StarMA Net: A star-shape multi-scale attention network for medical imaging classification
Junyang Cao, Junrui Lv, Xuegang Luo, Siyu Lai, Juan Wang, Bochuan Zheng

TL;DR
The paper introduces StarMA Net, a new neural network for medical image classification that improves accuracy by better capturing spatial and channel relationships.
Contribution
StarMA Net introduces a novel star-shaped multi-scale attention mechanism to enhance feature representation and inter-class discrimination in medical imaging.
Findings
StarMA Net outperforms existing methods in classification accuracy and robustness across five medical imaging datasets.
The proposed attention mechanism improves the model's ability to handle intra-class variability and complex structures.
Cross-spatial aggregation enhances the integration of multi-scale contextual information.
Abstract
Medical image classification is crucial for clinical diagnosis. However, medical datasets often face challenges such as limited characterization capabilities, difficulties in category differentiation, and the presence of individual differences. Although attention mechanisms can enhance feature representation, existing methods often struggle to utilize spatial information effectively and lack modeling of inter-channel interactions. We propose star-shaped multi-scale attention (StarMA). (1) It retains spatial information along different orientations within each channel through axial decomposition, enhancing the model’s perception of complex structures. (2) A star-shaped structure is employed to project feature maps into a high-dimensional nonlinear space, strengthening inter-channel interactions and improving inter-class discriminability. (3) A cross-spatial aggregation learning strategy…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
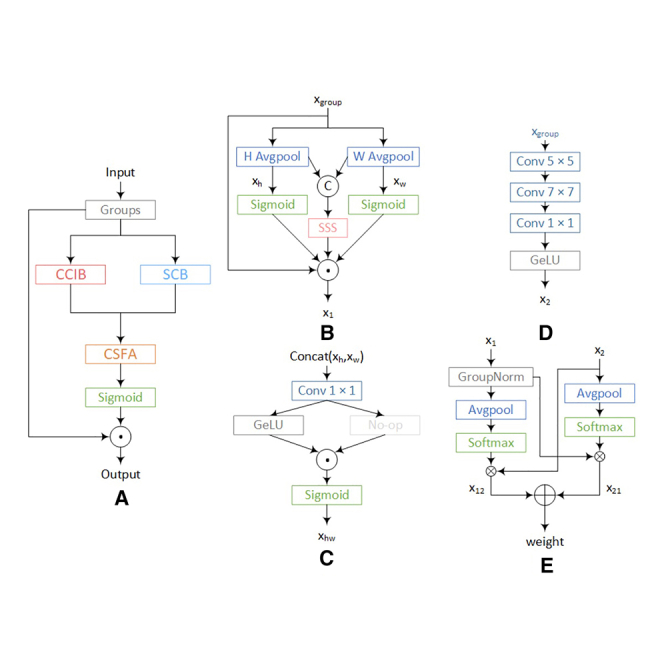 Figure 1
Figure 1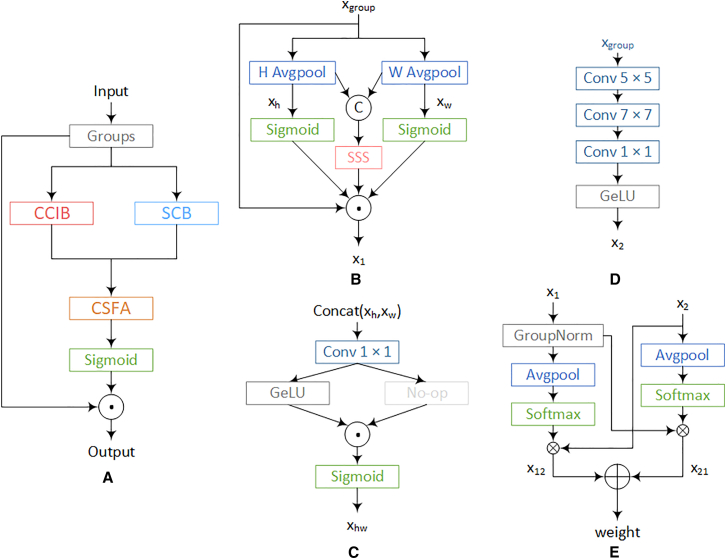 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4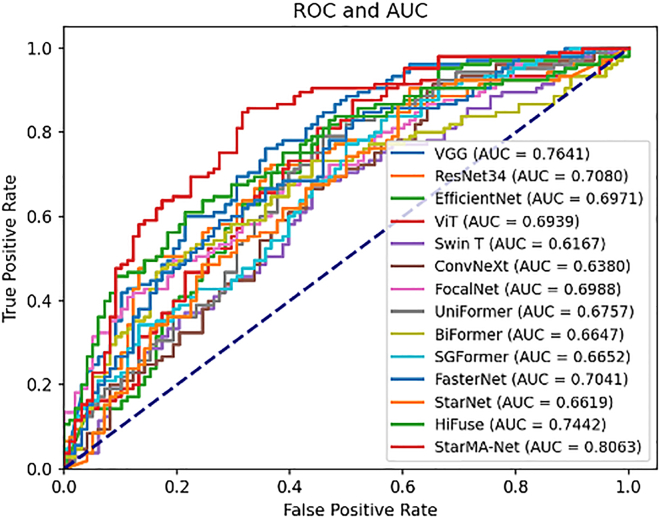 Figure 5
Figure 5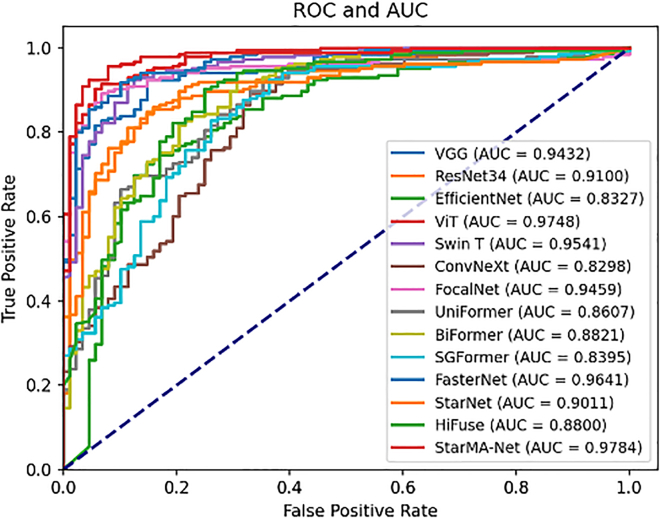 Figure 6
Figure 6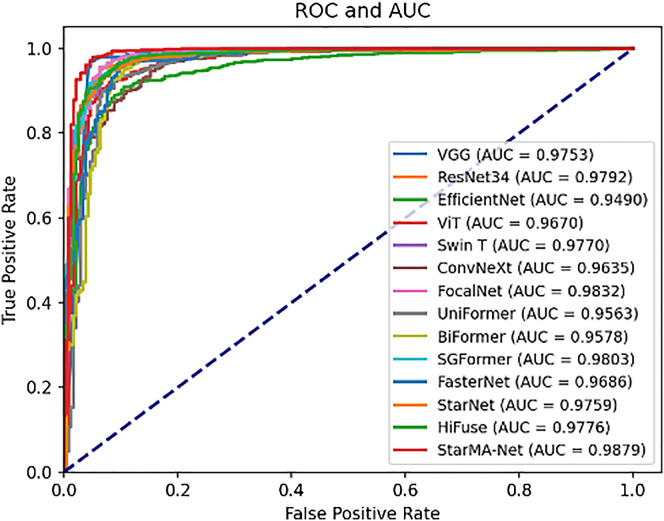 Figure 7
Figure 7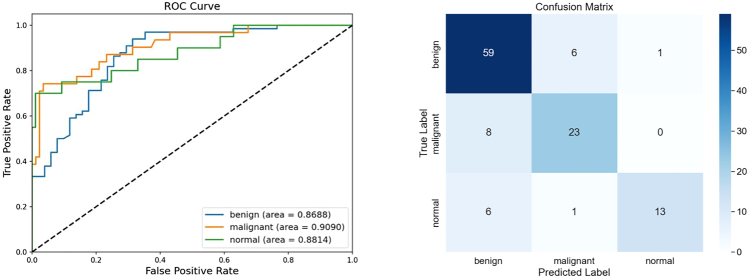 Figure 8
Figure 8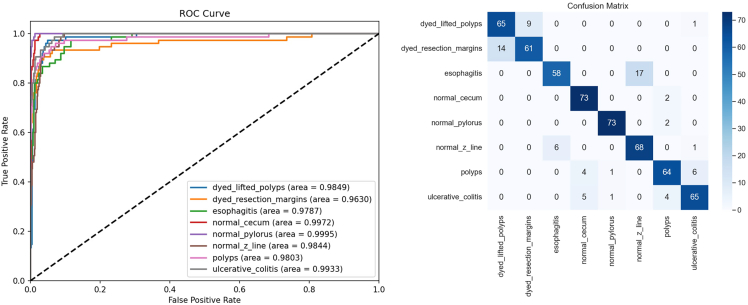 Figure 9
Figure 9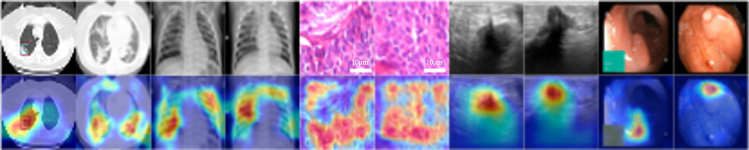 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCOVID-19 diagnosis using AI · AI in cancer detection · Medical Imaging and Analysis
Introduction
Medical image classification is crucial in medical imaging, significantly assisting doctors in clinical diagnosis. Mainstream diagnostic modalities such as ultrasound, endoscopy, and computed tomography (CT) play a pivotal role in diagnosing diseases early and evaluating treatment plans. Accurate classification of these medical images is essential for early disease detection and assessment of treatment efficacy. However, medical images often exhibit significant noise, and images of lesion areas frequently possess complex details, such as irregular shapes, varying sizes, and a lack of distinguishing features between categories, which contribute to the complexity of the task.1 Recently, deep learning has shown outstanding performance in natural image processing, prompting researchers to apply deep learning models to medical image tasks such as classification, segmentation, and target detection.2^,^3
Currently, models widely used in medical image classification fall into convolutional neural network (CNN)-based models and Transformer-based models.4 Both play key roles in the field of medical imaging. Computer-aided systems based on CNNs can effectively capture local information in images and have superior image classification performance. However, due to the inherent locality of the convolution kernel, CNNs focus on the fusion of local features,5 lacking an understanding of long-range dependencies in images, which is crucial to reflect the comprehensive information of the entire image. Attention mechanisms enable models to better capture global contextual information and effectively integrate long-range dependencies. Owing to their flexible structure, they facilitate the learning of more discriminative feature representations and can be seamlessly integrated into CNN backbones. As a result, CNN-based models incorporating attention mechanisms have been widely adopted. However, modeling cross-channel relationships through channel dimensionality reduction may have adverse effects on extracting deep visual representations.6
The self-attention mechanism in Transformer models effectively captures global context, encodes long-term dependencies, and has highly expressive representations.7 Consequently, Transformer-based models excel in image classification, segmentation, and other domains and are widely adopted. However, Transformer architectures have some limitations. Compared to CNNs, Transformer has a weaker ability to extract local information. This can lead to poor performance when the target area in an image is small, such as lesion areas in medical images. Additionally, the self-attention mechanism maps features to different spaces and constructs attention matrices through dot products, which is computationally inefficient and results in quadratic complexity with the increase in the number of tokens.8
