Considerations for evaluating the practical utility of machine learning in suicide risk estimation: the role of cost and equity
Christopher Kitchen, Anas Belouali, Paul S Nestadt, Holly C Wilcox, Hadi Kharrazi

TL;DR
This paper explores how machine learning can improve suicide risk prediction by focusing on precision and fairness in clinical settings.
Contribution
The study introduces AUPRC-maxima optimization for suicide risk prediction using machine learning models.
Findings
XGBoost achieved high precision in predicting suicide risk from hospital discharge and claims records.
Different ML models perform better depending on whether precision or sensitivity is prioritized.
No algorithmic bias was found by age, sex, or race, but performance varied with clinical characteristics.
Abstract
A key vulnerability in modeling suicide death is a lack of precision and therefore estimates are thought as ultimately unhelpful to clinicians, even with more advanced or nuanced machine learning (ML) techniques. We sought to fill several conceptual gaps by assessing performance, focusing on the precision-recall tradeoff, across multiple techniques, and with ad hoc contextualization for sensitivity, cost-balance, and fairness. To identify robust, differential performances of a cross section of ML techniques on a suicide risk task, emphasizing overall AUPRC maximization and downstream effects on hypothetical decision support. A retrospective cohort was selected for patients receiving care or having died per the Office of the Medical Examiner (OCME), between 2017 and 2020 using the Maryland Suicide Datawarehouse (MSDW). AUPRC-optimized settings yielded cross-validated AUPRC significantly…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
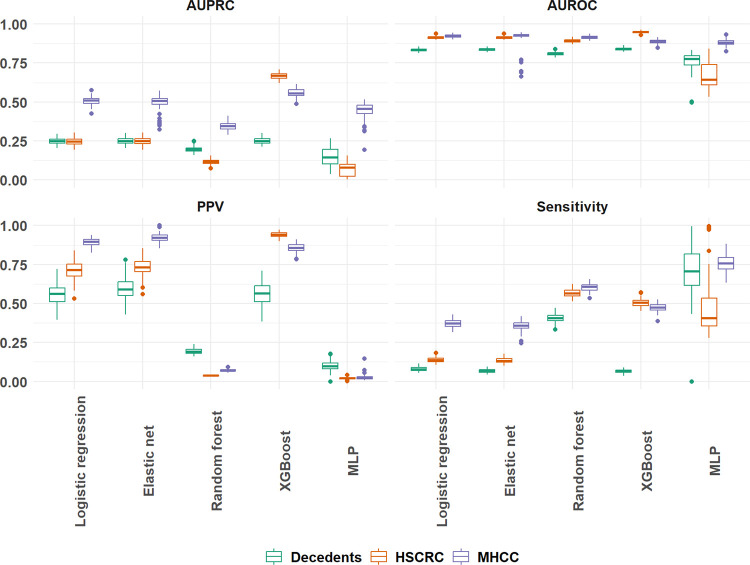 Figure 1
Figure 1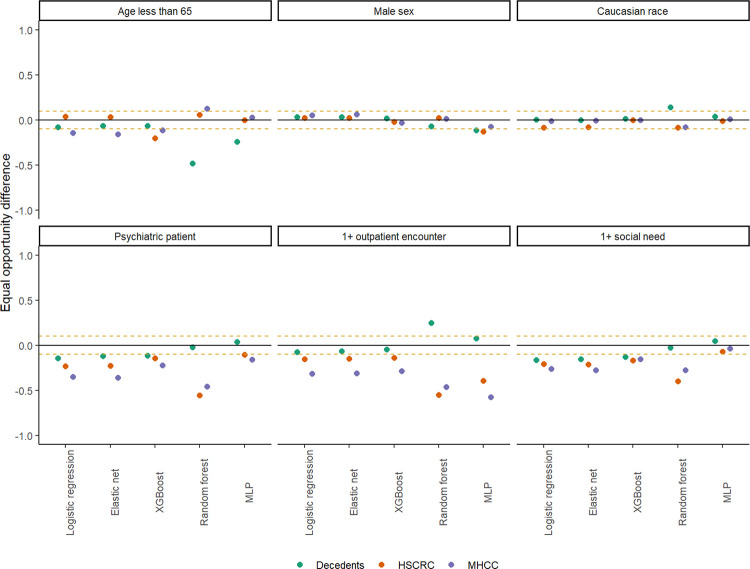 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSuicide and Self-Harm Studies · Mental Health via Writing · Machine Learning in Healthcare
BACKGROUND
Suicide risk models hold promise in identifying at-risk patients in large cohorts. [1–4] Lack of practical validity, however, often leads to models performing well in research settings but having limited use in clinical settings. The existing literature on machine learning in suicide risk estimation generally fails to measure and explain the practical validity of new models. This limitation has resulted in reduced clinical applicability of these tools unless they specifically link risk to narrow use cases and cohorts. [5–7]
Suicide risk models tend to be evaluated using area under receiver operating characteristics (AUROC) with some indication of how many correct suicide deaths could be identified out of various sensitivity settings. [1–4, 7, 8] A recent meta-analysis of suicide prediction literature concluded that the wealth of different methods and techniques applied to suicide prediction still falls short of having clinical utility due to lacking precision. [8–12] This lack of precision can be partly due to an improper framing of the risk prediction task as classification rather than event detection. [13, 14]
Multiple factors affect the precision of suicide risk models. Most importantly, suicide risk models are trained on very imbalanced data as models should generally be trained in the same conditions as their eventual use. [15–18] Another reason is that errors in suicide risk prediction are generally treated as equal in, though without considering real-world costs. Additionally, the desire for maximizing sensitivity of such models often result in alert fatigue and providers seeing diminished value in such predictive tools. [1]
Suicide risk models should balance precision (i.e., positive predictive value, or PPV) and false negatives (i.e., sensitivity, or recall). Past research has often addressed the trade-off of precision and recall by comparing risk sensitivity to a threshold (e.g., top 1% or 5% of the response distribution) and then evaluating the corresponding confusion matrix. However, this approach can worsen algorithmic bias in decision support or not generalize well with new data and be an unreliable basis for comparing performance across diverse algorithms. [19, 20] For example, the same 1% may come from an overrepresented group, be highly idiosyncratic, or lead to the wrong conclusion based on outlier cases.
