Enhancing cardiac disease prediction with explainable bidirectional LSTM
Swati Lipsa, Ranjan Kumar Dash, Subhra Debdas, Korhan Cengiz, Pankaj Kumar, Nitai Pal

TL;DR
This paper introduces explainable bidirectional LSTM models for predicting and classifying cardiac diseases using ECG data, improving accuracy and interpretability.
Contribution
The novel contribution is stacking bidirectional LSTM with deep learning for explainable cardiac disease prediction using SHAP explanations.
Findings
The proposed models outperform existing methods in accuracy, precision, f1-score, and recall.
SHAP is used to provide explanations for model predictions, aiding in ECG report annotation.
Abstract
Cardiovascular disorders (heart diseases) are the most prevalent cause of death on a global scale. So early detection and classification increase the likelihood of survival. In the context of machine learning techniques, there is always a need for an accurate and explainable predictive model for detecting various diseases, such as cardiac disorders. The work carried out in this paper stacks bidirectional long short-term memory with deep learning to propose two models. The first model is used to detect cardiac disease with a binary label classification, while the second one classifies cardiac disease, which is a multi-label classification problem. Bidirectional LSTM is used as an approximate algorithm for feature extraction. Deep learning is used for classification purposes. The proposed models are trained and validated over the PTB-XL dataset. The performance of these models is…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12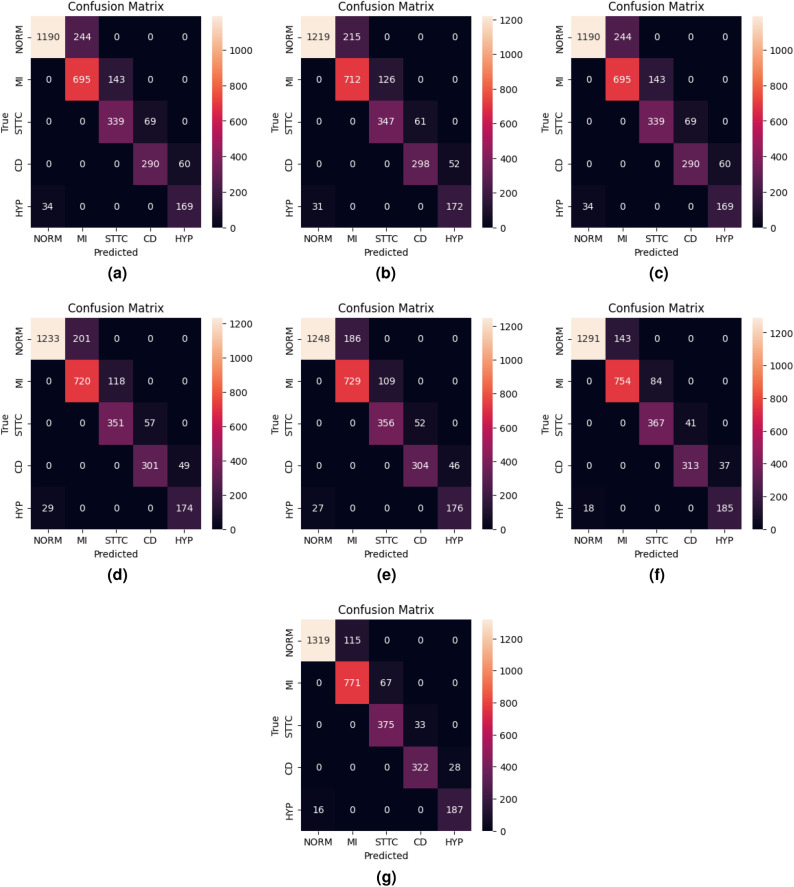 Figure 13
Figure 13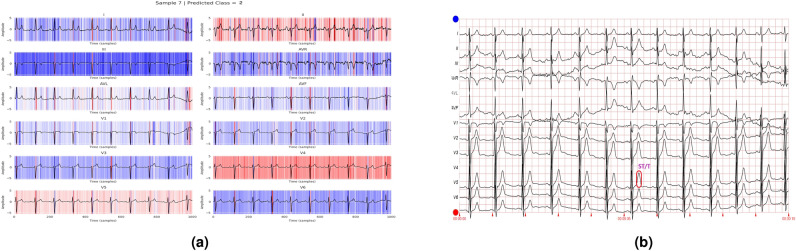 Figure 14
Figure 14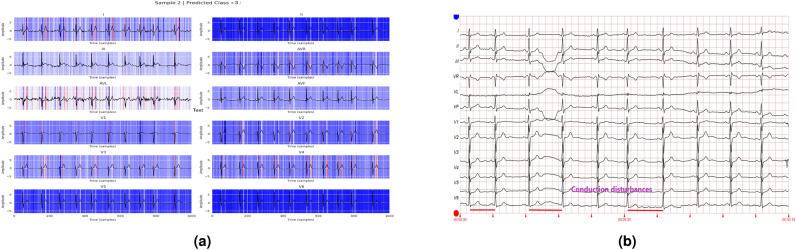 Figure 15
Figure 15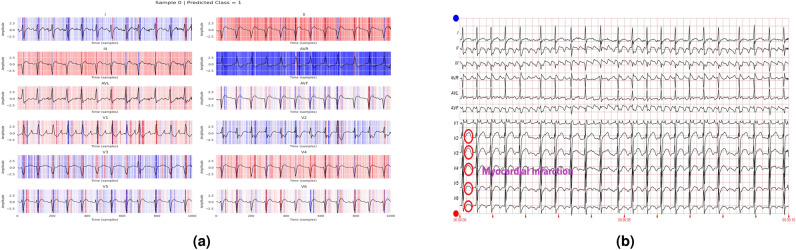 Figure 16
Figure 16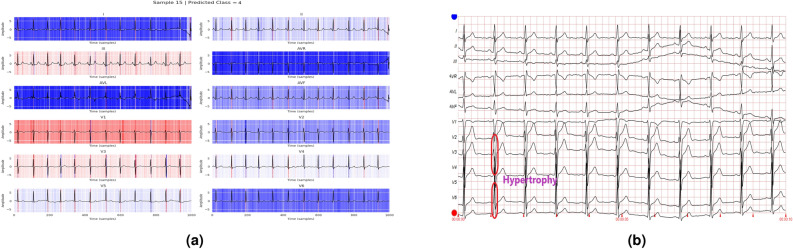 Figure 17
Figure 17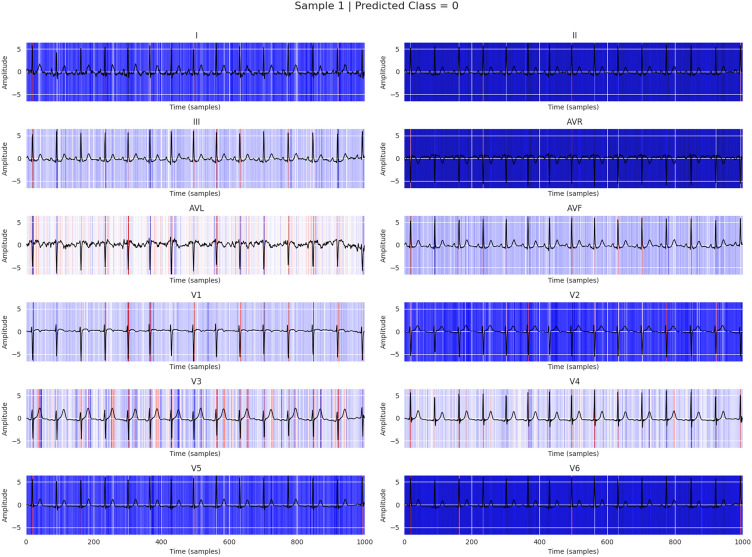 Figure 18
Figure 18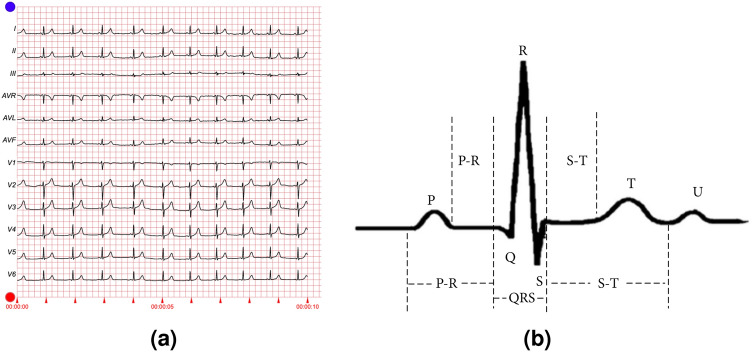 Figure 1
