Maritime Small Target Image Detection Algorithm Based on Improved YOLOv11n
Zhaohua Liu, Yanli Sun, Pengfei He, Ningbo Liu, Zhongxun Wang

TL;DR
This paper introduces an improved YOLOv11n algorithm for detecting small ships in complex maritime environments using infrared and visible light images.
Contribution
The novel contribution is the integration of BIE, C3k2-RepViTBlock, and ConvAttn modules to enhance small target detection in maritime settings.
Findings
The improved algorithm increased [email protected] by 1.9% and 1.7% on two datasets.
Average precision improved by 2.2% and 2.4% compared to the original model.
The model maintains lightweight design while reducing missed detections.
Abstract
Aiming at the problems of small-sized ships (such as small patrol boats) in complex open-sea backgrounds, including small sizes, insufficient feature information, and high missed detection rates, this paper proposes a maritime small target image detection algorithm based on the improved YOLOv11n. Firstly, the BIE module is introduced into the neck feature fusion stage of YOLOv11n. Utilizing its dual-branch information interaction design, independent branches for key features of maritime small targets in infrared and visible light images are constructed, enabling the progressive fusion of infrared and visible light target features. Secondly, RepViTBlock is incorporated into the backbone network and combined with the C3k2 module of YOLOv11n to form C3k2-RepViTBlock. Through the lightweight attention mechanism and multi-branch convolution structure, this addresses the insufficient capture…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
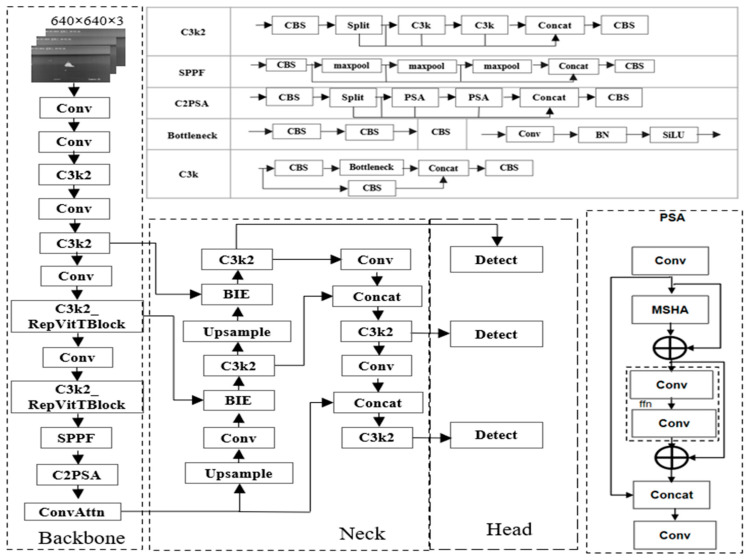 Figure 1
Figure 1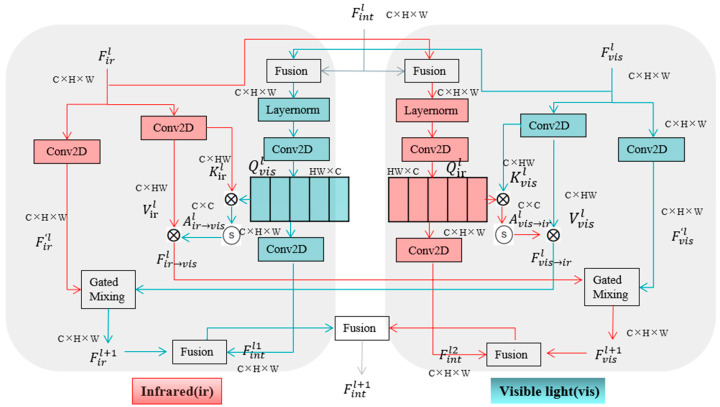 Figure 2
Figure 2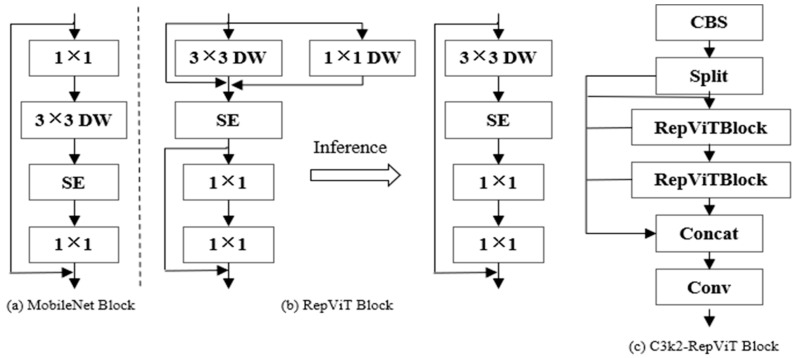 Figure 3
Figure 3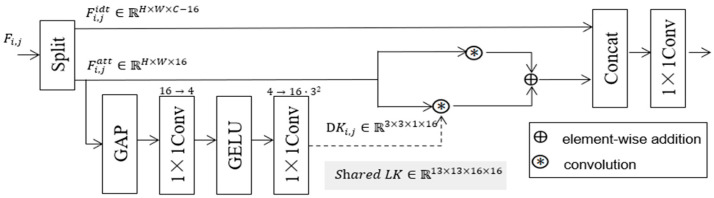 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6- —2023 University–Local Integration Development Project of Yantai City
- —National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsInfrared Target Detection Methodologies · Advanced Neural Network Applications · Image Enhancement Techniques
1. Introduction
Maritime target detection serves as the core technical support for maritime surveillance, maritime rights protection, and intelligent shipping systems. Its detection accuracy and real-time performance directly determine the response efficiency of maritime tasks. However, in scenarios such as maritime target detection using infrared and visible light images, ship targets often appear as small targets with low pixel proportions and sparse feature information. Traditional algorithms tend to suffer from false detection and missed detection due to issues like insufficient receptive fields and the easy suppression of small target features, making it difficult to meet the needs of practical applications.
