Evaluation of the reliability and risks of ChatGPT-4o in answering pediatric cough questions: A comparative analysis between pediatricians and pediatric pulmonologists
Hanife Tuğçe Çağlar, Emine Özdemir Kaçer, Sevgi Pekcan, Fatma Nur Ayman, Gauri Mankekar, Gauri Mankekar, Gauri Mankekar

TL;DR
This study evaluates how reliable and safe ChatGPT-4o is for answering questions about pediatric cough, comparing ratings from pediatricians and pulmonologists.
Contribution
The study provides a comparative analysis of ChatGPT-4o's reliability in pediatric cough management from two medical specialties.
Findings
ChatGPT-4o responses were generally rated as trustworthy and valuable, but with notable differences between pediatricians and pulmonologists.
For no question did more than 50% of participants indicate a problem with the AI-generated answers.
Pediatricians found the AI responses more trustworthy and less dangerous than pulmonologists did.
Abstract
Artificial intelligence tools such as ChatGPT are increasingly used by patients and healthcare professionals, yet their reliability in pediatric respiratory conditions remains unclear. This study aims to assess the trustworthiness, comprehensiveness, value, and potential dangers of ChatGPT-4o-generated responses to frequently asked questions about the management and care of cough in children. A total of 10 cough-related questions were selected for ChatGPT-4o. The questions and responses generated by ChatGPT-4o are presented to 32 pediatric pulmonologists and 32 pediatricians. An online questionnaire was developed for this study. Participants rated the answers generated by ChatGPT-4o on a scale of 1–10 in terms of trustworthiness, comprehensiveness, value, and danger. Higher scores indicate higher levels of trustworthiness, comprehensiveness, value and danger. In addition, a yes/no…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
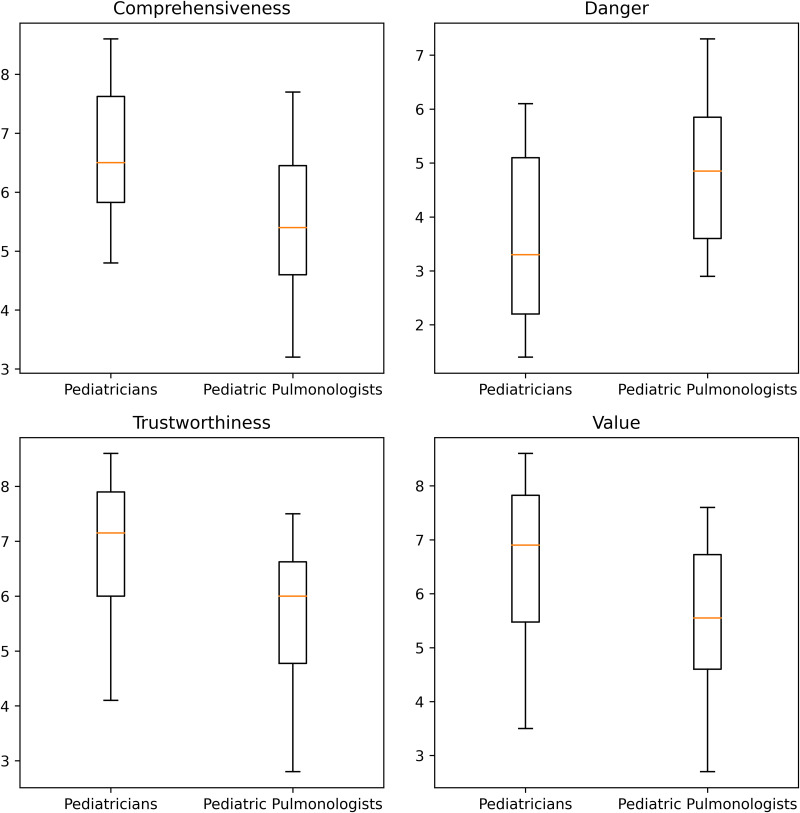 Fig 1
Fig 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Respiratory and Cough-Related Research · Misinformation and Its Impacts
1. Introduction
Coughing is a protective reflex that plays an important role in clearing secretions and foreign material from the respiratory tract [1]. Cough is one of the most common symptoms of respiratory disease and a leading cause of hospitalization in children [2]. Cough in children is often associated with viral infections, most of which usually resolve spontaneously. Cough following influenza infection; may last up to 10 days in 35–40% of school-aged children and up to 25 days in 10% of preschool children following respiratory tract infection. Bronchial hyperactivity, asthma, and gastroesophageal reflux disease are other common causes of cough in children [3]. In addition, environmental factors such as indoor and outdoor air pollution, humidity, irritant gases, and cigarette smoking cause cough in children [4].
