Multi-Scale Interactive Network with Color Attention for Low-Light Image Enhancement
Haoxiang Lu, Changna Qian, Ziming Wang, Zhenbing Liu

TL;DR
This paper introduces a new network for improving low-light images by combining local and global features with color attention.
Contribution
The novel MSINet uses a fusion module and color correction branch to enhance low-light images more effectively than existing methods.
Findings
MSINet outperforms state-of-the-art methods in low-light image enhancement.
The fusion module effectively combines local and global features across different scales.
Color correction branch ensures accurate color fidelity in enhanced images.
Abstract
Enhancing low-light images is crucial in computer vision applications. Most existing learning-based models often struggle to balance light enhancement and color correction, while images typically contain different types of information at different levels. Hence, we proposed a multi-scale interactive network with color attention named MSINet to effectively explore these different types of information for lowlight image enhancement (LLIE) tasks. Specifically, the MSINet first employs the CNN-based branch built upon stacked residual channel attention blocks (RCABs) to fully explore the image local features. Meanwhile, the Transformer-based branch constructed by Transformer blocks contains cross-scale attention (CSA) and multi-head self-attention (MHSA) to mine the global features. Notably, the local and global features extracted by each RCAB and Transformer block are interacted with by the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
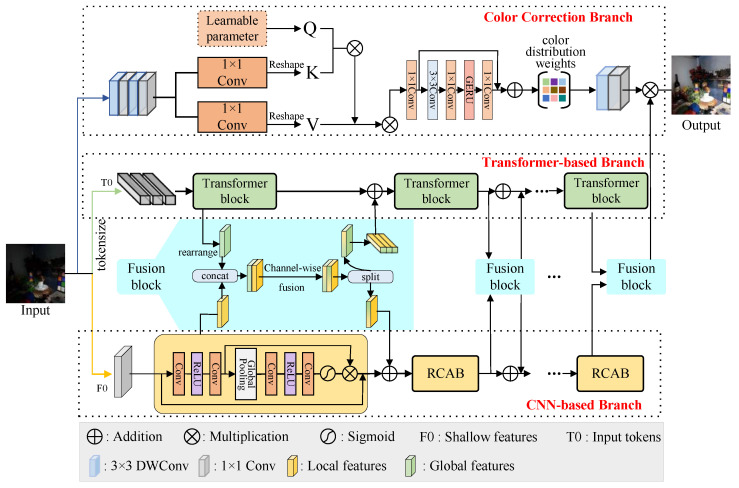 Figure 1
Figure 1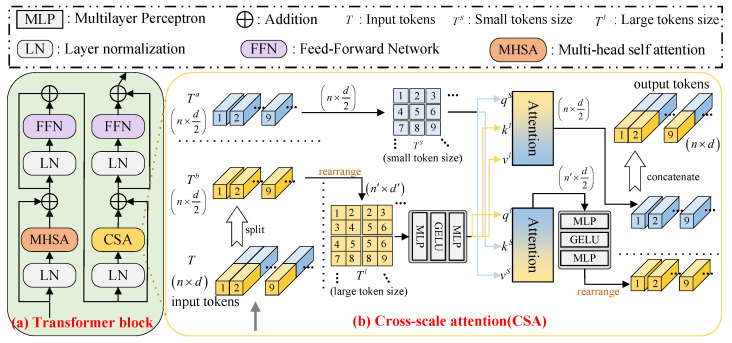 Figure 2
Figure 2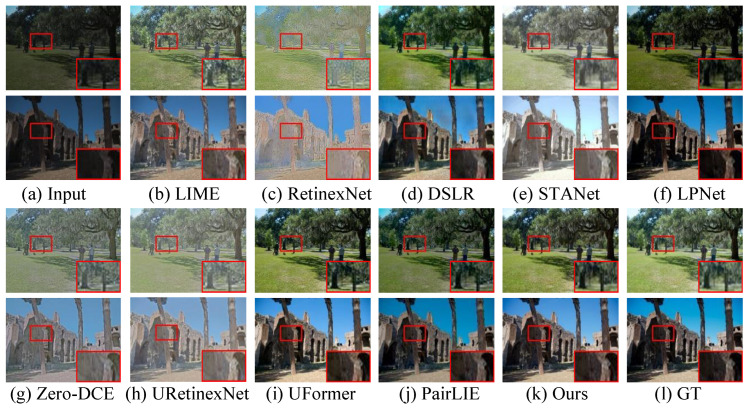 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5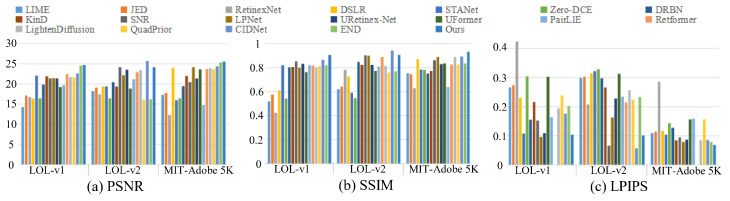 Figure 6
Figure 6 Figure 7
Figure 7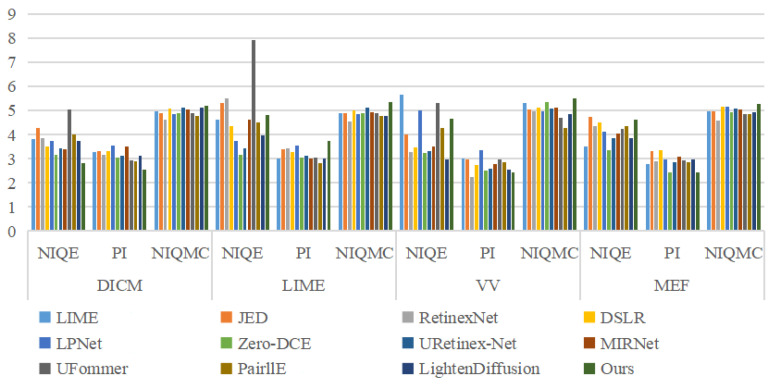 Figure 8
Figure 8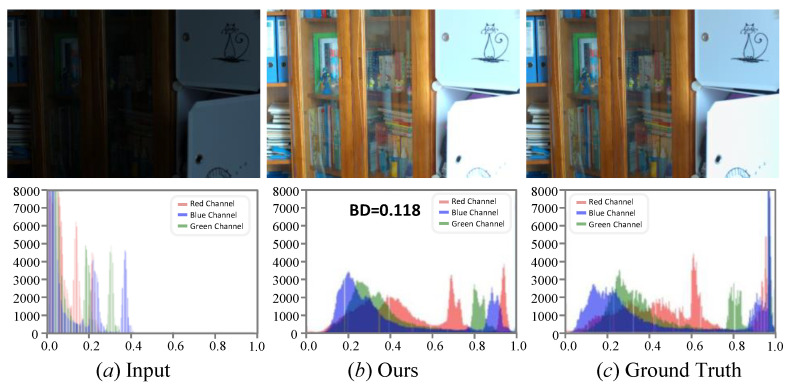 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11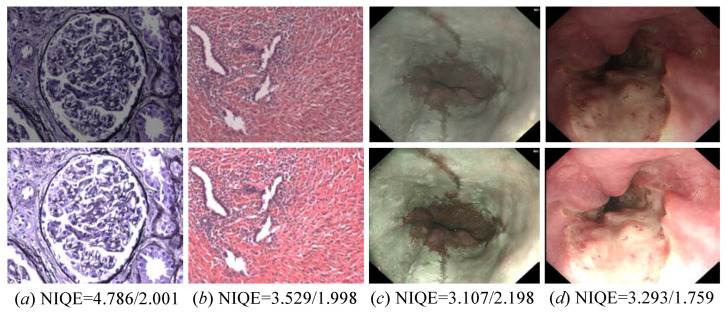 Figure 12
Figure 12 Figure 13
Figure 13- —National Natural Science Foundation of China
- —Guangxi Science and Technology Project
- —Guangxi Natural Science Foundation
- —Innovation Project of Guangxi Graduate Education
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsImage Enhancement Techniques · Generative Adversarial Networks and Image Synthesis · Advanced Image Fusion Techniques
1. Introduction
