A discontinuity in motion perception during fixational drift
Josephine C. D'Angelo, Pavan Tiruveedhula, Raymond J. Weber, David W. Arathorn, Jorge Otero-Millan, Austin Roorda

TL;DR
The study shows that during eye movements, people perceive motion differently depending on how it aligns with retinal slip, revealing a sharp boundary in visual perception.
Contribution
The research identifies a sharp discontinuity in motion perception during fixational drift, revealing a new boundary in how visual motion is processed.
Findings
Stimuli moving in the direction of retinal slip appear stable regardless of motion magnitude.
Stimuli moving in the direction of eye motion are perceived as moving.
Background content farther than 4° from the stimuli reduces the effect.
Abstract
The human visual system is tasked with perceiving stable and moving objects despite ever-present eye movements. Normally, our visual system performs this task exceptionally well; indeed, under conditions with frames of reference, our ability to detect relative motion exceeds the sampling limits of foveal cones. However, during fixational drift, if an image is programmed to move in a direction consistent with retinal slip, little to no motion is perceived, even if this motion is amplified. We asked: Would a stimulus moving in a direction consistent with retinal slip, but with a smaller magnitude across the retina, also appear relatively stable? We used an adaptive optics scanning light ophthalmoscope to deliver stimuli that moved contingent to retinal motion and measured subjects’ perceived motion under conditions with world-fixed background content. We also tested under conditions with…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
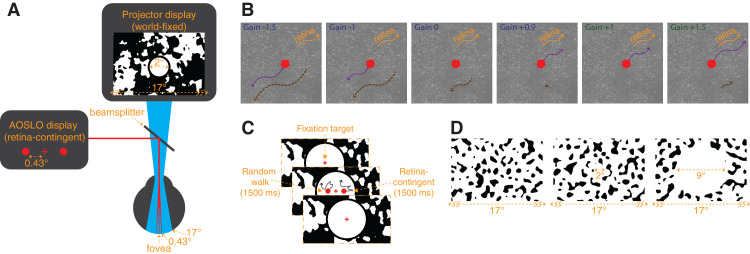 Figure 1
Figure 1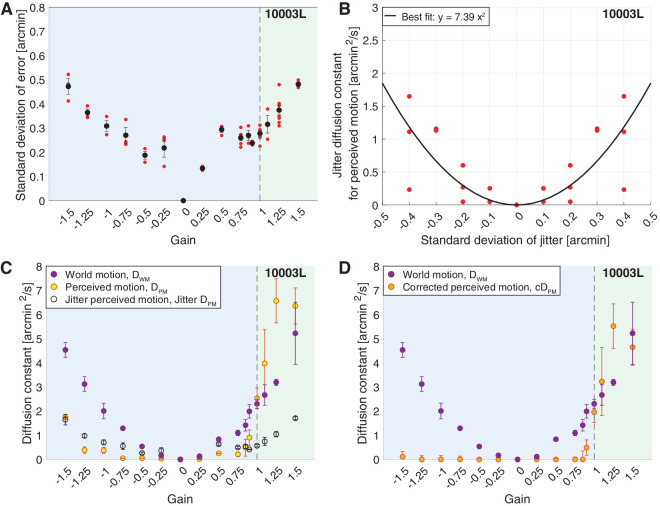 Figure 2
Figure 2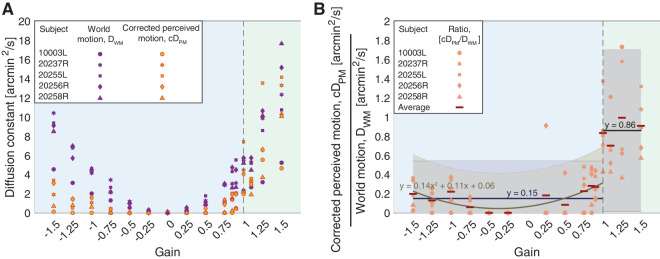 Figure 3
Figure 3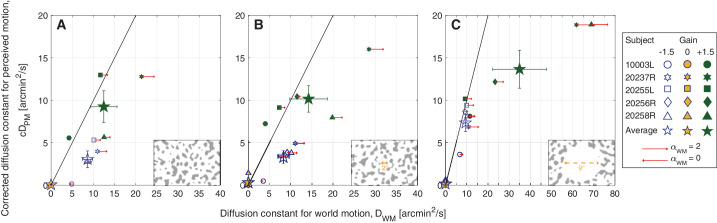 Figure 4
Figure 4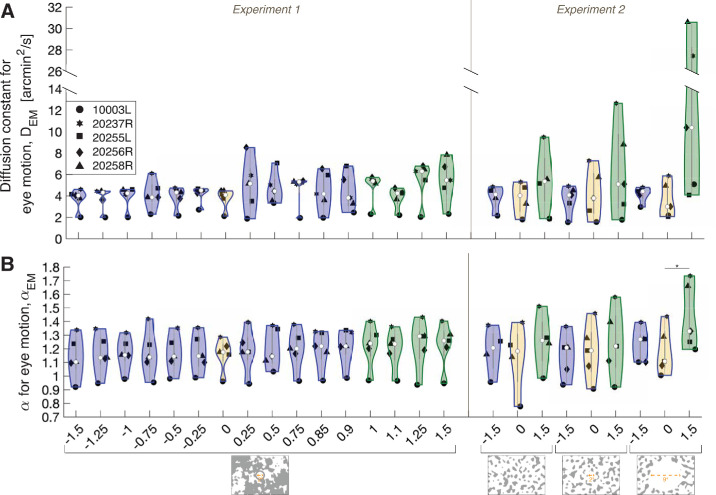 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsVisual perception and processing mechanisms · Ophthalmology and Visual Impairment Studies · Motor Control and Adaptation
Introduction
Our eyes are never stable; even when fixating on a small target, they make continuous miniature movements (Ratliff & Riggs, 1950). Despite this constant self-motion, the human visual system in general can properly perceive stable objects as stable and can detect moving objects with a level of precision that surpasses the sampling limits of the photoreceptors (Westheimer, 1975). To achieve this, the visual system requires world-fixed visual content which serves as a frame of reference (Legge & Campbell, 1981).
Yet, there exists a paradoxical exception: An image moving in a direction consistent with the direction of retinal slip appears relatively stable as long as the visual scene is filled with world-fixed retinal image background content (Arathorn, Stevenson, Yang, Tiruveedhula, & Roorda, 2013; D'Angelo, Tiruveedhula, Weber, Arathorn, and Roorda, 2024; Riggs, Ratliff, Cornsweet, & Cornsweet, 1953); and when all visual content is removed, this same image appears to be moving with a significantly higher magnitude of motion (D'Angelo et al., 2024). This phenomenon suggests that information from the retinal image informs the visual system about its direction of eye motion and renders everything in the perceived image that is moving in a direction consistent with retinal slip as being relatively stable.
