Fault Diagnosis of Motor Bearing Transmission System Based on Acoustic Characteristics
Long Ma, Yan Zhang, Zhongqiu Wang

TL;DR
This paper introduces a non-contact method for diagnosing motor bearing faults using acoustic signals and deep learning, achieving high accuracy.
Contribution
A novel CNN–attention–LSTM model with feature selection for high-accuracy, non-contact bearing fault diagnosis using acoustic signals.
Findings
The proposed model achieves 99.90% average diagnostic accuracy for bearing fault types.
Feature selection reduces model parameters and size without sacrificing accuracy.
Acoustic-based diagnosis shows strong potential for industrial applications.
Abstract
Traditional vibration-based methods for bearing fault diagnosis, while prevalent, often require contact measurement, and sound signal is a broadband signal relative to the vibration signal. To overcome these limitations, this paper explores the advantages of acoustic signals, non-contact sensing, and rich broadband information and proposes a fault diagnosis framework based on acoustic features and deep learning. The core of our method is a CNN–attention mechanism–LSTM model, specifically designed to process one-dimensional sequential features: the 1D-CNN extracts local features from Mel frequency cepstral coefficient (MFCC) features, the attention mechanism (selecting ECA as the optimal solution) selectively enhances features, and the LSTM captures temporal dependencies, collectively enabling effective classification of fault types. Furthermore, to enhance model efficiency, a…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
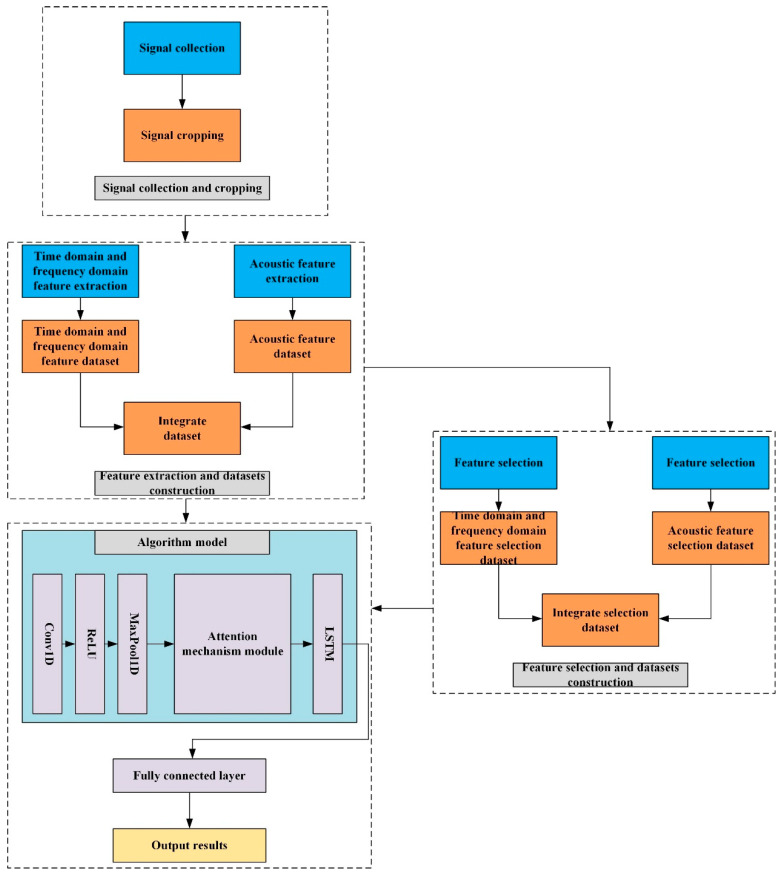 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8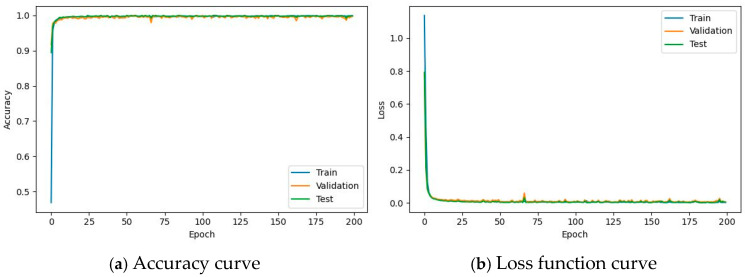 Figure 9
Figure 9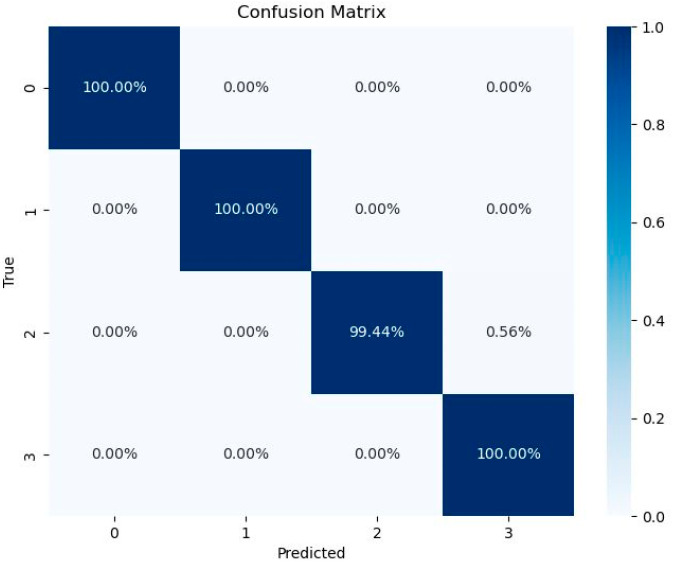 Figure 10
Figure 10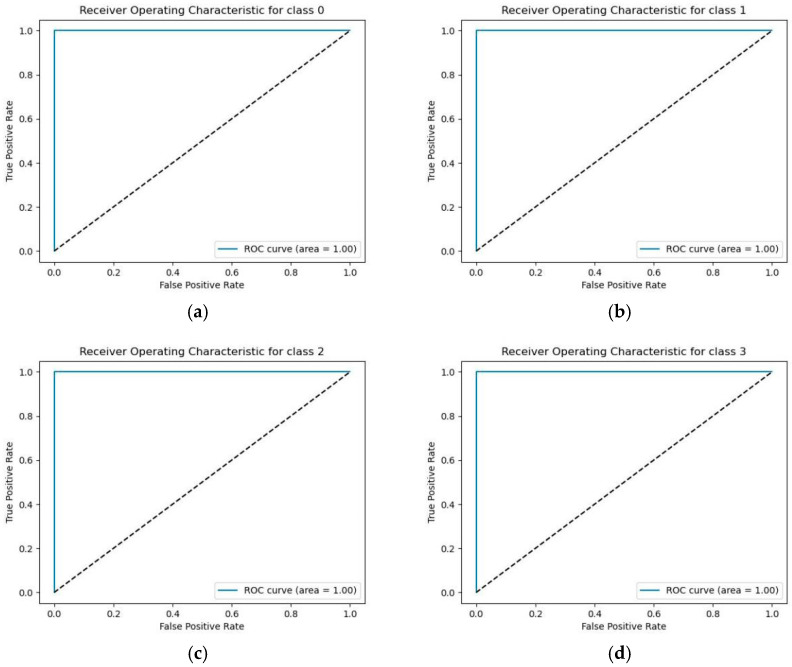 Figure 11
Figure 11- —National Natural Science Foundation of China General Project
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Fault Diagnosis Techniques · Gear and Bearing Dynamics Analysis · Machine Learning and ELM
