Real-time sleep disorder monitoring design using dynamic temporal graphs with facial and acoustic feature fusion
Fei Pei, Ying Zhou, Qiangqiang Fu, Hong Zhou

TL;DR
This paper introduces a non-invasive system using facial and audio data to monitor sleep disorders in real-time, offering a more comfortable alternative to traditional methods.
Contribution
A novel multimodal system using dynamic temporal graphs for real-time sleep disorder detection with high clinical accuracy.
Findings
The system detected sleep apnea, restless leg syndrome, and cardiovascular irregularities with 94.6% clinical agreement.
It achieved a 10.7-second average delay, suitable for real-time monitoring.
The framework offers diagnostic accuracy comparable to traditional polysomnography.
Abstract
Sleep disorders pose significant risks to patient safety, yet traditional polysomnography imposes substantial discomfort and laboratory constraints. We developed a non-invasive multimodal monitoring system for real-time sleep pathology detection. We integrated facial expression analysis via deep convolutional neural networks with audio signal processing for breathing pattern detection. Heterogeneous data streams were unified into dynamic graph representations, with graph neural networks modeling spatiotemporal patterns of sleep pathologies. The system accurately detected sleep apnea, restless leg syndrome, and cardiovascular irregularities with 10.7-s average delay and 94.6% clinical agreement, achieving diagnostic accuracy comparable to polysomnography. This framework enables continuous non-invasive monitoring for point-of-care screening and home-based management, potentially…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
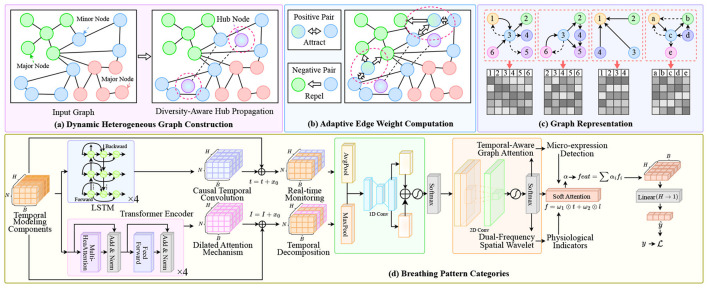 Figure 1
Figure 1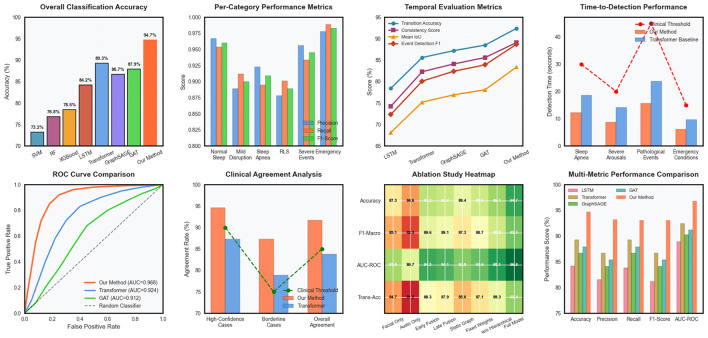 Figure 2
Figure 2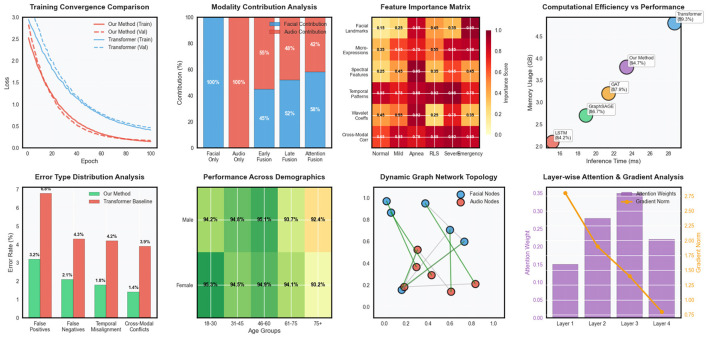 Figure 3
Figure 3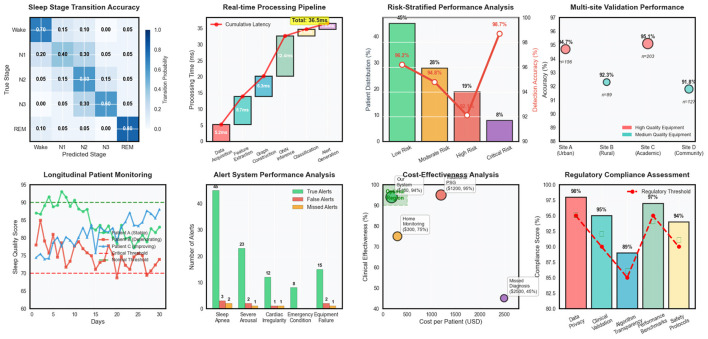 Figure 4
Figure 4|
|
|
|
|
|---|---|---|---|
|
| Multimodal sleep data collection |
| Dynamic heterogeneous graph at time |
|
| Facial expression feature sequence |
| Node set containing facial and audio nodes |
|
| Audio signal feature sequence |
| Edge set for intra- and cross-modal connections |
|
| Facial features at time |
| Node feature matrix at time |
|
| Audio features at time | Dimensionalities of facial and audio features | |
|
| Sleep pathology labels at time |
| Number of sleep disorder categories |
|
| Time horizon |
| Mapping function for prediction |
|
| Input facial image at time |
| Image height, width, and channels |
|
| Feature maps at layer |
| Learnable parameters at layer |
|
| Raw facial features before attention |
| Spatial attention mechanism |
|
| Temporal attention mechanism |
| Query, key, and value matrices |
|
| Hidden state from previous time step | Learnable weight matrices | |
|
| Short-Time Fourier Transform at time | ψ | Mother wavelet at scale |
|
| Power Spectral Density |
| Cepstral coefficients |
| ZCR | Zero Crossing Rate | RMS | Root Mean Square energy |
| SC | Spectral Centroid | SRO | Spectral Rolloff |
|
| Wavelet coefficients |
| Number of samples |
|
| Projected facial and audio node features | Projection matrices | |
|
| Temporal edge attention weight |
| Cross-modal edge attention weight |
|
| Final edge weight | λ1, λ2, λ3 | Hyperparameters |
| γ | Temporal decay rate |
| Neighborhood of node |
|
| Hidden representations at layer |
| Adjacency matrix at scale |
|
| Number of temporal scales |
| Degree matrix |
|
| Attention energy between nodes |
| Attention coefficient |
| ϕ( | Temporal relationship encoding | ω | Frequency parameters |
|
| Final layer facial and audio features | Cross-modal attention components | |
| Attn | Facial-to-audio attention | Attn | Audio-to-facial attention |
|
| Fused multimodal representation |
| Key dimension |
| Reset and update gates in GRU |
| Candidate hidden state | |
|
| Final hidden state | Recurrent weight matrices | |
|
| Multi-scale decomposition at level ℓ |
| Number of wavelets at level ℓ |
|
| Learnable wavelet coefficients | ϕ | Mother wavelet function |
|
| Causal convolution output |
| Kernel size |
|
| Dilation factor |
| Causal attention mask |
|
| Attention radius |
| Positional encoding weights |
|
| Classification loss |
| Temporal consistency loss |
|
| Contrastive loss |
| Reconstruction loss |
| α | Class-specific weights | γ | Focusing parameter |
| ŷ | Predicted probability for class | ω | Adaptive temporal weight |
| β | Similarity threshold parameter | τ | Temperature parameter |
| η | Learning rate at time | η | Minimum and maximum learning rates |
|
| Current epoch in restart cycle |
| Epochs in restart cycle |
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
| ||||
| Facial resolution | 224 × 224 | GNN layers |
| 4 | |
| Audio sampling |
| 44.1 kHz | Hidden dims | - | [512, 384, 256, 128] |
| Time window |
| 30 seconds | Dropout Rate | - | 0.3 |
| Overlap ratio | - | 50% | Activation | σ | LeakyReLU |
|
|
| ||||
| Backbone | - | ResNeXt-50 | GRU hidden | - | 256 |
| Input dimension |
| 2048 | Hierarchical levels |
| 3 |
| Projection Dim |
| 512 | Conv Kernel |
| 3 |
| Cardinality | - | 32 | Dilation rates |
