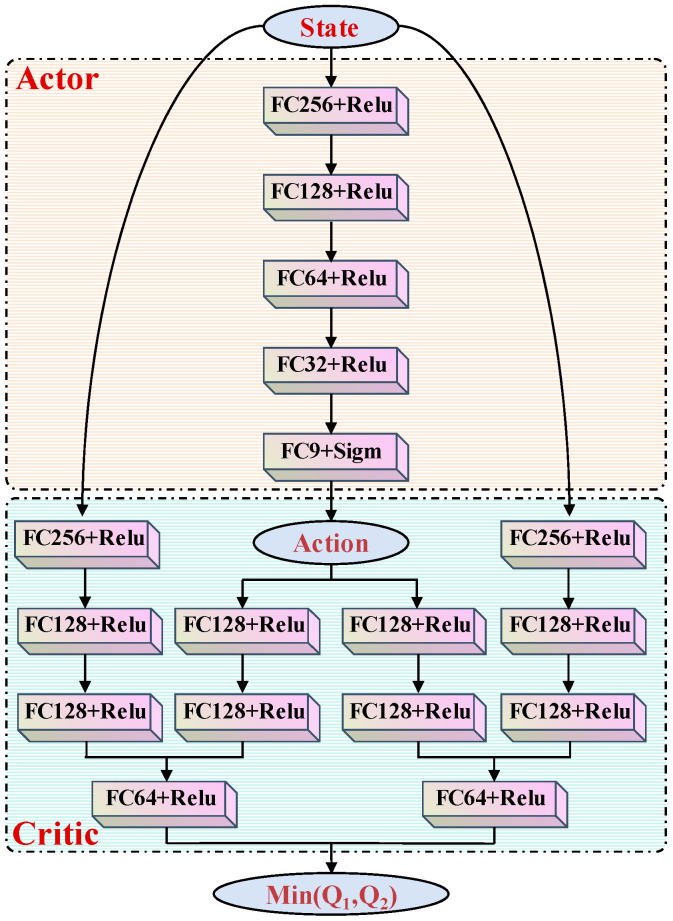 Figure 4
Figure 4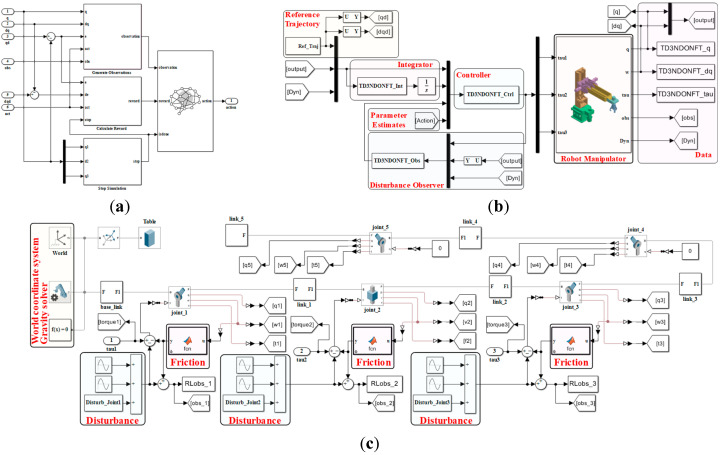 Figure 5
Figure 5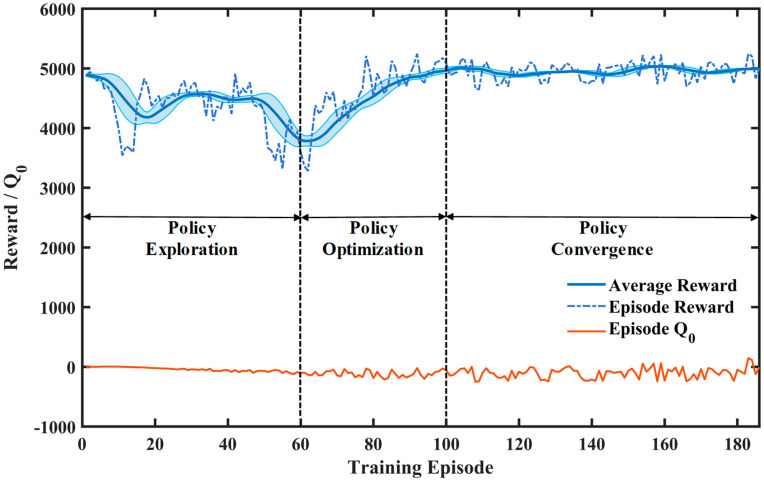 Figure 6
Figure 6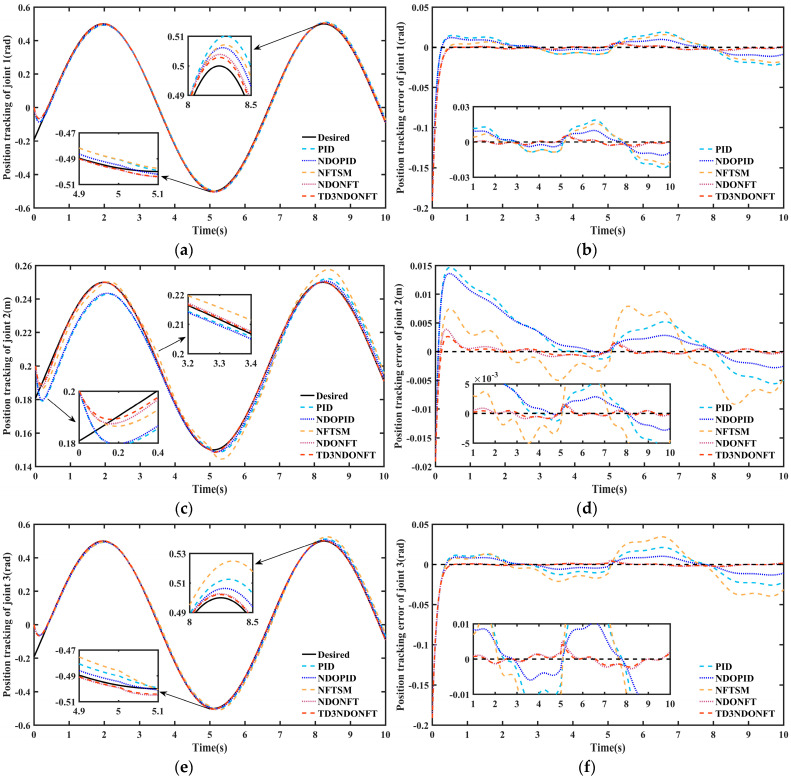 Figure 7
Figure 7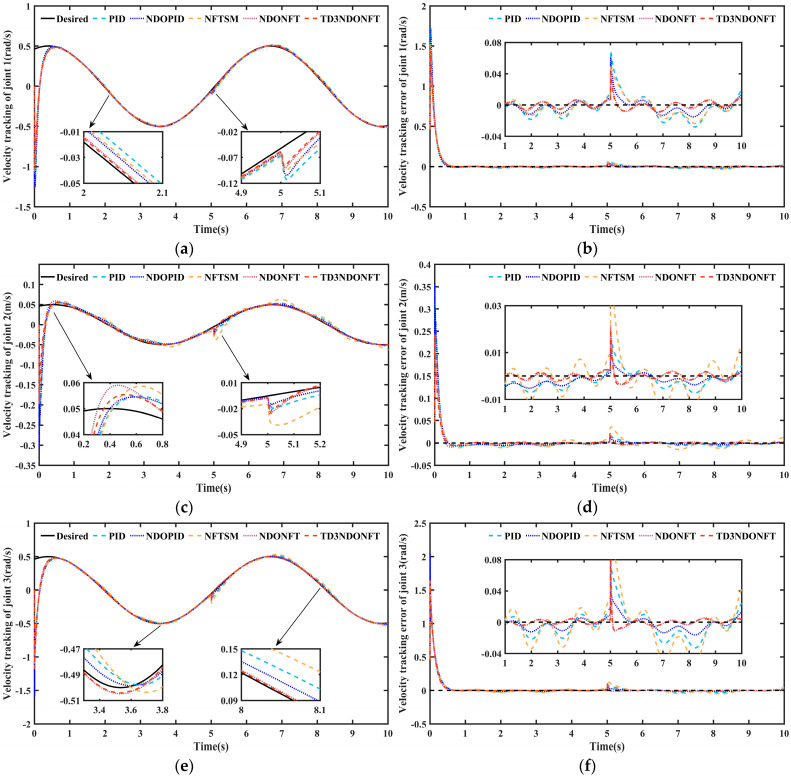 Figure 8
Figure 8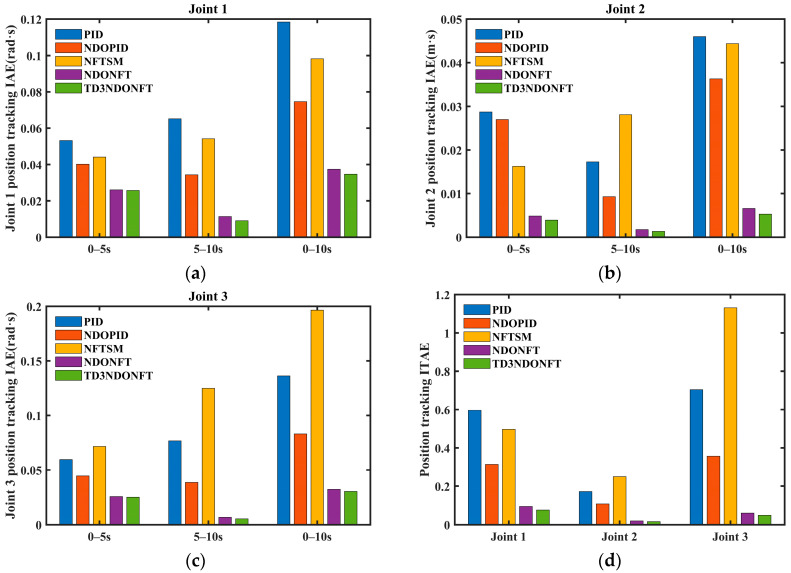 Figure 9
Figure 9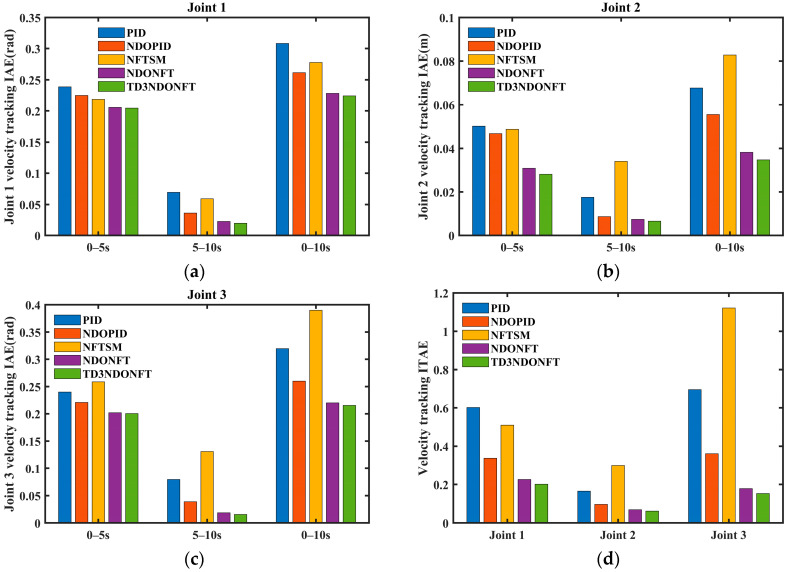 Figure 10
Figure 10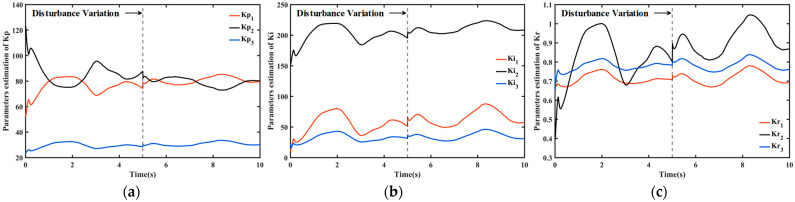 Figure 11
Figure 11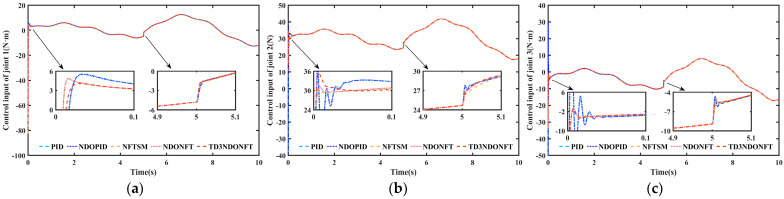 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16- —National Key Research and Development Program of China
- —National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdaptive Dynamic Programming Control · Adaptive Control of Nonlinear Systems · Reinforcement Learning in Robotics
1. Introduction
As the core executive units of modern industrial automation systems, robotic manipulators have expanded their application scenarios from traditional structured environments such as welding processing [1] and material handling [2] to highly dynamic unstructured environments including surgical assistance [3], space exploration [4], and service robots [5]. During the execution of complex tasks, the end-effector of the robotic manipulator must accurately complete high-precision spatial movements along a predefined trajectory. However, robotic manipulators are highly complex multi-input multi-output systems characterized by strong nonlinearity, time-varying dynamics, and strong coupling [6]. Additionally, the structural parameters of the robotic manipulator are difficult to obtain accurately, and the dynamic model is partially unknown, resulting in significant uncertainties in the mathematical state-space model describing the motion of the robotic manipulators [7]. Functional configuration design and high-precision trajectory tracking control are effective approaches to address these challenges.