1. Introduction
The transmission system is a mechanical system that comprises gears, bearings, and other mechanical components, essential for transmitting power or motion from one point to another [1]. Bearings, a prevalent mechanical component utilized across diverse fields and industries, play a crucial role in this system [2]. In the context of the country’s advancing development, there exists a substantial demand for bearings as indispensable consumables in the manufacturing process. Bearings serve functions such as friction reduction, load support, and precise positioning provision [3]. Thus, the significance of diagnosing bearing faults is inherently clear.
Currently, the mainstream approach for diagnosing bearing faults involves utilizing vibration signals [4,5,6,7]. Various methods are employed for this purpose, such as Wigner–Ville [8], spectrum auto-correlation analysis [9], sparsogram [10], KS test [11], wavelet transform [12], envelope analysis [13], wavelet denoising [14], cepstrum calculation [15], empirical mode decomposition [16], morphological wavelet slices [17], tachometer-less synchronously averaged envelope feature extraction technique [18], and envelope order tracking analysis [19], among others. Despite the prevalence of these methods, the utilization of wider bandwidth sound signals for bearing fault diagnosis remains relatively uncommon in comparison with traditional narrowband vibration signals. However, certain researchers have begun exploring this avenue [20,21]. Common situations for using sound signals aim to process transformer fault problems. Common methods include data-driven [22], poly-phase filtering and complex variational modal decomposition [23], Mel-GADF and ConvNeXt-T networks [24], support vector machine [25], WKPCA-WM and IPOA-CNN networks [26], Mel-spectrum convolutional neural network [27], blind source separation [28], improved MFCC and 3D-CNN networks [29], multi-characteristic voiceprint maps [30], etc.