The retinal contribution to stable motion perception aligns with conclusions from a series of investigations by Murakami, Cavanagh, and colleagues (Murakami & Cavanagh, 1998; Murakami & Cavanagh, 2001; Özkan, Anstis, ’t Hart, Wexler, & Cavanagh, 2021) with the caveat that the retina-derived signal also drives the “illusion of relative stability” that we report here and in previous papers. Retinal contributions to motion perception are also increasingly implicated in saccade detection and/or suppression. It has been found that the spatial frequency content of background image content on the retina affects saccadic suppression in human psychophysical measures as well as in retinal electrophysiology (Idrees, Baumann, Franke, Münch, & Hafed, 2020). It has also been shown that images moving across the retina in a manner that is consistent with saccades, but not driven by saccades elicit similar levels of saccadic suppression (Rolfs, Schweitzer, Castet, Watson, & Ohl, 2025).
The illusion of relative stability suggests that there is a discontinuity in motion perception during drift, where direction is the critical parameter that governs how motion is perceived. Specifically, for images moving in a direction consistent with retinal slip, little to no motion is perceived, and for images moving in any other direction, the motion is readily detectable. In the present study, we assessed the sharpness of this discontinuity by measuring the perceived motion of stimuli that moved in a direction consistent with retinal slip with decreasing magnitudes, and of stimuli that moved in the same direction as eye motion. Next, we determined the extent to which the world-fixed retinal image background content drives this phenomenon by performing a second experiment in which we varied the proximity of the background content to the stimuli.
This work builds on our understanding of this paradoxical phenomenon that disrupts our hyperacute sensitivity to detect relative motion. We make the following new contributions:
- 1)Our findings suggest a sharp discontinuity in motion perception during fixational drift. Even a stimulus moving in the same direction as eye motion but with a slower speed, and therefore slipping opposite to eye motion with 10% of the retinal motion of a world-fixed stimulus, appears relatively stable.
- 2)We discovered that, even if a stimulus is moving on top of or very close to high-contrast, high-spatial-frequency, world-fixed edges, as long as it moves opposite to eye motion, it appears relatively stable.
- 3)We determined that this phenomenon depends on the presence of retinal image background content within several degrees of the stimuli, and displacing background content approximately diminishes the effect.
Two objects moving in the same direction but with different retinal slip magnitudes is a unique and rare situation. We cannot think of a situation where this behavior we show here would have a functional use. Rather, we believe it is the exceptional outcome of a retina-based motion detection system that encodes directions and not magnitude for informing the percept.
Methods
Subjects
Five subjects provided informed consent and participated in the experiments (subject number, age, sex): (10003L, 58, M), (20237R, 27, F), (20255L, 24, M), (20256R, 23, F), and (20258R, 30, F). One subject is a co-author on this paper; the other four subjects were experienced with psychophysical tasks. All procedures were approved by the Institutional Review Board at the University of California, Berkeley. Before the experiment, subjects applied one drop of 1% tropicamide and one drop of 2.5% phenylephrine hydrochloride to dilate and cycloplege.
Adaptive optics scanning light ophthalmoscopy
Retinal imaging and stimulus delivery were performed using a multiwavelength AOSLO (Mozaffari, LaRocca, Jaedicke, Tiruveedhula, & Roorda, 2020; Roorda et al., 2002). Light from a supercontinuum laser (SuperK Extreme; NKT Photonics, Birkerod, Denmark) was split into three independent channels. The 940-nm wavelength was used to continuously measure the optical imperfections of the eye, which were corrected with a deformable mirror (DM97-08; ALPAO, Montbonnot-Saint-Martin, France), enabling near diffraction-limited resolution. The 840-nm wavelength imaged a 1.71° field of the retina. The 680-nm wavelength was modulated by an acousto-optic modulator (AOM) to deliver three independent stimuli (Figure 1A). This was possible by updating the FPGA board to allow up to three retina-contingent stimuli, rather than one. This new feature was an upgrade from previous work (D'Angelo et al., 2024). The system had a vertical frame rate of 60 Hz and a fast horizontal scan rate of approximately 16 kHz, rendering 512 × 256 pixel video recordings. Each pixel subtended 0.2 × 0.4 arcmin of visual angle. The average powers of the 940-nm, 840-nm, and 680-nm lasers were 50.3 µW, 110.1 µW, and 3.53 µW, which correspond to equivalent luminance values of 0.0031 cd/m^2^, 0.83 cd/m^2^, and 1,200 cd/m^2^ using methods described in Domdei et al. (2018).
Display configuration. (A) The AOSLO drew three 680-nm stimuli: a central fixation cross, and two horizontally offset circular stimuli positioned 0.43° nasal and 0.43° temporal from the cross. Concurrently, over its 17° field of view, the projector displayed world-fixed patterns, dependent on the experiment. In experiment 1, the background was filled with a blurred, then binarized 1/f noise pattern with a 2°-diameter central white circle with a surrounding black ring that overlayed the 680-nm stimuli, shown in (A). In experiment 2, the background was filled with a noise pattern that was generated by filtering white noise with a Gaussian bandpass filter at 0.5 cpd (0.5 cpd standard deviation), and binarizing the pattern, shown in (D). (B) Rules for the retina-contingent stimuli. Each panel shows examples of different retina-contingent stimuli undergoing identical retinal trajectories, indicated by the orange arrows. The purple arrows indicate the world trajectories of the retina-contingent stimuli. The dashed-brown arrows indicate the stimuli's image motion across the retina. Gains more than 1 move in the same direction as eye motion (orange and dashed-brown arrows point in the same direction), whereas Gains less than 1 move opposite to eye motion (orange and dashed-brown arrows point in opposite directions). (C) Experimental sequence. Subjects fixated on a world-stationary cross and initiated a 1,500-ms presentation of two stimuli that moved with different rules. The left stimulus moved in a random walk, independent of eye motion, and the right stimulus moved contingent to eye motion with a Gain that ranged from −1.5 to +1.5. (D) Experiment 2 background conditions. The patterns extended over the full 17° field of view (Left), or surrounded a 2°-diameter white circular opening (middle), or surrounded a 9°-diameter white circular opening (right). The AOSLO stimuli were presented at the center of the displays and the subject performed the same experimental protocol shown in (C). For the no-white-circle and 2°-diameter white circle conditions, the fixation cross remained on for the entire duration. For the 9°-diameter white circle condition, the fixation cross turned off during the 1,500-ms presentation of the stimuli.
Real-time eye tracking
When imaging with an AOSLO, eye movements expand, compress, or distort the retinal images. To mitigate these effects, the system recovers and then corrects for the eye movements in real time. This is achieved through the following: At the beginning of the experiment, the experimenter selects a reference frame. During the experiment, as the 512 × 16 pixel strips are acquired by the fast horizontal scanner, they are registered to the reference frame. The x and y offsets necessary for best registration are measures of the absolute eye movements during recording.
Targeted stimulus delivery
By recording the eye motion in real time, the AOSLO can perform targeted stimulus delivery. As the 840-nm laser images the retina and the system recovers the eye motion in real time, an acousto-optic modulator arms the 680-nm laser to deliver stimuli that move contingent to eye motion (Arathorn et al., 2007). These stimuli are called “retina-contingent stimuli.” The use of narrow strips for registration, combined with fast processing, enables an approximately 2-ms lag between eye motion prediction and stimulus delivery (Stevenson & Roorda, 2005; Stevenson, Roorda, & Kumar, 2010; Yang, Arathorn, Tiruveedhula, Vogel, & Roorda, 2010).
