A Unified GNN-CV Framework for Intelligent Aerial Situational Awareness
Leyan Li, Rennong Yang, Anxin Guo, Zhenxing Zhang

TL;DR
This paper introduces a unified GNN-CV framework to improve aerial situational awareness by processing radar-map-like data with high accuracy and resilience.
Contribution
The novel SET-GNNs and integrated CV techniques enable a unified, vision-centric approach for operational-level aerial SA tasks.
Findings
The framework achieves over 90.1% end-to-end recognition accuracy for aerial swarm tasks.
Configuration recognition remains above 85.0% in complex tactical scenarios with irregular flight patterns.
The system maintains over 80.4% accuracy despite position and heading disturbances with millisecond response times.
Abstract
Aerial situational awareness (SA) faces significant challenges due to inherent complexity involving large-scale dynamic entities and intricate spatio-temporal relationships. While deep learning advances SA for specific data modalities (static or time-series), existing approaches often lack the holistic, vision-centric perspective essential for human decision-making. To bridge this gap, we propose a unified GNN-CV framework for operational-level SA. This framework leverages mature computer vision (CV) architectures to intelligently process radar-map-like representations, addressing diverse SA tasks within a unified paradigm. Key innovations include methods for sparse entity attribute transformation graph neural networks (SET-GNNs), large-scale radar map reconstruction, integrated feature extraction, specialized two-stage pre-training, and adaptable downstream task networks. We rigorously…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
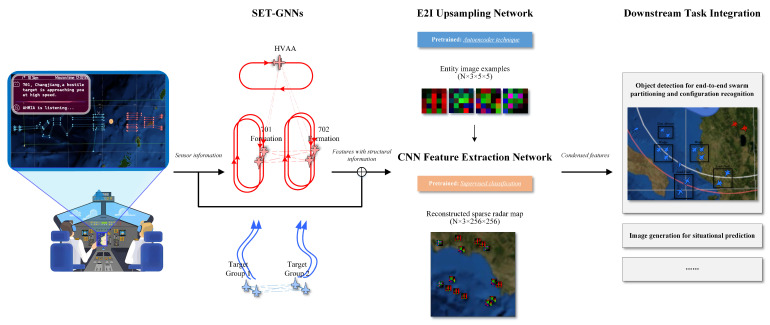 Figure 1
Figure 1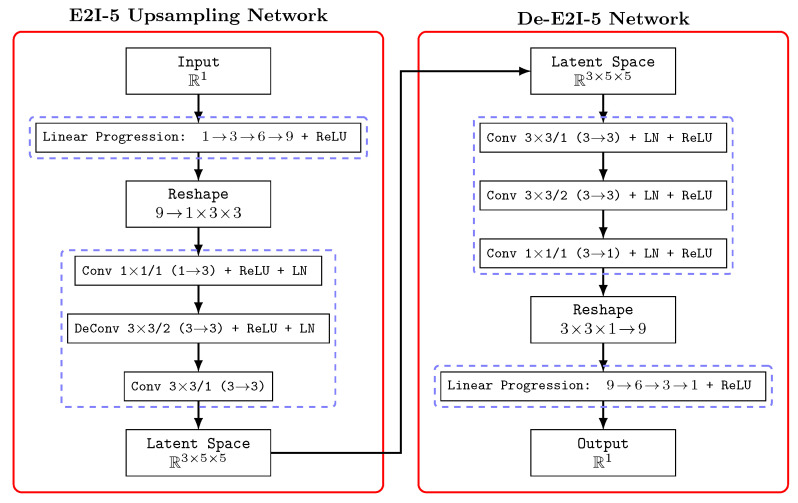 Figure 2
Figure 2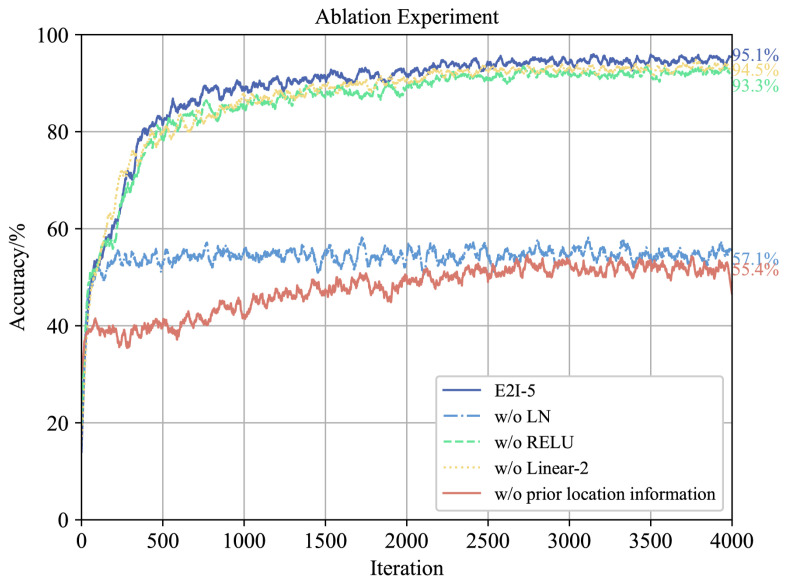 Figure 3
Figure 3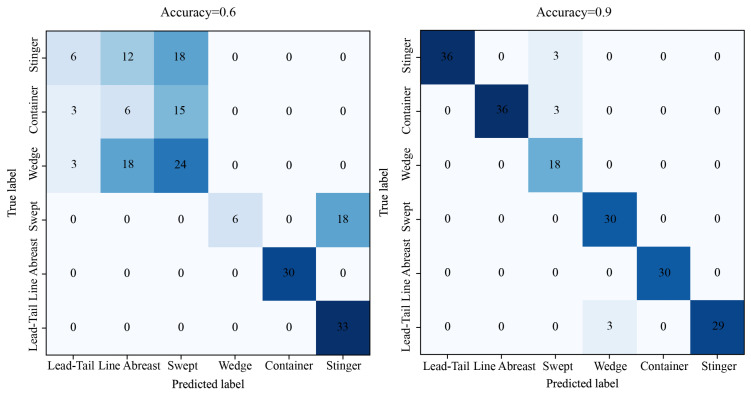 Figure 4
Figure 4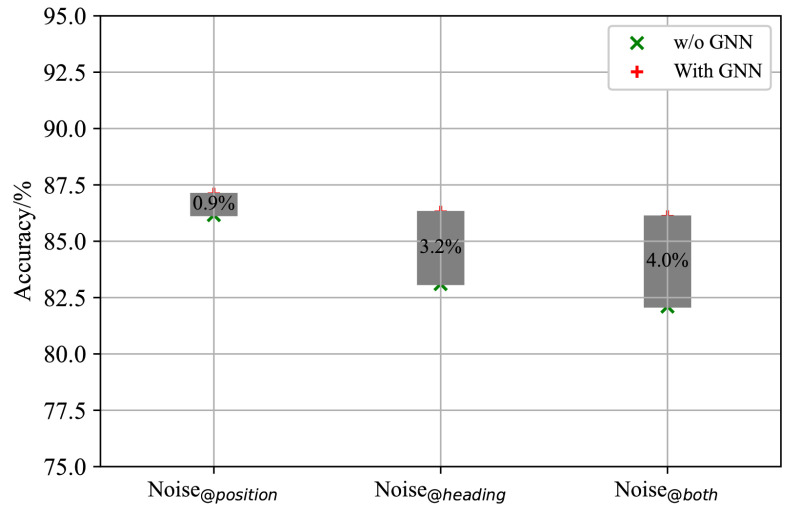 Figure 5
Figure 5 Figure 6
Figure 6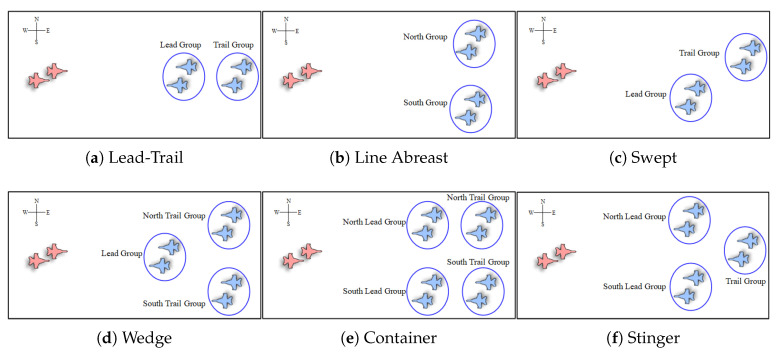 Figure 7
Figure 7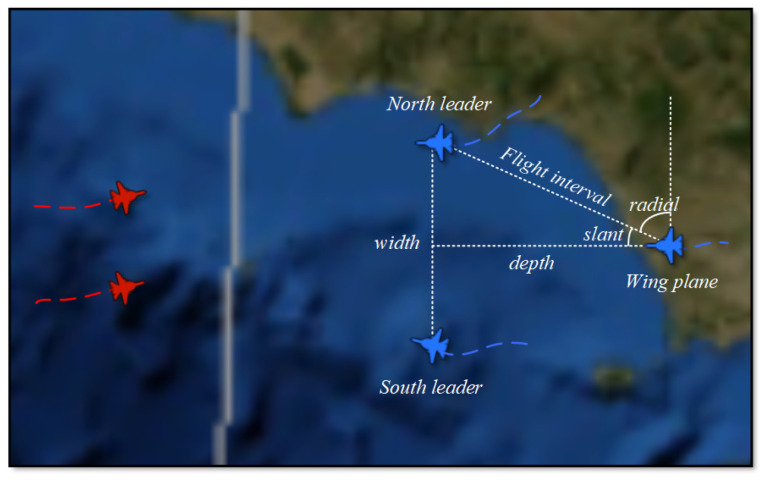 Figure 8
Figure 8 Figure 9
Figure 9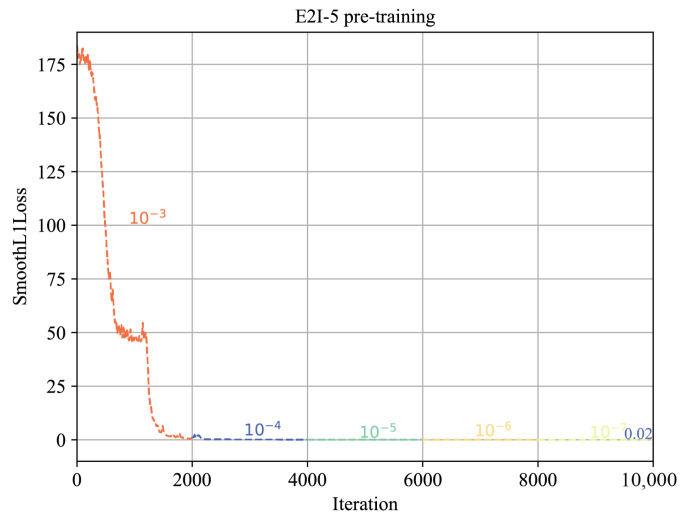 Figure 10
Figure 10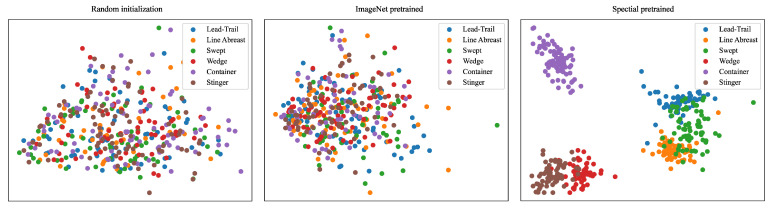 Figure 11
