E-Sem3DGS: Monocular Human and Scene Reconstruction via Event-Aided Semantic 3DGS
Xiaoting Yin, Hao Shi, Kailun Yang, Jiajun Zhai, Shangwei Guo, Kaiwei Wang

TL;DR
This paper introduces E-Sem3DGS, a new method that uses event cameras to improve 3D reconstruction of humans and scenes from motion-blurred videos.
Contribution
E-Sem3DGS is the first semantically augmented 3D Gaussian Splatting framework that uses event-intensity streams for joint human and scene reconstruction.
Findings
E-Sem3DGS improves PSNR by 49.7% on the ZJU-MoCap-Blur dataset.
The method achieves 13.48% PSNR improvement on the MMHPSD-Blur dataset.
The framework uses semantic attributes to separate dynamic and static content during optimization.
Abstract
Reconstructing animatable humans, together with their surrounding static environments, from monocular, motion-blurred videos is still challenging for current neural rendering methods. Existing monocular human reconstruction approaches achieve impressive quality and efficiency, but they are designed for clean intensity inputs and mainly focus on the foreground human, leading to degraded performance under motion blur and incomplete scene modeling. Event cameras provide high temporal resolution and robustness to motion blur, making them a natural complement to standard video sensors. We present E-Sem3DGS, a semantically augmented 3D Gaussian Splatting framework that leverages hybrid event-intensity streams to jointly reconstruct explicit 3D volumetric representations of human avatars and static scenes. E-Sem3DGS maintains a single set of 3D Gaussians in Euclidean space, each endowed with a…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
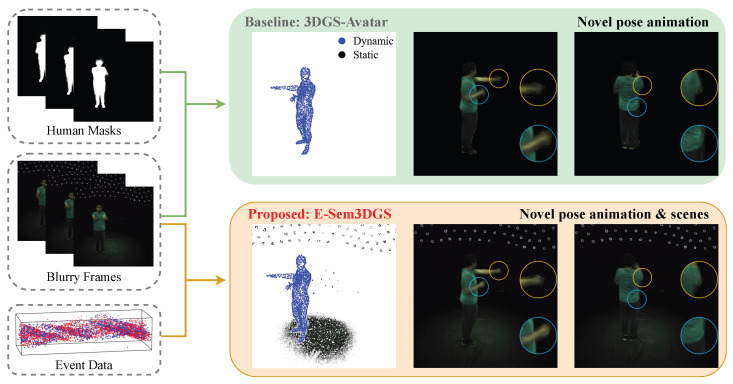 Figure 1
Figure 1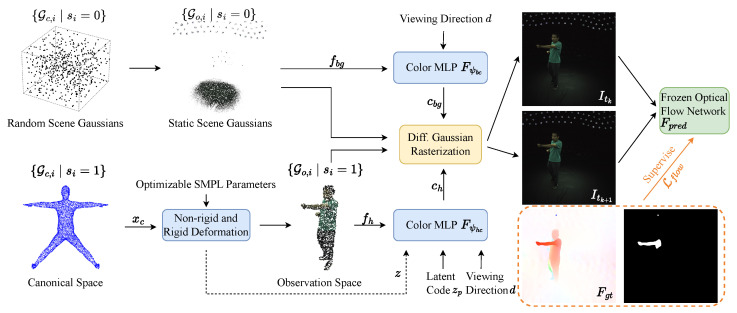 Figure 2
Figure 2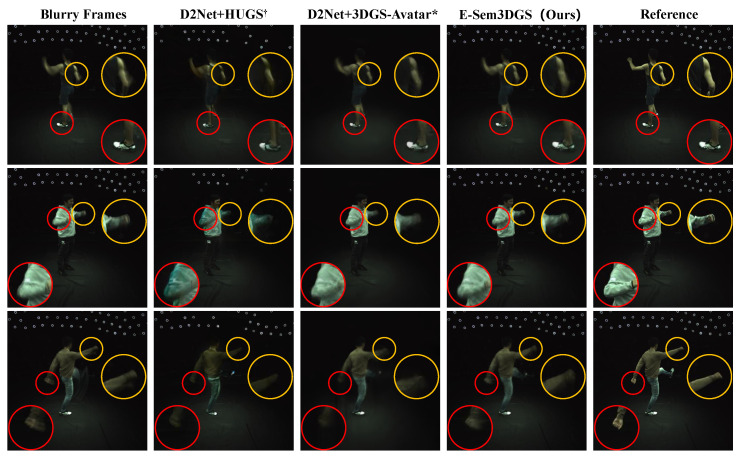 Figure 3
Figure 3 Figure 4
Figure 4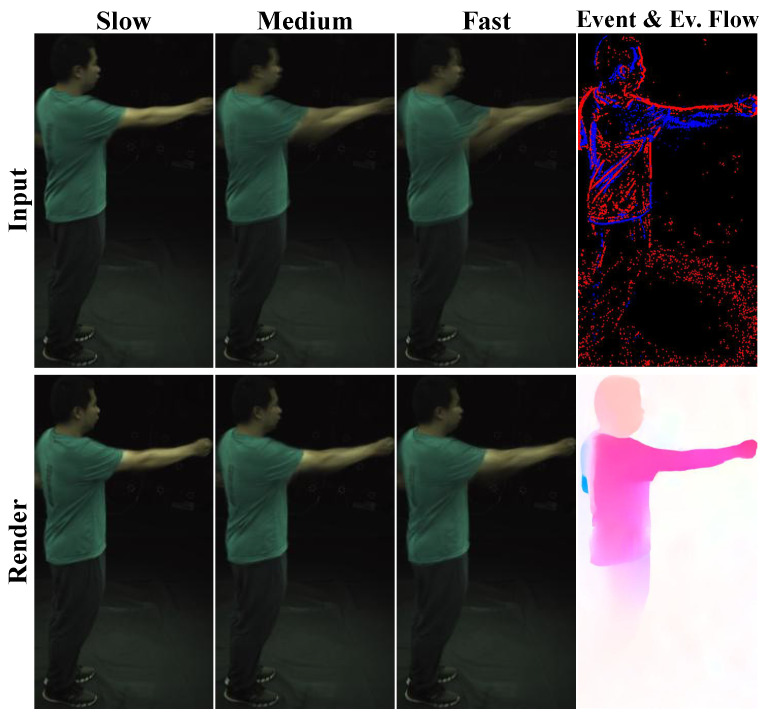 Figure 5
Figure 5- —Natural Science Foundation of Zhejiang Province
- —National Natural Science Foundation of China
- —Hunan Provincial Research and Development Project
- —Open Research Project of the State Key Laboratory of Industrial Control Technology, China
- —State Key Laboratory of Autonomous Intelligent Unmanned Systems
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGenerative Adversarial Networks and Image Synthesis · Advanced Image Processing Techniques · Human Pose and Action Recognition
1. Introduction
Reconstructing photorealistic, animatable human avatars, together with their surrounding static environments, from sensory input is a pivotal challenge in computer vision, with transformative applications in extended reality (XR), gaming, and visual try-on [1,2,3,4]. Recent advances in neural rendering integrate body articulation into Neural Radiance Fields (NeRFs) [5,6,7,8] and point-based rendering such as 3D Gaussian Splatting (3DGS) [9,10,11,12], enabling high-fidelity reconstruction of clothed human geometry and appearance from sparse or monocular videos. While these methods can utilize 3D volumetric representations to render high-quality human avatars under novel poses, they typically assume clean intensity inputs and mainly focus on the foreground human, often leaving static scenes under-modeled and degrading in the presence of motion blur [13].
