Artificial Intelligence in Neurology: Assessing the Diagnostic and Therapeutic Reasoning of Large Language Models
Skylar Bentley, Rees P Ridout, Nadiya A Persaud, Kevin M Sherin

TL;DR
This study evaluates how well AI models can diagnose and treat a complex neurological case, finding they perform well but lack personalization and long-term planning.
Contribution
The study introduces a novel evaluation of LLM diagnostic and therapeutic reasoning in a complex neurological case using expert scoring.
Findings
All three models correctly identified Guillain-Barré syndrome and proposed guideline-consistent therapies.
Claude 3.5 Sonnet outperformed others in differential diagnoses and intervention planning.
LLMs showed limitations in contextualizing SEL-specific considerations and longitudinal care planning.
Abstract
Background Artificial intelligence (AI) and large language models (LLMs) are increasingly integrated into medicine, yet their role in clinical decision-making remains underexplored. Neurology provides an important testing ground for these systems because neurological diagnoses often involve complex, overlapping syndromes, subtle clinical distinctions, and time-sensitive decision-making that can significantly affect patient outcomes. Objective This study evaluated the diagnostic and therapeutic reasoning of three LLMs: ChatGPT 4.0, Google Gemini, and Claude 3.5 Sonnet, using a complex neurological case of acute Guillain-Barré syndrome (GBS) in the setting of chronic spinal epidural lipomatosis (SEL). Methods Each model was prompted with an identical case and instructed to generate both a diagnostic assessment and a treatment plan. Four blinded, board-certified neurologists assessed…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
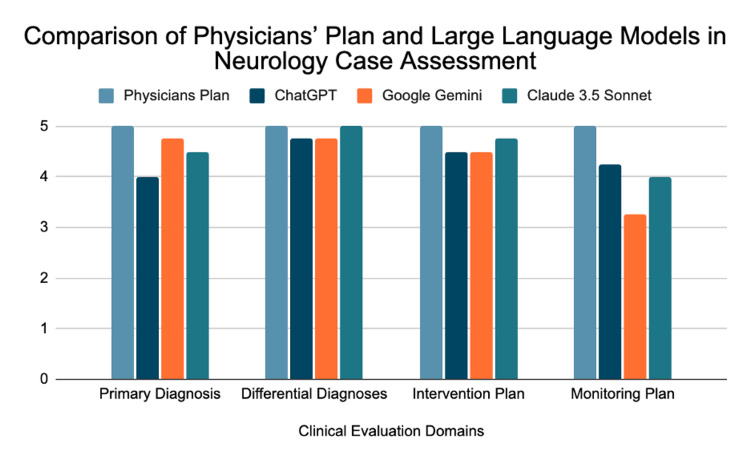 Figure 1
Figure 1| Evaluator | LLM | Primary Diagnosis | Differential Diagnoses | Intervention Plan | Monitoring Plan | Total Score |
| Evaluator 1 | ChatGPT | 3 | 4 | 3 | 2 | 12 |
| Evaluator 1 | Google Gemini | 4 | 4 | 3 | 3 | 14 |
| Evaluator 1 | Claude 3.5 Sonnet | 4 | 5 | 4 | 4 | 17 |
| Evaluator 2 | ChatGPT | 3 | 5 | 5 | 5 | 18 |
| Evaluator 2 | Google Gemini | 5 | 5 | 5 | 3 | 18 |
| Evaluator 2 | Claude 3.5 Sonnet | 4 | 5 | 5 | 3 | 18 |
| Evaluator 3 | ChatGPT | 5 | 5 | 5 | 5 | 20 |
| Evaluator 3 | Google Gemini | 5 | 5 | 5 | 4 | 19 |
| Evaluator 3 | Claude 3.5 Sonnet | 5 | 5 | 5 | 4 | 19 |
| Evaluator 4 | ChatGPT | 5 | 5 | 5 | 5 | 20 |
| Evaluator 4 | Google Gemini | 5 | 5 | 5 | 3 | 18 |
| Evaluator 4 | Claude 3.5 Sonnet | 5 | 5 | 5 | 5 | 20 |
| Large language model | Primary Diagnosis | Differential Diagnoses | Intervention Plan | Monitoring Plan | Total Score |
| Physician's Plan | 5 | 5 | 5 | 5 | 20 |
| ChatGPT | 4.0 | 4.75 | 4.5 | 4.25 | 17.5 |
| Google Gemini | 4.75 | 4.75 | 4.5 | 3.25 | 17.25 |
| Claude 3.5 Sonnet | 4.5 | 5.0 | 4.75 | 4.0 | 18.5 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Spinal Hematomas and Complications · Intracerebral and Subarachnoid Hemorrhage Research
Introduction
In the past decade, Artificial Intelligence (AI) has been transforming medicine by assisting with clinical workflows and providing decision support for complex medical cases. Since 2019, particularly in the United States and China, there has been a marked surge in AI-related publications, including in the field of neurology [1,2]. Several routine applications now involve utilizing AI to help read diagnostic imaging. These include CT and MRI for neurovascular and neuro-oncologic cases, electroencephalogram (EEG) recording analysis and monitoring for seizure detection, stereotaxic image guidance for surgical spatial positioning, and quantification of symptoms in diagnosis and monitoring of movement disorders [3]. Neurology, in particular, represents a meaningful testing ground for AI because many neurological disorders involve complex presentations, overlapping symptom profiles, and time-sensitive diagnostic and therapeutic decision-making.
