Rate-Splitting-Based Resource Allocation in FANETs: Joint Optimization of Beam Direction, Node Pairing, Power and Time Slot
Fukang Zhao, Chuang Song, Xu Li, Ying Liu, Yanan Liang

TL;DR
This paper introduces a new resource allocation method for directional flying ad hoc networks that improves efficiency and reduces latency by integrating rate-splitting techniques.
Contribution
The paper proposes an intra-beam rate-splitting-based resource allocation framework for directional FANETs, combining beam direction, node pairing, power, and time-slot optimization.
Findings
The proposed IBRSRA algorithm reduces the required number of transmission time slots by over 42% for a 16-node network.
Integrating constrained rate-splitting with beam-based scheduling significantly enhances spectral efficiency and reduces latency.
A two-stage algorithm using greedy scheduling and successive convex approximation solves the optimization problem efficiently.
Abstract
Directional flying ad hoc networks (FANETs) equipped with phased array antennas are pivotal for applications demanding high-capacity, low-latency communications. While directional beamforming extends the communication range, it necessitates the intricate joint optimization of the beam direction, power, and time-slot scheduling under hardware constraints. Existing resource allocation schemes predominantly follow two paradigms: (i) conventional physical-layer multiple access (CPMA) approaches, which enforce strict orthogonality within each beam and thus limit spatial efficiency; and (ii) advanced physical-layer techniques like rate-splitting multiple access (RSMA), which have been applied to terrestrial and omnidirectional UAV networks but not systematically integrated with the beam-based scheduling constraints of directional FANETs. Consequently, jointly optimizing the beam direction,…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
