Application of empirical likelihood ratio test in AR(1) time series model for PM2.5 forecasting in Guwahati city of Assam
Vinitha Serrao, Satyanarayana Poojari, Ismail B., K. Aruna Rao

TL;DR
This paper introduces a new statistical test for improving AR(1) model accuracy in forecasting PM2.5 levels in Guwahati, Assam.
Contribution
The study proposes an Empirical Likelihood Ratio Test (ELRT) for AR(1) model identification, showing better performance than traditional methods.
Findings
The ELRT outperforms the Ljung-Box test in empirical size and power according to Monte Carlo simulations.
Application of ELRT on PM2.5 data shows forecasts mostly in 'Poor' to 'Very Poor' air quality range.
The proposed ELRT method provides a robust alternative for AR(1) model identification in air quality forecasting.
Abstract
The Autoregressive model plays a vital role in time series analysis, as it efficiently captures short-term dependencies while maintaining simplicity. Accurate identification of the order of autoregressive models is essential for enhanced model performance and reliable forecasting. Traditional method of identifying AR (1) models relying on autocorrelation and partial autocorrelation plots, along with the Ljung-Box (LB) test, often suffer from subjectivity and potential overfitting. To overcome this limitation, this study proposes an Empirical Likelihood Ratio Test (ELRT) for assessing the suitability of AR (1) model in time series analysis. Through Monte Carlo simulation, performance of the ELRT is compared with the LB test in terms of empirical size and power. Simulation results indicate that the ELRT maintains empirical size more accurately while exhibiting superior power compared to…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
