Prediction of Water Quality Parameters in the Paraopeba River Basin Using Remote Sensing Products and Machine Learning
Rafael Luís Silva Dias, Ricardo Santos Silva Amorim, Demetrius David da Silva, Elpídio Inácio Fernandes-Filho, Gustavo Vieira Veloso, Ronam Henrique Fonseca Macedo

TL;DR
This study uses satellite data and machine learning to predict water quality in the Paraopeba River Basin, offering a cost-effective alternative to traditional monitoring.
Contribution
The study introduces a novel methodology using normalized PlanetScope data and decision-tree-based algorithms for improved water quality prediction.
Findings
Normalized PlanetScope data achieved the best performance in predicting water quality parameters.
Decision-tree-based algorithms outperformed other models in generalization capability.
The methodology is applicable for diverse environmental monitoring tasks using remote sensing.
Abstract
Monitoring surface water quality is essential for assessing water resources and identifying their quality patterns. Traditional monitoring methods, based on conventional point-sampling stations, are reliable but costly and limited in frequency and spatial coverage. These constraints hinder the ability to evaluate water quality parameters at the temporal and spatial scales required to detect the effects of extreme events on aquatic systems. Satellite imagery offers a viable complementary alternative to enhance the temporal and spatial monitoring scales of traditional assessment methods. However, limitations related to spectral, spatial, temporal, and/or radiometric resolution still pose significant challenges to prediction accuracy. This study aimed to propose a methodology for predicting optically active and inactive water quality parameters in lotic and lentic environments using…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
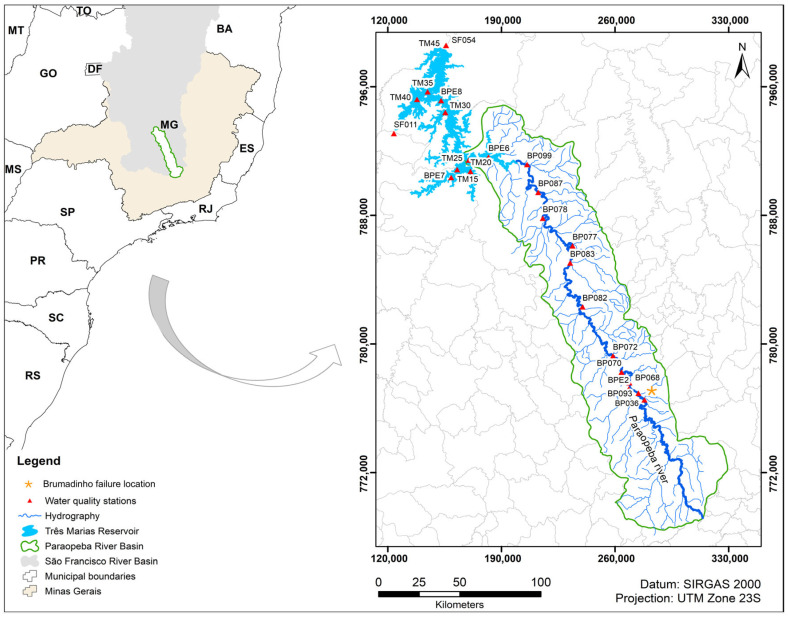 Figure 1
Figure 1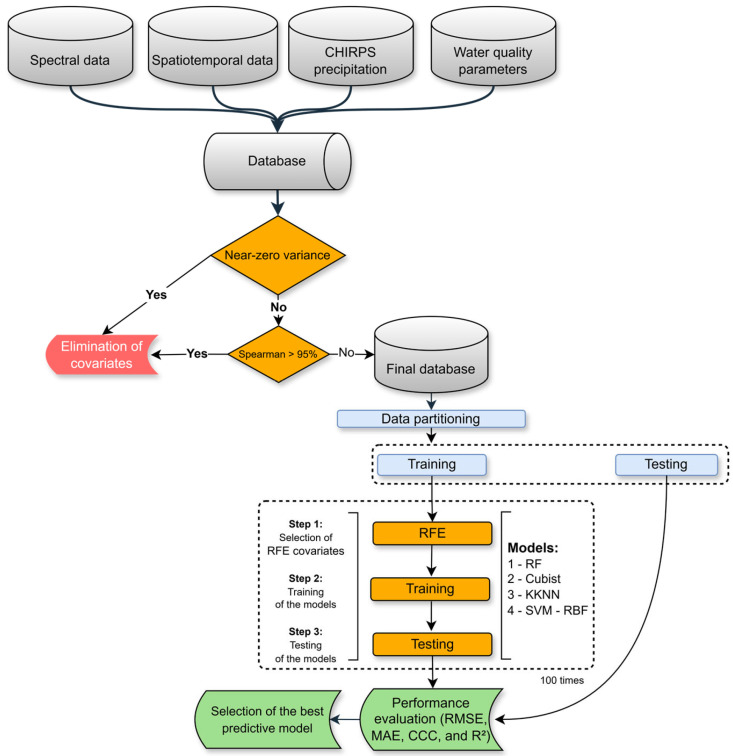 Figure 2
Figure 2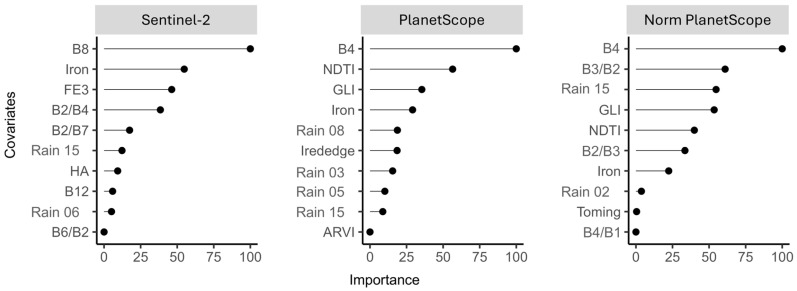 Figure 3
Figure 3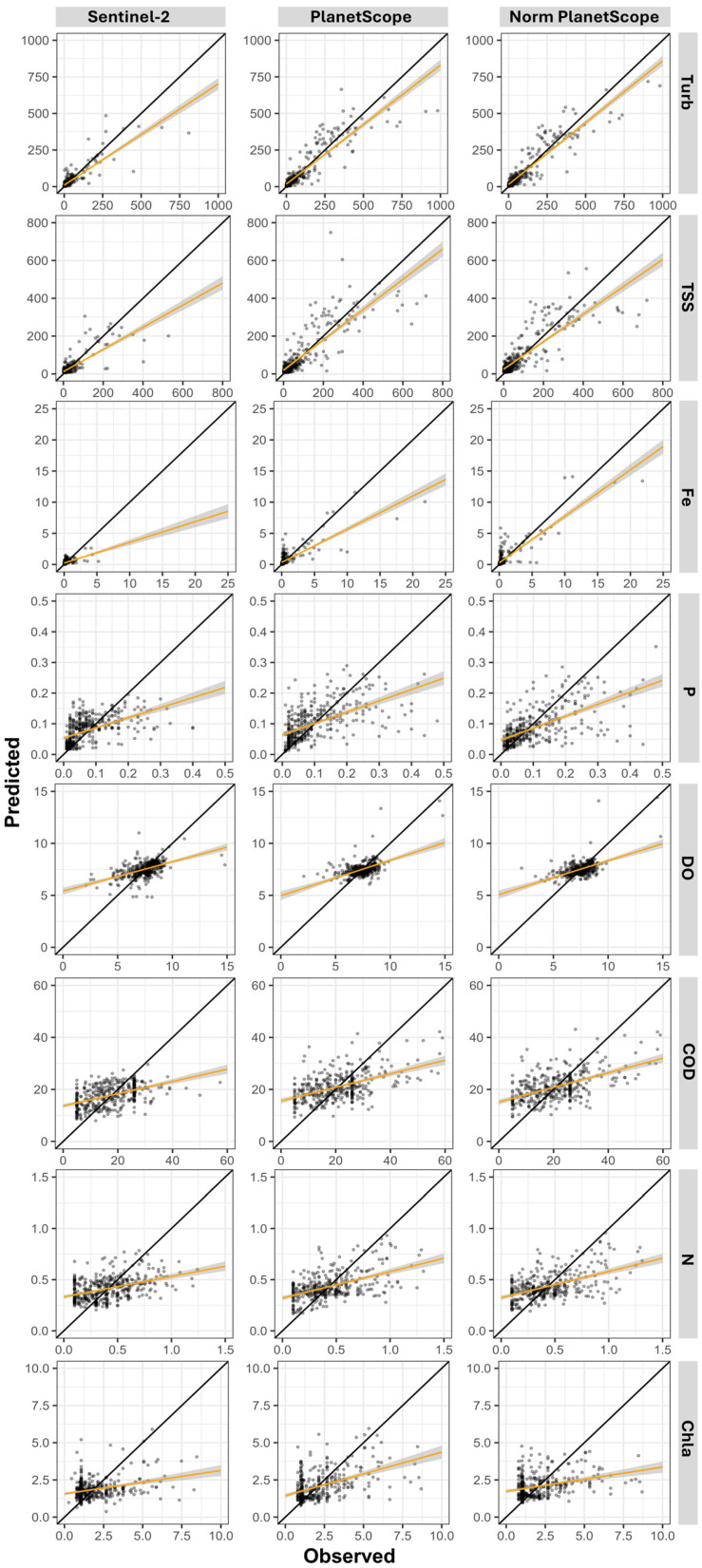 Figure 4
Figure 4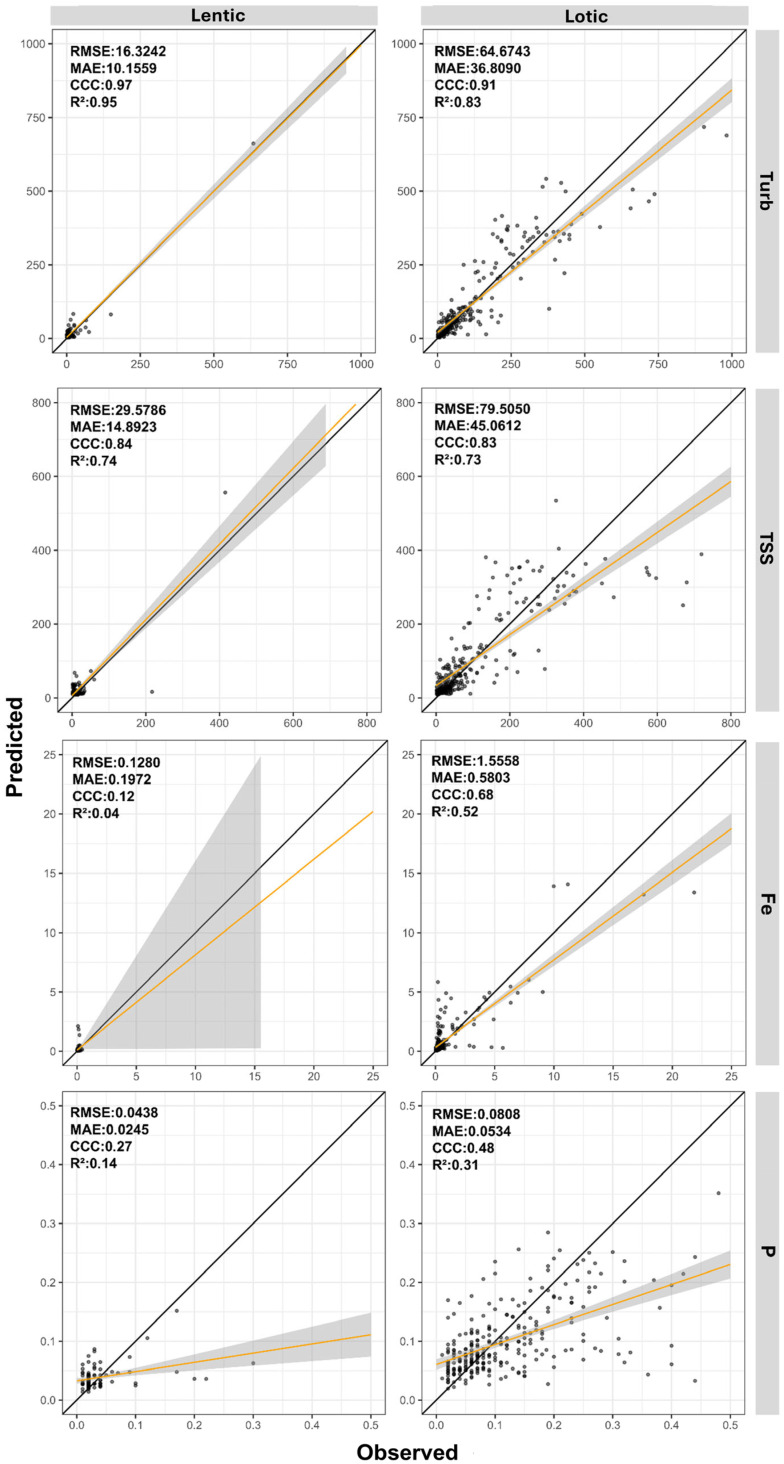 Figure 5
Figure 5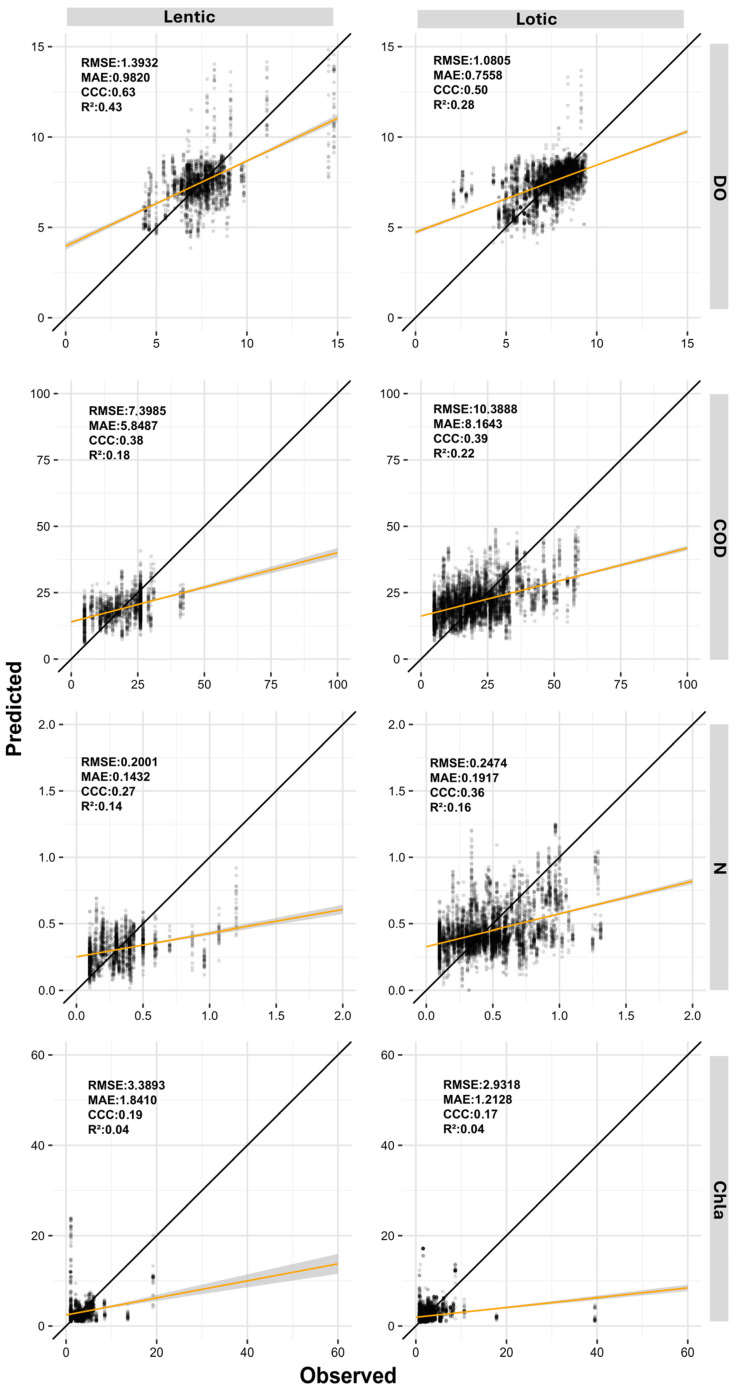 Figure 6
Figure 6- —Coordenação de Aperfeiçoamento de Pessoal de Nível Superior—Brazil (CAPES)
