The chromosomal genome sequence of the sponge Cliona cf. orientalis Thiele (1900) and its associated microbial metagenome sequences
Emma Marangon, Blake D. Ramsby, Heidi M. Luter, Sara C. Bell, Patrick Laffy, Nicole S. Webster, Ute Hentschel, Cara Fiore, Graeme Oatley, Torsten Thomas, Elizabeth Sinclair, Eerik Aunin, Noah Gettle, Camilla Santos, Michael Paulini, Haoyu Niu, Victoria McKenna, Rebecca O’Brien

TL;DR
This paper provides the genome sequence of the sponge Cliona cf. orientalis and its associated microbial genomes.
Contribution
The study presents a high-quality chromosomal genome assembly and metagenome sequences from the sponge Cliona cf. orientalis.
Findings
The sponge genome is 217.17 megabases long with 19 chromosomal pseudomolecules.
A mitochondrial genome of 19.63 kilobases and 25,502 protein-coding genes were identified.
A high-quality MAG of Parvibaculaceae and partial Symbiodiniaceae sequences were also assembled.
Abstract
We present a genome assembly from a specimen of Cliona cf. orientalis (Porifera; Demospongiae; Clionaida; Clionaidae). The genome sequence has a total length of 217.17 megabases. Most of the assembly (98.28%) is scaffolded into 19 chromosomal pseudomolecules. The mitochondrial genome has also been assembled and is 19.63 kilobases in length. Gene annotation of this assembly on Ensembl identified 25,502 protein-coding genes. Furthermore, three prokaryotic binned genomes were