HCNet: Multi-Exposure High-Dynamic-Range Reconstruction Network for Coded Aperture Snapshot Spectral Imaging
Hang Shi, Jingxia Chen, Yahui Li, Pengwei Zhang, Jinshou Tian

TL;DR
This paper introduces HCNet, a new method for improving hyperspectral image reconstruction by combining multi-exposure data in coded aperture snapshot spectral imaging.
Contribution
The novel HCNet network uses multi-exposure fusion to enhance high-dynamic-range hyperspectral reconstruction in CASSI systems.
Findings
HCNet improves reconstruction quality compared to single-exposure methods in both simulated and real-world CASSI systems.
The method shows robustness against exposure interval jitters and shot noise in practical scenarios.
Multi-exposure fusion enhances contrast and spectral correlation in bright and dark regions of HDR scenes.
Abstract
Coded Aperture Snapshot Spectral Imaging (CASSI) is a rapid hyperspectral imaging technique with broad application prospects. Due to limitations in three-dimensional compressed data acquisition modes and hardware constraints, the compressed measurements output by actual CASSI systems have a finite dynamic range, leading to degraded hyperspectral reconstruction quality. To address this issue, a high-quality hyperspectral reconstruction method based on multi-exposure fusion is proposed. A multi-exposure data acquisition strategy is established to capture low-, medium-, and high-exposure low-dynamic-range (LDR) measurements. A multi-exposure fusion-based high-dynamic-range (HDR) CASSI measurement reconstruction network (HCNet) is designed to reconstruct physically consistent HDR measurement images. Unlike traditional HDR networks for visual enhancement, HCNet employs a multiscale feature…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
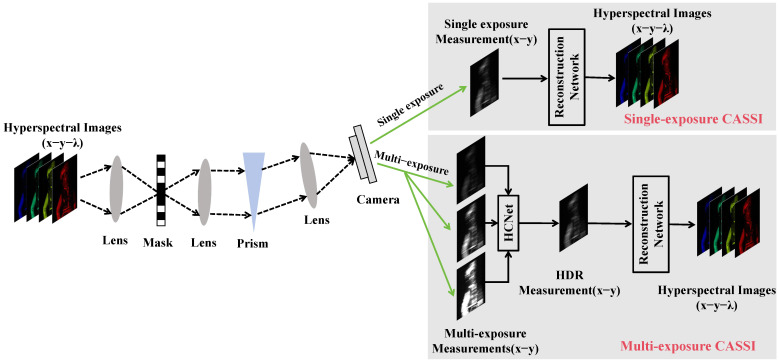 Figure 1
Figure 1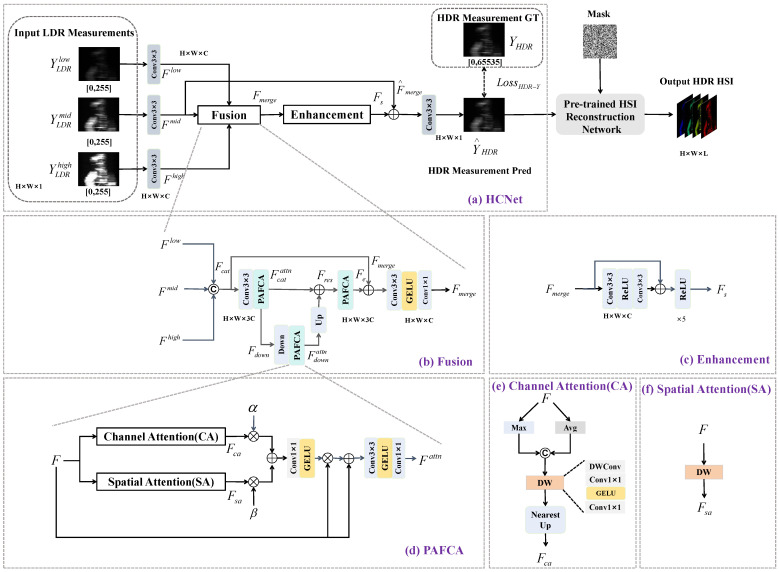 Figure 2
Figure 2 Figure 3
Figure 3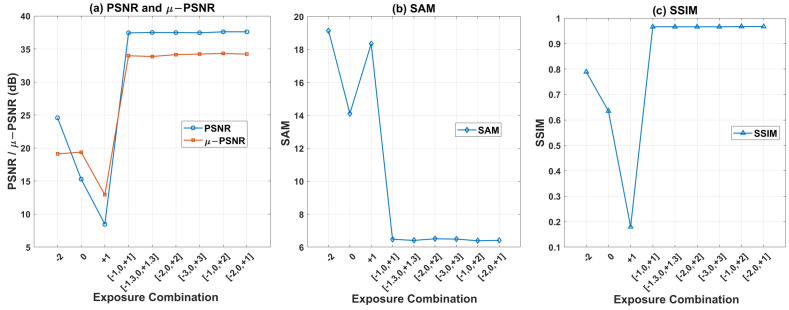 Figure 4
Figure 4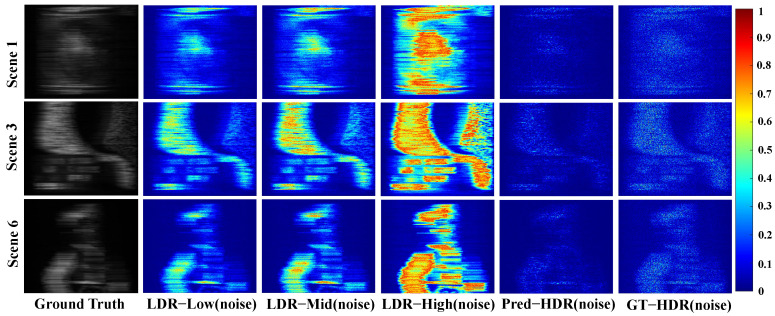 Figure 5
Figure 5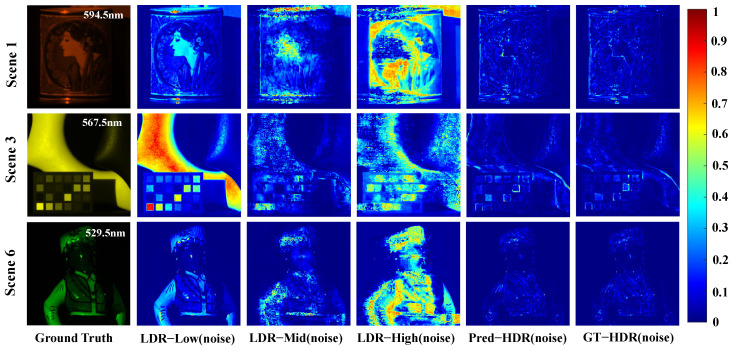 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8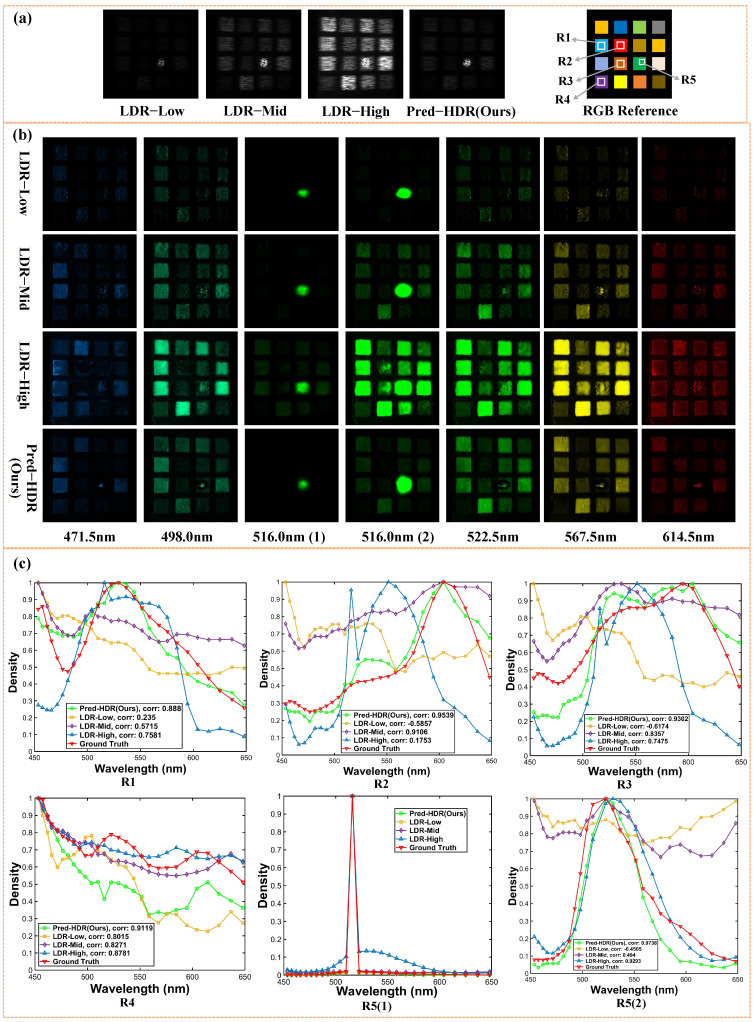 Figure 9
