Bridging the Computational-Experimental Gap: Leveraging Large Language Model to Prioritize Alzheimer’s Therapeutics Based on Comparison of Learning Models
Manqi Li, Shuteng Niu, Yifeng Xu, Jianfu Li, Xinyue Hu, Duan Liu, Merve Atik, Xiaolei Xu, Liewei Wang, Nilüfer Ertekin-Taner, Cui Tao

TL;DR
This paper introduces a new framework using large language models to prioritize Alzheimer’s disease drug candidates by combining computational predictions and literature evidence, aiming to speed up drug repurposing.
Contribution
A novel LLM-based prioritization framework that integrates computational methods and literature synthesis to bridge the gap between computational predictions and experimental validation in drug repurposing.
Findings
The framework generated a unified list of 90 candidate drugs for Alzheimer’s by integrating three computational methods.
LLM-based evidence synthesis reduced manual curation effort while maintaining clinical relevance and consistency.
Validation with real-world data confirmed the framework’s efficiency, scalability, and generalizability for drug repurposing.
Abstract
Alzheimer’s Disease (AD)1 is a progressive neurodegenerative disorder with limited therapeutic options, driving interest in drug repurposing to accelerate treatment discovery. Drug repurposing has emerged as a promising strategy to accelerate therapeutic discovery by repositioning existing drugs for new clinical indications. Recent computational repurposing approaches, including knowledge graph reasoning, transcriptomic signature analysis, and integrative literature mining, have demonstrated strong predictive capabilities2. However, these methods often yield divergent drug rankings, which makes it difficult to decide which candidates to advance for experimental follow-up and results in substantial gaps between computational predictions and feasible in vivo validation2. To bridge this computational-experimental gap, we proposed an advanced prioritization framework leveraging large…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
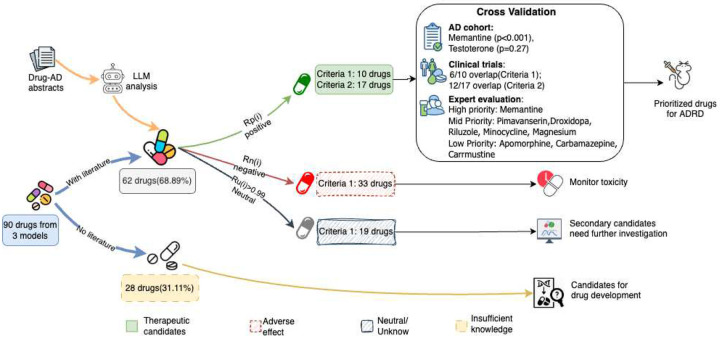 Figure 1
Figure 1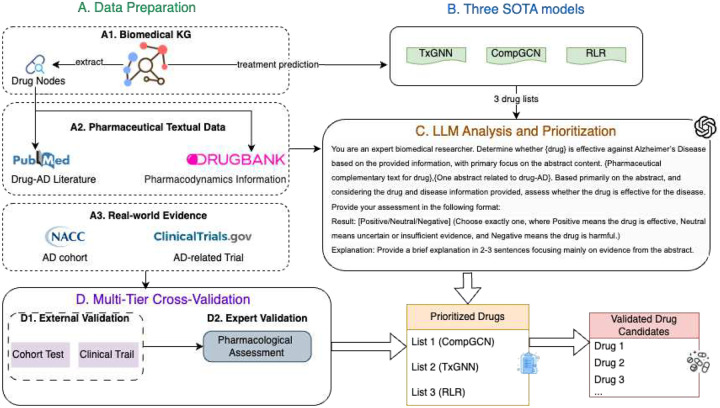 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsComputational Drug Discovery Methods · Biomedical Text Mining and Ontologies · Bioinformatics and Genomic Networks
Introduction
AD is a progressive neurodegenerative disorder characterized by memory loss, cognitive decline, and behavioral disturbances, and it remains a leading cause of disability among the elderly^1^. Despite decades of research, the available therapeutic options for AD are limited in both efficacy and scope, which has driven the biomedical community to explore alternative strategies for treatment development^2^. One promising approach is drug repurposing, a strategy that seeks to identify new therapeutic applications for existing FDA–approved compounds^6^. This method offers a significant advantage by bypassing many early-phase drug development challenges, including the time and financial costs of bringing a new drug to market^6^. As such, drug repurposing has garnered increasing attention as a viable, pragmatic pathway for addressing the urgent need for effective AD treatments.
