Optimized intrusion detection for IoT networks using Cauchy–Gaussian hybrid evolutionary feature selection
T. Saranya, S. Indra Priyadharshini

TL;DR
This paper introduces a new intrusion detection method for IoT networks using a hybrid evolutionary algorithm to improve performance and reduce complexity.
Contribution
A novel Cauchy–Gaussian hybrid evolutionary feature selection method is proposed for intrusion detection in IoT networks.
Findings
The proposed method achieved 99.88% and 99.72% accuracy on CICIDS 2017 and IoTID20 datasets.
It achieved low false positive rates of 0.000801 and 0.000165 on the same datasets.
The method outperforms conventional AOA and GA approaches in intrusion detection performance.
Abstract
The Internet of Things network is a prime target for attackers due to its vulnerabilities and the sensitive data it handles. Protecting these devices is critical, and an Intrusion Detection System serves as the first defence against breaches. While many intrusion classification methods exist, building low-complexity systems for IoT remains challenging. This paper introduces a novel method combining active feature selection and ensemble machine learning to address complexity issues for IDS in IoT. Specifically, a novel Cauchy–Gaussian genetic-arithmetic optimiser-driven variance-based active feature selection method is proposed. The proposed algorithm operates in two phases: in the first phase, the model learns active samples by representing them as a KD-tree based on feature variance; in the second phase, the Cauchy–Gaussian genetic-arithmetic optimiser uses the active samples to select…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
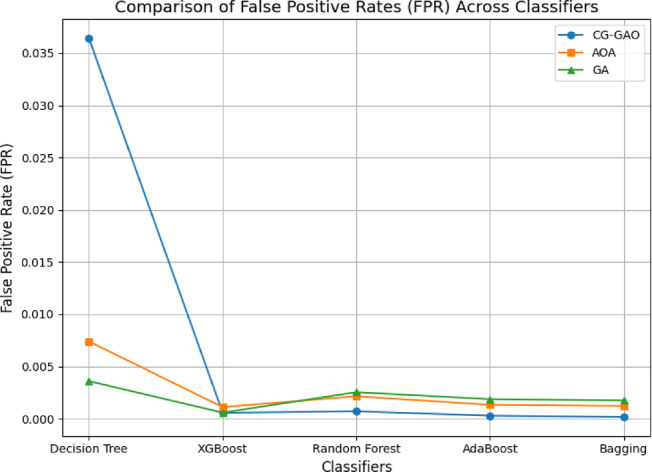 Figure 10
Figure 10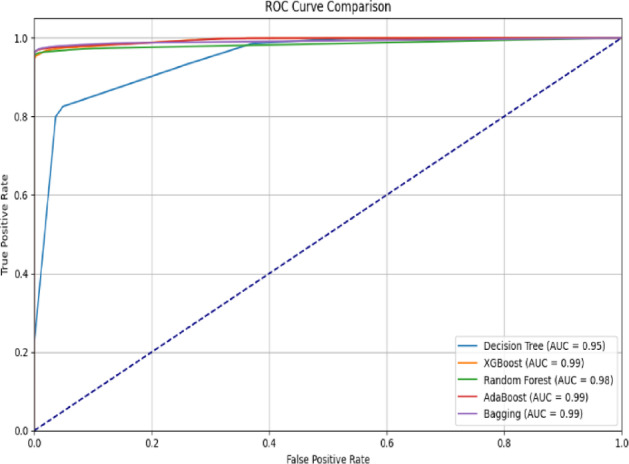 Figure 11
Figure 11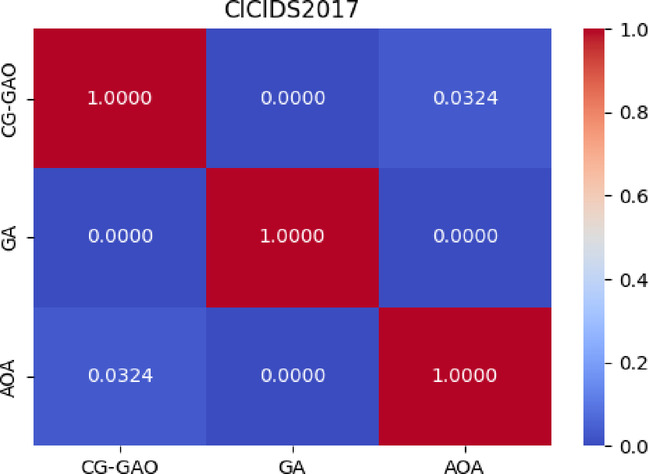 Figure 12
Figure 12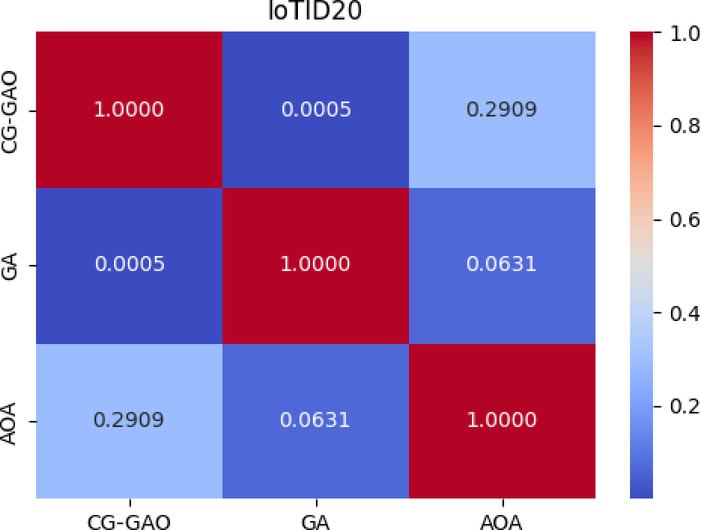 Figure 13
Figure 13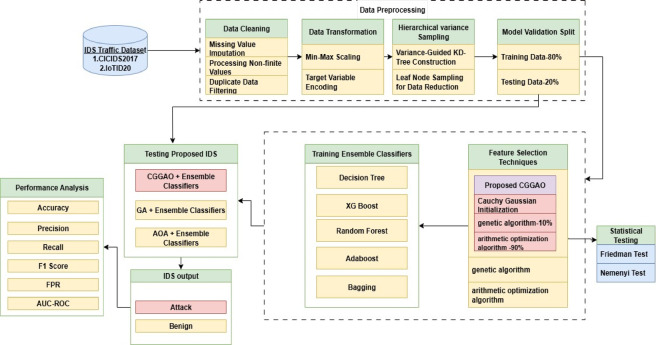 Figure 1
Figure 1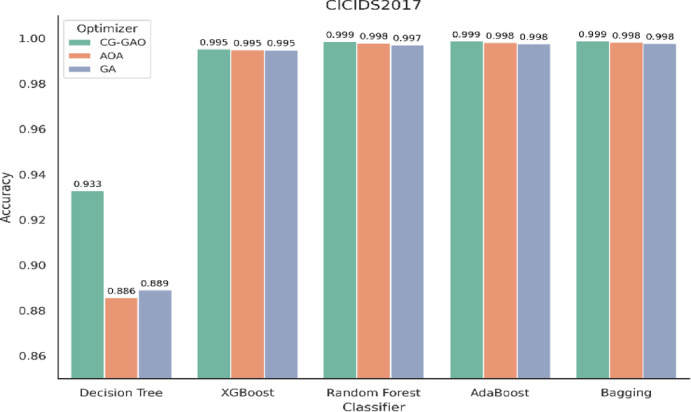 Figure 2
Figure 2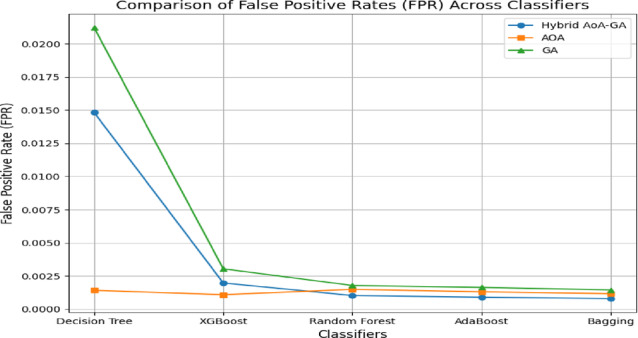 Figure 3
Figure 3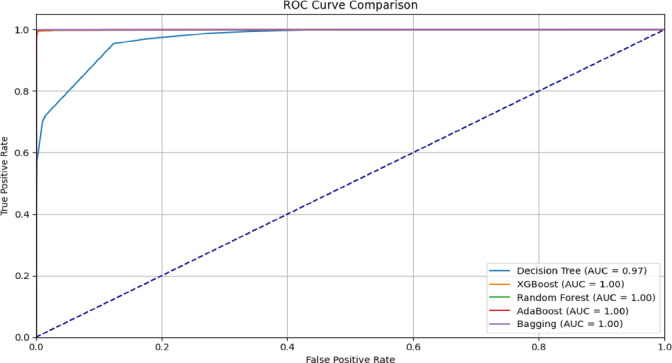 Figure 4
Figure 4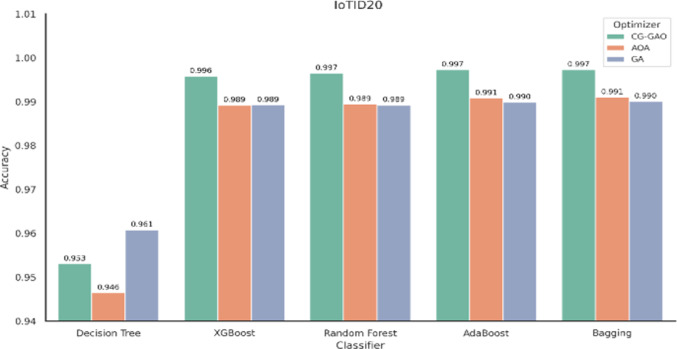 Figure 5
Figure 5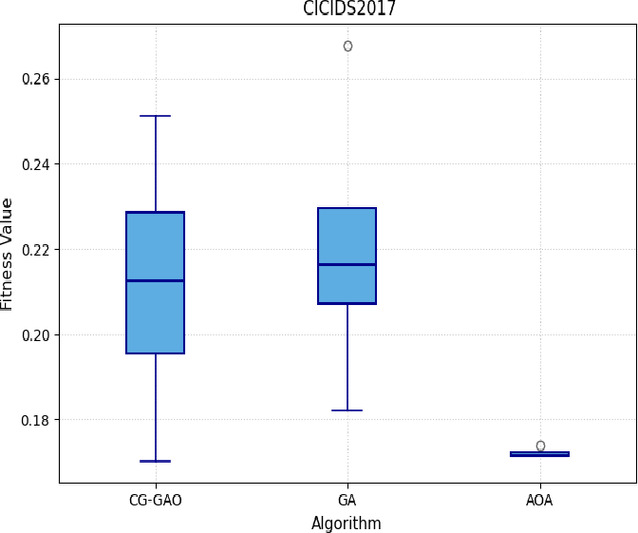 Figure 6
Figure 6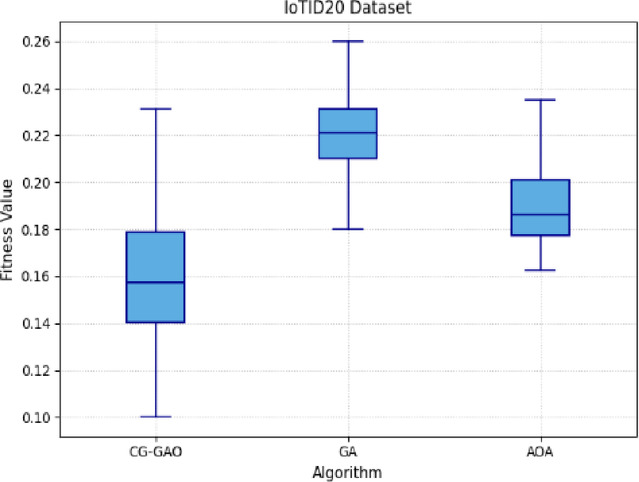 Figure 7
Figure 7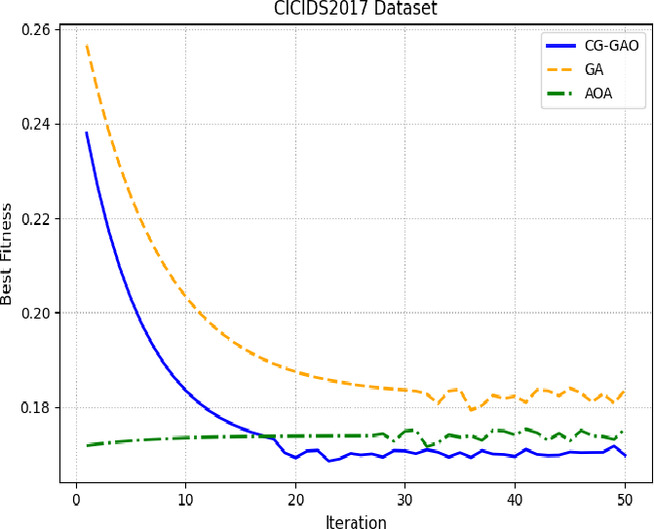 Figure 8
Figure 8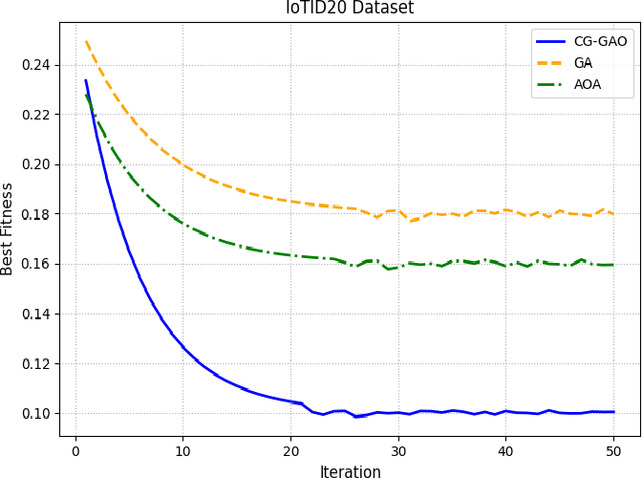 Figure 9
Figure 9 Figure 14
Figure 14 Figure 15
Figure 15- —Vellore Institute of Technology, Chennai
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNetwork Security and Intrusion Detection · Metaheuristic Optimization Algorithms Research · Smart Grid Security and Resilience
Introduction