Figure 9- —National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Image Fusion Techniques · Image Enhancement Techniques · Remote-Sensing Image Classification
1. Introduction
Hyperspectral imaging technology can simultaneously capture spatial and spectral information from a scene, exhibiting significant application prospects in fields such as environmental monitoring [1], agricultural detection [2,3], medical diagnosis [4], and cultural heritage diagnosis [5]. The Coded Aperture Snapshot Spectral Imaging (CASSI) [6] technique utilizes a coded mask and a dispersive element to encode and compress three-dimensional (3D) data into a two-dimensional (2D) measurement image. Through compressed sensing algorithms, it reconstructs the 3D data from the 2D compressed measurement, enabling snapshot hyperspectral imaging. Numerous advanced CASSI reconstruction algorithms have been developed, including numerical iterative methods [7,8] and deep learning approaches [9,10,11,12,13,14,15], all of which have demonstrated excellent performance on idealized synthetic datasets. However, practical CASSI systems inevitably encounter factors that significantly degrade reconstruction quality, such as dynamic range limitations. Therefore, it is urgent to develop high-quality hyperspectral imaging methods suitable for real CASSI systems. Regarding dynamic ranges, constrained by the system’s detection scheme and hardware limitations, all spectral channel images are compressed into a single measurement with a finite dynamic range. The recovered hyperspectral images have to segment the dynamic range of the measurement, leading to low-quality reconstruction due to dynamic range shrinking. The more spectral channels involved, the lower the reconstruction quality. Additionally, the system exposure level (overexposure or underexposure) directly determines the data acquisition quality of CASSI. Overexposure causes loss of highlight detail, while underexposure reduces dark-field signal-to-noise ratio (SNR, significantly affected by quantization noise and shot noise), further degrading or invalidating subsequent CASSI hyperspectral image reconstruction.