Preliminary explorations have been conducted in the field of deep learning-based maritime target detection for small ship image detection. Early studies mostly relied on two-stage detection frameworks to improve the detection accuracy for small ships. For instance, Tan et al. [1] modified Faster R-CNN by incorporating soft NMS and focal loss; Jian et al. [2] improved the two-stage target detection model of Mask R-CNN for marine ship detection. However, constrained by the large computational costs of two-stage frameworks and the lack of targeted optimization for fusion strategies, it remains challenging to balance accuracy and efficiency in small target detection scenarios.
With the gradual rise of one-stage detection algorithms, improved methods based on the YOLO series [3,4,5,6,7] have become a research focus in the field of small ship detection. For example, Xie et al. [8] focused on the SAR ship detection task, fused the coordinate attention mechanism into the YOLOv5 deep learning detector, enhanced the feature extraction and localization capabilities for ship targets, and meanwhile balanced the model’s real-time performance and detection accuracy. Liu et al. [9] proposed the CGSE-YOLOv5s algorithm, which improves the model’s capabilities in infrared ship detection in complex nearshore scenes by integrating contrast-limited adaptive histogram equalization with Gaussian filtering, replacing the feature pyramid network module, and introducing an efficient channel attention mechanism. Zheng [10] et al. optimized the structure of YOLOv7x and added a CBAM module to enable the model to focus more on small targets in images. Wang et al. [11] put forward an improved YOLOX_s ship target detection algorithm, introducing the focal loss function to effectively reduce the false detection rate. Li et al. [12] proposed the YOLO-Vessel ship detection model, which innovatively incorporates the ELAN-OD Conv backbone network structure based on YOLOv7 to enhance the feature extraction capabilities in complex backgrounds; they simultaneously introduced the idle depth structure and ASFF Predict network structure into the head network to improve the detection performance for small and medium-sized ship targets. Gong et al. [13] proposed Ship-YOLOv8, which improved the model’s ability to recognize long-distance ships (similar to small targets). Zhang et al. [14] proposed the Ship-FireNet algorithm based on YOLOv8n, which achieves lightweight and accurate ship fire detection by introducing GhostnetV2-C2F, spatial-channel construction convolution (SCConv), and omni-dimensional dynamic convolution and constructing a ship fire dataset. Zhao et al. [15] proposed MFAFNet, a multi-functional attention fusion network designed specifically for infrared remote sensing scenarios, which includes a functional interaction fusion module, a patch attention module and an asymmetric context fusion module, and it improved the detection performance on infrared small targets by integrating features and capturing different receptive field scales.