The Internet of Things (IoT) is a broad network of connected smart devices that communicate over the internet, found in homes, offices, healthcare, and more. This technology is rapidly transforming world and lifestyle by enabling real-time data sharing and smarter decision-making^1^. According to Fortune Business Insights’ 2023 IoT market report, the global IoT market was valued at USD 595.73 billion and is projected to rise to USD 714.48 billion in 2024, reaching USD 4,062.34 billion by 2032, with an anticipated compound annual growth rate (CAGR) of 24.3%^2^. However, the growing adoption of IoT devices and the increasing complexity of IoT network architectures have also introduced new security challenges and risks^3^. Most IoT devices lack essential built-in security mechanisms to defend against cyber-attacks; since they are typically designed for specific, limited functions, security considerations are often neglected, leaving them highly vulnerable to cyber threats^4^. An intrusion detection system (IDS) helps to increase network security by detecting hostile activity within a system. The incorporation of artificial intelligence (AI) techniques improves IDS capabilities, allowing for more accurate detection of new threats such as zero-day vulnerabilities. In IoT environments, IDS solutions need an efficient handling of a large volume of network logs with minimal computational overhead on resource-constrained devices. Consequently, researchers use techniques such as dimensionality reduction and normalisation to manage the increasing complexity of network logs in AI-based IDS systems^5^.
Feature selection removes noisy or redundant features while retaining the most relevant ones, reducing computational cost and improving model accuracy. It is generally categorised into filter, wrapper, and embedded methods^6^. The filter method evaluates statistical properties of data independently of any classifier, while the wrapper method assesses subsets using a specific algorithm for better accuracy. But the wrapper method is efficient and computationally intensive compared to filter-based methods. To perform efficient dimensionality reduction using the wrapper technique for datasets with many labelled samples, it’s crucial to balance computational efficiency and performance. Traditional feature selection methods reduce dimensionality using all available data, but as the dataset grows, random sampling is commonly used. However, random sampling is indiscriminate, ignores data characteristics. This work introduces active feature selection, which partitions data based on variance and samples representative instances to reduce noise and enhance feature accuracy and efficiency of feature selection^7^. To the best of current knowledge, this is the first application of active feature selection in an intrusion detection system (IDS).
