High-quality haplotype-resolved genome assembly and annotation of Malus baccata ‘Jackii’
Matthias Pfeifer, Ofere Francis Emeriewen, Henryk Flachowsky, Monika Höfer, Jens Keilwagen, Fang-Shiang Lim, Andreas Peil, Holger Zetzsche, Thomas Wöhner

TL;DR
This paper presents the first high-quality genome assembly of Malus baccata 'Jackii', a disease-resistant apple variety, which can aid in breeding new apple cultivars.
Contribution
The study provides the first haplotype-resolved genome assembly and annotation of Malus baccata 'Jackii' using advanced sequencing and bioinformatics methods.
Findings
The genome assembly includes 17 pseudochromosomes with scaffold N50 values exceeding 30 Mb for both haplotypes.
Over 42,000 genes were predicted and annotated with high accuracy, supported by BUSCO analysis exceeding 97.5%.
The dataset is expected to support future genomic studies and improve apple breeding for disease resistance.
Abstract
Malus baccata ‘Jackii’ has been observed to exhibit multiple disease resistances, thus rendering it a promising source for breeding new disease-resistant apple cultivars. Here, we present the first haplotype-resolved genome assembly and annotation of this genotype, achieved by integrating PacBio HiFi sequencing, Hi-C, and mRNA sequencing data with a range of bioinformatic tools and databases. The genome assembly comprises 17 pseudochromosomes with total scaffold lengths of 654.6 Mb and 637.5 Mb for the two haplotypes, respectively. Both haplotypes have scaffold N50 values exceeding 30 Mb, with 42,441 and 46,507 predicted genes, of which 99.9% were successfully annotated. The high quality of this genome is supported by BUSCO analysis values exceeding 97.5% for both haplotypes. This comprehensive dataset is well suited for a wide range of future genomic analyses and is anticipated to…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
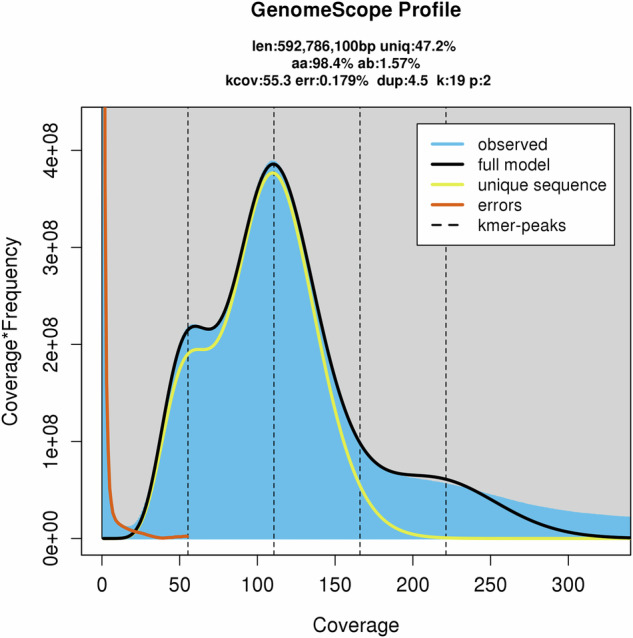 Figure 1
Figure 1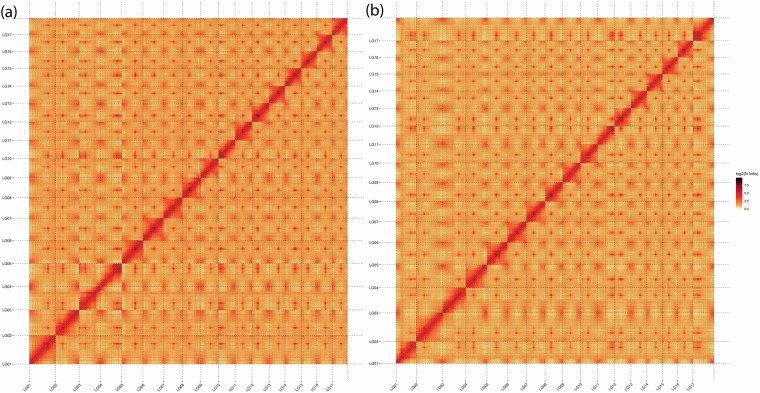 Figure 2
Figure 2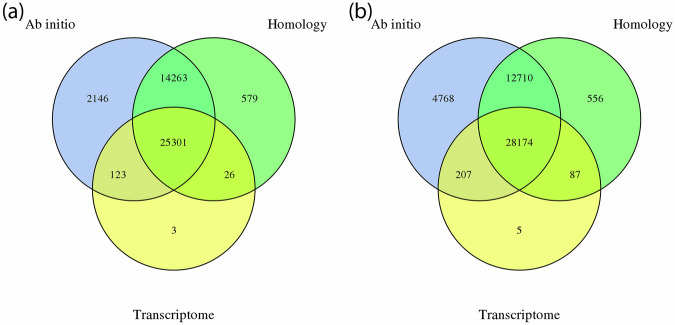 Figure 3
Figure 3 Figure 4
Figure 4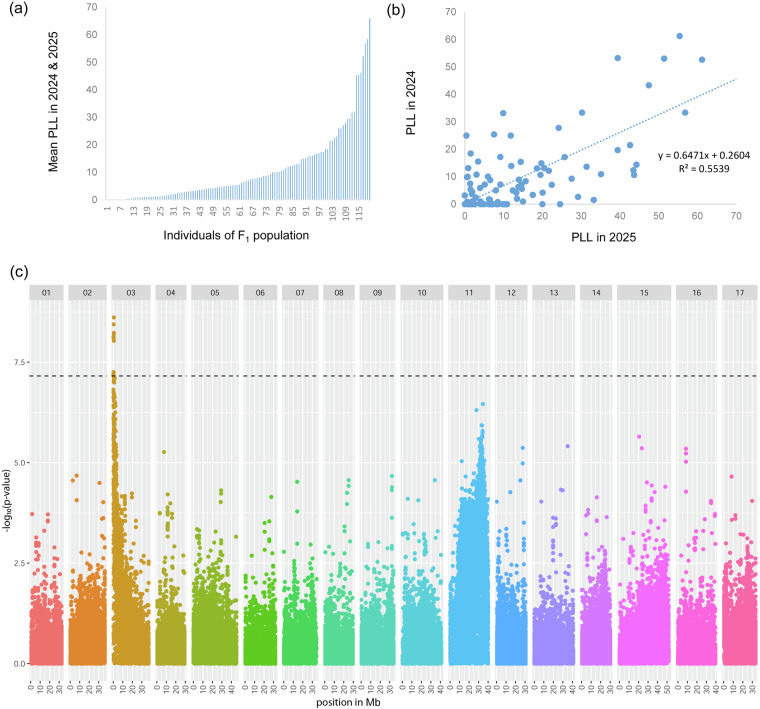 Figure 5
Figure 5- —Federal Ministry of Agriculture, Food and Regional Identity. Grant Reference Number: 281D108X21.
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFungal Plant Pathogen Control · Plant Physiology and Cultivation Studies · Plant Pathogens and Resistance
Background & Summary
The apple (Malus domestica Borkh.) is among the most popular and important fruits in the world. Different closely related species of apple (Malus spp.) can hybridize easily, and the domesticated apple of today contains genomic contributions from e.g. Malus sieversii, Malus sylvestris, Malus orientalis and Malus baccata^1^. M. baccata is native to Asia and is used for breeding cultivars and rootstocks due to its distinct cold hardiness and