Datagraphy: toward a systematic approach to dataset discovery
Pascal Petit, Nicolas Vuillerme

TL;DR
The paper introduces datagraphy, a systematic approach to finding and evaluating datasets to improve research transparency and efficiency.
Contribution
It proposes a 9-step framework for dataset discovery and evaluation, analogous to bibliographic methods.
Findings
Datagraphy enhances transparency, reproducibility, and interdisciplinary collaboration in data reuse.
Challenges include inconsistent metadata and variability among dataset discovery tools.
A datagraphic search on the exposome demonstrates the framework's practical application.
Abstract
Data have become central to scientific discovery. While primary data collection remains vital, there is growing recognition of the benefits of reusing existing datasets. However, identifying suitable datasets for specific research questions is increasingly difficult due to the fragmentation and heterogeneity of the big data ecosystem. Despite the expansion of data sharing, efficient dataset discovery remains elusive, with limited empirical research on how datasets are identified, interpreted, and reused. Current dataset search practices often lack standardization, leading researchers to rely on convenience rather than systematic criteria. Unlike bibliographic research, dataset selection lacks a formal methodology, increasing the risks of bias, inefficiencies, and reduced generalizability. To address this gap, we introduce datagraphy, a structured approach to dataset identification and…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
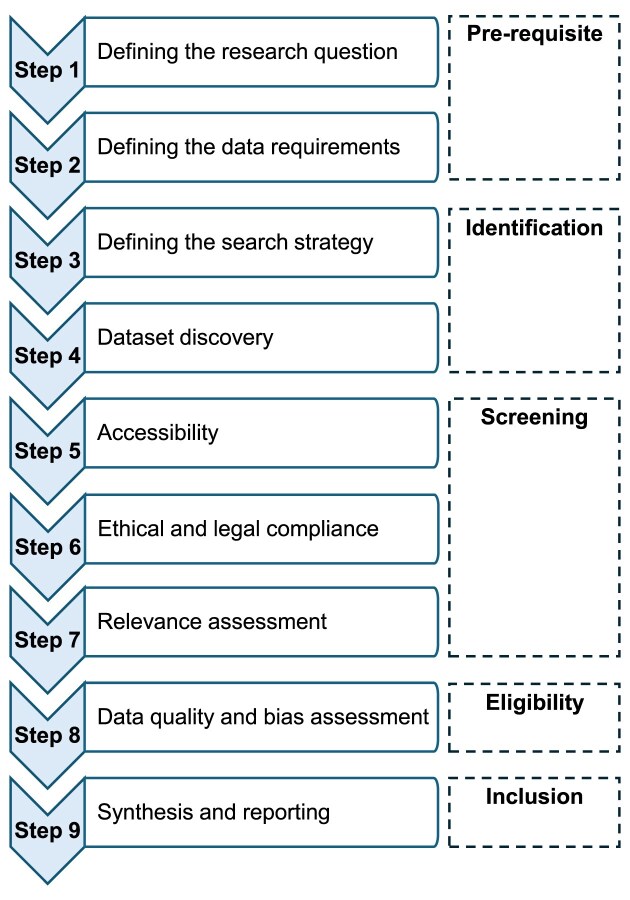 Figure 1
Figure 1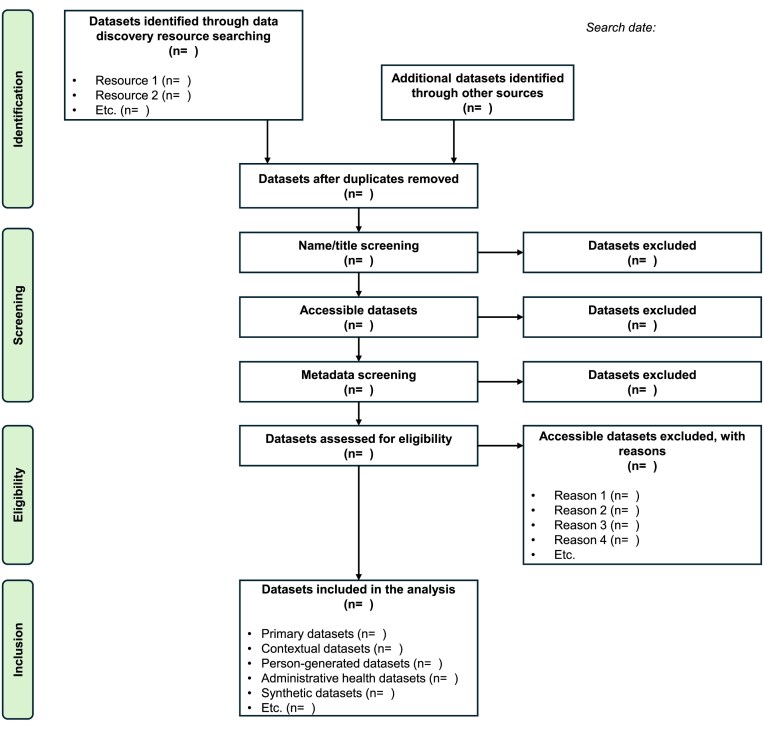 Figure 2
Figure 2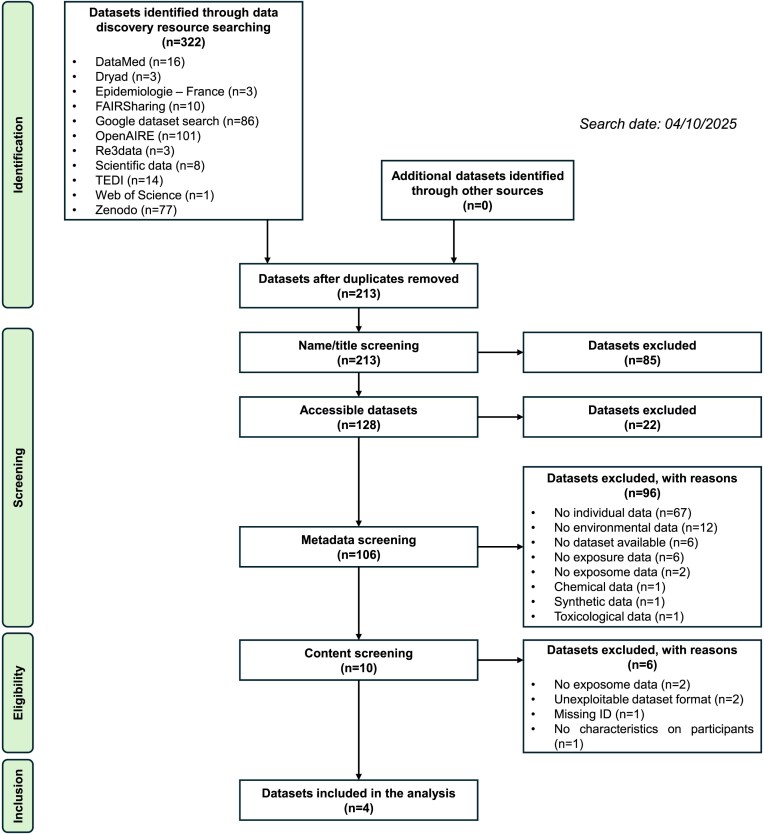 Figure 3
Figure 3| Name | Type | Country | Domain | RA | DL | Characteristics |
|---|---|---|---|---|---|---|
|
| Data repository | International | Multidisciplinary | FA | Yes | 10,322 datasets |
|
| Data search engine | International | Multidisciplinary | FA | Yes | |
|
| Data portal | Canada | Environmental health | FR | Yes | |
|
| Data repository | Netherlands | Multidisciplinary | FA | Yes | 313,603 datasets |
|
| Data-focused journal | International | Multidisciplinary | OA | Yes | |
|
| Data catalog | EU | Multidisciplinary | FA | No | 274 datasets |
|
| Dataset aggregator | International | Multidisciplinary | Sub | ? | >15 million datasets, 453 repositories |
|
| Governmental data portal | EU | Multidisciplinary | FA | Yes | 1,857,283 datasets, 195 catalogs |
|
| Data-focused journal | International | Multidisciplinary | OA | Yes | |
|
| Search tool | International | Multidisciplinary | FA | No | 25 repositories |
|
| Data-focused journal | International | Multidisciplinary | OA | Yes | |
|
| Data-focused journal | International | Multidisciplinary | OA | Yes | |
|
| Governmental data portal | France | Multidisciplinary | FA | Yes | 61,418 datasets |
|
| Data platform | International | Multidisciplinary | Sub | ? | |
|
| Data catalog | International | Biological | FA | No | 7,347 databases |
|
| Data repository catalog | International | Multidisciplinary | FA | No | >20 million datasets, 3,309 repositories |
|
| Data catalog | International | Multidisciplinary | FA | Yes | |
|
| Open-source data discovery system | International | Biomedical | FA | No | 1,280,165 datasets, 49 repositories |
|
| Data aggregator | International | Environment | FA | No | |
|
| Data repository | International | Multidisciplinary | FA | No | 466,000 datasets |
|
| Publication aggregator with dataset filter | International | Multidisciplinary | Sub | ? | 29 million datasets |
|
| Data repository | International | Multidisciplinary | FA | Yes | 50,000 data publications |
|
| Data repository | International | Environment | FA | Yes | 10,749 datasets |
|
| Data catalog | EU | Health | FR | ? | 480 datasets |
|
| Data repository | International | Environment | FA | Yes | |
|
| Data catalog | France | Public health | FA | No | 1,098 datasets |
|
| Data repository | EU | Multidisciplinary | FA | No | |
|
| Data platform | EU | Health | FA | ? | |
|
| Data platform | EU | Multidisciplinary | FA | ? | |
|
| Data-focused journal | International | Multidisciplinary | OA | Yes | |
|
| Data registry | International | Public health, environmental health | FA | No | |
|
| Data management platform | International | Biology | FR | ? | |
|
| Data catalog | International | Multidisciplinary | FA | No | 2,318 datasets |
|
| Data repository | International | Multidisciplinary | FA | Yes | 2,107,300 datasets |
|
| Data aggregator | International | Multidisciplinary | FA | Yes | 2,682 datasets |
