A jackknife approach to estimate the prediction uncertainty from binary classifiers under right-censoring
Antje Jahn-Eimermacher, Lukas Klein, Gunter Grieser

TL;DR
This paper introduces a new method to estimate prediction uncertainty in binary classifiers when dealing with time-to-event data that includes censored observations.
Contribution
The novel contribution is an adjustment to the jackknife estimator that incorporates inverse-probability-of-censoring-weighting for uncertainty estimation in machine learning models.
Findings
The adjusted jackknife estimator provides unbiased standard error estimates in simple parametric models.
Prediction uncertainty is higher when using binary classifiers on dichotomized data compared to survival models.
The method is demonstrated on kidney transplant survival data and validated through simulations.
Abstract
Clinical prediction models are developed to estimate a patient’s risk for a specific outcome, and machine learning is frequently employed to improve prediction accuracy. When the outcome is some event that happens over time, binary classifiers can predict the risk at specific time points if right-censoring is addressed by inverse-probability-of-censoring-weighting . Assessing prediction uncertainty is crucial for interpreting individual risks, but there is limited knowledge on how to consider inverse-probability-of-censoring-weighting when estimating this uncertainty. We propose an adjustment of the infinitesimal jackknife estimator for the standard error of predictions that incorporates inverse-probability-of-censoring-weighting. By using a nonparametric approach, it is broadly applicable, especially to machine learning classifiers. For a simple tractable example, we show that the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
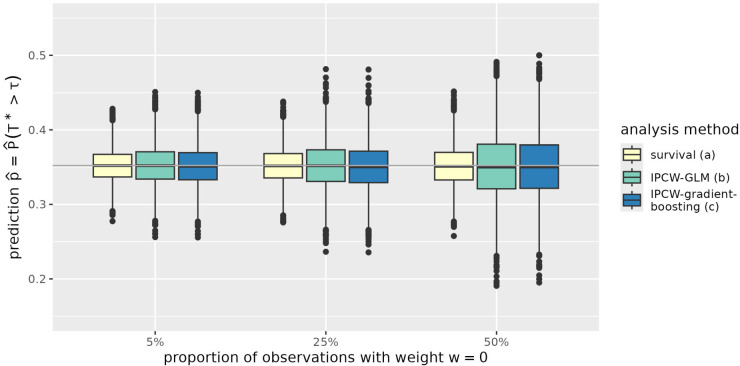 Figure 1
Figure 1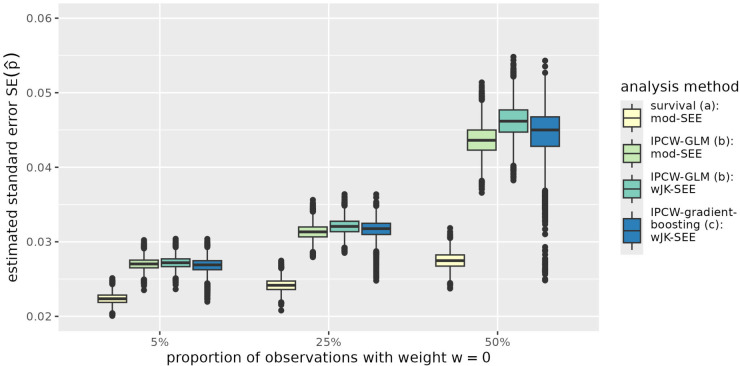 Figure 2
Figure 2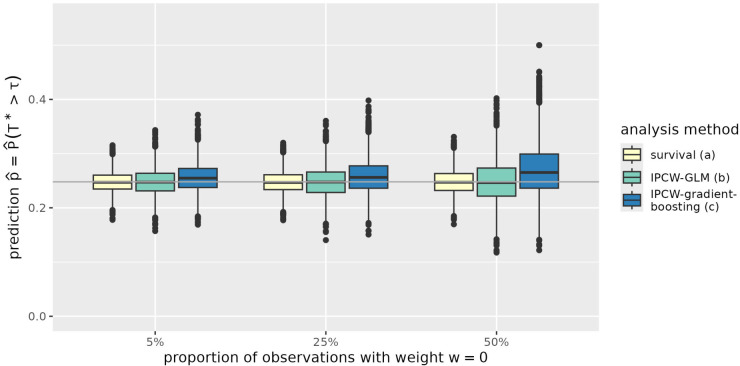 Figure 3
Figure 3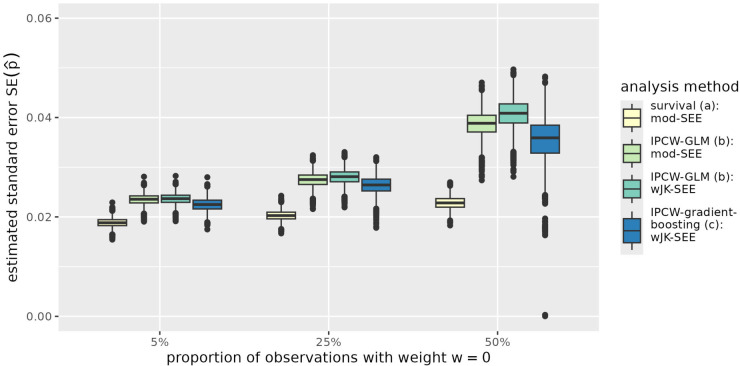 Figure 4
Figure 4- —Bundesministerium für Bildung und Forschunghttps://doi.org/10.13039/501100002347
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Inference · Risk and Portfolio Optimization · Statistical Methods and Bayesian Inference
Introduction
There is a significant interest in machine learning for predicting a patient’s long-term outcome after some medical intervention. An example motivating this paper is the patients’ and organ survival rate after organ transplantation.^1?–3^ Event time data are subject to censoring when patients enter the study cohort at different times, resulting in varying lengths of follow-up and/or when patients prematurely leave the study cohort and become lost to follow-up. Numerous survival analysis methods address censored event time data and many of them model the hazard function.