- —Conselho Nacional de Desenvolvimento Científico e Tecnológico (CNPq)
- —Fundação de Amparo à Pesquisa do Estado de Minas Gerais (FAPEMIG)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFlood Risk Assessment and Management · Marine and coastal ecosystems · Water Quality and Pollution Assessment
1. Introduction
Continental surface water bodies, such as rivers, lakes, reservoirs, and streams, are essential sources of potable water and support multiple uses, including recreation, industry, agriculture, energy generation, transportation, and fishing [1,2]. They also play a fundamental role in maintaining biodiversity and regulating hydrological flow [3]. Therefore, continuous monitoring of water quantity and quality is crucial for understanding natural and anthropogenic processes that influence aquatic systems and for supporting conservation actions [4].
Conventional monitoring of water quality, based on discrete point sampling, presents important limitations, especially during extreme events. Low sampling frequency and the limited spatial distribution of monitoring stations hinder the detection of spatiotemporal variability in water quality, particularly along lake and reservoir margins or following intense rainfall [5,6]. In such situations, continuous and spatially detailed monitoring becomes essential to complement traditional approaches and to more accurately assess the impacts of events such as dam failures and heavy precipitation.
Remote sensing techniques have emerged as effective alternatives for the continuous monitoring of optically active water quality parameters because of their broad spatial coverage, adequate temporal resolution, and favorable cost–benefit ratio. These techniques have been widely applied to estimate chlorophyll-a (Chla), turbidity (T), colored dissolved organic matter (CDOM), total suspended solids (TSS), and Secchi disk depth (SDD) [7,8,9,10].
In contrast, relatively few studies have focused on predicting non-optically active parameters such as phosphorus (P), nitrogen (N), chemical oxygen demand (COD), dis-solved oxygen (DO), and iron (Fe) [11,12]. These parameters exhibit weak or no relation-ships with spectral bands, which limits their direct detection by orbital sensors [13,14,15]. Consequently, their prediction relies on indirect approaches that explore correlations with optically active parameters, environmental variables, and machine-learning algorithms [12,16,17].