In recent years, optimization algorithms have shown strong potential in addressing feature selection problems^8^. Various metaheuristics inspired by biological evolution, swarm intelligence, and arithmetic operations, newer algorithms such as the reptile search algorithm (RSA), red fox optimiser (RFO), and crayfish optimization algorithm (COA) may of the algorithm face issues like premature convergence and limited exploration in high-dimensional spaces. According to Wolpert and Macready’s No Free Lunch (NFL) Theorem^9^, no single optimiser performs best across all problems; hence, this research integrates two well-established optimisers to create a complementary hybrid. This study combines the genetic algorithm (GA) and arithmetic optimization algorithm (AOA). The choice of GA and AOA is based on their proven ability to balance exploration and exploitation together, providing a balanced and effective approach for IDS feature selection^10^.
To develop an effective IDS for IoT networks, this study used the CICIDS2017^11^ and IoTID20^12^ datasets with essential preprocessing. Large training data were sampled using HVS sampling, followed by Cauchy–Gaussian genetic-arithmetic optimizer (CG-GAO) feature selection for dimensionality reduction. Ensemble classifiers were then employed for robust attack detection. On CICIDS2017, the state-of-the-art Hybrid OSMOGA (2024)^13^ achieved 99.43% accuracy, while the proposed CG-GAO achieved 99.88%, improves by 0.45%. On IoTID20, the IDSBPSO + RF (2022)^14^ achieved 99.84%, and the proposed method achieved 99.72%, offering comparable accuracy with fewer features.
The key contributions of this article are:
- Active Feature Selection and KD Tree Construction**:** A KD Tree-based active feature selection approach is employed to select relevant samples from large training datasets. The KD Tree is constructed based on feature variance to reduce redundancy.
- Population initialisation using Cauchy and Gaussian distributions enhances diversity by combining broad and balanced variations. This ensures wide exploration, prevents premature convergence, and helps the algorithm avoid local optima, and for finding the global optimum^15^.
- Hybrid GAO Algorithm and Feature Set Reduction: The proposed optimization algorithm combines the mutation, crossover, and selection operators of the genetic algorithm (GA) with the arithmetic optimization algorithm’s (AOA) exploitation mechanisms to achieve enhanced exploration–exploitation balance. This hybrid GAO efficiently reduces high-dimensional feature spaces and improves classifier performance.
- Ensemble Algorithms for IDS Implementation: To further increase the effectiveness of the intrusion detection system (IDS) ensemble algorithms is added with the CG-GAO Active feature selection is added for robust and generalised classification.
- Comprehensive Comparative Evaluation**:** The proposed method is compared with baseline AOA and GA algorithms, supported by an ablation study, statistical significance testing, and cross-fold validation to ensure generalisation and reliability of IDS performance.
The paper is structured as follows: section “Literature survey” reviews the literature on different types of dimensionality reduction techniques used in IoT IDS over the years. Section “Motivation” is about the motivation for the proposed IDS with CG-GAO. Section “Proposed active feature selection” details the proposed methodology section “Results and discussion” provides the experimental results and detailed discussions, while section “Conclusion” wraps up the paper and outlines possible directions for future research.
Literature survey
IoT devices are central to smart applications, which generate large amounts of sensitive data^16^, but their limited processing capability and lack of standard security protocols make them vulnerable. Signature-based IDS detects only known attacks. Anomaly-based IDS distinguishes normal and abnormal traffic^17^, thereby detecting unseen attacks better.IDS often struggle with IoT scalability and computational limits, leading to research on Efficient and lightweight IDS frameworks. Recent studies highlight diverse methods for efficient feature selection to lower the computational overhead and to improve the efficiency of IDS in IoT environments.
Filter-based methods
An Intrusion Detection System presented in^17^, the CL-GAN framework integrates fast correlation-based filter (FCBF) and Information Gain for feature selection with convolutional neural networks (CNN), long short-term memory (LSTM), and generative adversarial networks (GAN) to detect DoS and botnet attacks. This model was assessed using the NSL-KDD, CICIDS2018, and Bot-IoT datasets and achieved up to a 5% increase in accuracy. In^18^ stacked ensemble IDS for IoT devices with the Fisher Score algorithm for Feature selection. Tested on NB-IoT and UNSW-NB15 datasets, achieved 99.68% accuracy.
Wrapper-based methods
In^19^, bijective soft set is used to find optimal features using the CorrACC metric. Evaluated on the BoT-IoT dataset, it achieved over 95% accuracy with the C4.5 decision tree and Random Forest. In^20^, decision tree with recursive feature elimination (RFE) achieved 99.21% accuracy on NSL-KDD and 99.94% on CICIDS 2017, identifying key features and reducing computational costs.
Hybrid methods
In^21^, K-nearest neighbors (K-NN) classifier with hybrid feature selection using PCA, statistical tests, and genetic algorithms,tested on Bot-IoT dataset, it achieved 99.99% accuracy and prediction time was reduced from 51,182 s to under a minute. In^22^ a hybrid feature selection m ethod combines the residue number system (RNS),Bat algorithm and PCA. K-nearest neighbors and Naïve Bayes are employed for classification, tested on NSL-KDD dataset, the Bat with RNS obtained 99.15% accuracy,98.09% detection rate, and a training time of 55.65 s.
Metaheuristic algorithm-based methods
Metaheuristic algorithms have emerged as powerful tools in the design of intrusion detection systems (IDSs), particularly for addressing two critical challenges: feature selection (FS) and hyperparameter optimization. These algorithms explore high-dimensional search spaces by imitating biological or natural processes, which makes them perfect for cybersecurity applications where detection accuracy and model generalization are impacted by the selection of optimal features. The recently introduced Hazelnut Tree Search (HTS) algorithm (which incorporates growth, fruit scattering, and root spreading operators to balance exploration and exploitation)^23^. The Chaotic Election Algorithm (CEA)^24^ (an improved version of the Election Algorithm that incorporates chaotic positive advertisement and migration operators to enhance global search and maintain population diversity),the Chaotic local search–levy flight distribution (CLS–LFD)^25^ algorithm (which optimizes resource allocation by integrating chaotic search behavior with Levy flight for improved convergence—to optimize deep learning and ensemble classifiers. The Locally Weighted Salp Swarm Algorithm (LWSSA)^26^ enhances SSA with local weighting and mutation mechanisms, improving convergence and diversity; when combined with XGBoost, it achieved superior predictive accuracy in CVD risk assessment. Table 1 discusses some recent studies that use metaheuristic optimization algorithms for IDS from 2023 to 2025.Table 1. Overview of recent metaheuristic-based intrusion detection systems (2022–2025).YearMetaheuristic algorithm usedKey contribution2022^27^Time-based Leadership Particle Swarm-based Salp Algorithm (TPSOSA)Proposed TPSOSA achieved higher accuracy and better feature reduction than other metaheuristics, confirmed by Friedman and Wilcoxon tests Tested on CEC 2017, CEC2008lsgo, NSL-KDD and 19 datasets2023^28^pigeon-inspired optimization (PIO) + Local Search (tabu + hill climbing)LS-PIO enhances PIO with Tabu and Hill Climbing for feature selection. Achieved high accuracy and F1-score across BoT-IoT, UNSW-NB15, NSL-KDD, and KDDCUP99 datasets2024^29^squirrel search optimization (SSO)Combines SSO with Bengio Nesterov Momentum CNN (BNMCNN) to enhance precision (0.96) and reduce computational time on NSL-KDD and CICIDS 2017 datasets2023^30^Gaussian Mutation and Shrink Moth-Flame Optimization (GMSMFO)An improved version of MFO using Gaussian mutation and shrink strategy to enhance diversity and balance exploration–exploitation. Tested on CEC 2017 benchmarks and NSL-KDD. GMSMFO achieved higher accuracy and fewer features than other metaheuristics, confirmed by Friedman and Wilcoxon tests2023^31^capuchin search algorithm (CapSA)CNN-CapSA integrates CNN feature extraction with CapSA-based selection, improving accuracy and lowering computational cost across NSL-KDD, BoT-IoT, KDD99, and CICIDS 2017 datasets2025^32^genetic algorithm (GA)GA-tuned ensemble of deep transfer learning models (NFIoT-GATE-DTL IDS) for NetFlow-based intrusion detection, achieving 100% accuracy across 15 attack types and outperforming other optimizers2025^33^grey wolf optimization (GWO) + Quantum Binary bat algorithm (QBBA) (Hybrid: GWQBBA)Hybrid GWQBBA model for feature selection, achieving 98.5% accuracy with Random Forest on UNSW-NB15 using only 12 features, while maintaining high sensitivity and F-measure across classifiers2024^34^golden jackal optimization algorithm (GJOA) with salp swarm algorithm (SSA)GJOADL-IDSNS, a hybrid IDS combining GJOA-based feature selection with SSA-tuned attention-based BiLSTM, achieves superior accuracy and robustness on benchmark datasets2024^35^coati optimizationalgorithm (COA)ID-COADL, an IDS for VANETs, combines COA-based hyperparameter tuning with a Deep Belief Network. Achieved improved detection and classification2024^36^artificial bee colony (ABC) with fuzzy Temporal RulesFT-ABC-CNN, a hybrid IDS integrates fuzzy temporal rules, ABC optimization,for feature selection and CNN to enhance detection accuracy and minimise false positives.2024^37^chaotic honey badger optimization (CHBO)Introduced a CHBO-based feature selection with Dugat-LSTM classifier for IDS, achieving 98.76% and 99.65% accuracy on TON-IoT and NSL-KDD datasets2025^38^Enhanced whale optimization algorithm (EWOA)Utilized LDA for dimensionality reduction and EWOA for feature selection, combined with an RF-XGBoost, achieving 96.08% accuracy on the NSL-KDD dataset
