Deep learning-derived arterial input function for dynamic brain PET
Junyu Chen, Zirui Jiang, Jennifer M. Coughlin, Ian Cheong, Kelly A. Mills, Martin G. Pomper, Yong Du

TL;DR
This paper introduces a deep learning method to estimate arterial input functions for brain PET scans without invasive blood sampling, improving accuracy and convenience.
Contribution
DLIF is a novel deep learning framework that estimates metabolite-corrected AIFs from PET images without any blood sampling.
Findings
DLIF was validated using dynamic PET patient data and showed accurate AIF estimation.
The method leverages deep learning to capture complex temporal dynamics and prior AIF shape knowledge.
DLIF provides a non-invasive alternative to traditional AIF measurement methods.
Abstract
Dynamic positron emission tomography (PET) imaging combined with radiotracer kinetic modeling is a powerful technique for visualizing biological processes in the brain, offering valuable insights into brain functions and neurological disorders such as Alzheimer’s and Parkinson’s diseases. Accurate kinetic modeling relies heavily on the use of a metabolite-corrected arterial input function (AIF), which typically requires invasive and labor-intensive arterial blood sampling. While alternative non-invasive approaches have been proposed, they often compromise accuracy or still necessitate at least one invasive blood sampling. In this study, we present the deep learning-derived arterial input function (DLIF), a deep learning framework capable of estimating a metabolite-corrected AIF directly from dynamic PET image sequences without any blood sampling. We validated DLIF using existing dynamic…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1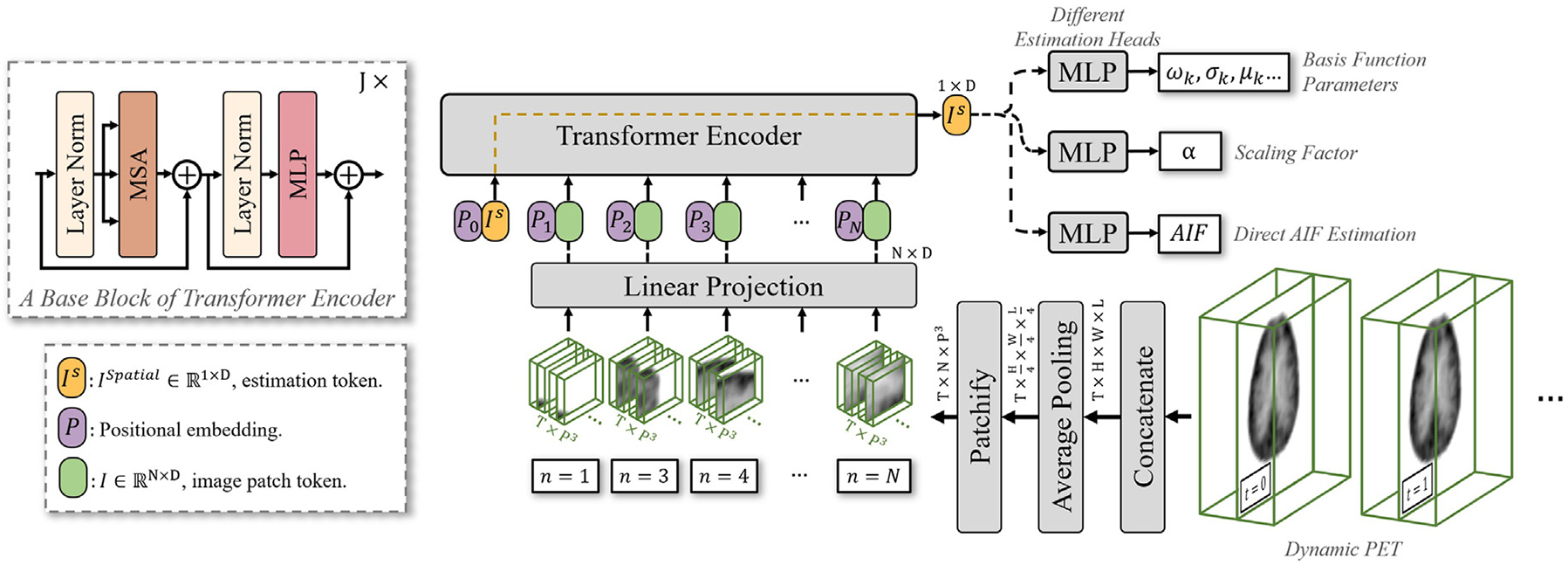 Figure 2