disease resistance^2^. Breeding of new apple varieties is a complex process that takes several years^3^. Sequencing the genomes of apple genotypes provides insights into genetic diversity, evolutionary history, and genotype-phenotype relationships. The availability of whole genome sequences facilitates the development of marker-assisted selection (MAS), which aids breeding by enabling more efficient and targeted selection strategies. Recently, many genomes from various apple cultivars and individual accessions of different Malus species have been sequenced and published^4^, including that of M. baccata^2^. However, until now, no genome sequence has been available for M. baccata ‘Jackii’, an ornamental genotype collected in 1905 by J. G. Jack in Seoul^5^, which exhibits resistance to several fungal diseases such as apple scab (Venturia inaequalis)^6^, powdery mildew (Podosphaera leucotricha)^7^ and apple blotch (Diplocarpon coronariae)^8^. In addition, M. baccata ‘Jackii’ is resistant to fire blight^9,10^, caused by the Gram-negative bacterium Erwinia amylovora, which is one of the most destructive bacterial diseases affecting the genus Malus^11^. Breeding resistant apple cultivars is a promising and desirable strategy against fire blight and would require pyramiding the different resistance gene (R-gene) candidates due to the fact that resistance is strain-dependent, with some R-gene donors already overcome by virulent strains of E. amylovora^11,12^. The first fire blight R-gene to be isolated and functionally characterized using a transgenic approach was FB_Mr5, which underlies the resistance QTL region at the top of chromosome 3 of Malus × robusta 5^13,14^. FB_Mr5 encodes a CC-NBS-LRR resistance protein that interacts with the cysteine protease AvrRpt2_Ea_ from E. amylovora, demonstrating a gene-for-gene relationship^9,13–16^. Moreover, sequence analysis of avrRpt2Ea from various E. amylovora strains, along with inoculation experiments using avrRpt2Ea knock-out mutants, revealed that FB_Mr5-mediated resistance in Malus × robusta 5 is lost when inoculated with knockout mutants and strains carrying a cysteine-to-serine substitution at amino acid position 156 in the bacterial effector avrRpt2Ea. Furthermore, it was shown that fire blight resistance in M. baccata ‘Jackii’ likely functions in a similar manner to that of Malus × robusta 5^9,16^. Additionally, a closely related homologue of FB_Mr5 was identified in M. baccata ‘Jackii’^17^. However, as it has been demonstrated that even a single amino acid substitution in specific regions of FB_Mr5 can have a significant impact and trigger autoactivity^18^, it is important to know the exact sequences of resistance genes and whether there are other candidate genes at an R-gene locus that show a very high sequence similarity. In this study, we generated a high-quality, haplotype-resolved