Dual contrastive learning-based reconstruction for anomaly detection in attributed networks
Hossein Rafieizadeh, Hadi Zare, Mohsen Ghassemi Parsa, Hocine Cherifi

TL;DR
This paper introduces DCOR, a new method for detecting anomalies in networks by improving reconstruction through dual contrastive learning.
Contribution
DCOR introduces reconstruction-level contrastive learning to better preserve structural and attribute patterns in attributed networks.
Findings
DCOR achieves the best AUROC on six benchmark datasets for anomaly detection.
Reconstruction-level contrast improves performance by up to 21.3% on the Enron dataset.
Ablation studies show that removing reconstruction-level contrast reduces performance by 25.5% on Amazon.
Abstract
Anomaly detection in attributed networks is critical for identifying threats such as financial fraud and intrusions across social, e-commerce, and cyber-physical domains. Existing graph-based methods face two limitations: (i) embedding-based approaches obscure fine-grained structural and attribute patterns, and (ii) reconstruction-based methods neglect cross-view discrepancies during training, leaving cross-view discrepancies underutilized. To address these gaps, we propose Dual Contrastive Learning-based Reconstruction (DCOR), a dual autoencoder with a shared Graph neural network (GNN) encoder that contrasts reconstructions (not embeddings) between original and augmented graph views. Instead of contrasting embeddings, DCOR reconstructs both adjacency and attributes for the original graph and for an augmented view, then contrasts the reconstructions across views. This preserves…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Fig 1
Fig 1 Fig 2
Fig 2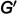 Fig 3
Fig 3 Fig 4
Fig 4 Fig 5
Fig 5 Fig 6
Fig 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Graph Neural Networks · Anomaly Detection Techniques and Applications · Complex Network Analysis Techniques
Introduction
Anomaly detection in attributed networks is crucial across various domains, including social media, e-commerce, finance, cybersecurity, and the Internet of Things (IoT). In these graphs, nodes carry attributes in addition to links, enabling rich modeling of behaviors and interactions. Detecting anomalies matters because they often correspond to security breaches, fraud, fake accounts, or sensor failures [1]. Prior estimates suggest that online payment fraud alone could amount to hundreds of billions of dollars over a few years [2], and fabricated influencer activity has incurred substantial losses annually [3]. Similar concerns arise in cyber-physical infrastructures, where anomalous nodes may indicate compromised devices or faulty sensors [4–7]. These examples motivate robust, scalable detectors for attributed graphs.
Anomalies in attributed networks typically fall into three categories (Fig 1) [1,8,9]: (i) Structural: unexpectedly dense communities or cliques, spam links, or isolated nodes; (ii) Attribute: unusual or implausible feature values (e.g., abnormal transaction rates or incomplete profiles); (iii) Interaction: inconsistencies between structure and attributes (e.g., a highly connected merchant with suspicious transactional attributes). Accurately capturing these diverse anomaly types is nontrivial, especially when structural and attribute signals conflict or evolve dynamically.
Anomalies in attributed networks.Structural anomaly: an unexpected inter-community bridge, where the orange node sits in the cut between two communities and forms a shortcut (dashed) edge to the right cluster. Attribute anomaly: the orange node’s feature vector (colored bars) deviates from those of its neighbors even though its connectivity looks normal. Interaction anomaly: a structure–attribute mismatch, where the orange node’s attributes align with the left community while its links embed it in the right community. Visual encoding: blue = normal nodes and edges; orange = anomalous node or edge; dashed orange edge = anomalous link; colored bars = node attributes.
Table 1: Abbreviations and notation.
To effectively detect these diverse anomaly types, researchers have developed various approaches. Early detectors such as Local Outlier Factor (LOF) [10] compute density-based scores in an embedding space and implicitly assume that proximity captures normal behavior, treating anomalies as sparsely connected or isolated points. Structural Clustering Algorithm for Networks (SCAN) [11] clusters nodes by structural similarity and labels those not belonging to any structural cluster as outliers. While simple and efficient, these heuristics are ill-suited to high-dimensional attributes and cannot capture anomalies arising from subtle feature deviations or complex interactions. They also presuppose homophily (connected neighbors tend to have similar attributes), which fails in many modern applications (user–item graphs, anti-fraud networks, knowledge graphs). In such heterophilous graphs (connected neighbors tend to have dissimilar attributes), purely structural signals can mislead detectors: normal nodes near anomalous ones may be falsely flagged, and anomalous nodes surrounded by normal neighbors may be overlooked, leading to high false positives and negatives when attribute-driven or mixed anomalies are present [1,12].
To address these limitations, recent self-supervised learning (SSL) methods learn node representations without labeled anomalies by creating multiple graph views via augmentations (edge dropping, feature masking, subgraph sampling, or diffusion) and training encoders to maximize agreement for the same node across views, while minimizing agreement between different nodes. Early variants such as GraphCL (graph contrastive learning), GRACE (graph contrastive representation learning), and MVGRL (multi-view graph representation learning) [13–15] rely on random augmentations, whereas newer frameworks like GADAM (graph anomaly detection with adaptive message passing), AD-GCL (adversarial graph augmentation to improve graph contrastive learning), CONAD (contrastive attributed network anomaly detection with data augmentation), and UniGAD (unifying multi-level graph anomaly detection) [16–19] add adaptive message passing, adversarial view generation, and multi-level stitching. Despite its effectiveness, most graph contrastive pipelines use a narrow augmentation set (edge or node dropping, feature masking, subgraph sampling, or diffusion [20–22]), which can overlook key anomaly facets and sometimes produce unrealistic augmented views. We therefore adopt a richer, taxonomy-aligned augmentation suite that instantiates all three anomaly categories in Fig 1. Further details are provided in the proposed framework section.
Nonetheless, in spite of strong downstream performance, these contrastive pipelines still compare compressed node embeddings produced by message passing. This compression can blur fine-grained anomaly cues, particularly in heterophilous graphs where anomalous nodes are largely surrounded by normal ones [23–26]. Moreover, message passing inherently smooths features across neighborhoods [27,28], leading to over-smoothing such as distinctive signals may be washed out [16,29] (see Fig 2).
Embedding vs. reconstruction-level contrast (RLC).Top: the encoder consumes two inputs (the original graph and an augmented view) and contrasts their node embeddings in the embedding space. Bottom: DCOR uses dual autoencoders to reconstruct the adjacency and the attribute matrices for the original graph and the augmented view, then applies contrastive learning directly to the two sets of reconstructions, which preserves cross-view discrepancies that message passing may smooth out.