Figure 2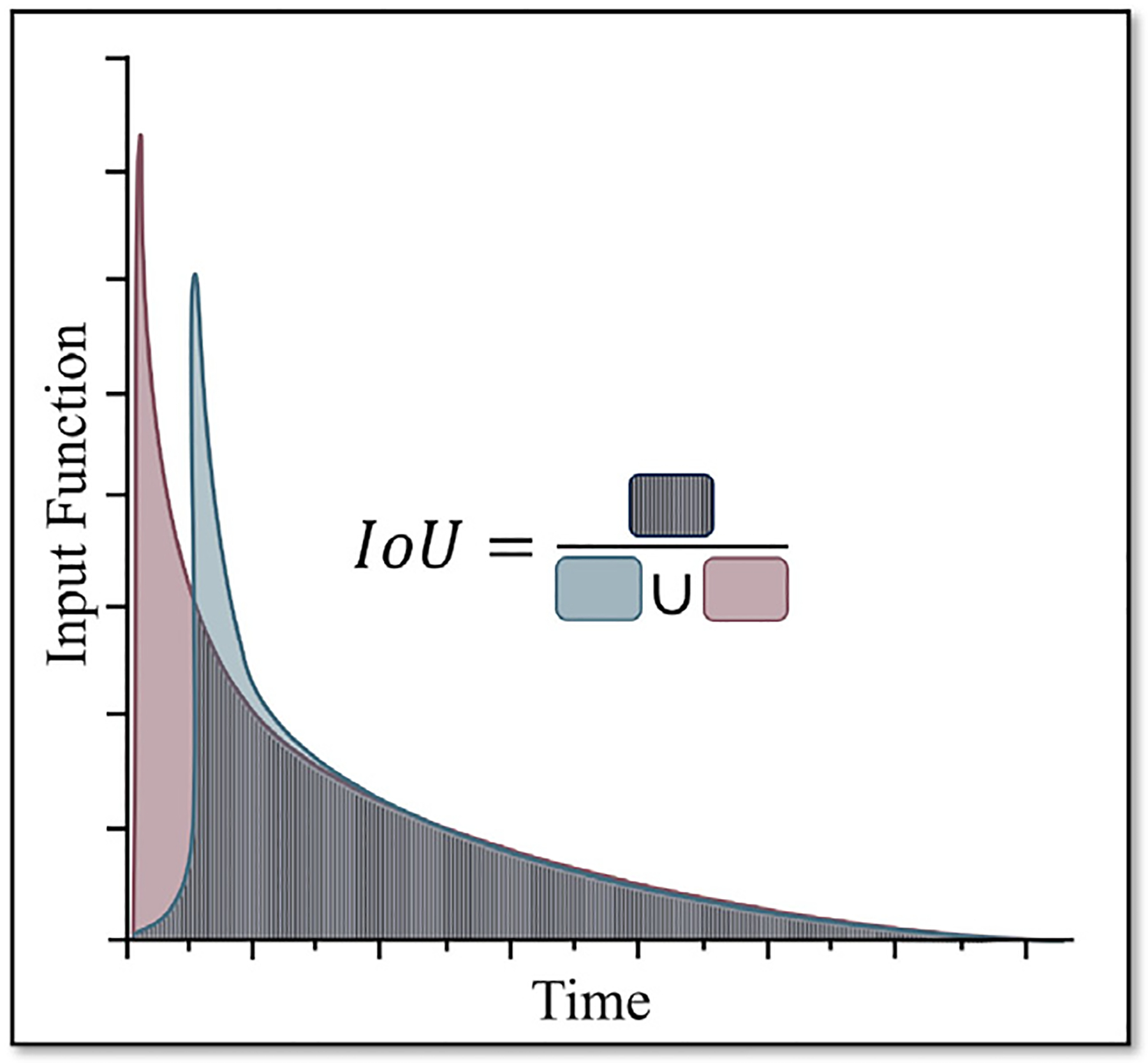 Figure 3
Figure 3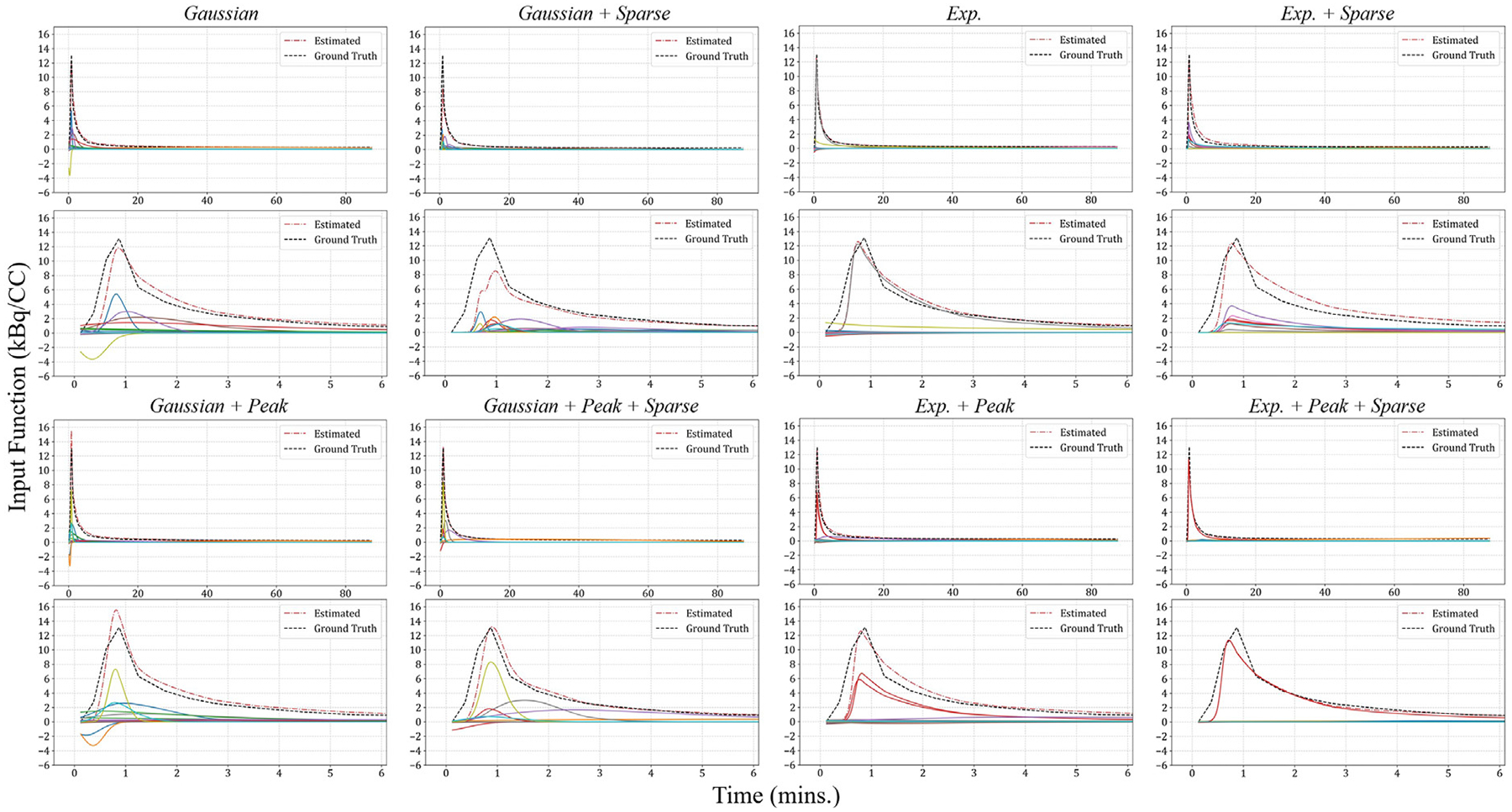 Figure 4
Figure 4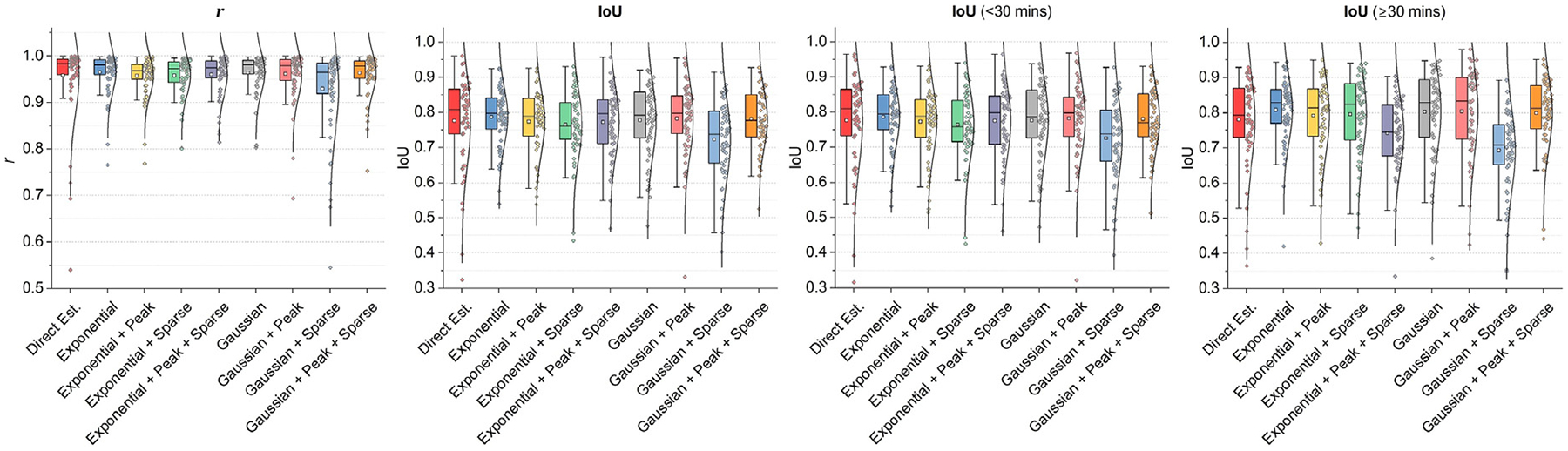 Figure 5
Figure 5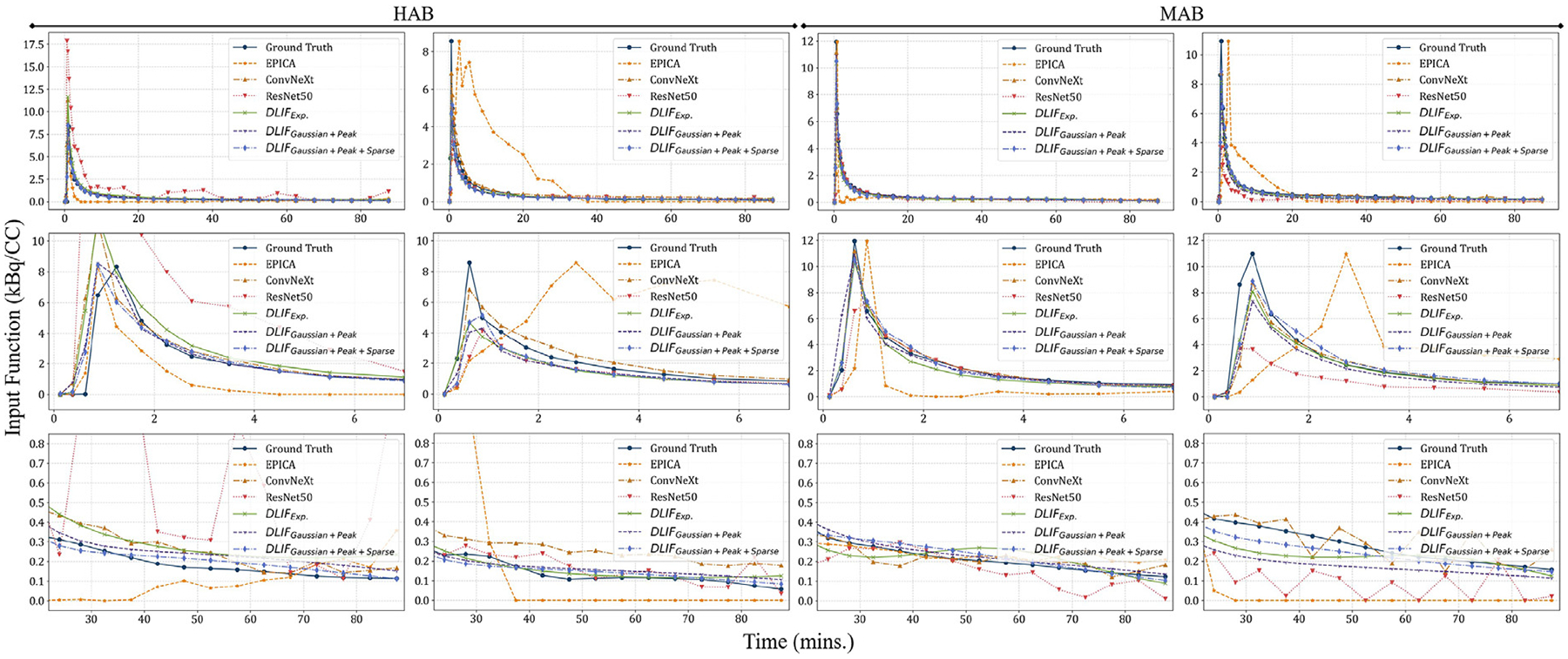 Figure 6
Figure 6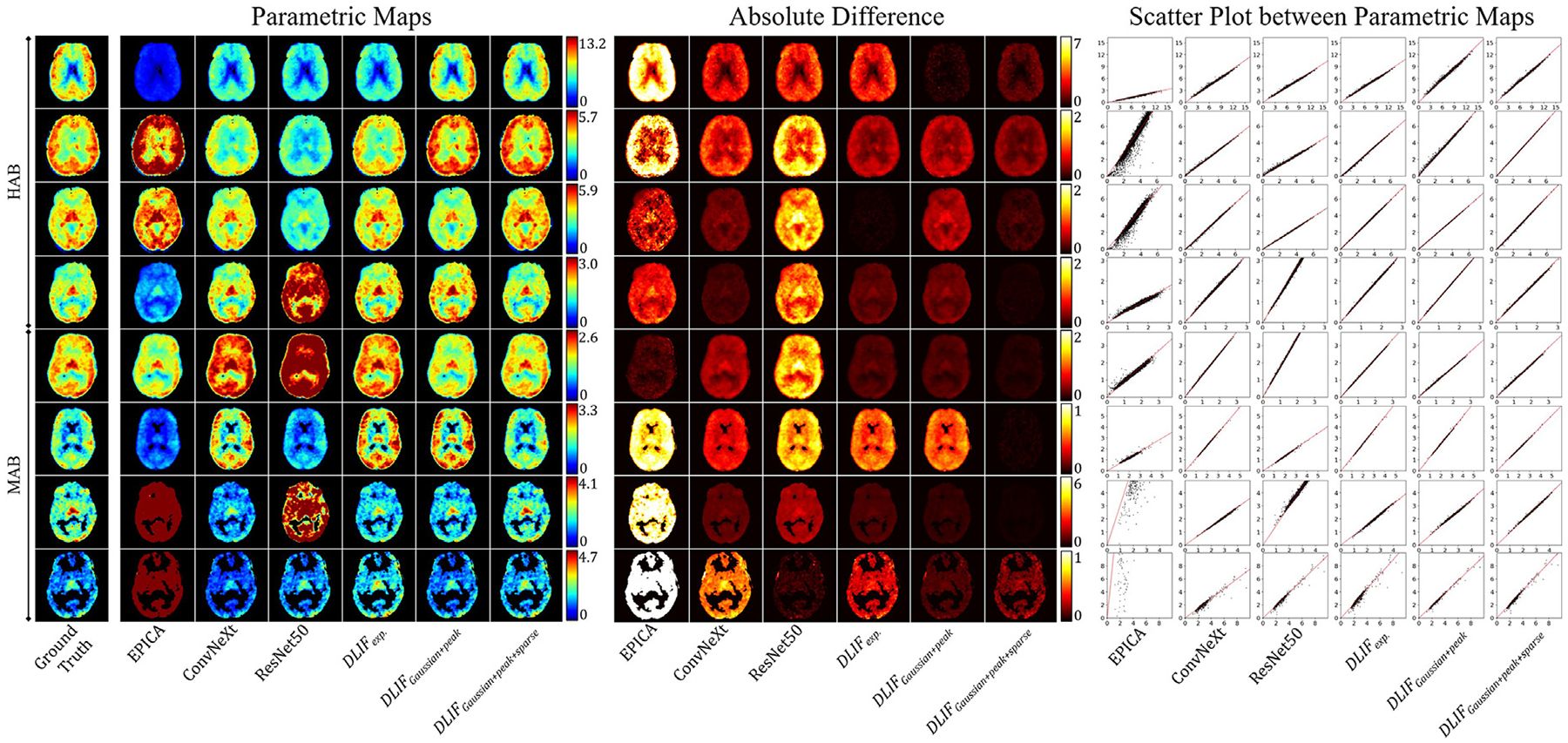 Figure 7
Figure 7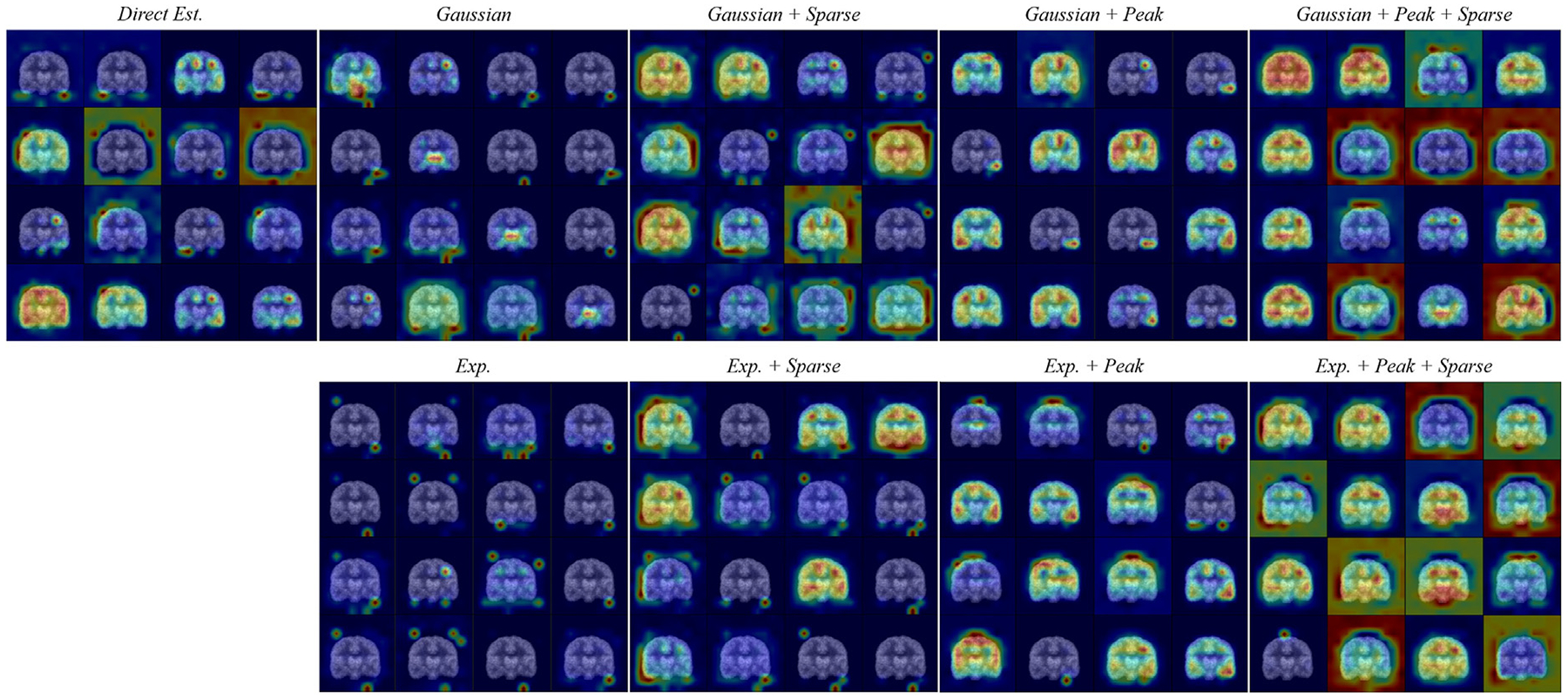 Figure 8
Figure 8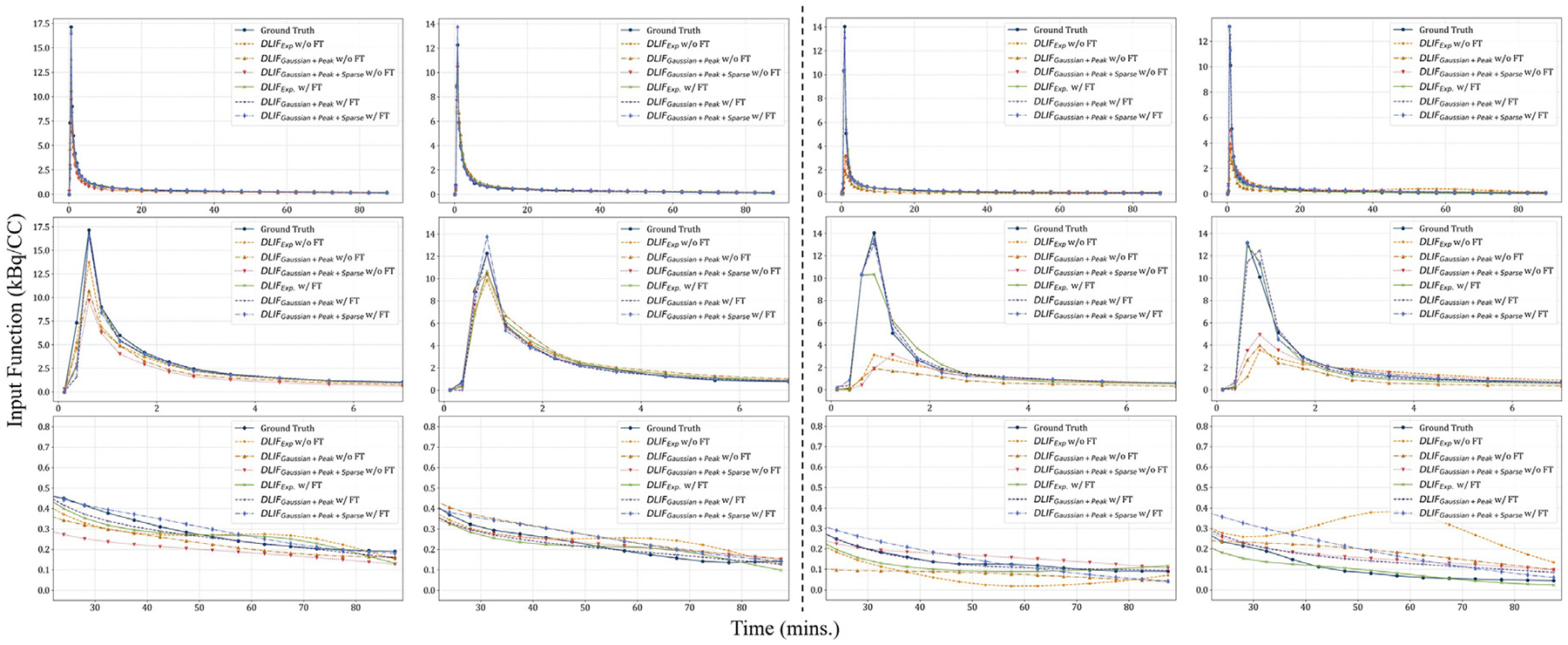 Figure 9
Figure 9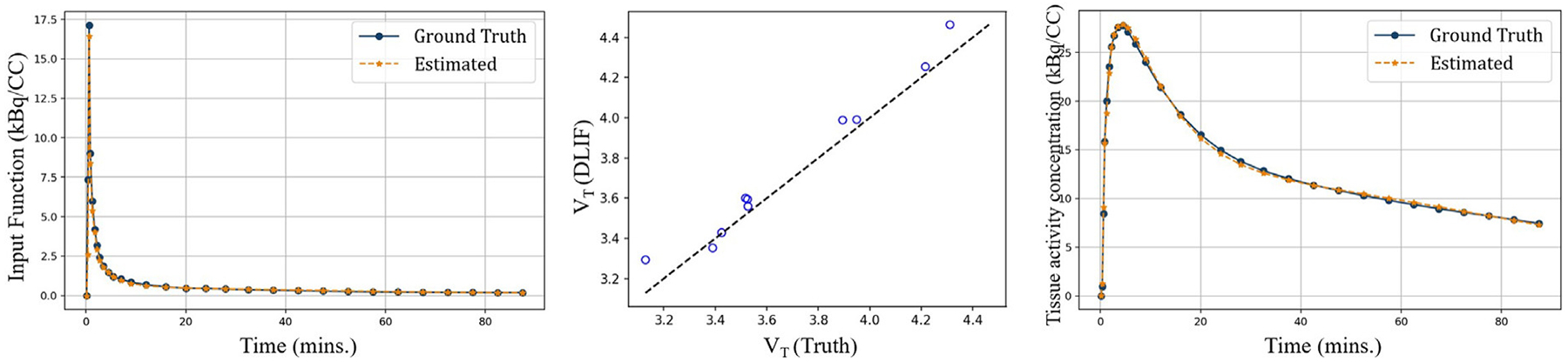 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMedical Imaging Techniques and Applications · Advanced MRI Techniques and Applications · Medical Image Segmentation Techniques
Introduction
Dynamic positron emission tomography (PET) is a molecular imaging technique involving the acquisition of sequential PET images over time, following radiotracer injection. By analyzing these dynamic PET data through kinetic modeling, one can quantify key physiological and biochemical parameters, including tissue receptor density, tracer influx or trapping rates, and competitive interactions between endogenous and exogenous ligands (Dimitrakopoulou-Strauss et al., 2021; Rahmim et al., 2019). Consequently, dynamic PET coupled with kinetic modeling has emerged as a crucial approach for investigating various diseases, particularly neurological disorders.
In kinetic modeling, sets of ordinary differential equations (ODEs) describe the dynamic relationships between a radiotracer, its physiological states, and the resulting PET images (Gunn et al., 2001). These tracer-specific models typically originate from compartmental frameworks