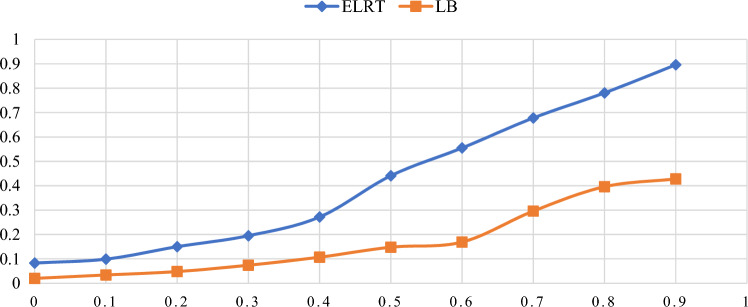 Figure 1
Figure 1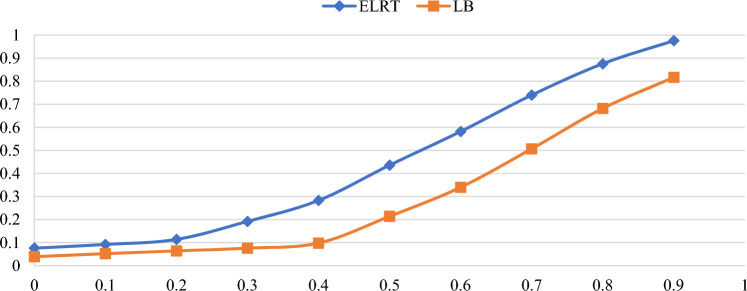 Figure 2
Figure 2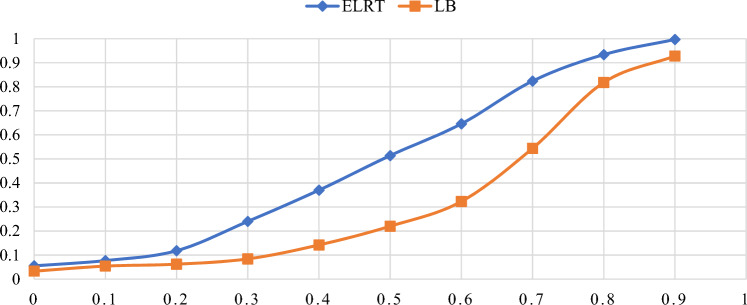 Figure 3
Figure 3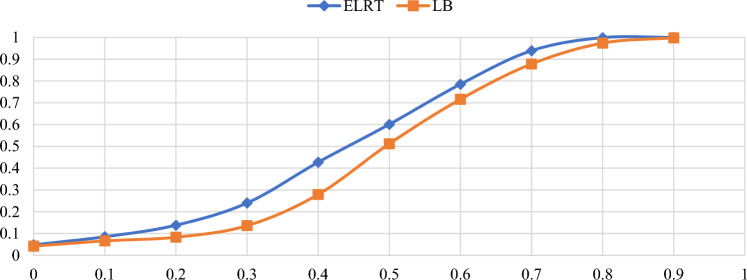 Figure 4
Figure 4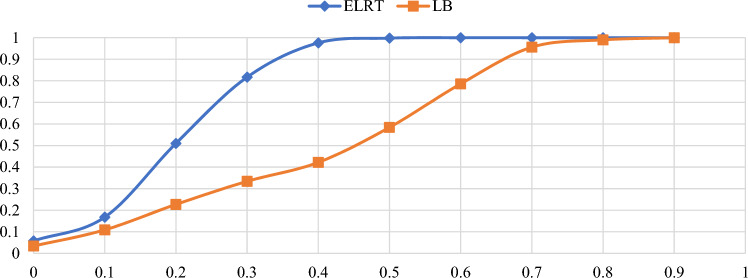 Figure 5
Figure 5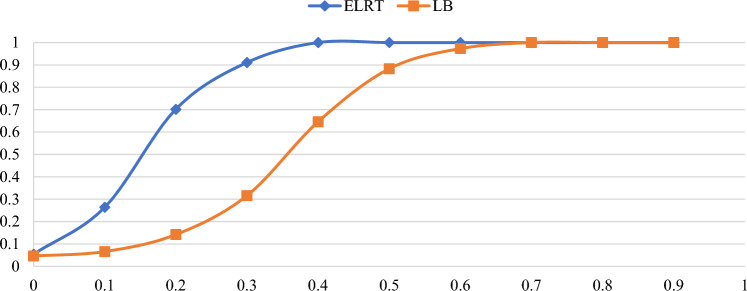 Figure 6
Figure 6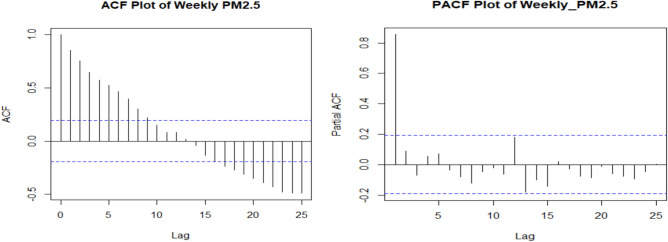 Figure 7
Figure 7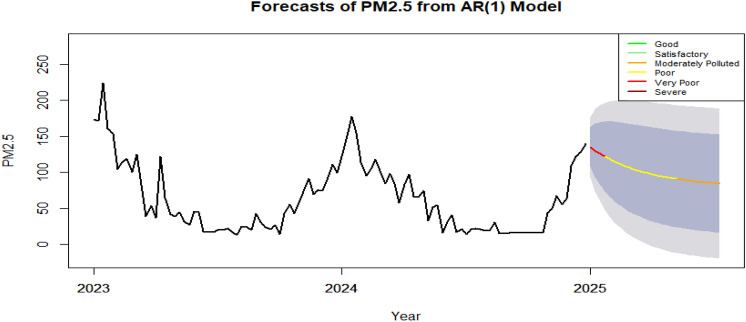 Figure 8
Figure 8- —Manipal Academy of Higher Education, Manipal
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAir Quality Monitoring and Forecasting · Air Quality and Health Impacts · Forecasting Techniques and Applications
Introduction
Time series analysis is a specialized field of data analysis that focuses on identifying patterns and trends in sequential data over time. Modelling and forecasting time series data are essential for informed decision-making and planning in various domains, such as air quality monitoring, meteorological prediction, finance, economics, and many other fields. Among the various times series models, the Autoregressive Integrated Moving Average (ARIMA) model introduced by Box and Jenkins^1^ is a commonly used method for analysing and forecasting time series data that exhibit non-stationarity. The ARIMA model is represented as ARIMA (p, d, q), where p indicates the number of autoregressive terms, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d$$\end{document} reflects the degree of differencing required to achieve stationarity, and q denotes the number of moving average terms. By combining both autoregressive (AR) and moving average(MA) elements, the ARIMA model efficiently captures the inherent trends and patterns in time series data, enabling accurate predictions.