Motivation
Intrusion Detection Systems (IDS) for the Internet of Things (IoT) face significant hardships due to the large and noise present in log data, both in terms of features and instances. While wrapper-based feature selection methods can provide better performance by tailoring features to specific algorithms, their high computational cost makes them impractical for large IoT datasets. Filter models are more efficient but may miss important feature interactions. A promising approach to overcome the above difficulties is active feature selection, which selects representative instances, reducing the need to evaluate the entire dataset. However, from the extensive literature survey research on applying active feature selection to optimize wrapper models for IDS in IoT systems remains unexplored. Moreover, while biological evolutionary algorithms often excel in optimization problems, they are not universally effective. Researchers have noted that these methods can struggle with increased complexity and dimensionality, in line with the no-free-lunch (NFL) theorem, which claims that no one optimization algorithm excels across all types of problems^10^. Therefore, this research proposes a novel hybrid optimization approach based on active feature selection, integrating mutation, crossover, selection operators of genetic algorithm (GA) exploration, and exploitation operators of arithmetic optimization algorithm (AOA) with population initialization using Cauchy and Gaussian distribution. The initialization of the population in an optimization algorithm significantly influences the entire optimization process. To enhance the optimization process, the Cauchy–Gaussian distribution is used for population initialization. The Cauchy distribution aids in exploring outliers, while the Gaussian distribution helps to avoid extreme or irrelevant regions. This hybrid method addresses the complexity of wrapper methods, overcomes AOA’s limitations such as local search weaknesses, the proposed method provides a balance between exploration and exploitation phases and it overcomes the genetic algorithm weakness of slow convergence. Moreover, the proposed method will be an effective strategy for finding optimal solutions in complex, high-dimensional feature selection problems.
Proposed active feature selection
This section outlines the steps involved in intrusion detection system (IDS) utilising the novel CG-GAO-based active feature selection with an ensemble algorithm. Figure 1 shows the IDS architecture.Fig. 1. Architecture diagram of proposed intrusion detection system.
Data pre-processing
Machine learning models need clean, well-structured data that is free from noise and redundancy for effective model training. Inconsistencies in raw log data, such as null values, duplicates, and irregular formats, affect model performance and result in poor classifications. A strong pipeline for data preprocessing is necessary to shape the data before training the classifier.
Handling null and duplicate values
To guarantee data quality, prevent bias, and preserve dependable model performance, handling null and duplicate values is crucial. To make the traffic data complete and balanced, null values (NaN) are filled with the class-wise average. Infinite values, resulting from operations like division by zero, are first converted to NaN and then replaced with the class-wise maximum to correct extremes. Negative values are converted to NaN and filled with the minimum positive value of each class, to make all features non-negative, and to make the dataset consistent for training the Classifier.
Feature normalisation
Normalisation ensures that all features are scaled uniformly, thereby improving model performance and convergence. Min–Max normalisation is widely used as it preserves data distribution, handles sparse datasets, and suits algorithms sensitive to feature scales. It is also less affected by outliers. This method scales values between 0 and 1 using the formula in Eq. (1)^39^.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\text{n}}_{{\text{i}}} ^{\prime } = \frac{{{\text{n}}_{{\text{i}}} {\text{ - N}}_{{{\text{min}}}} }}{{{\text{N}}_{{{\text{max}}}} {\text{ - N}}_{{{\text{min}}}} }}$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\text{N}}_{\text{min}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\text{N}}_{\text{max}}$$\end{document} are the lower and the upper bound values of the attribute N. The original and feature’s normalized value n, are indicated by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\text{n}}_{\text{i}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\text{n}}_{{\text{i}}} ^{\prime }$$\end{document} respectively.
Target variable encoding
As the proposed methodology is for binary classification, the target variable of the attack datasets is encoded to Attack as 1 and Normal as 0 using Label encoding, and any other features that have categorical columns are also encoded using Label encoding.
Phase-I
In phase I, a hierarchical variance-based KD-tree is used to sample the preprocessed data by identifying the most representative instances. Unlike conventional random sampling, this method utilises selective sampling, where the KD-tree partitions the dataset based on dissimilarity metrics^40^. The KD-tree structures the data in a multidimensional space, recursively selecting features with the highest variance for splitting. This process continues until the defined bucket size is reached, effectively capturing the original data distribution. A subset of data with similar statistical properties is grouped in each leaf of the KD-tree. This technique effectively reduces the dataset size by choosing balanced, variance-representative samples from each leaf. To maintain class balance, stratified sampling is used within each leaf node, selecting equal numbers of attack and benign samples whenever both classes are present. This approach preserves the data distribution while maintaining local class representativeness, which improves the computational efficiency and dependability of the feature selection algorithm^40^.
Algorithm 1 Hierarchical Variance Sampling using KD-Tree(HVS)
Phase-II
In the second phase, feature selection using a novel Cauchy–Gaussian Genetic-Arithmetic Optimiser (CG-GAO) is applied.CG-GAO improves the solution of population initialization by using Cauchy and Gaussian distributions, where the Cauchy distribution helps in exploring outliers, and the Gaussian distribution provides a refined search around potential regions. In the proposed hybrid algorithm, the genetic algorithm is chosen for its global search ability, population diversity and generalizability across different optimization problems. However, GA has slow convergence and gets stuck in local optima. To overcome this, the arithmetic optimization algorithm (AOA) is combined in later iterations after good exploration for better local search and faster convergence, creating a good balance between exploration and exploitation.
The process starts by initialising a population P of N individuals, where two different groups are obtained using Cauchy and Gaussian distributions. These groups are then combined together to form a hybrid population.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${P}_{{Cauchy}_{j}}={B}_{j}+Cauchy\left({\gamma }_{c},{x}_{0}\right)\times ({T}_{j}-{B}_{j})$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${P}_{{Gaussian}_{i}}={B}_{i}+N({\mu }_{n},{{\sigma }_{n}}^{2})\times ({T}_{j}-{B}_{j})$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_{j} = {\text{Concatenate}}\;(P_{Cauchy} ,P_{Gaussian} )$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${T}_{i}$$\end{document} = 1 and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${B}_{i}$$\end{document} = 0 represents the upper and lower bounds of the search space, respectively. And \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Cauchy\left({\gamma }_{c},{x}_{0}\right)$$\end{document} represents sampling a random value from a Cauchy distribution, with scale parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\gamma }_{c}$$\end{document} and location parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${x}_{0}$$\end{document} . And \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N({\mu }_{n},{{\sigma }_{n}}^{2})$$\end{document} is a random value from the Gaussian (normal) distribution with mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mu }_{n}$$\end{document} and variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\sigma }_{n}}^{2}$$\end{document} .
Each agent is converted into a binary representation to find the selected features. The Binary transformation rule:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$BP_{{ij}} = \left\{ {\begin{array}{*{20}l} {1,} \hfill & {if\;P_{{ij}} > 0.5} \hfill \\ {0,} \hfill & {otherwise} \hfill \\ \end{array} } \right.$$\end{document}After removing features with zeros in the binary vector B, the fitness score is then calculated using:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Fit}_{i}=\beta \times {C}_{i}+\left(1-\beta \right)\times \left(\frac{\left|{BP}_{i}\right|}{{n}_{f}}\right)$$\end{document}In the Eq. 6, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta \in \left[\text{0,1}\right]$$\end{document} is a weighting factor between the two components. Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${n}_{f}$$\end{document} is the total number of features, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left|{BP}_{i}\right|$$\end{document} is the number of features selected, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${C}_{i}$$\end{document} is the classification error found using the K-Nearest Neighbors (KNN) algorithm.