genome assembly and annotation of M. baccata ‘Jackii’ by combining PacBio HiFi sequencing with Hi-C and mRNA sequencing. Tunable genotyping-by-sequencing (tGBS)^19^ data of an F_1_ biparental population derived from an ‘Idared’ × M. baccata ‘Jackii’ cross were generated, and single-nucleotide polymorphisms (SNPs) were identified by mapping the sequences to the newly assembled genome. By additionally mapping the sequences of the tGBS analysis to the HFTH1 reference genome, chromosome names were assigned based on the HFTH1 assembly^20^. The genome assembly and annotation presented here for this multi-resistant genotype are of significant value and can be utilised directly for various resistance analyses and other applications.
Methods
Sampling, DNA and RNA extraction
Leaves from M. baccata ‘Jackii’ were collected at the Fruit Genebank of the Julius Kühn-Institut (JKI) in Dresden-Pillnitz, Germany. The QIAGEN Genomic-tip 20/G kit (QIAGEN, Hilden, Germany) was used for DNA extraction, while the RNAprep Pure Plant Plus Kit (Tiangen, Beijing, China) was employed for RNA extraction, with both procedures conducted in accordance with the manufacturer’s protocols.
Genome size estimation using Illumina sequencing
Genomic DNA from diploid M. baccata ‘Jackii’ was sequenced using the Illumina NovaSeq. 6000 platform (Illumina, Inc., San Diego, CA, USA) with a paired-end read length of 150 bp and a 350 bp sequencing library. Subsequently, the reads were quality-filtered (polyG tails trimmed, minimum length ≥ 100 bp, average read quality ≥ Q20, homopolymer filter ≤ 10% consecutive identical bases, ≤50% of bases with Q < 10). After filtering, a total of 80.14 GB of sequencing data was obtained, corresponding to an estimated sequencing depth of ~135.19 × . The GC content was 37.22%, with Q20 exceeding 97.85% and Q30 surpassing 93.87%. Genome analysis was conducted using the Jellyfish 2.1.4^21^ and GenomeScope 2.0^22^ software. The k-mer distribution map with k = 19 was generated, the haploid genome size of M. baccata was estimated to be 592.8 Mb and the heterozygosity rate was calculated to be ~1.57% (Fig. 1). The repeat sequence content was estimated at ~52.78%.Fig. 1K-mer distribution map (k = 19) of Malus baccata ‘Jackii’.
Haplotype-resolved genome assembly with PacBio and Hi-C
DNA from M. baccata ‘Jackii’ was used for PacBio HiFi sequencing on the PacBio Revio platform (Pacific Biosciences, Menlo Park, CA, USA) following the standard protocol. The DNA molecules were sequenced in zero-mode waveguides (ZMWs) over multiple cycles, and repeated subreads were combined to generate highly accurate, self-corrected HiFi reads. In total, 6,149,970 HiFi reads were produced, yielding 101.3 Gb of sequence data. The average HiFi read length was 16,479 bp, with an N50 of 16,808 bp, and the longest HiFi read measured 61,744 bp.
