Machine learning and Mendelian randomization identify key lifestyle factors in coronary heart disease: A NHANES-Based study
Yang yang Cui, Yonghong Zhang, Lang Zeng, Shikang Li, Xue Mei, Xiangmei Yang, Peng Zhou, Lijuan Xiong, Yijuan Huang, Jing Luo, Fenglin Wu, Rongchuan Yue

TL;DR
This study uses machine learning and genetic evidence to identify lifestyle factors that both predict and cause coronary heart disease.
Contribution
Combines machine learning with Mendelian randomization to identify causal lifestyle factors for coronary heart disease.
Findings
SVM model achieved 83.4% accuracy and 0.909 AUC for CHD prediction.
Mendelian randomization confirmed causal links for BMI, cholesterol intake, sleep, blood pressure, and smoking.
Recursive feature elimination identified age, sex, BMI, and other lifestyle factors as top predictors.
Abstract
This study aims to bridge the gap between predictive modeling and causal inference by utilizing lifestyle data from the National Health and Nutrition Examination Survey (NHANES) database to compare the predictive performance of multiple machine learning models for coronary heart disease (CHD). By incorporating Mendelian randomization, the study seeks to validate and identify the lifestyle variables with both predictive power and causal impact on CHD. We extracted variables related to demographic characteristics and lifestyle from the NHANES database (2013–2018; n = 29,400). Recursive feature elimination (RFE) was employed to rank variable importance and determine the optimal feature subset. Subsequently, eight machine learning models-including Support Vector Machine (SVM), Neural Network (NN), Naive Bayes (NB), Extreme Gradient Boosting (XGBoost), Multilayer Perceptron (MLP),…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
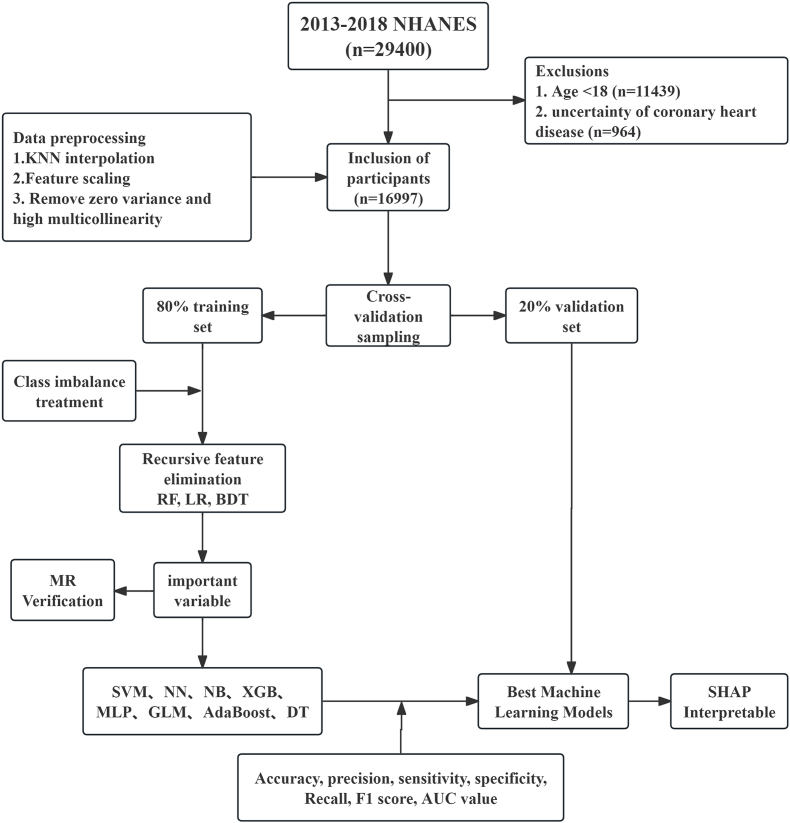 Figure 1
Figure 1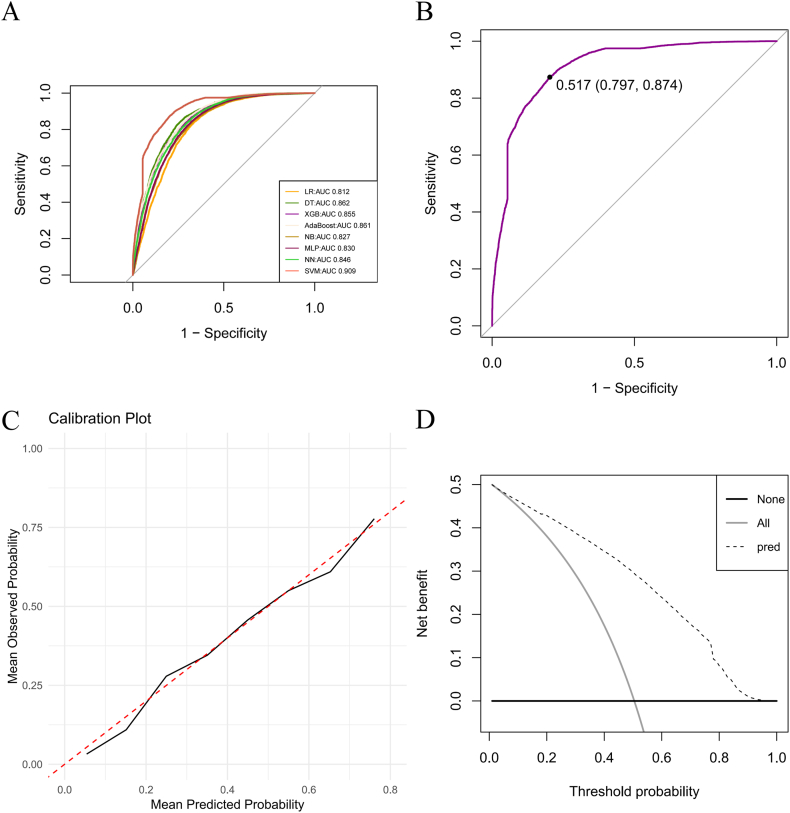 Figure 2
Figure 2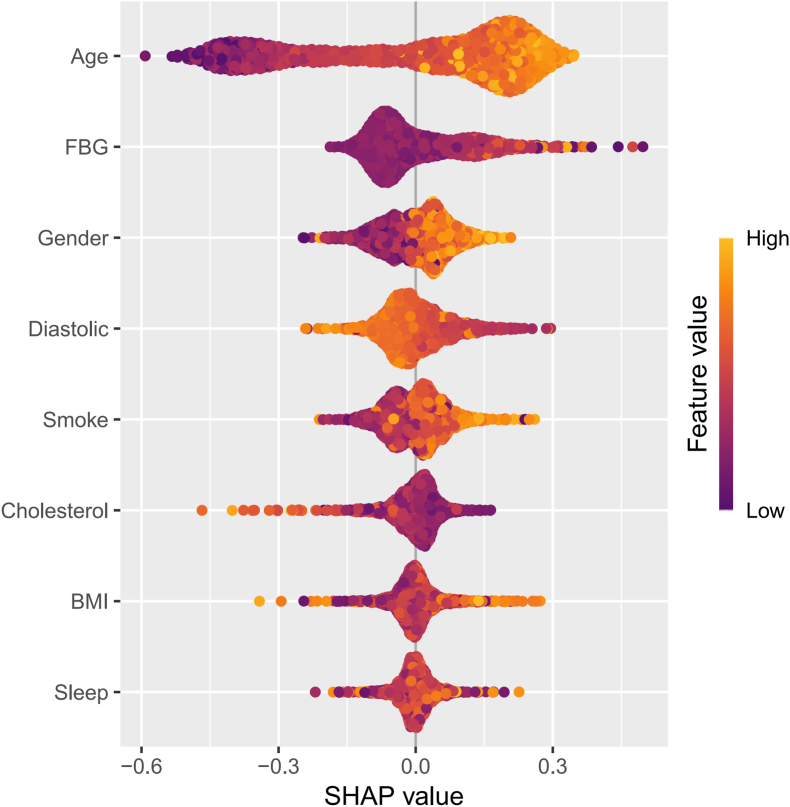 Figure 3
Figure 3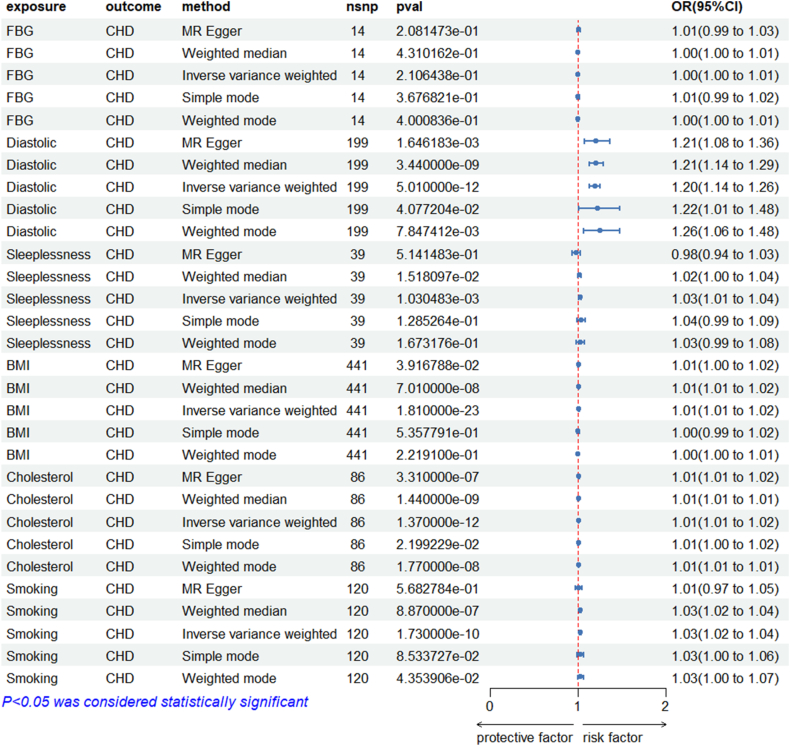 Figure 4
Figure 4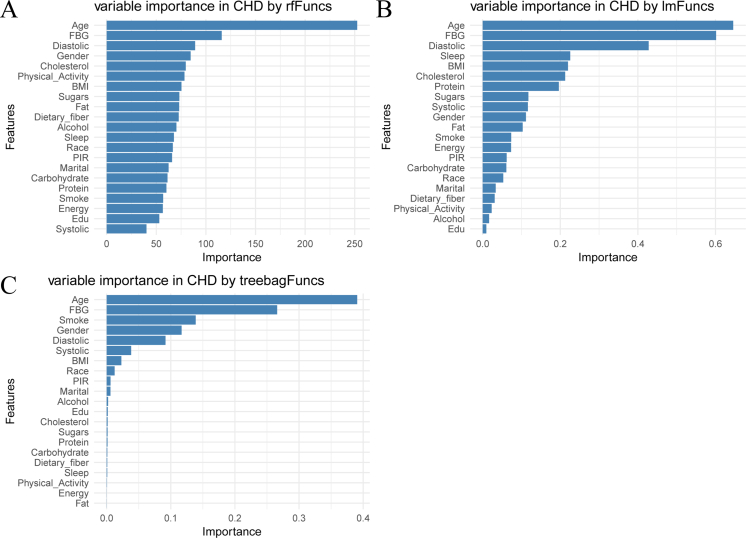 Figure 5
Figure 5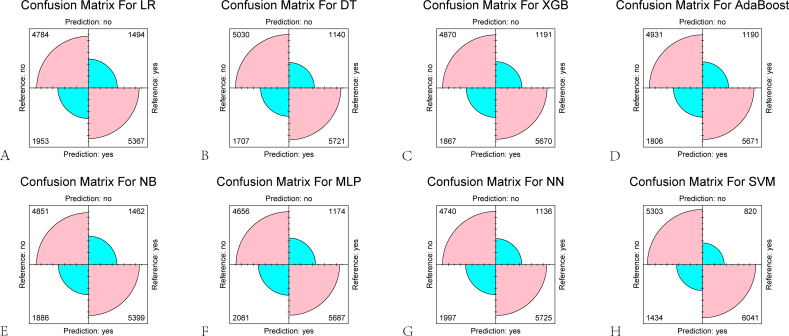 Figure 6
Figure 6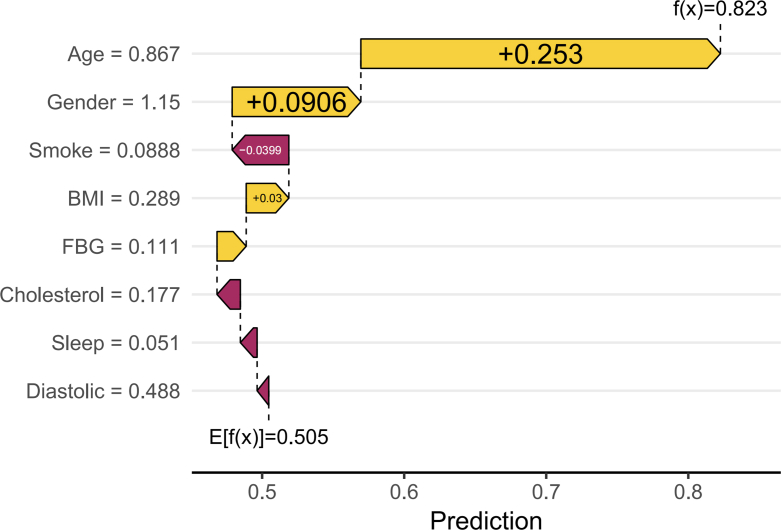 Figure 7
Figure 7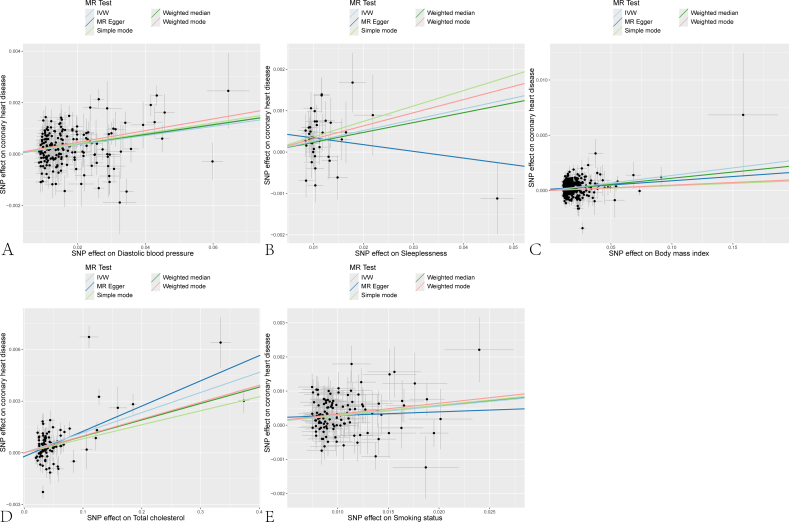 Figure 8
Figure 8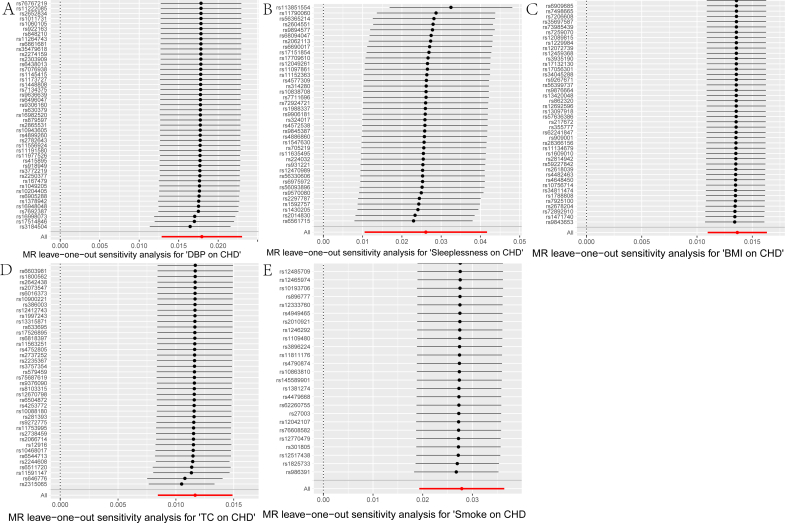 Figure 9
