Regularized regression outperforms trees for predicting cognitive function in the Health and Retirement Study
Kyle Masato Ishikawa, Deborah Taira, Joseph Keaweʻaimoku Kaholokula, Matthew Uechi, James Davis, Eunjung Lim

TL;DR
This study found that regularized regression models perform better than tree-based models in predicting cognitive function, offering a good balance between accuracy and interpretability.
Contribution
The study demonstrates that regularized regression outperforms tree-based models in predicting cognitive outcomes while maintaining interpretability.
Findings
Elastic net regression had the best performance with RMSE = 3.520 and R2 = 0.435.
Baseline cognitive function and computer use frequency were the most influential predictors.
Regularized regression models provided better interpretability and predictive performance than tree-based models.
Abstract
Generalized linear models have been favored in healthcare research due to their interpretability. In contrast, tree-based models, such as random forest or boosted trees, are often preferred in machine learning (ML) and commercial settings due to their strong predictive performance. However, for clinical applications, model interpretability remains essential for actionable results and patient understanding. This study used ML to detect cognitive decline for the purpose of timely screening and uncovering associations with psychosocial determinants. All models were interpreted to enhance transparency and understanding of their predictions. Data from the 2018 to 2020 Health and Retirement Study was used to create three linear regression models and three tree-based models. Ten percent of the sample was withheld for estimating performance, and model tuning used five-fold cross validation…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
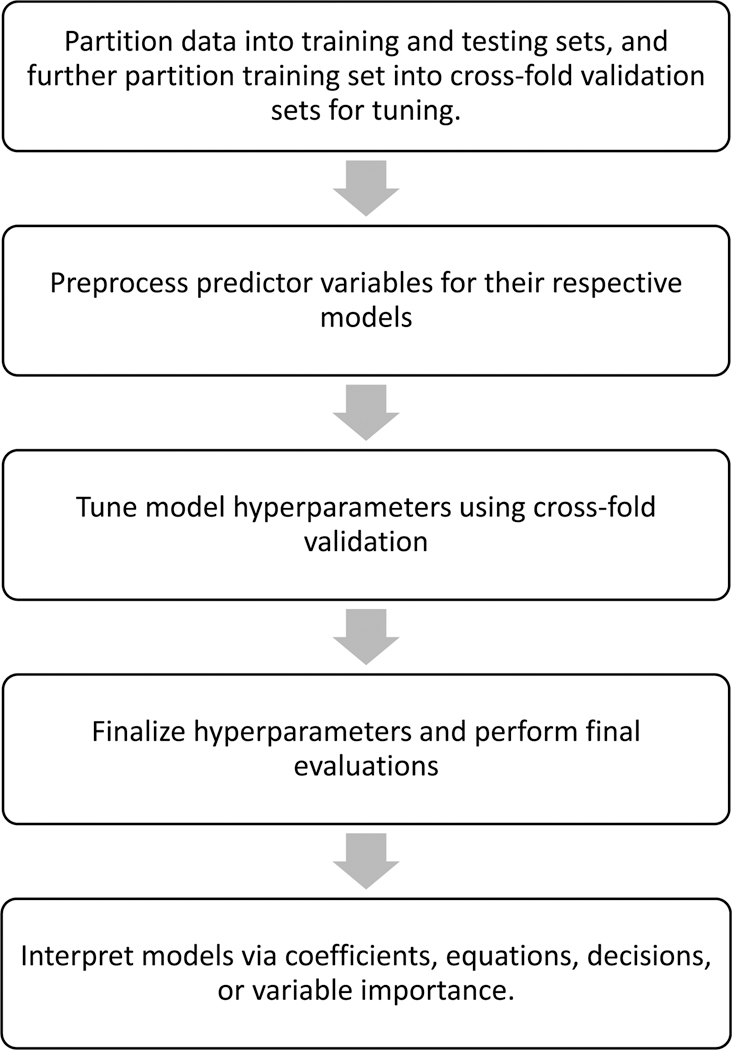 Figure 1
Figure 1 Figure 2
Figure 2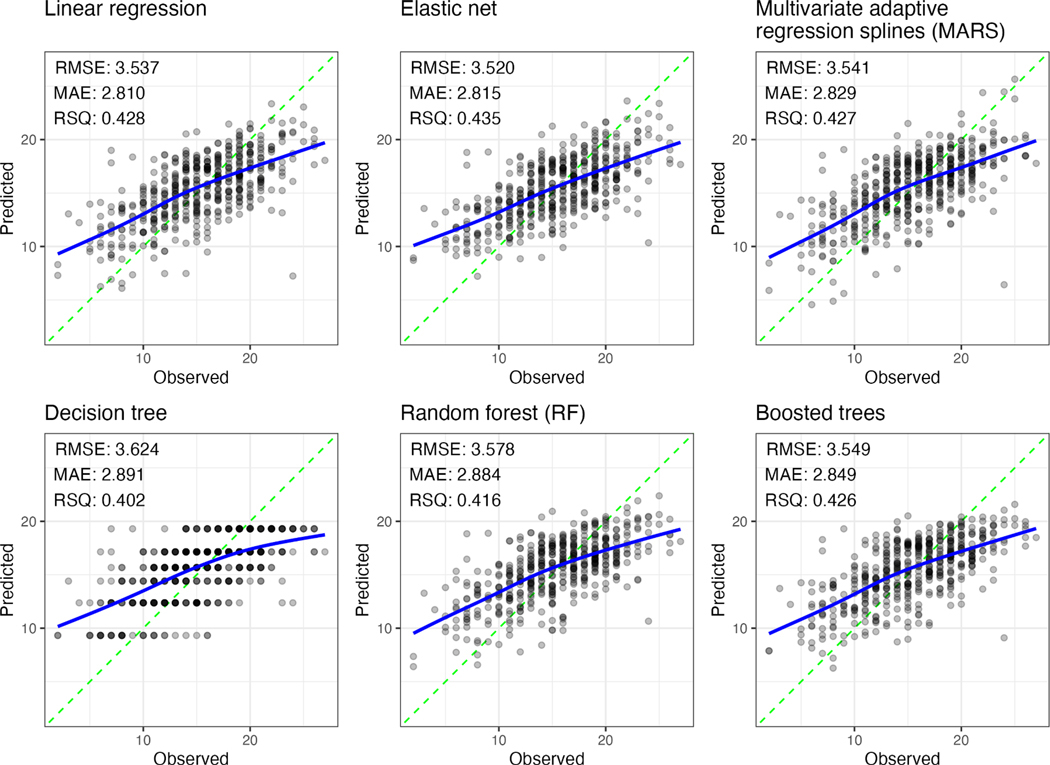 Figure 3
Figure 3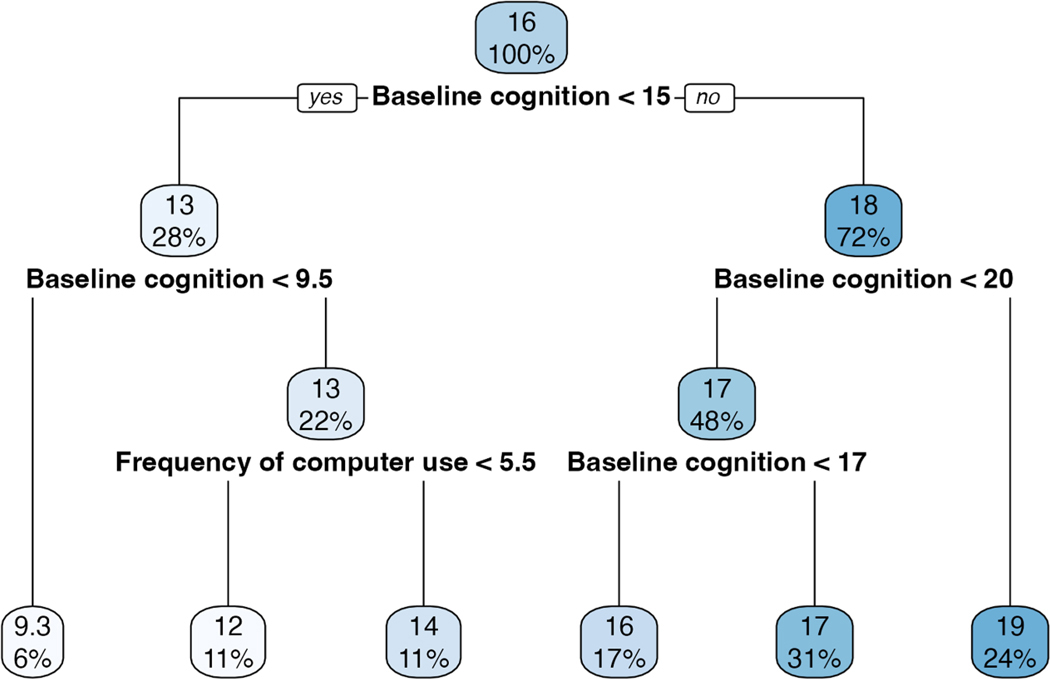 Figure 4