To address the issue of low-quality reconstruction caused by limited dynamic ranges, inspired by high-dynamic-range (HDR) imaging technology [16,17], this work proposes a high-quality CASSI hyperspectral imaging method based on multi-exposure fusion. Multiple CASSI compressed measurements with different exposure levels are captured to expand the system’s data acquisition dynamic range. Lower-exposure images preserve highlight details, while higher-exposure images improve SNRs in dark regions. The multi-exposure low-dynamic-range (LDR) measurements are then fused to generate an HDR measurement image. Multi-exposure HDR reconstruction networks have matured in RGB imaging (RGB-HDR), widely applied in visual enhancement fields like camera photography and image display, such as Hdr-gan [18], SelfHDR [19], SAFNet [20], Cen-HDR [21], DRHDR [22] and HDRFlow [23]. However, adapting these methods to HDR CASSI compressed measurement prediction presents fundamental differences and challenges. For input data, RGB-HDR reconstruction networks process RGB images containing spatial structures and three color channels, whereas the proposed HDR-CASSI reconstruction network operates on compressed measurement maps—two-dimensional grayscale images resulting from encoding and compressing three-dimensional spatiospectral data. For output targets, RGB-HDR aims to produce visually perception-friendly nonlinear HDR images, whereas HDR-CASSI prioritizes predicting a linear HDR compressed measurement that satisfies physical imaging models. This ensures high fidelity and physical consistency of subsequent hyperspectral reconstruction results. For loss functions, RGB-HDR accommodates visually driven tonal compression, whereas HDR-CASSI must preserve true physical proportions to avoid compromising spatial–spectral consistency.
Therefore, to enhance the imaging quality of real CASSI systems, this work proposes a multi-exposure data acquisition strategy based on CASSI and a multi-exposure fusion-based HDR CASSI measurement reconstruction network (HCNet). Without increasing hardware costs, it can effectively expand the dynamic range of CASSI-compressed measurements through the proposed data acquisition strategy and reconstruction algorithm, providing highly physically consistent HDR compressed measurements for subsequent high-quality hyperspectral image reconstruction. We construct a mathematical model of the multi-exposure CASSI system, comprehensively considering the effects of imaging exposure levels, overexposure clipping effects, and noise on LDR measurements. The composition and working principle of the proposed HCNet is introduced and evaluated by comparing the impact of traditional single exposure versus the proposed multi-exposure strategy on hyperspectral image reconstruction quality. HCNet’s reconstruction robustness under different multi-exposure settings and noise conditions is verified. A real CASSI imaging system is built to validate the high-quality hyperspectral imaging capabilities of the proposed method for scenes with relatively low and high dynamic ranges.
2. Methods
Figure 1 shows the working principle of the traditional single-exposure and proposed multi-exposure CASSI data acquisition strategies. For a CASSI system, a three-dimensional hyperspectral dataset ( ) is compressed into a two-dimensional (2D) measurement by spatially encoding, spectrally shifting, and data integrating on a camera. For single-exposure CASSI, a 2D compressed measurement is used to recover hyperspectral images via a hyperspectral reconstruction network. For multi-exposure CASSI, three measurements, captured with different exposure levels, are first fused into an HDR measurement using HCNet, which is then fed into the hyperspectral reconstruction network to provide high-quality hyperspectral images.
To achieve high-quality hyperspectral reconstruction, this section builds upon the single-exposure CASSI model to establish a mathematical description for the proposed multi-exposure strategy, clarifying the objective function and fusion mechanism. Subsequently, the proposed HDR CASSI measurement reconstruction network (HCNet) is described.
2.1. Mathematical Model for Single- and Multi-Exposure CASSI
2.1.1. Single-Exposure CASSI
For single-exposure CASSI, the target’s three-dimensional information ( ) can be represented as a cubic data block comprising L spectral bands, where denotes the spatial image of the lth spectral band.
For a real CASSI system, the camera’s exposure directly affects the number of photons received by the detector, thereby altering the intensity and noise level of the measurement. The exposure can be quantified by the exposure value , where G is the exposure coefficient and K is the reference coefficient. When , , indicating that the exposure value matches the reference exposure. In this work, stands for optimal exposure, where the gray values of the output image occupy the full dynamic range without overexposure.
After the spatial modulation with an encoding pattern , the lth spectral image detected by the camera can be expressed as
where ⊙ denotes Hadamard multiplication (element-wise multiplication). Subsequently, the modulated spectral channels undergo dispersion scanning via a dispersive element with distinct imaging positions. The shifted spectral channels overlap on the detector, providing a compressed image , which can be expressed as
where , , and d are the shifted pixels between adjacent channels, and denotes the spatial shift operation.