Figure 11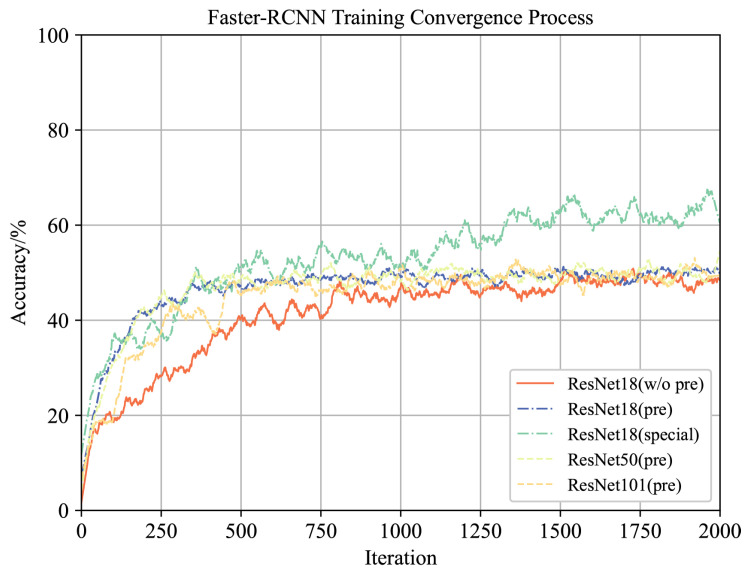 Figure 12
Figure 12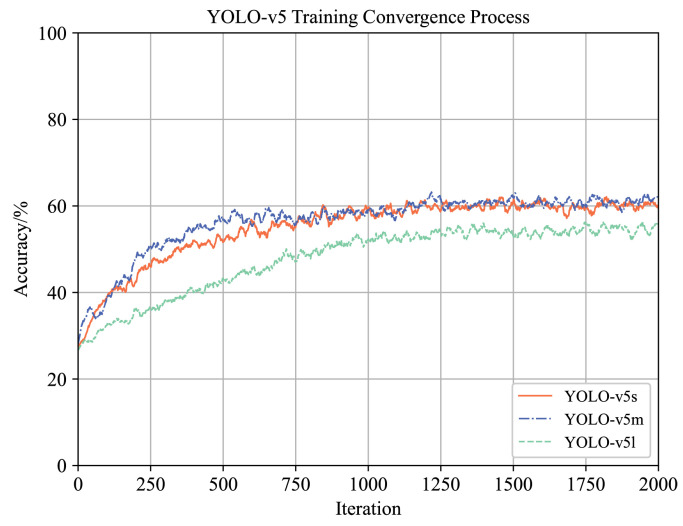 Figure 13
Figure 13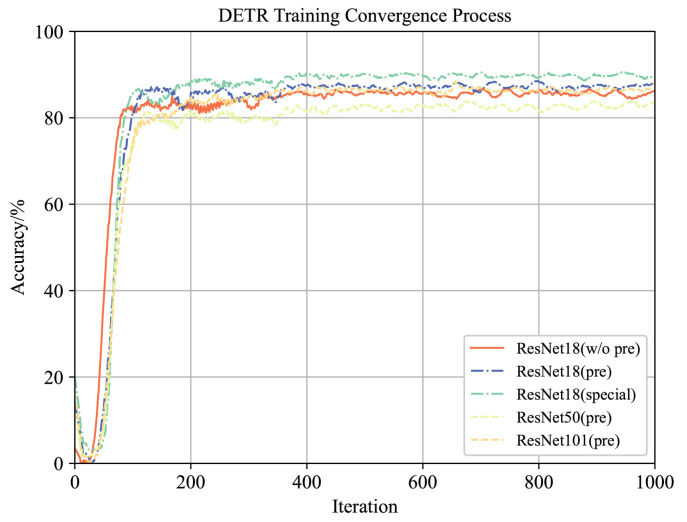 Figure 14
Figure 14- —Xi’an Young Talent Support Program
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced SAR Imaging Techniques · Advanced Neural Network Applications · UAV Applications and Optimization
1. Introduction
Advances in distributed sensors, ultra-wideband communications, and high-performance computing have significantly boosted the speed, scale, and diversity of intelligence data collection in large-scale aerial operations. However, translating this unprecedented data deluge into actionable operational-level SA—a cornerstone for agile, data-driven decision-making in time-critical aerial command and control scenarios—remains a critical and pressing bottleneck. Traditional reliance on manual SA processes severely depletes human operators’ cognitive bandwidth, often leading to decision delays or suboptimal judgments in constrained operational cycles, which can directly jeopardize mission success in dynamic aerial confrontations [1].
