A Combinatorial Approach to Synthetic Data Generation for Machine Learning
Krishna Khadka, Jaganmohan Chandrasekaran, Yu Lei, Raghu Kacker, D. Richard Kuhn

TL;DR
This paper introduces a new method for generating synthetic data that reduces the number of samples needed while maintaining model performance and improving privacy.
Contribution
The novel combinatorial sampling approach reduces sample size requirements and preserves model accuracy with fewer data points.
Findings
Combinatorial sampling achieves comparable model performance with fewer synthetic samples than random sampling.
The method maintains better accuracy when combined with differential privacy compared to traditional approaches.
Model predictions are often influenced more by feature interactions than by using all features.
Abstract
Datasets used in machine learning often contain sensitive information, including personally identifiable health and financial details. A common challenge faced by organizations and researchers is the risk of privacy breaches when using real-world data. Synthetic data can be used as an alternative to the real-world data. In existing synthetic data generation techniques, an encoder processes the real-world data to map it into a lower-dimensional latent space. Random sampling is then performed in this latent space. Subsequently, a decoder network is utilized to generate synthetic data from these sampled points in the latent space. Such approaches typically require generating a large number of synthetic samples to approximate the performance of real-world data, subsequently slowing down downstream machine learning tasks. Addressing this, we introduce a combinatorial approach to sampling the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
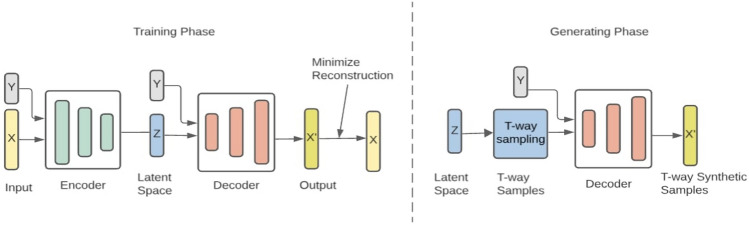 Figure 1
Figure 1 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPrivacy-Preserving Technologies in Data · Machine Learning in Healthcare · Big Data and Digital Economy