A retina-contingent stimulus has a Gain, which describes the stimulus’ world motion that is contingent on the eye motion. The movements of the retina-contingent stimulus are equal to the eye movements multiplied by the Gain. The sign of the Gain indicates the direction the stimulus moves with respect to the eye movement. Gains less than 0 move directly opposite to eye motion with amplified retinal slip. For example, the world motion of a Gain −1 stimulus is equal to −1 times the eye motion (Figure 1B, panel 2, purple arrow) and its motion across the retina is twice that of a world-fixed stimulus (Figure 1B, panel 2, dashed-brown arrow). Gain 0 describes a world-fixed stimulus; its world motion is equal to 0 times the eye motion (Figure 1B, panel 3, no purple arrow) and the stimulus naturally slips consistent to drift motion (Figure 1B, panel 3, dashed-brown arrow). Gain +1 describes a stabilized stimulus, its world motion is equal to 1 times the eye motion (Figure 1B, panel 5, purple arrow) and therefore is locked in place on a region of the retina (Figure 1B, panel 5, no dashed-brown arrow). Gains greater than +1 move faster than the eye motion and in the same direction. For example, the world motion of a Gain +1.5 stimulus is equal to +1.5 times the eye motion (Figure 1B, panel 6, purple arrow) and its motion across the retina is one-half that of a world-fixed stimulus (Figure 1B, panel 6, dashed-brown arrow).
Note that Gains greater than 0 but less than +1 move in a direction consistent with the direction of retinal slip, but with reduced retinal slip compared with a world-fixed stimulus. For example, if the eye moves to the right by 10 arcmin, a Gain +0.9 stimulus would move right by 9 arcmin with retinal slip equal to 1 arcmin. Although both move in a direction consistent with retinal slip, Gain +0.9 has only 10% the retinal slip of a world-fixed stimulus. The retinal slip of the Gains 0 and +0.9 are illustrated by dashed-brown arrows in Figures 1B panels 3 and 4, respectively. Gain +1 has zero retinal slip, and is therefore the transition point: For all Gains less than +1, the stimulus’ motion across the retina is in a direction directly opposite to eye motion, in a direction consistent with retinal slip; and for all Gains greater than +1, the stimulus’ motion across the retina is in the same direction as eye motion.
Projector display
A digital light projector (Lightcrafter DLP4500; Texas Instruments, Dallas, TX, USA) was used to display a 17° background that was coaligned with the AOSLO beams (Figure 1A). The average luminance was approximately 540 cd/m^2^. Background patterns were programmed with MATLAB (MathWorks, Natick, MA, USA) using the Psychophysics Toolbox (Brainard, 1997; Kleiner et al., 2007; Pelli, 1997).
Random walk analysis
Fixational drift is similar to a random walk and the magnitude of drift can be quantified by computing a diffusion constant (Clark, Intoy, Rucci, & Poletti, 2022; D'Angelo et al., 2024). The diffusion constant represents the amount the eye moves from its starting position as a function of time. Recent studies have found that drift motion is not truly random, instead having correlated or anti-correlated properties depending on the timescale (Engbert & Kliegl, 2004; Engbert, Mergenthaler, Sinn, & Pikovsky, 2011), which can be quantified by computing the parameter α (D'Angelo et al., 2024; Engbert & Kliegl, 2004; Engbert et al., 2011; Mergenthaler & Engbert, 2007; Roberts, Wallis, & Breakspear, 2013). We evaluated the mean square displacement (MSD) as a function of multiple time intervals (△T), to determine the magnitude of drift (D) and the extent to which the drift statistics deviate from Brownian motion (α), by fitting the model shown in Equation 1 to the empirical data. The dimension (d) is equal to 2 because we recorded the x and y positions of the eye. As shown in Equation 2, the empirical MSD was computed over non-overlapping pairs, where N is equal to the total number of time steps (total number of frames) and ⌊⌋ represents the greatest integer function. We plotted the log10(MSD) as a function of the log10(△T). The slope of the line across these data points is α and the y-intercept is log10(diffusion constant). The MATLAB code and full description of these parameters and methods are reported in D'Angelo et al. (2024).
In this study, we use the terms “Brownian motion” to describe uncorrelated motion (α = 1), “persistence” to describe positively correlated motion (α > 1), and “antipersistence” to describe negatively correlated motion (α < 1). We performed this random walk analysis on the random walk stimulus’ motion (DPM and α_PM, where PM denotes perceived motion), the retina-contingent stimulus’ motion (DWM_ and α_WM, where WM denotes world motion), and the eye's motion (DEM_ and α_EM_, where EM denotes eye motion).
Generating random walks and random jitter
Before the experiments, we generated 100s of 1,500-ms duration random steps that were either cumulatively summed to produce random walks or concatenated to produce random jitter. The method to generate random walks is described more fully in D'Angelo et al. (2024). Briefly, step lengths in x and y were drawn from a normal distribution with standard deviations ranging from 0.05 to 1.6 arcmin per step in increments of 0.05 arcmin. We computed the average diffusion constant from the trajectories generated for each step length. This was achieved by first solving for the MSD in Equation 2, where △X and △Y are equal to the step length, and then using this result in Equation 1 to solve for the diffusion constant. For each step length, we generated 100 random walks and then selected 10 paths of the 100 that had diffusion constants closest to the respective average diffusion constant. The α of the random walks was approximately equal to 1. To program random jitter, step lengths in x and y were drawn from a normal distribution with the following standard deviations: 0.1, 0.2, 0.3, and 0.4 arcmin per step. These steps were non-cumulative, meaning that each step began from the same starting position. Therefore, the α of the random jitter was approximately equal to 0.
Experimental design
Set up
Subjects’ aligned the pupil of one eye with the AOSLO beam and covered their fellow eye with an eye patch. Dental bite bars were used to immobilize the head. The bite bar apparatus was adjusted in the X, Y, and Z dimensions to position the eye's entrance pupil at the exit pupil of the AOSLO and the projector to optimize wavefront correction performance and to optimize the image of the retina.
Experimental procedure
The subject was presented three 680-nm stimuli through the AOSLO: a central fixation cross, and two horizontally offset circular stimuli positioned 0.43° nasal and 0.43° temporal from the cross. The fixation cross subtended 5 arcmin and the circular stimuli subtended 6 arcmin. Concurrently, the projector displayed a 17° background that was superimposed with the AOSLO rasters (Figure 1A).
In the first experiment, the background displayed a blurred, then binarized 1/f noise pattern that changed after each presentation. A 2°-diameter white circle, with a 0.33°-wide black ring around it, was overlayed onto the AOSLO rasters, therefore canceling perception of the 840- and 940-nm rasters (Figure 1A). The fixation cross remained on for the entire experiment.