By considering the inherent shot noise of the detected signal as well as the camera’s limited full well capacity (FWC) and analog-to-digital converter (ADC) bit depth, the detected image can be expressed as
where denotes the shot noise addition [12], represents the saturation clipping, is the maximum output value of the camera, and denotes the quantization via the ADC. Ideally, is the linear combination of all spectral channels, providing an optimal measurement for subsequent hyperspectral reconstruction. However, when the compressed measurement is overexposed, clipping occurs in bright regions, which is nonlinear and irreversible, leading to reconstruction distortion. Additionally, quantization errors obscure subtle contrasts within the compressed measurement, leading to the loss of spatial and spectral details in the recovered images, especially in dark regions.
2.1.2. Multi-Exposure CASSI
To enhance reconstruction quality and robustness, a multi-exposure CASSI measurement strategy is proposed. CASSI measurements with different exposure levels are captured for the same scene. Low exposure preserves bright-region details, while high exposure enhances dark-region contrasts, enabling higher-dynamic-range signal acquisition.
Referring to the common settings for HDR, three exposure levels are adopted, where the medium exposure serves as the reference with . The exposure coefficients are denoted as , , and for low, medium, and high exposures, respectively. According to Equations (2) and (3), the compressed measurements from the limited low-dynamic-range (LDR) camera under the three exposure levels can be expressed as
where
2.1.3. CASSI Measurement Fusion and Hyperspectral Reconstruction Objectives
Multi-exposure CASSI measurements are jointly fed into a HDR CASSI measurement reconstruction network for the prediction of an HDR CASSI measurement ,
where denotes the HDR CASSI measurement reconstruction network. The predicted is then input into a pretrained hyperspectral reconstruction network to recover the hyperspectral data cube .
2.2. HDR CASSI Measurement Reconstruction
CASSI-compressed measurements are two-dimensional projections obtained after spatial–spectral encoding and multiplexing. Existing HDR fusion methods are primarily designed for RGB formats and optimized for human visualization, including nonlinear operations such as gamma mapping, while the task of HDR CASSI measurement recovery is to maintain the linear mapping relationship. Ensuring fidelity is the priority, as it directly influences the reconstruction quality and physical interpretability of the hyperspectral images extracted from the HDR CASSI measurement.
To address the issue, an HDR CASSI measurement estimation framework is proposed for high-quality hyperspectral reconstruction. The overview of the framework is shown in Figure 2, composed of an HDR CASSI measurement reconstruction network (HCNet) (Figure 2a) and a pre-trained hyperspectral reconstruction network. Multi-exposure LDR measurements are first fused by HCNet into an HDR measurement, which is then fed into the pre-trained hyperspectral reconstruction network to produce a high-quality hyperspectral data cube. HCNet prioritizes physical consistency and structural efficiency, comprising a fusion module for preliminary merging of multi-exposure measurements and an enhancement module for feature compression and augmentation. HCNet is constrained using an HDR measurement loss, and the hyperspectral reconstruction network is trained on synthetic HDR measurements without clipping and quantization.
2.2.1. Fusion Module
The Fusion module centers on multi-scale context awareness and channel–spatial attention enhancement, integrating Parallel Adaptive Channel-Spatial Fusion Attention (PAFCA), context enhancement mechanisms, and cross-scale feature interaction. It constructs a feature fusion architecture with context modeling capabilities, as illustrated in the Fusion module block in Figure 2b. Firstly, three LDR measurements undergo convolutional feature extraction,
The three feature maps are concatenated along the channel dimension to form the fused input feature . Subsequently, passes through PAFCA to yield . PAFCA synergistically employs global channel statistical modeling and local spatial feature perception to adaptively enhance features, emphasizing HDR information in measurements while suppressing redundancy and noise. After attention-enhanced feature fusion, a lightweight single-layer downsampling–upsampling architecture is employed to expand the feature receptive field. Attention-enhanced features undergo downsampling convolution to yield a low-resolution contextual feature . Similarly, passes through PAFCA to obtain , strengthening cross-spatial-scale contextual information. is then upsampled to its original size via transposed convolution and residually fused with the previous features to yield . Finally, the fused features undergo progressive enhancement through PAFCA to produce , ensuring comprehensive and hierarchical feature representation.
To mitigate information loss and maintain feature consistency, the progressively attention-enhanced feature is added to the initial concatenated feature , forming the cross-stage residual fusion feature,
This residual connection retains the discriminative power of enhanced features while recirculating original information from shallow layers, mitigating potential feature drift or information dilution after multiple processing steps. Finally, the fused feature undergoes further integration of channel information through convolution and activation functions and the output serves as input for subsequent enhancement modules.
2.2.2. Parallel Adaptive Channel-Spatial Fusion Attention (PAFCA)
During multi-exposure feature fusion and context enhancement, efficiently modeling the response distribution within channels and the local–global dynamic characteristics of spatial regions is crucial for suppressing redundancy and enhancing detail preservation and generalization capabilities in HDR measurement prediction. Traditional convolutional attention mechanisms (e.g., BAM [24], CBAM [25]), and existing HDR fusion networks [21,26,27] typically employ compressed vectors from global pooling to model global information. However, local regions in CASSI’s HDR scene maps reflect not only brightness response and exposure intensity distributions but also band-specific information and mask-overlap effects. Simple global statistics struggle to capture these nuances, leading to dilution of critical features. To address this, we designed the Parallel Adaptive Channel-Spatial Fusion Attention Module (PAFCA), as shown in Figure 2d. PAFCA models local–global statistical properties along both the channel (CA) (Figure 2e) and spatial (SA) (Figure 2f) branches, then fuses them within a unified attention adjustment flow. This effectively enhances feature representation and contextual adaptability.