Images captured under low-light environments typically suffer from low brightness, low signal-to-noise ratio, and color distortion, which can significantly reduce the performance of high-level vision tasks such as object detection, segmentation, and scene understanding [1,2]. In the early stage, charge-coupled devices (CCD), complementary metal-oxide-semiconductor (CMOS) sensors and other advanced specialised-hardwares are used to obtain high-quality images under suboptimal lighting conditions [3]. But these hardwares are expensive and have operational complexity, limiting their application in the realworld. As a result, researchers gradually focus on designing software-driven low-light image enhancement (LLIE) approaches to restore degraded images with low illumination [4].
Numerous traditional LLIE methods containing histogram equalization (HE) [5], Retinex-based methods [6], and domain transformation-based methods [7] have been proposed for promoting the brightness and contrast of lowlight images. HE-based methods directly adjust the image pixels in a pixel-to-pixel manner to improve the contrast and illumination of lowlight images, but they may lead to over-enhancement and detail loss. Retinex-based methods typically decompose images into illumination and reflectance components to enhance the images’ visibility depending on the specific guidelines. For example, single-scale Retinex (SSR) and multi-scale Retinex with color restoration (MSRCR) [8] try to analyze lowlight images. They tend to introduce noticeable color deviations and blurry detail in enhanced images due to inaccurate estimation of illumination and reflectance components. The domain transformation-based methods transfer the original image into gradient, wavelet domains for detail enhancements, but suffer from a dramatic drop in restoration performance under complexity scenarios.
With the advancement of computing resources, learning-based methods [2,4,9], such as convolutional neural networks (CNNs), generative adversarial networks (GANs), and diffusion model, have proven effective in various computer vision tasks, with the help of their powerful feature extraction and representation capability. LLNet [10], the most groundbreaking learning-based LLIE work, stacked sparse denoising autoencoders for light improvement and denoising simultaneously. In recent years, researchers have proposed many advanced data-driven methods, such as JED [11], SID [12], IPT [13], PairLIE [14], etc., to entirely utilize the inherent relations among low-/normal-illumination images in training datasets, and these LLIE models exhibit outstanding performance in generating visually pleasing results with clearer details. Most above-listed LLIE models gain improvement by injecting the image pyramid [15], Retinex theory [16], meta-learning strategy [9], and other advanced technologies or substantially increasing the depth of the network. However, these LLIE methods seldom utilize the correlation and complementarity of global and local features. In addition, most existing methods only focus on enhancing brightness and contrast, while ignoring the color distribution of the original image.
