Explainable AI for forensic speech authentication within cognitive and computational neuroscience
Zhe Cheng, Haitao Yang, Yingzhuo Xiong, Xuran Hu

TL;DR
This paper introduces a deep learning model with explainable AI to detect fake speech, using features that highlight audio inconsistencies.
Contribution
A novel CNN-LSTM framework with XAI techniques for interpretable forensic speech authentication is proposed.
Findings
The model achieves high accuracy using LFCC features over MFCC and GFCC.
XAI methods reveal the model focuses on high-frequency and temporal artifacts.
The approach is validated on ASVspoof2019 LA and WaveFake datasets.
Abstract
The proliferation of deepfake technologies presents serious challenges for forensic speech authentication. We propose a deep learning framework combining Convolutional Neural Networks (CNNs) and Long Short-Term Memory (LSTM) networks to improve detection of manipulated audio. Leveraging the spectral feature extraction of CNNs and the temporal modeling of LSTMs, the model demonstrates superior accuracy and generalization across the ASVspoof2019 LA and WaveFake datasets. Linear Frequency Cepstral Coefficients (LFCCs) were employed as acoustic features and outperformed MFCC and GFCC representations. To enhance transparency and trustworthiness, explainable artificial intelligence (XAI) techniques, including Grad-CAM and SHAP, were applied, revealing that the model focuses on high-frequency artifacts and temporal inconsistencies. These interpretable analyses validate both the models design…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
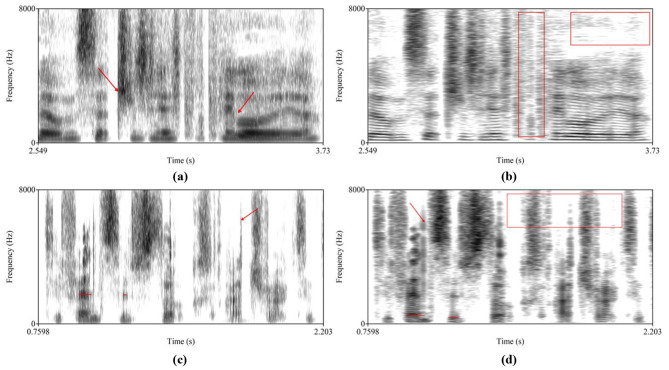 Figure 1
Figure 1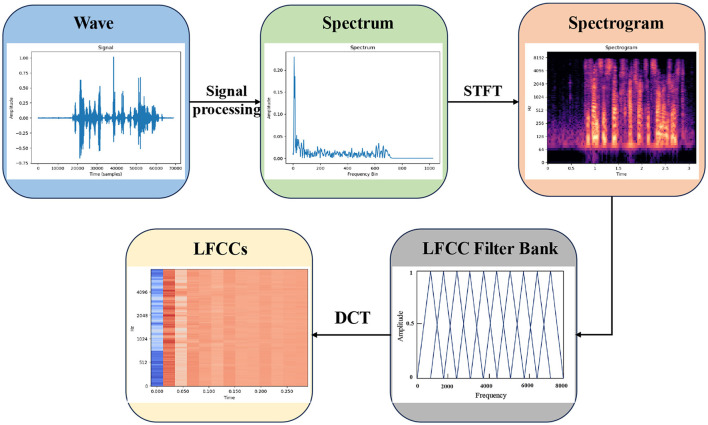 Figure 2
Figure 2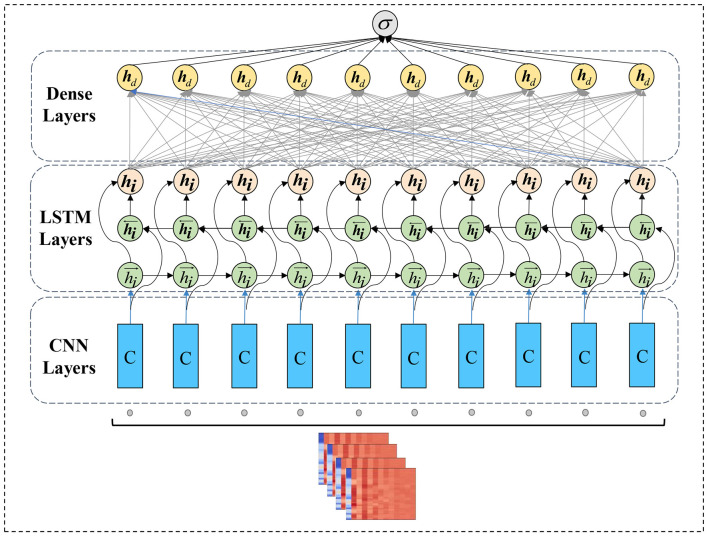 Figure 3
Figure 3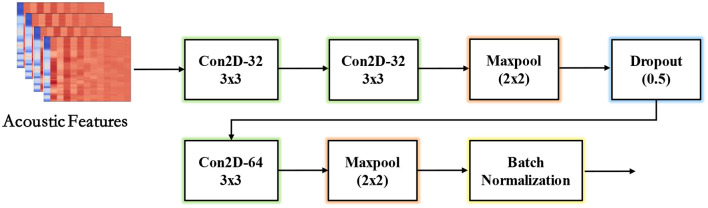 Figure 4
Figure 4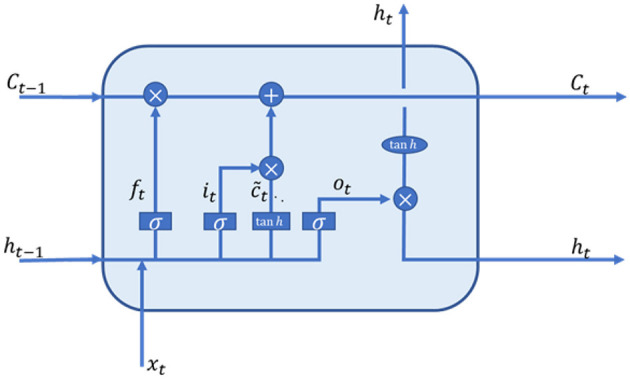 Figure 5
Figure 5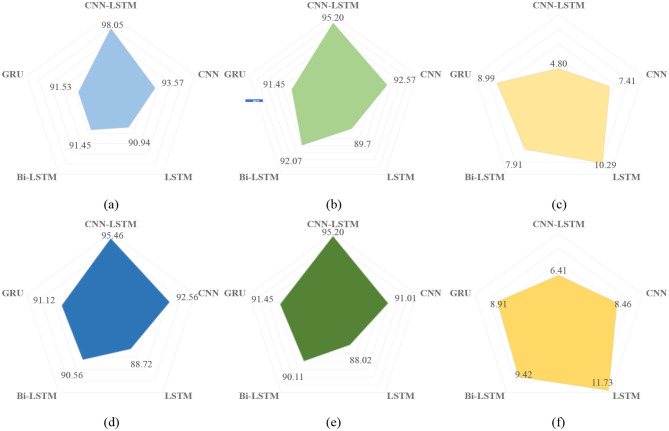 Figure 6
Figure 6 Figure 7
Figure 7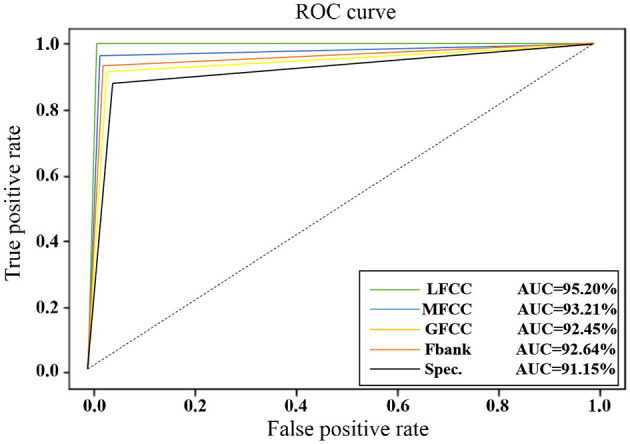 Figure 8
Figure 8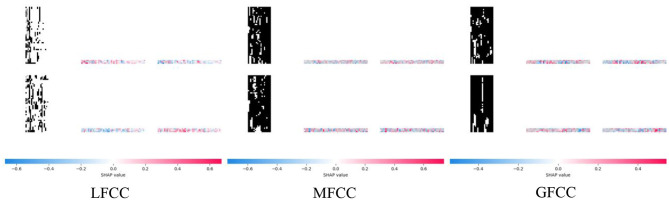 Figure 9
Figure 9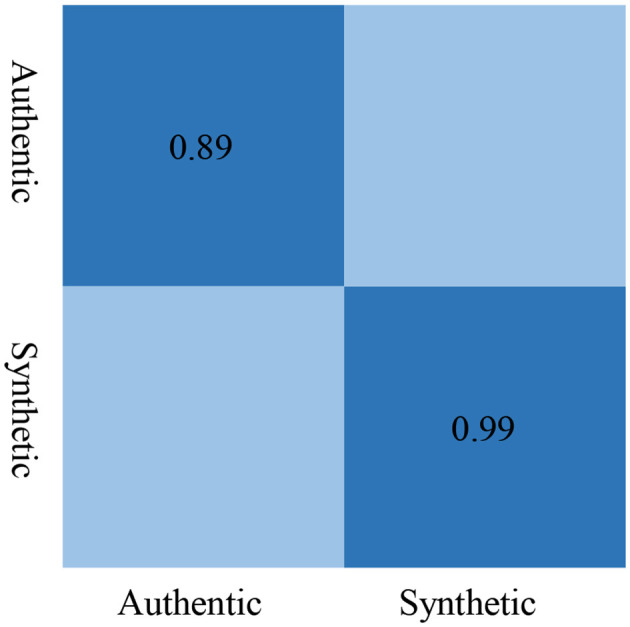 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMusic and Audio Processing · Speech Recognition and Synthesis · Digital Media Forensic Detection