Figure 9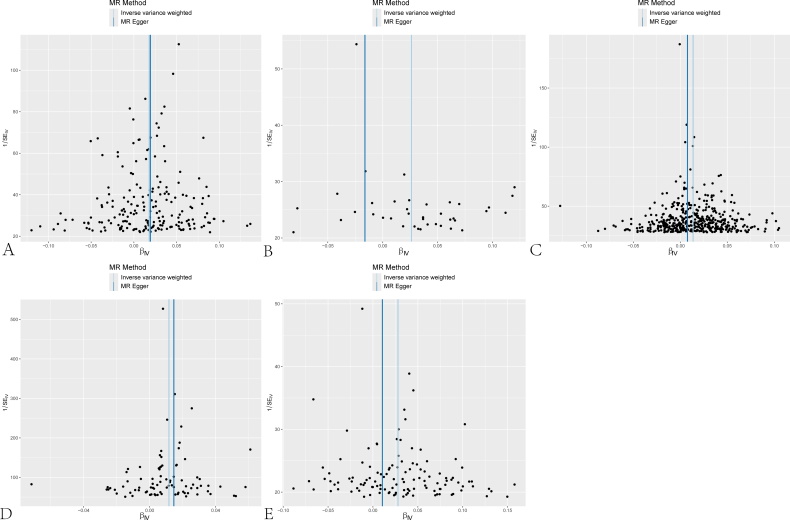 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCardiovascular Health and Risk Factors · Artificial Intelligence in Healthcare · Genetic Associations and Epidemiology
Introduction
1
Coronary heart disease (CHD), primarily driven by coronary atherosclerosis, remains a leading global cause of mortality despite advances in diagnosis and treatment [1]. Its rising prevalence is closely linked to population aging and unfavorable shifts in lifestyle and dietary patterns [2]. There is an urgent need for innovative strategies to effectively mitigate its prevalence, particularly through enhanced public health campaigns and the promotion of healthier lifestyles. A decade-long cohort study utilizing the UK Biobank database revealed a significant association between frequent night shift work and an increased risk of CHD, with a hazard ratio (HR) of 1.22 (95 % confidence interval: 1.11–1.35) [3]. Sedentary behavior, obesity, and smoking have also been shown to significantly increase CHD incidence, while higher red meat consumption has been positively correlated with disease risk [4,5]. Although these findings underscore the multifaceted role of lifestyle—encompassing diet, physical activity, sleep, and substance use—in CHD development, observational evidence is inherently limited by confounding and reverse causation. Establishing causal relationships between specific lifestyle factors and CHD risk therefore requires more robust analytical approaches.
Machine learning is increasingly used in medicine for high-dimensional prediction and feature selection [6,7]. In cardiovascular research, gradient-boosted trees and multi-layer perceptrons reached 95 % accuracy for CHD prediction, echoing the 95 % performance recently reported for deep-learning systems that use high-risk treadmill ECG features to detect obstructive CAD and for networks that forecast short-term mortality in acute pulmonary embolism [[8], [9], [10]]. These studies show that machine learning can both quantify CHD risk and flag its principal drivers. However, population-based models that predict CHD from lifestyle data rarely include sleep metrics and remain genetically untested; moreover, their associations are confounded and causally unverified [11,12]. Integrating prediction with Mendelian randomization addresses these gaps.
