MVIB-Lip: Multi-View Information Bottleneck for Visual Speech Recognition via Time Series Modeling
Yuzhe Li, Haocheng Sun, Jiayi Cai, Jin Wu

TL;DR
This paper introduces MVIB-Lip, a new framework for visual speech recognition that combines time series and image-based representations to improve accuracy and generalization.
Contribution
The novel contribution is the integration of multivariate time series and recurrence plot images with a multi-view information bottleneck for lipreading.
Findings
MVIB-Lip outperforms handcrafted baselines in visual speech recognition tasks.
The framework improves generalization to speaker-independent recognition.
Recurrence plots enhance data efficiency when combined with deep multi-view learning.
Abstract
Lipreading, or visual speech recognition, is the task of interpreting utterances solely from visual cues of lip movements. While early approaches relied on Hidden Markov Models (HMMs) and handcrafted spatiotemporal descriptors, recent advances in deep learning have enabled end-to-end recognition using large-scale datasets. However, such methods often require millions of labeled or pretraining samples and struggle to generalize under low-resource or speaker-independent conditions. In this work, we revisit lipreading from a multi-view learning perspective. We introduce MVIB-Lip, a framework that integrates two complementary representations of lip movements: (i) raw landmark trajectories modeled as multivariate time series, and (ii) recurrence plot (RP) images that encode structural dynamics in a texture form. A Transformer encoder processes the temporal sequences, while a ResNet-18…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
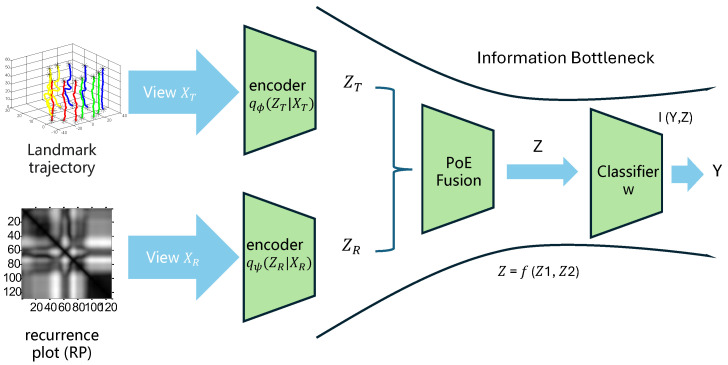 Figure 1
Figure 1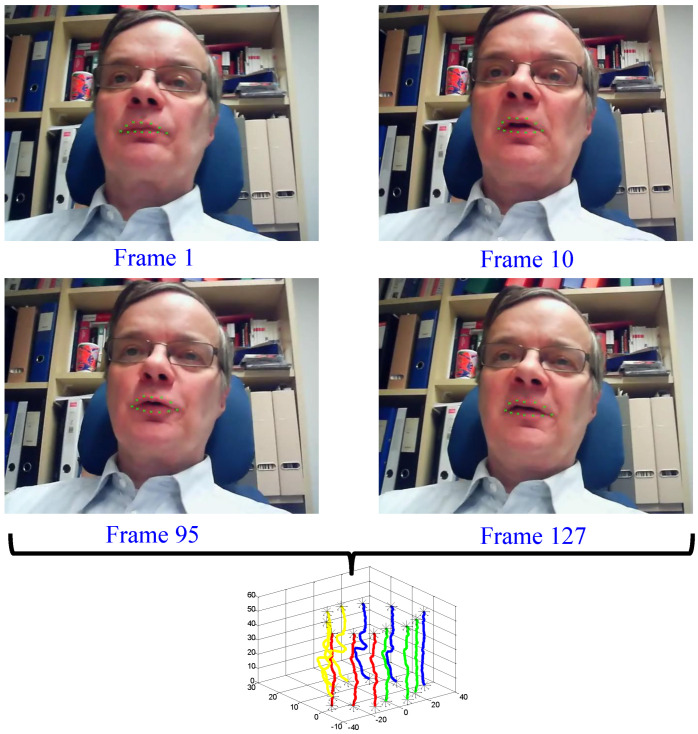 Figure 2
Figure 2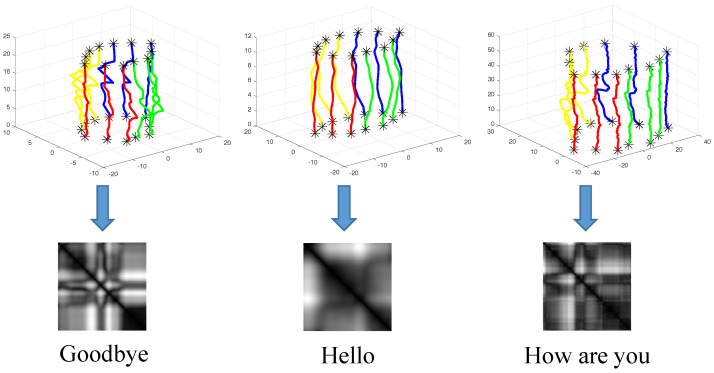 Figure 3
Figure 3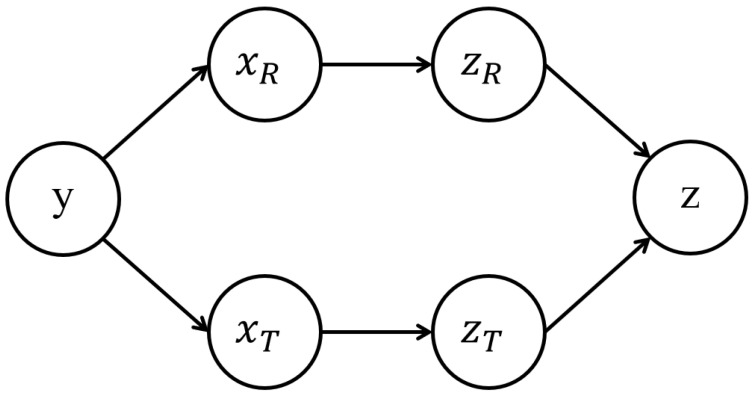 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSpeech and Audio Processing · Phonetics and Phonology Research · Face recognition and analysis