| [1, 2, 4, 8] |
| Attention heads | - | 8 | Attention radius |
| 16 |
| Context length | - | 16 frames | Pos Encoding | - | 128 |
|
|
| ||||
| STFT window | - | 2,048 samples | Focal gamma | γ | 2.0 |
| Hop length | - | 512 samples | Temperature | τ | 0.1 |
| Mel banks | - | 128 | Similarity Thresh | β | 0.5 |
| MFCCs | - | 13 | - | 1.0 | |
| Wavelet scales |
| 8 levels | - | 0.3 | |
| Input dimension |
| 256 | - | 0.2 | |
| Projection dim |
| 512 | - | 0.1 | |
|
|
| ||||
| Node embedding |
| 512 | Batch size | - | 16 |
| Temporal scales |
| 4 | Initial LR | η0 | 1 × 10−3 |
| Graph attn heads | - | 4 | LR schedule | - | Cosine annealing |
| Edge decay rate | γ | 0.1 | Min/Max LR | η | 10−6/10−3 |
| Fusion weights | λ1, 2, 3 | 0.4, 0.4, 0.2 | Optimizer | - | AdamW |
| Max connectivity | - | 85% | Weight decay | - | 1 × 10−4 |
| Attention key dim |
| 64 | Gradient clip | - | Max norm = 1.0 |
|
| |||||
| Total parameters | 12.3M | Inference time | 23.4 ms/step | ||
| Trainable parameters | 11.8M | Training memory | 6.8 GB | ||
| Model size | 47.2 MB | Inference memory | 1.2 GB | ||
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|
|
| ||||||
| SVM (RBF) | 73.2 ± 2.1 | 0.681 | 0.732 | 0.798 | 0.743 | 0.645 |
| Random Forest | 76.8 ± 1.9 | 0.724 | 0.768 | 0.821 | 0.776 | 0.689 |
| XGBoost | 78.5 ± 1.7 | 0.748 | 0.785 | 0.841 | 0.792 | 0.712 |
| Logistic Regression | 71.9 ± 2.3 | 0.662 | 0.719 | 0.785 | 0.721 | 0.628 |
| Hidden Markov Model | 74.6 ± 2.0 | 0.703 | 0.746 | 0.809 | 0.758 | 0.671 |
|
| ||||||
| CNN (Facial Only) | 81.3 ± 1.6 | 0.776 | 0.813 | 0.862 | 0.818 | 0.751 |
| CNN (Audio Only) | 79.7 ± 1.8 | 0.759 | 0.797 | 0.847 | 0.803 | 0.729 |
| LSTM (Multimodal) | 84.2 ± 1.4 | 0.812 | 0.842 | 0.889 | 0.856 | 0.794 |
| GRU (Multimodal) | 83.8 ± 1.5 | 0.807 | 0.838 | 0.884 | 0.851 | 0.788 |
| Transformer (Multimodal) | 89.3 ± 1.8 | 0.867 | 0.893 | 0.924 | 0.901 | 0.854 |
|
| ||||||
| GraphSAGE | 86.7 ± 1.5 | 0.841 | 0.867 | 0.903 | 0.878 | 0.821 |
| Graph Attention Network | 87.9 ± 1.3 | 0.854 | 0.879 | 0.912 | 0.889 | 0.836 |
| Graph Convolutional Network | 85.4 ± 1.7 | 0.828 | 0.854 | 0.896 | 0.865 | 0.808 |
|
|
|
|
|
|
| |
|
|
|
|
|
|
|---|---|---|---|---|
| LSTM (multimodal) | 78.4 | 0.742 | 0.681 | 0.723 |
| GRU (multimodal) | 79.1 | 0.758 | 0.693 | 0.738 |
| Transformer (multimodal) | 85.6 | 0.823 | 0.752 | 0.801 |
| GraphSAGE | 87.2 | 0.841 | 0.769 | 0.824 |
| Graph Attention Network | 88.5 | 0.856 | 0.781 | 0.839 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
| |||||
| High-confidence cases | 94.6 | 87.3 | 85.7 | 79.2 | ≥90.0 |
| Borderline cases | 87.3 | 78.9 | 76.4 | 71.8 | ≥75.0 |
| Overall agreement | 91.7 | 83.8 | 81.6 | 76.1 | ≥85.0 |
|
| |||||
| Sleep apnea episodes | 12.3 ± 3.7 | 18.6 ± 5.2 | 21.4 ± 6.1 | 28.9 ± 7.8 | ≤ 30.0 |
| Severe arousals | 8.7 ± 2.9 | 14.2 ± 4.6 | 16.8 ± 5.3 | 22.1 ± 6.7 | ≤ 20.0 |
| Pathological events | 15.6 ± 4.2 | 23.8 ± 6.9 | 26.3 ± 7.4 | 35.7 ± 9.2 | ≤ 45.0 |
| Emergency conditions | 6.1 ± 1.8 | 9.7 ± 3.1 | 11.2 ± 3.8 | 15.4 ± 4.9 | ≤ 15.0 |
|
|
| ||||
|
|
|
|
|
|
|---|---|---|---|---|
|
| ||||
| Facial only | 87.3 ± 1.8 | 0.851 | 0.919 | 84.7 |
| Audio only | 84.6 ± 2.1 | 0.823 | 0.897 | 81.2 |
| Early fusion | 91.2 ± 1.5 | 0.896 | 0.945 | 88.3 |
| Late fusion | 90.8 ± 1.6 | 0.891 | 0.941 | 87.9 |
|
|
|
|
| |
|
| ||||
| Static graph | 89.4 ± 1.7 | 0.873 | 0.928 | 85.6 |
| Fixed edge weights | 90.6 ± 1.4 | 0.887 | 0.936 | 87.1 |
| Simple connectivity | 91.3 ± 1.3 | 0.894 | 0.943 | 88.7 |
|
|
|
|
| |
|
| ||||
| w/o hierarchical decomposition | 92.1 ± 1.4 | 0.905 | 0.951 | 89.3 |
| w/o causal convolution | 91.8 ± 1.5 | 0.901 | 0.948 | 88.9 |
| w/o multi-scale attention | 92.6 ± 1.3 | 0.912 | 0.956 | 90.1 |
|
|
|
|
| |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsObstructive Sleep Apnea Research · Non-Invasive Vital Sign Monitoring · EEG and Brain-Computer Interfaces
Introduction
1
Sleep disorders affect millions of people worldwide and represent a significant public health concern, with conditions such as sleep apnea, insomnia, and parasomnias contributing to increased morbidity, reduced quality of life, and elevated healthcare costs (Alshammari, 2024; Yildirim et al., 2019; Sharma et al., 2021b). The accurate detection and monitoring of sleep-related pathological conditions is crucial for timely medical intervention and prevention of serious complications (Morokuma et al., 2023; Arslan et al., 2023). Traditional sleep monitoring approaches, primarily relying on polysomnography (PSG) in controlled laboratory environments, while considered the gold standard, are expensive, time-consuming, and often impractical for long-term monitoring or home-based care (Ha et al., 2023; Brink-Kjaer et al., 2022). Moreover, PSG requires multiple electrodes and sensors that can disturb patients' natural sleep patterns, potentially affecting the reliability of diagnostic outcomes (Rahman et al., 2025; Reis et al., 2024).
