mm2-ivh: simple and precise overlap detection in alpha satellite HORs with interval hashing
Hajime Suzuki, Masahiro Sugawa, Yoshitaka Sakamoto, Yuichi Shiraishi

TL;DR
This paper introduces mm2-ivh, a new algorithm that improves the detection of overlapping DNA repeats, especially in alpha satellite HORs.
Contribution
The novel contribution is the interval hashing algorithm, which enhances haplotype reconstruction in complex repeat regions.
Findings
mm2-ivh outperforms standard assemblers in reconstructing haplotypes from alpha satellite HORs.
Interval hashing distinguishes k-mers from different repeat sequences more accurately.
Abstract
We propose a new algorithm, “interval hashing,” which distinguishes identical k-mers arising from different repeat sequences, particularly in complex repeat arrays such as alpha satellite HORs. We implement this algorithm as a fork of minimap2, named mm2-ivh. In local assembly of alpha satellite HORs, mm2-ivh accurately reconstructs more haplotypes than assemblers using standard minimizers. mm2-ivh is available under the MIT license at https://github.com/ocxtal/mm2-ivh and runs on common Unix-compatible systems.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
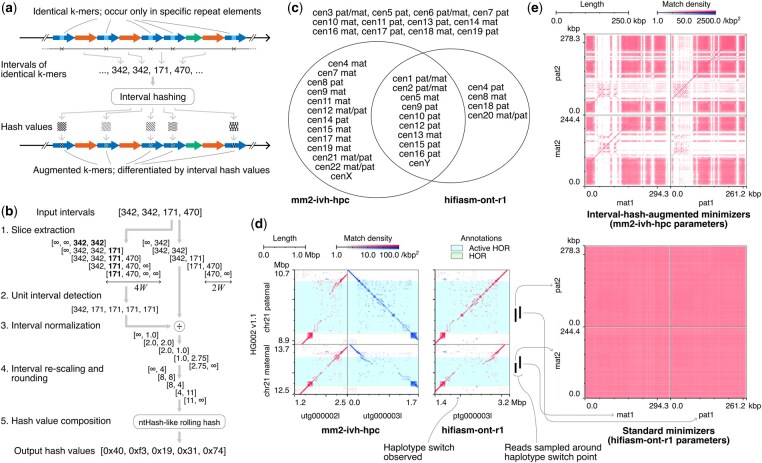 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGNSS positioning and interference · Soil Moisture and Remote Sensing · Precipitation Measurement and Analysis
1 Introduction
Resolving repeat regions in genome assembly has been a persistent challenge. Recent advances in long-read sequencing technologies, including PacBio’s HiFi sequencing (Wenger et al. 2019) and Oxford Nanopore Technologies’ (ONT) ultra-long (UL) read protocol (Jain et al. 2018), have significantly improved the ability to resolve complex repeat regions. HiFi reads, which are approximately 10–20 kilobase pairs (kb) long and have over 99.8% accuracy, enable the precise detection of minor variations between repeat elements (Dvorkina et al. 2020). UL reads, which exceed 100 kb in length, enable the resolution of long and complex repeat element arrangements that were previously intractable (Miga et al. 2020, Logsdon et al. 2021, Nurk et al. 2022). Assemblers such as Hifiasm (Cheng et al. 2021) and Verkko (Rautiainen et al. 2023) use HiFi reads to build accurate assembly graphs and UL reads to untangle these graphs into linear contigs, enabling the construction of nearly complete telomere-to-telomere sequences for a considerable number of chromosomes (Yang et al. 2023, Logsdon et al. 2024).
Nevertheless, accurately assembling long and highly homologous repeat regions remains challenging. For instance, the centromeric alpha satellite consists of 171 bp monomers that repeat over several megabases in a higher-order repeat (HOR) structure (Wu and Manuelidis 1980, Willard and Waye 1987, Thakur et al. 2021, Logsdon and Eichler 2022). Several methods have been developed to assemble and validate alpha satellite HORs using “unique k-mers,” observed only at specific locations within HOR regions, enabling the accurate reconstruction of HOR structures across several chromosomes (Bzikadze and Pevzner 2020, Miga et al. 2020, Logsdon et al. 2021, Bzikadze et al. 2022, Dishuck et al. 2023, Chakravarty et al. 2025). In long-read mapping within HOR regions and comparisons between HOR regions, methods that adaptively adjust the length of seeds based on uniqueness have also proven effective (Jain et al. 2022, Bzikadze and Pevzner 2023, Zhang et al. 2025). However, a broadly applicable method for overlap detection in diverse alpha satellite HORs has yet to be developed. Even state-of-the-art assemblers often produce misassemblies or inconsistencies among tools in alpha satellite HORs (Logsdon et al. 2025).