Large language models (LLMs) are examples of AI tools being used in medicine for diagnostic and therapeutic guidance. LLMs are pretrained on vast text corpora and can generate human-like responses to free-text prompts, including medical queries, without task-specific fine-tuning [4]. Common LLMs include ChatGPT, Google Gemini, and Claude 3.5 Sonnet. They also hold potential in improving patient education by expanding access to medical information to help patients understand their health conditions, prognosis, and therapeutic options [5]. However, there is currently a large gap in knowledge regarding the use of LLMs in patient care, and the diagnostic potential of these systems requires further evaluation in multifaceted clinical presentations. Although LLMs have shown impressive performance on medical reasoning examinations, prior studies have largely focused on board-style questions or straightforward clinical scenarios. Their ability to manage complex cases involving overlapping pathologies and comorbidities remains largely unexplored, and it is still unclear if these tools quantitatively improve physician diagnostic reasoning [6]. Because diagnostic errors are a substantial source of patient harm, this potential for improvement warrants further analysis.
Contextual understanding is an essential component of the diagnostic process. LLMs have consistently displayed the ability to strictly adhere to preset diagnostic and treatment guidelines, but it remains unclear whether they possess the ability to go beyond applying guidelines and incorporate specific nuances, patient variables, and real-world complexity that can complicate a patient case [6]. An example of this contextual capacity involves the ability to integrate overlapping pathology (i.e., recognize how one condition can alter or obscure the standard presentation of another condition, making diagnosis more difficult). Further, such scenarios involve potentially modifying the standard management for a condition to account for comorbidities.
This study involves a neurological case in which a patient presents with both Guillain-Barré syndrome (GBS) and spinal epidural lipomatosis (SEL). GBS typically presents as rapidly progressive, symmetric, ascending weakness with areflexia, often days to weeks after a preceding viral or gastrointestinal illness. SEL presents with signs of spinal cord or nerve root compression, including chronic back pain, neurogenic claudication, or progressive lower extremity weakness. This dual pathology was intentionally selected because it challenges both diagnostic reasoning (distinguishing overlapping neurological presentations) and therapeutic planning (adjusting interventions in the presence of comorbid disease), making it a rigorous test of LLM clinical applicability. This study aimed to determine how accurately and comprehensively three large language models can generate diagnostic assessments and treatment plans for a complex neurological case involving overlapping pathologies.
Materials and methods
Case prompt development
A standardized case presentation was structured using a real-world case report [7]. The case consisted of a challenging neurological case of a patient presenting with acute GBS in the setting of chronic SEL. Patient history was based on a standard GBS presentation: recent viral illness with rapid progression of ascending paralysis with areflexia and sensory deficits. Notably, the patient’s concurrent SEL could cause a similar presentation, particularly in morbidly obese patients, which created a contextual challenge. The case was written in a clear and concise manner to avoid ambiguity. Because this study relied on a single standardized case, it should be considered an exploratory pilot study rather than a generalizable performance evaluation. No identifiable patient information was used, and the case content was derived exclusively from a previously published report; therefore, no additional ethical approval was required. This prompt served as the standardized input for all AI models.
Only information directly relevant to distinguishing GBS from SEL was included; comorbidities such as hypertension, diabetes, or hypothyroidism were not incorporated, as the intent was to isolate the diagnostic and therapeutic impact of overlapping neurological pathology rather than multisystem disease. Similarly, disease stage and severity were described only to the extent reported in the source case, and no additional modifying factors were added. No additional inclusion or exclusion criteria were applied beyond selecting a published case that demonstrated overlapping symptomatology, and these choices are acknowledged as methodological constraints.
