Benchmarking speech-to-text robustness in noisy emergency medical dialogues: an evaluation of models under realistic acoustic conditions
Denis Moser, Nikola Stanic, Murat Sariyar

TL;DR
This study evaluates how well speech-to-text systems handle noisy emergency medical conversations, finding that some models perform better under realistic conditions.
Contribution
The study introduces a clinically relevant benchmark for evaluating speech-to-text systems in realistic emergency medical noise conditions.
Findings
recapp outperformed other systems across multiple transcription accuracy metrics.
Whisper v3 Turbo showed the lowest medical word error rate and best phrase-level accuracy.
Dense environmental noise, like crowd chatter, most significantly degraded transcription performance.
Abstract
To evaluate the transcription accuracy of 6 German-capable speech-to-text (STT) systems in simulated emergency medical services (EMS) environments, focusing on clinically relevant performance under noisy and multilingual field conditions. We generated a corpus of 99 synthetic emergency dialogues and overlaid them with ecologically valid noise types—crowd chatter, traffic, public spaces, and ambulance interiors—at 5 signal-to-noise ratios (SNRs), producing 1980 noisy audio samples. Each was transcribed by 6 STT systems (recapp, Vosk, Whisper v3 variants, and RescueSpeech). We assessed performance using 5 metrics: Word Error Rate (WER), Medical Word Error Rate (mWER), TF–IDF Cosine Similarity, BLEU, and semantic embedding similarity. Statistical models quantified the effects of system, noise, and SNR on transcription fidelity. recapp consistently outperformed all other systems across…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
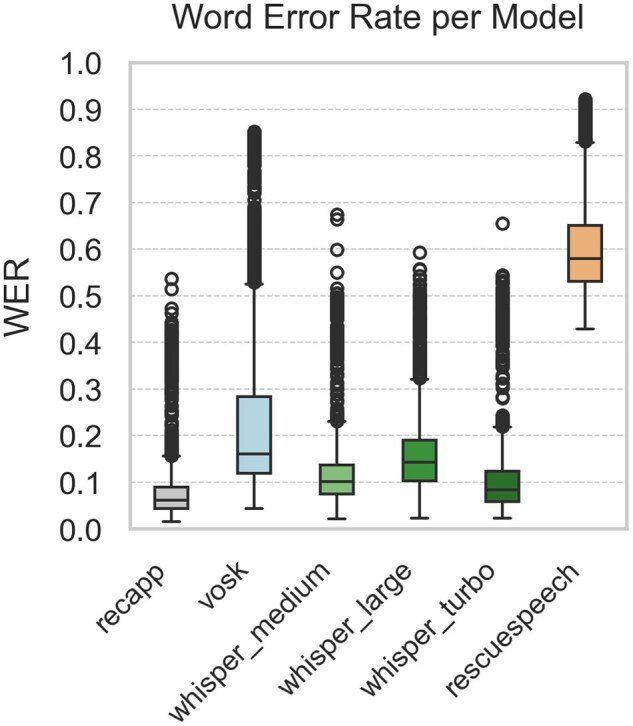 Figure 1
Figure 1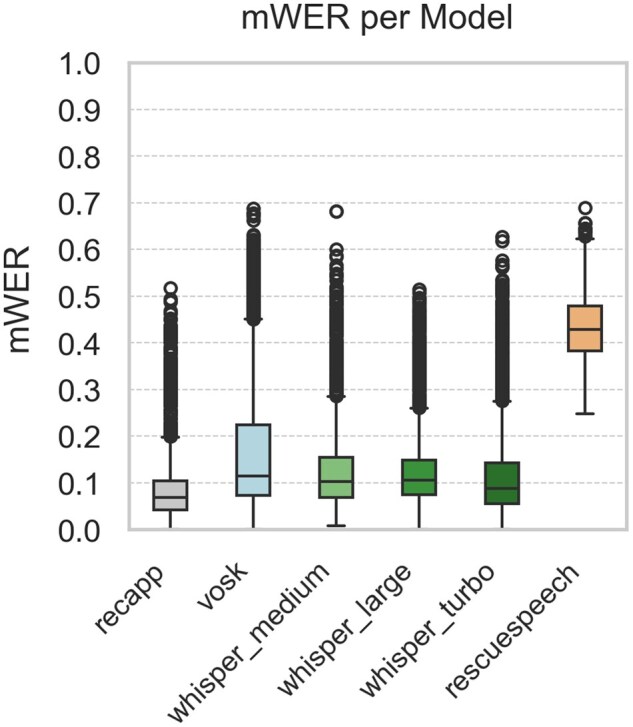 Figure 2
Figure 2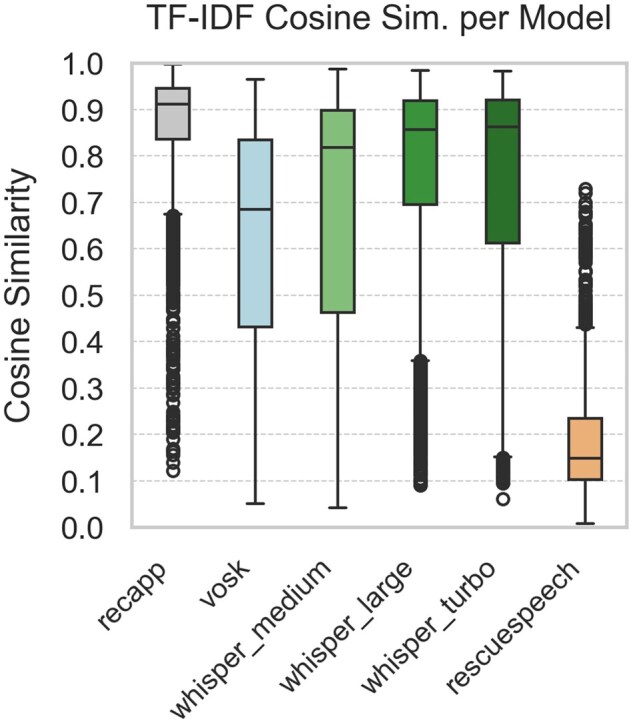 Figure 3
Figure 3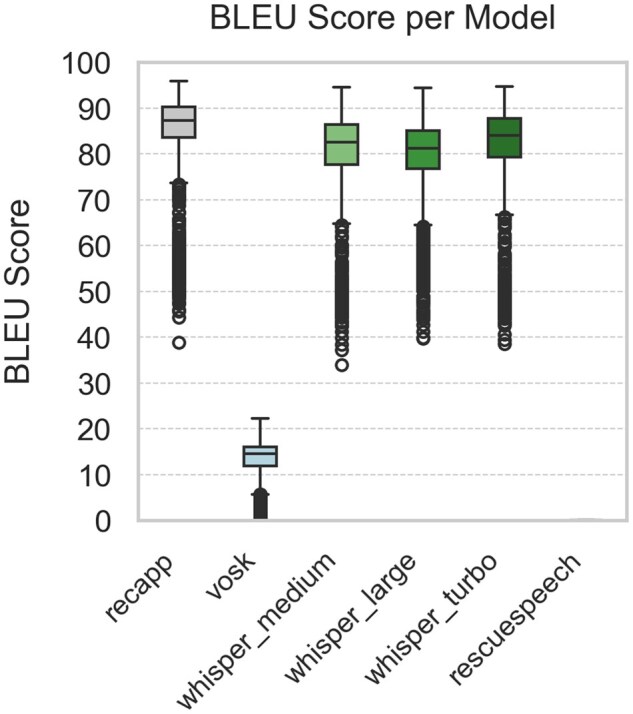 Figure 4
Figure 4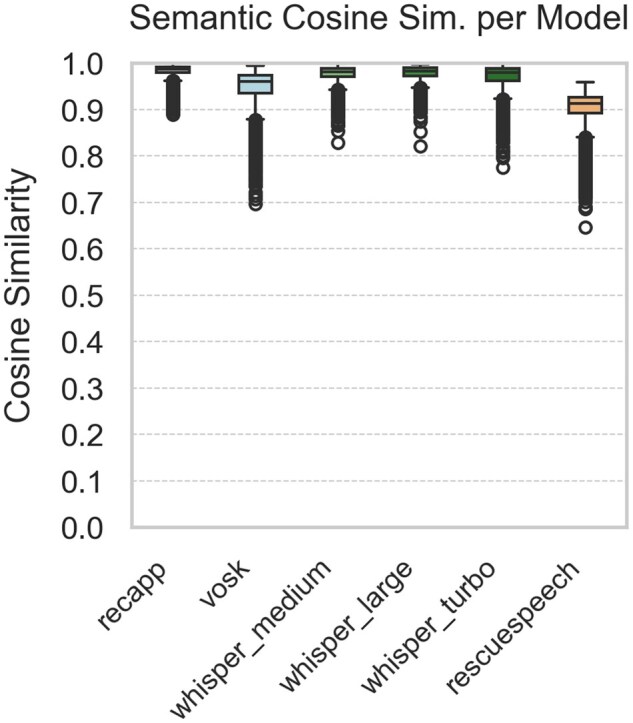 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSpeech Recognition and Synthesis · Speech and dialogue systems · Topic Modeling