The vibration signal is a narrowband signal, that is, the frequency band of the signal is narrow and the main frequency components of the signal are concentrated within a certain frequency range. The quality of sound signals is often determined by the frequency range of the sound. Therefore, sound signals are considered to be broadband signals. The frequency range of broadband signals is wider, and its main frequency components are distributed in a very wide frequency range [31]. Compared with traditional vibration signals, sound signals have the advantage of a wide frequency band. In some practical situations, vibration sensors may not be suitable for contact measurement due to harsh conditions. However, acoustic sensors offer the advantage of non-contact data collection by capturing sound signals, which is also one of the advantages [21].
Existing studies on bearing fault diagnosis can be broadly categorized by their learning paradigms. Supervised learning approaches require fully labeled datasets to train models for direct classification or regression. This category encompasses a wide range of methods, from traditional classifiers like support vector machines (SVMs) to modern deep neural networks such as convolutional neural networks (CNNs) and long short-term memory (LSTM) networks, which have been mainstream in vibration-based diagnosis [4,16,20]. Notably, advanced frameworks like the generalized Koopman neural operator demonstrate how deep learning can be integrated with dynamical system theory for efficient and high-fidelity modeling of complex mechanical systems [32]. In contrast, semi-supervised or self-supervised approaches have gained prominence for scenarios with limited labeled data, a common challenge known as data scarcity. These methods leverage both labeled and unlabeled samples to improve model generalization. A representative state-of-the-art method in this category is the adaptive fused domain-cycling variational generative adversarial network (AFDVGAN), which synthesizes high-quality data to augment scarce real samples, enabling robust fault diagnosis under imbalance conditions [33].
However, directly applying acoustic methods developed for transformers to bearing fault diagnosis faces specific challenges. These include the strong background noise in mechanical environments and the need for efficient model architectures suitable for one-dimensional feature inputs. To address these challenges and leverage the non-contact broadband advantages of acoustic signals, this paper proposes a novel fault diagnosis framework for bearing fault diagnosis. The overall process of this paper is shown in Figure 1. The main contributions of this work are summarized as follows:
- (1)This study uses the unique acoustic feature of the Mel frequency cepstral coefficient (MFCC) of acoustic signals to provide a feasible non-contact bearing fault diagnosis scheme.
- (2)We design a neural network architecture that integrates 1D-CNN for local feature ex-traction, an attention mechanism (with ECA selected as optimal) for highlighting critical information, and LSTM for capturing temporal dependencies. This model is specifically tailored for processing the sequential one-dimensional acoustic features.
- (3)By applying the ReliefF algorithm, we successfully reduce the acoustic feature dimension from 39 to 18. The results show that after using the feature selection algorithm, the number of parameters and the estimated total size are significantly reduced while ensuring that the accuracy remains basically unchanged, proving the feasibility of using a minimal yet effective feature set.
The rest of this paper is organized as follows: Section 2 presents the methodology and principles. Section 3 gives detailed information on the experimental setup and dataset. Section 4 describes the proposed algorithm and analyzes the training results. Finally, Section 5 draws the conclusion.
2. Methodology and Principles
The core modules function as follows:
- Acoustic feature extraction module: Extracts the unique acoustic features of the sound signal, Mel frequency cepstral coefficients (MFCCs), as inputs to the network model.
- CNN–attention mechanism–LSTM model:
- (1)One-dimensional convolutional layers: Automatically learn and extract locally sensitive patterns and abstract representations from the input feature sequences.
- (2)Attention mechanism: Dynamically calibrates the importance weights of different feature channels, enhancing the model’s ability to focus on critical discriminative information.
- (3)Long short-term memory (LSTM) network: Captures long-term dependencies and dynamic evolution patterns within the feature time series.
- Feature selection module: Applies the ReliefF algorithm to filter out feature subsets with higher weights, reduce data dimensionality, and improve model training efficiency.