Figure 4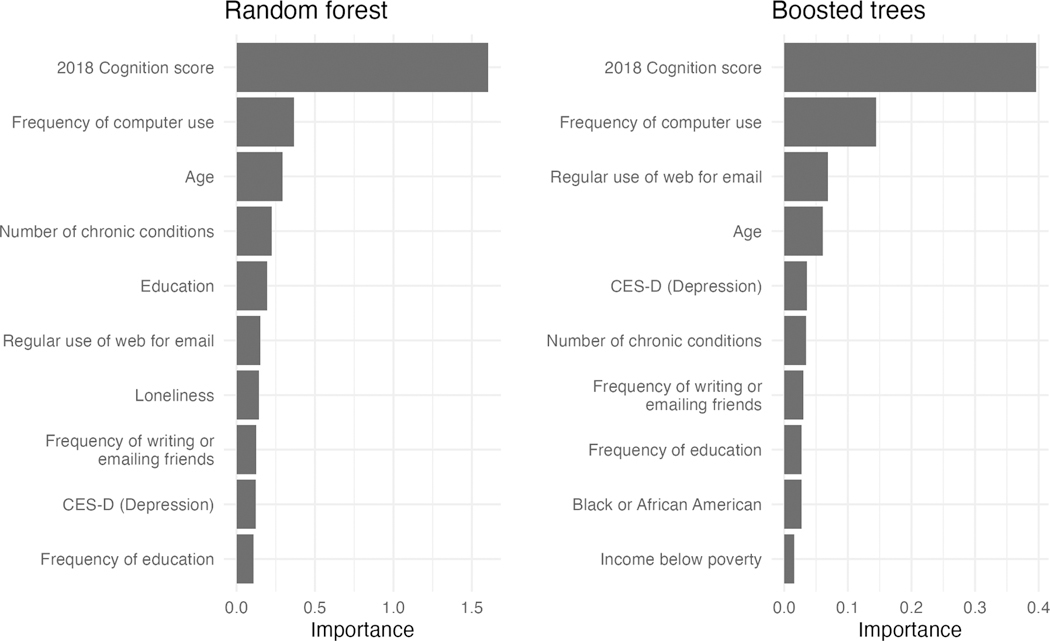 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare · Machine Learning in Healthcare · Explainable Artificial Intelligence (XAI)
Introduction
Parametric regression models are a standard in healthcare research due to their interpretability, but external validation (real-world performance) and generalizability are essential to provoke change in practice (Rose, 2020). For example, the significant odds ratio of a logistic regression model may be interpreted with less importance if the same model has a sensitivity of 0.6 on real world data. For applications such as disease diagnosis or screening, performance would be an additional requirement to explainability. To solve this problem, machine learning (ML) utilizes a technique called validation to determines a model’s performance on unseen, or real-world, data. ML models are becoming more prevalent in healthcare for tasks such as image recognition or natural language processing due to their performance and ability to process structured and unstructured data (Jiang et al., 2017).