In the field of machine learning, it is more common to predict the risk or survival probability at a specific time point, denoted as . Instead of relying on survival methodology, which involves modeling hazards, binary classifiers are often used for this purpose.^4??–7^ These classifiers dichotomize the event time outcome into a binary variable indicating whether a subject has survived up to time or not. However, the dichotomized outcome remains unknown for subjects that are lost to follow-up both before time and before experiencing the event of interest. Reps et al.^ 8 ^ and Kvamme and Borgan^ 9 ^ have demonstrated that treating these censored observations as missing data in binary classifiers performs poorly in terms of discrimination and calibration. To address this issue, an alternative approach has been proposed:^10?–12^ weighting the observations by their inverse-probability-of-censoring (IPC) and applying the classification algorithm to the IPC-weighted observations.
Predictions obtained from IPC-weighted binary classifiers have been demonstrated to be asymptotically unbiased employing concepts of maximum likelihoods^10,12^ or statistical functionals^11,13^ and some applications show promising results.^11,14^ However, existing research has primarily focused on bias, neglecting the investigation of prediction uncertainty under IPC-weighted classification. Prediction uncertainty arises from using a random sample from the target population. Binary classifiers derive their results from dichotomized sample data and thus do not use the full available information on event times. Consequently, IPC-weighted classification may introduce higher uncertainties in predicted survival probabilities compared to survival methodologies, such as (semi-)parametric survival regression, random survival forests^ 15 ^ or hazard-based neural networks.^ 16 ^
However, how to consider the IPC weights when estimating the prediction uncertainty of inverse-probability-of-censoring-weighting (IPCW) classifiers is—to the best of our knowledge—unknown. Available methods are rare and focus on selected parametric models.^ 12 ^ Targeting specific parametric models when estimating the uncertainty of predictions is common^17,18^ but limits its applicability in particular for machine learning. In this article, we will, therefore, first adjust the nonparametric infinitesimal jackknife estimator for the standard error of predictions to the IPC weights. Afterwards, this estimator will be employed to compare the prediction uncertainty of survival probabilities when derived from IPC-weighted classifiers compared to hazard-based algorithms.
Our investigation complements existing research on prediction accuracy of IPC-weighted binary classifiers with censored data by an investigation of prediction uncertainty. It will help to balance its potential disadvantage that results from using less information from the data against its potential benefits that can be summarized as follows: First, classification tasks are common in machine learning and artificial intelligence and thus novel algorithms often emerge first for classification (and regression) before adaptations to event time data are developed. For the same reason, widely used machine learning and deep learning libraries, such as scikit-learn and Keras, as well as automated machine learning (AutoML) solutions like H2O AutoML and SageMaker Autopilot/Canvas, integrate models and metrics for both classification and regression tasks, but not event time data. Second, the data structure itself can motivate a binary classifier. For example when events are recorded only annually (as in some registries or healthcare databases), estimating annual survival probabilities using binary classifiers can be reasonable. Third, binary classifiers can be appealing for their simplicity: when the interest lies in a single timepoint (e.g. annual survival probabilities) binary classifiers provide results that are easier to communicate than for example, hazard ratios, which may not always be the most intuitive measure of effect size.^12,19^
As an example the proposed methods are used to quantify the prediction uncertainty of machine learning classifiers when predicting the individual patient risks of death or graft failure after kidney transplantation. Kidney transplantation can be considered as the treatment of choice for patients with end-stage kidney disease, due to its potential for improved quality of life and longer life expectancy. However, the demand for donor kidneys far exceeds the organs available for donation, leading to important questions, for example, about the patients’ post-transplant prognosis.
The article is structured as follows: In Section 2, the infinitesimal jackknife estimator with an adjustment for IPCW is proposed, followed by an evaluation of its performance through simulation studies in Section 3. In Section 4, we apply the proposed estimator to assess prediction uncertainty when analyzing data from the German Organ Transplant Registry. Finally, Section 5 concludes with a discussion.
Methods
We first introduce some notations needed throughout this article: For individuals, realizations of the random variables are observed that are considered as independent identically distributed copies of . Thereby, denotes the potentially right-censored event time with and defining the time to event and the time to censoring, respectively. The symbol is used to define the minimum throughout the article. The random variable , with defining the indicator function, informs whether defines an event or censoring time. The random baseline covariate vector describes subject characteristics that might affect the survival probabilities over time. Thus, for a single observation , defines the p-dimensional vector of covariate values, defines the time to event or censoring and defines the indicator whether an event has been observed at time . We assume that and are independent conditional on .