To address the challenges of assembling alpha satellite HORs, we propose a simple yet effective algorithm to improve seeding in periodic repeats. This algorithm, interval hashing, encodes the distances between occurrences of identical k-mers or minimizers (Roberts et al. 2004) into hash values, enabling the distinction of identical k-mers based on their surrounding repeat contexts. We implemented the algorithm on top of minimap2 (Li 2018) and applied it in combination with miniasm (Li 2016) for the local assembly of alpha satellite HORs using high-quality human ONT UL reads. Minimap2 with interval hashing successfully reconstructed the full-length active HOR regions in 27 out of 46 haplotypes without macroscopic misassemblies, outperforming the original minimap2 and Hifiasm in ONT-only mode. The implemented tool, mm2-ivh, is freely available under the MIT license at https://github.com/ocxtal/mm2-ivh.
2 Algorithm
The difficulty of assembling alpha satellite HORs arises from the low specificity of seeds, which is caused by the presence of identical k-mers in multiple monomers. To improve seed specificity and make the overlap detection easier in alpha satellite HORs, we leverage an intrinsic property of the regions. In alpha satellite HORs, certain k-mers appear only in specific monomers and generate characteristic, sometimes non-equidistant patterns of k-mer occurrence intervals. The presence of truncated or rare HOR units, or the insertion of unrelated sequences such as transposable elements, also leads to distinct occurrence interval patterns compared to regions without such events. Our algorithm, interval hashing, encodes the k-mer occurrence intervals into hash values, serving as signatures to distinguish identical k-mers by their surrounding contexts (Fig. 1a).
(a) Concept of interval hashing. (b) Flow of the five steps of the core of our algorithm (depicts N=4 and W=1). (c) Haplotypes in which the full length of active HOR regions is reconstructed into a single unitig. (d) Dotplots of the assembled unitigs of alpha satellite HORs of chromosome 21 against the corresponding regions of HG002 v1.1. Only minimizers with (k, w)=(19, 15) occurring ≤10 times among all alpha satellite HOR regions in HG002 v1.1 are used. Red and blue dots are forward and reverse-complement matches, respectively. (e) Dotplots among four reads across the haplotype switch point in hifiasm-ont-r1assembly. Reads mat1/2 and pat1/2 were primarily mapped across the corresponding position on the HG002 v1.1 chromosome 21 maternal and paternal, respectively. The colors are the same as in the panel (d).
The algorithm takes a vector of ( ) intervals, derived from the occurrences of identical k-mers, and produces a vector of hash values corresponding to each occurrence. The core algorithm is defined by a wing length parameter that indicates the number of k-mer occurrences to consider in each direction and consists of five steps (Fig. 1b). In the first step, two vectors of slices are extracted from the input intervals, with slice lengths being and . The central span of -th -long slice overlaps with -th -long slice. The out-of-bound positions are assigned interval values of infinity. Next, the “unit interval,” representing the length of a canonical repeat element, is calculated for each -long slice by taking the minimum interval value. These unit intervals are then used to normalize the interval values in the corresponding -long slices. The normalized intervals are rounded to the nearest integer after being multiplied by a resolution constant (fixed at 4.0 in our implementation) to ensure sufficient resolution for truncated repeat elements. Then, the integer intervals in each slice are individually mapped to partial hash values and then combined into a final hash value using a rolling hashing algorithm similar to ntHash (Mohamadi et al. 2016). Infinite interval values are mapped to a special partial hash value of zero to indicate the absence of interval information, ensuring that the hash value computed for an empty input interval vector derived from singleton k-mers is zero.
In practical implementations, it is necessary to match k-mers that are in a reverse-complement relationship. Tools such as minimap2 canonicalize k-mers by selecting the numerically smaller k-mer between the two strands. Interval hashing achieves consistent canonicalization by reversing the slices when the corresponding central k-mer is computed from the reverse-complement strand. Additionally, to prevent encoding intervals that span distant repeat contexts, it is practical to split the interval vector at points where the intervals exceed a certain threshold before applying interval hashing.
3 Implementation
We implemented the interval hashing algorithm in a fork of minimap2 2.28, which applies interval hashing to all minimizers. Further implementation details are provided in Section 1, available as supplementary data at Bioinformatics online. The executable is named mm2-ivh and is compatible with minimap2 in terms of options and input/output formats. Based on preliminary experiments described in Section 3, available as supplementary data at Bioinformatics online, we added a preset option, -x ivh-ava-ont-ul, tuned for the latest UL reads with a mean quality value of 20 or higher. The preset uses interval-hash-augmented minimizers with parameters and sets the maximum minimizer separation for splitting interval vectors to 20 kb.
mm2-ivh is available at https://github.com/ocxtal/mm2-ivh under the MIT license, following the original minimap2. The program is implemented solely in C, requiring only a C compiler and make to build. It supports x86_64 and arm64 systems running Linux or macOS. The version used in our experiments is also available as an archive at 10.5281/zenodo.17143522.