Complementary to contrastive learning approaches, autoencoder- and graph neural network (GNN)-based architectures model graph data directly to address some of these limitations. DOMINANT (deep anomaly detection on attributed networks) [30], AnomalyDAE (anomaly detection through a dual autoencoder) [31], GAD-NR (graph anomaly detection via neighborhood reconstruction) [32]; CurvGAD (leveraging curvature for enhanced graph anomaly detection) [33], and MTGAE (mirror temporal graph autoencoder) [34] are representative examples in this category. These models score anomalies via reconstruction error but typically operate on a single view and therefore miss cross-view inconsistencies that often signal subtle anomalies. As a result, valuable discrepancies between reconstructions from different augmentations (e.g., a node well reconstructed in one view but poorly in another) remain underexplored.
These observations reveal two principal gaps:
(A) Embedding-based methods compare low-dimensional embeddings, erasing fine-grained anomaly signals (particularly in heterophilous networks where distinctive features become over-smoothed [26]).(B) Reconstruction-based methods reconstruct the adjacency matrix A and nodal features X but do not compare reconstructions across augmented views, leaving cross-view discrepancies (and the opportunity to improve reconstruction quality) unexploited.
We introduce Dual Contrastive Learning-based Reconstruction (DCOR), a dual autoencoder framework trained with a reconstruction-level contrastive objective that directly compares reconstructed adjacency and attribute matrices across two augmented views. By contrasting reconstructions rather than embeddings, DCOR preserves view-specific cues, improves reconstruction fidelity, and enhances anomaly separability. Across six public benchmarks, DCOR attains best or competitive performance in terms of Area Under the Receiver Operating Characteristic curve (AUROC). We also adopt a taxonomy-aligned augmentation suite that augments the structure, attributes, and their interaction, providing comprehensive self-supervised signals.
Our contributions are threefold: (i) a reconstruction-level contrastive objective over decoded structure and attributes; (ii) a domain-informed augmentation suite that covers structural, attribute, and interaction anomalies; and (iii) a practical dual-autoencoder design with a shared GNN encoder.
This work extends our earlier conference paper [35] with substantial modifications, including new sections, additional experiments and evaluation metrics, as invited for journal publication.
This paper is organized as follows. The Related work section reviews graph-based anomaly detection, including traditional methods, autoencoder- and GNN-based models, and contrastive learning. The Proposed framework section introduces DCOR, detailing the dual-autoencoders, the reconstruction-level contrastive objective, and taxonomy-aligned augmentations. The Experimental results section describes datasets, evaluation metrics, and implementation, and reports empirical findings, ablations, and robustness analyses. The Discussion section examines limitations, practical considerations, and future directions. The Conclusion section summarizes the paper and highlights the key findings.
Related work
This section reviews four strands: (i) traditional detectors, (ii) autoencoder- and GNN-based models, (iii) contrastive learning (including augmentation-oriented, adversarial, and RL-assisted variants), and (iv) domain applications. Table 2 provides a side-by-side summary of these approaches.
Table 2: Condensed summary of graph anomaly detection methods and their key strengths and limitations.
Traditional anomaly detection in graphs
Classical methods rely on local density, structural similarity, or low-rank and sparse decompositions. LOF [10] assigns density-based outlier scores and is effective in many tabular settings. However, LOF is sensitive to the neighborhood size k and the choice of distance metric, and repeated runs at scale can be costly. SCAN [11] clusters nodes by structural similarity and flags non-members as outliers. By design, SCAN focuses on topology and ignores node attributes, which causes limited sensitivity to attribute-driven irregularities.
The second category of works relies on modeling attributed graphs via matrix-based formulations. Residual Analysis for Anomaly Detection in Attributed Networks (RADAR) [36] couples structure-attribute effects with a low-rank and sparse decomposition and neighborhood regularization. The smoothness assumptions of RADAR often align with homophily and can degrade under heterophily. ANOMALOUS (joint modeling for anomaly detection on attributed networks) [37] factors the reconstructed structure-attribute matrix via column–row decomposition (CUR) and scores residuals. Like other decomposition methods, its cost grows with graph size and feature dimensionality.
Autoencoder and GNN-based approaches
These models reconstruct topology and attributes and typically score anomalies via reconstruction residuals. While effective on attributed graphs, they may suffer from over-smoothing under heterophily, and when trained in a single view, they overlook cross-view discrepancies. DOMINANT [30] jointly reconstructs A and X and mixes adjacency and feature errors to score anomalies; it often performs well. However, small reconstruction gaps can reduce sensitivity, and under strong heterophily, message passing may over-smooth distinctive cues [26,29]. AnomalyDAE [31] uses dual decoders to reconstruct adjacency and attributes, improving coverage of structural and attribute anomalies, yet training can be heavy on very large graphs, and it does not compare reconstructions across augmented views. GAD-NR [32] regularizes neighborhood reconstruction of structure and attributes to capture complex structural anomalies and often scales better than global matrix methods, but it depends on neighborhood assumptions and can degrade under pronounced heterophily or irregular local mixtures. CurvGAD [33] integrates discrete Ricci curvature to encode higher-order geometry at additional computational cost and still without cross-view comparison. MTGAE [34] is a multi-task graph autoencoder for topology and attributes (with temporal or auxiliary heads) and shares the trade-offs above: potential over-smoothing [26,29] and no explicit cross-view comparison.
Contrastive learning for graph representation
Beyond GraphCL [13], frameworks such as GRACE [14] and MVGRL [15] construct augmented graph views via random edge and node dropping, feature masking, subgraph sampling, or diffusion, and maximize agreement of the same node across views using the InfoNCE loss (Information Noise-Contrastive Estimation) [38]. While effective for unsupervised representation learning, these pipelines compare node embeddings in embedding space, which can attenuate fine-grained structural or attribute cues due to message passing and over-smoothing, particularly on heterophilous graphs. More recent variants add adaptive or adversarial guidance to better align with anomaly patterns: GADAM [16] adapts message passing; AD-GCL crafts adversarial augmentations to produce harder views [17]; and UniGAD [19] unifies multi-level detection (e.g., graph stitching). Nevertheless, most pipelines still rely on a limited augmentation set and compare in embedding space, where over-smoothing and over-squashing [39] can blur fine-grained cues, especially under heterophily. Our approach targets both gaps by enforcing reconstruction-level contrast across views on topology and attributes.