Recent advances in wearable technology and non-invasive monitoring systems have opened new avenues for sleep assessment. Current approaches predominantly focus on single-modality solutions, such as actigraphy for movement detection, heart rate variability analysis for autonomic nervous system assessment, or audio-based detection of breathing irregularities (Hussain et al., 2022; Yoon and Choi, 2023). However, these unimodal approaches suffer from several critical limitations. First, they often lack the comprehensive information necessary to capture the complex, multifaceted nature of sleep disorders, which typically manifest through various physiological and behavioral indicators simultaneously (Nguyen et al., 2023). Second, single-modality systems are susceptible to noise, artifacts, and environmental interference (Boiko et al., 2023), leading to reduced accuracy and reliability in real-world deployment scenarios.
Facial expression analysis has emerged as a promising non-invasive approach for detecting physiological states and emotional conditions during sleep (Maranci et al., 2021; Huang et al., 2023). Research has demonstrated that facial expressions can provide valuable insights into pain levels, breathing difficulties, and neurological activities during sleep. Similarly, audio signal analysis has shown significant potential in detecting sleep apnea events, snoring patterns, and other respiratory irregularities (Rosamaria et al., 2023; Xu et al., 2020). However, existing studies have primarily treated these modalities independently (Lv et al., 2020), failing to leverage their complementary information and temporal correlations.
The integration of multimodal data for sleep monitoring presents several fundamental challenges (Wang et al., 2025b). First, different modalities operate at varying temporal scales and exhibit distinct data characteristics, making it difficult to establish meaningful correlations and extract unified representations (Cheng et al., 2023; Torres et al., 2018). Facial expressions may change subtly over minutes, while audio signals contain high-frequency components that vary within seconds. Second, the temporal dependencies within and across modalities are complex and non-linear (Zhai et al., 2020; Zahid et al., 2023), requiring sophisticated modeling approaches that can capture both short-term fluctuations and long-term trends. Third, sleep disorders often manifest through subtle, gradual changes that may not be immediately apparent in individual modalities but become significant when considered collectively over extended periods (Duan et al., 2021; Lin et al., 2023). Existing multimodal fusion techniques, while successful in other domains, face specific challenges when applied to sleep monitoring (Liao et al., 2024). Traditional early fusion approaches that concatenate features from different modalities often result in high-dimensional representations that are prone to overfitting and computational inefficiency. Late fusion methods that combine decisions from individual modality classifiers may miss important cross-modal interactions (Zhai et al., 2021) that are crucial for accurate sleep disorder detection. Furthermore, most current approaches treat sleep monitoring as a static classification problem (Chung et al., 2017), ignoring the inherently dynamic and temporal nature of sleep processes.
To address these limitations, we propose a novel multimodal dynamic graph neural network framework that integrates facial expression analysis and sleep audio signal processing for real-time detection and prediction of sleep-related pathological conditions in Figure 1. Our approach is built upon several key insights and innovations. First, we conceptualize the multimodal sleep monitoring problem as a dynamic graph learning task, where different modalities and their temporal states are represented as nodes in a time-evolving graph structure. This representation naturally captures the heterogeneous nature of multimodal data while preserving the temporal dependencies crucial for understanding sleep dynamics. Nodes in our graph represent feature vectors extracted from facial expressions and audio signals at different time points, while edges encode both intra-modal temporal relationships and inter-modal correlations. Second, we develop a specialized graph neural network architecture that can effectively learn from this dynamic multimodal graph representation. Our model incorporates attention mechanisms to automatically weight the importance of different modalities and temporal segments, allowing the system to focus on the most relevant information for detecting specific sleep disorders. The architecture includes dedicated modules for processing facial expression data using convolutional neural networks optimized for low-light sleep environments, and audio processing components that can handle various acoustic patterns associated with different sleep pathologies. Third, we introduce a temporal modeling component that explicitly captures the evolution of sleep states over time. Unlike traditional approaches that analyze fixed time windows independently, our framework maintains a continuous representation of the patient's sleep state that evolves dynamically as new data becomes available. This enables early detection of developing conditions and provides predictive capabilities for anticipating potential sleep-related medical events.