in which the plasma concentration of the radiotracer over time serves as the input function (Watabe et al., 2006). The coefficients within these ODEs are solved using PET data, capturing the intrinsic kinetic properties of the tracer. Accurate determination of this input function is critical for robust kinetic modeling. Traditionally, this involves serial arterial blood sampling from the patient’s radial artery, beginning at tracer injection (the start of dynamic PET scanning) and continuing until the scan concludes (as shown in the left panel of Fig. 1). Collected blood samples are centrifuged to isolate plasma, and the radiotracer concentration is measured using a well counter, with corrections applied for radiolabeled metabolites, thus producing a metabolite-corrected AIF (Coughlin et al., 2018a). Although serial arterial sampling is considered reasonably safe, dynamic PET scans typically last 90 to 180 min, and patient tolerance to arterial sampling can vary significantly, especially among elderly or medically compromised populations. This variability may lead to slower recruitment or increased dropout rates in longitudinal studies. Moreover, risks associated with arterial cannulation rise in aging patients, particularly those on medications that affect blood coagulation, potentially contraindicating arterial line placement (Kang et al., 2018). Consequently, such concerns may deter researchers from adopting promising radiotracers in multicenter, longitudinal trials due to reluctance or the inability to perform arterial sampling. In addition, some PET research facilities may not have the capability to readily acquire dynamic, arterial measurements.