This research focuses on advancing intelligent SA for aerial C2 systems, with a deliberate emphasis on the operational level, distinct from lower-level signal-layer analytics or spectral-optical imaging tasks. Core operational-level SA tasks include track prediction [2], swarm partitioning, object detection [3], threat assessment [4], and intent recognition [5,6], among others. A fundamental and consequential limitation of existing state-of-the-art approaches is their inherent fragmentation: these diverse SA tasks are typically addressed in isolation using specialized algorithms tailored to specific data structures (e.g., static snapshots, time-series trajectories) or individual task characteristics. This disjointed paradigm stands in stark contrast to the integrated, holistic decision-making process employed by human commanders who synthesize comprehensive radar map information to simultaneously infer multiple SA-related insights, highlighting a critical misalignment between computational methods and real-world operational needs.
Consider the exemplar challenge of swarm partitioning and configuration recognition. Current methodologies typically employ sequential, disparate algorithms: one for swarm partitioning [7], followed by another for configuration recognition [8]. This disjointed approach introduces cumulative computational latency and potential error propagation, compromising the accuracy and real-time efficiency essential for cooperative operational cognition. Crucially, human commanders overcome this fragmentation through end-to-end visual analysis of the radar map, directly inferring group divisions and formations holistically. This observation highlights a fundamental gap: the absence of a computational framework that emulates this efficient, vision-centric cognitive process for operational SA. We posit that a wide range of SA tasks can be effectively addressed within a unified, vision-centric deep learning framework processing the confrontation space as a radar-map-like image.
Computer vision is a leading domain within artificial intelligence, incorporating robust models and techniques such as image classification [9,10], object detection [11,12], object tracking [13,14], and image generation [15]. However, applying computer vision directly to situation awareness encounters challenges. Firstly, the prevalent radar map is derived from secondary processing of static or temporal entity data within information systems, lacking a standardized and uniform image data structure. Additionally, the radar map exhibits sparse characteristics, with a large background and small entity targets. Consequently, commonly used image feature extraction networks and pre-trained weights obtained from datasets like ImageNet may not be entirely suitable for such sparse radar maps. Research utilizing Graph Neural Network (GNN) technology to reduce the sparsity of images has emerged as a widely studied research direction in the field [16,17]. Building upon these insights, we present a unified framework for addressing situational awareness challenges, covering the entire computer vision pipeline, as illustrated in Figure 1.
The framework includes:
- Sparse Entity Attributes Transformation Graph Neural Networks (SET-GNNs): Mitigates attribute sparsity within the image representation.
- Entity to Image (E2I) Upsampling Network: Reconstructs sparse radar images incorporating positional priors.
- CNN Feature Extraction Network: Demonstrated as effective for sparse radar imagery theoretically and empirically.
- Two-Stage Pre-training Method: Enables training of specialized image feature extractors.
- Downstream Task Integration: Extends the framework to diverse SA tasks (e.g., trajectory prediction, situation assessment).
It is critical to note that our framework operates on outputs from integrated C2 information systems. These systems fuse data from diverse radar/intelligence sources (e.g., Doppler radar providing velocity/azimuth, lidar providing range/3D shape) into a standardized input representation (e.g., target latitude, longitude, speed, altitude, radar cross-section). We empirically validate the framework’s efficacy and efficiency using two core SA tasks: aerial swarm partitioning and configuration recognition. The paper is structured as follows: Section 2 covers related work; Section 3 details the proposed model framework; Section 4 presents experimental results for the two tasks; Section 5 concludes the work and outlines future directions.
2. Related Work
2.1. Aerial Swarm Partitioning
Aerial swarm partitioning refers to the segmentation of collective aerial targets into cohesive and interacting subgroups, typically leveraging hierarchical structures and spatial relationships. Significant research efforts [18,19,20,21] have focused on enhancing the clustering of target groups, prioritizing improvements in accuracy, stability, and responsiveness during dynamic force aggregation scenarios. These approaches predominantly build upon advanced clustering algorithms, often augmented with domain-specific knowledge. For instance, Yan et al. [18] proposed a cell-based density clustering algorithm effective for grouping large-scale aircraft formations, particularly when the cluster count is unknown a priori. Ma et al. [19] enhanced the density peak clustering framework by incorporating manifold distance metrics and adaptive cluster center selection, enabling automated grouping of aerial targets.
2.2. Formation Configuration Recognition
Current methodologies for aerial formation recognition can be broadly categorized into two paradigms:
- Template Matching: This approach utilizes domain expertise to define preset formation templates, matching them against observed targets based on spatial relationships. Zhang et al. [22] combined Hough transform with clustering to identify naval formations. Leng et al. [23] leveraged domain knowledge to recognize formations by detecting key structural elements like reference targets and queue lines. While interpretable, these rule-based methods lack flexibility and exhibit limited robustness against noise, occlusions, or significant deviations from templates.