Although advanced CNN-based and Transformer-based models achieve high performance on natural images, their effectiveness in medical image processing is often limited. For instance, models such as ConvNeXt9 and Vision Transformer10 have complex architectures and numerous parameters, requiring large and comprehensive datasets for training. Unlike natural images, which are abundant in quantity and variety, medical images typically suffer from limited data and significant class imbalances. Additionally, while CNN-based models can reduce complexity by employing deep separable convolutions,11 these decomposed convolution operations may inadequately capture the subtle and significant features present in medical images.
To address these issues, we propose a star-shaped multi-scale attention (StarMA) mechanism. Building upon StarMA, we also introduce a visual backbone network designed for the accurate classification of medical images. We conducted experiments on datasets from five different modalities, Chest X-ray, BreakHis 400X, COVID-19 CT, BUSI, and Kvasir, to assess the generalizability of our proposed method. The results indicate that our algorithm performs exceptionally well on medical image datasets across various modalities, outperforming existing CNN-based and Transformer-based backbone networks. Our contributions are summarized as follows:
- 1.A StarMA mechanism is proposed to capture multi-scale information, enhance feature representation, and improve model generalization, enabling accurate identification of lesions with varying shapes and sizes.
- 2.We consider the star-shaped structure, which enhances inter-channel information interaction and improves inter-class discriminability by mapping feature representations into a high-dimensional nonlinear space.
- 3.Multi-scale cross-spatial feature aggregation is implemented to generate more discriminative feature representations through cross-dimensional interactions, effectively integrating multi-scale contextual information and enhancing the model’s ability to adapt to intra-class variations.
- 4.Building upon the StarMA attention mechanism, we propose a visual backbone: StarMA Net, which demonstrates superior classification performance and generalization capability across five different modalities of medical imaging datasets when compared to other state-of-the-art deep learning models.
Related work
Medical image classification is a crucial area of research for supporting clinical decision-making. This paper reviews recent advancements in the field, including the application of CNNs and Transformers to medical imaging, as well as the role of attention mechanisms and their applications in medical image analysis.
Applications of CNN in medical image analysis
Given the excellent performance of CNNs in natural image analysis, they are increasingly being applied to clinical-assisted diagnosis. Chen et al. established CNNs with UNet and residual neural network (ResNet) for image segmentation, from venous duplex ultrasonographic video images.12 Wang et al. evaluated the diagnostic performance of a multimodal deep learning (DL) model for ovarian mass differential diagnosis.13 Cheng et al. proposed a modular grouping attention block to capture key medical images from space, channel dimension, and their respective features, thereby improving classification performance.14 Cao et al. proposed an AI underdiagnosis bias discrimination pipeline for COVID-19.15 Jin et al. applied deep learning to achieve an accurate prediction of whole slide image (WSI) images for glioma.16 Wei et al. developed a 3D deep learning model to predict nonsteroidal anti-inflammatory drug efficacy for migraine.17 Kora et al. showed that transfer learning can achieve good results in medical image classification by fine-tuning the output of the last fully connected layer in the pre-trained ResNet-152 model.18 Shen et al. introduced a multi-scale crop pool strategy for DCNN to capture pulmonary nodule classification features in chest CT images.19 However, the convolution kernel has been focusing on local feature extraction, failing to collect enough contextual information and lacking an understanding of remote dependencies in the image, which is crucial in reflecting comprehensive details on the entire image.
Applications of Transformer in medical image analysis
Due to its strong capacity to capture long-range dependencies and learn global information, the Transformer is increasingly being utilized in medical image classification.20
Gheflati et al. used ViT to classify breast ultrasound images, and the effect was better than CNN.21 Sha et al. developed a hybrid CNN-Transformer-GRU model to enhance cervical lesion multi-classification.22 Li et al. proposed a local and global vision converter (LG-ViT) for the reconstruction of MRF parameters.23 Ding et al. proposed an automatic skin lesion segmentation network, named CTH-Net.24 Li et al. propose ViT-WSI, which is suitable for weakly supervised learning on histopathological images.25 Zhou et al., utilizing Transformer-based RNA sequential learning and high-order proximity preserved embedding, predict circRNA- microRNA interactions.26 Xu et al. designed a dual-branch encoder that combines a CNN and a Transformer to achieve accurate segmentation of skin lesions.27
While Transformers have made great strides in computer vision, Transformers’ self-attention mechanism often ignores local feature details. As a result, it is challenging for the model to distinguish the lesion area from the background when the lesion area in the medical image is small or the inter-class feature differentiation is low. In addition, Transformer-based models typically have numerous parameters and require extensive datasets for effective training, which is difficult to achieve for some medical images with relatively small amounts of data.