The AR models are effective in capturing short-term dependencies by predicting future values based on prior observations. The AR model is a fundamental tool in time series analysis, providing a comprehensive framework for identification, estimation, and diagnostic checking. The simplicity of AR models, combined with their capability to model temporal dependencies, makes them widely applicable. A simpler version of the AR model is the AR (1) model, which focuses exclusively on autoregressive dynamics of order 1.
Various estimation methods have been proposed to estimate parameters of AR (1) models, aiming to reduce bias and improve the precision of parameter estimates. One of the widely used techniques is the closed-form method known as the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${r}_{1}$$\end{document} estimator introduced by Yule^2^ and later refined by Walker^3^ and Box and Jenkins^4^. Young^5^ introduced the C-statistic, a method for estimating parameters in AR models. This study introduces an alternative Yule-Walker equations method, a form of Ordinary Least Squares (OLS) estimation particularly for small sample sizes and helps improve parameter estimation and forecasting accuracy. Additionally, Maximum Likelihood Estimation an iterative technique has been introduced for estimation of AR model along with Bayesian Markov Chain Monte Carlo Several simulation studies^6^^,^^7^^,^^8^^,^^9^ have been conducted to compare the performance of closed-form methods, particularly the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${r}_{1}$$\end{document} estimator, C-statistic, and OLS. The results suggest that when the length of time series data is short (e.g., length ≤50 observations), the estimates may be biased and show significant variability.
Philips and Han’s^10^ research marks a notable improvement in Gaussian inference for AR (1) models, presenting a unified approach that applies to both stationary and non-stationary cases. This method enhances the accuracy and consistency of parameter estimates, ensuring robust statistical inference across various autoregressive parameters. Hosein and Yeganegi^11^ highlight the critical role of selecting the appropriate lag order (H) when using the Ljung-Box test in time series analysis, as incorrect lag values may distort autocorrelation results. Arltova et al.^12^ suggest that the Augmented Dickey-Fuller test is better for shorter time series, while Phillips-Perron or Ng-Perron tests are more suitable for longer series, especially when the AR (1) parameter nears the unit root. These studies enhance the understanding of efficient inference techniques and test selection for AR (1) models.
There is a lack of comprehensive comparison between closed-form and iterative methods, leading to uncertainty about their relative performance in terms of bias and variability. Additionally, the robustness of these methods under model misspecification remains underexplored. Understanding their comparative performance and robustness is crucial for enhancing time series research and selecting methods that minimize bias, reduce variability, and ensure greater robustness in estimating empirical AR (1) models. Identifying the order of an AR series, particularly AR (1), is crucial for accurate time series analysis, as it impacts both estimation and forecasting. Accurate identification of the model’s order also avoids overfitting and underfitting.
The empirical likelihood (EL) method, first introduced by Owen in^13^ and^14^, has gained significant popularity for statistical inference due to its flexibility in constructing confidence regions that accurately capture the structure of the underlying distribution without assuming symmetry. EL approach has been extended to various applications, such as linear regression^15^, generalized linear models^16,17^. Later, Zhang et al.^18^ examined the robustness of EL for estimating integer-valued autoregressive (INAR) processes parameters. Extensions of the EL method have also been applied to time series models^19^. Ding and Wang^20^ further advanced the EL method by applying it to inference in INAR models. More recently, Satyanarayana et al.^21^ introduced an empirical likelihood ratio test for detecting AR (1) in regression model, demonstrating superior performance in both empirical size and power. Additionally, Zhang et al.^22^ proposed EL based test for INAR (1) models and derived the test statistic under null hypothesis. This approach provides unified inference for both stable and unstable processes.
As a real-life application, this study focuses on forecasting one of the most critical air pollutants i.e. PM_2.5_. Air pollution poses a major global challenge, significantly impacting human health, the environment, and the economy. Fine particulate matter (PM_2.5_), primarily emitted from transportation, industrial, and agricultural sources, presents serious health risks due to its ability to penetrate deep into the lungs and enter the bloodstream^23^. It is strongly associated with respiratory and cardiovascular diseases, lung cancer, and other chronic health conditions^24,25^. PM_2.5_ exposure can interfere with vital cellular processes such as autophagy, apoptosis, necrosis, and ferroptosis, contributing to tissue damage and disease progression^26^. Experimental studies further reveal that PM_2.5_ adversely affects kidney and epithelial cells by inducing epithelial-mesenchymal transition and altering the function of organelles^27^^,^^28^^,^^29^.
