RL-PMO: A Reinforcement Learning-Based Optimization Algorithm for Parallel SFC Migration
Hefei Hu, Zining Liu, Fan Wu

TL;DR
This paper introduces RL-PMO, a reinforcement learning algorithm that efficiently migrates multiple network functions in edge networks during hardware failures.
Contribution
The novel contribution is a two-stage offline reinforcement learning algorithm using Decision Mamba for parallel SFC migration optimization.
Findings
RL-PMO achieves a 95% migration success rate across varying load conditions.
It outperforms typical offline RL algorithms by 13-17% under low to high loads.
The method effectively handles distribution shift and Q-value overestimation using CQL regularization and a twin-critic architecture.
Abstract
In edge networks, hardware failures and resource pressure may disrupt Service Function Chains (SFCs) deployed on the failed node, making it necessary to efficiently migrate multiple Virtual Network Functions (VNFs) under limited resources. To address these challenges, this paper proposes an offline reinforcement learning-based parallel migration optimization algorithm (RL-PMO) to enable parallel migration of multiple VNFs. The method follows a two-stage framework: in the first stage, improved heuristic algorithms are used to generate high-quality migration trajectories and construct a multi-scenario dataset; in the second stage, the Decision Mamba model is employed to train the policy network. With its selective modeling capability for structured sequences, Decision Mamba can capture the dependencies between VNFs and underlying resources. Combined with a twin-critic architecture and CQL…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
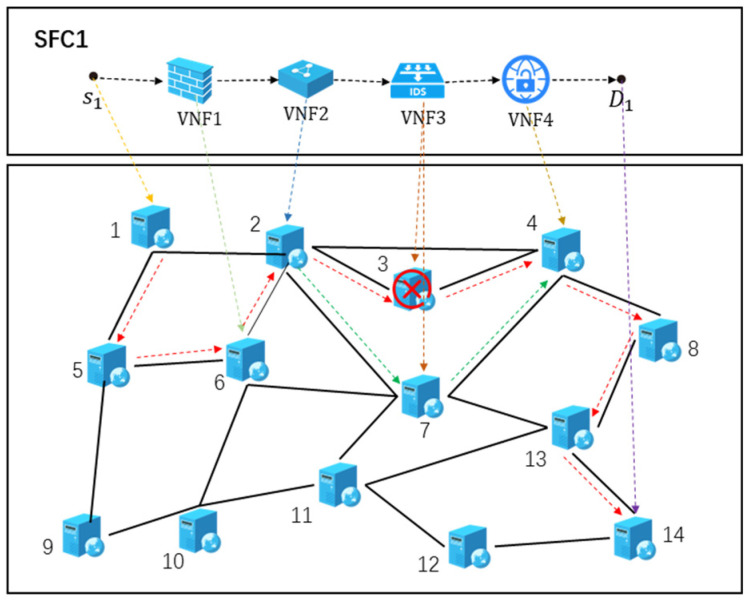 Figure 1
Figure 1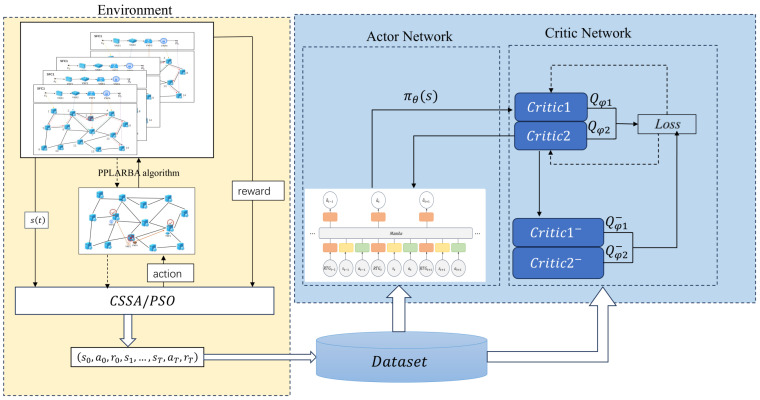 Figure 2
Figure 2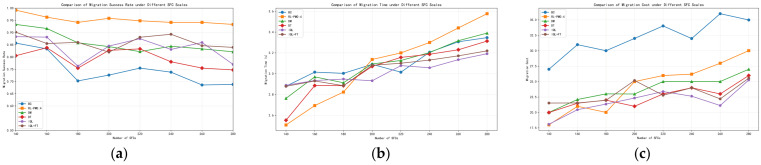 Figure 3
Figure 3 Figure 4
Figure 4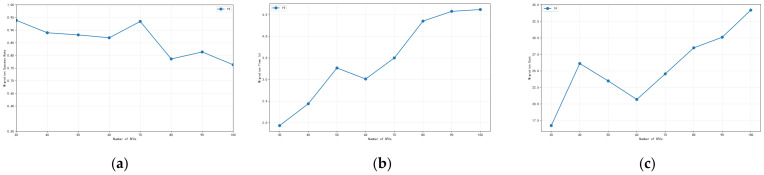 Figure 5
Figure 5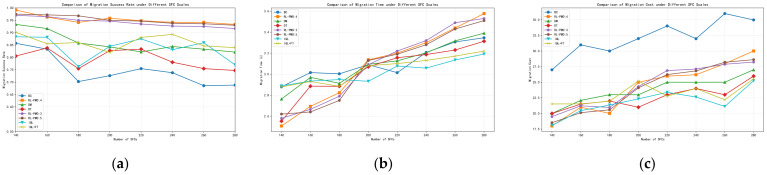 Figure 6
Figure 6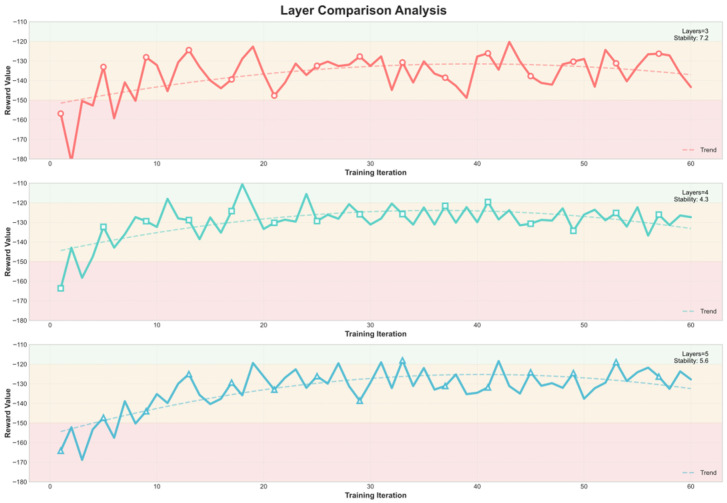 Figure 7
Figure 7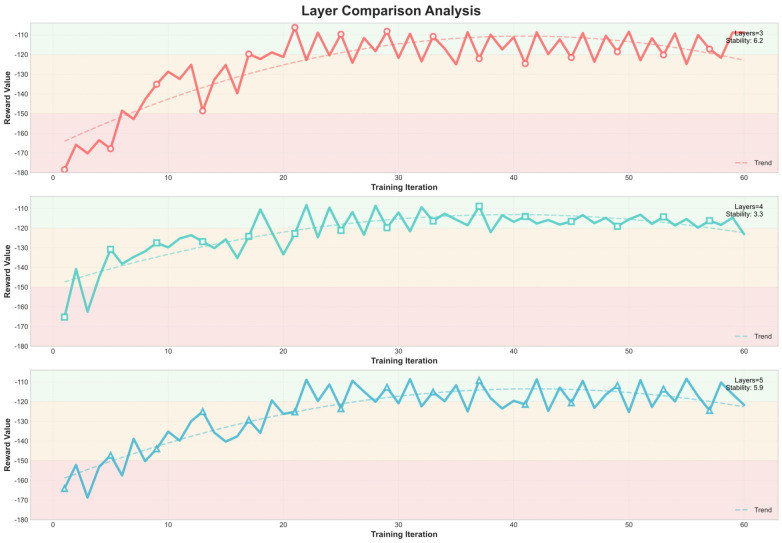 Figure 8
Figure 8- —Key Laboratory of Cybersecurity and Intelligent Technology, Ministry of Education
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSoftware-Defined Networks and 5G · Cloud Computing and Resource Management · Advanced Optical Network Technologies
1. Introduction
With the deep integration of 5G technology and edge computing, Network Function Virtualization (NFV) has leveraged its core advantage of “software-defined network functions” to decouple network functionalities from dedicated hardware. This paradigm shift has significantly transformed network architecture and has become a pivotal technology for enabling flexible deployment and dynamic scheduling in edge networks. Within the NFV framework, a Service Function Chain (SFC) connects multiple Virtual Network Functions (VNFs) in a predefined order according to service requirements, thereby forming a flexible delivery path for customized network services [1]. In representative edge-computing scenarios such as the Internet of Things (IoT) and sensor networks, large volumes of real-time sensing data must be processed by VNFs deployed at edge nodes; as a result, SFCs serve as a crucial component of the processing workflow.