Attention mechanism and its applications in medical image analysis
In recent years, attention mechanisms have emerged rapidly in computer vision. Woo et al. proposed the Convolutional Block Attention module (CBAM), which is a simple and effective feedforward CNN attention module.28 Wang et al. proposed an efficient channel attention (ECA) module. Through appropriate cross-channel interaction, the model complexity can be significantly reduced, while the performance can be maintained.29 To capture pixel-level pairings and channel dependence, Zhang proposed an efficient Shuffle Attention (SA) module to solve the problem of computational overhead.30 Through appropriate cross-channel interaction, the model complexity can be significantly reduced while maintaining performance. Liu et al. propose a new normalization-based attention module (NAM) that suppresses less-significant weights.31 Hou et al. proposed coordinate attention (CA) to enhance feature aggregation by embedding spatial location information into the channel attention graph.32 The EMA parallel substructure proposed by Ouyang et al.6 helps the network avoid more sequential processing and large depth, effectively describes the learning channel, and generates better pixel-level attention to advanced feature mapping. Hu et al. proposed a new architectural unit SE, which adaptively recalibrates the channel feature response.33 Guo et al. propose Large Kernel Attention to avoid the limitations associated with neglecting adaptability in the channel dimension.34 Liu et al. utilized the dual-branch channel-spatial feature enhancement network and the coordinated attention mechanism to address the diagnostic challenges brought about by small pulmonary nodules and poor contours.35 Xiang et al. overcame the difficulty of processing billion-pixel images like WSI by using two-branch deep neural networks and multi-scale representation attention mechanisms to extract features directly from all patches of each WSI.36 Tang et al. designed a two-stream attention neural network centered on texture and shape to judge benign and malignant thyroid nodules.37 Fan et al. proposed an attention-based auxiliary framework for jointly localizing and classifying breast masses in ultrasound images.38
In recent years, attention mechanisms have achieved remarkable success in image classification. They can generate more discriminative feature representations and enhance model performance. However, while CBAM, ECA, and CA are, respectively, limited by problems such as single-dimensional interaction, spatial information deficiency, or scale imbalance, StarMA has achieved spatial-channel joint modeling, high-dimensional nonlinear mapping, and multi-scale fusion through a star-shaped multi-scale framework, significantly enhancing the ability to capture subtle lesion differences and complex structures in medical images.
To address the above issues, we propose a multi-scale attention module. This mechanism extracts subtle inter-class differences in medical images through cross-spatial feature aggregation, while leveraging a star-shaped structure to capture subtle intra-class similarities. StarMA demonstrates superior classification performance on medical imaging tasks compared to other attention mechanisms. Building upon StarMA, we developed a type of visual backbone and conducted experiments on datasets of various imaging methods.
Results
Materials and methods
In this section, we first introduce the StarMA module, followed by the medical image classification network StarMA Net, which is built upon it.
Star-shaped multi-scale attention
StarMA retains spatial information along different directions within each channel through axial decomposition, enabling the capture of shared key features across individuals and enhancing the model’s recognition ability for various shapes and sizes of lesion areas. This dynamically strengthens the model’s response to key areas and reduces the influence of irrelevant or noisy places. In the star structure of the StarMA module, we perform element-wise multiplication between the input features and the multi-scale context features, achieving explicit fusion and enhancement of the features. This operation enhances the interaction information in the channel and spatial dimensions, effectively capturing the local and global dependencies. Subsequently, we use nonlinear activation functions (such as GeLU) and learnable linear transformations to transform the node features, enabling them to obtain richer expressions in the higher-dimensional implicit feature space and fully exploit the expressive power of the high-dimensional implicit feature space.
Additionally, a cross-spatial aggregation learning strategy is introduced to effectively integrate multi-scale contextual information, enhancing the model’s ability to adapt to intra-class variations while extracting more discriminative inter-class features. A schematic illustration of the proposed StarMA is shown in Figure 1. In the following, we provide a detailed description of its design.Figure 1. StarMA structure diagram(A) Overview of StarMA structure.(B) CCIB, cross-channel information interaction branch.(C) SSS, star-shape structure.(D) SCB, stacked convolution branch.(E) CSFA, cross-spatial feature aggregation.© Represents concat, ☉represents element-wise multiplication operation, ⊕ represents element-wise addition operation, and ⊗ represents matrix multiplication operation.
Feature grouping
We first divide the input feature map X along the channel dimension into N sub-features, denoted as . Each sub-feature is responsible for learning semantic information. The learned attention weight descriptors are used to reweight the feature representations of the regions of interest within each sub-feature.
Cross-channel information interaction branch
To capture inter-channel dependencies, we construct a cross-channel information interaction module, referred to as CCIB, to enhance the fusion and representation of multi-scale features, as shown in Figure 1B. This enables the model to effectively integrate lesion characteristics at different scales. Specifically, we perform axial decomposition to independently process two types of spatial information—along the height (H) and width (W) directions—in separate branches. This decomposition method can reduce the computational complexity, while still maintaining the modeling capability of long-term dependence. More importantly, for medical images, anatomical structures (such as blood vessels and lesion boundaries) usually extend mainly along a certain axis (vertical or horizontal). By separately modeling the H and W directions and combining them, the axial design can better capture the continuity in this direction compared to the traditional spatial attention mechanism. Lesions and tissue structures often show directional extension, and the independent modeling along the H/W direction enables the network to capture these continuous and structured patterns on a single axis. It will not be diluted by the mixed information in the other direction. It learns more refined dependency relationships in the vertical and horizontal directions, respectively, while retaining richer spatial details, thereby enhancing the model’s perception of complex structures and improving its ability to handle intra-class variations within the lesion area. Specifically, pooling kernels of size (H, 1) and (W, 1) are applied to encode the input x along the H and W directions for each channel, as shown in the Equation 1:
To establish inter-channel dependencies and enhance channel-wise interactions, a star-shaped structure is employed to improve the model’s discriminative ability in identifying lesion regions associated with different disease types. Unlike StarNet, we perform concatenation and downsizing operations on the obtained features along the h direction. Then, a star operation is adopted. At this point, the high-dimensional features contain not only height information but also width information. Each channel has complete row/column statistical features in the H + W dimension. In the subsequent 1 × 1 conv, interaction can be carried out on channels spanning h and w. The Star-shape structure is shown in the second formula in Equation 4,
Subsequently, the Sigmoid function is applied to generate attention weights for the features extracted along the H and W directions. These weights, along with the output of the star-shaped structure, are then aggregated via element-wise multiplication to obtain cross-channel interactive features. Finally, the resulting attention map is used to reweight the input features. The detailed operation is defined in Equation 3,
Star-shape structure
The lesion areas of some diseases often lack distinct distinguishing features, and the boundaries between classes are ambiguous. Therefore, effective recognition depends not only on spatial features but also on the subtle dependencies among the channels encoding the semantic attributes of lesions, which increases the complexity of the classification task. Therefore, we propose the SSS in Figure 1C. The high-dimensional space facilitates more effective modeling of inter-channel correlations and improves the model’s ability to capture complex feature patterns, thereby enhancing its discriminative power for lesion regions associated with different disease types. In addition, the star-shaped structure contributes to stronger modeling of inter-channel dependencies, enabling more effective information flow across channels. It further allows fine-grained weighting of different regions in the feature map, improving the model’s attention to both local and global features.
Specifically, a 1 × 1 convolution with a stride of 2 is employed for downsampling. The downsampled features are then passed through two separate branches, one of which incorporates a nonlinear activation function to increase nonlinearity. Finally, the features from both branches are fused using element-wise multiplication.
The mathematical formulation of the star-shaped structure is given by Equation4. Overall, this structure projects the features into a high-dimensional implicit feature space, enhancing the modeling of inter-channel correlations. It provides the model with richer representational capacity, enabling it to capture more complex feature patterns.