Figure 1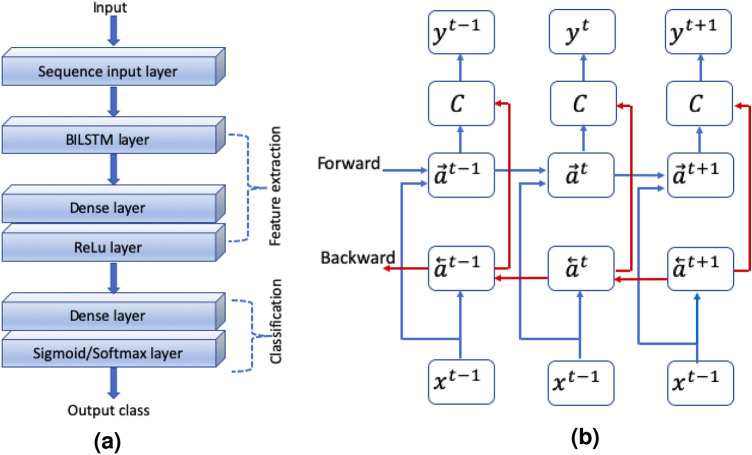 Figure 2
Figure 2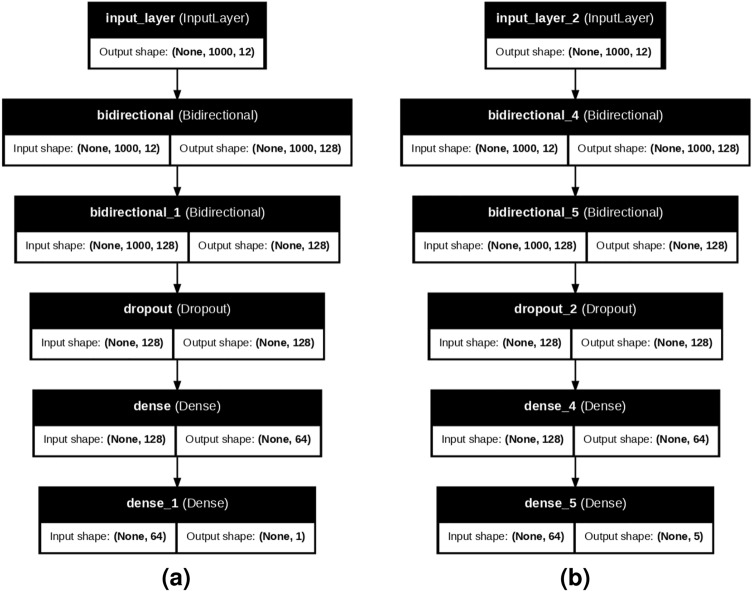 Figure 3
Figure 3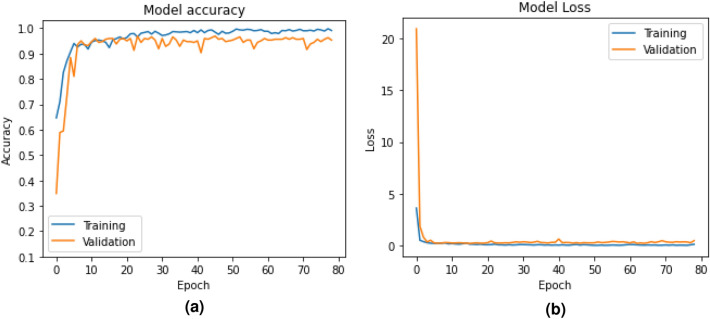 Figure 4
Figure 4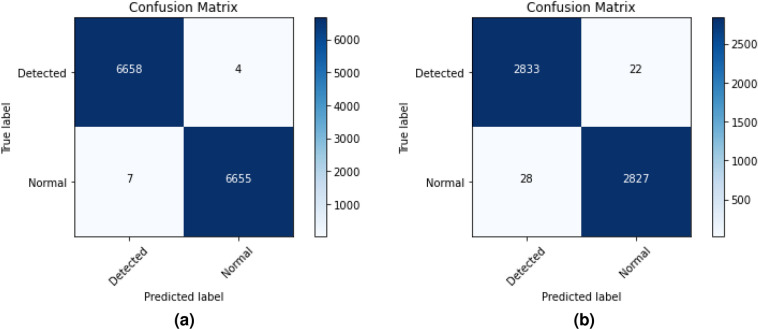 Figure 5
Figure 5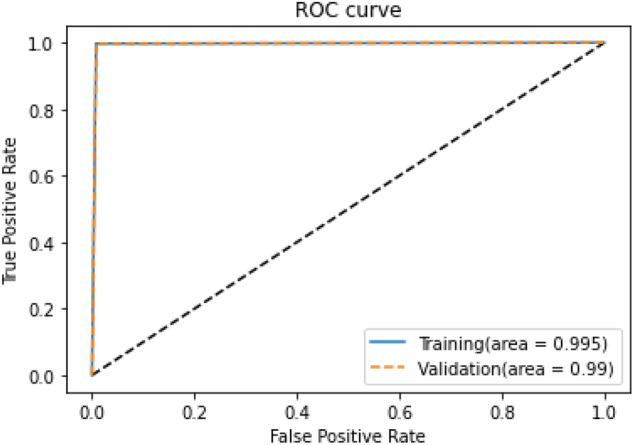 Figure 6
Figure 6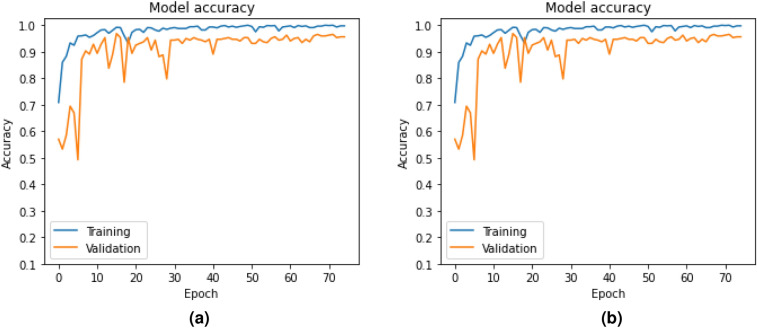 Figure 7
Figure 7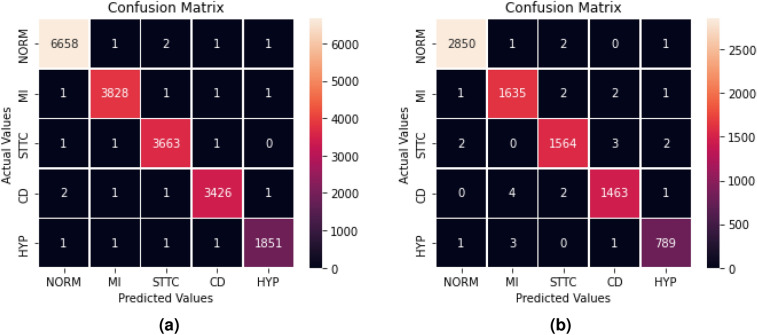 Figure 8
Figure 8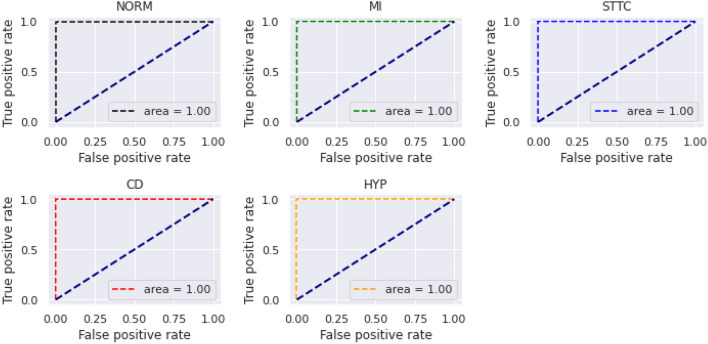 Figure 9
Figure 9- —Manipal Academy of Higher Education, Manipal
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsECG Monitoring and Analysis · Artificial Intelligence in Healthcare · Machine Learning in Healthcare
Introduction
Globally, cardiovascular diseases (CVDs) are the most prevalent cause of mortality, claiming around 17.9 million lives annually^1^. Cardiovascular diseases encompass a wide range of conditions that affect the heart and blood vessels. More than 80% of CVD-caused deaths are due to strokes and heart attacks, with 30% of these early deaths occurring in people under 70 years of age. Unhealthy lifestyle habits, such as inactivity, poor diet, smoking, and excessive alcohol intake, are the main factors contributing to cardiovascular disease and stroke. Furthermore, without quick diagnosis and treatment, these conditions can worsen or become life-threatening. The first step in assessing and classifying patients with chest discomfort is an electrocardiogram (ECG). The ECG visually records the electrical activity of the heart. It is a quick, inexpensive, safe, painless and noninvasive procedure commonly used to diagnose conduction problems, arrhythmias, myocardial infarction, and ventricular hypertrophy. The ECG waves are labeled with the letters P, Q, R, S, T, and U. The P wave reflects atrial depolarization, while the QRS complex and the ST-T-U complex (which include the ST segment, the T wave, and the U wave) represent ventricular depolarization and repolarization, respectively^2^. The results of an ECG are immediately available and fairly