generated, including a high-quality metagenome-assembled genome (MAG) of the family Parvibaculaceae. Although Symbiodiniaceae sequences were also identified, a complete genome assembly could not be generated due to low coverage.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1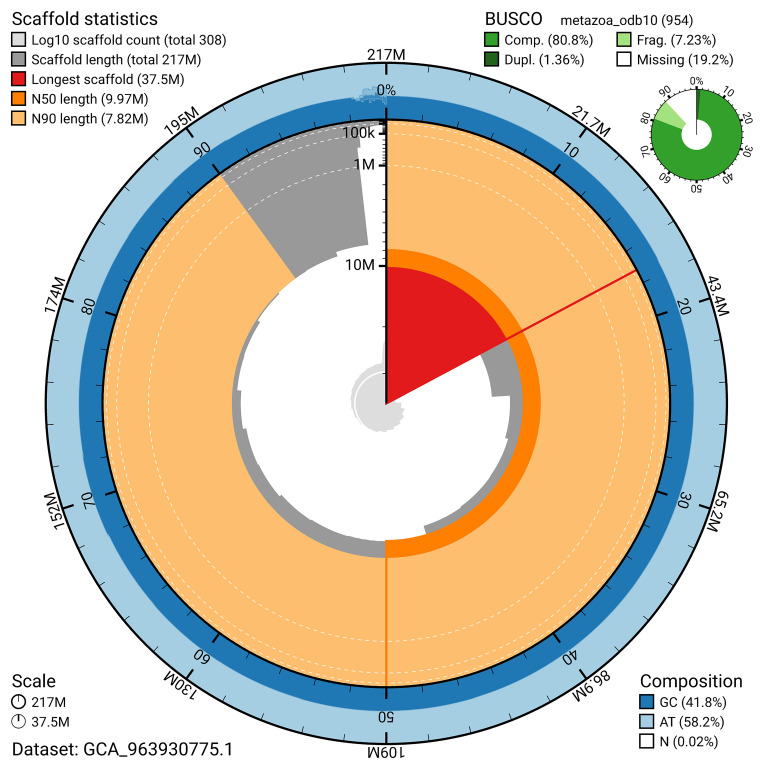 Figure 2
Figure 2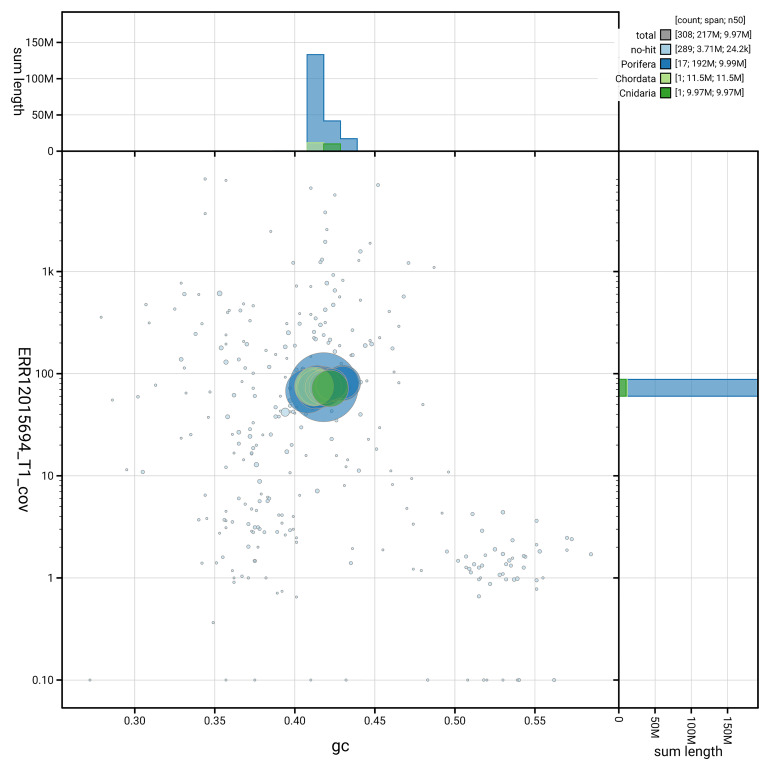 Figure 3
Figure 3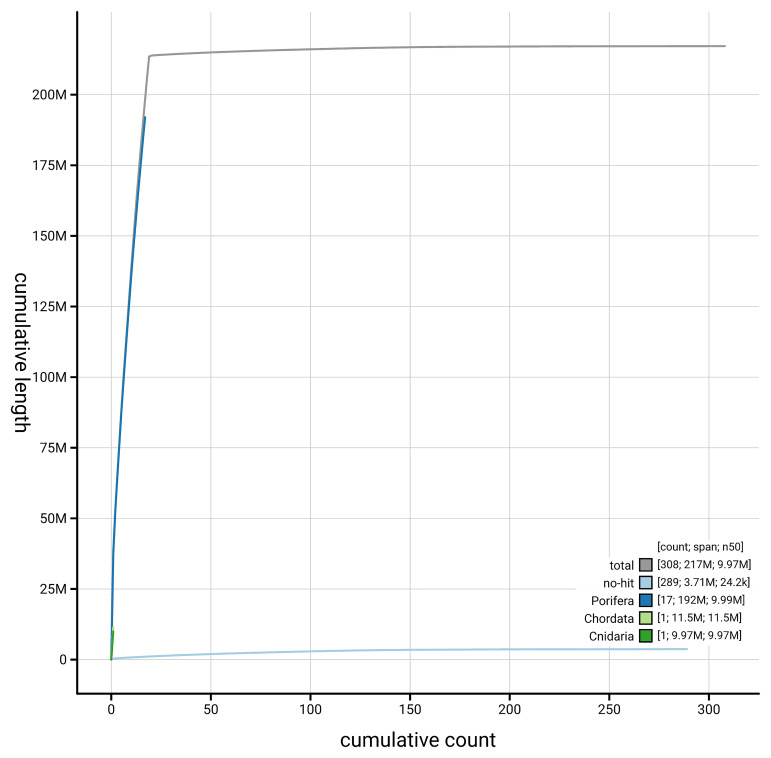 Figure 4
Figure 4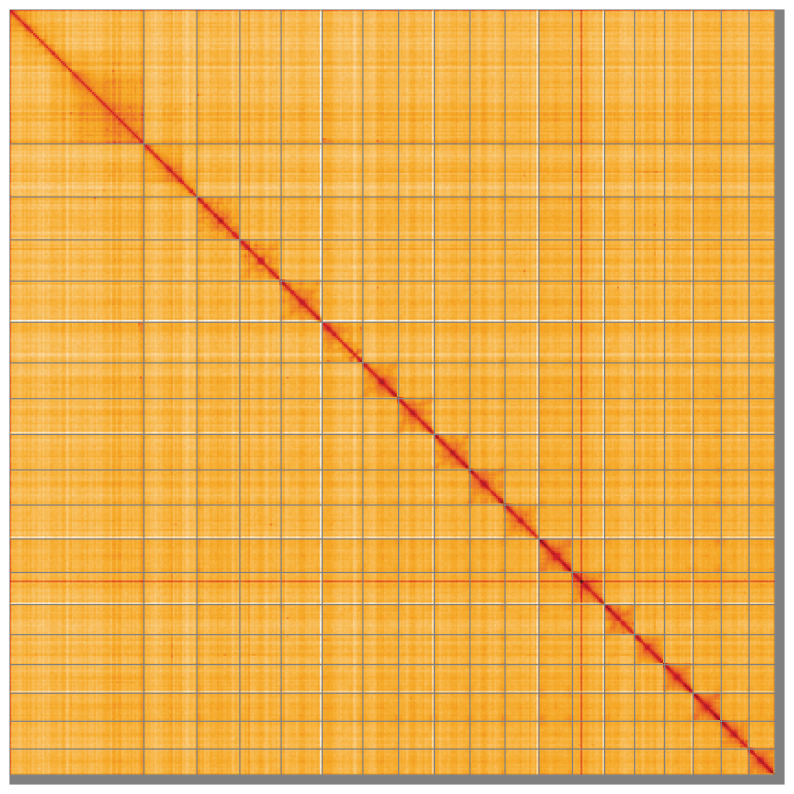 Figure 5
Figure 5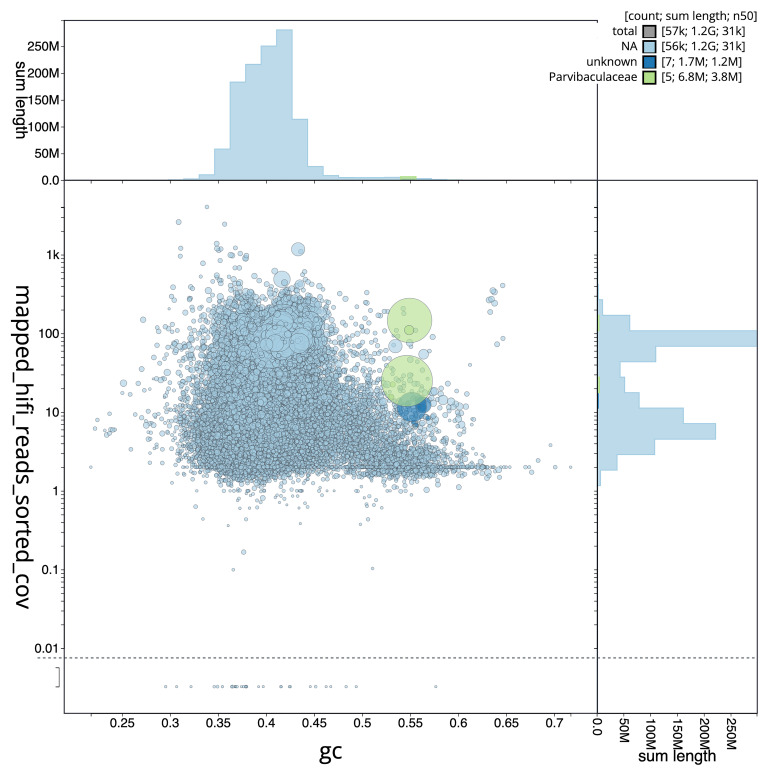 Figure 6
Figure 6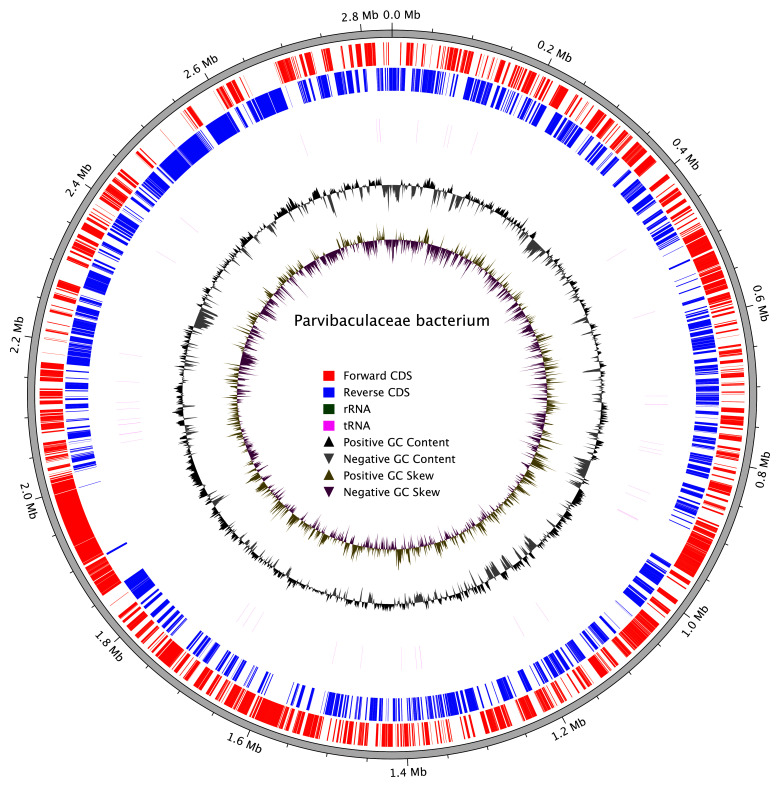 Figure 7
Figure 7| Project information | |||
|---|---|---|---|
|
| Cliona orientalis | ||
|
| PRJEB65616 | ||
|
|
| ||
|
| SAMEA9614640 | ||
|
| 281731 | ||
| Specimen information | |||
|
|
|
|
|
|
| odCliOrie1 | SAMEA9614697 | Somatic tissue |
|
| odCliOrie1 | SAMEA9614702 | Somatic tissue |
|
| odCliOrie1 | SAMEA9614702 | Somatic tissue |
| Sequencing information | |||
|
|
|
|
|
|
| ERR12512720 | 7.04e+08 | 106.35 |
|
| ERR12015694 | 2.40e+06 | 22.11 |
|
| ERR12408767 | 1.72e+06 | 16.36 |
|
| ERR13669944 | 1.16e+08 | 17.47 |
| Genome assembly | ||
|---|---|---|
| Assembly name | odCliOrie1.1 | |
| Assembly accession | GCA_963930775.1 | |
|
|
| |
| Assembly level for primary assembly | chromosome | |
| Span (Mb) | 217.17 | |
| Number of contigs | 523 | |
| Number of scaffolds | 307 | |
| Longest scaffold (Mb) | 37.5 | |
|
|
|