Stacked convolution branch
To overcome the limitations of a single spatial scale and enable the model to capture key features shared across different individuals, thereby improving its ability to adapt to intra-class variations, a multi-scale modeling strategy is adopted in this study. Specifically, a branch, referred to as SCB, is constructed by stacking convolutional layers, as shown in Figure 1D. The SCB, in tandem with the CCIB, builds multi-scale spatial feature representations. By stacking convolutional layers with different kernel sizes (7 × 7, 5 × 5, 1 × 1), the receptive field is expanded, enhancing the model’s spatial adaptability and enabling it to extract rich contextual information. At the same time, the stacked convolutional layers progressively extract more complex and higher-level features, allowing the model to capture finer patterns and structures, thus effectively mitigating the risk of overfitting and improving generalization. Furthermore, the use of convolutional kernels of different sizes from those in the axial decomposition branch helps capture multi-scale features, allowing the model to adaptively focus on regions of interest and enhancing its robustness and adaptability in complex scenarios. Finally, the GeLU activation function is applied to introduce nonlinearity, enabling the model to learn and represent more complex spatial features, as defined in Equation 5,
Cross-spatial feature aggregation
To enable the model to extract and integrate spatial information across different scales, capture intra-class features, and enhance adaptability to intra-class variations, we propose the CSFA, as shown in Figure 1E. This method establishes mutual dependencies between channels and spatial locations. While preserving the local information of each spatial location, it effectively captures the global contextual information across different channels, allowing the model to more accurately capture fine-grained features and share global context between channels, thereby improving its attention to important regions.
Specifically, the output ×1 of the CCIB undergoes a Group Normalization operation, and the global spatial information is encoded using 2D global average pooling. Then, a 2D Gaussian mapping’s natural nonlinearity is applied through the Softmax function on the output of the 2D global average pooling to provide a nonlinear mapping. The resulting output is then multiplied with ×2 via matrix dot product to obtain the global spatial attention representation ×12 on the current scale.
Based on this, the output ×2 from the SCB undergoes pooling and is subjected to the Softmax function to obtain a normalized channel descriptor. The matrix dot product between this output and ×1 is then computed, generating the second attention map ×21, which retains precise spatial location information, as defined in Equation 6,
Finally, the two generated spatial attention weights from each group are aggregated to produce the output feature map. Subsequently, the Sigmoid function is applied to create the weights, resulting in the final attention weight descriptor, and it is multiplied by the input to obtain the final output:
To more clearly illustrate the specific process of the scale fusion algorithm, we have written the pseudo-code as Algorithm 1.Algorithm 1The algorithmic process of scale fusionInput: x1, x2 x1 is the output of the CCIB path x2 is the output of the SCB pathOutput: weight weight is the final attention map1. x1 ← GroupNorm(x1)2. x2 ← x23. x11 ← Softmax(AvgPool(GroupNorm(x1)))4. x22 ← Softmax(AvgPool(x2))5. x12 ← x11 ⊗ x26. x21 ← x22 ⊗ x1 ⊗ represents matrix multiplication7. weight ← x12 + x21Output: weight
Network structure
CNNs have achieved significant success in computer vision tasks such as image classification and object detection. However, their performance tends to degrade rapidly in complex tasks involving low-resolution images or small objects.39 Transformer-based models, on the other hand, typically require large amounts of data for effective training. In contrast to the abundant natural images, most medical images are limited in quantity. Utilizing such high-complexity networks often leads to overfitting on the training set, resulting in poor model robustness and generalization. Therefore, we have designed a visual backbone to enable the accurate classification of multiple medical image datasets, as shown in Figure 2.Figure 2. Overall structure of the StarMA Net
The model consists of three components: an input stream, intermediate layers, and an output stream. The input stream includes two convolutional layers and three Base Blocks, performing four stages of spatial resolution reduction. Specifically, the input image is first processed by two convolutional layers with 3 × 3 kernels to perform downsampling, extract local features, and enhance training stability.
Subsequently, three Base Blocks are employed for further downsampling. Each Base Block is composed of a 3 × 3 convolution, followed by Batch Normalization and a GELU activation function, as illustrated in Figure 3 left. A max pooling layer is used to reduce the size of the feature maps while preserving essential features, and a Drop Path layer is embedded to prevent overfitting.Figure 3. Base Block and StarMA Block⊕ Represents adding by elements.
The intermediate layers of the model are composed of four StarMA Blocks, responsible for feature extraction. At this stage, no downsampling is performed, and the input and output dimensions remain consistent across all layers. Specifically, each StarMA Block first applies a 3 × 3 convolution to the input x, and the resulting feature maps are subsequently passed to the attention module for further processing. The structure of the StarMA Block is illustrated in Figure 3 (right).
The attention layer consists of two 3 × 3 convolutional layers followed by a StarMA module. After processing through the attention layer, the output is denoted as xa
By utilizing the weight calculation of multi-scale attention, the model can dynamically emphasize the feature responses of different spatial positions and channels. Based on the calculated attention weights, weighted summation or element-by-element multiplication of multi-scale features is performed to dynamically enhance the model’s response to key regions and reduce the influence of irrelevant or noisy regions.
To enhance the model’s generalization capability, we introduced a Drop Path layer in the StarMA Block. By randomly discarding certain branches, this approach helps to mitigate the problem of model overfitting. The DA is xa after passing through the Drop Path layer. The original input x of DA element is added by element, to get the output:
In this module, we employ a multi-layer perceptron to perform nonlinear mapping and transformation on the input features to obtain M. This process facilitates the model in learning abstract representations of the features, thereby enhancing its ability to capture higher-level features and patterns within the input data. The output M, after passing through the Drop Path layer, is transformed to DM. Finally, DM is elementwise added toxattn, followed by the GELU activation function to introduce nonlinearity. The resulting output constitutes the final output of the StarMA layer, as illustrated in Equation 10:
The output stream of the network begins with a Normal Block, which further refines the features produced by the StarMA Blocks to enhance feature representation and improve the model’s discriminative capability. This is followed by a sequence of a 3 × 3 convolutional layer, a 1 × 1 convolutional layer, a Batch Normalization layer, and a GELU activation function, which together perform additional downsampling. This process facilitates the extraction of more meaningful features while reducing the spatial dimensions of the feature maps, thereby lowering computational complexity and improving efficiency for the subsequent global average pooling and fully connected layers.
Experiment and results
To evaluate the effectiveness and generalization capability of the StarMA Net model, we conducted a series of experiments on five public medical image datasets (COVID-19 CT,40 BreakHis 400,41 Chest X-ray,42 BUSI,43 and Kvasir Dataset44) across different modalities. In the following sections, we will present and analyze the experimental results of our method on five datasets. Additionally, to ensure the performance of our attention mechanism, we conducted a series of ablation experiments to verify the effectiveness of the StarMA we proposed.
Experimental results
To evaluate the performance of the StarMA Net model, we compared it with several state-of-the-art models from recent years, including VGG19,45 Vision Transformer,10 Swin Transformer,46 EfficientNet,47 ResNet,48 ConvNeXt,9 Biformer,49 FocalNet,50 UniFormer,51 SGFormer,52 FasterNet,53 StarNet,8 and HiFuse,54 which perform well on medical images. The training parameters were consistent across the five datasets, and the highest validation accuracy was recorded for testing. The results from all test sets were summarized and compared to assess the effectiveness of the proposed network.