However, edge nodes are often constrained by complex deployment environments and limited hardware resources, making them highly susceptible to SFC disruptions caused by hardware failures, resource overload, or link congestion. Once an edge node hosting VNFs fails, all associated SFCs become paralyzed, leading to degraded Quality of Service (QoS) or even complete service outages. In Internet of Things (IoT) and sensor-network environments characterized by real-time sensing-data processing, such interruptions further compromise the continuity and accuracy of critical sensing tasks. Therefore, maintaining the continuity of SFCs is essential for ensuring the real-time performance and reliability of IoT and sensor-network systems.
To maintain SFC continuity under node failures, dynamic VNF migration has emerged as a key solution. Existing dynamic migration methods fall into two categories: serial migration and parallel migration. Serial migration transfers VNFs one at a time and effectively avoids resource conflicts but incurs considerable delay, making it unsuitable for latency-sensitive services. In contrast, parallel migration transfers multiple VNFs simultaneously to reduce overall migration latency. However, parallel migration is prone to higher failure rates due to resource contention during the migration process.
Based on the above background, this paper focuses on the failure-driven parallel migration of multiple VNFs. When a physical edge node fails, all Virtual Network Functions (VNFs) deployed on that node must be migrated simultaneously to other healthy nodes within a limited time to ensure the service continuity of the affected Service Function Chains (SFCs). This migration process must satisfy three core objectives: (i) maximizing the migration success rate; (ii) minimizing the migration time; and (iii) controlling the migration cost.
Under resource competition, bandwidth coupling, and multiple constraints, jointly optimizing these objectives becomes a typical NP-hard combinatorial problem. Therefore, this paper adopts an offline reinforcement learning (offline RL) approach. By generating diverse and safe migration trajectories using heuristic algorithms in a simulation environment, the model can learn globally coordinated migration strategies. Furthermore, to improve decision efficiency and representation capability, we employ the efficient sequence model Decision Mamba as the policy network to better capture the dependencies between VNFs and underlying resources.
The main contributions of this paper can be summarized as follows:
- Modeling the migration of all VNFs on the failed node as a single-step multi-objective optimization problem enables the system to maintain a high migration success rate while keeping the overall migration delay and resource overhead within acceptable limits.
- This paper designs an improved CSSA–PSO hybrid heuristic method to generate diverse and feasible migration trajectories under various failure patterns and load levels.
- To capture the dependencies among VNFs, network resources, and migration constraints, we adopt Decision Mamba as the policy network. In addition, we incorporate a twin-critic architecture together with a Conservative Q-Learning (CQL) regularization term to mitigate the inherent overestimation and distribution shift issues in offline reinforcement learning.