|
| Contig N50 length | 1.98 Mb |
|
| Scaffold N50 length | 9.97 Mb |
|
| Consensus quality (QV) | Primary: 58.0; alternate: 47.9; combined 48.5 |
|
|
| Primary: 60.50%; alternate: 91.43%; combined: 99.62% |
|
| BUSCO
| C:80.8%[S:79.4%,D:1.4%],
|
|
| Percentage of assembly mapped to chromosomes | 98.3% |
|
| Organelles | Mitochondrial genome: 19.63 kb |
|
| Genome annotation of assembly GCA_963930775.1 at Ensembl | ||
| Number of protein-coding genes | 25,502 | |
| Number of non-coding genes | 5,705 | |
| Number of gene transcripts | 41,693 | |
| INSDC accession | Name | Length (Mb) | GC% |
|---|---|---|---|
| 1 | 37.5 | 42 | |
| 2 | 14.8 | 41 | |
| 3 | 11.96 | 41.5 | |
| 4 | 11.51 | 41 | |
| 5 | 11.46 | 41.5 | |
| 6 | 11.33 | 41.5 | |
| 7 | 9.99 | 42 | |
| 8 | 9.97 | 42 | |
| 9 | 9.89 | 41.5 | |
| 10 | 9.79 | 42 | |
| 11 | 9.46 | 41.5 | |
| 12 | 9.36 | 43 | |
| 13 | 8.93 | 42 | |
| 14 | 8.4 | 42 | |
| 15 | 8.35 | 41.5 | |
| 16 | 7.98 | 42.5 | |
| 17 | 7.82 | 43 | |
| 18 | 7.76 | 42 | |
| 19 | 7.22 | 42.5 | |
| MT | 0.02 | 34 |
| NCBI taxon | Taxid | GTDB taxonomy | Quality | Size (bp) | Contigs | Circular | Mean
| Completeness
| Contamination
|
|---|---|---|---|---|---|---|---|---|---|
| Thermodesulfobacteriota
| 2202153 | g__GCA-014075295 | Medium | 1,686,746 | 7 | No | 6.43 | 87.82 | 4.62 |
| Parvibaculaceae
| 2813037 | f__RS24 | Medium | 4,006,238 | 4 | No | 13 | 90.92 | 6.82 |
| Parvibaculaceae
