Interactions Among Morphology, Word Order, and Syntactic Directionality: Evidence from 55 Languages
Wenchao Li, Haitao Liu

TL;DR
This study explores how language structure balances predictability and flexibility across 55 languages, showing that richer morphology supports more head-final structures.
Contribution
Quantitative evidence that syntactic directionality is more closely tied to morphological complexity than surface word order.
Findings
Morphological richness weakly correlates with word order entropy and is not a robust predictor after correction.
Languages with rich morphology favor head-final structures, while minimally inflected languages prefer head-initial patterns.
Languages balance redundancy and flexibility to optimize information transmission.
Abstract
This study investigates interactions among morphology, word order, and syntactic directionality across 55 languages from 11 families. We quantify morphological richness (moving-average mean size of paradigm), word order flexibility (entropy), and syntactic directionality (dependency direction), linking linguistic structure to information-theoretic principles. Analyses show that morphological richness is only weakly related to word order entropy and does not provide a robust predictor after statistical correction. Rich morphology facilitates the predictability of syntactic functions. Languages with richer morphology consistently favor head-final structures, whereas minimally inflected languages lean toward head-initial patterns, indicating that syntactic directionality is more closely associated with morphological complexity than with surface word order. Overall, the findings indicate…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
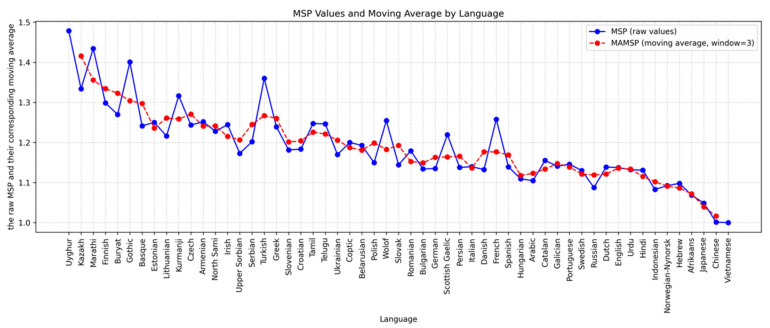 Figure 1
Figure 1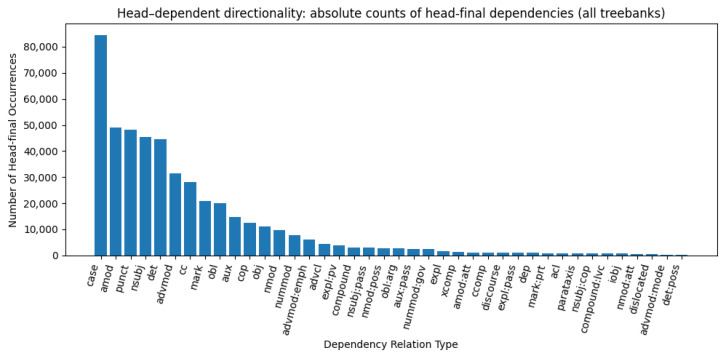 Figure 2
Figure 2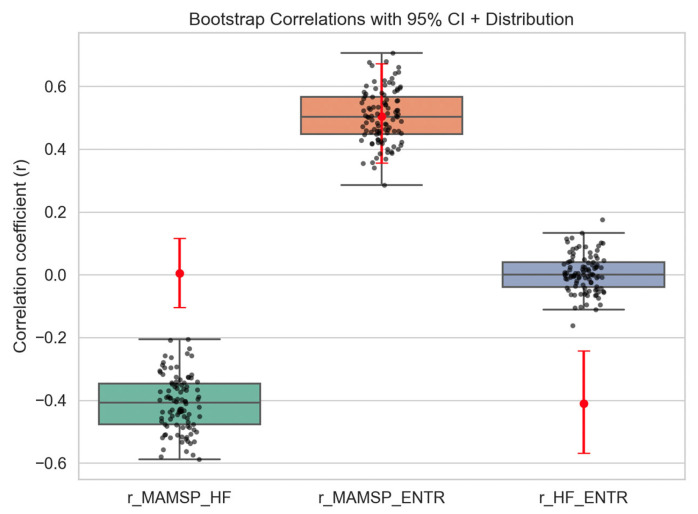 Figure 3
Figure 3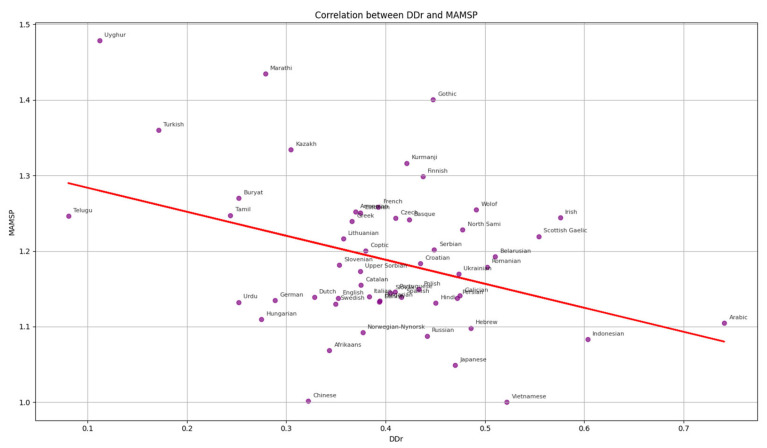 Figure 4
Figure 4 Figure 5
Figure 5- —National Office for Philosophy and Social Sciences, China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsLanguage and cultural evolution · Neurobiology of Language and Bilingualism · Language Development and Disorders
1. Introduction
Human language is a structured yet adaptive system governed by underlying regularities [1]. A central principle in linguistic typology is the complexity trade-off, which posits that when a language develops elaborate features in one domain—such as phonology, morphology, syntax, or semantics—it tends to simplify another, thereby maintaining an overall equilibrium in communicative complexity [2,3,4,5]. Finnish provides a canonical example of this trade-off. As a highly inflected language, it conveys dependency relationships through rich morphological markers, permitting flexible word order. For instance, the sentence “The boy reads a book” can be expressed in multiple orders: SVO (Poika lukee kirjan), SOV (Poika kirjan lukee), VSO (Lukee poika kirjan), VOS (Lukee kirjan poika), OSV (Kirjan poika lukee), and OVS (Kirjan lukee poika) (SVO: Poika lukee kirjan = poika.NOM boy, luke-a.3SG.PRS read, kirja-ACC book → ‘The boy reads the book.’ SOV: Poika kirjan lukee → ‘The boy reads the book.’ (object focus). VSO: Lukee poika kirjan → ‘It is the boy who reads the book.’ VOS: Lukee kirjan poika → ‘The boy reads the book.’ (subject focus). OSV: Kirjan poika lukee → ‘The book, the boy reads.’ OVS: Kirjan lukee poika → ‘It is the boy who reads the book.’). Thai, a Tai-Kadai language with minimal inflection, relies primarily on fixed word order and contextual cues to convey grammatical relations, following an SVO pattern: เด็กชาย อ่าน หนังสือ (dèk-chaai àan năng-sĕu; boy.NOM read.PRS book.ACC).