Three-Dimensional Gaussian Splatting (3DGS) has emerged as an efficient alternative to NeRFs, offering fast inference and high-fidelity rendering with reduced computational cost [10]. Methods such as 3DGS-Avatar [9] and ASH [11] leverage 3DGS to render animatable human avatars by integrating articulated deformation with Multi-Layer Perceptrons (MLPs) or Convolutional Neural Networks (CNNs) for real-time performance. HUGS [12] extends this line of work to jointly model humans and static backgrounds by employing two separate sets of 3D Gaussians—one for the human and one for the scene—yet guided by precomputed human foreground masks [14,15]. However, maintaining dual Gaussian sets increases representation and optimization complexity, and the reliance on 2D foreground masks becomes problematic under motion blur, where mask predictions are noisy and misaligned. This limits scene realism and robustness in immersive applications such as augmented reality (AR) [1,2].
Motion blur is a common artifact in monocular videos of fast-moving subjects, introducing temporal ambiguities that challenge consistent reconstruction of both geometry and appearance across frames [16]. Intensity-based deblurring methods such as MPR [17] and NAFNet [18] attempt to restore sharp frames, but they struggle in highly dynamic scenes with complex motion patterns [19]. Event cameras, which asynchronously capture per pixel brightness changes, naturally complement standard video sensors by providing high-temporal-resolution data that is robust to motion blur [20]. Hybrid event-intensity approaches, including EFNet [19] and D2Net [21], improve deblurring by fusing event streams and intensity images, yet they are typically formulated as 2D pre-processing modules that are decoupled from downstream 3D reconstruction and have limited generalization across diverse scenes. In human pose estimation, EventHPE [13] demonstrates that event-derived optical flow can drive high-precision 3D human pose and shape estimations under motion blur, highlighting the potential of event-based motion cues for dynamic 3D reconstruction.
In this work, we address the joint reconstruction of animatable humans and static scenes from monocular, motion-blurred videos by introducing E-Sem3DGS, a semantically augmented 3D Gaussian Splatting framework that leverages event-based optical flow. Building upon 3DGS-Avatar [9], E-Sem3DGS maintains a single set of 3D Gaussians, each endowed with a learnable semantic attribute that softly separates dynamic human content from static scene content within a unified representation, as illustrated in Figure 1. We initialize human Gaussians from Skinned Multi-Person Linear (SMPL) model priors with their semantic values set to 1 and scene Gaussians by sampling a surrounding cube with their semantic values set to 0, then jointly optimize geometry, appearance, and semantics. Unlike HUGS [12], which relies on separate Gaussian sets and precomputed foreground masks, our unified semantic representation simplifies the pipeline and avoids dependence on external segmentation under blur.
