Leveraging Large-Scale Public Data for Artificial Intelligence-Driven Chest X-Ray Analysis and Diagnosis
Farzeen Khalid Khan, Waleed Bin Tahir, Mu Sook Lee, Jin Young Kim, Shi Sub Byon, Sun-Woo Pi, Byoung-Dai Lee

TL;DR
This paper shows how AI models trained on large public chest X-ray datasets can help diagnose thoracic conditions effectively, even with noisy data.
Contribution
The novel contribution is demonstrating the effectiveness of general-purpose deep learning models trained on diverse, large-scale public datasets for robust CXR diagnosis.
Findings
EfficientNet achieved the highest diagnostic performance with an AUC of 0.8944.
Larger and more diverse datasets improved model generalizability and diagnostic accuracy.
Tuberculosis diagnosis remained challenging due to limited high-quality training samples.
Abstract
Background: Chest X-ray (CXR) imaging is crucial for diagnosing thoracic abnormalities; however, the rising demand burdens radiologists, particularly in resource-limited settings. Method: We used large-scale, diverse public CXR datasets with noisy labels to train general-purpose deep learning models (ResNet, DenseNet, EfficientNet, and DLAD-10) for multi-label classification of thoracic conditions. Uncertainty quantification was incorporated to assess model reliability. Performance was evaluated on both internal and external validation sets, with analyses of data scale, diversity, and fine-tuning effects. Result: EfficientNet achieved the highest overall area under the receiver operating characteristic curve (0.8944) with improved sensitivity and F1-score. Moreover, as training data volume increased—particularly using multi-source datasets—both diagnostic performance and…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
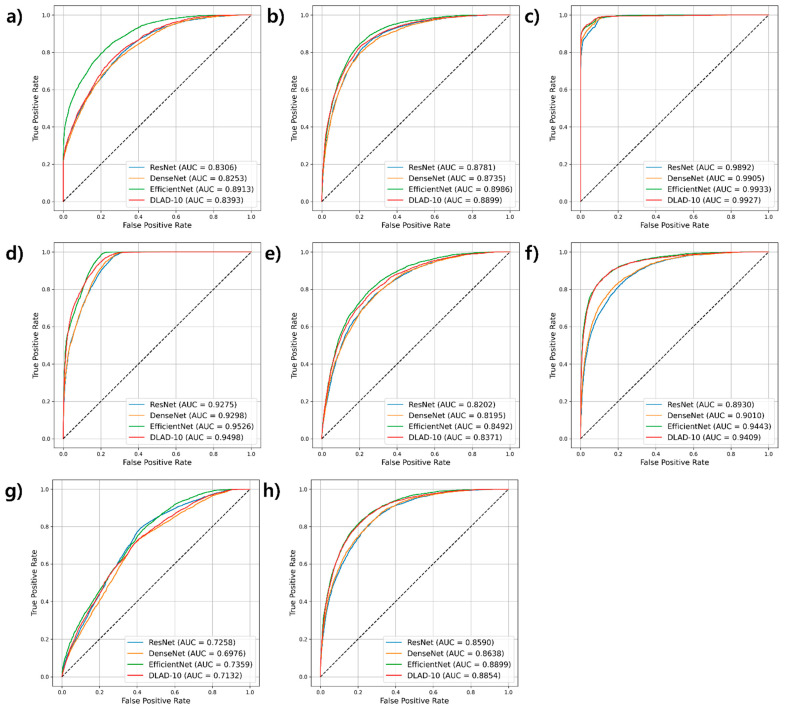 Figure 1
Figure 1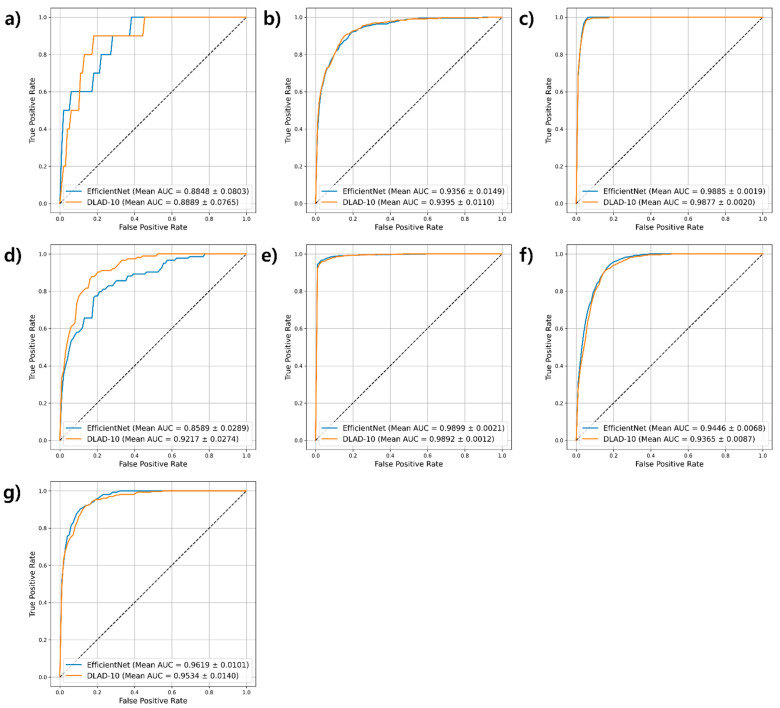 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCOVID-19 diagnosis using AI · AI in cancer detection · Lung Cancer Diagnosis and Treatment
1. Introduction
Chest X-ray (CXR) is an essential diagnostic tool in healthcare, providing a cost-effective, non-invasive, and widely accessible method for detecting thoracic diseases [1,2,3]. However, the increasing demand for CXR studies has placed a burden on radiologists, leading to diagnostic delays and highlighting the need for scalable automated diagnostic solutions to enhance efficiency and accuracy [4]. Although deep learning has achieved radiologist-level performance in CXR interpretation [5,6,7,8], its