Robust Deep Active Learning via Distance-Measured Data Mixing and Adversarial Training
Shinan Song, Xing Wang, Shike Dong, Jingyan Jiang

TL;DR
This paper introduces a new deep active learning framework that improves sample selection by combining distance-based uncertainty estimation with adversarial training to enhance model robustness and performance.
Contribution
The novel Distance-Measured Data Mixing (DM2) framework and boundary-aware adversarial training method for robust active learning.
Findings
DM2 outperforms uncertainty- and diversity-based baselines across multiple tasks and data types.
The adversarial training technique improves model robustness in noisy and imbalanced data scenarios.
The approach reduces the number of labeled samples needed for effective learning.
Abstract
Accurate uncertainty estimation in unlabeled data represents a fundamental challenge in active learning. Traditional deep active learning approaches suffer from a critical limitation: uncertainty-based selection strategies tend to concentrate excessively around noisy decision boundaries, while diversity-based methods may miss samples that are crucial for decision-making. This over-reliance on confidence metrics when employing deep neural networks as backbone architectures often results in suboptimal data selection. We introduce Distance-Measured Data Mixing (DM2), a novel framework that estimates sample uncertainty through distance-weighted data mixing to capture inter-sample relationships and the underlying data manifold structure. This approach enables informative sample selection across the entire data distribution while maintaining focus on near-boundary regions without overfitting…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
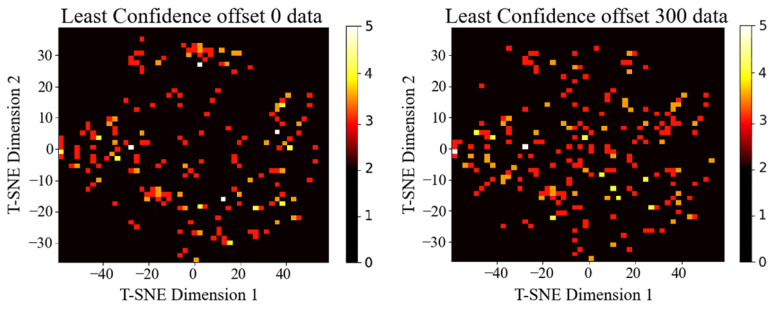 Figure 1
Figure 1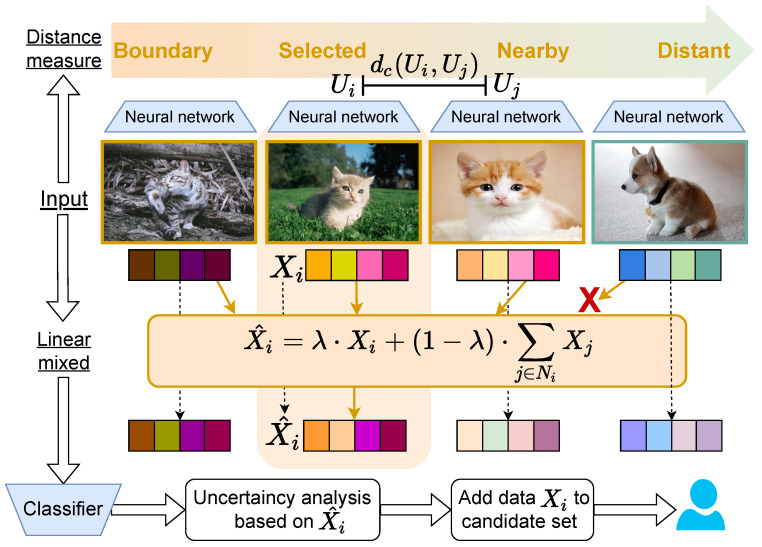 Figure 2
Figure 2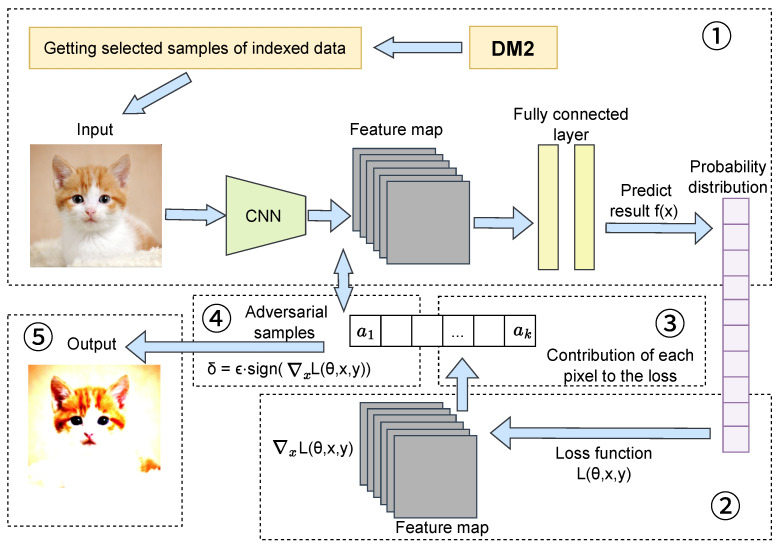 Figure 3
Figure 3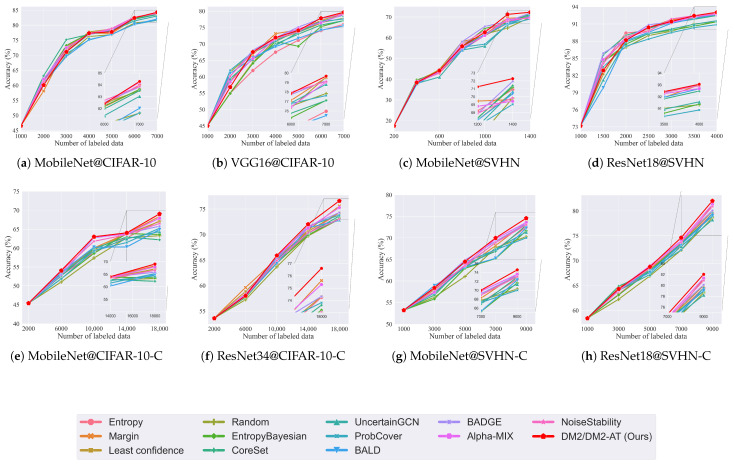 Figure 4
Figure 4- —Natural Science Foundation of Jilin Province
- —Shenzhen Science and Technology Program
- —Natural Science Foundation of Top Talent of SZTU
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Learning and Algorithms · Adversarial Robustness in Machine Learning · Machine Learning in Materials Science
1. Introduction
Deep neural networks typically require extensive labeled datasets for effective training, making data annotation a slow, expensive, and complex process [1]. Active learning (AL) addresses this challenge by strategically selecting the most informative samples from an unlabeled pool for annotation, thereby reducing the overall labeling burden [2]. A prevalent approach prioritizes samples with low-confidence predictions, as these high-uncertainty instances are empirically proven to provide valuable information for model improvement [3]. However, strategies that rely exclusively on uncertainty estimation often concentrate sample selection within narrow regions of the feature space, resulting in inadequate coverage of the overall data distribution and potential amplification of label noise [4]. Incorporating diversity considerations into the selection process can mitigate these issues by ensuring broader distributional coverage and capturing richer information content across the data manifold.
Recent active learning research has therefore pursued two complementary objectives: uncertainty estimation and diversity promotion. Uncertainty-based methods such as Least Confidence [3,5,6] prioritize samples exhibiting minimal predictive confidence. Deep Bayesian techniques further enhance uncertainty estimation by utilizing posterior predictive distributions to refine entropy-based and mutual-information-based selection criteria [7,8,9,10,11]. Alternative approaches employ auxiliary models to improve uncertainty estimation or guide the selection process [12,13,14,15,16,17]. Complementing these uncertainty-focused strategies, diversity-oriented