We are now interested in predicting the probability to survive a certain time point for subject . This probability is defined as follows:
The random variable represents the dichotomized outcome that a binary classifier could use as the dependent variable for predicting . When there is no censoring, is observable for all subjects and we can use any prediction model for classification tasks to estimate the prognosis . However, in the presence of censoring, for observations where , the information about surviving and thus about is missing. Ad hoc approaches that build a classification model using only observations with available information on will yield biased predictions of .^8,9^ This bias arises because the distribution of conditional on is obviously not the same as the distribution of , and the same holds for .
Weighting observations by their IPC has been proposed to prevent bias^10?–12^ and is investigated in the present article. The IPC weights are defined as follows:
Assigning the normalized weights to the observations of the learning sample will assign weight zero to observations with unknown . These discarded observations will then be represented by the observations to which greater weights were assigned. The use of IPC weights in classification algorithms can give unbiased predictions as shown in the following section.
Accuracy of predictions under IPC-weighted classification
2.1.
First, we will confirm that any binary classifier that employs the IPC-weighted binary log loss function yields unbiased predictions of . This, for example, refers to generalized linear models with logit link function where maximizing the log-likelihood with IPC-weighted contributions is equivalent to minimizing the weighted binary log loss function. Another example is gradient boosting or neural networks with customized weighted binary log loss function. To demonstrate this, consider a binary classifier that seeks to find a prediction model that minimizes the expected IPC-weighted binary log loss function, . Thereby, the expected value is considered as conditional on the covariates and refers to the distribution of new data that are independent of the training sample. For simplicity, we assume that is a known function in , although in practice it needs to be estimated. The proof builds upon ideas from Kvamme and Borgan^ 9 ^ for calculating the expected value of IPCW-Brier scores. It can complement other theoretical justifications of IPC-weighted classification that rely on maximum likelihood theory^ 10 ^ or on classification considered as functionals in the data distribution.^11,13^
This is the average cross-entropy across all data samples and thus reaches its minimum at according to Gibb’s inequality. Consequently, the classifier that minimizes the weighted loss is expected to predict , resulting in unbiased predictions. After having confirmed that IPC-weighted classification can yield accurate predictions, we will now investigate the uncertainty of predictions. An available method on standard error estimation for predictions that are derived from IPC-weighted binary classifiers refers to generalized linear models,^ 12 ^ which limits its generalizability. Consequently, our next step is to investigate model-free approaches for estimating standard errors in the context of IPC-weighted classification.
Adjusting the jackknife standard error estimate to IPC weights
2.2.
We start with the infinitesimal jackknife estimator for the standard error of predictions. By its nonparametric nature, jackknife estimators are not restricted to any particular classification algorithm. The infinitesimal jackknife standard error estimator is based on the concept of influence functions.^ 20 ^ To consider the IPCW within this concept, we introduce an adjustment as follows:
To simplify notation, we will omit the subject index when denoting the probability to survive time in the following and we will use the indices to indicate jackknife replications instead. Let be the (unknown) distribution where the observations are sampled from. The probability to survive the time point is assumed to be some functional of the distribution , . The estimator of is derived from the empirical distribution , thus . In general, the influence function of under distribution is defined as follows:
with being the distribution with all its mass on . The influence function can be used for a standard error estimate of .^ 21 ^ With being the influence function for some random observation sampled from , the variance of is then estimated by
In the unweighted situation, the sample weights of the empirical distribution are for each observation . In the weighted situation, observations are differentially weighted by the IPC weights . We will, therefore, adjust the variance estimator (2) by replacing with . Furthermore, in the unweighted situation the assumption is commonly used with being the estimate of when omitting observation from the sample. This results in the jackknife variance estimate . However, this association might no longer be true in the weighted situation, in particular as the influence of an observation might depend on its weight . We will illustrate this for an example in Section 2.3. We instead assume the following weighted association between influence components and jackknife replications for observations with :
We will show for the analytically tractable example in Section 2.3 that this assumption holds true. Equation (3) has been shown also for more complex scenarios.^ 22 ^ Finally, these two adjustments result in the following adjusted infinitesimal jackknife standard error estimate of
Observations with are assigned weight zero in the first sum and, therefore, do not contribute to the sum. They are excluded in the second sum only to well define , that is no longer required in the third sum because for observations with weight zero.
Relationship to delete-d jackknife estimators
2.2.1.
The proposed estimator can be considered as a generalization of the delete-d jackknife variance estimate^ 23 ^ defined as
with defining a subset of size and defining the estimator of p that results when is left out from the training data. Thus, in contrast to , when estimating , not only 1 but observations are left out. In total, different left-out-subsets of size d, , exist and the resulting estimates are averaged with respect to their squared difference to .
In the weighted situation, we no longer consider but as the amount of information that is left out when estimating . Consequently, the term in (5) can be replaced by . Furthermore, we no longer average over delete-d estimators. Consequently, averaging over the squared differences can be replaced by the weighted mean of squared differences. Both replacements then result in the same estimator as proposed in (4) as follows:
An analytically tractable example
2.3.
We will now substantiate our adjustment using the weighted mean as a simple, analytically tractable example. The weighted mean of the dichotomized outcomes is the simplest classifier for estimating , ignoring any covariate information during prediction. Consequently, it predicts the same probability for each subject. This prediction will be . In other words, , where is the empirical distribution of putting mass on each observed value . This is used as an estimate of with denoting the true distribution of . The influence components for an observation with will be
with and thus are an example where (3) instead of holds.