In the second experiment, the background displayed a noise pattern that was generated by filtering white noise with a Gaussian bandpass filter at 0.5 cycles per degree (cpd) (0.5 cpd standard deviation), and then binarizing the pattern. We tested three background conditions: extending over the full 17° field of view (Figure 1D, left), or with a 2°-diameter white circular opening (Figure 1D, middle), or with a 9°-diameter white circular opening (Figure 1D, right). Similar to Experiment 1, the patterns changed after each presentation. Under the no-white-circle condition, the pattern extended over the AOSLO rasters, and therefore, the 840- and 940-nm rasters were dimly visible in the regions where the pattern was black (Figure 1D, left). For the no-white-circle and 2°-diameter white circle conditions, the fixation cross remained on for the entire experiment while for the 9°-diameter white circle condition, the fixation cross turned off during the 1,500-ms presentation of the stimuli. For the 2°- and 9°-diameter white circle conditions, the subjects’ field of view was limited to only 17°. Using methods described in D'Angelo et al. (2024), we set up a white paper with an aperture in front of the display permitting only the AOSLO and projector beams to enter the eye. Notably, the aperture in our experiment was wider than the one used in D'Angelo et al. (2024), yielding a full 17° view of the projector and AOSLO displays. LEDs were positioned between the subject and the paper to illuminate the paper. Owing to its close proximity to the eye, the natural blur of the aperture in the paper rendered the transition between the display and luminance-matched paper invisible. The different choices for the binarized patterns from Experiments 1 and 2 yielded no difference in the results.
Retina-contingent conditions
In the first experiment, we measured the perceived motion of multiple retina-contingent stimuli. The Gains of the stimuli ranged from −1.5 to +1.5 in increments of 0.25. We additionally tested Gains +0.85, +0.9 and +1.1 to measure closer to Gain +1, the transition point between stimuli that move opposite to eye motion and stimuli that move in the same direction as eye motion. A total of 16 Gains were tested and the subjects performed at least three trials per Gain. Subjects performed at least six trials of Gain +1.25 and +0.75. Subjects performed nine trials of Gain +1 to mitigate the effects of uncertainty owing to fading (except for 10003L, who only performed six trials of Gain +1). In the second experiment, we tested only Gains −1.5, 0, and +1.5. Subjects performed two trials of Gain 0 and performed at least four trials of Gains −1.5 and +1.5 (except for 20237R, who only performed three trials for Gain −1.5 of the 9°-diameter white circle condition).
Task
One Gain was tested per trial. In a single trial, the subject began by fixating on the 680-nm cross. Using a gamepad, the subject initiated a 1,500-ms presentation of two horizontally offset circular 680-nm stimuli. The three 680-nm stimuli were programmed with different rules: the fixation cross remained stationary, the left stimulus moved in a pre-programmed random walk that was independent of eye motion, and the right stimulus moved contingent to the retina with a specific Gain (Figure 1C). After attending to the circular stimuli, the subject adjusted the magnitude of motion of the left stimulus (random walk) until it matched that of the right stimulus (retina contingent). The subject could initiate as many presentations as they wished while making their adjustments. When they reached a match, they were instructed to initiate at least three more presentations before submitting their response. The subjects were not given any specific criteria to make the match and in general expressed satisfaction in their ability to achieve one. After submitting the trial, the subject proceeded to the next trial which tested a new retina-contingent stimulus with a specific Gain. The Gains were presented in a pseudorandom order across multiple sessions. This experimental protocol applied to both Experiments 1 and 2.
Eye and stimulus motion traces
From each presentation of the experimental sequence, we recorded a 2-second duration video of the retina. Additionally, the system drew three digital markers that indicated the exact positions of the three 680-nm stimuli on each frame of the video. After the experiment, we extracted absolute eye motion traces from the videos through an offline software called ReVAS, which uses a similar cross-correlation method described in Real-time Eye Tracking (Agaoglu, Sit, Wan, & Chung, 2018). Next, we used an offline algorithm to locate and record the positions of the digital markers in each frame. The eye motion and stimulus motion traces were used for the following.
Quality control
First, we identified and removed videos where tracking failed. Tracking failure results in frames with no image captured or with poor image quality and ReVAS either fails to extract eye motion traces or produces fragmented traces. Tracking can fail for a variety of reasons: for example, if the subject blinks, saccades, or looks away from the fixation cross during the presentation. Dry tear film or a fallen eyelash can also disrupt the wavefront sensor and lead to tracking failures. These were usually recognizable to the subjects, who were instructed before the experiment to ignore presentations with poor tracking.
Second, we identified and removed videos where the tracking did not fail, but a microsaccade occurred during frames in which the stimuli were delivered. We kept a record of the number of videos per trial where a microsaccade occurred. Our goal was to measure the perceived motion during periods of fixational drift, and therefore including presentations with microsaccades would have confounded the analyses.
Third, we determined the number of videos where the tracking was poor but might not have been recognizable to the subject. This was achieved by comparing the retina-contingent stimulus motion trajectory with the eye motion trace. For every video, we computed the ideal retina-contingent stimulus motion trajectory computed from the eye motion trace and the specific Gain. For each frame, we computed the distances in x and y between the ideal retina-contingent position and the measured retina-contingent position. This distance represents stimulus misdelivery, where greater distances indicate greater error in stimulus delivery. For each dimension, we took the standard deviation of the distances across all frames. If the standard deviation of the stimulus misdelivery in either the x or y dimension was greater than 0.9 arcmin, we removed the video from further analysis. We tallied the number of poor videos—videos that had standard deviations of greater than 0.9 arcmin or that contained microsaccades—and if this number was greater than one-half the total number of videos in the trial, we dropped the trial and the subject was invited back to repeat the trial.
Quantifying the stimulus delivery error
With the remaining traces, we quantified the magnitude of stimulus delivery error for each trial. Using the same method described in Quality Control, we computed the distances in x and y between the ideal retina-contingent position and the measured retina-contingent position. In a single trial, we computed the standard deviation of all distances in x and y across all frames from all videos. An example from one subject is shown in Figure 2A, the red points indicate the standard deviation of error from a single trial and the black points indicate the average standard deviation of error across all trials. Note that this subject, 10003L, had the highest error out of the five subjects tested, with a maximum average standard deviation of error equal to approximately 0.48 arcmin, which is about the diameter of a foveal cone photoreceptor (Wang et al., 2019). The results of all subjects can be found in Figure A1.1 in Appendix A.
Results from subject 10003L. The blue region of graphs (A), (C) and (D) indicates the Gains where the stimulus’ motion across the retina is in a direction that is directly opposite to eye motion. The green region indicates the Gains where the stimulus’ motion across the retina is in the same direction as eye motion. (A) The magnitude of stimulus delivery error for each Gain. For each trial, we computed the distances in x and y between the ideal retina-contingent stimulus motion trace and the measured retina-contingent stimulus motion trace. The red points indicate the standard deviation of error from one trial—this is the standard deviation across the distances in x and y from all frames from all videos within a single trial. The black points indicate the average standard deviation of error across all trials, with SE of the mean bars. (B) Jitter diffusion constants for perceived motion, Jitter DPM, plotted as a function of the standard deviation which was used to generate the jitter stimulus. Each red point represents one trial and was reflected across the y-axis. The black curve is a best-fit quadratic function, which is anchored at 0 arcmin2/s. (C and D) Diffusion constants plotted as a function of the 16 Gains. Purple points indicate average diffusion constants for world motion, DWM, with SE of the mean bars. (C) Yellow points indicate average diffusion constants for perceived motion, DPM, with SE of the mean bars. Black-hollow points indicate average Jitter DPM with SE of the mean bars, given the standard deviation of error in (A). (D) Orange points indicate average corrected diffusion constants for perceived motion, cDPM, with SE of the mean bars. cDPM = DPM − Jitter DPM.