To address these challenges, this paper proposes a multi-scale interactive network with color attention for lighting up degraded images captured under suboptimal lighting conditions, named MSINet. The proposed MSINet can simultaneously capture local textures and global context to effectively enhance the brightness and details of the inputs as well as remove their color deviation. Our MSINet contains three parallel branches, i.e., CNN-based branch, Transformer-based branch, and Color correction branch. The former can extract local features from the original input by stacking CNN blocks, and the Transformer-based branch based on stacked cross-scale Transformer blocks, including multi-head self-attention (MHSA) and cross-scale attention (CSA), can dig up global features. Meanwhile, the fusion block is introduced to realize the interaction of global and local features for analyzing their correlation and complementarity. The color correction branch built upon the self-attention can fully explore the color distribution in the original images.
We emphasize the primary contributions of this work as follows.
(1)We propose an efficient and robust LLIE method named MSINet, which integrates CNN and Transformer structures for balancing local detail extraction and global feature encoding. Extensive experiments show our MSINet can generate visually pleasing images.(2)We proposed a cross-scale Transformer module combining cross-scale attention (CSA) and multi-head self-attention (MHSA) to enhance the model’s multi-scale feature learning. Meanwhile, the CNN-based branch can fully explore the local feature.(3)We proposed a self-attention-based color correction branch to dig up color distribution weighting for color correction in the LLIE tasks. Additionally, we design a fusion block to analyze the correlation and complementarity of global–local features.
We demonstrate the organization of the remainder of this paper as follows. The previous LLIE methods related to our MSINet are reviewed in Section 2. In Section 3, the architecture of our model is demonstrated. In Section 4, we evaluate the proposed method on public benchmarks. Additionally, the analysis of detail enhancement, computational complexity, ablation study, and applications as well as limitations and future work are presented. Finally, the conclusions are given.
2. Related Works
2.1. CNN-Based LLIE Enhancement
CNN-based LLIE approaches [17,18] have demonstrated dramatic improvements due to their powerful nonlinear representation ability, which can learn nonlinear mapping from the lowlight inputs to their corresponding normal-light versions. For example, Liu et al. [7] designed a Guided Filter-inspired Network (GFNet) for lighting up low-light RAW image enhancement in a guided filter (GF)-like manner. Lim et al. [19] applied the Laplacian pyramid in a multi-scale network to adjust global illumination and restore fine details. Zhang et al. [20] proposed a deep color-consistent network to enhance the naturalness of the image by preserving color information. Although the above-listed methods can light up low-illumination images, they suffer from poor interpretability. Hence, the physical model including Retinex, dehazing model, is used to enhance the interpretability of the LLIE models [17,21]. Wei et al. [18] first injected the Retinex theory into the traditional convolutional neural networks (CNNs) to develop an end-to-end architecture called RetinexNet. Subsuquently, URetinex-Net [16], including initialization, unfolding optimization, and illumination adjustment modules as well as CRetinex [22] decomposing an image into reflectance, color shift, and illumination, is proposed for the LLIE tasks. Recently, multi-scale feature fusion [23,24], perceptual fidelity estimation techniques [25], meta-learning [9], collaborative learning [26], and other advanced technologies are employed to design more efficient LLIE methods. But most of these existing LLIE methods heavily rely on the high-quality paired datasets, limiting their applicability in the real world. To address this challenge, Jiang et al. [27] developed an unsupervised method based on GANs, which integrates a global–local discriminator to improve performance. Guo et al. [28] used a lightweight network that learns enhancement curves and iteratively enhances images. Yao et al. [29] presented a gradient-aware and contrastive-adaptive (GACA) learning framework by estimating more accurate gradient information and introducing a regularization constraint. Yan et al. [30] proposed a Horizontal/Vertical-Intensity (HVI) color space based on the polarized HS maps and learnable intensity. These self-/un-supervised learning-based methods inevitably generate color deviation and blurry details in enhanced images.
2.2. Transformer-Based LLIE Methods
The vision transformer (ViT) model based on the self-attention mechanism demonstrates powerful potential in capturing the global dependency of the input feature [31,32]. Cai et al. [33] proposed a one-stage Retinex-based transformer to estimate the illumination information for lighting up the low-light image. Zhang et al. [34] injected the multiple heads into a single network to perform denoising, luminance adjustment, refinement, and detail enhancement for the LLIE. Wu et al. [35] presented two key innovations: an improved Gaussian filtering-based image enhancement module and a hierarchical feature extraction network. Dang et al. [36] employed a lightweight model PPformer to extract both local and non-local information, and further fused them by the dual cross-attention mechanism for the LLIE tasks. Pei et al. [37] proposed a fast Fourier transform embedded noise-aware CNN-Transformer, which removes noise in both the spatial and frequency domains. Brateanu et al. [38] proposed a lightweight transformer-based network containing Channel-Wise Denoiser (CWD), Multi-Stage Squeeze and Excite Fusion (MSEF), and Multi-Headed Self-Attention (MHSA) for promoting the quality of low-light images. Wen et al. [39] performed the pure CNN-based estimator to generate a light-up feature map and a lit-up image, and the restorer based on the U-shaped network equipped with an Illumination-Guided Dual Attention Block (IGDAB) was used to denoise the lit-up image. Dong et al. [40] presented a new multi-scale CNN-Transformer hybrid framework guided by structure priors. Notably, the illumination-invariant edge detectors based on the UNet encoder–decoder architecture with the CNN-Transformer hybrid structure were used to extract robust structure priors. Most ViT-based methods focus on channel modeling to reduce expensive computational costs; however, they introduce spatial illumination inconsistencies, artifacts, and blurry details in restored images.