Result on COVID-19 CT
We applied the data partitioning method described in the literature41 to divide the dataset. Table 1 summarizes the evaluation of our proposed model and other advanced models on the COVID-19 CT dataset. Table 1 shows that network architectures optimized for large datasets, such as Swin Transformer and ConvNeXt, did not perform well on this dataset. Although Vision Transformer exhibited high sensitivity, its specificity was only 0.5102. In contrast, smaller models like FasterNet and StarNet demonstrated more balanced performance. HiFuse, which performs well on medical images, also demonstrates good robustness. Our proposed model achieved classification accuracy and sensitivity of 0.7241 and 0.7238, respectively. Compared to other models, StarMA Net produced more balanced predictions and was less affected by category imbalances. All evaluation metrics for StarMA Net performed optimally, indicating that it excels in medical image classification with a small amount of data and high image complexity. This demonstrates that our proposed StarMA module effectively establishes short- and long-term dependencies through multi-scale parallel subnetworks; maps inputs to high-dimensional, nonlinear feature spaces; and captures subtle differences and critical information in lesion areas, thereby enhancing model classification performance. The comparison of the area under the curve (AUC) of each model on COVID-19 CT dataset is shown in Figure 4.Table 1. Summary table of results on COVID-19 CT datasetModelAccuracyPrecisionSensitivitySpecificityF1-scoreAUCVGG0.69950.68640.77140.62240.72650.7641ResNet0.64530.62790.77140.51020.69230.7080EfficientNet0.66500.62760.86670.44900.72800.6971Vision Transformer0.67490.64440.82860.51020.72500.6939Swin Transformer0.59610.59060.71430.46940.64660.6167ConvNeXt0.60590.60000.71430.48980.65220.6380FocalNet0.62560.65590.58100.67350.61620.6988UniFormer0.56160.61110.41900.71430.49720.6757BiFormer0.63550.65050.63810.63270.64420.6647SGFormer0.63550.60840.82860.42860.70160.6652FasterNet0.62070.61860.69520.54080.65470.7041StarNet0.61580.61540.68570.54080.64860.6619HiFuse0.68970.73330.62860.75510.67690.7442StarMA Net0.7241****0.73790.72380.72450.73080.8063The bolded items are the best indicators.Figure 4AUC-ROC curve on COVID-19 CT dataset
Result on BreakHis 400×
To further assess the generalization capabilities of StarMA Net, we conducted experiments using the BreakHis 400× dataset and summarized the results in Table 2. Unlike the COVID-19 CT dataset, which contains fewer than 800 images, BreakHis 400× includes 1,820 images. Although the dataset exhibits some class imbalance, it better aligns with the conditions required for training deep learning models. The results indicate that, with the increased data volume, all models demonstrated strong classification performance, even without resampling. Notably, StarMA Net achieved the highest F1 score and AUC on this dataset, with values of 0.9542 and 0.9784, respectively. This demonstrates that the StarMA Net has excellent generalization ability, and its classification performance also shows outstanding robustness on the pathological medical image dataset. The comparison of the AUC of each model on BreakHis 400X dataset is shown in Figure 5.Table 2. Summary table of results on BreaKHis 400X datasetModelAccuracyPrecisionSensitivitySpecificityF1-scoreAUCVGG0.87910.92700.89190.85230.90910.9432ResNet0.83150.85640.90270.68180.87890.9100EfficientNet0.79850.83160.88110.62500.85560.8327Vision Transformer0.91210.92150.95140.82950.93620.9748Swin Transformer0.90840.93960.92430.8750.93190.9541ConvNeXt0.82420.83410.92430.61360.87690.8298FocalNet0.89740.92430.92430.84090.92430.9459UniFormer0.82780.82550.94590.57950.88160.8607BiFormer0.81320.86020.86490.70450.86250.8821SGFormer0.82420.81860.95140.55680.88000.8395FasterNet0.89010.90160.94050.78410.92060.9641StarNet0.86810.89010.91890.76140.90430.9011HiFuse0.85350.86800.92430.70450.89530.8800StarMA Net0.93770.95160.95680.89770.9542****0.9784The bolded items are the best indicators.Figure 5AUC-ROC curve on BreakHis 400X dataset
Result on Chest X-ray
The Chest X-ray dataset comprises 5,856 images, with more than 1,000 images per class used during the training phase. As illustrated in Table 3, the models achieve accuracies above 0.9, with some models such as VGG19 and FocalNet reaching accuracies of 0.958 and 0.957, respectively. As the data volume increases, network architectures optimized for large datasets, such as BiFormer, also perform well. Although StarNet and Faster models are smaller, they achieve performance comparable to those of models like Swin Transformer and BiFormer. HiFuse also demonstrated good robustness on this dataset, with an F1 score reaching 0.9666. Nevertheless, our proposed model outperforms all others on this dataset, achieving an accuracy of 0.9692. This demonstrates that our model performs exceptionally well even on relatively large datasets, further validating its strong generalization capabilities. The comparison of the AUC of each model on the Chest X-ray dataset is shown in Figure 6.Table 3. Summary table of results on chest X-ray datasetsModelAccuracyPrecisionSensitivitySpecificityF1-scoreAUCVGG0.95790.95760.98600.88190.97160.9753ResNet0.94190.94560.97660.84810.96090.9792EfficientNet0.90090.92480.94070.79320.93270.9490Vision Transformer0.92480.94990.94700.86500.94840.9670Swin Transformer0.94420.95820.96570.88610.96190.9770ConvNeXt0.92480.93760.96100.82700.94920.9635FocalNet0.95670.96030.98130.89030.97070.9832UniFormer0.92600.93500.96570.81860.95010.9563BiFormer0.93740.94130.97500.83540.95790.9578SGFormer0.94760.95010.97970.86080.96470.9803FasterNet0.93850.94540.97190.84810.95850.9686StarNet0.94190.94430.97820.84390.96090.9759HiFuse0.95100.96140.97190.89450.96660.9776StarMA0.96920.97090.98750.91980.9791****0.9879The bolded items are the best indicators.Figure 6AUC-ROC curve on Chest X-ray dataset
Results on BUSI
BUSI is a three-classification ultrasound image with a small overall sample size and a lack of representative characteristics between benign and malignant nodules, and the image complexity is high, making classification difficult. Table 4 presents the evaluation of our proposed model alongside other advanced models on the BUSI dataset. ConvNeXt shows limited classification performance on this dataset. Similarly, HiFuse, SGFormer, and others based on Transformer also performed poorly on this dataset. In contrast, the smaller and more compact StarNet performs relatively well, while ResNet34 and VGG19 achieve better results. StarMA Net, however, demonstrates superior performance with a classification accuracy of 0.8120 and an F1 score of 0.7892 on BUSI dataset. Although StarMA Net has achieved the best results on the BUSI dataset, there is still room for further optimization. When examining failed cases, we observed that misclassification was often associated with nodules exhibiting blurred or indistinct boundaries, as well as the presence of ultrasound-specific artifacts (such as acoustic shadows and speckle noise), which obscured key diagnostic features. In addition, some nodules exhibit complex internal textures similar to those of the surrounding tissues, which poses a challenge to discriminative feature extraction.Table 4. Comparison of performance on BUSI datasetModelAccuracyPrecisionRecallF1-scoreVGG0.72650.71390.66520.6828ResNet0.71790.68470.63670.6456EfficientNet0.64100.53900.51060.5132Vision Transformer0.66670.61670.56060.5767Swin Transformer0.65810.60990.57260.5780ConvNeXt0.58120.47170.45220.4452FocalNet0.74360.71910.63480.6604UniFormer0.6410.57360.55130.5595BiFormer0.70090.64930.65580.6522SGFormer0.69230.7350.54680.5686FasterNet0.62390.57420.51820.5337StarNet0.67520.63540.62940.6279HiFuse0.66670.63090.57240.5916StarMA Net0.81200.83450.7620****0.7892The bolded items are the best indicators.
Therefore, in our future work, we will focus on enhancing multi-scale feature fusion and combining edge-preserving modules to better capture the morphology of nodules. In addition, we will also attempt to integrate ultrasound-specific denoising technology and adversarial training strategies to enhance the robustness against imaging artifacts. And the utilization of context semantic information and domain adaptation methods can help alleviate the differences caused by different acquisition devices or imaging protocols, thereby improving the classification performance in different clinical environments.
