Divergence unveils further distinct phenotypic traits of human brain connectomics fingerprint
Md Kaosar Uddin, Nghi Nguyen, Huajun Huang, Duy Duong-Tran, Jingyi Zheng

TL;DR
This paper introduces a new method for analyzing brain connectivity patterns that improves individual identification accuracy across different brain scans and resolutions.
Contribution
The Alpha-Z Bures-Wasserstein divergence provides a geometry-aware, parameter-free framework for functional connectome comparison.
Findings
Alpha-Z achieves higher identification rates in rank-deficient functional connectome regimes.
The method preserves performance across different parcellation schemes and scan conditions.
It requires no regularization tuning and works well with short scan durations.
Abstract
The accurate identification of individuals from functional connectomes (FCs) is central to individualized neuro/psychiatric assessment. Traditional metrics (Pearson and Euclidean) fail to capture the non-Euclidean geometry of FCs, and geodesic metrics (affine-invariant and Log-Euclidean) require task- and scale-specific regularization and degrade in high-dimensional settings. To address these challenges, we propose the Alpha-Z Bures-Wasserstein divergence, a geometry-aware divergence for FC comparison that operates effectively without meticulous parameter tuning. Across Human Connectome Project tasks, scan lengths, and spatial resolutions, we benchmark Alpha-Z against classical and state-of-the-art manifold-based distances and quantify how varying regularization influences geodesic performance. Alpha-Z yields consistently higher identification rates, with pronounced advantages in…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
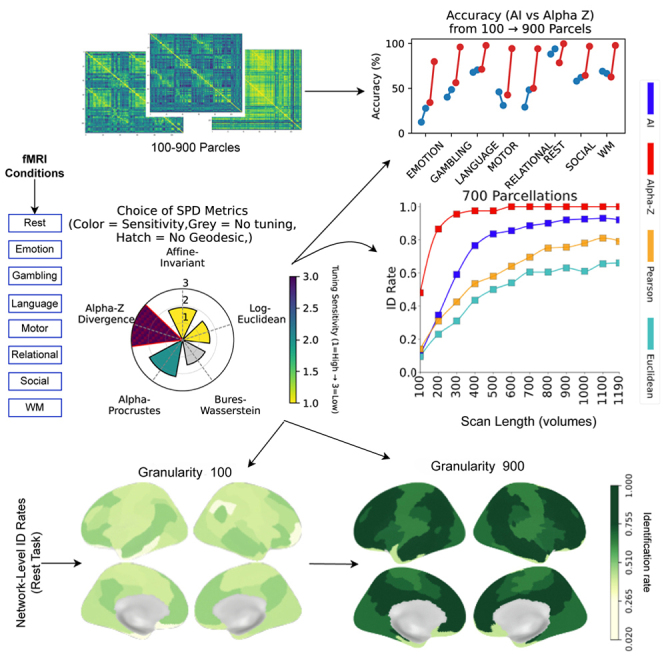 Figure 1
Figure 1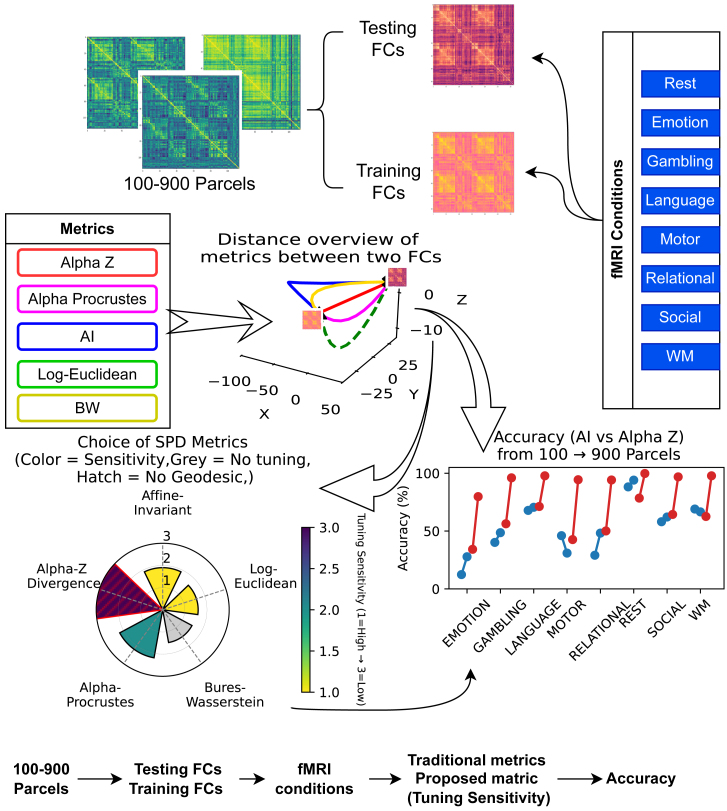 Figure 2
Figure 2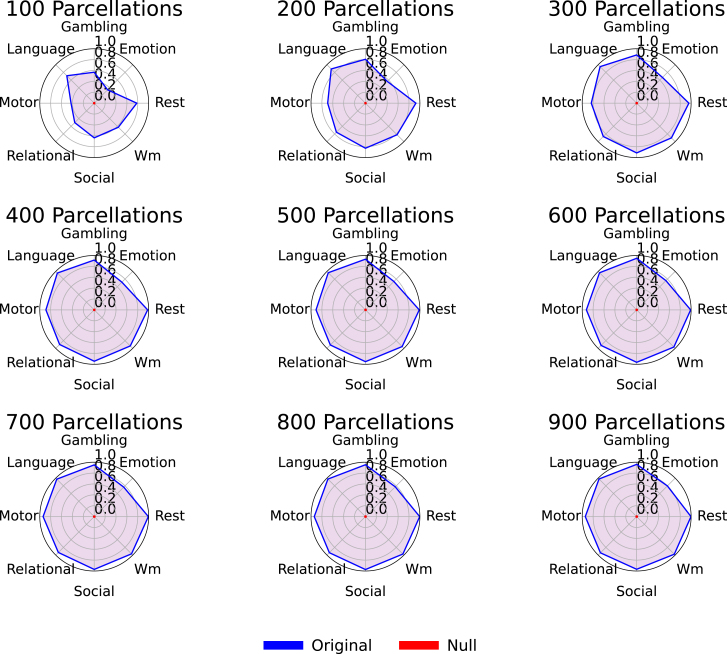 Figure 3
Figure 3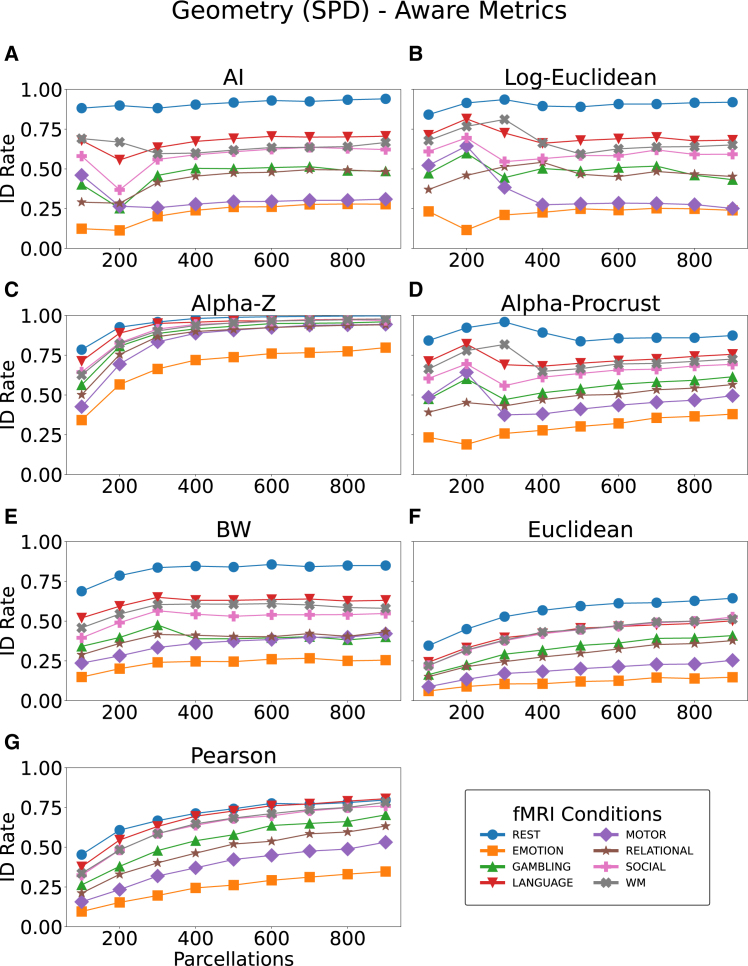 Figure 4
Figure 4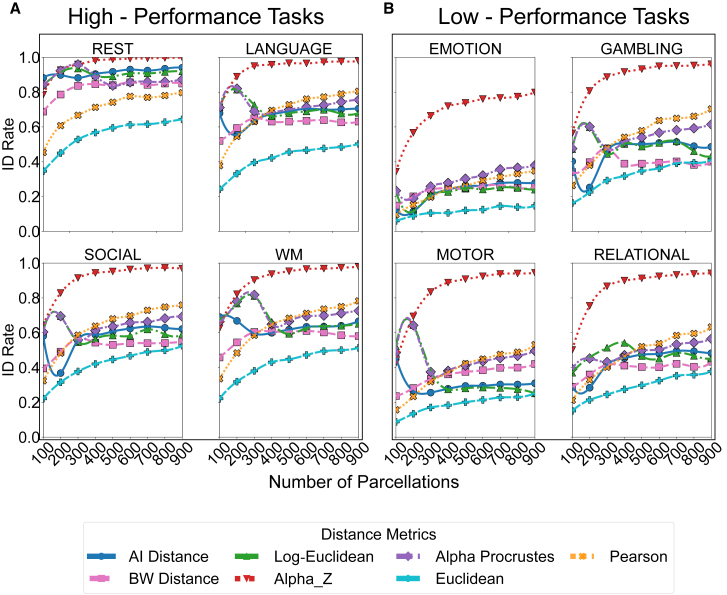 Figure 5
Figure 5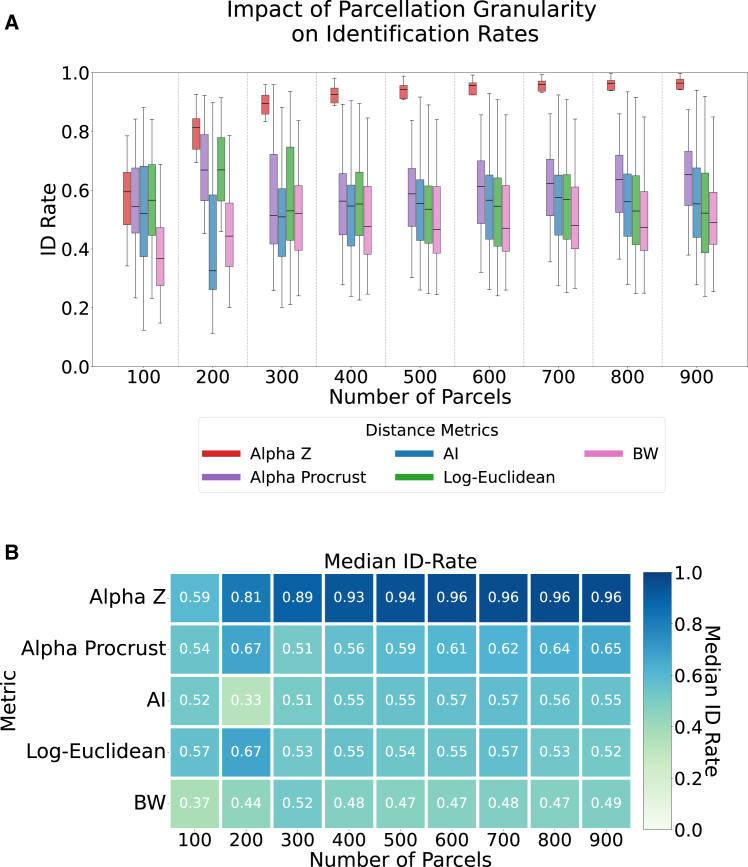 Figure 6
Figure 6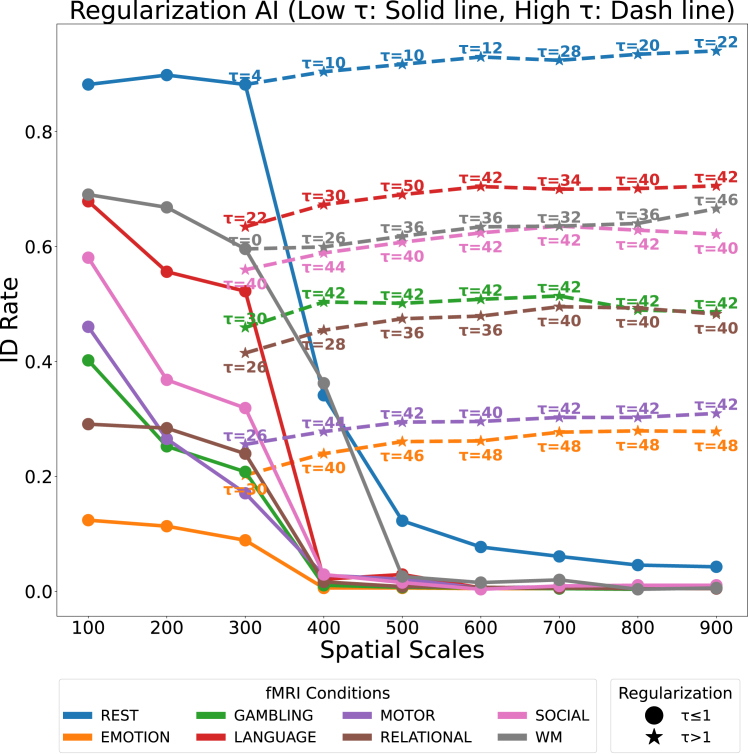 Figure 7
Figure 7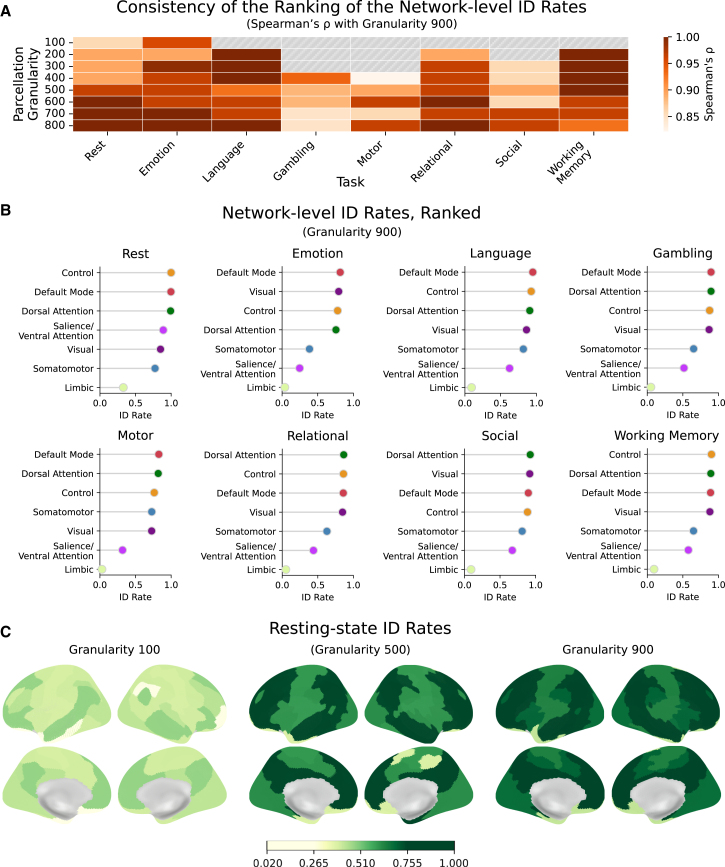 Figure 8
Figure 8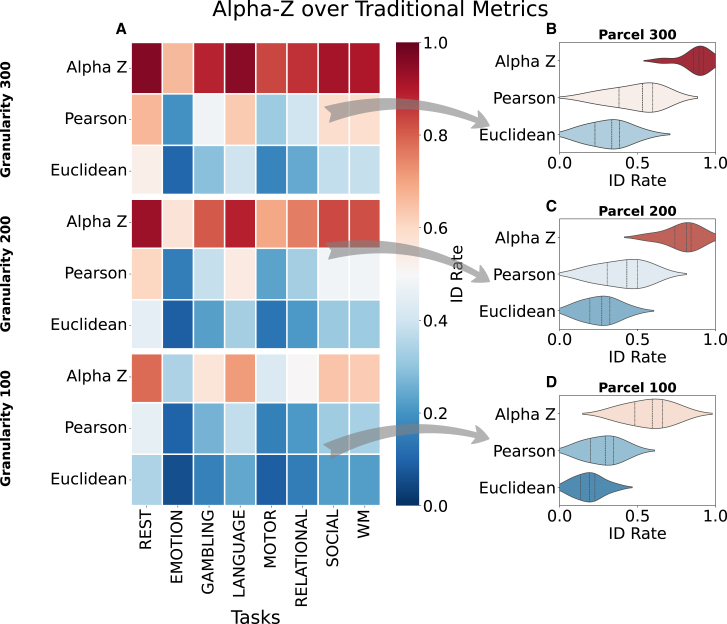 Figure 9
Figure 9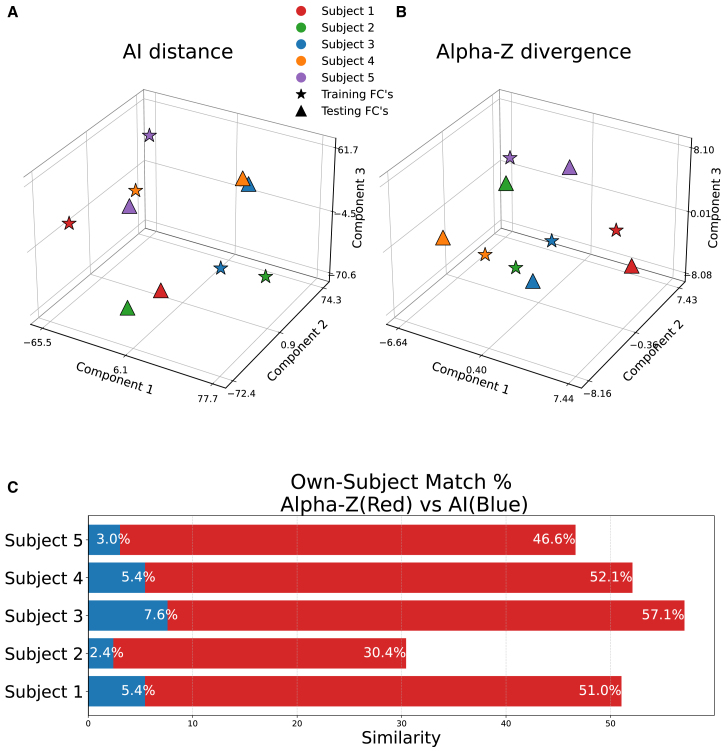 Figure 10
Figure 10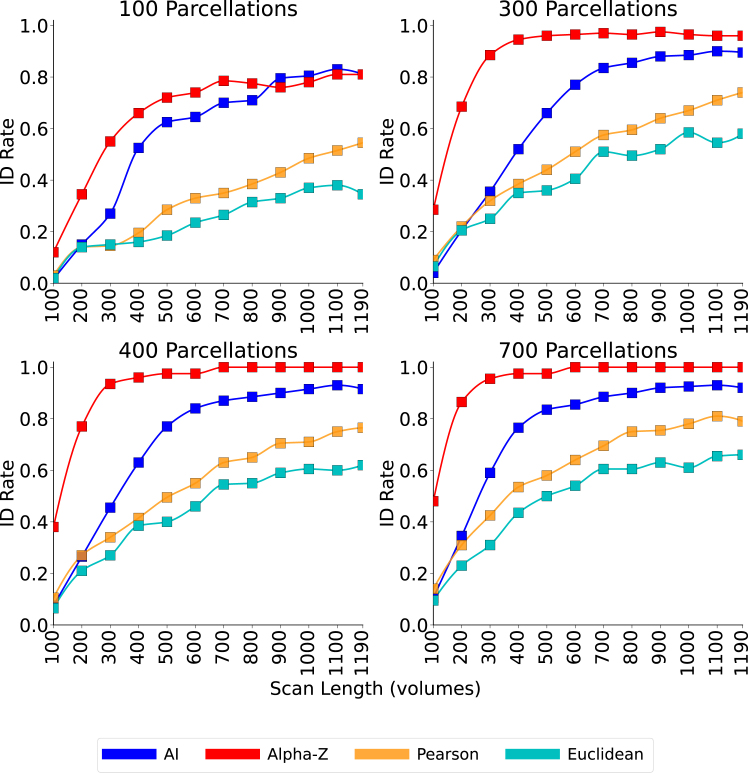 Figure 11
Figure 11Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFunctional Brain Connectivity Studies · Morphological variations and asymmetry · Face Recognition and Perception
