Spatial Clustering for Carolina Breast Cancer Study
Hongqian Niu, Melissa Troester, Didong Li

TL;DR
This paper introduces a new spatial clustering method to study how geography and demographics affect breast cancer risk in North Carolina.
Contribution
The paper introduces GPSC, a novel spatial clustering algorithm using Gaussian Processes for analyzing geospatial health data.
Findings
GPSC provides theoretical guarantees and successfully recovers true clusters in empirical studies.
The method identifies census tract clusters in North Carolina based on socioeconomic and environmental factors linked to cancer risk.
Abstract
In the Carolina Breast Cancer Study (CBCS), clustering census tracts based on spatial location, demographic variables, and socioeconomic status is crucial for understanding how these factors influence health outcomes and cancer risk. This task, known as spatial clustering, involves identifying clusters of similar locations by considering both geographic and characteristic patterns. While standard clustering methods such as K-means, spectral clustering, and hierarchical clustering are well-studied, spatial clustering is less explored due to the inherent differences between spatial domains and their corresponding covariates. In this paper, we introduce a spatial clustering algorithm called Gaussian Process Spatial Clustering (GPSC). GPSC leverages the flexibility of Gaussian Processes to cluster unobserved functions between different domains, extending traditional clustering techniques to…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
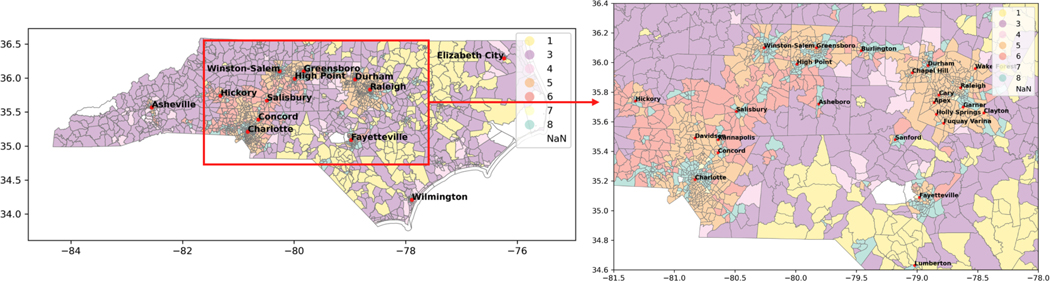 Figure 1
Figure 1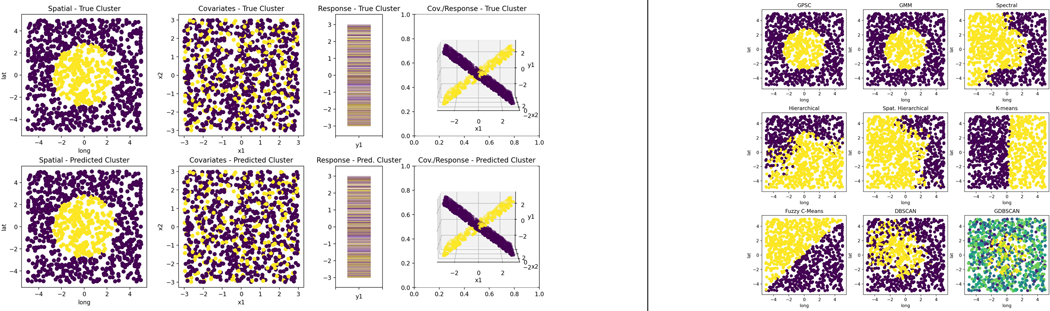 Figure 2
Figure 2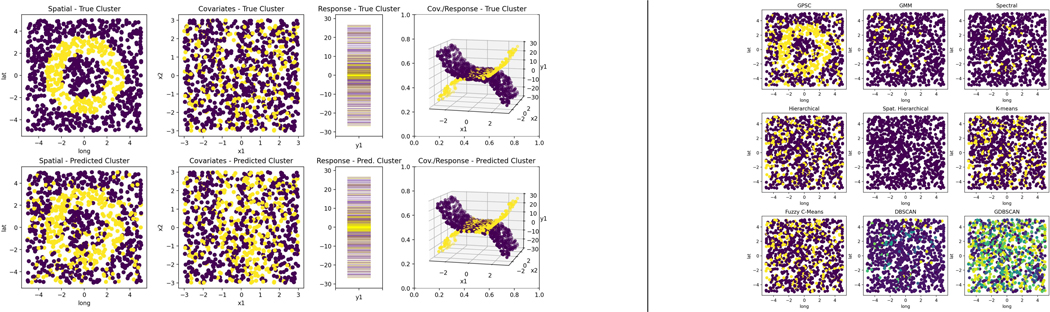 Figure 3
Figure 3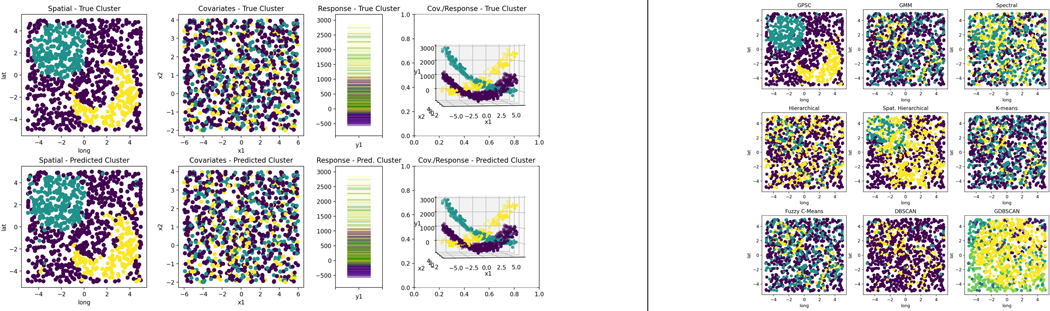 Figure 4
Figure 4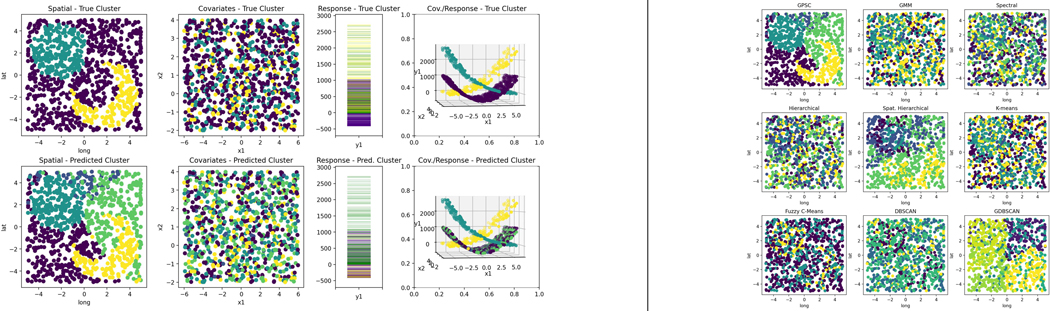 Figure 5
Figure 5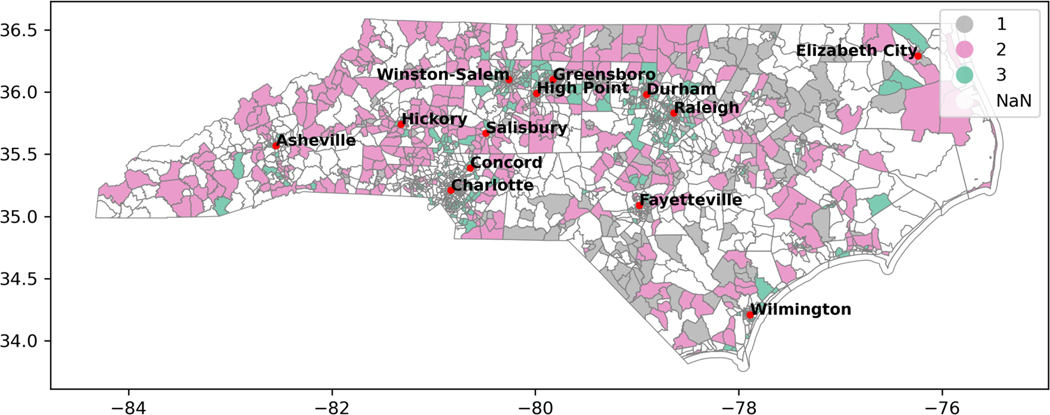 Figure 6
Figure 6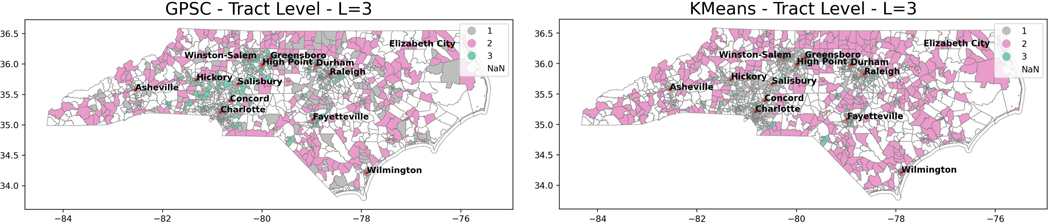 Figure 7
Figure 7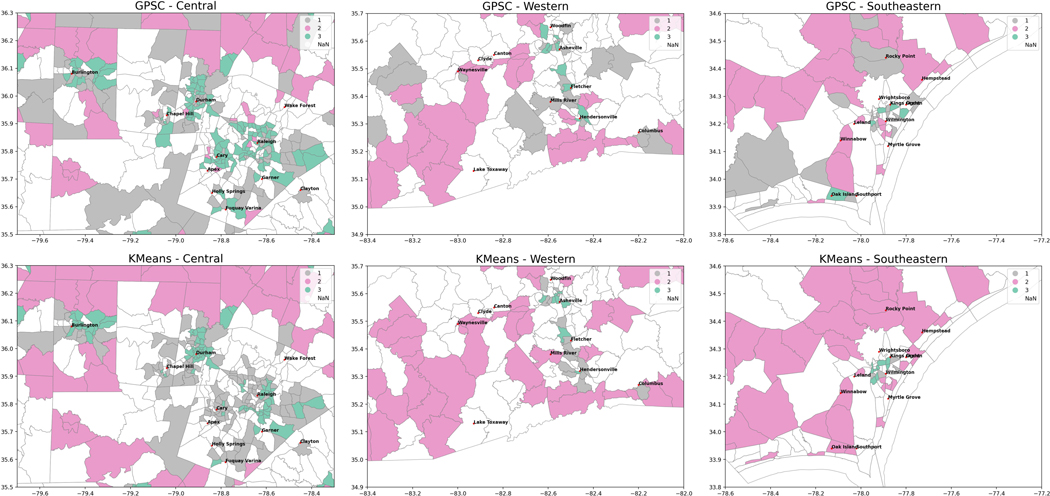 Figure 8
Figure 8| Input: data |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsData-Driven Disease Surveillance
Introduction
There is growing research suggesting that socioenvironmental factors can play a key role in affecting health outcomes, potentially contributing to health disparities in marginalized groups, and may even predictably impact outcomes at the molecular level with diseases such as cancer.^1,2^ However, identifying areas of such risk can be a difficult task. In the community-wide socioeconomic and environmental indicators dataset, the spatial locations of North Carolina census tracts were paired with socioeconomic data from the American Community Survey^3^ from 2014 chosen to reflect socioeconomic advantage and disadvantage,^4^ as well as environmental pollution data from the U.S. Environmental Protection Agency (EPA) National Air Toxics Assessment (NATA^2,5^). This then poses the problem: how can geographically spread NC census tracts be clustered together based on risk factors including socioeconomic indicators and environmental pollution? North Carolina is known to be an ethnically diverse state,^6^ with a wide range of spatially dependent differences in socioeconomic status such as access to healthcare, poverty rates, and education, while meaningful clusterings must take into consideration all these differences.^6^ A standard clustering algorithm applied to the data collected from the patients in each tract or to the environmental variables alone fails to necessarily capture the significant spatial dependence inherent in the data collected in the studies. This problem is known as spatial clustering or geospatial clustering.^7^
In spatial clustering, the goal is to identify clusters of similar locations based on regionalization, as well as patterns in characteristics over those locations. Clustering of geospatial data is a common unsupervised learning problem with many applications to areas, e.g., public health,^8^ urban planning,^9^ or transportation,^10^ where geography plays an essential role.