In recent years, advances in Artificial Intelligence (AI) and big data have reshaped the landscape of drug repurposing^7,8^. Traditional databases and expert systems cannot meet the demands of modern biomedical knowledge discovery^2^. As an effective solution, Knowledge graphs (KGs) have become a key data representation for high volume and complex biomedical knowledge^9–12^. Accordingly, Graph Neural Networks (GNN)-based models have been adopted to perform downstream tasks, such as KG reasoning^13,14^, transcriptomic signature analysis^15^, and integrative data mining from biomedical literature^11^. In particular, KG completion has emerged as a promising approach for drug repurposing for AD^13,16^. Additionally, such innovative methods have improved the quality and efficiency of drug repurposing by mining deep hidden relations in biomedical concepts without labor-based literature mining. While the SOTA GNN models have made promising progress on drug repurposing, there are several limitations: 1) the validation process remains a manual and human-centered task, resulting in poor efficiency, high costs, and a lack of scalability^3,16^, 2)different learning models show significantly varying prediction behaviors corresponding different biomedical KG characteristics^17^, and 3) the methods often lack the generalizability to be readily applied across different diseases without significant retraining.
Moreover, traditional validation methods involve expert reviews, manual literature curation, and wet-lab experiments in the standard drug repurposing framework. While these methods are effective in cases with small and manually-manageable data, they suffer from a few unique limitations in big data, such as high cost, insufficient expert input, and incomplete literature coverage. The validation has become the new bottleneck of the computational drug repurposing framework, which prevents professionals from releasing the full potential of high-volume data and computational tools^18^. Furthermore, despite powerful Natural Language Processing (NLP) tools and standard ontologies, existing biomedical KGs have inherent sparse connections, imbalanced node types and relation types, as well as inaccurate knowledge^9^. Recently, various advanced graph models have been proposed to address these fundamental issues. However, different types of graph models demonstrate highly variant advantages and shortcomings^10^ (details and insights provided in the section Discussion Model Divergence). Firstly, traditional statistical models (logistic regression, random forest) with manually-designed graph features are not suitable for complex graphs and multi-relation^19^. Secondly, regular GNN models mine deeper patterns and show better robustness to noise from KG curation, but their performance is compromised by sparse connections^20^. Lastly, GNNs equipped with node similarity matching^20^ improve node representation with sparse connections, but the drug recommendations are often less accurate in AD. To date, there is no efficient and scalable way of harmonizing the outputs of different models to produce a single, reliable, and actionable list of candidates for a given disease.
To overcome these limitations, we proposed a novel LLM-based Alzheimer’s Disease Drug Repurposing (ADDR) framework, which integrated the strengths of multiple graph models and leverages the reasoning capabilities of LLM to create an efficient, automated, and scalable pipeline. Our framework was designed to tackle three central questions. First, we investigated why different graph models produced divergent predictions for AD by conducting a comprehensive analysis of their architectural principles and output distributions. Second, we established how to effectively validate and prioritize these divergent predictions by developing an LLM-driven module that aggregated evidence from multiple sources, mitigating the risks of model hallucination. Finally, we demonstrated how to efficiently verify the computational findings by corroborating our top-ranked candidates against Real-World Data (RWD), including an Electronic Health Record cohort and clinical trial data, as well as expert pharmacological reviews. In this final step, expert validation codified a reusable human-in-the-loop framework for drug prioritization.
To these ends, we developed simple yet effective solutions to all challenges. Our investigation started with a comprehensive evaluation of the graph models from both an algorithmic and a data-driven, domain-knowledge perspective. We turned to the data and domain-knowledge facets by examining the criteria used for feature selection and analyzed how different pharmaceutical classes were represented in each model’s predictions. Through this two-pronged analysis, we uncovered shared patterns and key divergences across models that directly informed the design of our LLM-prioritization strategy. Specifically, we examined three SOTA ADDR models (RLR, CompGCN, and TxGNN) end-to-end, from their core design principles through to their output distributions. The methodological insights gained from this analysis directly informed the design of our LLM-powered framework to automate the validation and prioritization processes. This system intelligently aggregates and ranks drug candidates by synthesizing evidence from multiple sources. To confirm its efficacy, we benchmarked our top candidates against real-world outcomes from the NACC Alzheimer’s cohort and clinical trial data. In parallel, we conducted a structured pharmacological review in which two independent clinicians systematically scored leading candidates across safety, mechanism of action, therapeutic breadth, and preclinical evidence, providing a rigorous human-expertise benchmark for the LLM’s prioritization. The real-world applicability of our integrated methodology was ultimately demonstrated as several drugs prioritized by the LLM were subsequently stratified through expert pharmaceutical review, proving our framework can accelerate the transition from in silico modeling to viable therapeutic discovery.
The remainder of the paper is organized as follows: Results demonstrates key findings of the proposed framework, including prioritized and validated therapeutic candidates; Discussion presents technical insights into model scalability, generalization capabilities, and outlines future research directions; Data sources and preparation describes the data sources and preprocessing steps; Methodology details the model architecture and implementation; and References and Supplementary materials includes additional experimental results, implementation details, and supporting resources.