To capture fine-grained statistical distributions, PAFCA first employs localized global pooling. Feature map undergoes adaptive average pooling and max pooling with a scale factor s
Unlike traditional global pooling, this localized pooling preserves finer-grained statistical features. It reflects global trends within channels while perceiving local dynamic feature distributions. The concatenated channel features undergo local context enhancement through depthwise separable convolutions
Then, is upsampled back to the original size and fused with the spatial branch features.
The PAFCA spatial branch employs depthwise separable convolutions directly on the spatial dimension to perceive and enhance local structures and spatial variations, yielding . Feature results from the spatial and channel branches undergo dynamic adjustment via learnable parameters and to produce dual-branch fusion features. The fusion output is activated by GELU and undergoes feature weighting with the original input. It is then processed through a set of convolutional transformations and activations to enhance the expressive power of the features,
2.2.3. Enhancement Module
To compress channel information and obtain high-quality HDR measurements, the Enhancement module conducts further feature compression and prediction, as shown in Figure 2c. To reduce subsequent convolutional computations, the fused output features are fed into a convolution to compress the multi-channel features back to the original channel number . To enhance deep feature representation, supplement local details, and improve network robustness, inspired by the classic ResNet [28] architecture, the compressed features are fed into a ResNet with five stacked residual blocks for successive feature reconstruction:
To prevent information drift or degradation during deep feature processing and to incorporate reliable information from the reference measurement, the ResNet output features undergo element-wise residual connection with the medium exposure reference features
To reconstruct high-quality hyperspectral images, a physically consistent HDR measurement is required to avoid distortion. Different from existing HDR reconstruction networks for RGB images, we employ a convolution to generate HDR measurements inside of the activation function:
2.2.4. Loss Function for HDR CASSI Measurement Estimation
Existing HDR networks [20,21,23,27,29,30,31,32] usually employ -law mapping for constructing loss functions to reduce the dominance of bright areas in the loss, enhancing the perceptual performance of the overall details. However, this strategy is unsuitable for CASSI systems as the -law mapping will introduce strong nonlinear compression in bright regions. Therefore, the loss function is employed to provide high-fidelity HDR CASSI measurements for the subsequent hyperspectral reconstruction:
where i denotes the ith pixel in the image, and N is the pixel number of the measurement, .
3. Simulation Experiments
3.1. Experimental Setup
Two datasets, CAVE [33] and KAIST [34], are utilized for training and evaluation. The CAVE dataset comprises 32 hyperspectral scenes with a spatial resolution of pixels and a spectral resolution of 10 nm. It includes 31 spectral channels spanning from 400 nm to 700 nm with an image bit-depth of 16-bit. The KAIST dataset comprises 30 hyperspectral scenes with a spatial resolution of pixels and a spectral resolution of 10 nm. It includes 31 spectral channels spanning from 400 nm to 700 nm with an image bit depth of 16-bit. Referring to previous CASSI reconstruction methodologies [9,11,12,35], training data is sourced from the CAVE dataset. Training samples are randomly cropped into blocks with pixels for data augmentation. Via spectral interpolation, 28 spectral channels spanning from 450 nm to 650 nm are generated. Test data comprises 10 scenes from the KAIST dataset, cropped and interpolated into hyperspectral data cubes. The default exposure coefficient ( ) is used for medium exposure to include moderate overexposure. For instance, multi-exposure combination corresponds to exposure coefficients of . Except for the noise robustness experiment, simulation experiments were conducted under noise-free conditions.
LDR CASSI measurements are simulated as 8-bit images according to the mathematical model mentioned in Equation (4). The ground truth of the HDR measurement (GT-HDR) is generated with the forward imaging model (Equation (2), ) without clipping or quantization, serving as the supervised target for training the proposed HCNet to estimate HDR measurements. Our optimization objective is to minimize the HDR measurement prediction loss to provide a predicted HDR measurement (Pred-HDR). The classical DAUHST-3stg [9] is adopted as the downstream pre-trained hyperspectral reconstruction network, which is trained using GT-HDR measurements with a loss function. The model is constructed using PyTorch and trained on a single RTX 3090 GPU. Training HCNet for 100 epochs took approximately h and achieved convergence. Both HCNet and DAUHST are trained using the Adam optimizer [36] ( ) for 300 epochs. The learning rate is initialized to and scheduled by a cosine annealing strategy.
The evaluation metrics include , [37], and [38]. The results reported in the following simulations are the average values over 10 scenes from the KAIST test dataset.
The peak signal-to-noise ratio ( ) is defined as
where is the maximum pixel value of the image, and is the mean squared error
where N denotes the number of pixels in the image (width × height × number of channels), and and represent the reconstructed and ground-truth pixel values at pixel i, respectively.
To better preserve details in both dark and bright regions, we adopt the -law-modulated PSNR ( -PSNR), inspired by HDR RGB image quality evaluation methods [18,19,21,32,37,39,40], which is defined as
where
where is the normalized pixel value and is the compression parameter ( in this work).
The structural similarity index ( ) is defined as
where and are the mean intensities of and , and are the variances of and , represents the covariance between and , and and are small constants to stabilize the division.