A related line detects anomalies by comparing learned node representations, including CONAD. Representative examples include GCCAD (graph contrastive learning for anomaly detection) [40], GAD-MSCL (graph anomaly detection via multi-scale contrastive learning) [41], EAGLE (efficient contrastive-learning-based anomaly detector on graphs) [42], CoModality [43], and semi- and weakly supervised variants [44]. These methods inherit the strengths of contrastive learning yet remain vulnerable to information loss when embeddings are smoothed or when perturbations are subtle.
Recent surveys systematize a broad toolbox of graph augmentations, including edge perturbation (addition-removal-rewiring), node or edge dropping, feature masking or denoising, subgraph sampling, and diffusion-style transforms [20–22]. In practice, however, many graph anomaly detection (GAD) studies instantiate only a narrow subset (for example, random edge dropping or adding and simple feature masking), and overly aggressive or poorly matched perturbations can yield unrealistic structures or erase salient signals, thereby harming anomaly separability. In contrast, we adopt a broader, controlled suite with explicit budgets and topology and attribute constraints, covering structure-level patterns (clique injection, node isolation, random connections, inter- and intra-community rewiring or removal) and feature-level patterns (copying, scaling, masking) derived from domain knowledge.
Hybrid and robustness-oriented variants
Augmentation-based semi-supervised variants.
AugAN (augmentation for anomaly and normal distributions) [45] tackles generalized graph anomaly detection in a semi-supervised setting. It expands the scarce labeled set of normal and anomalous nodes via data augmentation and adopts a tailored episodic training strategy so that the learned representations and classifier remain effective on both unseen subgraphs and entire graphs. NodeAug (node-parallel augmentation) [46] applies feature and edge augmentations to regularize semi-supervised node classifiers. In contrast, we use structural and feature augmentations solely to synthesize training views and train via reconstruction-level contrast without any ground-truth labels. The final anomaly scores are derived from reconstruction discrepancies.
Reinforcement learning-assisted and adversarial variants. Subgraph-centric approaches (e.g., CoLA (contrastive self-supervised learning framework for anomaly detection) [47]) form positive and negative pairs between a node and random-walk subgraphs from its neighborhood versus other nodes to capture local structure-attribute dependencies, but constructing many subgraphs incurs non-trivial cost such as multi-view and multi-scale methods [48–50] with scalability limits. RL-assisted methods surface informative structure either via neighborhood selection (RAND [51]) or mutual information (MI)-driven pooling (SUGAR [52]). Adversarial formulations include embedding regularization (ARANE (adversarially regularized attributed network embedding) [53]), data synthesis (GAAN (generative adversarial attributed network) [54]), and domain-specific generators (RegraphGAN (graph generative adversarial network for dynamic network anomaly detection) [55], AdvGraLog (graph-based log anomaly detection via adversarial training) [56], SGAT-AE (self-learning graph attention network autoencoder) [57]), and inductive anomaly-aware layers AEGIS (adversarial graph differentiation networks) [58] with better robustness. These variants broaden robustness but add training complexity, and many still operate at the embedding level, risking information loss.
Anomaly detection in specialized domains
Graph-based anomaly detection is effective across multiple domains. In social networks, GNN-based detectors flag irregular user behavior and structural patterns such as fake profiles and misinformation spread [59]. In e-commerce, graph autoencoders uncover unusual co-purchase patterns and fraudulent transactions [60]. In IoT, modeling device-device interactions enables detection of sensor faults and malicious activities. Recent surveys review GNN- and AI-based IoT anomaly detection [61,62]. Financial networks benefit from large-scale graph benchmarks for fraud and risk detection [63]. In healthcare, graph analysis over patient-provider-claim relations has been used to detect anomalous or fraudulent behavior [64].
Synthesis and positioning. Traditional detectors (e.g., LOF) score local density and typically ignore joint modeling of structure and attributes [10]. Autoencoder- and GNN-based models (e.g., DOMINANT) jointly reconstruct A and X but are trained in a single view and can over-smooth signals [30]. Contrastive GAD (e.g., CONAD) compares augmented views in the embedding space, where fine-grained cues may be compressed [18]. RL and adversarial approaches (e.g., SUGAR) add complexity [52]. DCOR differs by addressing both gaps: it enforces reconstruction-level contrast across two augmented views with dual-autoencoders and a controlled augmentation suite, explicitly preserving cross-view discrepancies in A and X.
Proposed framework
In this section, we formalize the task and present DCOR’s end-to-end pipeline. The overall structure of the proposed approach is given as,
Employ domain-informed graph augmentations to induce realistic structural and attribute anomalies, including clique injection, node isolation, shortcuts, community-level changes, and feature copying, scaling, and masking.Use a sampling strategy to create mini-batch subgraphs maintaining alignment between original and augmented views for efficient, robust training.Implement a dual-autoencoder model with shared graph-attention encoder and separate reconstruction heads for adjacency and features, enabling fine-grained anomaly detection.Apply reconstruction-level contrastive loss to pull reconstructions close for normal nodes and enforce a learnable margin separation for augmented (anomalous) nodes in both modalities.Optimize a total loss combining reconstruction fidelity and contrastive separation, with adaptive margin to balance calibration and enhance anomaly differentiation.Define node-level anomaly scores as reconstruction discrepancies in structure and features, ranking nodes by deviation for anomaly detection as the output.
In the following, required definitions and notations are presented. Then, each of the steps is illustrated.
Notations and definitions
Lets consider an attributed, undirected, simple graph denoted by where V is the set of nodes and E is the set of edges between nodes . On the representation level, the graph is presented as , where is the adjacency matrix ( , Aii = 0) and stacks the node features (n nodes, d features per node).
A graph augmentation is an operator that maps (A,X) to a new view
where applies edge-level perturbations (adding or deleting edges) while preserving symmetry and no self-loops, and applies attribute-level perturbations (e.g., copying, scaling, or masking feature entries). For clarity, we use “augmentation” for the operator that generates the view, and “perturbations” for the concrete changes applied to (A,X).