We integrate machine learning with two-sample MR to unify prediction and causal testing. In 20,000+ NHANES adults we train and tune eight lifestyle-only models for incident CHD, select the best on nested cross-validation, then verify the top predictors by MR with publicly available GWAS summary statistics (Fig. 1). This yields an accurate, biomarker-free screening tool and a genetically supported shortlist of modifiable targets for precision prevention.Fig. 1Study design flow The flow shows the process of screening and machine learning the NHANES database data, including the validation of Mendelian randomization.Fig. 1
Study population and methods
2
Machine learning
2.1
Data source and participants
2.1.1
We used the 2013–2018 NHANES cycles (n = 29,400), a cross-sectional, nationally representative survey conducted by the CDC. NHANES records self-reported physician diagnoses of CHD, lifestyle, diet, and laboratory data; all participants gave informed consent and the NCHS Research Ethics Review Board approved the protocol [13].
Data preprocessing
2.1.2
The inclusion criteria were as follows: (1) participants aged ≥18 years; (2) participants who completed the questionnaire regarding whether a doctor had informed them of having coronary heart disease (CHD), with complete questionnaire content and data. The exclusion criteria were: (1) participants aged <18 years; (2) participants with a CHD status of 9 (indicating an uncertain CHD status) based on the NHANES questionnaire [14]. Ultimately, 16,997 participants were included in the analysis. We incorporated the latest cardiovascular health metrics updated by the American Heart Association—Life's Essential 8 (LE8) [15]—and included 21 variables from four domains: (1) Demographic data (age, gender, education level, race, marital status); (2) Questionnaire data (physical activity, sleep status, smoking, and alcohol consumption); (3) Examination data (body mass index [BMI], poverty index, fasting blood glucose, systolic and diastolic blood pressure); and (4) Dietary data (energy, protein, carbohydrates, total sugar, dietary fiber, total cholesterol [TC], and total fat). The diagnosis of CHD was based on participants' self-reported questionnaire data indicating that a doctor had informed them of having CHD. All analyses were performed without sample weights because the aim was to examine biological associations rather than produce nationally representative estimates.
