Large Language Models for Cardiovascular Disease, Cancer, and Mental Disorders: A Review of Systematic Reviews
Andreas Triantafyllidis, Sofia Segkouli, Stelios Kokkas, Anastasios Alexiadis, Evdoxia Eirini Lithoxoidou, George Manias, Athos Antoniades, Konstantinos Votis, Dimitrios Tzovaras

TL;DR
This paper reviews how large language models are being used for chronic diseases like heart disease, cancer, and mental disorders, highlighting their potential and challenges in healthcare.
Contribution
It is the first meta-review analyzing systematic reviews on LLMs for chronic diseases, identifying trends and challenges in their clinical application.
Findings
Most LLM-based solutions focus on mental health, particularly depression detection and suicidal ideation.
GPT-family models are most commonly used, followed by BERT variants, but methodological quality and data transparency are often lacking.
Key challenges include inconsistent accuracy, bias, data privacy, and the need for human oversight in LLM deployment.
Abstract
Background/Objective: The use of Large Language Models (LLMs) has recently gained significant interest from the research community toward the development and adoption of Generative Artificial Intelligence (GenAI) solutions for healthcare. The present work introduces the first meta-review (i.e., review of systematic reviews) in the field of LLMs for chronic diseases, focusing particularly on cardiovascular, cancer, and mental diseases, to identify their value in patient care, and challenges for their implementation and clinical application. Methods: A literature search in the bibliographic databases of PubMed and Scopus was conducted following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines, to identify systematic reviews incorporating LLMs. The original studies included in the reviews were synthesized according to their target disease, specific…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
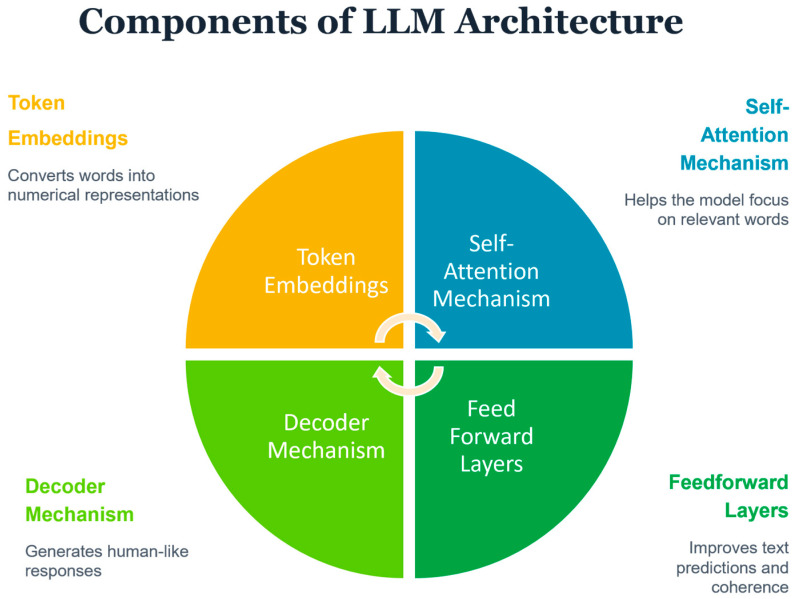 Figure 1
Figure 1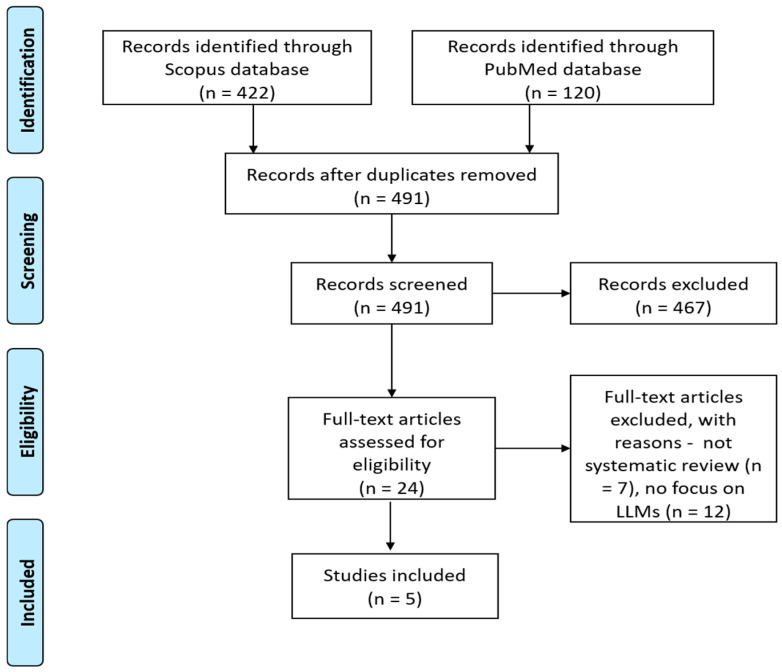 Figure 2
Figure 2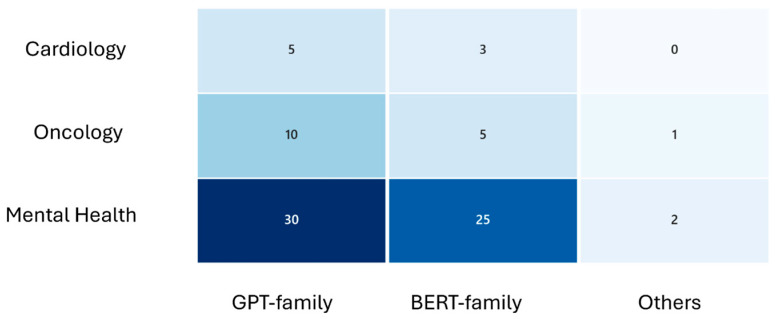 Figure 3
Figure 3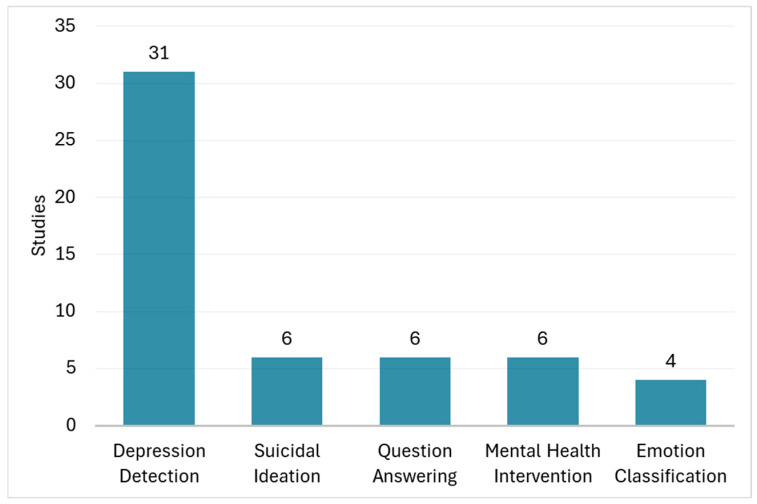 Figure 4
Figure 4- —European Union’s Horizon Europe research and innovation program
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Digital Mental Health Interventions · Mental Health via Writing
1. Introduction
The advent of Large Language Models (LLMs), exemplified by platforms such as ChatGPT, is a significant advancement in Generative Artificial Intelligence (GenAI) with far-reaching implications for improving healthcare [1]. LLMs are able to generate human-like text, answer questions, and complete other language-related tasks with high accuracy [2]. LLMs have demonstrated strong capacity for complex clinical reasoning, patient education, and decision support across a variety of medical fields such as psychiatry [3], cardiology [4], and oncology [5].