clinical integration is hampered by the reliance on private, expert-annotated datasets that limit reproducibility—especially in resource-constrained settings. Public datasets, including National Institute of Health (NIH) Chest X-ray-14 [9], CheXpert [10], and Medical Information Mart for Intensive Care-CXR (MIMIC-CXR) [11], offer diverse training data; however, noisy labels pose challenges for model reliability [12].
In this study, we aimed to demonstrate that the scale and diversity of training data can offset imperfections in label quality and model specificity. We leveraged large-scale, diverse public CXR datasets to train general-purpose image classification models that robustly classify multiple thoracic conditions without the need for specialized architectures. Moreover, we incorporated uncertainty quantification (UQ) to assess predictive performance and model reliability, offering insights into their real-world clinical applicability. Our findings indicate that, despite noisy labels, general-purpose deep learning models can achieve acceptable diagnostic performance when trained on expansive, varied datasets, thereby supporting the development of accessible, scalable artificial intelligence (AI) diagnostic tools for resource-limited settings.
While our study leverages publicly available datasets and standard deep learning models, its novelty lies in the systematic integration and analysis of these components. Specifically, we:
- Aggregate and harmonize 17 public CXR datasets, addressing label inconsistencies and cross-dataset duplication to enable robust generalization analysis and broaden coverage of rare diseases.
- Perform comprehensive UQ across multiple dataset scales, providing new insights into model stability, calibration, and reliability beyond what prior CXR studies have reported.
- Conduct class-specific uncertainty analysis for clinically important but underexplored categories, including tuberculosis, pneumothorax, masses/nodules, and the heterogeneous “Other” class, offering a granular understanding of class-dependent behavior.
- Characterize scaling-law behavior in both performance and uncertainty, demonstrating how increasing dataset size affects diagnostic accuracy and epistemic uncertainty, and offering actionable guidance for data collection and clinical deployment strategies.
These contributions underscore that our research extends beyond incremental improvements, providing new methodological and practical insights for scalable, uncertainty-aware CXR analysis.