affordable. Consequently, this method is vital for the diagnosis of heart problems and is of significant clinical importance. Although ECG machines are portable and suitable for both rural and urban settings, trained cardiologists are not always available in rural areas to interpret results and diagnose heart conditions. In addition, in emergencies, the diagnosis can lack accuracy; Even with rapid analysis, subtle changes in an ECG can be overlooked. The problem is amplified when noise interferes with ECG signals. This has led to research on machine learning (ML) models for the automatic diagnosis of heart disorders, since computational methods and ML algorithms can identify abnormalities in digital ECG data. Besides reducing misdiagnoses, implementing an effective ML model on ECG data can save a significant amount of time^3^. AI models often leave clinicians with a ‘‘black box” feeling because they lack transparency in decision-making processes^4,5^. The challenge of AI in clinical decision-making is that its results are not always straightforward to interpret. Since doctors are responsible for their decisions, AI models must be explainable if we aim to develop and implement cost-effective AI solutions in healthcare. Therefore, creating a reliable AI model capable of analyzing ECG data and providing visually interpretable results to assist cardiologists in diagnosing heart diseases is crucial. The main contributions of this paper are listed below.
- Two approaches are proposed: one for detecting heart disease and the other for classification.
- The models consist of stacking bidirectional long short-term memory (LSTM) and deep learning techniques. Bidirectional LSTM is used as an approximate algorithm for feature extraction, while deep learning is applied for classification.
- The models are compared against different classifiers and state-of-the-art methods.
- Additionally, the proposed model is designed as an explainable AI using SHAP, with healthcare professionals assisting in identifying various diseases in the ECG report.