Previous research has explored alternative, non-invasive methods for deriving the AIF, primarily focusing on population-based input functions (PBIF) and image-derived input functions (IDIF) (Zanotti-Fregonara et al., 2012). PBIF generates a standardized input function by averaging and normalizing arterial data across subjects, but it overlooks individual physiology, scanner differences, and acquisition quality, limiting accuracy (Zanotti-Fregonara et al., 2012; Boutin et al., 2007). Additionally, PBIF cannot effectively distinguish between the parent radiotracer and its radiolabeled metabolites in the blood, typically requiring supplementary blood samples to perform accurate metabolite corrections (Zanotti-Fregonara et al., 2011; Takikawa et al., 1993). In contrast, IDIF estimates the whole-blood time-activity curve directly from dynamic PET images, capturing patient-specific variability for more individualized results. IDIF methods generally fall into segmentation- or statistical decomposition-based categories. Nonetheless, challenges such as accurate carotid segmentation, calibration via blood samples, and metabolite correction continue to hinder clinical adoption (Zanotti-Fregonara et al., 2011).
Recently, deep learning has emerged as a promising technique across various areas of medical imaging. Although still in its early stages, initial studies integrating deep learning methods have demonstrated improved accuracy AIF estimation, surpassing traditional IDIF and PBIF approaches (Wang et al., 2020; Ferrante et al., 2022, 2024; Cui et al., 2022; Chen et al., 2023; Kuttner et al., 2024). Our group previously pioneered the use of deep neural networks (DNNs) to directly estimate AIF from PET images (Wang et al., 2020). In this approach, a DNN processes two 3D PET volumes – one at a particular time point and another averaged over all time points – to predict the AIF value at each moment and subsequently reconstruct the full AIF curve. However, the method has limitations: since the network does not incorporate the entire dynamic PET sequence, it occasionally produces suboptimal estimates with non-smooth tails. In contrast, Kuttner et al. (2024) introduced a DLIF approach in which a DNN processes the entire dynamic PET sequence to estimate AIF values at the corresponding discrete time points. Ferrante et al. (2022, 2024) further advanced this direction by introducing a physically informed neural network (PINN), which estimates parameters of an analytical AIF model represented by a combination of two Gaussians and an exponential term modulated by a sigmoid function. Alternatively, Cui et al. (2022) bypassed AIF estimation entirely, directly reconstructing parametric images using an unsupervised deep learning framework known as the conditional deep image prior. Nevertheless, these innovative methods remain constrained by limited sample sizes – stemming from inherent blood sampling difficulties – and by relatively low robustness when applied across different radiotracers.
In this study, we aim to overcome the limitations of current AIF estimation techniques and eliminate the need for manual intervention by developing a deep-learning-based method termed the deep-learning-derived input function (DLIF). Building upon our preliminary work (Wang et al., 2020; Chen et al., 2023), DLIF directly estimates metabolite-corrected AIF from dynamic brain PET data. Although conceptually related to the recent work by Ferrante et al. (Ferrante et al., 2022, 2024), which estimates analytical parameters of the Parker model, the proposed DLIF framework offers greater modeling flexibility by representing the input function through a composition of basis functions rather than enforcing a parametric functional form. This design enables DLIF to capture complex temporal dynamics beyond those expressible by a limited number of Gaussian or exponential terms. Once trained, DLIF provides a fully non-invasive alternative, circumventing the challenges associated with traditional image segmentation methods and invasive arterial blood sampling. This advancement promises immediate benefits to ongoing and future research by improving patient comfort, significantly cutting operational costs related to anesthesiologist services, blood sampling, personnel, and facility logistics. Additionally, DLIF has the potential to enhance participant recruitment and retention in longitudinal studies.
The remainder of the paper is organized as follows. Section 2 discusses related work. Section 3 describes the proposed methodology. The experimental setup, implementation details, and datasets used in this study are discussed in Section 4. Section 5 presents the experimental results. The findings drawn from these results are discussed in Section 6, and Section 7 concludes the paper. For clarity, all abbreviations used in this paper are summarized in Table C.5.
Related work
Segmentation-based IDIF methods
2.1.
Segmentation-based IDIF relies on identifying and segmenting large blood vessels, such as segments of the aorta or femoral arteries, to estimate the whole-blood time-activity curve for individual patients. These vessels are chosen primarily due to their large size, which facilitates effective correction of partial volume effects (PVE) (Zanotti-Fregonara et al., 2012). However, in brain PET studies, the small size of cerebral vessels often results in significant PVE, substantially decreasing the accuracy and precision of the derived IDIFs (Zanotti-Fregonara et al., 2012). To address this challenge, numerous segmentation methods have been proposed, utilizing either PET images alone or PET images co-registered with MRI (Litton, 1997; Chen et al., 1998; Wahl et al., 1999; Liptrot et al., 2004; Parker and Feng, 2005; Su et al., 2005; Mourik et al., 2008; Fung et al., 2009; Lee et al., 2012; Fung and Carson, 2013; Sari et al., 2017; Khalighi et al., 2018). Statistical decomposition approaches have further been introduced to mitigate PVE and noise. For example, Chen et al. (1998) modeled each voxel signal in the carotid region-of-interest (ROI) as a mixture of vascular and spillover activity:
where denotes the measurement at time from the defined carotid artery ROI, denotes the actual radioactivity from the artery, and represents the radioactivity from the surrounding tissue at the same time point. The coefficients and refer to the recovery and spillover coefficients, respectively, which account for the respective contributions of the plasma and tissue radioactivities to the measured signal. In practice, and are derived from dynamic PET data, using the carotid artery and adjacent tissue ROIs defined manually, whereas is estimated through venous blood samples collected at a few time points. Once , and are known, the least squares was employed to solve for and .
Subsequent work removed the need for invasive sampling. Su et al. (2005) applied ICA to the early dynamic PET frames and automated segmentation using Gaussian thresholding and dilation, while Parker and Feng (2005) incorporated PCA and graph-based Mumford-Shah segmentation to refine carotid delineation. More recent efforts further improved artery segmentation through multimodal imaging and advanced algorithms (Fung et al., 2009; Khalighi et al., 2018; Su et al., 2013; Sari et al., 2017; Fung and Carson, 2013).
Direct estimation of IDIF
2.2.
Alternatively, IDIF can be estimated directly from voxel values in dynamic PET, avoiding explicit segmentation of the carotid arteries (Naganawa et al., 2005a,b, 2008; Bödvarsson et al., 2006; Wang et al., 2006). Such approaches commonly rely on statistical decomposition techniques, particularly independent component analysis (ICA), to separate voxel signals into plasma and tissue components. For example, Naganawa et al. proposed the following model to describe voxel values in dynamic PET images (Naganawa et al., 2005a,b):
where and represent the plasma and tissue contributions of the voxel , respectively, while and denote the uncalibrated IDIF and the tissue time activity curve (tTAC) at time , respectively. When expressed in matrix form, Eq. (2) transforms into , where a modified ICA method known as EPICA decomposes the dynamic PET data matrix into component matrices and . The plasma-related component in provides the uncalibrated IDIF. Similarly, Bodvarsson et al. employed non-negative matrix factorization (NMF) to derive the IDIF (Bödvarsson et al., 2006). Later, Naganawa et al. (2008) advanced the intersectional searching algorithm (ISA) (Wang et al., 2006), developing EPISA, which estimates a time-integrated IDIF directly from PET images for Logan graphical analysis (Logan et al., 1990), using tTACs obtained from intensity-based clustering. A key limitation of decomposition-based methods is that they often cannot inherently determine the scale or sign of estimated components, requiring calibration with a single blood sample, typically taken at the AIF peak.
Methods
Let be the skull-stripped dynamic PET image series, where represents the temporal dimension and defines the spatial dimension. Echoing previous studies on IDIF estimation, as discussed in the Introduction section, we model the voxel values in as a combination of contributions from both whole blood and tissue. This is expressed mathematically as:
where and represent the contribution factors from whole blood and tissue, respectively, at voxel position , and and represent the respective factors from blood plasma and the rest of the blood components. Here, is the voxel index. The terms , and correspond to the plasma time activity curve or the metabolite-corrected AIF, the time activity curve in the rest of the blood (including radioactive metabolites and radioactivities in blood cells), and the tissue time activity curve (tTAC) at time , respectively.
Our goal is to estimate the metabolite-corrected AIF or the DLIF, , directly from the image sequence by employing deep learning. As illustrated in Fig. 2, we first reduce the size of PET images by spatially averaging each dimension by a factor of 4, resulting in an image size of . The primary purpose of this downsampling is to reduce the computational burden. It is worth noting that estimating , which, as shown in Eq. (3), is not dependent on the voxel location , and considering that neighboring voxels usually exhibit similar kinetic models, this size reduction theoretically should not affect the accuracy of the estimation.
To achieve our goal, we introduce a novel DNN framework. This network is built on top of ViT (Dosovitskiy et al., 2021), enhanced with additional modules customized to process time-sequenced image volumes, such as dynamic PET scans. The output of ViT consists of a set of parameters that define the shapes of basis functions, which are then used to model the DLIFs.
Network architecture
3.1.
Vision transformer
3.1.1.
Transformers, initially developed for natural language processing tasks (Vaswani et al., 2017), have demonstrated significant potential in computer vision tasks (Dosovitskiy et al., 2021; Liu et al., 2021; Han et al., 2022). Following these successes, they have been increasingly applied in the processing of medical images (Li et al., 2023). A notable advantage of Transformers is their scalability (Zhai et al., 2022; Liu et al., 2022) and their capacity to capture long-range relationships between parts of the input. The decision to choose ViT over convolutional neural networks (ConvNets) for our application of AIF estimation is based on clear reasoning. ConvNets typically adopt small convolution kernels, usually ranging in size from 3 to 7, which inherently assume strong correlations between adjacent points (i.e., inductive bias). This presents two drawbacks for our application. First, AIF estimation often involves comparing spatially distant voxels, as seen in ISA (Wang et al., 2006) and EPISA (Naganawa et al., 2008) described in the Introduction section. Localized convolution kernels in ConvNets are not as effective in capturing these distant relationships, which only become implicit as the network layers deepen. Second, for precise estimation across the temporal dimension, it is preferable to process the entire temporal data directly, rather than applying small convolution kernels across time points. It is important to acknowledge recent advancements that show that ConvNets can be optimized with much larger kernels (Ding et al., 2022; Liu et al., 2023) or advanced convolutional operations (Liu et al., 2022), potentially matching the capabilities of Transformers. However, optimizing the network architecture to balance Transformers and ConvNets is beyond the scope of our study. In this work, we have benchmarked the proposed network against commonly used DNNs, with further details and results presented in the Results section.