In addition, an in situ Hi-C experiment was conducted^23^. To preserve DNA-DNA interactions and maintain the 3D genome structure, cross-linking was performed with formaldehyde and subsequently DNA was digested with the HindIII restriction enzyme generating sticky ends that were filled in with biotin-labeled nucleotides. Blunt-end ligation was performed to form circular structures. After reversing the cross-linking, the DNA was purified and sheared into fragments between 300–700 bp. Biotinylated junctions were isolated using streptavidin beads, and purified fragments were utilised for library preparation and sequencing on an Illumina NovaSeq. 6000 PE150 (Illumina, Inc., San Diego, CA, USA). This process generated 689.2 M read pairs, corresponding to 206.3 Gb of sequence data, with an average GC content of 39.54%, a Q20 value of 97.98%, and a Q30 value of 94.70%. The Hi-C data were processed using HiC-Pro v2.10.0^24^, and the paired-end reads were aligned using BWA (v0.7.10-r789; mode: aln; default settings)^25^ to the preliminary assemblies of haplotype 1 and haplotype 2. These preliminary haplotype-resolved assemblies were generated using only HiFi reads with Hifiasm (v0.19.9-r616)^26^ through three main steps: haplotype-aware error correction, which preserves heterozygous sites to maintain phasing accuracy, phased string-graph construction, and contig generation. Of the total 1,378.4 M Hi-C reads, 1,174.7 M and 1,175.4 M reads were mapped to the preliminary assemblies of haplotype 1 and 2, respectively. Among these, 538.1 M and 538.9 M reads were uniquely mapped, resulting in 196.9 M (36.59%) and 196.6 M (36.48%) valid interaction pairs for haplotype 1 and 2, respectively. The preliminary assembly was segmented into 50-kb fragments and scaffolded into haplotype-resolved pseudochromosomes using Hi-C data with LACHESIS^27^. The following optimised parameters were applied: CLUSTER_MIN_RE_SITES = 118, CLUSTER_MAX_LINK_DENSITY = 2, ORDER_MIN_N_RES_IN_TRUNK = 75 (haplotype 1) / 15 (haplotype 2), and ORDER_MIN_N_RES_IN_SHREDS = 87 (haplotype 1) / 15 (haplotype 2). In total, 98.1% and 99.0% of the Hi-C-derived sequences were anchored for haplotypes 1 and 2, respectively, with 97.3% and 98.8% confirmed in correct order and orientation. A summary of the Hi-C-based haplotype-resolved genome assembly is presented in Table 1.Table 1. Summary of the Hi-C-based haplotype-resolved genome assembly (only scaffolds >1 kb were included).Haplotype12Number of scaffolds719272Total length of scaffolds (Mb)654.6637.6Scaffold N50 length (Mb)35.836.6Scaffold N90 length (Mb)30.230.1Maximum length of scaffold (Mb)51.851.8Number of contigs740292Total length of contigs (Mb)654.6637.6Contig N50 length (Mb)30.430.7Contig N90 length (Mb)9.911.5Maximum length of the contigs (Mb)51.851.8GC content (%)38.1438.02Gap numbers2120
The assembled genome sequence was cut into 300 kb bins, and the signal intensity between corresponding bins was visualized as a heatmap in Fig. 2. The signal intensity was stronger within the 17 chromosome groups than between them, indicating a high-quality genome assembly.Fig. 2. Heatmap of the assembled haplotype-resolved genomes. (a) Haplotype 1. (b) Haplotype 2.
Transcriptome sequencing and genome annotation
The assembled genome was then used for genome annotation, with transposable element prediction performed using the following programs and databases: RepeatModeler2 v2.0.1^28^, RECON v1.0.8^29^, RepeatScout v1.0.6^30^, LTR_retriever v2.8^31^, LTRharvest v1.5.9^32^, LTR_FINDER v1.1^33^, RepeatMasker v4.1.0^34^, Repbase v19.06^35^, REXdb v3.0^36^ and Dfam v3.2^37^. Tandem repeats were predicted using the Microsatellite identification tool (MISA v2.1)^38^ and the Tandem Repeat Finder (TRF, v409)^39^. The results of the aforementioned analyses are presented in Tables 2 and 3.Table 2. Summary of predicted transposable elements.Type of transposable elementNumber of predicted repetitive sequences (HT1/HT2)Sequence length in bp (HT1/HT2)Percentage of genome (HT1/HT2)Class I: DIRS2/3122/1690.00/0.00Class I: LINE33,232/29,75119,082,791/12,588,4482.92/1.97Class I: LTR Caulimovirus1,167/1,5111,680,429/1,567,8890.26/0.25Class I: LTR Copia74,041/75,76361,731,539/60,267,5619.43/9.45Class