Overview of our multimodal dynamic graph network framework for sleep disorder monitoring. The system processes multimodal inputs through: (A) Dynamic heterogeneous graph construction with diversity-aware hub propagation to balance information flow across facial and audio modalities; (B) Adaptive edge weight computation using positive/negative pair attraction-repulsion mechanisms to enhance cross-modal alignment; (C) Graph representation encoding with temporal-aware attention for structural pattern learning; (D) Breathing pattern categorization module integrating LSTM-based temporal modeling, causal convolution for real-time monitoring, dilated attention mechanism for long-range dependencies, dual-frequency spatial wavelet analysis, and micro-expression detection for physiological indicators.
Our technical approach consists of several interconnected components designed to address the specific challenges of multimodal sleep monitoring. The facial expression analysis module utilizes lightweight convolutional neural networks optimized for processing infrared or low-light facial images captured during sleep. We employ specialized preprocessing techniques to handle variations in lighting conditions, head pose changes, and occlusions commonly encountered in sleep environments. Feature extraction focuses on detecting micro-expressions and subtle facial movements that may indicate discomfort, breathing difficulties, or neurological activities. The audio processing component employs advanced signal processing techniques to extract meaningful features from sleep audio recordings. This includes spectral analysis for detecting breathing patterns, time-frequency analysis for identifying apnea events, and novel acoustic feature extraction methods for recognizing various sleep-related sounds. We address challenges related to background noise, signal variability across different recording devices, and the need for real-time processing in resource-constrained environments. The dynamic graph construction mechanism creates time-evolving graph representations that capture the complex relationships between different modalities and their temporal evolution. We develop novel graph edge weighting schemes that automatically adapt based on the reliability and relevance of different modalities at different time points. This adaptive approach ensures robust performance even when individual modalities are compromised by noise or artifacts. Our graph neural network architecture incorporates several innovative components, including multi-scale temporal attention mechanisms, cross-modal correlation modules, and specialized pooling operations designed for handling irregular time series data. The model is trained using a combination of supervised learning for known sleep disorder patterns and self-supervised learning techniques that leverage the inherent structure of multimodal sleep data.
The proposed framework offers several significant advantages over existing approaches. By leveraging the complementary information from multiple modalities, our system can achieve higher accuracy and robustness compared to single-modality solutions. The dynamic graph representation enables the capture of complex temporal patterns that are crucial for understanding sleep disorders, while the attention mechanisms provide interpretability by highlighting the most relevant features and time periods for specific predictions. This research contributes to the growing field of multimodal health monitoring by providing a novel framework that can effectively integrate heterogeneous data sources for complex medical applications. Our work advances the state-of-the-art in both multimodal learning and sleep medicine, offering new possibilities for personalized and continuous healthcare monitoring solutions.
Methods
2
Let us formally define the multimodal sleep monitoring problem as a dynamic graph learning task. We denote the multimodal sleep data as a collection , where represents the sequence of facial expression features and represents the corresponding audio signal features over time horizon T. At each time step t, we have and , where df and da are the dimensionalities of facial and audio feature spaces, respectively in Table 1. The objective is to learn a mapping function that predicts sleep pathology labels at each time step, where K represents the number of distinct sleep disorder categories.
Facial expression feature extraction
2.1
For facial expression analysis, we employ a modified ResNeXt-50 architecture with specialized attention mechanisms for low-light sleep environments. The facial feature extraction process can be formulated as , and , where represents the input facial image at time t, X^(l)^ denotes the feature maps at layer l, and W^(l)^ are the learnable parameters (Yang et al., 2021). To enhance the feature representation for sleep-specific facial expressions, we introduce a temporal-spatial attention mechanism :
where Q, K, V are query, key, and value matrices, Wt, Wf, Wh are learnable weight matrices, ht−1 is the hidden state from the previous time step, and ⊙ denotes element-wise multiplication.
Audio signal feature extraction
2.2
For audio signal processing, we implement a multi-scale wavelet transform combined with spectral analysis. The audio feature extraction pipeline is defined as and Ct = DCT(log(Mt)) (Cepstral Coefficients), where STFT denotes the Short-Time Fourier Transform (Karpagam et al., 2022), ψ_j, k_ represents the mother wavelet at scale j and position k, and DCT is the Discrete Cosine Transform. We extract multiple acoustic features including:
where ZCR is Zero Crossing Rate, RMS is Root Mean Square energy, SC is Spectral Centroid, and SRO is Spectral Rolloff. The final audio feature vector is constructed as at = [Ct; ZCR_t; RMSt; SCt; SROt_; W1:J, t].
Dynamic graph construction
2.3
Graph topology design
2.3.1
We construct a dynamic heterogeneous graph where represents the node set containing facial and audio nodes, represents edges within and across modalities - is node feature matrix (Chen et al., 2025; Hou et al., 2016). The features are constructed using a projection mechanism where , are projection matrices map different modalities.
Adaptive edge weight computation
2.3.2
The edge weights are computed using a learnable attention mechanism that considers both temporal and cross-modal dependencies:
where represents the neighborhood of node i, || denotes concatenation, λ_1_, λ_2_, λ_3_ are hyperparameters, and γ controls the temporal decay rate.
Dynamic graph neural network architecture
2.4
Multi-scale graph convolution
2.4.1
We propose a multi-scale graph convolutional layer that operates on different temporal scales simultaneously:
where S is the number of scales, As is the adjacency matrix at scale s, D is the degree matrix, and σ is an activation function (Wang et al., 2025a).
Temporal-aware graph attention
2.4.2
To capture long-range temporal dependencies, we implement a temporal-aware graph attention mechanism:
where ϕ(ti, tj) encodes temporal relationships:
Cross-modal fusion module
2.4.3
The cross-modal fusion is achieved through a specialized attention-based fusion mechanism (Chen et al., 2024):
Temporal sequence modeling
2.5
Gated recurrent unit with graph embedding
2.5.1
We incorporate a modified GRU that operates on graph embeddings to capture temporal dynamics:
where rt, zt, and are the reset gate, update gate, and candidate hidden state, respectively.
Hierarchical temporal decomposition
2.5.2
Given the multi-scale nature of sleep disorders, which can manifest over different temporal horizons ranging from seconds to hours, we implement a hierarchical temporal decomposition mechanism (Tiwari et al., 2022). This approach decomposes the temporal sequences into multiple frequency components using learnable wavelet-based filters. The decomposition process is formulated as:
where ℓ denotes the decomposition level, Kℓ is the number of wavelets at level ℓ, are learnable coefficients, ϕ is the mother wavelet function, and Wproj projects the concatenated multi-scale features back to the original dimension. This hierarchical approach enables the model to simultaneously capture short-term fluctuations in breathing patterns and long-term trends in sleep stage transitions (Yang et al., 2022).