To mitigate motion blur, we integrate event-based optical flow supervision. Specifically, we derive optical flow from event streams and use it to supervise image-based optical flow between rendered images at consecutive time steps, with the loss selectively applied to regions exhibiting high motion magnitude. This design enforces temporal coherence in high-motion regions and sharpens both human and background reconstructions, in contrast to approaches that apply 2D deblurring as a separate pre-processing stage [17,18,19,21]. Compared to 3DGS-Avatar [9] and HUGS [12] cascaded with intensity-based [17,18] or event-intensity deblurring [19,21] methods, our approach achieves superior performance on the ZJU-MoCap-Blur [6] and MMHPSD-Blur [13] datasets. On motion-blurred ZJU-MoCap-Blur, for full-frame rendering encompassing both humans and scenes, E-Sem3DGS improves the average PSNR from to , corresponding to a relative gain over 3DGS-Avatar [9]. On MMHPSD-Blur, our method improves PSNR from to , corresponding to a gain over HUGS [12].
Compared with prior 3DGS-based methods that either require precomputed masks for human–scene separation or treat deblurring as a stand-alone 2D pre-processing step, E-Sem3DGS integrates semantic disentanglement and event-based motion cues directly into a unified 3D representation and optimization pipeline.
In summary, our main contributions are threefold:
- We propose E-Sem3DGS, a semantically augmented 3D Gaussian Splatting framework that unifies human and scene reconstruction within a single Gaussian representation, enabling efficient human–scene disentanglement and high-quality rendering from monocular videos under motion blur.
- We introduce an event-based optical flow supervision strategy that exploits event-derived flows to guide image-based flows between rendered frames, enhancing temporal consistency and mitigating motion blur in high-motion regions.
- We construct motion-blurred ZJU-MoCap-Blur and MMHPSD-Blur benchmarks and conduct extensive experiments, showing that E-Sem3DGS significantly outperforms strong baselines and state-of-the-art methods on both human and full-frame reconstruction in blurry scenes.
2. Related Work
2.1. Neural Human Rendering
Early photorealistic rendering and animation utilized complex multi-camera setups [22] and manual rigging of human body meshes [23,24]. Subsequent statistical body-shape models [25,26,27,28,29] facilitated the representation of diverse body shapes yet lacked fine details such as clothing, hair, and accessories. Neural Radiance Fields (NeRFs) [5] have transformed 3D reconstruction by modeling geometry and appearance for view synthesis from multi-view images without extensive setup. Originally developed for static scenes [30,31], NeRF has been adapted for dynamic human rendering by incorporating body encodings [32,33,34] or by learning a canonical NeRF representation and transforming camera rays from the observation space to the canonical space to retrieve radiance and density values from the canonical NeRF [7,35,36]. However, most NeRF-based methods, reliant on large MLPs, suffer from slow training (hours to days) and rendering (seconds) [9,12]. Optimized schemes, such as learning functions at grid points [37,38], hash encoding [31], or the elimination of learnable components [39,40], have been developed. Three-Dimensional Gaussian Splatting (3DGS) [10] offers an efficient alternative to NeRF, modeling scenes as sets of 3D Gaussians splatted onto the image plane via alpha blending. The field of 3D Gaussian-based avatar reconstruction [9,12,41,42] has rapidly advanced. However, most existing methods primarily focus on reconstructing human avatars in isolation, often neglecting the concurrent reconstruction of static background scenes [9,41,42]. HUGS [12] represents a state-of-the-art approach by maintaining separate Gaussian sets for the human and scene. However, this hard separation relies heavily on precomputed 2D foreground masks [14]. In motion-blurred scenarios, mask prediction becomes unreliable, leading to severe error propagation where human parts are misclassified as background and fail to deform. In contrast, E-Sem3DGS employs a unified representation with soft, learnable semantic attributes. We use semantics as a differentiable gating mechanism to functionally control the deformation pathway. This enables a self-correcting convergence behavior: even if points are initially misclassified, flow-based supervision can update their semantic attributes, dynamically “activating” their deformation capabilities. This unified representation simplifies optimization complexity by maintaining a single Gaussian set while ensuring geometric robustness against mask failures.
2.2. Deblurring Neural Rendering
Several methods [43,44,45] have been developed to adapt NeRF and 3DGS for the generation of sharp outputs from blurry inputs. Deblur-NeRF [43] pioneered deblurring in NeRF for blurry inputs during training, using a compact MLP to model spatially dependent blur kernels. Subsequent advancements leverage physical priors from the blurring process [44] and jointly optimize Gaussian parameters with the camera trajectory to enhance rendering quality for dynamic human reconstruction [45].
With the development of event cameras, some works [16,46,47] have optimized NeRF and 3DGS solely using event streams. Recent works also integrate events and images for 3D reconstruction to mitigate blur from extreme camera shake [48,49,50]. DE-NeRF [51] reconstructs deformable neural radiance fields for fast-moving objects using event streams and sparse sharp RGB frames. EvaGaussians [49] integrates event streams to explicitly model motion blur and guide deblurring reconstruction, jointly optimizing 3DGS parameters and camera motion for high-fidelity novel view synthesis. EaDeblur-GS [50] utilizes an Adaptive Deviation Estimator (ADE) network and novel loss functions to achieve sharp 3D reconstructions. However, regarding the utilization of event streams, these methods [49,50,51] predominantly rely on event generation models, minimizing the discrepancy between captured events and those simulated based on brightness changes. While rigorous, this strategy requires precise calibration of sensor parameters (e.g., contrast thresholds), limiting generalization across different devices and lighting conditions. Notably, ExFMan [52] introduces a neural rendering framework that reconstructs high-quality dynamic humans from monocular blurry videos by leveraging event camera data and velocity-aware losses to mitigate motion blur. However, this approach explicitly estimates a 3D velocity field from the deformation network’s derivatives. It relies heavily on the accuracy of this internal velocity estimation, which is prone to failure under complex, non-linear articulated motions, and its event supervision remains sensitive to sensor calibration. In contrast, our E-Sem3DGS adopts event-based optical flow as a robust intermediate representation. By supervising the motion field directly with external flow cues, we abstract away sensor-specific signal variations and provide explicit geometric guidance.