Mild cognitive impairment (MCI) is the transitional period between normal cognitive aging and more serious forms of dementia. Early detection of cognitive decline enables timely lifestyle interventions that may help preserve cognitive function. It also allows families to make informed decisions and plan effectively to support the individual’s future needs (He et al., 2023). Every year for the past decade, publications which apply predictive ML to the domain of MCI have been on the rise (Liu et al., 2025). In a systematic review by Grueso and Viejo-Sobera (2021), support vector machines (SVM) and convolutional neural networks were the most common models applied to magnetic resonance images (MRI) and positron emission tomography to detect cognitive decline ranging from MCI to Alzheimer’s disease (AD). These models achieved an average accuracy of 75.4 % and 78.5 %, respectively. The authors noted that combining complex models with multidomain features such clinical, cognitive, genetic, and behavioral aspects, achieved the best performance. Within ML workflows that use complex imaging data, intermediate steps need to be taken to get the data into tabular format such as calculating surface area, detecting features, or counting objects (Grueso & Viejo-Sobera, 2021).
ML models can be grouped into two categories – white-box models that are explainable and black-box models whose inner mechanisms cannot be generalized into any equation or form (Linardatos et al., 2020). The latter requires post hoc methods such as variable importance to be calculated in order for the model to be interpreted (Sierra-Botero et al., 2024). Although the model’s inner workings are still unknown, each predictor’s importance can be interpreted with respect to the model’s performance, thereby turning the black-box model into a grey-box model. Research regarding “explainable machine learning” has been on the rise in the past decade (Linardatos et al., 2020) and shows that explainability is essential for performant models to be adopted into healthcare. In their 2025 study, Vlontzou et al. (2025) created an ML framework for diagnosing MCI and AD. Quantitative measurements such as hippocampal volume and cortical thickness were extracted from MRIs and placed in tabular format before being inputted into SVM and ensemble models. Variable importance calculations bring transparency to model predictions because their inputs mirror the same features clinicians use in their decision making.
Decision trees are the foundation for more complex models such as random forest or boosted trees. The model starts with a root node, or decision, that splits the outcome data by a predictor that explains the most variation in the outcome. Each subset of data branches into another node to be split again. This process continues until the node perfectly separates the outcome class or the number of observations at the node drops below a specified minimum. Algorithms such as C5.0 prevent overfitting by using cross-validation and pruning to eliminate branches that do not perform well (Pandya & Pandya, 2015). The result is a decision tree that explains most of the outcome variation without overfitting to the data. Although a decision tree provides paths that are easily interpretable, the model itself is considered a weak learner because it does not inference or predict well.
A random forest is a collection, or ensemble, of many decision trees. Each tree is built by selecting a random subset of predictors at each node to prevent overfitting. Therefore, each node chooses the predictor and cutoff value that explains the most variation in the outcome variable. If a node is downstream of another, the split depends on how the previous node splits the data and which subset of predictors is available to the current node. This randomness of predictors has a regularization effect, meaning that the model does not overfit to strong predictors at each node. All trees are independent of one another and considered weak learners. Random forest can be coupled with variable importance analysis to provide clear insights into the factors driving predictions. For example, Ooka et al. (2021) used this approach to identify key predictors of hemoglobin A1c changes in large-scale health check-up data, while Loef et al. (2022) applied it to uncover long-term health predictors in a 30-year cohort study, helping to clarify which variables most influenced their outcomes. A boosted tree model creates trees similarly to the random forest model, but with an important difference – each tree is fitted to the residuals of all previously created trees. This means that if previous trees performed poorly in certain areas, the next tree will try to correct those shortcomings. In ML competitions hosted on Kaggle, ensemble methods such as random forest outperform traditional regression models, and boosted methods such as boosted trees perform even better than random forest (Bojer & Meldgaard, 2021). In 2015, boosted trees were the most commonly used model, featured in 17 of the 29 winning Kaggle solutions (Chen & Guestrin, 2016). Accordingly, this study focuses on decision trees, random forests, and boosted trees – models that build upon one another, increasing in complexity and predictive performance.