If the cough persists for a long time, it becomes very distressing. It affects sleep, daily activities, and quality of life for the child and the parents or caregivers. Parents want the cough to go away immediately and search for solutions [5]. Online resources have become the first source of health information for many patients, allowing them to learn about their health condition [6]. The term “Dr. Google” refers to patients’ use of the Internet to search for health information [7]. Google® is the most popular search engine today and the most visited website in the world [8].
ChatGPT, a cutting-edge language model developed by Open Artificial Intelligence (OpenAI), based on the Generative Pre-trained Transformer (GPT) series [9], has demonstrated outstanding performance in natural language processing tasks that require the generation of coherent, contextually relevant, and human-like responses. ChatGPT, currently the fastest-growing consumer application, has shown increasing potential in medical education, research, and healthcare delivery [10–12]. This potential has been demonstrated in several medical fields such as radiology and dermatology [13,14]. It has the potential to assist individuals and communities in making informed decisions about their health, with its ability to generate human-like text based on large amounts of data [15–17]. However, a common criticism of ChatGPT is that the generated text is not always accurate. Challenges in this area have arisen in the areas of data quality and diversity, explainability and trust, and regulatory and ethical considerations of AI [18–20]. This study aims to assess the trustworthiness, comprehensiveness, value, and potential dangers of ChatGPT-4o-generated responses to frequently asked questions about the management and care of cough in children.
2. Materials and methods
2.1. Study design
An initial search was conducted on Google® to identify the “most frequently asked questions about pediatric coughing.” To reduce algorithmic bias, web browsing history and cookies were cleared prior to the search. Questions were excluded if they were semantically redundant, vague, subjective, or non-medical in nature. The final selection of 10 questions was reviewed by two pediatric pulmonologists (authors) to ensure clinical relevance. The final set of 10 questions was chosen because they consistently appeared across multiple independent searches and represented the most commonly encountered parent-driven concerns in outpatient pediatric respiratory practice. Ten unique, medically relevant questions related to coughing were submitted to ChatGPT-4o. The corresponding AI-generated responses are provided in the Supplementary Material.
In addition to the structured Likert questions, we considered open-ended questions during study planning. However, to minimize participant burden and ensure higher response rates among geographically dispersed physicians, we opted for a fully standardized questionnaire. This design enabled consistent quantitative comparisons between specialties. We acknowledge the limitation of not including open-ended responses, as they could have provided richer context.
We selected ChatGPT-4o because, at the time the study began, it was the most widely used large language model accessible to the general public. It also had multilingual capabilities relevant to the study population and demonstrated superior performance in several medical information tasks in recent evaluations. Using a widely adopted model also increases the real-world relevance of our findings.
The study was conducted in accordance with the latest version (2013) of the Declaration of Helsinki and approved by the Necmettin Erbakan University Ethics Committee with decision number (2025/5864).