I: LTR ERV4,421/4,361404,792/335,6170.06/0.05Class I: LTR Gypsy84,129/81,591102,424,853/99,955,95715.65/15.68Class I: LTR Ngaro285/30021,356/23,5800.00/0.00Class I: LTR Pao135/9312,134/6,1230.00/0.00Class I: LTR unknown176,052/180,63178,416,294/81,106,87211.98/12.72Class I: SINE16,693/16,4332,778,885/2,248,2110.42/0.35Total for Class I390,157/390,437266,553,195/258,100,42740.72/40.48Class II: Academ1/1138/1380.00/0.00Class II: CACTA2,613/3,0191,102,211/983,3750.17/0.15Class II: Crypton22/341,050/1,7590.00/0.00Class II: Dada243/23312,084/11,4970.00/0.00Class II: Ginger35/331,712/1,4070.00/0.00Class II: Helitron147,768/141,51637,977,788/42,416,7435.80/6.65Class II: IS3EU179/18710,934/10,1190.00/0.00Class II: Kolobok276/29020,418/23,0080.00/0.00Class II: Maverick156/24113,930/22,6660.00/0.00Class II: Merlin149/1407,271/7,5130.00/0.00Class II: Mutator461/54129,174/38,0090.00/0.01Class II: P75/815,351/4,7630.00/0.00Class II: PIF-Harbinger5,776/5,7503,113,051/3,104,7280.48/0.49Class II: PiggyBac66/663,304/2,6200.00/0.00Class II: Sola0/10/950.00/0.00Class II: Tc1-Mariner212/22512,471/13,4780.00/0.00Class II: unknown126,862/121,45030,761,945/28,104,5474.70/4.41Class II: Zisupton95/1004,301/4,5960.00/0.00Class II: hAT4,953/4,9852,128,608/2,120,0430.33/0.33Total for Class II289,942/278,89375,205,741/76,871,10411.49/12.06Unknown39/282,455/1,4920.00/0.00Total680,138/669,358341,761,391/334,973,02352.21/52.54HT: haplotype.Table 3. Summary of tandem repeat analysis.Type of tandem repeatNumber of predicted repetitive sequences (HT1/HT2)Sequence length in Mb (HT1/HT2)Percentage of genome (HT1/HT2)Microsatellite (1–9 bp units)262,351/257,1434.7/4.70.72/0.73Minisatellite (10–99 bp units)166,504/161,31015.9/15.32.42/2.40Satellite (≥100 bp units)24,351/23,00312.4/11.61.90/1.82Total453,206/441,45633.0/31.55.04/4.95HT: haplotype.
The coding gene prediction was performed using three complementary approaches: ab initio, homology-based, and transcriptome-based methods (with and without reference genomes). Ab initio coding gene prediction was carried out using Augustus v2.4^40^ and SNAP (2006-07-28)^41^. Homology-based predictions were performed with GeMoMa v1.7^42^, and for transcriptome-based predictions, mRNA sequencing was performed on Illumina Novaseq. 6000 platform (Illumina, Inc., San Diego, CA, USA) with a paired-end read length of 150 bp. This yielded a total of 40.3 M reads, corresponding to 12.1 Gb. The Q30 and Q20 values were 94.57% and 98.01%, respectively, and the GC content was 48.16%. Transcripts were predicted using HISAT v2.0.4^43^ and StringTie v1.2.3^44^ with different reference genomes^20,45–47^. Coding genes were then identified using GeneMarkS-T v5.1^48^. Additionally, transcripts were assembled without the use of a reference genome with Trinity v2.11^49^, and coding genes were predicted with PASA v2.0.2^50^. Finally, the genes predicted by the different methods were integrated using EVM v1.1.1^51^ and finalized by PASA v2.0.2^50^. The total number of coding genes predicted for haplotype 1 and 2 was 42,441 and 46,507, respectively. Detailed results are presented in Tables 4 and 5 and in Fig. 3.Table 4. Predicted coding genes using different software tools.Prediction methodGene prediction softwareUsed reference genomePredicted genes (HT1/HT2)Ab initioAugustus43,936/38,861Ab initioSNAP71,540/67,191Homology-basedGeMoMaA. thaliana35,054/34,405Homology-basedGeMoMaM. domestica HFTH159,817/58,640Homology-basedGeMoMaM. domestica GDDH1346,953/46,238Homology-basedGeMoMaM. prunifolia45,006/44,218Transcriptome-basedGeneMarkS-T25,498/25,141Transcriptome-basedPASA25,107/24,843Integration/FinalizationEVM/PASA42,441/46,507HT: haplotype.Table 5. Statistics of predicted coding genes of Malus baccata ‘Jackii’.Haplotype12Number of predicted genes42,44146,507Total length of genes (Mb)156.5157.3Average gene length3,687.963,382.22Total length of exons (Mb)69.671.2Number of exons234,373238,393Average exons per gene5.525.13Total length of CDS (Mb)59.060.7Total length of introns (Mb)86.986.1Number of introns191,932191,886Average introns per gene4.524.13CDS: coding DNA sequenceFig. 3Venn diagram of integrated predicted coding genes. (a) Haplotype 1. (b) Haplotype 2. Created with Venny^81^.