2. Materials and Methods
The Institutional Review Board of Keimyung University Dongsan Medical Center approved this retrospective study and waived the requirement for written informed consent. All procedures followed the approved protocol.
2.1. Target Conditions
To maximize clinical relevance and impact, this study focused on the following six prevalent and clinically significant thoracic conditions: pneumonia, pleural effusion, tuberculosis, mass, consolidation, and pneumothorax. These conditions include both specific diseases (e.g., pneumonia and tuberculosis) and radiological findings (e.g., pleural effusion, mass, and consolidation) that frequently indicate an underlying pathology. The selection was guided by global disease burden, potential for early intervention, and the diagnostic importance of CXR in routine clinical workflows. Pneumonia and tuberculosis remain the leading causes of morbidity and mortality, particularly in low-resource settings with limited diagnostic tools [13]. Pleural effusion, masses, and consolidation are common thoracic abnormalities that, if detected early, can alter patient management and improve outcomes. Pneumothorax, although less prevalent, is a life-threatening condition requiring immediate identification and intervention [14]. For cases involving abnormal findings not otherwise classified among these six target diseases, an “Other” disease category was included to ensure broad diagnostic coverage without compromising specificity. This strategy enhances the clinical utility while maintaining focus on conditions with the greatest potential impact on patient care.
2.2. Data Collection and Preparation
2.2.1. Development Dataset
To construct a comprehensive training dataset, we aggregated 17 public CXR datasets (Table 1) into 894,373 unique frontal-view images, excluding non-frontal projections to ensure clinical consistency. This strategy enhanced model generalizability by incorporating diverse patient demographics, imaging protocols, and disease prevalence. Five major datasets (NIH Chest X-Ray-14 [9], CheXpert [10], MIMIC-CXR [11], PadChest [15], and BRAX [16]) provided a substantial portion of the development dataset. These datasets employed natural language processing (NLP) tools or deep learning algorithms to automatically extract labels from radiological reports. These methods facilitate large-scale label generation and introduce variability in label quality, particularly in disease categories requiring subjective interpretation. To address this, we harmonized labels across datasets, treated low-confidence labels consistently, and ensured mutual exclusivity in training and test sets (see Appendix B for full details).
Table 1 highlights class imbalance—a pervasive challenge in public CXR datasets—across target diseases. To address this, we strategically adjusted per-disease sample counts and augmented underrepresented classes (tuberculosis, mass, consolidation, pneumothorax) via image duplication and online augmentation techniques. Augmentation was restricted to training and validation sets to preserve the integrity of the uniquely composed test set, thereby preventing data leakage. Table 2 provides the final class distribution across all dataset splits.
2.2.2. External Validation Dataset
To assess generalization and fine-tuning efficacy, we constructed an independent validation dataset of 3031 unique-patient, posterior–anterior CXR images (July 2017–December 2019) from our hospital’s picture archiving and communication system (Table 2), ensuring no overlap with training data. This dataset enabled (1) an unbiased assessment of baseline model performance and (2) evaluation of domain-specific fine-tuning. To evaluate domain-specific fine-tuning, we used 10-fold cross-validation (training on k−1 folds and validating on the remaining fold), whereas non-fine-tuned models were directly tested on the external set to isolate domain adaptation effects.
2.3. Deep Learning Models
The three deep learning models used in this study—ResNet-50 [28], DenseNet-121 [29], and EfficientNet-B5 [30]—were selected for their proven effectiveness in natural image classification tasks and served as robust baselines for comparison. Furthermore, Deep Learning-based Algorithm for Detecting 10 Abnormalities (DLAD-10) [5], a high-performance model designed for CXR classification and recognized as a base model in commercial services due to its superior performance, was also included in the experiment.