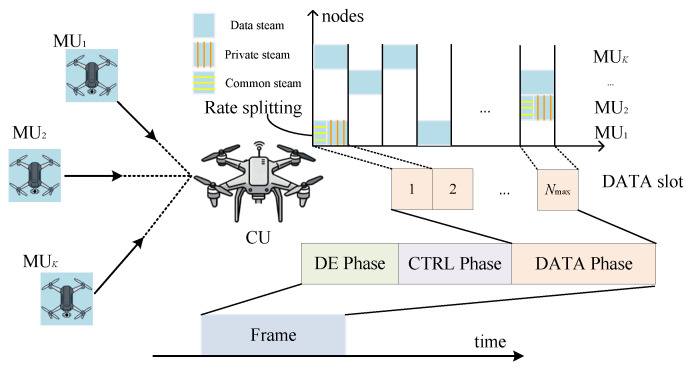 Figure 1
Figure 1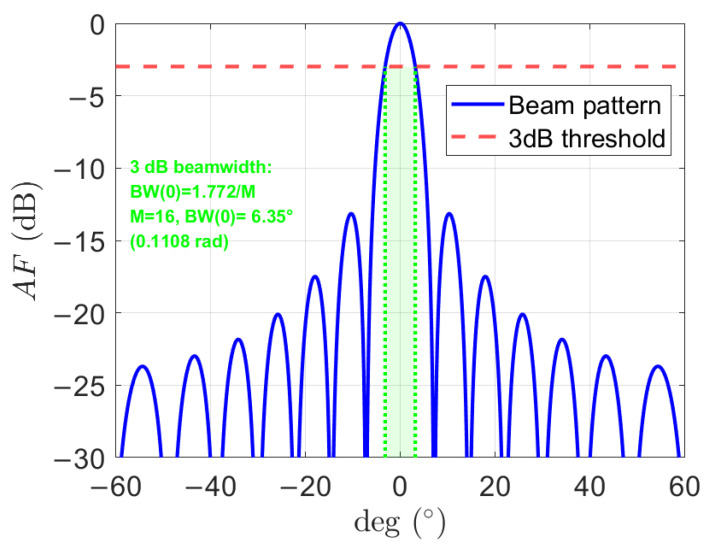 Figure 2
Figure 2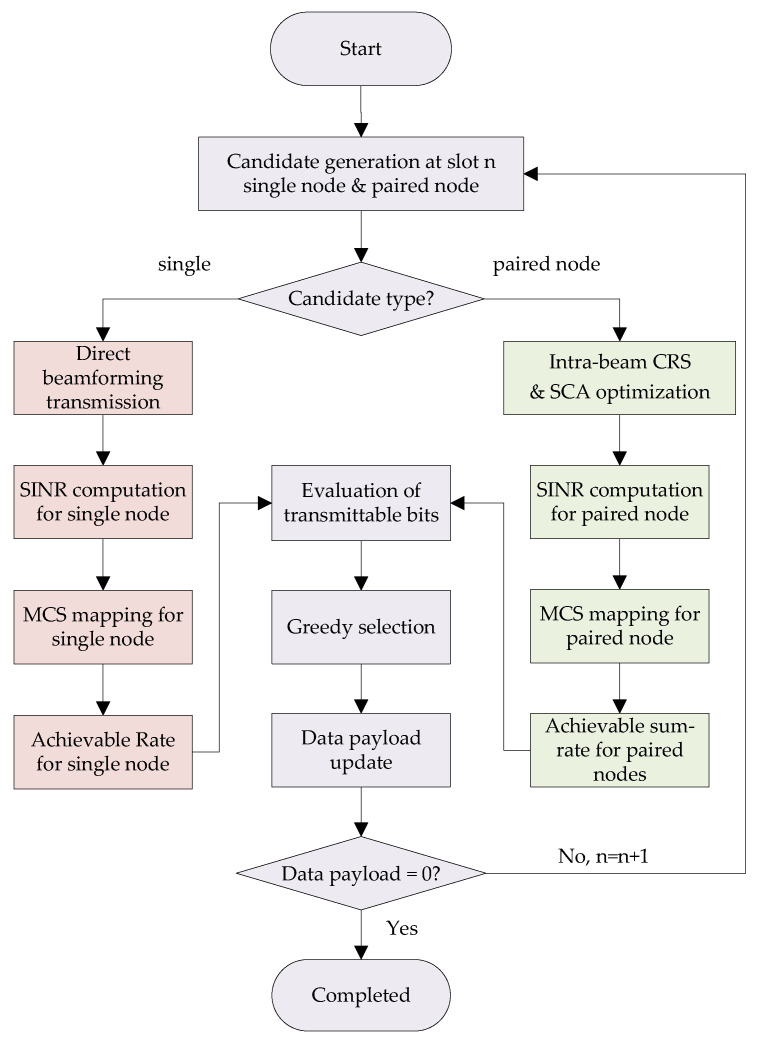 Figure 3
Figure 3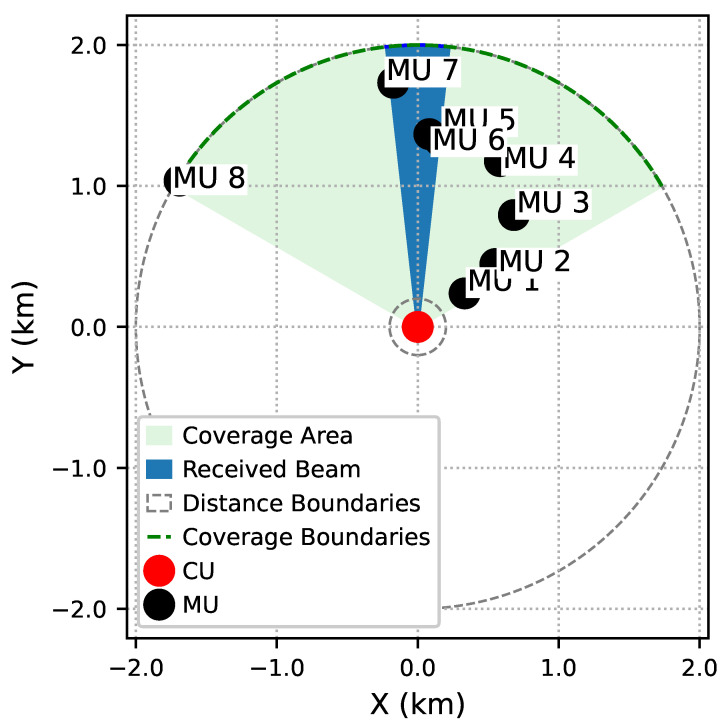 Figure 4
Figure 4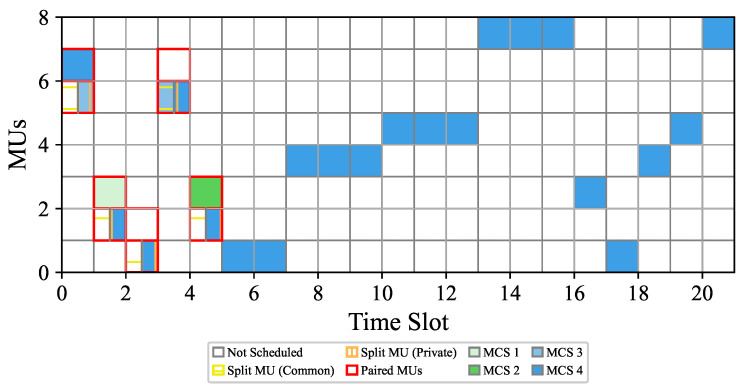 Figure 5
Figure 5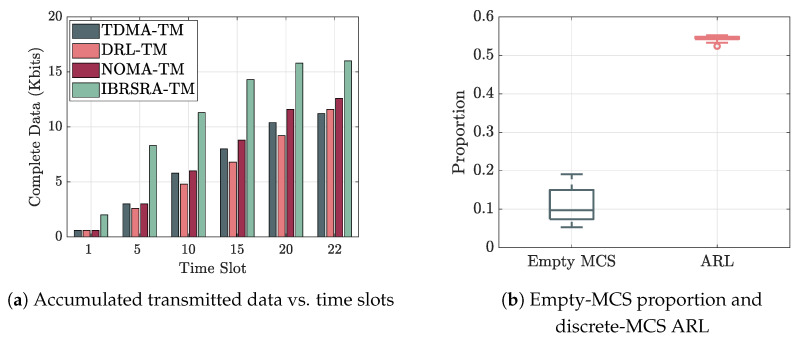 Figure 6
Figure 6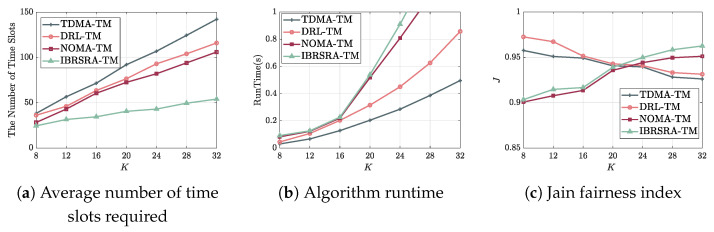 Figure 7
Figure 7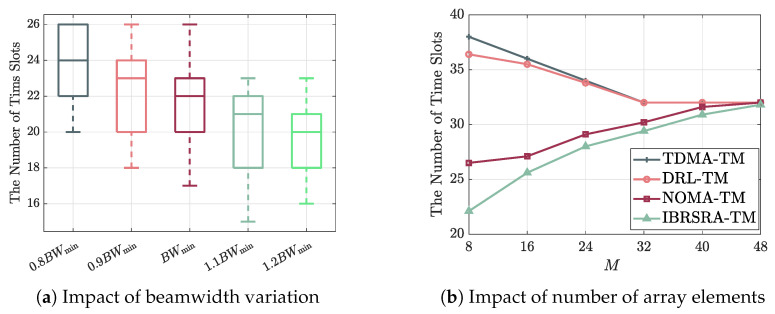 Figure 8
Figure 8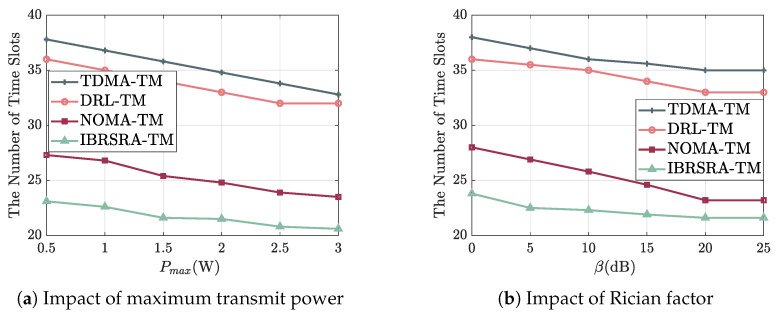 Figure 9
Figure 9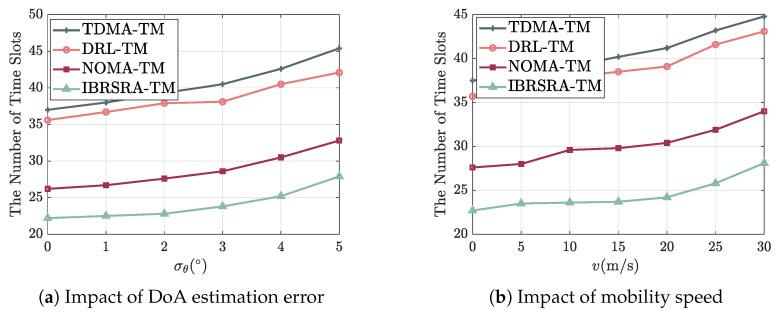 Figure 10
Figure 10- —Science and Technology Innovation Program of Xiongan New Area
- —Joint Funds of the National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsUAV Applications and Optimization · Advanced Wireless Communication Technologies · Satellite Communication Systems
1. Introduction
Unmanned aerial vehicles (UAVs) have become a key technology across both civilian and military domains, owing to their unique advantages in mobility and deployment flexibility. In civilian applications, they are regarded as a key enabler for sixth-generation (6G) wireless networks, which are capable of providing communication coverage in complex environments such as disaster areas, dense urban regions, and remote terrains [1,2]. UAVs also play a vital role in assisting ground-based sensors for efficient data collection [3]. In the military sphere, UAVs are indispensable for reconnaissance, surveillance, and precision strike missions [4]. To efficiently execute these complex and often collaborative tasks, multiple UAVs typically form a flying ad hoc network (FANET) [5]. Such networks enable distributed coordination, enhance overall system survivability, and improve the scalability of missions.