We first conducted a statistical analysis of missing values and chose the K-Nearest Neighbors (KNN) imputation method (with K = 5) to complete the dataset. This method is more accurate than simple imputation techniques (e.g., mean or median imputation), especially for small to medium-sized datasets [16]. To meet the data format requirements of machine learning algorithms, we normalized the data to a range of (0, 1) using feature scaling [17]. We removed variables with zero variance and those exhibiting high multicollinearity to enhance model performance, interpretability, and reduce the risk of overfitting [18]. The dataset was divided using K-fold cross-validation with K = 5, resulting in 4 training sets and 1 test set. The final training set contained 13,598 samples, and the validation set contained 3399 samples [19]. To address the significant disparity between positive (CHD) and negative (non-CHD) outcomes, we employed the Random Over-Sampling Examples (ROSE) method to balance the outcome variable, thereby reducing the numerical gap [[20], [21], [22]]. We utilized three common recursive feature elimination (RFE) algorithms-Random Forest (RF), Logistic Regression (LR), and Bagging Decision Trees (BDT)-to rank the importance of variables. These algorithms evaluate feature importance by iteratively building models and eliminating less important features, ultimately identifying the optimal feature subset [23].
Machine learning framework
2.1.3
The dataset was divided into 80 % for training (n = 13,598) and 20 % for testing (n = 3399). We employed eight different machine learning models to identify CHD caused by lifestyle exposures: Support Vector Machine (SVM), Neural Network(NN), Naive Bayes (NB), XGBoost, Multilayer Perceptron (MLP), Generalized Linear Model (GLM), Adaptive Boosting (AdaBoost), and Decision Tree (DT). Each machine learning algorithm has its unique characteristics, as described below: SVM is a maximum-margin classifier whose computational complexity grows polynomially with both the number of features and samples [24]. NN is a multilayered, non-linear model that captures high-dimensional interactions by mimicking neuronal signal transmission [25]. NB is a Bayes-theorem-based probabilistic classifier that assumes conditional independence of features; it is computationally light and scales well to high-dimensional data [26]. XGBoost is a gradient boosting algorithm that can handle imbalanced data by adjusting weights. It is widely used for classification problems [27]. MLP is a feedforward artificial neural network that effectively captures nonlinear relationships, making it an ideal choice for classifying complex and multifactorial diseases [28]. GLM is a flexible extension of linear regression that models non-normal dependent variables by linking predictors to outcomes. It can represent binary and count outcomes through different conditional distributions and functional relationships [29]. AdaBoost is a boosting method that typically achieves high training accuracy. However, it may reduce classification accuracy for imbalanced data and increase computational complexity [30]. 10.13039/100001588DT is a A nonparametric supervised learning method that is easy to understand and interpret, supports visual analysis, but is prone to overfitting [31].
Model evaluation
2.1.4
To evaluate and compare the predictive performance of the machine learning models, we employed various evaluation metrics, including: Accuracy and 95 % Confidence Interval (95 % CI), Precision, Sensitivity, Specificity, Recall, F1 Score, ROC Curve and AUC [32]. In addition to the aforementioned evaluation metrics, we introduced a confusion matrix to provide a more intuitive visualization of the predictions made by the machine learning models.
Model optimization
2.1.5
The best-performing model was re-trained with an exhaustive grid-search of candidate hyper-parameters; each configuration was evaluated by 10-fold cross-validation to stabilise performance estimates. Calibration plots (predicted vs. observed probability) and decision-curve analysis were then generated to confirm that the final model supplies both well-calibrated probabilities and net clinical benefit across the range of threshold probabilities encountered in practice.
Statistical methods
2.1.6
In this study, data selection, the establishment of machine learning models, model optimization, and the creation of key visualizations were conducted using R version 4.4.2. A seed number of 1234 was set for all analyses to ensure reproducibility.
Mendelian randomization
2.2
Concept introduction
2.2.1
Large-scale genome-wide association studies conducted over the past decade have identified numerous genetic variations associated with cardiac metabolic traits and risk factors. These findings have enabled the application of Mendelian Randomization (MR), a method that uses genetic variations as instrumental variables for causal inference between exposure and outcome, thereby determining whether the presumed risk factors might have a causal impact on disease [33]. Based on the selection of variables that significantly influence CHD from the optimal machine learning models, this study attempts to utilize Mendelian Randomization to validate the causal relationships, thereby enhancing its persuasive power and clinical applicability.
GWAS data collection and processing
2.2.2
Samples were obtained by accessing the IEU OpenGWAS project (mrcieu.ac.uk), collecting Genome-Wide Association Study (GWAS) data for the important variables identified through machine learning. The data for the exposure variables were preprocessed first, applying a threshold of P < 10^−8^ to filter single nucleotide polymorphisms (SNPs) significantly associated with the exposure variables. To ensure independence among the SNPs and to avoid the confounding effects of linkage disequilibrium, a linkage disequilibrium coefficient (r^2^ = 0.001) was established, limiting the correlation among adjacent SNPs. Additionally, to restrict the analysis scope, a region width of 10,000 kb was set, including only those SNPs within a certain distance from the target SNP, thereby excluding the influence of pleiotropy on the results to obtain instrumental variables related to the exposure variables [34]. After merging the exposure and outcome factors, a threshold of P < 10^−8^ was again applied to exclude SNPs that were directly associated with the outcome variable, CHD. The final dataset thus formed constitutes the requisite instrumental variables for further analysis and research in this study [35](Supplementary Table 1).
Mendelian randomization analysis
2.2.3
This study employed five regression models for Mendelian Randomization: MR-Egger regression, weighted median estimation (WME), inverse variance weighting (IVW), a simple model, and a weighted model. SNPs were used as instrumental variables to validate the causal relationship between the exposure variables and the outcomes. MR-Egger regression is a causal inference method that estimates the causal effect based on instrumental variables while accounting for potential instrument bias. The WME is another non-parametric approach that can reduce potential biases by excluding data based on the median. IVW estimates the overall effect by averaging the weights based on the variance of each study. The simple model is a linear regression method that establishes relationships by either weighting or not weighting the data, aiming to estimate the genetic correlation effect. The weighted model provides more accurate estimates by considering the sample size and error variance of each study.
Sensitivity analysis
2.2.4
Heterogeneity across SNPs was quantified with Cochran's Q (P < 0.05 indicates significant heterogeneity); when present, random-effects IVW was prioritised [36]. Directional horizontal pleiotropy was examined with the MR-Egger intercept [37]. Robustness was further assessed by leave-one-out analysis: exclusion of any single SNP should not materially alter the causal estimate [38].
Statistical methods
2.2.5
In this study, data import, instrumental variable selection, Mendelian Randomization analysis, and sensitivity analysis were all conducted using the TwoSampleMR package within R version 4.4.2. Key parameters and assumptions were adjusted to explore variations in the results. Additionally, a significance level of α = 0.05 was adopted throughout the analysis.