Climate change is expected to intensify exposure and worsen health outcomes, especially cardiovascular diseases^30–32^. Projections suggest mortality from PM_2.5_ could significantly decline under low-emission scenarios by 2100^33^. As PM_2.5_ pollution is common and long-lasting, there is a strong need for better air quality control and public health measures to reduce exposure. Accurate forecasting of PM_2.5_ helps to reduce the health and economic burden associated with pollution, making it a crucial tool for sustainable public health and environmental management. Recent studies in environmental monitoring and forecasting highlight the increasing complexity of datasets and the corresponding need for rigorous model adequacy testing. Pragasan and Ganesan^34^ conducted an assessment of air pollutants and identified pollution-tolerant vegetation for greenbelt development, highlighting the need for accurate identification of the appropriate time series model facilitates precise pollutant prediction, enabling timely and targeted greenbelt planning. Li et al.^35^ examined the interaction effects of PM_2.5_ and O₃ on respiratory health, underscoring the critical importance of accurate pollutant forecasting for PM_2.5_ public health interventions. Rabbani et al.^36^ applied machine learning, remote sensing, and chemometrics to assess environmental stress from air pollutants. This paper demonstrates robust pattern extraction from complex, high-dimensional data and highlights the diversity of modeling frameworks in air pollution research. Gu et al.^37^ proposed a Self-Adaptive Multiscale Transform Domain framework to integrate local and global information for improved air pollution monitoring, demonstrating how advanced data fusion methods can enhance spatio-temporal resolution in environmental datasets.
These studies highlight the increasing complexity of environmental datasets and the critical role of accurate forecasting for timely public health and mitigation policies. Consequently, there is a pressing need to correctly identify the order or suitable time series model to ensure reliable pollutant predictions. Robust model identification enhances forecast accuracy, thereby supporting effective and timely policy- making for environmental management.
The main objective of this study is to develop and evaluate an ELRT designed to assess the adequacy of an AR (1) time series model. The ELRT produces a data-driven test statistic that directly targets departures from the AR (1) hypothesis, rather than testing for generic form of autocorrelation. Methodologically, the ELRT differs from the Ljung–Box test by not relying on strict parametric distributional assumptions. Instead, it utilizes a nonparametric empirical likelihood framework, which enhances robustness and maintains validity across a wide range of real-world applications. In contrast, the widely used LB test is an omnibus portmanteau test, assessing overall serial correlation up to a chosen lag and often requiring subjective interpretation of ACF and PACF diagnostics. This limitation highlight the importance of need for a formal statistical test for order detection offering a more objective and dependable approach for identification compared to relying solely on visual plots. Under mild regularity conditions such as stationarity and standard moment assumptions, under the null hypothesis ELRT statistic follows a known asymptotic distribution. Simulation results indicate that the ELRT maintains nominal Type I error rates and achieves higher statistical power than the LB test in detecting subtle departures from the AR(1) structure, making it an appropriate choice for identifying AR (1) time series model. The paper is organized into five sections, with Section 2 outlining the proposed test. Section 3 compares the estimated type I error rate and power of the ELRT and LB tests using finite samples. Section 4 discusses a real-world example, with the paper’s conclusion presented in Section 5.