Compared with conventional FANETs employing omnidirectional antennas, directional FANETs equipped with phased array antennas achieve a significantly extended communication range, enhanced interference suppression, and improved spectral efficiency by focusing transmitted energy into narrow beams [6,7]. However, these advantages introduce strongly coupled resource interdependencies among beam direction, transmit power, and time-slot scheduling. In practice, given the stringent hardware and cost constraints of UAV platforms, single-port phased array antennas have emerged as a widely deployed solution [8]. Specifically, directional FANETs utilizing single-port phased array antennas typically operate under a time division multiple access (TDMA)-based medium access control (MAC) protocol, adhering to a one-beam-per-slot transmission model. Such a constraint necessitates the design of optimized resource allocation schemes to enable highly efficient directional FANET communications.
1.1. Related Work
To address the aforementioned resource allocation challenge in directional FANETs, existing research can be broadly categorized into two complementary paradigms: (i) conventional physical-layer multiple access (CPMA)-based resource allocation, and (ii) advanced physical-layer multiple access (APMA)-based resource allocation, specifically leveraging rate-splitting multiple access (RSMA).
(i) CPMA-Based Resource Allocation: Most existing resource allocation schemes for directional FANETs adopt CPMA technologies, where only one node is permitted to transmit within a single beam, otherwise leading to severe collisions. Early studies have focused on collision-avoidance MAC designs, adopting transmission reservation and directional handshake mechanisms to reduce collision risks [9]. Subsequent studies formulate concurrent transmission scheduling as graph-theoretic problems (e.g., graph coloring) to maximize spatial reuse while satisfying interference constraints [10,11,12]. Such schemes are required to avoid inter-node/inter-beam interference by assigning orthogonal time slots or beams.
More recent research explores the joint optimization of time-slot scheduling, beam direction, and power control to further enhance network performance. For example, the authors in [13] propose a fairness-aware weighted capacity maximization framework solved via iterative dual optimization, while [14,15] introduce deep reinforcement learning (DRL) techniques to enable adaptive and dynamic resource allocation. Although these methods improve scheduling efficiency and long-term performance, they inherently assume orthogonal intra-beam transmission. Consequently, the physical-layer transmission efficiency within each beam remains fundamentally limited.
(ii) APMA-Based Resource Allocation: Non-orthogonal multiple access (NOMA) and RSMA have been widely investigated as flexible physical-layer techniques for managing multi-user interference to improve spectral efficiency in 6G networks [16,17,18]. Power-domain NOMA enables simultaneous transmission by superimposing user signals with different power levels [16]. RSMA generalizes NOMA by splitting messages into common and private parts, allowing partial interference decoding and offering improved robustness against channel uncertainty and heterogeneous link conditions [19,20].
Most existing research on RSMA has predominantly focused on terrestrial downlink and uplink communications, addressing various resource allocation challenges. In downlink scenarios, the joint optimization of user pairing, rate allocation, power control, and beamforming has been widely investigated, as seen in works such as [19,21]. The authors in [19] also design an adaptive modulation and coding scheme (MCS) for rate-splitting (RS). Corresponding studies in the uplink domain [22,23,24] have pursued a similar approach, which involves applying constrained rate-splitting (CRS) exclusively at the weaker node while performing the joint optimization of user pairing, rate allocation, and power control. Beyond conventional terrestrial systems, recent efforts have extended RSMA to high-mobility and non-terrestrial networks. For example, an orthogonal time-frequency space (OTFS)-RSMA scheme is proposed for uplink transmission, where high-mobility users are served in the delay-Doppler domain while low-mobility users operate in the time-frequency domain [25]. RSMA has also been studied in satellite communication contexts with research focusing on the joint optimization of user pairing, rate allocation, power control, and beamforming [26]. Furthermore, RSMA has been adapted for massive access and internet of things (IoT)-oriented scenarios. One research direction integrates RSMA with slotted ALOHA, introducing a preconfigured signal-to-interference-plus-noise ratio (SINR) level allocation and an adaptive traffic load mechanism to maintain throughput stability under high traffic loads [27]. Another line of work explores a UAV-assisted IoT system employing RSMA, which jointly optimizes transmission scheduling, rate allocation, transmit power, and UAV trajectory to maximize the overall system throughput [28]. Despite these advances, existing RSMA frameworks are typically developed independently of slot-based MAC protocols and do not consider the tight coupling between beam direction, intra-beam CRS-based node pairing, transmit power, MCS selection, and time-slot scheduling in directional FANETs.
While CPMA-based approaches offer structured scheduling under orthogonality constraints, and APMA-based techniques (especially RSMA) provide higher spectral efficiency in various scenarios, significant potential remains for enhancing directional FANET performance through their integrated design. To the best of our knowledge, no existing work jointly optimizes beam direction, intra-beam CRS-based node pairing, transmit power, MCS selection, and time-slot scheduling for directional FANETs. Table 1 summarizes the key distinctions between prior research and the proposed work.
1.2. Motivation and Contributions
Motivated by the above observations, this paper proposes an intra-beam rate-splitting-based resource allocation (IBRSRA) algorithm for phased-array-antenna-based FANETs.
The main contributions of this work are summarized as follows:
- (i)This paper develops a system model that integrates directional beamforming, CRS-based intra-beam paired-node transmission, and slot-based MAC scheduling. This model explicitly captures the coupling among beam direction, intra-beam interference management, and time-slot allocation in low-latency cooperative UAV reconnaissance scenarios.
- (ii)This paper formulates a mixed-integer nonlinear programming (MINLP) problem aiming to minimize the total number of time slots required to complete multi-UAV data transmission. The problem jointly considers beam direction selection, intra-beam node pairing or single-node transmission, transmit power control, and MCS selection under CRS-based transmission. To efficiently solve this problem, a two-stage optimization framework is developed, where successive convex approximation (SCA) is applied to handle non-convex intra-beam parameter optimization, which is followed by a greedy scheduling strategy to determine time-slot allocation.
- (iii)Extensive simulations confirm that the proposed IBRSRA transmission mechanism substantially enhances per-slot transmission efficiency and reduces the overall delay. For a network with 16 nodes, it lowers the required number of time slots by over 42% compared to the best baseline.
1.3. Organization
The remainder of this paper is organized as follows. Section 2 introduces the system model. Section 3 formulates the problem of minimizing the total number of slots and presents the proposed IBRSRA algorithm. Section 4 provides the simulation parameters and performance evaluation. Finally, Section 5 concludes the paper.
2. System Model
2.1. Network Model
As illustrated in Figure 1, this paper considers a cooperative UAV reconnaissance scenario, where a central UAV (CU) and K mission UAVs (MUs) form a FANET. Each MU is required to transmit its reconnaissance data payload of bits to the CU.
All UAVs are time-synchronized and operate under a TDMA-based MAC protocol. The timeline is partitioned into frames, each consisting of three sequential phases: Direction-of-Arrival (DoA) Estimation (DE), Control (CTRL), and Data (DATA). Each phase is further divided into time slots. A resource allocation algorithm that determines the scheduling strategy and allocates up to slots for the DATA phase is executed in the CTRL phase, where is a predefined upper bound on the transmission horizon per frame. The operations of each phase are detailed as follows:
- (i)DE Phase: The CU estimates the DoA and distances to all MUs via beacon signals, thereby acquiring the spatial prior information (including location, speed, and direction of movement) required for subsequent resource allocation. The detailed DoA estimation procedure follows our prior work [29].