All classification models were initialized with ImageNet-pretrained weights, and their inputs were normalized using the standard ImageNet mean and standard deviation. This preprocessing preserves the activation scaling expected by pretrained backbones and contributes to stable optimization during fine-tuning. In contrast, the U-Net segmentation model used to extract lung masks was trained entirely from scratch, without ImageNet initialization; therefore, segmentation inputs were processed using only min–max intensity normalization, ensuring consistency between preprocessing and initialization strategies.
For classification experiments, all models were trained and evaluated on the same pooled dataset to ensure consistent comparisons. Training was performed using the Adam optimizer with an initial learning rate of 1 × 10^−3^ and a batch size of 32. A comprehensive list of all hyperparameters, ensuring full reproducibility, is provided in Appendix A.
Although more recent architectures—including Vision Transformers [31], ConvNeXt [32], and large foundation models [33]—have demonstrated strong performance in medical image analysis, they require substantially greater computational resources and specialized pretraining pipelines. Consistent with our objective of evaluating scalable and broadly deployable diagnostic models, we focused on representative convolutional architectures that are widely used, computationally accessible, and well supported in open-source frameworks. This design choice is particularly relevant for resource-limited clinical environments, where training or deploying heavy transformer-based models or large foundation models may not be feasible. Accordingly, our evaluation centers on general-purpose convolutional neural network-based classifiers, including DLAD-10, an early commercial model, to assess whether large-scale public datasets alone can enable clinically acceptable performance without reliance on computationally intensive architectures.
2.4. UQ Using Monte Carlo (MC) Dropout
We employed MC dropout [34] to estimate model uncertainty by enabling stochastic dropout during inference, thereby generating multiple predictions for each input. This approach captures both aleatoric uncertainty (inherent data noise) and epistemic uncertainty (model or data limitations). Multiple forward passes were performed, and their predictions were aggregated to compute predictive entropy (PE) [35]—reflecting total uncertainty—and variance of predictions (VP) [36]—a direct measure of epistemic uncertainty. For robust estimation, we used a dropout rate of 0.4 and 20 stochastic passes, balancing computational efficiency with reliable metrics. The final class prediction was selected by averaging the probabilities across all passes. The dropout rate follows the standard configuration in previous studies [30,37], and the number of stochastic passes was chosen based on sensitivity analysis on the test set (see Appendix C for details).
2.5. Statistical Analysis
Diagnostic performance was evaluated using precision, sensitivity, specificity, F1-score, and area under the receiver operating characteristic curve (AUROC). These metrics provided a comprehensive assessment of the ability of the model to accurately classify disease states in chest radiographs, offering insights into discriminative capability and clinical utility. A 10-fold cross-validation was conducted, with performance reported as the average values across all folds, and 95% confidence intervals were calculated to assess variability and reliability. Stratified splitting was applied to ensure that each fold was representative of all target diseases, and multiple random seeds were evaluated to prevent folds with zero samples in low-prevalence classes; a seed was ultimately selected that preserved at least two samples per disease in every fold.
Class-specific decision thresholds (provided in Table 3 and Table 4) were optimized on the validation set by selecting operating points that favor sensitivity while avoiding excessive loss of specificity. Consistent with the clinical imperative to minimize false-negative findings—particularly for conditions such as tuberculosis, pneumonia, or pneumothorax, where missed diagnoses carry substantial risk—sensitivity was modestly prioritized. This approach acknowledges that while false positives necessitate additional confirmatory evaluation, they present significantly lower clinical risk than delayed diagnosis and treatment.
3. Results
3.1. Model Performance on Internal Validation Sets
Figure 1 and Table 3 summarize the performance of four deep learning models—ResNet, DenseNet, EfficientNet, and DLAD-10—on the internal validation sets. EfficientNet achieved the highest overall performance, with an average AUROC (0.8944) among all models. This model consistently outperformed the other models in sensitivity (0.81) and F1-score (0.61), reflecting its ability to accurately detect diseases while maintaining a balance between precision and recall (Table 3). DLAD-10 closely followed with an average AUROC of 0.8810, and although EfficientNet had a slight edge overall, disease-specific analysis revealed instances where DLAD-10 outperformed EfficientNet in certain categories, indicating that the relative advantage can vary by disease. In contrast, ResNet and DenseNet had slightly lower average AUROCs (0.8654 and 0.8626, respectively), with DenseNet exhibiting a marginally better F1-score than ResNet.