Recent advances in natural language processing and the availability of large-scale dependency treebanks have enabled quantitative investigation of cross-linguistic patterns [3]. Prior research has examined interactions among linguistic subsystems, including the interplay between word class shifts and morphological marking [6], the effect of morphology on lexicalization of speech act markers [7], the relationship between word order and case marking [8,9], the connection between syllable structure, phonemes, and morphology [10], the influence of verb-final order and case marking [11], as well as the impact of verb order, semantic closeness, and cognitive load [10,11,12]. These studies highlight that word order emerges from complex interactions among morphology, syntax, and information-processing constraints.
Within this framework, Hawkins’ efficiency-based theory of grammar offers a processing perspective on word order optimization. It posits that grammars tend to select and arrange linguistic forms so as to provide the earliest possible access to the developing syntactic–semantic representation during incremental parsing [13]. This Maximize Online Processing (MOP) principle links grammatical organization to processing efficiency, suggesting that constituent ordering reflects pressures to minimize integration cost and maximize early structure building. Building on this view, the present study investigates how morphological richness and dependency directionality interact under such processing efficiency constraints. Empirical evidence by Sinnemäki & Haakana [14] supports this perspective: in genitive noun phrases, richer morphological marking correlates with shorter dependency distances. However, their analysis was restricted to noun phrases and did not consider other syntactic constituents such as adjectives, determiners, relative clauses, adverbs, or full clauses. Consequently, the broader impact of morphological richness on syntactic directionality and word order flexibility remains underexplored.
The present study addresses this gap using 80 UD treebanks representing 11 language families. Specifically, we examine three variables: morphological richness (moving-average mean size of paradigm), word order flexibility (entropy), and syntactic directionality (dependency direction). The study is guided by two research questions:
RQ1: Does morphological richness correlate with word order flexibility? Rich morphology may provide cues that facilitate dependency parsing, potentially allowing greater variation in word order.
RQ2: Does morphological richness influence syntactic directionality? Languages with richer morphology may favor specific structural patterns, such as head-final or head-initial configurations, optimizing the transmission of information while reducing cognitive load.
By quantifying these relationships across a large typologically diverse sample, this study aims to provide quantitative evidence for efficiency-driven trade-offs in human language, shedding light on how morphological complexity interacts with syntactic structure to balance redundancy and flexibility.