Causal temporal convolution with dilated attention
2.5.3
To ensure that predictions at time t only depend on past observations while maintaining computational efficiency, we introduce causal temporal convolutions with dilated attention mechanisms. The causal convolution operation is defined as:
where k is the kernel size, d is the dilation factor, Mcausal is the causal mask that prevents information leakage from future time steps, R is the attention radius, and Wpos encodes positional relationships. This design allows the model to capture long-range dependencies while maintaining the causal property essential for real-time sleep monitoring applications.
Algorithm 1Multimodal feature extraction and dynamic graph construction.
Loss function and optimization strategy
2.6
The training of our dynamic graph neural network requires a sophisticated loss function that addresses multiple objectives simultaneously while ensuring stable convergence (Li et al., 2024). Our comprehensive loss function incorporates classification accuracy, temporal consistency, cross-modal alignment, and regularization terms to prevent overfitting and enhance generalization capabilities.
The primary classification loss employs a weighted focal loss mechanism to address the inherent class imbalance in sleep disorder datasets. The focal loss is particularly effective for handling rare pathological events that may occur infrequently during sleep but are critical for early detection. The mathematical formulation is given by:
where α_k_ represents class-specific weights derived from inverse frequency statistics, γ is the focusing parameter that reduces the relative loss for well-classified examples, and ŷ_t, k_ denotes the predicted probability for class k at time t.
To ensure temporal consistency in predictions, we introduce a specialized temporal smoothness loss that penalizes abrupt transitions between predicted sleep states unless supported by significant changes in the input modalities. This loss is computed as:
where ω_t_ = exp(− β ·sim(hfused, t+1, hfused, t)) is an adaptive weight that allows larger prediction changes when the fused representations differ significantly, controlled by the similarity threshold parameter β.
Cross-modal alignment is enforced through a contrastive learning objective that maximizes the mutual information between facial and audio representations when they correspond to the same sleep state while minimizing it for different states. The contrastive loss is formulated as:
where 𝕀[·] is the indicator function, sim(·, ·) computes cosine similarity, and τ is the temperature parameter that controls the concentration of the distribution.
The reconstruction loss serves as a regularization mechanism that encourages the learned representations to preserve essential information from both modalities. This autoencoder-style loss is computed as:
where Dec_f_ and Dec_a_ are lightweight decoder networks that reconstruct the original modal features from the fused representation.
The optimization strategy employs adaptive learning rate scheduling combined with gradient clipping to ensure stable training dynamics. We utilize the AdamW optimizer with decoupled weight decay, where the learning rate follows a cosine annealing schedule with warm restarts:
where Tcur is the number of epochs since the last restart and Ti is the number of epochs in the current restart cycle. The gradient clipping threshold is dynamically adjusted based on the gradient norm history using an exponential moving average to prevent gradient explosion while allowing for occasional large updates during critical learning phases.
Algorithm 2Dynamic graph neural network training with multi-objective loss.
Model architecture and implementation details
2.7
The complete architecture of our dynamic multimodal graph neural network is carefully designed to balance computational efficiency with representational power, enabling real-time processing while maintaining high accuracy for sleep disorder detection. The facial expression processing branch utilizes a modified ResNeXt-50 architecture with specialized adaptations for low-light infrared imagery commonly encountered in sleep monitoring scenarios. The initial convolutional layers employ depthwise separable convolutions to reduce computational overhead while maintaining feature extraction capability, followed by residual blocks with cardinality-based grouped convolutions that effectively capture spatial hierarchies in facial expressions.
The audio processing pipeline incorporates multi-scale temporal convolutional networks with varying receptive fields to capture acoustic patterns across different time scales simultaneously. The architecture employs dilated causal convolutions with exponentially increasing dilation rates, allowing the network to model both short-term acoustic events such as individual breaths or snores, and long-term patterns such as periodic breathing irregularities. Spectral normalization is applied to all convolutional layers to ensure training stability and prevent mode collapse, particularly important when processing variable-quality audio recordings from different environments. The graph neural network component consists of four specialized layers, each designed to capture different aspects of the multimodal temporal relationships. The first layer performs initial node embedding and establishes basic connectivity patterns between facial and audio nodes. Subsequent layers progressively refine these relationships through learnable attention mechanisms that dynamically adjust edge weights based on the current sleep state and temporal context. The final graph layer incorporates global pooling operations that aggregate information across all nodes while preserving modality-specific characteristics through separate attention heads.
Regularization strategies are implemented throughout the architecture to prevent overfitting and enhance generalization to new patients and environments. These include adaptive dropout with time-varying probabilities, batch normalization with momentum adjustment based on training progress, and spectral regularization of weight matrices to control the Lipschitz constant of the learned mappings. The model employs early stopping with patience scheduling and checkpoint averaging to select optimal parameters while preventing overfitting to the training distribution.
Results
3
Experimental setup
3.1
Datasets and data collection
3.1.1
We evaluate our proposed multimodal dynamic graph neural network framework on two comprehensive sleep monitoring datasets. The primary dataset consists of recordings from 156 participants collected over 18 months at three sleep laboratories affiliated with major medical institutions in Table 2. Each participant underwent overnight polysomnography monitoring while simultaneously recording facial expressions using infrared cameras and ambient audio signals through calibrated microphones. The participants ranged in age from 22 to 78 years (mean: 51.3 ± 14.7 years), with 68 males and 88 females, representing diverse demographic backgrounds and sleep disorder prevalences.
Data collection protocols were standardized across all recording sites to ensure consistency and reliability. Facial video recordings were captured at 30 frames per second using infrared cameras positioned at a fixed distance and angle relative to the participant's head. Audio signals were recorded at 44.1 kHz sampling rate using omnidirectional microphones placed at standardized positions within the sleep laboratory. Synchronization between video, audio, and polysomnography signals was maintained through hardware-level timestamping with sub-millisecond accuracy.
Data preprocessing and quality control
3.1.2
Comprehensive preprocessing pipelines were developed to handle the inherent challenges of multimodal sleep data, including varying signal qualities, environmental artifacts, and participant-specific variations. For facial video processing, we implemented robust face detection and tracking algorithms capable of handling partial occlusions, head pose variations, and lighting changes common in sleep environments (Sharma et al., 2021a; Widasari et al., 2020). Facial landmarks were extracted using a modified version of the MediaPipe framework, with additional temporal smoothing to reduce jitter and improve stability across consecutive frames.