Experiment 1. Perceived motion and world motion of the retina-contingent stimuli. The blue regions indicate the Gains where the stimulus’ motion across the retina is in a direction that is directly opposite to eye motion. The green regions indicate the Gains where the stimulus’ motion across the retina is in the same direction as eye motion. (A) Diffusion constants from five subjects as a function of the Gains. Orange points indicate average corrected diffusion constants for perceived motion, cDPM. Purple points indicate average diffusion constants for world motion, DWM. Each point represents one subject and is the average across all matches. (B) Average cDPM/DWM from five subjects as a function of the Gains. Each point represents one subject and is the average ratio across all matches. The red bars indicate the average ratio across all subjects. Note that ratios for Gain 0 were removed. To the ratios of Gains less than +1, we fit a quadratic curve (y = 0.14x2 + 0.11x + 0.06) as well as a single-parameter line (y = 0.15). To the ratios of Gains +1 or greater, we fit a single-parameter line (y = 0.86). The intervals indicate the 95% confidence bounds of the fits.
Experiment 2. Average corrected diffusion constants for perceived motion (cDPM) versus diffusion constants for world motion (DWM) from five subjects. Experiments were tested under three background conditions: The patterns extended over the full 17° field of view (A), or surrounded a 2°-diameter white circular opening (B), or surrounded a 9°-diameter white circular opening (C). Background conditions are indicated by labels on the Lower Right corner of each graph. Note that subject 20256R was not tested under the no-white-circle condition. The small symbols represent each subject's average perceptual match for Gain −1.5 stimuli (blue open symbols), Gain 0 stimuli (yellow filled symbols), and Gain +1.5 stimuli (green-filled symbols). The large stars are the group averages with SE of the mean bars. The red arrows show the extent to which the eye motion, and consequent retina contingent stimulus’ world motion (αWM), deviated from Brownian. Arrows pointing right indicate persistence (αWM > 1), arrows pointing left indicate antipersistence (αWM < 1), and no arrow means that the motion was Brownian (αWM = 1 ± 0.02). Longer arrows correspond to higher deviations from Brownian motion. The arrow length in the legend indicates pure persistence (αWM = 2, straight line trajectory at constant velocity) if pointing right or pure antipersistence (αWM = 0, oscillatory motion) if pointing left.
Violin plots showing the distribution of the (A) diffusion constant for eye motion, DEM and (B) α for eye motion, αEM as a function of the Gains from Experiments 1 and 2. Background conditions are indicated by labels beneath the graph. The violins outlined in blue (including the yellow-filled violin, which labels the world-fixed stimulus) indicate the Gains where the stimulus’ motion across the retina is in a direction that is directly opposite to eye motion. The violins outlined in green indicate the Gains where the stimulus’ motion across the retina is in the same direction as eye motion. Within each violin, the central white circles represent the median and the dark gray bars represent the interquartile range. The surrounding intervals are the density traces. Each black point represents one subject and is the (A) average DEM or (B) average αEM across their trials for each Gain. The asterisk indicates statistical significance (p < 0.05) from a post hoc Tukey–Kramer test following a two-factor repeated-measures analysis of variance.
Overall, the AOSLO real-time tracking system demonstrates subarcminute tracking accuracy. It is noted here that tracking can never be perfect because of the approximately 2-ms latency between the last measurement of eye position and the delivery of the stimulus (Arathorn et al., 2007). Any motion that occurs during the 2-ms lag will not be accounted for and thus manifests as an error. Therefore, even in ideal conditions—high quality retinal images and slow drift motion—the latency can contribute some magnitude of stimulus delivery error.
Quantifying the perceived motion of the retina-contingent stimuli
After the experiment, we recovered the random walk stimulus traces at the setting of a perceptual match and computed a diffusion constant across these traces. The diffusion constant of the random walk stimulus represents the magnitude of motion that the subject perceived when they viewed the retina-contingent stimulus. We refer to this value as the diffusion constant for perceived motion, or DPM. An example from one subject is shown in Figure 2C (yellow points) and for all subjects in Figure A1.2 in Appendix A.
Accounting for motion perception due to error
Next, we were motivated to determine to what degree stimulus delivery errors, which were computed in Quantifying the Stimulus Delivery Error, contributed to the subjects’ motion judgments during the experiments. These errors manifest as approximately random, non-cumulative steps, or “jitter,” which are superimposed onto the retina-contingent stimulus’ motion. If the visual system indeed fully suppresses the perception of motion that is in a direction consistent with the direction of retinal slip, then it is possible that, under these conditions, the motion that the subjects matched was solely influenced by the jitter owing to the tracking errors.
To measure the perceived motion of jitter, we executed the same method-of-adjustment procedure, except that we replaced the retina-contingent stimulus with a stimulus that moved independently of eye motion. This stimulus jittered in place with step sizes in x and y that were determined by a standard deviation. We tested the following standard deviations: 0, 0.1, 0.2, 0.3, and 0.4 arcmin, refer to Generating Random Walks and Random Jitter for more details on the generation of this stimulus. Note that, because subject 20237R's average standard deviations of error were below 0.4 arcmin, we did not test this subject with a 0.4 arcmin standard deviation of jitter, as shown in Figure A1.1 in Appendix A. Subjects were instructed to adjust the magnitude of motion of the random walk stimulus until it matched the perceived motion of the jitter stimulus. We computed a diffusion constant of the random walk stimulus at the setting of a perceptual match, which represents the subjects’ perceived motion of the jitter stimulus. This value is referred to as the jitter diffusion constant for perceived motion, or Jitter DPM. The subjects performed three trials for each standard deviation condition. Figure 2B plots the Jitter DPM as a function of the standard deviations for one subject. We reflected the results across the y-axis and fit a quadratic function across the data points. Because perceived motion cannot be negative, we anchored the function to 0 arcmin^2^/s using the MATLAB function polyfitZero (Mikofski, 2025). Results for all subjects are reported in Figure A1.1 in Appendix A.
Using methods described in Quantifying the Stimulus Delivery Error, for each subject, we determined the magnitude of stimulus delivery error for each Gain (Figure 2A). Using the subjects’ perceptual responses of the jitter stimulus (black curve in Figure 2B), we estimated the perceived motion of this stimulus delivery error (black points in Figure 2A). For example, for 10003L, the average standard deviation of stimulus delivery error during presentations of Gain −1.5 stimuli was approximately 0.47 arcmin (Figure 2A) which corresponded with an approximate perceived motion of 1.65 arcmin^2^/s (Figure 2B).
The following were computed for each subject. For each Gain, we averaged the diffusion constants for perceived motion of the retina-contingent stimulus (average DPM, Figure 2C, yellow points) and we averaged the perceived motion of error (Jitter DPM, Figure 2C, black-hollow points). We subtracted average DPM − average Jitter DPM, and the result will be referred to as the “corrected diffusion constant for perceived motion,” or cDPM. Negative cDPM values were set equal to 0 because motion perception cannot be negative. Figure 2D shows the average cDPM for one subject and Figure 3A and Figure A1.2 in Appendix A show the average cDPM for all subjects.