Machine-learning algorithms have become increasingly prominent in water-quality modeling due to their ability to represent highly nonlinear relationships among environmental variables [18]. These methods have been applied across a variety of monitoring contexts, often outperforming traditional approaches for several water-quality parameters [19,20]. Recent studies, for example, demonstrate that backpropagation neural networks can accurately estimate indicators such as chemical oxygen demand (COD), permanganate index, total nitrogen (TN), and total phosphorus (TP) [21,22]. In addition to neural networks, techniques such as decision trees, support vector machines, random forests, and other supervised learning algorithms have shown broad applicability in aquatic systems [12,17,23,24].
These methodological limitations are compounded by constraints inherent to current orbital platforms such as Landsat, MODIS, and Sentinel-2 (S2), which have moderate-to-low spatial resolutions ranging from 10 to 1000 m. Furthermore, the temporal resolutions of Landsat and S2A/2B satellites are considered moderate—16 and 10 days, respectively [25,26]. As a result, their application for remote detection of water quality in small reservoirs, embayments of large reservoirs, and narrow rivers—where higher-frequency imagery is needed—is limited [27,28].
To overcome such limitations, Planet has deployed a large number of nanosatellites known as Doves. These Doves form a CubeSat 3U (10 × 10 × 30 cm) constellation capable of daily revisit to the same target on Earth′s surface. Since 2016, these satellites have provided imagery with 3.7 m spatial resolution and four spectral bands (B1—Blue: 420–530 nm; B2—Green: 500–590 nm; B3—Red: 610–700 nm; and B4—near-infrared [NIR]: 780–860 nm) [29]. They weigh approximately 4 kg, enabling much faster production and launch compared with traditional satellites. They also do not require a dedicated launch vehicle, as they can be delivered to orbit as secondary payloads [30].