The proposed network is built on the foundation of ViT (Dosovitskiy et al., 2021), which was originally designed for 2D image processing. Recognizing the limitations of ViT in this regard, we have expanded its functionality to effectively handle 3D image volumes. The architecture of the neural network is depicted in Fig. 2, and the details regarding the ViT and the associated attention mechanism are described in Appendix A
Estimation head
3.1.2.
In the original ViT (Dosovitskiy et al., 2021), the classification head is attached to the class token for the final prediction. In a similar fashion, our model attaches different estimation heads to the estimation token, , as shown in Fig. 2. Since this token engages with all others during self-attention, it is capable of learning the global information necessary for AIF estimation. The estimation heads are responsible for producing either a direct AIF estimation, which has an output dimension of , or a set of parameters to combine the basis functions. The latter is discussed in the following section.
Basis functions
3.2.
Given that AIFs generally exhibit certain smoothness characteristics, such as typically smoother tails, employing basis functions for their parameterization is beneficial for maintaining this smoothness in the estimations. An additional benefit of employing basis functions, as opposed to direct AIF estimation, is their ability to provide continuous functions. Direct estimation, in contrast, can only yield values at discrete time points and may require potentially error-prone interpolation to fill in values between these points. In our study, we explored the use of Gaussian and truncated exponential functions as basis functions. These have historically been used for modeling AIFs due to their inherent properties that align well with the characteristics of AIFs. Gaussian functions, for instance, have been employed in Mlynash et al. (2005), Parker et al. (2006), while exponential functions have seen use in Feng et al. (1993), Parsey et al. (2000). However, unlike these traditional methods where the number, scale, and sign of the basis functions are predetermined, our method capitalizes on the complex modeling capabilities of DNNs. This allows the DNN to freely learn and adjust all parameters of the basis functions to achieve the most accurate fit.
The proposed DLIF framework produces sets of parameters corresponding to basis functions. In theory, if equals (i.e., the number of time points), the AIF values at each of these points can be accurately represented using Kronecker delta functions. This can be achieved by aligning the amplitude of these functions with the AIF values and minimizing the width of the basis functions. Consequently, having is considered adequate for providing a precise estimation of the AIF. In the following paragraphs, we detail the basis functions that have been considered in this study.
Gaussian basis function
3.2.1.
The superposition of Gaussian functions can be expressed mathematically as:
where and determine the scale and location of the th Gaussian function, respectively, and specifies the weight of the th Gaussian function.
Exponential-sigmoid basis function
3.2.2.
When using exponential functions for modeling AIF, it is important to consider that these functions do not inherently reduce to zero. Yet, the AIF value prior to the injection of the radioactive tracer is in fact zero. To accommodate this, previous methods have employed a truncated exponential model that introduces a discontinuity for the AIF (Feng et al., 1993; Parsey et al., 2000). In such models, the estimated IDIF is set to zero before a specified time point. After this time point, the IDIF is then modeled to follow a form of exponential functions, aligning with the behavior observed pre- and post-tracer injection. However, the discontinuity inherent in previous AIF models using exponential functions poses a challenge, as it is not differentiable and thus prevents the backpropagation of gradients needed to update DNN parameters during training. To address this, we have devised a workaround by relaxing the discontinuity with a sigmoid function, as similarly done in by Parker et al. (2006). In our model, the superposition of exponential-sigmoid functions is formulated as:
where the first component represents the exponential function, and the second part embodies the sigmoid function. The center of each exponential-sigmoid function, represented by the th function, is located at . The scale and weight of these functions are characterized by and , respectively. Additionally, is the parameter that controls the steepness of the sigmoid function.
The parameters for these basis functions are produced by the proposed DLIF framework. For both types of basis functions, the scale parameters undergo a ReLU activation function, followed by an addition of , a small value introduced to prevent the scale parameters from assuming values equal to zero. In contrast, the other parameters are not subjected to any activation functions, allowing them the flexibility to assume any value as needed.
Scaling factor estimation head
3.3.
We take an additional step to differentiate the estimation of the AIF’s shape from its amplitude. This is achieved by incorporating a separate head in our DNN, dedicated to estimating a scaling factor . This factor adjusts the estimated IDIFs to align with the amplitudes of the true AIFs:
This echoes the approach commonly used in traditional decomposition-based IDIF estimation techniques (Naganawa et al., 2005a,b; Bödvarsson et al., 2006), where blood sampling at the peak of AIF is used to scale the IDIF. However, in our model, the scaling factor is determined by the DNN. Through empirical evaluation, we have found that this approach of using a scaling factor yields better results than having the DNN directly output the IDIF without any scaling. The evidence supporting this finding is detailed in a later section of the paper.
Loss function
3.4.
AIF similarity loss function
3.4.1.
To train the DNN, we employed an -based loss function. The preference for loss over loss is driven by the need to assign equal penalty strength to the IDIF values at each time point. Since the mean AIF values are typically dominated by the peak, which is several orders of magnitude higher, using loss would disproportionately assign a larger penalty to the peak. This is undesirable, as it can lead to an unbalanced focus on matching the peak value at the expense of other time points. Therefore, loss is chosen to ensure a more balanced training. The loss is defined as:
In the case of direct estimation, the predicted IDIF is directly compared with the true AIF. However, when employing basis functions, the values of the estimated IDIF are first derived from the aggregated basis functions at the same time points as the true AIF. Then, a comparison is made between these sampled values and the true AIF.
Sparsity constraint
3.4.2.
The selection of the optimal number of basis functions is a critical hyperparameter that necessitates careful adjustment. To mitigate the need for this tuning and to simplify the AIF representation via basis functions, thus preventing overfitting, we implement a sparsity constraint on the basis functions’ weights. This approach promotes sparse weight distributions, encouraging the majority of the weights to approximate zero. The constraint is formally defined as follows:
where is the total number of basis functions employed, and represents the weight of the th basis function. This sparsity constraint enables the use of a larger number of basis functions while mitigating the risk of overfitting in the AIF modeling.
Experiments
Dataset and preprocessing
4.1.
The dataset used in this work were de-identified dynamic [^11^C]DPA-713 brain PET images. [^11^C]DPA-713 is a second generation PET tracer targeting the translocator protein 18kDa (TSPO) for detecting microglial response or proliferation in vivo (Chauveau et al., 2008; Venneti et al., 2006; Tichauer et al., 2015; Muzi et al., 2012; Coughlin et al., 2014; Wang et al., 2017). It has shown superior binding affinity and signal-to-background ratio (Venneti et al., 2006; Tichauer et al., 2015; Muzi et al., 2012; Coughlin et al., 2014; Wang et al., 2017). The [^11^C]DPA-713 affiliation is affected by single nucleotide polymorphism (rs6971) TSPO genotyping, with C/C, C/T and T/T corresponding to high-affinity binders (HAB), mixed-affinity binders (MAB), and low-affinity binders (LAB), respectively (Owen et al., 2011; Milenkovic et al., 2018). The data used in this study were collected through several clinical research studies at Johns Hopkins University that used [^11^C]DPA-713-TSPO-PET in health control individuals (Endres et al., 2009), and several conditions that may cause neuroinflammation, such as HIV, Lyme disease, and repeated traumatic brain injury (Coughlin et al., 2015, 2018b; Rubin et al., 2018, 2023, 2022).
From these studies, de-identified data from HAB and MAB participants were collected, including 37 controls and 86 patients. Among those 67 were HAB and 56 were MAB. The data includes 90 min dynamic PET images and metabolite corrected AIF measured from blood sampling. The PET data were acquired on a brain-dedicated High Resolution Research Tomograph (HRRT, Siemens Healthcare, Knoxville, TN), with a fitted thermoplastic facemask for head fixation to reduce motion. The 90 min data were binned into 30 frames and reconstructed using the iterative ordered subsets expectation maximization algorithm (Coughlin et al., 2018b). The data were acquired from each participant through studies approved by the Johns Hopkins Institutional Review Board. Each participant provided written informed consent, which included the use of their data in secondary analyses.
All dynamic PET images of the brain were first aligned with a template through affine registration. Subsequently, skull stripping was applied to exclude non-brain regions. This procedure was carried out using SynthStrip, a publicly available learning-based method (Hoopes et al., 2022). In particular, SynthStrip was applied to an image averaged over all time frames, and the generated mask was then used to consistently strip the brain regions across the time frames. Subsequently, the images were uniformly cropped to a size of 160 × 192 × 160, maintaining an isotropic resolution of 1 mm. Additionally, the uptakes in the images were normalized to the Standardized Uptake Value (SUV), and the input function was correspondingly normalized to ensure consistency in the data. For training and evaluation, we implemented five-fold cross-validation, with each fold comprising an 8:2 split for training and testing.
Implementation details
4.2.
The models were implemented using the PyTorch framework (Paszke et al., 2019) on a PC equipped with two NVIDIA Quadro P6000 GPUs and an NVIDIA RTX A4000 GPU. The training was conducted over 500 epochs, using the Adam optimizer (Kingma and Ba, 2014) with a learning rate of 1e–4 and a batch size of 1. To enhance the robustness of the models, the dataset underwent augmentation through random spatial direction flipping during the training phase.
Baseline methods
4.3.
To evaluate the effectiveness of our proposed method, we conducted comparisons with two popular convolutional neural networks, ResNet50 (He et al., 2016) and ConvNeXt (Liu et al., 2022), as well as a traditional IDIF estimation method, EPICA (Naganawa et al., 2005a,b), that predicts AIF directly from dynamic PET image sequences. The specifics of these baseline methods are outlined below.
ResNet50—We first compare the proposed network architecture with a widely used ConvNet architecture, ResNet50 (He et al., 2016), which has found extensive applications across a diverse range of image classification and regression tasks. To ensure a fair comparison, the input configuration for ResNet50 mirrors that of our proposed network. This involves reducing the original spatial resolution of the dynamic PET sequence by a factor of 4 and concatenating it along the temporal axis, resulting in the formation of channels.ConvNeXt—We then evaluate the proposed DLIF against ConvNeXt (Liu et al., 2022), a recent ConvNet architecture that has been recognized as a strong counterpart to Transformer models. We employ the default configuration of ConvNeXt but convert its 2D modules into 3D modules with the input remaining consistent with the aforementioned specifications.EPICA—The final baseline method compared in this study is EPICA (Naganawa et al., 2005a,b), a statistical decomposition-based method discussed in the Introduction section. EPICA requires a scaling factor, typically derived from a single blood sample, to calibrate the estimated IDIF to align with the amplitude of the actual AIF. In our evaluation, we used the peak value of the ground-truth AIF as the scaling factor for the estimated IDIF.