2. Methodology
2.1. Data
The data used in this study comprised 55 languages, spanning 22 language branches across 11 language families. These families included Indo-European, Dravidian, Uralic, Altaic, Afro-Asiatic, Sino-Tibetan, Austronesian, Niger-Congo, and South Asian, as well as Basque and Japanese. Detailed information on the linguistic characteristics and the corresponding treebanks can be found in Appendix A and Appendix B. In Semitic languages such as Arabic and Hebrew, prepositions are often orthographically attached to nouns, forming a single word. However, for the purposes of dependency syntactic analysis, such constructions should be segmented into two distinct tokens, i.e., one representing the preposition and the other the noun. To ensure consistency and cross-linguistic comparability, all treebanks in this study employed the Universal Dependencies (UD) annotation framework [15]. UD systematically separates clitics and treats them as independent tokens, thereby minimizing errors arising from orthographic variation across languages. The UD framework provides part-of-speech tags, lemmas, and syntactic dependency trees for each word in the corpus. Each word is linked to a single syntactic head, and dependency relations are annotated using standardized labels such as nsubj (nominal subject), obj (direct object), and amod (adjectival modifier), among others. All metric computations and statistical analyses, including correlation tests between variables, were implemented using the Python programming language (version 3.11).
2.2. Metrics
This study evaluated three syntactic and morphological dimensions: morphological richness, word order flexibility, and syntactic directionality.
2.2.1. Metric for Morphological Richness
A wide range of corpus-based metrics has been developed to capture morphological richness, including type–token ratio, word and lemma entropy, information-theoretic measures, and paradigm-based counts [16]. While each metric offers a distinct perspective, many are sensitive to corpus size, structural domains (e.g., verbal vs. nominal), or text genre, making cross-linguistic comparison difficult. To address this, the present study adopts a paradigm-oriented measure inspired by Xanthos and Gillis [17]: the mean size of paradigm (MSP), which captures the average number of inflected forms per lemma. To enhance robustness across corpora of varying lengths and syntactic densities, we further refined this metric using a moving-average framework, resulting in the moving-average mean size of paradigm (MAMSP). This approach mitigates the impact of local fluctuations by computing paradigm size within fixed-size token windows. Formally, MAMSP is defined as follows:
(1)MAMSP where N refers to the number of text tokens in the data. W represents the window size, where W < N. Fi denotes the number of distinct inflected word forms in each window. Li represents the number of distinct word lemmas in each window. To illustrate, consider the following Japanese sentence:(2)朝早く駅に着いて彼女[が omitted]来るのをMorning early ADV station-DAT arrive-GER she-NOM [omitted] come-NMLZ-ACC待ったけど、電車[が omitted]遅れて会えなかった.wait-PST CONJ train-NOM [omitted] late-GER meet-POT-NEG-PST“I arrived early at the station and waited for her to come, but the train was late, so I could not meet her.”
This sentence contains 11 tokens (N = 11). Suppose the window size is W = 5. Then, we can slide the window to obtain N – W + 1 = 7 windows: 朝, 早く, 駅に, 着いて, 彼女; 早く, 駅に, 着いて, 彼女, 来るのを; 駅に, 着いて, 彼女, 来るのを, 待った; 着いて, 彼女, 来るのを, 待った, けど; 彼女, 来るのを, 待った, けど, 電車; 来るのを, 待った, けど, 電車, 遅れて; 待った, けど, 電車, 遅れて, 会えなかった. For each window, compute the ratio Fi/Li, i.e., the number of distinct inflected word forms divided by the number of distinct lemmas. The final MAMSP is the average of these seven ratios:
(3)MAMSP = = ≈ 0.548
This moving-average approach smooths local fluctuations and provides a stable estimate of morphological richness across different corpus lengths.
2.2.2. Metric for Word Order Flexibility
Word order is influenced by a multitude of linguistic factors, including adpositions, genitives, noun modifiers, demonstratives, numerals, adjectives, relative clauses, and adverbs, among others [18]. For the purpose of this study, our attention is centered on the sequence of the constituents: subject (S), object (O), and verb (V). This choice is justified by two main considerations: (a) S, O, and V are central syntactic elements that appear in the vast majority of sentences across different dialects, making them ideal for typological comparison, and (b) their identification is relatively straightforward across varied language datasets [19]. We considered the six canonical word orders, i.e., SVO, OVS, VSO, VOS, SOV, OSV, as well as partial orders such as SV, VO, and SO, which arise due to intransitive clauses, ellipsis, copula-drop, or nominal predications. Our Python-based tool extracts these linearizations directly from dependency structures, allowing the analysis to accommodate varied syntactic patterns and reflect actual language use. While some languages demonstrate strict word order constraints in subordinate clauses or coordinated structures [20], this study focuses exclusively on main clauses.