methods such as VAAL [18] explore varied regions within the latent space, while BADGE [19] selects points via k-means++ in gradient-embedding space to jointly encourage diversity and gradient-driven uncertainty. Mixing-based active learners like Alpha-Mix also synthesize inputs, but they score and select anchors before mixing and do not explicitly target boundary sensitivity within the AL loop. A brief comparison of pipeline choices highlights these differences: while BADGE relies on gradient embeddings for selection diversity and Alpha-Mix leverages mixing as post-selection augmentation, DM2 couples metric-driven neighbor matching with mixed-sample scoring and adversarial perturbations, thereby unifying diversity, calibrated uncertainty near the boundary, and robustness within a single AL loop. Despite these advances, a fundamental trade-off remains: uncertainty-centric querying can oversample noisy boundary points, whereas diversity-only selection may overlook the most decision-relevant instances in complex, imbalanced, or noisy data—motivating designs like DM2 that explicitly integrate boundary awareness with coverage.
From a decision boundary perspective, samples with high uncertainty typically reside near class separators, where noise and label ambiguity are most prevalent. Excessive emphasis on such points can propagate labeling errors and compromise training quality. To investigate this phenomenon, we conducted a preliminary study using Least Confidence on CIFAR-10 [20] with MobileNet [21] as the backbone architecture. Following an initial training phase, we selected 1000 samples per iteration based on lowest confidence scores and visualized the selections using t-SNE, comparing direct top-k selection (offset 0) with an offset strategy that skips the top 300 lowest-confidence samples. As illustrated in Figure 1, the offset strategy distributes selections more broadly across the feature space, enhancing both coverage and diversity. This approach achieved 84.11% accuracy compared to 83.5% without offset, demonstrating that strategically shifting away from the most uncertain samples can capture richer information content and improve overall performance.
Motivated by these observations and drawing inspiration from Alpha-Mix [1], which employs tuned mixing strategies to introduce variability while preserving salient features, we propose a distance-measured data mixing framework (DM2) for deep active learning that simultaneously addresses uncertainty estimation, diversity promotion, and robustness enhancement. Our method DM2 introduces three algorithmic novelties: (i) neighbor selection in the representation space using a combined distance to robustly pair anchors with semantically proximate yet distinct neighbors; (ii) scoring on mixed samples rather than on anchors, which directly estimates the informativeness of interpolated boundary cases; (iii) an explicit boundary-aware adversarial augmentation step integrated into each query round to probe model fragility near decision surfaces. Building upon this foundation, we further introduce a boundary-aware feature fusion mechanism via adversarial training: we generate adversarial counterparts for selected near-boundary samples using fast gradient methods and train them jointly with the original instances. This approach enhances generalization capabilities and robustness in complex, noisy environments by stabilizing the learning process around decision boundaries.
Our contributions are summarized as follows:
- We introduce Distance-Measured Data Mixing (DM2) Active Learning, a novel deep active learning framework that estimates sample uncertainty through distance-weighted mixing of data samples. By exploiting inter-sample relationships and distributional structure, this method selects informative instances across the data manifold, including near-boundary regions, thereby enhancing the diversity of queried samples.