Result
Our unified LLM-based framework systematically and automatically prioritized repurposable drugs for AD, starting from 90 candidates proposed by three SOTA models (TxGNN^3^, CompGCN^4^, and RLR^5^ on PrimeKG^21^). By leveraging the GPT-4.1 API^22^, we processed all 2,330 PubMed abstracts in approximately 1 hour and 11 minutes, yielding interpretable judgments of positive , neutral , and negative evidence for each candidate. As demonstrated in Figure 1, 62 out of 90 candidates were evidenced by AD-related literature and further evaluated using two evidence-based criteria (see Method: ADDR Framework). As shown in Table 1, under the stringent Criterion 1 (favoring a strong positive literature signal), 10 high-confidence candidates emerged, including both known and novel compounds (e.g., memantine, riluzole, minocycline, magnesium, and carmustine). A broader Criterion 2 identified 17 compounds with potential therapeutic relevance. Validation against a real-world AD patient cohort confirmed a statistically significant protective effect for memantine and a suggestive trend for testosterone , prioritized under Criterion 1 and 2 respectively. Furthermore, our method recapitulated 6 of 28 compounds previously evaluated in clinical trials under Criterion 1, and 12 under Criterion 2, demonstrating substantial alignment with existing translational efforts. Importantly, 28 candidates (31.1%) lacked any AD-related publications, which underscores both the novelty of LLM-discovered candidates and the current knowledge gap, suggesting promising directions for preclinical exploration. To this end, two domain experts scored prioritized compounds using a four-criterion rubric (efficacy, safety, mechanism, and indication breadth). Memantine emerged as the only “high-priority” candidate (13/16), consistent with its NMDA-antagonist mechanism and extensive clinical validation. Five additional compounds (pimavanserin, droxidopa, riluzole, minocycline, and magnesium) were classified as “mid-priority” (>8/16), reflecting strong preclinical support and safety profiles, yet lacking fully elucidated mechanisms in AD.
To draw a conclusion, our results demonstrate that LLMs can effectively bridge computational predictions with human-interpretable biomedical evidence, revealing both validated and underexplored candidates for AD drug repurposing. The framework offers a scalable, literature-grounded framework for accelerating therapeutic discovery and prioritization across other disease domains.
LLM-prioritized therapeutic candidates
We applied our unified LLM-based prioritization algorithm to the 90 candidate drugs identified by the three SOTA models (TxGNN^3^, CompGCN^4^, and RLR^5^, see Supplement materials: Preliminary work) on PrimeKG^21^. After retrieving AD-relevant PubMed abstracts for each drug, we obtained judgments per drug (partitioned into positive, neutral, and negative) and computed the rates , , and . Judgments were made on one abstract at a time (see Figure 1). Notably, 28 of these 90 candidates (31.11%) yielded no AD-related publications—most frequently among TxGNN predictions (13/30), then CompGCN (8/30), and finally RLR (7/30). This lack of literature evidence highlights a critical knowledge gap and indicates that these compounds may offer novel repurposing opportunities deserving experimental validation in vitro or in vivo.
Categorizing drug-AD relationships with LLM analysis
After excluding 28 compounds lacking AD-relevant literature, the remaining 62 candidate drugs were subjected to LLM-based evaluation using two criteria based on the statistical rates (positive), (neutral), and (negative).
Under Criterion 1, which deferred classification when neutral responses dominate and otherwise assigned labels based on whether exceeded , 10 drugs were identified as potentially therapeutic. These included istradefylline, pimavanserin, droxidopa, and apomorphine (from TxGNN); carbamazepine, memantine, riluzole, minocycline, and magnesium (from CompGCN); and carmustine (from RLR). In contrast, Criterion 2, which adopted a more permissive rule by flagging any compound with , yielded a broader set of 17 potentially therapeutic candidates. In addition to those identified by Criterion 1, this set included chlorpromazine (TxGNN); dextromethorphan (CompGCN); and testosterone, naproxen, doxycycline, histamine, and paclitaxel (RLR). These drugs constituted a prioritized shortlist for experimental validation and follow-up in drug repurposing framework.
The evaluation further stratified compounds with ambiguous or negative literature profiles following Criterion 1. We identified nineteen drugs with highly neutral sentiment distributions , reflecting either insufficient investigation or lack of definitive conclusions in the literature. These compounds warrant targeted reviews or meta-analyses to resolve their standing in the AD therapeutic landscape.
Finally, thirty-three drugs were classified as potentially adverse under Criterion 1 ( when ), indicating a preponderance of negative evidence or safety concerns. These compounds should be deprioritized for AD repurposing and considered for further toxicological and mechanistic scrutiny prior to any future translational efforts.
Divergent candidate rankings across learning models
The distribution of prioritized therapeutic candidates varied substantially across the three learning models. As shown in Table 1, under the stringent Criterion 1, CompGCN contributed half of therapeutics (5/10); whereas under the broader Criterion 2, all three models contributed similarly (CompGCN: 6/17; RLR: 6/17; TxGNN: 5/17). This divergence suggests the complementary strengths of different network-based learning approaches and the importance of ensemble-style integration for comprehensive drug repurposing frameworks. In response, our framework extracts candidate drugs from graph-based prediction models, retrieves relevant PubMed abstracts, and reasons abstract-level sentiment using an LLM-enabled systematic prioritization of repurposing candidates for ADDR.