LLMs are artificial intelligence systems built on Transformers [6], an Artificial Neural Network architecture which processes and generates human language by learning statistical patterns from massive amounts of data (e.g., books, websites, scientific papers). At their core, LLMs consist of billions of interconnected parameters (adjustable numerical values) that are trained to predict the next word in a sequence. The key components of an LLM are (Figure 1): (a) Token Embeddings: Converts words into numerical representations for the AI model to process, (b) Self-Attention Mechanism: Helps the model focus on the most relevant words in a sentence, (c) Feedforward Layers: Improves text predictions and sentence coherence, and (d) Decoder Mechanism: Generates human-like responses based on context. The two main types of LLMs used in healthcare are GPT (Generative Pre-trained Transformer) models [7], which excel at generating coherent text for tasks like answering patient questions or drafting clinical summaries [8,9], and BERT (Bidirectional Encoder Representations from Transformers) models [10], which specialize in understanding and classifying existing text for applications like detecting depression from social media posts or identifying suicide risk in clinical notes [11].
The adoption of LLMs in healthcare emerges as a promising step to provide more efficient, safer, and personalized care for patients, mainly because of their capability for swift natural language communication with the users, along with synthesis, summarisation, and contextual reasoning over diverse clinical information, around the clock. The acceptability, usability, and potential of LLMs in improving health and well-being have been explored in several previous studies [12,13,14].
As the body of peer-reviewed research on LLMs in healthcare expands rapidly, there is a pressing need to establish a solid evidence base regarding their clinical effectiveness and practical value. To address this gap, we present a review of systematic reviews examining the use of LLMs among patients with chronic diseases—with particular emphasis on cardiovascular, oncological, and mental health conditions because of their significant global burden. To the authors’ knowledge, this meta-review is the first in the field of LLMs for healthcare.
Our work aims to analyze the characteristics, performance, benefits and methodological challenges of LLM-based interventions and tools, in this fast-evolving domain. Unlike disease-specific analyses, the current review adopts a cross-condition perspective, enabling a broader understanding of how LLMs are being leveraged across diverse chronic care contexts. By systematically mapping the current state of applications, evaluating their effectiveness, and highlighting current challenges, this study seeks to inform researchers, developers, clinicians, and policymakers in designing and implementing more robust and impactful LLM-driven health interventions, towards realizing the full potential of GenAI application in clinical practice.