Introduction
Brain activity is commonly inferred indirectly by measuring fluctuations in the blood oxygenation level dependent (BOLD) signal through magnetic resonance imaging (MRI), a technique that tracks oxygen consumption in the brain.1^,^2^,^3^,^4^,^5 Functional (fMRI) has emerged as the gold standard for capturing this activity, offering noninvasive insights into brain function. Functional connectivity between two brain regions is typically defined as the statistical relationship between their respective BOLD signals; most often measured using Pearson’s correlation coefficient.6^,^7 These relationships are captured in symmetric correlation matrices, known as functional connectomes (FCs), which represent the structure of connectivity of the whole brain.8^,^9 FCs have become crucial tools in neuroscience, providing insight into how the brain’s network organization changes due to factors such as aging,10 cognitive abilities,11 and neuropsychiatric disorders.12^,^13^,^14^,^15^,^16 In addition to these large-scale patterns, FCs have been shown to reveal consistent, individual-specific connectivity patterns, referred to as “brain fingerprint.”12^,^17^,^18^,^19^,^20^,^21^,^22^,^23^,^24^,^25^,^26^,^27^,^28^,^29 These unique patterns are stable across repeat fMRI sessions (separated by days to weeks) and across different scanning conditions,30^,^31^,^32 allowing for accurate identification (ID) of individuals from a large group. The reproducibility of brain fingerprints has made them invaluable in predicting behavior, cognitive function, and even susceptibility to mental health conditions, further highlighting their potential in clinical neuroscience and personalized medicine.14^,^30^,^31^,^32
The study of FCs has significantly evolved, largely driven by advancements in neuroimaging and computational methods. Traditionally, Pearson’s correlation coefficient has been the primary method for comparing FCs.30 This method, while straightforward, has several limitations, particularly its assumption of linearity and its inability to capture the non-Euclidean geometry inherent in FC data. Such limitations have been highlighted in several key studies30 emphasizing the method’s limited accuracy in reliably distinguishing individual-specific connectivity patterns. Recognizing such shortcomings motivates the development of geometry-aware methods that better respect the underlying manifold structure of FC data.