To better achieve trajectory tracking control of robotic manipulators, researchers have proposed various control methods, including fuzzy control [8,9], sliding mode control [10,11], neural network control [12,13], reinforcement learning control [14,15], and model predictive control [16,17].
Xian et al. [18] established a dynamic model for coordinated robotic manipulators using fuzzy set theory and developed an approximate constrained following servo control to ensure the consistent boundedness and consistent ultimate boundedness of the controlled system. They selected optimal parameters by solving fuzzy-based performance metrics. Zhang et al. [19] proposed a three-dimensional fuzzy active disturbance rejection controller for the mechanical arm of an iron roughneck by adding a three-dimensional fuzzy module to the classical ADRC. The controller output is adjusted based on tracking differential error, error rate of change, and error acceleration. Obadina et al. [20] developed a hybrid optimization algorithm for gray-box model identification of robotic manipulators and applied the model for real-time fuzzy trajectory tracking control. Jiang et al. [21] combined the Beetle Antenna Search (BAS) algorithm with Particle Swarm Optimization (PSO), introducing fractional calculus to dynamically adjust inertia weight and fractional order, achieving high-precision trajectory tracking control for robotic manipulators. However, fuzzy strategies overly rely on human experience, and parameter selection based on intelligent algorithms is prone to being trapped in local optima.
Sun et al. [22] employed radial basis function neural networks (RBFNN) to compensate online for uncertainty and unknown dynamics of system parameters. Chen et al. [23] optimized RBFNN parameters using an immune algorithm and designed adaptive rate compensation for unknown hysteresis errors similar to recoil and RBFNN approximation errors. However, the high computational complexity of neural network algorithms results in poor real-time tracking performance and presents physical implementation challenges. Carron et al. [24] combined inverse dynamics feedback linearization and data-driven error models with model predictive control. They processed offline data using Gaussian filtering and utilized extended Kalman filtering to estimate residual disturbances online, achieving bias-free tracking of the robotic manipulator. Kang [25] proposed an event-triggered model predictive control strategy for robotic manipulators with model uncertainty and input constraints. Trigger conditions were defined based on the weights of the predictive model and predicted tracking error. However, MPC is sensitive to system modeling accuracy, and its time-domain optimization mechanism only solves local optima within a finite time interval, making it difficult to ensure global asymptotic stability of the closed-loop system.
Sliding mode control has been widely applied in robotic manipulator control due to its simple physical implementation, strong robustness, and fast transient response [26]. Kali et al. [27] used a linear sliding mode surface for the trajectory tracking control of robotic manipulators, but this method only guarantees asymptotic convergence of the state [28]. Rapid convergence requires high gains, whereas terminal sliding mode control can ensure system convergence within finite time. Xu et al. [29] designed a discrete integral terminal sliding mode control law that incorporates delayed estimation of unknown disturbances and discretization errors in the robotic manipulator system and introduces an adaptive switching term to suppress sliding mode chattering effects. However, the chattering issue in sliding mode control can cause actuator damage or even system instability. To reduce or eliminate chattering, Makrini et al. [30] designed a variable boundary layer (BLT) sliding mode control method, which achieves joint safety and high-performance control by adjusting torque limit parameters and the expansion factor of the variable boundary layer.
Additionally, since certain system states are unmeasurable in practical applications, system uncertainty can affect transient performance and even lead to instability in robotic manipulator systems. To better achieve disturbance compensation, Fan et al. [31] proposed a fuzzy control strategy based on a spatial extended state observer to address the trajectory tracking control problem of robotic manipulator capturing a floating object in a microgravity environment. Yin et al. [32] proposed an adaptive non-singular terminal sliding mode control method based on NDO to observe the internal modeling errors of robotic manipulator and the external unknown time-varying disturbances acting on each joint for feedforward compensation. Zha et al. [33] estimated lumped uncertainties of the entire system using a hybrid observer composed of an adaptive time delay estimator based on gradient compensation and a second-order adaptive sliding mode observer. They then constructed an adaptive integral non-singular fast terminal sliding mode algorithm based on the backstepping method to stabilize the system and reduce chattering. Hu et al. [34] achieved real-time disturbance estimation and compensation by combining load torque estimation based on an improved harmonic drive flexibility model with friction compensation using a hybrid friction model, effectively improving trajectory tracking performance of the robotic manipulator under high-speed variable load conditions.
The aforementioned methods have achieved good results in robotic manipulators, but with the rapid development of artificial intelligence technology, data-driven machine learning approaches offer new insights for the intelligent tracking control of robotic manipulators. Reinforcement learning does not require the establishment of precise dynamic models, which makes it advantageous for solving sequential decision-making problems under highly nonlinear and uncertain conditions [35]. Viswanadhapalli et al. [36] utilized deep reinforcement learning control based on the Deep Deterministic Policy Gradient (DDPG) framework to achieve precise servo tracking of a flexible robotic manipulator, and evaluated the controller performance through hardware-in-the-loop (HIL) testing. Lu et al. [37] proposed an adaptive proportional-integral robust control method based on DDPG, which searches for the optimal controller parameters in a continuous action space using the dynamic information of the robotic manipulator. They also designed a reward function that combines a Gaussian function with Euclidean distance to ensure stable and efficient agent learning. Ren et al. [38] proposed an adaptive sliding mode control method based on DDPG reinforcement learning, leveraging RL autonomous learning capabilities to adaptively adjust the key parameters of the controller online. However, the DDPG strategy is susceptible to Q-value overestimation and insufficient exploration efficiency. The TD3 algorithm introduces a double Q-network, target policy noise, and delayed policy update techniques, achieving significant improvements in mitigating over-bias in action-value function estimation and enhancing policy stability. Zhu et al. [39] designed an adaptive sliding mode controller based on TD3 parameter optimization for variable-speed trajectory tracking of underactuated vessels in scenarios involving model uncertainty and external environmental disturbances. Fan et al. [40] addressed path tracking of unmanned underwater vehicles by integrating an improved experience replay strategy into TD3 while enhancing learning efficiency through refined regularization methods and dynamic reward functions, achieving faster convergence and superior tracking performance compared with mainstream classical DRL approaches.