- To address noise susceptibility in challenging scenarios, we augment Distance-Measured Data Mixing with adversarial training (DM2-AT). We generate fast gradient adversarial samples for selected near-boundary instances and train them jointly with the original data, improving model robustness and generalization performance under complex data distributions.
- Comprehensive experiments across diverse tasks, model architectures, and data modalities demonstrate that our method achieves superior performance while significantly reducing labeling requirements compared to existing approaches.
2. Related Work
Uncertainty-based approaches select the most ambiguous unlabeled samples according to the current model. Since the model is initially trained with a limited dataset, these ambiguous samples provide valuable information for subsequent training rounds. (1) Prominent uncertainty selection methods include Least Confidence [5] and Entropy Sampling [22]. The Margin Sampling method [6] evaluates the difference between the confidence levels of the highest and second-highest prediction classes. BatchBALD [23] selects samples by maximizing the joint information gain of a batch. (2) Bayesian framework approaches focus on model parameters [4,24], often integrating Bayesian belief networks with Monte Carlo sampling [25]. Deep Bayesian approximation methods like MC-Dropout [7] are employed to address the challenge of probabilistic prediction. Query by Committee (QBC) methods facilitate multi-model training [26], while adversarial training methods [10,11,18] provide additional robustness. Furthermore, the variance between predicted probabilities within a set [27] has been proposed as a measure of uncertainty. (3) Model-based active learning trains a separate model for active instance selection. Variational Autoencoders (VAEs) [18] utilize a V-shaped autoencoder to model data distribution. CoreGCN [13] employs Graph Convolutional Networks (GCNs) to represent relationships between examples. LL4AL [14] integrates a lightweight module to learn the prediction error of unlabeled examples, capturing the learning loss in active learning. ProbCover [28] is a novel active learning algorithm designed for low-budget scenarios, aiming to maximize probability coverage. Methods like ISAL and ent-gn [15,16] propose using influence functions [17] to estimate potential model changes, thereby informing training strategies. These techniques often prioritize points near the decision boundary. However, they may overlook valuable data away from the decision boundary by relying solely on predicted class likelihood.
In active learning, diversity refers to selecting representative and varied samples for labeling. Methods often assign confidence scores based on classifier uncertainty and sample diversity [29]. One strategy uses entropy and mutual information within a CRF graphical model for query selection [30]. The state-of-the-art method Coreset [12] focuses on selecting data with diverse representations. BADGE [19] explores the relationship between data diversity and uncertainty using Bayesian methods and clustering. CoreGCN [13] employs graph embeddings for diverse data selection. Hierarchical agglomerative clustering (HAC) [31] distributes uncertain examples across clusters. BatchBALD [23] also considers sample diversity by selecting complementary samples to avoid redundancy. Recent advances utilize parameters from the final neural layer, while Alpha-Mix [1] employs feature mixing with alpha values. Noise Stability [32] introduces a greedy algorithm that adds noise to highlight differences between samples. These methods propose complex paradigms for modeling diversity, enhancing effectiveness but increasing computational complexity and model coupling.
3. Distance-Measured Data Mixing
This section presents our theoretical framework for Distance-Measured Data Mixing (DM2), as illustrated in Figure 2. Our approach focuses on selecting samples that effectively balance diversity and uncertainty considerations. The process begins by feeding unlabeled data through the model to extract feature-layer embeddings. We then compute similarity distances between samples within these embedding spaces and select multiple similar instances for linear mixing according to predetermined proportions. The model evaluates these mixed samples to determine their confidence levels. Finally, we rank samples by confidence scores and select data indices with the lowest-confidence values, adding the corresponding original samples to the labeled candidate set to complete each selection round.
3.1. Formal Definition
Given an unlabeled data pool U and an initially empty labeled data pool L, the objective of active learning is to select a subset of samples from U based on a predefined annotation budget (e.g., selecting 1000 samples at a time from a pool of 50,000 samples). These selected samples are annotated by human experts and added to L, such that , where represents the newly acquired annotations. The selected samples are subsequently removed from the unlabeled pool: .
A neural network model is defined as a function , where denotes the model parameters. For input data , the model generates predictions . The model is trained by minimizing the cross-entropy loss function:
where N represents the number of samples, C denotes the number of classes, and is the predicted probability that the i-th sample belongs to class c. The optimization objective is to minimize this loss function:
In subsequent data selection phases, the trained model evaluates samples from the unlabeled pool U to obtain confidence scores for each instance. Based on these confidence estimates, the method selects samples to be added to the labeled pool L, initiating the next cycle of training and data selection.
3.2. Feature Extraction
The feature representation from the final layer of a convolutional neural network (CNN) captures the highest-level, most abstract features from input images. These features effectively encapsulate global information and complex patterns, making them particularly valuable for tasks such as classification and recognition.
For each sample in the unlabeled data pool , we extract features from the last convolutional layer of the CNN. The output features are denoted as , where d represents the feature dimension. Here, denotes the feature representation of the i-th sample extracted through this layer. The feature extraction process is formalized as
3.3. Distance Measured
Euclidean distance effectively captures geometric relationships in continuous feature spaces, making it well-suited for detecting subtle differences between samples and demonstrating high sensitivity to small variations in data. In contrast, Manhattan distance is particularly effective for measuring differences in discrete or sparse feature spaces.