2.3. Video Deblurring Methods
Motion blur in monocular videos presents significant challenges for 3D human reconstruction due to its ill-posed nature [19,21]. Traditional intensity-based (RGB or grayscale) deblurring methods [53,54,55] estimate 2D blur kernels or leverage supervised deep learning with paired blurry–sharp datasets [17,18,56] to recover sharp frames. Event-intensity hybrid methods exploit the high temporal resolution of event cameras [19,21] to complement standard intensity data for motion deblurring. For 3D human reconstruction, these methods can serve as a two-stage baseline, first deblurring images, then reconstructing the 3D human model. However, their limited generalization across varied scenes and lack of human-specific priors often lead to failures in handling complex motion [16,52]. In contrast, our framework integrates event-based optical flow supervision to align rendered image flows and event-derived flows, emphasizing high-motion regions to provide explicit geometric cues, improving reconstruction accuracy.
3. Preliminaries
3.1. 3DGS-Avatar
3DGS-Avatar [9] introduces an efficient method for reconstructing animatable human avatars from monocular videos using 3D Gaussian Splatting (3DGS). It initializes a collection of 3D Gaussians ( ) in a canonical space derived from an SMPL mesh [26] and transforms them to the observation space via non-rigid and rigid deformations. The non-rigid deformation module is expressed as follows:
where is the deformation network that maps the canonical position ( ) and a latent code ( [57]), which encodes SMPL pose and shape parameters, to the Gaussian’s position, scale, and rotation offsets, as well as a feature vector:
resulting in deformed Gaussians with , , and . The rigid deformation uses Linear Blend Skinning (LBS) [26]:
where a skinning MLP ( ) predicts weights at position and are bone transformations. A neural color model is applied to generate view-dependent appearance from canonicalized viewing directions, a per Gaussian color feature, a pose-dependent feature, and a per frame latent code, while as-isometric-as-possible constraints on Gaussian positions and covariances enhance generalization to unseen poses.
3.2. Event-Based Optical Flow
Integrating event information into neural rendering techniques [16,46,47] commonly involves directly utilizing raw event data, often by deriving reconstruction losses from event generation models. However, this direct approach can be sensitive to diverse event sensor characteristics and varying acquisition environments. Inspired by EventHPE [13] and its ability to robustly extract motion information, we adopt an alternative strategy, inferring explicit geometric clues in the form of event optical flow. Specifically, EventHPE uses an unsupervised encoder–decoder Convolutional Neural Network (CNN)—namely, FlowNet [13,58]—to estimate optical flow from event frames. Its loss function combines a photometric term (warped image pixel differences) and a smoothness term (penalizing flow discrepancies).
In our method, this event-derived optical flow plays a crucial role. We apply this supervision primarily to regions exhibiting high motion intensity, i.e., areas where the event optical flow magnitude is significant. This selective application allows us to focus our deblurring efforts precisely where motion blur is most severe and where event data provides the most reliable motion estimates. By integrating these precise geometric constraints, our method significantly enhances the reconstruction of dynamic humans from blurry monocular videos, effectively mitigating severe motion blur.
4. Method
4.1. Overview
This section introduces the E-Sem3DGS framework, which reconstructs dynamic human avatars and static scenes from monocular, jointly calibrated blurry videos and event data, along with provided SMPL parameters [26]. Our approach leverages event-aided semantic 3DGS to effectively mitigate motion blur and bypasses the need for human foreground masks by semantically distinguishing human and scene points. The method augments 3D Gaussians with a semantic logit vector initialized from the SMPL mesh for human Gaussians and random cubic sampling for scene Gaussians, with human Gaussians deformed via rigid and non-rigid transformations while scene Gaussians remain static. Deformed human Gaussians and static scene Gaussians are rendered through a single rasterization process supervised by a frozen flow network using event-based optical flow to address motion blur, as depicted in Figure 2. Semantic logits enhance human–scene segmentation (Section 4.2), a scene-color MLP ensures robust static-region appearance (Section 4.3), and event-based flow supervision mitigates dynamic blur (Section 4.4). Joint optimization of semantic Gaussians, human deformation, skinning, event-based flow, and color networks is conducted to reconstruct humans and scenes from blurry video inputs and event data (Section 4.5).
4.2. Semantic 3D Gaussians
We introduce semantic attributes to the 3D Gaussian primitives to enable explicit segmentation of dynamic human bodies and static scenes. Each 3D Gaussian ( ) in the canonical space, defined by its mean , scaling factor ( ), rotation quaternion ( ), opacity ( ), and color features ( ), is augmented with a semantic logit vector ( , where represents the background (0) and human (1) classes).