2.3. Diffusion-Based LLIE Methods
The diffusion model is a generative framework that gradually adds noise to disrupt the data structure and then learns the reverse denoising process, which has been wildly used in image restoration [41,42], medical image processing [43], and so on. Yi et al. [44] formulated the low-light image enhancement problem into Retinex decomposition and conditional image generation. Subsequently, they proposed a LLIE method named Diff-Retinex++ containing the Denoising Diffusion Model (DDM) and the Retinex-Driven Mixture of Experts Model (RMoE) [45]. Lin et al. [46] proposed the Attribute Guidance Diffusion framework (AGLLDiff), a training-free method for effective real-world LLIE. Yang et al. [47] employed the Diffusion-guided Degradation Calibration (DDC) module to narrow the gap between real-world and training low-light degradation, further developing the Fine-grained Target domain Distillation (FTD) module to find a more visual-friendly solution space. Huang et al. [48] integrated a size-agnostic diffusion process with a reverse process reconstruction loss to more accurately recover fine details. Hu et al. [49] employed the conditional correlation module (CCM) to effectively integrate color and illumination priors, and the residual decomposition network (RDN) was introduced to generate the reflectance image representing the color object. Jiang et al. [50] injected the wavelet transformation into the conditional diffusion model to achieve stable denoising and reduce randomness during inference. Jin et al. [51] proposed Dual-Conditional Guidance Sparse Diffusion (DCGSD), a physically explainable and prior guidance model, to light up low-illumination images. Although diffusion-based LLIE approaches can generate visually pleasing images from the lowlight inputs, they suffer from time-consuming, excessive computational resource consumption, and unstable restoration.
3. Methodology
We present the motivation for our proposed method in Figure 1; it can effectively enhance low-light images and preserve color fidelity and fine details. The MSINet is composed of three main components: a CNN-based branch, a Transformer-based branch, and a color correction branch. Specifically, the CNN-based branch first extracts shallow features through a convolutional layer with a size of . Then, to fully explore the local image features, the shallow features is fed to the successive stacked Residual Channel Attention Blocks (RCABs) (pure CNN blocks). This stage can be formulated as
where is the lowlight images, represents the CNN-based branch, represents the convolutional layer with a size of , and represents the pure CNN block.
The Transformer-based branch performs the successive stacked pure Transformer blocks based on cross-scale attention (CSA) and multi-head self-attention (MHSA) on the inputs to their global features. Meanwhile, the global-local features are aggregated by the fusion blocks to explore their complementarity and correlation.
where represents the global features extracted by the Transformer-based branch , and represents the fused features generated by the fusion block .
Finally, the color correction branch employs two successive Conv layers with kernel sizes of and to detect low-level features, and the learnable self-attention mechanism is used, fully exploring color distribution. We further yield visually pleasing images with vivid color by performing color distribution weighting on the fused feature maps.
where is the final output, ⊗ represents the multiplication operation, and represents the convolutional layer with a size of .
3.1. CNN-Based Branch
The CNN shows powerful potential local perception ability for lighting up low-illumination images. In our proposed MSINet, we design a pure CNN-based branch by stacking some Residual Channel Attention Blocks (RCABs). Given a lowlight input , the convolutional layer with a size of is performed to extract the shallow features of local regions. Subsequently, we feed these features into the stacked Residual Channel Attention Blocks (RCABs) to fully dig up the local image features. And the processing procedure can be defined as
where denotes the Residual Channel Attention Block (RCAB), and represents the local features generated by the Residual Channel Attention Block (RCAB). Notably, each RCAB only contains a series of Conv layers, ReLU, and global pooling, and the skip connection is also introduced into the RCAB to explore the model’s hierarchical feature extraction ability.
3.2. Transformer-Based Branch
The Transformer-based branch is designed to analyze the long-range dependency of features for perceiving the global image features. This branch is a pure Transformer dependent upon a stacked transformer block (as illustrated in Figure 2a), and each block contains a cross-scale attention (CSA) module and multi-head self-attention (MSHA) to fully explore the self-correlation and scale correlation of the features. Firstly, the input image is converted into multiple tokens , and each token represents a part of the image with dimension d. Then, the token is fed into the transformer block, and the operations within each involve several steps, namely
where represents the normalization layer, represents the feedforward neural network, and and represent the MHSA and CSA, respectively.
CSA: The CSA can promote the model’s ability to represent cross-scale features, and its structure is shown in Figure 2b. We detail a description of the procedure of the CSA as follows: the input tokens are embedded into , and then split along the axial dimension (i.e., the last dimension) into two parts, and . These parts are then used to generate , which is subsequently reconstructed to retain the structure of the original token while obtaining larger tokens. In this process, the stride is closely related to both the number of tokens and their dimensionality.
With the help of the CSA, the MSINet can generate a large number of overlapping tokens at different scales, which helps in discovering cross-scale repetitive structures in the image. To better exploit image blocks at different scales and transfer large-scale features to smaller blocks, the model uses tokens of a larger size ( ) during reconstruction. The network then processes and to calculate the cross-scale attention weights, and further extract richer information from these tokens. Specifically, the first step is to generate query, key, and value from the two token sets and . And corresponds to , while corresponds to . Finally, by adjusting the dimensionality, the CSA improves the efficient information transfer between different scales, optimizing the image restoration process without additional computational burden.
