A dual enhanced stochastic gradient descent method with dynamic momentum and step size adaptation for improved optimization performance
Mohamed A. Mokhtar, Mohamed Fathy, Yasser A. Dahab, Emad A. Sayed

TL;DR
This paper introduces a new optimization algorithm called DESGD that improves training performance in complex machine learning landscapes.
Contribution
The novel dual enhanced SGD method dynamically adapts both momentum and step size within the same update rules.
Findings
DESGD outperforms SGDM and Adam in optimization test functions with fewer iterations and less CPU time.
On the MNIST dataset, DESGD achieves higher accuracy and lower test loss across most batch sizes.
The method offers a favorable cost-to-performance ratio with marginal computational overhead.
Abstract
In modern machine learning, optimization algorithms are crucial; they steer the training process by skillfully navigating through complex, high-dimensional loss landscapes. Among these, stochastic gradient descent with momentum (SGDM) is widely adopted for its ability to accelerate convergence in shallow regions. However, SGDM struggles in challenging optimization landscapes, where narrow, curved valleys can lead to oscillations and slow progress. This paper introduces dual enhanced SGD (DESGD), which addresses these limitations by dynamically adapting both momentum and step size on the same update rules of SGDM. In two optimization test functions, the Rosenbrock and Sum Square functions, the suggested optimizer typically performs better than SGDM and Adam. For example, it accomplishes comparable errors while achieving up to 81–95% fewer iterations and 66–91% less CPU time than SGDM and…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
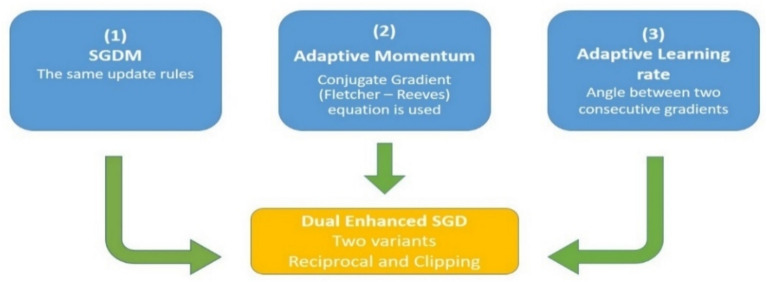 Figure 1
Figure 1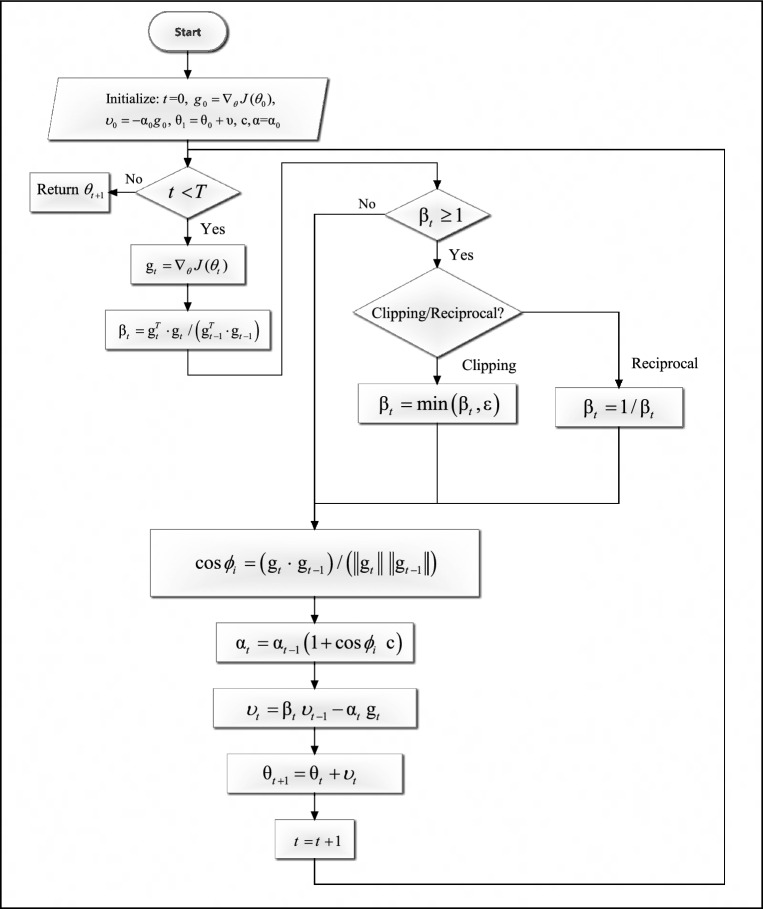 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4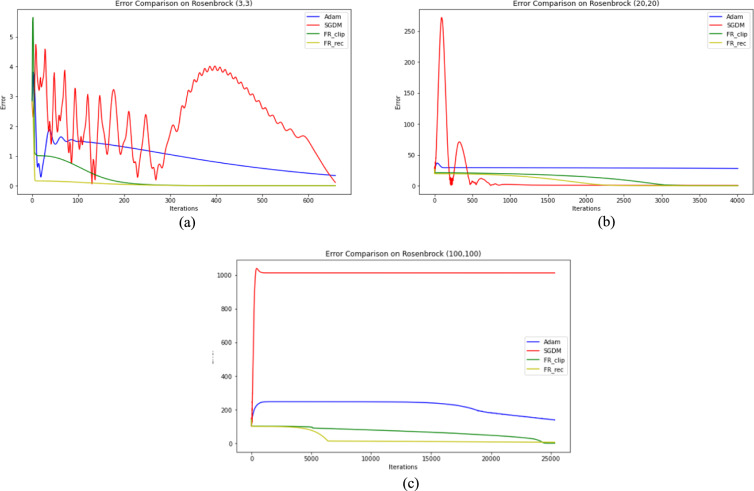 Figure 5
Figure 5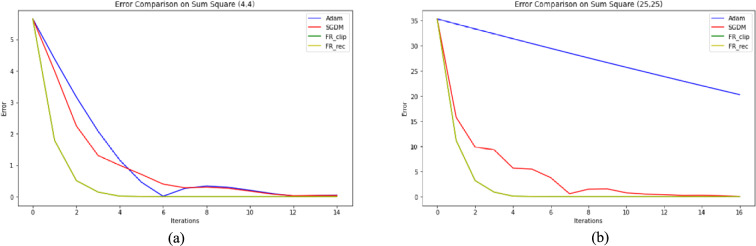 Figure 6
Figure 6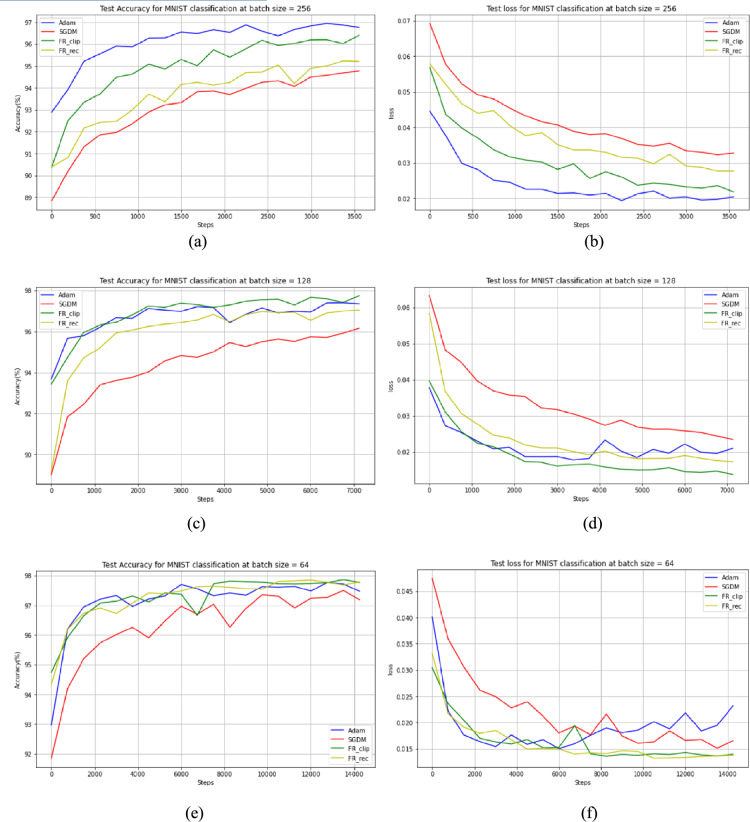 Figure 7
Figure 7 Figure 8
Figure 8Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStochastic Gradient Optimization Techniques · Metaheuristic Optimization Algorithms Research · Advanced Multi-Objective Optimization Algorithms