- (ii)CTRL Phase: Leveraging the spatial information obtained, the CU performs resource allocation for the upcoming DATA phase. This includes optimizing the parameters for intra-beam paired nodes under a CRS scheme, such as the transmit power, MCS, and receive beam direction, and determining the per-slot transmission strategy (i.e., scheduling either a paired-MU group or a single MU in each slot).
- (iii)DATA Phase: According to the decisions made in the CTRL phase, the scheduled MUs transmit their reconnaissance data to the CU within the assigned time slots.
2.2. Antenna Model
The CU is equipped with an M-element uniform linear array (ULA) having an inter-element spacing of , where is the signal wavelength. This phased array antenna allows the CU to form only one directive beam per time slot for either transmission or reception. The corresponding array steering vector for a signal from direction is given by
which captures the phase progression across the array elements. The receive beamforming vector is then designed by setting to steer the main lobe toward angle .
For such a ULA, the far-field radiation pattern is characterized by the array factor, which is defined as the inner product between the beamforming vector and the steering vector
According to the array factor, the 3 decibel (dB) beamwidth at a steering angle [29] can be approximated as
The beamwidth defines the angular coverage of the main lobe. The minimum 3 dB beamwidth is achieved for broadside steering ( )
Figure 2 shows the array factor for , showing sidelobe structures and confirming that the actual 3 dB beamwidth remains close to for steering angles near broadside.
Each MU employs a directional sector antenna with a constant gain of (in dB) within its main lobe and zero gain elsewhere. For analytical tractability, the beamwidth of each MU’s antenna is assumed to match the CU’s minimum 3 dB beamwidth , ensuring angular coverage consistency when the CU beam is steered to the broadside.
2.3. Mobile Model
All MUs follow a constant-velocity mobility model with fixed speed and direction within a frame [13]. In a frame comprising DATA slots, both the speed and moving direction of each MU remain unchanged.
This paper defines a two-dimensional Cartesian coordinate system with the CU located at the origin . The y-axis is aligned with the normal direction of the ULA. For the k-th MU, its initial position at slot is expressed as
where is the initial distance between the MU and the CU, and denotes the initial DoA, which is defined as the angle between the incident signal and the y-axis.
Let and denote the constant speed and moving direction of MU k, respectively, where is measured relative to the y-axis. The displacement per DATA slot along the x- and y-axes is given by
where is the duration of each DATA slot.
Accordingly, the position of MU k in slot updates as
The corresponding Euclidean distance between MU k and the CU at slot n is given by
and the DoA is geometrically determined by
which naturally captures the angular variation induced by mobility.
2.4. Channel Model
This paper considers a narrowband flat-fading air-to-air (A2A) channel between the MUs and the CU, which incorporates both large-scale path loss and small-scale Rician fading [30].
2.4.1. Large-Scale Path Loss
The large-scale path loss between the k-th MU and the CU captures the distance-dependent free-space path loss (FSPL) and random environmental fluctuations.
The distance-dependent FSPL is modeled as
To account for environmental shadowing, this paper introduces a log-normal random variable to model the shadow fading in dB. The shadow fading is given by
where represents the shadowing coefficient, which is assumed to be constant within one frame and varies independently across frames.
2.4.2. Small-Scale Rician Fading
To capture the dominant line-of-sight (LOS) component typical in A2A links, the small-scale fading vector is modeled as
where is the Rician factor, is the array steering vector corresponding to the DoA , and represents the scattered non-line-of-sight (NLOS) component.
Due to the mobility of the MUs, the channel experiences time-varying effects. The Doppler frequency shift for MU k is given by
which is the projection of its velocity onto the LOS direction. Consequently, the phase of the LOS component evolves as
The NLOS component is modeled as a temporally correlated Rayleigh fading process using a Jakes-inspired model
where is a fixed realization of a random variable uniformly distributed over , which remains constant for each MU k. The resulting temporal autocorrelation follows . The LOS and NLOS components are statistically independent.
2.4.3. Composite Channel and Its Estimation
The composite A2A channel vector for MU k at slot n is therefore
During the DE phase, the CU acquires beacon-assisted estimates of the DoA and the composite channel for each MU, which are denoted as and , respectively. These estimates serve as critical inputs for the CTRL phase. The DoA estimate is subject to a bounded error modeled as [31]
where is the estimation error standard deviation. The corresponding initial position estimate is , assuming an accurate distance measurement (e.g., via time of arrival). For , the estimated position is updated using the known constant velocity and direction , and the DoA estimate is computed geometrically as
where , , and . These expressions are consistent with Equations (6) and (7). This approach avoids per-slot re-estimation and is practical for TDMA-based FANETs.
The channel estimate is then modeled as
The effective channel for MU k at slot n, after applying the receive beamforming vector at the CU, is given by
where is the directional antenna gain of the MU.
For high-altitude FANETs operating at sub-6 GHz, ground reflections are minimal, leading to a small [32]. Furthermore, with typical UAV speeds ( [33]) and short slot durations ( [34]), both the angular drift and the small-scale fading variation within a single slot are negligible. This results in an approximate block-fading channel that remains quasi-static within each DATA slot but evolves slowly across slots due to the cumulative effects of mobility and Doppler phase shift. Notably, for high-speed UAVs, this quasi-static approximation may break down, necessitating joint optimization with predictive positioning, which is a challenge for future work.
2.5. Achievable Data Rate and Remaining Data Update
For data transmission, each MU selects an MCS from a finite set . The spectral efficiency (bit/s/Hz) for each MCS index q ( ) is defined as follows [35]:
- : QPSK with code rate , bit/s/Hz;
- : QPSK with code rate , bit/s/Hz;
- : 16-QAM with code rate , bit/s/Hz;
- : 16-QAM with code rate , bit/s/Hz.
An MCS q is considered feasible for a node if its linear-scale SINR satisfies , where . The dB-scale thresholds are [35] , , , .
In each slot n, let denote the set of scheduled MUs. The system supports two transmission modes: single-node transmission ( ) and paired-node transmission ( ).
2.5.1. Single-Node Transmission
For a slot scheduled with a single MU k (i.e., ), the SINR at the CU is
where is the transmit power of MU k, is the additive white Gaussian noise (AWGN) power, and is the effective channel gain under the CU’s receive beam .
Let denote the index of the highest feasible MCS for MU k, satisfying . The corresponding spectral efficiency is . The achievable data rate is then
where B is the system bandwidth.
2.5.2. Paired-Node Transmission
For a slot scheduled with a pair of MUs within the same beam (i.e., ), the system employs CRS. To limit implementation complexity, CRS is applied only to the weaker node, which is defined as the one with the smaller effective channel gain. Without loss of generality, assume , where , making MU i the RS node. This asymmetric design is motivated by two factors: first, the RS at one node is sufficient to achieve the two-node uplink MAC capacity region [22,23,24]; second, it balances high spectral efficiency with the computational and energy constraints of UAVs [29].
Transmission Strategy: The RS node i splits its message into a common stream and a private stream . Its total transmit power is divided as
where is the power-splitting factor. The stronger node j transmits a single stream with power .