Recognizing these methodological gaps in the literature, this study offers an innovative contribution by integrating the prediction of optically active and inactive water-quality parameters in both lotic and lentic environments, an aspect that remains underexplored, particularly in highly variable contexts such as post-disaster conditions. This approach is strengthened by the inclusion of systematic comparisons among different orbital products, including Sentinel-2, PlanetScope, and radiometrically normalized PlanetScope, which enables the assessment of model predictive performance and the relevance of the specific characteristics of each orbital dataset. Accordingly, the objective of this study is to propose a methodology for predicting optically active and inactive water-quality parameters in lotic and lentic environments using remote-sensing data and machine-learning techniques.
2. Materials and Methods
2.1. Study Setting
To apply and evaluate the proposed methodology, we selected an area located in the central region of the state of Minas Gerais, Brazil (Figure 1), encompassing the Paraopeba River Basin and the Três Marias Reservoir. According to IBGE [31], the Paraopeba River is one of the main tributaries of the São Francisco River, extending 510 km and supplying the Três Marias Reservoir after flowing through 48 municipalities in Minas Gerais.
The Paraopeba River Basin has an average altitude of 720 m and is characterized by predominantly strongly undulating to mountainous terrain [32]. The predominant soil classes in the basin are Red Latosols, Red-Yellow Latosols, Haplic Cambisols, and Humic Cambisols. According to Alvares et al. [33], the climate in the region is classified as tropical Aw, with two well-defined seasons: a rainy summer from October to March and a dry winter from April to September.
This basin was chosen due to its considerable diversity of soils, topography, vegetation cover, and the presence of continental water bodies. Additionally, on 25 January 2019, the Paraopeba River Basin was impacted by one of the most severe socio-environmental disasters in Brazil: the failure of the tailings dam (B-I) at the Córrego do Feijão mine, located in the city of Brumadinho. According to the Government of Minas Gerais [34], approximately 12 million m^3^ of tailings were released, of which an estimated 2 million m^3^ remained in the former B-I area; 7.8 million m^3^ were deposited along the Ferro-Carvão stream channel until its confluence with the Paraopeba River; and the remaining 2.2 million m^3^ reached the main Paraopeba channel.
2.2. Hydrological Data
For this study, we used water-quality parameter time-series data (2016–2023) from 24 monitoring stations distributed along the Paraopeba River channel and the Três Marias Reservoir, including station SF054, located downstream of the dam failure (Figure 1 and Table 1). These data included turbidity, TSS, Chla, P, N, COD, DO, and Fe.
Data were obtained from the institutional repository of the Instituto Mineiro de Gestão das Águas (IGAM) (http://repositorioigam.meioambiente.mg.gov.br (accessed on 15 December 2025)), the governmental agency responsible for water-resource monitoring in Minas Gerais. In the basic network, sampling campaigns were conducted quarterly until December 2018. However, after the dam collapse in January 2019, sampling at stations located along the Paraopeba River became monthly. In addition, monitoring records from stations located in the Três Marias Reservoir, under the responsibility of Companhia Energética de Minas Gerais (Cemig), were incorporated into the database.
2.3. Remote Sensing Data Acquisition and Processing
To predict water quality parameters, we selected images acquired by the multispectral instrument (MSI) onboard the S2A and S2B satellites as well as PlanetScope (PS) imagery from the three generations of Dove nanosatellites Dove Classic, Dove-R, and Super Dove. Additionally, PS imagery was normalized according to the methodology proposed by Dias [36]. The following subsections describe the characteristics of each product and the processing applied.
2.3.1. Multispectral Instrument/Sentinel-2
In this study, 10 spectral bands from S2 MSI were used, mounted on the S2A and S2B platforms. According to Müller-Wilm [37], the multispectral bands are distributed across different electromagnetic ranges: three visible bands (B2—Blue [490 nm], B3—Green [560 nm], and B4—Red [665 nm]); one NIR band (B8—NIR [842 nm]); four red-edge bands (B5 [705 nm], B6 [740 nm], B7 [783 nm], and B8a [865 nm]); and two shortwave-infrared bands (B11–SWIR [1610 nm] and B12 [2190 nm]). The visible and NIR bands have 10 m spatial resolution, whereas the red-edge and shortwave-infrared bands have 20 m resolution.
S2 scenes were obtained from the Copernicus Open Access Hub (https://dataspace.copernicus.eu, accessed on 15 March 2024). We selected Level-1C top-of-atmosphere reflectance products with no cloud cover and with a maximum temporal difference of two days relative to the in situ sampling dates (2016 to 2023).
All preprocessing of S2A and S2B imagery was carried out by the authors and included the following steps: (i) band stacking for each acquisition date; (ii) mosaicking of scenes acquired on the same day; (iii) atmospheric correction using ACOLITE [38], which removes attenuation effects caused by molecular and aerosol scattering and by absorption from water vapor, ozone, oxygen and carbon dioxide [39], (iv) computation of spectral indices (Table 2); and (v) extraction and compilation of reflectance values at the monitoring stations.
2.3.2. PlanetScope Sensor
PS imagery is acquired by small nanosatellites designed and operated by the private company Planet. PS sensors are carried by a constellation of small nanosatellites with a CubeSat 3U form factor (10 × 10 × 30 cm). At present, Planet operates more than 180 Dove nanosatellites that provide daily imagery of Earth′s surface with high spatial resolution (about 3.7 m). Scenes are captured in four spectral bands: B1—Blue (420–530 nm), B2—Green (500–590 nm), B3—Red (610–700 nm), and B4—NIR (780–860 nm). According to Planet Team [61], PS images are delivered orthorectified in the Universal Transverse Mercator projection and geometrically corrected, with about 10 m positional accuracy.
PS scenes were downloaded via the application programming interface (API) available from https://www.planet.com/explorer (accessed on 23 August 2024). We selected cloud-free scenes from the three available sensor generations (Dove Classic, Dove-R, and Super Dove) with acquisition dates coinciding with the water-sampling days between 2016 and 2023. Although PS images are not open access, they can be obtained at no cost through university affiliation by enrolling in the Planet Education and Research program (https://go.planet.com/research, accessed on 1 May 2025).
Preprocessing steps for PS imagery included (i) mosaicking acquisition strips; (ii) calculating spectral indices (Table 3); and (iii) extracting and tabulating data for the water-quality monitoring points.