Recognizing the need for more sophisticated methods, a recent study32 introduced the use of geodesic distance as a more accurate way to compare FCs. This method leverages the non-Euclidean geometry of the positive semidefinite cone, where FCs naturally resides. The introduction of geodesic distance represented a significant advancement, as it allowed for more precise measurement of differences between FCs by considering their curved manifold structure rather than treating them as flat, Euclidean objects. Geodesic distance was shown to significantly improve the ID rates of individual fingerprints, particularly when FCs were appropriately regularized to ensure that they were positive definite and invertible. However, this approach, which involved a fixed regularization parameter (e.g., τ = 1), did not fully address the variability inherent across different datasets, brain parcellation methods, and scanning lengths. This limitation was further demonstrated to be highly dependent on specific dataset characteristics.33 A one-size-fits-all approach to regularization, therefore, would potentially diminish the accuracy of geodesic distance in capturing individual differences.
The superiority of geodesic distance over conventional metrics such as Pearson-based correlations has been attributed to regularization techniques to ensure the invertibility of FC matrices.32^,^33 However, this success was primarily produced under “low-resolution” scenarios, defined here as brain parcellation scales, where the number of brain regions is smaller than the number of available time points, thus preventing rank deficiency. However, our current research specifically investigates “high-resolution” scenarios, characterized by parcellations, where the number of brain regions significantly exceeds the number of available time points, inherently resulting in rank-deficient FC matrices. Under these high-resolution conditions, the performance of geodesic distance measures notably declines even with a high tuning parameter. Notably, in a previous study,33 while a range of regularization values were investigated (including up to τ = 10) the ID rate generally declined as τ increased beyond certain optimal points. In this study, a smaller τ value was ultimately selected, i.e., τ = 0.1, to avoid the distortions that larger regularization values could introduce.
In general, Riemannian geodesic distances such as the affine-invariant and Log-Euclidean have demonstrated clear advantages over flat, Euclidean measures by respecting the curved geometry of FCs and substantially boosting subject-ID rates.32^,^33 However, these approaches introduce new challenges: their reliance on a regularization parameter (e.g., τ) requires careful, task- and scale-specific tuning; ID accuracy can drop sharply when the number of parcels exceeds the number of time points (i.e., in high-resolution parcellations); and exhaustive searches for optimal regularization parameter values impose significant computational overhead. This outcome suggests that although selecting a small τ value helps to preserve the original positions of the FC matrices within the manifold, the geodesic distance metric may still be suboptimal under certain conditions. These limitations motivate the exploration of alternative approaches that are both geometrically principled and robust to variations in resolution and task.
To address these issues, we introduce the Alpha-Z Bures-Wasserstein (BW) divergence,34 a two-parameter extension of the standard BW distance that balances robustness and sensitivity across parcellation resolutions and task conditions. Our motivation for proposing Alpha-Z divergence is therefore 3-fold: (1) to provide a geometry-aware distance measure that maintains high performance across tasks and parcellations without the need for exhaustive parameter tuning, (2) to offer a robust solution in high-resolution scenarios where rank deficiency significantly degrades the performance of existing methods, and (3) to address the challenge of short scan lengths, since most fMRI conditions in the Human Connectome Project (HCP) dataset (except rest) are acquired with limited durations, where traditional metrics struggle to maintain stable identifiability. While (α) and (z) could in principle be tuned for each scenario, we demonstrate that a single fixed pair (α^∗^,z^∗^) performs well across all resolutions and tasks, eliminating the need for separate regularization searches and preserving high ID accuracy. We propose a novel approach that integrates advanced metrics, namely BW,35 Alpha Procrustes distance36 and Alpha-Z divergence34 into the comparison of FCs. We hypothesize that these new methods provide more accurate and robust individual fingerprints, particularly when combined with adaptive regularization techniques tailored to the specific characteristics of each dataset. We present evidence supporting this hypothesis through extensive comparisons across multiple cognitive tasks and parcellation granularity, demonstrating that our approach significantly enhances the precision of FC comparisons. We also systematically evaluated a range of distance metrics for FCs, considering both traditional (e.g., Euclidean and Pearson) and state-of-the-art manifold-based approaches (e.g., affine-invariant [AI], Log-Euclidean, BW, and Alpha Procrustes) to support our findings. Figure 1 provides an overview of the metric domain explored in this study, where FCs across multiple tasks and spatial scales are compared under both classical and geometry-aware metrics. The diagram highlights how Alpha-Z divergence maintains robust ID performance across increasing parcellation granularities without requiring extensive parameter tuning, motivating its central role in our analysis.Figure 1A geometric overview of the metric domain explored in this studyTraining and testing FCs are generated from nine spatial granularities (100–900 parcels) and measured in eight fMRI tasks (blue column). The geometric behavior of metrics (the proposed Alpha-Z and Alpha Procrustes, together with the widely used affine-invariant [AI], Log-Euclidean, and Bures-Wasserstein [BW]) between two FCs is shown in the central 3D inset. The polar plot encodes overall performance, bar color encodes how delicately the metric must be tuned (high = yellow, low = purple). Hatched fill marks metrics that lack a geodesic formulation, and gray marks indicate methods that require no hyper-parameter tuning. As we increase spatial granularity (100 → 900 parcels), the line chart shows how much farther Alpha-Z can move along the manifold before distances collapse relative to each classical direction. The diagram highlights how both metric choice and hyper-parameter along with finer granularities demands drive identification performance, motivating to focus on Alpha-Z divergence as a promising direction for the functional connectomics analyses.
The paper is structured as follows: STAR Methods describes in detail the dataset and preprocessing protocols employed in our analysis. It also introduces our methodology along with algorithm, including the mathematical foundations of the BW, Alpha Procrustes distance, and Alpha-Z divergence. In the results section, we present our experimental results, comparing the performance of the proposed methods against existing metrics. Finally, the discussion section explains the implications of our findings for future research and clinical applications in personalized medicine. Our conclusion demonstrates that by incorporating these advanced metrics, we can achieve a significant improvement in the precision of FC comparisons, paving the way for more individualized approaches to brain connectivity analysis.
Results
Comparative connectome identifiability across metrics, tasks, and spatial resolutions
The ID performance of various distance metrics in distinguishing individual FCs was systematically evaluated across eight fMRI tasks (rest, emotion, gambling, language, motor, relational, social, and working memory [WM]) and a range of parcellation resolutions (100–900 regions). ID rate,30 defined as the percentage of correctly matched subjects based on their FCs, served as the primary performance metric. Figure 2 presents the overall ID rates for manifold-based metrics (Log-Euclidean, AI distance, Alpha-Z divergence, Alpha Procrustes distance, and BW distance) and classical distances such as Pearson and Euclidean, while Figure 3 breaks these results down by cognitive fMRI condition, highlighting key trends and relative metric strengths under each condition.Figure 2. Impact of different distance metrics on identification rates across parcellation resolutions and fMRI tasksThe seven metrics evaluated are as follows: AI distance (A), Log-Euclidean (B), Alpha-Z divergence (C), Alpha Procrustes distance (D), BW distance (E), Euclidean (F), and Pearson’s distance (G). Curves show fMRI conditions (rest and seven tasks) with markers for each state.Figure 3. Identification rates across parcellation scales for high- and low-performance fMRI tasksIdentification rate (ID rate) across parcellation scales for four fMRI conditions with generally higher discriminative performance (rest, language, social, and working memory [WM]) in (A) and lower discriminative performance (emotion, gambling, motor, and relational) in (B). Despite the default complex structure of tasks, the Alpha-Z consistently outperforms all other metrics, which shows rest is the best performances tasks among all of the cognitive tasks with Alpha-Z divergence.
To further probe how spatial granularity and matrix conditioning interact with identifiability, we analyzed the impact of parcellation resolution on both ID rates and the rank (stability/invertibility) of the resulting symmetric positive definite (SPD) FC matrices. Figure 4 provides a comparative view of ID rates across spatial scales, revealing how finer parcellations can both enhance discriminability and challenge metric robustness as matrix rank increases.Figure 4. Impact of parcellation granularity on identification rates across metricsImpact of parcellation granularity on identification rates across eight cognitive tasks (rest, emotion, gambling, language, motor, relational, social, and WM) using five methods: Alpha-Z, Alpha Procrustes, affine-invariant (AI), Log-Euclidean, and Bures-Wasserstein (BW). Each portion that divided by dashed line corresponds to a different parcellation scale (100–900 regions), illustrating how ID performance varies with spatial resolution in (A). In (A), boxplots summarize identification rates across the eight tasks at each parcellation scale: the central line denotes the median, the box indicates the 25th percentile–75th percentile, and the whiskers show the full range across tasks. In (B), each cell shows the median identification rate across tasks for a given metric and parcellation resolutions. The Alpha-Z method consistently achieves the highest identification rates across all parcellation levels, exploring its scalability and robustness to changes in network granularity.
Cross-metric ID performance
The performance of AI distance (Figure 2A) exhibits a more fluctuating pattern. Although it performs reasonably well at lower parcellations, the ID rate drops markedly beyond 300 regions for most tasks, including emotion and gambling, where performance does not exceed 50%. At higher resolutions (600–900 parcellations), AI shows signs of stabilization, particularly in tasks such as rest, but it still performs poorly compared to other metrics, such as Alpha-Z divergence.