LLM plan assessment and plan generation
Three LLMs were selected for evaluation based on their accuracy in medical reasoning: OpenAI’s ChatGPT 4.0, Google Gemini, and Claude 3.5 Sonnet. Each LLM was given an identical prompt of the patient case described above and instructed to produce two outputs. First, an assessment that included a diagnostic conclusion with other differential diagnoses and supporting reasoning for each. Second, a treatment plan with strategies for intervention, monitoring, and follow-up recommendations. The entire output from each LLM was saved for later evaluation.
For transparency and reproducibility, all models were accessed via their respective web interfaces using default settings (temperature and system parameters not user-modifiable). Access dates were documented (April 2025 for all models). No API calls, custom prompts, or fine-tuning were used.
Physician’s plan
The assessment and management plan by the treating physician in the real-world case report was retrieved. It served as the reference standard for comparison when evaluating LLM plans. The plan included the physician’s diagnostic conclusion and comprehensive management strategy for the patient. This terminology was chosen because expert management may vary among clinicians.
Evaluation rubric development
A standardized scoring rubric was created to help with quantitative, objective comparison of LLM assessments and plans. The rubric consisted of four categories. First, diagnostic accuracy and reasoning are used to evaluate the accuracy of the diagnosis and its associated clinical reasoning and justification. Second, differential diagnoses are used to evaluate the capacity of the system in weighing alternative possibilities. Third, an intervention/treatment plan, to evaluate the appropriateness and level of detail provided for the intervention. Fourth, monitoring/follow-up care to evaluate the appropriateness of the recommended monitoring and follow-up strategies. Each category was scored using a Likert scale from 1 to 5, with specific descriptions dictating the reasoning for scoring a given point value. In general, the following standards of scoring were used: 5 = Detail-rich, clinically sound approach aligning with expert standards; 3 = Basic assessment and plan with notable gaps or omissions; 1 = Inaccurate or inappropriate plan. The maximum total score achievable for an LLM’s given assessment and plan was 20 points. The rubric was developed specifically for this study and was not formally validated, which we acknowledge as a limitation; future work should include rubric validation and assessment of inter-rater reliability.
Scores of 2 and 4 represented intermediate performance between these anchors and were used when an evaluator determined that an LLM’s output partially met criteria for the next highest score but did not fully satisfy it. Although this allowed flexibility, the absence of explicit descriptors for these values may introduce variability in scoring, which we acknowledge as a limitation.
The four rubric domains were selected because they represent widely accepted components of clinical reasoning in neurology: accurate diagnosis, thoughtful differential generation, evidence-based intervention planning, and safe monitoring/follow-up. These domains were intended to capture the core elements most relevant to evaluating LLM clinical decision-making; however, they may not encompass all nuances of real-world practice, such as prognostication, interdisciplinary coordination, or shared decision-making.
The rubric was developed specifically for this study and was not formally validated. Future work should include rubric validation and assessment of inter-rater reliability to strengthen content validity and consistency.
Reviewer assessment
Four board-certified neurologists, each with experience treating GBS patients, were recruited to evaluate LLM assessments and management plans. The physicians were blinded to which specific LLM generated each assessment and plan to reduce bias. They were provided the standardized scoring rubric described above, and they used it to quantitatively evaluate each LLM’s output. Their scoring focused on several aspects: the accuracy of the LLM’s final diagnosis (GBS) and differential diagnoses, ability to generate relevant differential diagnoses, appropriateness of the treatment plan and interventions (e.g., IVIG, plasmapharesis, respiratory support), as well as follow-up and monitoring strategies. A total score was generated for each LLM output by summing each of the four categories. All reviewer scores were completed independently; no consensus scoring process was used. Although reviewer scoring was independent and blinded, inter-rater agreement metrics (e.g., kappa, ICC) were not computed due to the limited number of reviewers and are identified as important future methodological additions.
Statistical analysis
Mean total scores (sum of rubric domains) and mean domain-specific scores (diagnostic accuracy, differential diagnoses, intervention plan, and monitoring/follow-up) were calculated for each LLM. Mean scores were calculated by averaging the four independent reviewers’ numeric ratings for each rubric domain, and total scores represent the sum of these domain-level means. Analyses were limited to descriptive statistics; no formal hypothesis testing was performed, and no p-values are reported. Analyses were limited to descriptive summaries only; no inferential statistics were performed. A formal measure of inter-rater reliability (e.g., κ statistic or ICC) was not calculated due to the small number of raters and the limited number of ordinal scoring categories. Future studies with larger reviewer cohorts should incorporate inter-rater reliability testing to strengthen reproducibility, as well as measures of variance. All analyses were conducted in R (R Foundation for Statistical Computing, Vienna, Austria; version 4.4.3).