2.3.3. Normalized PlanetScope Sensor
For the normalized PS dataset, the same PlanetScope sensor data presented in the previous section were used. However, the PS imagery was normalized following the methodology proposed by Dias [36], who developed a procedure to correct radiometric inconsistencies in the PlanetScope constellation′s temporal image series using machine-learning models calibrated with synchronous samples of pseudo-invariant pixels extracted from paired PlanetScope and Sentinel-2 scenes. As a result, the normalized dataset exhibited more stable and comparable temporal series.
2.3.4. Climate Hazards Group Infrared Precipitation with Stations Data
In addition to PS and S2 imagery, we used daily precipitation estimates from the Climate Hazards Group Infrared Precipitation with Stations (CHIRPS) dataset [63]. CHIRPS is a reanalysis product that combines rain-gauge observations with satellite-derived precipitation estimates. It provides global daily data since 1981 at about 0.05° spatial resolution (about 5 km) [64].
Data preparation involved: first, delineating the upstream contributing area for each selected station; second, computing the mean of pixel values within that area; and third, downloading precipitation for the sampling day plus the preceding 14 days (a 15-day window). Accumulated precipitation was then computed in 24 h steps up to 360 h. These accumulated values were added to the database as 15 independent variables for predicting water quality parameters. All image and data preprocessing steps were performed in the R programming language [65].
2.3.5. Acquisition of Reflectance Values
After image preprocessing, we refined and extracted reflectance samples. Surface-water motion can produce direct (sunglint) and diffuse (skyglint) reflection of solar radiation, which markedly affects the spectral response of samples and can overestimate reflectance [66,67]. To reduce this effect in the modeling, pixels with reflectance > 0.6 were assigned NoData values [10].
Reflectance extraction considered two scenarios: (i) For S2 imagery, single-pixel values were extracted. To avoid shoreline interference in water pixels, we selected only stations located on river reaches with a minimum channel width of 30 m (equivalent to three S2 pixels). (ii) For PS imagery, a 3 × 3-pixel window was used, and the mean reflectance over that window was extracted.
2.4. Modeling of Water-Quality Parameters Using Machine-Learning Methods
To identify the remote-sensing product most suitable for predicting water quality parameters, modeling was performed using three datasets: (i) S2 imagery; (ii) PS imagery; and (iii) normalized PS imagery, following the methodology proposed by Dias [36].
The structured database was stratified and then randomly split into two subsets: 75% for training and 25% for testing. Stratification ensured sample representativeness according to two main criteria: (i) temporal proportion—training and test sets preserved the proportion of data before and after the dam failure; and (ii) climatic distribution—data were proportionally divided between wet and dry seasons, preserving the same 75/25 proportion within each season, with randomization applied only within each stratum.
Model performance metrics were computed as averages over 100 repetitions for both training and test sets. This procedure is effective for assessing algorithm performance and helps identify problematic samples or outliers in the datasets [10,68,69].
Figure 2 presents a flowchart of the three steps used in the implemented modeling: (i) selecting the optimal set of covariates for each algorithm by removing highly correlated variables and those with lower relevance for training; (ii) training models using the selected variables for each algorithm; and (iii) evaluating model performance on a dataset distinct from that used for training.
2.4.1. Covariate Selection
Covariate selection is a modeling step that aims to identify the smallest subset of original covariates capable of representing the modeled phenomenon/process while minimizing redundancy. It is used to reduce feature-space dimensionality, remove noisy covariates, and increase model parsimony [10,70,71].
First, covariate variance was assessed, and variables with zero or very low variability were removed based on the criteria defined by [72]. This assessment was performed with the nearZeroVar function from the caret package [73,74].
Next, Spearman′s correlation coefficient was computed [75]. For pairs of covariates with correlation ≥ 95%, the variable with the largest absolute correlation with the remaining variables was removed.
Finally, the importance-based removal of covariates was performed through the re-cursive feature elimination (RFE) procedure implemented in the caret package, which dis-cards variables that contribute least to the model according to the algorithm-specific im-portance measures [10,76,77,78,79,80]. The division into training and testing sets was performed prior to the application of the recursive feature elimination (RFE) procedure.
The structured database was stratified and then randomly split into two subsets: 75% for training and 25% for testing. Stratification ensured sample representativeness according to two main criteria: (i) temporal proportion—training and test sets preserved the proportion of data before and after the dam failure; and (ii) climatic distribution—data were proportionally divided between wet and dry seasons, preserving the same 75/25 proportion within each season, with randomization applied only within each stratum.
After applying RFE, the optimal covariate set was obtained for each algorithm and used in the subsequent modeling steps. For modeling water quality parameters, the predictors comprised individual bands, band ratios, spectral indices (Table 2 and Table 3), precipitation data (accumulated from 2 to 15 days prior to sampling), and image-acquisition period (before/after the dam failure and hydrological season).
2.4.2. Selection of Machine-Learning Models
To predict the concentration of water quality parameters, we employed the following algorithms: random forest (RF) [81], support vector machines with a radial basis function kernel (SVM-RBF) [82], kernel k-nearest neighbors (KKNN) [83], and cubist [84]. These algorithms were chosen because they represent distinct families of modeling approaches, providing a comprehensive assessment of the relationships within the data. This set includes: (i) tree-based ensemble methods (RF), (ii) kernel-based methods capable of capturing complex nonlinear relationships (SVM-RBF), (iii) instance-based learning algorithms (KKNN), and (iv) hybrid rule-based models that combine decision trees with linear regression components (Cubist). Such methodological diversity enables the exploration of different response patterns and follows established recommendations in the literature for environmental and limnological modeling, ensuring robustness and comparability across approaches [74,85].
RF and SVM-RBF are widely used to predict water quality parameters [2,86,87]. RF builds an ensemble of N regression trees, and the final prediction is the average over all trees. As a tree-based approach, RF is a nonparametric algorithm [81,88].
SVM-RBF allows predictions with a tolerable error controlled by the support vectors and governed by the hyperparameter C (cost) [82]. Like RF, SVM-RBF is nonparametric and becomes a nonlinear regression method by using a nonlinear kernel function [89].
KKNN is also kernel-based and identifies the k training points closest to a new sample using a distance metric such as Minkowski distance, a general form of Euclidean and Manhattan distances [90]. This nonparametric model assigns distance-weighted contributions so that nearer neighbors receive larger weights, avoiding explicit assumptions about underlying data distributions [91,92,93].
Cubist is a tree-based regression algorithm that combines a decision-tree structure with linear models fit within each terminal region [84]. It builds a set of decision rules to partition the attribute space and then applies local linear regression within each region, yielding a flexible and interpretable representation of relationships in data [94,95,96].
A more detailed description of these algorithms can be found in Kuhn and Johnson [85] and Murphy [74].
During training, each model′s internal hyperparameters were tuned using repeated cross-validation with 10 folds and 10 repetitions, applied to each algorithm′s tuning grid and testing 5 values of each hyperparameter (tuneLength). Hyperparameters are algo-rithm-specific configuration options that influence model behavior and predictive accura-cy. Each learning method relies on its own set of hyperparameters, and in this work we optimized the following: committees and neighbors for Cubist; kmax, distance, and kernel for KKNN; mtry for RF; and sigma and C for the radial-basis SVM-RBF.
