Pose estimation of differential drive robots using deep learning and raw sensor inputs
Gullu Boztas, Mustafa Can Bingol, Omur Aydogmus, Musa Yilmaz

TL;DR
This paper introduces a novel method for estimating a robot's position and orientation using raw sensor data and deep learning, achieving better accuracy than other models.
Contribution
The novelty lies in using raw sensor data directly in deep learning models without feature extraction for pose estimation.
Findings
CNN models outperformed LSTM, GB, and RF in estimating robot position and orientation.
Incorporating real IMU noise improved model accuracy in both simulated and real-world scenarios.
The approach avoids feature extraction, simplifying the estimation pipeline.
Abstract
This paper presents an estimation method for determining the position and orientation of a real mobile robot using raw data from an Inertial Measurement Unit (IMU) sensor, alongside linear and angular velocities obtained from simulation. The dataset was collected using a real TurtleBot3 differential drive wheeled mobile robot in the ROS-Gazebo simulation environment, encompassing 2018 routes-2009 from simulation and 9 from real-world experiments-each consisting of five randomly generated waypoints. To improve the accuracy of the estimation models, noise from the real IMU sensor was incorporated into the input data, and velocities derived from the pure pursuit algorithm were also included. Convolutional Neural Network (CNN), Long Short-Term Memory (LSTM), Gradient Boosting (GB), and Random Forest (RF) models were employed to estimate the robot’s position and orientation, and their…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
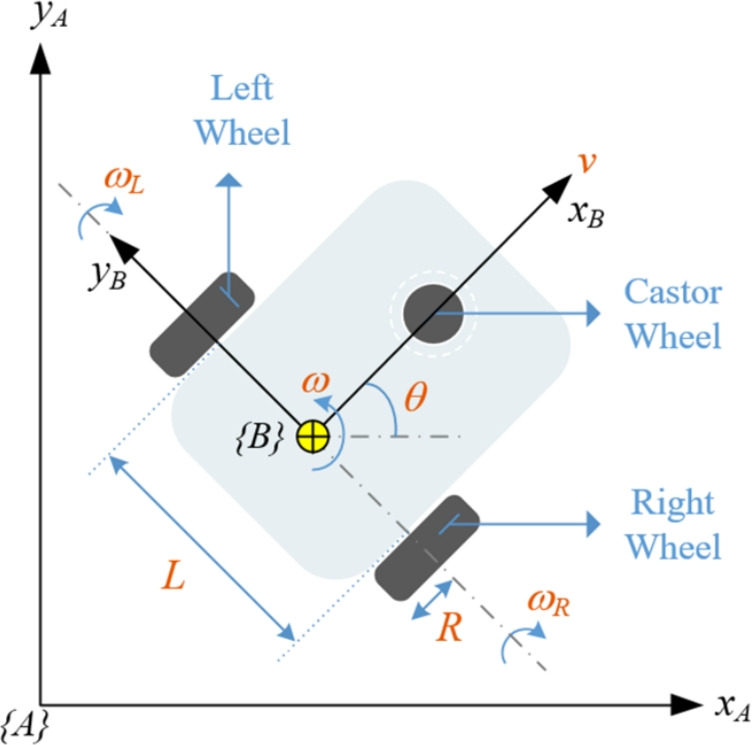 Figure 1
Figure 1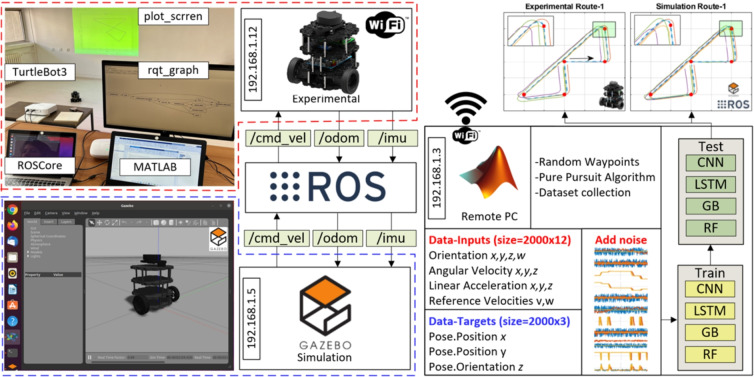 Figure 2
Figure 2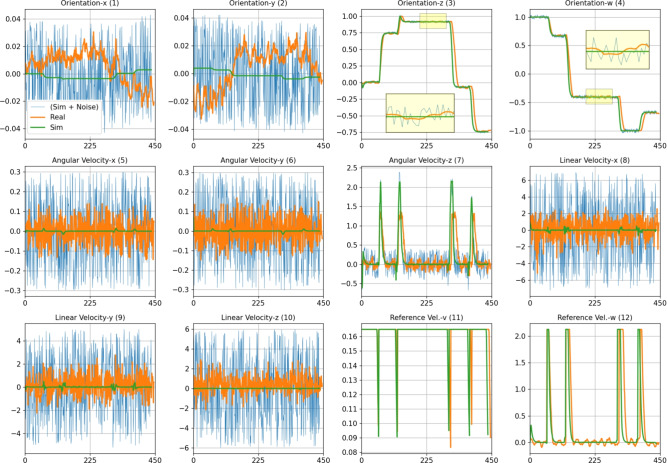 Figure 3
Figure 3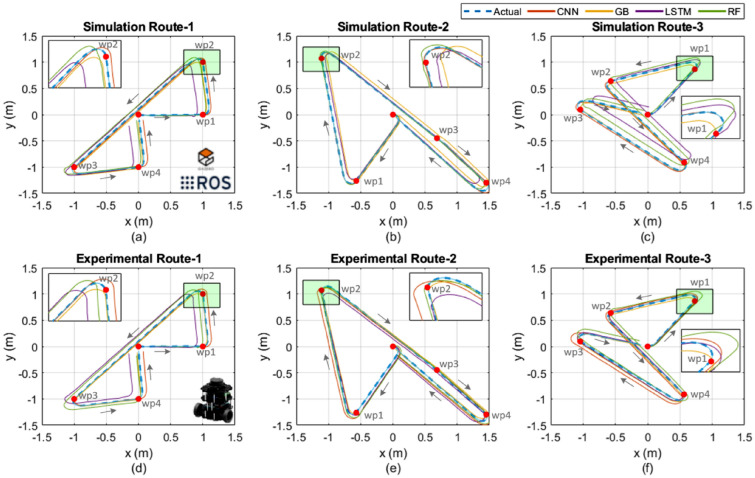 Figure 4
Figure 4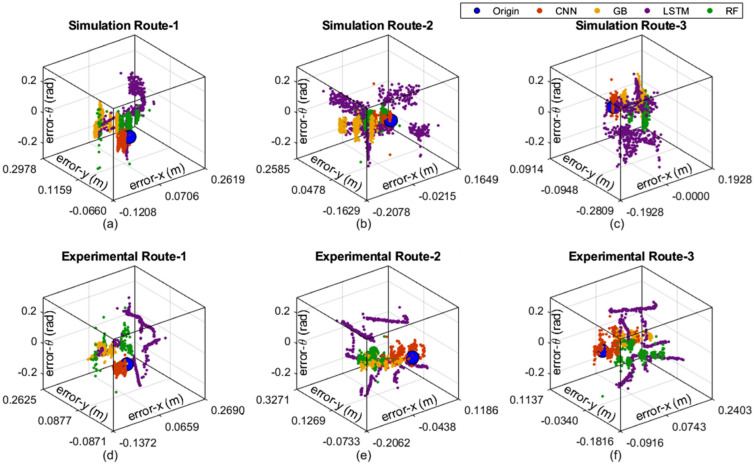 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobotics and Sensor-Based Localization · Robotic Path Planning Algorithms · Inertial Sensor and Navigation
Introduction