| 2813037 | f__RS24 | High | 2,895,071 | 1 | Yes | 86.76 | 92.44 | 0.45 |
| Software tool | Version | Source |
|---|---|---|
| BEDTools | 2.30.0 |
|
| BLAST | 2.14.0 |
|
| BlobToolKit | 4.3.3 |
|
| BUSCO | 5.5.0 |
|
| bwa-mem2 | 2.2.1 |
|
| CheckM | 1.2.1 |
|
| Cooler | 0.8.11 |
|
| DIAMOND | 2.1.8 |
|
| dRep | 3.4.0 |
|
| fasta_windows | 0.2.4 |
|
| FastK | 427104ea91c78c3b8b8b49f1a7d6bbeaa869ba1c |
|
| Gfastats | 1.3.6 |
|
| GoaT CLI | 0.2.5 |
|
| GTDB-TK | 2.3.2 |
|
| Hifiasm | 0.19.5-r587 |
|
| HiGlass | 44086069ee7d4d3f6f3f0012569789ec138f42b84aa44357826c0b6753eb28de |
|
| MAGScoT | 1.0.0 |
|
| MerquryFK | d00d98157618f4e8d1a9190026b19b471055b22e |
|
| MetaBat2 | 2.15-15-gd6ea400 |
|
| metaMDBG | - |
|
| Minimap2 | 2.24-r1122 |
|
| MitoHiFi | 2 |
|
| MultiQC | 1.14, 1.17, and 1.18 |
|
| Nextflow | 23.04.1 |
|
| PretextView | 0.2 |
|
| PROKKA | 1.14.5 |
|
| purge_dups | 1.2.3 |
|
| samtools | 1.18 |
|
| sanger-tol/ascc | - |
|
| sanger-tol/
| 0.3.0 |
|
| Seqtk | 1.3 |
|
| Singularity | 3.9.0 |
|
| TreeVal | 1.2.0 |
|
| YaHS | 1.1a.2 |
|
- —Wellcome Trust
- —Gordon and Betty Moore Foundation
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMarine Sponges and Natural Products · Genomics and Phylogenetic Studies · Microbial Natural Products and Biosynthesis
Species taxonomy
Eukaryota; Opisthokonta; Metazoa; Porifera; Demospongiae; Heteroscleromorpha; Clionaida; Clionaidae; Cliona; Cliona cf. orientalis Thiele, 1900 (NCBI:txid281731).