Due to the highly nonlinear, multivariable strong coupling and the difficulty of accurately obtaining physical parameters, establishing an accurate dynamic model of robotic manipulators is extremely challenging. At the same time, the time-varying and uncertain nature of friction and external disturbances further complicates modeling. Although traditional control methods achieve satisfactory performance in known systems, their adaptability remains insufficient for unknown or uncertain systems. In order to address the trajectory tracking problem of robotic manipulator under unknown time-varying disturbances and modeling uncertainties, this paper proposes an improved NFTSMC method based on the TD3 algorithm and NDO. The main contributions are summarized as follows:
- For tasks such as precision assembly and high-accuracy positioning that impose strict requirements on position and velocity control, a novel 5-DOF robotic manipulator configuration is designed, which reduces the end-effector load by positioning the joint motors at the front and simplifies dynamic model computation by introducing prismatic joint.
- A nonlinear disturbance observer is employed to estimate internal modeling errors and external unknown time-varying disturbances of the robotic manipulator, followed by feedforward compensation. An improved nonsingular fast terminal sliding mode control law is designed based on boundary layer technique, and global system stability is analyzed using Lyapunov theory.
- Adaptive control is achieved through DRL by proposing an adaptive NDONFT control method based on the TD3 algorithm, which employs a dual Q-network structure and selects the minimum Q-value to effectively mitigate value overestimation in DRL. The learning efficiency and stability of the agent are enhanced by modifying the reward function, thereby avoiding convergence to local optima.
- Using the three joints of the designed 5-DOF robotic manipulator as examples, this paper verifies that the proposed method achieves excellent trajectory tracking performance and demonstrates stronger robustness against external unknown sudden disturbances.
The remainder of this paper is organized as follows: Section 2 presents the system principles and mathematical models of the robotic manipulator; Section 3 introduces the design process and stability analysis of the TD3NDONFT algorithm-based controller; Section 4 analyzes the simulation results; and Section 5 summarizes the main contributions of this paper.
2. System Principles and Mathematical Models
2.1. System Principles
A 5-DOF robotic manipulator with a modular serial configuration is designed to meet the stringent position and velocity control requirements of precision assembly and high-accuracy positioning tasks, as shown in Figure 1a. The manipulator consists of a base, a lifting mechanism, a main arm, a secondary arm, and an end-effector gripper. The degrees of freedom of each joint are as follows: horizontal rotation of the base about a vertical axis (DOF1), linear translation of the lifting platform along a vertical rail (DOF2), pitch motion of the main arm about a horizontal axis (DOF3), independent pitch adjustment of the secondary arm about a parallel horizontal axis (DOF4), and rotation of the end-effector about a vertical axis (DOF5). DOF2 employs a screw-and-rail composite transmission mechanism, utilizing high-precision screw drives and low-friction rails to significantly enhance vertical positioning resolution and repeatability. The pitch joint of the secondary arm (DOF4) transmits power through two-stage bevel gear meshing, forming a front-mounted drive unit layout that effectively reduces end-effector inertia and enhances dynamic response capability. This arrangement accommodates high-speed, variable-acceleration trajectory tracking requirements. The overall symmetrical structure and compact transmission chain design reduce kinematic coupling effects and simplify the inverse kinematics model solution process. This configuration, through high-rigidity transmission, low-inertia drive, and decoupled motion chain design, lays the foundation for position closed-loop control in trajectory tracking.
In robotic manipulator modeling, the Denavit–Hartenberg (DH) method is a commonly used technique for describing the geometric structure and kinematic relationships of robotic manipulators. Compared to the standard DH method, the modified DH (MDH) method used in this study more accurately characterizes the geometric and kinematic features of the manipulator [41]. Table 1 lists the DH parameters of the manipulator based on the modified DH method. In this paper, the base coordinate system established using the MDH method is assumed to be the zero position, as shown in Figure 1b.
2.2. Dynamic Modeling
According to the Lagrange method, the dynamic model of an n-link robotic manipulator can be expressed as follows:
where represent the joint position, velocity, and acceleration vectors of the robotic manipulator system, respectively. is the symmetric positive definite inertia matrix of the system; is the Coriolis and centrifugal force matrix; is the gravity vector; is the friction vector; represents external time-varying disturbances. is the torque input to the joints. Due to the complexity of the robotic manipulator structure, environmental variations, and measurement errors, it is generally difficult to obtain accurate values of in the dynamic equations. Therefore, is defined as:
where represents the nominal value of the dynamic equation of the robotic manipulator, and represents the uncertainty term of the dynamic equation, i.e., the modeling error. Therefore, Equation (1) can be expressed as follows:
where is the total modeling error of the robotic manipulator system. Setting as the total disturbance of the system, including external disturbances, internal modeling errors, and friction. Equation (3) can be rewritten as:
The purpose of this paper is to design a controller for the robotic manipulator system that enables the joint positions and joint velocities of an n-DOF robotic manipulator to achieve high-precision tracking of the desired trajectory positions and velocities under disturbances. To achieve this goal, the following assumptions [25,32] are made regarding system (1).
Assumption 1. For , the symmetric positive definite inertia matrix is uniformly bounded, and there exists a normal constant such that the following inequality holds:
Assumption 2. For , is a skew-symmetric matrix, it satisfies the following equation:
Assumption 3. In practice, for , the gravity matrix satisfies, i.e., is always bounded.
3. TD3NDONFT Controller Design
In order to achieve trajectory tracking control of robotic manipulators under complex environmental influences, this paper proposes a non-singular fast terminal sliding mode control method based on NDO and DRL, as shown in Figure 2. The NDO is used to estimate and compensate for the lumped disturbance, while the autonomous learning capability of DRL is employed to learn the controller parameters.
In the n-link robotic manipulator system, let the desired joint position, velocity, and acceleration be , respectively, and the actual joint position, velocity, and acceleration be , respectively. Then, the tracking error and its derivative are defined as follows:
The error state variables and are constructed based on the position error , velocity error , and acceleration error of the robotic manipulator joints, that is . Then, the error dynamics equation of the manipulator can be written as:
3.1. Design of Nonlinear Disturbance Observer
The disturbance is estimated by correcting the estimated value based on the difference between the estimated output and the actual output. Combining with Equation (5), the following nonlinear disturbance observer is designed:
where is the gain matrix of the observer.
Since Equation (10) involves acceleration signals that cannot be accurately obtained by directly differentiating velocity signals in practical applications. This is because velocity signals inevitably contain sensor noise, quantization errors, and sampling jitter. Differentiation inherently amplifies high-frequency components, which significantly increases the influence of noise and results in severe distortion of the estimated acceleration. Furthermore, due to the high coupling of the manipulator system along with external disturbances, a nonlinear disturbance observer needs to be further designed to accurately estimate external disturbances in the manipulator system and feed them back to the controller for disturbance compensation.