As we know, the size of the large and small tokens plays a key role. Hence, we perform the CSA module with different combinations of large and small token sizes on the LOL-v1 dataset. The PSNR scores of our MSINet with different token sizes are presented in Table 1. It can be observed that the small and large token sizes are respectively set to 3 and 4 and can generate higher PSNR scores.
Fusion module: For fully capturing feature representation at different branches, we propose a multi-branch feature fusion module, which horizontally connects the intermediate features of each branch to enable more efficient feature interaction and integration. This design allows the model to leverage the unique strengths of each branch, improving the overall performance of the network. Figure 1 illustrates the specific structure and implementation of the fusion module.
Specifically, for the intermediate features and output from the RCAB and Transformer block, feature fusion is performed through the fusion module , which combines these features from different branches by capturing cross-branch dependency. The fusion is mathematically expressed as follows:
where represents the fused feature representation, where the ‘rearrange‘ operation indicates a reordering of image features, and the symbol ‖ denotes concatenation along the channel dimension. Additionally, the fusion module uses a convolutional layer to improve feature fusion along the channel dimension. Except for the final fusion module (i.e., ), the fused feature is evenly split along the channel dimension into two parts, denoted as and
3.3. Color Correction Branch
This paper introduces a unique color restoration branch designed to enhance the model’s ability to perceive and correct local color information in images. Specifically, the branch first extracts shallow features from the input image by combining deep convolution layers with standard convolution, and then expands the feature channels to enhance the image’s color representation. These enhanced shallow features are then passed through a specially designed Color Attention module, which uses learned query (Q), key (K), and value (V) to efficiently associate features. The Transformer-based self-attention mechanism in this module comprehensively explores and extracts the color features of the image.
This module effectively captures local color features in the image and performs color correction. Compared to traditional image enhancement methods, it more accurately restores the image’s color details. Specifically, by adjusting the convolution kernels and sizes of each convolution layer, the color restoration branch adapts the image’s color balance, reducing color deviations caused by lighting and noise. Finally, through the combination of multiple convolution and Transformer modules, the branch recovers the color details of the image and enhances its visual quality.
3.4. Loss Function
This paper employs and visual geometry group (VGG) perceptual loss functions to create our proposed method for enhancing lowlight images and detail enhancement. Among them, loss is robust and less sensitive to outliers, which can promote stable and faster convergence of the model by calculating the pixel-wise differences between the predicted image and its ground truth. And it can be expressed as
where N is the total number of samples. y and represent the reference and output images, respectively.
VGG loss can measure the difference between the predicted image and its ground truth in deep feature space to make the former exhibit visually satisfactory perception. The VGG loss function can be defined as
where denotes the pre-trained VGG network. and denote the feature maps extracted by the pre-trained VGG from the ground truth and enhanced images, respectively.
Finally, the total loss function used in this paper can be defined as
where is a weighting factor, empirically finding that the total loss function with can guarantee our method generates visually pleasing images.
4. Experimental Results and Analysis
This section first describes the implementation details and experimental settings. Next, we perform comprehensive evaluations on paired and unpaired datasets to verify the effectiveness of our MSINet. Finally, the analysis of detail enhancement, computational complexity, ablation study, and applications as well as limitations and future work is performed.
4.1. Implementation Details
We use the MIT-Adobe 5K [52], LOL-v1 [18], and LOL-v2 [53] datasets for verifying the performance in the LLIE tasks. Among them, the MIT-Adobe 5K [52] contains 4500 pairs of low-/normal-light training images and 500 pairs of low-/normal-light testing image pairs, the LOL-v1 [18] contains 485 pairs of low-/normal-light training image pairs and 15 pairs of low-/normal-light testing image pairs, and the LOL-v2 [53] contains 900 pairs of low-/normal-light training images and 100 pairs of low-/normal-light testing image pairs. Note that the training and testing images are resized to the size of . Additionally, we also perform our proposed LLIE model on four unpaired datasets, including DICM, LIME, VV, and MEF, to further test its robustness in real-world applications.
All validation experiments are implemented in the Pytorch framework on an NVIDIA Tesla P100 GPU. We augment the training dataset through rotating by and horizontal flipping. During training, the ADAM optimizer with , , and is used to train the parameters of our model. The initial learning rate is set to and fine-tuned to after 50 epochs. A batch size of 8 is applied.
4.2. Experimental Settings
Our method is compared with eighteen LLIE methods, including traditional methods, LIME [54], JED [11]; supervised learning-based methods, SID [12], IPT [13], RetinexNet [18], STANet [55], MIRNet [56], DRBN [57], KinD [58], LPNet [15], UFormer [16], PairLIE [14] and RetFormer [33], LightenDiffusion [41], QuadPrior [59], CIDNet [30], and END [60]; and self/un-supervised learning-based methods, RUAS [61], DSLR [19], Zero-DCE [28], URetinex-Net [16]. Notably, these above-listed comparison methods use publicly available source codes with recommended parameters to reproduce the enhanced results.