Now consider a simplified two-point discrete distribution for both time to event and time to censoring
Consider we are interested in with and want to estimate from an i.i.d. random sample of size using the IPC-weighted mean. Let be the number of observations that are censored at and thus receive a weight of 0. The other weights are estimated from the data and since for the normalized weight is assigned to the remaining m observations. W.l.o.g., let the index set refer to the observations that receive the non-zero weight . The weighted mean is then given by with well-known variance . The adjusted jackknife estimator of prediction uncertainty we have proposed in (4) then is
Thus, in this simplified scenario, the proposed estimator simplifies to the unbiased sample variance estimator of the mean of m i.i.d. random variables.
Comparison to the unadjusted jackknife and Greenwood’s standard error estimate
2.3.1.
The unadjusted jackknife standard error estimate is a scaled version of the unbiased sample variance with scaling factor and thus approximates the adjusted estimator with increasing and . We can also compare the adjusted jackknife estimator with another well-known variance estimate in this simplified scenario. The IPC-weighted mean corresponds to the Kaplan-Meier estimate at , , which can be written as a weighted sum.^ 24 ^ Therefore, Greenwood’s variance estimate, , would be an alternative estimator that turns out to be a scaled version of the unbiased adjusted jackknife estimate:
with being the number of observed events before .
Using standard error estimates to calculate confidence intervals
2.4.
Under certain distributional assumptions on the prediction estimate of interest, , standard error estimates can be used to construct an % confidence interval for the survival probability . If can be assumed to be (asymptotically) normally distributed, a Wald-type confidence interval can be derived as with . However, this approach can yield confidence intervals with boundaries outside the range , which is not reasonable for probabilities. To address this issue, an alternative approach transforms the boundaries of a confidence interval calculated on the logit scale,^ 25 ^ which ensures that the resulting interval lies within [0, 1]. This method still relies on the assumption of asymptotic normality of and uses the delta method to derive the confidence interval on the logit scale. The confidence interval is then given by the following equation:
where and are the lower and upper bounds of the % confidence interval for the logit of , respectively, which can be found by applying the delta method on the logit transformation of :
To inspect the asymptotic normality assumption of , a specific analysis model and data-generating process would have to be defined, which was not required for the nonparametric jackknife approach for estimating the standard error. Investigating the asymptotic behavior of is beyond the scope of the present article and has been done specifically for the IPC-weighted maximum likelihood solution of a generalized log linear model before.^ 12 ^ Instead, we will assess the coverage probability of the confidence interval given in (6) in a simulation study both with a parametric log linear model and a nonparametric gradient boosting approach.
Simulation study
In situations where less simple classifiers are applied, the adjusted jackknife variance estimator may no longer be analytically tractable and we will explore its properties through a simulation study. Our findings will be evaluated in a simulation study following the ADEMP structure.^ 26 ^ Applied analysis methods are available as an R package on GitHub (see the Data availability section).
Simulation design
3.1.
Objective:
We aim to investigate finite-sample properties of the predictions derived from IPC-weighted classification algorithms together with finite-sample properties of the proposed adjusted jackknife standard error estimator and the confidence intervals. In particular, we compare the predictions , their estimated standard error and the coverage probability of the derived % confidence interval for with the true probability to survive time , the empirical standard deviation of predictions and the nominal confidence level %, respectively. In the first step, we use a simple parametric generalized linear classification model (GLM), because for the GLM a model-based standard error estimator exists as a benchmark. In the second step, a gradient boosting classifier will be applied with a customized IPC-weighted binary log-loss function. Here, no benchmark exists for the standard error of predictions and the adjusted jackknife estimator will be compared to the empirical standard deviation of predictions across the simulation runs. For comparison, we will also apply a survival model that uses information on instead of the dichotomized IPC-weighted outcome.
Methods:
We evaluate event time scenarios with sample size . For each sample size, we examine censoring distributions where 25% and 50% of the observations are expected to have a weight of 0, respectively. For each subject , the values of two binary covariates, and , are drawn, respectively, from independent -distributions. Time to event is generated from a log-logistic distribution with shape parameter and scale parameter with the true values of the regression coefficients being set to . Time to censoring is generated from an exponential distribution with parameter to ensure an average proportion of , , and of observations receiving weight zero, respectively. Applying a log-logistic distribution ensures that the dichotomized outcome of the independent realizations can be considered as a sample from a generalized linear model with logit link function. At the same time, follows a parametric survival model. Consequently, any differences in the prediction performance of both modeling strategies cannot be attributed to one model violating its modeling assumptions.
For the simulation, we use the rllogis function of the R-package flexsurv (version 2.2.2) to generate replications for each combination of and . Each of these datasets is evaluated by the following three analysis methods:
- (a)A parametric log-logistic survival model fitted using the survreg function from the R package survival (version 3.5.5). Predicted probabilities are obtained as follows:
where is the maximum likelihood estimate of the model parameters. To simplify notation, we define the covariate vector to include a leading 1, that is, .
- (b)An IPC-weighted generalized linear model with logit link function fitted using the logitIPCW function of the R-package mets (version 1.3.3). Predicted probabilities are obtained as follows:
where minimizes the IPC-weighted loss (which is equivalent to maximizing the IPC-weighted log-likelihood):
In particular, can be considered as a functional of the empirical distribution putting mass on each observed value , as this distribution serves as the basis for the loss function.