2. Methodology
We searched the bibliographic databases of PubMed and Scopus to identify systematic reviews of the application of LLMs for cardiovascular disease, cancer, and mental disorders, as reported in manuscripts published after 2022, since this was the year in which the interest in LLMs exploded because of the landmark emergence of ChatGPT. The inclusion criteria were: (a) the review should be defined as systematic, focus on the effectiveness of the LLMs, and follow reporting guidelines such as the Preferred Reporting Items for Systematic review and Meta-Analyses (PRISMA) [15] or the Cochrane guidelines [16]; (b) the review should report LLM-based tools or interventions targeted at chronically ill individuals diagnosed with cardiovascular disease, cancer, or mental disorders; (c) the paper should be written in English. We used the keyword query (“LLM” OR “large language model” OR “chatbot” OR “conversational” OR “bot” OR “digital assistant” OR “virtual assistant” OR “digital agent” OR “virtual agent”) for search within the title, abstract and keywords of the manuscripts, and restricted the search to a review type of articles. Reviews examining interventions or tools which were not focused on leveraging LLMs were excluded. Furthermore, reviews focusing exclusively on other medical fields such as surgery or medical education were excluded. Reviews not examining quantitative outcomes, surveys, and protocol papers were also excluded from the review.
The selection and review of papers were conducted independently by four reviewers (authors AT, SS, AA, SK) to ensure relevance based on predefined inclusion and exclusion criteria and to minimize potential selection bias or errors. Following the literature search, both abstracts and full-text manuscripts were screened. Studies that did not meet the inclusion criteria were excluded, and only those for which consensus among all reviewers was achieved were retained.
The methodological quality of the included systematic reviews was evaluated using the second version of the AMSTAR tool (A Measurement Tool to Assess Systematic Reviews), which has demonstrated reliability [17]. Data from the primary studies included within these reviews were synthesized (by AT) according to several dimensions: Target disease, application area, LLM(s) used, leveraged data sources, model accuracy, and key outcomes. We report descriptive percentages because most studies provided only aggregated summaries and heterogeneity in outcomes and timing precluded pooling or more advanced meta-analytic techniques.
3. Results
3.1. Literature Search Outcomes
Our literature search in the PubMed and Scopus databases was conducted on November 2024 with the last search update taking place on May 2025, to identify relevant studies published since 2022. The search yielded 422 records from the Scopus database and 120 records from PubMed. After removing all duplicates in the Mendeley© bibliography management software [18], and applying our inclusion and exclusion criteria, 24 articles remained for full manuscript reading. Finally, 5 papers (systematic reviews) were included [19,20,21,22,23]. Reasons for paper exclusion are shown in Figure 2, which is a standard PRISMA flow diagram intended to document the process of study identification, screening, eligibility assessment, and inclusion.
3.2. Quality Assessment of Reviews and Original Studies
The quality of the included review studies as assessed through AMSTAR 2 criteria can be seen in Table 1. All reviews performed study selection in duplicate and discussed the heterogeneity of studies and results. However, AMSTAR 2 assessment revealed recurring methodological weaknesses across the included systematic reviews. The most frequently failed domains were: (i) lack of comprehensive search strategies—none of the reviews searched gray literature or consulted experts; (ii) absence of explicit PICO framing in research questions; (iii) insufficient justification for deviations from protocols; and (iv) limited assessment and consideration of risk of bias when interpreting results. Furthermore, most reviews did not report sources of funding for included studies and did not explain the rationale for study design selection. These gaps underscore the need for future systematic reviews in this field to adopt rigorous protocols, transparent reporting, and standardized bias assessment tools to enhance reliability and reproducibility.
Three reviews [20,22,23], assessed the risk of bias of the individual studies using tools such as Quality Assessment of Diagnostic Accuracy Studies (QUADAS 2), Risk of Bias 2 Tool, Risk Of Bias In Non-randomized Studies-of Interventions (ROBINS-I), and Prediction model Risk Of Bias Assessment Tool (PROBAST). The individual studies were reported to be of high risk of bias except one in the review for breast cancer management by Sorin et al. [20], while Guo et al. [22] have reported overall a low risk of bias in the studies for mental health applications. Omar and Levkovich [23] in their review focusing on depression, reported an overall mixed picture in terms of risk of bias assessment. Although most studies were reported to be of low risk of bias in measurements and outcomes, several studies presented moderate biases because of confounding factors and participant selection that may have affected the applicability of the results.
3.3. Characteristics of Individual Studies
In Table A1, the main characteristics of the 81 non-duplicate individual studies reported in the reviews are presented in terms of target disease, specific application, used LLMs, data sources, accuracy, and key outcomes. The majority of the solutions focused on mental health conditions (70 studies, 86%), followed by cancer (6 studies, 7%) and cardiovascular diseases (5 studies, 6%). Most studies employed GPT models (45 studies, 55%), while BERT model and its variants were used in 33 studies (40%) (Figure 3). The main application areas included depression detection and classification (31 studies, 38%), suicidal ideation detection (6 studies, 7%), question answering based on treatment guidelines and recommendations (6 studies, 7%), mental health intervention, e.g., support for loneliness (6 studies, 7%), and emotion classification (4 studies, 5%) (Figure 4). The studies showed substantial heterogeneity: about half (41 studies, 50%) concentrated on clinical or diagnostic accuracy—evaluating correct diagnosis, guideline alignment, or model performance—while others (34 studies, 42%) were descriptive, focusing on aspects such as narrative outcomes, usability, trust, or plausibility.