2. Related Work
In the integrated framework of Network Function Virtualization (NFV) and edge computing, dynamic migration of Service Function Chains (SFCs) plays a crucial role in maintaining the continuity of network services. Existing studies can be broadly categorized into performance-oriented migration and failure-recovery-oriented migration. While the former remains the mainstream direction, the latter continues to face challenges due to the unpredictable nature of edge node failures and stringent resource constraints. As a result, recent research has increasingly shifted toward failure-prediction-driven proactive migration.
For instance, Wang et al. [2] proposed a log-driven node failure prediction method that extracts critical system features from operation logs and employs machine learning models to enhance prediction accuracy, thereby supporting fault recovery and migration decision-making. Zhai et al. [3] proposed an enhanced LSTM model optimized by SA-PSO to identify high-risk servers and used an improved Sparrow Search Algorithm (ISSA) to perform proactive SFC migration, reducing migration cost and latency. Similarly, Kabdjou and Shinomiya [4] employed an LSTM model optimized by Super-SAPSO for failure prediction in MEC environments and designed a robust migration scheme that accounts for node security levels and user mobility. Building on these studies, this work focuses on VNF migration after a potential failure node has been predicted.
Traditional SFC migration and resource allocation approaches commonly rely on heuristic algorithms such as greedy selection or rule-based strategies. For example, the work in [5] proposed a prediction-based VNF migration mechanism that determines migration timing and target nodes through heuristic rules to mitigate performance degradation; the study in [6] introduced the VNF-RM algorithm, which employs a delay-aware heuristic strategy to sequentially select the migration order and destination nodes, thereby minimizing end-to-end latency; and [7] developed a migration cost model and adopted a greedy heuristic method to reduce additional overhead while ensuring service continuity.
Most of the above methods rely on serial migration. When multiple VNFs need to be migrated simultaneously, such a serial strategy leads to a nearly linear increase in migration time. Recently, studies such as [3,4] have begun exploring parallel migration, which schedules multiple VNF tasks concurrently to better utilize available link bandwidth and reduce queuing delay, thereby substantially improving overall migration efficiency.
Despite their practical feasibility and ease of engineering implementation, parallel heuristic algorithms still exhibit two inherent limitations: (1) Lack of global optimization capability. This limitation becomes more pronounced in multi-VNF parallel migration scenarios, where accurately modeling resource contention and coupling among VNFs is highly challenging. The problem is even more evident in sensor-network and IoT-edge environments driven by real-time sensing-data processing, where traffic patterns and resource usage are highly dynamic, making heuristic methods more prone to local optima. (2) Lack of learning ability and poor adaptability to dynamic environments, which makes it difficult for such methods to maintain stable migration performance when sensing data fluctuates frequently.
To overcome these limitations, researchers have explored data-driven and multi-VNF parallel migration strategies. In recent years, Deep Reinforcement Learning (DRL) has been increasingly applied to SFC migration to enable adaptive, intelligent decision-making. For instance, ref. [8] formulated migration as a Markov Decision Process (MDP) and used online RL for dynamic adjustment of VNF scaling and relocation. Ref. [9] adopted a deep Q-learning strategy to iteratively refine migration decisions and minimize service interruption, while ref. [10] proposed an interference-aware migration algorithm balancing throughput and cost. In addition, ref. [11] introduced a multi-agent DRL framework that coordinates multiple agents for joint migration of multiple SFCs, and ref. [12] proposed a cluster-based migration scheme that treats tightly coupled VNFs as a single migration unit to reduce embedding cost and satisfy latency constraints. These studies partially address the limitations of serial migration, but their parallelism remains limited to subsets or clusters of VNFs.
However, online reinforcement learning is not suitable for failure-driven multi-VNF parallel migration. Its trial-and-error exploration generates many unsafe decisions during early training. At the same time, failure scenarios require migration decisions within very short time windows, while online RL cannot converge within such limited time. This limitation is particularly critical in sensor-network and other latency-sensitive edge environments, where any unstable decision may directly interrupt sensing tasks, further amplifying the risks and infeasibility of online RL.
In recent years, Offline RL has demonstrated strong performance in robotics [13] and autonomous driving [14], where it can learn robust and interpretable decision policies from pre-collected datasets while ensuring operational safety. In networking systems, Offline RL has also begun to attract attention. For example, the work in [15] used Offline RL to build a bandwidth estimation model that reduces reliance on real-time probing and interaction, demonstrating the feasibility of Offline RL for network QoS assurance and bandwidth scheduling.
Compared with existing studies, this work constructs an offline dataset using heuristic migration trajectories and introduces a Decision Mamba-based policy network. Leveraging its capability for selective state-space sequence modeling, the framework captures resource contention and coupling among multiple VNFs. Combined with a twin-Critic architecture and a conservative regularization mechanism, our Offline RL framework jointly optimizes multiple objectives and provides a new solution for failure-driven multi-VNF parallel migration.
3. System Model and Problem Description
This section defines the mathematical model for failure-driven parallel VNF migration in edge networks, including the underlying network model, the modeling of Service Function Chains (SFCs) and Virtual Network Functions (VNFs), the migration scenario formulation, and the corresponding constraints and evaluation metrics.
3.1. Network Model
The substrate network is modeled as an undirected graph , where denotes the set of physical nodes and denotes the set of physical links.
A physical node represents the -th physical node. Each physical node is equipped with multiple types of resources to support VNF execution. Its CPU and memory resources are denoted by and , respectively, and the available residual resources are denoted by and .
For the set of physical links , an element represents the physical link connecting neighboring nodes and . The bandwidth and transmission delay of a physical link are denoted by and , respectively, and the residual bandwidth is denoted by .