Let denote the node index set. For each augmented view, we record the nodes whose structure or attributes are perturbed, yielding subsets (which may overlap), and define binary indicators
Equivalently, and , where counts nonzero entries and, for any matrix M, denotes row i. The superscripts (A) and (X) indicate whether the perturbation arises from the structural or attribute side, respectively. Due to training the model in a self-supervised manner without accessing to ground-truth values, these indicators serve only to gate the training loss and are never used during inference.
Graph data augmentation
We employ domain-informed augmentations to synthesize realistic structural and attribute anomalies. Interaction mismatches arise implicitly when structure and attributes are augmented on different (possibly overlapping) node subsets. An overview of the two views is shown in Fig 3 (left: original graph G, right: augmented graph ).
Structural and node-level augmentations for graph anomalies.Left: original attributed network G. Right: augmented attributed network G′. Middle: augmentation methods: (1) feature copying (attribute mimicking across distant nodes); (2) feature scaling (multiplying or dividing continuous attributes); (3) node isolation (dropping all incident edges of selected nodes); (4) random shortcut connections and clique injection (adding shortcuts or small dense cliques across and within communities). Color coding: green nodes are normal; red nodes are augmented (selected for structure or feature augmentations; isolated nodes appear red with no incident edges); gray edges are original connections; orange or red edges indicate injected connections (random shortcuts or clique edges); solid feature bars are original attributes; cross-hatched bars mark augmented features; the thin gray curved arrow in the feature panel indicates attribute copying. Collectively, these augmentations induce structural, attribute, and interaction anomalies, creating cross-view discrepancies leveraged by our reconstruction-level contrast.
On the structure side, several augmentations are employed including clique injection, node isolation, random shortcut edges, and community-level augmentations (inter-community bridging and intra-community edge removal). On the feature side, we apply feature copying (from another node), feature scaling, and feature masking. Optionally, light Gaussian noise is added to mimic measurement noise.
Sampling via GraphSAINT.
We adopt the GraphSAINT random-walk sampler [65] to construct mini-batch subgraphs. At each training step, a fresh subgraph is drawn from short random walks on the original graph, and the same node set is used to slice both the original and augmented views to maintain alignment. This resampling bounds memory usage and improves throughput while approximately preserving local connectivity. It also increases robustness by exposing the model to diverse, overlapping neighborhoods and by reducing brittleness to batch boundaries and occasional noisy or missing edges. Sampler settings are chosen to balance coverage and GPU (Graphics Processing Unit) budget.
Structural graph augmentation
We inject controlled topological augmentations to mimic common anomaly patterns [20,21]. These augmentations are used only to generate augmented views for reconstruction-level contrast. This stage consists of four types of augmentation ways,
(i) Clique Injection,(ii) Node Isolation,(iii) Random Shortcut Edges,(iv) Community-level augmentations containing inter-community bridging and intra-community edge removal.
Clique injection.
In social networks, tightly connected groups of anomalous nodes (cliques) often indicate coordinated malicious activities (e.g., fraud rings, botnets, organized misinformation). To reveal this behavior, a subset is randomly selected and then every pair within C is connected to form a complete subgraph. Formally,
where with , , and denotes the augmented (binary) adjacency matrix (entries equal 1 when an edge is present and 0 otherwise); self-loops are disallowed and symmetry is preserved. For all other off-diagonal pairs , we keep the original connectivity, i.e., . Typically . By adding these densely connected substructures, the model learns to recognize unusually dense local connectivity (Fig 3).
Node isolation.
Sometimes, anomalies such as compromised accounts or system failures can appear as users who become structurally isolated. To recognize this type of anomaly, we assign the isolation primitive to a random subset of nodes and delete all their incident edges, thereby zeroing the corresponding rows and columns in the augmented adjacency. This encourages the model to identify structural isolation as an anomalous connectivity pattern (Fig 3).
Let be the nodes assigned isolation. We set
For all , the original adjacency holds, i.e., . We also set and enforce symmetry as defined above.
Random shortcut edges.
We simulate unexpected links by adding a few shortcut edges between previously non-adjacent nodes. Additions are symmetric and exclude self-loops. Also, we avoid connecting to isolated nodes (Fig 3).
where specifies seed nodes for additions, each is a small non-neighbor set, and denotes logical OR.
Inter-community bridging.
Initially, a community partition of V is obtained by Louvain algorithm [66], where denotes the communities, and K is the number of communities. For distinct communities , we simulate unexpected cross-community ties by adding edges between non-neighbor pairs (measured w.r.t. A). Let
is uniformly sampled without replacement with (a small addition budget). On augmentation side, set:
To preserve isolation, additions are skipped incident to nodes in . This weakens community separation just enough to expose unusual cross-community interaction patterns.
Intra-community edge removal.
We first obtain a community partition (via the Louvain method [66]) and pick one community C. To simulate weakened internal cohesion, a small subset of edges is removed inside C:
where J denotes the set of removed intra-community edges with for a small budget . Symmetry and a zero diagonal properties are preserved by setting and .
Node-level feature augmentation
Controlled feature augmentations are applied to imitate attribute-driven anomaly patterns [20,21]. These augmentations are just used to generate augmented views for reconstruction-level contrast. Three methods are applied: (i) Feature Copying, (ii) Feature Scaling, and (iii) Feature Masking.
Feature copying (Attribute Mimicking).
To induce attribute mismatches, for each node we sample a candidate set of size uniformly without replacement, and copy the features from the farthest candidate in :
Ties in the are broken arbitrarily. Here, V is the node set, SX the feature-side augmented nodes, s the pool size, Ci the candidate set for node i, the Euclidean norm, k (i) the index of the farthest candidate, the feature matrix, and the updated feature vector of node i (Fig 3).
Feature scaling.
To simulate magnitude shifts, for each node , its (continuous) feature vector is rescaled by a fixed factor , randomly up or down,
where Xi is the original feature vector of node i, the scaled one, SX the set of nodes chosen for feature-side augmentation, the scale factor, and selects multiplication ( + 1) or division (–1) with equal probability. Only continuous features are scaled (Fig 3).
Feature masking.
Missing fields are simulated by zeroing a small random subset of feature dimensions for nodes on the feature side ( ). For node i with d features, sample uniformly without replacement with (masking rate ) and define the binary mask by if , otherwise 1. Then
where Xi is the original feature vector of node i, the masked one, SX the set of nodes chosen for feature-side augmentation, d the feature dimension, q the masking rate, Ii the zeroed indices, mi the binary mask, denotes element-wise multiplication, and denotes the floor operator.