3.4. Summary of LLMs Performance
The LLMs in depression applications (31 studies) achieved an accuracy in detecting the disease or its symptoms from 50% to 97% and an F1 score from 0.42 to 0.93. The studies reporting the highest performance used BERT, RoBERTa, AudiBERT, DistilBERT, and DeBERTa, and leveraged diverse datasets such as tweets, clinical interviews, or the mental health corpus database. The suicidal ideation studies (6 studies) used LLMs such as BERT, GPT, and XLNet, using social media posts (3 studies), as well as fictional patient data (3 studies). The reported achieved accuracy in 3 studies for suicidal ideation detection was from 87% to 95%. LLMs were found also to demonstrate good performance in several other mental health applications, such as classification of psychiatric conditions with BERT (F1 0.83) [24], mental health disorder prediction with BERT through Twitter (accuracy 97%) [25], and sentiment analysis through social media texts using GPT and Open Pre-trained Transformers (accuracy 86%) [26]. However, on other few occasions, LLMs did not demonstrate an acceptable performance, as in the case of the identification of diagnostic and management strategies in psychiatric conditions with GPT (accuracy 61%) [27]. All 6 studies reporting outcomes of diverse mental health interventions, e.g., support for loneliness, mindfulness, and self-discovery, did not provide quantitative performance metrics, however they highlighted the usefulness of LLMs in mental health support, with only one study criticizing the insufficiency of GPT in complex mental health scenarios.
In cardiology applications (5 studies), the LLMs were based on GPT, and they were used for answering clinical questions. The evaluation of the performance was descriptive in most of the studies (3 studies), while an accuracy up to 64.5% was reported in the studies showing performance metrics (2 studies).
In cancer applications (6 studies), GPT models were also used. 3 studies focused on tumor board clinical decision support, 2 studies on question-answering, and 1 study assessed the time and cost for developing LLM prompts. The accuracy of LLM responses compared with reviews of the tumor board varied, reaching up to 70% with real patient data, and up to 95% with fictional patient data. The question-answering applications reached up to 98% accuracy. Regarding time and cost evaluation, LLM-based prompting was found to offer an efficient approach to extract key information from the medical records of breast cancer patients and to generate well-structured clinical datasets. This method is expected to significantly reduce the effort required in routine clinical practice and research.
3.5. Benefits of Using LLMs
Across mental health, oncology, and cardiology, the most consistently reported benefits of LLMs include early detection and screening capabilities, which dominate mental health applications and are emerging in oncology through pathology report parsing. Decision-support functions are common to all three domains, but oncology demonstrates the highest complexity in multidisciplinary planning, while cardiology emphasizes guideline-concordant question answering. Patient education and engagement appear universally beneficial, with mental health leveraging conversational empathy and oncology focusing on informed consent. Documentation and research support are reported across all domains, but oncology highlights efficiency gains in tumor board preparation, whereas cardiology emphasizes educational utility.
3.5.1. Detection and Screening
LLMs have shown significant potential in the improvement of detection and screening for diseases. In mental health, transformer-trained LLMs have been applied to detect depression, suicidality, and anxiety, based on the examination of linguistic features and affectual cues within patient-written text or social media posts [21,22]. This strategy enables the early identification of mental illness within non-clinical environments, with the provision of scalable non-intrusive screening tools that can be used to monitor public health. The ability of LLMs to process large volumes of unstructured language data allows for timely detection of subtle indicators of distress that may escape conventional screening tools.
In oncology, benefits of screening procedures are also apparent. LLMs can extract tumor, receptor, and staging relevant variables from pathology as well as imaging reports with a high accuracy, reaching up to 98% [20]. This not only fastens the data-processing time but also helps standardized diagnostic workflows through the reduction in human failure as well as enhanced information-extraction consistency. Taken together, these outcomes establish that LLMs could bridge the gap between raw clinical data to usable diagnostic information to facilitate earlier treatment as well as personalized care.
3.5.2. Risk Assessment and Triage
In addition to screening and detection, LLMs enable risk assessment and triage procedures, especially in mental health applications. By analyzing the sentiment, tone, and complexity of language, such models can evaluate the psychological distress and guide those with increased risk of suicide or crisis [23]. This feature is particularly useful in online or resource-limited care environments, where fast triage can easily affect clinical outcomes.
The analytical power of the LLMs also helps practitioners in correlating large amounts of patient-reported information to assist with triage decisions regarding who needs immediate intervention as opposed to ongoing monitoring. As the systems evolve, the integration of the triage tools with the telepsychiatry platforms could allow long-term, passive surveillance of mental state with earlier detection of mental health emergencies.