3.2. Model Performance on External Validation Set
For the external validation set, analysis focused on EfficientNet, which demonstrated the best performance using the development dataset. As shown in Figure 2 and Table 4, EfficientNet demonstrated comparable or superior performance to DLAD-10 across most disease categories, consistent with its performance on the development dataset. Fine-tuning with a portion of the external validation dataset consistently improved the results of both models across most target diseases. However, performance variations were observed between internal and external datasets. Pneumonia, tuberculosis, and mass showed higher AUROC scores internally, whereas the external dataset yielded better performance for the remaining diseases. These differences likely stemmed from the smaller number of samples for certain diseases in the external dataset, affecting generalizability. Overall, EfficientNet maintained strong diagnostic accuracy on the external validation set, demonstrating adaptability to diverse clinical scenarios.
3.3. Impact of Training Data Scale and Diversity on Model Effectiveness
3.3.1. Diagnostic Performance Across Data Scales
To evaluate the impact of training data scale, we incrementally increased the dataset size (20%, 40%, 60%, and 100% of 40,000 CXR images per disease) while maintaining proportional representation from source datasets. Experiments were conducted under controlled conditions using a development dataset, with MC dropout applied during inference to estimate uncertainty.
As presented in Table 5, model performance consistently improved with larger datasets: the mean AUROC rose from 0.8680 (20%) to 0.8937 (100%), and precision (0.47–0.51), sensitivity (0.80–0.82), specificity (0.78–0.81), and F1-score (0.57–0.61) all increased. Disease-specific results revealed significant gains for pneumothorax (0.9115–0.9437), pleural effusion (0.8657–0.8978), mass (0.9416–0.9520), and pneumonia (0.8414–0.8905), underscoring the benefit of expanded training data. In contrast, tuberculosis showed a slight AUROC decline (0.9937–0.9926). Given the relatively small number of unique tuberculosis cases (3929 studies) and the substantial reliance on duplicated samples to reach the target dataset size, this trend may reflect the limited diversity of underlying image features. However, other factors—including label variability across datasets or differences in acquisition protocols—may also contribute, and therefore this behavior should be interpreted with caution. Consolidation and the “Other” disease category also improved, although less dramatically. Overall, these findings confirm that larger, more diverse training datasets enhance model performance for well-represented diseases but underscore the need for targeted strategies when addressing rare or underrepresented conditions, including tuberculosis.
3.3.2. Diagnostic Performance Across Data Diversity
We trained models using two configurations to assess the impact of data diversity. In the single-source setup, each disease category comprised 5000 samples drawn from one public dataset (Chest X-Ray-14, CheXpert, MIMIC-CXR, or PadChest), with duplicates added as needed. In the multiple-source setup, 1250 samples per disease were selected from each dataset to form a combined set of 5000 images, thereby increasing diversity. An independent test dataset (Table 2) ensured consistent evaluation under uniform conditions. All models were trained under uniform conditions.
Table 6 indicates that diagnostic performance generally improved with the multiple-source dataset: mean AUROC increased from 0.7061 (Chest X-Ray-14-only) and 0.7523 (MIMIC-CXR-only) to 0.7708, with sensitivity and specificity rising to 0.63 and 0.75, respectively. However, the degree of improvement varied across diseases and metrics. For example, the AUROC for mass increased substantially from 0.6765 to 0.8850, and similar trends were observed for pneumonia and pleural effusion, whereas the “Other” disease category exhibited only modest gains (AUROC from 0.5324 to 0.5669). In some cases, single-source datasets outperformed the multiple-source configuration for specific metrics (e.g., MIMIC-CXR-only achieved a higher specificity for pneumonia: 0.72 vs. 0.65).