|
| Data-focused journal | International | Multidisciplinary | OA | Yes | |
|
| Data platform | International | Multidisciplinary | FA | Yes | |
|
| Domain-agnostic data search engine | International | Multidisciplinary | FA | No | >25 million datasets |
|
| Data catalog | France | Environment, environmental health | FA | No | 177 datasets |
|
| Data-focused journal | International | Multidisciplinary | OA | Yes | |
|
| Data platform | International | Multidisciplinary | FR | Yes | 438,322 datasets |
|
| Data aggregator | International | Multidisciplinary | FA | Yes | >20 million datasets |
|
| Data catalog | US | Health | FA | No | 426 datasets |
|
| Data catalog | EU | Health | FA | No | 164 datasets |
|
| Data catalog | EU | Health | FA | No | 11 datasets |
|
| Data catalog | International | Health | FA | Yes | 4,914,243 datasets |
|
| Research platform | EU | Multidisciplinary | FA | No | 74 million datasets, 10 932 repositories |
|
| Management platform | International | Multidisciplinary | FA | Yes | 2,600 datasets |
|
| Repository catalog | International | Multidisciplinary | FA | No | 5,982 repositories |
|
| Data repository | International | Multidisciplinary | FA | Yes | |
|
| Bibliographic database | International | Multidisciplinary | FA | No | |
|
| Bibliographic database | International | Biomedical and life | FA | No | |
|
| Data repository catalog | International | Multidisciplinary | FA | No | 3,331 repositories |
|
| Research object management platform | International | Multidisciplinary | FA | Yes | 3,363 research objects |
|
| Data platform | International | Multidisciplinary | Sub | ? | 1.15 billion datasets |
|
| Data-focused journal | International | Multidisciplinary | OA | Yes | |
|
| Data catalog | International | Public health, toxicology, environmental health | FA | No | 1,055 datasets |
|
| Governmental data portal | UK | Multidisciplinary | FA | No | 9,877 datasets |
|
| Bibliographic database | International | Multidisciplinary | Sub | No | |
|
| Data portal | International | Health | FA | Yes | |
|
| Data repository | International | Multidisciplinary | FA | Yes | 403,919 datasets |
| Question | Description | Answer | |
|---|---|---|---|
| no | Yes/can’t tell | ||
|
| |||
|
| Does the name/title mention terms related to exposome? | 0 | 1 |
|
| Does the name/title mention terms related to humans? | 0 | 1 |
|
| Is the name/title in English or French? | 0 | 1 |
|
| |||
|
| |||
|
| Is the dataset freely accessible? | 0 | 1 |
|
| Can the dataset be reused for research purposes? | 0 | 1 |
|
| |||
|
| |||
|
| Is there a data dictionary explaining the dataset content? | 0 | 1 |
|
| Does the metadata mention terms related to exposome? | 0 | 1 |
|
| Does the metadata mention terms related to humans? | 0 | 1 |
|
| Is there any individual data available? | 0 | 1 |
|
| Is the data real (not synthetic)? | 0 | 1 |
|
| |||
|
| |||
|
| Is the data in English or French? | 0 | 1 |
|
| Does the dataset structure/format allow its reuse? | 0 | 1 |
|
| Does the dataset contain individual data? | 0 | 1 |
|
| Does the dataset contain an ID for each participant? | 0 | 1 |
|
| Does the dataset contain exposure data? | 0 | 1 |
|
| Does the dataset contain participants’ characteristics? | 0 | 1 |
|
| Does the dataset contain outcome data (e.g., presence or absence of a disease)? | 0 | 1 |
|
| |||
|
| |||
- —National Research Agency
- —France 2030 program
- —“Investissements d’avenir” program
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsBig Data Technologies and Applications
Background
Data are omnipresent, shaping nearly every aspect of our lives [1]. The digital revolution and the increasing reliance on technology have led to an exponential surge in data generation, creating a “data big bang.” This transformation has marked the onset of the fourth industrial revolution, in which information has become a central pillar and data are widely regarded as the “new gold” of the 21st century [2, 3]. Over the past years, data have evolved from being a mere by-product of digital activities to a highly valuable asset whose worth increases with use [2]. The web now provides access to millions of data sources [2], which are becoming increasingly vast, complex, and heterogeneous as societies undergo continuous digitization [4]. These sources originate from diverse domains and are of different natures [5], including contextual data (e.g., air pollution), person-generated data (e.g., wearables, social media), administrative health data (e.g., electronic health records), and synthetic data (e.g., digital twins) [6, 7].