Mobile robots have gained widespread popularity in recent decades, witnessing an increasing array of applications. They have transitioned from being merely subjects of research to commercially available products, underscoring the growing significance of studies in this field^1^. The diverse application areas of mobile robots include warehousing^2,3^, package delivery^4^, medical facilities^5^, customer service^6^, emergency response^7^, disaster recovery^8^), space exploration^9^, defense, and entertainment^10^. Mobile robots can be broadly categorized into legged robots and wheeled robots, serving as indoor robots, terrain robots, aerial robots, and underwater robots. Wheeled robots, especially those with easy control and high position accuracy, dominate the application landscape. Within wheeled mobile robots, there are distinctions between non-holonomic and holonomic types. Mathematical representation involves a set of non-integratable first-order differential constraints, assuming no slipping during movement. Developing a suitable controller for stabilization and trajectory tracking of non-holonomic robots is often a challenging task^11^. Accurate localization is a critical requirement for mobile robots^12^. While high-cost products like vision-based and lidar-based localization systems are commonly used for achieving precision, internal measurements offer a cost-effective alternative, enhancing accuracy and reliability. The Inertial Measurement Unit (IMU) sensor emerges as a favorable choice for predicting the robot’s position or localization due to its relatively low cost and easy installation on mobile robots. Despite its advantages, IMU sensors cannot provide absolute position or localization information. IMU sensors typically include gyroscope, accelerometer, and magnetometer as optional components, enabling the measurement of orientation, angular velocity, and linear acceleration in 3D. Consequently, the position or localization information must be calculated using the sensor’s data. Various approaches have been proposed in the literature for position and location estimation using IMU sensors, including combining IMU with LiDAR and encoder measurements to estimate robot position on complex terrains^13^.
