Activity Detection and Channel Estimation Based on Correlated Hybrid Message Passing for Grant-Free Massive Random Access
Xiaofeng Liu, Xinrui Gong, Xiao Fu

TL;DR
This paper introduces a new algorithm for detecting active users and estimating channels in 6G networks, improving efficiency in massive random access scenarios.
Contribution
The novel CHMP algorithm uses a channel prior model with three state variables and BFE minimization for adaptive AUDCE.
Findings
The CHMP algorithm accurately detects active users in wideband systems.
It achieves precise channel estimation without prior knowledge of sparsity or channel priors.
Simulation results validate the effectiveness of the proposed method.
Abstract
Massive machine-type communications (mMTC) in future 6G networks will involve a vast number of devices with sporadic traffic. Grant-free access has emerged as an effective strategy to reduce the access latency and processing overhead by allowing devices to transmit without prior permission, making accurate active user detection and channel estimation (AUDCE) crucial. In this paper, we investigate the joint AUDCE problem in wideband massive access systems. We develop an innovative channel prior model that captures the dual correlation structure of the channel using three state variables: active indication, channel supports, and channel values. By integrating Markov chains with coupled Gaussian distributions, the model effectively describes both the structural and numerical dependencies within the channel. We propose the correlated hybrid message passing (CHMP) algorithm based on Bethe…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1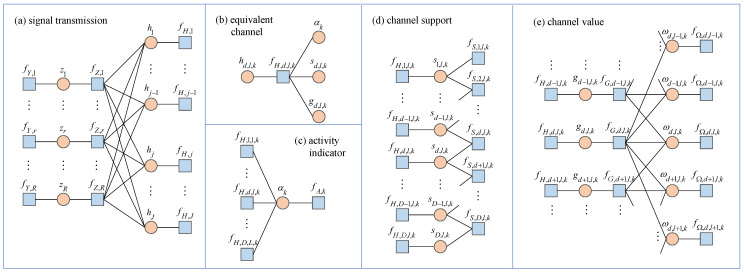 Figure 2
Figure 2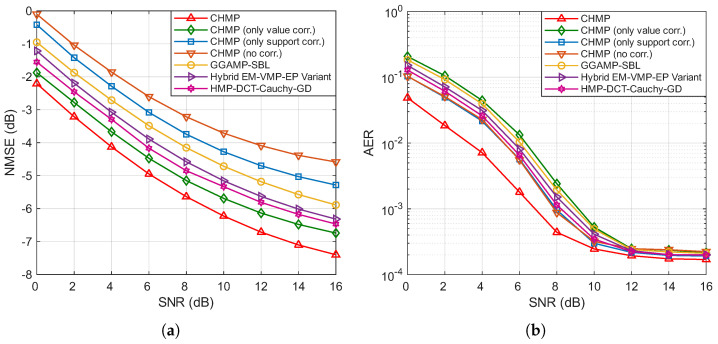 Figure 3
Figure 3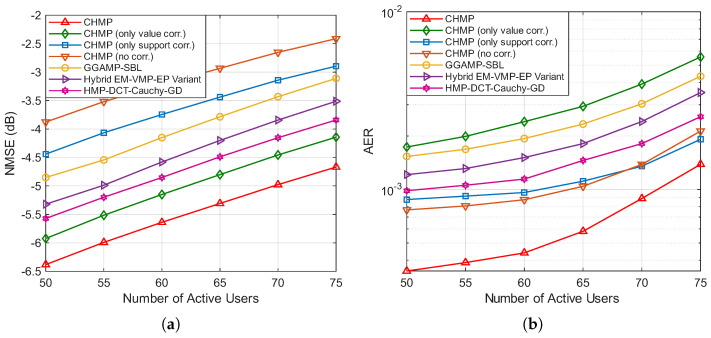 Figure 4
Figure 4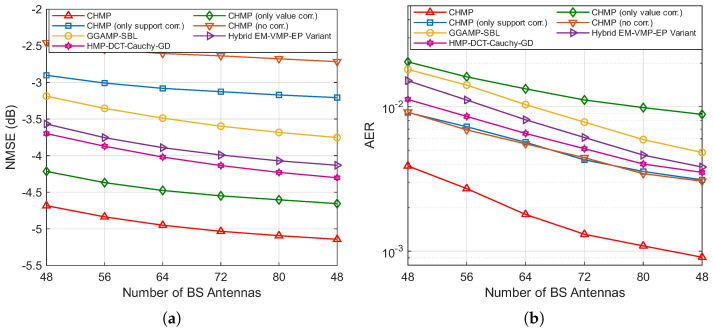 Figure 5
Figure 5- —Jiangsu funding program for excellent postdoctoral talent
- —China postdoctoral science foundation
- —funding project for basic science (natural science) research in higher education institutions in Jiangsu province
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsIoT Networks and Protocols · Advanced Wireless Communication Technologies · Wireless Networks and Protocols
1. Introduction
With the continuous evolution of mobile communication technology and the rapid development of Internet of Things (IoT) applications, future 6G technologies are required to support the massive connectivity of IoT devices. Massive access is integral to emerging fields such as smart homes, smart cities, and industrial automation, with the primary goal of providing ubiquitous connectivity for low-cost, energy-efficient devices [1,2]. However, due to the large scale, sporadic activity, and short data packet transmission characteristic of IoT devices, traditional grant-based random access methods, which rely on negotiation and resource allocation, can lead to heavy signaling overhead and high transmission latency [3]. To address these fundamental challenges, researchers have proposed grant-free access schemes. By allowing devices to transmit data without prior authorization, this paradigm significantly improves the communication efficiency and is considered a cornerstone technology for future massive access scenarios [4].
The successful implementation of grant-free access relies on a critical task at the base station (BS): the ability to efficiently perform joint active user detection and channel estimation (AUDCE) from a single snapshot of superimposed signals [5]. Leveraging the sporadic nature of user activity, this problem can be elegantly formulated as a sparse signal recovery task. Early and foundational approaches were largely based on traditional compressed sensing (CS) algorithms, such as orthogonal matching pursuit (OMP), which provided initial solutions but often exhibited limited performance, especially in low signal-to-noise-ratio (SNR) regimes or when the channel statistics are complex [6,7]. To achieve higher accuracy and robustness, the research paradigm has increasingly shifted towards model-based Bayesian inference, which offers a principled way to incorporate rich prior knowledge of the system’s structure and statistics. Within this paradigm, advanced message passing (MP) algorithms, including those derived from sparse Bayesian learning (SBL) and generalized approximate message passing (GAMP), have emerged as powerful and computationally efficient frameworks for AUDCE, demonstrating significant performance gains over their CS counterparts [8,9,10].