In summary, 62 of the 90 initial candidates were supported by AD-related literature. Of these, 10 met Criterion 1 for high-confidence therapeutic potential, 17 satisfied the broader Criterion 2, 19 were literature-neutral, and 33 showed potentially adverse signals. This clear stratification refined via LLM-based analysis, demonstrated our framework’s ability to transform diverse model outputs into a transparent and experimentally-actionable shortlist.
Validation against real-world clinical and trial data
To test the effectiveness of our LLM-based prioritization, we first cross-validated 90 candidate compounds against an AD patient cohort (hazard ratios with p-values were shown in Table 1) and then quantified its presence in AD-related trials by investigating registered clinical trials (counts and IDs of trials were shown in Table 1).
We first evaluated our LLM-based prioritization against an AD patient cohort. As the drugs in bold (Table 1) show, among the drugs exhibiting a statistically significant protective effect, the LLM correctly recovered memantine as a potential therapeutic under both Criterion 1 and Criterion 2. Of four drugs with moderate cohort-level signals (zolpidem , dexamethasone , prednisolone , and testosterone , only testosterone was prioritized under Criterion 2. Remarkably, the model also flagged magnesium and carmustine as candidate therapeutics under both criteria despite no supporting evidence in the AD cohort, underscoring the LLM’s capacity to surface plausible repurposing opportunities beyond those directly observed in clinical data. While the LLM appears somewhat more conservative than cohort analysis in recovering known signals, neither approach serves as a definitive gold standard: cohort associations may be confounded by unmeasured factors or limited by small sample sizes. Nonetheless, the concordance between cohort-derived associations and LLM predictions supports the utility of our LLM-prioritized framework for efficiently narrowing the search space of AD drug repurposing candidates.
Next, we assessed the 90 candidate drugs against AD-related clinical trial records (Table 1 Clinical Trial Count column). Among the candidates, twenty-eight drugs had at least one registered trial. Under Criterion 1, the LLM identified 6 of these trial-tested drugs as potential therapeutics; under Criterion 2, it recovered 12 of the 28. Using clinical trial inclusion as a proxy for prior expert endorsement, these results demonstrate that our LLM-based method can reproducibly highlight historically recognized candidates in a conservative manner, mirroring its performance in the cohort cross-validation. Moreover, of the 10 drugs flagged under Criterion 1, 6 overlapped with clinical trial compounds (leaving istradefylline, droxidopa, carbamazepine, and carmustine as novel predictions), and of the 17 drugs flagged under Criterion 2, 12 had trial records (leaving paclitaxel novel). These “new” candidates illustrate the model’s ability to leverage existing biomedical knowledge and propose fresh hypotheses for future AD drug-repurposing efforts.
Taken together, the cohort and trial validations demonstrate that the LLM-based framework can recover known therapeutic signals and propose candidates overlooked by existing evidence sources.
Expert pharmacological review for efficacy of prioritized candidates
To benchmark the LLM-based prioritization against human expertise, two independent clinicians scored 10 candidate therapeutics (those consistently highlighted by both criteria) across four domains: preclinical effectiveness, safety and tolerability, mechanism of action, and therapeutic breadth (0–4 points each, maximum 16; details were shown in Supplement File 1). This exercise was designed to stratify LLM-prioritized agents, not to validate the framework’s global performance (no negative-control drugs were included).
Memantine ranked highest by both approaches. As shown in Table 1, it met both LLM criteria and showed significant cohort protection (HR = 0.59, p < 0.001) and the largest AD trial footprint (97 trials). Expert scores (13/16 from both reviewers; mean = 13) were concordant with this status, citing robust preclinical/clinical evidence, favorable tolerability, and a well-defined NMDA-antagonist mechanism.
Pimavanserin, minocycline, magnesium, riluzole, and droxidopa were all classified as “potentially therapeutic” under LLM criteria, though trial and cohort support varied. Expert scoring placed these in the intermediate range (mean 8–9). Pimavanserin (mean 9) received solid safety and mechanistic ratings, consistent with LLM prioritization and its presence in four AD trials. Minocycline (mean 9) and magnesium (mean 9) were similarly reinforced by expert consensus, though magnesium lacked cohort signal (no HR available), highlighting the LLM’s role in surfacing candidates outside limited real-world datasets. Riluzole (mean = 8.5) and droxidopa (mean = 8) both exhibited stronger preclinical efficacy than breadth of action, which the LLM captured as therapeutic potential but with modest trial representation.