Furthermore, spatial data, also known as geospatial data, is commonly characterized by having a distinct geographic component.^11^ Unlike traditional data that only include observations as a single set of features , spatial data may be considered as a vector , where represents the spatial location of the observation and is the set of features or covariates. The analysis of such spatial datasets poses challenges, such as accurately capturing the relative effects between the spatial and covariate domains.^11^ Importantly, geographically close areas may still have very different patterns of characteristics, while separated areas may share similarities and constitute a single functional cluster. Together, this can pose challenges to traditional clustering methods that equally treat the separate domains inherent to geospatial data such as K-means, as the geographic locations of distinct clusters may be well mixed, or the measurements themselves of different variables at those locations may be well mixed.
Without the spatial component, clustering itself is a well-studied problem with many established techniques such as K-means clustering,^12^ spectral clustering,^13^ hierarchical clustering,^14^ and density-based spatial clustering of applications with noise (DBSCAN^15^), to name a few popular algorithms. Each of these algorithms offers distinct advantages based on their modeling assumptions when performed on different types of data. Additionally, common extensions of these algorithms include supervised fuzzy C-means,^16^ spatial hierarchical clustering,^17^ and the generalized DBSCAN (GDBSCAN^18^) algorithm. These algorithms are able to better incorporate either response labels or spatial data directly through customized distance metrics or connectivity constraints.
However, in this paper, we consider the case of supervised spatial data, with observations consisting of three components , where is the spatial component, is the feature component, while is the response variable of particular interests. Assuming that in the data there is a relationship between features , or between features and geography , and the response , we propose a new spatial clustering algorithm based on Gaussian Processes (GPs), called Gaussian Process Spatial Clustering (GPSC), which groups together clusters based on each group’s ability to predict the response variable . We focus on single-output cases in this paper for simplicity, but the extension to multi-output cases where with is straightforward.
For the motivating example from NC census tracts data, s is the longitude/latitude pairs defining each state census tract, is the set of environmental pollution variables such as levels of hexane, lead, mercury, etc, as well as average socioeconomic indicators such as unemployment rates, poverty rates, or education, and the y response to be predicted is a previously defined latent class^2^ measuring socioeconomic and environmental advantage-disadvantage.
In order to do so, GPSC leverages the flexibility of GPs, well-studied near-universal function approximators,^19,20^ to fit the true functional relationships within each clustering and to cluster tract locations and features pertaining to socioeconomic status. Simulation studies show that the GPSC algorithm is capable of accurately recovering and clustering these functional relationships even in cases of limited spatial dependencies such as in the case of irregular cluster shapes or sizes, and regardless of any dependencies in the covariate domain. This is important because, as in Figure 1, clusters may not always be completely separated, so it is essential to control the relative influence of each domain in the clustering done in GPSC by choosing the kernel. Furthermore, GPSC is less sensitive to dependencies in the covariate domain compared to traditional clustering methods such as K-means clustering. We prove that GPSC is able to find the true clusters as long as the functional relationships between the clusters are distinct. When applied to community-wide study, GPSC successfully clusters tracts in NC with finer detail than traditional methods and can be interpreted by domain experts.
In summary, our contributions in this paper are 1) a novel spatial clustering GPSC algorithm, 2) theoretical support to GPSC and 3) application to NC tract level data with new interpretable discoveries. Full proofs of theorems, implementation details, as well as extended simulations are presented in the Supplementary Material at https://github.com/hong-niu/gpsc-psb25.
Model
Gaussian Process Regression
2.1.
In this section, we review the GP model and its application towards regression and classification. By definition, a GP is a random function for which any finite realization follows a multivariate Gaussian distribution:^21^
Definition 2.1.
follows GP in domain ! with mean function and covariance function , denoted by , where , , if for any ,
where and .
A GP is completely determined by the mean function and the covariance function , also known as the kernel. In this paper, we assume for simplicity and use the radial basis function (RBF), also known as the squared exponential kernel, defined as: , but our model can be extended to other kernels. The two parameters, i.e., spatial variance and length scale are estimated by maximizing the likelihood (MLE). Given training data with MLE and a new observation , the best unbiased linear predictor (BLUP^22^) of is given by , where , and Rn. As a flexible regression algorithm, GP can be modified into a classifier using a link function^21^ for a discrete response variable , so we will not distinguish between Gaussian process regression (GPR) and Gaussian process classification (GPC) in this paper.