3.2. SFC and VNF
A SFC consists of multiple VNFs with different functionalities that are connected in a predefined business-logic order.
Let the set of SFCs be denoted by , where the -th SFC is modeled as a directed weighted graph . Each SFC is associated with a traffic demand , a maximum tolerable downtime , and a maximum tolerable delay .
The virtual node set of the -th SFC is denoted by , where and are the source and destination nodes, and is the -th VNF node. Let denote the set of all VNF types, and represent the specific VNF type of virtual node .
In the virtual link set , an element represents the virtual link connecting adjacent VNFs and . To describe the mapping relationship between VNFs and physical nodes, we define a binary variable . When VNF is deployed on physical node , we set ; otherwise, . Similarly, we define a binary variable to indicate the mapping of virtual links onto physical links. When virtual link is mapped onto the physical link , we set ; otherwise, .
3.3. SFC Migration
When a physical node fails, all VNFs deployed on that node must be migrated to ensure service continuity.
As shown in Figure 1, VNFs 1, 2, 3, and 4 of SFC1 are deployed on physical nodes 6, 2, 3, and 4, respectively. The red dashed line denotes the original service path of SFC1 before the occurrence of node failure.
Assume that physical node 3 fails, causing VNF3 of SFC1 to become unavailable and requiring its migration to another active node. In this scenario, VNF3 is migrated to server node 7, whose available CPU and memory resources meet the requirements of the migrating VNF. The green dashed line represents the re-mapped service path of SFC1 after migration.
Let the set of VNFs deployed on the faulty node be defined as , , where denotes the set of all VNFs for all SFCs.
For each affected SFC, we define: , i.e., all SFCs that contain at least one VNF to be migrated. Before selecting the target nodes for migration, the available resources of all physical nodes must be examined. Based on resource availability, link connectivity, and node health status, each migrating VNF selects a set of k nodes as candidate nodes to support subsequent service continuity. The candidate node set for each migrating VNF is defined as: .
Considering that different types of VNFs consume different processing resources, we assume a linear relationship between resource consumption and traffic volume [16]. We define a resource demand coefficient: and , where and denote the CPU and memory resources needed to process a unit of traffic for that VNF type.
Because different VNFs may increase or decrease the traffic volume during processing [17], we define the flow-scaling ratio of VNF type as: . Similarly, we define the memory-state dirty rate of VNF type as: .
For VNF in SFC , its bandwidth demand is calculated as:
Correspondingly, the CPU and memory demands of VNF are defined as:
3.4. SFC Migration Constraints Under Failure Scenarios
To address the core requirements of migrating all VNFs from the faulty node, three key constraints are introduced.
3.4.1. Complete Migration Constraint for VNFs on the Faulty Node
All VNFs deployed on the faulty node must be migrated, and each VNF can only be migrated to one feasible candidate node to ensure that no VNF is omitted. The constraint is formulated as:
3.4.2. Resource Constraints
The available resources of the target node must be sufficient to accommodate the total resource demands of all VNFs migrated to that node.
(a)CPU Resource Constraint:
(b)Memory Resource Constraint:
(c)Link Bandwidth Constraint
A physical link must support both service traffic and migration traffic. The total bandwidth demand must not exceed the link capacity:
denotes the migration bandwidth allocated to VNF after determining the target node, which is computed by the PPLARBA bandwidth allocation algorithm. To ensure successful migration, the migration bandwidth must satisfy:
3.4.3. End-to-End Delay Constraint
After migration, the end-to-end delay of each SFC must not exceed its maximum tolerable delay . The constraint is formulated as follows:
where, denotes the processing delay of the VNF of type .
3.5. Evaluation Metrics for SFC Migration
In failure scenarios, Service Function Chain (SFC) migration is required to preserve service continuity while minimizing its impact on user experience and network resources. As such, maximizing the migration success rate stands as the core objective of SFC migration in fault-related contexts. Concurrently, it is also essential to keep both the migration time and migration cost incurred during the process within reasonable and controllable bounds.
3.5.1. Migration Success Rate
According to the migration constraints defined earlier, if any constraint is violated during the migration process, the migration is considered unsuccessful. For an SFC to be deemed successfully migrated, all VNFs requiring migration within that SFC must be migrated successfully. Based on this criterion, the migration success rate is defined as:
where denotes the number of successfully migrated SFCs, and represents the total number of SFCs requiring migration.
3.5.2. Migration Time
VNF migration adopts the pre-copy mechanism [18], in which the memory state of the VNF is continuously transferred during migration. When the allocated migration bandwidth B is greater than the dirty rate D, the amount of updated memory to be retransmitted decreases in each round, resulting in shorter transmission time per round, until the remaining data becomes sufficiently small and the process enters the final stop-and-copy phase. We define the ratio between the dirty rate and the allocated migration bandwidth as: , when r < 1. After N rounds of pre-copy, the total migration time is:
where denotes the fraction of memory pages updated during each iteration.
To control service downtime, the number of pre-copy rounds N must satisfy: , thus, , where denotes the ceiling function.
In the parallel migration scenario, the total migration time required for all VNFs is determined by the VNF with the longest migration duration:
3.5.3. Average Migration Cost
The migration cost reflects the overall consumption of network resources during the migration process as well as the impact caused by changes in service paths after migration. It primarily consists of two components: the resource consumption incurred during VNF migration and the rerouting overhead introduced by remapping service paths.
Migration Cost
During migration, VNFs generate network resource consumption that depends on the amount of state data to be transferred and the length of the migration path. The migration cost is defined as:
where denotes the hop count of the migration path from the faulty node to the target node, obtained through the shortest-path computation in the PPLARBA algorithm.
Rerouting Cost
After migration, the virtual links of the affected SFCs must be remapped to new physical paths. These path changes alter network load and introduce additional overhead. The rerouting cost is defined as:
where is the change in hop count of the virtual link before and after migration. If both endpoints of a virtual link are not migrated, then , and the link incurs no rerouting cost.