Istradefylline, apomorphine, carbamazepine, and carmustine scored 6–6.5 on average, reflecting safety concerns, limited breadth, or unclear AD-relevant mechanisms. Notably, the LLM still classified each as “potentially therapeutic”, despite a lack of clinical trial activity for most (except apomorphine). This suggests that while the LLM effectively detects literature-level positive signals, expert domain knowledge remains critical for contextualizing translational feasibility and safety.
Within the LLM-selected set, expert review largely re-ordered and refined priorities rather than validating the framework in an absolute sense. Concordance at the top (e.g., memantine) and mid-tier alignment suggest that the LLM’s literature-level signals track key expert considerations, while expert adjudication adds penalties for safety liabilities and narrow mechanisms that are less evident from abstract-level text. This post-LLM triage step mirrors a human-in-the-loop workflow and is readily reusable across other domains and disease areas.
Discussion
In this study, we introduced a novel framework to bridge the persistent gap between high-throughput computational drug repurposing and practical experimental validation for AD. Our results demonstrate that by systematically reconciling the divergent outputs of multiple SOTA models and leveraging the evidence-synthesis capabilities of an LLM, we can produce a transparent, prioritized, and clinically relevant list of therapeutic candidates. This discussion will first interpret the underlying reasons for the observed model divergence, then evaluate the effectiveness, scalability, and generalizability of our proposed framework, and finally consider its current limitations and future potential.
Model divergence reveals complementary predictive strengths
A central challenge in computational drug repurposing is that models with comparable predictive performance often yield divergent candidate lists. Our analysis of TxGNN, CompGCN, and an RLR based on DWPC confirms this phenomenon and, more importantly, reveals that this divergence stems directly from their distinct architectures and feature representations.
TxGNN emphasizes disease-similarity embeddings to produce a “low-risk” shortlist of repurposing candidates whose approved indications cluster around neurodegenerative disorders topologically proximal to AD. More than half of TxGNN’s top 30 predictions target diseases such as Parkinson’s and other nervous-system disorders (Supplement Figure 1, Table 1), which may expedite clinical translation by leveraging established safety profiles. The tradeoff, however, lies in a potentially narrower search space that privileges well-characterized disease networks at the expense of uncovering less explored mechanisms^23^.
CompGCN’s edge-composition and node-aggregation message-passing framework embeds both node and relation semantics, propagating information through densely connected subgraphs. Consequently, it uncovers a remarkably broad array of pharmacological classes, including cholinesterase modulators, antineoplastics, neuropsychiatric agents, and latent links such as memantine, despite the absence of explicit indication edges (Supplementary Figure 2, Supplementary Table 2). This diversity makes CompGCN well-suited for exploratory hypothesis generation. Yet, operating on an undirected KG without explicit semantic constraints can lead to misattribution: for example, phenobarbital, an anticholinergic with mechanisms opposed to existing cholinergic AD therapies (donepezil, rivastigmine, and galantamine)^24^, was elevated despite counter-therapeutic mechanisms. Mitigating such semantic conflation may require integrating fine-grained relation-type modeling or attention-based supervision.
RLR based on DWPC transforms manually defined metapaths into interpretable graph features, favoring anti-inflammatory corticosteroids (Supplementary Figure 3, Supplementary Table 3) that align with epidemiological evidence of inflammation’s role in AD^25^. Its transparent, interpretable design readily surfaces known drug–phenotype associations, making RLR an efficient tool for phenotype-driven candidate validation. However, its reliance on shallow, predefined four-hop metapaths limits discovery of deeper or entirely novel pathways.
These distinct profiles underscore that there is no single “best” model; instead, their strengths are complementary. The choice of model can be tailored to specific strategic goals: TxGNN for safety-oriented repurposing, CompGCN for broad mechanistic exploration, and RLR for hypothesis confirmation based on known phenotypes.
Framework effectiveness: from model divergence to actionable insight
The inherent divergence among these models, while offering complementary perspectives, creates a significant challenge for downstream prioritization. Our LLM-driven framework was designed specifically to address this by harmonizing heterogeneous outputs through scalable, evidence-based curation. Its effectiveness was validated through retrospective cohort analysis and cross-referencing with registered clinical trials.
In our analysis of a real-world AD patient cohort, the framework demonstrated a balance of specificity and sensitivity. It correctly prioritized memantine , a drug with a robust protective signal, under both its stringent (Criterion 1) and permissive (Criterion 2) rules. For drugs with weaker cohort signals like testosterone , it selectively recovered them under the more sensitive Criterion 2, showcasing the utility of the dual-threshold design. Critically, the framework also identified candidates like magnesium, which, despite lacking a significant signal in our cohort data, was rated as a “mid-priority” compound in the subsequent expert evaluation. This illustrates the LLM’s capacity to surface plausible candidates that retrospective observational data alone might overlook.