Cost and equity are seldom the focus for suicide risk modeling even though they directly impact the appropriateness of their clinical use. Recent work in the measurement of algorithmic bias has formalized benchmarks for evaluating model performance, making it possible to identify when prospective tools fail a basic fairness test during development. [21–23] Additionally, costs can be calibrated to different balances of precision-recall and summarized using economic impact, confusion matrix or F-beta score. [24–26] However, cost means different concepts to different stakeholders. [24, 25] Advocating for use of one model versus another should be anchored to specific real-world effects (e.g., lives saved, patients screened, dollars spent) during validation. [1, 26]
Suicide risk models are frequently used to identify patients for further screening or intervention; however, these models often lack precision and limited application in clinical context. [9, 11, 12] Using machine learning approaches for suicide risk prediction has also shown improvement in AUPRC, which is critical to the prediction of rare events. [27–30] Nevertheless, using machine learning approaches has further complicated balancing precision and recall while keeping the models fair and cost effective. To address these challenges, this study aimed to: (1) evaluate the circumstances and techniques in which machine learning might be useful, including whether they are robustly better than the more interpretable regression-based models, and (2) compare different approaches to measure clinical utility of risk models, while considering fairness and cost. Results of this study could be used to assess whether the decisions made by the end users of suicide risk models are fair and enhanced for patient outcomes and not just performing adequately for development.
RESULTS
Sample Characteristics
The average age of suicide decedents was 49.3 years, making them generally older than either of the living control groups from HSCRC (42.0) or MHCC (40.4) but much younger on average than other decedents from the OCME record (64.4). Suicide decedents were also disproportionately more male (76.9%; χ^2^ = 5157, p < 0.001) and identifying as Caucasian (76.1%; χ^2^ = 7250, p < 0.001) than any other comparison group. Several key psychiatric and behavioral diagnoses were significantly greater among suicide decedents than any other groups, including depressive disorders (χ^2^ = 40036, p < 0.001), anxiety disorders (χ^2^ = 18049, p < 0.001), bipolar disorder (χ^2^ = 14559, p < 0.001), psychotic disorders (χ^2^ = 19006, p < 0.001), post-traumatic stress (χ^2^ = 7771, p < 0.001) and attention-deficit hyperactivity disorder (χ^2^ = 823.24, p < 0.001). Care utilization was noted to be significantly lower among suicide decedents compared to other decedents, but greater than living control groups (Table 1).
Predictive Modeling
The AUPRC is identified as the principal metric for selecting candidate models for each cohort. For decedents, both elastic net and XGBoost achieved an average, cross-validated AUPRC of 0.251, significantly different from all other performances except logistic regression (0.249). Average AUPRC obtained by XGBoost for HSCRC (0.667, 0.663:0.670) and MHCC (0.558, 0.554:0.563) are significantly greater than all alternative models for those cohorts, based on their respective 95% confidence intervals. HSCRC and MHCC-based XGBoost models also produced the highest PPVs of 0.941 and 0.857 with a classification threshold of 0.5 for response probability (Table 2).
PPV was compared to optimized AUPRC and sensitivity across all algorithms to assess divergences in performance. Elastic net and regression showed high precision but comparatively low sensitivity across each data source (sensitivity: Decedents 0.067, 0.065:0.069; HSCRC 0.133, 0.130:0.136; MHCC: 0.356, 0.350:0.361). In contrast, random forest models resulted in high sensitivity but at the expense of much lower precision across all cohorts (PPV: Decedents 0.193, 0.190:0.196; HSCRC 0.037, 0.037:0.038; MHCC 0.072, 0.070:0.073). XGBoost models produced higher precision and recall over other estimates, though only for the HSCRC and MHCC cohorts (F1: Decedents 0.115, 0.111:0.118; HSCRC 0.656, 0.652:0.660; MHCC 0.610, 0.606:0.614). Neither ensemble methods nor the MLP were as successful in achieving optimal AUPRC for the HSCRC and MHCC cohorts but resulted in better sensitivity than most alternatives (Fig. 1).