The optimal solution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${P}_{b}$$\end{document} is identified, after that the remaining agents are iteratively tuned using either genetic algorithm (GA) operators or Arithmetic Optimization Algorithm (AOA) mechanisms. This iterative process continues till the predefined maximum number of iterations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${I}_{t}$$\end{document} is reached, in accordance with the update strategy:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_{i} = \left\{ {\begin{array}{*{20}l} {GA\;phase} \hfill & {if\;t < 0.2 \times t_{max} } \hfill \\ {AoA \;Phase} \hfill & {Otherwise} \hfill \\ \end{array} } \right.$$\end{document}After reaching the stopping condition t = \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${I}_{t}$$\end{document} the individual with the best fitness score is chosen. The test set is then refined based on the selected features from this population, and classification performance is evaluated using the updated test set.
Genetic algorithm (GA phase)
Genetic algorithms (GA) are optimization methods that iteratively improve a population of candidate solutions. The process involves three main stages: selection, crossover, and mutation, and continues until a predefined termination criterion is satisfied.
Selection: Individuals are selected according to their fitness levels, where the roulette wheel selection method assigns a probability \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${V}_{rs}\left({P}_{i}\right)$$\end{document} to each candidate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${u}_{i}$$\end{document} based on fitness score \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f({P}_{i})$$\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${V}_{rs}\left({P}_{i}\right)=\frac{f({P}_{i})}{\sum_{j=1}^{m}{P}_{j}}$$\end{document}Crossover: Two parent solutions are combined to produce offspring. The Blend crossover technique generates new individuals using \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${P}_{b}$$\end{document} with the blending coefficient \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\alpha }_{g} set to 0.5$$\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_{i}^{1} = {\text{min}}\left( {P_{i}^{1} ,P_{i}^{2} } \right) - \alpha_{g} P_{b}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_{i}^{2} = {\text{max}}\left( {P_{i}^{1} ,P_{i}^{2} } \right) - \alpha_{g} P_{b}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_{b} = \left| {P_{i}^{1} - P_{i}^{2} } \right|$$\end{document}Mutation: Gaussian Mutation^41^ introduces small random perturbations to an individual by utilizing a Gaussian distribution with a standard deviation of σ = 0.1.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\text{mutate }}(P_{{ib}} ) = \times \left( {{\text{1}} + {\text{gaussian}}\left( \sigma \right)} \right)$$\end{document}These steps are iteratively repeated to improve the population until the algorithm converges.
Arithmetic optimization algorithm (AoA phase): initialization phase
Before the AOA process begins, it is necessary to compute the math optimizer acceleration operator (MOA) and the math optimizer probability (MOP). The MOA function governs the decision of whether the search will focus on exploration or exploitation, based on the value of the math optimizer accelerated (MOA) function^42^. The MOA function is defined as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\text{MOA}}(I_{c} )\, = \,MOA_{min} + I_{c} \times \left( {\frac{{MOA_{max} - MOA_{min} }}{{I_{m} }}} \right)$$\end{document}In this context, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${I}_{c}$$\end{document} refers to the current iteration, while \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${I}_{m}$$\end{document} indicates the maximum number of iterations. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${MOA}_{max}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${MOA}_{min}$$\end{document} represent the upper and lower bounds of the Acceleration function, respectively.
The math optimizer probability (MOP) is used to control the degree of exploitation during the optimization process. It is calculated using Eq. 14:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\text{MOP}}(I_{c} ) = {1} - \frac{{I_{c}^{{\frac{1}{\alpha }}} }}{{I_{m}^{{\frac{1}{\alpha }}} }}$$\end{document}where the sensitive parameter α is set to five and α influences the accuracy of exploitation across the iterations.
Exploration Phase
The Division (D) and Multiplication (M) operators are used during the exploration phase to explore the search space, help in improving diversity and prevent premature convergence.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_{{i,j}} \left( {I_{c} + 1} \right) = \left\{ {\begin{array}{*{20}l} {best(P_{j} ) \div (MOP + \epsilon ) \times ((T_{i} - B_{i} ) \times \mu + B_{i} ,} & {r2 < 0.5} \\ {best(P_{j} ) \times MOP \times ((T_{i} - B_{i} ) \times \mu + B_{i} ,} & {otherwise} \\ \end{array} } \right.$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$best({P}_{j})$$\end{document} is the best solution found, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon$$\end{document} is the smallest integer number to prevent division by zero, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${T}_{i}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${B}_{i}$$\end{document} are maximum and minimum bounds of the current position help in regulating the search process. The parameter µ, set to 0.5, is used to fine-tune the search process.
Exploitation Phase
In the exploitation phase, the optimizer focuses on local refinement by applying the Subtraction (S) and Addition (A) operators. These operators decrease the solution diversity, enabling the efficient convergence towards the optimal solution.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Q}_{i,j}\left({I}_{c}+1\right)=\left\{\begin{array}{l}best\left({P}_{j}\right)-MOP\times (({T}_{i}-{B}_{i})\times \mu +{B}_{i}, r3 < 0.5 \\ best\left({P}_{j}\right)+MOP\times (({T}_{i}-{B}_{i})\times \mu +{B}_{i}, otherwise\end{array}\right.$$\end{document}Algorithm 2 CG-GAO Feature Selection Algorithm
Classification
Machine learning (ML) comprises intelligent models that learn from data to detect patterns and make decisions without explicit programming. Ensemble ML techniques improve IDS performance by combining multiple learners. In the proposed IDS, attack classification is carried out by active feature selection and ensemble classifiers such as Random Forest, AdaBoost, XGBoost, Decision Tree and Bagging Classifier.Each model has its own strengths like Random Forest reduces overfitting by combining multiple trees; AdaBoost and XGBoost improve weak learners through iterative learning^32^; and Bagging increases accuracy by lowering variance, making it suitable for changing network conditions^43^. The performance of these classifiers is assessed using standard evaluation metrics to support the claim of efficient intrusion detection.
Results and discussion
This section presents the results of the proposed Intrusion Detection System (IDS), the experimental setup and the evaluation of the active feature selection method, including HVS sampling results and CGGAO feature selection results. Then, performance analysis of ensemble classifiers, an ablation study, comparison of the proposed with state of art techniques and crossfold validation results are discussed to highlight the performance of the proposed Intrusion Detection framework.
Simulation environment
The proposed intrusion detection system (IDS) performance was evaluated using two benchmark datasets: CICIDS2017^11^ and IoTID-20^12^. The proposed CGGAOIDS is experimented with using the Google Colab environment. Experiments were conducted on a system with an Intel Core i5 processor (6 cores, 3.4 GHz) and 16 GB RAM.Key libraries such as NumPy, Pandas, Keras, TensorFlow, and Scikit-learn ensure better data handling, feature selection, ensemble model training, and performance evaluation.
Dataset description
The CICIDS2017 dataset is a benchmark dataset for network intrusion detection, simulates real-world traffic has about 2.8 million records and 83 features. It includes labelled records of six major attack categories and 14 subtypes. The dataset is known for its quality and detailed labels. About 19.70% of the records are attack traffic, and the remaining 80.30% are normal traffic^44^
The second dataset, IoTID20, records network activity in a smart home environment with connected devices such as AI speakers, Wi-Fi cameras, smartphones, and laptops. It includes different types of IoT attacks like DDoS, Mirai, DoS, ARP Spoofing, and Man-in-the-Middle. In this setup, devices like AI speakers and cameras served as targets, while other devices generated attack traffic. The dataset has 86 features and was created using CICFlowMeter, with labels assigned based on IP behaviour. It contains 40,073 normal records and 585,710 attack records^45^.
Cleaning and preparation for IDS evaluation
To evaluate the proposed framework, the CICIDS2017 and IoTID20 dataset was cleaned and prepared. In CICIDS2017 columns, such as Flow ID, Source IP, Destination IP, Timestamp, Source Port, and Destination Port and in IoTID20 features such as pkSeqID, Category, Subcategory, Timestamp, Src IP, Dst IP, Src Port, and Dst Port are removed to avoid redundancy and data leakage. Missing or infinite values in both datasets (NaN or Infinity) were replaced with zeros, and columns with a large number of missing entries were removed. Categorical features are encoded into numerical values, and the target variable is converted into a binary format, labelling benign traffic as 0 and attacks as 1. Min–Max normalization is applied to scale the numerical features between 0 and 1. After preprocessing, the CICIDS2017 dataset has 78 columns and around 2.8 million records with 2,272,771 benign and 532,976 attack samples and the IoTID20 dataset contains 78 features and about 625,783 records with 40,073 benign and 585,710 attack samples.