Non-coding RNA prediction was conducted with tRNAscan-SE v1.3.1^52^ for tRNA, with barrnap v0.9^53^ based on Rfam v12.0^54^ for rRNA, with miRBase^55^ for miRNA, and with Infernal 1.1^56^ based on Rfam v12.0^54^ for snoRNA and snRNA. The results are summarised in Table 6.Table 6. Predicted numbers of non-coding RNAs.HaplotyperRNAtRNAmiRNAsnRNAsnoRNA17,2091,4001209611425,1029331199296
Homologous gene sequences without a complete gene locus were identified using GenBlastA v1.0.4^57^ and GeneWise v2.4.1^58^ was used to detect premature stop codons and frameshift mutations, resulting in the identification of 228 and 308 pseudogenes, respectively (Table 7).Table 7. Predicted pseudogenes in Malus baccata ‘Jackii’.HaplotypeNumber of predicted pseudogenesTotal length of predicted pseudogenes (bp)Average length of pseudogenes (bp)1228975,9094,280.3023081,282,9714,165.49
The predicted coding genes were functionally annotated using multiple databases, including GenBank Non-Redundant (NR, 20200921), eggNOG 5.0^59^, Gene Ontology (GO, 20200615)^60,61^, Kyoto Encyclopedia of Genes and Genomes (KEGG, 20191220)^62^, SWISS-PROT and TrEMBL (202005)^63^, Pfam v33^64^ and eukaryotic orthologous groups (KOG, 20110125). Overall, more than 99.9% of coding genes were successfully annotated. The statistics on gene function annotation are presented in Table 8.Table 8. Statistics of gene function annotation.DatabaseNumber of annotated genes (HT1/HT2)Percentage of annotated genes (HT1/HT2)GO33,072/33,95677.92/73.01KEGG30,493/31,76371.85/68.3KOG22,503/23,32553.02/50.15Pfam34,025/35,12880.17/75.53SWISS-PROT30,036/30,20270.77/64.94TrEMBL42,402/46,44999.91/99.88eggNOG34,189/35,05780.56/75.38NR41,015/44,86796.64/96.47Total42,408/46,46199.92/99.9HT: haplotype.
In the final step, InterProScan (5.34-73.0)^65^ was utilised for the prediction of motifs and domains. A total of 1,876 motifs and 45,003 domains were predicted in haplotype 1, and 1,820 motifs and 44,973 domains in haplotype 2.
Chromosome assignment according to HFTH1
DNA of 184 F_1_ individuals from the cross ‘Idared’ × M. baccata ‘Jackii’, including the parental genotypes, was analysed using tGBS^19^ by Data2Bio (Ames, IA, USA). The restriction enzyme Bsp1286I was used and sequencing was carried out on an Illumina HiSeq X instrument (Illumina, Inc., San Diego, CA, USA). Polymorphic sites were first identified, and in a second step, final SNP calling was performed. In the initial step, individual sequence reads were scanned for low-quality regions (PHRED score ≤15), and quality-trimmed sequence reads were aligned to the genome sequences of haplotypes 1 and 2 of M. baccata ‘Jackii’ reported here using GSNAP^66^. Only confidently mapped reads with ≤2 mismatches per 36 bp and no more than 4 bases as tails per 75 bp that aligned to a single location were used for SNP identification, based on the following criteria: for homozygous SNPs, the most common allele had to be supported by at least 5 unique reads and 80% of all aligned reads. For heterozygous SNPs, each of the two most common alleles had to be supported by at least 5 unique reads and at least 30% of all aligned reads. For both homozygous and heterozygous SNPs, polymorphisms in the first and last 3 bp of each quality-trimmed read were ignored, and a PHRED base quality value of 20 (≤1% error rate) was set as the threshold for each polymorphic base. In the second step, SNPs were classified for tGBS genotyping as follows: a SNP was classified as homozygous if ≥5 reads supported the major allele and ≥90% of all reads at that site matched, and heterozygous if ≥2 reads supported each of two alleles, both alleles individually made up >20%, and their combined reads were ≥5, covering ≥90% of all reads at that site. SNPs were then filtered based on a minimum calling rate of 50%, the allele number was set to 2, the number of genotypes ≥2, the minor allele frequency ≥10%, and the heterozygosity rate range between 0% and (2 × Frequency_allele1_ × Frequency_allele2_ + 20%). In a final step, imputation was used on chromosome-based SNPs that lacked a sufficient number of reads to make genotype calls using Beagle v5.4^67^ with 50 phasing iterations and default parameters. A total of 321,733 and 319,620 SNPs for haplotypes 1 and 2 were identified, with each site genotyped in at least 50% of the samples. SNP sequences from the tGBS data were then mapped to the HFTH1 genome sequence^20^ using BWA-MEM2^68^ on the JKI Galaxy Server (Galaxy v2.2.1 + galaxy1)^69^ and the data presented in this study were assigned and oriented according to the HFTH1 reference^20^. A Circos plot^70^ illustrating key genomic features and alignments between the two haplotypes is shown in Fig. 4.Fig. 4. Circos plot of the Malus baccata ‘Jackii’ haplotype-resolved genome assembly. (a) Chromosome names and lengths in Mb. (b) Frequency of tandem repeats in 50 kb windows. (c) Frequency of transposable elements in 50 kb windows. (d) Frequency of genes in 50 kb windows. (e) Sequences from the tGBS analysis of haplotype 1 mapped onto haplotype 2. kb: kilobase, Mb: million base pairs, tGBS: tunable genotyping-by-sequencing.