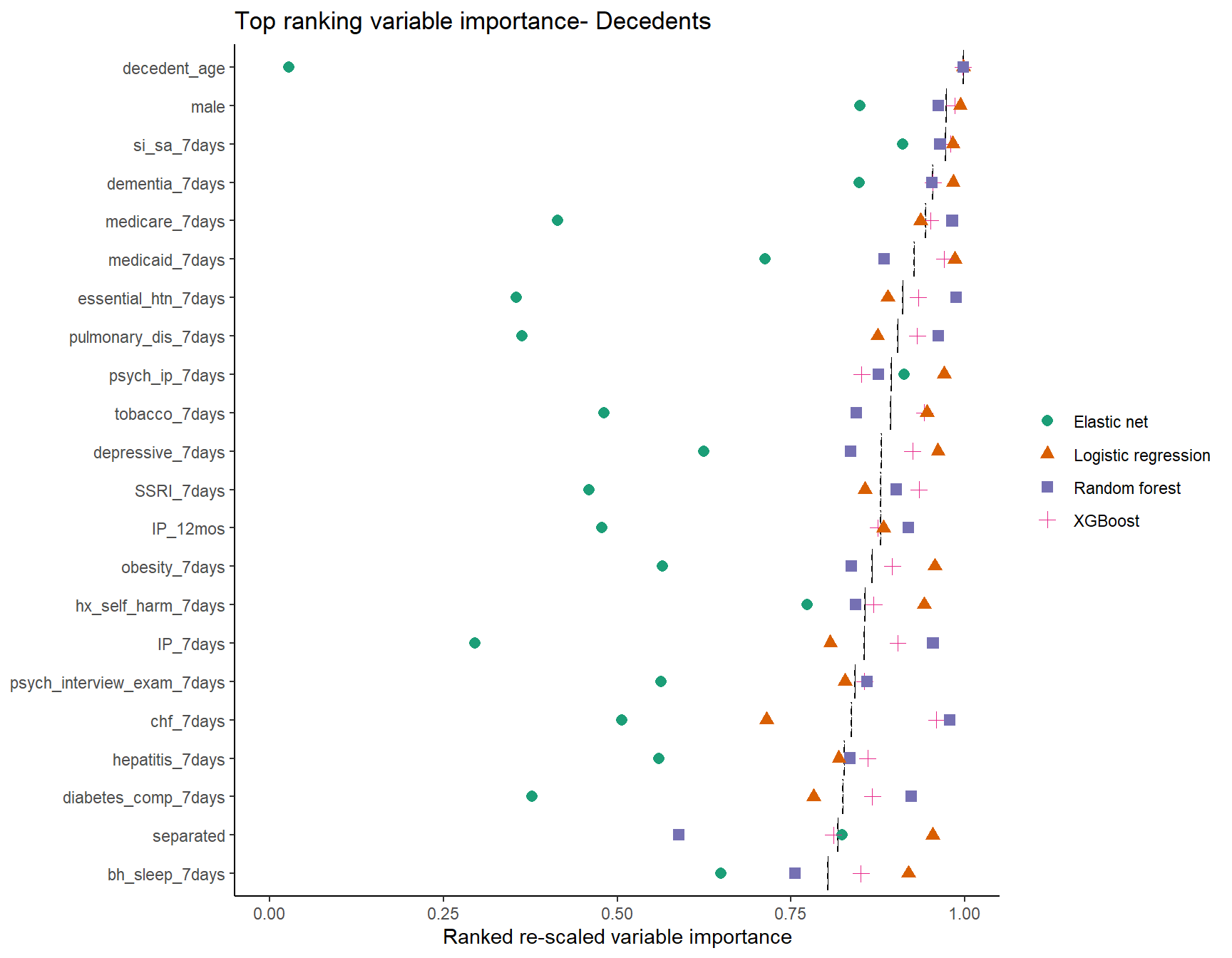
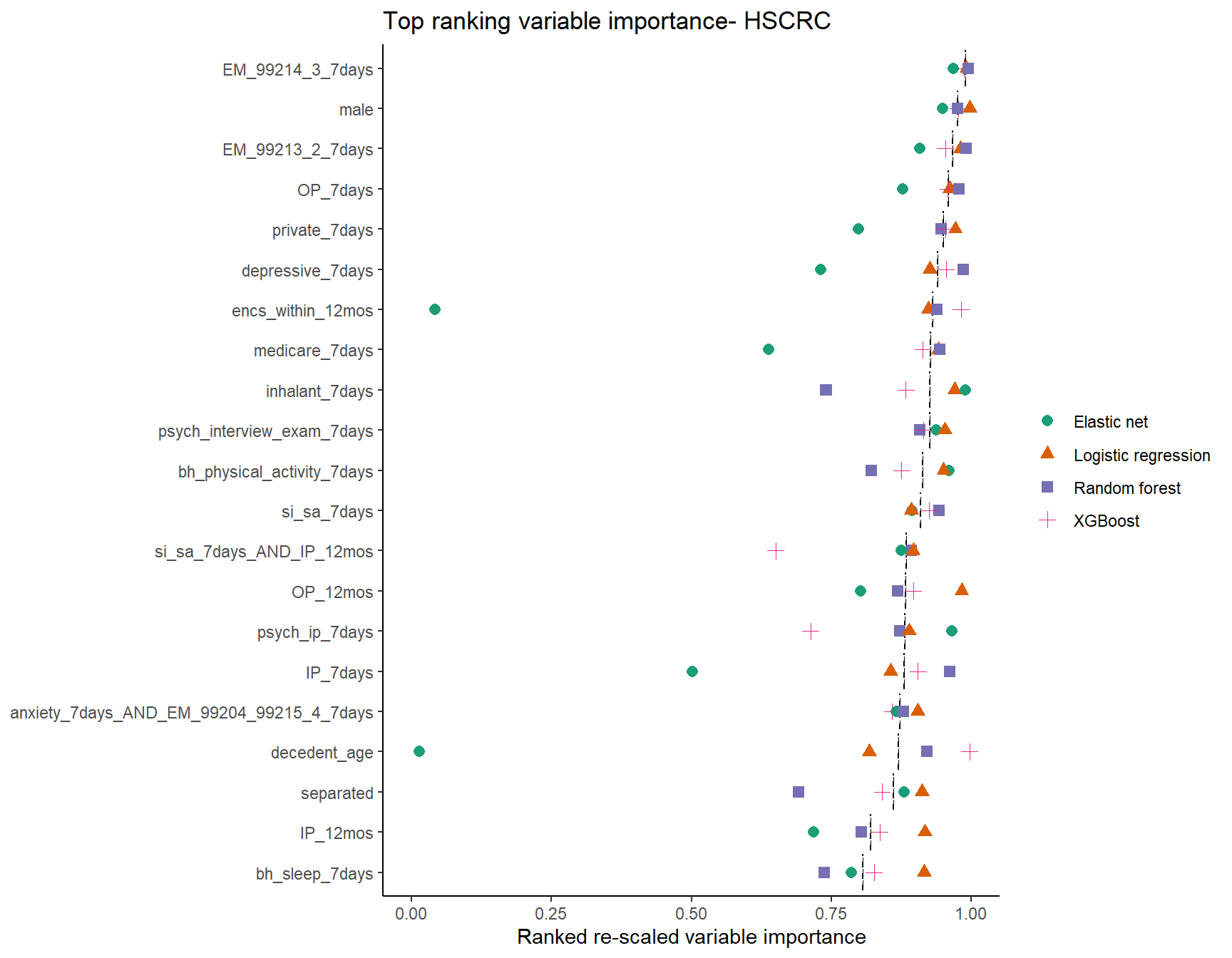
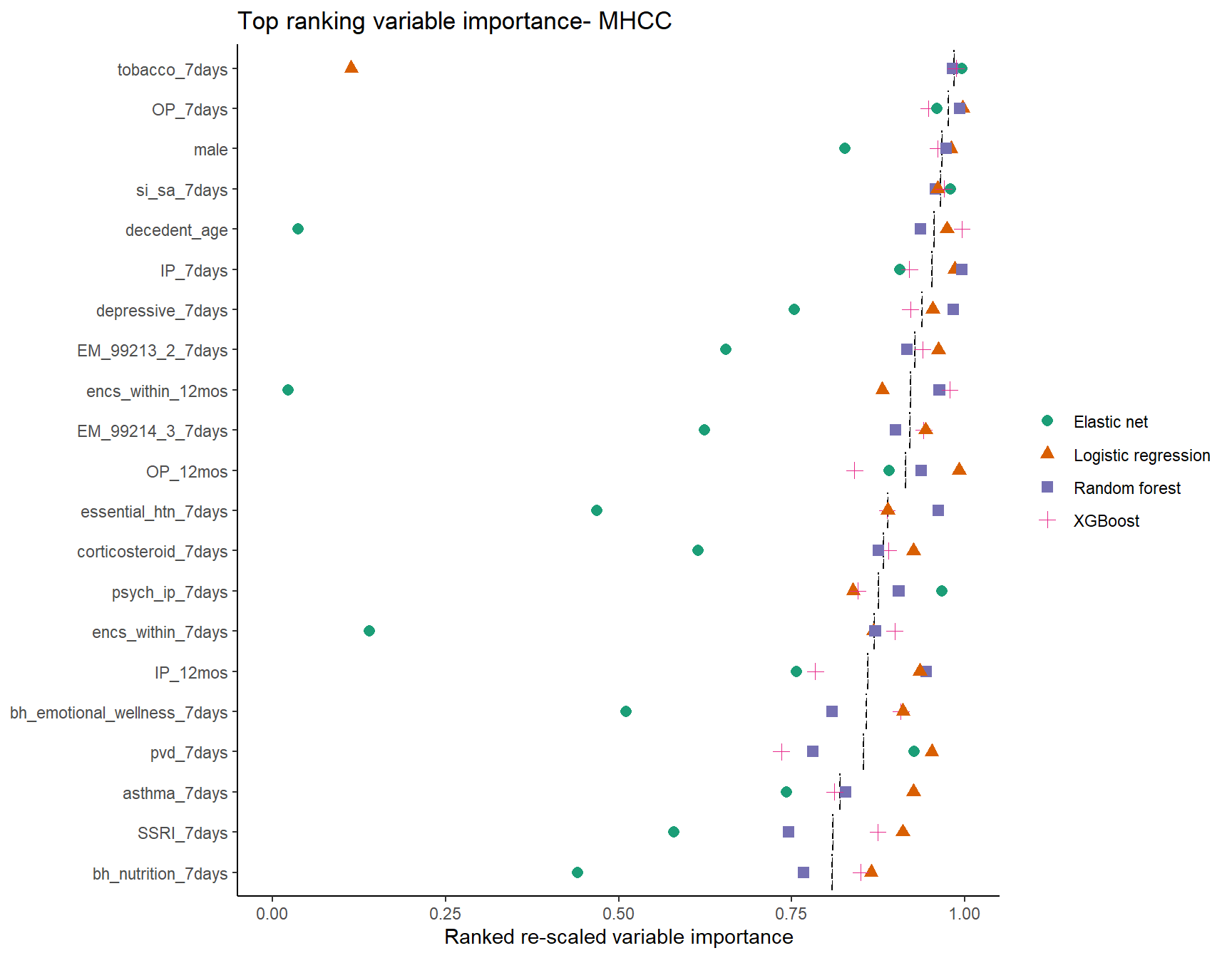
Variable importance for the top 20 most influential features was largely consistent across models for each cohort (Supplemental Figures S1A-S1C). More divergences in rank emerged from the elastic net, likely due to the manner it handles collinearity among features by penalized weights [54]. The median rescaled rank of most important features for each cohort tended to converge on age (Median: Decedents 0.998; HSCRC: 0.868; MHCC: 0.955), male sex (Decedents 0.974; HSCRC: 0.976; MHCC: 0.967), prior ideation or attempt (Decedents: 0.972; HSCRC: 0.909; MHCC: 0.966), depression diagnosis (Decedents: 0.881; HSCRC: 0.940; MHCC: 0.938), and hospitalization within 12 months (Decedents: 0.879; HSCRC: 0.847; MHCC: 0.860) (Supplemental Table S2).