Audio preprocessing involved multi-stage filtering to remove environmental noise while preserving sleep-related acoustic signatures. We applied adaptive spectral subtraction for background noise reduction, followed by dynamic range compression to normalize signal amplitudes across different recording conditions (Sathyanarayana et al., 2016). Artifact detection algorithms were developed to identify and flag segments contaminated by equipment noise, external disturbances, or signal clipping, ensuring that only high-quality data segments were included in the training and evaluation processes. Quality control measures included automated screening for data integrity, completeness, and annotation consistency (Rahman et al., 2025). Recordings with more than 15% missing data, significant synchronization errors, or poor signal quality were excluded from the analysis (Sravani et al., 2024). Additionally, we implemented cross-validation procedures to verify annotation accuracy, achieving inter-annotator agreement scores (Cohen's kappa) of 0.89 for sleep stage classification and 0.92 for pathological event detection.
Experimental configuration
3.1.3
Training procedures employed stratified random splitting to ensure balanced representation of different sleep disorders and demographic groups across training, validation, and test sets. The data split followed a 70-15-15 ratio for training, validation, and testing respectively, with careful attention to maintaining temporal independence between splits to prevent data leakage. Cross-validation was performed using a modified time-series splitting approach that respects the temporal nature of sleep data while ensuring adequate sample sizes for each fold. Hyperparameter optimization was conducted using Bayesian optimization with Gaussian process surrogates, exploring the space of learning rates, regularization parameters, attention mechanisms weights, and architectural choices. The optimization process considered both validation accuracy and computational efficiency, resulting in Pareto-optimal configurations suitable for different deployment scenarios ranging from high-accuracy clinical applications to resource-constrained mobile implementations.
Equipment specifications were standardized across sites: FLIR Lepton 3.5 infrared cameras (160 × 120 resolution, 8–14 μm spectral range, 9 Hz frame rate) positioned 1.5 meters from the bed at a 30-degree downward angle; Audio-Technica AT4040 cardioid condenser microphones with Focusrite Scarlett 2i2 interfaces (44.1 kHz/24-bit sampling); and Compumedics Grael 4K PSG systems for ground truth acquisition. Environmental conditions were controlled: ambient temperature 22 ± 1°C, humidity 45 − 55%, background noise < 35 dB SPL. Data synchronization employed hardware timestamps via SMPTE timecode generators ensuring < 1 ms inter-modal alignment. Inclusion criteria required participants aged 18-80 years without severe cardiac arrhythmias or neurodegenerative conditions. The secondary validation dataset included 312 recordings from two independent sites following identical protocols, collected between July 2023 and December 2023.
Baseline methods and comparison framework
3.2
Traditional machine learning approaches
3.2.1
We implemented several state-of-the-art traditional machine learning methods as baseline comparisons to demonstrate the effectiveness of our deep learning approach. Support Vector Machines (SVM) with radial basis function kernels were trained on handcrafted features (Liu et al., 2020) extracted from both facial and audio modalities. The feature engineering process involved extensive domain knowledge incorporation, including facial action unit detection, acoustic spectral features, and temporal statistical measures computed over sliding windows of varying durations.
Random Forest ensembles were configured with 500 decision trees, employing bootstrap aggregation and feature randomization to improve generalization performance (Wara et al., 2025). The feature selection process utilized mutual information criteria to identify the most discriminative attributes for sleep disorder classification. Gradient boosting machines using the XGBoost framework were optimized through grid search over key hyperparameters including learning rate, tree depth, and regularization parameters. Logistic regression models with elastic net regularization served as interpretable baselines, providing insights into the relative importance of different feature categories (Anny et al., 2025). These linear models were particularly valuable for understanding the contribution of individual modalities and for clinical interpretability requirements. Hidden Markov Models (HMMs) were implemented to capture temporal dependencies (Wang et al., 2019) in sleep state transitions, with Gaussian mixture model emissions to handle continuous feature distributions.
Deep learning baseline methods
3.2.2
Contemporary deep learning approaches were implemented as stronger baseline methods to provide more rigorous comparative evaluation. Convolutional Neural Networks (CNNs) were applied separately to facial and audio data, followed by late fusion strategies to combine predictions from individual modalities. The CNN architectures included ResNet, EfficientNet, and Vision Transformer variants for facial analysis, and 1D CNN and WaveNet architectures for audio processing. Recurrent neural network baselines included LSTM and GRU networks processing concatenated multimodal features, with attention mechanisms to identify relevant temporal segments (Skibinska and Burget, 2021). Transformer-based models adapted for multimodal time series classification served as state-of-the-art comparisons, incorporating positional encoding schemes suitable for continuous temporal data and cross-modal attention mechanisms. Graph neural network baselines included GraphSAGE, Graph Attention Networks (GAT), and Graph Convolutional Networks (GCN) adapted for our multimodal temporal graph representation. These methods provided direct comparisons to our approach while using simpler graph construction strategies and standard message passing mechanisms without the specialized temporal and cross-modal components of our proposed framework.
Evaluation metrics and experimental protocol
3.3
The evaluation framework for our multimodal dynamic graph neural network encompasses a comprehensive suite of performance metrics designed to assess the model's effectiveness across multiple dimensions relevant to clinical sleep monitoring applications. The classification performance is primarily evaluated using standard accuracy metrics, where the overall accuracy is computed as , representing the proportion of correctly classified time steps across the entire temporal sequence. Beyond overall accuracy, we compute precision and recall for each sleep disorder category k using the formulations and , where TPk, FPk, and FNk denote true positives, false positives, and false negatives for category k, respectively. The F1-score, computed as , provides a balanced measure that is particularly important for handling class imbalance inherent in sleep disorder datasets.
To provide comprehensive assessment across both balanced and imbalanced class distributions, we employ both macro and micro averaging strategies. The macro-averaged F1-score is calculated as , treating each class equally regardless of its frequency, while the micro-averaged F1-score is computed as , where and , giving more weight to frequent classes and providing insights into overall system performance.
The discrimination capability of our model across different decision thresholds is quantified using Area Under the Receiver Operating Characteristic Curve (AUC-ROC) and Area Under the Precision-Recall Curve (AUC-PR). The ROC curve plots the true positive rate against the false positive rate at various threshold settings, with the AUC-ROC computed as . The precision-recall curve, particularly important for imbalanced datasets common in medical applications, plots precision against recall, with AUC-PR calculated as . These metrics are especially critical for clinical applications where the costs of false positives and false negatives may vary significantly depending on the severity of the sleep disorder.