Hierarchical variance sampling (HVS) via KD-tree construction
After data preprocessing, both the CICIDS2017 and IoTID20 datasets were sampled using the Hierarchical Variance Sampling (HVS) algorithm, as detailed in Algorithm 1. The sampled distributions before and after HVS are listed in Table 2, while the configuration parameters used in HVS, including bucket size, target sample size, samples per leaf, and number of leaf nodes, are tabulated in Table 3. Figures S1 to S4 of Supplemenary shows the PCA Projection of data before and after sampling.Table 2. Dataset summary before and after hierarchical variance sampling (HVS).DatasetOriginal samplesBenignAttackAfter HVSBenign sampledAttack sampledCICIDS20172,805,7472,272,771532,97656,82428,41228,412IoTID20625,78340,073585,71020,23510,11710,118Table 3Parameters and configuration settings for hierarchical variance sampling via KD-tree.ParameterValueDescriptionbucket_size100The number of records per leaf node. Controls the minimum size of the leaf node before sampling occurssampled_rowsList (populated during sampling)A collection used to store sampled rows from each leaf node as the recursive process progressesDepth20The maximum recursion depth for splitting the dataset, limiting splits to prevent overfitting and excessive granularityVariancesCalculated during recursionThe computed variance of each feature (column) in the dataset, used to determine the optimal feature for splittingsplit_columnDetermined during recursionThe feature (column) with the highest variance, selected for dividing the dataset into two subgroupssplit_valueMean of the Split columnThe average value of the selected column used as the threshold to partition the dataset into left and right subtreesleft_subtreeData Frame (subset)The subset of records where the values in the selected column are less than the split valueright_subtreeData Frame (subset)The subset of records where the values in the selected column are greater than or equal to the split value
Feature selection via Cauchy–Gaussian genetic algorithm optimization (CG-GAO)
The learned samples from the HVS technique were input into the CG-GAO, AOA, and GA optimizers for feature selection. The setup for the CG-GAO algorithm is summarized in Table 4. Each optimizer was executed for 30 independent runs, owing to the stochastic nature of metaheuristics^46^, to ensure the reliability and statistical significance of the results, as depicted in Figs. 2, 3, 4, and 5.Table 4. Configuration parameters of the proposed CG-GAO-based feature selection.Framework parameterValuePopulation InitializationCombined Cauchy & Gaussian Distributions (Binary ThresholdingCauchy–Gaussian Mix Ratio50% Cauchy, 50% GaussianPopulation Size25Max Iterations100Chromosome EncodingBinary Vector (0/1 per feature)Initial Mutation Rate0.1 (increases to a max of 0.5 if no improvement is observed)Mutation StrategyBit flip with minimum-feature constraintCrossover MethodSingle-Point CrossoverSelection StrategyRoulette Wheel Selection based on fitnessClassifierK-Nearest Neighbors (KNN), k = 5Fitness FunctionFitness = λ × Classification Error + (1 − λ) × Feature Ratio, λ = 0.5Exploration–Exploitation BalanceControlled via AOA parameters (alpha = 0.5, mu = 0.5, e = 1)AOA ParametersMinMOA = 0.1, MaxMOA = 1, alpha = 0.5, mu = 0.5, e = 1Hybrid Strategy GA used during first 10% of iterations AOA used during remaining 90%Binary ConversionAOA updated individuals are thresholded: value > 0.5 → 1, else 0Best Fitness CriteriaMinimum fitness value among population
Fig. 2. Accuracy of ensemble classifiers with feature selection techniques on CICIDS2017 dataset.
Fig. 3. False positive rate of ensemble classifiers with feature selection techniques on CICIDS2017 dataset.
Fig. 4AUC-ROC performance of the proposed CG-GAO-with ensemble classifiers on the CICIDS17 dataset.
Fig. 5. Accuracy of ensemble classifiers with feature selection techniques on IoTID20 dataset.
Table 5 summarizes the best, worst, mean, and median fitness values, along with standard deviation, variance, and the number of selected features for each optimizer across both CICIDS2017 and IoTID20 datasets. In Supplementary file, Table S1 and Table S2 lists the features selected by CG-GAO, AOA, and GA from both datasets. The CG-GAO consistently achieved lower mean fitness values with relatively small variance, indicating more effective and stable feature selection. In contrast, GA showed higher mean values and greater variability, while AOA displayed consistent yet slightly sub-optimal fitness values. Figures 6 and 7 present the box plots of fitness values obtained across the independent runs, illustrating the distribution and stability of each optimizer’s performance.Table 5. Metaheuristic algorithm performance on CICIDS2017 and IoTID20.DatasetAlgorithmBestWorstMeanMedianStdVarFeature countCICIDS2017CG-GAO0.17010.25130.20390.22110.02670.000726GA0.18230.26780.21690.21560.01790.000330AOA0.17150.1740.17170.17150.00031.1e–0728IoTID20CG-GAO0.10000.23100.15370.16100.03070.000925GA0.18000.26000.22170.22000.02320.000529AOA0.16250.23500.18960.18250.02650.000728Significant values are in bold.
Fig. 6. Box plot of optimizers on CICIDS2017-HVS sample.
Fig. 7. Box plot of optimizers on IoTID20-HVS sample.
Figures 8 and 9 show the convergence behavior of CG-GAO, GA, and AOA across iterations for the CICIDS2017 and IoTID20 HVS samples. The CG-GAO optimizer reaches an optimal fitness value quickly and maintains stability throughout the iterations. The sensitivity analyses of CG-Gao for different hyperparameters were added in Supplementary, Table S3-S4. In contrast, GA exhibits oscillating behavior with poor convergence, while AOA converges early but to a sub-optimal level.
Fig. 8. Fitness convergence of optimizers on CICIDS2017-HVS sample
Fig. 9. Fitness convergence of optimizers on IoTID20-HVS sample.
Classification using ensemble classifiers
As outlined in Fig. 1, the features selected through hierarchical variance sampling (HVS) and optimized via CG-GAO, AOA, and GA algorithms were subsequently used to train a set of ensemble classifiers, including Decision Tree, XGBoost, Random Forest, AdaBoost, and Bagging. The hyperparameters of the Ensemble classifier are listed in Table 6.Table 6. Hyper parameters for the ensemble classifiers.AlgorithmHyperparametersDecision Treecriterion = ‘gini’, max_depth = 5, random_state = 2, splitter = ‘random’XGBoostbase_score = 0.3, n_estimators = 10Random Forestn_estimators = 1, random_state = 42AdaBoostbase_estimator = DecisionTreeClassifier(), random_state = 42Baggingbase_estimator = DecisionTreeClassifier(), random_state = 42
For the CICIDS2017 dataset, the IDS results are provided in Table 7, and the result graphs are illustrated in Figs. 2, 3 and 4. Among all combinations, CG-GAO with Bagging achieved the highest performance of precision 0.9980, recall 0.9982, F1-score 0.9981, and accuracy 0.9988. The proposed IDS with Bagging also showed an ROC AUC score of 0.9997, as in Fig. 3. In the IoTID20 dataset, performance metrics are detailed in Table 8 and result comparison graphs are added as Figs. 5, 10 and 11. Bagging achieved the highest accuracy, as shown in Fig. 5, with a precision of 0.9974, F1-score of 0.9884, and a low false positive rate of 0.000165, as in Fig. 10. In terms of AUC, Bagging achieved an ROC AUC of 0.9917, shown in Fig. 11. AdaBoost also performed well, with 0.9973 accuracy, 0.9965 precision, 0.9808 recall, 0.9885 F1-score, and a slightly higher FPR of 0.000285.