This data revolution is profoundly reshaping the scientific landscape. In recent years, the scientific field has undergone an epistemological shift, transitioning from knowledge-driven to data-driven research [1, 4, 8]. Data have become a cornerstone of scientific discovery and are increasingly regarded as a form of scientific currency (data commodification) [4, 8–10]. This shift has driven efforts to move away from isolated data silos toward more integrated, accessible, and reusable data ecosystems, where multiple data sources can be used or needed to address a research question [11]. To support this transition, major efforts have been made to establish mandates and standards promoting data sharing [12–14], including the adoption of the FAIR (Findable, Accessible, Interoperable, and Reusable) principles [2, 15–17]. The ultimate goal of the FAIR principles is to optimize the reuse of digital assets populating the Internet [2, 15–17].
While the collection of new data remains a central focus, there is growing recognition of the substantial benefits associated with reusing existing datasets [12, 18, 19]. For example, the European Union and the World Health Organization (WHO) have introduced supportive frameworks such as the Research Data Alliance (RDA) [20], the European Open Data Directive (Directive (EU) 2019/1024), the Data Governance Act (DGA) [21, 22], the General Data Protection Regulation (GDPR) [21, 23], and the European Health Data Space [21, 23, 24]. Nearly half of researchers frequently use data generated by other scientists [25]. Data reuse not only facilitates the validation and replication of findings but also enables the exploration of extended or novel research questions [18, 19]. When disseminated with sufficient quality and contextual information, data from diverse scientific communities can contribute to new knowledge through cross-disciplinary insights. Data reuse has become an established practice that mitigates unnecessary duplication of research, accelerates scientific progress, and optimizes resource allocation in terms of time, effort, staff, and costs, while limiting risks to research participants [9, 12, 18, 19]. In this regard, the reuse of data represents a resource-efficient approach that helps reduce the environmental footprint of research [26, 27]. Furthermore, leveraging existing data allows researchers to address high-impact scientific questions that would otherwise require substantial time and resources [28].
Beyond access, data reuse relies on effective data discovery [15], a fundamental aspect of the FAIR principles that involves identifying and locating relevant datasets [15–17]. The ability to find appropriate datasets is a prerequisite for their reuse [29]. However, locating relevant datasets remains challenging, often requiring researchers to navigate multiple resources, review numerous publications, and directly contact dataset owners or study authors [11, 14, 15, 29–32]. As data sharing becomes more common, the complexity of dataset discovery is becoming increasingly evident [10, 15, 33]. Traditionally, researchers identified relevant datasets by consulting the literature, attending conferences, and engaging with colleagues [10]. In today’s data-rich environment, web searches have become the primary method for locating datasets [10, 11, 31], but other resources also exist. However, the success of such searches varies widely, depending on the expertise of the researcher, the tools employed, and, to some extent, chance [10]. Despite the growing need for efficient dataset discovery, there is still limited large-scale empirical evidence on how researchers locate, access, interpret, and reuse datasets [34]. Consequently, the importance of improving dataset discovery within the scientific community is paramount.
For decades, scientific research has relied on bibliographic searches to systematically identify and synthesize relevant literature, which is an essential process for supporting hypotheses, contextualizing findings, and ensuring methodological rigor [35, 36]. However, in the era of data-driven science [20, 37], the ability to select appropriate datasets is equally critical for research validity and reproducibility. Despite the increasing availability of large-scale, open-access datasets across scientific disciplines, researchers still lack standardized methodologies for systematically identifying, evaluating, and selecting datasets that best address their specific research questions [6, 11]. To bridge this gap, we introduce the concept of “datagraphy” (or “datagraphic search”), a structured approach analogous to bibliographic research but focused on datasets rather than publications. The proposed methodology is designed to support researchers in the systematic identification, evaluation, and documentation of datasets that align with their research objectives. By providing a structured approach, we aim to strengthen reproducibility, transparency, and methodological rigor in data reuse. Here, we highlight the potential of datagraphy as well as hurdles that need to be overcome.
Defining Datagraphy
We propose to define datagraphy as the systematic process of identifying, evaluating, and documenting datasets most suitable for addressing specific research questions, akin to how bibliographic research is conducted to identify relevant scientific literature. Datagraphy extends beyond simple dataset discovery. It further advantageously incorporates the assessment of dataset quality, relevance, completeness, and ethical considerations [11], thereby ensuring that selected datasets align with research objectives in a rigorous and transparent manner. Datagraphy further emphasizes the detailed documentation of dataset provenance, licensing conditions, and metadata completeness, which could facilitate reproducibility and support integration across research projects [38, 39]. By formalizing datagraphy as a research practice, we advocate enhancing reproducibility, mitigating selection bias, and improving the overall integrity of dataset reuse investigations.
Rationale and Existing Gaps
A variety of resources are already available for conducting datagraphy (Table 1). Existing datasets are dispersed across an increasing number of repositories, article supplements, academic journals, websites, and other platforms, each employing distinct metadata structures, data standards, and search functionalities [15, 30, 32, 40, 41].
For instance, domain-agnostic dataset search engines, such as Google Dataset Search, enable broad searches before directing users to specific repositories, where more targeted queries and dataset exploration can be conducted [31, 34, 42–45]. Data catalogs [14], such as OccupationalCohorts.net [46] and OccupationalExposureTools.net [47], provide structured inventories of data assets through curated metadata records. In addition to repositories and catalogs, data papers [48, 49] serve as valuable resources for dataset discovery [50]. These scientific publications detail dataset collection, processing, and validation methodologies, thereby informing the research community about their availability, characteristics, and reuse potential [19]. Data papers undergo peer review and are published in both general scientific journals and specialized data journals, such as GigaScience, Data in Brief, and Scientific Data [19, 51]. To improve data accessibility, many traditional scientific journals now require data availability statements and mandate that datasets be stored either as supplementary materials or in designated repositories [25]. Numerous data repositories and registries exist [52], including Re3Data [15, 32, 53], Zenodo [17, 51], and Dataverse [18]. Government agencies also provide access to datasets, such as those available through the NYU Libraries Data Sources [14, 43] and other national or regional data portals [2, 54]. In addition, open platforms like GitHub and Kaggle host a range of datasets across multiple domains [2]. All of the aforementioned resources vary in scope, ranging from institutional (e.g., university-level) to international initiatives [29]. Some are domain-specific, such as TEDI for toxicology and public health [55], while others, like Re3Data, span multidisciplinary research areas [15, 32, 53] (Table 1). Access to these resources also differs, with some that are openly available (e.g., Dataverse), whereas others require institutional affiliation (e.g., Web of Science) or subscription-based access (e.g., Dimensions.ia). This heterogeneity underscores the necessity of a standardized approach to ensure comprehensive and unbiased dataset identification.
While the aforementioned resources facilitate dataset discovery, they primarily function as search engines rather than providing systematic evaluation frameworks [11, 31]. Unlike literature searches, dataset selection is complicated by repository-level differences in metadata, submission procedures, and access policies, making reproducibility challenging [56]. In contrast, bibliographic research methodologies, such as systematic reviews and meta-analyses, follow rigorous protocols for literature selection and synthesis [36]. Current dataset search strategies lack standardization, as researchers often select datasets based on convenience and opportunity rather than through systematic assessment. Unlike bibliographic research, to the best of our knowledge, no formalized methodology exists for dataset selection, making dataset integration and comparison particularly challenging [19]. The absence of structured dataset selection methodologies increases the risk of opportunistic dataset use, potentially introducing biases and limiting the generalizability of research findings.
The development of a standardized framework for dataset identification and evaluation is essential for strengthening the reliability and impact of dataset reuse research. Such a framework could not only enhance reproducibility but also maximize the scientific value of existing datasets and facilitate interdisciplinary research. To achieve these goals, it should incorporate explicit quality metrics, assess metadata completeness, and account for accessibility and compliance with FAIR principles, thereby ensuring that datasets are both discoverable and suitable for secondary analysis [38, 39].