Moreover, artificial neural networks are employed to extract valuable information from sensor data across various domains. In a study by Bangaru et al.^14^, data from electromyography and IMU sensors on a wristband developed for workers were classified using an artificial neural network, facilitating the analysis of worker movements. Convolutional Neural Network (CNN), an architecture comprising specialized layers, has found applications in diverse areas. Ding et al.^15^ utilized a CNN to analyze data from an accelerometer sensor placed in cargo boxes, determining the cause of box damage. Similarly, Suri and Gupta^16^ employed a CNN architecture to classify data from a wearable IMU, achieving sign language recognition. Long Short-Term Memory (LSTM), another artificial neural network architecture with specialized layers akin to a recurrent neural network (RNN), has been used in Peng et al.’s^17^ study to classify the behaviors of Japanese black cattle based on signals from video and IMU data. Studies combining these architectures are prevalent in the literature. For instance, Kim et al.^18^ investigated position estimation from IMU data using both CNN and LSTM structures. In another study, Zhao and Obonyo^19^ achieved posture estimation by utilizing data from multiple IMU sensors on a worker with both CNN and LSTM structures. Various machine learning algorithms are employed in processing sensor data. Qaroush et al.^20^ classified data received from IMU sensors on the hand using machine learning methods to recognize Arabic sign language. The Random Forest (RF) algorithm, a popular choice, was used by Kareem et al.^21^ to recognize walking behaviors of mobile phone users through gyroscope data. Additionally, Langroodi et al.^22^ performed action recognition using an RF-based classifier with data from IMU and GPS sensors on construction machines. The Gradient Boosting (GB) algorithm, frequently utilized in the literature, was employed by Tan et al.^23^ to predict ground reaction force using IMU and GB algorithms. Liu et al.^24^ measured runner performances with IMU and artificial intelligence algorithms, including CNN, GB, and MLP. Studies combining these two machine learning algorithms are also present, as seen in the work of Kiangala and Wang^25^. In their study, a regression model using the GB algorithm was followed by the creation of a classification model using the RF algorithm and the output of the regression model, exemplifying the integration of both algorithms in data classification after a regression process using the GB algorithm. In this study, the objective was to estimate the position and orientation of a differential drive wheeled mobile robot (DDWMR) using raw data from an IMU, in conjunction with reference linear velocity and reference angular velocity. The training and validation datasets were collected within the Gazebo robot simulator environment, incorporating IMU sensor noises from the real robot to enhance simulation realism. To reduce the sim-to-real gap, real IMU noise characteristics were added to the simulation data. The noise was modeled as zero-mean Gaussian noise based on empirical measurements from the physical IMU. The standard deviation was estimated from stationary sensor recordings and applied independently to each axis. This ensured that the simulated IMU outputs reflected both the sensor bias and high-frequency variability observed in the real device. The magnitude of the added noise corresponded to 0.02 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m/s^2$$\end{document} for accelerometer channels and 0.001 rad/s for gyroscope channels, consistent with the noise levels reported in the sensor datasheet. The dataset comprises 2009 different routes, each containing 12 inputs and 3 targets, with 5 randomly generated waypoints per route. The input data include x, y, z, w quaternion orientation, angular velocities of x, y, z, linear acceleration of x, y, z, and reference linear and angular velocities. The target outputs consist of the robot’s position x, position y, and orientation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} , measured using an odometry sensor. CNN, LSTM, GB, and RF models were trained and validated using this dataset. To assess model performance, a test dataset comprising 9 routes was collected from a real TurtleBot3 DDWMR. The analysis of model performance on the test dataset revealed consistent results between simulation and experimentation for all tested routes, with the CNN model exhibiting the best overall accuracy based on performance metrics.
Materials and methods
Problem descriptions
In this study, the TurtleBot3-Burger was used to collect data for the training and testing of estimation algorithms. Widely recognized in the literature, this robot is favored for its open-source features catering to developers. The TurtleBot3-Burger is a non-holonomic mobile robot characterized by constraint velocities^26^. Its technical specifications include a maximum translational velocity of 0.22 m/s, a maximum rotational velocity of 162.72 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^\circ /s$$\end{document} , and a maximum payload capacity of approximately 15 kg. The robot’s dimensions are 138 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 178 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 192 mm, with a weight of 995 g, including a single board computer, battery, and default sensors. It can traverse a maximum step of 10 mm. The mechanical and dynamic properties of the TurtleBot3-Burger can be effectively simulated using the Gazebo simulator-an open-source 3D simulation environment. This simulator provides a realistic depiction of robot dynamics and rendering views in complex indoor and outdoor environments. Supporting various physics engines such as ODE, Bullet, Simbody, DART, etc., the Gazebo simulator allows for the simulation of both the developed robots and algorithms, providing a realistic scenario for testing and development. Moreover, the simulator offers real-time sensor data with noise, and all actuators and sensors can be connected via TCP/IP as a remote interface service^1^. In this study, the TurtleBot3-Burger was controlled using a traditional pure pursuit algorithm (PPA). The control algorithm was implemented in MATLAB and communicated with the robot operating system (ROS). ROS distribution Noetic served as a bridge between the MATLAB control algorithm and the real robot/Gazebo simulator environments.Fig. 1. Free body diagram of differential drive wheeled mobile robot.