The spectral angle mapper ( ) is defined as the average angle between the reconstructed spectral vector and the ground-truth spectral vector for each pixel, which evaluates the spectral fidelity of hyperspectral reconstruction:
where and represent the spectral vectors (across all L spectral bands) at pixel i for the reconstructed and ground-truth hyperspectral images, respectively, and denotes the Euclidean norm. is typically expressed in degrees or radians. The smaller the values, the higher the spectral similarity.
3.2. Evaluation of Multi-Exposure Strategies
The performance of the proposed multi-exposure HDR measurement reconstruction framework is evaluated under different exposure combinations and interval settings.
3.2.1. Comparison of Single- and Multi-Exposure Strategies
To our knowledge, no HDR fusion algorithms currently exist for CASSI. Traditional methods and some existing deep learning-based HDR fusion approaches are designed for RGB images. To comprehensively demonstrate HCNet’s superiority and ensure fairness, we compared the hyperspectral reconstruction performances with three single-exposure LDR measurements (low-LDR , mid-LDR , high-LDR ), HDR measurements from five existing HDR fusion methods (PFM [41], Cen-HDR [21], DRHDR [22], HDRFlow [23], SAFNet [20]), the Pred-HDR measurement with HCNet and the GT-HDR measurement, using the same pretrained hyperspectral reconstruction network.
As shown in Table 1, Pred-HDR significantly outperforms the three single-exposure strategies and five HDR fusion methods in terms of the PSNR, -PSNR, SAM and SSIM metrics, approaching GT-HDR’s performance. This demonstrates that multi-exposure fusion effectively mitigates information loss caused by overexposure, underexposure, and LDR. Furthermore, compared to existing HDR fusion networks designed for RGB HDR, our HCNet approach significantly enhances the recovery of spatial and spectral information. The introduction of HCNet increases the computational load of the multi-exposure fusion process by 15.53 GFLOPs and adds 0.63 million(M) parameters.
To visualize the effectiveness of multi-exposure CASSI, reconstructed results for the fifth test scene in the KAIST dataset are shown in Figure 3. Figure 3a shows the CASSI-compressed measurements used for hyperspectral reconstruction and the RGB reference of the scene. Four spectral channels’ images are presented in Figure 3b, where three labeled regions’ spectral density curves are shown in Figure 3c with the spectral consistency metrics (corr). Figure 3d shows the magnified areas of the 636.5 nm channel.
For structures in the three areas (Regions 1–3 labeled with the white, green and yellow boxes, respectively), the results with low LDR exhibit severe detail loss and low contrast. Though more details are recovered with mid-LDR and high LDR, they suffer from reconstruction distortion and artifacts, which are obvious in the spectral density curves. This reveals that the reconstruction performances of the single-exposure measurements are sensitive to exposure levels and the quality will significantly deteriorate when overexposure occurs. Among all compared methods, the results with Pred-HDR are closest to the results with GT-HDR and the ground truth, maintaining high spatial and spectral fidelity. This demonstrates the best recovery of spatial details in Regions 1–3, indicating the proposed method’s superior adaptability and effectiveness in CASSI reconstruction tasks.
To further evaluate the recovery performance of local details, as shown in Table 2, PSNRs and SSIM indexes with different methods for Regions 1–3 (corresponding to Figure 3d) are compared. The results indicate that Pred-HDR with HCNet achieves the best performance across all three regions.
3.2.2. Hyperspectral Reconstruction Performances with Different Exposure Intervals
The CASSI system has a limited dynamic range. Lower exposures result in more severe underexposure in dark areas, while higher exposures cause overexposure in bright areas. We selected and expanded exposure interval combinations based on experimental settings from Cen-HDR [21] and HDRFlow [23] in RGB HDR research to evaluate our method’s reconstruction performance across different exposure intervals. Figure 4 shows PSNR, -PSNR, SAM and SSIM diagrams of hyperspectral reconstruction results for three single-exposure ( ) and six multi-exposure ( ) measurements.
Multi-exposure strategies outperform single-exposure strategies and are insensitive to exposure interval configurations, demonstrating robust fusion and reconstruction performance for practical experiments with exposure fluctuation.
3.3. Loss Functions for HDR CASSI Measurement Prediction
For HDR CASSI measurement prediction, the reconstruction performances are compared with , , and - -law loss functions for HCNet, as shown in Table 3. The DAUHST two-stage network [9] serves as the pre-trained HSI reconstruction network. The multi-exposure combination is . The results demonstrate that measurements recovered using the loss function yield superior hyperspectral reconstruction performance, achieving optimal values for PSNR, -PSNR, SAM and SSIM. The loss function performs slightly worse, while the -law-related loss function exhibits further degradation due to dynamic range compression. Therefore, the loss function is suitable for HDR CASSI measurement prediction to enable subsequent high-quality hyperspectral reconstruction.
3.4. Ablation Experiments
To validate the effectiveness of each key module in HCNet and its adaptation advantages for CASSI, ablation experiments are conducted with stepwise module removal. The pre-trained HSI reconstruction network is the two-stage DAUHST [9]. Here, and represent the channel branch and spatial branch in PAFCA (Figure 2b), respectively. w denotes the use of global pooling in , w denotes the adaptive pooling in , represents the HCNet’s enhancement module, indicates the Sigmoid activation at HCNet’s output layer, and signifies the nonlinear activation after HCNet’s initial feature extraction.