The semantic logits ( ) are initialized based on input labels. Given a point cloud with N points and corresponding labels ( ), we initialize the logits as follows:
where is a scalar hyperparameter that controls the initial class confidence, ensuring high probability for the correct class. The semantic probabilities are computed via a softmax activation:
where is a learnable parameter optimized during training. The predicted class for each Gaussian is obtained as
and segmentation masks are derived as for the human class and for the background class, identifying points belonging to each class. Semantic attributes are integrated into the 3DGS pipeline, where human points are deformed from canonical to observation space using rigid and non-rigid transformations, then rasterized alongside background points for unified rendering of both parts.
4.3. Scene-Color MLP
We introduce a scene-color MLP to model static background appearance in monocular video to achieve higher expressiveness, flexibility, and robustness to noise or blur data compared to traditional spherical harmonics (SH) methods. For scene Gaussians ( ), the MLP takes the feature vector ( ) and the SH basis ( ) of the viewing direction ( ) as input, predicting the appearance colors via
where is an MLP with one 64-dimension hidden layer and is the canonicalized direction derived from the relative position of the 3D Gaussian and the camera center. This approach enables fine-grained, non-linear color modeling and leverages end-to-end optimization for improved reconstruction quality while ensuring robust color prediction for static regions.
4.4. Event-Flow Supervision
To enhance the reconstruction of motion-blurred human bodies in monocular videos, we incorporate event-based optical flow [13] as a supervisory signal, leveraging the high temporal resolution of event cameras. We employ a lightweight, frozen flow network—either SPyNet [60] or MaskFlowNetS [61]—to predict optical flow ( ) from pairs of rendered frames ( , where denotes the current time step in the frame sequence ( )). The flow network, denoted as , is defined as follows:
where the frames are resized to a resolution scale of via bilinear interpolation to reduce computational cost, i.e.,
and is the bilinear resize operator.
The predicted flow ( ) is supervised by event-based optical flow to enhance the rendering quality of fast-moving human body parts in motion-blurred monocular videos. The flow loss is defined as follows:
where is a mask selecting pixels with significant flow magnitude, ensures numerical stability, and denotes the L1 norm of the vector difference. This masked L1 loss focuses supervision on regions with substantial motion, enhancing robustness to motion blur.
This supervision strategy is grounded in the premise that, despite originating from different modalities, both flows represent the same underlying physical velocity field. Consequently, minimizing their discrepancy enforces 2D motion consistency on the image plane. While this acts as geometric guidance for the projected deformation rather than strict 3D consistency under complex self-occlusions, it effectively provides structural constraints where intensity data is ambiguous. Moreover, the employment of flow networks acts as a robustness filter, abstracting away sensor noise and contrast threshold sensitivities to focus optimization on the correction of geometric deviations. Note that our framework is modular: while we employ specific pre-trained models in our experiments, the flow estimation module is compatible with general-purpose event optical flow networks (e.g., E-RAFT [62]), ensuring broad applicability across different datasets.
4.5. Optimization
We jointly optimize the 3D semantic Gaussians ( ), comprising canonical human and scene Gaussians, along with human deformation, skinning, color networks for human modeling [9], and the scene-color MLP ( ) (Section 4.3), using event-based optical flow supervision with a frozen flow network to reconstruct dynamic human avatars and static scenes from blurry monocular videos and event data. The optimization is driven by a loss function combining (1) L1 loss for alignment of rendered and ground-truth images, (2) event-based flow loss (Section 4.4) for motion supervision, (3) perceptual loss [9] to provide robustness to local misalignments, (4) skinning loss based on SMPL priors, and (5) as-isometric-as-possible regularization losses for human Gaussians’ position and coherence. Note that the integration of event cues is achieved via gradient-based supervision rather than direct feature concatenation. The flow-loss gradients specifically guide the deformation in high-motion regions, effectively fusing temporal motion cues with the 3D geometry during backpropagation. Furthermore, structural integrity is maintained without external depth priors by employing skinning loss and as-isometric-as-possible regularization to penalize unphysical distortions.
5. Experiments
5.1. Datasets
ZJU-MoCap-Blur. Following 3DGS-Avatar [9], we select six sequences (377, 386, 387, 392, 393, and 394) from the ZJU-MoCap dataset [6] and generate motion-blurred images using Super-SloMo [63] to simulate realistic monocular video conditions. We select view “1” to focus on reconstructing both humans and scenes from a fixed viewpoint, aiming to minimize hardware costs and isolate high-speed human motion from camera ego-motion. Since this dataset lacks real event data, we employ a simulation strategy for event-based supervision. Specifically, the target optical flow is inferred from the sharp ground-truth images using the pretrained RAFT model [64]. This serves as a high-fidelity proxy for ideal event optical flow, which would naturally be free from motion-blur artifacts. To ensure training and test sets evenly sample the sequence and minimize train–test discrepancies arising from a single 360° human rotation, we apply an interleaved split. Specifically, we partition the sequence into consecutive blocks of 10 frames each, assigning the first 7 frames of every block to the training set and the subsequent 3 frames to the test set. This strategy ensures both comprehensive sampling across the entire sequence and a consistent train–test ratio for optical flow-based training. Human masks derived from RobustVideoMatting [15] enable comparisons with methods requiring human masks, with rendering quality assessed via PSNR, SSIM, and LPIPS metrics for both full images and human regions defined by bounding boxes.