Decoding Order at CU: The CU applies successive interference cancellation (SIC) in the following fixed order: (1) decode the common stream ; (2) decode after subtracting ; (3) decode after subtracting both and .
The SINR for each stream is
MCS Selection and Achievable Rate: Each stream selects the highest feasible MCS independently based on its own SINR. Let , , and denote the selected MCS indices for streams , , and , respectively. Their corresponding spectral efficiencies are , , and . The achievable data rate for MU k in slot n is
Feasibility Analysis: When two nodes are paired within the same beam, their effective channel gains, denoted as and , may become comparable under certain conditions, for instance, when the nodes are allocated equal initial power ( ) and are located at similar distances from the UAV. In such scenarios, the fixed signal decoding order remains feasible, as its success is ultimately determined by whether the SINR at each decoding stage meets the minimum requirement of the selected MCS.
Furthermore, the algorithm incorporates a graceful degradation mechanism to sustain connectivity under challenging channel conditions:
- If the optimized intra-beam parameters yield SINRs that are insufficient to support the CRS scheme (i.e., the common stream cannot be decoded successfully), the transmission falls back to a conventional NOMA scheme while retaining the same fixed decoding order.
- If the SINRs of the common stream or the strong node’s stream fall below the lowest MCS threshold, the transmission further degrades to single-node transmission.
For the edge case where the channel gains are extremely close, an enhanced rule can be optionally applied: each node is tentatively designated as the RS node, and the corresponding joint optimization is carried out. The configuration that achieves the higher sum rate is then selected for transmission.
2.5.3. Remaining Data Update
All MU nodes are assumed to have the same finite amount of data to transmit. Let denote the remaining data payload of MU k at the beginning of slot n with initial condition . The payload is updated as follows
where is given by (22) for single-node transmission or (27) for paired-node transmission.
3. Problem Formulation and Proposed Algorithm
3.1. Problem Formulation
Let be a binary slot occupation indicator for , where if slot n is used for transmission (i.e., ), and otherwise. The total number of occupied slots is .
The joint resource allocation involves optimizing over the following variables:
- Scheduling: the set of scheduled MUs in each slot n with .
- Transmit Powers: , the transmit power of MU k in slot n (with if ), bounded by .
- Power Splitting: for paired transmission ( ), the factor that splits the weaker node i’s power into common and private parts: , .
- MCS Selection: the index of the selected MCS for each transmitted stream, which maps to its spectral efficiency:
- −For a single-node slot ( ): , yielding spectral efficiency .
- −For a paired-node slot ( ): for the common, private, and strong node’s streams, yielding efficiencies , , and .
- Beam Direction: The CU’s receive beam angle for slot n. For the paired-node slot ( ), the receive beam angle must be within the range , where and denote the minimum and maximum DoAs of MU pair , respectively.
The goal of the optimization problem is to minimize the total transmission time, leading to the following MINLP
where (30) defines the scheduling constraints. Equations (31) and (32) are the power constraints. Equation (33) defines the power splitting factor for paired transmission. Equation (34) restricts MCS selection to the predefined set. Equation (35) is the key physical-layer constraint, ensuring that the SINR of each stream supports its chosen MCS. Equation (36) defines the beam direction constraints. Equation (37) ensures that all data are transmitted by the last slot with updated via (28).
This problem is a challenging MINLP due to the combinatorial scheduling variables ( ), integer MCS selections, continuous variables ( , , ), and the nonlinear constraint (35). Finding the global optimum is NP-hard. Therefore, in the subsequent section, this paper proposes a practical two-stage optimization algorithm to obtain efficient solutions.
3.2. Proposed Algorithm
To efficiently solve the challenging MINLP problem (29)–(37), this paper proposes an intra-beam rate-splitting-based resource allocation (IBRSRA) algorithm. The core idea is to decompose the original joint optimization into two interconnected subproblems: (1) intra-beam parameter optimization at slot n and (2) time slot scheduling.
For a given time slot n, the CU serves either a single MU or a paired set of MUs within a single beam. A key observation from the payload update rule (28) is that maximizing the achievable data rate transmitted in each slot directly minimizes the total number of slots required to complete all transmissions. Therefore, the per-slot objective is to maximize the achievable data rate. For a candidate single node k, its maximum transmittable data in a slot can be computed directly via (22) with direct beamforming. For a candidate node pair , this requires solving the intra-beam parameter optimization subproblem, which jointly determines the optimal power allocation , MCS indices , and beam direction to maximize their transmittable data sum rate.
The time slot scheduling subproblem then utilizes the results from this intra-beam optimization. By evaluating the maximum achievable data rates for all possible single nodes and node pairs, it determines the optimal schedule, i.e., which node(s) to serve in each slot, to most efficiently reduce the residual payloads .
Figure 3 provides a block diagram summarizing the main processing steps of the proposed IBRSRA algorithm within each scheduled slot. These steps include candidate generation, intra-beam parameter optimization, SINR-based MCS mapping (jointly performing achievable rate computation), and greedy scheduling selection.
3.2.1. Intra-Beam Parameter Optimization via SCA
For a given node pair scheduled in slot n, we aim to maximize their total transmission rate by jointly optimizing the transmit powers , the power-splitting factor , the MCS indices , and the beam direction . The corresponding subproblem is formulated as
where and are computed via (27) and depend on the discrete MCS selections.
To handle the combinatorial complexity introduced by the discrete MCS variables, we relax the problem by approximating the achievable rate of each stream with the continuous Shannon capacity [36,37]. The SINR expressions for the common stream, strong node’s stream, and private stream are given by (24), (25), and (26), respectively. The relaxed problem remains non-convex due to variable coupling in the SINR expressions and the logarithmic objective.
SCA linearizes non-convex terms around the current iterate, yielding a convex subproblem that can be efficiently solved per iteration [36]. This paper employs the SCA framework to solve this non-convex problem iteratively. At each iteration l, given the current point , a concave lower-bound surrogate for the sum rate is constructed by applying the first-order Taylor expansion to each logarithmic term. For a generic rate term , the expansion yields
Applying this to the three streams gives the corresponding affine approximations , , and . The gradients required for these expansions are derived in Appendix B.
Summing these approximations yields the concave surrogate objective
Since a sum of affine functions is affine (and thus concave), is concave in . Furthermore, the constraints (39)–(41) are all linear or box constraints, defining a convex set.
Consequently, at each SCA iteration l, we solve the following convex optimization problem
This convex problem can be efficiently solved using standard convex optimization solvers. The SCA algorithm iterates by solving (44)–(45) to obtain , updating the expansion point, and repeating until convergence. The convergence criterion is based on the relative change in the surrogate objective
where this paper sets or until a maximum number of iterations is reached.
Let denote the optimized continuous variables after SCA convergence. Then, compute the resulting SINRs and map each to the highest feasible discrete MCS level by comparing with the thresholds . The selected MCS indices for the common, private, and strong node’s streams, yield spectral efficiencies . These efficiencies are substituted into (27) to obtain the final achievable rates and .
The complete SCA procedure for a node pair is summarized in Algorithm 1. A feasible initial point (e.g., equal power splitting and a beam angle between the estimated DoAs) ensures stable convergence. Algorithm 1 SCA-Based Intra-Beam Optimization for Pair in Slot n
-
Require: DoA estimates , distances , channel estimates , noise power , max power .