Classification metrics were measured across multiple thresholds for percentile risk (Table 3). For each cohort, PPV increased as a function of restricting the threshold to higher risk. Conversely, sensitivity was reduced, leaving uncertainty in which threshold is best suited to balancing precision and recall. The best F1 for each algorithm was obtained at the 90th percentile decedents (suicide rate = 0.041), but for HSCRC (rate = 0.002) and MHCC (rate = 0.002) best F1 was achieved at the 99.9th percentile. At these thresholds, XGBoost outperformed most alternatives for precision, with an average 941 cases correctly predicted among decedents (PPV: 0.198; sensitivity: 0.484), 908 in HSCRC (PPV: 0.961; sensitivity: 0.467) and 858 cases in MHCC (PPV: 0.906; sensitivity: 0.441) (Table 3).
Cost and Fairness of Estimated Risk
Different ad hoc interpretations of performance were obtained through F-beta estimates that reflect a preference for greater precision or recall [24]. At the 90th percentile among decedents, a beta of 0.1 corresponds to weighting precision 10 times over sensitivity and identifies the 99th or 99.9th as better thresholds of classification, across all algorithms. Conversely, for the remaining ‘low rate’ cohorts, valuing sensitivity 10 times over precision generally reduces the preferred threshold from the 99.9th to the 99th percentile, and only for the most precise models (i.e., excluding Random Forest) (Table 3).
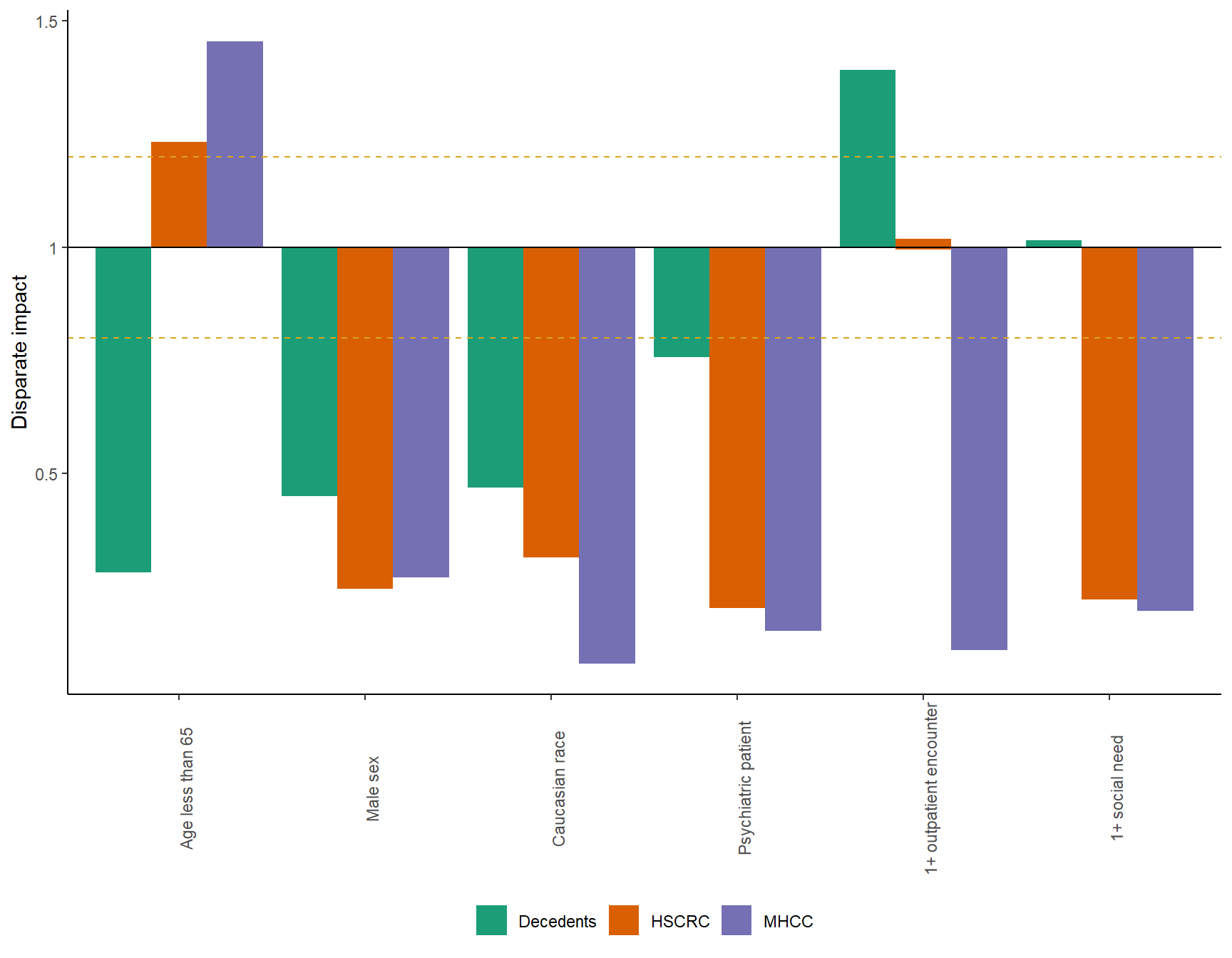
The disparate impact of suicide death among subgroupings was consistently imbalanced and less than 0.8 for male or Caucasian patients, and those with psychiatric conditions, outpatient care or social needs (See Supplemental Figure S2). Two notable exceptions were age greater than 65 years in MHCC (i.e., a higher rate of suicide death) and having zero outpatient encounters among decedents.