2.1. Feature Extraction
First, we need to perform feature extraction operations to extract one-dimensional features as input for the task.
Scholars typically extract the time domain features and frequency domain features of the bearing [4,34,35,36,37]. In this paper, we extracted a total of 22 time domain features and frequency domain features. The names and abbreviations of the extracted features can be found in Table 1.
Compared with vibration signals, sound signals also have the capability to extract their acoustic features. The Mel frequency cepstral coefficient (MFCC) is a feature widely used in audio processing and speech recognition [38,39]. In this study, we have opted to extract the Mel frequency cepstral coefficients (MFCCs). The steps involved in extracting this feature are illustrated in Figure 2.
Pre-emphasis: First, the signal needs to be pre-emphasized to enhance the high frequency part. Pre-emphasis can help balance the spectrum and prevent numerical problems.Frame segmentation: Divide the continuous sound signal into short frames.Windowing: Apply a window function to each frame, which is usually a Hamming window or a Hanning window.Fast Fourier transform (FFT): The frame signal after the window function is applied is transformed by fast Fourier transform to obtain the spectrum.Mel filter filtering: The spectrum is filtered through a set of Mel filter banks to simulate the perception behavior of the human ear.Logarithmic transformation: Take the logarithm of the energy of the Mel filter bank. This is because human hearing perceives the amplitude and frequency of audio in a logarithmic way, so this transformation makes the data closer to human perception; on the other hand, the logarithm can also compress the range of the data and overcome the impact of large values.Discrete cosine transform (DCT): The energy of the Mel filter bank after logarithm is subjected to discrete cosine transform. The purpose of this is mainly to remove the correlation between the filter energy coefficients and retain the most important cepstral coefficients.
After obtaining the MFCC features corresponding to the sound signal through the aforementioned steps, it is important to note that the basic MFCC features primarily capture static characteristics. In order to further enhance the comprehensiveness of the acoustic feature dataset, additional dynamic features are extracted, including the first-order differential MFCC and the second-order differential MFCC [22]. Each of these 3 feature sets encompasses 13 distinct features, thereby resulting in a total of 39 features within the entire acoustic feature dataset.
2.2. Convolutional Neural Network Theory
Convolutional neural networks, known as CNNs, are multi-layer neural network models that typically include convolutional layers, pooling layers, and activation functions. Primarily designed for processing image data, CNNs can also be applied to analyze video, text, sound data, or one-dimensional features [40,41]. Due to the strong fitting capabilities inherent in neural networks, CNNs are capable of extracting both traditional topological structure features and high-dimensional abstract features that may be challenging to represent using mathematical models [21].
The one-dimensional convolutional neural network is a variant of the widely known convolutional neural network. Specifically designed for handling sequence data like time series, signal data, or text data, it has proven to be more efficient and practical for processing such types of information. In contrast to the two-dimensional convolutional neural network, which is predominantly used in image processing applications, the one-dimensional convolutional neural network stands out for its effectiveness in processing sequential datasets [42].
The convolution layer is the core of the convolutional neural network. It uses the convolution kernel matrix to perform local convolution operations to extract the implicit correlation in the input data to achieve feature extraction.
The activation function is used to introduce nonlinear factors, allowing the network to learn complex patterns. Compared with the Sigmoid function and the Tanh function, the ReLU activation function has fast convergence and better model generalization ability.
The expression of the ReLU function is as follows:
where is the input and is the output.
The feature mapping layer, also known as the pooling layer, plays a crucial role in deep learning models. It is designed to reduce the dimensions of features while preserving essential information and improving the model’s generalization capabilities by minimizing the number of parameters and computational load. Among the various pooling operations available, such as average pooling, the maximum pooling operation is chosen for this study.
After the convolutional layer and the pooling layer, a convolutional neural network typically consists of one or more fully connected layers. The fully connected layer is responsible for integrating high-level features, mapping them to the output space, and adjusting the network output.
Based on these characteristics, CNNs have been extensively applied in image analysis, face recognition, speech recognition, and various other fields [40,41,42].
2.3. Attention Mechanism Theory
While CNN extracts informative hierarchical features, not all learned features contribute equally to fault discrimination. Therefore, we use the attention mechanism module. This technique enhances the model’s capability to focus on critical segments of the feature sequence, thereby improving its overall performance.