Results
3
Machine learning component
3.1
Baseline characteristics of NHANES participants
3.1.1
As is shown in Table 1, the characteristics of study participants with and without CHD from the NHANES conducted between 2013 and 2018 were summarized. A total of 16,997 participants were included in the analysis, of which 48.1 % were male, with an average age of 50.0 years. Among the participants, 741 individuals were diagnosed with CHD (4.5 %). Notably, CHD patients were predominantly male, older, and primarily non-Hispanic white compared to controls (all P < 0.05).Table 1. Baseline table of participants.Table 1[ALL]01p.overallN=16,997N=16,256N=741Age50.0 (17.7)49.1 (17.5)68.7 (10.7)<0.001Gender:<0.001 Male8169 (48.1 %)7678 (47.2 %)491 (66.3 %) Female8828 (51.9 %)8578 (52.8 %)250 (33.7 %)Edu:0.003 <High school1612 (9.50 %)1519 (9.36 %)93 (12.6 %) Completed high school2095 (12.3 %)1991 (12.3 %)104 (14.1 %) >High school13,267 (78.2 %)12,724 (78.4 %)543 (73.4 %)Race:<0.001 Mexican American2486 (14.6 %)2419 (14.9 %)67 (9.04 %) Other Hispanic1789 (10.5 %)1726 (10.6 %)63 (8.50 %) Non-Hispanic White6242 (36.7 %)5819 (35.8 %)423 (57.1 %) Non-Hispanic Black3664 (21.6 %)3552 (21.9 %)112 (15.1 %) Other Race2816 (16.6 %)2740 (16.9 %)76 (10.3 %)Marital:0.078 Married/Living with partner10,053 (59.2 %)9638 (59.3 %)415 (56.0 %) Widowed/Divorced/Separated/Never married6933 (40.8 %)6607 (40.7 %)326 (44.0 %)PIR2.49 (1.62)2.50 (1.63)2.33 (1.49)0.003BMI29.5 (7.21)29.5 (7.24)30.2 (6.66)0.008Smoke:<0.001 No9775 (57.5 %)9497 (58.4 %)278 (37.5 %) Yes7222 (42.5 %)6759 (41.6 %)463 (62.5 %)Alcohol:0.930 No12,957 (90.6 %)12,385 (90.6 %)572 (90.8 %) Yes1342 (9.39 %)1284 (9.39 %)58 (9.21 %)Sleep7.43 (2.35)7.42 (2.26)7.69 (3.81)0.062Physical_Activity:0.011 Inactive9961 (58.6 %)9504 (58.5 %)457 (61.7 %) Moderate3514 (20.7 %)3349 (20.6 %)165 (22.3 %) Vigorous728 (4.28 %)708 (4.36 %)20 (2.70 %) Both moderate and vigorous2794 (16.4 %)2695 (16.6 %)99 (13.4 %)Systolic125 (18.9)125 (18.6)133 (22.3)<0.001Diastolic70.6 (13.1)70.8 (12.9)65.7 (14.8)<0.001FBG6.20 (2.11)6.15 (2.04)7.20 (3.03)<0.001Energy2102 (1007)2110 (1012)1922 (857)<0.001Protein81.0 (44.0)81.3 (44.2)72.8 (37.0)<0.001Carbohydrate249 (126)250 (127)229 (112)<0.001Sugars107 (76.5)107 (76.6)101 (72.8)0.026Dietary_fiber17.0 (10.9)17.0 (10.9)16.1 (10.6)0.040Fat82.5 (48.3)82.7 (48.5)77.4 (44.5)0.004Cholesterol305 (250)306 (252)278 (210)0.001† “Cholesterol” in NHANES 2013–2018 denotes dietary cholesterol estimated from 24-h dietary recalls; it does not represent serum total cholesterol.
Preliminary selection of important variables
3.1.2
The results of the recursive feature elimination algorithm for the ranking of important variables are presented in Supplementary Fig. 1. After synthesizing the top five important variables from three different algorithms, eight significant variables were identified for further analysis in the machine learning models. These variables include age, sex, fasting blood glucose, BMI, TC, sleep duration, diastolic blood pressure, and smoking status.
Establishment and validation of machine learning models
3.1.3
After the preliminary selection of the eight important variables, eight different machine learning models-SVM, NN, NB, XGBoost, MLP, GLM, AdaBoost, and DT-were developed. The evaluation metrics for each model were computed, and confusion matrices were generated (Supplementary Fig. 2). A comparison of the various parameters is provided in Table 2, revealing that the SVM model exhibited the best AUC performance at 0.909 (Fig. 2A) and an average accuracy rate of 83.4 % (82.8 %–84.1 %), indicating that it performs well in identifying CHD. When the validation dataset was input into the SVM model, the AUC remained high at 0.835, suggesting that even with unfamiliar data, the SVM model is capable of maintaining strong recognition performance, further confirming its stability and generalizability.Table 2. Comparison of machine learning performance of different models.Table 2. ModelsAccuracy(95 % CI)PrecisionSensitivitySpecificityRecallF1AUCLR0.747(0.739,0.754)0.7330.7820.7100.7820.7570.812DT0.791(0.784,0.797)0.7700.8340.7470.8340.8010.862XGBoost0.775(0.768,0.782)0.7520.8260.7230.8260.7880.855AdaBoost0.780(0.773,0.787)0.7580.8270.7320.8270.7910.861NB0.754(0.747,0.761)0.7410.7870.7200.7870.7630.827MLP0.761(0.753,0.768)0.7320.8290.6910.8290.7770.830NN0.770(0.762,0.777)0.7410.8340.7040.8340.7850.846SVM0.834(0.828,0.841)0.8080.8800.7870.8800.8430.909Fig. 2Plot (A) Receiver operating characteristic (ROC) curves of different machine learning models The curves show the predictive performance of logistic regression (LR; AUC = 0.812), decision tree (DT; AUC = 0.862), Extreme Gradient Boosting (XGBoost; AUC = 0.855), Adaptive Boosting (AdaBoost; AUC = 0.861), Naive Bayes (NB; AUC = 0.827), multilayer perceptron (MLP; AUC = 0.830), neural network (NN; AUC = 0.846), and support vector machine (SVM; AUC = 0.909), with sensitivity versus 1-specificity. Different colors represent different machine learning models. Plot (B) Youden's index analysis of the classifier performance The ROC curve (SVM) demonstrates the trade-off between sensitivity (0.797) and specificity (0.874), with the optimal cutoff threshold of 0.517 identified by Youden's index. Plot (C) Calibration curve The curve illustrates the relationship between predicted values from the model and actual observed outcomes. Plot (D) Decision curves The decision curves display the net benefits of using the predictive model at various threshold probabilities. (For interpretation of the references to color in this figure legend, the reader is referred to the Web version of this article.)Fig. 2
Evaluation and optimization of the best model
3.1.4
The optimal machine learning model for predicting CHD was identified as the SVM. In machine learning models, a higher Youden's J statistic indicates a stronger overall classification capability [39]. The Youden's J statistic for the SVM model was found to be 0.517, with the best cut-off value achieving a sensitivity of 79.7 % and specificity of 87.4 % (Fig. 2B). These results demonstrate the model's solid performance in distinguishing positive cases (those with CHD) from negative cases (those without CHD). Subsequently, hyperparameter tuning was performed using a grid search algorithm, with the sigma parameter set to (0.01, 0.02, 0.05, 0.1) and the C parameter set to (1, 2, 3, 4, 5). This parametric setup systematically evaluated the performance of the SVM model under different combinations for the classification task, ultimately selecting the optimal parameter combination to enhance model accuracy. Following the optimization, evaluation on the test dataset yielded an AUC of 0.909, while the AUC for the validation dataset improved to 0.855. This result not only reflects a significant enhancement in the model's accuracy and generalizability but also indicates that the optimized model is more effective at differentiating between CHD patients and non-patients.
To further evaluate the performance of the optimal SVM model, we generated a calibration curve, as shown in Fig. 2C. The curve demonstrates a good fit with the diagonal line (dashed), indicating a high consistency between the model's predictions and the actual outcomes. Additionally, we plotted a decision curve to assess the net benefit of the model. As illustrated in Fig. 2D, the prediction curve is above both the All and None lines across most of the range (0, 1), suggesting that the model holds practical utility in clinical predictions.