Define auxiliary parameter variables as:
where is the designed function vector, according to [42], the gain matrix and function vector of the designed disturbance observer are given by:
where is an invertible matrix.
Substituting Equation (12) into Equation (11) and differentiating yields:
Substituting Equation (10) into Equation (13) yields:
In summary, Equations (11)–(14) constitute the designed nonlinear disturbance observer.
In order to enable the nonlinear disturbance observer to accurately estimate disturbances, the linear matrix inequality (LMI) method is introduced to solve . For convenience in derivation, the symbol is abbreviated as in the following steps.
To prove that the observation error converges asymptotically, define the Lyapunov function as:
where is the observation error, .
The derivative of the above Lyapunov function is:
According to Equations (11) and (14), the derivative of the observation error is:
Generally, without prior knowledge of , it is assumed that the dynamic disturbance relative to the observer changes slowly [43], that is . Further, the observer error equation is obtained as:
Substituting Equation (18) into Equation (16) yields:
Construct the following inequality:
where is a symmetric positive definite matrix, there exists such that the following equation holds:
It can be seen that the disturbance observer converges exponentially.
Since Equation (20) contains nonlinear terms, it must be converted to a linear matrix inequality to be solved. Define matrix , then Equation (20) can be transformed into:
Since , then , the sufficient condition for the above equation to hold is , which is equivalent to:
Based on the value of obtained from the solution, the observer gain matrix and auxiliary variable can be calculated.
3.2. NFTSM Controller Design
In traditional sliding mode control, the sliding surface is generally selected as a linear sliding surface. When the system state reaches the sliding surface, the linear sliding surface ensures that the error converges asymptotically to zero but does not guarantee finite-time convergence. In contrast, the terminal sliding surface guarantees that the error variable converges to zero within finite time.
Therefore, this paper adopts a non-singular fast terminal sliding mode surface [44]:
where , are all positive odd numbers, and , is the sign function. The derivative of Equation (24) with respect to time is as follows:
Combining Equations (9) and (25) yields:
Multiply both sides by the matrix to obtain:
Because the acceleration vector is difficult to obtain in practice, and to avoid its appearance in the control law, define the variable:
Substituting Equation (28) into Equation (27) yields:
According to the selected non-singular fast terminal sliding mode surface, the controller is formulated as follows:
is the equivalent controller obtained when the system reaches the sliding surface , and at this time the external disturbance is zero. and are the proportional gain and integral gain, respectively, with . is the sliding mode control term, which ensures that the system reaches stability. is employed to further eliminate errors and external disturbances. is a robust controller primarily used to suppress external disturbances outside the nonlinear disturbance observer and internal model reconstruction errors, thereby enhancing disturbance rejection capability.
At the same time, by introducing a nonlinear disturbance observer to estimate the disturbances, the control law after adding its compensation is:
From Equations (29) and (31), we can derive that:
In order to limit the control signal to the feasible range of the actuator and avoid output overshoot, thereby preventing input saturation, a saturation function is introduced to replace the sign function in the robust controller. The saturation function maintains linearity or smooth variation when the error is small, thereby reducing chattering, and gradually saturates when the error is large, thus preventing shocks caused by abrupt changes. The saturation function is defined as follows:
where is a positive constant representing the thickness of the boundary layer.
3.3. Stability Analysis of the Control System and Proof of Finite-Time Convergence
In the stability analysis of control systems, we consider a Lyapunov function in integral form:
Substituting Equation (15) into Equation (34), we obtain the derivative of with respect to time is:
Considering the skew-symmetric property of the robotic manipulator dynamic equation, we have , and substituting Equation (32) into Equation (35), we derive:
Substituting Equation (21) into Equation (36) and simplifying yields . According to Lyapunov stability theory, the system state converges asymptotically to the sliding surface . According to LaSalle’s invariance principle, when , , that is, , .
To prove that the system state converges to the sliding surface within a finite time, consider the Lyapunov function , and differentiate it to obtain:
Therefore , we obtain , let denote the system convergence time, and represent the initial state, at this time . Integrating the above yields:
The convergence time is calculated as , The trajectory tracking error of the robotic manipulator system tends to zero within finite time.
When , the saturation function behaves as the sign function , which does not affect the convergence of the control law. When , the convergence speed decreases to some extent, but has been controlled within a certain range. The robotic manipulator system achieves the desired convergence by adjusting , so the saturation function does not affect the final convergence properties of the system [34].
3.4. Deep Reinforcement Learning TD3 Adaptive Control
Reinforcement learning is a key branch of machine learning that obtains control strategies through interaction with the environment. RL problems are usually formulated as a Markovian decision process (MDP), which mainly includes the environment, agent, reward, state, and action [40]. Specifically, at each time step , the robotic manipulator agent selects an action based on the current state , and the environment provides a reward quantifying the performance of the robotic manipulator. The ultimate goal of RL is to find an effective control strategy that maximizes the cumulative long-term return , where is the discount factor indicating the importance of future rewards, and represents the initial time step.
TD3 is an advanced DRL method designed to address control problems with continuous action spaces. It employs an actor-critic architecture, where the critic evaluates the value function of actions and states. Specifically, at time step , represents the long-term reward obtained by taking action under policy . Under this formulation, the Q function satisfies:
The ultimate goal of DRL is to learn an optimal control strategy through Equation (40) so that the value function is maximized.
Generally, neural networks (NNs) are employed to solve Equations (39) and (40) within the actor-critic architecture, as shown in Figure 3. TD3 mainly consists of six NNs. Specifically, two evaluate critic networks are used to estimate the Q-functions, with parameter and with parameter . Additionally, an evaluate actor with parameters is used for policy updates. Each actor and critic network are paired with a target network to ensure training stability, denoted by , and . The update of the evaluate critics is expressed by the following loss function:
where is the batch size selected transitions at each step, is known as the time differencing error (TD error), and is the importance sampling weight (ISW) of the i-th sample. The target value estimate is calculated by selecting the minimum estimated Q value to reduce the error overestimation problem in traditional Q learning. Additionally, to ensure smoother updates of the critics and prevent overfitting, a noise signal is added as a regularization term to the target actor, , where is the noise standard deviation, denotes a standard normal distribution, and represents the noise clipping limit.
The evaluate actor updates by maximizing the learned Q-function and adopts the deterministic policy gradient for policy updates.
where is the expected return to be maximized, is the gradient of Q-value with respect to action, and is the gradient with respect to the evaluate actor parameter . Additionally, to ensure a stable training process, the target network parameters are updated by soft updating to track the evaluated network.
where is the soft factor that determines the update rate of the target networks. It is worth noting that the update frequencies of the actor and critic networks in TD3 are inconsistent. Generally, the critic network updates more frequently than the actor network to minimize the Q-value error before introducing policy updates.