The tuning process was carried out automatically through the train function in the caret package [73]. This function performs a structured exploration of the user-defined hyperparameter space. When minimum and maximum values are provided for each parameter, train constructs an evenly spaced grid—typically composed of five candidate values per hyperparameter—covering the specified range. The algorithm is then fitted for every combination in this grid and assessed using the selected resampling strat-egy (e.g., cross-validation). The configuration that maximizes the chosen performance met-ric is retained as the optimal set of hyperparameters.
In this study, hyperparameter selection was guided by the Lin′s Concordance Corre-lation Coefficient (CCC), which served as the optimization criterion. Initial values and search ranges followed the caret developers′ recommendations (see the manual, Chapter “Available Models”: https://topepo.github.io/caret/available-models.html (accessed on 15 January 2025)). Final optimized hyperparameters are shown in Table 4.
The processes of importance-based variable removal (RFE), model training, and performance evaluation were repeated 100 times. This repeated-resampling strategy enables assessing the ability of the algorithms to handle varying training subsets and to produce robust predictive results [97,98]. Model performance metrics for both training and testing sets were then computed as the mean values across the 100 repetitions. This approach enhances the reliability of performance estimates and facilitates the identification of potentially problematic observations or outliers within the datasets [10,68,69].
2.4.3. Model Evaluation
To evaluate model performance, predictions were compared with observations from the water quality monitoring stations in the study area (Table 1) using the following statistical metrics: root-mean-square error (RMSE; Equation (1)), mean absolute error (MAE; Equation (2)), Lin′s concordance correlation coefficient (CCC; Equation (3)), and the coefficient of determination (R^2^; Equation (4)). This set of metrics was chosen to capture complementary facets of performance [99,100,101].
where are model-predicted values; are observed values; is the mean of observed values; is the mean of predicted values; and are the variances of predicted and observed values, respectively; and is the number of observation pairs.
RMSE squares the difference between predicted and observed values, penalizing large errors more than small ones, and is therefore sensitive to outliers [102]. MAE measures the average magnitude of errors using the absolute difference [103]. CCC quantifies the proximity of the fitted relationship to the 45-degree identity line [101]. R^2^ represents the proportion of variance explained by the model [104]. Because RMSE and MAE share the variable′s units, they facilitate error interpretation. Models with lower RMSE and MAE were considered more accurate [105]. Following Altman [106], CCC and R^2^ can be interpreted as moderate (0.5–0.7), strong (0.7–0.9), and very strong (>0.9).
In addition to these metrics, RMSE (Equation (5)) and MAE (Equation (6)) were also computed for a null model. The null model predicts each parameter using the training-set mean, returning a single average for numeric outcomes. Models performing similarly to or worse than the null model are poorly rated. Model selection for a given parameter should favor cases in which RMSE and MAE are lower than those of the null model, indicating gains from the machine-learning approach [69].
where is the mean of the training samples, are the test-set observations, and is the number of test samples (loop size).
3. Results and Discussion
Table 5 presents the descriptive statistics of the water quality parameters used in this study, revealing large gaps between minimum and maximum values—i.e., a wide range in the observed measurements. In addition, the parameter means are generally closer to the minima, indicating right-skewed distributions with long upper tails. Such skewness is common in environmental datasets, where measurements cluster at low to moderate levels but rare extreme events stretch the upper tail [105].
Figure 3 ranks the most important covariates for the models used to predict water quality parameters across the three datasets (S2, PS, and normalized PS). Covariate-selection procedures substantially reduced the number of predictors, from an initial 151 to ten variables per model—an adequate and parsimonious set for modeling. These findings agree with Muñoz-Romero et al. [70] and Stevens et al. [76], who showed that reducing model complexity lowers computational costs and improves robustness and predictive performance.
Except for the NIR bands (B8 for S2 and B4 for PS), indices and band ratios dominate as the most important covariates compared with individual bands. This corroborates Sestini [107] and Lillesand, Kiefer, and Chipman [108], who showed that combining spectral bands via indices and ratios enhances discrimination of subtle spectral differences among targets, whereas individual bands tend to capture only more evident variations—making ratio-based indices more effective for identifying specific spectral features of natural objects or phenomena.
The NIR bands (B8 in Sentinel-2 and B4 in PlanetScope) stand out as the most influential predictors. This result is expected, since NIR reflectance responds strongly to increases in suspended particles, directly influencing the prediction of turbidity, TSS, and other optically active parameters. Even for optically inactive parameters, the NIR band provides indirect information because many chemical components are correlated with sedimentary and hydrodynamic processes, particularly in a post-disaster context where sediment mobilization is intensified.
Spectral indices and band ratios such as GLI, Iron, and NDTI also exhibit high importance. Their superior performance stems from their ability to highlight subtle variations in the water′s spectral response while reducing interference associated with illumination, solar geometry, and atmospheric variability. The Iron index, in particular, consistently appears among the most relevant predictors, reflecting the presence of mineral-rich particulate material that characterizes much of the sediment dynamics in the basin after the disaster. These indices provide a more stable and discriminative spectral signal than individual bands, contributing strongly to the prediction of optically active parameters and, indirectly, to optically inactive ones.
Precipitation-derived variables from the CHIRPS product also appear consistently among the ten most important predictors across all sensors. This behavior reflects the direct relationship between accumulated rainfall, increased surface runoff, sediment transport, and nutrient loading. Precipitation further exerts strong influence on sediment resuspension, especially in lotic environments, altering the optical properties of the water column and, consequently, the spectral response captured by the sensors. In reservoirs, these effects are more attenuated due to longer residence times and lower hydrodynamic energy, which explains the differences observed in model performance between lotic and lentic systems.
In addition to these direct effects on optically active parameters, precipitation also contributes to the prediction of optically inactive parameters through indirect relationships. Rainfall events intensify hydrological processes that mobilize organic matter, nutrients, and sediments, thereby altering optical variables such as turbidity, TSS, and indices sensitive to particulate material. Although these inactive parameters do not exhibit distinct spectral signatures, their variations are associated with these processes, enabling machine-learning models to estimate them indirectly.
Table 6 reports, for MSI/S2 data, the performance metrics for the machine-learning models used to predict water quality parameters in the Paraopeba River Basin.
The results demonstrate the superior robustness of tree-based algorithms, particularly RF and Cubist, when compared with KKNN and SVM-RBF. RF achieved the highest performance for five of the eight parameters, while Cubist ranked within the top two for six parameters. Both models produced the lowest prediction errors (RMSE and MAE) and the highest R^2^ and CCC values, reinforcing the ability of tree-based methods to represent nonlinear relationships and capture multiscale interactions among environmental and hydrological covariates [81]. These findings align with previous studies that emphasize the adaptability of ensemble-based approaches under conditions of high optical and hydrological heterogeneity [104,109,110].