In measuring word order flexibility, several metrics have been proposed, such as maximum–minimum distance, Euclidean distance, cosine similarity, and entropy [19]. Among these, Kubon et al. found a convergence in their ability to capture variability, suggesting any of these can serve as reliable indicators. Our study adopts entropy as the principal metric due to its interpretability and prevalence in recent linguistic research on syntactic variation [6,21]. Entropy (ENTR), the metric selected for this study, captures the randomness or unpredictability of word order use [22]. It is defined as follows:
(4)ENTR =
denotes the relative frequency of the i-th word order type, including both canonical (SVO, OVS, etc.) and partial orders (SV, VO, SO, etc.), with 0 and = 1. The index iii thus ranges over all attested word order variants. Entropy reaches its maximum when all word orders are equally probable, yielding ln 6 ≈ 1.794, and decreases as distributions become more skewed toward fewer dominant orders. By employing entropy in this way, our metric captures the degree of flexibility in the linear arrangement of syntactic elements, accommodating both complete and partial clause structures.
2.2.3. Metric for Syntactic Directionality
Syntactic directionality reflects the linear order between syntactic heads and their dependents. Cross-linguistically, some languages tend to favor head-initial structures, where the head precedes its dependent (as in English), while others prefer head-final structures, such as Japanese. Many languages display mixed or flexible ordering patterns [23,24]. In this study, we operationalized syntactic directionality in terms of dependency directionality. To capture this structural property, we adopted the dependency direction (DDir) score [20,23], a quantitative metric that summarizes the global syntactic ordering tendency of a language. It was computed over all dependency relations in a syntactically annotated corpus (treebank). For each dependency arc, we determined whether the head precedes or follows its dependent and then calculated the ratio between head-initial and head-final dependencies. Formally, the DDir score is defined as follows:
(5)
This definition normalizes the difference between head-initial (NHI) and head-final (NHF) dependencies by the total number of dependencies (Ntotal), yielding values between −1 and +1. A score close to +1 indicates a strongly head-initial language, a score near −1 suggests a predominantly head-final language, and values around 0 imply mixed directionality.
It is important to note that the DDir measure is based on head-dependent direction in the dependency tree, not on surface word order. For example, in English, both the active sentence ‘I ate an apple’ and its passive counterpart ‘An apple is eaten by me’ have the same head-dependent directions: the verb is the head, and both subject and object (or agent in the passive) are dependents. Therefore, passive constructions do not affect the dependency direction statistics in our UD-based analysis.
Furthermore, to assess the robustness of the three metrics across different data sources (treebanks), we conducted a pilot test by calculating MAMSP, ENTR, and DDir using multiple treebanks for three languages: German, Tamil, and Turkish. We compared German-HDT vs. German-GSD, Tamil-TTB vs. Tamil-MWTT, Turkish-Kenet vs. Turkish-Boun. Results revealed moderate variation. For German, DD_ir_ (0.6356 vs. 0.6576) and MAMSP (0.982 vs. 0.9622) are relatively close, indicating consistency in morphological annotation and dependency structure. ENTR shows greater divergence (1.157 vs. 1.3439), suggesting that syntactic variability is more corpus-sensitive. For Tamil, MAMSP remains stable (0.9995 vs. 0.9763), but DD_ir_ (0.6463 vs. 0.7105) and especially ENTR (0.1391 vs. 0.6663) vary substantially, implying differences in how word order patterns are captured. For Turkish, the two treebanks produce relatively consistent values across all three metrics, with only minor differences. These findings indicate that morphological richness is generally stable across treebanks, while word order flexibility is more sensitive to genre, domain, and annotation guidelines. Dependency relation directionality (DD_ir_) shows moderate variation. In light of this, we adopted a triangulation strategy to improve the reliability of our linguistic measurements. For languages with multiple treebanks, we computed each metric separately for each source. If results were consistent, we treated them as robust. If they diverged, we calculated the mean across treebanks to reduce bias.
2.3. Units of Analysis
The present study investigates cross-linguistic relationships among morphological richness, word order flexibility, and syntactic directionality. The intended level of inference is typological (i.e., across languages), whereas the empirical level of observation is corpus-based. To balance representativeness and statistical independence, each UD tree bank is treated as a single analytical unit. As summarized in Appendix B, some languages (e.g., German, Japanese, Turkish) are represented by multiple treebanks differing in domain and genre. Treating each treebank as one observation prevents languages with multiple treebanks from being overrepresented and avoids within-language autocorrelation. Accordingly, all statistical analyses (including ANOVA and Pearson correlation tests) were conducted using per-treebank mean scores as independent data points. Each tree bank contributed one averaged value per metric (MAMSP, ENTR, and DDir).
3. Results
3.1. Morphological Richness
Appendix C summarizes the MAMSP values for each language, where higher scores indicate greater morphological richness. Figure 1 illustrates both the raw MSP values (blue) and their moving averages (red).