Total Migration Cost
where and are weighting coefficients.
4. Algorithm Design
This paper proposes a Reinforcement Learning-Driven Parallel Migration Optimization (RL-PMO) method for Service Function Chain (SFC) migration in edge networks. The proposed approach targets the problem of parallel SFC migration under edge node failures and establishes a two-stage algorithmic framework that integrates heuristic-based offline data generation with offline reinforcement learning. The overall logical structure of the algorithm is illustrated in Figure 2.
In the first stage, an improved heuristic algorithm (CSSA or PSO) is employed to generate high-quality migration trajectories, addressing the common issues of low data quality and insufficient scenario coverage in offline datasets. Specifically, instead of retaining only the final optimized solutions, we also record all intermediate states and actions throughout the iterative optimization process, thereby constructing a rich and high-quality offline dataset with diverse samples.
In the second stage, the migration optimization process is formulated as a Markov Decision Process (MDP) and further transformed into a single-step sequential decision problem. Based on this formulation, we design a complete offline reinforcement learning framework composed of three core components:
Policy Network: The Decision Mamba model is adopted as the core decision module. Owing to its efficient temporal modeling capability, Mamba can effectively integrate state, goal, and temporal information from sequential inputs, enabling precise decision-making even in single-step migration scenarios [19,20].
Value Network: To stably evaluate the value of actions generated by the policy network and provide reliable optimization feedback, we employ a twin-Critic architecture.
These two identically structured but independently parameterized networks jointly estimate the value of each state–action pair. During policy gradient computation, the minimum value of the two Critics is used to mitigate overestimation, thereby improving the stability of training.
Conservative Learning: To address the distributional shift problem inherent in offline reinforcement learning [21], the Conservative Q-Learning (CQL) algorithm is incorporated into the Critic training objective. CQL encourages the Critics to assign higher values to actions within the data distribution while penalizing overly optimistic estimates of out-of-distribution actions, leading to a more conservative and robust value function.
Additionally, a PPLARBA module is designed to manage bandwidth scheduling and parallel execution of migration plans within the physical network, ensuring that the migration decisions generated by RL-PMO are practically executable in real deployment environments.
4.1. Offline Dataset Generation
During the trajectory construction phase, a hybrid heuristic method combining the Chaotic Sparrow Search Algorithm (CSSA) and the Particle Swarm Optimization (PSO) algorithm is employed. Traditional SSA algorithms are prone to premature convergence when handling complex optimization problems, and insufficient population diversity often weakens global search capability. To generate high-quality migration trajectories, this study enhances CSSA in both the initialization and update strategies.
In the initialization stage, a Tent chaotic mapping mechanism is introduced to improve population diversity. The mapping process is formulated as:
where denotes the chaotic sequence generated by the Tent map, and is the Tent mapping parameter that controls the distribution and complexity of the generated sequence.
In the updating phase, Gaussian perturbation and a symmetric reflection matrix are incorporated into the discoverer–joiner updating process to strengthen the balance between global exploration and local exploitation. The corresponding update rule is expressed as:
where A denotes a Gaussian random matrix. This enhancement enables the algorithm to achieve stronger global search capability and better local escaping ability, thereby improving the diversity and quality of the generated offline dataset.
In addition, CSSA introduces two enhancement mechanisms—Gaussian mutation for superior individuals and Tent disturbance for inferior ones—to further improve population diversity and convergence stability. The update strategy is defined as follows:
where denotes a Gaussian random variable with zero mean and unit variance, and represents the chaotic perturbation generated by the Tent mapping.
For individuals with higher fitness, a slight Gaussian mutation is applied to enhance local exploration; for those with lower fitness, Tent disturbance is employed to prevent stagnation and premature convergence, thereby maintaining population diversity and enhancing global convergence robustness.
To avoid overfitting and limited data coverage that may result from using a single heuristic algorithm, PSO is additionally incorporated to generate trajectory data under various network conditions. This integration enriches the dataset and enhances the generalization capability of the Decision Mamba (DM) model during training.
Under the MDP framework, trajectory data are constructed in the canonical state–action–reward–next-state format:
To cover service workloads of different scales, we randomly select 100–280 SFCs to be deployed in the physical network in each simulation round, thereby generating diverse network states. Based on these states, CSSA and PSO jointly produce a total of 831 migration trajectories, comprising 124,650 time steps for offline reinforcement learning training.
In addition, this study models SFC migration as a single-step parallel decision-making problem: given the current network state, the reinforcement learning agent selects target nodes for all VNFs in a single decision, without requiring sequential decisions or multi-step interactions.
4.2. Markov Decision Process (MDP) Modeling
In this work, we consider only single-node failure scenarios. At the beginning of each simulation episode, one physical node is selected uniformly at random from the node set and designated as the faulty node. Based on this selection, the corresponding set of VNFs to be migrated is constructed, and the initial state is generated.
The reinforcement learning process is formulated as a Markov Decision Process (MDP), denoted as , where each component is defined as follows.
State Space
The state space is given by:
where denotes the faulty node, denotes the number of VNFs to be migrated. The migration-related features of the -th VNF are defined as:
representing the CPU demand, memory demand, migration data volume, dirty rate, and maximum tolerable delay of the SFC to which the VNF belongs.
The migration-target-related features for candidate nodes are:
where is the number of candidate nodes for the -th VNF. is the upper bound on the number of VNFs that may require migration. Because the number of VNFs deployed on different physical nodes varies, when the remaining slots in the state vector are padded with zeros to ensure consistent state dimensionality.
Therefore, the total state dimension is: .
Action Space
where denotes the probability weight of selecting the -th candidate node for the -th VNF. These weights satisfy: . which guarantees normalization of the decision policy.