Proposed Framework for Datagraphic Search
The principles of systematic searching, traditionally associated with systematic reviews and meta-analyses [36], can be effectively extended to dataset discovery. This structured approach aims to identify all relevant datasets within resource constraints, enhance transparency in the search process, and ensure reproducibility. By providing a rigorous and replicable framework for dataset selection, it mitigates subjective biases and fosters collaboration across disciplines, benefiting not only researchers but also industry professionals, stakeholders, and other interested parties. Consequently, datagraphy has the potential to empower a wide range of users (e.g., researchers and policymakers) by facilitating access to diverse types of knowledge. At the same time, it must be acknowledged that this framework operates within the limitations of existing repository practices and infrastructures, which remain heterogeneous and largely unstandardized. Thus, the proposed methodology should be understood as a pragmatic, researcher-centric approach that enhances efficiency and rigor in dataset discovery, while recognizing that systemic repository-level improvements are still necessary to fully address the underlying challenges.
To ensure the relevance and utility of a datagraphic search, authors are encouraged to provide a transparent, comprehensive, and accurate account of the rationale behind the search, the methodology employed (including dataset identification and selection criteria), and the key findings (e.g., dataset characteristics). To operationalize this process, we propose a 9-step framework that mirrors the systematic approach used in bibliographic research (Fig. 1). The framework is intended to structure researcher activity and enhance reproducibility and efficiency.
Step 1 involves defining the research question, which represents a fundamental component of scientific inquiry [57]. The purpose of this step is to clearly articulate the rationale for seeking a dataset, whether for comparison, validation, or the development of a new study [10]. In some cases, this may also entail integrating data from multiple sources to construct a new dataset [31]. Establishing a well-defined research question helps determine the specific issues that should be addressed through dataset analysis but also provides direction for subsequent stages of datagraphy. Existing guidelines, such as those provided by the Joanna Briggs Institute, offer valuable support by applying structured frameworks, such as the population, concept, and context criteria (PCC) [58]. This ensures that the scope of the datagraphic search remains coherent, transparent, and aligned with the overarching scientific objectives.Step 2 involves specifying dataset requirements, that is, the characteristics a dataset must possess to serve the formulated purpose(s). These may include essential variables, study population, time frames, geographic scope, granularity, and data formats [10]. Importantly, initial requirements and constraints may evolve as the search progresses [10]. By clearly defining these parameters, researchers can more effectively target datasets that are directly relevant to the research question while excluding irrelevant datasets early in the process, thereby improving both efficiency and rigor.Step 3 involves defining the dataset search strategy, analogous to approaches used in bibliographic literature searches. Queries should be strategically designed while accounting for the heterogeneity of repository functionalities [10]. Several recommendations developed for systematic reviews can provide useful guidance in balancing between sensitivity and specificity [59]. However, because relevant information is often distributed across multiple datasets and resources, search strategies frequently need to be adapted [11, 31]. For example, administrative health databases such as the French National Health Data System (SNDS) [60] may lack key epidemiological variables, such as environmental factors (e.g., air pollution, climate data) [6]. In such cases, distinct search strategies may be required to identify both administrative health records and complementary contextual datasets that can be integrated. Dataset search systems typically rely on query languages and information retrieval principles, in which information needs are expressed through keywords or faceted filters based on metadata attributes [31]. Some platforms, such as DataONE, support semantic technologies that automatically expand user-entered keywords to include relevant synonyms [10]. In contrast, if a search portal lacks this functionality, users must manually include appropriate synonyms to ensure comprehensive results [10, 32]. Several systems also allow the use of search operators (e.g., OR, AND) to refine results, but several queries are often necessary to achieve adequate coverage [11, 31]. Based on initial outputs, queries may need to be broadened or narrowed, mirroring the iterative refinement process common in bibliographic searching [10]. Repository-specific facets and filters, such as those for data format, type of analysis, or availability, can further improve efficiency by enabling the rapid identification of usable datasets [10, 11, 31]. Overall, dataset discovery is inherently iterative. Successive query reformulation, combined with the use of filters and the inspection of preliminary results, progressively sharpens the search strategy [61]. Nevertheless, most repositories currently rely primarily on keyword-based searches over metadata, which often fail to capture the full content and context of datasets. This limitation highlights the need for iterative refinement and careful adaptation of strategies during the search process [30].Step 4 focuses on dataset discovery, that is, the process of identifying datasets potentially suitable for the defined research purpose(s) [11]. Researchers can leverage various data repositories, platforms, catalogs, data papers, and other resources to identify potentially eligible/relevant datasets. Searches may be conducted globally using services, such as Google Dataset Search [31], Auctus [30], and DataMed [30, 31, 62, 63], or locally within individual repositories [31]. The choice of the dataset discovery resource(s) should consider factors such as domain relevance, repository trustworthiness, and technical features. In many cases, discipline-specific repositories provide the most effective means of discovery, as researchers with similar interests are more likely to store and share datasets within these specialized platforms [15]. Domain-specific portals further streamline the search process by offering interfaces and filters tailored to the needs of particular research fields [10]. Data aggregators such as DataONE and DataMed allow users to search multiple repositories through a single interface [10, 31, 63]. However, not all data discovery resources are equally trustworthy. For example, repositories certified by the CoreTrustSeal must meet 16 criteria related to accessibility, usability, reliability, and long-term data preservation [10, 64]. Understanding the standards and practices a searchable dataset resource applies to its data and metadata can increase confidence in dataset quality and reusability [10]. Beyond repositories, datasets can also be located through publications using resources such as the Data Citation Index [11]. Data citation itself plays a critical role in making datasets findable and accessible by providing persistent identifiers and descriptive metadata, which ensure reliable referencing, tracking, and reuse [11, 65]. It is also possible to locate datasets associated with papers in bibliographic databases, such as PubMed. Finally, a recent study has also outlined 11 practical tips for dataset discovery, providing a useful starting point or foundational guidance for this endeavor [10]. Other helpful guidelines and examples have also been proposed [66].Step 5 evaluates whether a dataset is accessible and under what conditions. While some datasets can be downloaded directly from the web, others may require a subscription, direct contact with the authors, or approval from data custodians. Key access considerations include data format, file size, transfer costs, availability of mirrors, and data proximity [67]. Evaluating these factors at an early stage helps avoid wasted effort and ensures compliance with repository policies and usage restrictions [67].Step 6 pertains to ensuring ethical and legal compliance. This includes verifying adherence to data-sharing policies, privacy regulations, and licensing constraints to safeguard responsible dataset use. The central question at this stage is whether, and under what conditions, a dataset can be legally and ethically reused. For instance, the CARE (Collective benefit, Authority to control, Responsibility, Ethics) principles were created by Native Americans to guide how research data generated from Indigenous populations should be governed and made available [68–70]. While open-access datasets generally involve minimal restrictions, sensitive data may require institutional review board (IRB) approval or multifactor authentication [62].Step 7 involves assessing dataset relevance (eligibility) by evaluating its alignment with the research objectives, including considerations such as scope, granularity, and contextual applicability. An initial review of the metadata is often sufficient to determine whether a dataset meets the preliminary requirements defined in steps 1 and 