A one-way ANOVA tested differences in MAMSP across 22 language branches, using per-treebank mean MAMSP scores as independent data points. The analysis revealed a significant effect of language branch on morphological richness (F (21, 33) = 2.470, p = 0.0097, η^2^ = 0.611, ω^2^ = 0.360). Based on MAMSP (the smoothed measure), the ten morphologically richest languages are predominantly agglutinative, including Uyghur and Kazakh (Turkic branch, Altaic family), Marathi (Indo-Aryan, Indo-European), Finnish and Estonian (Finno-Ugric, Uralic), Buryat (Mongolic, Altaic), Kurmanji (Iranian, Indo-European), Tamil and Telugu (Dravidian), and Wolof (Atlantic, Niger-Congo). These results confirm that agglutinative systems, which express grammatical meaning through concatenated, segmentable morphemes, tend to yield a larger number of distinct surface forms per lemma—hence higher MAMSP values. This correlation aligns with typological findings in the literature [17,25,26,27]. French and Gothic, which rank relatively high in raw MSP but not in MAMSP, illustrate that inflectional irregularities and portmanteau morphemes (e.g., je vais, tu vas) can temporarily inflate raw morphological counts. The MAMSP-based results, therefore, provide a more stable and typologically coherent measure of morphological richness across language families.
Within-family contrasts further support these trends. In the Uralic family, the Finnic languages (Finnish, Estonian) show significantly higher MAMSP scores than Finno-Ugric members (Hungarian, North Sámi): t = −12.83, p = 1.76 × 10^−36^. In the Indo-European family, Polish is morphologically richer than Ukrainian (t = −3.76, p = 0.00056), and Marathi, the only agglutinative Indo-Aryan language, exceeds Urdu and Hindi in richness. Within the Altaic family, Turkic languages exhibit significantly higher MAMSP values than Mongolic languages (t = 3.77, p = 0.00017). At the lower end of the scale, Chinese and Vietnamese show minimal MAMSP values, consistent with their isolating morphological type. Languages from the Celtic, Basque, Uralic, Baltic, and Slavic branches display moderate morphological richness, while most Romance and Germanic languages are comparatively low. Interestingly, Japanese, despite its agglutinative character, ranks lower than expected. This likely results from its limited nominal inflection—grammatical relations are encoded primarily by independent case particles (が, を, に) rather than by affixal morphology. Because the MAMSP metric quantifies affix-based morphological productivity, Japanese appears less morphologically rich under this measure. This effect is reinforced by the UD annotation scheme, which treats Japanese particles as separate tokens rather than bound morphemes.
3.2. Syntactic Directionality
Languages with greater morphological richness show a tendency toward head-final dependency structures (Pearson r = −0.369, 95% CI [−0.611, −0.085], p = 0.0055). Languages with high MAMSP values, such as Uyghur, Marathi, Turkish, Kazakh, Kurmanji, Buryat, Tamil, and Telugu, exhibit a strong preference for head-final dependencies. Across all treebanks, we analyzed a total of ≈856,000 dependency relations (excluding ROOT). Among these, ≈330,000 were head-final (38.5%) and ≈526,000 were head-initial (61.5%). Figure 2 summarizes absolute counts of head-final occurrences by dependency relation type, aggregated across all treebanks. For interpretability, Appendix D reports, for each relation, both (i) the within-relation head-final percentage and (ii) the share of the full corpus. For example, for nmod, there are 9688 head-final instances, which correspond to 13.84% of all nmod relations (9688/69,981) and about 1.1% of all dependencies in the dataset (9688/856,000). Consistent head-final behavior is observed for case, det, cc, mark, amod, advmod, nsubj, and aux, particularly within morphologically rich (high-MAMSP) languages. By contrast, relations such as obj, obl, acl:relcl, xcomp, and nmod show lower head-final proportions in the aggregate. These distributional patterns align with typological observations that languages with more robust inflectional/agglutinative morphology tend to favor head-final sequencing in core phrasal domains [9,25], while also reflecting cross-branch mixing in relations sensitive to clause structure (obj, obl, xcomp). Overall, head-final dependencies constitute a numerical minority in the aggregated corpus, yet they are typologically concentrated in morphologically rich languages with predominantly head-final syntactic structures.