Quantifying the world motion of the retina-contingent stimuli
We collected the retina-contingent stimulus motion traces from every video within a trial, excluding videos that were removed after the filtering steps in Quality Control. We computed the diffusion constant across all traces within each trial and this value will be referred to as the diffusion constant for world motion of the retina-contingent stimulus, or DWM. Figures 2C and 2D show the average DWM for one subject and Figure 3A and Figure A1.2 in Appendix A show the average DWM for all subjects. Observe that while the instantaneous speed of the stimulus motion increases linearly with the magnitude of the Gain, the associated diffusion constants increase with the square of the Gain.
Ratio analysis
For each subject we performed the following: For each Gain, we computed the ratio of the [average corrected diffusion constant for perceived motion] to the [average diffusion constant for world motion], or average cDPM/DWM. Because world-fixed stimuli have DWM = 0 arcmin^2^/s, we removed the ratios for Gain 0. Figure 3B shows the average cDPM/DWM for each subject, and Figure A1.3 in Appendix A reports the individual trial distributions of cDPM/DWM for all subjects. We expect the ratio to be one if subjects perceived the motion veridically. Ratios of less than one indicate that subjects underestimated the motion and ratios greater than one indicate that subjects overestimated the motion.
Model comparison metric
We performed multiple function fits to the ratios in Figure 3B to assess the sharpness of the discontinuity in motion perception during drift, where x represents the Gain and yi represents the average cDPM/DWM. If the discontinuity is sharp, then the data would be best fit with two independent functions on either side of a breakpoint. To evaluate the different fits, we computed the least squares (corrected) Akaike information criterion or AICc. This model comparison metric evaluates goodness-of-fit while penalizing models with increasing number of parameters. As recommended by Burnham and Anderson (2002), the AIC is added to a penalty term to reduce small-sample bias. After computing the AICc for each model, we computed evidence ratios to assess the strength of evidence for each model, using methods described in Burnham and Anderson (2002). Higher evidence ratios indicate stronger evidence for the best model. Lower evidence ratios indicate weaker support for the best model and suggest more uncertainty for model selection (Burnham & Anderson, 2002). An extended description of the models and the equations for the AICc and evidence ratio are reported in Appendix A.
Statistics
For Experiment 2, we performed a two-factor, repeated-measures analysis of variance of the diffusion constant for eye motion (DEM), α for eye motion (α_EM), and corrected diffusion constant for perceived motion (cDPM_). There were three Gains (−1.5, 0, and +1.5) and three background conditions (no-white-circle, 2°-diameter white circle, and 9°-diameter white circle conditions), which were within-subject factors. If the repeated-measures analysis of variance found an effect, indicated by a p value of less than 0.05, we performed a post hoc Tukey-Kramer test to measure the significance of the pairwise comparisons.
Results
Experiment 1
Figure 3A plots the average diffusion constants as a function of the 16 Gains for the 5 subjects. The orange points indicate average corrected diffusion constants for perceived motion, cDPM, of the retina-contingent stimuli. The purple points indicate average diffusion constants for world motion, DWM, of the retina-contingent stimuli. Each point represents one subject and is the average across at least three trials.
Figure 3B plots the average cDPM/DWM as a function of the 16 Gains for the 5 subjects. A cDPM/DWM equal to one indicates that the subject perceived the stimulus’ actual motion in the world, a cDPM/DWM lower than one indicates that the subject underestimated the world motion, and a cDPM/DWM of greater than one indicates that the subject overestimated the world motion.
A sharp discontinuity in motion perception during drift
We performed multiple fits to the ratios in Figure 3B to assess the sharpness of the discontinuity in motion perception during drift. We tested linear fits on either side of a breakpoint, the breakpoints ranged from Gains −0.75 to +1.1. We tested single-parameter linear fits as well as two-parameter linear fits in slope–intercept form. We tested a quadratic curve to the left of the breakpoint and a single-parameter linear fit to the right. Last, we tested a single fit across all ratios: a quadratic, a cubic, and a quartic function. Examples are shown in Figure 3B and Figure A1.4 of Appendix A.
The AICc values are lowest (best) for two models: a quadratic curve to the left of Gain +1 and a single-parameter linear fit to the right, as well as single-parameter linear fits on either side of Gain +1; both models are shown in Figure 3B. The evidence ratios for these models are 1 and 1.57, respectively. The third lowest AICc value is from a model with two-parameter linear fits on either side of a breakpoint at Gain +1, although its evidence ratio is approximately 6.11, suggesting that there is little evidence in favor of this model. The AICc values for all other models are more positive, with evidence ratios greater than 200, meaning that evidence is reasonably strong against these models. Thus, given the dataset and the models tested, these model evaluation metrics suggest that there is reasonably strong evidence that either of the top two performing models are the best fit, although there is high uncertainty which of these two is the best. Our results suggest that there is a sharp discontinuity in motion perception during drift where direction with respect to eye motion is the critical parameter in governing how motion is perceived. Stimuli moving opposite to eye motion (Gains <1) are underestimated, while stimuli moving in the same direction as eye motion (Gains ⩾1) are perceived as moving, and the motion perceived is similar to the stimulus’ actual motion in the world (∼0.86×). Model comparison metrics for all models are reported in Table A1.1 in Appendix A. We additionally performed the same calculations using the original, uncorrected diffusion constants for perceived motion (DPM) in place of the cDPM of the ratio, and we found the same trends, which are reported in Table A1.2 in Appendix A.
Experiment 2
Figure 4 plots the average diffusion constants for each of the three Gains tested (Gains −1.5, 0, and +1.5) under three background conditions (no-white-circle, 2°-diameter white circle, and 9°-diameter white circle conditions). Because there were only three Gains, we plotted the average corrected diffusion constants for perceived motion (cDPM) as a function of the average diffusion constants for world motion (DWM). If the subjects perceived the actual motion of the stimulus in the world, then the data points would lie along the 1:1 line. The small symbols represent each subject's average perceptual match for Gain −1.5 stimuli (blue open symbols), Gain 0 stimuli (yellow filled symbols), and Gain +1.5 stimuli (green filled symbols). The large stars are the group averages with SE of the mean bars. The red arrows show the extent to which the eye motion, and consequent retina contingent stimulus’ world motion (α_WM), deviated from Brownian. Arrows pointing right indicate persistence (αWM_ > 1), arrows pointing left indicate anti-persistence (α_WM_ < 1), and no arrow means that the motion was Brownian (α_WM_ = 1 ± 0.02). We did not show red arrows for the Gain 0 stimuli because motion statistics do not apply to world-fixed stimuli. As discussed in D'Angelo et al. (2024), the presence of persistent eye motion generally gives rise to relatively higher values of the DWM and relatively lower values of the diffusion constant of the random walk at the perceived match (DPM). As a result, subjects with greater degrees of persistence tend to plot below the 1:1 line. Note that subject 20256R was not tested under the no-white-circle condition. Figure A1.5 of Appendix A reports individual trial distributions of the matches for all subjects, and Figure A1.6 of Appendix A reports the standard deviation of stimulus delivery error distributions for all subjects.