2 [10, 66]. Some searchable dataset resources, such as Figshare, offer preview features that allow users to quickly evaluate the dataset’s structure and content. Ideally, metadata should be accompanied by comprehensive documentation to support a thorough evaluation of the dataset’s relevance and fitness for use. This includes details on data collection methods, quality assurance procedures, and prior applications of the data [10]. If a dataset fails to meet any of the established criteria, it may be advisable to exclude it from further consideration [10]. Data summarization tools have also been proposed to help in this endeavor [66].Step 8 requires evaluating data quality by examining attributes, such as provenance, completeness, representativeness, interoperability, generalizability, timeliness, validity, and potential limitations, including missing data or measurement errors [28, 66, 71]. Assessing dataset quality and fitness for purpose is paramount, as shared data may be erroneous or unsuitable for reuse [45]. Key considerations include whether the dataset contains the necessary variables to address the research question, whether the data collection and its sampling methodology are appropriate, how variables are defined and measured, and whether the sample size is sufficient to ensure adequate statistical power. Other critical factors include the extent of missing data and, in longitudinal studies, the degree of loss to follow-up [10]. To facilitate a robust quality assessment, predefined metrics (e.g., accuracy, completeness, consistency, timeliness, currency, conformance, and uniqueness) can be applied [72]. This step also aims to assess whether data management or wrangling is required and, if so, to determine its potential scope [73]. The feasibility of dataset reuse may decline if the effort required to standardize a dataset (i.e., make it research-ready) for research purposes is disproportionately high relative to its potential benefits [73]. In addition, ensuring high dataset quality is essential for deriving meaningful insights [72]. For instance, a recent study offers guidance on evaluating dataset quality in the context of machine learning [72], which can serve as a valuable starting point for implementing step 8 of the proposed framework. Reusability indicators such as machine readability, data annotation, and data validation further ensure that datasets are reported in ways consistent with their intended use [38]. Understanding how datasets were produced, including their provenance and relationships to other sources, is also paramount for determining whether a dataset can be reused [65]. Repository-level quality indicators, FAIRness scores, and standardized metrics can provide objective measures of completeness, representativeness, and overall usability, supporting informed decisions about dataset selection and reuse.Step 9 involves transparently documenting the dataset identification and selection process, following a structured approach similar to that of systematic reviews (e.g., a Preferred Reporting Items for Systematic Reviews and Meta-Analyses [PRISMA]–like flowchart [36]) (Fig. 2). This documentation ensures clarity and reproducibility, ultimately strengthening the reliability of dataset reuse research. All steps, including queries, refinements, access conditions, and integration procedures, should be recorded in a reproducible and transparent manner.
Proposed datagraphy framework. Operationalization of the datagraphy concept with a 9-step approach that mirrors the systematic method used in bibliographic research.
PRISMA-like flowchart for datagraphy. Flowchart illustrating the datagraphy concept.
Illustrative and Working Example: The Exposome Case
To demonstrate the application of the proposed framework, we conducted a datagraphic search focused on the exposome. The research question was formulated using the Joanna Briggs Institute’s PCC framework [58]. The population of interest included any human subjects exposed to environmental factors. The concept encompassed any studies involving at least 1 health-related outcome. No restrictions were applied for context.
When possible, we used the same search query (i.e., exposom*) as in a prior bibliometric analysis on the exposome [7]. For searchable dataset resources that did not support wildcard characters, we used the simplified query “exposome.” The search was carried out across 11 dataset discovery platforms, following a process inspired by the PRISMA guidelines [36] and the practical recommendations outlined by Gregory et al. [10] and Koesten et al. [66]. For this example, screening was performed by a single author (P.P.). To minimize bias due to temporal variability in dataset availability, all data were collected on the same day, 10 April 2025.
The selection of the 11 dataset discovery resources was guided by informed judgment, aiming to capture, as far as possible, the heterogeneity and fragmentation of the current landscape. We therefore included different categories of resources: a web crawler (Google Dataset Search), a data aggregator (DataMed), domain-specific repositories (Epidemiologie—France and TEDI), a data-focused journal (Scientific Data), a bibliographic database (Web of Science), a data platform (OpenAIRE), a trusted data portal (FAIRSharing), as well as widely used general-purpose repositories (Dryad and Zenodo) and a repository catalog (Re3Data). Whenever possible, we preferentially selected resources that were openly accessible or freely available. For 5 resources, filter or facet options were used, with the “catalog” facet for Epidemiologie—France, the data paper option in Web of Science (from the document types filter), and the dataset option in FAIRSharing (from the object types filter), OpenAIRE (from the document type filter), and Zenodo (from the resource types filter). Regarding Re3Data, the content-type filter to select datasets was not used because only 3 results were obtained with the general search query.
To ensure the relevance and representativeness of the included datasets, titles/names, metadata, and dataset content were assessed based on predefined inclusion and exclusion criteria (Table 2). When titles or metadata lacked sufficient information, full-content screening was conducted. Datasets were included if they addressed the human exposome. Exclusion criteria encompassed datasets involving only animal or in vitro data, those irrelevant to the exposome concept, or those lacking individual-level data on exposures, outcomes, and participant characteristics. For this illustrative example, we deliberately excluded datasets that contained adverse outcome data without environmental exposure/factor information, even though some could potentially be linked to contextual environmental datasets (e.g., via geographic data).
Results from the datagraphic search are presented in Fig. 3, with step-by-step details provided in Supplementary Table S1. Of the 11 searchable dataset resources, 6 supported the use of the wildcard query “exposom*.” A total of 322 datasets were initially retrieved. After removing 109 duplicates (34%), 213 unique records remained for screening. Duplicate identification was challenging due to variations in dataset names and the presence of subsets nested within larger datasets. In cases where subsets offered no additional unique information, only the original dataset was retained.
PRISMA-like flowchart of the exposome datagraphic search. Flowchart summarizing the results of the exposome datagraphic search.
Title-based screening excluded 85 datasets (40%). Of the remaining 128, 22 (17%) were inaccessible, resulting in 106 datasets for metadata screening. Of these, 96 (91%) were excluded, most commonly due to the absence of individual-level data (n = 67, 70%) or a lack of exposure/environmental data (n = 20, 21%).
The final screening phase involved a full-content review of the remaining 10 datasets, from which 4 met the inclusion criteria. These included 2 datasets from the National Health and Nutrition Examination Survey (NHANES) [49, 74], 1 from a Pakistani cohort study [48], and 1 from the EXPOsOMICS Personal Exposure Monitoring Study [75]. Dataset quality assessment was not conducted for this illustrative example.
Discussion
Challenges
The successful implementation of datagraphy faces multiple challenges.
Metadata availability, heterogeneity, and quality
One of the primary obstacles is the limited availability of metadata, which is essential for assessing the existence and characteristics of datasets. Current deposition practices impose only minimal restrictions on the descriptors used [17]. The substantial variability in metadata and the lack of standardized protocols for data collection, storage, and format/structure across repositories create major barriers to the effective identification and reuse of datasets. While datagraphy could help researchers navigate this fragmented landscape more systematically, it does not resolve the underlying heterogeneity. In the absence of consensus on core repository services, each organization tends to implement systems aligned with its specific goals [64], making cross-repository integration challenging. For example, in data papers and data-focused journals, publication requirements and the amount of data that can be attached vary by journal, making it challenging to find comprehensive and useful content. In addition, limited accessibility and machine readability of existing metadata, particularly for population health data, further hamper effective dataset discovery and reuse [76–78].