4 Results
We evaluated mm2-ivh for the local assembly of human alpha satellite HOR regions using the HG002 high-accuracy UL data published by ONT (Section 4.1, available as supplementary data at Bioinformatics online). After quality control, we obtained 89.0 Gb of reads with a mean length of 116.9 kb and a mean quality value of 24.64. The reads were then aligned to CHM13 v2.0 (Nurk et al. 2022), which consists of the autosomes and chromosome X of CHM13 and chromosome Y derived from HG002, using minimap2 with the -x map-ont preset. Reads mapped to HOR regions with 500 kb margins were extracted for each chromosome (Table 3, available as supplementary data at Bioinformatics online). The extracted reads were assembled using the following three assemblers (Section 4.2, available as supplementary data at Bioinformatics online). The first assembler computes overlaps using mm2-ivh and outputs a pairwise alignment format (PAF) file, which is then filtered to remove overlaps with low match rates and supplied to miniasm to generate assembly graphs (denoted as mm2-ivh-hpc). The parameters for mm2-ivh and miniasm were set as -x ivh-ava-ont-ul -H (additionally enabling homopolymer compression) and -h5000 -c2 (setting the maximum overhang length to 5 kb and minimum coverage to 2), respectively. The filtering step allows only overlaps with >20% match columns relative to the alignment length. The second assembler, based on mm2-ivh-hpc, disables interval hashing and instead increases the minimizer length to (Section 2, available as supplementary data at Bioinformatics online for details on supporting long minimizers; denoted as mm2-k133-hpc). The third assembler is Hifiasm 0.25.0, run with -ont -r1 options (one round of error correction; denoted as hifiasm-ont-r1). The -r1 setting was chosen because it yielded the best results in our tests.
mm2-ivh-hpc reconstructed unitigs that fully covered the active HOR regions of the HG002 v1.1 reference assembly (Rautiainen et al. 2023) in 27 out of 46 haplotypes, while hifiasm-ont-r1 achieved this in 16 haplotypes (Section 4.3, available as supplementary data at Bioinformatics online, Table 8, available as supplementary data at Bioinformatics online). mm2-k133-hpc reconstructed the full length of active HOR regions only in chromosome Y. The number of active HOR regions that could be reconstructed into a single unitig by both mm2-ivh-hpc and hifiasm-ont-r1 was 11, while 16 were reconstructed only by mm2-ivh-hpc, 5 only by hifiasm-ont-r1, and 14 were not reconstructed by either (Fig. 1c). The effectiveness of interval hashing is clearly demonstrated in some HOR arrays. For instance, for the active HOR region in chromosome 21, mm2-ivh-hpc was able to assemble the full length for both haplotypes without haplotype mixing, whereas hifiasm-ont-r1 introduced a haplotype switch in the middle (Fig. 1d and Section 4.4, available as supplementary data at Bioinformatics online). The dotplot of four reads mapped across the haplotype switch position (Table 9, available as supplementary data at Bioinformatics online) showed that interval hashing clearly distinguished haplotypes, while standard minimizers obscured them with dense matches (Fig. 1e and Fig. 5, available as supplementary data at Bioinformatics online).
Execution time and memory consumption varied widely among chromosomes for mm2-ivh-hpc and mm2-k133-hpc, whereas hifiasm-ont-r1 exhibited stable performance (Section 4.2, available as supplementary data at Bioinformatics online, Tables 4–6, available as supplementary data at Bioinformatics online). In both mm2-ivh-hpc and mm2-k133-hpc, the overlap detection step consumed the dominant proportion of execution time. The total CPU time was 11.8 h for mm2-ivh-hpc, 339.7 h for mm2-k133-hpc, and 3.5 h for hifiasm-ont-r1. The geometric mean of memory usage per chromosome (worst case in parentheses) was 6.4 GiB (14.0 GiB), 40.5 GiB (181 GiB), and 16.5 GiB (16.8 GiB) in the same order. The total size of the overlap detection outputs (PAF files) was 77.0 GiB and 1.08 TiB for mm2-ivh-hpc and mm2-k133-hpc, respectively (Table 7, available as supplementary data at Bioinformatics online).
5 Discussion
The benchmark clearly demonstrated that interval hashing is effective for precise overlap detection in alpha satellite HORs. The substantial reductions in execution time, memory usage, and output file size for overlap detection compared to the control using standard minimizers (mm2-k133-hpc) also indirectly support that interval hashing reduces false-positive matches. These findings suggest that the intervals of k-mers within repeats are a critical feature for distinguishing alpha satellite HORs. We also noticed that the concept of k-mer intervals aligns with early studies of alpha satellites in which HORs are characterized by analyzing the lengths of DNA fragments after restriction enzyme digestion (Wu and Manuelidis 1980). This indicates that interval hashing essentially examines the same feature, renovating one of the most fundamental features of alpha satellite HORs using modern techniques.