The Log-Euclidean metric (Figure 2B) demonstrates relatively high ID rates at lower parcellation resolutions (100–300 regions). However, a sharp decline is observed as the parcellation resolution increases, particularly for tasks such as motor and gambling, where ID rates drop significantly beyond 400 parcellations. The accuracy rate curve follows the same trend as the other geodesic distance (AI). Performance remains below 60% for motor, gambling, and relational, especially after 400 parcellations. This suggests that while Log-Euclidean distance is effective for low-dimensional FC comparisons, it struggles to capture the complexity inherent in high-resolution parcellations though regularized, the matrices with high tuning values such as AI distance, resulting in reduced accuracy.
Alpha-Z divergence (Figure 2C) consistently provides superior performance across all tasks and parcellation resolutions. Unlike the other metrics, Alpha-Z divergence shows a steady increase in ID rates as the parcellations resolution increases, reaching high accuracy even at the maximum tested resolution (900 regions). All tasks, except emotion, show particularly strong performance, maintaining high ID rates regardless of parcellation size. The robustness of Alpha-Z highlights its ability to handle the complex geometric structure of FCs, making it the most effective metric in high-dimensional settings.
The performance of Alpha Procrustes (Figure 2D) closely mirrors that of Alpha-Z divergence, though with marginally lower ID rates across most tasks. This metric performs well across a wide range of parcellations, particularly for tasks such as rest and social, where it maintains high accuracy even at the highest resolutions. Its stability across varying resolutions underscores its suitability for high-dimensional FC comparisons. Therefore, it is a strong alternative to Alpha-Z divergence.
BW distance (Figure 2E) performs moderately well, showing comparable results to AI distance at lower parcellations but without the need for regularization. However, its ID rates for tasks such as emotion and gambling remain relatively low, even as parcellation resolution increases. Despite this, rest achieves reasonably high ID rates, suggesting that BW distance may be a viable option for specific tasks where tuning parameter is not desirable. Nevertheless, its overall performance does not match that of Alpha-Z divergence or Alpha Procrustes distance in high-dimensional settings.
The Pearson distance (Figure 2G) performs moderately at lower parcellations but drops sharply beyond 300 regions, with tasks such as gambling and relational rarely exceeding 50% accuracy. This indicates that while Pearson captures simple linear dependencies, it fails to scale in high-dimensional FCs. The Euclidean distance (Figure 2F) shows the weakest performance overall, with ID rates consistently low across all tasks and resolutions, underscoring its inadequacy as a metric for high-dimensional FC comparisons.
Task- and performance-specific trends
For the rest task, as shown in top-left of Figure 3A, Alpha-Z divergence consistently outperforms the other metrics across all parcellations. ID rates for this metrics remain high even as the number of regions increases, with Alpha-Z divergence approaching an accuracy rate of nearly 1.0 at all parcellation levels. Log-Euclidean distance and AI distance show relatively stable but lower performance compared to Alpha-Z divergence, while BW and Alpha Procrustes distance experience 2%–3% decline compared to AI and Log-Euclidean distance as parcellation resolution increases. The trend indicates that Alpha-Z divergence captures the individual variations in the rest task more effectively, maintaining high accuracy even as the data complexity increases.
In the social task (Figure 3A, bottom-left), similar trends are observed, with Alpha-Z outperforming all other metrics, maintaining ID rates above 0.9 across the entire range of parcellations. Unlike rest task, Alpha Procrustes follows closely behind Alpha-Z, performing consistently well. AI and Log-Euclidean distance provide moderate performance after 300 parcellations but their performance still lags behind Alpha Procrustes distance, reinforcing its limitations in complex, high-dimensional FC data. BW distance performs below AI while it does not require any tuning parameter.
For the language task (Figure 3A, top-right), the same pattern emerges. Alpha-Z divergence dominates across all parcellations, retaining high accuracy even with 900 regions. AI distance and Log-Euclidean distance exhibit stable, though lower, ID rates, while BW follows the pattern, as the dimensionality increases, leading to a significant reduction in performance. The performance for all distances stays above 60% throughout all parcellations.
In the WM task (Figure 3A, bottom-right), Alpha-Z and Alpha Procrustes continue to outperform, though BW, Log-Euclidean and AI distance perform reasonably well compared to the other tasks. However, until 300 parcellations, AI distance and Log-Euclidean distance performance slightly increase or decrease, but both show consistency throughout all higher parcellations, once again demonstrating its reduced effectiveness in handling higher-resolution parcellations.
As seen in Figure 3B (top-left), the emotion task exhibits a clear separation between the metrics. Alpha-Z divergence significantly outperforms the others, achieving 80% ID rates at all parcellation levels. In contrast, AI, BW, and Log-Euclidean maintain very low performance, achieving 30% ID rates at all parcellation levels though tuning parameter added, while Alpha Procrustes achieves second-best results but still trails behind Alpha-Z divergence. It highlights their challenges in capturing the complex task-specific FC structures associated with emotional processing.
In the gambling task (Figure 3B, top-right), a similar trend is observed, with Alpha-Z divergence outperforming the other metrics across all parcellations. Alpha Procrustes follows but shows a notable gap compared to Alpha-Z. BW distance stays a little behind the AI and Log-Euclidean distance. Both AI and Log-Euclidean follow same pattern for higher parcellations but exhibit significant variability at lower parcellation levels, they do not exceed 50% for all parcellations.
For the motor task (bottom-left, Figure 3B), Alpha-Z divergence and Alpha Procrustes continue to dominate, maintaining high accuracy even at the highest parcellation resolutions. AI and Log-Euclidean exhibit moderate performance, while performing around 30% for all parcellations. BW distance exhibits higher performance compared to AI distance and Log-Euclidean distance but could not come close to the Alpha Procrustes distance. These results further reinforce the adaptability of Alpha-Z divergence in capturing FC patterns in motor tasks.
Finally, in the relational task (Figure 3B, bottom-right), Alpha-Z divergence and Alpha Procrustes once again show the best performance across parcellation resolutions, with Alpha-Z divergence reaching high ID rates close to 0.9 the highest ID rates across all conditions. BW distance shows minimal effectiveness in this task, maintaining low ID rates throughout. AI and Log-Euclidean deliver moderate ID rates, with Log-Euclidean slightly outperforming AI distance at certain resolutions. However, the accuracy rate for AI distance and Log-Euclidean distance are staying below 50% throughout the parcellations.
Parcellation granularity and performance trends
As parcellation resolution increases from 100 to 900 regions, the box-and-whisker distributions (Figure 4A) show a clear metric-dependent divergence in fingerprinting performance. Alpha-Z divergence and Alpha Procrustes show the highest central tendencies across all granularities, approaching ceiling levels (>0.95) by 400–500 parcels, while their inter-quartile ranges contract, signaling consistently strong and stable ID. AI and Log-Euclidean distances track closely at coarse resolutions but plateau near 0.60 after 500 parcels, and their wider boxes and longer whiskers indicate greater variability once dimensionality increases. BW remains the least effective throughout, never surpassing the lower-mid accuracy band and showing the broadest dispersion of outcomes.
Collectively, (Figure 4A) demonstrates two main trends. First, finer spatial resolution generally enhances individual ID, though gains diminish for most metrics beyond 600 parcels. Second, the relative ordering of methods becomes more pronounced with dimensionality, especially manifold-aware metrics. Alpha-Z retains both high accuracy and low variance, whereas classical or noise-sensitive metrics (AI and Log-Euclidean) suffer noticeable performance degradation and spread. These patterns highlight the importance of choosing a robust distance measure when scaling analyses to high-resolution FCs.
Figure 4B presents a heatmap of median subject-identification accuracy (ID-rate) for five symmetric-positive-definite distance metrics as the cortical parcellation is progressively refined from 100 to 900 regions. Across all metrics, increasing the number of parcels generally boosts fingerprinting performance, but the magnitude of this gain differs markedly. Alpha-Z dominates at every granularity, climbing steeply from 0.59 at 100 parcels to >0.94 by 400 parcels and plateauing at ≈0.96 for 600 parcels and above. Alpha Procrustes shows the next-best performance, rising from 0.54 to 0.65 across the range, while AI and Log-Euclidean display more modest improvements (peaking around 0.57). BW is the weakest throughout, never exceeding 0.52 and flattening near 0.49 for denser parcellations. These trends indicate that (1) finer parcellation improves individual ID, but with diminishing returns beyond ≈600 parcels, and (2) the choice of metric is critical, with Alpha-Z offering a pronounced advantage over alternative SPD metrics.
Rank of SPD matrices and its implications
FCs are represented as symmetric correlation matrices, which are symmetric positive semidefinite (SPSD).37 The rank and invertibility of these matrices are determined by their eigenvalues: an FC is full-rank and invertible only if all eigenvalues are strictly positive. When one or more eigenvalues approach zero, the FC becomes rank-deficient and non-invertible. This issue becomes particularly relevant when the number of brain regions (denoted as m) in the parcellation exceeds or approaches the number of time points (T) in the BOLD signal.
The rank of an FC can be expressed as
To illustrate, consider the two extreme cases from Tables 1 and 2. For the resting-state condition, each run contains T = 1190 frames (t = 14.28 min). Even at the highest parcellation (m = 914 regions in Schaefer-900), the number of time points still exceeds the number of regions (T > m). Thus, FCs remain theoretically full rank and invertible.Table 1. Number of ROIs (m) per Yeo network across Schaefer parcellation granularitiesGranularityVisualSomatomotorDorsal attentionSalience/ventral attentionLimbicControlDefault mode100171415125132420029352622123046300475734342040684006177464726529150074965659336911360089112727342821307001201288775499214980013415199875410517090014717310410560117194Table 2Number of frames per run (T) and scanning length in minutes (t) for each HCP conditionConditionRESTEMGAMLANMOTRELSOCWMT (frames per run)1190166243306274222264395t (min)14.281.992.923.673.292.663.174.74
In contrast, for the emotion task, each run contains only T = 166 frames (t = 1.99 min). At higher resolutions (e.g., Schaefer-400 with m = 400 or Schaefer-900 with m = 914), the number of regions far exceeds the number of time points (m ≫ T). This guarantees rank-deficiency, since rank < T < m, and renders FCs non-invertible.
This mismatch between m and T explains why traditional SPD metrics such as Log-Euclidean and AI Riemannian distance degrade in performance at high parcellation resolutions. Their reliance on invertibility is fundamentally compromised in conditions such as the emotion task, while they remain stable under conditions such as rest where T ≫ m.
Handling high-dimensional FC data
Alpha-Z divergence and Alpha Procrustes distance, in contrast, demonstrate robustness even in high-dimensional settings where FC matrices may approach a rank-deficient state as we can see in Figure 4. These metrics do not rely as heavily on matrix invertibility34^,^36^,^37 and are less sensitive to the inherent challenges posed by high-dimensional parcellations. For instance, as shown in the analysis for 500–900 parcellations, Alpha-Z and Alpha Procrustes consistently deliver higher ID rates compared to AI Distance and Log Euclidean. This is particularly relevant for high-dimensional FC analysis, where the number of brain regions exceeds the number of time points in the data, a scenario where traditional metrics struggle.