To further push the performance boundaries, a pivotal research direction has been the exploitation of inherent correlation structures within the massive access channel. This body of work can be broadly summarized by the dimension of correlation explored. The core strategy in the time domain is to leverage the temporal dependency of user activity, where a user tends to remain active or inactive over consecutive time slots. Representative works, such as [11,12], have captured this slow-varying behavior using methods like message passing with temporally correlated priors or Bernoulli–Gaussian–Markov chain models. Beyond the time domain, the primary approach in the frequency domain is to mitigate the effects of frequency-selective fading by transforming the channel into a domain where it exhibits a more compact, sparse representation. For instance, the work in [13] effectively exploits channel sparsity in the discrete cosine transform (DCT) domain using a hybrid message passing algorithm. Furthermore, the spatial domain offers yet another layer of rich structural information, where researchers have capitalized on large antenna arrays from two main perspectives. One line of inquiry leverages the channel’s spatial correlation, where works like [14] have incorporated the channel’s spatial covariance matrix into the compressed sensing framework as prior information to enhance the estimation accuracy. Another powerful approach, adopted in [15,16], is to exploit the inherent channel sparsity that emerges when the channel is characterized in the angle domain, which is a direct consequence of the clustered nature of physical scatterers. This research direction has also been successfully extended to next-generation architectures like cell-free massive MIMO systems [17].
Parallel to the advancements in correlation modeling, the research community has explored the AUDCE problem from a diverse set of methodological perspectives, reflecting the vibrancy of this field. A significant recent trend is the rise of data-driven methods; for example, a deep learning-based approach was introduced in [18], which combines a preamble detection neural network and a data detection neural network. Another type of advanced signal processing, namely tensor-based methods, has been utilized to handle more complex, high-dimensional scenarios, such as those involving high user mobility [19]. Furthermore, some works have expanded the problem’s scope to include the subsequent data decoding stage, tackling the entire processing chain from detection to decoding within a unified framework [20]. Concurrently, innovation continues in transmission schemes and problem formulations. Novel techniques like differential modulation have been proposed to simplify detection [21], while others have tackled the more challenging blind access problem in demanding mmWave settings [22] or considered broader system-level requirements such as multi-service provisioning [23].
While the aforementioned works have made significant progress by exploiting individual channel correlations, their focus on a single facet of the channel’s complex statistical topology may be insufficient to provide the full descriptive power needed for the challenging conditions of wideband massive MIMO-OFDM systems. Therefore, a notable avenue for performance enhancement lies in more comprehensive modeling of the channel’s statistical properties. The primary limitation of existing models is their partial exploitation of these properties. They typically focus on the correlation within only one of the channel’s components, such as its structure or its values, while treating the other with a simpler, often independent prior. By not simultaneously modeling both the intricate structural patterns and the nuanced value dependencies, these approaches fail to leverage the full statistical richness of the physical channel. The core challenge, therefore, is to develop a unified probabilistic framework that can cohesively model this dual correlation, which involves capturing both the structured correlation within the channel support and the value correlation within the channel gains, all under a single comprehensive prior. In this paper, we address this critical gap by proposing a novel framework for joint AUDCE under the massive MIMO-OFDM system. The main contributions of our work can be summarized as follows:
- To characterize the sparse properties of the channel in the user–angle–delay domain, we construct a novel hierarchical probabilistic structure that includes three state variables: active indication, channel supports, and channel values. The innovation of this model lies in its layered structure, which provides a principled way to factorize the joint prior distribution and cohesively model sparsity at different levels. This model accurately captures the user-domain sparsity through the active indication variable and, critically, utilizes the channel support and channel values variables to enable the modeling of what we term the dual correlation of user channels. This dual correlation refers to the modeling of two distinct statistical phenomena under a unified prior: the structural correlation, which captures the clustered nature of non-zero channel paths using a Markov chain, and the value correlation, which describes the statistical dependency between the gains of adjacent patterns using a coupled Gaussian distribution.
- Based on the proposed system and probability model, the joint active user detection and channel estimation problem is formulated as a Bethe free energy (BFE) minimization problem under hybrid constraints. Through the optimization and reconstruction of the constraint conditions, we propose the correlated hybrid message passing (CHMP) algorithm. The hybrid nature of the algorithm lies in its tailored message passing schedule, which applies exact inference for discrete state variables (active indication, channel supports) and efficient, moment-based approximate inference for continuous variables (channel values). This approach, derived rigorously under our hybrid constraint framework, achieves a favorable balance between estimation accuracy and computational complexity. Furthermore, this algorithm can adaptively update model parameters without prior knowledge of user sparsity or channel prior information.
- Numerical simulations demonstrate that the proposed joint correlation modeling significantly enhances performance. The reason is that, by exploiting these dual correlations, our algorithm gains powerful prior information that regularizes the ill-posed estimation problem. The structural correlation helps to more accurately locate clusters of active channel taps, while the value correlation helps to refine their coefficient estimates, leading to more robust and precise joint detection and estimation.
To provide a clear overview and roadmap for the reader, we summarize the structure of our proposed solution here. We begin by establishing the system model for a grant-free massive MIMO-OFDM network. Then, to capture the channel’s inherent structure, we develop a novel hierarchical probabilistic prior model that characterizes the dual correlations of channel support via Markov chains and channel values via coupled Gaussian distributions. Based on this model, we formulate the joint estimation problem as a BFE minimization task. Finally, we derive the CHMP algorithm as an efficient iterative solution to this problem, which jointly yields the active user set and their corresponding channels.
The remainder of this paper is organized as follows. In Section 2, the system model is presented for grant-free massive random access in massive MIMO-OFDM systems. In Section 3, the probability model is developed by utilizing three types of state variables—active indicators, channel supports, and channel values—to model the equivalent angle–delay domain channel. Section 4 formulates the joint active user detection and channel estimation problem as a constrained BFE minimization problem. Section 5 provides the detailed theoretical foundation of the CHMP algorithm by solving the constrained BFE minimization problem. Section 6 describes the proposed algorithm, including the procedure details and computational complexity analysis, while Section 7 presents the simulation experiment results. Section 8 concludes this paper.
Notation: The boldface lowercase (uppercase) letters denote vectors (matrices). , , and denote the matrix conjugate, transpose, and conjugate transpose, respectively. , , and denote floor, natural logarithm, and real part operations, respectively. and denote continuous and discrete delta functions, respectively. , , and denote the statistical expectation, entropy, and relative entropy, respectively. ⊗ denotes the Kronecker product, denotes the norm, ∝ denotes the scalar proportionality between two real-valued functions, and denotes the complex Gaussian distribution with mean and variance . For the reader’s convenience, we summarize the key notations used throughout this paper in Table 1.
2. System Model
Consider the uplink grant-free random access in a single-cell massive MIMO-OFDM system, as shown in Figure 1. The BS is equipped with a uniform linear array consisting of M antennas and serves K single-antenna users within the cell. Due to the sporadic transmission characteristic of IoT devices, only a small number of users in the potential user set remain active during uplink access, while the remaining users remain dormant, i.e., , where denotes the set of active users and [24]. This section will first present the channel model for the grant-free massive access system and then provide the received signal model based on the sparse channel representation in the transform domain.