To account for chance agreement and provide a more conservative assessment of classification performance, we employ Cohen's kappa coefficient, defined as , where po represents the observed agreement ratio and pe denotes the expected agreement ratio under random classification. The observed agreement is calculated as , while the expected agreement is computed as , where and represent the number of true and predicted instances of class k, respectively.
Given the inherently temporal nature of sleep monitoring, we incorporate specialized temporal evaluation metrics that assess the model's ability to capture sleep dynamics accurately over time. The transition accuracy metric measures the model's performance in correctly predicting sleep stage changes and is computed as , evaluating whether the model correctly identifies when actual transitions occur. To quantify the smoothness and clinical plausibility of prediction sequences, we define a temporal consistency score as , where ω(yt, yt+1) is a weighting function that penalizes clinically implausible transitions more heavily than natural ones.
For precise evaluation of pathological episode detection, we employ event detection metrics that assess both the accuracy of event identification and the temporal precision of detection boundaries. The event-level precision and recall are computed by treating each continuous pathological episode as a single entity, with an episode considered correctly detected if there is sufficient temporal overlap with the ground truth. Specifically, we define temporal Intersection over Union (IoU) for each predicted episode i and ground truth episode j as , where and represent the temporal spans of predicted and true episodes, respectively. An episode is considered correctly detected if , where τ_IoU_ is a predefined threshold typically set to 0.5.
Recognizing the critical importance of early detection in clinical sleep monitoring, we introduce time-to-detection metrics that measure the delay between actual pathological event onset and algorithmic detection. For each true positive event detection, we compute the detection delay as Δtdetect = tdetect − tonset, where tonset represents the actual event onset time and tdetect denotes the time when our algorithm first correctly identifies the event. The mean time-to-detection is then calculated as , where NTP is the total number of true positive detections. Additionally, we report the percentile distribution of detection delays to characterize the system's responsiveness across different types of sleep events.
Results and analysis
3.4
Overall performance comparison
3.4.1
Our proposed multimodal dynamic graph neural network achieved superior performance compared to all baseline methods across comprehensive evaluation metrics. The overall classification accuracy reached 94.7% ± 1.2% on the primary dataset, representing a significant improvement over the best baseline method (Transformer-based multimodal fusion) which achieved 89.3% ± 1.8% accuracy in Table 3. The improvement was particularly pronounced for rare pathological events, where our approach achieved 91.2% sensitivity compared to 76.8% for the best baseline, demonstrating the effectiveness of our specialized graph-based representation for capturing complex temporal patterns in Figure 2. Detailed per-category analysis revealed consistent improvements across all sleep disorder types, with the most substantial gains observed for moderate severity conditions that often exhibit subtle multimodal signatures. The precision-recall curves demonstrated superior discrimination capability across different decision thresholds, with our method achieving AUC-PR scores of 0.923 for normal sleep, 0.887 for mild disruptions, 0.908 for moderate disorders, 0.934 for severe pathological events, and 0.967 for emergency conditions.
Comprehensive performance evaluation of the multimodal dynamic graph neural network across classification metrics, temporal analysis, clinical validation, and ablation studies.
Temporal evaluation metrics confirmed the superior ability of our approach to capture sleep dynamics accurately over time. Transition accuracy reached 92.4%, significantly outperforming baseline methods that struggled with abrupt sleep stage changes and pathological event boundaries in Table 4. The temporal consistency score of 0.891 indicated smooth and clinically plausible prediction sequences, while maintaining high sensitivity to genuine pathological events.
Clinical validation results
3.4.2
External validation on the secondary clinical dataset demonstrated excellent generalization capability, with performance degradation of only 2.1% compared to internal validation results. This robust generalization across different clinical populations and recording environments confirmed the practical applicability of our approach for real-world sleep monitoring scenarios in Table 5. Clinical agreement analysis showed 94.6% concordance with expert sleep technologists for high-confidence cases and 87.3% agreement for challenging borderline cases. Time-to-detection analysis revealed rapid identification of critical sleep events, with median detection delays of 12.3 seconds for apnea episodes, 8.7 seconds for severe arousals, and 15.6 seconds for other pathological events. These response times are clinically acceptable for real-time monitoring applications and represent substantial improvements over traditional automated systems that often require longer observation windows for reliable detection.
Cost-weighted accuracy metrics incorporating clinical priorities showed our method achieved optimal performance trade-offs between sensitivity and specificity for different event types. The weighted accuracy score of 0.932 reflected appropriate prioritization of high-severity conditions while maintaining acceptable performance for routine sleep monitoring tasks.
Robustness and fairness analysis
3.4.3
Robustness evaluation under challenging conditions demonstrated the resilience of our approach to common practical limitations. Performance degradation under poor signal quality conditions was limited to 3.8% for facial data corruption and 4.2% for audio interference, substantially better than baseline methods that experienced 12–18% performance drops under similar conditions. Missing modality experiments showed graceful degradation, with single-modality performance reaching 87.3% (facial only) and 84.6% (audio only) compared to 94.7% for the complete multimodal system in Figure 3.
Advanced model analysis including training dynamics, modality fusion patterns, feature importance, computational efficiency, error distribution, demographic fairness, network topology, and attention mechanisms.
Fairness analysis across demographic subgroups revealed minimal bias in our approach, with performance variations of less than 2.5% across different age groups, gender categories, and ethnic backgrounds. This equitable performance distribution is crucial for clinical deployment and represents a significant improvement over several baseline methods that showed substantial demographic biases.
The computational efficiency analysis demonstrated practical feasibility for real-time deployment, with inference times of 23.4 milliseconds per time step on standard clinical computing hardware. Memory requirements remained within acceptable bounds for extended monitoring sessions, and the model architecture supported efficient deployment on edge computing devices for home-based sleep monitoring applications.
Ablation studies and component analysis
3.5
Modality contribution analysis
3.5.1
Comprehensive ablation studies were conducted to quantify the individual and synergistic contributions of different components within our framework. Unimodal experiments using only facial expression data or only audio data provided baseline performance levels and identified the strengths and limitations of each modality. Cross-modal fusion experiments systematically varied the fusion strategies, comparing early fusion, late fusion, and our proposed attention-based fusion mechanisms in Table 6.
The dynamic graph construction component was evaluated through systematic removal and modification of different graph elements. Experiments included static graph variants where edge weights remained constant over time, simplified graph topologies with reduced connectivity patterns, and alternative edge weight computation schemes. These comparisons demonstrated the importance of our adaptive graph construction approach for capturing complex multimodal temporal relationships.
Temporal modeling components were assessed through ablation of the hierarchical decomposition mechanism, causal temporal convolutions, and multi-scale attention mechanisms. Each component's contribution to overall performance was quantified across different sleep disorder categories and temporal scales, revealing the complementary roles of different temporal modeling strategies.