Cross-validated equal odds difference (EOD) was estimated to be fair for most fitted models when patient demographics defined a privileged group in (Fig. 2, Supplemental Table S4). Some exceptions were noted among decedents for high sensitivity models (e.g., random forest and MLP). XGBoost was again observed to perform well with these first three demographic strata across each cohort, the range being − 0.203 to −0.066 for age less than 65; −0.032 to 0.020 for male sex; and − 0.086 to 0.013 for Caucasian race. These values were consistent across each algorithm and grouping, though more biased towards younger decedents (i.e., higher predicted odds) when using random forest and MLP. The three clinically defined groups were also more favorable to their respective out-groups. EOD favored correct classifications between − 0.557 to − 0.020 (across all models, cohorts) for patients with psychiatric conditions, with the random forest model generally being the least fair for HSCRC and MHCC records. For those with 1 + outpatient encounter the range was − 0.583 and 0.248, and for 1 + ICD-10-CM coded social need it was − 0.398 and 0.044 with both MLP and random forest methods proving to be among the least equitable (Supplemental Table S4).
DISCUSSION
A key restriction in predicting suicide risk is the lack of precision thus limiting the scalability and practical utility of such models. Cost-weighting suicide risk models are challenging, especially when the consequence of a false negative is patient death, and a monetary value applied to false positives. To address this challenge, this study frames suicide risk modeling as a signal detection task by incorporating AUPRC-maxima optimization. The study hypothesizes that deciding candidate suicide risk models for implementation should depend both on the cross-validated AUPRC and the theoretical cost and fairness for different cohorts of interest.
Similar values for AUROC and classification metrics have been observed for suicide risk prediction models from prior literature, especially where large class imbalance is present. [8] For example, McCarthy et al found ROC, PPV and sensitivity values of 0.90, 0.38 and 0.001, using logistic regression with a threshold setting of the 90th percentile and a cohort where the rate of suicide death was 36 per 100,000 patients. [55] The Belsher et al. meta-analysis generally observed the same benchmark sensitivity statistics for these thresholds with very low associated PPV across all threshold settings (between < 0.001 and .19). Similarly, in this study, for the most imbalanced cohorts of HSCRC and MHCC, results showed an analogous tradeoff of precision and recall (Table 2), and no value for interpreting ROC for logistic regression at the 90th percentile (i.e., 0.913 and 0.922 for ROC, 0.016 and 0.017 for PPV, 0.766 and 0.810 for sensitivity, using HSCRC and MHCC cohorts respectively) (Table 3). However, classifying the top 10% of patients using this approach identifies around 95,000 individuals as at risk, which are too many patients to intervene on and the reason for distorted PPV estimates.
Results of this study differ in that the candidate machine learning model, AUPRC-optimized XGBoost, was associated with the best average AUPRC in each of the full samples (Decedents: 0.251; HSCRC: 0.667; MHCC: 0.558) (Table 3). XGBoost also showed a significantly greater performance in the most imbalanced cohorts. By raising the classification threshold and using AUPRC-optimization of hyperparameters, it was possible to obtain a better overall balance between precision and recall, and enhanced precision. At the 99.9th percentile, XGBoost obtained a cross-validated F1 of 0.629 and 0.594, PPV of 0.961 and 0.906 and sensitivity of 0.467 and 0.441, for HSCRC and MHCC respectively (Table 3). For the less imbalanced decedents cohort, XGBoost was again among the top performing models for AUPRC but fell behind random forest classification metrics (Fig. 1).
Rates of suicide are unequal across different clinical cohorts. This study reported on the disparate impact of suicide death from these samples but also demonstrate that the EOD of XGBoost models tended to yield largely unbiased responses for age, sex and race (Fig. 2). Better estimation of suicide risk was generally possible when clinical groups for psychiatric diagnosis, outpatient care utilization, and social needs were present (Supplemental Table S4). These findings could be partially due to missingness of clinical information, often through limited healthcare utilization or access. Consequently, this could lead to training biased models that detect high risk cases among clinically vulnerable populations and not the population at large. Thus, a one-size-fits-all approach to estimate suicide risk seems to be inappropriate, and separate models for points of care or clinical composition may be best for the task.
A way to separate risk estimation from the degree of class imbalance might be to focus on cost weighting or the F-beta classification score. Critically, these values illustrate how the preferred candidate model changes as a function of differentially weighting precision and recall. For example, the random forest model was seen to yield the best classification performance when recall was 10 times preferred over precision among decedents, but not when greater precision was needed (e.g., F0.1 versus F10 score). In highly imbalanced data, the XGBoost and weighted ensemble models performed well across all betas except those representing the greatest preference for sensitivity (Table 3).
This study provides context around the sentiment shared in a prior meta-analysis, that in suicide risk modeling “precision is not adequate to be useful.” [9] Although this statement can be true, this could merely be a consequence of the threshold settings and class imbalance found in each study included in the meta-analysis. This study showed that when the threshold is restricted to a small proportion of the cohort (i.e., very high percentiles) or class imbalance is left to something resembling the epidemiological rate of suicide (i.e., no resampling), it is still possible to calibrate useful machine learning tools by using parameters that maximize AUPRC. Additionally, maximizing AUPRC does not appear to drastically affect the theoretical fairness of these models, even though the lack of clinical information does.
Findings of this study do not replace the need for rigorous external validation using new data sources and randomized samples for testing decision support, nor does it replace eventual randomized trials for such applications. The explored methodology merely illustrates how downstream considerations of cost and fairness might be addressed as part of the development of risk models, particularly those with severe class imbalance. The performance estimates, though robustly cross-validated, are not necessarily a firm indicator of the generalizability of findings, nor are the variable importance estimates necessarily correct estimates of individual risk factors.