The kinematics equations of the DDWMR can be derived by using the parameters given in Fig. 1 The robot motion is represented by linear velocity v (m/s) and angular velocity w (rad/s). The equations of forward kinematics are given in Eqs. (1) and (2). The inverse kinematics of the robot is given in Eq. (3) and (4).Fig. 2. Experimental and simulation framework for development and testing of algorithms using TurtleBot3.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & \begin{aligned} v = \frac{R}{2}\left( \omega _R + \omega _L\right) \end{aligned} \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & \begin{aligned} \omega = \frac{R}{L}\left( \omega _R - \omega _L\right) \end{aligned} \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & \begin{aligned} \omega _L = \frac{1}{R}\left( v - \frac{\omega L}{2}\right) \end{aligned} \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & \begin{aligned} \omega _R = \frac{1}{R}\left( v + \frac{\omega L}{2}\right) \end{aligned} \end{aligned}$$\end{document}where R is the wheel radius of the motorized wheels, L is the wheelbase of the robot, wL and wR are the angular velocity of left and right wheel, respectively. The PPA requires the actual positions of the robot x, y, z and the waypoints xy in order to determine the references of the linear and actual velocities. The kinematic model of the robot can be expressed as shown in Eq. 5.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} \begin{bmatrix} \dot{x} \\ \dot{y} \\ \dot{\theta } \end{bmatrix} = \begin{bmatrix} cos(\theta ) & -sin(\theta ) & 0 \\ sin(\theta ) & cos(\theta ) & 0 \\ 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} v \\ 0 \\ \omega \end{bmatrix} \end{aligned} \end{aligned}$$\end{document}The PPA calculates the distance between robot pose and the waypoints. In addition, it calculates the course of the path. The equations of the PPA are given in Eq.6 and Eq.7.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & \begin{aligned} d = \sqrt{\left( x_{ps}-x_{wp}\right) ^2+\left( y_{ps}-y_{wp}\right) ^2} \end{aligned} \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & \begin{aligned} c = atan2\left( \left( y_{wp}-y_{ps}\right) ,\left( x_{wp}-x_{ps}\right) \right) \end{aligned} \end{aligned}$$\end{document}where d is the distance between robot pose and the reference waypoint. c is the course of path. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{ps}$$\end{document} any \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{ps}$$\end{document} are the robot positions on the xy-plane. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{wp}$$\end{document} any \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{wp}$$\end{document} are the waypoints on the xy-plane.
The block diagram of the system used for data collection is shown in Fig. 2. The orientation x, y, z, w, angular velocity x, y, z, linear acceleration x, y, z, and references of linear and angular velocities are used as inputs for training models. Each input is reproduced by using one-unit delay and two unit delays. Thus, the input size was increased from 12 to 36. The robot was traveled for 5 randomly assigned waypoints using PPA. This situation was repeated 2009 times to create a ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t\times$$\end{document} 2009 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 12 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 3) dataset. The real IMU sensor noise were added for all simulation inputs in order to obtain realistic results for training procedure. The output signals of the real and simulation IMU sensors are given in Fig. 3.Fig. 3. Comparison of IMU sensor outputs from simulation with added noise (Sim + Noise), real experimental data (Real), and ideal simulation data (Sim) during the training process. Plots include orientation (quaternion) components, angular velocities, linear velocities, and reference velocities across x, y, z, and w axes. Highlighted areas indicate regions of higher noise and discrepancies between real and simulated data.
Algorithms for prediction
The collected dataset was divided into three different datasets for training, validation and testing. All sensor inputs and target values were normalized prior to training. Each input channel was standardized using the mean and standard deviation computed from the training set, and the same transformation was applied to the validation and test sets. The same procedure was used for the target values. This normalization ensured that all features were on a comparable scale, which improved training stability and convergence. The dataset used in the CNN algorithm have 3 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 12 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} N inputs and 3 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} N outputs. Multiplying by 3 at the input represents the results at moments t, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t-1$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t-2$$\end{document} . The IMU provides the data of quaternion orientations (x, y, z, w), angular velocities (x, y, z), and linear acceleration (x, y, z). In addition, the data of the reference linear and angular velocities are determined by the PPA. Thus, 10 different data from IMU sensor and 2 data from PPA were used as inputs for the proposed estimation algorithm. N is the input and output component of the dataset represents the number of the total steps in the dataset. Additionally, the number 3 in the output of the dataset presents the position variable on the x-axis \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Delta (x) = x(t) - {x(t - 1)}$$\end{document} and y-axis \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Delta (y) = y(t) - {y(t - 1)}$$\end{document} , and the orientation angle \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} variables of the mobile robot. The outputs of the dataset used in GB, LSTM and RF algorithms were the same and the input size was 1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 12 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} N. The number 1 in the input datasets represents the results at time t. GB, LSTM, and RF algorithms are also trained using data having inputs in 3 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 12 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} N size just like CNN. However, significant results were not obtained in this situation. Dataset having input in the 1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 12 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} N size was used in other algorithms except for CNN due to the computational time of the CPU. In addition, datasets with an input size of 3 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 12 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} N were used in the CNN algorithm to be more reliable of the convolution process. The CNN architecture is shown in Algorithm 1. For the CNN, all convolutional layers used kernel size 3 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 3, stride 1, and “same” padding, followed by ReLU activations. The final dense layers had 128 ReLU units and 3 linear units. For the LSTM model, we used a single LSTM layer with 1024 hidden units (tanh activation, sigmoid recurrent activation), followed by a dense layer of 1024 ReLU units and a linear output layer. Both models were trained with the Adam optimizer (learning rate 1e-4) and MSE loss. Dropout and Gaussian noise layers were tested but not used in the final version. The filter sizes (32, 64) and LSTM hidden dimension (1024) were selected after preliminary experiments balancing accuracy and computational complexity. Smaller models showed underfitting, while larger ones increased computation without noticeable accuracy gains.