- (c)An IPC-weighted gradient boosting approach fitted using the xgb.train function from the R-package xgboost (version 1.7.7). With this approach predictions cannot be expressed in closed form due to the nonparametric nature of the algorithm. However, as in (b), predictions are obtained by minimizing the IPC-weighted loss
without an explicit parametric form of . Nonetheless, can still be considered as a functional of the empirical distribution putting mass on each observed value , as this distribution still serves as the basis of the loss function. For estimating the IPC weights that are passed to the classifiers in (b) and (c) we use a model-free Kaplan-Meier estimator. For each simulation run , we extract the prediction estimates from each model fit. These estimates are for a subject with and , and they are derived as a function of the regression coefficient estimates in (a) and (b) and as the predicted outcome in (c). Model-based standard error estimates of predictions can be derived in (a) and (b) from the standard error of regression coefficient estimates using the delta method. In addition, for all models the proposed adjusted jackknife standard error estimates are derived. Each standard error estimate is also used to compute a % confidence interval following the approach given in (6). Furthermore, we estimate each model’s IPC-weighted Brier score . Based on these data, we calculate the following measures of evaluation for each model in each scenario:
- : Empirical mean of the predictions .
- : Empirical standard deviation of .
- : Empirical mean of the Brier scores .
- : Empirical mean of the proposed model-free standard error estimates .
- : Empirical mean of the model-based standard error estimates (available for (a) and (b) only).
- : Empirical coverage probability of the CI, calculated by (6) and using the proposed model-free standard error estimates. Empirical coverage probability is defined as the proportion of simulations in which the CI contains the true .
- : Empirical coverage probability of the CI, calculated by (6) and using the model-based standard error estimates (if available). Empirical coverage probability is defined as the proportion of simulations in which the CI contains the true .
Simulation results
3.2.
As an example, we show the results of the prediction estimates and for a subject with and , respectively. The true probability of surviving time is and , respectively. The mean predictions over the simulation runs are provided in Tables 1 and 2 for the different sample sizes and censoring rates investigated. The parametric survival model, which does not require IPCW, provides unbiased predictions as expected. Unbiased predictions are also achieved by the generalized linear model and the gradient boosting, that both employ the IPC-weighted log-loss function. This finding confirms our analytical results derived in Section 2.1. However, both appear to need a substantial number of observations with non-zero weights to produce unbiased predictions. While the IPC-weighted GLM stabilizes with observations, up to 50% of which may have zero weight, weighted gradient boosting stabilizes not before (for ) or even (for ), in particular when up to half of the observations have zero weight. Severe bias is observed for the XGBoost even with sample sizes up to n=1000 for and only with large sample sizes of do these predictions become approximately unbiased. One reason might be that the machine learning method often performs better with higher number of covariates and more hyperparameter tuning might lead to better predictions. However, this result also underscores that the results presented in Section 2.1 refer to expected bias only, and that finite-sample behaviors may still differ—particularly when using data-demanding machine learning methods.
Table 1.: Mean predicted probabilities to survive time point τ=5 for an individual with x1=1 and x2=1 ( p¯11 ) in simulated data with sample size n.
Table 2.: Mean predicted probabilities to survive time point τ=5 for an individual with x1=1 and x2=0 ( p¯10 ) in simulated data with sample size n.
Tables 3 and 4 present the simulation results for the standard errors of and , respectively, estimated using the proposed IPCW-adjusted jackknife estimator (Section 2.2). For comparison, model-based standard error estimates are also shown, which are, however, not available for general machine learning approaches like XGBoost. The empirical standard errors over the simulation runs (SE) are expected to closely resemble the true standard error of predictions when derived from the different analysis methods and for different sample sizes and censoring rates. The model-based standard errors (mod-SEE) of the survival and IPC-weighted GLM are asymptotically unbiased and, consequently, closely match the empirical standard errors for larger sample sizes and lower censoring rates. The IPC-adjusted jackknife estimates for the IPCW-GLM model exhibit a bias of up to 6.2% relative to the empirical standard error estimate in certain scenarios ( , with 50% of observations having zero weight). However, in all cases where only 25% of observations have zero weight, the relative bias remains below 4%. For IPCW-weighted XGBoost, in scenarios where prediction bias arises due to insufficient sample sizes, the IPCW-based standard error estimates also exhibit bias, which can be substantial (up to for and up to for . Since the Jackknife variance estimator is based on predictions from leave-one-out subsamples, it is not surprising that biased predictions can lead to biased Jackknife standard errors. For sufficiently large sample sizes, when the bias of predictions diminishes, also the bias of the weighted Jackknife standard error estimates decreases to < . Irrespective of the applied method, all standard error estimates increase with decreasing sample size and increasing censoring rates, because both lead to a reduced number of observed events.
Table 3.: Standard error of the predicted probability to survive time point τ=5 for an individual with x1=1 and x2=1 ( SE(p^11) ) in simulated data with sample size n .
Table 4.: Standard error of the predicted probability to survive time point τ=5 for an individual with x1=1 and x2=0 ( SE(p^10) ) in simulated data with sample size n .