This study aimed to evaluate the performance and interpretability of three regression-based models and three tree-based models in predicting follow-up cognitive function scores. The regression models include linear regression, elastic net, and multivariate adaptive regression splines (MARS), and the tree-based models include decision tree, random forest and boosted trees. It also provides plausible explanations for why models perform well relative to other models. For this comparison, we used data from the Health and Retirement Study (HRS) to predict change in cognitive function.
Methods
Study data
HRS is a longitudinal study documenting how middle-aged Americans transition to- and live out their retirement. The study’s design is multidisciplinary, incorporating elements of economics, sociology, psychology, epidemiology, and medicine. This study used data from the leave behind questionnaire of 2018 as baseline characteristics to predict cognitive function in 2020.
Variables
The outcome variable was the 27-point Langa-Weir Classification Scale, which measured cognitive function with three main components – immediate and delayed recall of 10 words, counting backwards in increments of seven from 100, and counting backwards in increments of one from 20. Predictor variables included demographics and psychosocial factors such as social network support, social participation, and depression. These variables can be seen in more detail in Table 1, as well as their projected or weighted estimates for the entire older adult US population. Predictors were selected based on a literature review and what clinicians thought to be relevant to cognitive function. Even though some predictors had natural collinearity, such as activities of daily or instrumental living, these predictors were not removed during preprocessing, but rather, relied on the regularization ability of each model.
Data analysis
Within each stratum provided by the HRS, 90 % of the data was randomly sampled and assigned to the training set, while the remaining 10 % was assigned to the test set and used solely for evaluating model performance. Within the training set, tuning was performed using five-cross fold validation with two repeats, resulting in ten estimates of performance for each set of model hyperparameters. The range of candidate hyperparameters were those suggested by the dials package (Kuhn & Frick, 2022). For each model, a set of 20 or 30 equally spaced hyperparameters were created withing the hyperparameter space. A list of candidate hyperparameters for tunable models are presented in Table 1, along with their finalized values. The hyperparameters finalized in the model were those that produced the lowest weighted root mean squared error (RMSE) during cross-validation. Since tuning can be computationally intensive, an ANOVA-based racing method was used to eliminate poorly performing hyperparameters at each iteration of tuning. Lastly, weighted metrics such as RMSE, mean absolute error (MAE), and R-squared value were calculated for each model’s predictions on the test set. Predictions from each model were plotted against their true observed values, with performance metrics overlaid on each plot.
Before modeling, the data had to be transformed to improve model performance and satisfy each model’s requirements. First, categorical variables with a substantial amount of missing data such as children live within ten miles, financial transfer to kids, and financial transfer from kids had an explicit “unknown” category assigned to their missing values. For all other missing values, a bagged trees imputation method was used to ensure complete data for regression models that cannot accommodate missing values. The only models that required further transformation were the elastic net and boosted trees models. Due to the regularization ability of the elastic net, numeric variables had to be normalized, centered, and scaled to a mean of zero and a standard deviation of one. Next, both the elastic net and boosted trees model required categorical variables to be in a numeric input matrix, so all categorical variables were transformed into dummy variables represented by ones and zeros. Although tree-based models can handle missing values, imputation was applied to their data for consistency. This was the minimal amount of preprocessing for each model suggested by Kuhn and Silge (2022) with the exception of removing correlated variables and variable with zero variance, which were not present. In the section “A Recommended Preprocessing,” Kuhn and Silge (2022) had also suggested normalizing the continuous predictors in the regression models for potential performance gains, but this was not implemented because interpretability was prioritized over marginal performance gains.
Variable importance for the random forest and boosted trees models was determined using the permutation method after each model was trained. Variable importance was assessed using the permutation method where the decrease in performance after shuffling each predictor’s values indicated its relative importance. This method of determining variable importance is considered model agnostic because it calculates importance after the model has been trained, making it applicable to any model.
All data analyses were performed in R version 4.4.1 using packages from the tidyverse (Wickham et al., 2019) and Tidymodels (Kuhn & Wickham, 2020). Code reproducibility was managed by the targets package (Landau, 2021). Weighted descriptive statistics were created using the srvyr package (Ellis & Schneider, 2019) and tables were produced using the gtsummary package (Sjoberg et al., 2021). An overview of the entire ML workflow previously described can be seen in Fig. 1. All computations were implemented on Apple’s M2 Max chip which had a 12-core central processing unit and 64 gigabytes of random-access memory.