The data is reshaped as 1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} N size in the Flatten layer after performing the necessary feature extraction in the Convolution Layer^27^. The reshaped data is subjected to mathematical operations in Dense layers^28^ to produce output. The dense layer was used to establish associations between all inputs and outputs, where each neuron connects to every neuron in the preceding layer. This layer serves to connect the outputs of specialized Convolutional and LSTM layers. The mathematical relationships within this layer, along with learning algorithms, are utilized to minimize residual errors. The LSTM structure being another deep learning structure is given in Algorithm 2. LSTM layer is a specialized architecture which records or forgets the input data depending on their relevance to one another and the result^29^. Detailed information about the layers and activation functions in Algorithm 1 and Algorithm 2 can be found in^30,31^. Adam optimization algorithm was used when both CNN and LSTM architectures were trained. In this study, ADAM, a derivative-based learning algorithm, was used. The ReLU activation function was employed to expedite the calculation of derivative operations. The total epochs of the training took 25. The learning rate applied throughout the training was dynamically changed by using learning rate decay function algorithm. Each neural network was trained for 25 epochs with a batch size of 2048. A learning rate scheduler was applied, using 1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 10e-3 for the first 10 epochs, 1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 10e-4 for epochs 10-19, and 1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 10e-5 for epochs 20-25. Early stopping was not employed, since preliminary experiments indicated that 25 epochs with scheduled decay provided stable convergence without overfitting. In this study, the models were trained using differences in positions. These position variances were observed to be quite small in some cases. Consequently, the learning rate was adjusted by decreasing it during training to move closer to the global minimum. ReLU activation is employed in the CNN layers because it is widely adopted in convolutional architectures, providing robustness against vanishing gradients and enabling efficient training. In the LSTM, the tanh activation is used for the hidden state since it normalizes outputs to the range [−1,1], which contributes to stable temporal learning dynamics. The recurrent gates utilize the standard sigmoid activation to regulate information flow.
Algorithm 1CNN Architecture
Algorithm 2LSTM Architecture
Algorithm 3Random Forest (RF)
Algorithm 4Gradient Boosting (GB)
The RF algorithm is based on the generation of the output by using multiple decision trees in parallel. In regression problems such as this study, RF generates the output value by averaging the outputs of the used trees. Detailed information about the algorithm can be found in^32^. In this study, the total number of trees was determined as 25. In addition, there is no limit on the number of leaf nodes. The RF structure was given in Algorithm 3.
The GB algorithm is based on the strong model formed by more than one consecutive weak model. The principle of the algorithm is to create a new estimator by using the residual error from the previous estimator. The detailed information about the algorithm can be found in^32^. In this study, 25 decision trees were used for each output. The each tree was set to have maximum of 10 nodes and the learning rate was chosen as 0.1. Tree numbers of the both RF algorithm and GB algorithm were tested with 1, 10, 25, 50, and 100, respectively. The best result was obtained with 25 as a result of the performance analysis. The GB structure was given in Algorithm 4. For Random Forest and Gradient Boosting, the number of trees was varied in (1, 10, 25, 50, 100). Validation performance improved significantly when increasing from 1 to 25 trees, but showed only marginal gains beyond 25 while increasing computation time. Therefore, 25 trees were selected as a trade-off between accuracy and efficiency.
To investigate the impact of temporal input structure on model performance, an ablation study was conducted by comparing a 1-step CNN model, which uses only the current time step, with a 3-step CNN model that incorporates temporal information from the current and two previous time steps (t, t-1, t-2). The 1-step CNN achieved a training loss of 0.0728 and a test loss of 0.0739, whereas the 3-step CNN significantly outperformed it, with training and test losses of 0.0290 and 0.0282, respectively. These results demonstrate that incorporating a short temporal window substantially improves estimation accuracy by enabling the model to capture short-term temporal dependencies. While the 1-step CNN is computationally lighter, this comes at the cost of reduced predictive performance. This analysis confirms that the superior performance of the CNN model is primarily due to the inclusion of temporal context in the input representation.