The structural and node-level feature augmentations illustrated in this section apply small, controlled modifications that mirror realistic anomaly patterns in social networks to enhance the model’s ability to detect subtle yet critical irregularities and improving robustness. We control augmentation budgets with per-dataset node-wise rates and sample independently (Bernoulli). Rates are tuned empirically via small ablation sweeps, and mean ± std are reported over three seeds. Formally, for each node i, and , independently across nodes and across the two views, with .
Augmented-view diversity metrics. To sanity-check that our augmented views are realistic yet diverse, we quantify the similarity between G and with scale-free metrics:
where and are edge sets; and are neighbor sets. and denote the (normalized) empirical degree distributions of A and , and is the Kullback–Leibler divergence. In (11d), xi and are the i-th rows of X and (equivalently, and ), is the dot product, is the Euclidean norm, and is a small constant.
Contrastive learning framework
Contrastive learning distinguishes similar from dissimilar samples in a self-supervised manner. On graphs, comparing node embeddings across views can blur fine-grained structural or attribute cues, especially in heterophilous settings where message passing smooths distinctive signals [23–26,29]. In addition, reconstruction-based detectors usually operate on a single view and thus miss cross-view inconsistencies that are informative for anomalies. To address both issues, we contrast at the reconstruction level. Two views are considered,
Then, a dual-branch reconstructor based on values of (12) is computed with shared weights to obtain
where denotes the shared dual-branch reconstructor comprising structure and attribute autoencoders. A,X are the original adjacency and feature matrices, are their augmented counterparts (hats indicate reconstructions).
During augmentation, we record which nodes were manipulated via the indicators in Eq (2). Our objective maintains cross-view reconstructions of non-augmented nodes close and applies an adaptive-margin penalty to augmented nodes: minimize structural and feature discrepancies for and , and add a margin penalty when or . “Non-augmented” and “augmented” are determined per node by , i.e., for structure and for features. The chosen discrepancy measures and the adaptive margin are detailed in the next subsection. are the structure- and feature-side augmentation indicators.
Dual autoencoder model
Fig 4 illustrates our reconstruction-level contrast architecture for anomaly detection in attributed networks. The model uses a shared GAT-based encoder that produces node embeddings Z, followed by two reconstruction heads: a structural head that reconstructs the adjacency via an inner-product decoder, and an attribute head that reconstructs node attribute vectors via a linear decoder. The same weights are applied to both views and , yielding and that feed the contrastive objective. The rationale is specialization with sharing: structural and attribute anomalies have different signatures, so separate reconstruction heads preserve fine-grained cues in each modality, while a shared encoder ties the representations across views. By reconstructing both A and X for the original and augmented graphs and contrasting the two sets of reconstructions, the model highlights cross-view differences for augmented nodes, while maintaining consistency for non-augmented ones.
Dual autoencoder with reconstruction-level contrast.Left: an attributed network G and an augmented view G′ produced by graph data augmentation. Middle: a shared graph-attention encoder yields node embeddings Z, which feed two decoders: a structure decoder reconstructing A^ and an attribute decoder reconstructing X^ for the two views, yielding (A^,X^) and (A^′,X^′). Right: reconstruction-level contrast compares, for each node i, the reconstructions via D(A^i,A^i′) and D(X^i,X^i′); it minimizes D when si(A)=0 and si(X)=0, and enforces a learnable margin m when si(A)=1 or si(X)=1. Color coding: green nodes denote non-augmented nodes; red nodes denote augmented nodes; the dotted green arc indicates minimization of D; the dashed orange arc indicates margin enforcement; cross-hatched bars mark augmented features; gray edges are neutral; blue heatmaps depict reconstructed matrices.
Structure autoencoder
We use a shared GAT-style encoder to map node features to latent embeddings Z, which feed both decoders.
Encoder.
First project node features to an intermediate representation
with and learnable. Then apply a GAT-style attention layer [67] to obtain node embeddings
where dz is the latent embedding dimension and A is the adjacency used for message passing after adding self-loops. Here I denotes the identity matrix, and is the neighbor set of node i.
The (additive) pre-softmax attention score between nodes i and j is
with learnable and ; here Hi denotes the i-th row of H.
Masked softmax over the neighbor set gives
where I is the identity matrix; this ensures for each i. Node embeddings then aggregate neighbor messages:
with applied element-wise.
Decoder.
The adjacency matrix is reconstructed as,
where Z is the latent representation obtained from the encoder and σ denotes the sigmoid activation. This yields a symmetric edge-likelihood matrix . Following standard practice, we adopted the inner-product decoder used in graph autoencoders [68].
Attribute autoencoder
This branch reconstructs node features by combining the shared node embeddings Z with a global attribute factor F learned from the current view’s features X (via ).
Encoder (global feature factorization).
We form a feature–feature summary matrix and encode it as
followed by
where , , , and ; here ha is the attribute-encoder hidden width, and is applied element-wise. The same encoder is applied per view.
Decoder.
Attribute reconstruction is factorized as
where are the node embeddings from the shared GAT (graph attention network) encoder. For the augmented view, analogously have .
Taken together, the shared encoder with dual decoders reconstructs the topology via and the attributes via (and for ).
Contrastive loss function
We use a reconstruction-level contrastive objective: given the original graph and an augmented view, the dual-autoencoders reconstruct both, and the loss pulls together reconstructions for non-augmented nodes while pushing apart those for augmented nodes via an adaptive margin. This focuses learning on structure and feature discrepancies introduced by augmentation and sharpens the separation between normal and anomalous nodes.
Structural contrastive loss.
The structural contrastive loss compares the reconstructed adjacency information from the original and augmented graph views. It encourages small reconstruction discrepancy for normal nodes and enforces at least a margin for nodes flagged as anomalous are depicted in the top-right panel of Fig 4:
where denotes the squared Frobenius norm, are the i-th rows of the reconstructed adjacencies, is the indicator, flags structural augmentation, and m > 0 is a learnable margin.
Attribute contrastive loss.
Analogously, the attribute contrastive loss compares reconstructed features across views (visualized in the bottom-right panel of Fig 4):
where are the i-th rows of the reconstructed feature matrices, and flags feature-side augmentation; and m are as defined above.