3.5.3. Clinical Reasoning and Decision Support
The LLMs showed increasing abilities to mimic clinical reasoning and facilitate decision-making within psychiatry, cardiology, and oncology. They can enable diagnosis and treatment planning in psychiatry, typically producing guideline-concordant reasoning when presenting with clinical vignettes [21,22]. This helps the clinician in challenging diagnostic situations but also provides a useful instrument within medical education, as it enables students to practice structured ways of reasoning.
In cardiology, the LLMs proved effective in accurately answering board-style examination questions and depicting clinical reasoning in case discussions [4]. Such functions advance both educational use and ongoing professional development with the option to present an adaptive learning environment that resembles clinician-level judgment.
In oncology, the LLMs aid in the synthesis of multidisciplinary cases and tumor board planning with 50–70% agreement with the expert panels [5]. This analytical potential, in turn, leads to the possibility of summarizing variable clinical facts and helping with decision-making processes, most specifically where combined therapies need to be incorporated.
3.5.4. Patient Education and Participation
A major advantage of LLMs is their ability to encourage patient engagement by using natural, conversational interfaces. In mental health, conversational agents that use LLMs can provide psychoeducation, empathetic dialog, and stigma reduction by offering support to individuals who might otherwise avoid seeking for help [2]. These systems can deliver round-the-clock guidance and emotional validation, contributing to improved accessibility and continuity of care. In cardiology, the LLMs were shown to produce accurate and sympathetic responses to patient questions, enhancing compliance with regimens as well as health literacy [4]. Similarly, in oncology, they enable the development of patient education materials and consent summaries incorporating the most current clinical practice guidelines [5]. Such functionalities endow the patient with reliable, easy-to-read information, enforcing shared decision-making as well as faith in communication with the clinician.
3.5.5. Summary, Documentation, and Research Support
In all areas, LLMs bring significant advantages in automating research and documentation procedures. They help in psychiatry to summarize transcripts of therapy and to produce structured sets of data for Natural Language Processing (NLP) studies, minimizing manual labor and maximizing analytical potential [22]. They help in cardiology and oncology to prepare discharge summaries, clinical notes, and guideline overviews to minimize administrative workload [19,20]. In addition, the models aid clinical researchers in scientific paper writing through the automation of evidence synthesis and paper composition [19]. This aspect can accelerate the publication of clinical evidence, boosting the efficiency of medical scholarship. As the science of LLMs advances, this integration into research workflows could revolutionize the creation, curation, and communication of medical knowledge.
3.6. Challenges of Using LLMs
The most critical challenges for real-world adoption of LLMs are consistent across domains: hallucinations and output correctness remain universal concerns, particularly acute in oncology where treatment decisions carry high stakes. Bias and transparency issues are pervasive, with mental health applications most vulnerable to demographic and linguistic skew due to reliance on social media data. Data privacy and regulatory compliance challenges are emphasized in oncology and cardiology because of sensitive clinical records. Continuous human oversight is unanimously recommended, but mental health reviews stress its necessity for emergency scenarios, while cardiology and oncology focus on diagnostic validation. Methodological rigor and lack of real-world trials are cross-cutting limitations, hindering generalizability and safe deployment.
3.6.1. Accuracy, Safety, and Efficacy of LLMs in Real World Settings
Although LLMs showed better results than traditional tools such as machine learning [28,29], and even exhibited capabilities comparable to those of human experts in some cases [30,31], variations in accuracy and output correctness across different tasks persist. As an example, Levkovich and Elyoseph [32], evaluated ChatGPT’s performance in assessing suicide risk highlighting that ChatGPT could underestimate or overestimate suicide risks compared to mental health professionals, especially in complex scenarios with high perceived burdensomeness and thwarted belongingness. Advanced models such as GPT-4 have been effective in interpreting clinical and unstructured data to manage, detect, and classify depression [33]. However, studies often rely on fictional clinical vignettes, limiting the generalizability of these findings in real-world clinical practice [34]. In this context, researchers and industrial stakeholders should gather enough evidence of efficacy and safety—through rigorous clinical studies, testing, and oversight—before deploying LLMs at scale in real-life, to prevent causing harm due to unverified performance.
All reviews underscore the enduring risk of hallucinations, wherein models generate information that is incorrect, incomplete, or entirely fabricated. Such outputs—ranging from inaccurate facts to invented citations—pose danger in clinical settings, where they may inadvertently mislead healthcare professionals or patients. The reviews consistently identify hallucination control as a fundamental technical challenge that must be addressed prior to any autonomous clinical deployment of LLMs.
3.6.2. Bias and Model Transparency
Training data biases (demographic, geographic, linguistic) may propagate into LLM outputs. Several reviews note age, language and population skews (e.g., social-media datasets over-represent younger, English-speaking users), leading to uneven performance and potential amplification of disparities in care. Detecting and mitigating bias is made harder because training corpora and curation processes for commercial models are often undisclosed. Reviews call for benchmark datasets with diverse, annotated examples and for bias-auditing pipelines. Ensuring demographic inclusivity, representational diversity, and transparency in LLM development is essential to safeguard public trust in AI-driven healthcare systems.