Results
The study data contained 4889 older participants who completed the 2018 leave-behind survey and had a 2020 cognitive function score (Fig. 2). The weighted and unweighted characteristics of the study population are presented in Table 1. The distributions of baseline- and follow-up cognitive function scores are shown in Figure S1. Both distributions are approximately normal, slightly skewed to the left, with modes of 17.
Further subgroup analysis was performed to see if there were differences in baseline cognition stratified by various demographic characteristics. Table 2 shows that individuals who are younger, female, White, non-Hispanic, married, above poverty, or have higher educational attainment tend to have higher baseline cognitive function scores. If the assumption can be made that follow-up cognitive function scores are correlated to baseline scores, then these demographic features will be good predictors for the ML models.
Tuning took up the largest amount of time in the ML workflow. The elastic net, RF, and boosted trees model took 4.2, 6.1, and 13.1 min to tune, respectively. Their range of candidate hyperparameters and their final values are listed in Table 3. Random forest benefited from having its trees trained in parallel, but boosted trees had to have its trees trained sequentially due to the fact that each subsequent tree was trained on the residuals of the previous tree. The final tree depth of boosted trees ended up being one, meaning that each tree was a stump and the minimum number of predictors was negligible. The linear regression and MARS models did not require tuning because the earth package (Milborrow et al., 2017) selected the number of predictors during training. However, the earth package notes that, “in the current implementation, building models with weights can be slow.” Hence, a single MARS model took 10.5 min to train. If there was an optimized algorithm for training MARS models with weights, then the MARS model would have been tuned for the degree of interactions. Tuning without weights determined that one degree of interaction was the optimal hyperparameter.
The performance of each model is plotted in Fig. 3. Elastic net was the best performing model followed by linear regression, boosted trees, random forest, MARS, and lastly, decision trees. The predictions of the best performing model could be interpreted as, “the average error for all predictions is 2.8 cognitive function points” based on the MAE metric. The metrics of all final models were recorded from the cross-fold validation sets so that all measures of performance were comparable. Analysis of variance of RMSE and R^2^ values showed that there were differences in performance, and post hoc analysis determined that those differences lied between decision trees and all other models that performed better. Based on this result, the difference in performance of all models besides decision trees can be considered marginal.
The coefficient values for the linear regression and elastic net models are presented in Table 4. The variables selected from the elastic net model were inputted into a linear regression model so that coefficients could be estimated with raw values instead of centered and scaled values – this improved coefficient interpretability. Variable inflation factors (VIF) were calculated after modeling and confirmed variables with high correlation (VIF > 10). These 14 variables included the following groups - (1) Financial transfer to and from children; (2) number of unpaid helpers and family members; and (3) days and hours that participant got help from paid helpers, unpaid helpers, family, and non-family. Of the variables mentioned, the elastic net removed 10 of them and retained financial transfer to kids, and days or hours that participant got help from non-family or paid helpers. The model further removed predictors that were highly correlated or did not improve model performance. For example, there were four variables for positive or negative support from family or friends, of which only positive friend support was retained.
The MARS model did not perform as well the linear regression or elastic net models, but was able to present an interpretable set of rules for follow up cognitive function, shown in Equation 1. The equalities shown in the parentheses are hinge functions which can only be positive, indicated by the “+” sign. For example, for each year that a participant is younger than 69, their follow-up cognitive function decreases by 0.03, but for each year that a participant is older than 69, their follow-up cognitive function decreases by 0.12. In the end, the model retained 12 predictors. Characteristics that decrease follow-up cognitive function are a baseline cognitive function lower than 16, older age, being male or Black/African American, using Medicaid, attending non-religious activities, utilizing unpaid helpers, and negative friend support.
Equation 1. Equation of the multivariate adaptive regression splines model.