In general, the IPCW-adjusted jackknife estimates tend to slightly overestimate the standard errors. They can therefore be considered conservative, for example, with respect to coverage probabilities when applied to calculate confidence intervals of predictions. This is consistent with the results on coverage probabilities shown in Tables 5 and 6. Except for cases where sample size limitations introduce bias that adversely affects coverage (GLM with or with and 50% observations with zero weight and gradient boosting with ( ) and ( ), the coverage probabilities using the IPCW-adjusted jackknife standard error come close to the nominal level of 95%. In general, they slightly exceed the nominal level, whereas those using the model-based standard error sometimes fall slightly below it. Overall, the IPCW-adjusted jackknife standard error seems to provide a useful method for constructing confidence intervals, particularly in situations where model-based solutions are not available. However, coverage probabilities of CI depend not only on reliable standard error estimates, but also on unbiased predictions. The latter explains the very poor coverage probabilities in certain scenarios with gradient boosting and , as shown in Table 6.
Table 5.: Coverage probabilities of 95% confidence intervals for the probability to survive time point τ=5 for an individual with x1=1 and x2=1 in simulated data with sample size n .
Table 6.: Coverage probabilities of 95% confidence intervals for the probability to survive time point τ=5 for an individual with x1=1 and x2=0 in simulated data with sample size n .
In general, the construction of confidence intervals from the logit scale, as given in (6), can be recommended over Wald-type intervals, as they yield coverage probabilities closer to the nominal level of 95% (results for the Wald-type intervals not shown).
When only a small proportion—5%—of all subjects receive weight of zero, weighted approaches may suffer from increased uncertainty in estimating the censoring distribution, which determines the weights. Additionally, smaller weights can lead to numerically instability in the weighted estimators, as known from other IPCW-based approaches.^ 27 ^ However, our simulation results do not indicate any adverse effects resulting from small censoring proportions. One possible explanation is that a lower censoring rate implies fewer subjects with weight zero, that are represented by up-weighting remaining observations. This benefit might outweigh the potential drawbacks of smaller weights.
When comparing the prediction uncertainty between the different applied analysis models, the survival model exhibits the lowest degree of uncertainty when measured as the standard error of prediction. Survival models utilize the full information from the data, whereas classification models dichotomize the information, which could explain this result. However, it must be considered that the applied survival model perfectly fits the data generation process, whereas in real data applications, model misspecifications might also affect the prediction uncertainty. When comparing the IPC-weighted classifiers, the generalized linear model exhibits slightly higher prediction uncertainties than the gradient boosting. However, this is accompanied by a higher prediction accuracy, as described before.
Interestingly, the differences in prediction uncertainties seem to be too small to be reflected in the Brier scores presented in Table 7. Here, all methods show comparable results with respect to the Brier scores averaged over the simulation runs.
Table 7.: Mean Brier score of the different prediction models for predicting the probability to survive time point τ=5 in simulated data with sample size n.
The results are further illustrated in Figures 1 to 4 exemplarily for the situation of a sample size of . The figures illustrate the findings described before: Whereas all methods exhibit unbiased predictions for , variability of predictions is higher when IPC-weighted classifiers are applied as compared to the survival model (Figure 1). This can also be observed from Figure 2. Furthermore, Figure 2 also reflects the slightly conservative results of the IPCW-adjusted jackknife estimates of standard error when compared to the model-based estimates of IPC-weighted GLM. For , Figure 3 reflects the bias of the IPCW-weighted gradient boosting, that also adversely affects the standard error estimates based on the Jackknife replicates of predictions (Figure 4).
Predictions of the probability to survive time point τ=5 for an individual with x1=1 and x2=1 ( p^11 ) in simulated data with sample size n=1000 . The expected proportion of observations with assigned IPC weight of 0 is 5%, 25%, and 50% depending on the censoring distribution. Predictions are derived from a parametric log-logistic survival model (survival), an IPCW-GLM and an IPC-weighted gradient boosting model (IPCW-gradient-boosting) described as (a) to (c) in Section 3.1. IPC: inverse-probability-of-censoring; IPCW-GLM: inverse-probability-of-censoring-weighted generalized linear model; IPCW: inverse-probability-of-censoring-weighting.
Standard error of the predicted probability to survive time point τ=5 for an individual with x1=1 and x2=1 ( p^11 ) in simulated data with sample size n=1000 . The expected proportion of observations with assigned IPC weight of 0 is 5%, 25%, and 50% depending on the censoring distribution. Standard errors of predictions are derived from the standard errors of regression coefficients using the delta method in the parametric log-logistic survival model and the IPC-weighted-GLM (survival:mod-SEE, IPCW-GLM:mod-SEE) and by the adjusted jackknife estimator in the IPC-weighted-GLM and the IPC-weighted-gradient boosting model (IPCW-GLM:wJK-SEE, IPCW-gradient-bosting:wJK-SEE). The analysis methods (a) to (c) are described in Section 3.1. IPC: inverse-probability-of-censoring; IPCW-GLM: inverse-probability-of-censoring-weighted generalized linear model; IPCW: inverse-probability-of-censoring-weighting.