This study has a few limitations. First, the experiments only used portions of MSDW, which may have inadvertently contributed to a degree bias in the results. The MHCC record, for example, consists of commercial claims records, and so tends to represent employer insured individuals of working age, rather than Medicare and Medicaid beneficiaries. Second, the study limited the identification of patients with social needs through ICD-10-CM coding alone. Many have limited access to care or are uninsured, making it more uncertain whether algorithmic bias was adequately avoided. Finally, the proposed methodology does not address the common sampling techniques used to adjust class imbalance in training. Prior work has shown that relying on such techniques as under/oversampling cases tend to negatively bias AUPRC performance and inflate classification sensitivity at the cost of precision. [56]
Suicide risk estimation benefits from a careful understanding of how clinical decisions are to be supported. A highly sensitive model can be calibrated out of a diversity of ML techniques, and similarly a high-precision tool can be achieved if that is instead desired. Few studies to date have explored model efficiency, fairness and cost. Clinical composition and intended use, dictate which tools are best suited for each task, but our findings suggest a generalizable risk model might be best achieved through use of extreme gradient boosted trees in conditions of significant class imbalance.
METHODS
Participants and setting
Observational data from the Maryland Suicide Data Warehouse (MSDW) were used in this study. MSDW is a repository of administrative records, electronic health records (EHRs), and claims data sources, spanning 2012 to 2020. MSDW contains 104,516 decedents linked to the state Office of the Chief Medical Examiner (OCME) records. [31–33] MSDW also contains records from 6,658,990 living patients largely from hospital discharges of the Health Services Cost Review Commission (HSCRC) and commercial claims of the Maryland Health Care Commission (MHCC). [35, 36] All MSDW records have been deidentified by their constituent providers and required by respective data use agreements. Use of MSDW for this project was reviewed and approved by the Johns Hopkins Bloomberg School of Public Health Institutional Review Board. All work was conducted according to relevant guidelines and regulations concerning human subject designs, using retrospective data. This research was approved as minimal risk and informed consent was waived given the risk to participants being reidentified.
The study population included 5,059 decedents from MSDW whom had been identified as having died in a manner consistent with suicide. The study population also included three control groups from MSDW to assess the performance of suicide risk models: (1) Decedents identified by the OCME who have died in a manner other than suicide; (2) Living population represented by the statewide HSCRC hospital discharge data source (capped at 1 million random sample); and, (3) Living population represented by the statewide MHCC administrative claims data (capped at 1 million random sample). These controls were selected to simulate actual use cases by state level stakeholders such as the ME, HSCRC or MHCC. For example, models for classifying manner of death may be useful for identifying probable cases for psychiatric autopsy and OCME review. [34, 35]
Additional inclusion criteria included having a non-missing and valid value for age, sex, and residential address (i.e., Census tract or 5-digit zip code) within the state of Maryland; and having at least one clinical encounter between 2016 and 2020. Decedents were required to have had a date of death 2017 or later. After applying these criteria, 47,529 (45.5% selected) ME-identified decedents were found in the HSCRC or MHCC records, 1,944 (4.1%) of whom died by suicide. Total of 846,542 (84.7%) living patients remained from the HSCRC (hospital discharge) records and 844,331 (84.4%) living patients from the MHCC (administrative claims) records. [36, 37]
Study design
A retrospective cohort analysis was employed to construct the study population. The study used validated cases of suicide death linked across several data sources, which has been often missing in prior research. [32] Performance optimization was conducted using the AUPRC as a benchmark for comparison in addition to using a competing model framework for assessing risk of suicide. Optimization using AUPRC was applied to decrease the failure of models to generalize properly to new sources of data due to differences in case balance during training and validation. [13–16, 38]
Variable definitions
The MSDW aggregates observed values from multiple sources on patient demographics (age/sex), marital status and residency. Many clinical indicators were identified in the MSDW using diagnostic categories from the 2020 Clinical Classifications Software, published by the Agency for Healthcare Research and Quality (AHRQ). [39–41] The number of diagnostic and procedure-coded observations identified using this approach was generally limited to chronic diseases or known correlates of suicide risk, substance use disorders, and socio-behavioral needs as supported by literature and independent expert review by two licensed psychiatrists.[42] The Charlson comorbidity score and associated clinical markers were also calculated using diagnostic codes. [43] Pharmacological classes were attached to records for which pharmacy records exist (i.e., MHCC), using the openFDA programming interface and linkage through 11-digit national drug code (NDC). [44] Patient residency information from the OCME and HSCRC records at Census tract level were clustered using the SaTScan procedure for identifying regions with significantly greater than expected suicide cases. [45] This was included to control geographic effects for each model, though only available by Census tract, which precluded its use in MHCC.
Clinical and geographic variables were discretized for a period of observation beginning January 1st, 2016, and ending 7 days prior to recorded date of death for decedents, or a randomly chosen date between 2017 and 2020 for living controls. Each patient had at least 1 year of observation recorded and 1 clinical encounter throughout the full observation period as a result. Additional features reflect the counts of clinical encounters at different points of care within 12 months of each patient’s index date.
A total of 180 variables were identified across the sources of data (i.e., OCME, HSCRC and MHCC). An additional 531 variables were created as interactions between select diagnostic categories and factors known to be associated with suicide risk in observational research. These factors included depressive diagnoses, anxiety, bipolar, psychotic disorders, attention-deficit hyperactivity disorder, post-traumatic stress, opiate or alcohol use disorder, and suicide ideation or attempt. Least absolute shrinkage and selection (LASSO) were applied using the decedents cohort to narrow down the final features to 220 variables (HSCRC:172, MHCC:180). LASSO is frequently used in machine learning workflows to reduce collinearity of inputs and select features. [4, 8]
Statistical analysis
The main findings of this analysis are centered on the evaluation of AUPRC-optimized suicide risk models in a cross-validation framework. Sampling consisted of repeated 5-fold cross-validation with 20 iterations, for a total distribution of performance metrics on 100 model fits to evaluate uncertainty. Average performance metrics that exceed or fall below the 95% confidence interval of comparison distributions were considered significantly different for the purpose of understanding the value of using algorithm over another.