The decision tree model performed the worst but identified that baseline cognitive function score and frequency of computer use explained most of the variation in follow-up cognitive function. These two variables were considered important by all other models either through significance, inclusion, or importance. However, computer use only played a small role for those with a baseline cognitive function between 10 and 14. For those in this range, their estimated follow-up cognitive function was 13, with a point subtracted if they only use the computer once a week (12) or less and a point added if they use it more (14). All other decisions were based on baseline cognitive score. If someone had <9.5 points at baseline, their predicted follow-up score would be 9.3 points; if someone had between 15 and 16 points at baseline, their predicted follow-up score would be 16 points; if someone had between 17 and 19 points at baseline, their predicted follow-up score would be 17 points; and lastly, if someone had 20 or more points at baseline, their predicted follow-up score would be 19 points. Fig. 4 illustrates the model’s decisions. The top number at each node represents the estimated follow-up cognitive function score before making the decision, while the percentage below indicates the proportion of data at that split. Surprisingly, this model does not contain age.
Variable importance plots for the random forest and boosted trees models’ top ten important variables are shown in Fig. 5. Characteristics that appear in both models are baseline cognitive function, frequency of computer use, age, number of chronic conditions, regular use of email, depression (CES-D), and frequency of writing or emailing friends.
Discussion
The practical goal of social science-based research is to explain some, but not all, of the variation in outcome. Therefore, Ozili (2023) proposed that regression models with R-squared values of at least 0.1 are reasonable if accompanied by significantly associated variables. Although this study’s aim was to have good predictive performance, the significant variables and R-squared values ranging from 0.402 to 0.435 are more than decent. It is clear among all models that follow-up cognitive function is largely determined by baseline condition and that lower frequency of web use is a risk factor. There were no significant differences between the best performing models, so the interpretability of the traditional regression models had more clinical importance than the tree-based models.
It is common that decision tree and MARS do not perform as well as linear regression due to their simplicity. This study’s results are comparable to a study using ML techniques to predict mortality during an acute myocardial infraction hospitalization – the logistic regression model performed the best, followed by the MARS and decision tree models. Another study using a regression model and two kinds of decision trees to predict anxiety and depression among youth found that the decision trees did not perform as well as the regression models but selected the same important variables (Battista et al., 2023). Nonetheless, cases do arise where a decision tree can outperform regression models. To predict readmission in a United Kingdom hospital, Demir (2014) used a decision tree that outperformed logistic regression and MARS. The success of the decision tree could be explained by a single node which classified all patients with an emergency readmission within the past 30 days as a future readmission. Out of the 166 patients in this node, 88 % of them were readmitted. This shows that decision trees perform best when they can generalize the data to a set of simple rules. Perhaps the cumulative effect of secondary predictors such as age, education, chronic conditions, and web use in this study is what gave the regression, ensemble, and boosted methods a slight edge in performance.
Surprisingly, the complex tree-based models did not outperform the regression models. This could mean that the data did not contain higher order terms (for example, age^2^ or age^3^) or interaction terms that are suitable for spline or ensemble methods to capture (Zhang et al., 2019). But not only is the data simple and suited for regression models, it also contains predictors which are highly correlated, thereby amplifying their effect on the model’s predictions. The elastic net model achieved better performance than the linear regression model by eliminating these redundant features, whereas decision trees and MARS simplified the data too much. Yıldırım (2024) applied many ML models to data with known multicollinearity issues and found that linear regression using the Liu estimator outperformed complex tree-based methods and MARS.
Although this study uses the permutation method to calculate variable importance, there are other model-specific and model-agnostic techniques that could be employed. Specific to the random forest model, variable importance could have been calculated by recording the purity at each node as the trees were being built. Purity is defined as how well the predictor at each node can separate the outcome into its true values. The better the predictor can split the outcome, the more important it is considered. The important variables calculated by this method were not shown, but they were similar to those obtained through the permutation method, with eight out of ten of the same predictors, albeit in slightly different order. On the other hand, model-agnostic techniques such as Local Interpretable Model agnostic Explanation (LIME) (Ribeiro et al., 2016) or SHapley Additive exPlanations (SHAP) (Lundberg & Lee, 2017) could be used to calculate each variable’s importance and their positive or negative relationship to the outcome. However, LIME is sensitive to changes in the input data and the locality of input features that the user wants to be explained (Bhattacharya, 2022, p. 97). Even within the same input dataset, explanations of different parts of the feature space could be completely different. If the model is non-linear or complex, SHAP may be a better method of explainability. The only caveat of SHAP is its time complexity of O(2^n^) where n is the number of predictors in the dataset (Bhattacharya, 2022, p. 140). Given that the data in this study was fit well to linear models, either of these variable importance methods could have been used to explain black box models such as random forest or boosted trees.