MMHPSD-Blur. The MMHPSD dataset [13], captured using a single fixed CeleX-V event camera, provides event–grayscale image pairs, SMPL ground-truth parameters, and event-based optical flow. Specifically, the provided optical flow is inferred from event frames using the unsupervised FlowNet framework proposed in EventHPE [13,58]. Technically, this inference aggregates asynchronous events into multi-channel frames to explicitly encode polarity and high-temporal-resolution information into the motion estimation. Originally designed for 3D human pose estimation, the dataset is now extended for 3D reconstruction and rendering of dynamic human avatars in this work. To evaluate performance across diverse motion speeds and subjects, six sequences (s1g2t3, s5g1t1, s7g1t1, s10g3t4, s14g2t2, and s15g3t4) are selected. Motion-blurred images are generated using Super-SloMo [63] to replicate the visual effects of motion blur in monocular videos, with human masks derived via RobustVideoMatting [15] to enable comparisons with methods reliant on human segmentation.
5.2. Comparison with Baselines
Baseline methods include 3DGS-Avatar [9], which is a state-of-the-art method specifically designed for animatable human avatar rendering using 3D Gaussian Splatting, and HUGS [12], a prominent approach that simultaneously reconstructs and renders both animatable humans and static scenes within the 3DGS framework. For a fair comparison, the HUGS implementation adopts the official codebase [12], with scene point-cloud initialization modified from the original COLMAP-based approach [65,66] to random cubic sampling, denoted as HUGS^†^. To extend 3DGS-Avatar for simultaneous human and scene rendering, scalar semantic attributes are incorporated, with initialization combining the human body-mesh sampling and random cube sampling, setting initial semantic values to , referred to as 3DGS-Avatar*. Additionally, 3DGS-Avatar* and HUGS^†^ are cascaded with intensity-based deblurring methods (MPR [17] and NAFNet [18]) and Intensity+Event-based deblurring methods (EFNet [19] and D2Net [21]) for comparison. Deblurring results are input to 3DGS-Avatar* and HUGS^†^ for 3D reconstruction, denoted as Deblurring method + Reconstruction method.
First, we analyze the performance on the ZJU-MoCap-Blur dataset from multiple perspectives. Quantitative Evaluation on Full-Frame Rendering: Table 1 evaluates PSNR, SSIM, and LPIPS metrics across full images. 3DGS-Avatar, designed for human rendering, exhibits the lowest performance across sequences. Incorporating scalar semantic attributes in 3DGS-Avatar (3DGS-Avatar*) enables simultaneous human and scene rendering, boosting the PSNR from to , with an improvement of . Cascading with intensity deblurring enhances HUGS^†^ accuracy, whereas 3DGS-Avatar* remains unchanged, which is attributed to the limited discriminative power of scalar semantic attributes initialized at 0.5, constraining its responsiveness to deblurred inputs. Furthermore, D2Net with Intensity + Event methods further improves deblurring for HUGS^†^, while EFNet, trained on datasets with significant domain gaps relative to the current dataset, shows improvement over blurred inputs but underperforms compared to intensity-only deblurring. Our proposed method, integrating one-hot semantic attributes and event flow supervision, achieves the highest accuracy across all sequences. Quantitative Evaluation within Human Bounding Boxes: Table 2 reports average rendering metrics within human bounding boxes; the ZJU-MoCap-Blur dataset exhibits minimal background detail within these regions. 3DGS-Avatar*, with basic human–scene discrimination, increases the PSNR from to compared to 3DGS-Avatar, with the PSNR and SSIM trailing only the proposed method when cascaded with the Intensity + Event (D2Net) deblurring method. The proposed method yields the best PSNR, SSIM, and LPIPS values within human bounding boxes. Qualitative Analysis: In Figure 3, each column illustrates the input blurred image, D2Net + HUGS^†^, D2Net + 3DGS-Avatar*, the proposed method, and the reference image. Relative to the original blurry frames (with motion trailing highlighted in the first column’s yellow-circled zoomed inset), both the cascaded methods and the proposed method mitigate this artifact, demonstrating the benefit of event information in reducing dynamic blur. Compared to D2Net + HUGS^†^ and D2Net + 3DGS-Avatar*, the proposed method delivers sharper arm and hand contours, underscoring the advantage of event flow supervision over direct event deblurring cascades. Additionally, in the reconstruction of the static scene, HUGS^†^’s optimization proves challenging with random background initialization, and 3DGS-Avatar*’s scalar semantic attributes yield inadequate results (e.g., top regions), whereas the proposed method achieves a more realistic reconstruction.