Results
The dataset was generated by recording the robot’s traversal along 2,018 distinct routes. In this study, 2,000 routes collected in the simulation environment were used exclusively for training. For validation, the same nine routes that were later executed on the real robot were also evaluated in the simulation environment to ensure consistency between simulated and real-world scenarios. For testing, real-world data collected from the robot operating along these nine routes were directly utilized to assess the model’s performance in real conditions. Approximately 9.1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times 10^5$$\end{document} steps were involved in the training routes, while the verification and testing routes comprised approximately 4 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^3$$\end{document} steps. The dataset occupied 97.5 MB of disk space. The training dataset played a crucial role in training the artificial intelligence model. The validation dataset was employed to refine the hyperparameters of the model during the training process. The performance of the trained system was evaluated using the test dataset. Table 1 presents the Mean Absolute Error (MAE) values of the proposed algorithms. The CNN algorithm achieved the best results for both the validation and test datasets. The RF algorithm demonstrated the best performance in the training dataset. Algorithmic performance was statistically compared using only the test dataset. To assess real-time feasibility, the inference performance of CNN, LSTM, GB, and RF models was measured using a synthetic test set. Average inference times and memory usage are summarized in Table 1. CNN achieved 0.93 ms per prediction with 71 MB memory, while LSTM required 3.97 ms with the same memory footprint. Tree-based methods (GB and RF) were orders of magnitude faster (0.001-0.007 ms) and used negligible memory. These results indicate that while deep learning models may offer higher accuracy, tree-based models provide near-instantaneous inference suitable for computationally constrained real-time robotic applications.Table 1. Training, validation, and testing performance of proposed algorithms (MAE in meters).AlgorithmTrainingValidationTestingTime / ms****Memory / MBCNN0.02880.0281****0.05890.93071.24GB0.10450.11610.32840.0010.00LSTM0.07540.08140.06733.97471.24RF0.02830.07920.20050.0070.00
Three different routes were selected randomly from the test dataset and the actual and estimated routes traveled by the real and simulation robot are shown in Fig.4. The robot traveled towards CCW (counter clockwise) direction in Fig. 4a and Fig. 4b. The robot traveled CW (clockwise) and CCW directions in the last route as shown in Fig. 4c. The results showed that the estimated routes were best obtained by CNN for simulation and experimental tests.Fig. 4. Experimental and simulation results for actual and estimated routes; Route-1 waypoints: [1 0; 1 1; -1 -1; 0 -1; 0 0], Route-2 waypoints: [-0.5692 -1.2615; -1.1086 1.0704; 0.6845 -0.4487; 1.4507 -1.2967; 0 0], and Route-3 waypoints: [0.7281 0.8641; -0.5719 0.6391; 0.5653 -0.9122; -1.0430 0.0951; 0 0] – (a) Sim. Route 1, (b) Sim. Route 2, (c) Sim. Route 3, (d) Exp. Route 1, (e) Exp. Route 2, (f) Exp. Route 3.
The estimation errors of the pose-x, pose-y, and orientation- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} are given in Fig. 5 for all models. The blue point was placed at the origin of the coordinates in the figures in order to show easy comparison of the estimation errors. It can be observed that the CNN model gives the values closest to zero errors for all estimation axes. LSTM estimated the far points from the zero error point compared to other estimation models for both simulation and experimental routes.Fig. 5. Estimation errors of experimental and simulation results; (a) Sim. Route 1, (b) Sim. Route 2, (c) Sim. Route 3, (d) Exp. Route 1, (e) Exp. Route 2, (f) Exp. Route 3.
The performance metrics of the models were calculated by using the average of the error square (MSE), the square root of the average of the error square (RMSE), the mean absolute error of N predicting series (MAE), and the coefficient of how well the values fit compared to the actual values ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R^2$$\end{document} ).