-
Ensure: Optimal powers , splitting factor , beam angle , and selected MCS indices .
-
1:Initialize iteration counter . Set initial point .
-
2:repeat
-
3: Compute effective channel gains using (20).
-
4: Compute SINRs via (24)–(26) and their gradients.
-
5: Construct concave surrogate via first-order Taylor expansion of all terms.
-
6: Solve the convex problem (44) and (45) to obtain .
-
7: Update .
-
8:until or
-
9:Compute final SINRs using .
-
10:For each stream, select the highest MCS index q such that .
-
11:return .
Nevertheless, an empty MCS assignment occurs when the SINR obtained from the relaxed optimization falls below the minimum threshold required for the lowest-order MCS (MCS_1_). This indicates that the relaxed continuous solution becomes infeasible after discrete MCS mapping. In such cases, the transmission scheme degrades gracefully: the RSMA transmission falls back to power-domain NOMA, then to single-node transmission, or may even be skipped entirely and rescheduled in a subsequent time slot.
Furthermore, the relaxation based on the continuous Shannon capacity formula introduces an achievable rate loss (ARL) due to the discrete nature of practical MCS selection. The ARL of node k at slot n is quantified as
where is the rate achievable under continuous SINR and is the achieved rate from (22) and (27) under discrete SINR. The observed gap is primarily attributable to the limited granularity of the four-level MCS set adopted in this study. Employing a finer-grained MCS table, such as those specified in 5G NR [20], would effectively reduce this loss.
3.2.2. Time Slot Scheduling
The scheduling subproblem determines which node(s) to serve in each time slot. It operates on the set of feasible scheduling candidates for slot n, which is denoted by . Each candidate is a subset of that can be served by a single beam, i.e., either a single node or a node pair . Specifically, the following apply:
- A single node k is a candidate if .
- A node pair is a candidate if both and , and their angular separation is less than the beamwidth, ensuring they can be covered simultaneously by the same beam.
For each candidate , we calculate the total data it can deliver in slot n as
where and are the achievable rates obtained from the intra-beam optimization (Algorithm 1 for pairs, (22) for single nodes).
The scheduler adopts a greedy, per-slot maximization strategy: it selects the candidate that yields the largest immediate data delivery,
Ties are broken by preferring the candidate that serves more nodes (a pair over a single node). The selected candidate then becomes the scheduling decision for slot n; i.e., we set
After transmission, the remaining payloads are updated via (28), and the candidate set for the next slot is recomputed based on the updated .
The proposed greedy scheduling rule prioritizes the candidate that maximizes the number of bits delivered per time slot. While nodes with higher SINRs tend to be scheduled more frequently in the early stages, low-SINR nodes are naturally served in subsequent stages once high-rate nodes complete their transmissions. This phenomenon can be attributed primarily to two key factors:
- All MU nodes are assumed to have identical finite data volumes of data to transmit with the overarching objective of minimizing the total number of time slots required for all nodes to complete their data transmission. Under this completion-time minimization criterion, every node must ultimately be scheduled, as failure to do so would render the system’s core objective unachievable.
- A minimum SINR guarantee is inherently embedded in the system design. Specifically, the maximum transmission distance is capped at 2 km, and a transmit power of 0.5 W ensures that the SINR resulting from single-node transmission under FSPL satisfies the minimum SINR requirement of (3.61 dB). Consequently, no node is permanently precluded from transmission due to infeasible SINR conditions.
3.2.3. Algorithm Summary
The complete IBRSRA algorithm, integrating the intra-beam optimization and greedy scheduling, is summarized in Algorithm 2. The algorithm proceeds slot by slot until all data payloads are cleared. Algorithm 2 IBRSRA Algorithm
-
Require: Initial payloads , DoA estimates , distances , channel estimates .
-
Ensure: Schedule , and corresponding parameters for each scheduled slot.
-
1:Initialize remaining data: , for all .
-
2:Initialize slot index: .
-
3:**while ** do
-
4: Construct candidate set :
-
5: Single nodes: for each k with .
-
6: Node pairs: for each with , , and .
-
7: for each candidate do
-
8: if (single node) then
-
9: Compute optimal beam direction .
-
10: Obtain rate via (22) with optimal power and highest feasible MCS.
-
11: Set .
-
12: else if (node pair) then
-
13: Run Algorithm 1 to obtain optimal and rates .
-
14: Set .
-
15: end if
-
16: end for
-
17: Select candidate . Break ties by preferring pairs over single nodes.
-
18: Set schedule , and record corresponding parameters.
-
19: Update remaining payloads: result of (28) for all k.
-
20: .
-
21:end while
-
22:Set total used slots .
-
23:return , and associated parameters.
3.2.4. Analysis of Computational Complexity
The computational complexity of IBRSRA primarily stems from two parts: intra-beam optimization and greedy scheduling. A detailed breakdown is provided below:
(1) Intra-Beam Parameter Optimization (per candidate pair): For each candidate node pair, the SCA algorithm solves a convex subproblem iteratively. Each subproblem has four variables ( ) and a constant number of constraints, which can be solved by an interior-point method in time per iteration. Let denote the average number of SCA iterations needed for convergence. The complexity per pair is therefore . After obtaining the continuous solution, the discrete MCS mapping involves a simple lookup over four possible levels for each of the three streams, which is also .
(2) Greedy Scheduling (per slot): In each slot, the algorithm evaluates all feasible candidates. Let be the number of MUs with positive remaining data at slot n. The number of single-node candidates is . For node pairs, we only consider those whose angular separation is within the beamwidth, which typically reduces the number of candidate pairs from to a much smaller set, which is denoted as . For each single node, the rate computation is closed-form ( ). For each candidate pair, we run Algorithm 1, incurring complexity. Hence, the per-slot complexity is .
(3) Overall Complexity: In the worst case, where all nodes always have data and every pair is considered ( ), and assuming the maximum possible number of slots is used, the overall worst-case complexity becomes
In practice, angular-based pruning significantly reduces , and the algorithm typically terminates in fewer than slots. Notably, since each node has a maximum achievable transmission rate per slot, an additional pruning strategy can be incorporated: during the candidate evaluation, if either stream of a node pair reaches its maximum rate, the pair is prioritized for scheduling, further reducing the search space. Moreover, the SCA subproblems for different candidate pairs are computationally independent and can be parallelized on multi-core processors, enabling additional speedups. Thus, the proposed IBRSRA algorithm remains computationally feasible for real-time resource allocation in FANETs with a moderate number of UAVs.
To address the scalability bottleneck in large-scale node networks, a promising direction is to reformulate the resource allocation problem within the Alternating Direction Method of Multipliers (ADMM) framework. While ADMM does not change the theoretical worst-case complexity order, it enables a decomposition of the centralized pairing and resource allocation process into parallelizable local subproblems, thereby alleviating the practical computational burden and improving scalability. Key challenges for future research include designing an efficient decomposition strategy that preserves the CRS properties and establishing convergence guarantees for the resulting non-convex formulation.
3.2.5. Analysis of Fairness
The fairness of the scheduling policy is evaluated using Jain’s Fairness Index [14], which is applied to the per-node completion times. While the primary objective of the IBRSRA is to minimize the total completion time, the fairness of the scheduling strategy must be carefully examined, especially since a greedy scheduler that prioritizes channel quality may, in principle, lead to the starvation of nodes with persistently poor channel conditions.