Except for comparison of visual perception, we also adopt commonly used image quality evaluation metrics to quantitatively assess their performance. The peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), and perceptual image patch similarity (LPIPS) are used to evaluate the MIT-Adobe 5K [52], LOL-v1 [18], and LOL-v2 [53] datasets. While the former two metrics are full-reference evaluation, the LPIPS is no-reference evaluation. Among them, a higher PSNR or SSIM score indicates more realistic restoration results, while a lower LPIPS score suggests a better visual perception. For the DICM, LIME, VV, and MEF datasets, the natural image quality evaluator (NIQE), perceptual index (PI), and no-reference image quality metric (NIQMC) are used to assess the enhanced images. And these three metrics are no-reference evaluation. Among them, a lower NIQE or PI score suggests a better natural-looking and visual perception. A higher NIQMC score indicates a greater amount of image information.
4.3. Comprehensive Evaluation on Paired Datasets
The visual evaluation of our MSINet is compared with state-of-the-art LLIE approaches on the 5K, LOL-v1, and LOL-v2 datasets to verify their performance in the LLIE tasks.
Qualitative Evaluation. On the MIT-Adobe 5K dataset, as shown in Figure 3, LIME [54] and RetinexNet [18] struggle with overexposure and unnatural color shifts. And the latter yields unnatural-looking visual experience and blurry details. DSLR [19] creates high-contrast images with observable artifact haloes. STANet [55] introduces local overenhancement and unwanted color deviation. Although LPNet [15] effectively lights up the brightness of lowlight images, it is unsatisfactory in removing local underenhancement. Zero-DCE [28] and URetinex-Net [16] yield hazy-like and visually unnatural-looking images from the lowlight inputs, and they also fail in removing color distortion and inherent noise. UFormer [16] shows satisfactory performance in the LLIE task, but some UFormer-enhanced images exhibit hazy-like (e.g., the second row in Figure 3i) and local dark areas (e.g., the third row in Figure 3i). PairLIE [14] struggles to balance the contrast stretch and detail enhancement for the low-illumination images. In contrast, our proposed method achieves a more balanced enhancement performance, characterized by refined texture rendition and minimized perceptual distortion, thereby yielding superior visual fidelity.
Figure 4 and Figure 5 present the enhanced results randomly selected from the LOL-v1 and LOL-v2 datasets. For the LOL-v1 dataset, RetinexNet [18] and Zero-DCE [28] generate a greenish tone and unsatisfactory visual perception. LIME [54] cannot yield high-contrast images or remove local darkness. DSLR [19], URetinex-Net [16], and LPNet [15] fail to achieve color correction, and the former two methods inject blurry details and edges in enhanced images. STANet [55] and PairLIE [14] promote the quality of lowlight images, but successfully remove artifact haloes. For the LOL-v2 dataset, all comparison methods cannot light up the partially dark areas. Among them, the performance of the UFormer [16] is the poorest, followed by that of PairLIE [14]. URetinex-Net [16] generates high-brightness images with unsatisfactory contrast. LightenDiffusion [41] introduces color deviation (e.g., the sky part of the image in Figure 5g), and QuadPrior [59] fails in removing inherent noise and making details clearer. CIDNet [30] injects observable color deviation and partial darkness. In comparison, our method effectively removes color deviations, highlights the structural details, and improves visibility without over-enhancement or oversaturation.
Quantitative Evaluation. From the quantitative evaluation scores on the LOL-v1, LOL-v2, and MIT-Adobe 5K datasets in Table 2, it can be seen that our MSINet has higher scores of the PSNR, SSIM, and LPIPS on the MIT-Adobe 5K dataset than the compared methods. On the LOL-v1 dataset, the proposed MSINet has comparable and higher values of the PSNR and SSIM. Additionally, our MSINet achieves the second-best performance on the LOL-v2 dataset. To clearly demonstrate the PSNR, SSIM, and LPIPS scores on the LOL-v1, LOL-v2, and MIT-Adobe 5K datasets, we further drew their bar charts in Figure 6. The qualitative and quantitative results suggest that our MSINet can effectively produce high visibility and natural color with significant enhancement of the contrast, brightness, and texture details.
4.4. Comprehensive Evaluation on Unpaired Datasets
We perform them on unpaired datasets, including DICM, LIME, VV, and MEF, to further evaluate the robustness of our MSINet and other compared LLIE methods in both qualitative and quantitative assessments.
Qualitative Evaluation. Figure 7 demonstrates enhanced results generated by these state-of-the-art approaches randomly selected from the DICM, LIME, VV, and MEF benchmarks. The following observations from these enhanced images can be easily obtained: The original lowlight images suffer from local low-contrast and unsatisfactory contrast and illumination as well as blurry details. RetinexNet [18] successfully lights up lowlight images, but generates unnatural-looking visual experience and unwanted artefact haloes. LIME [54] consistently yields visually pleasing results without fine-tuning its parameters on these four datasets. But the LIME-enhanced images still confront lower contrast and color deviation. DSLR [19] inevitably introduces blocking effects in enhanced results (e.g., the third/forth rows in Figure 7d) and fails in removing local extremely lowlight areas. URetinex-Net [16] and UFommer [31] show unsatisfactory performance in removing local over-enhancement. In addition, UFommer [31] introduces an observable checkerboard effect in some enhanced images. Zero-DCE [28] can effectively remove unwanted local extremely-low-illumination areas, while it fails in detail enhancement and noise suppression. RetFormer [33], UFormer [16], DSLR [19], PairLIE [14], and STANet [55] cannot tackle local under-exposure and fail in local detail boosting. STANet [55] introduces color distortion (e.g., the second/third rows in Figure 7e) and local over-enhancement (e.g., the third row in Figure 7e) for some low-illumination images. PairLIE [14] can yield observable artefact haloes, as demonstrated in the first row in Figure 7j. RetFormer [33] also fails in removing color distortion. LPNet [15] generates high-contrast images and clearer details, while unsuccessfully removing local over-enhancement (e.g., the third row in Figure 7f) and enhancing the contrast of the dark areas. In comparison, our model produces visually appealing results with better control over exposure, preserving the details in both bright and dark regions. The image sharpness and clarity are enhanced while maintaining a natural appearance. The fine textures, especially in the foreground and background, are well-preserved, and there are no noticeable color shifts or over-enhancement.