- Computer Vision: This paradigm constructs abstract graphical representations of formations and employs deep learning models, primarily CNNs, for classification [8,24,25,26,27]. Studies such as [8,24] encode target positions using binary ( ) matrices as input to image classification networks. A critical limitation of this binary encoding is the omission of essential kinematic attributes (e.g., heading, velocity), constraining algorithm versatility and reducing recognition accuracy, especially for complex motion-based formations.
3. Methodology
This section presents the components of the proposed GNN-CV architecture for intelligent operational-level SA. Firstly, we introduce a sparse map reconstruction method using SET-GNNs with an E2I upsampling network and a CNN feature extractor. Subsequently, we develop a two-stage pre-training strategy to enable rapid adaptation of the pre-trained networks to downstream tasks. Finally, we apply an end-to-end object detection algorithm for aerial swarm partitioning and configuration recognition problems, effectively validating the rationale of the theory.
3.1. Sparse Entity Attribute Transformation Graph Neural Networks
Entity attributes for large-scale situation images are often independent and sparse, making it difficult to reconstruct the overall image. To address this issue, we aim to incorporate structural information into entity features before transforming them into images. GNNs are a popular choice for modeling graph structure information through message passing mechanisms, enabling the reduction of sparsity in entity attributes.
Basic GNN theory is not discussed in depth in this paper. Commonly used GNN models include GCN [28], GAT [29], GraphSAGE [30], GIN [31], and their variants, each with unique characteristics that affect problem-solving efficacy. The formula representation of the current mainstream graph neural network is given below.
Applying GNNs directly to entity data feature transformation encounters an obstacle in the absence of a natural adjacency matrix to represent graph connections. To address this, we propose three graph adjacency matrix construction methods. The first method utilizes an all-ones matrix, indicating that all entities are related with each other and have an edge weight of 1. Building on this, the second method determines edge weight based on the location difference of entities, where the weight is inversely proportional to the relative distance between nodes. The third method constructs adjacency matrix according to the relative distance between nodes and a group distance threshold relationship. The formula representation of these methods is provided below.
where , , and denote three adjacency matrices, denotes the relative distance between entities, denotes the maximum possible entity distance, and denotes as the designated distance threshold for groups. These methods are designed based on the characteristics of the situation awareness problem domain.
3.2. E2I Upsampling Network and Matched Feature Extraction Network
The E2I network utilizes deep learning to convert structural features into depth images, albeit not directly into standard sizes like or . Initially, the E2I network translates structural features extracted from GNNs into depth images of size ( ), integrating this information into a radar situational map based on latitude and longitude positions ( / ). This reconstruction method leverages the strength of convolutional networks in processing location data. Empirical evidence underscores the benefits of incorporating prior positional details. It is crucial to highlight that reconstructed radar situational maps diverge from traditional images (e.g., photos, video frames) due to the absence of graphical edges, color data, and the presence of relatively small entities in a vast situational expanse, resulting in distinct sparsity within the radar situational maps.
The design of the E2I upsampling network requires careful consideration of its interaction with the feature extraction network. Mainstream image feature extraction networks typically employ a pyramid convolutional structure, consisting mainly of multiple convolutional layers and residual connections. Therefore, our E2I network adopts a square-shaped design with dimensions of , which aligns with standard computer vision methodologies and maintains the entity images as three-channel outputs. For example, when and there is one entity attribute present, the structure of the E2I-5 network is detailed in Figure 2.
The E2I network incrementally processes entity attributes to a format. Drawing inspiration from convolutional module designs found in networks like ResNet [32] and AlexNet [33], the E2I network incorporates multiple ReLU activation layers to enhance non-linear fitting capacity, along with LN layers to expedite network training speed.
Theorem 1. Traditional shallow convolutional neural networks, comprising convolution kernels, demonstrate proficiency in extracting small objects and non-edge features.
The theorem proof is provided in Appendix A. The reconstructed radar situational map introduced in this research exhibits sparse, edgeless, and structured attributes. In addition, not all established feature extraction networks like ResNet50, AlexNet, DenseNet [34], etc., are represented. Consequently, the shallower layers of ResNet18 demonstrate higher efficiency in feature extraction, as supported by the experimental Section 4.2.1. For further clarification, Table 1 outlines the subnetwork structure for feature extraction within ResNet18.
3.3. Pretrained Tasks
The reconstructed radar map and feature extraction network can benefit from pre-training techniques for weight initialization, thereby reducing the fine-tuning costs for subsequent tasks. In this study, the sparse radar map reconstruction involves the E2I and ResNet18 feature extraction networks. To address this challenge, we develop a two-stage pre-training process outlined in Figure 1.
The initial step involves unsupervised pre-training of E2I using the autoencoder technique [35]. This ensures that the resulting three-channel images effectively capture the transformed entity attributes, aligning the encoding and decoding processes accordingly. We utilize the E2I-5 network described in Section 3.2 as the encoder and design a symmetric decoder to reconstruct the upsampled entity images back to their original attribute outcomes. The De-E2I-5 network structure is detailed in Figure 2.