3.3. Word Order Flexibility
Appendix E reports the ENTR values for all languages, where higher scores reflect greater freedom in constituent ordering. A one-way ANOVA tested branch-level differences in ENTR, using per-treebank mean ENTR scores as independent observations (F (21, 33) = 2.13, p = 0.025). The analysis yielded a moderate-to-large effect size (η^2^ = 0.576, ω^2^ = 0.302), indicating that language branch accounts for a substantial share of the observed variation in word order flexibility. The top five most flexible languages are as follows: agglutinative: Wolof (Atlantic), Kurmanji (Iranian); inflectional: Lithuanian (Baltic), Slovak, Czech (Slavic). These are followed by Finnic, Slavic, Germanic, and Basque languages. In contrast, Indo-Aryan, Celtic, Sinitic, and Vietic languages exhibit more rigid word order. Appendix F further provides the distribution proportions of six word-order types across 55 languages. Among these, Lithuanian stands out with a high degree of inflectional variation and the most extensive case system among Indo-European languages. This rich inflectional variation and case system contribute to Lithuanian having the most relaxed word order. Kurmanji, an agglutinative language, ranks second in word order freedom. Czech, Slovak, Slovenian, German, Finnish, and Hungarian demonstrate the most balanced proportions of S, V, and O combinations. The Slavic language family showcases all possible word orders, with preferences in the order of SVO > OVS > VOS > SOV > VSO > OSV. Among the eleven Slavic languages, Czech, Slovak, and Slovenian exhibit the most balanced distribution of word order types. This explains why these three languages have higher ENTR values compared to other Slavic languages. Within the Uralic sample examined here (Finnish, Estonian, Hungarian, and North Sámi), all six canonical word orders are attested in the UD treebanks. Among them, SVO is the most frequent pattern overall, though its proportion varies substantially across languages. Estonian shows a strong SVO preference (≈85%), Hungarian favors SVO (≈59%) but also displays considerable SOV and OVS variation, while Finnish exhibits the most flexible ordering, with SVO ≈ 41% and a notably high proportion of OSV and OVS (≈38%). The Altaic language family exhibits all word orders but has a preference for SOV. The Turkic language family (Turkish, Kazakh, Uyghur) shows a word order preference of SOV (78%) > OVS (15%) > SVO (3%) > OSV (4%) > VSO (1%) > VOS (0%). Within the Altaic language family, Mongolic Buryat shows a higher proportion of SVO (27.45%) and a lower proportion of OVS. This is due to the influence of Slavic languages (dominated by SVO) on the Buryat language, despite it being part of the Mongolic language family and administratively belonging to one of the autonomous republics of the Russian Federation. This explains why the word order preference of Buryat is not related to the Altaic type but clusters with Slavic languages.
The Afro-Asiatic Semitic family exhibits distinct word order preferences. Arabic and Maltese strongly favor verb-initial (VSO) patterns (about 70%), reflecting a consistent syntactic profile. Modern Hebrew shows more variable distributions: fully realized SVO and VSO clauses are relatively infrequent, while a large share of clauses contain only two constituents (SV, VS, VO, or OV). This structural variability contributes to Hebrew’s higher word order entropy compared to Arabic and Maltese. Table 1 and Table 2 summarize the distribution of major word orders in these three languages, based on UD treebank data.
Irish is a verb-initial language, with the VO pattern accounting for 98%. The Afro-Asiatic Egyptian language family’s Coptic language, which is agglutinative, exhibits more word order variation than the Semitic languages in the same family. Marathi, Urdu, and Hindi show slightly more flexibility in word order compared to Arabic, tending towards SOV > SVO > OSV. In the previous analysis of morphological richness, Marathi demonstrated the highest diversity among Indo-Aryan languages, and in this word order test, it exhibits the highest flexibility as well. This observation is consistent with the tendency that languages with richer morphology often display greater flexibility in constituent order. Additionally, the Dravidian languages Telugu and Tamil, belonging to the Dravidian language family, exhibit moderate rigidity in word order and a preference for verb-final structures (cf. SOV > OSV > OVS).
Looking at the Indo-European language family, most of the 34 languages examined in this study show a preference for SVO. However, German, Dutch, Gothic, and Greek display verb-initial word order (VOS, VSO) in interrogative and negative sentences. Within the Romance language family, Galician primarily employs SVO but combines it with a certain proportion of VSO and SOV. Basque is an agglutinative language with a balanced distribution of word orders, preferring SVO (58.84%) > SOV (30.39%) > OSV (4.76%) > OVS (3.97%) > VOS (1.70%) > VSO (0.34%). Armenian, while morphologically similar to Turkish, with suffixes used to indicate grammatical information, differs from Turkish in word order preference. Armenian primarily favors SVO and exhibits all possible word orders. Finnish, due to its rich derivation and inflectional morphology, enjoys relatively free word order. The Germanic language family prefers SVO > VSO > OVS. English, within the Germanic language family, is the least flexible in word order, strongly favoring the SVO pattern.
3.4. Cross-Linguistic Correlations
To synthesize the patterns observed in Section 3.1, Section 3.2 and Section 3.3, we performed Pearson correlation analysis among the three metrics: MAMSP (morphological richness), DDir (dependency direction), and ENTR (word order flexibility). Each UD treebank contributed one averaged value per metric, which served as an independent observation in the cross-linguistic correlation tests. The following correlations were observed: MAMSP vs. DDir: r = −0.370, 95% CI [−0.62, −0.09], p = 0.005. MAMSP vs. ENTR: r = 0.267, 95% CI [0.00, 0.50], p = 0.049. DDir vs. ENTR: r = 0.013, 95% CI [−0.27, 0.30], p = 0.924. After correction for multiple comparisons, the MAMSP–DDir correlation remained significant under both Bonferroni and FDR procedures, while the MAMSP–ENTR trend did not. DDir–ENTR showed no relationship under any threshold.
These results show that morphological richness is negatively correlated with head-initial directionality—languages with richer morphology tend to favor head-final structures—while its positive association with word order flexibility is weak and not statistically robust. No meaningful correlation is found between syntactic directionality and word order flexibility.