A total of 100 physicians (50 pediatricians and 50 pediatric pulmonologists) were invited to participate. Sixty-four (32 pediatric pulmonologists and 32 pediatricians) of them completed the survey, yielding a response rate of 75.3%. Recruitment for the study began on June 28, 2025, and ended on July 5, 2025. The participating physicians had an age range of 30–65 years and reported between 5 and 35 years of clinical experience. All participants were practicing in various regions across Türkiye, representing urban healthcare settings. An online questionnaire was developed for this study. Participants rated the AI-generated responses on a 10-point Likert scale across four dimensions: trustworthiness, comprehensiveness, value, and potential danger. Higher scores indicate higher levels of trustworthiness, comprehensiveness, value and potential danger. Although the Likert scale provides quantifiable measures of trustworthiness, value, comprehensiveness, and danger, it is inherently subjective. To mitigate this, we included a binary (yes/no) question asking whether there was anything clinically wrong in each ChatGPT-4o response. Because the Likert items measured straightforward constructs (trustworthiness, comprehensiveness, value, and danger) and were developed by two pediatric pulmonologists, content and face validity were ensured through expert review. However, formal psychometric validation (e.g., Cronbach’s alpha) was not performed because the four items measured distinct constructs intentionally. Written informed consent was obtained from the participants and no compensation was paid. Participants were allowed to stop completing the questionnaire at any time. The questionnaire contained no identifying information, and the data were confidential.
In this study, the responses generated by ChatGPT-4o were evaluated against the clinical judgment and expertise of pediatricians and pediatric pulmonologists, who served as the reference standard. Pediatric pulmonologists, in particular, were considered a benchmark due to their advanced training and specialization in respiratory diseases in children. While acknowledging that AI tools may occasionally outperform human judgment in certain tasks, this study positions physicians’ assessments as the current clinical gold standard for evaluating the medical appropriateness and safety of the information provided.
2.2. Statistical analysis
As the study utilized Likert-type responses (1–10 scale), data were summarized using medians and interquartile ranges (IQR). Categorical data are presented as frequencies and percentages. Differences in categorical variables were assessed using the chi-squared test, while comparisons of numerical (Likert-type) responses between groups were performed using the Mann–Whitney U test. Data were analyzed using SPSS version 22.0 (SPSS Inc, Chicago, IL, USA). A p-value of <0.05 was considered statistically significant.
Additionally, a post hoc power analysis was performed using G*Power 3.1 based on the observed between-group differences in the overall Likert scores. With 32 pediatricians and 32 pediatric pulmonologists, the study had adequate statistical power (>80%) to detect the observed effect sizes for the trustworthiness, value, comprehensiveness, and danger ratings (Cohen’s d was approximately 0.82–0.98, and the achieved power was 0.82–0.88 at α = 0.05).
3. Results
The ChatGPT-4o-generated answers were generally rated by participants as trustworthy (median: 6.45, IQR:1.97), valuable (median: 6.15, IQR:2.3), comprehensiveness (median: 6.15, IQR:1.83), and not dangerous (median: 4.35, IQR:2.65). There was a statistically significant difference in all overall ratings between pulmonologists and pediatricians. All but two of the ten responses received median scores of 5 or higher from participants. The overall ratings of ten answers are summarized in Table 1. The distribution of the Likert scores between pediatricians and pediatric pulmonologists is illustrated in Fig 1.
Table 1: The overall ratings of the ChatGPT-4o-generated answers.
Boxplots comparing pediatricians and pediatric pulmonologists for trustworthiness, value, comprehensiveness, and danger ratings.
Pediatricians rated ChatGPT-4o-generated answers as more trustworthy, valuable, comprehensive, and less dangerous compared to pediatric pulmonologists. Table 2 summarizes the comparison between pediatricians and pediatric pulmonologists for each ChatGPT-4o-generated answer.
Table 2: The comparison between pediatricians and pediatric pulmonologists for each ChatGPT-4o-generated answer.
Among the ten questions evaluated, “What are the different types of cough in children?” and “When does a child need antibiotics for a cough?” received the highest overall ratings for trustworthiness and value across both groups. In contrast, “How do you stop a child from coughing at night?” and “What are three common causes of cough?” were rated the lowest, particularly by pediatric pulmonologists. Notably, significant discrepancies between pediatricians and pediatric pulmonologists were observed in several questions. For instance, the largest divergence in danger ratings was seen in the question about stopping a child from coughing at night, where pulmonologists assigned a significantly higher danger score (median:8.00, IQR:3) compared to pediatricians (median:4.00, IQR:5). These results indicate not only varying perceptions of AI reliability across subspecialties but also the importance of clinical nuance in interpreting AI-provided advice.