Background
The demosponge Cliona orientalis (Thiele, 1900) is widely distributed in the Indo-Pacific region, where it accelerates coral reef erosion due to its significant bioeroding capacity ( Schönberg et al., 2017). Like other members of the Cliona viridis species complex, C. orientalis is associated with intracellular dinoflagellates of the family Symbiodiniaceae ( LaJeunesse et al., 2018; Ramsby et al., 2018a), whose photochemical activity promotes the energetically demanding excavation rates of the host ( Achlatis et al., 2021). In C. orientalis, the Symbiodiniaceae community is highly conserved across geographic regions, and consists primarily of Gerakladium endoclionum, which belongs to one of the more ancestral Symbiodiniaceae lineages ( Hill et al., 2011; LaJeunesse et al., 2018; Ramsby et al., 2017; Ramsby et al., 2018a; Schönberg & Loh, 2005). The Symbiodiniaceae play a key role in the direct assimilation of inorganic carbon and nitrogen within this phototrophic sponge, as well as in the recycling of host nitrogenous waste ( Achlatis et al., 2018; Achlatis et al., 2019). In addition to algal symbionts, C. orientalis harbours a sparse prokaryotic community dominated by Alphaproteobacteria ( Ramsby et al., 2018b). A recent metagenomic study indicates that the dominant prokaryotes associated with C. orientalis are affiliated to Parvibaculales ( Robbins et al., 2021); notably, bacteria belonging to the family Parvibaculaceae were found associated with cultured Symbiodiniaceae and possess genes that could be involved in bacterial-algal interactions, such as a metabolic potential for vitamin B _12 _biosynthesis ( Shoguchi et al., 2024). However, the prokaryotic contribution to Cliona metabolic processes appears to be limited, at least in the outer sponge layer ( Achlatis et al., 2018; Achlatis et al., 2019).
Similar to cnidarian-Symbiodiniaceae associations, the symbiosis is destabilised under severe thermal stress, leading to the onset of bleaching and mortality ( Ramsby et al., 2018a). Remarkably, sponge-Symbiodiniaceae relationships show higher thermotolerance compared to coral symbioses ( Ramsby et al., 2018a; Schönberg et al., 2008), suggesting that distinct molecular mechanisms may govern these mutualistic interactions. Hence, the genome assembly of C. cf. orientalis and the sequence data of its dinoflagellate endosymbiont G. endoclionum provides an unprecedented opportunity for better understanding the molecular basis underlying the adaptive capacity of this resilient symbiosis, and elucidating the ecology and evolution of host-Symbiodiniaceae relationships.
Furthermore, the genome of C. cf. orientalis represents a valuable resource for enhancing our understanding of the molecular mechanisms underpinning sponge bioeroding capacity. Recent studies on Cliona species belonging to the C. viridis complex suggest that the dissolution of calcium carbonate (CaCO 3) is promoted by the release of protons from intracellular vesicles at the etching sites, and that carbonic anhydrase enzymes may convert the resulting bicarbonate ions to carbon dioxide, which may be utilized by the sponge-associated Symbiodiniaceae ( Achlatis et al., 2021; Webb et al., 2019). However, the mechanisms governing the active transport of protons, as well as the removal of calcium ions from the dissolution site, have yet to be fully elucidated ( Achlatis et al., 2021; Sullivan & Faulkner, 1990; Webb et al., 2019). Following the chemical dissolution of CaCO 3, the CaCO _3 _chips are mechanically removed ( Zundelevich et al., 2007), possibly via tissue coordination pathways formed by myocyte-like cells ( Webb et al., 2019). The Cliona genome holds the potential to provide key insights into the regulation of both the chemical and mechanical mechanisms involved in the complex process of bioerosion.
Genome sequence report
Sequencing data
The genome of a specimen of Cliona cf. orientalis ( Figure 1) was sequenced using Pacific Biosciences single-molecule HiFi long reads, generating 38.47 Gb (gigabases) from 4.11 million reads. Based on the estimated genome size, the sequencing data provided approximately 90.0x coverage of the host genome. Chromosome conformation Hi-C data produced 106.35 Gb from 704.32 million reads. Table 1 summarises the specimen and sequencing information.
In-situ image of the Cliona cf. orientalis individual (odCliOrie1) used for sequencing.The individual was collected from Davies Reef on the Great Barrier Reef.
Table 1.: Specimen and sequencing data for Cliona cf. orientalis.
Assembly statistics
The primary haplotype was assembled, and contigs corresponding to an alternate haplotype were also deposited in INSDC databases. The assembly was improved by manual curation, which corrected 201 misjoins or missing joins and removed 81 haplotypic duplications. These interventions reduced the total assembly length by 32.33%, decreased the scaffold count by 77.49%, and also decreased the scaffold N50 by 1.89%. The final assembly has a total length of 217.17 Mb in 307 scaffolds, with 216 gaps, and a scaffold N50 of 9.97 Mb ( Table 2).
Table 2.: Genome assembly data for Cliona cf. orientalis.
The snail plot in Figure 2 provides a summary of the assembly statistics, indicating the distribution of scaffold lengths and other assembly metrics. Figure 3 shows the distribution of scaffolds by GC proportion and coverage. Figure 4 presents a cumulative assembly plot, with separate curves representing different scaffold subsets assigned to various phyla, illustrating the completeness of the assembly.
Genome assembly of Cliona cf. orientalis, odCliOrie1.1: metrics.The BlobToolKit snail plot provides an overview of assembly metrics and BUSCO gene completeness. The circumference represents the length of the whole genome sequence, and the main plot is divided into 1,000 bins around the circumference. The outermost blue tracks display the distribution of GC, AT, and N percentages across the bins. Scaffolds are arranged clockwise from longest to shortest and are depicted in dark grey. The longest scaffold is indicated by the red arc, and the deeper orange and pale orange arcs represent the N50 and N90 lengths. A light grey spiral at the centre shows the cumulative scaffold count on a logarithmic scale. A summary of complete, fragmented, duplicated, and missing BUSCO genes in the set is presented at the top right. An interactive version of this figure is available at https://blobtoolkit.genomehubs.org/view/GCA_963930775.1/dataset/GCA_963930775.1/snail.