Furthermore, since this experiment only performed division (training set, validation set, test set) and normalization operations on the dataset, and there were 133 normal samples, 437 benign samples, and 210 malignant samples in the dataset, with significant differences in the number of categories, if preprocessing operations such as reuse and data augmentation are adopted in clinical practice, better results can be achieved. We also plotted the receiver operating characteristic (ROC) curve and confusion matrix of StarMA Net. The AUC-ROC curve and confusion matrix of StarMA Net on the BUSI dataset are shown in Figure 7. As can be seen from the ROC curve, the model demonstrates excellent discriminatory ability for all categories, with AUC values exceeding 0.86 in all cases. Among them, the AUC of malignant category was the highest (0.9090) and its classification performance was the best. The AUCs of the normal and benign categories were 0.8814 and 0.8688, respectively, indicating that the model has good diagnostic value for all three types of lesions. The confusion matrix also shows that the overall classification effect of the model is good, with 59 correct benign categories. The accuracy of the malignant category is the highest, and it has strong reliability. The main misclassification of the model is concentrated in the mutual judgment between benign and malignant categories. Subsequently, the discrimination between the two categories can be further strengthened.Figure 7AUC-ROC curve and confusion matrix of StarMA Net on the BUSI dataset
Result on Kvasir
All the datasets exhibit class imbalance issues, so we conducted additional tests using the Kvasir dataset. The Kvasir dataset consists of 8 categories, each with an equal number of 500 images. This test aimed to assess whether StarMA Net could maintain its high performance on a class-balanced dataset. The results, presented in Table 5, indicate that, in a scenario with balanced categories, all models perform well. StarMA Net achieved classification accuracy and F1 scores of 0.8783 and 0.8778, respectively, outperforming other advanced models. These findings demonstrate that our model possesses strong robustness and generalization capabilities. We also plotted the ROC curve and confusion matrix of this dataset to evaluate the classification performance of the model. In the ROC graph, the AUC of normal_pylorus reaches 1.000 and the classification is nearly perfect. normal_cecum AUC is 0.997, and the recognition accuracy is also very high. The AUCs of other categories such as dyed_lifted_polyps (0.985) and esophagitis (0.979) are also at a relatively high level. Overall, the model performed exceptionally well in these medical image category classification tasks. It can be seen from the confusion matrix that the main diagonal values of categories such as normal_cecum and normal_pylorus account for a high proportion and the classification accuracy is high. However, there are also some misjudgments, mainly concentrated between the dyed_lifted_polyps and dyed_resection_argins categories and the esophagitis and normal_z_line categories. Subsequently, the model can be optimized for these easily confused categories to improve the discrimination. The AUC-ROC curve and confusion matrix of StarMA Net on the Kvasir dataset are shown in Figure 8.Table 5. Comparison of performance on Kvasir datasetModelAccuracyPrecisionRecallF1-scoreVGG190.77830.77670.77830.7763ResNet340.77670.77560.77670.7755EfficientNet b30.71830.72820.71830.7188Vision Transformer0.79330.80130.79330.7898Swin Transformer0.77830.78290.77830.7756ConvNeXt0.73000.72720.73000.7253FocalNet0.80000.80460.80000.7972UniFormer0.69170.69900.69170.6891BiFormer0.74330.74460.74330.7396SGFormer0.75330.77370.75330.7411FasterNet0.76330.76660.76330.7609StarNet0.72000.71840.72000.7115HiFuse0.79830.80570.79830.7948StarMA Net0.87830.88040.8778****0.8778The bolded items are the best indicators.Figure 8AUC-ROC curve and confusion matrix of StarMA Net on the Kvasir dataset
Comprehensive analysis of experimental results in multi-class classification tasks
We further compared ROC curves, confusion matrices, Matthews correlation coefficient (MCC), Kappa, and AUC of the proposed model against other advanced classification models on the BUSI and Kvasir datasets for a more comprehensive evaluation. As shown in Table 6, StarMA Net outperforms other models in terms of MCC, Kappa, and AUC on both the BUSI and Kvasir datasets. We show the AUC-ROC curve and confusion matrix of each model on BUSI and Kvasir datasets in the additional material. From the confusion matrix for the BUSI dataset, it is evident that StarMA Net exhibits superior capability in distinguishing normal category images compared to other models. For the Kvasir dataset, classification errors were primarily concentrated in the categories of dyed_lifted_polyps and dyed_resection_margins. StarMA Net demonstrated improved classification performance in these categories, attributed to its ability to capture subtle differences and critical information about lesion areas. This demonstrates that our model exhibits superior robustness and generalization.Table 6. Comparison of MCC, Kappa, and AUC performance for various models on the BUSI and Kvasir datasetsBUSIKvasirMCCKappaAUCMCCKappaAUCVGG0.51640.51350.87560.74700.74670.9746ResNet0.50290.49840.83050.74500.74480.9726Efficient Net0.34250.33340.78950.67940.67810.9605Vision Transformer0.39430.38580.8080.76590.76380.9758Swin Transformer0.39820.39480.82410.74790.74670.9780ConvNeXt0.22910.22250.73910.69250.69140.9690FocalNet0.53850.5230.87150.77280.77140.9739UniFormer0.36550.36310.79640.64940.64760.9648SGFormer0.43290.39540.83370.72410.71810.9766BiFormer0.49110.49080.84510.70810.70670.9561FasterNet0.31150.30380.81760.73060.72950.9717StarNet0.44540.44370.80890.68230.68000.9512HiFuse0.39590.38760.81880.77140.76950.9806StarMA Net0.66850.66400.91340.86100.8614****0.9857The bolded items are the best indicators.
Ablation study
We select StarMA Net as the benchmark model and demonstrate the effectiveness of the proposed method on the Kvasir dataset through ablation experiments that investigate replacement attention mechanisms. During the experiment, the experimental environment and parameter settings remain consistent with the above experiments. Table 7 provides a summary of the performance of our proposed method in comparison with other advanced models on the Kvasir dataset. The results indicate that the attention mechanism incorporated into our baseline model performs well on this dataset. Notably, our proposed StarMA mechanism outperforms other attention mechanisms in key performance metrics. This demonstrates that StarMA can effectively capture subtle differences and crucial information within the focal areas of the image, thereby enabling the model to concentrate more accurately on the target regions.Table 7. Different attention mechanisms were employed for ablation studies on the Kvasir datasetModelAccuracyPrecisionRecallF1-scoreSA0.85830.86170.85830.8577CBAM0.85330.86100.85330.8524ECA0.85500.86300.85500.8540Ca0.86830.87110.86830.8678NAM0.86000.86470.86000.8593EMA0.86500.87050.86500.8642StarMA0.87830.88040.8783****0.8778The bolded items are the best indicators.
Meanwhile, we also conducted ablation experiments on each sub-module in StarMA Net to verify the effectiveness of each sub-module. The experimental results are shown in Table 8.Table 8. Ablation research of each sub-module of StarMA NetCCIBSSSSCBCSFAAccuracyPrecisionRecallF1-score✓✓––0.85330.85440.85330.8533––✓–0.85830.86280.85830.8576✓✓✓–0.86330.86630.86330.8626✓–✓✓0.86500.86940.86500.8652✓✓✓✓0.87830.88040.8778****0.8778The bolded items are the best indicators.
As can be seen from the table, when the attention mechanism only uses the SCB or the CCIB module, the classification accuracy is 0.8583 or 0.8533, respectively, which is lower than the classification effect of the model. However, compared with other classification models, it still has a good classification effect. When the SCB and CCIB dual-branch attention mechanisms are employed, the model achieves a notable improvement over the single-branch attention mechanism, attaining a classification accuracy of 0.8650 and a classification precision of 0.8626. Compared with the model without CSFA, the accuracy of the attention mechanism without the SSS module reached 0.8650 and the F1 score was also higher.