At the parameter level, Turbidity and TSS exhibited the strongest generalization capacity, with CCC values close to 0.82 and 0.72 and R^2^ values ranging from 0.75 to 0.59, accompanied by low RMSE and MAE. Both variables are optically active and strongly governed by suspended-sediment dynamics, which enhances their detectability across multisensor imagery. In contrast, Fe, P, DO, COD, and N showed limited predictive performance (CCC ≈ 0.44–0.31; R^2^ ≈ 0.27–0.15), reflecting their weak or indirect spectral signatures and their sensitivity to short-term hydrological fluctuations. For Chla, all algorithms performed poorly; even the best model (SVM-RBF; CCC = 0.12; R^2^ = 0.05) produced a test-set RMSE higher than the null model.
These results are consistent with the well-known physical–optical limitations of these parameters. DO, Nitrogen, and COD are not optically active and therefore do not exhibit direct spectral signatures detectable by orbital sensors. Their estimation relies on indirect relationships with covariates, which naturally limits model accuracy [67]. In the case of Chla, although characteristic absorption bands exist, its detection in rivers is strongly hindered by low pigment concentrations, high turbidity, and spectral overlap with TSS and CDOM [111,112,113]. These conditions are particularly relevant in the study area, where turbidity remains elevated due to the Brumadinho dam failure, reducing the effective optical depth and weakening the Chla signal.
Overall, there was no evidence of overfitting, as training and test results were concordant. Except for Chla, all parameters showed gains over the null model in RMSE and MAE: RMSE improvements ranged from 47.38% (T) to 6.75% (N); MAE improvements ranged from 61.12% (T) to 7.85% (N). For Chla, no advantage over the null model was observed for RMSE; however, MAE improved by 8.21%.
Table 7 reports, for PS data, the performance metrics for the machine-learning models used to predict water quality parameters in the Paraopeba River Basin.
Table 7 indicates a clear dominance of tree-based models, with Cubist and RF consistently ranking among the top two performers for all eight parameters derived from PS data. For Turbidity, TSS, Fe, and P, CCC values ranged from 0.878 to 0.513 and R^2^ values from 0.796 to 0.337, accompanied by low RMSE and MAE. The close agreement between CCC and R^2^ further reinforces the internal consistency and robustness of the modeling framework [36].
The comparison of RMSE and MAE across training and test sets shows only minor discrepancies, suggesting a low risk of overfitting. As reported in Table 7, RMSE values improved by 52.65 percent to 11.82 percent relative to the null model, while MAE improved by 66.04 percent to 13.82 percent. Similar to the MSI/S2 results, Chla was the only parameter for which the model did not outperform the null model, yielding an RMSE 9.85 percent below the mean and a marginal MAE improvement of 7.28 percent. This reinforces the known difficulty of retrieving Chla from PS imagery in highly turbid and optically complex environments.
Table 8 reports, for normalized PS data, the performance metrics used to evaluate the machine-learning models applied to predicting water quality parameters in the Paraopeba River Basin. For all evaluated parameters, RF and Cubist were among the two best models; only for Fe, P, and Chla did these algorithms perform worse than SVM-RBF and KKNN.
Analyzing model performance by parameter, the models for turbidity, TSS, Fe, P, and DO showed good generalization, with CCC values between 0.918 and 0.553. Corresponding R^2^ values ranged from 0.848 to 0.39. The strong agreement between these two indices is an important indicator of the robustness of the applied methodology.
When analyzing the RMSE and MAE indices, the results show low values and good agreement among the data. Examining the percentage gain of the developed models relative to the NULL RMSE and NULL MAE values, all evaluated parameters demonstrated real improvements, with gains ranging from 59.95% to 13.98% for RMSE. For MAE, the models showed an advantage between 68.77% and 15.04%.
Overall, with the exception of the Chla models derived from S2 and PS datasets, all developed models (Table 6, Table 7 and Table 8) achieved MAE and RMSE values lower than those of the null model, which constitutes the minimum statistical benchmark for acceptable predictive skill [69,85]. This systematic reduction in error metrics indicates that the proposed modeling framework provides a demonstrably superior predictive capability compared with the use of simple mean-based estimates.
The Chla parameter presented the lowest CCC and R^2^ values, indicating significant difficulty for the algorithms to generalize across the three analyzed datasets. From an optical perspective, Chla is often affected by the presence of other Optically Active Components (OACs), such as TSS and colored dissolved organic matter (CDOM) [111,112,113]. In this context, it is noteworthy that the study area was impacted by a mining tailings dam failure, which led to high TSS levels in the datasets used for modeling. This significantly contributed to the poor performance of the machine learning models in predicting the Chla parameter.
Additionally, the characteristics of the predominant soils in the region, classified by Embrapa [114], as Red Latosols, Red-Yellow Latosols, Haplic Cambisols, and Humic Cambisols, directly influence water color and, consequently, its spectral response.
Table 9 presents the performance statistics of the best-performing machine learning models for each evaluated parameter under the three distinct approaches. Figure 4 complements this information by displaying scatter plots of predicted versus observed values along a 1:1 line, allowing a visual assessment of prediction accuracy.
When analyzing Table 9 and Figure 4, the dataset derived from normalized PS images achieved the best results across all evaluated parameters. Models for turbidity, TSS, Fe, P, and DO presented CCC values between 0.92 and 0.55, while R^2^ values ranged from 0.85 to 0.39. The MAE and RMSE values were lower than the thresholds established by the null models. For the parameters COD, N, and Chla, although the results were higher than those obtained with the other two datasets, the CCC values remained below 0.50, varying between 0.45 and 0.26, while R^2^ ranged from 0.30 to 0.11.
These patterns and value magnitudes are consistent with the findings of Gao et al., [115] who predicted non-optically active parameters using S2 data. These results are justified because the predictive capability arises from indirect relationships with optically active constituents and with short-term hydrological dynamics captured by the CHIRPS precipitation covariates. These factors co-vary due to sediment resuspension, nutrient transport, and seasonal changes in streamflow, allowing the models to identify nonlinear environmental patterns.
The results demonstrate the superior performance of the models developed using the PS dataset—both raw and normalized—compared with the S2 data across all analyzed parameters. This advantage arises directly from the characteristics of the PS sensor, such as its high spatial resolution (3.7 m), which enables the detection of finer-scale features, and its daily temporal resolution, which allows for a more accurate characterization of aquatic variability. These findings suggest that PS data offer significant advantages for water quality modeling, especially in complex aquatic systems where spatial and temporal variability is critical.