State Transition Probability
The state transition probability denotes the probability that, after executing action in the current state , the system moves to the next state .
Reward Function
where are the weights assigned to migration time, migration success rate, and migration cost, respectively. The terms denote the normalized migration time, success rate, and migration cost: , , , where , , and are the upper and lower bounds obtained from multiple rounds of preliminary simulations.
4.3. Offline Reinforcement Learning Policy
Given the trajectory dataset , the training process converts it into an RTG-form sequence:
where is the discount factor and denotes the number of time steps, the parallel migration decision sequence covering VNFs. For the single-step decision-making scenario, the RTG degenerates into the immediate reward corresponding to the current state–timestep pair: .
DM serves as the core decision module: essentially, it learns a policy that generates high-quality migration plans conditioned on the current network state. It takes as input and, through the Mamba encoder, captures the complex resource dependencies among VNFs and the long-horizon decision patterns, ultimately producing the action distribution .
The Critic loss consists of two parts: a Bellman regression term and a CQL conservative regularization term:
Here is the Bellman regression loss, computed as
In the above, denotes a mini-batch sampled from the dataset, and is the target value. For the single-step decision setting, we take to avoid training oscillation.
The conservative regularization term is defined as
Here, denotes actions sampled from the policy network, i.e., .
During training, the main Q-network parameters are updated jointly with the soft target update.
Because the state space and modeling structure of Mamba naturally align with the multi-VNF parallel migration problem studied in this work—where complex resource-competition patterns exist among VNFs—the decision Mamba is adopted as the policy network. Mamba can capture sequential features and implicitly model global and local resource dependencies over time. Compared with transformers, Mamba is more suited for processing long sequences and optimization-related tasks.
The actor aims to maximize the value of the action estimated by the critics. Its loss is
where are the DM model parameters and is the action generated by the actor.
The actor parameters are updated by gradient descent:
These objectives guide the offline RL agent to produce reliable SFC migration decisions in NFV environments by discouraging over-optimistic Q-values while improving the policy that selects target nodes for VNF migration.
Target-network soft update. We adopt a soft-update rule to update the Critic target networks:
To prevent the policy network from prematurely tracking a Q-function that has not yet converged, we introduce an update-frequency parameter d: during training, the actor (policy network) is updated only once after every d critic (Q-network) updates, resulting in an update ratio of d:1 between the critic and the actor.
Execution layer. After obtaining the migration candidates for all VNFs, the RL agent interacts with the NFV environment to generate effective VNF migration decisions. Once the actor outputs target nodes, the PPLARBA algorithm is invoked to allocate migration bandwidth for each VNF and evaluate migration feasibility, thereby completing one full migration cycle.
In summary, the pseudocode of our RL-PMO algorithm is given in Algorithm 1:
Algorithm 1: Reinforcement Learning-Driven Parallel Migration Optimization AlgorithmInputs: Offline data offline dataset ; number of epochs ; number of training steps ; soft-update coefficient ; CQL factor ; batch size ; update frequency ; learning rate Output: SFC migration policy Initialize Critic1, Critic2 and Actor (DM) parameters as Initialize target Critic parameters , 1for epoch = 1 to E do2 for i = 1 to T do3 Sample a mini-batch from 4 with no_grad:5 Generates policy actions .6 The main Critic networks predict Q-values: Q1, Q2.7 Calculate Critic loss using Equations (23)–(25)8 Update main Critic parameters by gradient descent.9 if i % d == 0 then10 Generate the policy action in the current state: 11 Calculate actor loss by Equation (26)12 Update actor parameters by Equation (24)13 end if14 Soft-update target critics by Equation (28): 15 end for16end for17return
5. Performance Evaluation
5.1. Simulation Setup
We use the open-source NFV resource-allocation simulator SFCSim [22]. The reinforcement learning models are implemented using PyTorch 2.2.1 and executed on a Linux-based system. The substrate network is a cellular topology with 127 nodes and 342 links; each node offers 20 CPU cores and 64 GB of memory. Each physical link has a fixed bandwidth of 8 Gbps and a latency of 0.5 ms.
The catalog includes 8 VNF types. For each VNF, the traffic scaling factor follows ; the CPU coefficient per MBps lies in , and the memory coefficient lies in MB/MBps. The dirty-page rate is fixed at 50 MBps. Service demand follows MBps, and the SFC length (number of VNFs per chain) ranges from 3 to 6.
Network Architecture and Hyperparameter Configuration
For the heuristic baseline algorithms, the population size of the Chaotic Sparrow Search Algorithm (CSSA) is set to 30, with 150 iterations, and the Tent chaotic mapping parameter is configured as . For the Particle Swarm Optimization (PSO) algorithm, the swarm size is set to 30, with 100 iterations.
The Decision Mamba policy network consists of four Mamba blocks with a hidden dimension of 256. A final linear output layer is used to generate the probability distribution over candidate nodes. Each of the twin-critic value networks contains three fully connected hidden layers with 256 neurons per layer.
Both the policy network and the critic networks are optimized using the Adam optimizer, with a learning rate of . The key reinforcement learning hyperparameters include a discount factor of , a soft update coefficient of , and a CQL regularization weight of .
5.2. Simulation Result and Analysis
We assess each method under varying SFC counts using three metrics: migration success rate, migration time, and migration cost. Figure 3 report the results for six SFC-migration algorithms across different load levels; the x-axis is the number of deployed SFCs, which serves as the load indicator.