The attention mechanism, a technique utilized in deep learning, enhances the model’s capability to concentrate on specific pieces of information by mirroring the operational mechanism of human attention. This technique enables the model to prioritize crucial segments when handling extensive data, thereby improving its focus, interpretability, and performance within a sequence model while facilitating information integration. Through the integration of the attention mechanism, neural networks gain the ability to autonomously learn and selectively emphasize key details from the input data, consequently augmenting the model’s overall performance and generalization capacity [43].
2.4. Long Short-Term Memory Network Theory
Long short-term memory (LSTM) is a specialized form of recurrent neural network (RNN) utilized for handling and forecasting long-term dependencies in sequential data. Unlike traditional RNNs, LSTM is engineered to address challenges such as gradient vanishing and exploding that emerge when processing lengthy sequence data. By incorporating the gating mechanism, LSTM retains information via the cell state, where the forget gate is responsible for dictating the removal of irrelevant information, the input gate governs the addition of new information to the cell state, and the output gate influences the value output based on the existing cell state [44].
The specific calculation formula in LSTM is shown as follows:
Forget gate:
where is the hidden state at the previous moment, and is the input at the current moment.
Input gate:
where is the cell state at the current moment, and is the candidate vector.
Output gate:
Due to its ability to handle long-term dependencies, LSTM has become an important tool for processing time series data.
2.5. Loss Function Theory
The loss function is a function used to quantify the difference between the predicted value and the true value of a model. It is a scalar that measures the “degree of error” of a model.
The cross-entropy loss function is the most crucial loss function in classification tasks, and its mathematical derivation is based on information entropy theory. It guides model optimization by measuring the difference between predicted probability distributions and true distributions.
The cross-entropy loss function avoids the gradient vanishing problem in the Sigmoid and Softmax saturation region, providing a stable and efficient update direction for optimizers.
3. Experimental Setup and Dataset Construction
3.1. Experimental Setup
The experimental platform described in this paper comprises several key components, including a magnetic powder brake, torque sensor, three-phase asynchronous motor, rolling bearing, acoustic sensor, data acquisition card, bearing seat, and bracket. Specifically, the setup features an HKDJ-26 three-phase asynchronous motor, an HCNJ-101 torque sensor, a CZ-2 magnetic powder brake, a DAQ122 data acquisition card, an LM386 acoustic sensor, and P6004 closed bearings with an inner diameter of 20 mm. Additionally, 0.5 mm hole defects have been intentionally created on both the inner and outer rings of the bearing, resulting in three types of defects: inner ring defect, outer ring defect, and mixed inner and outer defects. Figure 3 illustrates the layout of the entire setup. In the figure, the components are labeled as follows: 1 represents the three-phase asynchronous motor, 2 stands for the torque sensor, 3 represents the acoustic sensor, 4 represents the data acquisition card, 5 denotes the bearing and bearing seat, and 6 corresponds to the magnetic powder brake. Additionally, Figure 4 displays a comparison between the normal intact state bearing and the defective bearing. The red boxes (in the Figure 4) are used to highlight the different types of defects.
In the experiment, the motor speed was set to remain at 500 rpm with no load applied. The sampling rate for sound acquisition was set at 48 KHz.
In this experiment, we collected sound signals of four groups of transmission systems: normal intact state bearing, the bearing of inner ring defect, the bearing of outer ring defect, and the bearing of mixed outer and inner defects. Sound signals were collected in a quiet laboratory environment, with sound signal collection times of 140 s.
The time domain representations of the four groups of signals are visualized in Figure 5, Figure 6, Figure 7 and Figure 8.
To implement subsequent work effectively with the collected periodic signal, it is essential to divide the entire signal into several segments. Considering that the motor speed is 500 rpm, equivalent to approximately 8.3 revolutions per second and 1 revolution lasting about 0.12 s post-conversion, it can be deduced that 1 revolution corresponds to 5760 sampling points at the sampling frequency of 48 KHz. Maintaining at least 1 revolution in a signal segment is crucial. Hence, when trimming the signal, the segment length was fixed at 7000 with an overlap length of 3500. Upon signal trimming, subsequent feature extraction can be executed.
According to Section 2.1, the corresponding time domain, frequency domain features, and acoustic features of the cropped signal were extracted and further composed into the datasets required in this paper.