Table 7. Performance comparison of classifiers using CG-GAO, AOA, and GA optimizers on the CICIDS2017.ClassifierAccuracyPrecisionRecallF1_scoreFPRCG-GAO Decision Tree0.9328270.9287030.8525660.8840440.014824CG-GAO XGBoost0.9953060.9940260.9911320.9925710.001971CG-GAO Random Forest0.9986150.9975650.9980660.9978150.001027CG-GAO AdaBoost0.9987360.9978360.9981750.9980050.000899CG-GAO Bagging 0.998809
0.998030
0.998212
0.998121
0.000801 AOA Decision Tree0.8856760.9314530.7125760.7645280.001419AOA XGBoost0.9949880.9951750.9889800.9920410.001093AOA Random Forest0.9979540.9964450.9971030.9967730.001491AOA AdaBoost0.9981540.9968460.9973320.9970890.001309AOA Bagging0.9982730.9971380.9974150.9972760.001166GA Decision Tree0.8890180.8758980.7513980.7924260.021220GA XGBoost0.9949370.9921790.9918350.9920070.003041GA Random Forest0.9971220.9954740.9954430.9954590.001783GA AdaBoost0.9976200.9960130.9964790.9962460.001636GABagging0.9977630.9963890.9965510.9964700.001447Significant values are in bold.
Table 8. Performance comparison of classifiers using CG-GAO, AOA, and GA optimizers on the IoTID20.ClassifierAccuracyPrecisionRecallF1_scoreFPRCG-GAO-Decision Tree0.9530610.7927550.8813660.8298730.036435CG-GAO-XGBoost0.9958130.9937120.971010.9820900.000563CG-GAO-Random Forest0.9965000.9931360.9774300.9851360.000706CG-GAO-AdaBoost 0.997294 0.996542 0.980766
0.988507 0.000285CG-GAO-Bagging 0.997278
0.997376
0.979826
0.988419
0.000165 AoA-Decision Tree0.9464510.8331350.6313240.6819310.007380AoA-XGBoost0.9892080.9854270.9231220.9518150.001110AoA-Random Forest0.9894430.9779580.9320250.9536530.002145AoA-AdaBoost0.9908120.9849340.9371450.9596110.001326AoA-Bagging0.9910140.9858720.9379910.9605010.001218GA-Decision Tree0.9607740.9278840.7175850.7838900.003596GA-XGBoost0.9892770.9896120.9200520.9517740.000580GA-Random Forest0.9892510.9750390.9332040.9530080.002538GA-AdaBoost0.9898900.9803130.9336230.9555920.001866GA-Bagging0.9900600.9813070.9341410.9563220.001747Significant values are in bold.
Fig. 10. False positive rate of ensemble classifiers with feature selection techniques on IoTID20 dataset.
Fig. 11AUC-ROC performance of the proposed CG-GAO with ensemble classifiers on the IoTID20 dataset.
In Table 9, the proposed Hybrid CG-GAO model performance is compared with recent metaheuristic-based feature selection approaches on the same CICIDS2017 and IoTID20 datasets. The Proposed CG-GAO shows better performance than the recent state of art methods.Table 9. Comparison of proposed CG-GAO IDS with recent metaheuristic-based feature-selection IDS methods.YearRefMetaheuristic feature selectionDatasetClassifierAccuracyFeatureCountDetection time (s)2024^13^Hybrid OSMOGA(opposition-based learning + Slime Mold Algorithm + Genetic Algorithm)CICIDS2017Artificial NeuralNetwork99.43%1917.262023^47^Binary White Shark Optimizer with transfer function,cross over operatorsCICIDS2017Modified K-Means clustering99.14%15–2024^49^Binary Opposition Cellular Prairie dog optimization algorithm (BOC-PDO)CICIDS2017KNN99.21%105.122022^14^IDSBPSO + RFIoTID20Random Forest99.84%302882025^48^Binary Butterfly optimization AlgorithmIoTID20LSTM98.8740-ProposedHybrid CG-GAO(Cauchy Gaussaian initialized Genetic Algortihm + Arithmetic Optimization Algorithm)CICIDS2017IoTID20Bagging99.88% and **99.72%**26 and 25****48 and 36Significant values are in bold.
K-fold cross-validation
To assess the generalizability of the proposed CG-GAO intrusion detection framework, a fivefold cross-validation was performed on both the CICIDS2017 and IoTID20 datasets. The average performance across all folds is presented in Table 10. The results shows that the CG-GAO–Bagging model achieves the highest accuracy, recall, and F1-score on both datasets—99.88% accuracy, 99.82% recall, and 99.81% F1-score for CICIDS2017, and 99.73% accuracy, 97.98% recall, and 98.84% F1-score for IoTID20. Other models such as Random Forest, AdaBoost, and XGBoost also exhibit stable performance, confirming the efficacy of the proposed hybrid optimization approach.Table 105-Fold cross-validation results of CG-GAO models.DatasetClassifierAccuracyPrecisionRecallF1-scoreCICIDS2017DecisionTree93.2892.8785.2688.40XGBoost99.5399.4099.1199.26Random Forest99.8699.7599.8199.78AdaBoost99.8799.7899.8299.80Bagging99.8899.8099.82****99.81IoTID20Decision Tree95.3179.2888.1482.98XGBoost99.5899.3797.1198.21Random Forest99.6599.3197.7498.51AdaBoost99.7299.6598.0798.85Bagging99.7399.7497.98****98.84Significant values are in bold.
Ablation study of the proposed CG-GAO
An ablation study was performed to systematically assess the contribution of each component in the proposed CG-GAO pipeline using the Bagging classifier. The full framework integrates KD-tree based Hierarchical Variance Sampling (HVS), Cauchy–Gaussian population initialization, hybrid GA–AOA optimization, and the Bagging ensemble for classification.
Controlled variants were constructed by removing or modifying one component at a time, while keeping other settings identical. Each configuration was executed ten times, and the results (mean ± standard deviation) are presented in Table 11. The results indicate that the complete CG-GAO pipeline consistently achieves the best accuracy, recall, and F1-score. Replacing the hybrid initialisation with standard random initialisation leads to a larger decline in performance. The KD-tree HVS module contributes to efficiency by improving data compactness without degrading accuracy. The performance of IDS without feature selection shows the lowest performance.Table 11. Ablation study results of the proposed CG-GAO IDS pipeline.Components activeDatasetAccuracyRecallF1-scoreTraining time (s)Memory (MB)KD-tree + Cauchy–Gaussian Init + GA + AOA + Bagging (Full)CICIDS201799.88 ± 0.0699.82 ± 0.0899.81 ± 0.07145 ± 9370 ± 18IoTID2099.65 ± 0.0897.89 ± 0.4098.60 ± 0.30118 ± 7245 ± 15Cauchy–Gaussian Init + GA + AOA + Bagging (no KD-tree)CICIDS201799.70 ± 0.0899.68 ± 0.0999.65 ± 0.08185 ± 12480 ± 22IoTID2099.55 ± 0.1097.70 ± 0.4598.55 ± 0.35160 ± 10430 ± 20KD-tree + Gaussian Init + GA + AOA + Bagging (no Cauchy)CICIDS201799.67 ± 0.0799.69 ± 0.0899.68 ± 0.07140 ± 9410 ± 19IoTID2099.65 ± 0.0997.85 ± 0.4298.60 ± 0.32118 ± 7380 ± 16KD-tree + Cauchy Init + GA + AOA + Bagging (no Gaussian)CICIDS201799.74 ± 0.0799.68 ± 0.0899.67 ± 0.07142 ± 9412 ± 18IoTID2099.62 ± 0.0997.80 ± 0.438.55 ± 0.33119 ± 8378 ± 16KD-tree + Standard Init + GA + AOA + BaggigCICIDS201798.65 ± 0.1298.60 ± 0.1498.58 ± 0.13138 ± 9408 ± 20IoTID2099.50 ± 0.1397.55 ± 0.5098.47 ± 0.40116 ± 8372 ± 18KD-tree + Standard Init + GA + Bagging (no AOA)CICIDS201798.87 ± 0.1198.54 ± 0.1398.55 ± 0.12130 ± 8425 ± 21IoTID2097.12 ± 0.2592.65 ± 0.9094.87 ± 0.70110 ± 7368 ± 17KD-tree + Standard Init + AOA + Bagging (no GA)CICIDS201797.71 ± 0.1497.62 ± 0.1597.60 ± 0.15125 ± 8495 ± 24IoTID2097.51 ± 0.2092.10 ± 0.8594.46 ± 0.65108 ± 7365 ± 16Full Dataset + Bagging (no FS or optimization)CICIDS201798.25 ± 0.1098.20 ± 0.1298.15 ± 0.11120 ± 8490 ± 22IoTID2099.20 ± 0.1397.00 ± 0.1798.02 ± 0.40105 ± 6363 ± 14Significant values are in bold.