2.1. Channel Model
Assume that there are propagation paths from user k to the BS in the wireless scattering environment. The system employs OFDM modulation with subcarriers, where the spacing between adjacent subcarriers is , and signal transmission occurs over N effective subcarriers. The space–frequency domain channel vector for user k on the n-th effective subcarrier can be expressed as
where and represent the small-scale complex channel gain and propagation delay of the i-th path for user k, respectively, and , where is the angle of arrival of the i-th path for user k. denotes the relative frequency of the n-th effective subcarrier with respect to the carrier frequency , where . The array response vector is given by
where represents the wavelength of the carrier, and denotes the half-wavelength antenna spacing. Thus, the space–frequency domain channel matrix for user k can be constructed from its space–frequency domain channel vectors of the effective subcarriers as follows:
where the delay response vector is given by
Then, by implementing quantization sampling in the angle and delay domains, we can establish the transformation relationship between the space–frequency domain channel and the angle–delay domain channel. Since , its value ranges within . Assuming that the cyclic prefix (CP) length of the OFDM system is system sampling intervals, which exceeds the maximum path delay, the value range of is , where is the system sampling interval. Consider uniformly sampling the value ranges of and using D and L grid points, respectively. To ensure sufficient quantization accuracy, the conditions and should be satisfied. Therefore, the sampled angle and sampled delay can be expressed as
Next, we can construct the angle domain sampling matrix and the delay domain sampling matrix , which are composed of their respective sampling response vectors and are specifically given by
With the angle and delay domain sampling matrices and now defined, we can express the physical space–frequency channel in terms of its angle–delay domain counterpart, which we denote as . Therefore, the space–frequency domain channel matrix in (3) can be re-expressed as
2.2. Received Signal Model
Define the active indicator factor to denote the active status of the user k. When , we have , indicating that the user is active; conversely, when , we have , indicating that the user is dormant. Thus, the received signal at the BS for the t-th OFDM symbol can be given by
where , represents the equivalent space–frequency domain channel for user k; and denote the signal transmission power and large-scale fading factor of user k when active, respectively; and represents the equivalent large-scale fading factor for user k. denotes the unit energy transmitted signal of the user k, satisfying the power constraint , and represents the additive white Gaussian noise matrix with zero mean and variance . Assuming effective power control, each user’s signal transmission power can compensate for channel large-scale fading, resulting in equal equivalent large-scale factors for all users [11,25], i.e., , . To simplify the discussion, let . The small-scale channel matrix is assumed to have the same power, i.e., , . This ensures that the total received signal power from each active user in the BS is equal, avoiding the impact of the near–far effect on the users [26]. Finally, the equivalent space–frequency domain channel matrix for all users is defined as .
Assume that all users transmit uplink access pilots using the same subcarrier set when active, with the number of pilot subcarriers being P, embedded uniformly in the N effective subcarriers. The system assigns a unique Gaussian access pilot sequence to each user, where represents the set of G OFDM symbols used for access, and , with elements following the standard complex Gaussian distribution . Then, the received pilot signal at the BS for the t-th OFDM symbol, , can be expressed as
where is the index matrix for the pilot subcarriers, composed of columns from corresponding to . and represent the received pilot signal and noise matrix, respectively. , and . is the equivalent angle–delay domain channel matrix for user k, is the equivalent angle–delay domain channel matrix for all users, and is the pilot matrix for the t-th OFDM symbol. Therefore, the overall received pilot signal at the BS can be formulated as
where , , , and . By vectorizing the received signal , (12) can be further transformed into the following matrix–vector multiplication form:
where , , , and are the sensing matrices, where and . To simplify subsequent notations, we define and and also define the subscript and . It is important to note that, while we assume unique Gaussian pilots, this choice serves as a standard model for the non-orthogonal pilot scenario common in massive access systems [20,23,27] and is widely adopted for its analytical tractability. The specific properties of the pilot sequences are entirely captured within the sensing matrix . Therefore, the algorithm subsequently proposed in this paper is a general framework that is not restricted to a specific pilot type.
The goal of this paper is to jointly detect the activity of all users and estimate the space–frequency domain channels of active users using the pilot reception signal from the BS and the received signal model (13). Since the user’s activity status is embedded in the equivalent channel, this target is equivalent to estimating the equivalent space–frequency domain channels of all users [9]. Furthermore, based on the domain transformation relationship of the channel (9), the space–frequency domain channels can be reconstructed by obtaining the equivalent angle–delay domain channels .
3. Probability Model
This section establishes a probability model to characterize the active sparsity of the equivalent channel in the user dimension and the sparse correlation in the angle–delay domain. Based on the previous system model, we first provide a probability representation of the received signal model. Then, the prior probabilities of the equivalent angle–delay domain channel are modeled using three types of state variables: active indicators, channel support, and channel values. The sparse correlation between channel support and channel values is detailed using a combination of Markov chains and coupled Gaussian distributions. Finally, the corresponding posterior probability representation is constructed for the joint problem of active user detection and channel estimation.
3.1. Received Signal Probability Formulation
Based on the received signal model (13), we begin by expressing the problem in a probabilistic form. The likelihood of the received signal given the channel can be written as a marginalization over an auxiliary noiseless signal variable :
where the auxiliary vector represents the BS’s received pilot signal in the absence of noise. Specifically, the conditional probability density can be expressed as
where and represent the r-th elements of and , respectively, and denotes the corresponding factor function form, provided here for ease of subsequent discussion. The conditional probability density is specifically given by
where denotes the -th element of , denotes the j-th element of , and denotes the continuous Dirac delta function. This representation is a crucial modeling choice with a threefold purpose. Fundamentally, it embeds the deterministic linear constraint into the probabilistic factor graph. Structurally, this factorization allows the global problem to be decomposed, which facilitates the modular derivation of our algorithm. Most importantly, it is a prerequisite for the subsequent constraint reconstruction within the BFE framework, where the belief associated with this factor is relaxed.
3.2. Prior Model of the Equivalent Channel
To reveal the sparsity characteristic of the equivalent angle–delay domain channel in terms of users, angles, and delays, we further construct the corresponding prior probability models. To model the channel’s inherent sparse structure in the angle–delay domain, we decompose the physical channel matrix into its structural and numerical components using two types of latent state matrices:
where the channel support is a binary matrix designed to describe the sparse structure of the channel; the channel value is a complex matrix representing the numerical response of the channel. Specifically, the element of indicates whether a particular channel element in is zero, while the element of is a complex-valued random variable representing the channel gain of the corresponding non-zero path. Here, the indices correspond to the d-th angle grid point, the l-th delay grid point, and the k-th user, respectively. Thus, given , , and , the conditional probability density of the equivalent channel is expressed as
in which and are mutually independent. Next, we will establish probability models for these latent variables separately to fully leverage their sparse characteristics.