3.4.1. State Space Design
The state represents the environmental information perceived by the robotic manipulator agent. The objective is to design a controller that integrates sliding mode control based on disturbance observation compensation with TD3 to reduce the errors between the actual and target positions, as well as between the actual and desired velocities of the robotic manipulator. Based on the design of the NDONFT controller and considering the structural characteristics of the designed 5-DOF robotic manipulator, the first three joints are sufficient to cover most of the target workspace, while the two joints at the end are mainly used to adjust the posture of the actuator. Therefore, simulation is conducted on the three joints of the designed robotic manipulator, and the current state is defined as follows:
For , the observed values consist of the joint information of the robotic manipulator, specifically the sine and cosine of the joint position and the joint velocity. By replacing the joint position with and , the discontinuous position measurements can be expressed through continuous two-dimensional parameterization, while constraining the joint position to . This approach greatly reduces the complexity of the DRL training process and facilitates training convergence. For , the observed values include the joint position error and the error integral. The error integral reflects the long-term deviation of the system, and its inclusion helps to reduce the steady-state error. For , the observed values comprise the action at the previous time step and the disturbances observed at each joint. Observing the action helps prevent training from converging to extreme values and enhances the stability of the strategy, whereas observing the disturbances enables rapid assessment of the tracking performance and timely adjustment of the strategy. It should be noted that the observations are normalized to prevent gradient explosion.
3.4.2. Action Space Design
Based on the designed nonlinear disturbance observer-based terminal sliding mode control method, the action space of DRL is defined as the proportional gain, integral gain, and robust gain of NDONFT, that is .
The network structure of the critic and actor in TD3NDONFT is shown in Figure 4. The two critic networks share the same structure, with an input layer consisting of the state vector and the action vector . The four intermediate hidden layers are fully connected with 256, 128, 128, and 64 nodes, respectively. The output layer produces a one-dimensional Q-value evaluating the action. The input layer of the actor network is the state vector . The intermediate hidden layers are fully connected with 256, 128, 64, and 32 nodes, respectively. The output layer is a parameter vector representing the action vector . According to the action parameter constraints, the output parameters are limited by a sigmoid layer to restrict actions within (0, 1). Additionally, the actions are scaled up by applying gains during simulation.
3.4.3. Reward Function Design
During DRL training, the reward function plays a crucial role in effectively guiding the agent to meet task requirements. To address the problem of sparse rewards, a composite reward function integrating trajectory tracking control is designed, consisting of the following components.
(1) Tracking error: To reduce the tracking error of the robotic manipulator, a distance-based reward is established based on the distance between the current position and the desired position. The tracking error includes position tracking error and velocity tracking error, the reward is expressed as follows:
where , , and are the weights assigned to the penalty components of position and velocity. As shown in Equation (46), when the position and velocity tracking errors approach zero, a higher reward is returned; when these errors are large, a lower reward is received.
(2) Influence of the previous time step: To reduce the influence of the previous control input on the current step and prevent actions from approaching extreme values that cause the agent to converge to a local optimum, the following equation is incorporated into the reward function:
where is the weight assigned to penalizing the action.
(3) Boundary reward: when the joint position exceeds a predefined limit, the following reward function applies:
Through all the above designs, the reward for robotic manipulator trajectory tracking is summarized as .
Based on the above design, a NFTSMC method for robotic manipulators combining NDO and TD3 algorithm is proposed. The NDO estimates and compensates for lumped disturbances online, while the TD3 algorithm achieves parameter adaptation in terminal sliding mode control. Before training, random parameters are first used to initialize the evaluate critic network, evaluate actor network, target critic network, target actor network, and parameters in the experience replay buffer. Then, the robotic manipulator dynamics model is loaded as the environment. To better improve the adaptive performance of the controller, the desired trajectory of the robotic manipulator is randomly initialized at the beginning of each episode. At each time step, the current state of the robotic manipulator is input into the target network to obtain the action vector . The action vector is proportionally scaled and input into the sliding mode controller together with the disturbance estimate observed by the NDO. The reward at the current time step is calculated based on data including position error and velocity error, and then the next state of the robotic manipulator is obtained. The tuple data generated during this process is stored in the experience replay buffer. When the buffer reaches the predefined size, a mini-batch of tuple data is randomly sampled to update the six NNs mentioned above.
4. Simulation Studies
The recommended workstation configuration and simulation environment for this study are as follows: operating system, Windows 11; processor, intel(R) Core (TM) i7-10700 CPU @ 2.90 GHz; RAM, 32.0 GB; 64-bit operating system; simulation software, MATLAB, Version: R2024a. We also used the Simulink environment and Simscape toolbox in MATLAB. The development code is in MATLAB language.
In this section, in order to verify the effectiveness of the proposed algorithm, the two end joints of the designed robotic manipulator are fixed, and simulation is performed using the initial three joints as an example. Simulink and Simscape toolboxes are used to build a simulation model of the controlled robotic manipulator. The simulation results validate the effectiveness of the designed control algorithm. The simulation model of the designed robotic manipulator trajectory tracking control algorithm is shown in Figure 5.
During the training process, the desired trajectory of the robotic manipulator is set as shown in Equation (49). Since the initial position of the prismatic joint is set at the base during dynamic modeling, an initial position offset exists for .
The initial joint positions of the three joints for the robotic manipulator are set to . The initial desired positions can be calculated using Equation (49). The physical parameters of the designed manipulator are listed in Table 2.
To demonstrate the robustness of the proposed control scheme, modeling errors, friction, and external disturbances are introduced into the robotic manipulator system. In this study, 80% of the dynamic parameters correspond to the nominal model, while 20% represent modeling errors in the system dynamics.
The disturbance acting on each joint of the robotic manipulator is assumed to be time-varying and consists of three components:
where is a small time-varying disturbance, is joint friction, and is an unknown large time-varying disturbance introduced at 5s to verify the adaptability and robustness of the proposed control method.
The proposed algorithm is compared with non-singular fast terminal sliding mode control based on disturbance observer (NDONFT), non-singular fast terminal sliding mode control (NFTSM), NDOPID, and PID controllers to verify its effectiveness.
(1) PID: Proportional-integral-derivative controller, the control law is as follows:
For the PID controller, represent the proportional, integral, and derivative coefficients, respectively. The selection of parameters mainly relies on experience and tuning. The selection principle is to minimize oscillations during the initial position tracking phase while ensuring trajectory tracking accuracy.
(2) NDOPID: PID controller incorporating the nonlinear disturbance observer; the control law is as follows:
For the NDOPID controller, in order to ensure the fairness of the comparison, its basic parameters are selected based on those of the PID controller. The disturbance observer estimates disturbances to compensate the PID control.