Subsequently, explorations on the improvement of lightweight models have gradually unfolded, and researchers have put forward higher requirements for the inference speeds of models. For example, Zhao et al. [16] proposed a lightweight SAR small ship detection network, LWSARDet, based on the YOLOv5 framework. By constructing a feature extraction module, designing a lightweight detection head, and proposing a corresponding loss function, it addresses challenges such as high-frequency noise interference and computing power limitations in SAR ship detection under complex sea conditions. Zhao et al. [17] proposed a maritime target recognition and localization system based on a lightweight neural network, which reduces the missed detection rate of the YOLO model in detecting small targets. Bao et al. [18] developed a lightweight enhanced detection model named YOLO-LDFI, which incorporated four architectures, including linear deformable convolution (LDConv), to improve the model’s positioning ability for small ship targets. Sun et al. [19] proposed an infrared ship detection network (IRSD-Net) based on the YOLOv11n framework, which significantly enhanced the model’s ability to detect small-scale ships in cluttered backgrounds and difficult scenarios. These works have verified the application potential of lightweight models in small ship detection scenarios. The work of existing scholars has, to a certain extent, advanced the research progress of maritime small target image detection, but there are still the following shortcomings:
- Although some improved methods perform well on specific datasets, their generalization ability under different modal data, cloud-shaded, or nighttime scenarios still needs further verification.
- The balance between model lightweighting and real-time performance remains a challenge, especially when deployed on resource-constrained maritime monitoring equipment.
- The fine-grained detection capabilities for the type, size, and posture of maritime small targets still need to be improved, which is crucial for the accurate recognition and classification of maritime small targets [20].
To address these problems, we propose a maritime small target image detection algorithm based on the improved YOLOv11n, which includes three innovations:
- Bilateral Information Interaction (BIE) Module: The BIE module adopts a dual-branch information interaction design, focusing on the thermal radiation semantic features of infrared images and the texture detail features of visible light images. Afterwards, the dual-channel information fully interacts to dynamically suppress background interference (such as clouds, fog, and sea surface reflection) and amplify the key feature information of small maritime targets.
- Novel Lightweight Convolution (C3k2-RepViTBlock): RepViTBlock is combined with the C3k2 module of YOLOv11n to form C3k2-RepViTBlock. By leveraging the structural reparameterization technology of RepViTBlock, the feature processing branch of C3k2 is enhanced, and the key features of small targets are strengthened through local self-attention, ensuring the lightweight nature of the model while achieving the real-time detection of maritime small targets.
- Convolutional Self-Attention (ConvAttn) Module: The ConvAttn module is introduced into the backbone network. With the adaptive perception of input features by its dynamic small-kernel convolution, it strengthens the weak texture details of ship targets in the tail features of the backbone network and improves the model’s ability to extract features of small ship targets.
2. Methods
2.1. Model Structure Based on Improved YOLOv11n
To enhance the detection accuracy and efficiency for small ship targets in infrared and visible light datasets, this study conducts targeted improvements based on YOLOv11n [21]. The structure diagrams of the improved YOLOv11n and its respective modules are shown in Figure 1. YOLOv11n is mainly composed of three parts—the Backbone (backbone network), Neck (neck network), and Head (detection head)—where “conv” denotes the convolution operation. The C3k2 module is improved from C3k. Specifically, CBS consists of Conv (convolution layer), BN (batch normalization), and SiLU (activation function); Bottleneck is composed of two CBS components; C3k is formed by Bottleneck, CBS, and Concat; and the C3k2 module is composed of CBS, C3k, and Concat. To optimize the small target feature extraction capabilities of the C3k2 module, the C3k2-RepViTBlock module replaces C3k in the C3k2 module with RepViTBlock. This modification not only maintains the lightweight property of C3k2 but also improves the model’s ability to detect small ship targets. SPPF refers to spatial pyramid pooling fast. The C2PSA module is derived by replacing C3k in C3k2 with partial self-attention (PSA). Specifically, PSA first uniformly divides the input features into two parts via 1 × 1 convolution; it then feeds one part of the features into the NPSA block (composed of multi-head self-attention (MHSA) and a feed-forward network (FFN)). Finally, the two groups of features are connected and fused through 1 × 1 convolution. ConvAttn is the convolutional self-attention module. BIE is the bilateral information interaction module, which leverages the advantages of dual-channel feature information interaction to improve the model’s ability to extract features of small ship targets in infrared and visible light datasets. The Neck realizes the integration of high-level semantic features and low-level detailed features, while the Head fulfills functions such as target classification and the prediction of the bounding box size.