Metadata quality represents a further critical bottleneck. Because dataset search relies heavily on metadata, it is imperative that descriptions are accurate and consistent [31]. Metadata are essential for establishing dataset existence, scope, and suitability for reuse, yet they are frequently incomplete, restricted to high-level descriptors, inconsistent, or nonstandardized [20, 30, 31]. Metadata quality also varies across disciplines and repositories, reflecting differences in cultural practices and curation priorities [71]. Errors, inconsistencies, and incompleteness in metadata are common, sometimes diverging from the underlying dataset [30]. Consequently, relying solely on metadata constrains discoverability and hampers systematic evaluation of dataset fitness for purpose [30, 31].
Data discovery infrastructure and landscape
One major issue for dataset discovery is the broad freedom repositories have to implement their own discovery procedures, metadata standards, and data packaging approaches [2, 64]. This heterogeneity creates structural challenges that go beyond the capacity of individual researchers to address. While existing resources accept a wide variety of data types and formats, they generally do not attempt to integrate, harmonize, or assess the quality of deposited data. Datasets may be incomplete, sometimes intentionally so [25]. Complex datasets, such as collections of tables, longitudinal records, or multimodal data, remain poorly supported [45]. Certain dataset types, including administrative health records, lack comprehensive catalogs and are underrepresented in existing data repositories [6]. Searchable dataset discovery resources, whether general repositories or domain-specific catalogs, also differ in functionality and coverage, including subject matter, geographical and temporal scope, language, and scientific domain [2, 35]. Consequently, the data ecosystem is becoming increasingly fragmented and heterogeneous, creating a “needle in a haystack” paradox that further complicates dataset discovery [17], particularly in domains where data lakes may contain tens of thousands of tables [61].
Dataset search is largely keyword-based, restrictive, and iterative, often requiring multiple query reformulations to assess relevance [31, 61]. Such keyword-based approaches, which rely on limited metadata, are insufficient for comprehensive dataset search and discovery [11, 30, 31]. They fail to capture dataset granularity, provenance, and methodological context [31, 61]. Many repositories only support simple keyword-based queries, which limits users’ ability to express complex information needs [30]. Although some tools allow searches for spreadsheets or published data in formats such as CSV or JSON, most do not support complex datasets, such as collections of tables, text, or temporal data [11, 31]. In addition, existing searchable data discovery resources often exhibit limited data discovery capabilities and provide only superficial query responses [11, 31, 61]. Translating search strategies and user queries across searchable dataset resources with differing syntax requirements can be a complex and time-consuming task [59]. To address this issue, the adoption of standardized vocabularies (e.g., taxonomies tailored to domain-specific terminology) is essential. One promising direction is the development of web-based search systems leveraging semantic metadata, as recently proposed in the field of information science for literature searches of scientific publications [79]. Current standards such as Wikidata, Schema.org, and Dublin Core provide structured vocabularies for describing digital resources in a consistent, machine-readable way, while domain-specific ontologies enable richer semantic annotation [31, 32, 44, 65, 80, 81]. There is a growing need for richer, content-aware indexing and semantic search methods [11, 30, 61].
Several initiatives have developed dataset discovery indexes and search engines to mitigate repository heterogeneity and search limitations. Examples include DataMed, designed as a “PubMed for datasets” [62, 63, 82, 83]; OmicsDI, which aggregates resources across proteomics, genomics, and metabolomics [40]; Auctus, a web crawler and search engine dedicated to datasets for data augmentation in machine learning [30]; and Google Dataset Search, which indexes a broad range of datasets published on the web [30, 31]. These search engines attempt to index heterogeneous repositories by exposing standardized metadata fields. Most repositories, however, still support only simple searches over metadata [30], although some, such as Auctus, enable more complex queries incorporating spatial, temporal, and integration constraints based on dataset content [30]. While these approaches demonstrate the feasibility of federated search, they remain constrained by the heterogeneity and incompleteness of the underlying metadata [11, 31]. Advanced approaches, including semantic search, artificial intelligence (AI)–assisted query reformulation [61], and content-aware indexing, offer potential improvements [11, 30, 61]. Nevertheless, search effectiveness continues to be limited primarily by metadata heterogeneity and repository-specific practices [11, 31].
Data accessibility, legal, and ethical considerations
Challenges also extend to repository functionality and scope. Dataset documentation and access conditions vary tremendously across resources, making selection difficult for researchers. Dataset accessibility is further complicated by licensing, ethical, and legal constraints. Licenses, data use agreements (DUAs), and authentication requirements introduce additional barriers and shape who can access datasets and under what conditions [62]. Open-access datasets may be freely available, but many sensitive datasets require IRB approval, registered access, or multifactor authentication, adding layers of complexity and potential delays [60, 62]. The time required to acquire existing datasets and obtain IRB approval can also vary considerably [28]. While some datasets can be directly downloaded from the web (e.g., Comparative Toxicogenomics Database [84]), others require multiple layers of permissions and security measures (e.g., SNDS [60]), and in certain cases, data must be analyzed within a dedicated data-processing environment (e.g., SNDS [60]). These examples illustrate the wide diversity of access conditions researchers must navigate. Furthermore, national and international ethical and legal obligations can restrict data sharing, grouped analyses, and data deposition [25, 85]. Regulations such as the European GDPR require organizations to implement robust data protection measures, including data retention and deletion protocols, which can impede data reuse efforts and may result in substantial financial penalties in case of noncompliance [23, 86].
Finally, access to published data is not always guaranteed due to broken links, missing metadata, or a lack of author cooperation [25]. For example, in a large-scale study of around 900 articles published in Nature and Science between 2000 and 2019, 61% of papers that included “data available upon request” statements did not provide the data when contacted [25]. Broken links, missing metadata, or author unresponsiveness therefore remain major obstacles.
Data quality and reusability
Researchers frequently encounter poorly described and nonstandardized data, which limits reusability [20]. Assessing dataset fitness is often difficult, as available metadata rarely capture essential attributes such as granularity, provenance, or methodological context [31, 61]. As a result, substantial time and effort are often required to manually sift through large volumes of irrelevant datasets.
Another major challenge in assessing data quality and reusability lies in the original data collection methods and processes (i.e., data capture), which are beyond the control of secondary users and can highly vary [72, 87]. In addition to variability in metadata completeness and repository practices, the lack of standardized indicators or score systems for assessing dataset reusability (e.g., FAIRness) and quality further complicates efforts to identify the most appropriate datasets for specific research questions [2, 19, 76]. Practical considerations such as transit costs, storage, and access proximity may also influence dataset reusability [67].
Sharing data via supplementary materials remains common practice and is highly encouraged by journals [88]. However, unlike public repositories, supplementary files are not necessarily persistently discoverable or archived. They frequently lack persistent identifiers (e.g., digital identifiers of an object [DOIs] or accession numbers), making them vulnerable to link rot and content drift [88]. Moreover, supplementary datasets are often available only in aggregated or summary form, rather than as raw or individual-level data, which limits systematic reuse. Publishing datasets solely as linked data or supplementary materials is insufficient to support reproducibility and reuse, as such approaches fail to capture life-cycle information, provenance, versioning, and methodological context [89–91].
Data visibility, data decay, and sustainability
Systemic challenges such as dataset invisibility, data decay, broken links, and paywalls exacerbate discovery difficulties [25]. Some datasets remain inaccessible behind paywalls, making them invisible to many researchers [35], while others are never deposited in open repositories, resulting in so-called invisible data or dark data [14] and increasing the risk of data graveyards (i.e., unused data) [92]. Organizations frequently store vast numbers of tables and records in data lakes [61]. Over time, the availability of originally accessible data tends to decline (a phenomenon known as data decay), which can ultimately lead to data loss [25]. Estimates suggest that up to 80% of archived scientific research data are lost within 20 years [67].