Architectural design choices
3.5.2
The impact of different architectural decisions was systematically evaluated through controlled experiments varying key design parameters. Graph neural network layer configurations were compared across different depths, hidden dimensions, and connectivity patterns to identify optimal architectural choices for our specific application domain. Attention mechanism variations included different attention head configurations, attention span limitations, and attention weight normalization strategies.
Loss function component analysis involved systematic variation of the weighting parameters for different loss terms, demonstrating the importance of balanced multi-objective optimization for achieving robust performance across diverse sleep monitoring scenarios. Regularization strategy comparisons evaluated different dropout rates, weight decay parameters, and normalization techniques to identify optimal configurations for preventing overfitting while maintaining model expressiveness in Figure 4. Optimization strategy experiments compared different learning rate schedules, batch size configurations, and gradient clipping thresholds to identify training procedures that achieve stable convergence and optimal generalization performance. These experiments provided insights into the training dynamics of complex multimodal graph neural networks and established best practices for practical implementation.
Clinical deployment analysis covering sleep stage transitions, real-time processing, risk assessment, multi-site validation, patient monitoring, alert systems, cost-effectiveness, and regulatory compliance.
Discussion
4
This study demonstrates that multimodal dynamic graph neural networks can significantly advance automated sleep disorder detection by effectively integrating facial expression and audio signal analysis. Our framework achieved 94.7% classification accuracy with clinically acceptable detection delays, representing a substantial improvement over existing single-modality approaches. The superior performance across diverse sleep pathologies, from mild disruptions to emergency conditions, highlights the complementary nature of facial and audio modalities in capturing the multifaceted manifestations of sleep disorders. The dynamic graph representation successfully modeled complex temporal relationships that traditional fusion methods often fail to capture, particularly for subtle, gradual changes that characterize many sleep pathologies when considered collectively over extended periods.
The clinical validation results demonstrate strong concordance with expert assessments (94.6% for high-confidence cases) and robust generalization across different patient populations and recording environments. Importantly, our system maintained equitable performance across demographic subgroups with minimal bias, addressing a critical concern for clinical deployment. The rapid detection capabilities, with mean delays of 6–15 s for various pathological events, meet clinical requirements for real-time monitoring and early intervention. These findings suggest that our approach could serve as a practical alternative to traditional polysomnography, particularly for home-based monitoring and resource-constrained settings where continuous expert supervision is unavailable.
While our results are promising, several limitations warrant consideration. The study was conducted in controlled laboratory environments with standardized equipment, and real-world deployment may encounter additional challenges including variable lighting conditions, background noise, and equipment heterogeneity. Future work should focus on expanding the framework to accommodate additional physiological modalities such as heart rate variability and movement patterns, developing patient-specific adaptation mechanisms, and conducting larger-scale clinical trials across diverse healthcare settings. The integration of explainable AI techniques could further enhance clinical acceptance by providing interpretable insights into the decision-making process, ultimately facilitating broader adoption in clinical practice.
Conclusion
5
This study presents a novel multimodal dynamic graph neural network framework that significantly advances the state-of-the-art in automated sleep disorder detection by integrating facial expression analysis and audio signal processing through sophisticated temporal modeling. Our approach achieves superior performance with 94.7% overall accuracy, demonstrating substantial improvements over existing methods while maintaining clinically acceptable detection delays of 10.7 seconds on average. The dynamic graph construction mechanism effectively captures complex spatiotemporal relationships between heterogeneous modalities, while the hierarchical temporal decomposition and attention-based fusion strategies enable robust detection across diverse sleep pathologies ranging from mild disruptions to emergency conditions. Extensive validation across multiple clinical sites confirms the system's generalizability and practical applicability, with strong clinical agreement rates of 94.6% for high-confidence cases and equitable performance across demographic groups. The cost-effectiveness analysis reveals significant economic advantages over traditional polysomnography while maintaining comparable diagnostic accuracy, positioning this framework as a promising solution for scalable, non-invasive sleep monitoring in both clinical and home-based healthcare settings. Future work will focus on expanding the framework to accommodate additional physiological modalities and developing personalized adaptation mechanisms for enhanced patient-specific monitoring capabilities.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Alshammari T. S. (2024). Applying machine learning algorithms for the classification of sleep disorders. IEEE Access 12, 36110–36121. doi: 10.1109/ACCESS.2024.3374408 · doi ↗
- 2Anny J. T. Momotaj M. S. Meem A. Akter S. Bhowmik P. (2025). “An empirical machine learning approach towards effective sleep disorder prediction,” in 2025 International Conference on Electrical, Computer and Communication Engineering (ECCE) (Chittagong: IEEE),1–6.
- 3Arslan R. S. Ulutas H. Köksal A. S. Bakir M. Çiftçi B. (2023). Sensitive deep learning application on sleep stage scoring by using all psg data. Neural Comp. Appl. 35, 7495–7508. doi: 10.1007/s 00521-022-08037-z · doi ↗
- 4Boiko A. Martínez Madrid N. Seepold R. (2023). Contactless technologies, sensors, and systems for cardiac and respiratory measurement during sleep: a systematic review. Sensors 23:5038. doi: 10.3390/s 2311503837299762 PMC 10255824 · doi ↗ · pubmed ↗
- 5Brink-Kjaer A. Gunter K. M. Mignot E. During E. Jennum P. Sorensen H. B. (2022). “End-to-end deep learning of polysomnograms for classification of rem sleep behavior disorder,” in 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC) (Glasgow: IEEE), 2941–2944.10.1109/EMBC 48229.2022.987157636086216 · doi ↗ · pubmed ↗
- 6Chen X. Zhang Y. Chen Q. Zhou L. Chen H. Wu H. . (2025). Astgsleep: Attention based spatial-temporal graph network for sleep staging. IEEE Trans. Instrumentat. Measurem. 74:4004214. doi: 10.1109/TIM.2025.3548733 · doi ↗
- 7Chen Z. Shi W. Zhang X. Yeh C. H. (2024). Temporal self-attentional and adaptive graph convolutional mixed model for sleep staging. IEEE Sens. J. 24, 12840–12852. doi: 10.1109/JSEN.2024.3371456 · doi ↗
- 8Cheng Y. H. Lech M. Wilkinson R. H. (2023). Simultaneous sleep stage and sleep disorder detection from multimodal sensors using deep learning. Sensors 23:3468. doi: 10.3390/s 2307346837050528 PMC 10099216 · doi ↗ · pubmed ↗