The user-domain sparsity is captured by the activity indicator , which is modeled as a Bernoulli random variable with the following prior probability:
where denotes the activity probability of user k. Considering the practical finite scattering environment, the angle–delay domain channel exhibits a clustered sparse structure, with the non-zero elements of primarily concentrated in specific angles corresponding to a limited number of scattering paths. Therefore, a Markov chain can be used to capture the clustered characteristics in the angle domain for each path delay. The prior distribution of the channel support can be given by
where denotes the transition probability from 1 to 0, and denotes the transition probability from 0 to 1. and . For , the conditional probability distribution is specifically written as
When , the initial probability distribution is modeled as the steady-state distribution of the Markov chain:
Finally, to describe the correlation characteristics of adjacent elements in the channel values , a coupled Gaussian distribution is used for modeling, which is given by
where represents the latent precision of the coupled Gaussian distribution, and is a latent precision matrix aligned with the element positions of . The set defines the nearest neighbors and the index of in the angle–delay domain, and represents the vector consisting of and its nearest neighbors. Specifically, when the coordinate of is inside the angle–delay domain, i.e., and , we have and . When the coordinate of is on the edge or corner of the angle–delay domain, the definitions of and need to be adjusted accordingly. This indicates that the channel value shares the latent precision with its neighboring elements. The coupling connection of the latent precision illustrates the statistical correlation between channel value responses. Furthermore, the latent precision matrix is further modeled as the following Gamma distribution:
where denotes the Gamma function, and a and b are preset hyperparameters corresponding to the shape parameter and rate parameter, respectively. When prior knowledge about random variables is lacking, a and b are often set to very small positive numbers close to zero, such as , to ensure that the prior does not contain any information [28].
We note that a similar probabilistic structure, which also employs a Bernoulli–Gaussian process and a Markov chain, has been considered in [12] for grant-free NOMA systems. However, there are several fundamental distinctions between our proposed dual correlation model and the model presented in that work. First, our model is tailored to the massive MIMO-OFDM system and thus operates in the user–angle–delay domain, whereas the previous work was focused on a single-antenna BS system. Second, and more critically, the application of the Markov chain is fundamentally different. We employ it to capture the spatial structural correlation of the channel supports across the angular dimension for each delay tap. In contrast, the referenced work uses it to model the temporal correlation of the binary user activity state across time slots. Third, our model introduces a second, distinct layer of correlation by capturing the intrinsic dependency between adjacent channel patterns via a coupled Gaussian distribution, a component that is absent in the model from the other work. Fourth, our primary objective is the fundamental problem of AUDCE, while the objective in the referenced work is data detection. In summary, by jointly modeling both spatial structural and numerical value correlations for a distinct problem, our proposed framework provides a more comprehensive and accurate prior for the complex channels found in wideband massive MIMO systems.
3.3. Probability Representation of the Target Problem
Based on the probability models provided above, the joint posterior probability density function of the equivalent channel, activity indicator, channel support, and channel value can be decomposed as follows:
where Z is a normalization constant; , , , , and represent the set of model parameters. The joint active user detection and channel estimation can be approached by obtaining the equivalent channel. Based on (25), the minimum mean square error (MMSE) estimator of the equivalent channel can be given by
and the marginal posterior probability density can be specifically expressed as
To clearly demonstrate the relationships between the probabilities, we visualize the factorization of the joint posterior probability in (25), as shown in Figure 2, where blue squares represent factor nodes, while orange circles represent variable nodes. The factor graph in Figure 2 comprises five main modules, corresponding to signal transmission, equivalent channels, activity indications, channel support, and channel values.
Due to the large number of potential users, the factor graph exhibits a complex multi-loop structure, requiring that the exact calculation of the MMSE estimator of the equivalent channel in (26) involves high-dimensional integrals, which are difficult to handle. The next section will transform this complex probability density function integral into a solvable optimization problem based on the constrained BFE minimization theory, combining Bethe approximation and constraint reconstruction methods, thereby laying a solid theoretical foundation for subsequent algorithm design.
4. Constrained BFE Minimization Problem
This section will transform the high-dimensional probability density integral calculation into a constrained BFE minimization problem, laying the theoretical foundation for the hybrid message passing algorithm. First, the original BFE expression for the proposed probability model will be established using the Bethe approximation method. Next, a series of constraints on the beliefs of the free energy will be reconstructed to facilitate algorithm design. Finally, the constrained BFE minimization problem will be formulated.
4.1. Free Energy and Bethe Approximation
To calculate the marginal posterior probability density , we first consider the joint posterior probability density . To solve for the marginal posterior probabilities, we turn to the framework of variational inference. According to the definition provided in [29,30,31], the variational free energy is given by
where is the normalization constant. Directly minimizing this free energy is intractable. Therefore, we approximate the true belief with the Bethe approximation, which factorizes the belief according to the structure of the factor graph:
where denotes the cardinality of the set . The factor beliefs and variable beliefs can also be divided into five categories, corresponding to signal transmission, equivalent channels, activity indicators, channel support, and channel values, as listed in Table 2.
Moreover, the Bethe approximation requires that the factor beliefs and variable beliefs satisfy the following marginal consistency constraints:
where the constraint (35) uses three-dimensional coordinates to clearly demonstrate the relationship between the beliefs. Additionally, the factor beliefs and variable beliefs need to satisfy the following normalization constraints:
where (37) is listed separately to facilitate the discussion in the next subsection. Since the marginal consistency constraints and normalization constraints ensure that the non-negativity constraints of the beliefs are always satisfied, their non-negativity constraints can be omitted. Finally, by substituting the Bethe approximation (29) into the variational free energy expression (28), the specific BFE expression can be obtained as
Thus, the original BFE minimization problem can be formulated as
By solving the problem (39), the optimal solutions for the factor beliefs and variable beliefs can be obtained. Using the optimal variable belief , the marginal posterior probability density can be well approximated.
4.2. Constraint Reconstruction
The Bethe approximation introduces auxiliary beliefs through factor relationships in the joint posterior probability density, aiming to maintain the connections between probability factors and to avoid the complex integrals involved in computing the marginal posterior probability densities. However, since the original marginal consistency constraints still contain some high-dimensional integrals, these constraints need to be reconstructed into a more manageable form to reduce the computational burden.
To simplify the factor belief , the latent precision can be assumed to be independent of other variables, which allows it to be separated from through a factorization constraint as
where is the factor belief after separation. It can be observed that still satisfies the normalization constraint, which is given by
Further, by substituting the factorization constraint (40) into the KL divergence , we obtain
By substituting the marginal consistency constraint (34) and the factorization constraint (40) back into the BFE in (38), the channel value part in the last line of (38) can be rewritten as
Then, by replacing the BFE in (38) with the expression in (43), it is denoted as . For further simplification, following the idea of expectation propagation approximation, the marginal consistency constraint (30) can be relaxed to the following mean and variance consistency constraints:
For the constraint (31), considering that the factor belief under any r includes the variable , an average variance consistency constraint can be used to further reduce the complexity. To ensure estimation accuracy, the mean consistency constraint remains unchanged, yielding
Similarly, since is a continuous variable, the constraint (33) can be relaxed by applying mean and variance consistency constraints as
Since the integration of binary variables is relatively simple, there is no need to relax the constraints (32) and (35). Combining the reconstruction design above, the BFE minimization problem under hybrid constraints can be finally formulated as
where is treated as an unknown model parameter and is optimized together with the factor beliefs and variable beliefs in problem (50).