Let denote the completion time (in time slots) for node k, which is defined as the time slot when node k finishes transmitting its entire data payload. Jain’s Fairness Index J is computed as
4. Simulation
4.1. Simulation Setup
This section details the simulation setup for evaluating the proposed IBRSRA transmission mechanism (IBRSRA-TM) against three benchmark schemes: a power-domain NOMA-based mechanism (NOMA-TM) [16], a conventional TDMA-based single-node mechanism (TDMA-TM), and a deep reinforcement learning-based dynamic mechanism (DRL-TM) [15]. In NOMA-TM, paired nodes transmit without CRS with only power allocation and beamforming optimized via SCA. For the SCA procedure used in IBRSRA-TM and NOMA-TM, the convergence tolerance and maximum iteration count are set to and , respectively [36,37]. DRL-TM employs a learning agent that adapts scheduling based on real-time channel states, using an empirically set learning rate of .
The number of MUs, K, varies from 8 to 32. Their angular positions are uniformly distributed over , and their distances to the CU, , are uniformly drawn from the range m, satisfying the far-field assumption [38]. The carrier frequency is 3 GHz, and each MU has a data payload of Kbits. The standard deviation of shadowing coefficient is 1 dB [30]. The SINR thresholds for the MCS levels are dB, dB, dB, and dB [35].
Key variable parameters include the number of ULA elements (determining ); the maximum transmit power per MU W; the Rician factor (varied from 0 to 25 dB); the standard deviation of the DoA estimation error ; and the MU speed m/s to model mobility. The default simulation parameters are set as follows: , , , , , .
Performance is assessed through 50 independent Monte Carlo simulations. The primary performance metric is the average number of time slots needed to complete all transmissions, where results for all schemes are obtained under identical channel realizations and initial conditions (i.e., the same set of random seeds). To ensure a fair and meaningful comparison, all schemes are evaluated under consistent system assumptions, including beamwidth constraints, maximum transmit power limits, MCS sets, SINR thresholds, DoA error models, channel models, and mobility configurations. No scheme is afforded additional degrees of freedom beyond its inherent transmission strategy.
4.2. Simulation Analysis
Figure 4 illustrates an exemplary operation of the IBRSRA-TM scheme, in which MU 5, MU 6, and MU 7 are all located within the coverage of a single beam. Under this setting, the CU executes the IBRSRA algorithm to jointly optimize intra-beam CRS and time-slot scheduling. The resulting resource allocation results are presented in Figure 5.
Figure 5 illustrates that MU 6 and MU 7 transmit simultaneously within the same beam during time slot 1. Specifically, MU 6 employs rate splitting: its common stream is unmodulated (i.e., assigned an empty MCS), while its private stream uses . In contrast, the stream for MU 7 is transmitted using . The empty common stream occurs because the corresponding SINR does not meet the minimum threshold required for the lowest available discrete MCS. Similarly, during time slots 2–5, paired MUs continue to transmit concurrently, as they are all located within the same beam (see Figure 4). From time slot 6 onward, no further simultaneous transmissions are scheduled. This is because after rate splitting, the achievable sum rate for any two nodes within the same beam no longer exceeds the rate achievable by scheduling only one of them individually in the same time slot.
Figure 6a shows that the proposed IBRSRA-TM completes data transmission for all MUs in fewer time slots than the baseline algorithms. This gain stems from CRS, which splits a single data stream into common and private parts, enabling more flexible interference management through superposition coding in the power domain and thereby achieving higher spectral efficiency.
Figure 6b further illustrates two effects of the discrete MCS constraint: the proportion of empty MCS selections and the corresponding ARL. The Shannon capacity relaxation used in the SCA leads to a mismatch where the SNR corresponding to the continuous achievable rate may fall below the minimum threshold required for the lowest MCS ( ), while the actual rate under the selected discrete MCS is lower than the continuous-rate counterpart. During the execution of the IBRSRA, an empty MCS is selected in approximately 10% of cases (median over 50 runs), indicating that the algorithm can assign a suitable discrete MCS in the majority of scenarios. However, the average ARL computed for all scheduled nodes incurred by the discrete MCS set reaches about 54.5% compared to the ideal continuous rate (median over 50 runs), which is mainly due to the limited granularity of available MCS levels. Although expanding the MCS set could reduce this loss, it would also increase computational complexity. Nevertheless, even with only four MCS options, the proposed algorithm already requires fewer time slots than the baseline schemes.
Figure 7a depicts the average number of time slots required to complete data transmission versus the number of MU nodes. As the number of MUs increases, all algorithms require more time slots due to the larger total data volume to be transmitted. For a given number of MUs, the algorithms can be ranked in ascending order of slot consumption as follows: IBRSRA-TM, NOMA-TM, DRL-TM, TDMA-TM. TDMA-TM employs a greedy strategy that selects the node with the highest instantaneous rate in each slot, which leads to low slot utilization. DRL-TM improves upon this by learning time-varying channel characteristics via deep reinforcement learning, achieving better long-term scheduling. NOMA-TM further increases the per-slot sum rate by enabling a power-domain superposition of multiple nodes within the same beam. The proposed IBRSRA-TM builds on NOMA-TM by incorporating rate splitting, which divides a data stream into common and private parts, thereby offering more flexible interference management and higher spectral efficiency. Quantitatively, with 16 MUs, IBRSRA-TM reduces the required time slots by 42.98% compared to NOMA-TM, by 45.67% compared to DRL-TM, and by 51.82% compared to TDMA-TM.
Figure 7b shows the algorithm runtime as a function of the number of MUs K. Runtime grows with the node count owing to the nonlinear increase in computational complexity. For a fixed number of nodes, the algorithms are ordered from shortest to longest runtime as TDMA-TM, DRL-TM, NOMA-TM, and IBRSRA-TM. The greedy logic of TDMA-TM incurs minimal overhead. DRL-TM introduces additional cost for the training and inference of the DRL agent. Both NOMA-TM and IBRSRA-TM rely on SCA to solve non-convex optimization problems with IBRSRA-TM requiring extra optimization variables for rate-splitting parameters (e.g., power allocation between common and private streams), which increases its computational load. Notably, when the number of MUs exceeds 16, the runtime gap between IBRSRA-TM and TDMA-TM widens sharply. Considering the trade-off between transmission efficiency and computational cost, IBRSRA-TM is most suitable for FANET reconnaissance scenarios where the number of nodes is moderate (e.g., ).
Figure 7c shows Jain’s Fairness Index versus the number of nodes K. As K increases, the fairness of TDMA-TM and DRL-TM decreases because more nodes compete for the same time slot, leading to a wider gap in completion times. In contrast, the fairness of NOMA-TM and IBRSRA-TM improves, since a larger node pool enhances multinode diversity and increases the probability of forming efficient node pairs, thereby balancing the transmission progress across all nodes. When , the schemes are ranked in fairness as follows: DRL-TM performs best, followed by TDMA-TM, then IBRSRA-TM, and finally NOMA-TM. This is because with fewer nodes, each node in DRL-TM and TDMA-TM requires at least four time slots, resulting in relatively small differences among the nodes. In contrast, under IBRSRA-TM and NOMA-TM, certain nodes may be scheduled multiple times in a single slot due to multiplexing, which leads to a greater variation in the number of time slots needed per node and thus lower fairness. When , increased node participation in slot reuse allows IBRSRA-TM to achieve the highest fairness, which is followed by NOMA-TM, then DRL-TM, and finally TDMA-TM.