The MSI/S2 sensor, despite being widely used, has notable limitations in narrow water bodies (< 30 m wide), where its 10 m spatial resolution induces spectral mixing errors. Moreover, its reflectance is highly sensitive to external interferences (riverbed, riparian vegetation, and sediments), as reported by Barbosa et al. [67], Greb et al. [116], and Isidro et al. [117], which reduces its accuracy in more complex aquatic systems.
In summary, when analyzing the characteristics of each sensor across the three evaluated datasets, the results indicate that the models developed using normalized PS data achieved the best performance, surpassing those based on raw PS and MSI/S2 data. This superior performance suggests that normalized PS data are more suitable for predicting water quality parameters, particularly turbidity, TSS, Fe, and P.
Figure 5 and Figure 6 present the predicted and observed values of turbidity, TSS, Fe, P, DO, COD, N, and Chla parameters modeled using normalized PS data for lentic and lotic environments. Overall, due to environmental characteristics, lentic systems exhibited lower dispersion, with values closely grouped. In contrast, lotic environments displayed greater dispersion across all parameters.
Analyzing the statistical indices reveals that turbidity, TSS, COD, and N showed only minor variations in model performance between lentic and lotic environments. Conversely, Fe, P, DO, and Chla exhibited more pronounced differences between the two environments. In lentic systems, turbidity, TSS, and DO achieved the best performances, with CCC values ranging from 0.97 to 0.72 and R^2^ values between 0.95 and 0.65. Meanwhile, Fe, P, COD, N, and Chla had CCC values between 0.43 and 0.12 and R^2^ between 0.28 and 0.04. In lotic environments, turbidity, TSS, and Fe stood out, with CCC values ranging from 0.91 to 0.68 and R^2^ from 0.83 to 0.52. The parameters DO, P, COD, N, and Chla, however, displayed lower CCC and R^2^ values, ranging from 0.48 to 0.19 and 0.31 to 0.06, respectively.
The methodology proposed in this study proved robust for assessing water quality using a historical series of PS images. The comparative analysis between PS data and those from well-established constellation such as S2 demonstrated that PS imagery can provide valuable information despite its lower spectral resolution and the inherent radiometric differences among sensors. Although PS presents certain limitations, it shows strong potential for monitoring water-quality parameters in inland waters, particularly when radiometric normalization is applied. Normalization enhances radiometric consistency across different PS sensor generations (Dove Classic, Dove-R, and Super Dove), reducing calibration discrepancies and improving the temporal comparability of images acquired by different satellites. It also mitigates sensor-specific noise, including variations in gain, offset, and illumination, resulting in more stable and reliable spectral indices that are less susceptible to radiometric distortions.
The proposed methodology not only validates the use of PS data to predict water-quality parameters, but also offers relevant contributions to integrating different data sources to improve predictive accuracy. Based on the evidence presented, Planet′s nanosatellites are a promising tool for environmental monitoring, particularly in contexts that demand continuous, large-scale observations, opening new possibilities for water-resource management and for understanding environmental impacts.
It is important to emphasize that, although PS data stand out for their high spatial resolution and frequent temporal coverage, these images are not free, unlike those provided by the MSI/Sentinel-2 sensor. For this reason, the use of PS imagery requires a careful cost–benefit assessment to determine whether the financial investment is compatible with the monitoring objectives. In the context of this study, the use of PS data was made possible through the Planet Education and Research Program, which justified their inclusion in the analysis. However, in professional applications, the acquisition cost must be weighed against the specific requirements of each monitoring project, considering whether the advantages offered by PS outweigh the free alternative provided by S2.
However, MSI/S2 imagery also presents limitations, such as lower spatial resolution compared with PS, which may hinder the detection of small-scale targets or phenomena. In addition, frequent cloud cover and lower temporal revisit in some regions can limit the applicability of S2 data in studies that require both high spatial and temporal resolution.
4. Conclusions
Based on the results, we conclude:
- 1.The methodology that combines orbital remote-sensing data with machine-learning techniques is suitable for predicting turbidity, TSS, Fe, P, and DO, but shows limitations for N, COD, and Chla.
- 2.The NIR band was a key covariate in all approaches (B8 for S2, B4 for PS). In addition, spectral indices, band ratios, and CHIRPS precipitation products exhibited strong predictive value for estimating water-quality parameters.
- 3.To improve model performance with PS data, radiometric normalization of the imagery is essential.
- 4.Tree-based models—particularly RF and Cubist—were more robust and higher-performing than KKNN and SVM-RBF.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ogashawara I. Mishra D.R. Gitelson A.A. Remote Sensing of Inland Waters: Background and Current State-of-the-Art Elsevier Inc.Amsterdam, The Netherlands 20179780128046548
- 2Saberioon M. Brom J. Nedbal V. Souček P. CísařP. Chlorophyll-a and Total Suspended Solids Retrieval and Mapping Using Sentinel-2A and Machine Learning for Inland Waters Ecol. Indic.202011310623610.1016/j.ecolind.2020.106236 · doi ↗
- 3Barbosa G.R. Introdução Ao Sistema de Informações Geográficas Available online: https://www.kufunda.net/publicdocs/sig-bd-jai.pdf(accessed on 15 December 2025)
- 4Arango J.G. Nairn R.W. Prediction of Optical and Non-Optical Water Quality Parameters in Oligotrophic and Eutrophic Aquatic Systems Using a Small Unmanned Aerial System Drones 20204110.3390/drones 4010001 · doi ↗
- 5Gholizadeh M.H. Melesse A.M. Reddi L. A Comprehensive Review on Water Quality Parameters Estimation Using Remote Sensing Techniques Sensors 201616129810.3390/s 1608129827537896 PMC 5017463 · doi ↗ · pubmed ↗
- 6Winston R.J. Dorsey J.D. Hunt W.F. Quantifying Volume Reduction and Peak Flow Mitigation for Three Bioretention Cells in Clay Soils in Northeast Ohio Sci. Total Environ.2016553839510.1016/j.scitotenv.2016.02.08126906696 · doi ↗ · pubmed ↗
- 7de Aragão R. Cruz M.A.S. Correia E.C.d.O. Machado L.F.M. de Figueiredo E.E. Impacto Do Uso Do Solo Pelo Aumento Da Densidade Populacional Sobre o Escoamento Numa Área Urbana Do Nordeste Brasileiro via Geotecnologias e Modelagem Hidrológica Rev. Bras. Geogr. Fís.20171054355710.5935/1984-2295.20140015 · doi ↗
- 8Bonansea M. Rodriguez M.C. Pinotti L. Ferrero S. Using Multi-Temporal Landsat Imagery and Linear Mixed Models for Assessing Water Quality Parameters in Río Tercero Reservoir (Argentina)Remote Sens. Environ.2015158284110.1016/j.rse.2014.10.032 · doi ↗