A critical assessment of the safety and trust of LLMs was conducted in included review studies, highlighting the “black box” nature of AI systems. This means that LLMs are associated with limited interpretability and transparency (why the model generated a given answer), which undermines trust and makes clinical validation and regulatory assessment challenging. The reviews recommend model documentation, provenance of training data, auditing, and research into explanatory methods (attention analyses, knowledge graphs, causal embeddings), to improve model transparency.
3.6.3. Data Privacy, Security, and Regulatory Challenges
All reviews identify significant challenges related to data protection and regulatory compliance when applying LLMs in healthcare. Cloud-based model architectures risk exposing sensitive health information to third-party servers, while conventional anonymization is often inadequate, as models may inadvertently reconstruct or reveal personal data. The literature highlights the need for privacy-preserving solutions such as federated learning, encrypted inference, and local on-premise deployments. Regulatory frameworks—including the GDPR and the forthcoming EU AI Act—remain ill-equipped to address GenAI, leaving uncertainties over accountability, liability, and data-control roles. The opacity of commercial models further complicates auditability and certification under existing medical device standards. Reviews therefore call for transparent data-governance mechanisms, regulatory sandboxes, and privacy-by-design principles to ensure both ethical integrity and legal compliance. Ultimately, safeguarding patient privacy is viewed as a prerequisite for the responsible clinical integration of LLMs.
3.6.4. Data Availability and Generalizability
Data scarcity and imbalance have been identified as core barriers to reliable LLM performance in healthcare. Most models are trained or tested on English-language, high-resource datasets—such as PubMed abstracts or online social media—rather than representative clinical data, limiting generalizability across cultures, age groups, and care settings. Under-representation of non-English, minority, and low-income populations leads to systematic performance gaps and potential inequities in care. The opacity of proprietary training corpora further restricts reproducibility and independent bias auditing, raising concerns about compliance with ethical and data protection standards. To address these gaps, the reviews call for open, multilingual benchmark datasets annotated by domain experts, and privacy-preserving data sharing approaches. Strengthening data diversity, transparency, and accessibility is seen as essential to ensure that LLMs achieve equitable, safe, and scientifically valid integration into healthcare practice.
3.6.5. Continuous Human Oversight and Ethical Governance Frameworks
All five reviews converge on the principle that large language models must operate under continuous human supervision when applied in clinical or mental health contexts. While LLMs demonstrate promise in tasks such as information retrieval, triage support, and patient education, their susceptibility to hallucinations, bias, and contextual misinterpretation makes their unsupervised use unsafe. The reviews emphasize that LLMs should function as decision-support tools rather than autonomous agents, complementing but not replacing expert judgment. Ongoing human monitoring is also crucial for detecting subtle model drift or unexpected behavior following software updates. In this direction, structured human-in-the-loop frameworks, with clearly defined escalation procedures for high-risk outputs (e.g., suicide ideation detection, diagnostic recommendations) are required [35].
All five reviews stress that deploying LLMs in healthcare demands clear ethical governance frameworks ensuring transparency, accountability, and respect for patient rights. Current practice often outpaces regulation, leaving uncertainty around responsibility, informed consent, and fairness. Reviews highlight core principles such as accountability (clinicians retain final responsibility), transparency (users must know when AI is involved), non-maleficence (preventing harm through validation), justice (equitable performance across populations), autonomy (informed consent for AI interaction), and data ethics (responsible stewardship and privacy protection). Overall, the literature emphasizes that robust, enforceable ethical frameworks—combining technical, institutional, and societal safeguards—are essential to maintain public trust and ensure that GenAI serves healthcare’s fundamental moral obligations.
3.6.6. Methodological Quality of LLM Studies
All reviews highlight significant methodological weaknesses in current research on LLMs in healthcare. Most studies rely on retrospective, simulated, or vignette-based data rather than real-world clinical trials, limiting external validity and generalizability. Evaluation protocols vary widely, with inconsistent reporting of datasets, prompts, metrics, and baseline comparisons, making cross-study synthesis difficult. Few investigations employ standardized bias or risk-of-bias tools (e.g., QUADAS-2, PROBAST), and many omit details about model versioning or update cycles—critical for reproducibility. Reviews call for prospective, pre-registered, and multi-institutional studies using transparent methods and benchmark datasets that reflect clinical complexity and population diversity. They also emphasize the need for longitudinal evaluations assessing safety, performance drift, and human–AI interaction over time. Overall, improving methodological rigor and transparency is seen as essential to move the field from proof-of-concept experimentation toward clinically validated, ethically sound, and policy-relevant evidence. A thematic synthesis of outcomes and challenges for LLMs covering mental health, oncology, and cardiology applications can be seen in Table 2.