Related works
The study^6^ presents a systematic review of recent methods for cardiovascular disease detection and classification, highlighting advancements in machine learning and deep learning techniques. A spatio-temporal CNN with five layers was proposed in Ref. 2 for classifying different heart diseases. They trained and validated their proposed model on the PTB-XL and Arrhythmia Dataset, respectively. The work in Ref. 7 compares various convolutional neural network (CNN) models for heart disease classification, suggesting that inception- and ResNet-based architectures perform better in terms of accuracy. They used the ICBEB2018 and PTB-XL datasets. The work in Ref. 8 employed a CNN on the PTB-XL dataset for heart disease classification. They also demonstrated that using CNN with QRS complexes and entropy-based features provides higher accuracy than other methods. The work in Ref. 9 used a deep LSTM, trained and validated on the PTB-XL dataset, to detect one type of heart disease, namely myocardial infarction, with an accuracy of 77.12%. The author in Ref. 10 proposed a hybrid model combining Recurrent Unit (GRU) and Extreme Learning Machine (ELM), called CIGRU-ELM, to address the class imbalance problem across five classes of the PTB-XL dataset. They used this model to classify various heart diseases with an average accuracy of 0.89. A CNN with a non-local convolutional block attention module was proposed in Ref. 11 for heart disease classification. This model was trained separately on the MIT-BIH arrhythmia database and PTB-XL, achieving F1 scores of 0.9644 and 0.8507, respectively. In Ref. 12, features were extracted from the PTB-XL dataset using a CNN for heart disease classification; a random forest model then classified these features with an accuracy of 99.2%. The authors in Ref. 13 proposed a hybrid model consisting of two CNN layers and one SincNet network for heart disease classification, which was trained and validated on the PTB-XL dataset. A Multifeatured Transformer (MF-Transformer) model was introduced in Ref. 14 for classifying heart disease, achieving an accuracy of 75.82% by training and validating on the PTB-XL dataset. In Ref. 15, four classifiers–namely, Random Forest, Radial Basis Function, K-Nearest Neighbor, and Decision Tree–were applied to the PTB-XL dataset for binary heart disease classification. They concluded that Random Forest had the highest accuracy, which was further fine-tuned to 99.62%. A deep learning model based on loss optimization was proposed in Ref. 16 for multi-class cardiac disease classification, achieving an overall accuracy of 96%. In Ref. 17, Orthogonal Matching Pursuit (OMP) algorithms were used for cardiac disease classification, achieving accuracies of 90% for binary and 78% for multi-class classification, all trained and validated on the PTB-XL dataset. ResNet-50 was proposed in Ref. 18 for classifying multiple cardiac diseases, achieving an accuracy of 99% when trained and validated on PTB-XL. An explainable AI model for cardiac disease classification was detailed in Ref. 19, claiming an accuracy of 89%. The study in Ref. 20 extracted spectrograms from the PTB-XL dataset and fed them into CNNs for binary heart disease classification, achieving an accuracy of 99%. The widespread use of deep learning and its variants for classifying various cardiac diseases from ECG data is likely due to their ability to effectively extract key features during training. Among these variants, LSTM is especially suited for sequential input. Compared to LSTM, bidirectional LSTM(BiLSTM) has two networks: one processing past data in a forward direction and the other using future data in reverse, making it more effective at feature extraction. Additionally, as a recurrent neural network variant, bidirectional LSTM can approximate any algorithm^21^. The paper^22^ proposes a hybrid deep learning model combining M2MASC with CNN-BiLSTM to enhance the precision of heart disease classification. The study^23^ introduces a modified mixed attention mechanism integrated with a deep BiLSTM for enhanced multiclass heart disease classification. The authors propose^24^ a Deep Bidirectional long short-term memory classifier (SCN-Deep BiLSTM) model that captures both spatial and temporal features to improve heart disease prediction. This motivates us to propose a stacked model that combines bidirectional LSTM and deep learning techniques for classifying cardiac diseases from ECG data. Bidirectional long short-term memory is used as an approximate algorithm for feature extraction, while deep learning is employed for classification purposes.
Dataset
The PTB-XL dataset^21,25^ consists of 21837 clinical 12-lead ECG records with a duration of 10 s from 18,885 patients. The patient population is split into 52 percent males and 48 percent women, with ages ranging from 0 to 95 years (median 62 and interquartile range 22).
A sample ECG report is shown in Fig. 1, consisting of an ideal waveform in Fig. 1a and a single heartbeat waveform in Fig. 1b . The training and validation data (Table 1) are prepared from the dataset mentioned above separately for binary classification and multi-class classification as follows:
- For binary classification purposes, the number of records containing the normal ECG and not normal ECG is the same, i.e. 9517. The number of records for training and validation is 6662 and 2855, respectively.
- The training and validation datasets are prepared class-wise, with a split ratio of 70% and 30%, respectively, totaling the number of records for training and validation (Table 1). Table 1. Different heart disease types along with their instances.TypeClassNumeric valueNo. of recordsNumber of recordsTrainingValidationNormal ECGNORM0951766622855Myocardial infarctionMI1547338321641ST/T ChangeSTTC2523736661571Conduction disturbanceCD3490134311470HypertrophyHYP426491855794194468331
Fig. 1A sample ECG report.
Patient-wise split of training, validation, and testing data
Unlike spit on the instance side of the data set, the data set is now split into patient-wise to train, validate, and test the data set. The details are presented in Table 2.Table 2. Different heart disease types along with their instances.TypeClassNumeric valueNo. of recordsNumber of recordsTrainingValidationTestingNormal ECGNORM09528662714671434Myocardial infarctionMI154413809794838ST/T ChangeSTTC228231985430408Conduction disturbanceCD323271662315350HypertrophyHYP413119062022031498932083233
Data preprocessing
To ensure the electrocardiogram (ECG) signals are suitable for deep learning, several preprocessing steps are applied: sampling, filtering, normalization, windowing, padding, and trimming. Each step has a mathematical foundation, described below.
Sampling frequency
The continuous-time ECG signal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_c(t)$$\end{document} is sampled at a frequency \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_s$$\end{document} to obtain a discrete-time signal x[n]:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} x[n] = x_c(nT_s), \quad T_s = \frac{1}{f_s}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_s$$\end{document} is the sampling period. According to the Nyquist theorem,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} f_s \ge 2 f_{\max } \end{aligned}$$\end{document}with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{\max }$$\end{document} being the maximum frequency component of the ECG (typically 150 Hz)^26^.
Filtering
To remove baseline wander and high-frequency noise, a bandpass filter (e.g. 0.5–40 Hz) is applied:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} y[n] = \sum _{k=0}^{M} b_k , x[n-k] - \sum _{j=1}^{N} a_j , y[n-j], \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b_k$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_j$$\end{document} are the filter coefficients^27^.
Normalization
Normalization ensures consistent amplitude scaling across signals. Two common approaches are
Min–Max normalization
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} x_{\text {norm}}[n] = \frac{x[n] - \min (x)}{\max (x) - \min (x)}. \end{aligned}$$\end{document}Z-score normalization
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} x_{\text {norm}}[n] = \frac{x[n] - \mu }{\sigma }, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu$$\end{document} is the mean and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma$$\end{document} is the standard deviation^28^.
Windowing
ECG signals are segmented into fixed-length windows using a window function w[n]:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} x_w[n] = x[n] \cdot w[n], \quad 0 \le n \le L-1. \end{aligned}$$\end{document}For instance, the Hamming window is defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} w[n] = 0.54 - 0.46 \cos \left( \frac{2\pi n}{L-1}\right) , \end{aligned}$$\end{document}which reduces spectral leakage^29^.
Padding
To standardize sequence lengths, zero-padding is applied:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} x_p[n] = {\left\{ \begin{array}{ll} x[n], & 0 \le n< L, \\ 0, & L \le n < L_p \end{array}\right. } \end{aligned}$$\end{document}where L is the original length and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_p$$\end{document} is the padded length^30^.
Trimming
If the ECG sequence is longer than required, it is truncated:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} x_t[n] = x[n], \quad 0 \le n < L_t, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_t$$\end{document} is the target trimmed length^31^.