Then, we extend the evaluation to the performance on the MMHPSD-Blur dataset. Table 3 records per sequence results, with the proposed method attaining the highest PSNR and SSIM values, alongside the lowest LPIPS across most sequences. Unlike ZJU-MoCap-Blur, HUGS^†^ ranks second, with performance degrading when cascaded with deblurring methods due to the dataset’s complex background. Switching scene initialization from COLMAP to random sampling increases optimization difficulty for the two Gaussian groups (human + scene), where HUGS^†^’s reconstruction capability outweighs the impact of human blur severity. Table 4 presents quantitative results within human bounding boxes, with the proposed method achieving the best metric performance. Figure 4 displays the blurred image, HUGS^†^, 3DGS-Avatar*, the proposed method, and the reference image. As noted, HUGS^†^ (second column) maintains the human foreground and static scene background via two Gaussian groups, but random background initialization, unlike COLMAP’s facilitative structure, heightens optimization challenges, impairing human rendering quality. 3DGS-Avatar* outperforms HUGS^†^ for human rendering but misclassifies much of the background as human due to limited scalar semantic attribute capacity, causing co-deformation. The proposed method accurately reconstructs both humans and scenes, with event information supervision yielding clearer contours compared to the original blurred image.
5.3. Ablation Study
Ablation experiments are conducted on Subject 386 of the ZJU-MoCap-Blur dataset unless otherwise specified. As shown in Table 5, comparisons are made using only blurred image inputs, evaluating the effect of semantic attributes. 3DGS-Avatar [9], focused on human rendering, achieves a PSNR of when tasked with simultaneous human and scene reconstruction due to its lack of scene modeling capability. Adding scalar semantic attributes enables differentiation of human and scene Gaussians, raising the PSNR to . Upgrading to one-hot semantic attributes further enhances this distinction, yielding the best rendering metrics, with a PSNR of .
Next, the integration of event information is ablated, as detailed in Table 6. Building on the blurred image baseline (last row of Table 5), the E2VID approach [67,68] converts events to grayscale images and blends them with blurry intensity images using a foreground human mask. This process disrupts image continuity and temporal consistency, lowering the PSNR from to . Applying D2Net [21] for Intensity+Event deblurring modestly improves rendering, though the cascaded deblurring–reconstruction approach is limited by the deblurring model’s training scenarios. Incorporating event loss supervision [16,69], which computes loss from the log-intensity differences between pairs of rendered images compared to real events, effectively leverages event data to address motion blur, significantly enhancing rendering performance. While event loss supervision is effective, it often lacks generalizability across different event cameras due to varying sensor parameters (e.g., contrast thresholds) and inconsistent data formats (e.g., the polarity-free CeleX-V sensor in MMHPSD [13]). In contrast, optical flow [60,64,70,71] provides a more robust and universal representation of motion. Its effectiveness as an intermediate modality is well documented across a range of event-based downstream tasks, including Visual–Inertial Odometry (VIO) [72,73], keypoint detection [74], and human pose estimation [13]. By leveraging supervision from event-based optical flow to deblurring, our method achieves the highest evaluation metrics, improving the baseline with a gain of in PSNR ( vs. ), a gain of in SSIM ( vs. ), and a reduction of in LPIPS ( vs. ).
Since the introduction of 3D Gaussian Splatting (3DGS) [10], the initialization problem has been a critical focus for researchers. In Table 7, we explore the impact of different initialization strategies on the reconstruction performance of our proposed method. When both human and scene points are randomly initialized, successful reconstruction is achieved. This is because our method leverages SMPL model parameters as a prior to optimize all learnable parameters, including 3D Gaussians, the deformation network, the skinning network, and the color network. Nonetheless, initializing only the human points based on the SMPL model while leaving scene points uninitialized leads to inferior reconstruction quality compared to random initialization of both human and scene points, as 3DGS relies on initial points for splitting and cloning. SMPL-based human initialization with random scene points improves performance over dual random initialization, with gray initialization of scene points to distinguish white human points, achieving the best rendering quality.
In our method, we employ semantic differentiation between human and scene Gaussians. Table 8 illustrates the impact of semantic initialization on reconstruction performance. Assigning an initial semantic value of to all points (with human Gaussians corresponding to a semantic value of 1 and scene Gaussians corresponding to a semantic value of 0) enables successful reconstruction. However, this initialization significantly increases the learning complexity for the Gaussian model and associated networks. In contrast, initializing points on and inside the SMPL model surface with a semantic value of 1 and all other points with a semantic value of 0 results in superior rendering performance. Therefore, in our method, we initialize human Gaussians based on the SMPL model, randomly initialize scene Gaussians using a cubic volume, and assign a semantic value of 1 to Gaussians on and inside the SMPL model surface, with all other Gaussians assigned a value of 0. The performance gap suggests that while random initialization allows for reasonable convergence, the lack of explicit geometric guidance leads the optimization into suboptimal local minima with ambiguous semantic separation. In contrast, our SMPL-based initialization acts as a strong geometric prior, placing the system within a favorable basin of attraction. Furthermore, the stability during optimization is maintained by the synergy of loss constraints: the masked flow loss prevents dynamic parts from drifting into the static background, while the photometric intensity loss anchors the background, preventing it from drifting into the dynamic class. This mechanism effectively focuses the optimization on boundary refinement, though it remains sensitive to gross tracking errors where the prior is spatially decoupled from the image content.
Figure 5 illustrates the rendering performance of our method under different blur levels (slow, medium, and fast), with the first row displaying input blurry images and the second row showing the corresponding rendering results. As the speed of the arm motion increases, the blur level in the arm region intensifies accordingly. Across varying blur levels, our method, by incorporating constraints from event optical flow, consistently produces arm contours that are sharper than those in the input blurry images. However, as the blur level increases, the arm edges in the rendering results become progressively more blurred, aligning with the changes observed in the input images.