To ensure fair comparisons and prevent magnitude differences from skewing similarity, we first normalize feature vectors. Let and denote the original feature vectors of samples i and j, respectively. We define their normalized counterparts as
where denotes the Euclidean (L2) norm.
Because Euclidean and Manhattan distances have different scales, directly averaging them can introduce bias. We therefore compute each distance on the normalized vectors and additionally normalize each distance by the feature dimension d to align scales before aggregation. The (per-dimension) Euclidean and Manhattan distances are then defined as
The combined distance metric, obtained by averaging the normalized distances in Equations (4) and (5), is expressed as
3.4. Linear Data Mixing
The distance function calculates the similarity between feature samples and . In this step, we select n samples that are most similar to sample for linear mixing. We denote the set of nearest neighbors of based on as , and employ the parameter to control the degree of mixing. This process operates directly at the data level rather than on feature representations. The mixing formula is expressed as
where represents the mixed data sample derived from , denotes the index set of the n nearest neighbors of sample , and controls the mixing weight of the original sample . The linearly mixed sample is then fed into the pre-trained model for prediction:
The output of the classification model, , is typically a vector representing the predicted logits for each class. This output is converted into a probability distribution using the softmax function:
where C represents the number of classes and denotes the model’s logit score for sample belonging to class c.
The probability distribution from the classification model’s output is utilized to determine the confidence level for each sample. The highest predicted probability typically serves as a confidence indicator:
This represents the model’s maximum predicted probability for sample , indicating its confidence level. Samples are ranked by their confidence scores, and those with the lowest confidence are selected for the next active learning batch. When confidence levels are sorted in ascending order, corresponds to the index of the sample with the lowest confidence, while represents the highest confidence sample. From this sorted arrangement, we select the n samples with the lowest confidence scores for annotation. The indices of these selected samples constitute the active learning dataset :
We return the selected n sample indices for active learning annotation. The corresponding samples are retrieved from the original unlabeled dataset using these indices and added to the labeled pool L. This process is repeated iteratively throughout the entire active learning cycle, as shown in Algorithm 1. Algorithm 1 Distance-Measured Data Mixing Active Learning (DM2)
- 1:Input: : randomly initialized neural network, U: unlabeled data pool,
- 2: L: initial labeled data pool, B: query budget per round,
- 3: T: number of acquisition rounds, k: number of neighbors, : MixUp parameter
- 4:Output: L: updated labeled pool
- 5:Begin:
- 6: for to T do
- 7: Train the model on the current labeled pool L.
- 8: Extract features for all samples .
- 9: for each sample do
- 10: Compute distance to all other samples .
- 11: Identify , the set of k-nearest neighbors to based on .
- 12: end for
- 13: Initialize an empty set for acquisition scores, .
- 14: for each sample do
- 15: Randomly select one neighbor from its neighbor set .
- 16: Generate a synthetic sample: .
- 17: Calculate model output probabilities for the synthetic sample: .
- 18: Compute the uncertainty score .
- 19: end for
- 20: Select a set of B samples corresponding to the highest scores in S.
- 21: Query the true labels for the selected samples in .
- 22: Add the newly labeled data to the labeled pool: .
- 23: Remove the selected samples from the unlabeled pool: .
- 24: end for
- 25:Return L
4. Adversarial Training for Boundary Data Feature Fusion
This section presents an active learning algorithm that integrates adversarial training with feature fusion for boundary data samples. This method employs adversarial training to enhance model robustness, thereby strengthening performance when processing noisy and complex data. Simultaneously, the active learning strategy reduces the required number of training samples, lowering overall training costs. Specifically, in our boundary data feature fusion approach for active learning, samples selected in each round are initially augmented through adversarial training to generate adversarial counterparts. These adversarial samples are subsequently merged with the existing labeled pool, enabling the model to fully exploit the augmented data during updates.
The advantage of this approach lies in its incorporation of active learning properties to reduce labeled data requirements while leveraging adversarial training to enhance the model’s classification capabilities, particularly when confronting noise and interference in real-world scenarios. Through this combination, the model’s information recognition performance is significantly improved, achieving more accurate classification in complex environments and demonstrating adaptability across diverse application scenarios. This algorithm not only improves model stability and classification accuracy but also reduces training sample requirements while adapting to large-scale dataset challenges, offering substantial practical value, especially in applications requiring rapid deployment and efficient training. The complete methodological process is illustrated in Figure 3.
4.1. FGSM Confrontation Training
Adversarial training serves as a method to improve model generalization by incorporating adversarial samples into the training dataset. This approach compels the model to learn from these challenging examples, thereby improving its ability to defend against adversarial perturbations. The Fast Gradient Sign Method (FGSM) represents one of the most widely used techniques to generate adversarial samples, and FGSM adversarial training constitutes a training methodology that employs FGSM to generate adversarial samples and incorporate them into the training set [33].
FGSM is an algorithm that efficiently generates adversarial perturbations by computing the gradient of the loss function with respect to the input. The fundamental principle involves applying a small perturbation along the direction of the loss function’s gradient to input samples, thereby causing the model to produce erroneous predictions. This perturbation is computed individually for each input sample, making it inherently sample-specific [34]. The FGSM generation process follows these steps:
Calculate the gradient: For each input sample and its corresponding label, we first compute the gradient of the loss function with respect to the input:
where represents the loss function with model parameters , input sample x, and true label y. This gradient indicates the direction in which small changes to the input would most significantly increase the loss.