Results
Four board-certified neurologists, blinded to the identity of each model, evaluated the assessment and management plans generated by ChatGPT 4.0, Google Gemini, and Claude 3.5 Sonnet. The physician’s plan, serving as the reference standard, scored 5.00 in all categories for a total score of 20. Scores for each LLM were assigned across four domains (primary diagnosis, differential diagnoses, intervention plan, and monitoring plan) and then summed to generate a total score for each evaluator-LLM pairing, as shown in Table 1. Mean scores for each model by category and total score are presented in Table 2 and illustrated in Figure 1.
Comparison of Physician’s Plan and Large Language Models Across Clinical Evaluation Domains in a Neurology CaseGrouped bar chart of mean domain scores (1–5; higher = better) assigned by four blinded, board-certified neurologists for a single complex case (acute GBS with chronic SEL). Models shown: Physicians Plan (reference), ChatGPT 4.0, Google Gemini, and Claude 3.5 Sonnet. Domains: primary diagnosis, differential diagnoses, intervention plan, monitoring plan. Bars represent means across raters; no error bars are plotted.
Claude 3.5 Sonnet achieved the highest mean total score among the LLMs at 18.50, followed by ChatGPT at 17.50 and Google Gemini at 17.25. All three models accurately identified acute Guillain-Barré syndrome and recommended guideline-adherent therapies, including IVIG and plasmapheresis.
In primary diagnosis, Google Gemini had the highest mean score (4.75), followed by Claude 3.5 Sonnet (4.50) and ChatGPT (4.00). In differential diagnoses, Claude 3.5 Sonnet achieved a perfect mean of 5.00, while both ChatGPT and Google Gemini scored 4.75. For the intervention plan, Claude 3.5 Sonnet again led with 4.75, while ChatGPT and Google Gemini each scored 4.50. In monitoring and follow-up, ChatGPT had the highest mean (4.25), followed by Claude 3.5 Sonnet (4.00) and Google Gemini (3.25).
Reviewer observations were consistent with the quantitative results. Claude 3.5 Sonnet consistently produced the most complete and well-supported differential diagnoses and intervention plans. ChatGPT performed well in differential diagnoses and demonstrated its greatest strength in monitoring and follow-up recommendations, where it outscored both other models. Google Gemini showed the highest primary diagnostic accuracy but provided less detailed follow-up recommendations, resulting in its lowest score in the monitoring category. Despite these strengths, none of the LLMs matched the physician reference standard in addressing SEL-specific considerations or providing detailed, personalized longitudinal care.
Although no statistically significant differences were observed in total scores, the category-level analysis highlighted distinct performance patterns, with each model demonstrating unique strengths relative to the physician’s gold standard.
These descriptive findings illustrate that while all models demonstrated strong diagnostic accuracy and evidence-based management capability in this exploratory case-based study, domain-level variation and limited contextual reasoning highlight the continued need for physician oversight.
Discussion
Key findings
This study evaluated the ability of three LLMs (ChatGPT 4.0, Google Gemini, and Claude 3.5 Sonnet) to produce outputs with both diagnostic and therapeutic plans for a given patient case. Despite the neurological challenge provided, all three of the models correctly diagnosed acute GBS in the setting of chronic SEL. In addition, all of the LLMs provided treatment plans that were adherent to established treatment guidelines (IVIG, plasmapharesis). Claude 3.5 Sonnet performed at the highest level overall. However, there were no statistically significant differences amongst the performance of the LLMs (ANOVA p = 0.29). Consistent with prior literature, all models demonstrated strong performance on structured diagnostic tasks but variability in contextual reasoning. Monitoring/follow-up care was the weakest performance area for the LLMs overall when compared to the physician gold standard, suggesting better acute care recommendations but limited thoroughness in long-term management and rehabilitation plans.