For all ten questions, at least one participant answered “yes” to the question, “Is there anything wrong with the answer generated by ChatGPT-4o?”. This indicates that every AI-generated response raised concern for at least one physician. However, none of the questions received “yes” responses from more than half of the participants, suggesting that perceived issues were neither consistent nor consensus-based. Table 3 summarizes the comparison between pediatricians and pediatric pulmonologists for this yes/no question.
Table 3: The comparison between pediatricians and pediatric pulmonologists for each ChatGPT-4o-generated answer. “Is there anything wrong with the answer generated by ChatGPT-4o?”.
4. Discussion
This study assessed the trustworthiness, comprehensiveness, value, and potential dangers of ChatGPT-4o-generated responses to common questions regarding the management and care of cough in children. Our findings indicate that, overall, ChatGPT-4o-generated responses were perceived as trustworthy, valuable, and comprehensive, with median scores exceeding 5 in most cases. However, a notable variation was observed between general pediatricians and pediatric pulmonologists in their evaluations, highlighting differences in expectations and clinical perspectives regarding AI-generated medical information.
One of the key findings of this study is that pediatricians rated ChatGPT-4o-generated responses more favorably in terms of trustworthiness, value, and comprehensiveness compared to pediatric pulmonologists. This may reflect a difference in the level of clinical expertise and familiarity with specialized aspects of respiratory diseases. Pediatric pulmonologists, having a deeper knowledge of complex respiratory conditions, may have been more critical in their assessments, particularly regarding comprehensiveness and the potential for misinformation. Pediatric pulmonologists may have rated the responses more critically because they routinely manage complex, atypical, and high-risk respiratory cases. Their training increases their sensitivity to nuances, red flags, and rare differential diagnoses. This makes them more likely to detect omissions or oversimplifications in AI-generated content. Some disagreement among physicians may reflect ongoing clinical controversies or differences in interpretation, rather than clear-cut errors in the AI-generated text. This highlights the complexity of defining a single “correct” answer in certain pediatric scenarios. These findings align with previous research indicating that AI-generated medical responses can be useful but may require domain-specific validation before clinical implementation [21,22].
Despite the generally positive ratings, concerns regarding the accuracy and comprehensiveness of AI-generated responses remain. At least one participant flagged an issue with every ChatGPT-4o-generated response, though the number of “yes” responses did not exceed 50% for any question. This underscores the importance of human oversight in AI-generated health information. AI models like ChatGPT-4o have demonstrated impressive linguistic fluency and knowledge synthesis capabilities, but they may still produce responses that lack nuance or fail to consider individual patient contexts [23]. Furthermore, AI-generated content may not always reflect the latest medical guidelines, which is a significant limitation in the rapidly evolving field of pediatric medicine [24]. While it is true that AI-generated content may not always reflect the latest clinical guidelines, it is equally important to recognize that not all physicians are consistently up to date with evolving standards of care. Continuing medical education varies between practitioners, and even specialists may occasionally rely on outdated or incomplete information. Therefore, discrepancies between AI responses and expert opinions could stem from limitations in either source. This observation further supports the need for AI tools to serve as complementary aids rather than replacements for professional medical judgment.
Another critical aspect explored in this study is the potential risks associated with AI-generated medical information. While ChatGPT-4o responses were generally not considered dangerous, some variability in danger ratings was observed. Pediatric pulmonologists tended to assign higher danger scores compared to general pediatricians, possibly due to their awareness of subtle clinical nuances and the potential consequences of misinformation in complex respiratory cases. This highlights the necessity of ensuring that AI-generated health information is reviewed by medical professionals and supplemented with expert validation before being used in clinical practice.
The growing reliance on AI-based tools such as ChatGPT-4o for medical information raises important ethical and practical concerns. The accessibility of AI-generated medical advice can empower patients and caregivers by improving health literacy and facilitating informed decision-making. However, it also poses risks, such as the spread of misinformation, over-reliance on AI in place of professional medical consultation, and challenges in ensuring accountability for AI-generated recommendations. Regulatory frameworks and quality assurance measures should be developed to enhance the reliability of AI in healthcare and mitigate potential risks associated with its widespread use.