GP Spatial Clustering
2.2.
Now we will consider observations , where is the spatial location, is the covariate, and is the response variable. Let be the unobserved cluster label such that ^,^ where is a partition of . We focus on the following model. , where is unknown function on in certain function class that will be discussed in Section 3. That is, the functional relation between and varies across spatial clusters supported by . The goal is to recover the cluster label , called spatial clustering since the clusters are rooted in the spatial domain .
For example, in the NC tracts data, each consists of tracts in NC, while the relationship between the latent class and the socioeconomic and environmental covariates varies across the tracts spatially. The goal is to partition NC into several clusters so that each cluster admits a unique functional relationship.
For a given observation in cluster with response , we expect the prediction error of to be the lowest among all ‘s, and hence we can assign to the cluster with the lowest prediction error. However, neither the cluster label or domain partition , nor the functions is observed. Motivated by the flexibility of GP models, we use GP to approximate the unobserved functions , denoted by , and assign to the cluster labeled by with the lowest prediction error: . Then we update the cluster and iteratively. The GPSC algorithm is summarized in algorithm 1.
Algorithm 1: Gaussian Process Spatial Clustering
In this flexible construction, it is also possible to extend the reassignment function for different applications, such as reinforcing spatial contiguity constraints as is common in geographical clustering:
Here, is the center in the spatial domain of the current cluster , while is a tuning parameter that controls the penalization of assigning points to clusters that are spatially distant. For the rest of the paper, we will focus on the case , but will demonstrate the effects of adding such penalties in the simulation studies.
In summary, the inputs to the algorithm are observations , along with tuning parameters including the number of iterations and the number of clusters . In practice the number of iterations need not necessarily be large, and can be replaced with the stopping criterion when the cluster assignments stabilize. The proper choice of the number of clusters is a typical challenge in the field of clustering,^23^ which is beyond the scope of this paper. The choice of often requires domain expertise specific to the application at hand, see Section 5 for more detailed discussion. In practice, we also typically bound the parameters of the covariance function during optimization to prevent overfitting.
Theory
In this section, we provide theoretical support to the GPSC algorithm. We start with the necessary definitions to state the assumptions and theorems.
Definition 3.1.
Let be a positive definite kernel on , then with inner product form , so that is a pre-Hilbert space with a reproducing kernel . The linear mapping , is injective. Then the image of , is a Hilbert space with a reproducing kernel K equipped with the inner product .
For simplicity, we fix to be the RBF kernel with from now on.
Definition 3.2.
Given observations and with unobserved to be predicted. Let , where is the maximum likelihood estimator of based on potential observations . That is, is the BLUP of based on observations . By the definition of , the smoothness of the Gaussian density function and the linearity of BLUP, is differentiable.^22^ We also introduce the following assumptions:
(A1) is compact and , , where is the density function of .
(A2) , .
Theorem 3.3.
Under assumptions (A1)-(A2), at any iteration in Algorithm 1, let , then the current is a assigned to the correct cluster if for any ,
where and are constants, and
In particular, let , , and let , , Equation (1) becomes: That is, the mis-clustered proportion is small enough.
The right-hand side of inequality (1) is highly interpretable. The ratio - measures the robustness of the BLUP, that is, how the BLUP changes with training data . The less robust the BLUP, the smaller the ratio, and the harder it is to find the correct clusters. The ratio measures the separation between functions . The smaller the separation, the smaller the ratio, and the harder it is to find the correct clusters. Theorem 3.3 also implies that the state of correct clustering is an absorbing state, that is, if the current clusters are close enough to the true clusters, then perfect clustering results will be achieved in the next iteration. Note that even if the inequality does not hold, the algorithm may still converge to a better state with more correctly clustered data, although not within one single step. This is because even when the right-hand side of Equation (1) is small, there might be some region where the ’s are relatively well separated so that the right-hand side is relatively large on , so that samples within will be assigned to true clusters. Meanwhile, for the region where ’s are well mixed, it is challenging for all clustering algorithms.