BLSTM-DNN- A stacked model of Bidirectional LSTM and DNN for heart disease detection and its classification
The proposed model is a stacked model of bidirectional LSTM and deep neural network (Fig. 2a). The proposed model consists of a sequence input layer as the first layer, followed by a bidirectional LSTM layer and two dense layers. The feature extraction is performed by stacking the output of the bidirectional LSTM layer into the first dense layer. The second dense layer is meant for classification purposes. The sigmoid activation layer is used for binary classification, whereas the softmax layer is used for multi-class classification. The intuitive reason to combine these two techniques is explained below.Fig. 2BLSTM-DNN: A combined model of Bidirectional LSTM and DNN for heart disease detection and its classification.
Bidirectional LSTM as an approximation for a feature extraction algorithm
Bidirectional LSTM is a recurrent neural network that allows input data to flow in both the forward and backward directions. Thus, the input sequence holds information related to its present and past.
If f is a computable function, there exists a finite recurrent neural network (RNN) that can compute f. Furthermore, certain finite RNNs are Turing complete, and hence, can approximate any algorithm^32^. This, in turn, implies that bidirectional long short-term memory (BiLSTM) networks can also approximate any algorithm. Therefore, BiLSTMs can be effectively implemented for feature extraction from ECG data. The working principle of a bidirectional LSTM is illustrated in Fig. 2b for better insight.
At each time t, the LSTM takes the following three inputs: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x^{t}$$\end{document} from the input layer, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a^{t-1}$$\end{document} the output of the previous layer, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c^{t-1}$$\end{document} the output of the previous cell. The outputs produced are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a^{t}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c^{t}$$\end{document} , representing the new activation and new cell state, respectively. Each LSTM cell contains three gates: an update gate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\digamma _{u}$$\end{document} , a forget gate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\digamma _{f}$$\end{document} , and an output gate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\digamma _{o}$$\end{document} . The values of these gates at time t can be updated by:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \digamma _u= & \sigma (\omega _u[a^{<t-1>}, x^{<t>}]+ \beta _u), \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \digamma _f= & \sigma (\omega _f[a^{<t-1>}, x^{<t>}]+ \beta _f), \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \digamma _o= & \sigma (\omega _o[a^{<t-1>}, x^{<t>}]+ \beta _o), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _k$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k\epsilon \{u, f, o\}$$\end{document} are the weight matrices associated with the update gate, forget gate, and output gate, respectively. Similarly, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _k$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k\epsilon \{u, f, o\}$$\end{document} is the bias. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ()$$\end{document} and tanh() are the sigmoid and hyperbolic tangent activation functions. The new candidate value \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c^{N<t>}$$\end{document} to replace the cell can be written as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} c^{N<t>}= tanh (\omega _c[a^{<t-1>}, x^{<t>}]+ \beta _c). \end{aligned}$$\end{document}The two outputs obtained from the LSTM can be expressed as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} c^{<t>}= & \digamma _u \times c^{N<t>} + \digamma _f \times c^{<t-1>}, \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} a^{<t>}= & \digamma _o \times c^{<t>}. \end{aligned}$$\end{document}Deep neural network (DNN)
Deep learning is an artificial neural network consisting of multiple computational layers that learns by exploring the intricate structure of input data. Due to its architecture, it inherently reduces data complexity through implicit feature extraction and dimensional reduction. Furthermore, it is more suitable to handle non-linear type input data.
Proposed model for heart disease detection (BLSTM-DNN-BC)
The proposed model for heart disease detection (Fig. 3a) consists of one input layer, one bidirectional LSTM layer, and two dense layers. The bidirectional layer processes the input (None, 1000, 12) to provide the output (None, 64). Similarly, the dense layer further reduces the features to (None, 8), which is eventually used by the second dense layer to detect heart disease. The total number of trainable parameters of the proposed model is 153,920.Fig. 3BLSTM-DNN A combined model of Bidirectional LSTM and DNN for heart disease detection.
Proposed model for heart disease classification (BLSTM-DNN-MC)
The proposed model for the classification of heart disease (Fig. 3b) has an architecture similar to that explained above for binary classification. However, the first dense layer provides an output (none, 8) which is further processed by the second dense layer to classify the five different heart diseases listed in Table 1.
Simulated results and discussion
The simulation of the proposed models is carried out in a Google Colab environment with GPU support as needed. The accuracy and loss curves generated during the training and validation of BLSTM-DNN-BC are shown in Fig. 4. Similarly, for model BLSTM-DNN-MC, these are shown in Fig. 5. These figures, on the one hand, ensure that neither of the models suffers from data overfitting, while on the other hand, they ensure that both models predict with high accuracy. The performance of both models is evaluated using the following performance metrics.
- Precision (P) - \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P=\frac{TP}{FP}$$\end{document} , where TP is the true positive and FP is the false positive
- Recall (R) - \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R=\frac{TP}{FN}$$\end{document} , where FN is the false negative
- F1-score - \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F1-score=\frac{2\times P \times R }{P+R}$$\end{document}
- Receiver operating characteristic curve (ROC) Implementation details of the proposed models The network parameters of the proposed models are presented in Table 3.Table 3. Network parameters of the proposed models.ParameterBLSTM-DNN-BCLSTM-DNN-MCNumber of BLSTM units2 layers, 128 units each2 layers, 128 units eachHidden layers1 layer, 64 units1 layer, 64 unitsDropout0.50.5Activation functionsReLU, SigmoidReLU, SoftmaxOptimizerAdamAdamLearning rate0.0050.05Batch size256256Epochs8080Early stoppingYesYesParameter counts439,685 (1.68 MB)440,465 (1.68 MB)Trainable params146,561 (572.5 KB)146,821 (573.5 KB)Non-trainable params0 (0.00 B)0 (0.00 B)Optimizer params293,124 (1.12 MB)293,644 (1.12 MB)Total Parameters + Memory439,685 (1.68 MB)440,465 (1.68 MB)
Fig. 4. Accuracy and loss of BLSTM-DNN-BC during training and validation.
Performance of BLSTM-DNN-BC
The different performance measurement of the proposed BLSTM-DNN-BC model for heart disease detection is presented in Table 4. The confusion matrices for training and validation are shown in Fig. 5.Fig. 5. Confusion matrices for training and validation of BLSTM-DNN-BC.
The precision, recall, F1 score, and accuracy generated by the proposed BLSTM-DNN-BC model are presented in Table 4 for both training and validation on the respective datasets. This process is repeated five times, and the mean and standard deviation are computed.Table 4. Performance of proposed BLSTM-DNN-BC model during training and validation.PRF1-scoreAccuracyTraining1.00–0.010.99 ± 0.0011.00–0.010.995 ± 0.005Validation0.99 ± 0.0010.99 ± 0.0010.99 ± 0.0010.99 ± 0.001
The ROC of the proposed BLSTM-DNN-BC during training and validation is depicted in Fig. 6.
The performance of the proposed BLSTM-DNN-BC achieves an accuracy of 99%, as evident from the performance metrics presented in this section. Thus, it is quite robust for heart disease detection if employed for clinical trials.Fig. 6ROC of the proposed BLSTM-DNN-BC during training and validation.