Generate adversarial perturbations: Using the computed gradient to generate adversarial perturbations, the key principle of FGSM involves computing the sign of the gradient (representing the direction of the gradient) and adding perturbations along that direction. The perturbation magnitude is controlled by a small constant parameter:
where is the sign function that extracts the sign of each element in the gradient vector, and is the hyperparameter that controls the perturbation magnitude. This formula represents the process of applying a small perturbation to input samples along the direction of the loss function’s gradient. The sign function ensures that the perturbation moves in the direction that would maximally increase the loss, while the parameter bounds the perturbation size to maintain the adversarial sample’s similarity to the original input.
The generated adversarial samples are incorporated alongside the original samples during the training process, enabling the model to learn correct predictions when confronted with adversarially perturbed inputs. This approach enhances the model’s robustness by exposing it to challenging examples that lie near the decision boundary.
In adversarial training, the training process comprises two complementary components. First, positive sample training follows the traditional approach by utilizing original data for model training. Second, adversarial sample training incorporates adversarial samples generated using FGSM into the training data. During each training step, a batch of data is selected from the training set, where each sample consists of an input x and its corresponding label y. FGSM is then applied to generate adversarial perturbations for each sample, producing the corresponding adversarial examples.
The training procedure calculates losses for both the original samples and their adversarial counterparts, combining these losses for backpropagation to update model parameters, where represents the loss computed on the original sample, and denotes the loss computed on the adversarial sample:
where this combined loss function ensures that the model simultaneously learns to make correct predictions on both normal and adversarially perturbed inputs.
For all hyperparameters, unless otherwise specified, we adopt the following settings in all experiments. FGSM perturbation magnitude ϵ: We search over , 2/255, 4/255, 8/255 for image input (pixel range ) and report the results for the selected value in each experiment; the default is . Loss mixing coefficient λ: We weight clean and adversarial losses as . We tune over the range and use by default (corresponding to Equation (14)). Number of neighbors k: For modules that require neighbor retrieval (e.g., regularization of the consistency of k-NN or augmentation based on neighborhood, when applicable in our pipeline), we select k from with a default of .
FGSM adversarial training constitutes an effective method for improving model robustness. By generating adversarial samples and incorporating them into the training data, this approach enhances the model’s ability to adapt to input perturbations, enabling the model to maintain performance when confronted with adversarial examples during inference.
4.2. Adversarial Training for Sample Selection
This method combines active learning and adversarial training to enhance model stability and performance through the following process:
First, the trained model performs forward propagation to extract feature representations from the final layer for each sample, as expressed in Equation (3). We then select the most representative samples by computing pairwise similarity using a combined Manhattan and Euclidean distance metric, as shown in Equation (6). This combination leverages the strengths of both metrics to achieve stable similarity calculations, particularly for features with varying scales.
After identifying the n most similar samples through inter-sample similarity calculations, we merge them using the MixUp fusion method to generate new training instances that enhance model generalization, as shown in Equation (7). The model evaluates classification confidence and returns the corresponding index list for active learning selection.
Following sample selection by the boundary data feature fusion algorithm, the original images undergo forward propagation through the neural network to obtain prediction results via the fully connected layer. FGSM then calculates the gradient of the loss function with respect to the input image through backpropagation, revealing how each pixel should be modified to maximize the loss. Larger gradient magnitudes indicate greater pixel impact on the loss function.
The perturbation is computed and adversarial samples are generated according to
where represents the perturbation step size, denotes the gradient of the loss function with respect to input sample x, is the model’s loss function, and is the sign function. The parameter determines the perturbation magnitude: smaller values (e.g., ) are used for simpler tasks like MNIST or SVHN, while larger values (e.g., ) are selected for complex tasks like CIFAR-10. Larger perturbations make training for robust performance more challenging.
The calculated perturbations are added to the original samples to generate adversarial samples:
where H represents the adversarial sample resulting from adding the perturbation to the original input x.
Algorithm overview: We work with a model that iteratively improves using an unlabeled pool U and a labeled set L. For each , we extract a feature embedding from the model’s penultimate layer and measure pairwise similarity using the combined distance . Each example x has a neighborhood consisting of its top-n most similar peers under D. We synthesize interpolated examples using MixUp with and to probe the decision boundary and calibrate uncertainty.
Based on uncertainty , we select the B most uncertain samples to form batch for labeling, obtaining labels . For each selected sample , we create an adversarial counterpart using FGSM: we form a pseudo-label from the model’s current prediction, compute the input gradient , and craft a perturbation , producing the adversarial example (clipped to the valid input range). The labeled set is augmented with both clean and adversarial pairs for .
Training minimizes the combined objective , where balances clean accuracy and robustness, and controls perturbation strength. This cycle—feature extraction, neighborhood identification, uncertainty-based selection, and adversarial augmentation—repeats until convergence. By selecting samples that are uncertain and lie in dense feature regions, then training on their adversarial variants, the algorithm enhances model robustness while reducing labeling costs, as shown in Algorithm 2. Algorithm 2 Distance-Measured Data Mixing with Adversarial Training (DM2-AT)
- 1:Input: Model , unlabeled pool U, labeled pool L, batch size B, neighbor count n, MixUp parameter , FGSM step size
- 2:Output: Trained model
- 3:Begin:
- 4: while model has not converged do
- 5: Extract features for all .
- 6: For each , find its top-n neighbors using L1+L2 distance.
- 7: Generate synthetic set via MixUp on pairs from U and their neighbors.
- 8: Score with model uncertainty to select the B most uncertain original samples .