Evaluation metrics
4.4.
The DLIFs generated by the proposed framework have been applied in Logan graphical analysis. However, it is important to note that the potential applications of the proposed DLIF are not confined to this specific analysis technique. Logan graphical analysis employs linear regression to analyze the data after a specified time, estimating the slope of the resulting line to determine the total volume of distribution, as discussed in Carson (2005). In this context, an exact match between the DLIF and the actual AIF before this chosen time is not critical. The crucial aspect is that the integral of the DLIF (i.e., the area under its curve) matches that of the AIF prior to this time. After this time point, the curves should align as closely as possible. This precise alignment is vital for accurately estimating the slope, which is crucial for the correct calculation of the total volume of distribution. Given these considerations, using metrics such as the mean squared error or the mean absolute error to assess the accuracy of the DLIFs may not provide the most meaningful insights. This is because such metrics could be disproportionately influenced by the errors in matching the peak values, which are significantly higher in amplitude compared to the input function values at later time points.
Pearson’s correlation coefficient (r)
4.4.1.
To evaluate the accuracy of AIFs estimated by various methods, we adopt Pearson’s correlation coefficient or , a metric also employed in related research on AIF estimation in perfusion CT (de la Rosa et al., 2021). This metric quantifies the correlation between the estimated AIF and the ground truth, and is mathematically defined as:
where represent, respectively, the estimated AIF and the ground truth AIF. Note that specifically quantifies the linear relationship between two variables, essentially measuring the similarity in the shape of two curves. However, does not assess the absolute matching of the amplitudes or the integrals of these curves.
Intersection over union
4.4.2.
To complement , we propose employing an additional metric, Intersection over Union (IoU), that evaluates the integrals or the areas under the curves of the two entities. Illustrated in Fig. 3, the IoU metric we propose for evaluating AIFs is mathematically defined as:
Although IoU is a metric frequently used in computer vision for measuring the overlap between two areas or volumes in image segmentation or detection tasks, we propose to adapt it here to measure the ratio of the overlap between two areas under the input function curves. Considering the pronounced sharpness typically seen in the peaks of AIFs, the IoU metric inherently places less emphasis on matching these peak points. Instead, IoU focuses more on the alignment of the overall amplitude and the cumulative area under the curve, which is more aligned with the accuracy needs of downstream Logan graphical analysis.
Root mean squared error
4.4.3.
We also incorporated the widely recognized root mean square error (RMSE) to evaluate estimated AIF. Its mathematical formulation is:
Logan graphical analysis
4.4.4.
The Logan graphical analysis is widely used for quantifying dynamic PET images of a reversible tracer, where the tissue time-activity curve (TAC) is mathematically transformed and plotted against “normalized time” to estimate the total distribution volume . It is mathematically defined as:
where is the measured tissue activity and is the input curve. For the reversible compartment, this expression results in a straight line with a slope of after an equilibration time . In previous studies, we have demonstrated that Logan graphical analysis with a could provide robust values that agree with those produced from compartmental models (Endres et al., 2009).
Recognizing the possibility of bias in evaluation metrics, which may lean towards error in peak matching, as the peak value in an AIF usually overshadows other values, we considered additional steps in our analysis. Specifically, in Logan graphical analysis, the alignment of AIFs post-30 min is of greater significance than peak matching. To address this, we divided the AIFs into two segments: one before 30 min and one after. This division allowed us to separately assess and report the and metrics for each segment, ensuring a more balanced and relevant assessment. Meanwhile, for , which primarily measures the correlation or shape similarity between the estimated and true AIFs, we report the evaluation for the entire duration.
Statistical tests
4.4.5.
To statistically analyze and compare the performance of the proposed DLIF framework with baseline models, including EPICA, ResNet50, and ConvNeXt, we used the Wilcoxon signed rank test. This non-parametric test is commonly employed to compare the performance of machine learning models on paired samples, particularly when the data does not meet the assumption of normal distribution required for a t-test. We applied this statistical test to compare the top-performing model with the second-highest performing model among the baseline methods, including EPICA, ResNet50, and ConvNeXt. We conducted repeated tests for identical scores with Bonferroni correction to adjust the -values for multiple comparisons.
Furthermore, we used the Mann–Whitney U test to evaluate the performance of the models in two different genotypes. This test is also non-parametric and is used on independent samples where the data does not meet the assumption of normal distribution, making it suitable for testing statistical significance between subjects of different genotypes.
Ablation study and component analysis
4.5.
In pursuit of optimizing the proposed DLIF framework, we undertook an ablation study and component analysis. This process aimed to pinpoint the most effective AIF estimation strategy within our framework. Each evaluated model is described by the following:
- “Direct Est.”—This model directly predicts AIF values at specific discrete intervals, in accordance with the AIF values acquired using arterial sampling.
- “Exp.”—This model generates parameters for the exponential-sigmoid basis functions, which are then superimposed to create a continuous estimate of the AIF.
- “Exp. + Peak”—In addition to generating parameters for the exponential-sigmoid basis functions, this model adds a scaling factor to adjust the amplitude of the estimated AIF.
- “Exp. + Sparse”—In addition to generating parameters for the exponential-sigmoid basis functions, this model applies a sparsity constraint to encourage employing a smaller set of basis functions.
- “Exp. + Peak + Sparse”—This model not only generates parameters for the exponential-sigmoid basis functions and a scaling factor but also includes a sparsity constraint.
- “Gaussian”—This model outputs parameters for Gaussian basis functions, which are used to model the AIF as a sum of Gaussian curves.
- “Gaussian + Peak”—In addition to the Gaussian basis function parameters, this model includes a scaling factor to scale the amplitude of the estimated AIF.
- “Gaussian + Sparse”—In addition to the Gaussian basis function parameters, this model adds a sparsity constraint on the Gaussian basis functions, aiming to reduce the number of basis functions required for representing the AIF.
- “Gaussian + Peak + Sparse”—This model generates parameters for the Gaussian basis functions, includes a peak scaling factor and applies a sparsity constraint during training.
Results
Composition of DLIFs using basis functions
5.1.
We begin with a qualitative analysis of how basis functions combine within DLIFs across different configurations. Fig. 4 illustrates the superposition process and highlights several key findings.
First, configurations employing Gaussian basis functions typically activate a larger number of functions compared to those using exponen tial-sigmoid basis functions. Even when applying a sparsity constraint, multiple Gaussian functions remain active (e.g., “Gaussian + Peak + Sparse”), enabling DLIFs to accurately capture subtle details of the ground-truth AIF. Conversely, exponential-sigmoid configurations often utilize fewer basis functions. Notably, under sparsity constraints, the DNN can converge to solutions involving a minimal number of exponential-sigmoid functions – such as the “Exp. + Peak + Sparse” configuration – where only one function remains active, effectively suppressing the others. This outcome highlights the intrinsic compatibility between the exponential-sigmoid shape and true AIF curves, facilitating concise yet accurate representations.
Overall, despite training the DNN exclusively on discrete AIF samples at defined time points, all DLIF configurations yield continuous, closed-form solutions capable of being evaluated at any arbitrary time. Although the number of active basis functions differs among configurations, each effectively captures the general shape and dynamics of the ground-truth AIF with commendable accuracy.
Ablation and component analysis
5.2.
Next, we analyze the key elements that contribute to the improved quantitative performance of the proposed DLIF framework. To evaluate this, we used Pearson’s correlation coefficient to quantify the alignment of the DLIF shapes with the ground-truth AIFs. Additionally, we introduce a novel metric, Intersection-over-Union (IoU), which measures the overlap between the areas under the estimated and true input function curves. Unlike metrics focused on matching peak values, IoU emphasizes the integral areas, which are critical for downstream analyses such as Logan graphical analysis (Logan et al., 1990). Details of these metrics are provided in the Methods section.
To refine the evaluation, we partition the input functions into two temporal segments: before and after 30 min, corresponding to the peak and stable phases of the input functions. Fig. 5 presents the results of the component analysis using five-fold cross-validation on the validation datasets. The first plot in Fig. 5 depicts values, representing the shape correspondence between the DLIFs and the actual AIFs. Although direct estimation of input functions (labeled “Direct Est.”) achieves an average of 0.958, DLIF configurations using basis functions, either exponential or Gaussian, consistently outperform this approach. Specifically, the “Exp.”, “Gaussian”, “Gaussian+Peak”, and “Gaussian+Peak+Sparse” configurations attain average values of 0.965, 0.964, 0.961, and 0.964, respectively. The second plot evaluates IoU, capturing the agreement in amplitudes and the total areas under the curves. Here, the “Exp.”, “Gaussian”, “Gaussian+Peak”, and “Gaussian+Peak+Sparse” configurations achieve mean IoU scores of 0.787, 0.777, 0.781, and 0.780, respectively, slightly outperforming “Direct Est.” (0.776).
Performance in the different temporal phases reveals further insight. During the peak phase (<30 min), the top-performing configurations, “Exp.”, “Gaussian+Peak”, and “Gaussian+Peak+Sparse”, record average IoU scores of 0.786, 0.781, and 0.779, respectively, compared to 0.776 for “Direct Est.”. During the tail phase (>30 min), these configurations achieve average IoU scores of 0.808, 0.803, and 0.799, respectively, compared to 0.780 for “Direct Est.”. Notably, the “Gaussian” configuration slightly underperforms in the peak phase, with an average IoU of 0.776.
Furthermore, the scatter plots demonstrate tighter distributions with shorter tails for “Exp.”, “Gaussian+Peak”, and “Gaussian+Peak+Sparse” compared to “Direct Est.”, indicating more consistent performance. Based on these findings, we selected the top three configurations – “Exp.”, “Gaussian+Peak”, and “Gaussian+Peak+Sparse” – for further quantitative and qualitative comparisons against baseline methods, as detailed in the subsequent section.
Qualitative and quantitative analysis
5.3.