2.2. Bilateral Information Exchange (BIE) Module
For the detection of small ship targets in infrared and visible light image datasets, we introduce and improve the BIE module [22] in the Neck network of YOLOv11n. The BIE module is shown in Figure 2. Here, , , and are the upper-layer global input feature, infrared branch feature, and visible light branch feature, respectively. First, is divided into two parts for feature fusion with and . Then, they are updated through layer normalization and a Conv2D, respectively. After this, queries and are obtained through a 1 × 1 convolution layer, and then and are obtained through a Conv2D. Taking the infrared branch feature in the left part of Figure 2 as an example, the key and value are obtained by through a Conv2D. Subsequently, and are multiplied by matrix operation, and then an attention score matrix is obtained through a Softmax function operation, which reflects the semantic correlation between and . Then, is multiplied by to obtain containing visible light branch features. Similarly, the visible light branch feature in the right part of Figure 2 is used to obtain containing infrared features. After this, and obtained through Conv2D are dynamically fused through a gating mechanism to output the updated . Similarly, is obtained. and are feature-fused, and are feature-fused, and finally the two obtained groups of features are fused to output new feature information . The formulas of the BIE module are shown in Equations (1)–(7).
Among them, is the feature containing visible light information, and is the feature containing infrared information. , , , and , , are, respectively, the queries, keys, and values of infrared and visible light image features. H and W are the height and width.
Among them, and are the updated features, and are gating coefficients, and are weight coefficients, is element-wise multiplication, is the Sigmoid function, is weighted feature fusion, and is the final output feature.
The BIE module solves the problem of single-modality feature information loss in infrared and visible light image datasets. Meanwhile, it addresses the difficulty in extracting the global structures of small ships and long-distance vessels. It fully integrates global contextual information features. Its internal gating mechanism dynamic fusion module not only retains the original ship features but also supplements the inter-modality global structure, outputting more robust fused features. For possible sea clutter and environmental interferences in ship images (such as the impact of clouds and fog on infrared images and the impact of water surface reflection on visible light images), the BIE module is used to screen effective features and suppress misleading interferences, significantly improving the detection capabilities of YOLOv11n for small-target ships.
2.3. A Three-Scale Convolution Dual-Path Variable-Kernel Module Based on RepViTBlock (C3k2-RepViTBlock)
To improve the ability of the C3k2 module in YOLOv11n to capture fine-grained spatial information and long-range dependencies, while a pure Transformer module has a large computational overhead and is not conducive to the feature perception of small target ships, we combine the C3k2 module of YOLOv11n with the RepViTBlock module [23] to form C3k2-RepViTBlock. C3k2-RepViTBlock is composed by replacing the C3 module in C3k2 with RepViTBlock. While retaining the multi-branch residual structure of the C3 module, it enhances the model’s ability to capture the spatial details and global semantic associations of small targets. The structure diagram of the C3k2-RepViTBlock module is shown in Figure 3c.
The RepViTBlock module adopts a dual-branch structure consisting of a token mixer and a channel mixer. The RepViTBlock module is simulated by a MobileNet block. The MobileNet block uses 1 × 1 expansion convolution and a 1 × 1 projection layer to realize inter-channel interaction (i.e., channel mixer). Then, a 3 × 3 depthwise separable convolution (DW) is added to perform spatial convolution independently for each channel. The channel dimension is weight-calibrated through the squeeze-and-excitation (SE) layer and 1 × 1 convolution (i.e., token mixer), enhancing the model’s key channel features for small targets. The MobileNet block is shown in Figure 3a. To separate the token mixer and channel mixer, RepViTBlock moves the DW convolution and SE layer upward. It adopts multi-scale convolution branches in the training phase and merges the multi-branches into a single branch through reparameterization technology in the inference phase. This significantly improves the detection accuracy for small vessels and the inference efficiency of edge devices. The structure diagram of the RepViTBlock module is shown in Figure 3b.