Table 2 presents a comprehensive performance evaluation of four machine learning models-CNN, GB, LSTM, and RF-across three distinct routes. The models’ predictive accuracy for trajectory coordinates (x, y) and orientation ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} ) was assessed using both simulated (Sim.) and experimental (Exp.) datasets, with performance measured using MSE, RMSE, MAE, and the coefficient of determination ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R^2$$\end{document} ). A key and unambiguous finding is the superior performance of the CNN model across all routes, conditions, and evaluation metrics. For simulated data, CNN consistently achieved \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R^2$$\end{document} values exceeding 0.99 and extremely low error rates (e.g., MSE on the order of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^{-6}$$\end{document} ), indicating a near-perfect fit. Although its performance slightly declined when applied to the noisier experimental data, it remained robust, with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R^2$$\end{document} values consistently above 0.92. In contrast, the GB, LSTM, and RF models constituted a clear second tier, displaying significantly higher error metrics and lower \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R^2$$\end{document} values, generally ranging from 0.60 to 0.84. Another noteworthy observation is that all models performed better on simulated data than on experimental data, a predictable outcome reflecting the idealized conditions of simulations. Notably, the prediction of orientation ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} ) was exceptionally accurate for the CNN model, often yielding \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R^2$$\end{document} values above 0.999, suggesting that its architecture is particularly well-suited for capturing rotational dynamics in this context.Table 2. Combined comparison of model performance across three routes (1, 2, and 3), various models, and prediction types (x, y, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} ).RouteStudyMetricCNNGBLSTMRFxy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} xy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} xy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} xy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} 1Sim.MSE1.51E-061.37E-060.0005634.74E-054.05E-050.02084.74E-054.71E-050.00974.97E-054.68E-050.0116RMSE0.00120.00120.02370.00690.00640.14430.00690.00690.09840.0070.00680.1077MAE0.0004870.0004960.0190.0020.00180.11060.00130.00120.03350.00160.00160.0375 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R^2$$\end{document} 0.99190.99090.99980.63210.67140.99090.63740.60370.99640.70270.67560.9957Exp.MSE1.29E-058.09E-060.0002244.21E-053.91E-050.01774.13E-053.96E-050.00496.20E-054.86E-050.000824RMSE0.00360.00280.0150.00650.00630.13320.00640.00630.07030.00790.0070.0287MAE0.00230.00190.01020.00280.00230.11020.00270.00230.010.00290.00250.013 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R^2$$\end{document} 0.92930.94380.99990.68090.6580.99220.68220.64250.99810.65480.67520.99972Sim.MSE6.68E-071.18E-060.000631.99E-053.60E-050.04062.16E-054.09E-050.02761.90E-053.66E-050.0618RMSE0.0008170.00110.02510.00450.0060.20150.00460.00640.16620.00440.00610.2486MAE0.0003990.0004460.01740.00130.00190.11720.0009470.00120.03590.0009840.00130.0399 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R^2$$\end{document} 0.9940.99440.99980.76640.79720.98270.7620.76330.98980.80180.8160.9772Exp.MSE6.81E-061.17E-050.06582.16E-053.62E-050.03642.13E-053.36E-050.03122.33E-053.59E-050.0402RMSE0.00260.00340.25650.00470.0060.19090.00460.00580.17670.00480.0060.2005MAE0.00190.00260.02780.0020.00290.11790.00210.00290.02510.00210.00290.0239 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R^2$$\end{document} 0.93720.94180.97620.75450.78380.98450.75690.79110.98850.75620.81160.98533Sim.MSE9.82E-076.89E-070.0006592.85E-051.98E-050.06894.81E-052.91E-050.01793.00E-052.12E-050.0446RMSE0.0009910.000830.02570.00530.00450.26250.00690.00540.13380.00550.00460.2111MAE0.0004310.000420.01930.00170.00140.13220.00130.00110.03790.00120.00110.0426 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R^2$$\end{document} 0.9950.99480.99980.81990.82930.97750.68570.71560.9950.8340.83720.9874Exp.MSE1.42E-058.70E-060.07944.75E-052.38E-050.04084.41E-051.72E-050.02865.47E-053.21E-050.0446RMSE0.00380.00290.28190.00690.00490.2020.00660.00410.1690.00740.00570.2113MAE0.00260.0020.03270.0030.00230.12960.0030.00220.02930.00310.00240.0285 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R^2$$\end{document} 0.92380.93270.97880.70180.79850.98730.68610.82150.99230.70430.76930.988The studies include both simulated (Sim.) and experimental (Exp.) data. Lower is better for MSE, RMSE, MAE; higher is better for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R^2$$\end{document} .
Table 3 presents the mean ± standard deviation of the MSE for all models across the three routes, considering both simulated (Sim.) and experimental (Exp.) data. Each model’s results are summarized in two rows, with the first row showing simulated data and the second row showing experimental data. This format allows for a clear comparison of the variability and accuracy of each model while highlighting the consistency of performance between simulation and real-world conditions. Only MSE is reported in this revised table to focus on a single, widely recognized performance metric.Table 3. Mean ± standard deviation of MSE across three routes for Simulated and Experimental data.ModelDatax \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(mean \pm std. dev.)$$\end{document} y \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(mean \pm std. dev.)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(mean \pm std. dev.)$$\end{document} CNNSim. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.05 \times 10^{-6} \pm 3.47 \times 10^{-7}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.08 \times 10^{-6} \pm 2.87 \times 10^{-7}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$6.17 \times 10^{-4} \pm 4.02 \times 10^{-5}$$\end{document} Exp. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.13 \times 10^{-5} \pm 3.22 \times 10^{-6}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$9.50 \times 10^{-6} \pm 1.58 \times 10^{-6}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$4.85 \times 10^{-2} \pm 3.46 \times 10^{-2}$$\end{document} GBSim. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.19 \times 10^{-5} \pm 1.15 \times 10^{-5}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.21 \times 10^{-5} \pm 8.89 \times 10^{-6}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$4.34 \times 10^{-2} \pm 1.97 \times 10^{-2}$$\end{document} Exp. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.71 \times 10^{-5} \pm 1.12 \times 10^{-5}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.30 \times 10^{-5} \pm 6.64 \times 10^{-6}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.16 \times 10^{-2} \pm 1.00 \times 10^{-2}$$\end{document} LSTMSim. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.90 \times 10^{-5} \pm 1.23 \times 10^{-5}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.90 \times 10^{-5} \pm 7.47 \times 10^{-6}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.84 \times 10^{-2} \pm 7.32 \times 10^{-3}$$\end{document} Exp. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.56 \times 10^{-5} \pm 1.02 \times 10^{-5}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.01 \times 10^{-5} \pm 9.47 \times 10^{-6}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$2.16 \times 10^{-2} \pm 1.18 \times 10^{-2}$$\end{document} RFSim. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.29 \times 10^{-5} \pm 1.27 \times 10^{-5}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.49 \times 10^{-5} \pm 1.05 \times 10^{-5}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.93 \times 10^{-2} \pm 2.08 \times 10^{-2}$$\end{document} Exp. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$4.67 \times 10^{-5} \pm 1.68 \times 10^{-5}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.89 \times 10^{-5} \pm 7.06 \times 10^{-6}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$2.85 \times 10^{-2} \pm 1.97 \times 10^{-2}$$\end{document} Lower values are better.