SHAP interpretability analysis
3.1.5
SHAP was employed to visually depict the impact of significant variables on CHD. Fig. 3 illustrates the influence of each variable on the detection dataset's ability to identify CHD within the SVM model. On the left panel of the figure, the variables are ranked in order of importance based on their SHAP values, from top to bottom. The right panlee of the figure shows that yellow indicates higher parameter values, while purple represents lower values. Furthermore, a waterfall plot (Supplementary Fig. 3) is presented to exemplify a single prediction. In the plot, the estimated model value is 0.823, while the predicted value for the sample is 0.505. The variables contributing most significantly to the model are age, sex, smoking status, BMI, and fasting blood glucose levels.Fig. 3SHAP Interpretable This figure displays the SHAP values for the features used in the predictive model. On the left side, features are ranked in order of importance from top to bottom based on their SHAP values. The right side of the plot employs a color gradient, where yellow indicates higher parameter values and purple signifies lower parameter values. This visualization helps to elucidate each feature's contribution to the model's predictions and highlights the variables that have the most significant impact on the outcome. Caution: The negative SHAP values for DBP reflect reverse causation—low DBP is driven by advanced CHD or its treatment (see Discussion and Supplementary Table 2) and should not be interpreted as a protective risk factor. (For interpretation of the references to color in this figure legend, the reader is referred to the Web version of this article.)Fig. 3
Mendelian randomization component
3.2
Instrumental variable selection for mendelian randomization
3.2.1
Following the identification of eight significant factors affecting CHD through machine learning, SHAP interpretability analysis was used to rank these factors by importance. Due to the consensus that age and sex are critical factors influencing CHD and the difficulties in obtaining relevant SNPs for these variables from the GWAS data, the remaining six factors were selected for MR analysis. The GWAS ID for the exposure variables, along with the number of SNPs excluded during the selection process due to duplicate naming and palindrome SNPs with intermediate alleles, is summarized in Table 3. The outcome variable was standardized as CHD, with the GWAS ID designated as ukb-d-I9_CHD.Table 3. Statistical table of exposure variables.Table 3. VariablesGWAS IDUnit of MeasurementExclusion of SNPsFinal SNPsHeterogeneity P-valueHorizontal polytropic p-valueFBGebi-a-GCST000568Per 1 mmol/L0140.0660.404Diastolicebi-a-GCST90000059Per 10 mmHg4199<0.0010.818Insomniaukb-b-3957Odds (Ever vs. Never)3390.0070.078BMIukb-b-19953Per 1 SD (kg/m^2^)17441<0.0010.083TCieu-a-301Per 1 SD (mmol/L)286<0.0010.155Smokeebi-a-GCST90029014Odds (Ever vs. Never)91200.0380.333
Results and testing of mendelian randomization
3.2.2
The results of the five Mendelian Randomization analyses for fasting blood glucose indicated P > 0.05 (Fig. 4), suggesting a lack of statistical significance. Furthermore, both the heterogeneity test and the horizontal pleiotropy test yielded results of P > 0.05 (Table 3), indicating that there is no evidence of heterogeneity or horizontal pleiotropy in the analysis.Fig. 4Summary forest plot of the results of Mendelian randomization The analysis was conducted using multiple methods, including MR Egger, weighted median, inverse variance weighted, simple mode, and weighted mode. The p-value threshold for statistical significance was set at P < 0.05. The forest plot at the bottom indicates the direction of the effect, with protective factors on the left and risk factors on the right.Fig. 4
The results of the five Mendelian Randomization analyses for diastolic blood pressure revealed P < 0.05 (Fig. 4), indicating statistical significance. The heterogeneity test yielded P < 0.001, suggesting the presence of certain heterogeneity, which prompts us to focus on the random IVW results. The horizontal pleiotropy test indicated P > 0.05, demonstrating no evidence of horizontal pleiotropy (Table 3). The scatter plot (Supplementary Fig. 4A) suggests a consistent directional effect among the five methods, indicating that an increase in diastolic blood pressure is associated with an elevated risk of developing CHD. The leave-one-out analysis results (Supplementary Fig. 5A) show all error bars on one side of zero, while the funnel plot (Supplementary Fig. 6A) reflects a relatively even distribution of points around the IVW method, confirming the robustness of the study. These results suggest that diastolic blood pressure exerts a causal effect on CHD, with an odds ratio (OR) of 1.02 (1.01, 1.02).
In the five MR analyses for insomnia, the P-values for the IVW and WME methods were less than 0.05, while the P-values for the remaining three methods were greater than 0.05, indicating partial statistical significance (Fig. 4). The heterogeneity test yielded a P < 0.05, suggesting the presence of some heterogeneity, which indicates a need to focus on the random IVW results. The horizontal pleiotropy test indicated P > 0.05, demonstrating no evidence of horizontal pleiotropy (Table 3). In the scatter plot (Supplementary Fig. 4B), the direction of the MR-Egger method was opposite to that of the other four methods; however, it did not achieve statistical significance. In contrast, both the IVW and WME methods showed consistent directionality, suggesting that as the rate of insomnia increases, the risk of developing CHD also rises. The leave-one-out analysis (Supplementary Fig. 5B) revealed that all error bars were confined to one side of zero, and the funnel plot (Supplementary Fig. 6B) illustrated a relatively even distribution of points around the IVW method, reinforcing the robustness of the findings. The results indicate that insomnia has a causal effect on CHD, with OR of 1.03 (1.01, 1.04).
In the analyses for BMI, the P-values for MR-Egger, IVW, and WME were less than 0.05, while the P-values for the remaining two methods were greater than 0.05, indicating partial statistical significance (Fig. 4). The heterogeneity test yielded a P < 0.001, suggesting the presence of significant heterogeneity, which underscores the importance of focusing on the random IVW results. The horizontal pleiotropy test indicated P > 0.05, demonstrating no evidence of horizontal pleiotropy (Table 3). In the scatter plot (Supplementary Fig. 4C), the directions of the MR-Egger, IVW, and WME methods were consistent, indicating that as BMI increases, the risk of developing CHD also rises. The leave-one-out analysis (Supplementary Fig. 5C) showed that all error bars were on one side of zero, and the funnel plot (Supplementary Fig. 6C) reflected a relatively even distribution of points around the IVW method, further confirming the robustness of the findings. The results suggest that an increase in BMI has a causal effect on CHD, with an OR of 1.01 (1.01, 1.02).
The results of the five Mendelian Randomization analyses for TC indicated P-values less than 0.05, establishing statistical significance (Fig. 4). The heterogeneity test yielded a P < 0.001, suggesting significant heterogeneity, which highlights the need to focus on the random IVW results. The horizontal pleiotropy test returned P > 0.05, indicating no evidence of horizontal pleiotropy (Table 3). The scatter plot (Supplementary Fig. 4D) reveals consistent directional effects across all five methods, suggesting that an increase in TC is associated with a heightened risk of developing CHD. In the leave-one-out analysis (Supplementary Fig. 5D), all error bars were located on one side of zero, and the funnel plot (Supplementary Fig. 6D) displayed a relatively even distribution of points around the IVW method, further confirming the robustness of the findings. The results indicate that an increase in total cholesterol has a causal effect on CHD, with an OR of 1.20 (1.14, 1.26).