After pre-training E2I network, we freeze it and proceed to pre-train the feature extraction network. Common methods for pre-training image feature networks include Masked Autoencoder [36] and unsupervised contrastive learning. However, Masked Autoencoder, which predicts masked pixels in images, is not suitable for sparse radar image reconstruction in our study. Instead, we opt for unsupervised contrastive learning [37] but utilize supervised learning for feature extraction through a classification method. By creating labeled flight formation radar state maps, we employ supervised image classification for pre-training. We adjust only the output categories of the final layer’s classification head to six types of flight formation configurations on ResNet18, successfully completing the pre-training of the ResNet18 feature extraction network in conjunction with the E2I network.
3.4. Object Detection Method for End-to-End Swarm Partitioning and Configuration Recognition
The technology for end-to-end swarm partitioning and configuration recognition involves three primary steps: swarm database construction, radar map reconstruction, and implementation of the object detection algorithm.
In the absence of labeled swarm databases, we propose a method to generate uniformly distributed configuration data based on six typical flight formation configurations. The key parameters and features of these configurations are outlined in Appendix B. Our study underscores the importance of positional relationships and aircraft headings in assessing formation configurations based on radar map observations. Therefore, our method generates configuration data by reverse-engineering the positions and headings of individual aircraft within the formation according to the formation type. To enhance database diversity, we incorporate substantial randomization and noise. The algorithm produces data in a list format containing the horizontal and vertical coordinates, along with the headings of each aircraft. The pseudocode Algorithm 1 illustrating the method for generating flight formation configuration data is provided. Algorithm 1 Formation Configuration Data Generation1:procedure GenerateData( )2: if {Lead-Trail, Line, Swept} then3: 4: else if {Wedge, Stinger} then5: 6: else if {Container} then7: 8: end if9: 10: 11: while do12: if then13: 14: 15: end if16: 17: 18: if then19: 20: else21: add to 22: end if23: end while24: 25: return 26:end procedure
Notably, experimental findings in Section 4.3 demonstrate that the DETR method achieves the highest accuracy for end-to-end recognition. DETR utilizes a CNN backbone for initial image feature extraction and compression. These compressed features undergo flattening, positional encoding augmentation, and are input into a transformer. We propose that DETR leverages the integration of feature compression and the attention mechanism to demonstrate robust sparse image object detection capabilities.
4. Experiment
4.1. Sparse Attributes Transformation Graph Neural Network
The introduction of the GNN architecture represents a crucial innovation in the model for extracting entity structural attributes from situation information. In this section, we perform experiments on the construction of adjacency matrices and the GNN model architectures.
4.1.1. Adjacency Matrix Construction Method
To apply GNN for extracting structural information, an adjacency matrix needs to be constructed between the entities of situation information. This study experimentally compares three construction methods outlined in Equations (6)–(8) in Section 3.1 to determine the most optimal adjacency matrix. A two-layer GCN model with a hidden layer dimension of 32 is utilized, along with a ReLU activation layer following each layer. The experiments involve using E2I-5, ResNet18, and DETR for swarm partitioning and configuration recognition in downstream networks. Training is conducted for 20 epochs with 50 iterations per epoch, starting with an initial learning rate of and decay by 0.1 every 10 epochs. Specifically, in Equation (7) is set at 300 and in Equation (8) is set at 15. The results of the experiments are summarized in Table 2.
The experimental results demonstrate that Method 2 utilizes entity relative distance to adjust the weight of adjacency matrix, aligning with the problem scenario of situation cognition and offering more structural information. This method is further employed in subsequent experiments for adjacency matrix construction.
4.1.2. Ablation
To identify the optimal GNN model architecture, this section employs variable control methods and conducts a series of ablation experiments on GNNs. The basic experimental setup is consistent with Section 4.1.1.
w/o GNNs: We remove the GNNs part of the model and directly deal with sparse entity features with E2I network.w/o residual connection-1: We remove the residual connections before and after GNN in the model.w/o residual connection-2: We change the residual connection before and after GNN from summation to concatenation.
The results in Table 3 illustrate the outcomes of a series of ablation experiments. The experimental findings indicate that incorporating a GNN model for extracting structural features of sparse entities can alleviate the sparsity characteristics of situation maps to a certain degree. Among the GNN variants (GCN/GIN/GAT) in this model, GCN demonstrates superior performance. Furthermore, integrating residual connections into the GNN model enhances its overall performance.
4.2. E2I Upsampling Network and Matched Feature Extraction Network
The size and structure of the E2I upsampling network, as determined by Theorem 1, significantly impact the effectiveness of radar map reconstruction in downstream applications. Through experiments, we identify the optimal image size and corresponding feature extraction network for improved radar map reconstruction.
4.2.1. Image Classification for Matching Image Features and Extraction Networks
In image classification tasks, the network comprises the input image, backbone feature extractor, and classification head. This setup enables a direct evaluation of the synergy between image reconstruction and feature extraction networks. To determine the ideal size for the E2I-n network and its paired feature extractor, we conducted configuration classification experiments using one flight formation per radar map. Our experiments assessed the compatibility between entity images at varying scales and conventional image feature extraction networks like ResNet and AlexNet. The initial learning rates were set at for ResNet18, for ResNet50 and ConvNeXt-Tiny, and for ResNet101 and AlexNet. These rates decay by 0.1 every 10 epochs during the 40-epoch training process, with 100 iterations per epoch and a batch size of 64, using CrossEntropy loss. Specific experimental findings are detailed in Table 4.