- 9: for each do
- 10: // is the model’s predicted label
- 11:
- 12: end for
- 13: Query true labels for the selected samples .
- 14: Update and .
- 15: Retrain on L using a combined loss for original and adversarial samples.
- 16: end while
- 17:Return
5. Theoretical Analysis
5.1. Notation and Setup
Let denote the unlabeled pool and L the labeled pool. A model with parameters produces class probabilities and is trained by minimizing the cross-entropy loss in (1), with optimal parameters given by (2). Feature embeddings are extracted by as in (3). Distances are measured by and in (4)–(5) and combined as in (6). For each anchor , a neighbor set is defined as the indices of the n nearest neighbors under . Mixed inputs are formed at the data level by
as in (7). The model outputs logits , which are mapped to probabilities via softmax (9), and the confidence is in (10). The acquisition set comprises the indices of the n lowest-confidence samples, cf. (11).
5.2. Geometric Rationale for Distance-Weighted Mixing
We analyze the effect of DM2 on two axes crucial for active learning: (i) uncertainty exposure at decision boundaries; (ii) diversity preservation through local neighborhood mixing.
We work under standard conditions often met in deep representation spaces: (A1) The embedding is locally Lipschitz: for some . (A2) The classifier head of is -Lipschitz in input space on compact domains. (A3) Nearby points under have high label-correlation: there exists such that for , ; equivalently, neighborhoods are label-homogeneous with bounded noise. (A4) Calibration around the decision boundary: near regions where class posteriors are close (small margin), confidence decreases monotonically with the distance to the margin hyper-surface.
Assumption (A1)–(A3) capture that is a surrogate for semantic proximity, while (A4) links geometric proximity to predictive uncertainty.
Consider a first-order expansion of w.r.t. the input:
with a remainder term by (A2). Thus, to first order, the logits on the mixed input approximate an average of neighbor logits. When is label-homogeneous, the average logit sharpens the predicted class; when straddles a class boundary, the average logit becomes ambiguous, lowering confidence.
5.3. Uncertainty Amplification Near Class Boundaries
Define the pointwise margin for logits as
the gap between the top-two logits. By softmax monotonicity, smaller implies lower confidence .
Lemma 1. Margin reduction under heterogeneous neighborhoods. Let have neighbors with class proportions ( ), and suppose is locally linear around . Then, for the mixed input with weight ,
where is the top-two logit gap of the neighbor-averaged prediction . If spans multiple classes so that is class-ambiguous, then is small, and hence , yielding reduced relative to .
Proof. Local linearity yields . Let denote the top-two logit gap (an affine functional restricted to the two dominant coordinates). Then for any logits sharing the same top-two ordering; otherwise, the gap cannot increase beyond the convex combination by triangle inequality. Hence, . If neighbors are heterogeneous, is small due to averaging conflicting logits, which lowers and therefore by softmax monotonicity in the gap. □
Samples whose neighbor sets cross decision boundaries are systematically assigned lower confidence after mixing and are thus prioritized by DM2. This aligns selection with true boundary regions where labels are most informative for reducing model uncertainty.
5.4. Diversity Preservation via Distance Coupling
Let be the k-NN graph on under . DM2 forms mixes anchored at many distinct nodes with their local neighborhoods. If the acquisition selects the n lowest-confidence anchors after mixing, these anchors tend to be located on edges or cuts of that cross clusters. Under mild clusterability:
(A5) The embedding decomposes into r well-separated clusters with inter-cluster distances larger than intra-cluster distances under .
Then, boundary regions appear around each cut ; mixed inputs that pool neighbors from both and reduce confidence within each cut. Consequently, the n lowest-confidence anchors are spread across multiple cuts, promoting diversity without explicit diversity regularizers.
5.5. Stability of Mixed Confidence Under Neighbor Noise
Consider neighbor noise: a fraction of are erroneous neighbors (e.g., misembedded or outliers). Let be the average logits over true semantic neighbors and over noisy neighbors. Then
If (bounded contamination), the perturbation to logits is at most , so the induced confidence change satisfies
where is the Lipschitz constant of the softmax–max operator. Thus, DM2 confidence is robust to small neighbor noise for moderate .
5.6. Choice of the Combined Distance dc
The combined metric inherits the following:
(i) Metric property: Since and are metrics on , any positive weighted sum is a metric. Hence satisfies non-negativity, symmetry, and the triangle inequality.
(ii) Sensitivity balance: is sensitive to dense directions, while is robust to sparse, axis-aligned deviations. Averaging thus mitigates anisotropy and promotes stable neighbor sets in heterogeneous embeddings.
defined by (6) is a metric on .
Proof. For all : Non-negativity and identity of indiscernibles follow from those of and . Symmetry is immediate. For the triangle inequality,
□
5.7. Acquisition Optimality Under a Localized Fisher Criterion
Let denote the conditional Fisher information of at input x with respect to parameters (under the model distribution). For classification with softmax outputs, points near the decision boundary tend to have larger Fisher trace , which correlates with higher expected gradient magnitude.
Define the mixed-point Fisher score
Under (A1)–(A4) and local linearization, if is heterogeneous, approaches the boundary and increases. Therefore selecting minimum-confidence approximately maximizes among anchors, aligning DM2 with a proxy of information gain.