Considering the discrepancies in feature representation across different hierarchical levels of the YOLOv11n backbone network, the C3 modules within the first two shallow C3K2 blocks of the YOLOv11n backbone network are retained. This hierarchical level primarily extracts detailed features (e.g., textures and edges) of maritime targets, where excessive enhancement would amplify background interferences such as ocean waves and cloud/fog noise. In contrast, the C3 modules in the last two deep C3K2 blocks of the YOLOv11n backbone network are modified by substituting them with RepViTBlock modules. As a critical component in fusing detailed features and global semantic features, this deep hierarchical level leverages the dual-branch structure (consisting of the token mixer and channel mixer) of the RepViTBlock module, combined with the residual structure of C3K2, to synergistically enhance the model’s capabilities in extracting the global semantic features of small maritime targets.
2.4. Convolutional Self-Attention Module (ConvAttn)
Due to the large computational overhead of traditional attention modules and the insufficient modeling abilities of convolution modules for long-range feature dependencies, we introduce the ConvAttn module [24] at the end of the backbone network of YOLOv11n. It adopts shared long-range convolution kernels to enhance the model’s detection abilities for long-distance small target ships. The structure diagram of the ConvAttn module is shown in Figure 4. First, the input feature map is split along the channel dimension to obtain the attention branch feature and the identity mapping branch feature , which are, respectively, used for subsequent attention weight calculation and multi-scale fusion. For the attention branch , global information compression is performed on through global average pooling (GAP) to capture global features in the channel dimension. Then, two layers of 1 × 1 convolution are used to generate kernel parameters adapted to 3 × 3 depthwise convolution. After this, a dynamic depthwise convolution kernel ( ) is generated through a nonlinear activation function (GELU) to enhance the feature expression ability. Then, is element-wise multiplied by and (shared long-range convolution kernels), respectively, and the two results are added to obtain . Finally, and are concatenated, and then a 1 × 1 convolution is applied to realize multi-scale feature fusion to obtain the final output . The formulas of the ConvAttn module are shown in Equations (8)–(11).
Among them, (i, j) are the position coordinates of elements in the feature map, is the attention branch feature, is the identity mapping branch feature, is the dynamic depthwise convolution kernel, is the upsampling convolution, is the downsampling convolution, is the activation function, is the convolution operation, is the channel concatenation operation, and is the multi-scale feature fusion feature.
The ConvAttn module utilizes the dynamic depthwise convolution kernel ( ) to extract the fine-grained features of small targets (such as tiny components of small ships) and (shared long-range convolution kernel) to fuse cross-modal semantic information (the global association between infrared thermal contours and visible light shapes). This solves the problems whereby small targets are easily obscured by the background and cross-modal feature fusion is insufficient. In addition, compared with the self-attention module, the ConvAttn module significantly reduces the number of model parameters through (shared long-range convolution kernel) and improves the operating efficiency of the model.
3. Experimental Results and Analysis
3.1. Experimental Environment and Parameter Configuration
The experimental environment has a crucial impact on the efficiency and accuracy of model training. A scientific and reasonable configuration can realize the optimal utilization of hardware resources, improve the training efficiency, and ensure the repeatability and reliability of the experimental results. We summarize the specific software and hardware configurations adopted in the experiment in Table 1.
The configuration of the hyperparameters is also of key significance to the performance and generalization ability of the model. Scientific tuning can improve the learning efficiency, increase the detection accuracy, and reduce the degree of overfitting, thereby enabling the model to effectively adapt to detection in long-distance small target scenarios. The details of the hyperparameters adopted in our experiment are shown in Table 2 below.
3.2. Dataset
This study uses two types of datasets. The first is a dataset (IVships) collected by visible light and infrared acquisition devices, which contains two types of images—infrared and visible light—covering 7 categories of targets; specifically, these are cargo ships, ferries, coast guard ships, buoys, fishing boats, tugboats, and rescue ships. The dataset contains a total of 6518 images, with 4563 images in the training set, 1304 images in the validation set, and 651 images in the test set. The dataset information is shown in Table 3.
The second is a public dataset (SeaShips), which is mainly composed of visible light images and includes 6 categories: bulk cargo carriers, container ships, fishing boats, general cargo ships, ore carriers, and passenger ships. Details of this dataset are shown in Table 4.
3.3. Experimental Evaluation Metrics
This experiment adopts the mean average precision (mAP, with an IoU threshold of 0.5) as the evaluation metric for algorithm performance. The formulas for precision (P) and recall (R) are as follows:
where TP is the number of ships correctly predicted as positive examples by the model, FP is the number of ships incorrectly predicted as positive examples by the model, and FN is the number of ships incorrectly predicted as negative examples by the model.