Diagnostic performance and contextual understanding
In this patient case (Appendix), with considerable amounts of overlapping pathology, the LLMs managed to display contextual comprehension and identify the primary disease and cause of presenting symptoms. However, the plans included minimal incorporation of SEL-specific considerations (e.g., rehab modification) within the overall GBS management plan. This indicates a potential gap in patient-specific adaptation. Further, the physician provided a comprehensive, detailed follow-up plan, while the LLMs fell short with adequate but general recommendations that lacked specificity and contained omissions in timelines and personalization. Although this study did not compare LLM diagnostic performance to that of the physician (the physician’s diagnostic plan was used as the gold standard), other studies have suggested LLMs have statistically superior diagnostic accuracy when compared to human physicians in several contexts [8]. This is believed to be due to improved interpretation of information and pattern recognition in LLMs, rather than any difference in history taking or information acquisition [8]. Further, humans consistently display diagnostic bias. However, this study’s prompt did not include additional comorbidities (e.g., diabetes, hypertension) or gradations of disease severity, which are known to influence diagnostic reasoning. The absence of these confounders may have simplified the clinical scenario for the models and limited their applicability to more complex real-world presentations.
Physician burnout and physician shortage
One of the strongest arguments in support of increasing AI systems in healthcare is to combat the growing national physician shortage, as well as increasing rates of physician burnout. Particularly in neurology, an aging population presents an increasing demand for more neurologists. The shortage of neurologists in the U.S. has increased over the past decade and is expected to worsen, particularly in rural areas [9]. Similarly, another study showed that up to 60% of neurologists in the U.S. report at least one symptom of burnout [10]. Emerging studies suggest that LLM-based documentation and decision-support tools can reduce clinician workload by decreasing time spent on administrative and EHR-related tasks, thereby easing one contributor to physician burnout [11,12]. Although these systems have shown promise by documenting critical information discussed in patient encounters and expediting note writing, this study aimed to explore the ability of AI systems to assist with clinical decision-making, including diagnostic and treatment plans. More studies should be performed to explore the performance of AI in this specific context and whether it can be employed as a physician substitute, co-pilot, or helpful aid.
Health equity
Although AI is easier to implement in a high-resource medical setting, it holds the most potential for improving care in low-resource settings. In small rural hospitals or community health clinics, specialists are often unavailable. In these settings, AI could transform the types of care that could be offered to underserved populations. An example of this already being used is the IDx-DR machine learning software program that utilizes AI to analyze retinal images and diagnose diabetic retinopathy [13]. It is being utilized in areas without available ophthalmologists and providing expertise to primary care physicians that can aid with diagnoses that may not otherwise be found [13]. Further, these low-resource areas often show extensive waiting periods to be seen by specialists, and AI can increase earlier detection for increased clinical outcomes. However, these scenarios represent situations in which AI and LLMs are aiding human physicians in diagnosis, rather than being the sole source of diagnosis. Our study displays limitations that still exist, and AI recommendations should be used with caution and at the discretion of a physician.
Strengths of this study
There are a few aspects that increase the validity of this study’s findings. First, there was significant ambiguity in the patient case. By incorporating two conditions with significant overlap, a complex, contextual challenge was created for the LLM. One in which its ability, or lack thereof, to personalize diagnostic and treatment plans would be displayed. Second, the blinding of the expert reviewers helped minimize evaluator bias so that their scoring was objective. Third, utilization of a rubric with predefined scoring criteria and definitions for each point assignment helped make scoring reproducible across reviewers.
Limitations of this study
The generalizability of this data is limited by using only a single case prompt. The LLMs may vary in performance depending on the type or complexity of presenting neurological conditions. While Claude 3.5 Sonnet consistently performed the highest in this case, the other LLMs could potentially show superiority in simpler cases with less multisystem involvement or fewer overlapping conditions. Another limitation is the use of only three LLM models. These results do not apply to all LLMs, and other AI systems may drastically differ in performance when attempting complex neurological care. Although the phrasing and length of the prompt for each LLM were identical in this study, different prompts and provided information would almost certainly have resulted in different outputs from each LLM. In the real world, there would be no standardized input for a given case. Rather, it would depend on what the LLM user decided to input. In addition, the plan created by the physician in the case report was utilized as the gold standard, but this plan only reflects that of a single expert’s approach. This approach may not align with other experts and clinical practices. Lastly, LLMs constantly evolve, so their performance in this study only represents their abilities at the time data was collected.
The study also has several methodological limitations. Although the case prompt was written to be clear and neutral to minimize bias, it is not possible to prevent LLMs from having been previously exposed to similar cases during pretraining, and their internal training data cannot be controlled. The scoring rubric was developed specifically for this exploratory pilot study and was not formally validated. Inter-rater reliability was not calculated due to the small number of reviewers (N = 4), limiting the feasibility of meaningful κ or ICC analysis. Future studies should include rubric validation, reliability testing, and expanded reviewer cohorts to strengthen methodological rigor.