(3) NFTSM: Non-singular fast terminal sliding mode control excluding disturbance compensation observed by the NDO and parameter adaptation via the TD3 algorithm. The control law is as follows:
To ensure fairness in the controller comparison, the sliding mode coefficient is set equal to those in the NDONFT and TD3NDONFT controllers, and the coefficient is set equal to that in the NDONFT controller.
(4) NDONFT: Non-singular fast terminal sliding mode controller based on the NDO, excluding the adaptive strategy of TD3. The control law is as follows:
For the NDONFT controller, is an invertible matrix used to calculate the observer gain matrix and auxiliary variables. The same value of is used across controllers involving disturbance observers.
(5) TD3NDONFT: Non-singular fast terminal sliding mode control based on TD3 and NDO, with adaptive adjustment of control parameters achieved via the TD3 algorithm. The control law is as follows:
For the TD3NDONFT controller, the adaptive parameters are obtained via the TD3 algorithm. Sensitivity analysis of the controller parameters is conducted to set the range of parameter variation during training. The training parameters of the TD3 algorithm are listed in Table 3.
The parameter settings of the five control laws mentioned above are listed in Table 4.
Figure 6 shows the reward curve of the TD3 algorithm presented in this paper, which serves as a key indicator for evaluating the training effectiveness of DRL algorithms. During the policy exploration phase, the curve shows considerable volatility with a low and unstable average reward level, indicating that the strategy of the agent has not yet effectively explored action sequences with higher rewards and remains in an exploratory learning phase. Subsequently, the performance enters an optimization phase, with the average reward showing an overall upward trend and volatility gradually decreasing, indicating the strategy begins to learn more effective action selection mechanisms, leading to significant performance improvement. In the strategy convergence phase, the average reward tends to stabilize and the standard deviation converges to a low level, indicating the strategy has reached a stable convergence state, demonstrating strong robustness and generalization capability.
To further compare the dynamic characteristics of the five controllers, this paper evaluates controller performance using the mean absolute error (MAE) of joint position and joint velocity, the integral absolute error (IAE), and the integral time absolute error (ITAE).
where represents the total time.
After the training is completed, the desired trajectories of joint 1 and joint 3 of the robotic manipulator are set to , and the desired trajectory of joint 2 is set to for simulation. Figure 7 shows the simulation results of joint position tracking and tracking errors. All five algorithms ensure trajectory tracking within a certain error range before and after sudden disturbances. Under different control methods, the tracking errors of each joint fall within the ranges of [−0.03, 0.03] rad, [−0.01, 0.015] m, and [−0.04, 0.04] rad, respectively, demonstrating a certain degree of disturbance rejection under sudden disturbances. In the initial stage, the PID and NDOPID control methods exhibit significant overshoot, while the NFTSM, NDONFT, and TD3NDONFT controllers track the desired trajectory at a relatively fast speed. At 5 s, the joints experience a large unknown sudden disturbance. The maximum position tracking errors of the three joints after the disturbance are 0.0048 rad, 0.0014 m, and 0.0041 rad for the proposed TD3NDONFT algorithm; 0.0054 rad, 0.0016 m, and 0.0051 m for the NDONFT method; and 0.0188 rad, 0.0092 m, and 0.0393 rad for the NFTSM method. The results indicate that the proposed control strategy better suppresses external unknown time-varying disturbances.
The MAE indicators for position tracking under different control strategies are presented in Table 5. Both before and after applying sudden disturbances, the proposed control method demonstrates superior tracking performance. During 0–10 s, the MAE of joint positions using the TD3NDONFT algorithm reduce by 7.14%, 19.94%, and 6.14% compared to NDONFT, by 64.58%, 88.06%, and 84.53% compared to NFTSM, by 53.35%, 85.40%, and 63.43% compared to NDOPID, and by 70.60%, 88.48%, and 77.70% compared to PID, respectively. The NDONFT algorithm reduces the MAE by 49.76%, 81.77%, and 61.04% compared to NDOPID.
Figure 8 shows the joint velocity tracking of the robotic manipulator and its error. In the initial stage, the velocity tracking exhibits a distinct reverse sudden change. This occurs because the initial state of the robotic manipulator does not match the desired state, which causes the controller to overcompensate at this stage and subsequently enables it to quickly track the desired velocity. Analysis of the velocity tracking error in Figure 8 indicates that although the system velocity experiences significant disturbance after a sudden disturbance, all five control methods converge to the desired velocity. The maximum velocity tracking error of joint 1 after a sudden disturbance using the proposed TD3NDONFT algorithm is 0.0409 rad. 0.0436 rad using the NDONFT method, 0.0506 rad using the NFTSM method, 0.0602 rad using the NDOPID method, and 0.0691 rad using the PID method.
Table 6 shows the MAE performance indicators of velocity tracking under different control methods. Before and after applying sudden disturbances, the algorithm proposed maintains a smaller MAE of velocity after reaching the steady state. Within 0–10 s, the MAE of the velocity of each joint using the TD3NDONFT algorithm reduces by 1.78%, 9.10%, and 2.11% compared to NDONFT, by 19.26%, 58.01%, and 44.64% compared to NFTSM, by 14.18%, 37.37%, and 17.03% compared to NDOPID, and by 27.18%, 48.67%, and 32.45% compared to PID, respectively. This indicates that the proposed algorithm achieves high velocity tracking accuracy and robustness.
Figure 9 and Figure 10 show the IAE and ITAE indicators for position and velocity tracking using the five algorithms. The IAE indicators for the three joints of the proposed algorithm are the lowest in the 0–5 s, 5–10 s, and 0–10 s intervals, indicating that the TD3NDONFT algorithm achieves high position and velocity tracking accuracy before and after experiencing unknown time-varying disturbances. Next, the effectiveness of the TD3 adaptive algorithm, nonlinear disturbance observer, and improved non-singular fast terminal sliding mode within the proposed TD3NDONFT algorithm is analyzed.
Within 0–10 s, the TD3NDONFT algorithm reduces the IAE of joint position tracking by 7.16%, 19.97%, and 6.16% compared to NDONFT, and reduces the IAE of velocity tracking by 1.78%, 9.11%, and 2.11%, indicating that introducing the TD3 adaptive algorithm improves the tracking performance of the robotic manipulator. Compared to NFTSM, NDONFT reduces the IAE of position tracking for each joint by 61.91%, 85.11%, and 83.56%, and reduces the IAE of velocity tracking by 17.81%, 53.82%, and 43.47%, respectively. Compared to PID, NDOPID reduces the position tracking IAE by 37.01%, 21.09%, and 39.05%, and the velocity tracking IAE by 15.17%, 18.05%, and 18.60%, indicating the effectiveness of introducing the nonlinear disturbance observer. Compared to NDOPID, NDONFT reduces the position tracking IAE by 49.82%, 81.79%, and 61.11%, and the velocity tracking IAE by 12.63%, 31.11%, and 15.25%, demonstrating the effectiveness of the improved non-singular fast terminal sliding mode. At the same time, the ITAE of position and velocity tracking for the three joints using the TD3NDONFT algorithm is the lowest among the five algorithms.