Data Records
The raw data and assembled sequences and annotations can be accessed from the European Nucleotide Archive (ENA) under the BioProject accession number PRJEB89942^71^ and study number ERP172974. The SNPs and their corresponding sequence data, as well as the adjusted genome sequences (Mbj_HT1/Mbj_HT2.fasta), gene and peptide sequences (cds.fasta and pep.fasta), and annotation data (final tandem repeats, TE final, EVM.final.gene, domains and motifs) are available from Figshare^72^.
Technical Validation
BUSCO analysis
To assess the completeness of the genome assembly, a BUSCO analysis with BUSCO v4.0^73^ was performed using the Embryophyta database containing 1,614 core genes. The results, presented in Table 9, demonstrate the high integrity of the haplotype-resolved genome assembly, with 97.58% and 97.52% of the core genes identified in haplotype 1 and 2, respectively.Table 9BUSCO analysis results using the Embryophyta database (1,614 core genes).HaplotypeTotal number of identified core genesNumber of identified single-copy core genesNumber of identified duplicated core genesNumber of identified fragmented core genesNumber of missing core genes11,575 (97.58%)1,012 (62.70%)563 (34.88%)15 (0.93%)24 (1.49%)21,574 (97.52%)1,020 (63.20%)554 (34.42%)12 (0.74%)28 (1.73%)
Mapping back Illumina short and PacBio HiFi reads
In addition, Illumina short reads were mapped back to the haplotype-resolved assemblies using BWA (v0.7.10-r789; mode: aln; default settings)^25^ to assess completeness and read distribution. The mapping ratio exceeded 99.3% for both haplotypes, and approximately 83.5% of reads were properly mapped, i.e., paired clean reads that mapped to the same reference sequence within a defined distance threshold (Table 10), confirming the high assembly integrity. Sequencing depth and coverage analysis revealed an average depth of 114–116 × , with >99.3% of the genome covered at ≥20× (Table 11). These metrics indicate uniform sequence representation and negligible missing regions, demonstrating that the assembled genomes are highly complete and suitable for downstream analyses.Table 10. Statistics of Illumina short read mapping.HaplotypeTotal reads (M)Mapped readsProperly mapped reads1535.7 M532.3 M (99.4%)447.4 M (83.5%)2535.7 M532.2 M (99.4%)447.3 M (83.5%)Table 11. Sequencing depth and coverage of Illumina short reads.HaplotypeAverage sequencing depthCoverageCoverage (≥5×)Coverage (≥10×)Coverage (≥20×)1114×99.7%99.6%99.5%99.3%2116×99.8%99.7%99.7%99.6%
PacBio HiFi reads were also mapped back to the haplotype assemblies using Minimap2^74^, yielding similar results, with mapping ratios above 99.7% for both haplotypes, average sequencing depths of 154–155×, and ≥20× genome coverage for >99.1% of the genome.
k-mer-based evaluation with Merqury
The quality and completeness of the haplotype assemblies were further assessed using a k-mer-based approach with Merqury^75^. HiFi raw reads were first adapter-trimmed using Cutadapt^76^ (Galaxy v5.1 + galaxy0^69^), and the trimmed reads were then processed with Meryl^75^ (Galaxy v1.3 + galaxy6^69^) to generate 31-mer counts. The individual k-mer databases were merged using the union-sum method to create a comprehensive reference k-mer database representing the full diploid sequence content. Merqury^75^ (Galaxy v1.3 + galaxy4^69^) was then used to evaluate how many of the raw-read k-mers were present in each assembly, enabling an independent assessment of completeness for haplotype 1, haplotype 2, and the combined diploid assembly. The Merqury analysis demonstrated a high level of completeness for both haplotype assemblies: 77.2% of the expected 578.5 M k-mers were recovered in haplotype 1 and 76.9% in haplotype 2. The combined diploid assembly recovered 99.5% of the k-mers, demonstrating that the two haplotypes together capture nearly the entire diploid genome with high completeness.