3.2. Datasets Construction
Through Section 3.1, the corresponding time domain, frequency domain, and acoustic features were extracted and compiled into the datasets essential for the experiment. Three datasets were created: one for time domain and frequency domain features, one for acoustic features, and one for combined complete features. The number of categories and features within each dataset is documented in Table 2, Table 3 and Table 4. In Table 2, Table 3 and Table 4, the numerical values under the columns “Number of 0”, “Number of 1”, “Number of 2”, and “Number of 3” indicate the sample count for each corresponding fault category (i.e., 1800 samples per category). The value in the “Number of Features” column represents the number of features in the dataset (i.e., 22, 39, and 61 features for the three datasets, respectively).These categories include 0 for the normal intact state bearing (nor), 1 for the bearing with outer ring defect (out), 2 for the bearing with inner ring defect (in), and 3 for the bearing with mixed inner and outer ring defects (all2).
After obtaining the datasets, we began to build the algorithm model required for this experiment.
4. Fault Diagnosis of Motor Bearing Transmission System Based on CNN–Attention Mechanism–LSTM Model
4.1. Construction of Algorithm Model
To perform fault diagnosis of the motor bearing transmission system, a suitable algorithm model is designed based on the characteristics and quantity of the feature datasets. The one-dimensional features extracted guide the selection of an algorithm model that is tailored to such features. Thus, the choice of algorithm model is crucial for effectively achieving the task at hand.
Based on the achievements of acoustic signals in transformer fault diagnosis, it is decided to propose a CNN–attention mechanism–LSTM network model to realize the fault diagnosis of motor bearing transmission system.
The overall framework of the algorithm model can be divided into four parts.
First, the model starts with a one-dimensional convolutional layer aimed at capturing local features in the input data. This is followed by the utilization of a ReLU activation function, enhancing nonlinearity in the module. Subsequently, a maximum pooling layer is employed to reduce feature dimensionality while retaining essential features within the data. Notably, the convolutional layer in this module uses a kernel size of 3 and a stride of 1, while the maximum pooling layer employs a kernel size of 2 with a stride of 2.
The attention mechanism module comes second in the model. Various types of attention mechanisms are available and, for this study, we employ five specific attention mechanism modules, namely SE, CBAM, ECA, SA, and SpatialAttention [43]. These modules selectively enhance the features processed by the one-dimensional convolutional neural network module.
The third part consists of the long short-term memory (LSTM) module, configured with a single layer containing a hidden size of 128.
The fourth part involves a fully connected layer that converts the processed features into output categories.
The construction of the entire algorithm model begins with capturing local features in the input using one-dimensional convolution, followed by enhancing nonlinearity through the ReLU activation function. Subsequently, the feature dimension is reduced via maximum pooling to retain key features. The processed features are then fed into the attention mechanism module for selective enhancement. Next, the features are flattened, a new dimension is added, and the data are then passed to the LSTM module. Finally, the data undergo direct conversion into the output of each category through a fully connected layer.
Rationale for Hyperparameter Selection
Convolutional layer (kernel size = 3, stride = 1): The kernel size of 3 is a standard choice for 1D-CNNs processing sequential features. It is large enough to capture local patterns and interactions between adjacent feature points, yet small enough to maintain a high degree of model efficiency and avoid overfitting. A stride of 1 is employed to ensure dense, sliding-window feature extraction, preserving the maximum amount of information from the input sequence.
Maximum pooling layer (kernel size = 2, stride = 2): It effectively reduces the spatial dimensions (length) of the features by half, thereby decreasing computational complexity and providing a degree of translational invariance. It helps to retain the most salient features while controlling overfitting. We choose maximum pooling over average pooling because bearing fault features are often manifested as impulsive components in the signal/feature domain, and maximum pooling is more effective at preserving such high amplitude, salient activations.
LSTM hidden size (128): The hidden state dimension of 128 represents a balance between model capacity and computational efficiency. It provides sufficient representational power to learn complex temporal dynamics from the condensed features output by the preceding CNN and attention modules.
4.2. Equipment Environment Configuration
The computer hardware environment parameters and computer software environment parameters used in this paper are shown in Table 5 and Table 6.
4.3. Preliminary Results and Analysis
After the preliminary work is completed, training can be carried out using the feature datasets obtained as the input for the constructed algorithm model. The training set, validation set, and test set are divided at a ratio of 8:1:1. The training parameters include a batch size of 128, 200 epochs, a fixed learning rate of 0.001, utilization of the Adam optimizer, and the cross-entropy function as the loss function. Training is conducted using GPU acceleration.