Cross-validation against clinical trial data further confirmed the framework’s fidelity. It successfully recovered a substantial portion of previously tested drugs (6/28 under Criterion 1, 12/28 under Criterion 2), affirming its ability to reproduce expert-endorsed hypotheses. More importantly, it generated high-confidence, novel predictions such as droxidopa and carmustine, which have no prior AD trial record but were deemed plausible by our framework and, in the case of droxidopa, received a “mid-priority” expert rating. This dual capability to both confirms existing evidence and generate novel, high-potential leads underscores its value as both a validation tool and an engine for discovery.
Scalability and generalizability: a versatile discovery platform
A primary bottleneck in drug repurposing is the manual, labor-intensive process of evidence reviews. Our framework automates and accelerates this step. The retrieval and classification of 2,330 PubMed abstracts for 90 candidates were completed in just 1 hour and 11 minutes—a task that would typically demand weeks of expert effort. This efficiency demonstrates that the framework can scale with a growing volume of candidates and literature without prohibitive resource demands, making rapid, literature-grounded hypothesis generation feasible across diverse therapeutic areas.
Crucially, we pair automation with an expert-in-the-loop triage step. After LLM prioritization, two independent clinicians scored the shortlisted agents to refine ordering based on translational considerations (e.g., preclinical effectiveness, safety/tolerability, mechanism, breadth). This post-LLM review mirrors a human-in-the-loop framework that is easy to reuse in other domains and diseases, adding a lightweight layer of clinical judgment without re-introducing the full burden of manual curation. Together, automated literature synthesis and targeted expert adjudication deliver a scalable, generalizable platform that balances discovery breadth with translational plausibility.
Limitations and future directions
Despite its promising performance, our framework has several limitations that open avenues for future refinement.
First, the quality and structure of the underlying KG are paramount. Sparse or undirected relationships can bias predictions, as seen with CompGCN’s mis-ranking of phenobarbital. Future work should focus on incorporating more granular, directed relation types and supervision to mitigate such semantic ambiguities.
Second, our literature analysis relies on PubMed abstracts, which may not capture the full context available in full-text articles or account for publication bias^26^. Furthermore, some novel predictions lacked any literature, highlighting a knowledge gap. To probe the reliability of our LLM’s abstract classifications, we performed a manual validation on a subset of 50 abstracts, revealing an 82.00% agreement rate with human experts. The primary sources of disagreement were twofold: 1) the LLM acted conservatively on preclinical (animal or cell) studies, often classifying them as ‘neutral’ where an expert would see a ‘positive’ signal, and 2) the LLM sometimes classified abstracts as ‘negative’ when drug-AD keywords co-occurred without a stated relationship, whereas an expert would deem this ‘neutral’. This latter issue suggests opportunities for refinement through prompt engineering. Expanding the evidence base to include full-text articles, RWD from electronic health records, and multi-omic datasets would enhance the robustness and depth of the evidence synthesis.
Third, the framework’s reasoning is dependent on the pre-training knowledge of LLM. While we opted for a constrained, non-web approach using curated corpora to ensure reproducibility and avoid hallucination, performance could be enhanced by fine-tuning models on domain-specific biomedical literature.
Looking forward, we envision a dynamic, iterative discovery ecosystem. The knowledge graph could be continuously updated with emerging biological data. A virtuous cycle could be established where the top in-silico predictions are validated in preclinical models (e.g., organoids), with the experimental results feeding back to refine both the graph models and the LLM classifier. This closed-loop approach would progressively enhance predictive accuracy and accelerate the translation of computational insights into tangible clinical impact.
Conclusion
Computational drug repurposing for complex illnesses like Alzheimer’s Disease is frequently hampered by predictive models that produce divergent and overwhelming lists of candidates, creating a significant bottleneck for experimental validation and clinical translation. In this work, we have demonstrated a novel hybrid framework that successfully overcomes this challenge. By integrating the outputs of complementary graph-based algorithms and leveraging a Large Language Model for rapid, automated evidence synthesis, we transformed a wide array of computational predictions into a single, prioritized list of therapeutic candidates.
Our approach was validated through real-world patient data, clinical trial records, and expert pharmacological review, confirming its ability to identify both established treatments and promising new candidates. The framework’s true strength lies in its capacity to harmonize high-throughput in silico screening with deep, contextualized evidence appraisal in a manner that is transparent, scalable, and reproducible. This methodology not only accelerates the discovery of viable therapeutics for AD but also provides a powerful and generalizable blueprint for bridging the critical gap between computational prediction and clinical application across a spectrum of human diseases.