The adaptive parameters change proposed in this paper are shown in Figure 11. During the variation in adaptive parameters, the proportional gain is initially small to generate low joint torque, thereby avoiding excessive initial torque, and then gradually increases to improve joint tracking capability. However, the prismatic joint must overcome its own weight at startup, so a larger initial proportional gain is required. The integral gain is larger for the prismatic joint than for the revolute joint to reduce the system steady-state error. Since the nonlinear disturbance observer has estimated most disturbances, only a small robust gain is required to compensate the remaining disturbance. At 5 s, when a sudden disturbance occurs, all parameters adjust accordingly to ensure tracking accuracy under unknown time-varying disturbances.
Figure 12 shows the control input torque for each joint of the robotic manipulator. In the initial stage, the PID and NDOPID algorithms exhibit large torque oscillations, which may adversely affect the joint actuator and may cause motor driver overload or failure. At 5s, when a sudden disturbance occurs, the torques of all five control methods fluctuate significantly. The torque response under the proposed TD3NDONFT algorithm is smoother, indicating that the method maintains good dynamic performance while ensuring steady-state accuracy.
Figure 13 shows the actual disturbances during trajectory tracking and the disturbances estimated by the nonlinear disturbance observer. The nonlinear disturbance observer within the proposed TD3NDONFT algorithm effectively estimates disturbances affecting each joint of the robotic manipulator. The joint disturbance estimation errors are shown in Figure 14.
To further validate the generalization capability of deep reinforcement learning, this paper introduces desired trajectories with more complex dynamic characteristics for testing. The desired trajectories for joint 1 and joint 3 of the robotic arm are set as , while the desired trajectory for joint 2 is set as . Figure 15 presents the position tracking curves and corresponding tracking errors of each joint under different control strategies, while Figure 16 illustrates the velocity tracking performance and velocity tracking errors of the joints. Experimental results demonstrate that the proposed method maintains excellent accuracy and robustness even in complex trajectory tracking tasks, fully reflecting its strong generalization performance.
5. Conclusions
This paper studies the trajectory tracking control problem of a novel robotic manipulator configuration. The main contributions are as follows:
- For robotic manipulator system with modeling uncertainties, friction, and unknown external time-varying disturbances, an adaptive non-singular fast terminal sliding mode control strategy based on the Twin Delayed Deep Deterministic policy gradient algorithm and a nonlinear disturbance observer is proposed. Stability and finite-time convergence of the closed-loop system are established via Lyapunov analysis.
- A nonlinear disturbance observer estimates the lumped uncertainty of the robot manipulator and provides feedforward compensation. Based on boundary layer techniques, the non-singular fast terminal sliding mode is modified to reduce chattering in sliding mode control. Adaptive control of the desired trajectory is achieved using the Twin Delayed Deep Deterministic policy gradient algorithm.
- Training simulations are conducted using the designed 5-DOF robotic manipulator as an example. Convergence of training is ensured through the design of the observation space and reward function for the Twin Delayed Deep Deterministic policy gradient algorithm. The training process considers trajectory tracking accuracy under sudden disturbances to ensure that the robotic manipulator can handle emergency situations.
- Using the trained agent, different control strategies are compared. Compared with PID, NDOPID, NFTSM, and NDONFT controllers, TD3NDONFT achieves higher trajectory tracking accuracy, lower MAE, IAE, and ITAE across time intervals, and stronger robustness against sudden disturbances. By randomizing the desired trajectory, the proposed algorithm exhibits improved generalization and attains higher tracking accuracy across different trajectory configurations.
This study provides a new approach for the development of robotic manipulators with novel configurations and the realization of high-precision trajectory tracking control. Although the simulation results are promising, a systematic comparison with other mainstream deep reinforcement learning algorithms is still lacking, and exploring a broader hyperparameter space to obtain more generalizable conclusions also represents a valuable direction for future research. In addition, the performance of robotic manipulators is affected by various factors such as sensor noise and communication delays in practical applications. Future work will focus on establishing an experimental platform to validate the effectiveness of the proposed algorithm and exploring its application in trajectory tracking tasks for other nonlinear systems.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Wang X. Zhou X. Xia Z. Gu X. A Survey of Welding Robot Intelligent Path Optimization J. Manuf. Process.202163142310.1016/j.jmapro.2020.04.085 · doi ↗
- 2Wu X. Chi J. Jin X.-Z. Deng C. Reinforcement Learning Approach to the Control of Heavy Material Handling Manipulators for Agricultural Robots Comput. Electr. Eng.202210410843310.1016/j.compeleceng.2022.108433 · doi ↗
- 3Mancino F. Fontalis A. Grandhi T.S.P. Magan A. Plastow R. Kayani B. Haddad F.S. Robotic Arm-Assisted Conversion of Unicompartmental Knee Arthroplasty to Total Knee Arthroplasty: Feasibility, Safety, and Clinical Outcomes Bone Jt. J.2024106-B 68068710.1302/0301-620X.106B 7.BJJ-2023-0943.R 238945538 · doi ↗ · pubmed ↗
- 4Li Z. Zhou Y. Zhu M. Wu Q. Adaptive Fuzzy Integral Sliding Mode Cooperative Control Based on Time-Delay Estimation for Free-Floating Close-Chain Manipulators Sensors 202424371810.3390/s 2412371838931503 PMC 11207610 · doi ↗ · pubmed ↗
- 5Park K.-H. Lee H.-E. Kim Y. Bien Z.Z. A Steward Robot for Human-Friendly Human-Machine Interaction in a Smart House Environment IEEE Trans. Autom. Sci. Eng.20085212510.1109/TASE.2007.911674 · doi ↗
- 6Kumar A. Kumar V. Evolving an Interval Type-2 Fuzzy PID Controller for the Redundant Robotic Manipulator Expert Syst. Appl.20177316117710.1016/j.eswa.2016.12.029 · doi ↗
- 7Tian G. Tan J. Li B. Duan G. Optimal Fully Actuated System Approach-Based Trajectory Tracking Control for Robot Manipulators IEEE Trans. Cybern.2024547469747810.1109/TCYB.2024.346738639378256 · doi ↗ · pubmed ↗
- 8Chang C.-W. Tao C.-W. Design of a Fuzzy Trajectory Tracking Controller for a Mobile Manipulator System Soft Comput.2024285197521110.1007/s 00500-023-09298-z · doi ↗