Statistical evaluation of optimisers
To validate the effectiveness of the proposed CG-GAO algorithm compared to the standard Genetic Algorithm (GA) and Arithmetic Optimization Algorithm (AOA), we employed a non-parametric statistical testing approach. The Friedman test was applied with degrees of freedom (df = k − 1 = 2), where k is the number of algorithms. The test ranks each algorithm’s performance across datasets, and the Friedman statistic (χ^2^) quantifies whether the mean ranks differ significantly. The Nemenyi test was then used for pairwise comparisons, computing q-statistics, p-values, and the critical difference (CD) — the minimum difference in average ranks is required to prove significance. To overcome the multiple comparison problem, the Nemenyi test adjusts significance thresholds based on the number of pairwise tests. All tests were performed at a 95% confidence level (α = 0.05).
As in Table 12, For the CICIDS2017 dataset, the Friedman test yielded χ^2^(2) = 61.35, p < 0.0001, with average ranks CG-GAO = 1.12, AOA = 2.23, and GA = 2.65. The critical difference (CD) was 0.825, and the Nemenyi test confirmed that CG-GAO significantly outperformed GA (q = 5.67, p < 0.001) and AOA (q = 2.81, p = 0.032).For the IoTID20 dataset, the Friedman test reported χ^2^(2) = 14.25, p = 0.0008, with average ranks CG-GAO = 1.35, AOA = 2.23, and GA = 2.42, and CD = 0.905. The Nemenyi test indicated that CG-GAO significantly outperformed GA (q = 4.25, p = 0.0005), while the difference between CG-GAO and AOA (q = 1.05, p = 0.291) was not statistically significant, suggesting comparable performance in that scenario. Figures 12 and 13 present heatmaps of the Nemenyi post-hoc test p values for the CICIDS2017 and IoTID20 datasets, respectively. These visualisations highlight the statistical significance of performance differences between algorithm pairs, supporting the numerical results in Table 12.Table 12. Friedman and Nemenyi test results on CICIDS2017 and IoTID20.DatasetFriedman \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\chi }^{2}$$\end{document} p valueAvg.Rank(CG-GAO)Avg.Rank(AOA)Avg.Rank(GA)CDCG-GAO versus GACG-GAO versus AOAGA versus AOACICIDS201761.35< 0.0011.122.232.650.855.67, < 0.00012.81, 0.03243.45, < 0.0001IoTID2014.250.00081.352.232.420.954.25, 0.00051.05, 0.29091.63,0.0631Fig. 12Pairwise p values from Nemenyi post-hoc test for CICIDS2017.Fig. 13. Pairwise p values from Nemenyi post-hoc test for IoTID20.
Complexity analysis of hierarchical variance sampling with hybrid GA-AOA feature selection
The proposed method combines Hierarchical Variance Sampling (HVS) with a Hybrid CG-GAO algorithm for efficient feature selection in high-dimensional data.
HVS Phase: Calculates variance in O(n⋅b) where n is Number of data instances and b is Number of features whose variance is calculated for splitting and recursively partitions data using a KD-Tree until subset size t(bucket size), Since the KD-Tree has a depth of log(n/t) the overall complexity becomes:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\text{O}}(({\text{n}} \cdot {\text{b}}){\text{log}}\left( {{\text{n}}/{\text{t}}} \right))$$\end{document}Since HVS samples based on feature variance, it selects fewer yet more informative instances compared to random or stratified sampling. This reduces input size for feature selection while maintaining performance.
Feature Selection Phase: Hybrid CG-GAO uses Cauchy–Gaussian initialization, GA for exploration, and AOA for exploitation. The time complexity is driven by the number of individuals N, the number of iterations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${I}_{t}$$\end{document} , and the cost per evaluation, approximated as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(N.{I}_{t}.(0.1a+0.9b))$$\end{document}where a is the Complexity of genetic operations and b is the Complexity of AOA arithmetic updates. Compared to conventional feature selection methods, which often rely on exhaustive search (high complexity, typically \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O({2}^{b})$$\end{document} for b features) or greedy algorithms (complexity of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(n.{b}^{2})$$\end{document} in some cases), the HVS combined with CG-GAO is relatively low in complexity, particularly for large datasets Table 13 shows a comparison of the CG-GAO, GA, and AOA optimization algorithms based on their computational complexity, iteration strategy, number of function evaluations (FFEs), and overall resource usage. The CG-GAO hybrid method provides a good balance between speed and cost by combining both GA and AOA steps. In contrast, GA has the highest cost because it runs a full genetic search, while AOA is the least costly but may stop early before finding the best solution. A detailed breakdown of the computational cost for each stage of the proposed framework—HVS sampling, CG-GAO feature selection, and ensemble classification—across both datasets is provided in Table S5 in supplementary file.Table 13. Comparative computational complexity and resource cost of metaheuristic optimizers.AlgorithmOptimization methodComplexityFFEsRelative costAdvantagesCG-GAOGA (10%)AOA (90%) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(N.{I}_{t}.(0.1a+0.9b))$$\end{document} (a > b)Moderate to highBalancedBest accuracy; efficient blend of global and local searchGAGA only \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(N.{I}_{t}.a)$$\end{document} HighHighestPure exploration; lacks local refinementAOAAoA only \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(N.{I}_{t}.b)$$\end{document} LowLowestFastest; lower accuracy in complex feature spaces
Conclusion
This research presents a novel sampling and hybrid Feature optimization techniques to enhance anomaly detection efficiency and reduce the computational burden. The proposed approach Cauchy–Gaussian Genetic-Arithmetic Optimizer (CG-GAO) based active feature selection integrated with ensemble machine learning classifiers supports effective binary classification. The Proposed IDS lowers computation cost and improves population diversity, convergence speed, and feature relevance, resulting in effective dimensionality reduction.
Experiments on CICIDS2017 and IoTID20 datasets showed that CG-GAO with Bagging achieved the best accuracy—99.89% and 99.72%, respectively, with high precision, recall, and F1-scores and minimal false positive rates. The statistical significance of the proposed framework is confirmed by Friedman test with p < 0.0001 for CICIDS2017, p = 0.0008 for IoTID20, followed by Nemenyi post-hoc analysis, where CG-GAO showed significant performance over GA (p < 0.001) and AoA (p = 0.032 on CICIDS2017. Despite its promising performance, the proposed CG-GAO framework has certain limitations. The framework has been evaluated only on CICIDS2017 and IoTID20 datasets, and its effectiveness on broader, more diverse IoT and real-world traffic remains to be validated. While the proposed method demonstrates strong performance, this study does not explicitly address certain practical deployment aspects such as real-time operation, generalisation under dynamic network conditions, and concept drift. These remain important considerations for fully operational IDS environments. In future work, we plan to extend the CG-GAO framework to additional IoT and real-world datasets to further assess its generalizability, evaluate its robustness against zero-day attacks, and incorporate Explainable AI (XAI) for improved interpretability. We also intend to develop and test mechanisms suitable for real-time IDS deployment, ensuring efficient adaptation to evolving threat patterns.
Supplementary Information
Below is the link to the electronic supplementary material.
Supplementary Material 1
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1https://www.fortunebusinessinsights.com/industry-reports/internet-of-things-iot-market-100307.
- 2Liu, H., Yu, L., Dash, M., & Motoda, H. (2003). Active feature selection using classes. In Advances in Knowledge Discovery and Data Mining: 7th Pacific-Asia Conference, PAKDD 2003, Seoul, Korea, April 30–May 2, 2003 Proceedings, Vol. 7 474–485 (Springer, Berlin, 2003).
- 3Ullah, I. & Mahmoud, Q. H. A scheme for generating a dataset for anomalous activity detection in Io T networks. In Canadian Conference on Artificial Intelligence 508–520 (Springer, Cham, 2020)
- 4Wang, R., & Liu, Q. Improved arithmetic optimization algorithm based on sigmoid function and Cauchy Gaussian fusion mutation. In 2022 3rd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE) 589–594 (IEEE, 2022).
- 5Mohy-Eddine, M., Guezzaz, A., Benkirane, S., & Azrour, M. An efficient network intrusion detection model for Io T security using K-NN classifier and feature selection. Multimedia Tools and Applications, 82(15), 23615–23633 (2023).
- 6Higashi, N. & Iba, H. Particle swarm optimization with Gaussian mutation. In Proceedings of the 2003 IEEE Swarm Intelligence Symposium. SIS’03 (Cat. No.03EX 706), Indianapolis, IN, USA, 26 April 72–79 (2003)