The proposed algorithms were compared statistically as given in Table 4 by using only the test dataset. Tukey multiple comparison test was used to compare more than one group. As a result of this test, no significant statistical difference was found between only LSTM and RF algorithms. However, there was a significant statistical difference between the other groups. In this case, it shows that LSTM and RF algorithms approach the problem solution with the same perspective while other algorithms produce results independent of each other.Table 4. Tukey HSD multiple comparison results for model MSE on the test dataset. Group 1Group 2Mean Differencep-valueSignificantCNNGB0.00430.9098NoCNNLSTM-0.00150.9957NoCNNRF0.00320.9628NoGBLSTM-0.00580.8077NoGBRF-0.00120.9978NoLSTMRF0.00470.8921NoThe p-values indicate whether differences between model pairs are statistically significant ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha = 0.05$$\end{document} ).
Discussions and conclusions
The precise determination of a mobile robot’s position is crucial for autonomous navigation. Odometry sensors provide position estimates based on wheel encoders, but their accuracy can degrade if wheels slip or rotate without forward motion. To mitigate these limitations, IMU sensors are commonly integrated, offering quaternion, angular, and linear velocities along three axes. When coupled with a robust estimation model, IMUs can deliver highly accurate position information, enhancing reliability while providing a cost-effective solution.
Predicting real-world robot positions based solely on noiseless simulation data is insufficient. Introducing noise to the input data significantly improved model estimation performance. In this study, 2,018 routes were generated to form the datasets for training, validation, and testing. Various architectures-including CNN, LSTM, RF, and GB-were employed for position estimation, with hyperparameters tuned using the validation data.
The superior performance of the CNN can be attributed to its ability to capture short-term temporal dependencies and complex multi-channel sensor correlations, as confirmed by the 1-step vs 3-step ablation study (Train loss: 0.0728 vs 0.0290, Test loss: 0.0739 vs 0.0282). This indicates that the CNN effectively exploits temporal information and multi-channel sensor correlations, which explains its superior accuracy compared to 1-step CNN and other models. In contrast, LSTM and RF models produced similar results but were less effective at exploiting these temporal features, explaining the observed performance gap. The slight decline in CNN performance on real-world data compared to simulation is likely due to unmodeled sensor noise, calibration errors, and environmental variations, highlighting the importance of domain adaptation and robust noise handling for practical deployment.
Compared to traditional methods such as Kalman and particle filters, which require careful noise modeling and may struggle with high-dimensional, multi-sensor inputs, CNNs and other deep learning models learn complex sensor relationships directly from data, enabling real-time inference with minimal manual tuning. While CNN achieved the best accuracy, all learned models offer advantages in adaptability, scalability, and reduced calibration effort, underscoring the potential benefits of data-driven approaches for mobile robot localization.
Several limitations should be noted. The study relies mainly on simulated data with added noise, and the real-world test set is relatively small, potentially limiting generalizability. Scaling the approach to dynamic environments, uneven terrain, or surfaces with variable friction may challenge model accuracy. Wheel slip, which is neglected in this study, could degrade performance in real deployments. Future work should incorporate larger real-world datasets, test in complex and dynamic environments, include wheel-slip compensation, and explore multi-sensor fusion techniques such as attention mechanisms. Model compression methods like pruning or quantization could further enhance computational efficiency.
Overall, the results indicate that IMU sensors, when combined with CNN-based estimation, can provide a reliable alternative for mobile robot positioning without requiring extensive additional sensing, offering promising directions for real-world applications.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Szegedy, C. et al. Going deeper with convolutions. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1–9, 10.1109/CVPR.2015.7298594 (2015).
- 2He, K., Zhang, X., Ren, S. & Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification (2015). ar Xiv:1502.01852.