Full-rank conditions
In the preprocessing of the Destrieux parcellation, the FC matrices were generally full-rank33^,^37 when the number of time points exceeded the number of regions. However, when the number of regions approached or exceeded the number of samples, rank deficiency became a concern for traditional metrics such as AI and Log-Euclidean, further exacerbating their performance issues. In contrast, Alpha-Z divergence and Alpha Procrustes demonstrated resilience, maintaining their high ID rates even when the matrices were approaching rank-deficiency. This indicates that these newer metrics are better suited for analyzing high-resolution parcellations where traditional metrics become unstable.
In summary, as parcellation resolution increases, the performance of traditional metrics such as AI and Log-Euclidean deteriorates due to rank-deficient matrices, particularly when the number of brain regions exceeds the number of samples. Alpha-Z divergence and Alpha Procrustes, however, exhibit strong and consistent performance across all resolutions, making them highly suitable for high-dimensional FC analysis.
Regularization and its impact on geodesic distance
The impact of regularization32^,^33 on geodesic distance performance was analyzed across different fMRI tasks, with the results presented in Figure 5. It illustrates the ID rate performance for AI comparison as a function of parcellation resolutions, highlighting the role of the regularization parameter τ across a range of values (τ ≤ 1 and τ > 1). The objective of this analysis was to assess how varying τ affects the ID rates across multiple parcellation resolutions (100–900 regions) and different fMRI tasks.Figure 5. Sensitivity of the AI distance metric to regularization strength across parcellation levelsThe solid line shows identification rates (ID rates) under low regularization conditions (τ ≤ 1), where performance rapidly declines as the number of parcels increases. The dashed line illustrates the effect of higher regularization values (τ > 1), where appropriate tuning improves performance stability across tasks and scales. These findings emphasize the critical role of regularization in geodesic-based metrics and motivate the need for more robust alternatives like which does not depend on regularization parameter τ.
Effect of low regularization (τ ≤ 1)
For low regularization values (τ ≤ 1) in the solid line, the ID rate initially performs well in low parcellations (100–300 regions), but it deteriorates rapidly as the number of parcellations increases. This effect is particularly pronounced for tasks including rest, where the ID rate begins above 0.8 at 100 parcellations but declines to nearly zero by 500 parcellations. Similar trends are observed in tasks such as emotion, gambling, and social, which also experience significant drops in performance as parcellation resolution increases. This pattern highlights the limitations of geodesic distance in handling high-dimensional FCs when low τ values are used, as regularization is insufficient to maintain effective ID rates in these more complex settings.
Impact of high regularization (τ > 1)
In contrast, from the Figure 5 in dashed line, higher regularization values (τ > 1) exhibit markedly different trends. For tasks with larger τ values, such as gambling, motor, and social, ID rates remain more stable across all parcellation resolutions. For instance, in the gambling task, ID rates stay above 0.5 even at 900 parcellations when τ = 42, indicating that higher regularization parameters reduce the challenges posed by increased dimensionality.
Performance curves for regularization values ranging from τ = 10 to τ = 48 show that these higher values stabilize ID rates across most tasks, preventing the sharp declines seen in the low-τ settings. This stabilization is particularly beneficial for tasks such as social and WM, where the ID rates remain consistent across all parcellations. Furthermore, in tasks such as motor, high regularization values such as τ = 30 and τ = 40 result in relatively flat performance curves, maintaining ID rates around 0.6 even at higher parcellation resolutions.
Figure 5 also reveals that the optimal regularization parameter τ varies across different tasks and parcellation resolutions. For example, rest experiences a sharp decline in ID rate performance at higher parcellations when τ ≤ 1, but this performance stabilizes when larger τ values are applied. Conversely, tasks such as language and relational benefit more significantly from higher regularization values. These tasks maintain stable ID rates around 0.8 even at 900 parcellations when τ = 40, illustrating the need for task-specific tuning of the regularization parameter to optimize performance. Importantly, the results demonstrate that there is no fixed τ value that works optimally for all tasks and parcellations. For example, while gambling and social show significant improvements at higher τ values (e.g., τ = 42), tasks such as emotion and rest benefit from more moderate increases in τ. This variability underscores the importance of adjusting the regularization parameter based on both the specific task and the parcellation resolution in question.
This analysis highlights the critical role that regularization plays in optimizing AI distance performance for high-dimensional FC comparisons. While geodesic distance can perform reasonably well with low τ values for lower parcellation (100–300 resolutions), the dimensional complexity of higher parcellations requires higher regularization values (τ = 10 to τ = 48) to maintain stable and accurate ID rates across tasks. Crucially, the optimal τ value is not fixed across tasks, which is earlier said that tuning parameter is fixed18^,^32^,^33; different tasks (e.g., social and gambling) benefit more from higher τ values, while others (e.g., emotion and rest) require more moderate regularization levels. This variability emphasizes the necessity of fine-tuning the regularization parameter according to the specific characteristics of the data being analyzed.
Alpha-Z divergence preserves identifiability rankings of functional networks across spatial scales
To test whether the Alpha-Z divergence can reliably capture individual-specific signatures at the level of functional networks, we performed subject ID using only one of the seven Yeo networks.38^,^39 This analysis was performed at varying levels of parcellation granularity (from 100 to 900 parcels) and at all seven HCP task states, plus the resting state. As expected, increasing parcellation granularity improved ID rates. Under the resting state condition, in particular, the default mode and frontoparietal control networks alone were sufficient for near-perfect ID at granularities 500 and above (Figures 6B and 6C). This is in line with prior literature suggesting that transmodal networks, such as these two, carry rich information about personal functional traits,30^,^40 and these differences become increasingly accessible at finer spatial scales.41Figure 6. Consistent network ranking of ID rates across tasks and spatial scalesUsing Alpha-Z divergence, personal identification is feasible even when functional connectivity information is restricted to a single subset of the brain, i.e., a single Yeo resting-state network. When brain parcellation reaches a granularity of 400 or higher, the identifiability ranking of networks (based on identification rates) stabilizes across all HCP tasks and becomes consistent (via Spearman’s rank-order correlation) with those observed at granularity 900, (A) Gray cells indicate non-significant Spearman’s correlation). By rendering the network rankings robust to spatial scaling, this stabilization strongly reflects the relationship between task structure and functional variability. (B) For example, during resting state, the default mode and control networks exhibit higher identification rates than others, indicating greater group-level functional variability. This pattern persists across parcellation levels ranging from 100 to 900. (C) The consistency of which is reproducible across all tasks, resulting in other patterns outlined in (B).
However, beyond absolute performance, we also asked whether the relative ranking of network-level ID rates within a specific task remains stable across spatial scales. This question hinges on the idea that different task structures engage different functional systems, which should in turn exhibit varying levels of inter-subject variability. For example, tasks that are tightly structured and rely on stereotyped perceptual processes (e.g., simple visual discrimination) may induce similar computations across subjects in visual regions, resulting in lower variability and, hence, lower ID rates. Conversely, tasks that elicit higher-order reasoning or flexible engagement of control systems should show greater interpersonal variability within relevant networks. If Alpha-Z divergence is sensitive to such structure-function relationships, it should be able to capture these inter-subject patterns even at spatial scales as coarse as 200.42 This reasoning led to two possibilities. If network-level ID patterns consistent with task structure only emerge at fine granularity (e.g., 900), it would suggest that Alpha-Z divergence requires high spatial resolution to detect task-relevant individual differences structure-function relationships. On the other hand, if such patterns are detectable and stable even at coarser scales, it would demonstrate that Alpha-Z divergence is sensitive enough to pick up such relationships, despite the blurring effects introduced by coarser parcellation.
We found support for the latter. For each task, we computed Spearman’s rank-order correlation between the network-level ID rate rankings at coarser granularities and those at granularity 900. At this resolution, for all tasks except emotion, the number of regions within each Yeo network (see Table 1) remained lower than the number of time points in the fMRI runs, ensuring that the corresponding FC matrices were not rank-deficient. We then tested whether these correlations exceeded chance expectations using permutation-based null models, with p values corrected for the false discovery rate from multiple comparisons. This analysis revealed the granularity levels at which the network rankings began to converge with those at the finest scale (Figure 6A). Interestingly, for the resting state and the emotion task, these rankings stabilized as early as granularity 100, where the default mode and control networks already emerged as the most individually distinctive, and the somatomotor and limbic networks as the least. Other tasks required higher resolution: for instance, the motor task only began to exhibit stable rankings at granularity 400, with lower resolutions failing to achieve significant alignment with the rankings observed at 900.
In general, all HCP tasks exhibited stable network-level ID rate rankings starting at granularity 400 and above (Figure 6A). These stable rankings align well with expectations derived from task designs. For example, the social task, which demands individualized processing of dynamic social cues, resulted in ID rates in the visual network that are among the highest, which suggests high variability in visual encoding strategies across individuals (Figure 6B). In contrast, the language and motor tasks, which present time-locked blocks of stimuli with predictable perceptual demands, elicited lower ranked visual network ID rates, consistent with the suppression of inter-subject variability in early sensory encoding (Figure 6B).43
Altogether, these results demonstrate that Alpha-Z divergence not only robustly identifies individuals but also preserves meaningful signatures of task structure across a broad range of spatial scales. Its ability to uncover functionally relevant patterns, even at coarse granularities, suggests that it captures mesoscopic organizational features of human brain function. This expands the practical utility of connectome fingerprinting approaches in lower resolution datasets and deepens our theoretical understanding of how individual traits are embedded within the fundamental, large-scale architecture of cognition.
Discussion
Superior performance of Alpha-Z divergence and Alpha Procrustes distance
This advantage becomes particularly pronounced as parcellation resolution increases and the complexity of the FCs grows, specifically in higher dimensional settings, where the rank of the SPD matrices and the effect of regularization become critical factors.37 As discussed in the results section, increasing parcellation resolutions can lead to rank-deficiency in the SPD matrices, particularly when the number of brain regions (m) exceeds the number of samples (T). In such cases, geodesic distance such as AI, which rely on full-rank matrices for accurate computation, suffer significant performance degradation. In contrast, Alpha-Z Divergence and Alpha Procrustes distance exhibit resilience to rank-deficiency and other high-dimensional challenges over other classical methods (Pearson and Euclidean), maintaining high ID rates across tasks, even as parcellations reach 900 regions, at the same time there tuning parameter is fixed.
Regularization and its impact on AI distance performance
The limitations of AI distance were further highlighted in the analysis of regularization effects section. While regularization can help compensate for rank-deficiency,31^,^33 AI distance requires careful tuning of the regularization parameter τ to achieve optimal performance. As the results show, with low regularization values (τ ≤ 1), AI distance experiences a steep decline in performance as parcellation resolutions increases. Even with higher regularization values (τ > 1), while performance stabilizes, AI still cannot match the consistent and high ID rates of Alpha-Z and Alpha Procrustes. This indicates that although AI distance can benefit from regularization, it remains highly sensitive to the choice of τ and lacks the flexibility to perform well across a broad range of parcellation resolutions and tasks.