This indicates that introducing either the channel or spatial branch alone (Entries 2, 3, and 4 in Table 4) improves performance, while combining both (5 in Table 4) yields superior results. Adding a residual enhancement module (Enhancement) (6 in Table 4) further improves PSNR and -PSNR metrics, demonstrating that residual enhancement effectively optimizes the structure and detail of predicted measurements. Using Sigmoid activation at the output layer (7 in Table 4) or introducing activation operations in the initial stages (8 in Table 4) imposes unnecessary nonlinear compression or disturbance on the feature distribution. This hinders the maintenance of physically consistent measurement predictions and leads to degraded reconstruction performance.
3.5. Evaluation of Noise Robustness
To assess the robustness of HCNet under noisy conditions, shot noise is added based on the multi-exposure CASSI imaging mathematical model (Equation (4)). Exposure intervals are set to , corresponding to exposure coefficients G of .
Single-exposure strategies’ measurements are injected with 8-bit shot noise. The noisy LDR measurements are denoted as low/mid/high(noise) LDR. The predicted HDR measurements with the proposed HCNet are denoted as Pred-HDR(noise). GT-HDR measurements include 11-bit shot noise, denoted as GT-HDR(noise).
The experimental results (Table 5) demonstrate that Pred-HDR(noise) exhibits significantly superior reconstruction performance compared to (low/mid/high)(noise) LDR, approaching that of GT-HDR(noise). This indicates that the complementary nature of multi-exposure information partially suppresses noise and enhances hyperspectral image reconstruction quality.
Figure 5 displays difference maps between noisy measurements ( ) and true noise-free HDR measurements (Y) for Scenes 1, 3 and 6 in the KAIST test set under various exposure strategies. It is evident that Pred-HDR(noise) exhibits fewer and lower noise compared to the single-exposure LDR noisy measurements. Figure 6 shows the difference maps between the hyperspectral reconstruction results ( ) using the CASSI compressed measurements based on different exposure strategies and the ground truth hyperspectral images (X) for the 594.5 nm channel in Scene 1, the 567.5 nm channel in Scene 3, and the 529.5 nm channel in Scene 6. Results with Pred-HDR(noise) exhibit clearer texture details and more faithful glossiness compared to those from (low/mid/high)(noise) LDR. The reconstructions from low-exposure measurements show significant discrepancies from the ground truth with unrealistic brightness and severe loss of spatial information with medium and high exposure measurements. These results validate the proposed method’s noise robustness and generalization capability for practical CASSI systems with noise.
4. Real-World Experiments
A practical CASSI system was built, as shown in Figure 7, to validate the effectiveness of HCNet for real-world hyperspectral reconstruction. The object is projected on the spatial coding mask with a coupling lens . After the spatial modulation, the coded object’s image passes through a 4f system with lenses and (focal lengths mm), between which a dispersion prism with a top angle of 30° and two filters are placed. The two filters limit the valid detected spectral range from 450 nm to 650 nm. After spectral dispersion and spatial integration, a grayscale camera captures 8-bit CASSI-compressed measurements with a valid area of 760 × 814 pixels. Two scenes are constructed and LDR measurements are captured under low-, medium- and high-exposure conditions with . To capture as much of the object’s information as possible, medium exposure serves as a prediction reference, low exposure is not overexposed to preserve the bright details, and high exposure is overexposed to enhance the dark details. Training for the real system uses the CAVE [33] dataset, where training samples are randomly cropped into 380 × 380 pixels blocks for data augmentation.
The reconstruction results for the two scenes are shown in Figure 8 and Figure 9, respectively. Figure 8a shows the three LDR measurements and Pred-HDR measurement with HCNet for Scene 1, whose ground truth is shown as the RGB reference. Figure 8b shows the recovered hyperspectral images at seven wavelengths for different exposure strategies. The reconstruction results with Pred-HDR are visually better than those with the single-exposure strategies, restoring superior details in both bright and dark areas. Although low LDR shows better detail preservation than mid-LDR and high LDR, the spatial contrast is lower than Pred-HDR, suffering from more noise and artifacts. This indicates that it is important to avoid overexposure for traditional single-exposure systems, and the multi-exposure fusion strategy can effectively enhance the reconstruction quality with HDR.
To validate the robustness for higher-dynamic-range scenarios, an HDR scene is constructed by illuminating Scene 1 on the green pattern with a high-power laser (516 nm), as shown in Figure 9. Figure 9a shows the three LDR measurements and Pred-HDR measurement with HCNet for Scene 2, whose ground truth without the laser is shown as the RGB reference. To cover the intensity range from the bight laser spot to the darker patterns, LDR measurements have to be adapted to ensure that the low-LDR measurement is not overexposed and the three LDR measurements follow the optimized exposure interval scheme. Since no similar HDR hyperspectral dataset exists, we simulate the constructed HDR scenes during training by adding a randomly positioned and sized high-intensity Gaussian spot at the 516 nm band in each training sample. Figure 9b shows the recovered hyperspectral images at six wavelengths for different exposure strategies. To clearly demonstrate the HDR imaging performance, the 516.0 nm channel containing the bright laser spot is presented with two gray-level ranges, 516.0 nm (1) and 516.0 nm (2), showing the bright and dark details, respectively. Figure 9c shows the spectral density curves for the selected regions (R1: blue, R2: red, R3: brown, R4: purple, R5: green) labeled in the RGB reference range in Figure 9a.