The illusion of relative stability depends on the extent of retinal image background content
The illusion of relative stability persisted when the retinal image background content extended into—and even overlapped with—the retina-contingent stimulus. There was no statistically significant difference in perceived motion of Gain −1.5 stimuli between the no-white-circle and 2°-diameter white circle conditions (Figures 4A and 4B). For both backgrounds, Gain +1.5 stimuli were perceived to have more motion than Gain −1.5 stimuli (p = 0.036 for no-white-circle condition and p = 0.037 for 2°-diameter white circle condition, post hoc Tukey–Kramer test). This is surprising considering that, under the no-white-circle condition, the stimulus in many instances would have crossed from dark to light background regions while the matches were being made.
In contrast, subjects perceived significantly higher magnitudes of motion of Gain −1.5 stimuli when the retinal image background content was further displaced (the 9°-diameter white circle condition shown in Figure 4C) from the retina-contingent stimulus (P = 0.010 compared with the no-white-circle condition and p = 0.043 compared with the 2°-diameter white circle condition, post hoc Tukey–Kramer test). By spatially offsetting the background content approximately from the stimuli, subjects perceived significantly higher magnitudes of motion of Gain −1.5 stimuli and perceptually underestimated the motion of Gain +1.5 stimuli (Figure 4C), results that lean toward those tested in a Ganzfeld reported in a prior paper (D'Angelo et al., 2024).
For Gain +1.5 stimuli, perceived motions were not significantly different between any background conditions (Figures 4A–C).
As an additional check, we performed the repeated-measures analysis of variance and post hoc Tukey–Kramer tests using the original, uncorrected diffusion constants for perceived motion (DPM) for all Gains and background conditions from Experiment 2 and these trends held.
Additional analyses: Effect of Gain on eye motion statistics
Figure 5 plots the average diffusion constants for eye motion (DEM) and average α for eye motion (α_EM_) for all subjects as a function of the Gains tested in Experiments 1 and 2. Within the violins (Bechtold, 2016), the central white circles represent the median and the dark gray bars represent the interquartile range. The surrounding intervals are the density traces (Hintze & Nelson, 1998).
Experiment 1
Undergoing the same eye motion, increasing the magnitude of the Gain gives rise to greater magnitudes of the stimulus’ world motion. Therefore, we computed the ratio [average corrected diffusion constant for perceived motion]/[average diffusion constant for world motion], or cDPM/DWM, to account for the world motion. We were motivated to ensure that Gain conditions did not impact the eye motion statistics, in particular the diffusion constant for eye motion, DEM (Figure 5A, Experiment 1) and α for eye motion, α_EM_ (Figure 5B, Experiment 1). We found no significant difference between DEM for Gains less than +1 compared to DEM for Gains +1 or greater (p = 0.092, Paired t-test). We found no significant difference between α_EM_ for Gains less than +1 compared with the α_EM_ for Gains +1 or greater (p =0.12, paired t-test).
Experiment 2
A repeated measures analysis of variance revealed no significant effect of Gain or background condition on DEM (p = 0.11 and p = 0.085, respectively); however, the interaction of Gain and background had a significant effect on DEM (p = 0.034). A post hoc Tukey–Kramer test showed no significant differences between pairwise comparisons of DEM (Figure 5A, Experiment 2). This is likely due to small effect sizes between conditions, which are not robust to the post hoc correction, given the current sample size (n = 5 subjects).
Additionally, a repeated measures analyses of variance revealed a significant effect of Gain on α_EM_ (p = 0.030), but no significant effect of background condition on α_EM_ (P = 0.094). The interaction of Gain and background had a significant effect on α_EM_ (p = 0.018). Under the 9°-diameter white circle condition, the α_EM_ of Gain +1.5 stimuli were significantly higher than those of Gain 0 stimuli (Figure 5B, Experiment 2).
Thus, the perceived motion (cDPM) cannot be explained by changes in eye motion statistics, DEM and α_EM, across Gain conditions. Offsetting the background content and turning off the fixation cross (9°-diameter white circle condition) can explain the higher DEM_ and α_EM_ (Figures 5A and 5B, Experiment 2), which is consistent with a previous report (D'Angelo et al., 2024).
Discussion
We demonstrate that perception of moving objects during fixational drift is discontinuous, governed by the direction those objects move with respect to eye motion. Our results build on previous studies (Arathorn et al., 2013; D'Angelo et al., 2024) and show that the direction that objects move with respect to eye motion is a critical parameter that governs an exception to our ability to detect relative motion.
Two paradoxes in motion perception during drift
The human visual system relies on paradoxical methods to veridically perceive stable and moving objects.
Paradox 1
To perceive world-fixed objects in high resolution, the eye attempts to stabilize images-of-interest onto the fovea (Epelboim & Kowler, 1993; Clark et al., 2022); yet, paradoxically, if the eye achieves perfect stability, the image will quickly fade from view (Ditchburn & Ginsborg, 1952; Riggs & Ratliff, 1952). The eye therefore is in constant motion, and the human visual system evolved to discount the image motion owing to eye motion, and even leverages its motion to improve spatial vision (Ratnam, Domdei, Harmening, & Roorda, 2017; Rucci, Iovin, Poletti, & Santini, 2007).
Paradox 2
The visual system relies on world-fixed frames of reference to properly detect moving objects in the world (Legge & Campbell, 1981). However, the same frames of reference serve as retinal image background content to perceptually stabilize images that move in a direction consistent with retinal slip giving rise to the illusion of relative stability (D'Angelo et al., 2024).
Where in the visual pathway does the illusion take place?
As discussed in D'Angelo et al. (2024), the mechanisms underlying the illusion of relative stability at the earliest stages may rely on signals from the directionally sensitive retinal ganglion cells whose existence in primate have been recently reported (Wang et al., 2023). Of course, the information from these cells could only be used to inform about eye motion; the percept could only be rendered after processing in higher cortical areas. A functional, circuit-level hypothesis has been proposed to explain how the behavior reported here and in previous papers might arise (Arathorn, D'Angelo, & Roorda, 2025).
Although the exact mechanisms remain unknown, the current study adds three important factors to consider: First, the illusion persists for Gains between 0 and +1, where the retinal image slip is consistent with, but less than, the eye's motion (Figure 3). Second, the illusion is so profound that it persists even when the retinal image background content overlaps entirely with the retina-contingent stimuli (Figure 4A). Third, if the retinal image background content is too far from the retina-contingent stimuli, then the effect diminishes (Figure 4C), suggesting that the effect might not be a true discontinuity, but rather a graded response. To further elucidate possible mechanisms, the dependence on proximity to retinal image background content, and also the dependence on spatial frequency of that content can be explored. These remain parameters for future study.
Evaluating the sharpness of the discontinuity
As mentioned, the illusion of relative stability may not be a true discontinuity, but rather a graded response. We review several reasons. First, if the retinal image background content is too far from the retina-contingent stimuli, then the effect diminishes (Figure 4C), suggesting that the magnitude of this effect is driven by proximity to retinal image background content. Second, if it were a true discontinuity, the perceived motion (diffusion constant for perceived motion, DPM) for Gains less than +1 would be close to 0, regardless of the Gain magnitude. However, all subjects showed a slightly increasing perception of motion (higher DPM) as the Gains approached +1 or increased in retinal slip (Figure A1.2 in Appendix A). Third, in our experiments, all motion was restricted in two dimensions to be always aligned with the eye motion, either in the same direction or opposite; orientations of motion in other directions not aligned with eye motion also show a more gradual transition (Arathorn et al., 2013).