Tuberculosis exhibited unique behavior because its samples were exclusively derived from the PadChest dataset, rendering its data effectively single-source even in the multiple-source configuration. The AUROC improved from 0.3891 (PadChest-only) to 0.6440 with the multiple-source dataset, while precision and specificity showed inconsistent trends. This discrepancy likely reflects the influence of diverse non-tuberculosis samples on overall model calibration, while limited variability in tuberculosis-specific data constrained further improvements. Overall, these results demonstrate that data diversity enhances performance for common thoracic conditions, while highlighting the need for targeted data collection strategies to improve generalization for rare or heterogeneous diseases.
3.3.3. Uncertainty and Data Scale Relationship
As presented in Table 7, a descriptive analysis of PE and VP across increasing training data scales (20%, 40%, 60%, and 100%) reveals that VP generally decreases or stabilizes across all disease categories. Pleural effusion, consolidation, other diseases, and no finding exhibited clear decreases followed by stable low VP values (e.g., consolidation: 0.0007 at 20% to 0.0004 from 40% onward). Mass showed the largest reduction (0.0009 to 0.0005 and then to 0.0004), while pneumothorax remained unchanged through 60% (0.0004) and then decreased at 100% (0.0003). Pneumonia displayed a mild non-monotonic pattern, and tuberculosis remained constant at 0.0001 across all data scales.
Conversely, PE varied substantially by class and did not follow a monotonic trend. Most diseases showed a noticeable reduction between 20% and 40% data—such as pneumonia (1.9592 to 1.616) and consolidation (2.2179 to 1.893)—but increased again at 60% or 100%. Additionally, pneumothorax decreased sharply at 40% and partially rebounded at higher scales, while tuberculosis demonstrated the largest fluctuation relative to its scale (0.1858 → 0.0812 → 0.3547 → 0.2172) despite stable VP. The “Other” disease category exhibited a distinct pattern, with PE increasing from 20% to 60% (1.0883 to 1.3439) but decreasing sharply at 100% (0.6445). This substantial drop is attributable to the broad heterogeneity of the class: with limited data, the model is highly uncertain because it has insufficient exposure to the diverse subpatterns within this category. As data volume increases, the model encounters a wider and more representative range of these patterns, reducing epistemic uncertainty and yielding more stable calibration across this heterogeneous class.
Overall, these results demonstrate that scaling the training data reliably reduces VP across diseases, whereas PE is driven predominantly by class-specific factors including heterogeneity, rarity, and label consistency. Therefore, total predictive uncertainty does not necessarily decrease with more data, even when epistemic uncertainty becomes stable.
4. Discussion
Our study demonstrates that large-scale, diverse public CXR datasets with noisy labels can effectively train deep learning models for disease classification, overcoming limitations of imperfect data through scalability and diversity. However, rare and underrepresented conditions remain challenging, underscoring the need for targeted strategies, including higher-quality data collection and advanced model architectures tailored to their characteristics.
A key contribution of our study is the integration of UQ to analyze how predictive certainty evolves with increasing data sizes and across disease categories. As shown in our results, VP consistently decreased or stabilized as the training data expanded from 20% to 40%, 60%, and 100%, indicating improved parameter certainty under more balanced data regimes. In contrast, PE displayed heterogeneous and frequently non-monotonic trajectories, demonstrating that total predictive uncertainty is shaped not only by dataset size but also by inherent class characteristics, including heterogeneity, annotation quality, and imaging variability. For example, pneumonia, pleural effusion, and consolidation showed an initial reduction in PE but exhibited secondary increases at larger data scales, suggesting the presence of persistent aleatoric uncertainty that cannot be resolved solely by increasing training samples. Pneumothorax exhibited a similar pattern, with PE decreasing substantially at 40% data and subsequently increasing at higher scales despite stable VP.