Average precision (AP) is the area under the P-R curve. The mAP is obtained by averaging the AP values calculated for all categories. The formulas for AP and mAP are as follows:
where P(R) is the p value when the abscissa is R in the P-R curve, and n is the number of target categories in the dataset.
3.4. Ablation Experiment
As shown in Table 5, to verify the effectiveness of the improvement, we conducted ablation experiments based on YOLOv11n on the collected IVships dataset and the public SeaShips dataset, so as to evaluate the enhancement effects of each module on the model. “×” denotes non-inclusion, and “√” denotes inclusion.
It can be seen from the comparison results in Table 5 that, in the two datasets of IVships and SeaShips, after YOLOv11n introduces BIE, the [email protected] values increase by 1.4% and 1.1%, respectively. This module efficiently extracts features and realizes information complementation through the bilateral information interaction mechanism. After YOLOv11n adds C3k2-RepViTBlock, the [email protected] values increase by 0.6% and 0.2%, respectively, and its dual-branch structure composed of a token mixer and channel mixer greatly improves the cross-modal ship detection accuracy. After YOLOv11n introduces ConvAttn in the backbone network, the [email protected] values reach 86.8% and 98.3%, which are 0.3% and 1% higher than those of the original YOLOv11n, respectively; this feature enhancement module realizes multi-scale feature fusion by using shared long-distance convolution kernels. In addition, when C3k2-RepViTBlock and BIE are introduced simultaneously, the [email protected] values are 1.6% and 1.2% higher than those of YOLOv11n, respectively. Compared with the original model, YOLOv11n, the improved algorithm increases the [email protected] values by 1.9% and 1.7%, respectively, and the precision by 2.2% and 2.4%, respectively, significantly enhancing the model’s small target detection capabilities.
3.5. Comparative Experiment
3.5.1. Comparative Experiment with Mainstream Algorithms
To further demonstrate the advancement of the improved YOLOv11n model, we conducted a comparative experiment by comparing the algorithm presented in this paper with other mainstream object detection algorithms (Faster-RCNN, YOLOv10n, YOLOv8n, YOLOv5s, etc.). The comparative experiment is shown in Table 6. It can be seen from Table 6 that the algorithm introduced in this paper outperforms other advanced algorithms in terms of the [email protected]. Since the overall number of parameters of the improved algorithm is increased compared with the original algorithm, the training time and FLOPs are higher than those of the original algorithm but lower than those of most advanced algorithms, and the FPS is better than that of the original algorithm. This ensures the real-time performance and light weight of the model.
3.5.2. Performance Analysis of Object Detection for Each Category
We now conduct a refined performance analysis for each object category. As shown in Table 7, we compare the AP (%) of the original model and the improved model for each single object category to evaluate the improvement effect and detection consistency in specific categories.
As can be seen from Table 7, the AP values of the improved YOLOv11n have been stably improved for all maritime object categories. Especially in the IVships dataset, the improvement effects on buoys, tugboats, and rescue ships are relatively significant. Compared with the original model, they are increased by 3.6%, 2.4%, and 2.4%, respectively. This indicates that the detection performance of the model for small maritime targets has been significantly enhanced.
4. Visualization Analysis
4.1. Analysis of Test Images
To verify the performance of the improved algorithm under infrared and visible light images, this paper compares the detection performance of the improved algorithm and the original algorithm under different images. We take the images in the IVships dataset as an example. The test results of the improved YOLOv11n are shown in Figure 5a, and the test results of the original YOLOv11n algorithm are shown in Figure 5b. The visible light images in the first row were captured in a low-light scene at night. The ship lights are bright and there is obvious light and shadow interference on the sea surface, which easily affects the normal detection and classification of the model. The visible light images in the second row were captured in a scene obscured by clouds and fog. Affected by cloudy and foggy weather, small maritime targets have poor overall light penetration and loss of visual information, which makes the model detection difficult. The infrared images in the third row were captured in a night-time open-sea scene, with multiple types of targets distributed in a scattered manner, some targets occluded, and a large number of small targets, making model detection extremely difficult. As shown in Figure 5, the improved model has higher detection confidence and more accurate bounding box selection for targets in various complex scenarios. At the same time, it solves the problems of missed detection and the insufficient confidence of the original model in small targets and low-light/foggy scenarios, and the small target detection capabilities are significantly improved.