In practice, the response variable is often subject to measurement error, leading to a more realistic model: , where represents noise. The following theorem serves as the counterpart to Theorem 3.3 in the presence of Gaussian noise:
Theorem 3.4.
Under the same assumption and notation as of Theorem 3.3, with the addition of Gaussian noise, the current is assigned to the correct cluster if for any ,
where is the sum of independent -distributions with degrees of freedom 1, and rescaled by , and respectively.
In particular, when , , , and , , the right-hand side simplifies to with probability one. When , that is, the noise vanishes, then so Theorem 3.4 coincides with Theorem 3.3.
Simulation Studies
To evaluate the performance of GPSC, we present three simulation studies in this section, with detailed implementation details in the Supplementary Materials. The first simulation will demonstrate an application of Algorithm 1 in the case of responses generated by linear functions with two clusters, while the second simulation shows the performance of GPSC in the case of responses generated by nonlinear functions. The third simulation shows the robustness of GPSC to noisy data and over-specified number of clusters. In all simulations, we compare the performance of GPSC with traditional clustering algorithms: K-means, spectral clustering, hierarchical clustering, and DBSCAN, as well as spatial or supervised analogs: supervised fuzzy C-means, spatial hierarchical clustering, generalized GDBSCAN, and also the Gaussian mixture model (GMM^24^). We evaluate the performance using the adjusted Rand index (ARI^25^) and adjusted mutual information (AMI^26^) against the true labels. The data used in these simulations take the form , where is the spatial domain, is the covariate domain, and is the response domain, taken for visualization purposes. Note that for all algorithms, including GPSC and the aforementioned traditional, nonspatial clustering algorithms, the input is taken to be the full vector with the spatial domain included, so that all competitors always use the full information. The results can be directly extended to higher p and multivariate responses.
Simulation 1 - Linear Functions
4.1.
In this simulation, y is a linear function of x for visualization purposes, where both si and xi are generated from independent uniform distributions. After generating the data , the spatial domain is subdivided into two clusters, the center ball and the background region. The are then generated as distinct linear functions of for each cluster. For visualizations of the resulting clusters in the domain and all ARI/AMI scores, see Supplement D.1.
It can be seen that this simulation is challenging for several reasons. First, there is almost no separation considering any dimension *, *, or on its own as in the first three columns in Figure 2 (left); the separation is solely in the functional domain . As a result, most traditional algorithms cannot capture this functional relationship, as supported by Panels 3–7 in Figure 2 (right). Although it can seen that the Gaussian mixture model is able to rediscover the clusters in this case (Panel 2), this is due to GMM’s ability to estimate the pairwise linear correlation between each domain. However, we expect GMM to fail to capture nonlinear functional relationships, as shown in the following Simulation 2. It is also noted that DBSCAN and GDBSCAN (Panels 8 and 9) also perform reasonably well, but have challenges of their own such as GDBSCAN greatly overestimating the number of clusters.
Simulation 2 - Nonlinear Functions
4.2.
In this simulation, we will show that in an irregular spatial distribution with nonlinear relationships between the covariates and the response variable, GPSC is still able to recover the true functional relationships in contrast to the competitors. After generating the data from independent uniform distributions, the spatial domain is subdivided into two clusters, the ring and the background region. The are then generated as distinct nonlinear functions of for each cluster (the first row of Figure 3).
It can be seen that in this more challenging simulation, only GPSC is able to recover the true functional clusters, with the results of each clustering algorithm plotted in the spatial domain in Figure 3 (see Supplement D.2 for more details).
Simulation 3 - Model Robustness
4.3.
In Simulation 3, we present a more realistic scenario of three clusters that have some degree of spatial separation. Motivated by our real-world application of clustering North Carolina census tracts, the sun and moon clusters could be interpreted to represent two urban centers surrounded by a larger rural region. By applying the spatially penalized version of GPSC, we will show that the clustering results remain stable across both increasing levels of noise, as well as to overspecification of the input number of clusters. Full visualization and comparisons can be found in Supplement D.3, D.4 and D.5.
After generating the data from independent uniform distributions, the spatial domain is subdivided into the three clusters, the sun and moon shape, and the background region. The are then generated as distinct nonlinear functions of for each cluster with varying degrees of zero-mean Gaussian noise. For an extension of Simulation 3 to nonlinear functions of both and , see Supplement D.5.