Theorem 1. Informative selection under DM2. Suppose (A1)–(A5) hold and that is locally linear in a neighborhood containing . Then, for any fixed , ranking anchors by ascending confidence on mixed inputs is equivalent to ranking by a non-increasing function of the margin and thus, up to a monotone transform, by . Consequently, the DM2 acquisition set approximates a maximizer of the localized Fisher score among anchors, favoring boundary-spanning, diverse regions of the data manifold.
Proof sketch. Softmax confidence is a monotone function of the logit gap ; hence, ordering by equals ordering by . Under local linearization and (A4), smaller implies proximity to the decision boundary, where the Fisher information increases for multinomial logistic models. Thus, ranking by approximates ranking by . Cluster separation (A5) ensures that anchors selected across different cuts yield coverage of multiple boundary regions (diversity). □
5.8. On the Mixing Coefficient λ
The coefficient trades off anchor faithfulness and boundary probing.
If , , recovering standard uncertainty sampling. If , collapses to neighbor averages, which may over-smooth and obscure fine boundaries. Under (A3), there exists an interval such that for , heterogeneous neighborhoods strictly reduce relative to while homogeneous neighborhoods preserve or increase it. Therefore, DM2 self-selects anchors with heterogeneous .
Existence of a beneficial mixing range. Assume there exist anchors with and heterogeneous such that in Lemma 1. Then, for any ,
Thus, confidence strictly decreases for such anchors; conversely, if is homogeneous with large margin, confidence is non-decreasing for near 1.
Proof. Immediate from Lemma 1 and the strict inequality . □
5.9. Considerations and Summary
Let and d be the feature dimension. Computing pairwise naively is ; approximate k-NN reduces this to near-linear time in m. Mixing and forward passes scale as , where and is model inference cost. Hence, with approximate neighbors and mini-batched evaluation, DM2 scales to large pools.
Mixing within -based neighborhoods yields mixed inputs whose logits approximate convex combinations of neighbor logits. Heterogeneous neighborhoods reduce the logit margin and thus confidence, preferentially surfacing boundary samples for labeling. The acquisition is robust-to-moderate neighbor noise and approximates selection by localized Fisher information. The combined distance is a proper metric that balances Euclidean and Manhattan sensitivities, stabilizing neighbor selection.
6. Experimental Results
We evaluate our method against state-of-the-art and baseline active learning approaches, including random selection, least confidence selection, and entropy sampling. Our approach is validated on both balanced and imbalanced image classification tasks using MobileNet [21] architectures. Experiments employ 7 to 10 active learning cycles with labeling budgets ranging from 20 to over 2500 samples per cycle. Data selections follow standard active learning practices without replacement, and all results are averaged over 5 runs. All experiments are implemented using PyTorch 2.2 [35].
For MNIST [36], we employ a CNN classification model with the Adam optimizer [37] at learning rate and batch size 96, training for 50 epochs per cycle. For CIFAR-10, CIFAR-10s [38], CIFAR-10C [39], and SVHN [40], we use MobileNet [21] with the SGD optimizer [41], initial learning rate 0.1, batch size 128, momentum 0.9, and weight decay . Training proceeds for 200 epochs with learning rate decay to 0.01 at epoch 160. We compare against established baselines including Random Selection [3], Entropy [22], Least Confidence [5], Margin [6], BALD [4], CoreSet [12], EntropyBayesian [7], UncertainGCN [42], BADGE [19], ProbCover [28], Alpha-Mix [1], and NoiseStability [32], using identical parameters for fair comparison.
Table 1 demonstrates that our method outperforms all other active learning approaches across most datasets. The DM2 method achieves superior performance compared to all baseline active learning methods on all datasets except MNIST. For the MNIST dataset, the simplicity and limited data volume result in the boundary-based selection model failing to learn useful information more rapidly than simpler selection strategies. The excellent performance on the SVHN dataset demonstrates that the DM2 method exhibits strong stability when handling imbalanced datasets. This robustness likely stems from the method’s design, which avoids data imbalance issues that can negatively impact auxiliary model training and subsequently degrade task model performance. In experiments with CIFAR-10s containing noisy data, the DM2 method successfully identifies samples conducive to model learning and demonstrates superior noise stability compared to competing approaches.
To further validate our method’s robustness, we conducted additional experiments using CIFAR-10s and SVHN datasets with ResNet18 [43] and VGG16 [44] architectures. Standard data augmentation techniques were applied during training, including random horizontal flipping and cropping. As shown in Table 2, our method consistently outperforms all other active learning approaches across these more complex architectures.
6.1. Robustness for Adversarial Training
The comparative experimental results for different active learning strategies are presented in Table 3. The results demonstrate that our method incorporating adversarial training achieves higher model accuracy compared to other active learning approaches, indicating that the boundary data feature fusion algorithm with adversarial training proposed in this work effectively improves model performance.
The experiments also reveal that conventional active learning methods often struggle to enhance performance on test sets in complex environments. Traditional active learning approaches learn only from clean datasets and exhibit reduced effectiveness when recognizing data in challenging conditions. By integrating adversarial training with the method from Section 4, our approach generates adversarial samples based on selected data, enhancing the model’s ability to learn from difficult-to-classify samples. This enables more effective integration and learning from data in complex environments, thereby improving overall performance.
The experimental results in Table 3 show that the DM2-AT method proposed in this work significantly outperforms competing methods across different models and datasets, confirming the effectiveness of our approach. The method increases learning challenges by generating adversarial samples through adversarial training on selected samples. When facing real-world scenarios with complex environments, this approach demonstrates stronger capability in identifying samples under noise interference, efficiently reducing the data requirements for building machine learning models while achieving superior performance.