Positive and negative semantics. We treat each modality independently. For structure, the pair is positive if (minimize ) and negative if (enforce the adaptive margin m) as in Eq (23). For attributes, the pair is positive if and negative if as in Eq (24). Thus, a node can be positive in one modality and negative in the other, depending on the applied augmentation. We do not construct inter-node negatives; contrast is performed intra-node across views only.
Combined contrastive loss. The reconstruction-level contrast is defined as,
Margin parameter.
The margin m > 0 in Eq (23) and Eq (24) sets the minimum discrepancy required between cross-view reconstructions for augmented nodes via the hinge term . We treat m as a learnable scalar, and optimize it jointly with all model parameters by backpropagation, so the separation strength adapts to the data and augmentation difficulty. Unless stated otherwise, a single shared m is used for both structure and attributes; extending to modality-specific margins is straightforward.
Why learn m? An adaptive margin reduces manual tuning, calibrates the loss across datasets and augmentation budgets, and mitigates under- or over-separation (collapsed positives or trivially large gaps). In contrast, most prior graph contrastive or reconstruction-based detectors rely on a fixed margin (or no margin at all), which can be miscalibrated across settings.
Total loss function
A single objective is optimized to balance fidelity and separation by combining a reconstruction term and a reconstruction-level contrast term. Concretely, the total loss is a weighted sum of the reconstruction loss and the reconstruction-level contrast loss . Notably, also acts as a cross-view regularizer: it enforces consistency of reconstructions for non-augmented nodes, thereby refining and and improving overall reconstruction fidelity.
where (with defined in Eq (23) and in Eq (24)), and control the trade-off between accurate reconstruction and discriminative separation.
Reconstruction term. We combine structural and attribute reconstruction errors with a modality weight :
where and . We use the Frobenius norm (element-wise, without squaring) to linearly penalize reconstruction errors, complementing the squared discrepancies used in the contrastive terms.
Discussion and settings. Inside , interpolates between structural and attribute fidelity. At the outer level, control the trade-off between pure reconstruction and reconstruction-level contrast. Because in and the squared discrepancies in can have different scales, each term is normalized by its mini-batch moving average before weighting, then fixed coefficients are applied. This objective yields faithful reconstructions for non-augmented nodes and, via , enlarges cross-view discrepancies for augmentation-affected nodes, while regularizing reconstructions to remain view-consistent.
Anomaly scoring
The proposed approach assign a node-level anomaly score from reconstruction discrepancies across both modalities. Intuitively, nodes whose reconstructed features or adjacency rows deviate substantially from the originals are more likely to be anomalous. The score combines structure- and attribute-side errors for each node as,
Here, balances attribute vs. structural error. Nodes with larger are ranked as more anomalous. The dual-autoencoder is trained to reproduce prevalent (normal) structural and attribute patterns; augmented nodes are reconstructed poorly in the augmented view, and the reconstruction-level contrast further enlarges their cross-view discrepancies, yielding higher .
Experimental results
The proposed approach DCOR is evaluated on six standard attributed network datasets. This section details the datasets and the experimental setup. Then, the main results are presented along with training dynamics, ablations, augmentation-diversity checks, and robustness to anomaly prevalence shifts.
Datasets and evaluation metric
Six widely used attributed network datasets are used in our study, which are given in Table 3 with important statistics, application domains, and anomaly rates. Enron [69] (an employee email communication network that captures interaction patterns and organizational relationships), Amazon [70] (a product co-purchase network in which nodes are products and edges indicate frequently co-purchased pairs, reflecting consumer buying behavior), Facebook [71] (a social network where nodes represent users and edges denote friendships (social ties)), Flickr [72] (an online photo-sharing network in which nodes are users and edges represent interactions among users), ACM [73] (an academic citation network whose nodes and edges capture publication entities and citation links; we follow the processed split commonly used for attributed graphs), and Reddit [74] (an online discussion forum network in which nodes represent users and edges reflect interactions such as replies or mentions; node attributes summarize content and metadata).
Table 3: Description of the datasets statistics and their anomaly ratios.
Evaluation metric. Following prior work, we report the area under the receiver operating characteristic curve (AUROC) [75]. AUROC is threshold-free and rank-based, making it robust to severe class imbalance that is typical in anomaly detection.
Implementation details
Our implementation uses Python and PyTorch [76] and runs on a single NVIDIA T4 GPU (Google Colab). We fix random seeds across Python, NumPy, and PyTorch, and enable deterministic settings in cuDNN (the CUDA Deep Neural Network library) for reproducibility. Raw graphs are loaded from MATLAB .mat files (adjacency, attributes, labels). Graphs are treated as undirected and unweighted: A is symmetrized, self-loops are added for message passing, and Louvain communities are computed on the unweighted graph without self-loops. The model input is the symmetrically normalized adjacency , while serves as the structure-reconstruction target. Here, I is the identity and is the degree matrix of . The architecture is a dual-autoencoder (GAT encoder; inner-product adjacency decoder; linear attribute decoder). Training uses Adam [77]. To scale to large graphs, we adopt GraphSAINT-style random-walk mini-batch sampling without reweighting; since our objective contrasts reconstructions across two views on matched node sets, we avoid estimator reweighting and accept the mild sampling bias for efficiency.
Complexity and runtime. Let n be the number of nodes, edges, d input features, and dz the embedding size. Message passing with sparse ops is . The inner-product decoder involves forming (sub)matrices like at if materialized. Parameter memory depends on layer sizes (e.g., ) and is independent of n; the dominant memory terms are activations and any explicit reconstruction buffers for (up to O(n^2^) if a full matrix is stored). On Amazon ( , , dz = 128), we measured ∼190k parameters (∼0.7 MB), ∼265 MFLOPs (million floating-point operations) per forward pass, and ∼3 ms inference per 1k nodes; wall-clock scales roughly linearly with the number of epochs.
Comparative note (vs. SOTA). Training DCOR is costlier than single-view reconstructors (e.g., DOMINANT [30], AnomalyDAE [31]) because each training step involves encoding and decoding two views. Unlike common InfoNCE-style pipelines (e.g., CONAD [18]), it typically does not build dense similarity matrices or maintain large negative banks; and unlike adversarial schemes (e.g., GAAN [54]), it avoids generator and discriminator updates. With GraphSAINT subgraph sampling [65], the inner-product decoder’s O(n^2^) pairwise scoring reduces to per mini-batch (full-pair scoring), where B is the number of nodes in the sampled subgraph (mini-batch size). Runtime memory is dominated by node and edge activations (and any optional buffers). In inference, DCOR is single-pass (no augmentation or contrast), yielding a runtime comparable to DOMINANT and AnomalyDAE.