Performance of BLSTM-DNN-MC
Heart disease classification is a multi-class problem with five different major classes. The proposed BLSTM-DNN-MC model is trained and validated for this classification purpose by using the data mentioned in Table 5. The respective accuracy and loss obtained during training and validation are plotted in Fig. 7a and b.Fig. 7. Accuracy and loss of BLSTM-DNN-MC during training and validation.Table 5. Performance of proposed BLSTM-DNN-MC model during training and validation.ClassPRF1-scoreMacro-F1AccuracyTraining00.99 ± 0.0010.98 ± 0.0010.99 ± 0.0010.992 ± 0.0050.995 ± 0.00511.00-0.0010.99 ± 0.0011.00-0.0121.00-0.0010.99 ± 0.0011.00 -0.0131.00-0.0010.95 ± 0.0010.99 ± 0.00141.00-0.010.95 ± 0.0010.98 ± 0.001Validation00.98 ± 0.0010.97 ± 0.0010.98 ± 0.0010.98 ± 0.0050.99 ± 0.00511.00-0.0010.99 ± 0.0011.00-0.0121.00-0.0010.99 ± 0.0011.00-0.0130.93 ± 0.0010.99 ± 0.0010.96 ± 0.00141.00-0.0010.93±0.0010.96 ± 0.001
Fig. 8. Confusion matrices for training and validation of BLSTM-DNN-MC.
The confusion matrix generated during training and validation of the proposed model is shown in Fig. 8. The ROC curve for the proposed BLSTM-DNN-MC is shown in Fig. 9.Fig. 9ROC of the proposed BLSTM-DNN-MC during training and validation.
Comparison with state-of-the-art methods
The proposed methods are compared with some standard stand-alone classifiers such as Deep neural network (DNN) (Fig. 10), Convolutional neural network (CNN) (Fig. 11), and LSTM (Fig. 12), as well as some hybrid classifiers like Deep neural network and support vector machine (DNN-SVM), neural network and random forest (DNN-RF), convolutional neural network and support vector machine (CNN-SVM). The results of these comparisons are presented in Tables 6 and 7, respectively.Fig. 10. Architecture of DNN model.Fig. 11. Architecture of CNN model.Fig. 12. Architecture of LSTM model.Table 6. Comparison of proposed BLSTM-DNN-BC against state-of-the-art classifiers.ModelPrecisionRecallF1-scoreAccuracyAUROCAUPRCMCC/KappaDNN0.90 ± 0.0010.87 ± 0.0010.88 ± 0.0010.89 ± 0.0010.89 ± 0.0050.88 ± 0.0050.87 ± 0.005DNN-SVM0.92 ± 0.0010.90 ± 0.0010.90 ± 0.0010.91 ± 0.0010.91 ± 0.0050.90 ± 0.0050.89 ± 0.005DNN-RF0.92 ± 0.0010.91 ± 0.0010.91 ± 0.0010.91 ± 0.0010.92 ± 0.0050.91 ± 0.0050.90 ± 0.005LSTM0.89 ± 0.0010.85 ± 0.0010.88 ± 0.0010.87 ± 0.0010.88 ± 0.0050.87 ± 0.0050.86 ± 0.005CNN0.93 ± 0.0010.91 ± 0.0010.92 ± 0.0010.93 ± 0.0010.93 ± 0.0050.92 ± 0.0050.91 ± 0.005CNN-SVM0.97 ± 0.0010.95 ± 0.0010.96 ± 0.0010.96 ± 0.0010.96 ± 0.0050.95 ± 0.0050.94 ± 0.005BLSTM-DNN-BC0.99 ± 0.0010.99 ± 0.0010.99 ± 0.0010.99 ± 0.0010.99 ± 0.0050.99 ± 0.0050.99 ± 0.005Table 7Comparison of proposed BLSTM-DNN-MC against state-of-the-art classifiers.ModelClassPRF1-scoreMacro-F1AccuracyMacro-AUROCAUPRCMCCKappaDNN00.895 ± 0.0050.875 ± 0.0050.885 ± 0.005––0.8850.8750.7150.70510.905 ± 0.0050.895 ± 0.0050.905 ± 0.005––0.8950.8850.7250.71520.915 ± 0.0050.895 ± 0.0050.905 ± 0.0050.893 ± 0.0050.895 ± 0.0050.9050.8950.7350.72530.905 ± 0.0050.885 ± 0.0050.895 ± 0.005––0.8950.8750.7250.71540.885 ± 0.0050.875 ± 0.0050.875 ± 0.005––0.8750.8650.7050.695DNN-SVM00.895 ± 0.0050.915 ± 0.0050.915 ± 0.005––0.9150.9050.7450.73510.905 ± 0.0050.915 ± 0.0050.905 ± 0.005––0.9150.9150.7550.74520.905 ± 0.0050.905 ± 0.0050.905 ± 0.0050.907 ± 0.0050.905 ± 0.0050.9250.9150.7650.75530.885 ± 0.0050.905 ± 0.0050.895 ± 0.005––0.9050.9050.7350.72540.895 ± 0.0050.925 ± 0.0050.915 ± 0.005––0.9250.9150.7550.745DNN-RF00.905 ± 0.0050.935 ± 0.0050.915 ± 0.005––0.9350.9250.7950.78510.945 ± 0.0050.955 ± 0.0050.935 ± 0.005––0.9550.9450.8150.80520.955 ± 0.0050.955 ± 0.0050.955 ± 0.0050.947 ± 0.0050.915 ± 0.0050.9650.9550.8350.82530.935 ± 0.0050.955 ± 0.0050.945 ± 0.005––0.9550.9450.8150.80540.985 ± 0.0050.985 ± 0.0050.985 ± 0.005––0.9850.9750.8750.865LSTM00.925 ± 0.0050.945 ± 0.0050.935 ± 0.005––0.9450.9350.8150.80510.965 ± 0.0050.915 ± 0.0050.955 ± 0.005––0.9550.9450.8250.81520.985 ± 0.0050.975 ± 0.0050.975 ± 0.0050.957 ± 0.0050.945 ± 0.0050.9750.9650.8450.83530.965 ± 0.0050.975 ± 0.0050.975 ± 0.005––0.9750.9650.8450.83540.9950.955 ± 0.0050.945 ± 0.005––0.9850.9750.8550.845CNN00.895 ± 0.0050.905 ± 0.0050.895 ± 0.005––0.9050.8950.7350.72510.945 ± 0.0050.915 ± 0.0050.925 ± 0.005––0.9450.9350.8050.79520.945 ± 0.0050.925 ± 0.0050.945 ± 0.0050.925 ± 0.0050.925 ± 0.0050.9550.9450.8150.80530.965 ± 0.0050.955 ± 0.0050.945 ± 0.005––0.9650.9550.8350.82540.9950.955 ± 0.0050.915 ± 0.005––0.9650.9450.8250.815CNN-SVM00.965 ± 0.0050.945 ± 0.0050.945 ± 0.005––0.9650.9550.8450.83510.985 ± 0.0050.975 ± 0.0050.965 ± 0.005––0.9750.9650.8650.85520.975 ± 0.0050.935 ± 0.0050.955 ± 0.0050.953 ± 0.0050.955 ± 0.0050.9750.9550.8550.84530.955 ± 0.0050.945 ± 0.0050.945 ± 0.005––0.9550.9450.8350.82540.985 ± 0.0050.955 ± 0.0050.955 ± 0.005––0.9750.9550.8550.845Proposed BLSTM-DNN-MC00.975 ± 0.0050.965 ± 0.0050.975 ± 0.005––0.9850.9750.8750.86510.9950.985 ± 0.0050.995 ± 0.005––0.9850.9850.8950.88520.9950.985 ± 0.0050.9950.975 ± 0.0050.985 ± 0.0050.9850.9850.9050.89530.925 ± 0.0050.985 ± 0.0050.955 ± 0.005––0.9650.9550.8450.83540.9950.925 ± 0.0050.955 ± 0.005––0.9650.9550.8550.845