The tuberculosis category exhibited a distinctive uncertainty pattern: VP remained constant at 0.0001 across all data scales, whereas PE fluctuated substantially. This behavior likely reflects the limited diversity of tuberculosis images in the original datasets and the extensive oversampling required to match the training volume of other diseases. Because the model repeatedly encounters a narrow set of visual patterns during training, epistemic variability remains minimal, resulting in stable VP values. However, PE remains sensitive to residual data-level ambiguities—such as heterogeneous imaging conditions, variations in disease presentation, and inconsistencies in text-derived labels—leading to the observed fluctuations. This contrast highlights how VP and PE capture different aspects of model uncertainty: while VP reflects stability in parameter estimates under repeated sampling, PE is influenced more strongly by intrinsic variability within the underlying data distribution.
These class-specific uncertainty profiles can be further interpreted by examining the dataset composition and adjusted training counts presented in Table 1 and Table 2, respectively. Several rare diseases—most notably tuberculosis—were severely underrepresented in the original datasets (~3.9 k of ~1.08 M) and required extensive oversampling and augmentation to balance the training distribution. Under these conditions, VP naturally stabilized due to repeated sampling of similar examples, whereas PE remained sensitive to unresolved label inconsistencies and limited intra-class diversity. Mass and pneumothorax, both of which rely heavily on NLP-derived labels, also showed PE fluctuations consistent with known variability in automated labeling pipelines and cross-dataset domain heterogeneity. Conversely, the substantial PE reduction observed for the “Other” diseases category at 100% data reflects the stabilizing effect of its exceptionally large and diverse original sample pool; only when exposed to the full dataset could the model approximate the underlying distribution sufficiently to reduce total uncertainty.
Direct comparisons with previous studies are challenging because of differences in dataset composition, labeling quality, and model architectures. Many previous studies relied on private or mixed private-public datasets, whereas our approach used only public datasets, enhancing accessibility but introducing variability and noise. Moreover, our study incorporated UQ to assess predictive certainty, a dimension frequently overlooked in similar research. Tang et al. [38] demonstrated robust binary classification using well-established models, while our study extends this approach to multiclass classification using an even larger dataset and highlights the benefits of fine-tuning for domain adaptation. Wu et al. [6] developed a custom model to classify 72 thoracic diseases from 353,818 CXR images from the NIH and MIMIC datasets using NLP-based automated labeling, achieving a mean AUROC of 0.807—comparable to a third-year radiology resident. Similarly, Cid et al. [7] utilized 1,896,034 images from three UK hospitals to classify 37 diseases, attaining a mean AUROC of 0.864, underscoring the impact of dataset scale on diagnostic accuracy. More recently, Seah et al. [8] trained EfficientNet on 821,681 images from five public datasets (including NIH Chest X-ray-14 and MIMIC) with radiologist-labeled high-quality data, achieving an outstanding mean AUROC of 0.957. A key distinction of our study is the methodological focus imposed by our open-source approach. While these large-scale studies [7,8] utilized private or highly curated institutional data and concentrated on maximizing accuracy within custom, complex taxonomies, our use of entirely public datasets necessitates and introduces multi-dataset harmonization and a focus on cross-dataset generalization. This methodological foundation, combined with our uncertainty-aware analysis, demonstrates high diagnostic performance using fully open-source resources across clinically significant multiclass conditions, broadening the applicability of automated diagnostic solutions, particularly in resource-constrained settings.
This study had some limitations. First, the external validation dataset was derived from a single institution, and the uneven distribution of cases for different diseases may not reflect real-world prevalence, potentially limiting generalizability. Second, although we aggregated 17 public datasets, substantial upsampling was required for several rare disease classes to maintain controlled comparisons across categories. While all unique and duplicated sample counts are transparently reported, reliance on duplicated images may constrain feature diversity for these underrepresented classes. Third, the “Other” diseases category encompasses a broad and heterogeneous set of abnormalities, and although we provide detailed label mappings, such heterogeneity inevitably reduces class-specific interpretability compared with well-defined disease categories. Fourth, although labels were harmonized and cross-dataset duplicates were removed, residual domain shifts arising from differences in imaging protocols, patient demographics, and disease prevalence across the 17 public datasets may still affect model generalizability, particularly for conditions with inconsistent labeling strategies. Fifth, we focused on six thoracic conditions, restricting their applicability to various diseases. Sixth, we employed MC dropout as the sole UQ method, leaving alternative techniques unexplored. Finally, we utilized a subset of state-of-the-art deep learning models, which may not fully leverage more recent architectures, including Vision Transformers or large foundation models; while our findings on scalability and uncertainty are expected to generalize, evaluating these newer models remains an avenue for future investigation.