Genome assembly of Cliona cf. orientalis, odCliOrie1.1: BlobToolKit GC-coverage plot.Blob plot showing sequence coverage (vertical axis) and GC content (horizontal axis). The circles represent scaffolds, with the size proportional to scaffold length and the colour representing phylum membership. The histograms along the axes display the total length of sequences distributed across different levels of coverage and GC content. An interactive version of this figure is available at https://blobtoolkit.genomehubs.org/view/GCA_963930775.1/dataset/GCA_963930775.1/blob.
Genome assembly of Cliona cf. orientalis, odCliOrie1.1: BlobToolKit cumulative sequence plot.The grey line shows cumulative length for all scaffolds. Coloured lines show cumulative lengths of scaffolds assigned to each phylum using the buscogenes taxrule. An interactive version of this figure is available at https://blobtoolkit.genomehubs.org/view/GCA_963930775.1/dataset/GCA_963930775.1/cumulative.
Most of the assembly sequence (98.3%) was assigned to 19 chromosomal-level scaffolds. These chromosome-level scaffolds, confirmed by Hi-C data, are named according to size ( Figure 5; Table 3).
Genome assembly of Cliona cf. orientalis: Hi-C contact map of the odCliOrie1.1 assembly, visualised using HiGlass.Chromosomes are shown in order of size from left to right and top to bottom. An interactive version of this figure may be viewed at https://genome-note-higlass.tol.sanger.ac.uk/l/?d=I1ESe8w9TSqDpEz7j8Lrrw.
Table 3.: Chromosomal pseudomolecules in the genome assembly of Cliona cf. orientalis, odCliOrie1.
The mitochondrial genome was also assembled. This sequence is included as a contig in the multifasta file of the genome submission and as a standalone record in GenBank.
While sequence data associated with the Symbiodiaceae symbiont were found in the sample, low coverage (~2×) precluded the generation of a complete assembly.
Assembly quality metrics
The primary haplotype has a QV of 58.0, and the combined primary and alternate assemblies achieve an estimated QV of 48.5 ( Table 2). The k-mer completeness for the primary haplotype is 60.50%, and for the alternate haplotype it is 91.43%. The combined primary and alternate assemblies achieve a k-mer completeness of 99.62% ( Table 2). BUSCO v.5.5.0 analysis using the metazoa_odb10 reference set ( n = 954) indicated a completeness score of 80.8% (single = 79.4%, duplicated = 1.4%; Table 2).
Metagenome report
Three binned genomes were generated from the metagenome assembly ( Figure 6), of which one, a Parvibaculaceae bacterium ( Figure 7), was classified as a high-quality metagenome assembled genome (MAG) (see methods). For details on binned genomes see Table 4.
Blob plot of base coverage in mapped against GC proportion for sequences in the Cliona cf. orientalis metagenome.Binned contigs are coloured by family. Circles are sized in proportion to sequence length on a square root scale, ranging from 510 to 5,997,640. Histograms show the distribution of sequence length sum along each axis. An interactive version of this figure may be viewed here.
Circular genome map of the Parvibaculaceae bacterium MAG.The outer rings represent coding sequences (CDS) on the forward (red) and reverse (blue) strands, with rRNA (green) and tRNA (purple) annotations. The inner rings depict GC content (black) and GC skew (green and purple), indicating variations in nucleotide composition across the genome.
Genome annotation report
The Cliona cf. orientalis genome assembly (GCA_963930775.1) was annotated at the European Bioinformatics Institute (EBI) on Ensembl Rapid Release. The resulting annotation includes 41,693 transcribed mRNAs from 25,502 protein-coding and 5,705 non-coding genes ( Table 2; https://rapid.ensembl.org/Cliona_orientalis_GCA_963930775.1/Info/Index). The average transcript length is 5,724.28. There are 1.34 coding transcripts per gene and 5.78 exons per transcript.
Methods
Sample acquisition
A specimen of Cliona cf. orientalis specimen ID GHC0000115, ToLID odCliOrie1; Figure 1) was collected from Davies Reef on the Great Barrier Reef (latitude 18.91, longitude 147.7) on 2020-09-23 by SCUBA diving. The specimen was transported in a shaded aquarium to the National Sea Simulator at the Australian Institute of Marine Science (Townsville, Australia) where it was snap frozen in liquid nitrogen and stored at –80°C until further processing.
Nucleic acid extraction
The workflow for high molecular weight (HMW) DNA extraction at the Wellcome Sanger Institute (WSI) Tree of Life Core Laboratory includes a sequence of procedures: sample preparation and homogenisation, DNA extraction, fragmentation and purification. Detailed protocols are available on protocols.io ( Denton et al., 2023). Prior to DNA extraction, the sponge sample was bathed in “L buffer” (10 mM Tris, pH 7.6, 100 mM EDTA, 20 mM NaCl), minced into small pieces using a scalpel and the cellular interior separated from the mesohyl using forceps ( Lopez, 2022).