4. Discussion
4.1. Main Findings
We conducted a review of systematic reviews on the application of LLMs in critical healthcare domains, including cardiology, oncology, and mental health. The main goal was to examine the characteristics, outcomes, and challenges of LLMs by drawing, exploring, and synthesizing the findings of systematic reviews in this novel area of research. The key finding of the review is that LLMs have emerged as potential enhancers of diagnostic and decision-support processes in cardiology, oncology, and mental health. Nonetheless, the limited rigorous evidence to date underscores the need for robust, real-world research to validate LLM effectiveness and safety in clinical practice.
The predominant research focus was on depression detection and classification, complemented by investigations into suicidal ideation detection, question answering aligned with clinical guidelines, AI-driven mental health interventions such as loneliness support, emotion recognition and classification, and tumor board clinical decision support. More than half of the included studies applied GPT-based models, while BERT and its derivatives were employed in approximately 40% of the studies. The performance of LLMs was variable across their broad spectrum of applications, and therefore no clear evidence of their effectiveness can be demonstrated currently.
Across cardiology, oncology, and mental health, the reviewed evidence indicates that LLMs have substantial potential to enhance various aspects of clinical care, education, and research. Their strongest demonstrated benefits lie in detection, triage, and decision support, where transformer-based architectures can process vast volumes of unstructured text to identify early markers of disease, assess patient risk, and generate structured diagnostic information with high accuracy.
In mental health, LLMs have been applied to detect depression, anxiety, and suicidality through linguistic and affective cues, enabling scalable, non-intrusive screening beyond traditional clinical environments. In this context, LLMs may facilitate risk stratification and triage, helping clinicians identify individuals in need of early intervention—particularly in resource-limited or telehealth settings [36]. Their capacity for clinical reasoning and decision support has been demonstrated also in cardiology and oncology, where models often produce guideline-concordant responses and may assist in diagnostic synthesis and multidisciplinary planning [37].
Another prominent advantage of LLMs is their ability to enhance patient education and engagement through empathetic, conversational interfaces that provide accessible health information and encourage adherence and shared decision-making [38]. Additionally, LLMs streamline documentation, summarization, and research workflows, reducing administrative burden and accelerating knowledge generation. By automating report generation, the literature synthesis, and evidence summarisation, they can increase efficiency across clinical research domains [39].
Despite the potential of LLMs in improving clinical care, several limitations and challenges toward their wide adoption can be highlighted. Model output correctness and hallucinations remain fundamental challenges in applying LLMs to healthcare. Models frequently produce plausible but inaccurate or fabricated information, including erroneous clinical facts or nonexistent references [40]. Such hallucinations undermine reliability and pose safety risks when used for diagnosis or patient communication. The literature attributes these errors to limitations in the inherent logical structure of LLMs, training data, probabilistic text generation, and lack of factual grounding.
Furthermore, the included reviews consistently highlighted bias and lack of transparency as critical obstacles to the safe deployment of LLMs in healthcare. In several cases, the opacity of proprietary model architectures and datasets prevents independent auditing, bias detection, and accountability [41]. In this direction, transparent reporting of data provenance, inclusive and diverse training corpora, and bias-auditing frameworks that systematically evaluate fairness and performance across demographic and linguistic groups before clinical implementation, are important steps toward the improvement of LLMs’ reliability.
The reviewed evidence underscores major challenges related to data privacy, availability, human oversight, and methodological rigor in LLM research. Most models rely on proprietary or web-scraped data with uncertain consent and provenance, raising privacy and compliance concerns under frameworks such as GDPR. Simultaneously, the lack of open, diverse, expert-labeled, and representative datasets limits reproducibility and generalizability across languages and populations. The reviews stress that continuous human oversight is indispensable—LLMs should function as decision-support tools, with clinicians validating outputs and managing escalation for high-risk content. Methodologically, the current literature remains exploratory, dominated by simulated or retrospective designs with inconsistent evaluation metrics and scarce real-world validation. To advance clinical integration responsibly, the field must prioritize transparent data governance, ethical data sharing, standardized evaluation protocols, and prospective trials that rigorously test performance, safety, and reliability in real-world healthcare settings. Ensuring computational efficiency is also essential for real-time clinical applications, as models must deliver accurate outputs with minimal latency to support tasks like triage, decision support, and patient communication without disrupting care workflows.
The findings of this meta-review have important implications for the future of AI-driven healthcare. By synthesizing evidence across cardiology, oncology, and mental health, this work highlights that LLMs have the potential to transform clinical workflows through language-driven intelligence. Their demonstrated benefits in early detection, triage, decision support, and patient engagement suggest that LLMs could significantly improve clinical decision making and enable more personalized care delivery. At the same time, the variability in performance and methodological gaps underscore the need for rigorous validation before widespread adoption. These insights call for a strategic focus on developing transparent, bias-resistant, and ethically governed LLM systems, ensuring that innovation translates into safe, equitable, and clinically meaningful outcomes. Ultimately, the integration of LLMs into healthcare could redefine how clinicians interact with data, patients, and decision-making processes, accelerating the transition toward more efficient and patient-centered care.
