Point‐Guided Latent Diffusion Model for Novel View Synthesis in Laparoscopic Liver Surgery
Wenzhe Tang, Tao Chen, Yamid Espinel, Shahid Farid, Emmanuel BUC, Adrien Bartoli, Sharib Ali

TL;DR
This paper introduces a new method for generating detailed surgical views from limited laparoscopic footage, improving accuracy and situational awareness during liver surgery.
Contribution
A point-guided latent diffusion model is proposed for novel view synthesis in laparoscopic liver surgery, using geometric cues and adaptive camera planning.
Findings
The method outperforms existing approaches in terms of PNSR, SSIM, and LPIPS metrics on the P2ILF dataset.
It effectively handles occlusions and shape deformation through adaptive camera trajectory planning and a spatial-transformer enhanced decoder.
The approach generates anatomically consistent views, enhancing surgical scene reconstruction and training.
Abstract
Despite recent progress in diffusion‐based video synthesis, synthesizing accurate novel views from sparse input frames in laparoscopic liver surgery remains challenging due to occlusions, complex shape of anatomical structures and limited field of views. We propose point‐guided latent diffusion model, specifically designed for generating high‐quality intermediate frames in laparoscopic liver surgery from only the first and last video frames. Our method leverages the powerful generative capability of latent diffusion models combined with geometric cues from 3D point clouds reconstructed via dense stereo matching. To robustly handle occlusions and shape deformation, we use an adaptive camera trajectory planning strategy based on next‐best‐view algorithms. Furthermore, we introduce a spatial‐transformer enhanced decoder to effectively preserve detailed anatomical features from reference…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
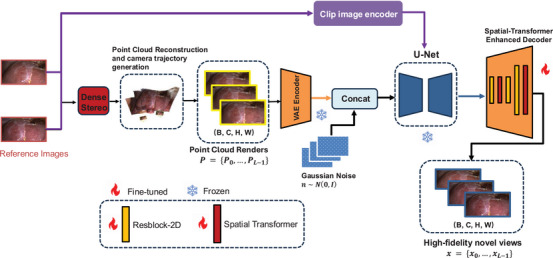 Figure 1
Figure 1 Figure 2
Figure 2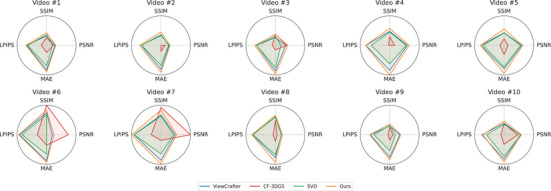 Figure 3
Figure 3 Figure 4
Figure 4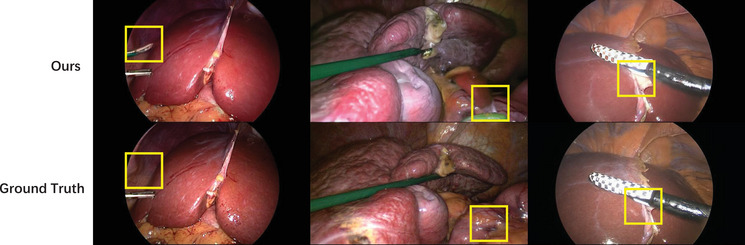 Figure 5
Figure 5 Figure 6
Figure 6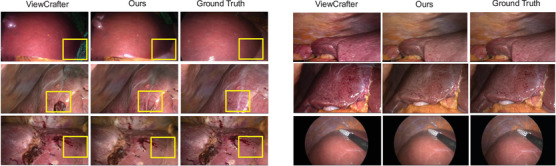 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Vision and Imaging · Generative Adversarial Networks and Image Synthesis · 3D Shape Modeling and Analysis