HMW DNA was extracted using the Automated MagAttract v2 protocol ( Oatley et al., 2023a). For ULI PacBio sequencing, DNA was fragmented using the Covaris g-TUBE method ( Oatley et al., 2023c). Sheared DNA was purified by solid-phase reversible immobilisation, using AMPure PB beads to eliminate shorter fragments and concentrate the DNA ( Oatley et al., 2023b). The concentration of the sheared and purified DNA was assessed using a Nanodrop spectrophotometer and Qubit Fluorometer using the Qubit dsDNA High Sensitivity Assay kit. Fragment size distribution was evaluated by running the sample on the FemtoPulse system.
RNA was extracted from tissue of odCliOrie1 in the Tree of Life Laboratory at the WSI using the RNA Extraction: Automated MagMax™ mirVana protocol ( do Amaral et al., 2023). The RNA concentration was assessed using a Nanodrop spectrophotometer and a Qubit Fluorometer using the Qubit RNA Broad-Range Assay kit. Analysis of the integrity of the RNA was done using the Agilent RNA 6000 Pico Kit and Eukaryotic Total RNA assay.
Sequencing
Pacific Biosciences HiFi circular consensus DNA sequencing libraries were prepared according to the manufacturer’s instructions. Poly(A) RNA-Seq libraries were prepared using the NEB Ultra II RNA Library Prep Kit. DNA sequencing was carried out by the WSI Scientific Operations core using Pacific Biosciences Sequel IIe and Revio instruments (HiFi), while RNA sequencing was performed on anIllumina NovaSeq X instrument. Tissue from odCliOrie1 was processed using the Arima2 kit, and Hi-C data were generated by sequencing on the Illumina NovaSeq 6000.
Genome assembly, curation and evaluation
** Host assembly and curation **
The HiFi reads were assembled using Hifiasm ( Cheng et al., 2021) with the --primary option. Haplotypic duplications were identified and removed using purge_dups ( Guan et al., 2020). The Hi-C reads were mapped to the primary contigs using bwa-mem2 ( Vasimuddin et al., 2019). The contigs were further scaffolded using the provided Hi-C data ( Rao et al., 2014) in YaHS ( Zhou et al., 2023) using the --break option for handling potential misassemblies. The scaffolded assemblies were evaluated using Gfastats ( Formenti et al., 2022), BUSCO ( Manni et al., 2021) and MERQURY.FK ( Rhie et al., 2020).
The mitochondrial genome was assembled using MitoHiFi ( Uliano-Silva et al., 2023), which runs MitoFinder ( Allio et al., 2020) and uses these annotations to select the final mitochondrial contig and to ensure the general quality of the sequence.
The assembly was decontaminated using the Assembly Screen for Cobionts and Contaminants (ASCC) pipeline. Flat files and maps used in curation were generated via the TreeVal pipeline ( Pointon et al., 2023). Manual curation was conducted primarily in PretextView ( Harry, 2022) and HiGlass ( Kerpedjiev et al., 2018), with additional insights provided by JBrowse2 ( Diesh et al., 2023). Scaffolds were visually inspected and corrected as described by Howe et al. (2021). Any identified contamination, missed joins, and mis-joins were amended, and duplicate sequences were tagged and removed. The curation process is documented at https://gitlab.com/wtsi-grit/rapid-curation.
** Host assembly quality assessment **
The Merqury.FK tool ( Rhie et al., 2020), run in a Singularity container ( Kurtzer et al., 2017), was used to evaluate k-mer completeness and assembly quality for the primary and alternate haplotypes using the k-mer databases ( k = 31) that were computed prior to genome assembly.
A Hi-C contact map was produced for the final version of the assembly. The Hi-C reads were aligned using bwa-mem2 ( Vasimuddin et al., 2019) and the alignment files were combined using SAMtools ( Danecek et al., 2021). The Hi-C alignments were converted into a contact map using BEDTools ( Quinlan & Hall, 2010) and the Cooler tool suite ( Abdennur & Mirny, 2020). The contact map is visualised in HiGlass ( Kerpedjiev et al., 2018).
The blobtoolkit pipeline is a Nextflow port of the previous Snakemake Blobtoolkit pipeline ( Challis et al., 2020). It aligns the PacBio reads in SAMtools and minimap2 ( Li, 2018) and generates coverage tracks for regions of fixed size. In parallel, it queries the GoaT database ( Challis et al., 2023) to identify all matching BUSCO lineages to run BUSCO ( Manni et al., 2021). For the three domain-level BUSCO lineages, the pipeline aligns the BUSCO genes to the UniProt Reference Proteomes database ( Bateman et al., 2023) with DIAMOND blastp ( Buchfink et al., 2021). The genome is also divided into chunks according to the density of the BUSCO genes from the closest taxonomic lineage, and each chunk is aligned to the UniProt Reference Proteomes database using DIAMOND blastx. Genome sequences without a hit are chunked using seqtk and aligned to the NT database with blastn ( Altschul et al., 1990). The blobtools suite combines all these outputs into a blobdir for visualisation.