6.2. Convergence Analysis
To analyze the performance trends of our method across different data selection cycles, we plotted convergence graphs based on the results from Table 1 and Table 2. Figure 4 presents trend plots for six different datasets and model combinations. All experimental values are averaged over three runs using consistent learning rates and parameters across all methods for fair comparison.
Figure 4 is organized into two groups: the upper panels show results for DM2, while the lower panels display results for DM2-AT. The method demonstrates gradual improvement across subsequent epochs, particularly in CIFAR-10 experiments using MobileNet and VGG16 architectures, where our approach surpasses competing methods. For CIFAR-10s, the model quickly learns to select more relevant data, ultimately outperforming all alternatives. On SVHN, our method demonstrates clear superiority by the 6th round, consistently outperforming other approaches throughout the remaining cycles.
Our method exhibits significant advantages across multiple datasets and model architectures, demonstrating broad applicability. In contrast, competing methods show less adaptability and inconsistent performance. Panel (e) reveals that the CIFAR-10C dataset presents challenges, with the trend chart showing some fluctuations in data selection performance. In panel (f), experiments using CIFAR-10C with ResNet34 show smoother progression and higher performance compared to MobileNet.
The ResNet18 model trained on SVHN-C in panel (h) exhibits favorable convergence trends. Except for the 3000th iteration where DM2-AT did not surpass several competing methods, it achieved excellent results across all other iterations. In panel (g), SVHN-C initially presents challenges during early training. However, after processing 5000 data points, the model rapidly identifies samples with stronger feature information, leading to sharp performance improvements and ultimately achieving superior results. These findings demonstrate the effectiveness of our active learning approach that fuses features from adversarial training boundary data.
6.3. Time Efficiency
The computational efficiency of active learning methods depends on the cost of sample distance calculations and subset selection procedures, as presented in Table 4. We evaluated the time efficiency of several effective methods using identical hyperparameters from our experiments. Our methods demonstrate computational efficiency comparable to state-of-the-art algorithms and exhibit favorable scalability as the annotation budget or number of categories increases.
6.4. Ablation Study
The active learning method proposed in this work incorporates two key components: boundary data feature fusion and adversarial training. Since removing adversarial training yields a method similar to that in Section 3, we conduct ablation experiments focusing on sample distances, fusion ratios, and perturbation values.
To assess method validity, we replace components in the ablation study: using Euclidean distance instead of the combined Euclidean and Manhattan distance, employing equal-weight fusion instead of adaptive fusion ratios, and using a fixed perturbation value of 0.05 instead of adaptive values. Table 5 presents the ablation results, demonstrating that adversarial training significantly enhances fault tolerance and robustness.
According to the experimental results in Table 5, replacing the combined distance metric with Euclidean distance alone struggles to accurately capture data distributions across different datasets, frequently leading to model confusion and suboptimal performance. Ablation experiments using equal-weight fusion show that uniform fusion causes merged features to lose distinctiveness, resulting in deteriorated model recognition performance.
The ablation study confirms that the adversarial training-based boundary data feature fusion algorithm enhances sample efficiency in active learning while improving the model’s generalization capability across diverse datasets and challenging conditions.
Active learning represents a prominent research direction for deep neural networks, enabling efficient model training with reduced sample requirements. We propose a simple yet stable method that exploits inter-sample relationships and data distribution characteristics. Through uncertainty prediction based on similarity measures and weighted mixing strategies, our approach demonstrates superior performance in both theoretical analysis and experimental evaluation across multiple tasks. The integration of adversarial training with boundary data feature fusion further enhances model robustness and generalization capability in complex environments.
Future work will focus on more challenging scenarios where the computational efficiency and cost reduction benefits of active learning become increasingly significant. We aim to extend our approach to handle larger-scale datasets and more complex domain adaptation problems, where traditional supervised learning approaches face substantial annotation costs and computational constraints.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Parvaneh A. Abbasnejad E. Teney D. Haffari G.R. Van Den Hengel A. Shi J.Q. Active learning by feature mixing Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition New Orleans, LA, USA 18–24 June 20221223712246
- 2Munjal P. Hayat N. Hayat M. Sourati J. Khan S. Towards robust and reproducible active learning using neural networks Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition New Orleans, LA, USA 18–24 June 2022223232
- 3Settles B. Active Learning Literature Survey. Technical Report 2009 Available online: https://minds.wisconsin.edu/handle/1793/60660(accessed on 1 January 2024)
- 4Gal Y. Islam R. Ghahramani Z. Deep bayesian active learning with image data Proceedings of the International Conference on Machine Learning, PMLR Sydney, Australia 6–11 August 201711831192
- 5Lewis D.D. A sequential algorithm for training text classifiers: Corrigendum and additional data Proceedings of the ACM SIGIR Forum New York, NY, USA 3–6 July 1994 Volume 291319
- 6Kremer J. Steenstrup Pedersen K. Igel C. Active learning with support vector machines WIR Es Data Min. Knowl. Discov.2014431332610.1002/widm.1132 · doi ↗
- 7Gal Y. Ghahramani Z. Dropout as a bayesian approximation: Representing model uncertainty in deep learning Proceedings of the International Conference on Machine Learning PMLR, New York, NY, USA 20–22 June 201610501059
- 8Freund Y. Seung H.S. Shamir E. Tishby N. Selective sampling using the query by committee algorithm Mach. Learn.19972813316810.1023/A:1007330508534 · doi ↗