Anomaly detection performance
We compare against strong baselines on six datasets and report AUROC (higher is better) in Table 4. DCOR attains the best AUROC on all six datasets.
Table 4: Anomaly detection performance (AUROC).Best per column in bold.
Analysis. Relative to the strongest non-DCOR baseline per dataset, absolute AUROC gains are + 15.6 percentage points on Enron, + 14.4 on Amazon, + 2.9 on Facebook, + 4.0 on Flickr, + 6.8 on ACM, and + 4.0 on Reddit (avg. + 8.0 pp). In relative terms, these correspond to , , , , , and improvements, averaging ( micro-averaged).
Beyond final AUROC, training dynamics are examined. Normalized losses over epochs are plotted, where each curve is divided by its own value at the first epoch to remove scale effects (Eq (29)). For DCOR, we reported both the reconstruction term and the total objective (with RLC); for baselines we reported the reconstruction-only term (Fig 5).
Normalized training loss vs. baselines (Facebook).DCOR reports both reconstruction-only and total (with RLC); baselines report reconstruction-only. Each curve is normalized as in Eq (29) by dividing by its epoch-1 value and EMA-smoothed (exponential moving average) with β=0.97, where the EMA is computed as y(e)=βy(e−1)+(1−β)ℒ~(e) with y(1)=ℒ~(1). This normalization enables fair visual comparison across methods with different objectives and scales; the plot therefore emphasizes relative convergence trends (shape and stability) rather than raw magnitudes. Consistent with DCOR’s design, RLC regularizes late-phase training: the reconstruction curve decreases more conservatively than methods that minimize reconstruction alone, while the total objective continues to decrease.
where denotes the per-epoch loss and E is the number of epochs.
Ablation study
We ablate three components on Amazon: (i) structural augmentation, (ii) feature augmentation, and (iii) the reconstruction-level contrast (RLC). Each variant removes exactly one component; the encoder and decoders, schedule, and all other hyperparameters are fixed. Results are summarized in Table 5.
Table 5: Ablation on Amazon.Δ is the signed difference vs. the full model (Δ=Variant−Full; negative indicates a drop).
To visualize how RLC affects optimization, the total objective is tracked over epochs and report a scale-free version normalized as in Eq (29) (Fig 6).
Augmentation diversity. Table 6 reports diversity metrics on representative datasets. Structural diversity is moderate ( –0.31), while the symmetric Kullback–Leibler (KL) on degrees remains small ( ), indicating local edge perturbations without global distortion. Feature-level diversity differs by dataset: Facebook shows small changes ( ), whereas Flickr exhibits stronger shifts (sparser bag-of-tags). DCOR’s reconstruction-level contrast is trained to be invariant to such moderate view differences while preserving anomaly separability.
Table 6: Diversity of augmented graphs.Similarities (↑ larger = more overlap) and complementary diversities (↑ larger = more diverse). Lower is better for Ddeg.
Normalized total loss on the Facebook dataset (DCOR with and without RLC).To enable a fair visual comparison of training dynamics, each curve is normalized as in Eq (29) by dividing by its epoch-1 value and EMA-smoothed (exponential moving average) with β=0.9. The EMA is computed as y(e)=βy(e−1)+(1−β)ℒ~(e) with y(1)=ℒ~(1). This normalization emphasizes relative convergence behavior (shape and stability) rather than raw magnitudes: with RLC, the total objective continues to decrease in late epochs, whereas without RLC it plateaus, consistent with the ablation trends in Table 5.
As summarized in Table 5, removing RLC yields the largest AUROC drop (0.203). Using only feature augmentation reduces AUROC by 0.083, and using only structural augmentation reduces it by 0.122. On Amazon, feature-only outperforms structural-only by 0.039 (0.712 vs. 0.673), indicating a stronger self-supervised signal from attribute augmentations.
Notation. and correspond to Edge-Jaccard and Neigh-Jaccard in Eq (11a) and Eq (11b); equals Deg-symKL in Eq (11c); equals Feat-cosine-mean in Eq (11d); and .
Robustness to varying anomaly ratios
To stress-test the robustness of our method to variations in anomaly prevalence, we keep the training procedure unchanged and vary, only during evaluation, the fractions of labeled structural and feature anomalies, using the same augmentation-based labeling protocol described in Subsection Graph data augmentation. On Enron, a mild setting (20% structural, 10% feature) yields an AUROC of 0.783, and a moderate setting (30%, 20%) yields 0.747. On Flickr, a mild setting (10%, 10%) yields 0.822, and a moderate setting (30%, 40%) yields 0.815. These results indicate that the ranking performance of our approach remains largely invariant under moderate shifts in anomaly prevalence.
Discussion
This section summarizes the paper’s scientific contributions, highlights open challenges observed in practice, discusses the limitations and practical considerations of DCOR, and outlines future research directions that are closely aligned with our reconstruction-level contrast framework. The objective is to provide a transparent perspective on what DCOR accomplishes, where it faces challenges, and how it can be further extended.
Contributions
The key contributions of this work are summarized, ensuring consistency with our formulation and experimental findings.
Reconstruction-level contrast (RLC) on decoded structure and attributes. Instead of contrasting embeddings, DCOR performs contrastive learning directly on the reconstructions across two views, directly on and (Eq 23 to Eq 26), as illustrated in Fig 2. This preserves cross-view discrepancies that message passing may smooth out and improves anomaly separability.Domain-informed augmentation suite. We design a comprehensive and domain-informed augmentation suite that integrates both structural and attribute-level transformations. On the structural side, we employ techniques such as clique injection, node isolation, inter-community bridging, and intra-community edge removal. On the attribute side, we utilize feature copying, scaling, and masking to enrich feature diversity. This carefully controlled augmentation strategy provides self-supervised signals covering all three major anomaly taxonomies (structural, attribute, and interaction anomalies) while ensuring that the generated views remain realistic and faithful to the underlying graph semantics.Learnable adaptive margin. A positive, learnable margin are considered within the hinge terms of the reconstruction-level contrast loss. This adaptive margin automatically calibrates the separation strength across different datasets and augmentation budgets, thereby reducing the need for manual tuning and improving the robustness of the framework.Scalable training with GraphSAINT. We leverage GraphSAINT to enable scalable training through random-walk-based mini-batches with matched node sets across views. This strategy bounds memory consumption, preserves local connectivity, and stabilizes the reconstruction-level contrast during training.Empirical validation across six benchmarks. Extensive experiments on six real-world benchmarks revealed that DCOR outperforms state-of-the-art competitors in terms of AUROC (Table 4).