The blobtoolkit pipeline was developed using nf-core tooling ( Ewels et al., 2020) and MultiQC ( Ewels et al., 2016), relying on the Conda package manager, the Bioconda initiative ( Grüning et al., 2018), the Biocontainers infrastructure ( da Veiga Leprevost et al., 2017), as well as the Docker ( Merkel, 2014) and Singularity ( Kurtzer et al., 2017) containerisation solutions.
Table 5 contains a list of relevant software tool versions and sources.
** Metagenome assembly **
The metagenome assembly was generated using metaMDBG ( Benoit et al., 2024) and binned using MetaBAT2 ( Kang et al., 2019). The resulting bin sets were optimised and collectively refined using DAS Tools. PROKKA ( Seemann, 2014) was used to identify tRNAs and rRNAs in each bin, CheckM was used to assess bin completeness/contamination, and GTDB-TK ( Chaumeil et al., 2022) was used to taxonomically classify bins. Taxonomic replicate bins were identified using dRep ( Olm et al., 2017). All bins were assessed for quality and categorised as metagenome-assembled genomes (MAGs) if they met the following criteria: contamination ≤ 5%, presence of 5S, 16S, and 23S rRNA genes, at least 18 unique tRNAs, and either ≥ 90% completeness or ≥ 50% completeness with fully circularised chromosomes. Bins that did not meet these thresholds, or were identified as taxonomic replicates of MAGs, were retained as ‘binned metagenomes’ provided they had ≥ 50% completeness and ≤ 10% contamination. Software tool versions and sources are given in Table 5.
The closed genome of the Parvibaculaceae MAG was annotated using Prokka ( Seemann, 2014) with default parameters against the UniRef database.
Genome annotation
The Ensembl Genebuild annotation system ( Aken et al., 2016) was used to generate annotation for the Cliona cf. orientalis assembly (GCA_963930775.1) in Ensembl Rapid Release at the EBI. Annotation was created primarily through alignment of transcriptomic data to the genome, with gap filling via protein-to-genome alignments of a select set of proteins from UniProt ( UniProt Consortium, 2019).
Wellcome Sanger Institute – Legal and Governance
The materials that have contributed to this genome note have been supplied by a Tree of Life collaborator. The Wellcome Sanger Institute employs a process whereby due diligence is carried out proportionate to the nature of the materials themselves, and the circumstances under which they have been/are to be collected and provided for use. The purpose of this is to address and mitigate any potential legal and/or ethical implications of receipt and use of the materials as part of the research project, and to ensure that in doing so we align with best practice wherever possible. The overarching areas of consideration are:
• Ethical review of provenance and sourcing of the material
• Legality of collection, transfer and use (national and international)
Each transfer of samples is undertaken according to a Research Collaboration Agreement or Material Transfer Agreement entered into by the Tree of Life collaborator, Genome Research Limited (operating as the Wellcome Sanger Institute) and in some circumstances other Tree of Life collaborators.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abdennur N Mirny LA : Cooler: scalable storage for Hi-C data and other genomically labeled arrays. Bioinformatics. 2020;36(1):311–316. 10.1093/bioinformatics/btz 540 31290943 PMC 8205516 · doi ↗ · pubmed ↗
- 2Achlatis M Pernice M Green K : Single-cell visualization indicates direct role of sponge host in uptake of Dissolved Organic Matter. Proc Biol Sci. 2019;286(1916): 20192153. 10.1098/rspb.2019.2153 31795848 PMC 6939258 · doi ↗ · pubmed ↗
- 3Achlatis M Pernice M Green K : Single-cell measurement of ammonium and bicarbonate uptake within a photosymbiotic bioeroding sponge. ISME J. 2018;12(5):1308–1318. 10.1038/s 41396-017-0044-2 29386628 PMC 5932049 · doi ↗ · pubmed ↗
- 4Achlatis M van der Zande RM Webb AE : Photosynthetically stimulated bioerosion in symbiotic sponges: the role of glycerol and oxygen. Coral Reefs. 2021;40(3):881–891. 10.1007/s 00338-021-02091-0 · doi ↗
- 5Aken BL Ayling S Barrell D : The Ensembl gene annotation system. Database (Oxford). 2016;2016: baw 093. 10.1093/database/baw 093 27337980 PMC 4919035 · doi ↗ · pubmed ↗
- 6Allio R Schomaker-Bastos A Romiguier J : Mito Finder: efficient automated large-scale extraction of mitogenomic data in target enrichment phylogenomics. Mol Ecol Resour. 2020;20(4):892–905. 10.1111/1755-0998.13160 32243090 PMC 7497042 · doi ↗ · pubmed ↗
- 7Altschul SF Gish W Miller W : Basic Local Alignment Search Tool. J Mol Biol. 1990;215(3):403–410. 10.1016/S 0022-2836(05)80360-2 2231712 · doi ↗ · pubmed ↗
- 8Bateman A Martin MJ Orchard S : Uni Prot: the Universal Protein Knowledgebase in 2023. Nucleic Acids Res. 2023;51(D 1):D 523–D 531. 10.1093/nar/gkac 1052 36408920 PMC 9825514 · doi ↗ · pubmed ↗