Multiple discrete approaches were considered for predicting suicide risk: two regression-based models (i.e., logistic regression and elastic net regression) were contrasted with two decision tree ensemble methods (i.e., random forest and extreme gradient boosted trees, i.e., XGBoost) to contrast methods that have underlying assumptions about these data. Finally, a separate multilayer perceptron (MLP) was was added to test whether complex associations between features and suicide could be accounted for and imrove classification. [9, 45] All analyses were conducted using the R programming language (version 4.0.2). [47–53]
Optimization involved a single 5-fold cross validation for each of the chosen hyperparameters in a truncated grid search. Hyperparameters were considered optimal when average AUPRC was highest for each cohort and algorithm pairing. Full ranges of performance (i.e., dispersion per setting) as well as inspection of local maxima were part of this process, but the chosen parameters were generally univariate on their impact in performance, except for learning rate (η). Tested parameters included (a) alpha and lambda-solution (maximum AUROC, minimized error and 1 standard deviation below minimized error) for elastic net, (b) depth, number of trees and positive class weight for random forest, (c) depth, number of trees and learning rate for extreme gradient boosting (XGBoost), and (d) learning rate, dropout rate and batch size for 3-layer perceptrons using a ReLU activation and a structure of 128, 64 and 32 hidden nodes. Selected parameters are summarized in the supplemental material (Supplemental Table 1).
The interpretability of model effects was limited due to incomparable indices of variable importance. These were algorithm-specific and different between regression and decision tree methods. Average standardized t-values (significant at 0.001 alpha level) and penalized parameters of elastic net were used to indicate variable importance in regressions and mean cross-entropy for both random forest and XGBoost. All measures of variable importance were converted to a ranked value for total remaining attributes in each model and rescaled to a range of zero to one, which facilitated comparison. A list of 5 of the most important features were identified across all models and tabulated with their respective 95% confidence interval (CI). Additionally, importance scores of the top 20 features of the models were plotted for comparison for each data source.
Candidate models were selected based on cross-validated AUPRC and a separate ad hoc cost-fairness analysis. Responses were limited to 1/10th of the total number of CV iterations. Cost was explored as a calibration of F-beta at different threshold settings, indexing classification by the relative value of precision to sensitivity. [24, 25] The F1 score was reported with other classification metrics and represents equal weight being applied to precision and sensitivity. Six demographic and clinical strata were identified as group characteristics to address algorithmic bias. Average cross-validated equal opportunity difference (EOD) was reported across all cross-validated performances and considered fair if falling between − 0.1 and 0.1. [21–23] The disparate impact of suicide death was reported for each strata.
Supplementary Material
Supplementary Files
This is a list of supplementary files associated with this preprint. Click to download.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bentley KH, Zuromski KL, Fortgang RG, Implementing Machine Learning Models for Suicide Risk Prediction in Clinical Practice: Focus Group Study With Hospital Providers. JMIR Form Res. 2022;6(3):e 30946. Published 2022 Mar 11. doi:10.2196/3094635275075 PMC 8956996 · doi ↗ · pubmed ↗
- 2Barak-Corren Y, Castro VM, Nock MK, Validation of an Electronic Health Record-Based Suicide Risk Prediction Modeling Approach Across Multiple Health Care Systems. JAMA Netw Open. 2020;3(3):e 201262. Published 2020 Mar 2. doi:10.1001/jamanetworkopen.2020.126232211868 PMC 11136522 · doi ↗ · pubmed ↗
- 3Kessler RC. Clinical Epidemiological Research on Suicide-Related Behaviors-Where We Are and Where We Need to Go. JAMA Psychiatry. 2019;76(8):777–778. doi:10.1001/jamapsychiatry.2019.123831188420 · doi ↗ · pubmed ↗
- 4Simon GE, Predicting Suicide Attempts and Suicide Deaths Following Outpatient Visits Using Electronic Health Records. The American Journal of Psychiatry. 2018; 175 (10), 951–960.29792051 10.1176/appi.ajp.2018.17101167 PMC 6167136 · doi ↗ · pubmed ↗
- 5Coppersmith Daniel D.L., Kleiman Evan M., Millner Alexander J., Wang Shirley B., Arizmendi Cara, Bentley Kate H., De Marco Dylan, Fortgang Rebecca G., Zuromski Kelly L., Maimone Joseph S., Haim Adam, Onnela Jukka-Pekka, Bird Suzanne A., Smoller Jordan W., Mair Patrick, Nock Matthew K., Heterogeneity in suicide risk: Evidence from personalized dynamic models, Behaviour Research and Therapy, Volume 180, 2024, 104574, ISSN 0005–7967, 10.1016/j.brat.2024.104574 · doi ↗
- 6Corke M, Mullin K, Angel-Scott H, Xia S, Large M. Meta-analysis of the strength of exploratory suicide prediction models; from clinicians to computers. BJ Psych Open. 2021;7(1):e 26. Published 2021 Jan 7. doi:10.1192/bjo.2020.16233407984 PMC 8058929 · doi ↗ · pubmed ↗
- 7Franklin JC, Ribeiro JD, Fox KR, Risk factors for suicidal thoughts and behaviors: A meta-analysis of 50 years of research. Psychol Bull. 2017;143(2):187–232. doi:10.1037/bul 000008427841450 · doi ↗ · pubmed ↗
- 8Belsher BE, Smolenski DJ, Pruit LD, Prediction models for suicide attempts and deaths: a systemic review and simulation. JAMA Psychiatry. 2019; 76(6): 642–65130865249 10.1001/jamapsychiatry.2019.0174 · doi ↗ · pubmed ↗