First, the time domain and frequency domain feature dataset is used as input for training. The results are shown in Table 7.
Secondly, the acoustic feature dataset is used as input for training. The results are shown in Table 8.
Finally, the complete dataset consisting of time domain and frequency domain features and acoustic features is used as input for training. The results are shown in Table 9.
Upon analysis of the results, it is evident that the fault diagnosis task is successfully completed, with a good classification effect achieved by utilizing acoustic features. Nonetheless, the accuracy obtained from solely employing time domain, frequency domain features, or a combined feature dataset is significantly lower and falls short of the desired outcome. Subsequent experimentation with these feature groups reveals persistently unstable accuracy levels ranging from 25% to 49%, rendering classification unattainable. Hence, it can be inferred that selecting acoustic features can a achieve classification task.
Next, we explore whether fault diagnosis can be achieved with fewer features. To investigate, we will select and verify the better features.
4.4. Feature Selection
Although the features of the datasets are rich, the contribution of different features to classification varies. Therefore, we conducted feature selection. Feature selection can identify and retain the most discriminative features, thereby achieving efficient and robust diagnosis.
Feature selection is a critical process in machine learning and data analysis since it involves choosing a subset of features from the original data that contribute to the model’s predictive performance [4,44]. ReliefF is a feature selection method that quantifies this “discriminative ability” by calculating a weight score for each feature. The higher the weight, the greater the contribution and importance of the feature to classification. The ReliefF algorithm was chosen for its effectiveness in handling multi-class problems and its ability to evaluate features based on their ability to distinguish between instances of different classes that are close to each other [45].
In this paper, we utilized the ReliefF feature selection algorithm [46] to select 18 features and created new datasets for analysis. The feature selection process was carried out twice. Initially, the top nine features were chosen from the time domain and frequency domain feature dataset and combined with the top nine features from the acoustic feature dataset, resulting in a 9 + 9 integrated dataset. Subsequently, the top 18 features from the acoustic feature set were selected to form the selected acoustic feature dataset. Given the large number of features involved, we showed the importance scores and rankings of the top 9 time domain and frequency domain features, as well as the top 18 acoustic features. To mitigate the impact of randomness, each set of experiments was repeated four times, and the features that appeared most frequently were selected for analysis. Considering the length of this paper, only one specific result of the selection will be presented here. Table 10 and Table 11 present the results from one experiment conducted. The final features selected for the two new datasets are detailed in Table 12 and Table 13, while the specific descriptions of the two new datasets are provided in Table 14 and Table 15.
4.5. Results and Analysis After Feature Selection
The feature datasets obtained after feature selection are used as input for training. Other parameters remain unchanged as above. The results are shown in Table 16 and Table 17:
From the above two sets of tables, it is evident that classification cannot be achieved when using the complete selection feature set that combines the two. Conversely, when utilizing the selected acoustic feature set, the classification performance is very good. Therefore, it can be concluded that the acoustic features chosen by the feature selection algorithm are effective in achieving classification.
To shed light on the advantages of selecting acoustic features for fault diagnosis, two parameters—parameter quantity and estimated total size—are introduced as reference points for comparison. The results of this analysis are presented in Table 18. This approach allows us to examine the efficiency and effectiveness of selecting acoustic features both before and after performing fault diagnosis tasks.
It is evident from Table 18 above that the ReliefF feature selection algorithm significantly reduces the number of parameters and estimated total size while maintaining the accuracy almost unchanged. This indicates the effectiveness of feature selection for acoustic features in fault diagnosis of motor efficiently bearing transmission systems. Consequently, fewer acoustic features can be utilized to achieve this task. After a comprehensive comparison of the above five models, the CNN-ECA-LSTM algorithm model was finally selected as the final structural choice for this task. The ECA attention mechanism module consists of an adaptive average pooling layer (AdaptiveAvgPool1d), a one-dimensional convolutional layer (Conv1d), and a sigmoid activation function, which enhances the features of important channels and suppresses the features of unimportant channels in a lightweight manner. The accuracy curve and loss function curve of its training are shown in Figure 9.
The confusion matrix is shown in Figure 10. These categories include 0 for the normal intact state bearing (nor), 1 for the bearing with outer ring defect (out), 2 for the bearing with inner ring defect (in), and 3 for the bearing with mixed inner and outer ring defects (all2).