To account for potential biases due to genealogical non-independence among languages, we performed a one-per-family bootstrap (100 iterations) for these three pairwise correlations. Figure 3 presents the bootstrap distributions: r_MAMSP_HF: median ~ −0.5, 95% CI mostly negative, confirming a robust negative correlation; r_MAMSP_ENTR: median ~0.5, 95% CI overlaps zero, indicating a non-significant positive trend. r_HF_ENTR: median ~0, 95% CI spans zero, confirming no significant relationship between head-final dependency preference and word order flexibility. These results reinforce that the negative correlation between morphological richness and head-final preference is robust, while positive trends between morphology and word order flexibility are inconclusive, and syntactic directionality and word order flexibility are uncorrelated.
4. Discussion: Interactions Among Morphology and Syntactic Directionality
The central finding of this study is that morphological richness reliably predicts dependency directionality, whereas its association with word order flexibility is weaker. Languages with richer inflectional systems consistently favor head-final dependency structures, and this effect remained significant even under conservative Bonferroni correction, reinforcing the view that morphological richness plays a stable role in shaping dependency directionality across languages. The effect size was moderate (r ≈ −0.37), indicating a substantial but not deterministic influence of morphology on syntactic organization. This result is consistent with Dryer [28] in that our measure of syntactic directionality (DDir) captures the same type of head-directional tendencies he reported for OV and VO languages, for example, the association of OV with RelN and VO with NRel structures. Our analysis builds on Dryer’s typological framework by extending it into a quantitative, corpus-based approach that integrates morphological richness (MAMSP) with syntactic directionality.
The observed correlation between morphological richness and head-finality may reflect a structural alignment between morphological and syntactic organization. In most languages, morphological complexity is largely realized through suffixation, and suffixes are often analyzed as syntactic heads. From this perspective, rich morphology, being predominantly suffixing, can be viewed not merely as an independent correlate but as a morphological manifestation of head-final organization. In other words, the same underlying head-final principle that governs syntactic ordering may also shape morphological structure. This interpretation suggests that the correlation is not accidental but reflects a cross-level structural consistency between morphology and syntax. Future research could empirically test this account by quantifying the cross-linguistic balance between suffixing and prefixing patterns.
The correlation between morphological richness and word order flexibility was weaker and did not remain significant after correction for multiple comparisons. This suggests that morphology may sometimes enable freer constituent order, but such effects are less stable and context-dependent. No evidence was found for a correlation between word order flexibility and dependency directionality. This pattern is broadly consistent with typological observations under the OV/VO contrast, which indicate that while certain structural correlations are robust, others may be region- or language-specific rather than universal. Figure 4 visualizes raw bivariate trends between morphological richness and syntactic directionality, while Figure 5 presents the network of dependencies, showing that morphology exerts a primary influence on syntax, whereas word order flexibility plays a more peripheral role.
While our results largely support Dryer’s observations, it is worth noting that Benítez-Burraco et al. [29] report a contrasting finding, suggesting that there may be no systematic trade-off between morphological and syntactic complexity across languages. The differences between their results and ours may be partly attributable to variations in data sources, methodology, and metrics. Our study relies on annotated treebanks from 55 languages across 11 language families, using per-treebank measurements of dependency direction (DDir), word order flexibility (ENTR), and morphological richness (MAMSP). Benítez-Burraco et al. use the cross-linguistic typological database (WALS), which aggregates language-level features. Furthermore, our metrics quantify syntactic linearity and dependency structures, capturing more subtle interactions between morphology and syntax in naturalistic language use. Their indicators focus on broader typological categories and feature counts, which may not distinguish head-dependent directionality or word order variability. Finally, our analysis applies statistical correlations and ANOVA on per-treebank measures, which may be sensitive to micro-level co-variation patterns. Taken together, the discrepancy likely stems from differences in data granularity and methodological scope rather than genuine theoretical conflict. Within our corpus-based framework, we observe that languages with richer morphology favor head-final dependencies and show a mild, non-significant trend toward greater word order flexibility, which may indicate a subtle interaction between morphological richness and syntactic structure that emerges in annotated corpus data.