Patient-wise split of dataset
The performance of different models on the patient-wise split of the dataset is presented in Table 8.Table 8. Per-class classification metrics of different models.ModelClassPrecisionRecallF1-scoreSupportAccuracyMacro-AUROCAUPRCMCCKappaDNN00.950 ± 0.0050.820 ± 0.0050.880 ± 0.0051434–0.840 ± 0.0050.820 ± 0.0050.720 ± 0.0050.710 ± 0.00510.720 ± 0.0050.820 ± 0.0050.767 ± 0.005838–0.840 ± 0.0050.820 ± 0.0050.720 ± 0.0050.710 ± 0.00520.700 ± 0.0050.810 ± 0.0050.751 ± 0.0054080.820 ± 0.0050.840 ± 0.0050.820 ± 0.0050.720 ± 0.0050.710 ± 0.00530.780 ± 0.0050.820 ± 0.0050.800 ± 0.005350–0.840 ± 0.0050.820 ± 0.0050.720 ± 0.0050.710 ± 0.00540.740 ± 0.0050.820 ± 0.0050.778 ± 0.005203–0.840 ± 0.0050.820 ± 0.0050.720 ± 0.0050.710 ± 0.005DNN-SVM00.955 ± 0.0050.835 ± 0.0050.891 ± 0.0051434–0.860 ± 0.0050.840 ± 0.0050.740 ± 0.0050.730 ± 0.00510.735 ± 0.0050.835 ± 0.0050.782 ± 0.005838–0.860 ± 0.0050.840 ± 0.0050.740 ± 0.0050.730 ± 0.00520.710 ± 0.0050.830 ± 0.0050.766 ± 0.0054080.830 ± 0.0050.860 ± 0.0050.840 ± 0.0050.740 ± 0.0050.730 ± 0.00530.790 ± 0.0050.830 ± 0.0050.810 ± 0.005350–0.860 ± 0.0050.840 ± 0.0050.740 ± 0.0050.730 ± 0.00540.755 ± 0.0050.835 ± 0.0050.793 ± 0.005203–0.860 ± 0.0050.840 ± 0.0050.740 ± 0.0050.730 ± 0.005DNN-RF00.965 ± 0.0050.850 ± 0.0050.904 ± 0.0051434–0.880 ± 0.0050.860 ± 0.0050.760 ± 0.0050.750 ± 0.00510.755 ± 0.0050.850 ± 0.0050.800 ± 0.005838–0.880 ± 0.0050.860 ± 0.0050.760 ± 0.0050.750 ± 0.00520.730 ± 0.0050.850 ± 0.0050.786 ± 0.0054080.850 ± 0.0050.880 ± 0.0050.860 ± 0.0050.760 ± 0.0050.750 ± 0.00530.810 ± 0.0050.850 ± 0.0050.829 ± 0.005350–0.880 ± 0.0050.860 ± 0.0050.760 ± 0.0050.750 ± 0.00540.770 ± 0.0050.850 ± 0.0050.808 ± 0.005203–0.880 ± 0.0050.860 ± 0.0050.760 ± 0.0050.750 ± 0.005LSTM00.970 ± 0.0050.860 ± 0.0050.912 ± 0.0051434–0.890 ± 0.0050.870 ± 0.0050.770 ± 0.0050.760 ± 0.00510.770 ± 0.0050.860 ± 0.0050.812 ± 0.005838–0.890 ± 0.0050.870 ± 0.0050.770 ± 0.0050.760 ± 0.00520.740 ± 0.0050.860 ± 0.0050.796 ± 0.0054080.860 ± 0.0050.890 ± 0.0050.870 ± 0.0050.770 ± 0.0050.760 ± 0.00530.820 ± 0.0050.860 ± 0.0050.840 ± 0.005350–0.890 ± 0.0050.870 ± 0.0050.770 ± 0.0050.760 ± 0.00540.780 ± 0.0050.860 ± 0.0050.818 ± 0.005203–0.890 ± 0.0050.870 ± 0.0050.770 ± 0.0050.760 ± 0.005CNN00.978 ± 0.0050.870 ± 0.0050.921 ± 0.0051434–0.910 ± 0.0050.890 ± 0.0050.790 ± 0.0050.780 ± 0.00510.790 ± 0.0050.870 ± 0.0050.828 ± 0.005838–0.910 ± 0.0050.890 ± 0.0050.790 ± 0.0050.780 ± 0.00520.765 ± 0.0050.873 ± 0.0050.815 ± 0.0054080.870 ± 0.0050.910 ± 0.0050.890 ± 0.0050.790 ± 0.0050.780 ± 0.00530.839 ± 0.0050.869 ± 0.0050.854 ± 0.005350–0.910 ± 0.0050.890 ± 0.0050.790 ± 0.0050.780 ± 0.00540.793 ± 0.0050.867 ± 0.0050.828 ± 0.005203–0.910 ± 0.0050.890 ± 0.0050.790 ± 0.0050.780 ± 0.005CNN-SVM00.985 ± 0.0050.900 ± 0.0050.941 ± 0.0051434–0.930 ± 0.0050.910 ± 0.0050.810 ± 0.0050.800 ± 0.00510.820 ± 0.0050.900 ± 0.0050.858 ± 0.005838–0.930 ± 0.0050.910 ± 0.0050.810 ± 0.0050.800 ± 0.00520.800 ± 0.0050.900 ± 0.0050.847 ± 0.0054080.900 ± 0.0050.930 ± 0.0050.910 ± 0.0050.810 ± 0.0050.800 ± 0.00530.860 ± 0.0050.900 ± 0.0050.879 ± 0.005350–0.930 ± 0.0050.910 ± 0.0050.810 ± 0.0050.800 ± 0.00540.820 ± 0.0050.900 ± 0.0050.858 ± 0.005203–0.930 ± 0.0050.910 ± 0.0050.810 ± 0.0050.800 ± 0.005ProposedBLSTM-DNN-MC00.990 ± 0.0050.920 ± 0.0050.954 ± 0.0051434–0.950 ± 0.0050.930 ± 0.0050.830 ± 0.0050.820 ± 0.00510.850 ± 0.0050.920 ± 0.0050.884 ± 0.005838–0.950 ± 0.0050.930 ± 0.0050.830 ± 0.0050.820 ± 0.00520.830 ± 0.0050.920 ± 0.0050.872 ± 0.0054080.920 ± 0.0050.950 ± 0.0050.930 ± 0.0050.830 ± 0.0050.820 ± 0.00530.885 ± 0.0050.920 ± 0.0050.902 ± 0.005350–0.950 ± 0.0050.930 ± 0.0050.830 ± 0.0050.820 ± 0.00540.850 ± 0.0050.920 ± 0.0050.884 ± 0.005203–0.950 ± 0.0050.930 ± 0.0050.830 ± 0.0050.820 ± 0.005
The confusion matrix generated by different models on the patient-wise split of the dataset is shown in Fig. 13.Fig. 13. Confusion matrix of different models generated over testing dataset.