Stability and flexibility of Alpha-Z divergence and Alpha Procrustes distance
In contrast, Alpha-Z divergence and Alpha Procrustes distance (with fixed tuning parameter α = 0.6 for higher granularity) demonstrate both stability and flexibility. They perform robustly across all tasks and parcellations without requiring extensive regularization, as evidenced by their high ID rates even in the absence of aggressive regularization. Alpha-Z divergence while choosing fixed tuning parameter (α = 0.99 and z = 1), in particular, achieves near-perfect ID rates across all parcellation resolutions, including 900 regions, indicating its ability to handle complex, high-dimensional FC data with minimal performance degradation. This robustness suggests that these metrics are well-suited for large-scale neuroimaging analyses, where the data are often high-dimensional and traditional metrics face difficulties in maintaining accuracy. The analysis also emphasizes that the optimal regularization parameter τ for AI distance is not constant across tasks or parcellation resolutions. Some tasks, including gambling and social, benefit more from higher τ values (e.g., τ = 42), while others, such as language and rest, perform better with more moderate regularization (e.g., τ = 22). This variability underscores the need for task-specific tuning when using AI distance, adding complexity to its application in FC analysis. In contrast, Alpha-Z and Alpha Procrustes demonstrate consistently high performance without the need for such extensive parameter tuning, making them more reliable and efficient for general applications across different tasks and datasets. Overall, the superior performance of Alpha-Z divergence and Alpha Procrustes distance is clear from their ability to handle high-dimensional FC data, maintain high ID rates across a wide range of tasks and parcellation resolutions, and function effectively without heavy reliance on regularization. These metrics offer a significant advantage over AI distance, which requires fine-tuning of the regularization parameter and still struggles in higher dimensional settings. Alpha-Z divergence and Alpha Procrustes distance’s ability to adapt to varying data characteristics while maintaining robust performance make them ideal for future large-scale neuroimaging studies and FC analyses.
Advancement over traditional metrics
The performance of Alpha-Z divergence is clearly shown to be superior when compared to traditional metrics32 such as Pearson’s correlation and Euclidean distance,44^,^45 as depicted in Figure 7. This advancement becomes more pronounced as the number of parcellations increases, highlighting the robustness of Alpha-Z in identifying FCs across a wide range of tasks. The figure presents a comparison of ID rates across three different parcellation resolutions: 100, 200, and 300 parcellations, providing a clear view of how each metric performs in different settings. In Figure 7A (Granularity 100) and Figure 7D, Alpha-Z divergence consistently outperforms both Pearson’s correlation and Euclidean distance across all tasks. This superiority is particularly evident in tasks such as rest, where Alpha-Z divergence achieves an ID rate of above 0.8, compared to Pearson’s 0.5 and Euclidean’s 0.4. The gap between Alpha-Z divergence and traditional metrics is substantial, especially in tasks such as emotion and motor, where Pearson and Euclidean struggle to maintain accuracy. These results indicate that Alpha-Z is more capable of capturing the nuanced relationships within the FC matrices, even at relatively low resolutions compared to traditional metrics. As granularity increase to 200, Figure 7A shows a continuation of the trend, with Alpha-Z divergence maintaining its superior performance. While Pearson’s correlation shows slight improvements across some tasks, such as gambling and relational, it still lags behind Alpha-Z divergence, particularly in tasks such as rest and social. It is also clear from Figure 7C that Euclidean distance continues to show weaker performance, with ID rates remaining around 0.4 for most tasks. Alpha-Z divergence, on the other hand, maintains high accuracy, consistently achieving ID rates above 0.9 across nearly all tasks. This further highlights the ability of traditional metrics to handle increasing parcellations complexity without sacrificing ID accuracy. As parcellation resolutions increases to 300 regions (Figure 7B), the gap between Alpha-Z and traditional metrics widens even further. Figure 7A shows Pearson’s correlation and Euclidean distance experience significant performance drops in tasks such as language, motor, and social, where ID rates fall below 0.5 for both metrics. Conversely, Alpha-Z maintains its high ID rates, reaching almost 1.0 for tasks such as rest and language. This result showcases the robustness of Alpha-Z divergence in high-dimensional settings, where traditional metrics fail to fully capture the complex structure of high-resolution FCs. Overall, the results presented in Figure 7 demonstrate the clear advancement of Alpha-Z divergence over traditional metrics such as Pearson’s correlation and Euclidean distance. Across all parcellation resolutions and tasks, Alpha-Z consistently delivers higher ID rates, showcasing its superior capability in capturing the complex and intricate relationships within FC data. This is particularly important as the dimensionality of the data increases, where traditional metrics exhibit significant performance degradation. The strong and stable performance of Alpha-Z divergence again proves that it is an ideal candidate for use in high-resolution FC analysis, where accuracy and robustness are paramount.Figure 7. Identification rate comparison between classical similarity measures and Alpha-Z divergence(A) Heatmaps of ID rates for Pearson’s correlation, Euclidean distance, and the proposed Alpha-Z at three parcellation granularities (100, 200, and 300 regions); warmer colors denote higher accuracy. Across every cognitive task, Alpha-Z yields markedly higher rates, illustrating its superior discriminative power even at low-to-moderate spatial resolutions.**(**B–D) Violin plots of the same metrics at 300, 200, and 100 parcels, respectively, summarizing the distribution of task-wise ID rates across the eight cognitive tasks: the width of each violin reflects the kernel density of ID rates, the central marker indicates the median, and the thick bar denotes the interquartile range, confirming that Alpha-Z maintains a consistently higher and less variable performance than the classical distances. Together, the results highlight the limitations of Pearson and Euclidean metrics and underscore the advantage of geometry-aware divergences for functional connectome analysis.
Eigenvalue information and its impact on matrix rank
The eigenvalue distribution is a crucial factor in understanding the performance of various distance metrics and their ability to handle FC data, particularly as the dimensionality of the data increases. The behavior observed in the eigenvalue curves emphasizes that with increasing parcellation resolution, the matrices become increasingly ill-conditioned. This ill-conditioning arises due to the accumulation of eigenvalues close to zero, which makes it more difficult for distance metrics to accurately compare matrices without sufficient regularization. The rank-deficiency, as indicated by the increasing proportion of near-zero eigenvalues, explains why metrics such as AI and Log-Euclidean, which depend on the matrix being full-rank, suffer significant performance degradation at higher parcellations. In contrast, metrics such as Alpha-Z divergence and Alpha Procrustes distance are less sensitive to this issue and continue to perform well despite the increasing number of small eigenvalues. These metrics are designed to handle the intrinsic geometric structure of the FCs more robustly, even when the data become rank-deficient. The growing proportion of eigenvalues close to zero at higher parcellations has a direct impact on the ability of distance metrics to function effectively. Metrics that rely on matrix invertibility or assume full-rank matrices struggle as the eigenvalue distribution becomes skewed toward zero. This is where Alpha-Z divergence and Alpha Procrustes distance show their advantage. Unlike traditional metrics, these newer metrics do not depend on full-rank matrices and can effectively handle the increased dimensionality of the data without suffering the same performance declines. The eigenvalue highlights the critical role that matrix rank plays in the performance of distance metrics for FC comparisons. As parcellation resolution increases, the growing number of eigenvalues close to zero leads to rank-deficiency, which impairs the effectiveness of traditional metrics such as AI distance. The robustness of Alpha-Z and Alpha Procrustes, even in the presence of a large number of near-zero eigenvalues, underscores their suitability for high-dimensional FC analysis, making them the metrics of choice for scenarios where matrix rank is compromised.
3D visualization of performance: AI distance vs. Alpha-Z divergence
Figures 8A and 8B provide a 3D visualization32 comparing the performance of AI distance and Alpha-Z in clustering FCs from the same subject across different sessions. These visualizations are based on data from the rest task at 400 parcellations, plotted across three principal components, with the percentage of same subject (five subjects chosen randomly from the 428 subjects) labeled annotated for each subject. In Figure 8A, which depicts results for the AI distance, clustering of FCs from the same subject shows large variation in same-subject matching. For example, Figure 8C reports correct-match rates of 7.6% and 5.4% for subjects 3 and 4, whereas subject 2 achieves only 2.4%. This variability indicates that AI distance struggles to consistently group FCs from the same individual, yielding a scattered and less coherent distribution of points in the 3D embedding. Moreover, the visualization reveals significant overlap between FCs from different subjects. Notably, in Figure 8C for AI, subjects such as 1, 3, and 4 show higher mislabeling rate, which are clustered closely with points from other individuals, indicating that AI distance has difficulty distinguishing between subjects. The considerable overlap and broad distribution of points suggest that AI fails to capture the unique structural similarities within FCs of the same individual across different sessions, particularly at higher parcellation levels. In contrast, Figure 8B, which depicts the performance of Alpha-Z divergence, demonstrates markedly improved clustering of FCs for the same subject. In Figure 8C for Alpha-Z, the same-subject correct-match percentages are significantly higher across all participants. For instance, subject 1 achieves a similarity rate of 51.0%, a dramatic improvement over the results achieved with AI distance. Similarly, subjects 2 and 5, which exhibited lower labeling rates using AI, show much better performance with Alpha-Z divergence, achieve correct-match rates of 30.4% and 46.6%, respectively. The clustering of data points is far more distinct and tighter with Alpha-Z divergence, indicating that it better captures the intrinsic similarities within the FCs of the same individual. Importantly, there is minimal overlap between FCs from different subjects, suggesting that Alpha-Z divergence is much more effective at differentiating between individuals. The clear separation of points in the 3D embedding further confirms that Alpha-Z divergence excels at preserving subject-specific information, even in the context of high-dimensional data. Figure 8 provides compelling evidence of the superior performance of Alpha-Z over AI in identifying FCs from the same subject. AI exhibits substantial overlap between FCs from different subjects and generally lower same-subject matching rates, reflecting its limitations in capturing FC structure across sessions at high parcellations. In contrast, Alpha-Z divergence shows tighter clustering, minimal overlap, and consistently higher same-subject ID percentages. These results underline Alpha-Z divergence’s robustness and efficacy in handling high dimensional FC data, making it a more suitable metric for FC analysis, particularly in scenarios where AI distance struggles.Figure 83D visualization of subject-level embedding using two different distance measuresAffine-invariant (AI) distance (A) and the proposed Alpha-Z divergence (B). Each point represents a subject’s left-right fMRI pair projected in reduced component space. The percentages in (C) indicate accurately labeled participants for these five random participants chosen from rest task (400 spatial). While the AI metric fails to clearly cluster corresponding pairs, Alpha-Z achieves significantly better alignment and separation, resulting in improved identification accuracy.