LTR Assembly Index
The LTR Assembly Index (LAI)^77^ was calculated separately for each haplotype to assess assembly continuity within long terminal repeat (LTR) retrotransposon-rich regions. For each haplotype, the assembly was first indexed using the GenomeTools suffixerator (GenomeTools v1.6.2)^78^. LTR retrotransposon candidates were then identified with LTRharvest^32^ (GenomeTools v1.6.2)^78^ and subsequently curated and filtered using LTR_retriever v2.9.0^31^. Haplotype 1 yielded a genome-wide LAI of LAI₁ = 11.4, while haplotype 2 showed a comparable value of LAI₂ = 12.6. With LAI values ≥ 10, both assemblies meet the criteria for reference-quality genomes^77^, indicating that LTR retrotransposons are reconstructed with high continuity across both haplotypes.
Application of the genome assembly in fire blight resistance mapping
To demonstrate the usability and quality of the genome assembly for downstream applications, we applied it in an association mapping approach to identify the fire blight resistance locus of M. baccata ‘Jackii’, which had been previously proposed^17^. A total of 119 progenies derived from an ‘Idared’ × M. baccata ‘Jackii’ cross, as well as both parental genotypes, were grafted onto rootstock MM111, and up to five replicates per genotype were phenotyped for fire blight incidence i.e., length of shoot tip necrosis after artificial inoculation using E. amylovora strain Ea222, as described in Peil et al.^14^. Mean percent lesion length (PLL) was calculated for each F_1_ genotype by dividing the length of necrotic shoot by the total shoot length and averaging data from experiments conducted in 2024 and 2025. To identify potential associations between SNPs and fire blight incidence, each SNP from the aforementioned tGBS analysis with a minor allele frequency (MAF) ≥ 0.05 was analysed using the following procedure: genotypes were divided into two groups according to the observed allele. Using ‘Idared’ as a reference for the susceptible allele, phenotypic values of the two groups were used for a non-parametric Wilcoxon rank-sum test performed in R v4.4.2^79^. The genome-wide significance threshold was determined using Bonferroni correction as -log_10_(0.01/number of SNPs tested). A Manhattan plot was generated using the ggplot2 package^80^ and it showed a significant association of SNP markers at the top of chromosome 3 with the fire blight phenotypic data of the F_1_ progeny, shown for haplotype 2 in Fig. 5. Haplotype 1 produced a comparable plot (not shown). The sequence of the FB_Mr5 homolog in M. baccata ‘Jackii’ (GenBank accession KT013244.1^17^) was found to be 100% identical over 4,164 bp to a region at the top of chromosome 3 of haplotype 2 between positions 598,337 and 602,501 bp, and this homolog is only 43,365 bp distant from the SNP marker with the highest -log₁₀(p) value and the strongest association with fire blight resistance. This supports the accuracy of the haplotype-resolved genome assembly, the correctness of chromosome assignment and orientation, as FB_Mr5 has been described to be located on the distal part of chromosome 3^14^, and the reliability and usability of the genomic data presented here for further analyses.Fig. 5PLL in the F_1_ biparental (‘Idared’ × M. baccata ‘Jackii’) population after artificial fire blight inoculation. (a) Mean necrosis (%) across 2024 and 2025. (b) Correlation of necrosis between years across F_1_ genotypes. (c) Manhattan plot of the genome-wide association for mean PLL in the F_1_ population with newly generated SNP markers of haplotype 2. The dashed line indicates the Bonferroni-corrected significance threshold. Mb: million base pairs, PLL: percent lesion length, SNP: single-nucleotide polymorphism.
Supplementary information
quant_function_0_100 run_analysis_0_100_with filter_R1
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Genome Database for Rosaceae. https://www.rosaceae.org/species/malus/all (2025).
- 2Fiala, J.L. Flowering crabapples: The genus Malus (Timber Press, Portland, 1994).
- 3Li, H. Aligning sequence reads, clone sequences and assembly contigs with BWA-MEM. Preprint at ar Xiv 10.48550/ar Xiv.1303.3997 (2013).
- 4ENA. European Nucleotide Archive. https://identifiers.org/ena.embl:PRJEB 89942 (2025).
- 5R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/ (2023).
- 6Wickham, H. ggplot 2: Elegant Graphics for Data Analysis. (Springer-Verlag New York, 2016).
- 7Oliveros, J.C. Venny: An interactive tool for comparing lists with Venn’s diagrams. https://bioinfogp.cnb.csic.es/tools/venny/index.html (2007-2015).