From these comparisons, it can be observed that the proposed model outperforms other classifiers in terms of the different performance metrics discussed earlier.
Making the proposed model an explainable AI model
Deep learning models such as BiLSTM often function as “black boxes,” making it difficult to understand the reasoning behind their predictions. In medical applications like ECG analysis, explainability is crucial for building trust among clinicians and ensuring that automated decisions can be verified. SHAP (Shapley Additive Explanations) addresses this challenge by providing feature-level importance scores derived from cooperative game theory.
By applying SHAP to the proposed BiLSTM model, each prediction can be explained in terms of how much individual ECG features (such as waveform segments, peaks, or intervals) contribute positively or negatively to the classification outcome. This not only enhances transparency but also allows physicians to visualize disease-relevant patterns in the ECG report directly. Thus, SHAP enhances the proposed model’s interpretability, clinical reliability, and suitability for decision support in healthcare.
In addition to the work carried out in Refs. 33 and 34 to explain the contribution of different features to the class labels, the current work further utilizes these values to annotate various diseases in the ECG report. A healthcare professional manually validates each annotated ECG report. The tall T waves present in all leads in Fig. 14 show the presence of ST/T change in the report. Figure 15 depicts varying RR intervals in all leads, which are classified as conduction disturbances. Figure 16 shows ST elevation in leads V2-V6, classifying it as myocardial infarction. As the addition of all the boxes covered by the QRS complex of lead V2 and lead V6 exceeds 8, it represents hypertrophy, as shown in Fig. 17.Fig. 14. Annotation of ST/T on ECG report.Fig. 15. Annotation of conduction disturbance on ECG report.Fig. 16. Annotation of myocardial infarction on ECG report.Fig. 17. Annotation of hypertrophy on ECG report.
Validation of proposed BLSTM-DNN-MC over PTB-XL v1.0.3 with temporal split
The working of the proposed model (BLSTM-DNN-MC) is PTB-XL v1.0.3^35^, a large, publicly available electrocardiography (ECG) dataset hosted on PhysioNet. It contains more than 21,800 12-lead clinical ECG recordings from nearly 19,000 patients, each lasting 10 seconds, with rich demographic and clinical metadata. The dataset includes annotations from up to two cardiologists per record, covering 71 diagnostic, rhythm, and morphological statements based on the SCP-ECG standard, making it suitable for both multi-label classification and arrhythmia detection tasks. The class-wise performance of the proposed model (BLSTM-DNN-MC) with the temporal split of the dataset is presented in Table 9. The detection capability of the proposed model for a single sample is presented in Table 10, while its explanation is shown in Fig. 18.Table 9. Per-class performance of proposed BLSTM-DNN-MC over PTB-XL ver 1.0.3 with temporal split.ClassAccuracyPrecisionRecallF1-scoreAUCNORM0.920.900.880.890.95CD0.870.850.820.830.91MI0.900.890.860.870.93HYP0.850.800.760.780.89STTC0.840.810.770.790.88Table 10Per-class prediction for a single ECG sample.ClassPredicted probabilityTrue labelNORM0.87211MI0.03420STTC0.11290CD0.05670HYP0.00980
Fig. 18. Explaining the prediction capability of proposed model BLSTM-DNN-MC for detecting normal ECG report.
Conclusion
In terms of sheer prevalence, cardiovascular diseases (CVDs) account for approximately 31% of all deaths worldwide. Therefore, early detection of CVD is of paramount importance for timely treatment and prevention of irreversible damage. This study proposes two models: one for disease detection (BLSTM-DNN-BC) and another for disease classification (BLSTM-DNN-MC). The following procedures are carried out on ECG signals in an automated process: preprocessing, feature extraction, and classification of cardiovascular diseases. The developed models are then evaluated against other state-of-the-art methods using performance metrics such as precision, recall, F1-score, and accuracy. The results show that both models perform well in comparison to different models, with an accuracy of 99%. Thus, the proposed models are preferable for detecting and classifying heart disease and have the potential to be implemented as a helpful tool for clinical specialists to rapidly confirm their diagnostic results.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Lipsa, S. & Dash, R. K. Malnet–an optimized cnn based method for malaria diagnosis. In 2022 2nd Int. Conf. on Intelligent Technologies (CONIT), pp. 1–6. 10.1109/CONIT 55038.2022.9847725 (IEEE, 2022).
- 2Qiu, J. et al. Cardiac disease diagnosis on imbalanced electrocardiography data through optimal transport augmentation. In ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. 10.1109/ICASSP 49357.2023.10096371 (IEEE, 2023).
- 3Liu, J., Zeng, M., Shan, K. & Tian, L. Loss optimization based algorithm for multi-classification of ecg signal. In Proc. of the 3rd Int. Symposium on Artificial Intelligence for Medicine Sciences, pp. 537–541. 10.1145/3569136.3569219 (ACM, 2022).
- 4Sakli, N., Ghabri, H., Zouinkh, I. A., Sakli, H. & Najjari, M. An efficient deep learning model to predict cardiovascular disease based on ecg signal. In 2022 19th International Multi-Conference on Systems, Signals & Devices (SSD), pp. 1759–1763. 10.1109/SSD 54175.2022.9826333 (IEEE, 2022).
- 5Siegelmann, H. T. & Sontag, E. D. On the computational power of neural nets. In Proc. of the fifth annual workshop on Computational Learning Theory, pp. 440–449. 10.1145/130385.130432 (ACM, 1992).
- 6Wagner, P., Strodthoff, N., Bousseljot, R., Samek, W. & Schaeffter, T. Ptb-xl, a large publicly available electrocardiography dataset (version 1.0.3). 10.13026/kfzx-aw 45 (2022).10.1038/s 41597-020-0495-6PMC 724807132451379 · doi ↗ · pubmed ↗