Challenges
Extending the framework to million-node graphs remains challenging due to computational and memory constraints, even with efficient sampling strategies such as GraphSAINT. While the dual-autoencoder architecture is effective, it introduces additional training overhead. Furthermore, balancing the reconstruction and contrastive objectives requires careful tuning, as over-weighting either objective can degrade overall anomaly detection performance. Another practical challenge lies in selecting a compact yet representative set of anomaly scenarios for augmentation. In this study, we prioritized patterns most likely to occur in practice, including structural, attribute, and structure-attribute mismatches, consistent with established taxonomies [78–80]. This choice trades off some diversity for greater realism, a decision supported by our ablation study (Table 5). Finally, although DCOR effectively captures subtle irregularities, distinguishing true anomalies from naturally occurring network dynamics such as community evolution or legitimate attribute updates remains difficult. Prior work in dynamic community detection and temporal graph anomaly analysis highlights the prevalence of such phenomena [9,81,82]. Incorporating temporal information, domain-specific constraints, and post hoc validation pipelines may help mitigate false positives and enhance robustness in real-world deployments.
Limitations
Although the proposed graph augmentation suite is designed to capture the three principal anomaly categories in graphs (structural, attribute, and interaction), it cannot fully encompass the diversity of real-world scenarios. Rare or domain-specific anomalies may fall outside this augmentation design space. Since DCOR relies on realistic augmented views, misaligned or overly aggressive augmentations can generate implausible structures or provide insufficient contrast between normal and anomalous nodes, thereby reducing detection accuracy. To mitigate this risk, we adopt a taxonomy-guided set of augmentations and examine sensitivity to augmentation budgets; nevertheless, broader and domain-adapted augmentation strategies remain necessary.
Another limitation pertains to the learnable margin in the contrastive loss. While the adaptive margin is intended to enhance separation, it can introduce training instabilities during early epochs if it adapts too rapidly or too slowly relative to batch difficulty. Achieving stable convergence therefore benefits from safeguards such as careful initialization, mild regularization, explicit lower and upper bounds on the margin, a brief warm-up phase, and gradient clipping.
Future work
In future work, we aim to explore LLM (large language model)-guided, semantically coherent graph augmentations that produce context-aware modifications while preserving the underlying graph statistics and attribute semantics. These augmented views will be integrated into our dual-autoencoder contrastive framework to improve the detection of subtle, domain-specific anomalies.
We plan to perform comprehensive evaluations on datasets including Enron, Amazon, Flickr, and Facebook, with the goal of achieving higher AUROC scores. Furthermore, we intend to extend our approach to dynamic graphs and knowledge-rich networks, enabling more robust and temporally aware anomaly detection.
Conclusion
DCOR introduces a novel paradigm for anomaly detection by contrasting reconstructed structures and attributes (rather than embeddings) across augmented graph views. This design preserves fine-grained, view-specific cues and significantly enhances the fidelity of both structural and attribute reconstructions, leading to superior anomaly separation.
Across six diverse benchmarks–including social, e-commerce, and academic networks–DCOR establishes new state-of-the-art results, achieving the highest AUROC on six datasets. It outperforms the strongest prior baseline by 11.3% on average, with a peak gain of 21.3% on Enron. ablation studies validate the method’s robustness: removing the reconstruction-level contrast causes a 25.5% AUROC drop on Amazon. These findings underscore the critical synergy between reconstruction-level contrast and complementary augmentations.
The effectiveness of DCOR can be attributed to four main aspects: the use of reconstruction-level contrast on decoded structure and attributes, a domain-informed augmentation suite that covers structural, attribute, and interaction patterns, a learnable margin that adapts the separation strength, and a dual-autoencoder architecture with a shared GAT encoder trained with GraphSAINT sampling for scalability.
Future work will extend DCOR to heterogeneous and dynamic graphs (e.g., temporal fraud networks) and optimize decoders for web-scale deployments, leveraging LLM-guided augmentations to handle complex data distributions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Akoglu L, Tong H, Koutra D. Graph based anomaly detection and description: a survey. Data Min Knowl Disc. 2014;29(3):626–88. doi: 10.1007/s 10618-014-0365-y · doi ↗
- 2Juniper Research. Online Payment Fraud: Emerging Threats, Segment Analysis & Market Forecasts 2021 –2025. Juniper Research. 2021. https://www.experian.com/blogs/global-insights/wp-content/uploads/2022/07/2021_04_Juniper_Online-Payment-Fraud.pdf
- 3Cavazos R. The economic cost of bad actors on the internet: fake influencer marketing in 2019 . CHEQ in collaboration with the University of Baltimore. 2019. https://info.cheq.ai/hubfs/Research/THE_ECONOMIC_COST_OF_BAD_ACTORS_Influencers.pdf
- 4Irofti P, Pătraşcu A, Băltoiu A. Fraud detection in networks. Studies in computational intelligence. Springer; 2020. p. 517–36. 10.1007/978-3-030-52067-0_23 · doi ↗
- 5Abshari D, Sridhar M. A survey of anomaly detection in cyber-physical systems. ar Xiv preprint 2025. https://arxiv.org/abs/2502.13256
- 6Gulzar Q, Mustafa K. Interdisciplinary framework for cyber-attacks and anomaly detection in industrial control systems using deep learning. Sci Rep. 2025;15(1):26575. doi: 10.1038/s 41598-025-89650-5 40695948 PMC 12284207 · doi ↗ · pubmed ↗
- 7Qiao H, Tong H, An B, King I, Aggarwal C, Pang G. Deep graph anomaly detection: a survey and new perspectives. ar Xiv preprint 2025. https://arxiv.org/abs/2409.09957
- 8Ekle OA, Eberle W. Anomaly detection in dynamic graphs: a comprehensive survey. ACM Trans Knowl Discov Data. 2024;18(8):1–44. doi: 10.1145/3669906 · doi ↗