From Figure 3a, BC (behavior cloning) merely reproduces trajectories present in the dataset; it is highly dependent on data quality and generalizes poorly to unseen fault scenarios, leading to weaker performance. DT (Decision Transformer) is relatively stable, with a migration success rate of roughly 80%. By contrast, DM (Decision Mamba) extracts richer contextual and structural cues from the inputs and therefore achieves a higher overall success rate than DT. The standard IQL algorithm (without fine-tuning) exhibits moderate performance [23], achieving 87% under a load of 140 SFCs but dropping to 77% when the load increases to 280 SFCs. IQL+FT, which incorporates online fine-tuning, shows more stable performance compared with plain IQL; however, its effectiveness still degrades noticeably under heavier loads, falling to around 85% at 280 SFCs. This indicates that although brief online fine-tuning is beneficial, its generalization capability remains limited under high-load conditions with severe resource contention. We also observe that as the network load increases, the success rates of BC and DM drop noticeably, indicating that intensified resource contention makes migration decisions more constrained by underlying compute and bandwidth limits. Notably, RL-PMO, which augments DM with twin-critic value estimation, sustains a success rate above 90% and degrades more slowly as load grows, demonstrating stronger robustness and reliability under high-load stress.
From Figure 3b, as load (number of SFCs) increases, the migration time of all six algorithms rises. Overall, BC, DT, and DM exhibit similar average migration time across load levels, with differences of about 0.2 s. The overall migration time of the IQL algorithm is relatively stable and remains at a low level. Under light load, RL-PMO is slightly faster than the other five; however, as the load grows, its average migration time increases more noticeably, and when the SFC count exceeds 200, RL-PMO becomes slower than the baselines. This behavior stems from RL-PMO’s design choice to favor more robust but slightly slower migration and bandwidth-allocation plans under tight resources in order to preserve a high success rate. The resulting overhead is expected and acceptable, and in a proactive migration setting—where failures are predicted and migration is triggered in advance—such fraction-of-a-second increases have negligible impact on service continuity.
Figure 3c compares the migration cost of all methods. BC is consistently and significantly more expensive than the others, indicating that pure imitation learning struggles to make resource-efficient decisions in complex, dynamic NFV/SFC environments. Consistent with Figure 3b, RL-PMO performs better under light load; however, as the load grows, it favors more resource-rich target nodes and conservative bandwidth allocation to keep the success rate stable, leading to a modest increase in both cost and time. In fault-driven scenarios, maintaining a high and stable success rate is paramount, so a controlled increase in time and cost is a reasonable trade-off.
To provide a comprehensive quantitative comparison, Table 1 summarizes the average performance of all algorithms across varying load levels (140–280 SFCs).
As shown in Table 1, RL-PMO achieves an average migration success rate of 95.26% across all load levels, outperforming IQL+FT and DM by approximately 9.2 and 9.7 percentage points, respectively, demonstrating significant superiority over other offline reinforcement learning baseline methods. BC exhibits an average success rate of only 74.73%, indicating that pure behavioral cloning fails to maintain reliable migration performance across diverse load scenarios. Although IQL achieves slightly better average migration time (3.02 s) and migration cost (21.94), its success rate is only 84.09%. In fault-driven SFC migration scenarios, success rate takes priority over time and cost. Overall, RL-PMO maintains a high success rate while controlling migration time at approximately 3.09 s and migration cost at around 24.41, achieving a reasonable trade-off between reliability and efficiency in multi-VNF parallel migration scenarios.
We further analyze the performance of RL-PMO under different values of k. In SFC migration, determining how many candidate nodes to assign to each VNF is a key trade-off: a larger candidate set expands the search space and may lead to better solutions, but it also increases decision complexity and computational overhead. To evaluate this trade-off, we set k = 4, 6, 8 and , compare the migration performance of RL-PMO under each configuration, and examine its sensitivity across different network load conditions.
As shown in Figure 4a, the success rate remains above 85% under all load levels, but clear performance differences appear across different values of k. Under light load, k = 4 achieves a success rate of 93.5%, while k = 6, k = 8 and k = 10 reach 97.2%, 97.0%, and 98.7%, respectively. Even in such resource-rich conditions, using more candidate nodes still yields a 3–5% improvement.
As the load increases, the success rate of k = 4 drops noticeably, whereas k = 6, k = 8 and k = 10 show better stability. Among them, k = 10 maintains a success rate between 92% and 98.7% across all load levels, and still reaches 92.2% at the highest load (280 SFCs), outperforming k = 4 by about 2.4 percentage points. The performance of k = 8 is similarly strong.
As shown in Figure 4b, migration time increases as the number of SFCs grows, but the differences across k values remain mild and follow a clear pattern. Under light load (140 SFCs), the migration times for all four k settings are almost identical, ranging from 2.5 to 2.6 s. This indicates that when resources are sufficient, the number of candidate nodes has minimal influence on migration time. As the load continues to rise, the time differences gradually appear, but under heavy load the curves for all four k values converge. This shows that under high load, the true bottleneck is the limitation of physical resources such as link bandwidth, rather than the number of candidate nodes.
As shown in Figure 4c, under light load, the migration cost for all four k values is concentrated within 16–17.5 units, with only small differences. However, as the load increases, the cost gap among different k values becomes more pronounced. Moreover, as the network load grows, the migration cost exhibits a similar pattern to the migration time, first increasing and then gradually converging. These results indicate that the choice of does have an impact on performance optimization: overly simplifying the action space is not always beneficial, and appropriately enlarging the action space can help the algorithm find higher-quality solutions.
We then conducted multiple tests of RL-PMO on a 19-node cellular network topology. It is important to emphasize that all training data for RL-PMO were collected exclusively from the 127-node topology, and the algorithm had never encountered any information from the 19-node network during training. This experiment is designed to verify whether the algorithm has learned transferable underlying strategies, rather than merely memorizing superficial characteristics of a specific topology.