Noisy Responses
We first show that GPSC works under noisy conditions as per Theorem 3.4. In Figure 4, we present Simulation 3 with noise variance = 100, showing that the spatially penalized version of GPSC still performs well under noisy conditions. In particular, GPSC is able to outperform competitors at all tested noise levels, where no other competitor is able to recover the true clusters (with exact ARI/AMI scores and additional details in Supplement D.3).
Overspecified Number of Clusters
Finally, we show that GPSC is stable when the number of clusters is overspecified. Specifically, it can be seen in Figure 5 when the number of specified clusters is 5, the sun (teal) and moon (yellow) clusters remain stable, while the background cluster (originally purple) is split into three purple, indigo, and light green clusters. In contrast, the competitors are unable to recover the true clusters when the number of clusters are overspecified, while further visualizations and comparisons to the competitor models are presented in Supplement D.4.
Applications to NC Tract Data
This dataset consists of 29 community-wide covariates aggregated by census tracts in North Carolina. Such covariates ranged from measures of environmental pollution to averages of socioeconomic indicators such as unemployment, housing environment, education, etc (see Supplement E for a full list). Each census tract is associated with a single (longitude, latitude) pair of coordinates. The overall socioeconomic indicators were previously aggregated using latent class analysis into a single advantage/disadvantage class with 8 categories.^2^
Based on the distribution of the full latent classes seen in Figure 1, we can see that there is some degree of separation in the spatial domain between certain groups. Thus, we initialized our GPSC algorithm by performing traditional K-means clustering on solely the spatial domain. We then applied our GPSC algorithm using this latent class as the response variable, taking all other features as the set of covariates. Here, we focus on K-means clustering for comparison due to its interpretable results from previous studies,^2^ with results from other clustering algorithms presented in Supplement E. Based on our results, we find that L = 3 produced the most interpretable clusters, and thus aggregated the 8 latent classes into 3 as a baseline against GPSC seen in Figure 6. Using the language of Larson et al. (2020)^2^ for our predicted 3 clusters, we will consider the overall socioeconomic and environmental advantage to be three levels: low (pink), medium (gray), and high (green).
At first glance, the general spatial distribution of our GPSC and K-means algorithms tends to agree. However, the GPSC predicted clusters differ from K-means and baseline in several meaningful ways. First, in the central region depicted in the first row of Figure 8, GPSC identifies more areas of high advantage (green). Notably, this includes the area surrounding cities such as Chapel Hill, Cary, and the capital city Raleigh (Research Triangle Park), as well as Greensboro and High Point (the Piedmont Triad), which are known to be wealthier and more urbanized regions of the state, whereas the K-means algorithm puts tracts within this region in the medium (gray) advantage group.
Towards the edges of the state we can also see significant differences as the GPSC algorithm tends to further differentiate tracts around the extremities between low and medium advantage. Most notably, around Asheville and Wilmington, two more prominent cities in North Carolina, we are able to distinguish further differences between low and medium advantage tracts, as seen in the second and third rows in Figures 8. Considering the ARI and AMI scores between the two clusterings, we find the scores to be both 0.002, suggesting that clusterings, despite visually seeming to separate the tracts spatially in similar patterns, are actually very different. One challenge of K-means clustering when determining the original 8 latent classes^2^ was a potential lack of finer detail from the K-means predicted clusters. However, here we have shown that despite using the same L = 3 clusters, GPSC is able to further differentiate between areas of low and medium disadvantage, in less dense areas of the state along the coast and the western region. Furthermore, there is reason to believe that not all 8 classes are necessary to describe the different advantage groups. In the original grouping, the latent class 2 is actually an empty group, as seen in Figure 1. Thus, the results from GPSC in comparison to K-means and baseline suggest that the algorithm is able to better balance nuance against a traditional clustering algorithm, while also retaining simpler interpretability by using fewer clusters.
Discussion
Spatial clustering offers unique challenges in comparison to traditional clustering problems due to the spatial domain inherent to geographic data. In our application, the census tract data have distinctly different properties compared to the measured covariates over the tracts. In this paper, we propose a GP-based clustering algorithm and demonstrate its performance in both simulation studies and a real data application. The advantages of GPSC include being able to capture the relative effects between the spatial domain and the measured covariates, largely independent of intersections in the covariate domain as long as the clustered functions themselves have some degree of separation. We also provide theoretical guarantees to the convergence of GPSC and extend it to noisy settings.