5. Theoretical Foundation of Correlated Hybrid Message Passing
This section aims to solve the aforementioned constrained BFE minimization problem to develop the hybrid message passing algorithm for joint active user detection and channel estimation. In the algorithm design, Lagrange multipliers are first used to weight the constraints, constructing the Lagrangian function. Then, the first-order partial derivatives of the Lagrangian function with respect to the beliefs, model parameters, and Lagrange multipliers are set to zero, yielding a set of stationary point equations. These equations include expressions for the beliefs, model parameters, and hybrid constraints. Finally, by solving the stationary point equations, update rules for the Lagrange multipliers or auxiliary variables can be obtained.
5.1. Lagrangian Function Construction
This subsection introduces the corresponding Lagrange multipliers for the hybrid constraints in problem (50) and constructs the required Lagrangian function accordingly. To solve the constrained minimization problem, we construct the Lagrangian function by introducing Lagrange multipliers for each of the hybrid constraints. The complete Lagrangian function can be decomposed into the following six parts:
where represents the BFE, and , , , , and denote the Lagrangian function components corresponding to the five types of beliefs in (29). Specifically, corresponds to the signal transmission-type beliefs , , and with respect to the constraints (44), (45) and the relevant parts of constraint (36), expressed as
Here, the symbol represents the Lagrange multipliers for the mean consistency constraints, represents the Lagrange multipliers for the variance consistency constraints, and represents the Lagrange multipliers for the normalization constraints. Then, corresponds to the constraints on the equivalent channel-type beliefs and in the relevant parts of constraints (46), (47), and (36), which is given by
Next, corresponds to the constraints on the activity indicator-type beliefs and in the relevant parts of constraints (32) and (36), expressed as
where the symbol represents the Lagrange multipliers for the marginal consistency constraints. Further, corresponds to the constraints on the channel support beliefs and in the relevant parts of constraints (35) and (36), which can be specifically written as
Finally, corresponds to the constraints on the channel value-type beliefs , , and in the relevant parts of constraints (41), (46), (47), and (36), given in
5.2. Belief Representation
For the Lagrangian function (51), by setting the first-order partial derivatives with respect to the auxiliary beliefs and model parameters to zero and solving, we derive the expressions for the factor beliefs, variable beliefs, and model parameters. By combining these expressions with the hybrid constraints, the stationary point equations can be formulated. These equations can be solved according to the modular structure of the factor graph in Figure 2, leading to the hybrid message passing algorithm. Due to the connections between probabilities, some beliefs are shared among modules. For ease of reference, we next list the specific representations of the factor beliefs and variable beliefs.
First, the specific expressions for the signal transmission-type beliefs , , and are provided. The factor belief is given by
and the variable belief is expressed as
while the factor belief is expressed as
Next, the specific expressions for the equivalent channel-type beliefs and are shown below. The variable belief is given by
and the factor belief is given by
Then, we present the specific expressions for the activity indicator beliefs and . The variable belief is given by
and the factor belief is expressed as
Furthermore, the specific expressions for the channel support-type beliefs and are provided. The variable belief is given by
When , the factor belief is written as
When , the factor belief is given by
Finally, the specific expressions for the channel value beliefs , , and are given. The variable belief is expressed as
the factor belief is given by
and the factor belief is given by
5.3. Signal Transmission Module
This subsection will detail the message passing process of the signal transmission module. By simplifying the mean expression of the factor belief in (57), we can obtain
Based on the mean expression of the variable belief in (58), we can obtain . By substituting the factor belief from (57) and the variable belief from (58) into the variance consistency constraint in (45), we get . Combining the equations , , and (70), the auxiliary mean in (59) can be rewritten as
Then, based on the variance expression of the variable belief in (60), the variance consistency constraint in (47) can be re-expressed as
By substituting the variable belief from (58) and the factor belief from (59) into the variance consistency constraint in (45), and further simplifying this constraint, we can obtain
Next, based on the mean consistency constraints (44) and (46), the auxiliary mean in (57) can be given by
According to the definitions of the auxiliary mean in Equation (57) and the auxiliary mean in (59), we have
Then, based on the factor belief in Equation (59), we calculate the mean expressions and . By connecting and simplifying these means, the relationship between the Lagrange multipliers and can be derived as follows:
Furthermore, by substituting the factor belief from (59) and the variable belief from (60) into the variance consistency constraint in (47) and simplifying, we derive
Finally, based on the mean expression of the variable belief in Equation (60), we obtain . Combining this with (76), the auxiliary mean in (61) can be reconstructed as
5.4. Equivalent Channel Module
This subsection will detail the message passing process of the equivalent channel module. Based on the factor belief in (61), the auxiliary messages are introduced as follows:
where and are the log-likelihood ratios of and , respectively. Here, the subscript is equivalent to the subscript . With these definitions, the factor belief in (61) can be reformulated as
First, we present the derivation related to in the equivalent channel module. By integrating the factor belief in (81) over all variables except , this yields the following equation:
where , , and are expressed as
Thus, the mean and the variance can be calculated as
Then, we provide the derivation related to in the equivalent channel module. Based on (62) for the variable belief , the auxiliary message is defined as
where is the log-likelihood ratio of . By substituting the variable belief in (62) and the factor belief in (81) into the marginal consistency constraint in (32) and simplifying this constraint, we can obtain
Next, the following derivation concerns the part related to the channel support . Based on the variable belief in (64), the auxiliary message is defined as
where represents the log-likelihood ratio of . By substituting the variable belief in (64) and the factor belief in (81) into the marginal consistency constraint in (35) and simplifying this constraint, we have
Finally, the derivation related to is presented. By marginalizing the factor belief in (81) over all variables except , we can obtain its marginal belief as
where , , and are given in (83), (84), and (85), respectively. Therefore, can be calculated as
5.5. Activity Indicator Module
This subsection will detail the message passing process of the activity indicator module. Based on the variable belief in (63), an auxiliary message is introduced, which is expressed as
where is the log-likelihood ratio of . By substituting the factor belief in (61) and the variable belief in (62) into the marginal consistency constraint in (32) and simplifying, and by combining the definitions of the auxiliary messages in (88) and in (94), the following result is obtained:
Then, by substituting the variable belief from (62) and the factor belief from (63) into the marginal consistency constraint in (32) and simplifying it, and then combining this with the definitions of the auxiliary messages in (79) and in (88), we can get
where represents the log-likelihood ratio of the active probability . Next, by taking the first partial derivative of the Lagrangian function (51) with respect to the active probability and setting it to zero, the update rule for the active probability can be derived as
where the mean can be calculated according to (63). The expression represents the updated active probability, where denotes the active probability before the update. To avoid confusion, the superscript is used for distinction throughout this paper. Finally, (97) can be rewritten in the following equivalent form of the log-likelihood ratio:
5.6. Channel Support Module
This subsection will provide a detailed description of the message passing process in the channel support module. For ease of notation, the subscript will be rewritten as in this subsection. Referring to the auxiliary message in (80), and based on the factor belief in (65), the following auxiliary messages are introduced:
where and are the log-likelihood ratios of and , respectively. Referring to (90), the auxiliary message is defined as
where is the log-likelihood ratio of . Similarly, define the auxiliary message as
where is the log-likelihood ratio of .