Figure 8a illustrates the average number of time slots required under different beamwidths, which is expressed relative to the minimum 3 dB beamwidth . When the beamwidth is reduced to , the time slots required by IBRSRA increase by about 9.1%; conversely, widening the beam to reduces the slot count by approximately 9.1%. This occurs because a broader beam can cover more paired nodes within the same beam, thereby improving resource utilization and decreasing the total number of slots needed.
Figure 8b shows the average number of time slots versus the number of ULA array elements (M). As M increases, the 3 dB beamwidth narrows, which reduces the likelihood of covering multiple nodes within the same beam. Consequently, NOMA-TM and IBRSRA require more time slots with larger M. In contrast, TDMA-TM and DRL-TM exhibit a downward trend in slot count as M grows; this is attributed to the higher array gain provided by a narrower beam, which allows each scheduled node to achieve its maximum instantaneous rate per slot. Specifically, when , the slot counts of TDMA-TM and DRL-TM reach their minimum of 32. As M increases further (e.g., ), the beamwidth of NOMA-TM and IBRSRA becomes so narrow that each beam effectively covers only a single node, causing their required slot counts to converge to those of TDMA-TM and DRL-TM.
Figure 9a plots the number of required time slots versus the maximum transmit power . As increases, the slot count for all algorithms decreases monotonically, because higher transmit power improves the SINR and enables the selection of higher-order MCSs, thereby raising the per-slot throughput. For any given power level, IBRSRA-TM achieves the lowest slot count, which is followed by NOMA-TM, DRL-TM, and TDMA-TM. This performance gap originates from their transmission principles: TDMA-TM schedules only one node per slot, whereas NOMA-TM allows two nodes to transmit simultaneously via power-domain superposition. IBRSRA-TM further incorporates CRS, which provides more flexible interference management and MCS adaptation than pure NOMA, leading to higher spectral efficiency. When the transmit power reaches 3 W, both TDMA-TM and DRL-TM close their minimum possible slot counts under the given system setup.
Figure 9b shows the number of time slots required under different Rician factors ( ). A larger reduces the slot count for all schemes, as the channel becomes increasingly dominated by the strong LOS component. For a fixed , TDMA-TM requires the most slots, while IBRSRA-TM consistently uses the fewest. This result confirms that IBRSRA-TM can effectively exploit the available channel state to jointly optimize power allocation, beam direction, and MCS selection. When exceeds 20 dB, the channel is essentially deterministic, and the slot counts of all algorithms converge to stable minimum values.
Figure 10a shows the number of time slots required under different levels of DoA estimation error. As the error increases, the slot count rises for all algorithms because misalignment reduces the beamforming gain and degrades the SINR. Across the range of errors, IBRSRA-TM consistently requires the fewest slots. This is due to its embedded CRS mechanism, which offers more flexible interference management and thus sustains higher per-slot spectral efficiency even under imperfect beam steering. When the angular deviation stays below , the increase in slot count remains mild, indicating that all algorithms are reasonably robust to small DoA estimation inaccuracies.
Figure 10b presents the slot count versus the mobility speed of MUs. Higher speeds lead to larger required slot numbers for all schemes, mainly because of increased beam misalignment (due to faster channel variations) and larger Doppler spread, both of which reduce the effective SINR. Again, IBRSRA-TM maintains the lowest slot count owing to its ability to adapt the CRS strategy to the changing channel. At speeds below 20 m/s, the performance degradation is gradual, demonstrating that the algorithms remain effective in low mobility regimes.
5. Conclusions
This paper proposes an IBRSRA scheme for single-port phased array antennas in FANETs. To improve the single-beam transmission rate, a CRS technique is incorporated, which systematically models and analyzes the minimum transmission time required for predefined data volumes. To minimize this transmission time, an MINLP problem is formulated to jointly optimize beam direction, CRS-based node pairing, transmit power, and time-slot allocation. This problem is solved via a two-stage optimization framework integrating greedy search and SCA. Extensive simulation results validate that the proposed IBRSRA outperforms state-of-the-art baseline algorithms in terms of lower time-slot consumption.
However, this paper has several limitations that merit attention. First, the proposed algorithm operates in dedicated control time slots with optimization results transmitted to MUs via control channels; however, the overhead associated with these control slots is not analyzed in detail. Second, out-of-network interference is not taken into account. Third, the channel state is assumed to be slowly time-varying, whereas UAVs with higher mobility may necessitate low-complexity dynamic resource allocation strategies to adapt to rapid channel fluctuations. Future work will focus on addressing these limitations and further enhancing the communication efficiency of FANETs in UAV reconnaissance missions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Song L. Guo D. Slot Allocation Protocol for UAV Swarm Ad Hoc Networks: A Distributed Coalition Formation Game Approach Entropy 20252725610.3390/e 2703025640149180 PMC 11941670 · doi ↗ · pubmed ↗
- 2Miao S. Ye N. Li J. Wang Y. Pan J. Optimal Load Allocation of On-Board Detection for Multi-UAV Cooperative NOMA Under Payload Constraints IEEE Trans. Veh. Technol.202574148051481010.1109/TVT.2025.3561204 · doi ↗
- 3Wang Y. Chen M. Pan C. Wang K. Pan Y. Joint Optimization of UAV Trajectory and Sensor Uploading Powers for UAV-Assisted Data Collection in Wireless Sensor Networks IEEE Internet Things J.20229112141122610.1109/JIOT.2021.3126329 · doi ↗
- 4Li X. Lu X. Chen W. Ge D. Zhu J. Research on UA Vs Reconnaissance Task Allocation Method Based on Communication Preservation IEEE Trans. Consum. Electron.20247068469510.1109/TCE.2024.3368062 · doi ↗
- 5Song Y. Zeng L. Liu Z. Song Z. Zeng J. An J. Cross-Layer Optimization Spatial Multi-Channel Directional Neighbor Discovery with Random Reply in mm Wave FANET Electronics 202211156610.3390/electronics 11101566 · doi ↗
- 6Xie T. Zhao H. Xiong J. Sarkar N.I. A Multi-Channel MAC Protocol with Retrodirective Array Antennas in Flying Ad Hoc Networks IEEE Trans. Veh. Technol.2021701606161710.1109/TVT.2021.3054646 · doi ↗
- 7Li J. Han C. Ye N. Pan J. Yang K. An J. Instant Positioning by Single Satellite: Delay-Doppler Analysis Method Enhanced by Beam-Hopping IEEE Trans. Veh. Technol.202574144181443110.1109/TVT.2025.3566629 · doi ↗
- 8Shmonin O. Kuptsov V. Trushkov S. Ponur K. Serebryakov G. Wang H. Zhang J. Phase-Independent Beamspace MUSIC Algorithm for a Single Port Phased Antenna Array Proceedings of the 2023 31st Telecommunications Forum (TELFOR)Belgrade, Serbia 21–22 November 202314