GPSC can also be highly scalable; the complexity of the algorithm stems from the fitting of each GP in each iteration, where standard Gaussian processes regression is in the size of the input. In our case, we applied a standard Gaussian process regression model from the scikit-learn package^27^ since our sample size was relatively small. However, in cases of large sample size, scalable GP methods can be applied for a reduction in runtime to .^28^ The GPSC model also has few tuning parameters, notably the number of clusters, optional spatial penalty for data thought to contain spatially contiguous clusters, and and can also be highly flexible through the choice of GP kernel. Although the form of our theorem is independent of the specific choice of kernel (only the convergence rate will differ), in practice more nuanced anisotropic or nonstationary kernels may be more suitable for datasets with strong heterogeneity, for which the actual design of such kernels remains an open problem.
In the real-world application, we applied GPSC to a North Carolina socioeconomic and environmental indicator dataset and found distinct patterns of advantage-disadvantage across the state that captured finer details around the less dense outer regions of the state in comparison to K-means and other clustering methods (presented in Supplement E), while our method also offered simpler interpretability than previous analysis. When utilized by domain experts, the goal of the results of these models is to supplement the identification of marginalized communities, which could be targeted with interventions. Furthermore, in context of our long-term goal of designing interventions, ensuring the accuracy of these models is also of high ethical importance. Therefore in our case, before any application, we can perform sensitivity analyses that tile the geographic region with alternative regional classifiers (county, AHEC region, latitude and longitude tiles of uniform size) to confirm that the same areas arise in multiple boundary definitions. This will confirm that the boundary definitions are not driving artifactual associations. More broadly, it is important that in these high-stakes applications we do not over-rely on any one method. We envisage the possibility of using these clustering results (and GPSC in general) as a supplementary tool for experts to potentially better identify marginalized communities and areas that may be otherwise overlooked.
Supplementary Material
Supplementary_9789819807024_0025
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Lord BD, Harris AR and Ambs S, The impact of social and environmental factors on cancer biology in black americans, Cancer Causes & Control, 1 (2022).10.1007/s 10552-022-01664-w 36562901 · doi ↗ · pubmed ↗
- 2Larsen A, Kolpacoff V, Mc Cormack K, Seewaldt V and Hyslop T, Using latent class modeling to jointly characterize economic stress and multipollutant exposure, Cancer Epidemiology, Biomarkers & Prevention 29, 1940 (2020).10.1158/1055-9965.EPI-19-1365 PMC 757490232856601 · doi ↗ · pubmed ↗
- 3American community survey, U.S. Department of Health and Human Services, Substance Abuse and Mental Health Services Administration, O!ce of Applied Studies (2014).
- 4Palumbo A, Michael Y and Hyslop T, Latent class model characterization of neighborhood socioeconomic status, Cancer Causes & Control 27, 445 (2016).26797452 10.1007/s 10552-015-0711-4PMC 4763341 · doi ↗ · pubmed ↗
- 5National air toxics assessment, U.S. Environmental Protection Agency (2014).
- 6Emerson MA, Golightly YM, Tan X, Aiello AE, Reeder-Hayes KE, Olshan AF, Earp HS and Troester MA, Integrating access to care and tumor patterns by race and age in the Carolina Breast Cancer Study, 2008–2013, Cancer Causes & Control 31, 221 (2020).31950321 10.1007/s 10552-019-01265-0PMC 7188189 · doi ↗ · pubmed ↗
- 7Aldstadt J, Spatial clustering, in Handbook of applied spatial analysis, (Springer, 2010) pp. 279–300.
- 8Fonseca-Rodríguez O, Gustafsson PE, San Sebastián M and Connolly A-MF, Spatial clustering and contextual factors associated with hospitalisation and deaths due to covid-19 in sweden: a geospatial nationwide ecological study, BMJ Global Health 6, p. e 006247 (2021).10.1136/bmjgh-2021-006247 PMC 832201934321234 · doi ↗ · pubmed ↗