In the MR analyses for smoking, the P-values for IVW, WME, and the weighted model were all less than 0.05, indicating statistical significance. In contrast, the P-values for the remaining two methods were greater than 0.05, suggesting partial statistical significance (Fig. 4). The heterogeneity test yielded a P < 0.05, indicating the presence of significant heterogeneity, which emphasizes the importance of focusing on the random IVW results. The horizontal pleiotropy test indicated P > 0.05, demonstrating no evidence of horizontal pleiotropy (Table 3). The scatter plot (Supplementary Fig. 4E) illustrates consistent directional effects across all five methods, indicating that an increase in smoking is associated with an elevated risk of developing CHD. The leave-one-out analysis (Supplementary Fig. 5E) showed that all error bars were positioned on one side of zero, and the funnel plot (Supplementary Fig. 6E) demonstrated a relatively even distribution of points around the IVW method, reinforcing the robustness of the findings. The results suggest that increased smoking is causally linked to CHD, with an OR of 1.03 (1.02, 1.04).
Discussion
4
Key findings
4.1
This study employed eight common machine learning methods, including SVM, NN, NB, XGBoost, MLP, GLM, AdaBoost, and DT, to predict CHD based on lifestyle-related variables. Among them, SVM showed the best performance among the eight machine learning models, achieving an AUC of 0.909 and an accuracy of 83.4 %. The results of MR analyses demonstrated positive associations for five variables: diastolic blood pressure, insomnia, BMI, TC, and smoking. These findings suggest that as the parameters of these five variables increase, the risk developing CHD also rises, indicating that these variables significantly influence the occurrence and progression of the disease. Notably, fasting glucose showed predictive but not causal association (P = 0.21), suggesting its role as a biomarker rather than therapeutic target - a critical distinction enabled by our dual-method design.
Comparative performance analysis and innovation
4.2
Numerous studies have previously attempted to establish machine learning models for predicting CHD. Liu and Zengjing developed a CHD risk prediction model for patients with human immunodeficiency virus using seven machine learning techniques and electronic health record data. Their results indicated that the Light Gradient Boosting Machine (LightGBM) model exhibited superior overall performance, showing enhanced reliability in assessing risk prediction factors for CHD [40]. In another study, Ma and Cai-Yi analyzed the risk of CHD among more than 300,000 diabetic patients in Southwest China using three traditional machine learning models. The random forest model produced an AUC of 0.701 on the test samples, providing personalized guidance for early CHD warning in the diabetic population [41]. Similarly, Xu and Hu utilized machine learning algorithms to predict CHD among diabetic patients, drawing on data from the General Hospital of the PLA. Their study employed five different machine learning algorithms, finding that the established XGBoost model demonstrated significant predictive value for elderly diabetic patients with CHD, achieving an AUC of 0.880 [42]. Compared to previous studies, this research. Unlike previous studies limited to either prediction or correlation analysis, our research advances CHD risk assessment through three key innovations: (1) systematic comparison of eight machine learning algorithms identifying SVM as optimal (AUC = 0.909, accuracy = 83.4 %) using readily obtainable lifestyle variables; (2) integration of MR to distinguish causal risks (smoking, sleep duration) from mere biomarkers (fasting glucose); and (3) development of a clinically actionable tool requiring only non-invasive measurements, bridging a critical gap between risk prediction and causal prevention strategies.
Model features and evaluation
4.3
In this study, we selected demographic data and 16 lifestyle-related factors from the NHANES database as the feature variables. These included age, sex, education level, race, marital status, physical activity, sleep status, smoking, alcohol consumption, BMI, poverty index, fasting blood glucose, systolic blood pressure, diastolic blood pressure, energy intake, protein intake, carbohydrate intake, total sugars, dietary fiber, TC, and total fats, totaling 21 variables. In contrast to most previous studies [[40], [41], [42]], which have predominantly considered biochemical indicators as key variables in CHD prediction models, our model focuses on lifestyle-related indicators. These indicators are generally easier to obtain and less invasive, with only fasting blood glucose being a minimally invasive measurement that can be self-collected at home. Therefore, the models we established operate independently of biochemical indicators. Once high-risk individuals are flagged, their modifiable lifestyle targets (sleep, physical activity, diet, alcohol, smoking) can be delivered to patients and clinicians through mobile health (mHealth) apps and telemedicine portals, tools that have already improved heart-rate variability in high-risk diabetics and are poised to expand scalable, guideline-aligned CHD prevention [43,44]. Our goal was to develop a practical, convenient, and highly acceptable screening model, which can facilitate early identification of individuals at risk of CHD based on easily accessible lifestyle-related factors.
As is shown in Fig. 4, the relative importance of various variables identified in the final selection, with age, gender, fasting glucose, diastolic blood pressure, smoking status, TC, BMI, and sleep quality being the most significant factors influencing model design. Given the inherent complexity of machine learning methods and the challenges in intuitively presenting results, we applied SHAP values for interpretability within the SVM model to achieve optimal variable representation and clarity. A positive SHAP value indicates that the associated feature contributes to a higher risk of CHD, whereas a negative SHAP value indicates a lower risk.
The interpretation of SHAP in conjunction with the causal validation through MR reveals results that align closely with earlier studies on coronary heart disease risk factors. Data from 102 prospective studies indicate that for populations without a history of diabetes, fasting glucose levels or impaired fasting glucose do not significantly improve the predictive metrics for vascular diseases when considered alongside several conventional risk factors [45]. A recent meta-analysis assessing various hypertension diagnostic guidelines found that isolated diastolic hypertension is associated with increased cardiovascular risk, and higher diastolic blood pressure thresholds correlate with elevated cardiovascular risk [46]. Although the ML model correctly reproduces the empirical observation that lower DBP is associated with higher contemporaneous probability of CHD (Fig. 3), this association is unlikely to be causal. Because the model was trained on contemporaneous measurements, the captured associations may reflect consequences of already-established disease or its treatment rather than aetiological risk factors. Supplementary Table 2 shows that participants with manifest CHD were more frequently prescribed antihypertensive medications and had lower cardiac output, both of which reduce measured DBP. Consequently, low DBP should be interpreted as a marker of advanced disease or aggressive treatment rather than a causal risk factor for CHD. We attempted prospective validation using the NHANES 2013–2018 linked mortality files; however, the follow-up duration is short and cardiovascular deaths are too few to meet the minimum event-per-variable requirement of Cox regression. Notably, prior NHANES analyses reported a sharp rise in cardiovascular mortality when DBP exceeded 75 mmHg, a direction consistent with our MR estimates and further supporting a positive causal effect of long-term elevated DBP on CHD [47]. Hypertension is widely considered as an independent risk factor for CHD; however, initial discussions often prioritize systolic blood pressure, leading to an underappreciation of diastolic pressure. Our study demonstrates that diastolic pressure plays an indispensable role in the risk associated with coronary heart disease, suggesting that healthcare professionals and the public should equally weigh diastolic pressure alongside systolic pressure when evaluating cardiovascular health. Existing data indicate that insomnia is linked with an increased risk of hypertension, coronary heart disease, and recurrent acute coronary syndrome [48]. Due to societal pressures and health-related issues, insomnia has become a pervasive sleep disorder, significantly impacting the daily lives and mental health of many individuals. Our study further validates the significant role of insomnia in the risk of CHD, indicating that the cardiovascular health risks among individuals with insomnia may be more severe than those in the general population. We emphasize the importance of sleep quality and encourage the public to develop good sleep habits, which could potentially incidence CHD Regarding the well-known cardiovascular risk factor, BMI, a prospective cohort study from the China Biobank indicates that participants who are overweight have a 41 % higher risk of developing CHD compared to those with BMI [49]. With the advancement technology and the rise a smart society, increasing of individuals are opting for modes of, resulting in a general increase in BMI. To mitigate the risk of CHD, recommend that individuals engage in exercise, their BMI, and maintain a healthy. Elevated levels of TC have long been recognized as one of the primary causes of atherosclerosis and cardiovascular diseases. We emphasize that the “cholesterol” entry in Table 1 quantifies dietary cholesterol intake, whereas the MR exposure is based on serum TC. The inverse cross-sectional association between dietary cholesterol and prevalent CHD (Table 1) is therefore not contradictory to the positive genetically-predicted effect of serum cholesterol on incident CHD (Fig. 4). The observed inverse association likely reflects reverse causation: individuals with diagnosed CHD frequently reduce consumption of high-cholesterol foods, attenuating their apparent intake. Circulating cholesterol, in contrast, captures systemic lipid metabolism that causally elevates CHD risk. This distinction underscores the limitation of interpreting dietary variables as proxies for biological exposure and reinforces the need for MR designs that leverage serum lipid biomarkers. Our MR analysis of TC implicates genetically elevated TC as a causal CHD driver; this aligns with evidence that saturated fat and added sugar—rather than dietary cholesterol itself—are the main dietary determinants of TC. Reducing animal-source foods rich in these fats and sugars (e.g., fatty red meat, full-fat dairy, sugar-sweetened items) would therefore be expected to lower serum TC and consequent CHD risk. Smoking has long been recognized as an independent risk factor for cardiovascular diseases, and our study similarly highlights its significant impact on the risk of CHD. Research indicates that the risk of cardiovascular events decreases significantly within five years after quitting smoking, and this risk can diminish to levels comparable to never smokers over several decades [50]. This finding suggests that it is never too late to take action to quit smoking, regardless of when one begins the cessation process. It is crucial for individuals to recognize the harmful effects of smoking on health; distancing oneself from cigarettes can effectively reduce the risk of CHD. By quitting smoking, individuals not only improve their own health status but also contribute to creating a healthier environment for those around them.