The experiments underscore the superior performance achieved by pairing the E2I-5 upsampling network with ResNet18 for feature extraction, surpassing other network combinations. Moreover, the convergence speed of the E2I-5 and ResNet18 combination significantly outpaces that of other combinations. Employing ResNet18, a compact backbone network, the feature extractor effectively complements the sparse radar reconstruction images. These findings support the conclusions drawn from Theorem 1 at an experimental level. Furthermore, we visualized layer activations from ResNet18/50/101 to analyze shallow network performance, demonstrating comparable capability to deeper networks on sparse images. Visualizations are provided in Appendix C.
4.2.2. Ablation
After conducting the configuration classification experiment outlined in Section 4.2.1, a series of ablation experiments were performed to validate the efficacy of the proposed E2I upsampling network architecture:
- w/o LN: We remove LN layers in the E2I network.
- w/o RELU: We remove ReLU activation in the E2I network.
- w/o Linear-2: We remove the second Linear layer and make adjustments to the input–output dimensions of linear Layers 1 and 3 in the E2I network.
- w/o prior location information: Rather than relying on prior position information, we directly upsample all flight attributes to a standard image size of .
Refer to Figure 3 for the convergence results of classification accuracy during training across various cases. The experimental findings demonstrate the effectiveness of the developed E2I network structure and sparse radar map reconstruction method.
4.3. End-to-End Swarm Partitioning and Configuration Recognition
In this section, we first compare the recognition accuracy of three prominent object detection algorithms. Subsequently, we conduct three sets of robustness tests tailored for aerial application scenarios. Lastly, we demonstrate the practical application effect.
4.3.1. Comparison of Classical Object Detection Algorithm in the Method Based on Reconstruction Sparse Radar Map
We assess the end-to-end recognition accuracy of three object detection architectures: Faster R-CNN, YOLOv5, and DETR. The experiment utilizes the E2I-5 upsampling network and ResNet18 backbone network, pre-trained as described in Section 3.3. Details concerning the pre-training of the image feature extraction network and the training process of the overall model are provided in Appendix D and Appendix E. The recognition accuracy results for the three object detection algorithms are summarized in Table 5.
Based on the results presented in Table 5, it is evident that ResNet18, used as the backbone network, significantly outperforms larger backbone networks. This difference in performance could be attributed to suboptimal training parameters, challenges associated with training larger networks, and other contributing factors. However, it is suggested that larger networks excel in capturing intricate edge and detail features within images, although this might not align well with the scale of formation configuration images. On the other hand, the ResNet18 network, focusing on image scale, aligns better with formation configuration images, aiding in the recognition of formation configurations through depth of field analysis and aircraft positioning relationships. Furthermore, DETR, a computer vision network leveraging transformer architecture, outperforms pure CNN architectures due to the transformer’s self-attention mechanism, which excels at capturing sparse features within images.
The confusion matrix illustrates the outcomes of configuration classification during the training phases of the DETR network, achieving accuracies of approximately 0.6 and 0.9, as depicted in Figure 4. Analysis of the sparse matrix reveals that at 0.6 accuracy, DETR demonstrates proficient anchor box regression and basic shape recognition capabilities, distinguishing between Lead-Trail/Line Abreast/Swept, Container, and Wedge/Stinger formations, yet it lacks the ability to capture heading information and depth of field representation in images. With further training, at an accuracy of 0.9, only a subset of configurations is misclassified, highlighting the seamless integration of the E2I network with DETR’s overarching architecture.
4.3.2. Robustness Analysis of End-to-End Partitioning and Configuration Recognition in the Method Based on Reconstruction Sparse Radar Map
In real-world aerial confrontation scenarios, numerous sources of information interference and uncertainty are present. To evaluate the robustness and practical applicability of computer vision technology in downstream tasks utilizing the sparse radar map reconstruction method, this section examines two factors potentially impacting recognition outcomes for end-to-end partitioning and configuration recognition: information noise errors and aircraft spacing within formations.
Firstly, we assess the algorithm’s robustness under significant levels of information noise interference. Information noise errors primarily stem from two sources: radar detection inaccuracies due to detection errors and enemy interference as well as operational deviations resulting from the flight control process. To guarantee the resilience of the algorithm and its efficacy in practical applications, this section constructs a formation recognition database utilizing noise indicators outlined in Table A1. These indicators encompass positional deviations within ±1 km and heading deviations within ±11.5°, categorized as 1× noise. Supplementary positional and heading noise factors are incorporated to evaluate the precision of formation recognition. The algorithm’s capacity to withstand noise interference is demonstrated in Table 6.
Due to the unique message-passing mechanism of GNNs, aircraft in formation exhibit “homogeneity,” similar to complex averaging through high-dimensional operations. Based on this, we hypothesize that incorporating GNNs improves the model’s resistance to interference, which we test through experiments. In these experiments, training parameters are kept constant. The results in Figure 5 show that course noise has a more significant impact on identification accuracy than coordinate noise. The GNN module notably enhances the model’s resilience to course noise when entity attributes are fused. However, the model’s performance against coordinate noise appears to be influenced primarily by the convolutional neural networks.