Effect of resting-state fMRI scan length (number of TRs)
To examine the proposed method’s performance with respect to scan length, we analyze resting-state fMRI (10–190 volumes) condition across four parcellation granularities (100, 300, 400, and 700 regions of interest [ROIs]). Across all resolutions (Figure 9), the ID-rate increases monotonically with additional volumes, but the magnitude of improvement is strongly metric-dependent. Alpha-Z climbs rapidly and reaches near-ceiling accuracy at moderate scan lengths, about 40–70 volumes for 300–700 parcels, and, even at 100 parcels, it approaches ≈0.80 at the shortest scans. On the other hand, AI improves steadily and is competitive at coarse granularity: with 100 parcels, it eventually catches up to Alpha-Z around ∼900 volumes and then tracks alongside it for the remainder of the longest scans, though at short scans, it lags far behind from Alpha-Z. However, for 300–700 parcels, AI never closes the gap to Alpha-Z even as volumes increase, highlighting a limitation beyond its need for regularization tuning. By contrast, Pearson improves more gradually and levels off near 0.75–0.80, while Euclidean remains lower overall (approximately 0.60–0.65 at the longest scans); neither approach Alpha-Z even with extended scan length. Two points are clearly observed from the (Figure 9). First, longer acquisitions and finer parcellations generally improve fingerprinting performance, but gains are most clear for Alpha-Z at shorter scans, indicating superior sample efficiency. Second, the performance gap between metrics widens as dimensionality (parcels) and data length increase: Alpha-Z consistently dominates across resolutions, while Pearson and Euclidean exhibit slower growth and lower asymptotes. Together, the curves indicate that Alpha-Z yields robust, high-accuracy ID with substantially fewer volumes than conventional metrics.Figure 9. Identification accuracy vs. scan length at four parcellation resolutions (resting-state fMRI)ID-rate as a function of scan length (100–1,190 volumes) for 100, 300, 400, and 700 ROI parcellations, computed on HCP resting-state LR/RL (left-to-right and right-to-left phase-encoding directions) runs (N = 100 subjects). Curves compare AI (blue), Alpha-Z (red), Pearson (orange), and Euclidean (teal). For the AI metric, the SPD regularization parameter τ varies by parcellation: 100 ROIs: τ ≤ 1; 300 ROIs: τ = 4; 400 ROIs: τ = 10; 700 ROIs: τ = 28.
Validation of performance via null model analysis
To establish the statistical significance of the ID performance achieved with the Alpha-Z divergence, we performed a comprehensive null model analysis across eight cognitive tasks and multiple spatial parcellations (ranging from 100 to 900 regions). As illustrated in Figure 10, each radar plot compares the ID accuracy from the original data (blue) to that of a null model (red), where subject labels were randomly permuted to disrupt individual-specific signal. Across all tasks and parcellation levels, the null model consistently yielded ID rates close to chance level approximately 10%, whereas the original data maintained substantially higher accuracy approximately 95% for other tasks and 100% for rest task. This consistent separation confirms that the performance of Alpha-Z divergence is not driven by random effects or label artifacts but instead captures meaningful subject-specific brain connectivity structure. These results provide strong evidence for the robustness and discriminative power of Alpha-Z divergence in FC analysis. In conclusion, our results clearly show that Alpha-Z BW divergence and Alpha Procrustes distance outperform other geometry-aware metrics such as AI and Log-Euclidean, particularly as parcellation resolution increases. Alpha-Z consistently achieved ID rates above 0.90, reaching 1.0 at fine resolutions, while Alpha Procrustes followed closely behind. In contrast, AI and Log-Euclidean required substantial tuning and still plateaued near 0.60, especially for complex tasks such as emotion and gambling, and Pearson/Euclidean fell below 0.50. Figure 9 and Table 2 further confirm that Alpha-Z did not reach ideal accuracy in the emotion task due to limited scan length rather than shortcomings of the method; even under these conditions, Alpha-Z remained 30%–40% ahead of other metrics that stayed around 50%. Notably, Alpha-Z proved particularly effective for high parcellations and short scan lengths, maintaining robust performance across all tasks without parameter tuning, even in high-dimensional, rank-deficient settings where other methods degraded. These findings establish Alpha-Z as a scalable, reliable, and generalizable tool for brain fingerprinting, offering both methodological simplicity and superior accuracy, with strong potential for advancing individualized assessments and clinical translation.Figure 10. Null model analysis validating the statistical significance of observed identification rates across tasks and parcellation levelsEach radar chart compares the performance of the original data (blue) against a null model (red) across eight cognitive tasks for a specific parcellation resolution (ranging from 100 to 900). The consistent separation between original and null performances across all settings confirms that the observed results are not due to chance and reflect meaningful subject-level discriminability driven by the underlying brain connectivity patterns.
Limitations of the study
While our findings highlight the robustness of Alpha-Z divergence across high dimensional FCs, several limitations remain. First, although our method shows robustness even with preprocessing differences and lower data quality, its performance still needs to be validated on larger and more diverse clinical and demographic groups to confirm generalizability beyond high-quality research data. Second, although we extended the evaluation to behavioral prediction tasks such as age, gender, and individual traits, the achieved accuracies remain modest. This is consistent with prior evidence that fingerprinting and behavioral prediction draws on distinct functional systems, and suggests that stronger predictive performance may require integration with advanced modeling approaches (e.g., deep or dynamic connectivity models). Finally, while Alpha-Z reliably enhances ID rates, the underlying neurobiological substrates driving variations in its distance estimates remain unclear, underscoring the need for future work to link metric behavior with structural and physiological mechanisms.
Resource availability
Lead contact
Requests for further information and resources should be directed to and will be fulfilled by the lead contact, Jingyi Zheng ([email protected]).
Materials availability
This study did not generate new unique biological materials, cell lines, or other reagents. All brain atlases and third-party software used in this work are publicly available as listed in the key resources table and in the data and code availability section.
Data and code availability
- •HCP young adult data are available from the HCP data portal (ConnectomeDB; https://www.humanconnectome.org).
- •FCs generated in this study (including the validation dataset FCs) have been deposited to https://auburn.app.box.com/folder/244365587358.
- •All original code has been deposited at Github https://github.com/KaosarUddin/b_f and https://hub.docker.com/r/kaosar148/spd-metrics-id is publicly available. An archived snapshot of the software used in this paper is available on Zenodo (https://doi.org/10.5281/zenodo.15891140).46^,^47
- •Any additional information required to reanalyze the data reported in this paper is available from the lead contact upon request.
Acknowledgments
This work was funded by the 10.13039/100000001National Science Foundation via grant no. 2153492. The authors thank all members of the lab for their support.
Author contributions
Conceptualization, H.H., D.D.-T., and J.Z.; methodology, M.K.U. and J.Z.; investigation, M.K.U., N.N., J.Z., and D.D.-T.; writing – original draft, M.K.U. and J.Z.; writing – review and editing, M.K.U., N.N., H.H., D.D.-T., and J.Z.; funding acquisition and supervision, J.Z.; resources, J.Z. and D.D.-T. All authors read and approved the current version of the manuscript.
Declaration of interests
The authors declare no competing of interests.
STAR★Methods
Key resources table
REAGENT or RESOURCESOURCEIDENTIFIERDeposited dataTime series and functional connectomes of HCP datasetThis paperBox: https://auburn.app.box.com/folder/244365587358HCP Young Adult (public raw/derivatives)WU-Minn HCP ConsortiumConnectomeDB: https://db.humanconnectome.orgValidation dataset FCsThis paperBox: https://auburn.app.box.com/folder/244365587358Code snapshot for analysesThis paper (Zenodo)DOI: https://doi.org/10.5281/zenodo.15891140Software and algorithmsspd-metrics-id(Alpha–Z/BW/AI metrics)KaosarUddin (PyPI/Zenodo)PyPI: https://pypi.org/project/spd-metrics-id/; DOI: https://doi.org/10.5281/zenodo.15891140; Version: v1.0.1PythonPython Software Foundationhttps://www.python.orgConnectome WorkbenchHuman Connectome Projecthttps://www.humanconnectome.org/software/connectome-workbenchFreeSurferLaboratory for Computational Neuroimaging at the Athinoula A. Martinos Center for Biomedical Imaginghttps://surfer.nmr.mgh.harvard.edu/AFNINational Institute of Healthhttps://afni.nimh.nih.gov/FSLFMRIB, Univ.of Oxford, UKhttps://fsl.fmrib.ox.ac.uk/fsl/fslwiki
Experimental model and study participant details
Experimental data
In this study, we utilized a set of functional brain atlases, specifically the Schaefer parcellation of the cortex. This parcellation is derived from resting-state fMRI data collected from 1,489 participants, which were aligned using surface-based registration techniques. To generate the Schaefer parcellation, a gradient-weighted Markov random field approach was employed, combining local gradient information with global similarity metrics. The Schaefer parcellation is available in ten levels of granularity, ranging from 100 to 1000 regions in increments of 100. These parcellations are provided in both volumetric and grayordinate formats. Since the grayordinate parcellations share the same surface space as the HCP fMRI data, they can be mapped onto the fMRI data with relative ease. Surface-based mapping offers superior alignment between the fMRI data and the Schaefer parcellations compared to volumetric mapping. Therefore, we used surface-based mapping to align the 100–900 region Schaefer parcellations with the fMRI data. During the data processing phase of this study, we were unable to successfully map the 1,000 region Schaefer parcellation for the HCP Young Adult dataset. Additionally, 14 subcortical regions were integrated into each parcellation, as provided by the HCP release filename: Atlas_ROI2.nii.gz. This file was converted from NIFTI to CIFTI format using the HCP Workbench software, via the command wb_command -cifti-create-label. For example, the Schaefer-100 parcellation resulted in a total of 114 brain regions, and the Schaefer-900 parcellation resulted in a total of 914 brain regions. The Schaefer parcellation atlases contain labels of Yeo canonical functional networks38^,^48 whose numbers of regions for all parcellation levels are included in Table 1. In this work, we used data from the HCP 1,200 Participants Release49 and extracted three different subsets.This study relied exclusively on human participants; no animals, plants, microbes, or cell lines were used. The primary subset consists of 428 unrelated participants (223 women; mean age: 28.67 years; range: 22–36 years). All participants contributed functional MRI data from all available HCP tasks and Rest conditions. There were no experimental treatment groups or randomization; analyses treat each individual as a unique class for identification. Although the HCP Young Adult cohort includes both men and women (223 women among 428 unrelated participants), we did not explicitly model sex or gender effects. As a result, any sex or gender related differences in functional connectomes are averaged across the cohort, and our findings may not fully capture sex or gender-specific variability.
Preprocessing of HCP dataset
The HCP dataset underwent a minimal preprocessing pipeline, which included artifact removal, motion correction, and registration to a standard template, as detailed in earlier publications. To further process the resting-state fMRI data, we added the following steps: (i) regressed out the global gray matter signal from voxel time courses, (ii) applied a first-order Butterworth bandpass filter in both forward and reverse directions [0.001–0.08Hz; MATLAB functions butter and filtfilt], and (iii) z-scored and averaged voxel time courses for each brain region, excluding outlier time points beyond three standard deviations from the mean (workbench software, wb_command -cifti-parcellate). FC matrices were constructed by computing the Pearson correlation coefficient between the mean time series of every pair of brain regions. This resulted in symmetric, weighted adjacency matrices with values ranging from –1 to 1. FC matrices were computed for each participant individually.