Data sources and preparation
Biomedical KG selection
PrimeKG is a comprehensive biomedical KG comprising 129,375 nodes across 10 entity types and 4,050,249 edges across 33 relation types^21^. It integrates data from 20 publicly available resources to enable rich and multi-domain connectivity, including DisGeNET, DrugBank, SIDER, Gene Ontology, Reactome, UBERON, etc. Compared with existing networks such as Hetionet^27^, iBKH^11^, and PharmKG^28^, PrimeKG is particularly adept at reasoning about repurposable drugs due to its significantly more extensive drug-drug relation(33.0%). PrimeKG categorizes drug-disease relations into three types: ‘Drug_contraindication_Disease’, ‘Drug_indication_Disease’, and ‘Drug_off-label use_Disease’. This unique classification facilitates machine learning and deep learning efforts to explore drug-disease connectivity with different semantic meanings. Our study focuses on predicting the “indication” relation between AD and each of the 7,957 drug nodes in PrimeKG.
Complementary pharmaceutical corpora for LLM analysis
To leverage the summation and classification capabilities of LLM, we assembled two complementary corpus, pharmacological descriptions from DrugBank(https://go.drugbank.com)^29^ and drug–AD abstracts from PubMed^30^. DrugBank has served as a gold-standard repository of drug information since 2006, offering detailed annotations of drug targets, pharmacodynamics, and chemical categories. For each of the 7,957 PrimeKG drug entities, we extracted the “Description”, “Pharmacology” (indication, pharmacodynamics, mechanism of action, protein binding), and “Category” fields. This textual metadata enriches the purely structural information in PrimeKG, mitigating the limitations of graph-only representations.
PubMed (https://pubmed.ncbi.nlm.nih.gov/about/) provides access to MEDLINE^31^ and contains over 38 million biomedical citations. We queried PubMed using the names and synonyms (from DrugBank and MeSH) of the top 90 candidates predicted by three ADDR models, in conjunction with “Alzheimer Disease.” Limiting retrieval to abstracts published from 2000 onward and capping at 200 abstracts per query, we collected a total of 2,330 abstracts. These texts supply context on reported drug–AD associations and serve as input for the LLM’s evidence-synthesis framework.
External validation resource
We leveraged both Alzheimer’s cohorts dataset and clinical-trial registries to externally validate our LLM-based prioritization.
First, we obtained the Uniform Data Set (UDS) from the National Alzheimer’s Coordinating Center (NACC)^32^, one of the largest, longest-running Alzheimer’s cohorts, on June 17, 2024. The dataset comprises 188,701 longitudinal visit records through the March 2024 data freeze. We fitted a left-truncated, right-censored Cox proportional hazards model to investigate the drug efficacy. The detailed methodology is elaborated in the Methodology Statistical Analysis of the NACC Alzheimer’s Cohorts part.
Second, we queried ClinicalTrials.gov (https://clinicaltrials.gov/) for AD–related drug trials and cross-referenced these against our LLM-prioritized list. By triangulating real-world outcomes from NACC with prospective evidence from registered trials, this multi-faceted approach demonstrates the robustness of our LLM validation and highlights candidates already evaluated in human studies for further investigation.
Methodology
The methodology for this study is organized into four principal stages: data preparation, candidate generation, LLM-driven prioritization, and multi-tier validation. A detailed schematic of this framework is presented in Figure 2, which outlines the flow from data aggregation to the final validated drug candidates.
Problem definition
The central problem this research addresses is the systematic prioritization of existing drugs for repurposing as AD therapeutics. This involves bridging the gap between divergent computational predictions and actionable experimental validation. We formulate this as a multi-stage process involving knowledge graph-based prediction, LLM-driven evidence synthesis, and multi-faceted evaluation.
Let be a biomedical KG whose nodes include drug nodes and disease nodes . Given a target disease and a biomedical corpus , where is a candidate drug and is the set of textual evidence for drug candidates , the objective is to generate a prioritized and stratified list of drug candidates for treating . We employ graph models that predict the probability that each treats :
For each model, let denote the top-ranked predictions under a threshold. The candidate pool is the union:
To aggregate textual evidence, an LLM–based labeling function, maps each drug’s textual evidence to a relevance label (positive, neutral, negative) with respect to . A universal prioritization function determines whether should be included in the prioritized list. The final output is a stratified collection of validated drug candidates:
where and denote validation functions using external evidence (e.g., medical cohort for , trials) and expert assessment, respectively.
ADDR Framework
The LLM-based framework was executed within the Google Colaboratory environment on a virtual machine equipped with an NVIDIA T4 GPU and 16 GB of GDDR6 memory. The analysis of all PubMed abstracts was completed in approximately 1 hour and 11 minutes. To generate an initial candidate set, we first evaluated three SOTA models on the PrimeKG knowledge graph for AD indication prediction. We extracted the top 30 ranked candidates from each model, yielding a consolidated set of 90 unique drugs. For each drug–AD pair, we retrieved the relevant abstracts and utilized a structured prompt (see Figure 2) for an LLM (GPT4.1 API) to classify the relationship between drug and AD in each abstract as “positive”, “neutral”, or “negative”. For each drug , the LLM produced a set of judgements from a total of abstracts, which can be partitioned into positive , neutral , and negative . From these, we defined three rates to quantify the drug’s overall evidence profile:
where and consequently . These rates form the basis of our unified ranking algorithm, ensuring each candidate is assessed by the same quantitative criterion.