Limitations and future directions
4.4
Several limitations are present in our study. First, the diagnosis of CHD was defined based on self-reported data from interview questionnaires in the NHANES database, which may introduce information bias due to cognitive deficits or recall bias. Any inaccuracies in CHD classification could, to some extent, affect the accuracy of machine learning models in identifying CHD. Second, during the inclusion of overall data for machine learning model analysis, there were still some missing metrics for certain participants. Although we employed rigorous statistical methods for imputation, some residual bias may persist. Furthermore, as our study is based on the NHANES database and the GWAS gene repository, the results may only be applicable to the U.S. population and may not be directly generalizable to other global populations. Future research should focus on validating our model across diverse populations, such as those from UK and Asian biobanks, while also incorporating clinical diagnoses, including data from electronic health records, to mitigate self-report bias. Additionally, the use of advanced methodologies like federated learning, deep learning architectures, and multi-omics integration, such as proteomics, has the potential to enhance the model's robustness and biological interpretability. Moreover, implementation studies are crucial to assess the real-world applicability, cost-effectiveness, and development of clinician-friendly interfaces, which are essential for the scalable adoption of the model in preventive healthcare.
Conclusion
5
While previous researchers have developed predictive models for CHD, most of these models have incorporated laboratory metrics from hospital settings and utilized traditional statistical methods. With the continuous advancement and refinement of machine learning in recent years, its applications in healthcare have become increasingly prevalent. This study demonstrates the potential of using lifestyle-related data to predict CHD through machine learning methodologies. We utilized data from 29,400 respondents from the NHANES, incorporating 21 lifestyle variables and applying eight common machine learning models for analysis. Following model training, we evaluated and compared the models using the AUC. The performance ranking of the eight machine learning models was SVM > DT > AdaBoost > XGBoost > NN > MLP > NB > GLM, with the SVM model achieving an accuracy of 83.4 % and an AUC of 0.909. Subsequently, SHAP interpretability and Mendelian randomization validation were performed, and our cumulative results indicate that the SVM model can better predict CHD using lifestyle-related indicators. In daily life, individuals can reduce their risk of developing CHD by minimizing cholesterol intake, paying attention to changes in diastolic blood pressure, managing sleep duration appropriately, maintaining BMI within a normal range, and avoiding smoking or quitting as early as possible. To summarize, by synergizing machine learning and MR, we developed and causally validated a practical CHD prediction tool. Our findings shift prevention paradigms from biomarker-centric approaches to modifiable lifestyle factors, offering a scalable strategy to reduce the global CHD burden.
CRediT authorship contribution statement
Yang yang Cui: Writing – original draft, Methodology, Investigation, Formal analysis. Yonghong Zhang: Writing – review & editing, Software, Methodology. Lang Zeng: Writing – review & editing, Methodology, Investigation. Shikang Li: Validation, Methodology, Investigation. Xue Mei: Investigation. Xiangmei Yang: Writing – review & editing, Investigation. Peng Zhou: Investigation. Lijuan Xiong: Investigation. Yijuan Huang: Software, Resources. Jing Luo: Investigation. Fenglin Wu: Supervision, Conceptualization. Rongchuan Yue: Writing – review & editing, Writing – original draft, Methodology, Funding acquisition, Conceptualization.
Funding
This study was supported by the Nanchong science and technology plan project (23JCYJPT0059); Research and development program of North Sichuan Medical College (CBY23-TD01); Research and Development Plan project of Clinical School and Affiliated Hospital of North Sichuan Medical University(2024PTZK007); Scientific Research Program of Sichuan Medical Association(2024TG38) and Funding from the Scientific Startup Foundation for Doctors of North Sichuan Medical College to Xue Mei (CBY23-QDA11).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1de Oliveira Laterza Ribeiro M.Correia V.M.Herling de Oliveira L.L.Soares P.R.Scudeler T.L.Evolving diagnostic and management advances in coronary heart disease Life 13420239513710948010.3390/life 13040951 PMC 10143565 · doi ↗ · pubmed ↗
- 2Tang M.M.Zhao S.T.Li R.Q.Hou W.Therapeutic mechanisms of ginseng in coronary heart disease Front. Pharmacol.142023127102910.3389/fphar.2023.1271029 PMC 1057960537854713 · doi ↗ · pubmed ↗
- 3Wang N.Sun Y.Zhang H.Long-term night shift work is associated with the risk of atrial fibrillation and coronary heart disease Eur. Heart J.42402021418041883437475510.1093/eurheartj/ehab 505 · doi ↗ · pubmed ↗
- 4Ferreira-González I.The epidemiology of coronary heart disease Rev. Esp. Cardiol.6720141391442479512410.1016/j.rec.2013.10.002 · doi ↗ · pubmed ↗
- 5Al-Shaar Laila Red meat intake and risk of coronary heart disease among US men: prospective cohort study BMJ Clin. Res.371202010.1136/bmj.m 4141 m 4141. 2 Dec PMC 803011933268459 · doi ↗ · pubmed ↗
- 6Kononenko I.Machine learning for medical diagnosis: history, state of the art and perspective Artif. Intell. Med.23120018910910.1016/s 0933-3657(01)00077-x 11470218 · doi ↗ · pubmed ↗
- 7Qin Yifan Machine learning models for data-driven prediction of diabetes by lifestyle type Int. J. Environ. Res. Publ. Health 192220221502710.3390/ijerph 192215027 PMC 969006736429751 · doi ↗ · pubmed ↗
- 8Hassan Ch Anwar Ul Effectively predicting the presence of coronary heart disease using machine learning classifiers Sensors (Basel, Switzerland)22202210.3390/s 2219722719 7227. 23 Sep.PMC 957310136236325 · doi ↗ · pubmed ↗