Preprocessing of validation dataset
The validation dataset was processed using an in-house pipeline based on AFNI, FSL, and MATLAB, adhering to state-of-the-art guidelines. The same cortical parcellation scheme (Schaefer parcellation) introduced earlier was employed, while subcortical regions were derived from the Tian parcellation at scale I.
Method details
Distance description
Affine invariant (AI) distance
The Affine Invariant (AI) distance is a robust measure used to compare covariance matrices, particularly in the context of diffusion tensor imaging (DTI) and brain connectivity analysis. This distance metric is invariant under affine transformations, making it especially useful when the data undergoes non-linear deformations. The AI distance between two positive definite matrices A and B is defined as:
where log denotes the matrix logarithm and ∥·∥F represents the Frobenius norm. This distance captures the dissimilarity between matrices by accounting for both shape and orientation, making it particularly useful for tasks that involve structural variability.
Log-Euclidean distance
The Log-Euclidean distance is a metric designed to measure the distance between symmetric positive definite (SPD) matrices by leveraging the Log-Euclidean framework. This method simplifies the comparison of SPD matrices by applying the matrix logarithm to transform the original space into a Euclidean space. The distance between two SPD matrices A and B is given by:
where log(·) is the matrix logarithm and ∥·∥F is the Frobenius norm. The Log-Euclidean distance is advantageous due to its computational efficiency and the ability to retain the geometric properties of the space, making it suitable for various applications in brain imaging and functional connectivity.
Bures-Wasserstein (BW) distance
The Bures-Wasserstein (BW) distance is a metric that stems from optimal transport theory, specifically tailored for comparing probability measures with a focus on Gaussian distributions. In the context of covariance matrices, the BW distance between two SPD matrices A and B can be expressed as:
where tr(·) denotes the trace of a matrix. The BW distance captures both the spread (variance) and the mean (location) of the distributions, making it a powerful tool for comparing functional connectomes and other brain imaging data where Gaussian assumptions are reasonable.
Alpha Procrustes distance
The Alpha Procrustes distance defines a parametrized family of metrics on the space of symmetric positive definite (SPD) matrices, generalizing both the Bures-Wasserstein and Log-Euclidean distances. This distance emerges from an extension of the Procrustes distance problem, which aims to align two shapes as closely as possible under a set of transformations. The Alpha Procrustes distance between two SPD matrices A and B is defined as:
where U(n) denotes the set of unitary matrices of size n×n, and ∥·∥F is the Frobenius norm. The parameter α modulates the influence of the transformation, with specific values of α corresponding to well-known distances:
- • : This case corresponds to the Bures-Wasserstein distance, scaled to match its conventional form.
- •α = 0: This case results in the Log-Euclidean distance, which reflects the Riemannian distance in the space of SPD matrices.
Riemannian geometry interpretation
The Alpha Procrustes distance can also be interpreted as the Riemannian distance associated with a family of Riemannian metrics on the manifold of SPD matrices. This family encapsulates both the Log-Euclidean and Wasserstein Riemannian metrics as special cases, thereby offering a unified framework for these distances. In special cases, Alpha Procrustes distance introduces Bures-Wasserstein distance and Log-Euclidean distance,
Bures-Wasserstein Distance ( ):
Log-Euclidean Distance (α → 0):
Generalization to infinite-dimensional spaces
The concept of Alpha Procrustes distance is further extended to positive definite Hilbert-Schmidt operators on an infinite-dimensional Hilbert space. This extension includes the Bures-Wasserstein and Log-Hilbert-Schmidt distances, making it applicable in settings such as Gaussian measures and reproducing kernel Hilbert spaces (RKHS). The Alpha Procrustes distance is particularly effective in scenarios where the comparison of SPD matrices is required, such as in brain connectivity analysis, diffusion tensor imaging, and shape analysis. It offers a versatile and mathematically robust framework for modeling dissimilarities between SPD matrices under various transformations and metrics.
Alpha-Z-Bures Wasserstein Divergence
The Alpha-Z divergence, as described in the paper, introduces a new divergence measure specifically tailored for positive semidefinite matrices. This divergence is referred to as the Alpha-Z-Bures Wasserstein divergence and serves as a generalization of the classical Bures-Wasserstein distance. The divergence is defined mathematically as:
where A and B are positive semidefinite matrices, and Qα,z(A,B) is defined as:
This matrix function Qα,z(A,B) is derived from the alpha-z-Rényi relative entropy, which is a family of entropy measures used in quantum information theory.
Key Properties of Alpha-Z-Bures Wasserstein Divergence:
- 1.Quantum Divergence: The Alpha-Z-Bures Wasserstein divergence is shown to be a quantum divergence, satisfying several essential properties, such as:
- •Non-negativity: Φ(A,B) ≥ 0 with equality if and only if A = B.
- •Data Processing Inequality: This divergence is invariant under completely positive trace-preserving maps, which implies that it satisfies the data processing inequality in quantum information theory.
- 2.In-Betweenness Property: The divergence also satisfies the in-betweenness property, meaning that for any pair of positive semidefinite matrices A and B, and the matrix power mean50
(sometimes referred to as the quasi-arithmetic mean),51 the inequality
holds. This property ensures that the divergence between A and the power mean μp(t;A,B) is always less than or equal to the divergence between A and B.
The Alpha-Z-Bures Wasserstein divergence is particularly useful in quantum information theory, where it can be applied to measure the dissimilarity between quantum states represented by positive semidefinite matrices. Its ability to generalize well-known divergences and its compatibility with quantum mechanical operations make it a versatile tool for analyzing quantum systems. The introduction of the Alpha-Z-Bures Wasserstein divergence provides a new and flexible framework for quantifying differences between positive semidefinite matrices, extending traditional concepts like the Bures-Wasserstein distance. Its properties, such as the data processing inequality and the in-betweenness property, make it a robust and applicable divergence in various mathematical and physical contexts.
Metric summary
Table 3 summarizes the performance characteristics of various distance metrics applied to functional connectomes across parcellation scales. While geodesic-based methods such as the Affine-Invariant, Log-Euclidean, and Bures-Wasserstein distances theoretically align with the non-Euclidean geometry of FCs, they often require careful tuning and are sensitive to the choice of regularization. In contrast, metrics like Alpha-Z Bures Wasserstein offer a balance of strong performance and low tuning sensitivity, making them particularly suitable for robust FC comparison across varying conditions. Our proposed method builds upon these insights, addressing the limitations of conventional metrics by offering a more stable and accurate alternative that generalizes well across dataset and parcellation granularities.Table 3. Performance-based comparison of distance metrics across parcellation scalesMetricFormulaGeodesicPerformanceTuning sensitivityAffine-invariant∥log(X^−1/2^YX^−1/2^)∥Fyesneeds tuninghighLog-Euclidean∥log(X)−log(Y)∥Fyesneeds tuninghighBures-Wasserstein yesno neednoAlpha Procrustes yesagoodmediumbAlpha-Z-Bures Wassersteintr((1-α)X+αY)−tr(Qα,z(X,Y))nobestlowcEuclidean∥X-Y∥_F_noneeds tuninghighPearson’s correlation noneeds tuninghighaIn special cases, Alpha Procrustes is a geodesic distance.bMedium, but the tuning parameter is fixed for higher parcellations.cLow, and the best case is that the tuning parameter is fixed.
Quantification and statistical analysis
Participant identification
Participant identification involves mapping an unknown participant’s data to one of the participants in the database. Since each task in the HCP data contains two runs for every participant, we used one run as training data (i.e., to form the database) and the other run for testing. Identification was performed on each condition (resting-state or task) separately. Participant identification is equivalent to N-class classification, where the objective is to label an individual’s FC matrix in the test data to one of the N participants in the training data. To achieve this, we used a 1-Nearest Neighbor approach.30 An FC matrix in the test data is labeled with the participant identity of the FC matrix that is most similar to it in the training data. Suppose is an unknown participant’s FC matrix. Then, the label of x is given by:
where is the ith participant’s FC matrix in the training data, and d(·,·) is a distance or similarity measure. Here, we compare the use of a different distance metric to a metric that gets from the Alpha-z-Bures Wasserstein divergence measure.
Identification rate computation algorithm
Algorithm 1Computation of identification rate between functional connectivity matrices Input:
- • : A set of functional connectivity (FC) matrices representing one session or condition.
- • : A set of functional connectivity (FC) matrices representing another session or condition.
Output: Identification rate between the two sets of FC matrices. Compute Distance Matrix for to 428 do for to 428 do Compute distance DAB[i,j] between Ai and Bj Prediction Using as Training Set for to 428 do
Prediction Using as Training Set for to 428 do
Compute Correct Identifications , for to 428 do if Pred_B[i]=i then for to 428 do if PredA_[j]=j then Compute Identification Rates
return IDRate
Identification accuracy
Participant identification was performed using the first run as training data and the second run as testing data. For the N participants in the testing data, accuracy was defined as:
Then, the roles of the training and testing data were reversed, and accuracy was computed again. The reported identification accuracy was the mean of the two accuracy values.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Glover G.H.Overview of functional MRI methods Neurosurg. Clin. N. Am.22201113313910.1016/j.nec.2010.11.00121435566 PMC 3073717 · doi ↗ · pubmed ↗
- 2UludağK.Blinder P.Linking brain vascular physiology to hemodynamic response in ultra-high field MRI Neuroimage 168201827929510.1016/j.neuroimage.2017.02.06328254456 · doi ↗ · pubmed ↗
- 3Polimeni J.R.Lewis L.D.Imaging faster neural dynamics with fast f MRI: A need for updated models of the hemodynamic response Prog. Neurobiol.207202110217410.1016/j.pneurobio.2021.102174 PMC 868832234525404 · doi ↗ · pubmed ↗
- 4Setsompop K.Gagoski B.A.Polimeni J.R.Witzel T.Wedeen V.J.Wald L.L.Blipped-controlled aliasing in parallel imaging for simultaneous multislice echo planar imaging with reduced g-factor penalty Magn. Reson. Med.6720121210122410.1002/mrm.2309721858868 PMC 3323676 · doi ↗ · pubmed ↗
- 5Uğurbil K.Imaging at ultrahigh magnetic fields: History, challenges, and solutions Neuroimage 168201873210.1016/j.neuroimage.2017.07.00728698108 PMC 5758441 · doi ↗ · pubmed ↗
- 6Hastie T.Tibshirani R.Friedman J.The Elements of Statistical Learning: Data Mining, Inference, and Prediction 2nd ed.2009 Springer
- 7Stigler S.M.The Seven Pillars of Statistical Wisdom 2016 Harvard University Press
- 8Fornito A.Zalesky A.Bullmore E.T.Fundamentals of Brain Network Analysis 2016 Academic Press