4.2. Limitations
This review should be interpreted within the context of its limitations. The authors used a limited set of terms for the search of literature, which might have resulted in the omission of other relevant studies. Our search design likely missed relevant reviews that used terms referring to specific health conditions, alternative AI terminology, or did not mention the AI tool specifically in those fields. We limited our literature search to PubMed and Scopus, which are widely used databases internationally. This choice, however, represents an important methodological constraint that may introduce selection bias and affect the conclusiveness of our synthesis. We also recommend that future updates of this review expand the search to additional databases such as Embase and Cochrane, which are likely to index systematic reviews with rigorous clinical trial data. The review was based on the findings from systematic reviews of LLM studies and different populations in terms of disease, age, education and socioeconomic level were studied in different settings, which prevented the conduction of meta-analysis. The limitations of the included systematic reviews (introduced, for example, in their inclusion and exclusion criteria) might have affected the representation of the progress of LLMs. This review presented characteristics and outcomes of LLMs for cardiovascular disease, cancer, and mental disorders, considering their global burden. LLMs for other chronic conditions such as diabetes, arthritis, or liver disease were not examined. Our literature search was restricted to reviews published after 2022, due to the landmark emergence of ChatGPT. Different results could emerge if older studies were also included. Most included studies examined by the included reviews relied on controlled or simulated datasets rather than real-world clinical data, which limits the generalizability of findings and underscores the need for prospective evaluations in diverse, real-world settings. The generalizability of the findings is further restricted by the fact that only a small number of studies were found to be eligible for inclusion in this review.
5. Conclusions
In conclusion, the collective evidence from recent systematic reviews demonstrates that LLMs hold substantial promise for enhancing healthcare through improved detection, triage, decision support, and patient engagement. Overall, the reviews converge on the view that while LLMs are not yet ready for autonomous deployment in clinical settings, their augmentation of human expertise—from early detection and clinical reasoning to patient communication and research support—positions them as valuable tools for improving efficiency, consistency, and accessibility of healthcare services. Yet, their clinical integration remains constrained by persistent challenges, including hallucinations, bias, lack of transparency, data privacy risks, and limited methodological robustness. Current research is largely exploratory, emphasizing the need for rigorous, real-world evaluations supported by transparent data governance and ethical oversight. Ensuring reliability, fairness, and human supervision will be essential to build trust and safeguard patient welfare. As these models evolve, interdisciplinary collaboration among clinicians, data scientists, ethicists, and policymakers will be crucial to translating technical innovation into safe, equitable, and accountable clinical practice. Properly governed and validated, LLMs could become transformative instruments in shaping the future of evidence-based, human-centered healthcare.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Carchiolo V. Malgeri M. Trends, Challenges, and Applications of Large Language Models in Healthcare: A Bibliometric and Scoping Review Futur. Internet 2025177610.3390/fi 17020076 · doi ↗
- 2Kasneci E. Sessler K. Küchemann S. Bannert M. Dementieva D. Fischer F. Gasser U. Groh G. Günnemann S. Hüllermeier E. Chat GPT for Good? On Opportunities and Challenges of Large Language Models for Education Learn. Individ. Differ.202310310227410.1016/j.lindif.2023.102274 · doi ↗
- 3Volkmer S. Meyer-Lindenberg A. Schwarz E. Large Language Models in Psychiatry: Opportunities and Challenges Psychiatry Res.202433911602610.1016/j.psychres.2024.11602638909412 · doi ↗ · pubmed ↗
- 4Quer G. Topol E.J. The Potential for Large Language Models to Transform Cardiovascular Medicine Lancet Digit. Health 20246 e 767e 77110.1016/S 2589-7500(24)00151-139214760 · doi ↗ · pubmed ↗
- 5Iannantuono G.M. Bracken-Clarke D. Floudas C.S. Roselli M. Gulley J.L. Karzai F. Applications of Large Language Models in Cancer Care: Current Evidence and Future Perspectives Front. Oncol.202313126891510.3389/fonc.2023.126891537731643 PMC 10507617 · doi ↗ · pubmed ↗
- 6Vaswani A. Brain G. Shazeer N. Parmar N. Uszkoreit J. Jones L. Gomez A.N. KaiserŁ. Polosukhin I. Attention Is All You Need Proceedings of the 31st International Conference on Neural Information Processing Systems Long Beach, CA, USA 4–9 December 2017
- 7Brown T.B. Mann B. Ryder N. Subbiah M. Kaplan J. Dhariwal P. Neelakantan A. Shyam P. Sastry G. Askell A. Language Models Are Few-Shot Learners Adv. Neural Inf. Process. Syst.20203318771901
- 8Ayers J.W. Poliak A. Dredze M. Leas E.C. Zhu Z. Kelley J.B. Faix D.J. Goodman A.M. Longhurst C.A. Hogarth M. Comparing Physician and Artificial Intelligence Chatbot Responses to Patient Questions Posted to a Public Social Media Forum JAMA Intern. Med.202318358959610.1001/jamainternmed.2023.183837115527 PMC 10148230 · doi ↗ · pubmed ↗