Our study contrasts the proposed DLIF framework with the established traditional EPICA method (Naganawa et al., 2005a,b). This method relies on decomposing uptake values categorized into different regions through independent component analysis. Originally, EPICA required invasive arterial sampling to obtain the peak value for scaling the estimated IDIF. However, for the purposes of our evaluation, we use the peak value from the actual ground-truth AIF as the scaling factor. Furthermore, given that DLIF represents a novel approach by integrating deep learning for input function estimation, it stands without direct predecessors employing a similar methodology. As a result, we benchmark the DLIF framework against two prominent DNNs in image classification, ResNet50 (He et al., 2016) and ConvNeXt (Liu et al., 2022). These models are adapted to produce discrete input function values at specified time points. They serve as strong comparatives to the ViT architecture within the DLIF framework, providing a comprehensive comparison within the deep learning domain.
For the quantitative evaluation of these methods, we extend our set of metrics beyond and IoU from the component analysis to include RMSE for assessing overall amplitude accuracy between the input functions, and percent peak bias for evaluating peak value correspondence. Given that EPICA uses the ground truth peak value for scaling, we exclude it from the peak bias assessment. Additionally, we analyze both the IoU and RMSE metrics across two distinct time intervals, before and after 30 min, to accurately capture the performance of the various methods during the initial peak phase and the tail of the input functions.
Fig. 6 shows the qualitative results of the DLIFs under the three top performing configurations, “Exp.”, “Gaussian+Peak”, and “Gaussian+ Peak+Sparse”, alongside the input functions estimated by EPICA, ResNet50, and ConvNeXt for four different subjects. The first two subjects are characterized by HAB genotypes, while the last two are MAB genotypes. The EPICA method noticeably falls short, failing to closely match the true AIF shapes. This is particularly evident in the zoom-in views, where EPICA often inaccurately identifies peak time points, resulting in jagged and inferior amplitude alignment in the input functions’ tails. This limitation is likely due to its reliance on an unsupervised strategy that estimates AIFs by decomposing voxel values across the dynamic PET scan sequence using independent component analysis, which may be affected by noise presented in the PET images. In contrast, the DNN-based supervised learning approaches show significantly better adherence to the ground truth AIF shapes. Within this group, ResNet50 exhibits the least effectiveness in capturing both the shape and amplitude of the AIFs. ConvNeXt, while adept at pinpointing peak values and time points, tends to produce results that are not as smooth, with less accurate amplitude matching post-peak. Upon closer examination, highlighted in the second and third rows of Fig. 6, it is evident that the proposed DLIF framework generates AIFs with a smoother consistency and a closer match to the ground truth across both patient genotypes compared to other methods, which show greater fluctuations in their estimated input functions.
Table 1 showcases the quantitative analysis comparing various methods, with the top performances emphasized in bold. Statistical significance tests, specifically the Wilcoxon signed-rank tests, were conducted between the top-performing non-DLIF model, ConvNeXt, and the top DLIF models to assess significance, with Bonferroni correction applied to results with the identical scores. The quantitative results for EPICA, which correlate with its qualitative evaluations, indicate it as the least effective method. It shows mean values of approximately 0.5 and suboptimal mean IoU values of about 0.35, demonstrating poor correspondence in both shape and integral matching of the input functions. In contrast, the deep learning-based methods surpass EPICA across all metrics, with the proposed DLIF models showing exceptional performance, particularly achieving mean values of 0.94 for both HAB and MAB patients, which indicates strong shape agreement with the ground truth AIFs from arterial blood sampling. Look at the other metrics, the “Gaussian+Peak” configuration of the proposed DLIF demonstrated statistically significant improvements in IoU and RMSE for the tail of the AIFs (i.e., IoU (30+)), with mean IoU values of 0.76 and 0.77, and mean RMSE values of 0.06 and 0.07, respectively, for HAB and MAB genotypes. The “Gaussian+Peak+Sparse” configuration yielded the best peak matching, showing the least peak bias with values of 0.31 and 0.26 for HAB and MAB genotypes respectively. In the peak regions (i.e., < 30 mins or 30−), all deep learning-based methods performed reasonably well, with the proposed DLIFs achieving the highest mean IoU and RMSE values, surpassing ResNet50 significantly and being slight better than the results of ConvNeXt.
Logan graphical analysis
5.4.
We also undertook secondary, indirect comparisons using the parametric maps generated from the estimated input functions. These brain distribution volume maps were derived using Logan graphical analysis, as detailed in the Methods section (Logan et al., 1990). Fig. 7 provides qualitative comparisons of these parametric maps for eight patients spanning two genotypes: the upper four rows illustrate HAB genotypes, and the lower four rows show MAB genotypes. The left panel displays the parametric maps, the middle panel highlights absolute differences between estimated and ground truth values, and the right panel features scatter plots comparing voxel-wise estimations to ground truth values.
Inspection of these parametric maps reveals that EPICA-generated results exhibited substantial deviations from the ground truth, with pronounced over- and underestimations across subjects. In contrast, all deep learning-based methods consistently produced input functions closer to the ground truth. Among these, ResNet50 was notably less effective, aligning with its previously documented limitations in AIF estimation. The DLIF approach proposed here demonstrated the most accurate visual representations within parametric maps. These qualitative observations are quantitatively supported by the absolute difference images (middle panel), which clearly illustrate that EPICA produced large voxel value discrepancies, whereas DLIF approaches displayed significantly smaller differences, outperforming other deep learning methods. Scatter plots (right panel), based on 10,000 randomly selected voxels within brain regions, further confirm these results, showing strong correlations for all deep learning methods with ground truth values. In particular, DLIF-generated results yielded regression slopes approaching unity, underscoring their high fidelity to ground truth.
Table 2 summarizes quantitative assessments of parametric maps estimated from the various AIF methods. Remarkably, DLIF-Gaussian+Peak achieved superior performance, presenting the lowest mean MAE (0.66) and RMSE (0.68). ConvNeXt closely followed, with similarly robust performance (mean MAE of 0.66, mean RMSE of 0.69). Conversely, ResNet50 and EPICA delivered notably poorer results, with EPICA, despite requiring invasive arterial sampling at peak time points, demonstrating the weakest performance overall.
Discussion
Performance of DLIF configurations and evaluation metrics
6.1.
We performed extensive experiments to optimize the selection and configuration of basis functions within the DLIF framework and compared its performance against existing IDIF methods and alternative deep learning approaches that directly estimate discrete AIF values. Analysis of the initial two plots in Fig. 5 showed that all tested DLIF configurations strongly correlated with the ground-truth AIF shapes, yielding average correlation coefficients exceeding 0.9. Such high correlation demonstrates that the DLIF effectively captures metabolite-corrected AIF shapes and underscores its suitability in clinical scenarios where a single arterial sample could be available for scaling, mirroring conventional clinical practices.
To further compare the estimated and ground truth AIFs, we introduced a novel evaluation metric based on the ratio of the integrated area of overlap, or IoU. This metric emphasizes the integral areas under the curves, which is physiologically important for determining total distribution volume, rather than focusing solely on matching peak values at specific time points. Based on the and IoU metrics, we identified three particularly effective configurations of the DLIF on the validation dataset: “Exp.”, “Gaussian+Peak”, and “Gaussian+Peak+Sparse”. We compared these configurations against various baseline methods on the test set. Qualitative results in Fig. 6 confirmed the capability of DLIF to match the peak of ground truth while producing a smooth tail that closely matches the original data. Other methods resulted in a less smooth tail, with the traditional method EPICA performing the lowest, as its estimated input function struggled to match the ground truth even though it required the ground truth peak value as a scaling factor. Quantitative results shown in Table 1 further validate our findings, with DLIF configurations significantly outperforming others. When comparing the parametric maps estimated using the AIFs predicted by various methods, all DLIF configurations showed a good match with the ground truth, as indicated by the absolute difference images and the scatter plots shown in Fig. 7. The “Gaussian+Peak” configuration demonstrated the least quantitative error, as detailed in Table 2.
Genotype-specific analysis
6.2.
We also investigated whether the model outcomes would differ according to the genotypes of the subjects (i.e., HAB and MAB). Table 3 presents the -values of the Mann–Whitney U test, comparing the quantitative scores in two distinct genotype groups. The results indicate that all models showed no statistically significant differences in values, IoU metrics, or peak bias, suggesting that the models produce similar AIF shapes, peak values, and integrals regardless of the genotype differences. However, there was a statistically significant difference in RMSE during the first 30 min across all models, indicating that the average magnitude of the prediction errors significantly varies between the two groups during the peak phase. This discrepancy is likely due to inherent differences in peak AIF values and the uptake of pharmaceuticals in brain tissues between genotypes. Statistical analysis confirmed significant differences in the mean and peak AIF values between the two genotypes, with -values ≪ 0.001. Conversely, the proposed DLIFs reported non-significant RMSE scores in predictions for the tail phase (i.e., longer than 30 min). In contrast, both ConvNeXt and EPICA exhibited significant differences in RMSE scores between the two genotype groups during this phase. The consistency in RMSE observed with the DLIFs beyond 30 min likely benefits from the inclusion of basis functions, demonstrating robust performance in the later stages of AIF analysis despite variations in genotypes.
Architectural flexibility of DLIF
6.3.
The quantitative scores presented in Tables 1 and 2 show that ConvNeXt performs comparable to the proposed method. This outcome aligns with the foundational design objectives of ConvNeXt, which was conceived as a robust alternative to vision Transformers. It is imperative to note that the proposed DLIF framework is designed to be agnostic of any specific network architecture, thus facilitating the easy incorporation of future sophisticated architectures to potentially enhance performance measures. As such, ConvNeXt could be effectively used as the backbone for the DLIF framework. However, the decision to employ ViT in this research is based on its ability to visualize attention mechanisms, providing an explainable model for the network predictions, which is essential for validation and interpretation in clinical contexts.
Interpretability through attention maps
6.4.
DL models are often described as “black-box” models due to their limited ability to explain how specific estimates are derived. However, a notable advantage of using ViT within the DLIF framework is its inherent capability to generate attention maps, elucidating the regions of focus during prediction. Fig. 8 illustrates attention map visualizations from the final self-attention layer of the ViT for sixteen randomly selected datasets across various DLIF configurations. Given that DLIF aims to directly estimate metabolite-corrected AIFs from dynamic PET images reflecting radiotracer uptake in the brain, it is expected that the ViT predominantly attends to regions of high uptake (higher intensity voxels). In the “Direct Est.” configuration, while the ViT’s attention is generally centered on the brain tissue, it occasionally diverts to less pertinent background regions. The introduction of basis functions without peak estimation or sparsity enforcement, seen in the “Gaussian” and “Exp.” configurations, led to attention mechanisms occasionally fixating on confined background regions, making interpretation non-intuitive. Imposing sparsity constraints slightly refined the attention mechanisms’ focus within the brain, although some attention still lingered on the background. In contrast, integrating peak estimation markedly improved focus on brain regions, with attention spreading to areas of high uptake, especially evident in the “Gaussian+Peak” and “Exp.+Peak” configurations. However, adding a sparsity constraint redirected the attention mechanisms towards the background again, possibly because enforcing sparsity prompted the ViT to leverage small values in these regions to assign smaller weights to certain basis functions.