Based on the definitions in Equations (80), (101), and (102), the following log-likelihood ratio relationship can be derived:
Then, using the definitions from (90), (99), and (102), the corresponding log-likelihood ratio relationship is expressed as
Based on Equations (90), (100), and (101), the following log-likelihood ratio relationship can be further given:
Following this, the marginal consistency constraint involving the variable belief and the factor belief or in (35) can be restated as
Moreover, when , the marginal consistency constraint involving the beliefs and in (35) can be rewritten as
Subsequently, by taking the first-order partial derivative of the Lagrangian function (51) with respect to the transition probability and setting it to zero, can be expressed as the solution to the following quadratic equation:
where , , and are, respectively, given by
Specifically, the solution for in (108) is expressed as
Similarly, by taking the first-order partial derivative of the Lagrangian function (51) with respect to the transition probability and setting it to zero, can be expressed as the solution to the following quadratic equation:
where , , and are, respectively, given by
Specifically, the solution for in (113) can be calculated as
Finally, considering the expression for the transition probability in (112) and the expression for the transition probability in (117), both are related to the mean of the factor belief . When , based on the factor belief in (65), we can derive the following series of mean expressions:
where , , , , , and . When , based on the factor belief in (66), the mean expression can be obtained as
where denotes the probability that the variable equals 1, with the corresponding log-likelihood ratio given by .
5.7. Channel Value Module
This subsection will provide a detailed description of the message passing process in the channel value module. Based on the mean expression for the variable belief in (67), we have . For the factor belief in (68), by expanding and simplifying the term , the following can be obtained:
where . By substituting the variable belief from (67) and the factor belief from (122) into the variance consistency constraint in (49), we have
By then substituting and into (122), and combining the mean consistency constraint from (48) with the definition of the auxiliary mean in (61), after simplification, it follows that the mean of the factor belief is given by . Consequently, the auxiliary mean can be expressed as
Next, by expanding and simplifying the term in the factor belief from (69), the following expression can be obtained:
where is given by
As stated in (24), we have . To simplify the calculation, it is desirable for the function in (125) to be proportional to a Gamma distribution so that also follows a Gamma distribution, which would facilitate the computation of the mean . However, due to the presence of variable coupling in the function, obtaining a closed-form solution for in (126) is very challenging. Notably, the function in (125) contains both linear and nonlinear parts in , which are coupled with other variables. We refer to this as the fully coupled model. Next, consider an alternative scenario where all in the prior (23) are replaced by , leading to . In this case, we can derive
which we refer to as the decoupled model. To strike a balance between computational convenience and variable correlation, we can retain the linear part of the function in under the fully coupled mode, while replacing the nonlinear part with the nonlinear part from the uncoupled mode, thus obtaining
where the factor belief after the replacement is referred to as the semi-coupled model. The mean of this semi-coupled factor belief can be computed as follows:
where the second equality arises due to the consistency constraint between the mean and variance, which implies that , and is given by (93).
5.8. Active User Detection Strategy
This section will provide a detailed description of the active user detection strategy. After obtaining the estimated values of the effective angle–delay domain channel (i.e., ), the equivalent space–frequency domain channel estimate for user k can be derived based on the channel transformation relationship in (9) as
where represents the -th element of the matrix . The algorithm determines the active status of user k using a detector based on the user’s activity log-likelihood ratio, as described in [32,33,34], and this is expressed as
where the update for is given in (98). Then, based on the activity detection metric , the equivalent space–frequency domain channel estimation for user k is adjusted as
Finally, the equivalent space–frequency domain channel estimation matrix for all users can be obtained as , along with the activity detection vector .
6. Algorithm Description
6.1. Procedure Details
The detailed procedure of the proposed CHMP algorithm is summarized in Algorithm 1. In this algorithm, the equivalent channel module, serving as a connecting component, is divided into its corresponding modules. The Markov chain of the channel support module corresponds to Steps 17 to 24 of the algorithm, while the coupled Gaussian distribution in the channel value module corresponds to Steps 32 and 33. The algorithm will iterate according to the rules until convergence is achieved.
The CHMP algorithm adopts an EM-like iterative update strategy and utilizes the damping technique to enhance the convergence stability [35,36,37]. Every iterations, the algorithm executes the update steps corresponding to the aforementioned correlated probability model. In the remaining iterations, the channel support module executes the update Step 26, which corresponds to the i.i.d. Bernoulli prior
The channel value module executes Step 35, which corresponds to the i.i.d. zero-mean complex Gaussian prior
6.2. Computational Complexity
Considering that Step 6 of the CHMP algorithm involves a matrix–vector product of the form , where (with and ), and i can take the value 1 or 2, we define and as the matrix obtained by squaring the modulus of each element in . Storing the matrix is computationally expensive, and calculating this product requires multiplications and additions. According to (13), we have , where and . Using this relationship, the matrix–vector product can be rewritten as
where , and . By left-multiplying with and then right-multiplying with , the computational complexity is reduced to multiplications and additions. Alternatively, by right-multiplying with and then left-multiplying with , the computational complexity is reduced to multiplications and additions. Therefore, depending on the specific system configuration, the optimal implementation method can be selected to minimize the computational cost.
Additionally, Step 8 involves a matrix–vector product of the form , which can similarly be computed using the following relation:
where , and . If we first right-multiply by and then left-multiply by , the computational complexity is reduced to multiplications and additions. Alternatively, if we first left-multiply by and then right-multiply by , the computational complexity is reduced to multiplications and additions. Thus, depending on the specific system configuration, the implementation method with the minimal computational cost can be chosen.
Next, the computational complexity is assessed using real-valued floating-point operations (FLOPs), where the FLOP cost is determined by the type of operation. Specifically, addition, subtraction, multiplication, division, and the square root of two real numbers each require one FLOP; the addition and subtraction of two complex numbers each require two FLOPs; the multiplication and division of a complex number by a real number each require two FLOPs; the square of the modulus of a complex number requires three FLOPs; and multiplying two complex numbers requires six FLOPs (excluding complex conjugation). Additionally, the and functions for real numbers can be implemented using lookup tables, which does not consume computational resources [38,39]. Consequently, the total computational complexity of the CHMP algorithm is . Algorithm 1 CHMP
- 1:Input: , , , , , , , .