Sustainability poses an additional systemic risk. Many data-sharing platforms lack long-term funding models, which threatens not only the durability and accessibility of datasets but also the continued relevance of the information they host [93]. Without sustained funding and community support, data search tools risk becoming outdated or abandoned, which compromises their reliability and long-term utility for researchers. For example, DataMed has not received new additions since 2024 [62, 63, 82, 83]. Some repositories risk becoming unsustainable “data lakes,” where uncurated, poorly described data accumulate without integration or retrieval mechanisms [35]. Without investment in long-term infrastructure, persistent identifiers, harmonized metadata standards, and robust governance structures, repository heterogeneity, metadata gaps, and fragmentation will persist [56]. In the absence of such measures, both discoverability and reuse remain severely undermined.
Standardized metadata frameworks and packaging
Efforts to improve data discoverability across the social sciences, biomedical domains, omics research, and public datasets emphasize the need for metadata harmonization, advanced search interfaces, and distributed resource indexing [32, 40]. Implementing repository-wide FAIR-compliant practices and semantic metadata frameworks could help address existing limitations [38, 39, 81, 94, 95]. While the FAIR principles provide an overarching vision for dataset reuse, their adoption at the repository level remains highly uneven [20, 64]. Two recent reviews, covering 35 [20] and 25 [64] data repositories, respectively, identified interoperability and sustainability as major obstacles to achieving FAIR compliance.
Repositories differ in the metadata standards they apply, the search interfaces they provide, and the approaches they adopt for data packaging. This diversity produces structural fragmentation that cannot be addressed at the level of individual researchers [2, 64]. Most attempts to mitigate these limitations have focused on standardized, machine-readable metadata and packaging approaches. By adopting FAIR digital objects (FDOs) or research object (RO)–Crate packages, repositories could ensure that metadata, provenance, licensing, and dataset structure are consistently available, machine-actionable, and interoperable, thereby facilitating automated discovery and reuse across platforms [38, 39, 81, 91, 94–98].
ROs are structured bundles of data, methods, and metadata that capture life-cycle information, ownership, versioning, attribution, provenance, quality, and methodological context [89–91]. RO-Crate extends this concept by providing a lightweight, machine-readable packaging framework for aggregating research artifacts with their metadata and relationships, creating a multimodal scholarly knowledge graph that can help “FAIRify” and combine metadata from existing resources [91, 94, 97, 99]. FDOs, in turn, are digital objects explicitly designed to be FAIR, embedding metadata, provenance, and other descriptive information in a machine-actionable format [38, 65]. Other packaging standards, such as BDBags (Big Data Bags), provide mechanisms for content enumeration, fixity checking, and lightweight referencing without requiring centralized hosting [45, 100]. The integration of canonical workflows, including pipelines based on the Common Workflow Language (CWL), could further support reproducibility and enable systematic evaluation of search queries and analyses across repositories [101, 102].
Validation frameworks, reusability metrics, and machine-readable metadata derived from RO-Crates or FDOs could enable semi-automated or automated assessments of dataset fitness and quality [38, 103, 104]. For instance, the FAIRO framework has been proposed to measure the compliance of ROs with FAIR criteria [103], while reusability indicators and automated quality checks have been incorporated into RO and RO-Crate packaging [38, 105]. However, the effectiveness of automation remains limited by the lack of harmonized metadata across repositories [65, 89, 106].
Additional complementary approaches could further enhance discoverability. Persistent identifiers (e.g., DOIs) can ensure long-term accessibility, prevent broken links, and support dataset citation [13, 67]. The adoption of persistent identifiers is essential for datagraphy, yet remains underdeveloped [13, 19]. Assigning persistent identifiers guarantees long-term accessibility, facilitates citation, and prevents link rot caused by website migrations [107]. Metadata harmonization frameworks, such as the Data Tag Suite (DATS), also enable standardized descriptions of heterogeneous datasets and support automated search and retrieval [62, 63, 108].
Despite these advances, the adoption of standardized packaging and metadata frameworks remains limited, constraining automation, reproducibility, and scalability in dataset discovery [65, 89, 106].
Potential implications and future directions
The aforementioned structural challenges underscore the necessity of harmonizing both repository-level infrastructures and researcher-level practices.
Datagraphy as a systematic research methodology
Establishing datagraphy as a recognized research methodology could have profound implications across scientific disciplines. By promoting systematic dataset selection, datagraphy may enhance the reliability and reproducibility of data reuse research, mitigate selection bias, facilitate transparent dataset reuse, and foster interdisciplinary collaboration through improved dataset discoverability. As scientific data grow in volume and complexity, the need for a structured approach to dataset selection becomes increasingly urgent. Integrating datagraphy as a foundational research practice would ensure that dataset selection adheres to the same methodological rigor as literature reviews, ultimately strengthening the integrity and impact of data-driven discoveries.
Standardization efforts
To advance datagraphy, standardization efforts are essential, much as they have been for bibliographic search. Establishing reporting guidelines analogous to PRISMA [36] could be a viable strategy. Another option could be extending existing frameworks (e.g., adapting PRISMA for dataset discovery). Unified guidelines for cloud architectures [109], the promotion of common data elements [110, 111], and the standardization of reporting formats and metadata sharing remain essential priorities [112]. Richly described metadata in machine-readable formats will enhance interoperability, enabling efficient data harvesting, attribution, and semantic understanding [77, 107, 110–112]. Ongoing harmonization initiatives, such as those in toxicology [85], should be further supported and expanded.
Aligning researcher and repository-level practices
For datagraphy to realize its full potential, it must operate in synergy with repository-level improvements. Sustainable and reproducible datagraphy requires alignment with community standards for metadata and packaging. This includes the adoption of standardized, machine-readable metadata schemas (e.g., DATS), harmonized vocabularies, persistent identifiers (e.g., DOIs), and lightweight packaging formats such as RO-Crates, BDBags, Frictionless Data Packages, or FDOs [39, 62, 63, 80, 94, 95, 100, 105, 113]. Integrating provenance-aware workflows and schema-validated metadata could further strengthen reproducibility and automation [99, 114, 115]. These implementations would provide the foundations for machine-actionable dataset discovery and ensure that datasets remain discoverable, comparable, and citable across repositories [39, 95, 106]. Repository-level innovations, including semantic search, canonical workflows, and federated queries across FAIR-compliant repositories, can further reduce manual search effort while increasing reproducibility [10, 101, 106, 116].
FAIRness, reusability, and sustainability
Developing sustainable and trustworthy FAIR-compliant searchable data discovery resources (e.g., data repositories) is essential for supporting datagraphy. The creation of a comprehensive search index could enable dataset comparison [32]. However, empirical insights into what makes a dataset more reusable remain limited [2]. Guidelines such as FAIR, which promote universal metadata standards, are essential for dataset comparison and integration [19, 76]. While measuring “FAIRness” is not yet an established practice, several efforts (e.g., the FAIR metrics group) are paving the way [2]. Validation frameworks such as FAIRO [103] and automated FAIRness metrics [38, 105] could provide objective indicators of dataset quality. Implementing FAIR principles enhances discoverability and reuse, ensuring seamless dataset discovery, access, and integration across diverse research domains [76, 77, 107]. Complementing the FAIR principles with the TRUST (Transparency, Responsibility, User focus, Sustainability, and Technology) principles could provide a more comprehensive framework for data sustainability [93]. In addition, operationalizing the FAIR principles alongside other standards, such as the CARE principles, can enhance machine actionability while also ensuring that data are used appropriately across the entire data life cycle [68].