Generalizability of the DLIF framework
6.5.
We evaluated the generalizability of the proposed DLIF framework by testing it on two new tasks designed to probe its adaptability and potential for transfer learning. First, to assess robustness to hardware variability, we applied DLIF to 21 [^11^C]DPA-713-TSPO-PET dynamic scans acquired on a newer generation scanner (Siemens Biograph mCT, a time-of-flight whole body system). Second, to examine adaptability across tracers, we applied DLIF to 10 [^11^C]CPPC-CSF1R-PET dynamic scans acquired with [^11^C]CPPC on the Siemens Biograph mCT system (Coughlin et al., 2022; Horti et al., 2019; Mills et al., 2025). [^11^C]CPPC binds to a different target, CSF1R, and exhibits pharmacokinetic properties very distinct from [^11^C] DPA-713, which binds to TSPO. Compared to [^11^C]DPA-713, [^11^C]CPPC exhibits a slower washout and lower peak in the AIF, representing behavior not encountered during the original DLIF training. All PET images were normalized to SUVs and the datasets included associated metabolite-corrected AIFs.
For both tasks, we first evaluated the zero-shot capability of DLIF framework by directly applying the model trained on [^11^C]DPA-713 data from HRRT scanners. We then fine-tuned the model by allowing only the estimation heads and the final Transformer block to remain trainable, while freezing all other parameters. The model was fine-tuned for 100 epochs with a learning rate of 1e–4. This transfer learning strategy reduces the number of trainable parameters, enabling effective adaptation to new domains under limited data availability while mitigating overfitting. We performed five-fold cross-validation for both tasks, with each fold using 8:2 split for training and evaluation.
New scanner
6.5.1.
The left panel of Fig. 9 shows two examples of DLIF estimates compared with the ground-truth AIFs. Despite the change in scanners, the DLIF outputs without fine-tuning closely matched the reference AIFs, though with slightly lower peak values. This observation is corroborated by the quantitative results in the upper panel of Table 4, where zero-shot application of the DLIF framework to the new scanner data achieved performance comparable to that reported in Table 1, which was obtained from test images drawn from the same distribution as the training dataset. Specifically, the correlation coefficient remained around 0.95, IoU values exceeded 0.7, and both RMSE and peak bias were relatively small across all three DLIF variants. These findings indicate that the proposed DLIF framework achieves strong zero-shot performance for [^11^C]DPA-713 scans acquired on different scanners, suggesting that it captures prior knowledge of [^11^C] DPA-713 AIFs in a manner largely invariant to scanner differences. Further investigation is needed to determine whether this robustness extends to additional scanner types and acquisition protocols.
Although the zero-shot performance was already strong, additional improvements were achieved through fine-tuning. Qualitative results in Fig. 9 demonstrate a closer match between the DLIF estimates and the ground-truth AIFs after fine-tuning. Quantitative scores in Table 4 also showed statistically significant gains, particularly in shape and peak matching, with the best performance achieved by the “Gaussian+Peak+Sparse” variant. Improvements were most pronounced in peak-related metrics: IoU and RMSE within the first 30 min, as well as peak bias, all showed significant improvement relative to their zero-shot counterparts, whereas performance during the later 60–90 min period remained comparable.
New tracer & scanner
6.5.2.
The right panel of Fig. 9 illustrates results for [^11^C]CPPC. In this case, the pretrained DLIF model failed to produce accurate predictions, with both the peak amplitude and overall AIF shape deviating substantially from the ground truth. Quantitative results in the lower panel of Table 4 confirm this observation: without fine-tuning, the correlation coefficient remained in the suboptimal range of 0.7–0.8, IoU values were consistently below 0.7, and both RMSE and peak bias were relatively high. These findings support our hypothesis that a model trained exclusively on [^11^C]DPA-713 data develops prior knowledge specific to [^11^C]DPA-713 AIF characteristics, which enables robustness to scanner variability but limits generalization to tracers unseen from training with distinct pharmacokinetics such as [^11^C] CPPC.
The key question is whether the DLIF framework trained on [^11^C]DPA-713 can be effectively transferred to [^11^C]CPPC, which was also acquired on a different scanner (mCT instead of HRRT). The results demonstrate that it can: with only eight subjects used for fine-tuning in each fold, performance improved substantially. This improvement is evident in both the qualitative results (Fig. 9) and the quantitative results (Table 4), where the scores became comparable to those obtained on [^11^C]DPA-713 data (Table 1). Consistently, most metrics also showed statistically significant improvements relative to their zero-shot counterparts.
In this work, the metabolite-corrected AIFs were used as ground truth for training; therefore, the DLIF framework directly predicts metabolite-corrected AIFs without explicitly modeling metabolite kinetics. For tracers that do not produce metabolites, require whole-blood rather than metabolite-corrected input functions, or exhibit tracer-specific metabolite behavior such as metabolites crossing the blood–brain barrier, additional training or transfer learning using the appropriate input functions would be required. Despite these tracer-specific considerations, the underlying DLIF framework is general and can be adapted beyond the current scope. Although this study focused on dynamic PET imaging of the brain, the framework can, with fine-tuning on small tracer-specific datasets or retraining with new data, be extended to other tracers, anatomical regions, and imaging protocols. Overall, these findings highlight the potential of DLIF to provide accurate and fully non-invasive estimates of arterial input functions across diverse PET imaging applications.
Compartment analysis using DLIF
6.6.
Given the close agreement between the DLIF- and AIF-derived curves, we further investigated whether DLIF could be extended beyond Logan graphical analysis to support full compartmental modeling. As a proof of concept, we analyzed a representative [^11^C]DPA-713 scan acquired on the Siemens Biograph mCT scanner (as described in Section 6.5.1) using the fine-tuned DLIF model for AIF estimation. A two-tissue compartment model was applied, and the total distribution volume values across multiple brain regions were compared with those obtained using ground-truth AIFs. The results are presented in Appendix B (Fig. B.10), which shows a correlation plot where the -axis represents estimates derived from ground-truth AIFs and the -axis represents those derived from DLIF, with each circle corresponding to a distinct brain region. The correlation between DLIF- and AIF-based estimates was close to unity (dashed line), indicating strong agreement. An example fit for the frontal cortex further demonstrates that the DLIF- and AIF-driven model fits closely overlap. This proof-of-concept analysis illustrates that DLIF-derived AIFs can reliably support compartmental kinetic modeling, highlighting their potential utility beyond simplified approaches such as Logan graphical analysis.
Conclusion
In this study, we introduced DLIF, a deep learning-based framework designed to non-invasively estimate AIF, entirely eliminating the necessity of invasive arterial blood sampling. The DLIF framework incorporates prior physiological knowledge from existing literature by representing AIFs using continuous basis functions, such as Gaussian and exponential-sigmoid functions. By leveraging the flexibility of DNNs, DLIF accurately models complex temporal dynamics through an overcomplete representation of these basis functions, producing input functions as combinations of individually predicted parameters. Unlike traditional methods, including IDIF and PBIF, which yield a non-personalized estimation of AIF (Zanotti-Fregonara et al., 2012; Boutin et al., 2007) or often require a scaling factor from single or multiple time points invasive arterial or venous blood sampling to calculate AIFs for patients (Zanotti-Fregonara et al., 2011; Takikawa et al., 1993; Naganawa et al., 2005a,b, 2008; Litton, 1997; Chen et al., 1998), DLIF completely avoids such invasive procedures. It offers fast and robust estimation of AIFs using only the subjects’ dynamic PET sequences. This makes the DLIF framework a promising tool for broader adoption of dynamic PET imaging in routine clinical settings, replacing current semi-quantitative analysis methods. This advancement could substantially enhance diagnostic accuracy for neurological conditions such as Alzheimer’s disease and Parkinson’s disease, particularly during early-stage evaluations.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ba JL, Kiros JR, Hinton GE, 2016. Layer normalization. ar Xiv preprint ar Xiv: 1607.06450.
- 2Bödvarsson B, Mørkebjerg M, Hansen LK, Knudsen GM, Svarer C, 2006. Extraction of time activity curves from positron emission tomography: K-means clustering or non-negative matrix factorization. Neuroimage 31 (Suppl 1), S 154.
- 3Boutin H, Chauveau F, Thominiaux C, Gregoire M-C, James ML, Trebossen R, Hantraye P, Dolle F, Tavitian B, Kassiou M, 2007. 11C-DPA-713: A novel peripheral benzodiazepine receptor PET ligand for in vivo imaging of neuroinflammation. J. Nucl. Med 48 (4), 573–581.17401094 10.2967/jnumed.106.036764 · doi ↗ · pubmed ↗
- 4Carson RE, 2005. Tracer kinetic modeling in PET. In: Positron Emission Tomography: Basic Sciences. Springer, pp. 127–159.
- 5Chauveau F, Boutin H, Camp NV, DolléF, Tavitian B, 2008. Nuclear imaging of neuroinflammation: a comprehensive review of [11C]PK 11195 challengers. Eur. J. Nucl. Med. Mol. Imaging 35 (12), 2304–2319.18828015 10.1007/s 00259-008-0908-9 · doi ↗ · pubmed ↗
- 6Chen K, Bandy D, Reiman E, Huang S-C, Lawson M, Feng D, Yun L.s., Palant A, 1998. Noninvasive quantification of the cerebral metabolic rate for glucose using positron emission tomography, 18f-fluoro-2-deoxyglucose, the Patlak method, and an image-derived input function. J. Cereb. Blood Flow & Metab 18 (7), 716–723.9663501 10.1097/00004647-199807000-00002 · doi ↗ · pubmed ↗
- 7Chen J, Jiang Z, Coughlin J, Pomper M, Du Y, 2023. Estimating arterial input function for dynamic PET via deep regression. In: 2023 IEEE Nuclear Science Symposium, Medical Imaging Conference and International Symposium on Room-Temperature Semiconductor Detectors. NSS MIC RTSD, IEEE, 1–1.
- 8Coughlin JM, Du Y, Lesniak WG, Harrington CK, Brosnan MK, O’Toole R, Zandi A, Sweeney SE, Abdallah R, Wu Y, , 2022. First-in-human use of 11C-CPPC with positron emission tomography for imaging the macrophage colony-stimulating factor 1 receptor. EJNMMI Res. 12 (1), 64.36175737 10.1186/s 13550-022-00929-4PMC 9522955 · doi ↗ · pubmed ↗