- 2:Initialize: , , , , , .
- 3:for do
- 4: // Signal Transmission
- 5: Update the auxiliary precision according to (72), .
- 6: Update the auxiliary precision and the auxiliary mean according to (73) and (74), .
- 7: Update the auxiliary multiplier according to (75), .
- 8: Update the auxiliary precision and the auxiliary mean according to (77) and (78), .
- 9: // Activity Indicator
- 10: Update the log-likelihood ratio according to (89), .
- 11: Update the log-likelihood ratio according to (95), .
- 12: Update the user activity log-likelihood ratio according to (98), .
- 13: Update the log-likelihood ratio using (96), .
- 14: // Channel Support
- 15: Update the log-likelihood ratio using (91), .
- 16: if t is an integer multiple of then
- 17: Update the log-likelihood ratios and according to (104) and (105), .
- 18: Update the mean according to (118) and (121), .
- 19: Update the mean according to (119), , .
- 20: Update the mean according to (120), , .
- 21: Update the probability using (109)–(112), .
- 22: Update the probability using (114)–(117), .
- 23: Update the log-likelihood ratios and according to (106) and (107), .
- 24: Update the log-likelihood ratio using (103), .
- 25: else
- 26: Update the log-likelihood ratio using (133), .
- 27: end if
- 28: // Channel Value
- 29: Update the non-zero probability , the Gaussian mean , and the Gaussian variance according to (83)–(85), .
- 30: Update the mean square according to (93), .
- 31: if t is an integer multiple of then
- 32: Update the mean according to (129), .
- 33: Update the precision according to (123), .
- 34: else
- 35: Update the precision according to (134), .
- 36: end if
- 37: Update the mean and the variance according to (86) and (87), .
- 38:end for
- 39:Detect the user activity and obtain the equivalent space–frequency domain channel according to (130)–(132), .
- 40:Output: The equivalent space–frequency domain channel estimation and the activity detection for all users.
7. Simulation Results
This section presents the simulation results and analysis of the CHMP algorithm. The channel parameters in the simulation were generated using the QuaDRiGa platform [40], with the simulation scenario set to ‘3GPP_38.901_UMa_NLOS’ [41]. The simulation parameters are shown in Table 3. This work employs the Normalized Mean Square Error (NMSE) and Activity Error Rate (AER) as performance metrics to evaluate the accuracy of channel estimation and active user detection, respectively. The NMSE and AER are defined as follows:
where and denote the Frobenius norm and norm, respectively, and represents the number of Monte Carlo trials. To ensure a high degree of statistical reliability and to minimize the impact of random fluctuations, all subsequent simulation results are averaged over 1000 independent Monte Carlo trials, which is consistent with [14,19]. This large number of repetitions is standard practice for performance evaluation in this field and ensures that the presented curves are stable and robust estimates of the true performance.
The baseline algorithms compared in the simulation include (1) the CHMP algorithm with channel support correlation only, which does not consider channel value correlation, where channel values follow a complex Gaussian distribution with mean 0 and variance ; (2) the CHMP algorithm with channel value correlation only, which does not consider channel support correlation, where channel support follows a Bernoulli distribution with ; (3) the CHMP algorithm without correlation, which does not consider either channel support or value correlation; (4) the GGAMP-SBL algorithm in [42], which combines SBL with the Gaussian GAMP framework to achieve robust performance; (5) the hybrid EM-VMP-EP variant algorithm in [43], which uses expectation–maximization (EM) to learn model parameters, variational message passing (VMP) to decouple the estimation of parameters, and an EP variant to perform sparse signal recovery; (6) the HMP-DCT algorithm in [13], which combats frequency-selective fading by first employing the discrete cosine transform (DCT) to create a sparse representation of the channel and then performs joint UAD and CE using an efficient hybrid message passing (HMP) algorithm, where the prior of the DCT coefficients is modeled with a Cauchy distribution and its unknown hyperparameters are learned via a gradient descent method.
7.1. Impact of SNR
Figure 3a,b illustrate the variation in the NMSE and AER with respect to the SNR for different algorithms, with the number of BS antennas M set to 64 and the number of active users set to 60. It can be observed that the NMSE and AER of all algorithms decrease as the SNR increases. Specifically, the rate of NMSE reduction for all algorithms gradually slows as the SNR increases, with all curves exhibiting smooth and consistent downward trends. For the AER, starting from 0 dB, the values initially decrease rapidly with increasing SNRs, but, beyond 10 or 12 dB, further increases in the SNR result in only marginal reductions in the AER. From the performance comparison of the algorithms, it is evident that the CHMP algorithm, which simultaneously considers both channel support and value correlations, achieves the best performance in both channel estimation and active user detection.
In the NMSE curves shown in Figure 3a, compared to the CHMP algorithm without correlation, incorporating the correlation of channel values using a coupled Gaussian distribution and modeling channel support correlation with a Markov chain both enhance algorithm performance. The performance improvement from channel support correlation is relatively modest, while the channel value correlation yields a more substantial improvement. The joint utilization of both correlations results in the greatest performance gain. Among the baseline algorithms, HMP-DCT-Cauchy-GD demonstrates strong performance, consistently outperforming the general-purpose GGAMP-SBL and hybrid EM-VMP-EP variant across the entire SNR range. This highlights the effectiveness of using the discrete cosine transform to exploit channel sparsity. However, our proposed CHMP algorithm and the CHMP with only value correlation still maintain a clear performance gap regarding HMP-DCT-Cauchy-GD. This underscores the substantial benefit of our proposed dual-correlation channel model, which provides a more accurate channel prior than the models implicitly or explicitly used in these advanced algorithms.
In the AER curves shown in Figure 3b, the CHMP algorithm again demonstrates the best performance. Notably, in the low-to-medium SNR range (0 dB to 8 dB), the proposed CHMP algorithm demonstrates clear and substantial superiority in the AER. In this range, HMP-DCT-Cauchy-GD achieves competitive AER performance, which is better than that of the hybrid EM-VMP-EP variant but slightly worse than that of the CHMP algorithm with only support correlation. GGAMP-SBL and the hybrid EM-VMP-EP variant, in turn, outperform CHMP with only value correlation, but their performance is worse than that of CHMP with only support correlation and CHMP without correlation. As the SNR increases into the high regime (above 10 dB), the performance improvement for all algorithms becomes marginal. Here, the performance of GGAMP-SBL becomes similar to that of CHMP with only value correlation and CHMP without correlation, while the hybrid EM-VMP-EP variant performs comparably to CHMP with only support correlation. However, all these algorithms remain slightly inferior to the proposed CHMP algorithm, which maintains the lowest AER. Furthermore, CHMP with only value correlation shows less competitive AER performance, primarily because the coupled Gaussian distribution affects the judgment of activity indicators. Furthermore, it can be seen that the Markov chain mitigates the negative impact of the coupled Gaussian distribution on the AER. Their joint modeling effectively captures the internal structure of channel support and the inherent correlation of channel values, leading to the most significant performance improvement.