Interval hashing resembles seed-and-extend alignment algorithms for optical mapping (Leung et al. 2017, Salmela et al. 2020) in that both use subsequences of interval values as seeds. Our contribution lies in demonstrating that subsequences of interval values are useful as signatures of repeats, which has been less explored in the field of optical mapping. The specific structure of interval hashing is also similar to RawHash, a hashing algorithm for matching on Nanopore raw signals, in that both construct hashes from coarsened numerical sequences (Firtina et al. 2023). In comparison with algorithms in the sequence space, interval hashing is similar to spaced seeds (Ma et al. 2002) and strobemers (Sahlin 2021) in that these algorithms construct a single seed from multiple exact submatches separated by gaps. We found interval hashing and existing algorithms essentially differ in whether or not the submatches are synchronized with the underlying repeat structure. Interval hashing uses synchronized submatches, which effectively capture repeat contexts.
The weakness of interval hashing is its susceptibility to sensitivity degradation due to sequencing errors. This stems from the algorithm’s reliance on the preservation of all k-mers within occurrences before and after a match. In our experiments, the low error rates of ONT reads appeared to mitigate the sensitivity issue. Improvements to the algorithm will be necessary to apply interval hashing to data with higher error rates. In the field of optical mapping, algorithms for obtaining error-robust seeds on interval information have been explored (Salmela et al. 2020), which may help improve our algorithm.
Although our benchmark focused on alpha satellite HORs, interval hashing is likely to be compatible with unique genomic regions, segmental duplications, and isolated interspersed repeat elements. This compatibility stems from the property that singleton or isolated minimizers maintain the same values after applying interval hashing, thereby not affecting the behavior of the algorithms that use minimizers. Moreover, interval hashing potentially enhances specificity in less structured repeat regions, such as various satellite repeats and clusters of interspersed repeats, similar to its effect on alpha satellite HORs. These properties could make interval hashing applicable to pipelines relying on all-versus-all overlaps of reads [i.e. without probing or filtering, such as whole-genome assembly and read error correction (Espinosa et al. 2024, Stanojevic et al. 2024)], potentially improving accuracy in various repeat contexts. Our implementation, mm2-ivh, facilitates evaluation of how interval hashing improves the performance in these pipelines on diverse data.
Supplementary Material
btaf648_Supplementary_Data
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bzikadze AV , Mikheenko A, Pevzner PA. Fast and accurate mapping of long reads to complete genome assemblies with Verity Map. Genome Res 2022;32:2107–18.36379716 10.1101/gr.276871.122PMC 9808623 · doi ↗ · pubmed ↗
- 2Bzikadze AV , Pevzner PA. Automated assembly of centromeres from ultra-long error-prone reads. Nat Biotechnol 2020;38:1309–16.32665660 10.1038/s 41587-020-0582-4PMC 10718184 · doi ↗ · pubmed ↗
- 3Bzikadze AV , Pevzner PA. Uni Aligner: a parameter-free framework for fast sequence alignment. Nat Methods 2023;20:1346–54.37580559 10.1038/s 41592-023-01970-4 · doi ↗ · pubmed ↗
- 4Chakravarty S , Logsdon G, Lonardi S. R Ambler resolves complex repeats in human chromosomes 8, 19, and X. Genome Res 2025;35:863–76.40037839 10.1101/gr.279308.124PMC 12047272 · doi ↗ · pubmed ↗
- 5Cheng H , Concepcion GT, Feng X et al Haplotype-resolved de novo assembly using phased assembly graphs with hifiasm. Nat Methods 2021;18:170–5.33526886 10.1038/s 41592-020-01056-5PMC 7961889 · doi ↗ · pubmed ↗
- 6Dishuck PC , Rozanski AN, Logsdon GA et al GAVISUNK: genome assembly validation via inter-SUNK distances in oxford nanopore reads. Bioinformatics 2023;39:btac 714.36321867 10.1093/bioinformatics/btac 714PMC 9805576 · doi ↗ · pubmed ↗
- 7Dvorkina T , Bzikadze AV, Pevzner PA. The string decomposition problem and its applications to centromere analysis and assembly. Bioinformatics 2020;36:i 93–101.32657390 10.1093/bioinformatics/btaa 454PMC 7428072 · doi ↗ · pubmed ↗
- 8Espinosa E , Bautista R, Larrosa R et al Advancements in long-read genome sequencing technologies and algorithms. Genomics 2024;116:110842.38608738 10.1016/j.ygeno.2024.110842 · doi ↗ · pubmed ↗