Complexity analysis
Furthermore, we calculated the parameter count, FLOPs, and inference speed of StarMA Net and summarized all the comparison models. It can be seen from Table 9 that the parameter scale of StarMA Net is approximately 47.5M, which is much smaller than models such as ViT-Base or Swin-B. Meanwhile, it shows better accuracy and generalization in medical image tasks, proving its good practicability and cost performance. At the same time, it achieves a good balance between computational overhead and classification performance. Although it is not the lightest model, it can significantly improve accuracy while maintaining an acceptable complexity, which is of great significance for medical image analysis scenarios.Table 9. Analysis of computational efficiencyModelImage sizeparamsFLOPsAverage inference timeVGG224^2^143.67M19.63G7.09 msResNet224^2^22M3.7G2.91 msEfficientNet224^2^12M1.02G10.21 msVision Transformer224^2^86M17.6G8.76 msSwin Transformer224^2^88M15.4G18.50 msConvNeXt224^2^89M15.4G8.93 msFocalNet224^2^88.1M15.3G9.88 msUniFormer224^2^49.78M7.77G18.89 msBiFormer224^2^57M9.8G26.13 msSGFormer224^2^77.64M14.99G49.70 msFasterNet224^2^15M1.91G3.13 msStarNet224^2^5.75M0.76G5.31 msHiFuse224^2^132.31M20.24G14.00 msStarMA Net224^2^47.5M18.11G8.53 ms
The original design intention of this study is to evaluate the feature representation ability and generalization performance of the proposed model itself without relying on additional regularization or data augmentation. Some datasets have a relatively small sample size, but the image complexity is high and the differences are large. A sufficient number of model parameters are required for effective fitting, so there is inevitably a certain risk of overfitting.
To further verify the rationality of the model complexity design, we conducted a channel reduction experiment, halving the number of model channels, and retrained it on the COVID-19 dataset. The results show that after the channel halving, the overall accuracy of the model decreased from 0.7241 to 0.7094, the F1-score decreased by approximately 3.3 percentage points, the recall rate decreased significantly, while the precision and specificity improved slightly.
This experiment indicates that the model complexity design of StarMA-Net is appropriate and can achieve good feature fitting and generalization performance on small-sample and complex medical image datasets. The performance declined after the channel was halved, indicating that an appropriate model capacity is necessary for capturing fine-grained lesion features. Therefore, this model strikes a good balance between computational complexity and recognition accuracy, and it has the ability to perform stably on small datasets. The comparison results are shown in Table 10.Table 10. Complexity analysis experimentModelAccuracyPrecisionRecallF1-scoreThe number of channels of StarMA Net is halved0.70940.75560.64760.6974StarMA Net0.72410.73790.72380.7245
In addition, we conducted a quantitative analysis of the star-shaped structure in enhancing channel interaction to verify its effectiveness. Specifically, we calculated the variance of the channel coupling index (CCI) and the channel attention weights. The results show that after the introduction of the SSS module, the CCI significantly increased (0.0092 → 0.0198, a 115% increase), indicating a stronger dependence between channels. Meanwhile, the variance of channel weights has also increased, indicating that the responses among different channels are more differentiated. These findings provide strong quantitative evidence and further theoretical support for the role of star-shaped structures in enhancing channel interactions. The relevant experiments are shown in Table 11.Table 11. Quantitative analysis of the SSS module at the channel interaction levelModelAverage CCI of the test setThe average pooled channel variance of the test setNo SSS0.00920.012542 ± 0.007090StarMA net0.01980.023966 ± 0.024171
StarMA visualization
To further illustrate the information capture capabilities of the proposed StarMA mechanism, we used the Grad-CAM55 method to visualize the model and react to the regions of interest in the model in the form of thermal maps. Figure 9 presents the visual results of this method applied to five different modality datasets.Figure 9. The Grad-CAM visual results of StarMA Net on medical image datasets of five different modalitiesThe scale of the pathological image in the figure is used as an approximate reference.
It is evident that StarMA responds to higher calorific value in the lesion area and accurately covers the lesion area. This experiment demonstrates that our proposed StarMA mechanism effectively integrates features across different scales, captures subtle differences and critical information within focal regions, and enhances the model’s focus on regions of interest, thereby improving classification performance.
Discussion
The StarMA module employs a parallel substructure strategy, using multi-branch parallel subnetworks to establish both short-term and long-term dependencies to adapt to the lesion areas in various images. Simultaneously, precise spatial structure information is retained within the channels to enhance image feature representation and capture broader contextual information. The star-shaped operation maps the input to a high-dimensional, nonlinear feature space without expanding the network, thereby improving the model’s representational capability. The integration of context information at different scales enables the network to achieve better pixel-level attention to high-level feature maps, allowing the model to more effectively capture subtle differences and critical information, thus enhancing classification performance for medical images.
The proposed StarMA Net is a visual backbone based on StarMA, exhibiting outstanding classification performance across five distinct medical imaging modalities: COVID-19-CT, Breast ×40, Chest X-ray, BUSI, and Kvasir. This verifies the validity and generalizability of our proposed model.
In this paper, we propose a StarMA mechanism to enhance image feature representation, generate more recognizable feature representations, and improve the classification performance of models on medical images. The algorithm employs multi-scale parallel subnetworks to establish both short-term and long-term dependencies, effectively utilizing spatial information to capture subtle differences and critical details in focal areas without reducing the channel dimension. Based on this attention mechanism, we designed a visual backbone and conducted experiments on datasets with various imaging methods to evaluate the feature representation and generalization ability of the model. Extensive experimental results demonstrate that our algorithm exhibits excellent robustness and generalization ability across various modal medical datasets, consistently maintaining high classification performance. We anticipate that this work could play an important role in a variety of downstream tasks involving medical images across different modalities.
Limitations of the study
Of course, our experiment also has limitations. Our current research only focuses on the medical image field of the above five diagnostic datasets and has not yet expanded to study other medical images and natural images. We believe that exploring how the StarMA mechanism performs with large medical and natural image datasets could be a promising direction for future research. On the other hand, we plan to extend StarMA Net toward 3D feature modeling and cross-modal fusion to better align with clinical practice. Specifically, 3D convolutions or slice-level aggregation strategies can be employed to capture volumetric dependencies in magnetic resonance imaging/CT data, while cross-attention-based multi-branch architectures may facilitate integration of imaging and clinical text features. As these extensions inevitably increase computational cost, lightweight modules, patch-based training, and progressive optimization strategies will be considered to strike a balance between performance and efficiency. Furthermore, due to the limitations of current data acquisition, our current research is limited to medical image classification, and there are also relatively few related images, including those of low quality and those with overlapping lesions. We will collaborate closely with the hospital in the subsequent work, further exploring its value in clinical applications and investigating the application of the model in other downstream tasks, such as segmentation and object detection.
Resource availability
Lead contact
Requests for further information and resources should be directed to and will be fulfilled by the lead contact, Juan Wang ([email protected]).
Materials availability
This study did not generate new unique reagents.
Data and code availability
- •All data reported in this paper will be shared by the lead contact upon request.
- •The original code can be obtained from the lead contact as upon request.
- •Any additional information required to reanalyze the data reported in this paper is available from the lead contact upon request.
Acknowledgments
This work was supported partly by General Program of 10.13039/501100001809National Natural Science Foundation of China (nos. 62176217), supported by the Innovation Team Funds of 10.13039/501100007433China West Normal University (grant nos. KCXTD2022-3), in part supported by the Chinese Government Guidance Fund on Local Science and Technology Development of Sichuan Province under grant 2024ZYD0272, and supported by the Intelligent Medicine and Health Big Data Key Laboratory of Sichuan Province (grant no. ZNYX2505).
Author contributions
J.C., conceptualization, methodology, software, investigation, validation, visualization, writing – original draft, and writing– review & editing; J.L., investigation and validation; X.L., investigation and validation; S.L., validation and data curation; J.W., funding acquisition, supervision, and project administration; B.Z., resources.
Declaration of interests
The authors declare no competing interests.