This study has several limitations. The evaluation was conducted by medical professionals rather than the general public, which may not fully capture how non-medical users perceive and interpret AI-generated responses. The Likert scale was not formally validated, which could impact its internal consistency. However, the constructs were intentionally kept independent, and the items underwent expert review to maximize content validity. The study assessed a limited number of questions related to pediatric cough management, and findings may not be generalizable to other areas of medicine. AI models continue to evolve, and future versions of ChatGPT may demonstrate improved accuracy and reliability in medical applications. Although the yes/no question identified that at least one participant found issues in each answer, we did not ask participants to explain the reasons behind their “yes” responses. Without qualitative explanations, it is difficult to interpret these concerns. Future studies should incorporate open-ended follow-up questions to better understand why physicians judge certain AI-generated statements as problematic. The generalizability of the findings may be limited by the homogeneity of the physician population and the cultural-linguistic context.
5. Conclusion
Our study highlights both the potential benefits and limitations of ChatGPT-4o in providing medical information about pediatric cough. While AI-generated responses were generally rated as trustworthy and valuable, differences in assessment between pediatricians and pediatric pulmonologists emphasize the need for careful interpretation of AI-derived medical content. Future research should aim to refine AI algorithms for greater medical accuracy, while also exploring how both healthcare professionals and laypeople interpret and respond to AI-generated content across diverse settings. Incorporating qualitative feedback and broader participant profiles will help ensure the safe and effective integration of AI into clinical practice.
Supporting information
S1 FileThe corresponding AI-generated responses.(DOCX)
S2 FileDataset.(RAR)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Irwin RS, Baumann MH, Bolser DC, Boulet L-P, Braman SS, Brightling CE, et al. Diagnosis and management of cough executive summary: ACCP evidence-based clinical practice guidelines. Chest. 2006;129(1 Suppl):1S–23S. doi: 10.1378/chest.129.1_suppl.1S 16428686 PMC 3345522 · doi ↗ · pubmed ↗
- 2Chang AB, Glomb WB. Guidelines for evaluating chronic cough in pediatrics: ACCP evidence-based clinical practice guidelines. Chest. 2006;129(1 Suppl):260S–283S. doi: 10.1378/chest.129.1_suppl.260S 16428719 · doi ↗ · pubmed ↗
- 3Brodlie M, Graham C, Mc Kean MC. Childhood cough. BMJ. 2012;344:e 1177. doi: 10.1136/bmj.e 1177 22395925 · doi ↗ · pubmed ↗
- 4Fuentes-Leonarte V, Tenías JM, Ballester F. Levels of pollutants in indoor air and respiratory health in preschool children: a systematic review. Pediatr Pulmonol. 2009;44(3):231–43. doi: 10.1002/ppul.20965 19206181 · doi ↗ · pubmed ↗
- 5Marchant JM, Newcombe PA, Juniper EF, Sheffield JK, Stathis SL, Chang AB. What is the burden of chronic cough for families? Chest. 2008;134(2):303–9. doi: 10.1378/chest.07-2236 18641100 · doi ↗ · pubmed ↗
- 6Stevenson FA, Kerr C, Murray E, Nazareth I. Information from the Internet and the doctor-patient relationship: the patient perspective--a qualitative study. BMC Fam Pract. 2007;8:47. doi: 10.1186/1471-2296-8-47 17705836 PMC 2041946 · doi ↗ · pubmed ↗
- 7Lam-Po-Tang J, Mc Kay D. Dr Google, MD: a survey of mental health-related internet use in a private practice sample. Australas Psychiatry. 2010;18(2):130–3. doi: 10.3109/10398560903473645 20175669 · doi ↗ · pubmed ↗
- 8List of most-visited websites. [Accessed 27 January 2025]. https://en.wikipedia.org/wiki/List_of_most-visited_websites