Predictions of the probability to survive time point τ=5 for an individual with x1=1 and x2=0 ( p^10 ) in simulated data with sample size n=1000 . The expected proportion of observations with assigned IPC weight of 0 is 5%, 25%, and 50% depending on the censoring distribution. Predictions are derived from a parametric log-logistic survival model (survival), an IPCW-GLM and an IPCW-weighted gradient boosting model (IPCW-gradient-boosting) described as (a) to (c) in Section 3.1. IPC: inverse-probability-of-censoring; IPCW-GLM: inverse-probability-of-censoring-weighted generalized linear model; IPCW: inverse-probability-of-censoring-weighting.
Standard error of the predicted probability to survive time point τ=5 for an individual with x1=1 and x2=0 ( p^10 ) in simulated data with sample size n=1000 . The expected proportion of observations with assigned IPC weight of 0 is 5%, 25%, and 50% depending on the censoring distribution. Standard errors of predictions are derived from the standard errors of regression coefficients using the delta method in the parametric log-logistic survival model and the IPC-weighted GLM (survival:mod-SEE, IPCW-GLM:mod-SEE) and by the adjusted jackknife estimator in the IPC-weighted GLM and the IPC-weighted gradient boosting model (IPCW-GLM:wJK-SEE, IPCW-gradient-bosting:wJK-SEE). The analysis methods (a) to (c) are described in Section 3.1. IPC: inverse-probability-of-censoring; IPCW-GLM: inverse-probability-of-censoring-weighted generalized linear model; IPCW: inverse-probability-of-censoring-weighting.
Application
We illustrate the methods by quantifying the prediction uncertainty of parametric and machine learning classifiers when predicting the individual patient risks of death or graft failure after kidney transplantation. For prediction, modeling data from the German Organ Transplant Registry are used. These data include information on donors, recipients, and the transplantation process of the solid organ transplants performed between 2006 and 2016. Additionally, follow-up information on patient survival and organ failure is incorporated, which hospitals are required to report at least annually. Due to this reporting schedule, it may be more reliable to derive only annual predictions. These predictions will serve to illustrate the methods developed within this article.
Data were filtered to include first-time, kidney-only recipients of deceased donor organs with available information on graft and patient survival data. Donors and recipients above 65 years of age were excluded due to differences in organ allocation for this age group (Eurotransplant Senior Program). This resulted in a sample size of kidney transplantations. We further removed 102 observations with implausible values (weight <30 kg, height <100 cm, years on dialysis >100 years or negative, creatinine >1000 mol/L, cold ischemia time > 80 hours or 0 minutes, ABO-incompatible transplants).
The outcome of interest was graft and patient survival probabilities at , and years after transplantation. Observations with graft failure or patient death within the first 5 days after transplantation ( ) were excluded, as well as patients with follow-up information <5 days after transplantation ( ) resulting in a total of 9707 observations. The proportion of censored observations before time was , and , respectively.
A Cox proportional hazards model, an IPC-weighted GLM with logit link function and an IPC-weighted gradient boosting classifier were fitted to estimate the graft and patient survival probabilities at time . Hyperparameter selection is described in Appendix A. All models were based on the following donor, transplant and recipient factors: donor age, donor height, donor smoking, recipient age, recipient’s years on dialysis, log cold ischemia time, recipient pretransplant blood transfusion, recipient presenting PRA (panel-reactive antibodies), and recipient sex. The details about the variable selection method and handling of missing values are given in Appendix B. For the Cox model and GLM, model-based standard error estimates of predictions were derived, where methods derived by Blanche et al.^ 12 ^ are used for the weighted GLM. Additionally, the adjusted jackknife estimator for the standard error of predictions is employed for all models.
Table 8 presents the predictions from the different models exemplarily for a male recipient, of mean age, with mean years of dialysis, without pretransplant blood transfusion, not presenting panel reactive antibodies, receiving a transplant from a non-smoking donor of mean age and height, after the mean log cold ischemia time of the transplant. The predicted patient and graft survival probability at time is similar, irrespective of whether a Cox regression approach or an IPC-weighted binary classifier has been applied. The survival probability at 2 years after transplantation is predicted to be 93% and decreases to around 90% and 87% after 3 and 4 years, respectively. The gradient boosting seems to exhibit a slight bias when the proportion of observations with zero weight is 22.5% or 53.7%. Regarding prediction uncertainty, the application confirms the finding of the simulation studies that IPC-weighted classifiers have higher prediction uncertainty compared to the survival analysis approach that utilizes the full data. The results also indicate that the adjusted jackknife estimate of prediction uncertainty tends to be slightly conservative compared to the model-based approach for GLM. However, when machine learning classifiers such as XGBoost are employed with right-censored data, no model-based approach for prediction uncertainty exists and the proposed adjusted jackknife estimator provides a way to quantify the prediction uncertainty also in these situations.
Table 8.: Predicted probability with standard error for the graft and patient survival at time τ (years) for the specific patient as described in Section 4.
Table 9.: Variables considered in the backward variable selection process to select the variables for prediction modeling of the graft and patients survival probability using data of the German Organ Transplant Registry (Section 4).
Discussion
IPCW classifiers have been introduced as a flexible tool for applying in particular machine learning models to survival data. We have proposed a method to consider the IPCW when estimating the uncertainty of individual predictions derived from these classifiers.