To align with sustainable computing standards, we report our method’s efficiency. On a single NVIDIA RTX 3090 Ti GPU, training takes ∼35 min for a ∼400-frame sequence (256 × 256). Furthermore, inference operates at ∼19 FPS, demonstrating a favorable balance between high-fidelity reconstruction and computational cost.
6. Limitations and Future Work
Despite the effectiveness of our method in reconstructing both human bodies and scenes from a monocular hybrid sensor camera, several limitations remain. First, while optical flow supervision enhances reconstruction, it also introduces additional training complexity due to the computational overhead. However, during inference, rendering relies solely on the optimized 3D Gaussians and associated networks. Additionally, regarding hardware, the framework relies on hybrid sensors providing aligned intensity frames to ensure high-fidelity static scene reconstruction. Second, our evaluations are limited to indoor scenes due to the scarcity of real-world event camera datasets, leaving outdoor robustness under dynamic lighting and complex backgrounds unexplored. It is worth noting that despite these data constraints, our framework is theoretically extensible to broader settings. For varying camera trajectories, the optical flow supervision remains mathematically valid, as it naturally captures combined ego-motion and object motion. For multi-person scenes, our unified semantic representation can be extended by assigning distinct semantic identifiers to different subjects. Furthermore, the use of optical flow as an intermediate modality acts as a spatio-temporal filter, offering inherent robustness against sensor noise (e.g., hot pixels) and background clutter typical of unstructured environments. Furthermore, the limited pose space in training data may lead to suboptimal performance on unseen poses, especially for out-of-distribution motions.
To address these challenges, future work could explore the following directions. First, our method has demonstrated robust performance across diverse indoor and controlled lighting conditions. For a more comprehensive evaluation of its real-world applicability and robustness, future work could focus on testing its performance in more unconstrained settings, including complex outdoor environments characterized by dynamic natural light and intricate shadow variations, as well as scenarios involving moving cameras and multi-person interactions. Second, integrating generative models, such as diffusion-based approaches [75,76], could help augment the pose space and improve the model’s ability to generalize to previously unseen poses, improving performance in real-world scenarios. Finally, leveraging large-scale human motion datasets, such as AMASS [77], combined with zero-shot learning techniques, could enable the model to generalize across new identities, capturing a broader range of body shapes and appearances.
7. Conclusions
We presented E-Sem3DGS, a semantically augmented 3D Gaussian Splatting framework for joint reconstruction of animatable humans and static scenes from monocular intensity frames and collocated event streams. By maintaining a single set of 3D Gaussians endowed with learnable semantic attributes, our method explicitly disentangles dynamic human content from static backgrounds within a unified representation: human Gaussians are deformed through articulated networks, while scene Gaussians remain static. To cope with severe motion blur, we derive optical flow from events and use it to supervise image-based optical flow between rendered views, enforcing temporal coherence in high-motion regions and sharpening both geometry and appearance. Extensive experiments on synthetic and real-world motion-blurred datasets demonstrate that E-Sem3DGS consistently outperforms strong baselines and state-of-the-art methods on both human and full-frame reconstruction, achieving superior PSNR, SSIM, and LPIPS metrics. In future work, we plan to extend our framework to more complex interactions and multi-person scenarios and to further explore training on large-scale real event-camera datasets.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Chen L. Peng S. Zhou X. Towards efficient and photorealistic 3D human reconstruction: A brief survey Vis. Inform.20215111910.1016/j.visinf.2021.10.003 · doi ↗
- 2Kyrlitsias C. Michael-Grigoriou D. Social interaction with agents and avatars in immersive virtual environments: A survey Front. Virtual Real.2022278666510.3389/frvir.2021.786665 · doi ↗
- 3Morgenstern W. Bagdasarian M.T. Hilsmann A. Eisert P. Animatable Virtual Humans: Learning Pose-Dependent Human Representations in UV Space for Interactive Performance Synthesis IEEE Trans. Vis. Comput. Graph.2024302644265010.1109/TVCG.2024.337211738466595 · doi ↗ · pubmed ↗
- 4Ren Y. Zhao C. He Y. Cong P. Liang H. Yu J. Xu L. Ma Y. Li DAR-aid Inertial Poser: Large-scale Human Motion Capture by Sparse Inertial and Li DAR Sensors IEEE Trans. Vis. Comput. Graph.2023292337234710.1109/TVCG.2023.324708837027736 · doi ↗ · pubmed ↗
- 5Mildenhall B. Srinivasan P.P. Tancik M. Barron J.T. Ramamoorthi R. Ng R. Ne RF: Representing scenes as neural radiance fields for view synthesis Commun. ACM 2022659910610.1145/3503250 · doi ↗
- 6Peng S. Zhang Y. Xu Y. Wang Q. Shuai Q. Bao H. Zhou X. Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)Nashville, TN, USA 20–25 June 202190509059
- 7Jiang T. Chen X. Song J. Hilliges O. Instant Avatar: Learning Avatars from Monocular Video in 60 Seconds Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)Vancouver, BC, Canada 17–24 June 20231692216932
- 8Yu Z. Cheng W. Liu X. Wu W. Lin K.Y. Mono Human: Animatable Human Neural Field from Monocular Video Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)Vancouver, BC, Canada 17–24 June 20231694316953