Recalling Section 2.2.3, to assess the robustness of the three metrics across different treebanks, we compared German-HDT vs. German-GSD, Tamil-TTB vs. Tamil-MWTT, and Turkish-Kenet vs. Turkish-Boun. The results revealed that word order flexibility is more sensitive to factors such as genre, domain, and annotation scheme. Still, one would argue that for languages with “free word order,” such flexibility is not absolute; word order often carries pragmatic meaning related to information packaging, such as focus, topic, or stylistic considerations. For example, in Russian, which exhibits relatively free word order, the most important or emphasized element is typically placed first or last. A comparable example in English is the sentence “YOU, I do not understand,” which deviates from typical word order to emphasize “YOU.” These patterns may be influenced by genre or content/topic (e.g., poetry vs. news). The differences in genre and content composition within the corpora used in this study may influence the word order metrics. In languages characterized by ‘free word order,’ variation in constituent order often reflects information–structural adjustments, such as the arrangement of focus and topic. Therefore, preferences for word order use vary across genres, such as news reporting, spontaneous spoken dialogue, and poetry, impacting the statistical expression of dependency directionality and word order flexibility. Our analyses were based on the overall data from each treebank and did not distinguish between genres or pragmatic functions. This limitation may have partially obscured the influence of pragmatic factors on the word order metrics. Addressing this issue will require finer-grained analysis. Future studies could examine genre- or pragmatics-specific word order preferences to refine these metrics. While the present study treats each UD treebank as an independent corpus (per-treebank design), future research focusing on intra-language variation, such as stylistic, genre, or register effects, could adopt a per-document framework to capture subcorpus-level dynamics. Such an extension would provide a complementary, fine-grained perspective to the typological approach taken here.
5. Summary and Future Work
This study investigated the interactions among morphological richness, word order flexibility, and syntactic directionality across 55 languages from 11 major families. Using three quantitative metrics, i.e., MAMSP (morphological richness), ENTR (word order flexibility), and DDir (dependency direction), we examined how morphology relates to syntactic structure. Our results indicate that morphological richness strongly predicts dependency directionality, whereas its link to word order flexibility remains weaker and context-dependent. Substantial intrafamilial variation was observed; for instance, Finnic languages (e.g., Finnish, Estonian) exhibit more complex morphology than Finno-Ugric languages (e.g., Hungarian), and Turkic languages generally show richer inflection than Mongolic counterparts.
These findings align with Dryer’s typological generalizations. Consistent with his observation that OV languages often exhibit head-final dependencies, we found a moderate negative correlation between MAMSP and DD_ir_ (r ≈ −0.37, p = 0.005). Similarly, the weak trend linking morphological richness to word order flexibility resonates with Dryer’s point that certain structural tendencies, such as RelN/NRel patterns, manifest more strongly in some language types but are not universal. Our corpus-based, per-treebank measures complement Dryer’s genus- and language-level analysis by quantifying effect sizes, capturing confidence intervals, and revealing fine-grained variation in dependency direction and word order.
Several methodological and empirical considerations need attention. First, word order flexibility is sensitive to genre, domain, and annotation scheme, as shown by comparisons across multiple treebanks for German, Tamil, and Turkish. Second, current NLP pipelines differ in tokenization strategies (e.g., Stanza splits the French aux into à + les), which may affect cross-linguistic comparability. Third, the language sample remains typologically imbalanced, with some major families underrepresented, such as Austronesian, Sino-Tibetan, Indo-Aryan, and Niger-Congo, and features such as syllable structure, mean word length, and pragmatic constraints were not incorporated. Future work should address these limitations by expanding typological coverage, integrating genre- and pragmatics-specific analyses, and standardizing tokenization and syntactic annotation frameworks across corpora. Through such efforts, we can deepen our understanding of the interaction between grammar and cognition, and build more robust models of language as a complex adaptive system. Beyond linguistic theory, the findings also have implications: the observed trade-offs between morphology and syntax can inform typological modeling, enhance natural language processing systems by guiding cross-linguistic parser design.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Fenk-Oczlon G. Pilz J. Linguistic Complexity: Relationships Between Phoneme Inventory Size, Syllable Complexity, Word and Clause Length, and Population Size Front. Commun.2021662603210.3389/fcomm.2021.626032 · doi ↗
- 2Sinnemäki K. Complexity Trade-Offs: A Case Study Measuring Grammatical Complexity Newmeyer F. Preston L. Oxford University Press Oxford, UK 2014179201
- 3Feng Z. On Computational Complexity of Natural Language [Zìrán Yǔyán de Jìsuàn Fùzá Xìng Yánjiū]Foreign Lang. Teach. Res.2015659672
- 4Levshina N. Token-Based Typology and Word Order Entropy: A Study Based on Universal Dependencies Linguist. Typology 20192353357210.1515/lingty-2019-0025 · doi ↗
- 5Berdicevskis A. Schmidtke-Bode K. Seržant I. Subjects Tend to Be Coded Only Once: Corpus-Based and Grammar-Based Evidence for an Efficiency-Driven Trade-Off Proceedings of the 19th International Workshop on Treebanks and Linguistic Theories Association for Computational Linguistics Düsseldorf, Germany 20207992
- 6Shao B. Yan J. Zheng J. Quantitative Investigation into the Relationship between Word-Class Conversion and the Morphological Typology of Languages Foreign Lang Teach Res 202355497508
- 7Kong L. Qin H. Multilingual Analysis of Act of Speaking Markers: An Event Encoding Perspective Foreign Lang. Teach. Res.202355483496
- 8Yan J. Morphology and Word Order in Slavic Languages: Insights from Annotated Corpora Vopr. Jazyk.2021413110.31857/0373-658X.2021.4.131-159 · doi ↗