5. Conclusions
This study demonstrated the feasibility of leveraging public datasets and open-source deep learning models to achieve robust diagnostic performance in CXR analysis. Using data scale and diversity, our approach achieved results comparable to those obtained with proprietary datasets while providing a fully reproducible and accessible framework. Our uncertainty analysis further highlighted that, although epistemic uncertainty decreases with increasing data, total predictive uncertainty remains strongly influenced by class-specific characteristics, label quality, and inherent data heterogeneity. These findings underscore the need for more diverse and high-quality datasets—particularly for rare or underrepresented conditions—to further improve model reliability and stability. Despite these challenges, our study advances the democratization of AI tools for medical imaging by providing a scalable, uncertainty-aware framework that facilitates broader adoption in diverse and resource-constrained clinical settings.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Raoof S. Feigin D. Sung A. Raoof S. Irugulpati L. Rosenow E.C. Interpretation of plain chest roentgenogram Chest 201214154555810.1378/chest.10-130222315122 · doi ↗ · pubmed ↗
- 2WHO (World Health Organization) Chest Radiography in Tuberculosis Detection: Summary of Current WHO Recommendations and Guidance on Programmatic Approaches World Health Organization Geneva, Switzerland 2021 Available online: https://www.who.int/publications/i/item/9789241511506(accessed on 30 October 2025)
- 3Ellis S. Aziz Z. Radiology as an aid to diagnosis in lung disease Postgrad. Med. J.20169262062310.1136/postgradmedj-2015-13382527535941 · doi ↗ · pubmed ↗
- 4Rimmer A. Radiologist shortage leaves patient care at risk, warns royal college BMJ 2017359 j 468310.1136/bmj.j 468329021184 · doi ↗ · pubmed ↗
- 5Nam J.G. Kim M. Park J. Hwang E.J. Lee J.H. Hong J.H. Goo J.M. Park C.M. Development and validation of a deep learning algorithm detecting 10 common abnormalities on chest radiographs Eur. Respir. J.202157200306110.1183/13993003.03061-202033243843 PMC 8134811 · doi ↗ · pubmed ↗
- 6Wu J.T. Wong K.C.L. Gur Y. Ansari N. Karargyris A. Sharma A. Morris M. Saboury B. Ahmad H. Boyko O. Comparison of chest radiograph interpretations by artificial intelligence algorithm vs radiology residents JAMA Netw. Open 20203 e 202277910.1001/jamanetworkopen.2020.2277933034642 PMC 7547369 · doi ↗ · pubmed ↗
- 7Cid Y.D. Macpherson M. Gervais-Andre L. Zhu Y. Franco G. Santeramo R. Lim C. Selby I. Muthuswamy K. Amlani A. Development and validation of open-source deep neural networks for comprehensive chest x-ray reading: A retrospective, multicentre study Lancet Digit. Health 20246 e 44e 5710.1016/S 2589-7500(23)00218-238071118 · doi ↗ · pubmed ↗
- 8Seah J.C.Y. Tang C.H.M. Buchlak Q.D. Holt X.G. Wardman J.B. Aimoldin A. Esmaili N. Ahmad H. Pham H. Lambert J.F. Effect of a comprehensive deep-learning model on the accuracy of chest x-ray interpretation by radiologists: A retrospective, multireader multicase study Lancet Digit. Health 20213 e 496e 50610.1016/S 2589-7500(21)00106-034219054 · doi ↗ · pubmed ↗