Secondly, we assess the accuracy of end-to-end partitioning and configuration recognition under diverse flight intervals. In formation flying, the spacing between aircraft is tactically adjusted based on mission objectives and aircraft capabilities. During covert operations, aircraft fly in close formation to reduce exposure risks, creating the illusion of a larger entity. Conversely, in routine training exercises, a more conservative spacing is adopted for safety. However, this variability poses a challenge for computer vision techniques. The relationship between recognition accuracy and flight interval is illustrated in Table 7.
Table 7 presents the recognition accuracy of fixed flying intervals within formations. The algorithm exhibits strong versatility, achieving high accuracy even when the intervals between aircraft within the same formation are not uniform. While there may be a reduction in accuracy with excessively small or large formation intervals, this phenomenon is directly linked to the model range specified in Table A1 for the configuration recognition database. As indicated in Table A1, the model’s flying intervals are constrained within the range of [5 km, 15 km], rendering cases such as 3 km and 20 km as novel formation image types for the algorithm. This study aims to expand the flying intervals in the formation configuration model to a broader range of [1 km, 20 km] during network training. This adjustment is anticipated to enhance the recognition accuracy of formations with smaller or larger (1 km/25 km) flying intervals by 5–10%; however, the overall average recognition accuracy is projected to decrease to 87.9%.
4.3.3. Practical Application Effect of End-to-End Swarm Partitioning and Configuration Recognition Algorithm
To evaluate the effectiveness of the proposed GNN-CV architecture in realistic air command and control systems, we deployed a representative air confrontation scenario on a human–machine interaction (HMI) simulation platform. The proposed end-to-end swarm partitioning and configuration recognition algorithm is initiated by the “request picture” voice command, which triggers the tactical display generation process. The swarm partitioning and configuration recognition results for the aerial formations are presented in Figure 6.
Validation results demonstrate the efficacy of integrating graph neural networks and computer vision techniques with radar map reconstruction. Experimental evaluations conducted on the i9-12900K CPU and NVIDIA A5000 GPU platform reveal that the target detection framework, which employs a six-layer eight-head DETR architecture with ResNet18 as the backbone, yields an approximate throughput of 30 FPS and exhibits a millisecond-level recognition latency. Crucially, in engineering practice, the flight separation distance can be readily scaled to the model’s input range via straightforward multiplicative or divisive operations, without compromising identification accuracy. This approach has undergone rigorous real-world validation, yielding robust performance outcomes.
5. Conclusions
This paper introduces a unified framework that leverages computer vision techniques to address various situational awareness challenges. We propose SET-GNNs and E2I upsampling network that utilize prior location data to convert sparse entities into standard image formats. To efficiently extract features from reconstructed radar images, we advocate for shallow pyramid structure convolutional neural networks, demonstrating their efficacy through both theoretical analysis and practical application. To facilitate the integration of image conversion and feature extraction networks across diverse situational awareness tasks, we introduce a two-stage pre-training approach for the relevant networks. We validate our framework through aerial swarm partitioning and configuration recognition tasks. The experimental results confirm the architecture’s utility, effectiveness, and resilience, aligning with human cognitive principles.
The provision of databases tailored for SA training in computer vision is likely to be the primary obstacle that restricts the further application of this model. In the future, we anticipate leveraging this architecture to explore applications such as target tracking and video generation for situational prediction. Additionally, we aim to employ image segmentation techniques to achieve large-scale situational awareness.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Minh Dang L. Min K. Wang H. Jalil Piran M. Hee Lee C. Moon H. Sensor-based and vision-based human activity recognition: A comprehensive survey Pattern Recognit.202010810756110.1016/j.patcog.2020.107561 · doi ↗
- 2Seong Y.M. Park H. Multiple target tracking using cognitive data association of spatiotemporal prediction and visual similarity Pattern Recognit.2012453451346210.1016/j.patcog.2012.03.005 · doi ↗
- 3Chalavadi V. Jeripothula P. Datla R. Ch S.B. Chalavadi K.M. m SODA Net: A network for multi-scale object detection in aerial images using hierarchical dilated convolutions Pattern Recognit.202212610854810.1016/j.patcog.2022.108548 · doi ↗
- 4Yang F. Yang L. Zhu Y. A physics-informed deep learning framework for spacecraft pursuit-evasion task assessment Chin. J. Aeronaut.20243736337610.1016/j.cja.2024.02.011 · doi ↗
- 5Li L. Yang R. Lv M. Wu A. Zhao Z. From Behavior to Natural Language: Generative Approach for Unmanned Aerial Vehicle Intent Recognition IEEE Trans. Artif. Intell.202456196620910.1109/TAI.2024.3376510 · doi ↗
- 6Ding P. Song Y. A cost-sensitive method for aerial target intention recognition Acta Aeronaut. Astronaut. Sin.20244532855110.7527/S 1000-6893.2023.28551 · doi ↗
- 7Li L. Yang R. Li H. Lv M. Yue L. Wu A. Mo L. Unsupervised Contrastive Learning for Automatic Grouping of Aerial Swarms IEEE Trans. Veh. Technol.2024736249625810.1109/TVT.2023.3342186 · doi ↗
- 8Liang F.T. Zhou Y. Zhang H.N. Zhang Y. Zhao X.R. An Intelligent Recognition Method of Aircraft Formation Radio Eng.20235316041611