Quantitative Evaluation. We further employ the NIQE, PI, and NIQMC to evaluate the performance of these LLIE methods quantitatively. The NIQE, PI, and NIQMC scores of different LLIE methods on the DICM, LIME, VV, and MEF datasets are shown in Table 3. From the quantitative evaluation scores in Table 3, it can be found that our MSINet achieves the best scores in NIQE (2.816), PI (2.553), and NIQMC (5.219) on the DICM dataset. On other datasets, our method also yields lower NIQMC and the second-best PI scores than the compared LLIE methods. For clearly demonstrating the NIQE, PI, and NIQMC scores on the DICM, LIME, VV, and MEF datasets, we further drew their bar charts in Figure 8. In conclusion, the qualitative and quantitative results suggest that our MSINet works better in color correction, detail boosting, and contrast stretch for the LLIE tasks.
4.5. Comprehensive Evaluation of Detail Enhancement
High-quality images with clearer details play an important role in object detection and scene understanding. We compare our proposed MSINet with other compared LLIE in terms of detail boosting. As illustrated in Figure 3, Figure 4, Figure 5, Figure 6 and Figure 7, our proposed MSINet significantly lights up lowlight images and removes color deviation from a global view. From a local view, our method can effectively make the fine structural details clearer than other compared methods. Furthermore, we introduce the average gradient (AG), local variance (LVar) and local standard deviation (LSTD) to verify the detail enhancement capability of the model. Among them, the AG can measure the detail information, while the LVar and LSTD can measure the spatial variations in noise and features. Table 4 presents the AG, LVar, and LSTD scores of different LLIE methods. From Table 4, it can be easily found that our proposed MSINet yields more satisfactory AG, LVar, and LSTD scores than the compared approaches. The quantitative and qualitative results indicate that our MSINet is superior compared to LLIE methods in detail enhancement.
4.6. Comprehensive Evaluation of Color Correction
Most LLIE methods can light up images and enhance details, but inevitably introduce color deviations. In our experiments, we further verify the color correction ability of our MSINet on the LOL-v1 dataset. Additionally, the [7] and Bhattacharyya Distance (BD) [63] are introduced to quantitatively evaluate the color correction capability of the compared LLIE methods and our MSINet. Among them, the former is a metric for color distortion, and the latter can measure the color difference between the enhanced images and their reference ones. Table 4 presents the average and Bhattacharyya Distance (BD) scores of different LLIE methods. It can be easily observed that our method yields lower BD and scores than the compared methods, indicating that the enhanced images generated by the MSINet share similar color distribution with the reference image.
Following references [64,65], we present the visual and corresponding histogram of the original, enhanced, and reference images (as shown in Figure 9) to further demonstrate the physical process of our MSINet for the LLIE tasks. From Figure 9, we can observe that the original image exhibits low illumination and color deviation, and its corresponding histogram is distributed in the area with smaller pixel values. The image processed by our MSINet shows high brightness and vivid color, and its corresponding histogram is distributed more uniformly by pixel interpolation for the lowlight input. The most likely reason is that the Bayer filter sensors make only the smaller value pixels receive the wavelength light under suboptimal lighting conditions. Our proposed MSINet reduces the difference in spectral response among the wavelengths of the R, G, and B channels for removing the color deviation from the enhanced results.
4.7. Comprehensive Evaluation of Computational Complexity
Table 5 presents the Param, Flops, and runtime of our MSINet and all the above-listed comparison LLIE methods on the LOL-v1 dataset to comprehensively evaluate their computational complexity. It can be easily found that Zero-DCE [28] enjoys lower computational complexity and faster inference speed. LightenDiffusion [41] encounters a heavy computational burden, limiting its application in the real-world. In contrast, our proposed MSINet can balance the computational complexity as well as inference speed and enhanced results for the LLIE tasks.
4.8. Ablation Study
We further perform an ablation study on our proposed MSINet to test the effectiveness of each component. The ablation studies include (a) our method without residual channel Attention block (-w/o RCAB), (b) our method without Cross-Scale Attention Module (-w/o CSA), and our method without color correction Branch (-w/o CCB).
Figure 10 shows the visual comparisons on the MIT-Adobe 5K, LOL-v1, and LOL-v2 datasets. The following visual results can be observed: (1) -w/o RCAB fails in detail boosting for the LLIE tasks and introduces unnatural-looking visual experience in some enhanced images; (2) -w/o CSA lights up low-illumination images and promotes contrast, but the enhanced images suffer from blurry boundaries and details; (3) -w/o CCB generates observed color deviation in enhanced images; (4) the full model (MSINet) with all key components can effectively yield visually pleasing images with vivid color and clearer details.
Furthermore, we present the quantitative scores of the ablated models for the MIT-Adobe 5K, LOL-v1, and LOL-v2 datasets in Table 6. It can be found that our MSINet can create more satisfactory quantitative scores than the ablated models across three public benchmarks, benefiting from each key component.