7.2. Impact of the Number of Active Users
Figure 4a,b illustrate the NMSE and AER performance of various algorithms as a function of the number of active users, with the number of BS antennas M set to 64 and the SNR set to 8 dB. It is observed that the performance of all algorithms degrades as the number of active users grows, increasing the difficulty of the sparse recovery problem.
Specifically, in the NMSE curves shown in Figure 4a, compared to the CHMP algorithm without considering correlations, utilizing channel value correlation yields a more significant improvement than channel support correlation, and the joint utilization of both results in the greatest performance enhancement. Notably, the proposed CHMP algorithm maintains a clear performance advantage over all baselines. Among these, HMP-DCT-Cauchy-GD delivers a better NMSE than both GGAMP-SBL and the hybrid EM-VMP-EP variant across the entire range of user loads. In the AER curves shown in Figure 4b, the superiority of the proposed CHMP algorithm is even more pronounced. The HMP-DCT-Cauchy-GD algorithm’s AER performance is competitive, surpassing the hybrid EM-VMP-EP variant and performing just below CHMP with only support correlation. The curves for the algorithm without correlations and the one considering only channel support correlation are quite similar. GGAMP-SBL and the hybrid EM-VMP-EP variant are superior to CHMP with only value correlation but are clearly outperformed by the other three CHMP algorithms. The coupled Gaussian distribution, which is used in CHMP with only value correlation, has a negative impact on the AER. The proposed CHMP algorithm, which jointly utilizes both support and value correlations, consistently maintains the lowest NMSE and AER across all tested user loads. This demonstrates not only the effectiveness but also the robustness of our method, as its performance advantage is sustained over all baselines, even under the increasingly difficult conditions of a crowded massive access scenario. This again suggests that our tailored dual-correlation model provides a more accurate representation of the channel’s physical structure than the general-purpose sparsity assumption exploited by the HMP-DCT-Cauchy-GD algorithm.
7.3. Impact of the Number of BS Antennas
Figure 5a,b illustrate the NMSE and AER performance as a function of the number of BS antennas, with the number of active users set to 60 and the SNR set to 6 dB. As expected, the performance of all algorithms improves as the number of antennas increases, owing to the enhanced spatial resolution and array gain.
In the NMSE curves, the performance hierarchy remains consistent, with the full CHMP algorithm and the CHMP algorithm with only value correction leading. The HMP-DCT-Cauchy-GD algorithm performs well, showing a better NMSE than the other baselines. However, the performance gap between our proposed CHMP algorithm and all other methods, including HMP-DCT-Cauchy-GD, remains significant and even appears to widen slightly as the number of antennas grows. This trend is particularly revealing. In the AER curves shown in Figure 5b, the proposed CHMP algorithm again shows a significant advantage over all other methods. The HMP-DCT-Cauchy-GD algorithm’s AER is competitive and better than that of the hybrid EM-VMP-EP variant, while being slightly outperformed by CHMP with only support correlation and CHMP without correlation. This again highlights that joint correlation modeling effectively captures the internal structure of channel support and the inherent relationships of channel values. The widening performance gap demonstrates that our angle–delay domain dual-correlation model is exceptionally effective at leveraging the additional spatial information afforded by larger massive MIMO arrays. While HMP-DCT-Cauchy-GD effectively handles frequency-domain structures, our approach’s explicit modeling of the spatial channel characteristics allows it to better capitalize on the increase in antenna elements, leading to more accurate detection and estimation.
8. Conclusions
This paper investigates the joint active user detection and channel estimation problem in the uplink grant-free random access scenario of massive MIMO-OFDM systems. First, we propose an effective probability model that accurately characterizes the sparse nature of the massive random access channel in the user–angle–delay domain by introducing three types of state variables: active indicators, channel supports, and channel values. The proposed probability model not only captures the sparsity of the channel in the user domain but also leverages Markov chains and coupled Gaussian distributions to deeply explore the correlation properties of the channel in the angle–delay domain. Then, based on this probability model, the joint active user detection and channel estimation problem is formulated as a BFE minimization problem under hybrid constraints. To address this problem effectively, we further propose the CHMP algorithm, which adaptively adjusts the model parameters under unknown user sparsity and channel prior information. Numerical simulations validate the advantages of the proposed method in active user detection and channel estimation. While this work provides a robust framework for joint detection and estimation, we acknowledge that our analysis is based on a quasi-static channel model. In practical grant-free scenarios, impairments such as channel aging due to user mobility and imperfect synchronization can affect performance. Extending the proposed CHMP algorithm to account for these dynamic, non-ideal conditions and evaluating its robustness is an important and valuable direction for future research.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Sun G. Li Y. Yi X. Wang W. Gao X. Wang L. Wei F. Chen Y. Massive grant-free OFDMA with timing and frequency offsets IEEE Trans. Wirel. Commun.2021213365338010.1109/TWC.2021.3121066 · doi ↗
- 2Di Renna R.B. de Lamare R.C. Joint channel estimation, activity detection and data decoding based on dynamic message-scheduling strategies for m MTCIEEE Trans. Commun.2022702464247910.1109/TCOMM.2022.3151775 · doi ↗
- 3Wu Y. Gao X. Zhou S. Yang W. Polyanskiy Y. Caire G. Massive access for future wireless communication systems IEEE Wirel. Commun.20202714815610.1109/MWC.001.1900494 · doi ↗
- 4Wang B. Dai L. Zhang Y. Mir T. Li J. Dynamic compressive sensing-based multi-user detection for uplink grant-free NOMAIEEE Wirel. Commun. Lett.2016202320232310.1109/LCOMM.2016.2602264 · doi ↗
- 5Jiang J.C. Wang H.M. Poor H.V. Performance analysis of joint active user detection and channel estimation for massive connectivity IEEE Trans. Signal Process.2022703647366210.1109/TSP.2022.3185844 · doi ↗
- 6Zhang W. Li J. Zhang X. Zhou S. A joint user activity detection and channel estimation scheme for packet-asynchronous grant-free access IEEE Wirel. Commun. Lett.20211133834210.1109/LWC.2021.3127680 · doi ↗
- 7Guo Y. Liu Z. Sun Y. Low complexity joint activity detection and channel estimation with partially orthogonal pilot for asynchronous massive access IEEE Internet Things J.2024111773178310.1109/JIOT.2023.3290976 · doi ↗
- 8Ahn J. Shim B. Lee K.B. EP-based joint active user detection and channel estimation for massive machine-type communications IEEE Trans. Commun.2019675178518910.1109/TCOMM.2019.2907853 · doi ↗