4.2. Heatmap Analysis
Heatmaps can indicate information such as target positions and confidence levels through color intensity, providing an intuitive visualization of the model’s attention to different targets and its detection results. We take the images in the IVships dataset as an example. The original images and the heatmaps of the model (before and after improvement) are shown in Figure 6.
As can be seen from Figure 6b,c, under both infrared and visible light images, the improved model’s heatmaps can almost fully cover the targets—whether they are long-distance cargo ships or small targets like buoys and fishing boats in cloudy and foggy environments. Meanwhile, it reduces the interference of irrelevant backgrounds on the model. In contrast, the original model exhibits missed detections: it fails to detect the buoy (class_3) in the infrared image, and its heatmap does not fully cover the fishing boat (class_4) in the visible light image. This further demonstrates the feasibility of the improved model proposed in this paper.
5. Conclusions
This paper proposes a small maritime target detection algorithm based on the improved YOLOv11n. Specifically, the BIE module is introduced into the neck network of the algorithm, and its bilateral information interaction mechanism is utilized to realize the fusion of small target features under infrared and visible light images, thereby enhancing the feature extraction capabilities of the model. The C3k2 module in the backbone network is improved to C3k2-RepViTBlock; on the premise of maintaining the light weight of the model, reparameterization technology is adopted to improve the detection accuracy of the model for small maritime targets. Finally, the ConvAttn module is added to the backbone network, which uses dynamic depth convolution and long-distance convolution to enhance the model’s ability to detect small targets at long distances. Extensive experiments conducted on infrared and visible light image datasets verify the effectiveness of the improved algorithm proposed in this paper. Compared with the original algorithm, the improved algorithm increases the [email protected] values by 1.9% and 1.7% in the IVships and SeaShips datasets, respectively, and increases the average precision by 2.2% and 2.4%, respectively. Although the improved YOLOv11n has achieved a significant improvement in detection performance for small maritime targets under complex scenarios (such as night-time low-illumination, cloud and fog occlusion, and open-sea infrared scenes), the algorithm still has the problems of an increased parameter quantity and computational cost. In the future, we will continue to explore structural pruning and quantization strategies for the improved model to reduce the parameter quantity and computational cost while maintaining the detection accuracy. On the other hand, we will expand the dataset to cover more extreme maritime scenarios to further optimize the generalization ability and robustness of the algorithm.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Tan X. Tian T. Li H. Inshore ship detection based on improved Faster R-CNN Autonomous Target Recognition and Navigation, Proceedings of the Eleventh International Symposium on Multispectral Image Processing and Pattern Recognition (MIPPR 2019)Wuhan, China 2–3 November 2019 The International Society for Optics and Photonics Bellingham, WA, USA 2020 Volume 1142910.1117/12.2536638 · doi ↗
- 2Ling J. Zhiqi P. Lili Z. Yao T. Liang X. SS R-CNN: Self-Supervised Learning Improving Mask R-CNN for Ship Detection in Remote Sensing Images Remote Sens.202214438310.3390/RS 14174383 · doi ↗
- 3Bochkovskiy A. Wang C.Y. Liao H.Y.M. Yolov 4: Optimal speed and accuracy of object detectionar Xiv 202010.48550/ar Xiv.2004.109342004.10934 · doi ↗
- 4Li C. Li L. Jiang H. Weng K. Geng Y. Li L. Ke Z. Li Q. Cheng M. Nie W. YOL Ov 6: A single-stage object detection framework for industrial applicationsar Xiv 202210.48550/ar Xiv.2209.029762209.02976 · doi ↗
- 5Wang C.Y. Bochkovskiy A. Liao H.Y.M. YOL Ov 7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Vancouver, BC, Canada 17–25 June 202374647475
- 6Wang C.Y. Yeh I.H. Mark Liao H.Y. Yolov 9: Learning what you want to learn using programmable gradient information Proceedings of the European Conference on Computer Vision Milan, Italy 29 September–4 October 2024121
- 7Wang A. Chen H. Liu L. Chen K. Lin Z. Han J. Ding G. Yolov 10: Real-time end-to-end object detection Adv. Neur. Inf. Proc. Sys.202437107984108011
- 8Xie F. Lin B. Liu Y. Research on the Coordinate Attention Mechanism Fuse in a YOL Ov 5 Deep Learning Detector for the SAR Ship Detection Task Sensors 202222337010.3390/s 2209337035591063 PMC 9102707 · doi ↗ · pubmed ↗