4.9. Generalization of Our Proposed Method
We first perform our method on underwater images to test the generalization of our proposed method. The training/testing datasets are randomly selected from the UCCS benchmark in the ratio of 7:3. Figure 11 demonstrates the enhanced results randomly selected from the UCCS benchmark. Intuitively, the input underwater images exhibit unsatisfactory visual perception, whereas our method can effectively promote the quality of the underwater images. We also present the NIQE score of the input and its corresponding enhanced images, and the latter has a superior NIQE score.
The proposed MSINet also works well on medical images including endoscopic and pathological images with low contrast. Notably, the endoscopic images are randomly selected from the CVC-ClinicDB dataset (https://tianchi.aliyun.com/dataset/93690 (accessed on 20 October 2025)), and the pathological images are randomly selected from the LUAD-HistoSeg dataset (https://drive.google.com/drive/folders/1E3Yei3Or3xJXukHIybZAgochxfn6FJpr (accessed on 20 October 2025)). As illustrated in the first rows of Figure 12, the original endoscopic images and pathological images encounter low contrast and blurry details, which may deliver compromised information for disease diagnosis, prognosis analysis, and therapeutic effect prediction in clinical analysis. On the contrary, our MSINet shows satisfactory performance in contrast stretch and detail boosting for endoscopic images and pathological images. In addition, we also present the NIQE score of the original input and its corresponding enhanced results. It can be easily found that the enhanced results generated by the MSINet can generate more satisfactory NIQE scores. Experiments suggest that our MSINet exhibits solid generalization in restoring the quality of the endoscopic images and pathological images.
4.10. Limitations and Future Work
The LLIE method can enhance lowlight images and further promote the performance of object detection, image classification, and other advanced computer vision tasks. Our proposed MSINet can work well in yielding more satisfactory results with vivid color and clearer details from low-illumination images in most situations, whereas it fails in noise reduction, local exposure control for lowlight images with local over-exposure, boosted noise, and so on. For example, Figure 13 illustrates some failure instances created by our proposed MSINet. Intuitively, the enhanced images exhibit vivid color and high contrast, but they also contain observed noise, artefact halos, and local over-enhancement. The reason may be that our MSINet directly processes high-frequency components with the inherent noise of the lowlight input. Additionally, our method does not take into account the enhancement of images with local overexposure. In the future, we will promote learning and a specialised denoising module for tackling these challenging issues.
5. Conclusions
This paper presents a multi-scale interactive network with color attention named MSINet for light enhancement and color correction. The MSINet is a three-branch CNN-Transformer hybrid structure containing CNN-based branch, Transformer-based branch, and a color correction branch. The CNN-based branch, a pure CNN network, can fully explore the local image features by the stacked residual channel attention blocks (RCABs), and the Transformer-based branch, a pure Transformer network, can mine the global features by the stacked Transformer blocks containing cross-scale attention (CSA) and multi-head self-attention (MHSA). Meanwhile, we design a fusion module to integrate the global and local features extracted by each RCAB and Transformer block. Additionally, we further employ the color correction branch based on self-attention (SA) to learn the color distribution information for removing the color deviation. Experimental results on different datasets have shown that our MSINet can generate visually pleasing images with clearer details and more vivid color compared with LLIE methods.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Nasir M.F. Rehman M.U. Hussain I. A self-attention guided approach for advanced underwater image super-resolution with depth awareness IEEE Open J. Comput. Soc.202561715172510.1109/OJCS.2025.3623788 · doi ↗
- 2Li M. Jia T. Wang H. Ma B. Lu H. Lin S. Cai D. Chen D. AO-DETR: Anti-overlapping DETR for X-Ray prohibited items detection IEEE Trans. Neural Networks Learn. Syst.202536120761209010.1109/TNNLS.2024.348783339504297 · doi ↗ · pubmed ↗
- 3Li C. Guo C. Loy C.C. Learning to enhance low-light image via zero-reference deep curve estimation IEEE Trans. Pattern Anal. Mach. Intell.2021444225423810.1109/TPAMI.2021.306360433656989 · doi ↗ · pubmed ↗
- 4Huang C. Wang Y. Jiang Y. Li M. Huang X. Wang S. Pan S. Zhou C. Flow 2GNN: Flexible two-way flow message passing for enhancing GN Ns beyond homophily IEEE Trans. Cybern.2024546607661810.1109/TCYB.2024.341214938985552 · doi ↗ · pubmed ↗
- 5Li C. Liu J. Zhu J. Zhang W. Bi L. Mine image enhancement using adaptive bilateral gamma adjustment and double plateaus histogram equalization Multimed. Tools Appl.202281126431266010.1007/s 11042-022-12407-z · doi ↗
- 6Yang W. Wang W. Huang H. Wang S. Liu J. Sparse gradient regularized deep retinex network for robust low-light image enhancement IEEE Trans. Image Process.2021302072208610.1109/TIP.2021.305085033460379 · doi ↗ · pubmed ↗
- 7Liu X. Zhao Q. Guided filter-inspired network for low-light RAW image enhancement Sensors 202525263710.3390/s 2509263740363077 PMC 12074441 · doi ↗ · pubmed ↗
- 8Wang F. Zhang B. Zhang C. Yan W. Zhao Z. Wang M. Low-light image joint enhancement optimization algorithm based on frame accumulation and multi-scale Retinex Ad Hoc Netw.202111310239810.1016/j.adhoc.2020.102398 · doi ↗