In this design, the 19-node network was configured with node resources and link parameters similar to those of the 127-node topology, while its overall size was reduced by approximately 85%. To match the reduced network scale, the number of SFCs used for testing was adjusted to 30–100. As shown in Figure 5a, the success rate fluctuates between 76.3% and 93.2%, exhibiting larger variance compared with the experiments on the 127-node topology. As shown in Figure 5b,c, both the migration time and migration cost also increase noticeably as the network load grows. However, such increases are reasonable. More importantly, the algorithm does not experience cost escalation or collapse when exposed to an unseen topology. This demonstrates that RL-PMO has captured the underlying logic of SFC migration rather than memorizing a specific environment. Even without having seen the 19-node topology during training, the algorithm is still able to complete 76–94% of the migration tasks, providing strong evidence that the learned policy possesses cross-topology transferability and environmental adaptability.
Finally, we evaluated the performance of the proposed RL-PMO framework under different neural network depths to examine its sensitivity to model complexity. As the number of hidden layers increases, the total number of neurons grows correspondingly, leading to higher computational overhead during both training and inference. Figure 6 illustrate the performance of RL-PMO with three, four, and five hidden layers under various network load levels. The results indicate that the number of hidden layers has only a marginal effect on RL-PMO’s overall performance. Across all configurations, RL-PMO consistently achieves higher migration success rates than the DT, DM, IQL, BC and IQL+FT algorithms. Under light-load conditions, RL-PMO also attains lower migration time and cost; however, as the network load increases, its migration time and cost become slightly higher than those of the baseline algorithms. This trade-off reflects RL-PMO’s conservative resource allocation strategy designed to maintain high reliability under heavy-load conditions.
Figure 7 and Figure 8 further depict the training dynamics of Decision Mamba and RL-PMO with different hidden-layer depths. For Decision Mamba (Figure 7), the model with three hidden layers converges to a lower average return compared with those with four or five layers, stabilizing after roughly 20 iterations. In contrast, RL-PMO (Figure 8) shows minimal sensitivity to network depth: its training curves for all configurations converge smoothly to an average return of around −110 after about 20 iterations. These observations demonstrate that RL-PMO not only achieves more stable and better-quality convergence than DM but also maintains robustness and adaptability across different neural network depths.
6. Conclusions
This study investigates the optimization of Service Function Chain (SFC) migration in Network Function Virtualization (NFV) environments under impending node failure scenarios and proposes a Reinforcement Learning-driven Parallel Migration Optimization algorithm (RL-PMO). On the decision side, RL-PMO leverages the Decision Mamba model for sequential modeling and contextual representation, integrating high-quality offline migration trajectories generated by heuristic algorithms such as CSSA and PSO to enable efficient high-dimensional state encoding and policy learning in complex migration environments. On the evaluation side, a twin-critic structure coupled with Conservative Q-Learning (CQL) regularization is employed to penalize out-of-distribution actions, thereby enhancing policy stability and generalization under heavy-load conditions.
Extensive simulation results show that RL-PMO maintains nearly a 95% migration success rate across different scales and load conditions, and its performance degrades slowly as network load increases. In terms of migration efficiency and cost, RL-PMO performs better under low load, while under high load, it proactively selects more reliable paths and resource allocations to ensure successful migration. Overall, RL-PMO achieves higher success rates and more stable performance with only small additional overhead, demonstrating strong robustness in complex NFV environments. This capability is particularly important in sensor-network and IoT-edge systems that rely on stable, continuous, and low-latency SFCs to maintain the reliability and responsiveness of critical applications.
Although RL-PMO demonstrates strong performance in the simulation environment, several directions remain worth further exploration: The current offline dataset is constructed from only a single 127-node topology. Future work can incorporate multiple network topologies during training to improve cross-topology generalization. This study focuses on batch VNF migration triggered by a single-node failure, and future research may extend this to multi-node failure scenarios and coordinate parallel migration across multiple failure regions. The current evaluation covers network sizes of up to 127 nodes. Future work could further scale the study to networks with thousands of nodes and explore model compression, knowledge distillation, and distributed inference to reduce computational overhead.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bhamare D. Jain R. Samaka M. Erbad A. A Survey on Service Function Chaining J. Netw. Comput. Appl.20167513815510.1016/j.jnca.2016.09.001 · doi ↗
- 2Wang Y. Ye Q. Zhou P. Li B. Wang X. Zhang L. Research on fault prediction of computer network nodes driven by log information Telecommun. Sci.202440112210.11959/j.issn.1000-0801.2024168 · doi ↗
- 3Zhai D. Meng X. Yu Z. Hu H. Liang Y. A Migration Method for Service Function Chain Based on Failure Prediction Comput. Netw.202322210955410.1016/j.comnet.2022.109554 · doi ↗
- 4Kabdjou J. Shinomiya N. A Method for Service Function Chain Migration Based on Server Failure Prediction in Mobile Edge Computing Environment IEEE Access 202513786647867810.1109/ACCESS.2025.3564967 · doi ↗
- 5Tang L. He X. Zhao P. Zhao G. Zhou Y. Chen Q. Virtual Network Function Migration Based on Dynamic Resource Requirements Prediction IEEE Access 2019711234811236210.1109/ACCESS.2019.2935014 · doi ↗
- 6Cho D. Taheri J. Zomaya A.Y. Bouvry P. Real-Time Virtual Network Function (VNF) Migration toward Low Network Latency in Cloud Environments Proceedings of the 2017 IEEE 10th International Conference on Cloud Computing (CLOUD)Honolulu, HI, USA 25–30 June 2017
- 7Xia J. Cai Z. Xu M. Optimized Virtual Network Functions Migration for NFV Proceedings of the 2016 IEEE 22nd International Conference on Parallel and Distributed Systems (ICPADS)Wuhan, China 13–16 December 2016340346
- 8Qu K. Zhuang W. Shen X. Li X. Rao J. Dynamic Resource Scaling for VNF Over Nonstationary Traffic: A Learning Approach IEEE Trans. Cogn. Commun. Netw.2021764866210.1109/TCCN.2020.3018157 · doi ↗