Integrating dataset search tools with bibliographic databases and data management platforms represents a promising step toward improving the findability of datasets [34]. For instance, databases such as Web of Science and PubMed enable users to filter search results specifically for data papers. This can be achieved via a dedicated filter box in Web of Science or by appending searches with the term data[filter] in PubMed. However, this functionality is not yet available in other bibliographic databases. In contrast, some literature repositories like PubMed Central offer more sophisticated search capabilities that allow users to limit queries to articles associated with data. This can be done by utilizing specialized search operators, including hassuppdata, hasdataavail, hasdatacitations, and hasassociateddata, which target papers containing data availability statements or supplemental data files.
Governance and community initiatives
Community-driven initiatives will play a central role in advancing datagraphy. Projects such as the RDA [20], DCAT [2], DATACC, and schema.org [2] can enhance datagraphy by improving dataset discoverability and enabling federated searches across multiple data catalogs. A unified data service is needed to efficiently retrieve relevant and reliable datasets [32]. For example, Wikidata provides a community-maintained knowledge graph that supports semantic enrichment and linking across datasets [31, 65]. Another example is the Global Data Sharing Initiative that proposed a pipeline that collects relevant information from diverse sources, integrates multiple sharing streams, and merges them into a unified dataset for statistical analysis or secure data examination [117]. The European initiative DataGEMS [118] aims to address this challenge by developing an advanced data discovery platform based on FAIR principles. DataGEMS will integrate data sharing, discovery, and analysis into a comprehensive ecosystem covering the entire data life cycle (i.e., storage, management, discovery, analysis, and reuse). This EU-funded initiative involves 12 partners across 8 countries working to create open-source tools that facilitate access to FAIR-by-design datasets. By promoting data FAIRness, DataGEMS will bridge the gap between data providers and users, fostering a more efficient and transparent data-sharing ecosystem. Complementary efforts, such as Make Data Count [19], further legitimize datasets as scholarly outputs, enabling proper citation and attribution alongside traditional publications.
AI integration in dataset discovery
The integration of AI-based tools for automated dataset discovery could represent a promising avenue for enhancing datagraphy. For example, DataGEMS will leverage state-of-the-art data management, natural language processing, and machine learning to support dataset discovery and analysis across diverse data modalities, including tabular data, text documents, knowledge graphs, and images [118]. AI-based tools such as DataScout [61] and large language models promise to enhance dataset discovery through query reformulation, semantic filtering, and relevance scoring [119–124]. These innovations complement, rather than replace, necessary repository-level changes such as metadata harmonization and packaging. Together, technological innovation and metadata harmonization must evolve in concert, rather than in isolation.
Conclusion
Datagraphy and community-driven efforts should be advanced in synergy. Datagraphy provides a structured methodology for the systematic identification and evaluation of datasets, whereas systemic solutions (e.g., metadata standardization) strengthen the underlying infrastructure that supports dataset discovery. As a reproducible, pragmatic, and researcher-centered approach, datagraphy offers a valuable means of navigating the fragmented landscape of dataset discovery. However, its full effectiveness depends on addressing repository heterogeneity through the implementation of standardized and machine-readable metadata, persistent identifiers, provenance-aware workflows, and FAIR-compliant packaging formats such as RO-Crates or FDOs. By aligning datagraphy with repository-level standards and community best practices, researchers can substantially improve dataset discoverability and foster sustainable reuse. In this way, datagraphy functions both as a practical methodology and as a conceptual framework that underscores the necessity of harmonized infrastructure. When integrated with FAIR-aligned repositories and robust reporting guidelines, datagraphy has the potential to transform dataset selection into a transparent, durable, and scalable research practice, thereby enabling researchers to engage more effectively and confidently with increasingly complex data landscapes.
Additional File
Supplementary Table S1. Step-by-step details results from the exposome datagraphic search.
giaf134_Table_S1
giaf134_Authors_Response_To_Reviewer_Comments_Original_Submission
giaf134_GIGA-D-25-00204_Original_Submission
giaf134_GIGA-D-25-00204_Revision_1
giaf134_Reviewer_1_Report_Original_SubmissionJasper Jan Koehorst -- 7/13/2025
giaf134_Reviewer_2_Report_Original_SubmissionNicole Contaxis -- 7/16/2025
giaf134_Reviewer_2_Report_Revision_1Nicole Contaxis -- 10/6/2025
Abbreviations
AI: artificial intelligence; CARE: Collective benefit, Authority to control, Responsibility, Ethics; CWL: Common Workflow Language; DATS: Data Tag Suite; DGA: Data Governance Act; DOI: digital identifier of an object; DUA: data use agreement; EU: European Union; FAIR: Findable, Accessible, Interoperable, and Reusable; FDO: FAIR digital object; GDPR: General Data Protection Regulation; IRB: institutional review board; NHANES: National Health and Nutrition Examination Survey; PCC: population, concept, and context criteria; PRISMA: Preferred Reporting Items for Systematic Reviews and Meta-Analyses; RDA: Research Data Alliance; RO: research object; SNDS: French National Health Data System; TRUST: Transparency, Responsibility, User focus, Sustainability, and Technology; WHO: World Health Organization.
Competing Interests
The authors declare that they have no competing interests.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Pastorino R, De Vito C, Migliara G, et al. Benefits and challenges of Big Data in healthcare: an overview of the European initiatives. Eur J Public Health. 2019;29(Suppl. 3):23–27. 10.1093/eurpub/ckz 168.PMC 685950931738444 · doi ↗ · pubmed ↗
- 2Koesten L, Vougiouklis P, Simperl E, et al. Dataset reuse: toward translating principles to practice. Patterns. 2020;1(8):100136. 10.1016/j.patter.2020.100136.33294873 PMC 7691392 · doi ↗ · pubmed ↗
- 3Peterson ED . Machine learning, predictive analytics, and clinical practice: can the past inform the present?. JAMA. 2019;322(23):2283–84. 10.1001/jama.2019.17831.31755902 · doi ↗ · pubmed ↗
- 4Li C, Huang M. Environmental sustainability in the age of big data: opportunities and challenges for business and industry. Environ Sci Pollut Res. 2023;30(56):119001–15. 10.1007/s 11356-023-30301-5.37919492 · doi ↗ · pubmed ↗
- 5Näher AF, Vorisek CN, Klopfenstein SAI, et al. Secondary data for global health digitalisation. Lancet Digit Health. 2023;5(2):e 93–e 101. 10.1016/S 2589-7500(22)00195-9.36707190 · doi ↗ · pubmed ↗
- 6Petit P, Vuillerme N. Leveraging administrative health databases to address health challenges in farming populations: scoping review and bibliometric analysis (1975-2024). JMIR Public Health Surveill. 2025;11:e 62939. 10.2196/62939.39787587 PMC 11757986 · doi ↗ · pubmed ↗
- 7Petit P, Vuillerme N. Global research trends on the human exposome: a bibliometric analysis (2005-2024). Environ Sci Pollut Res. 2025;32(13):7808–33. 10.1007/s 11356-025-36197-7.PMC 1195319140056347 · doi ↗ · pubmed ↗
- 8Tenopir C, Rice NM, Allard S, et al. Data sharing, management, use, and reuse: practices and perceptions of scientists worldwide. P Lo S One. 2020;15(3):e 0229003. 10.1371/journal.pone.0229003.32160189 PMC 7065823 · doi ↗ · pubmed ↗