Future directions
Future research should investigate LLM performance when delivering a diverse array of cases with varying neurological complexity and multisystem involvement. This study included an acute presentation, but future studies could include both acute and chronic presentations, with an emphasis on the use of LLMs for guiding longitudinal care. Studies should also be performed to explore LLM performance in other specialties, rather than neurological cases, to help highlight the specific strengths and weaknesses of each LLM and increase the generalizability of the data. This information could help guide policy regarding AI use in clinical settings and its appropriate role in relation to physician oversight. Effort should be made to improve the ability of LLMs to create detailed, personalized treatment plans that do not simply follow standard guidelines, especially in patients with several comorbid conditions. Studies should also explore the variation in LLM performance based on different iterations of prompt inputs from the same patient case. There should be real-world implementation studies that include LLMs in clinical workflows and analyze patient outcomes to measure their practical value. Finally, these models should be provided with large, diverse datasets and trained to minimize bias to maximize patient safety and promote health equity in a variety of healthcare settings.
Future studies should also evaluate LLM performance in cases that include multiple comorbidities, atypical disease presentations, or severity gradients, as these factors more accurately reflect real-world diagnostic challenges and may reveal additional model limitations.
Because LLMs evolve rapidly, these findings represent a time-bound snapshot of performance; future work should include version-specific reporting and periodic re-evaluation using standardized benchmarks to ensure ongoing validity as models are updated.
Conclusions
LLMs displayed diagnostic accuracy and the ability to generate guideline-adherent treatment recommendations for a complex neurological case involving GBS in the setting of SEL. Although model performance varied, all LLMs demonstrated important limitations in contextual reasoning and personalized, longitudinal care planning, reinforcing the need for physician oversight. Given the single-case design and limited statistical power, these findings should be interpreted as exploratory and hypothesis-generating rather than definitive, and broader conclusions about LLM performance in neurology will require larger, more diverse clinical evaluations. Going forward, improving LLM capacity to incorporate comorbidities, disease severity, and patient-specific factors will be essential for safe clinical use. Developing standardized evaluation frameworks, incorporating version-specific benchmarking, and integrating LLMs into supervised clinical workflows may support their future role as reliable decision-support tools. While LLMs show promise, they are not substitutes for clinical expertise; continued refinement, validation, and real-world testing are necessary before broader implementation in neurological care.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Trends and global productivity in artificial intelligence research in clinical neurology and neuroimaging: a bibliometric analysis from 1980 to 2024 Cereb Cortex Ersoy S Ersoy EH Danis A Turkoglu SA 35202510.1093/cercor/bhaf 14840543094 · doi ↗ · pubmed ↗
- 2A bibliometric analysis of studies on artificial intelligence in neuroscience Front Neurol Tekin U Dener M 14744841620254004090910.3389/fneur.2025.1474484 PMC 11877006 · doi ↗ · pubmed ↗
- 3Artificial intelligence in neurology: opportunities, challenges, and policy implications J Neurol Voigtlaender S Pawelczyk J Geiger M 2258227327120243836704610.1007/s 00415-024-12220-8PMC 12239762 · doi ↗ · pubmed ↗
- 4Large language models in medicine Nat Med Thirunavukarasu AJ Ting DS Elangovan K Gutierrez L Tan TF Ting DS 193019402920233746075310.1038/s 41591-023-02448-8 · doi ↗ · pubmed ↗
- 5Current applications and challenges in large language models for patient care: a systematic review Commun Med (Lond) Busch F Hoffmann L Rueger C 26520253983816010.1038/s 43856-024-00717-2PMC 11751060 · doi ↗ · pubmed ↗
- 6Large Language Model Influence on Diagnostic Reasoning: A Randomized Clinical Trial JAMA Netw Open Goh E Gallo R Hom J 07202410.1001/jamanetworkopen.2024.40969 PMC 1151975539466245 · doi ↗ · pubmed ↗
- 7Bilateral Lower Extremity Weakness: Spinal Epidural Lipomatosis or more?Orthop Rev (Pavia) Krishnan A Stead T Oldano K Ganti L 339751420223577503710.52965/001c.33975 PMC 9239394 · doi ↗ · pubmed ↗
- 8Towards conversational diagnostic artificial intelligence Nature Tu T Schaekermann M Palepu A 44245064220254020505010.1038/s 41586-025-08866-7PMC 12158756 · doi ↗ · pubmed ↗