Future studies could use a longitudinal design since the HRS provides data in two-year increments. This would open the door to models that deal with repeated observations such as a linear mixed-effects model. Even within patient observations, fluctuations in scores can make detecting trends difficult unless many observations are gathered (Jonaitis et al., 2019). Global associations may exist, but individual variation and baseline characteristics must be considered to make accurate predictions relative to each individual. By using longitudinal data, interactions may arise between age and characteristics that affect cognitive trajectory.
Conclusion
Elastic net regression provided the best balance of predictive performance, interpretability, and regularization in modeling follow-up cognitive function. The results suggest that the relationship between predictors and cognitive function is largely additive and linear, with limited benefit from modeling complex interactions. The performance gains of elastic net over standardized linear regression highlight the value of addressing multicollinearity by penalizing or removing highly correlated predictors. Notably, tree-based models such as random forest and boosted trees, while powerful in other machine learning applications, underperformed in this structured clinical dataset due to the absence of strong interaction effects and the presence of correlated features.
These findings have important implications for clinical practice, health policy, and future machine learning applications. Simpler, interpretable models not only achieve robust predictive performance but also enhance clinician trust and facilitate seamless integration into clinical workflows, reducing reliance on complex post hoc explainability tools. Furthermore, incorporating longitudinal designs that incorporate patient-specific variation may further strengthen predictive accuracy and relevance for delivering individualized, patient-centered care.
Supplementary Material
1
2
Supplementary materials
Supplementary material associated with this article can be found, in the online version, at doi:10.1016/j.mlwa.2025.100694.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Battista K, Diao L, Patte KA, Dubin JA, & Leatherdale ST (2023). Examining the use of decision trees in population health surveillance: an application to youth mental health survey data in the COMPASS study. Health Promotion and Chronic Disease Prevention in Canada: Research, Policy and Practice, 43(2), 73–86.36794824 10.24095/hpcdp.43.2.03PMC 10026612 · doi ↗ · pubmed ↗
- 2Bhattacharya A (2022). Applied machine learning explainability techniques: Make ml models explainable and trustworthy for practical applications using LIME, SHAP, and more (p. 97). Packt Publishing Ltd.
- 3Bojer CS, & Meldgaard JP (2021). Kaggle forecasting competitions: an overlooked learning opportunity. International Journal of Forecasting, 37(2), 587–603.
- 4Chen T, & Guestrin C (2016). Xgboost: a scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining (pp. 785–794).
- 5Demir E (2014). A decision support tool for predicting patients at risk of readmission: a comparison of classification trees, logistic regression, generalized additive models, and multivariate adaptive regression splines. Decision Sciences, 45(5), 849–880.
- 6Ellis GF, & Schneider B (2019). Srvyr:“dplyr”-like syntax for summary statistics of survey data. Retrieved from CRAN Repository: https://CRAN.R-project.org/package=srvyr.
- 7Grueso S, & Viejo-Sobera R (2021). Machine learning methods for predicting progression from mild cognitive impairment to Alzheimer’s disease dementia: a systematic review. Alzheimer’s Research & Therapy, 13, 1–29.
- 8He Z, Dieciuc M, Carr D, Chakraborty S, Singh A, Fowe IE, Zhang S, Lustria MLA, Terracciano A, & Charness N (2023). New opportunities for the early detection and treatment of cognitive decline: adherence challenges and the promise of smart and person-centered technologies. BMC Digital Health, 1(1), 7.40093660 10.1186/s 44247-023-00008-1PMC 11908691 · doi ↗ · pubmed ↗