Two distinct criteria were defined to accommodate different decision-making needs. Criterion 1 was designed to identify candidates with a clear signal by first filtering out those with overwhelmingly inconclusive evidence. Criterion 2 was designed to maximize sensitivity, flagging any candidate with even a single piece of positive evidence. Formally, for each drug for each drug :
Together, captures nuanced, context-dependent judgments while ensures that no candidate with even minimal positive evidence is overlooked.
Statistical analysis of the NACC Alzheimer’s cohorts
The UDS from the NACC^32^ comprised 188,701 longitudinal visits from 50,962 participants. At baseline, the mean age was 71.18 ± 10.41(mean ± standard deviation (SD)) years and mean years of education were 15.85 ± 7.96 (mean ± SD); 57.19% were female and 42.81% male. At enrollment, marital status was distributed as 63.20% married, 16.06% widowed, 11.68% divorced, and the remainder separated, never married, cohabiting/domestic partner, or other. The living situation at enrollment was 61.63% with spouse/partner, 23.12% alone, 9.05% with a relative or friend, 4.00% in group residence, and the rest other or unknown. Cognitive status at enrollment was 40.39% normal cognition, 4.43% impaired-not-MCI, 22.30% MCI, and 32.88% dementia; at the end of follow-up, these proportions were 41.39%, 4.09%, 18.29%, and 36.22%, respectively. Drug exposures in the UDS were mapped to PrimeKG drugs via UMLS and Drugbank identifiers. To approximate chronic use, only drugs documented at two or more consecutive visits were included in the analysis.
To estimate each drug’s association with the time to cognitive decline, we fitted a Cox proportional hazards model. This semi-parametric model is ideally suited for this analysis as it accommodates time-to-event data characterized by left-truncation (participants entering the study at different ages) and right-censoring (participants leaving the study for reasons other than the event of interest, such as death or loss to follow-up), both of which are features of the NACC longitudinal cohort^33^. The model was defined as:
where is the baseline hazard function, the covariates included the binary indicator for chronic drug use as well as baseline age, sex, education, marital status, and living situation for participant , and each is the log-hazard coefficient for its covariate. Our analysis focused on the hazard ratio for the drug effect, , which quantifies the relative hazard of cognitive decline for exposed versus non-exposed participants. An indicates an increased risk (adverse effect), while an suggests a protective effect.
Statistical significance was evaluated at two distinct thresholds. We used the conventional alpha level of to declare a statistically significant association, as this standard minimizes the probability of a Type I error (a false positive)^34^. In addition, we considered a more relaxed threshold of for exploratory purposes, as noted in Table 1. This less stringent cutoff is often used in epidemiological and discovery-oriented research to identify potentially meaningful trends or signals that might be missed with a stricter threshold, thereby reducing the risk of Type II errors (false negatives) at the cost of including some false positives in a preliminary screening phase^35,36^.
Supplementary Material
1
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 12023 Alzheimer’s disease facts and figures. Alzheimers Dement. 19, 1598–1695 (2023).36918389 10.1002/alz.13016 · doi ↗ · pubmed ↗
- 2Pushpakom S. Drug repurposing: progress, challenges and recommendations. Nat. Rev. Drug Discov. 18, 41–58 (2019).30310233 10.1038/nrd.2018.168 · doi ↗ · pubmed ↗
- 3Huang K. A foundation model for clinician-centered drug repurposing. Nat. Med. 30, 3601–3613 (2024).39322717 10.1038/s 41591-024-03233-x PMC 11645266 · doi ↗ · pubmed ↗
- 4Vashishth S., Sanyal S., Nitin V. & Talukdar P. Composition-based Multi-Relational Graph Convolutional Networks. Preprint at 10.48550/ARXIV.1911.03082 (2019). · doi ↗
- 5Himmelstein D. S. Systematic integration of biomedical knowledge prioritizes drugs for repurposing. e Life 6, e 26726 (2017).28936969 10.7554/e Life.26726 PMC 5640425 · doi ↗ · pubmed ↗
- 6Cummings J., Lee G., Zhong K., Fonseca J. & Taghva K. Alzheimer’s disease drug development pipeline: 2021. Alzheimers Dement. Transl. Res. Clin. Interv. 7, e 12179 (2021).
- 7Yan C. Leveraging generative AI to prioritize drug repurposing candidates for Alzheimer’s disease with real-world clinical validation. Npj Digit. Med. 7, 46 (2024).38409350 10.1038/s 41746-024-01038-3PMC 10897392 · doi ↗ · pubmed ↗
- 8Li Y. Ref AI: a GPT-powered retrieval-augmented generative tool for biomedical literature recommendation and summarization. J. Am. Med. Inform. Assoc. ocae 129 (2024) doi:10.1093/jamia/ocae 129. · doi ↗