STAR★Methods
Key resources table
REAGENT or RESOURCESOURCEIDENTIFIERDatasetsCOVID-19 CTHe et al.40https-github.com-UCSD-AI4H-COVID-CT/Images-processed at master · desaisrkr/https-github.com-UCSD-AI4H-COVID-CT · GitHubBreakHisSpanhol et al.41BreakHis (kaggle.com)Chest X-rayKermany et al.42Chest X-Ray Images (Pneumonia) (kaggle.com)BUSIDhabyani et al.43Breast Ultrasound Images Dataset (kaggle.com)KvasirPogorelov et al.44Kvasir Dataset (kaggle.com)Software and algorithmsPython (version 3.9.0)Python softwarehttps://www.python.org/PyTorch (version 1.12.0)Python libraryhttps://pytorch.org/PyCharm version (2023.1.2)Python IDEhttps://www.jetbrains.com/pycharm/
Experimental model and study participant details
The datasets used in this experiment are all public datasets, and it does not involve clinical experiments.
Data sets
COVID-19 CT
The COVID-19 CT dataset comprises 746 CT scan images, including 349 positive cases for COVID-19 and 397 negative or indicative of other diseases. Following the partitioning method described in the literature, the dataset is divided into training, validation, and test sets.
BreakHis 400X
The Breast Cancer Histopathological Image Classification (BreakHis) dataset comprises 9,109 microscopic images of breast tumor tissue from 82 patients. It is categorized into benign and malignant tumors and includes images at four magnifications: 40X, 100X, 200X, and 400X, totaling 2,480 benign and 5,429 malignant samples. For this experiment, we used the 400X magnification subset, which includes 588 benign and 1,232 malignant samples, totaling 1,820 images. The dataset was divided into training, validation, and test sets in a 7:1.5:1.5 ratio.
Chest X-ray
The pneumonia Chest X-ray dataset consists of two types of images: pneumonia and normal. The dataset contains a total of 5,856 images, including 1,583 normal and 4,273 pneumonia cases (2,780 bacterial and 1,493 viral). The dataset is partitioned into training, validation, and test sets in a 7:1.5:1.5 ratio.
BUSI
The Breast Ultrasound Images Dataset (BUSI) comprises ultrasound images of breast tissue from women aged 25 to 75, collected in 2018. It includes 600 patients and a total of 780 images, each with an average size of 500 × 500 pixels. The images are categorized into three classes: 133 normal, 437 benign, and 210 malignant. For experimentation, the dataset was split into training, validation, and test sets in a 7:1.5:1.5 ratio.
Kvasir
The dataset comprises 4,000 endoscopic images of gastrointestinal disorders, categorized into eight groups, each containing 500 images. It encompasses a range of images featuring anatomical markers (e.g., Z-line, pylorus, cecum) and pathological findings (e.g., esophagitis, polyps, ulcerative colitis). The dataset is partitioned into training, validation, and test sets with a 7:1.5:1.5 ratio.
The number of datasets and their division methods are shown in Datasets Table.Datasets tableExperimental environment configurationThe number of datasetsDivision ratioCOVID-19 CT7467:1.5:1.5BreakHis 400X1,8207:1.5:1.5Chest X-ray5,8567:1.5:1.5BUSI7807:1.5:1.5Kvasir4,0007:1.5:1.5
Method details
Training settings
The experimental platform is configured as follows: an NVIDIA GeForce RTX 3060 12GB GPU and 16GB (8GB x 2) of memory. The code is written in Python 3.9, utilizing PyTorch56 as the deep learning library and CUDA version 12.0. During training, the learning rate is set to 1e-5, the batch size is 16, the AdamW optimizer is used, and the cross-entropy loss function is employed. To ensure fairness in comparisons, the Drop Path value was set to 0. To minimize random errors, no online data augmentation methods, such as random rotation or cropping, were applied. Input images were resized to 224 × 224 pixels using bilinear interpolation. Each model was trained for 100 iterations, and the weights of the model with the highest validation accuracy were saved for testing. Detailed parameter Settings are shown in Experimental Setting Table.Experimental platform table.Experimental environment configurationVersion numberGraphics cardNVIDIA GeForce RTX 3060 12GB GPUMemory stick16GB (8GB x 2) of memory.CUDA12.0Experimental setting table.Training configParameter valueImage size224 × 224OptimizerAdamLearning Rate1e-5Batch size16Epoch100Online data enhancementNoDrop path rate0
Quantification and statistical analyses
Evaluation metrics formulas
We used accuracy, precision, sensitivity, specificity, F1 score, MCC, Kappa, and AUC as evaluation metrics to evaluate the performance of our proposed methods. Accuracy measures the proportion of correctly classified samples out of the total number of samples and is the most used metric for assessing classification performance. Precision, also known as positive predictive value, represents the proportion of correctly predicted positive samples among all predicted positives. Sensitivity, which is equivalent to Recall, indicates the proportion of true positive samples correctly identified out of the total true positives. Specificity measures the proportion of correctly classified negative cases out of the total number of negatives. The F1 score is the harmonic mean of precision and recall, providing a comprehensive view of the model's predictive power. A higher F1 score indicates a more effective test method. Accuracy, precision, sensitivity, specificity, and F1 scores are defined by Eq:
The Matthews correlation coefficient (MCC) is primarily used to assess binary classification problems. Its value ranges from -1 to 1, where 1 indicates a perfect prediction, 0 signifies a random prediction, and -1 denotes a completely incorrect prediction. The MCC is calculated as follows:
TP (True Positive): The number of positive samples (foreground pixels) correctly classified as positive.
FP (False Positive): The number of negative samples (background pixels) incorrectly classified as positive.
TN (True Negative): The number of negative samples (background pixels) correctly classified as negative.
FN (False Negative): The number of positive samples (foreground pixels) incorrectly classified as negative.
The Kappa coefficient is another metric used to evaluate the performance of classification models by measuring the agreement between predicted and observed classifications. It ranges from 0 to 1, where 1 indicates complete agreement and 0 indicates agreement by chance. The Kappa coefficient is calculated using the following formula:
P0 represents the observed consistency, which is the actual accuracy. Pe represents the random consistency, which is the accuracy achieved by random guessing.
The Area Under the Receiver Operating Characteristic Curve (AUC-ROC) is also a crucial metric for evaluating models. It is plotted with the False Positive Rate (FPR) on the x-axis and the Taxis.57 A curve closer to the point (0, 1) indicates a better discriminative ability of the model.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ghosh S.Das S.Multi-scale morphology-aided deep medical image segmentation Eng. Appl. Artif. Intell.137202410904710.1016/j.engappai.2024.109047 · doi ↗
- 2Kumar A.Kim J.Lyndon D.Fulham M.Feng D.An ensemble of fine-tuned convolutional neural networks for medical image classification IEEE J. Biomed. Health Inform.212017314010.17010/ijom/2016/v 46/i 3/8899628114041 · doi ↗ · pubmed ↗
- 3Jiang H.Diao Z.Shi T.Zhou Y.Wang F.Hu W.Zhu X.Luo S.Tong G.Yao Y.D.A review of deep learning based multiple-lesion recognition from medical images: classification, detection and segmentation Comput. Biol. Med.157202310672610.1016/j.compbiomed.2023.10672636924732 · doi ↗ · pubmed ↗
- 4Vaswani A.Shazeer N.Parmar N.Uszkoreit J.Jones L.Gomez A.N.KaiserŁ.Polosukhin I.Attention is all you need Adv. Neural Inf. Process. Syst.30201710.48550/ar Xiv.1706.03762 · doi ↗
- 5He X.Tan E.-L.Bi H.Zhang X.Zhao S.Lei B.Fully transformer network for skin lesion analysis Med. Image Anal.77202210235710.1016/j.media.2022.10235735121468 · doi ↗ · pubmed ↗
- 6Ouyang D.He S.Zhang G.Luo M.Guo H.Zhan J.Huang Z.Efficient Multi-Scale Attention Module with Cross-Spatial Learning 2023 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2023 IEEE 1510.1109/ICASSP 49357.2023.10096516 · doi ↗
- 7Liu S.Wang L.Yue W.An efficient medical image classification network based on multi-branch CNN, token grouping Transformer and mixer MLP Appl. Soft Comput.153202411132310.1016/j.asoc.2024.111323 · doi ↗
- 8Ma X.Dai X.Bai Y.Wang Y.Fu Y.Rewrite the Stars 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition 2024 CVPR 56945703