To ensure experimental reliability, we used the ROC curve and corresponding AUC value as references. In a multi-classification task, we examined the ROC curve and AUC value for each class. These results are displayed in Figure 11.
The dashed line represents the performance benchmark for a random classifier. When used as a reference, if a model’s ROC curve lies above this line, it indicates that the model possesses effective discriminatory power. The AUC value of each classification is 1, which means that the model can perfectly distinguish between positive and negative examples, that is, the performance of the model is optimal. The precision, recall and F1 score are shown in Table 19.
Finally, we repeated the experiments on the selected algorithm model several times, and the results are shown in Table 20.
The average of the seven results is 99.90% and the average training time is 36.64 s.
Our entire process involves only signal cropping without any additional signal processing step from the perspective of signal processing. We are able to achieve the recognition task with an average accuracy of 99.90%. Additionally, the AUC value corresponding to the ROC curve of each classification is 1, demonstrating the effectiveness of our method. Realize the classification of fault types in bearings and research on bearing fault diagnosis methods using sound signals and one-dimensional acoustic features.
5. Conclusions
This paper mainly conducts bearing fault diagnosis by collecting sound signals and extracting corresponding acoustic features (MFCC). This research proposes a fault diagnosis method for the bearing based on acoustic features and deep learning. Initially, sound signals from four types of bearings—the normal state bearing, the bearing of inner ring defect, the bearing of outer ring defect, and the bearing of mixed inner and outer defects—are gathered, and the respective acoustic features are extracted. Subsequently, the one-dimensional acoustic features are input into the CNN–attention mechanism–LSTM model for fault type classification. To optimize the model, a feature selection algorithm is employed to streamline the features, resulting in a reduced number of algorithm model parameters and estimated total size without compromising accuracy. Ultimately, the CNN-ECA-LSTM algorithm model is chosen based on its superior performance.
The acoustic diagnosis model proposed in this study demonstrates significant effectiveness in experimental environments; however, its feasibility for practical deployment is impacted by the following key challenges: firstly, ambient noise can diminish the model’s robustness; secondly, training under fixed operating conditions limits its generalization capability in variable load and speed scenarios. In order to develop a comprehensive and practical bearing fault diagnosis method based on sound signals, future research must focus on improving the adaptability of the model in complex industrial environments and expanding the range of fault types it can diagnose.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Cai S. Kirtley J.L. Lee C.H.T. Critical Review of Direct-Drive Electrical Machine Systems for Electric and Hybrid Electric Vehicles IEEE Trans. Energy Convers.2022372657266810.1109/TEC.2022.3197351 · doi ↗
- 2He C. Zhang J. Geng K. Wang S. Luo M. Zhang X. Ren C. Advances in ultra-precision machining of bearing rolling elements Int. J. Adv. Manuf. Technol.20221223493352410.1007/s 00170-022-10086-6 · doi ↗
- 3Yu X. Gao W. Feng Y. Shi G. Li S. Chen M. Zhang R. Wang J. Jia W. Jiao J. Research Progress of Hydrostatic Bearing and Hydrostatic-Hydrodynamic Hybrid Bearing in High-End Computer Numerical Control Machine Equipment Int. J. Precis. Eng. Manuf.2023241053108110.1007/s 12541-023-00796-6 · doi ↗
- 4Zhang X. Zhao B. Lin Y. Machine Learning Based Bearing Fault Diagnosis Using the Case Western Reserve University Data: A Review IEEE Access 2021915559815560810.1109/ACCESS.2021.3128669 · doi ↗
- 5Lin H.-C. Ye Y.-C. Reviews of bearing vibration measurement using fast Fourier transform and enhanced fast Fourier transform algorithms Adv. Mech. Eng.201911168781401881675110.1177/1687814018816751 · doi ↗
- 6Patil M.S. Mathew J. Rajendra Kumar P.K. Bearing Signature Analysis as a Medium for Fault Detection: A Review J. Tribol.200813001400110.1115/1.2805445 · doi ↗
- 7Rai A. Upadhyay S.H. A review on signal processing techniques utilized in the fault diagnosis of rolling element bearings Tribol. Int.20169628930610.1016/j.triboint.2015.12.037 · doi ↗
- 8Dong G. Chen J. Noise resistant time frequency analysis and application in fault diagnosis of rolling element bearings Mech. Syst. Signal Process.20123321223610.1016/j.ymssp.2012.06.008 · doi ↗