For laser-illuminated bright regions, mid-LDR and high-LDR loss spatial details exhibit overexposed flat tops, while Pred-HDR restores a Gaussian-shaped spot, which is consistent with the true spatial distribution of the laser (Figure 9b 516.0 nm (1)). For darker background patterns, Pred-HDR performs the best with a higher SNR, less distortion, and fewer artifacts, demonstrating the effectiveness of HDR reconstruction in the spatial domain.
In the spectral domain, for the regions without laser illumination (R1, R2, R3 and R4), spectral density curves with Pred-HDR (green curves in Figure 9c) demonstrate the highest spectral consistency with the ground truth (red) measured using a spectrometer. For the region with laser illumination, Figure 9c R5(1) and R5(2) show the spectral curves with and without the laser, receptively, revealing that Pred-HDR can extract reliable underneath spectral information even with strong interference.
5. Conclusions
To address the limitations of reconstructing hyperspectral images in real CASSI systems constrained by the detector’s finite dynamic range, this paper proposes a high-quality CASSI hyperspectral image reconstruction method based on multi-exposure fusion. This method acquires multiple compressed measurements under varying exposure conditions using the CASSI system to capture brighter and darker scene information with a higher dynamic range. In addition, a multi-exposure compressed measurement fusion network (HCNet) is introduced to effectively generate HDR-compressed measurements suitable for CASSI reconstruction tasks, enabling high-quality hyperspectral reconstruction. Unlike traditional HDR reconstruction algorithms focused on visual enhancement, HCNet prioritizes physical consistency as its core design objective, ensuring high fidelity in both spatial and spectral dimensions. Considering real-world system factors such as exposure levels, overexposure clipping, and grayscale quantization, a data acquisition model for the multi-exposure fusion CASSI system is constructed. To validate the proposed method, both simulated and real-world experiments were conducted to compare the hyperspectral image reconstruction quality between multi-exposure and traditional single-exposure strategies. In simulations, HCNet based on multi-exposure fusion effectively generates HDR-compressed measurements, yielding higher-quality hyperspectral reconstructions. Additionally, it demonstrates high robustness against small exposure interval shifts and shot noise, making it suitable for real experimental systems. In real-world experiments, the CASSI experimental system was built to shoot two scenes with relatively low and high dynamic ranges. The proposed method consistently demonstrates optimal reconstruction quality, including higher-contrast spatial details and more coherent spectral information, validating its effective measurement capability in real-world HDR scenarios.
Compared to single-exposure CASSI reconstruction pipelines, the proposed HCNet exhibits increased computational complexity due to the incorporation of multi-exposure fusion. The experimental results demonstrate that embedding HCNet or existing HDR algorithms exhibits increased GFLOPs and parameter counts. Although this entails additional computational costs during training, experiments reveal that the testing time with the pre-trained HDR fusion network increases by only approximately 0.1 s compared to single-exposure strategies. This enables direct deployment in real-time imaging applications, delivering superior HDR-compressed measurements and significantly enhancing hyperspectral reconstruction quality for HDR scenes. Future work will focus on exploring lightweight network architectures to reduce computational complexity during training while maintaining high reconstruction performance.
Furthermore, the current framework assumes that multi-exposure measurements are obtained from static or quasi-static scenes with neglectable spatial movement during the data acquisition process. For dynamic scenes with significant spatial position variations, this remains a challenge and can be explored in the future with regard to network improvements and system optimizations.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Turner K.J. Tzortziou M. Grunert B.K. Goes J. Sherman J. Optical classification of an urbanized estuary using hyperspectral remote sensing reflectance Opt. Express 202230415904161210.1364/OE.47276536366633 · doi ↗ · pubmed ↗
- 2Xie C. Yang C. A review on plant high-throughput phenotyping traits using UAV-based sensors Comput. Electron. Agric.202017810573110.1016/j.compag.2020.105731 · doi ↗
- 3Ishida T. Kurihara J. Viray F.A. Namuco S.B. Paringit E.C. Perez G.J. Takahashi Y. Marciano J.J.Jr. A novel approach for vegetation classification using UAV-based hyperspectral imaging Comput. Electron. Agric.2018144808510.1016/j.compag.2017.11.027 · doi ↗
- 4Fei B. Hyperspectral imaging in medical applications Data Handling in Science and Technology Elsevier Amsterdam, The Netherlands 2019 Volume 32523565
- 5Sandak J. Sandak A. Legan L. Retko K. KavčičM. Kosel J. Poohphajai F. Diaz R.H. Ponnuchamy V. SajinčičN. Nondestructive evaluation of heritage object coatings with four hyperspectral imaging systems Coatings 20211124410.3390/coatings 11020244 · doi ↗
- 6Wagadarikar A. John R. Willett R. Brady D. Single disperser design for coded aperture snapshot spectral imaging Appl. Opt.200847 B 44B 5110.1364/AO.47.000B 4418382550 · doi ↗ · pubmed ↗
- 7Bioucas-Dias J.M. Figueiredo M.A. A new Tw IST: Two-step iterative shrinkage/thresholding algorithms for image restoration IEEE Trans. Image Process.2007162992300410.1109/TIP.2007.90931918092598 · doi ↗ · pubmed ↗
- 8Figueiredo M.A. Nowak R.D. Wright S.J. Gradient projection for sparse reconstruction: Application to compressed sensing and other inverse problems IEEE J. Sel. Top. Signal Process.2008158659710.1109/JSTSP.2007.910281 · doi ↗