Whereas we have focused on classifiers that customize the log-likelihood or loss function using IPCW, bagging with IPC-weighted bootstrapping has been proposed as an alternative.^ 11 ^ This approach enables ensemble learning and prediction estimates are expected to be unbiased, following similar arguments as given in Section 2.1. For standard error estimation, the jackknife after bootstrap method^28,29^ could be adapted to incorporate IPC weights, which will be the topic of future work.
Jackknife methods can be computationally challenging in particular for large sample sizes and time-consuming prediction algorithms as for example random forests or deep neural networks. For this reason, our simulation study investigates only a single machine learning algorithm (gradient boosting), which is a limitation. The simulation study is also restricted to a data generation model, which does not reflect non-linear or non-additive effects or a larger number of predictors as for example proposed by Infante et al.^ 30 ^ Nevertheless, we chose this simulation model, because for the IPCW-GLM a parametric standard error recently has been proposed^ 12 ^ that could serve as a comparator.
Three issues appear with the presented approach similarly to how it does with unadjusted jackknife estimates of standard errors: First, our estimator gives slightly conservative results as typical for the jackknife method.^ 31 ^ Second, we rely on the assumption (3) that is similar to the assumption used in the unadjusted jackknife approach. We demonstrate that assumption (3) holds true in the simplified example given in Section 2.2. However, in more complex scenarios, the influence functions may not be reducible to simpler formulas making this assumption difficult to verify. Third, Jackknife variance estimators are based on predictions from leave-one-out subsamples. Consequently, when the underlying method produces biased predictions—as we observed for the machine learning approach under insufficient sample sizes—this bias can negatively affect the Jackknife variance estimates and, in turn, reduce the coverage probabilities of the confidence intervals.
In situations where IPC weights are close to zero, the proposed adjustment will have less impact on the estimator than in situations with larger weights. This can be observed in the simple tractable example of Section 2.3 where the scaling factor approximates with increasing and thus with decreasing IPC weights.
Prediction is a common task in statistical and machine learning. We consider reporting the uncertainty of individual risk predictions as crucial, especially when these predictions inform medical decisions. However, there is no firm conclusion on the best measure for reporting individual prediction uncertainties.^ 32 ^ The TRIPOD statement^ 33 ^ provides guidance on how to report a prediction model, but it does not address how to report the resulting predictions. Recently, Thomassen et al.^ 17 ^ proposed the effective sample size as a metric to quantify prediction uncertainty, which may be a more intuitive measure than standard errors or confidence intervals. Although the effective sample size is currently limited to certain parametric prediction models and thus out of the scope of this article, the authors discuss extending it to more flexible models.
It should be mentioned that uncertainty in individual predictions does not only arise from sampling data from the target population. There are other sources of uncertainty, which we have not considered here. One potential source is model misspecification, which is of more concern in statistical modeling than in machine learning due to the flexibility of many machine learning algorithms. Another source is sampling bias. This issue is particularly relevant for machine learning algorithms, which often are trained on large datasets that are more susceptible to sampling bias compared to clinical study data with pre-specified inclusion and exclusion criteria.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Gotlieb N Azhie A Sharma D , et al. The promise of machine learning applications in solid organ transplantation. npj Digit Med 2022; 5: 89.35817953 10.1038/s 41746-022-00637-2PMC 9273640 · doi ↗ · pubmed ↗
- 2Truchot A Raynaud M Kamar N , et al. Machine learning does not outperform traditional statistical modelling for kidney allograft failure prediction. Kidney Int 2023; 103: 936–948.36572246 10.1016/j.kint.2022.12.011 · doi ↗ · pubmed ↗
- 3Szili-Torok T Tietge UJ Verbeek MJ , et al. Machine learning: it takes more than select models to draw general conclusions. Kidney Int 2023; 104: 1035–1036.37863623 10.1016/j.kint.2023.07.018 · doi ↗ · pubmed ↗
- 4Lisboa PJ Jayabalan M Ortega-Martorell S , et al. Enhanced survival prediction using explainable artificial intelligence in heart transplantation. Sci Rep 2022; 12: 1–14.36376402 10.1038/s 41598-022-23817-2PMC 9663731 · doi ↗ · pubmed ↗
- 5Nitski O Azhie A Qazi-Arisar FA , et al. Long-term mortality risk stratification of liver transplant recipients: real-time application of deep learning algorithms on longitudinal data. Lanc Digit Health 2021; 3: e 295–e 305.10.1016/S 2589-7500(21)00040-633858815 · doi ↗ · pubmed ↗
- 6Ershoff BD Lee CK Wray CL , et al. Training and validation of deep neural networks for the prediction of 90-day post-liver transplant mortality using UNOS registry data. Transplant Proc 2020; 52: 246–258.31926745 10.1016/j.transproceed.2019.10.019PMC 7523496 · doi ↗ · pubmed ↗
- 7Kampaktsis PN Tzani A Doulamis IP , et al. State-of-the-art machine learning algorithms for the prediction of outcomes after contemporary heart transplantation: results from the UNOS database. Clin Transplant 2021; 35: e 14388.10.1111/ctr.1438834155697 · doi ↗ · pubmed ↗
- 8Reps JM Rijnbeek P Cuthbert A , et al. An empirical analysis of dealing with patients who are lost to follow-up when developing prognostic models using a cohort design. BMC Med Inform Decis Mak 2021; 21: 43.33549087 10.1186/s 12911-021-01408-x PMC 7866757 · doi ↗ · pubmed ↗