Further, even after accounting for stimulus delivery errors by computing the corrected diffusion constant for perceived motion, cDPM, the perceived motion of stimuli moving opposite to eye motion (Gains <+1) did not go down to 0 for most subjects. All subjects perceived slightly increasing magnitudes of motion as the Gains approached +1 or increased in retinal slip (Figure A1.2 in Appendix A). This finding suggests that the motion the subjects saw was not solely due to stimulus delivery errors. And this suggests that greater magnitudes of stimulus motion, compared with the magnitude of eye motion, serve to diminish the illusion, supporting that this is a graded response. This is illustrated in Figure 3B, the ratios for Gains less than +1 are well fit with a quadratic function. Although the DPM and cDPM increased slightly with Gain magnitude for Gains less than +1, it is important to note that the DPM and cDPM remained well below the magnitude of the stimulus’ motion in the world (diffusion constant for world motion, DWM).
Comparison with previous work
In Arathorn et al. (2013) and D'Angelo et al. (2024), under background-present conditions, stimuli moving in the same direction as eye motion (Gains ⩾+1) appeared readily in motion. For Gain +1 or greater, we would expect that the motion the subjects perceived would be equal to the motion of the stimuli in the world. Arathorn et al. (2013) did not quantify the magnitude of eye motion or the retina contingent stimulus’ world motion so we cannot make any claims on whether the subjects veridically perceived the world motion of the retina-contingent stimuli. However, D'Angelo et al. (2024) computed the diffusion constant and α of the eye motion (DEM and α_EM) and retina-contingent stimulus’ world motion (DWM_ and α_WM_); the same method is used in this study, so we can compare the two studies as shown in Figure A2.1A in Appendix B. Note that D'Angelo et al. (2024) only tested three Gains while this current paper tested 16 Gains, and we therefore could only compare the results for Gains −1.5, 0, and +1.5 under background-present conditions. The results are generally the same, but the differences in the experimental parameters and possible consequences of those are discussed in Appendix B.
In D'Angelo et al. (2024), we report results from experiments under a Ganzfeld condition. In the current study, as a control, we did the same method-of-adjustment experiments under a Ganzfeld as well, and we found the same trends: that motion perceptions reversed in the Ganzfeld. Similar to D'Angelo et al. (2024), α_EM_ was significantly higher under the Ganzfeld (p < 0.001, paired t-test). Results from those experiments are included in Figure A1.7 of Appendix A.
Comparison with similar research
The jitter after-effect (JAE) illusion provides the best support for a retinal-image-based signal that gives rise to perceptual stability during fixation (Murakami & Cavanagh, 1998). The JAE is a phenomenon whereby adapting retinal regions to dynamic random noise gives rise to perceptions of jittering motion in nearby unadapted regions. They proposed a motion-based model in which the visual system estimates the lowest velocity region and subtracts this velocity from all points on the retina. Our work complements this proposed model with the added observation that the retina-derived signal also drives the illusion of relative stability reported here. They also investigated the spatial extent of the JAE and found that it declined as the adapting field was separated from the test field, becoming nearly zero at gap-widths between 4° and 8° of visual angle (Murakami & Cavanagh, 2001). Although we did not test the separation between the background content and the test stimuli very finely, we found that the illusion of relative stability diminishes as the size of the uniform window increases, nearly disappearing when it is open to a 9° visual angle.
Causal inference in perception
The discontinuity that leads to the illusion of relative stability may arise from a causal inference process where, before estimating the actual motion of the stimuli, the visual system must decide if a given object is part of the world-fixed background or a moving object. Therefore, the illusion is in line with the notion of a visual system that has evolved to discount images moving with amplified retinal slip, as they are more likely to be part of the world-fixed stimuli. Given that it is highly unlikely that any object would ever move with amplified retinal slip for an appreciable time relative to other retinal image background content in the visual scene, it makes sense that such motion should never contaminate our perception. A causal inference framework could be used to formalize and explain this process. Causal inference has been used to explain perceptual processing in a growing number of studies (Acerbi, Dokka, Angelaki, & Ma, 2018; Dokka, Park, Jansen, DeAngelis, & Angelaki, 2019; Shams & Beierholm, 2010). Future work could uncover a causal inference model in motion perception during drift.
Conclusions
We showed that, during fixational drift, the direction an object moves with respect to eye motion is a crucial parameter in giving rise to perceptions of stability and motion. Images moving opposite to eye motion, in a direction consistent with retinal slip, were perceived as relatively stable while the motion of images moving in the same direction was readily detected. This held even for stimuli that were slipping opposite to eye motion but with a smaller magnitude across the retina. We determined that this misperception persists even if the image moves on top of or close to retinal image background content, which is surprising and paradoxical given how this same content is used as a frame of reference to detect relative motion of images moving in any other direction with respect to eye motion.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Acerbi, L., Dokka, K., Angelaki, D. E., & Ma, W. J. (2018). Bayesian comparison of explicit and implicit causal inference strategies in multisensory heading perception. P Lo S Computational Biology, 14(7), e 1006110.30052625 10.1371/journal.pcbi.1006110 PMC 6063401 · doi ↗ · pubmed ↗
- 2Agaoglu, M. N., Sit, M., Wan, D., & Chung, S. T. (2018). Re VAS: An open-source tool for eye motion extraction from retinal videos obtained with scanning laser ophthalmoscopy. Investigative Ophthalmology & Visual Science, 59(9), 2161.
- 3Arathorn, D. W., D'Angelo, J. C., & Roorda, A. (2025). Stimulus motion perception studies imply specific neural computations in human visual stabilization. ar Xiv preprint ar Xiv:2506.13506.
- 4Arathorn, D. W., Stevenson, S. B., Yang, Q., Tiruveedhula, P., & Roorda, A. (2013). How the unstable eye sees a stable and moving world. Journal of Vision, 13(10), 22.10.1167/13.10.22PMC 452530223988388 · doi ↗ · pubmed ↗
- 5Arathorn, D. W., Yang, Q., Vogel, C. R., Zhang, Y., Tiruveedhula, P., & Roorda, A. (2007). Retinally stabilized cone-targeted stimulus delivery. Optics Express, 15(21), 13731–13744.19550644 10.1364/oe.15.013731 · doi ↗ · pubmed ↗
- 6Bechtold, B. (2016). Violin plots for matlab. Github Project, 10.
- 7Bower, J. D., Bian, Z., & Andersen, G. J. (2012). Effects of retinal eccentricity and acuity on global-motion processing. Attention, Perception, & Psychophysics, 74, 942–949.10.3758/s 13414-012-0283-2PMC 338185822382583 · doi ↗ · pubmed ↗
- 8Brainard, D. H. (1997). The psychophysics toolbox. Spatial Vision, 10(4), 433–436.9176952 · pubmed ↗