Methods
Autoregressive (AR) model
A time series \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left\{{X}_{t} ;t\in I\right\}$$\end{document} that follows an \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$AR(p)$$\end{document} process can be represented as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${X}_{t}={\phi }_{1}{X}_{t-1}+{\phi }_{2}{X}_{t-2}+\dots +{\phi }_{p}{X}_{t-p}+{\varepsilon }_{t}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left\{{\varepsilon }_{t} ;t\in I\right\}$$\end{document} a white noise process with mean 0 and variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\sigma }^{2}$$\end{document} . This model is denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${X}_{t}\sim AR(p)$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${X}_{t}$$\end{document} represents the current observation, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${X}_{t-1},{X}_{t-2},\dots ,{X}_{t-p}$$\end{document} are the observations at the previous \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p$$\end{document} time points, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\phi }_{1},{\phi }_{2},\dots ,{\phi }_{p}$$\end{document} are the autoregressive coefficients, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varepsilon }_{t}$$\end{document} is the error term. For the AR (1) process, the model simplifies to:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${X}_{t}={\phi }_{1}{X}_{t-1}+{\varepsilon }_{t }, t=\text{2,3},\dots n$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\phi }_{1}$$\end{document} represents the autocorrelation coefficient, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varepsilon }_{t}$$\end{document} are assumed to be serially independent and independent of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${X}_{t-1}$$\end{document} for all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t,$$\end{document} with mean 0 and variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\sigma }_{\varepsilon }}^{2}$$\end{document} . The mean of AR (1) model i.e \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E\left({X}_{t}\right)=0$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V({X}_{t})= \frac{{{\sigma }_{\varepsilon }}^{2}}{1-{\rho }^{2}}$$\end{document} . The autocorrelation between observations h time periods apart is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\rho }_{h}=\frac{cov({X}_{t},{X}_{t+h})}{V\left({X}_{t}\right)}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\rho }_{h}={{\phi }_{1}}^{h}$$\end{document}The ACF shows a specific pattern for autocorrelations. When \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\phi }_{1}$$\end{document} is positive, as the lag (h) increases, ACF gradually decreases to zero. If \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\phi }_{1}$$\end{document} is negative, the ACF also decays exponentially to zero, but the signs of the autocorrelations alternate between positive and negative. On the other hand, PACF clearly shows a sharp drop after lag 1, signifying that the AR process has an order of 1.
Ljung –Box (LB) test
The LB test is a statistical method designed to check whether the autocorrelations in a time series differ significantly from zero. Unlike tests that assess randomness at single lags, this test evaluates multiple lags simultaneously, making it a comprehensive or portmanteau test.
The hypotheses for this test are defined as follows:
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}_{o}:$$\end{document} The residuals are uncorrelated, indicating the absence of autocorrelation.
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}_{1}:$$\end{document} The residuals are correlated, suggesting the presence of significant autocorrelation.
The test statistic is calculated using the formula
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q=n(n+2)\sum\nolimits_{k=1}^{h}\frac{{{\widehat{\rho }}_{k}}^{2}}{n-k}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n$$\end{document} represents the sample size, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{\rho }}_{k}$$\end{document} denotes the sample autocorrelation at lag \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h$$\end{document} indicates the number of lags under consideration. Under the null hypothesis, the Q statistic follows an asymptotic chi-squared distribution with h degrees of freedom.
Proposed empirical likelihood ratio test for autoregressive of order 1
The ELRT is proposed to assess the adequacy of the AR(1) time series model as a nonparametric approach. The term “non-parametric” refers to the empirical likelihood approach employed in developing the ELRT statistic. The EL method combines the reliability of nonparametric methods with the effectiveness of the likelihood approach. Unlike traditional parametric methods, empirical likelihood does not assume a specific distribution for the data^13,14^. Instead, empirical likelihood is constructed based on moment conditions derived from the AR (1) model. This data-driven framework offers greater flexibility and robustness, as it allows for valid inference without imposing any specific distributional assumptions. This makes it especially effective in detecting subtle departures from the AR(1) structure in complex real-world data. The methodological development of the ELRT for the AR(1) time series model is outlined as follows.
Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${x}_{1}, {x}_{2},. . . {x}_{n}$$\end{document} are the samples from a distribution with continuous cumulative distribution function. Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${p}_{i}$$\end{document} denote the probability attached to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${x}_{i}$$\end{document} .The hypothesis of interest is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}_{0}$$\end{document} : \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\phi }_{1} = 0$$\end{document} against \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}_{1}$$\end{document} : \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\phi }_{1}> 0$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho$$\end{document} denotes the autocorrelation coefficient. Under \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}_{0}$$\end{document} , the ELRT statistic is given by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R\left(\phi \right) = {max}_{{p}_{2}, {p}_{3}\dots {p}_{n}}\left\{{\prod_{i=2}^{n}(n-1)}p_{i} | {p}_{i}\ge 0, \sum_{i=2}^{n}{p}_{i} = 1 , \sum_{i=2}^{n}{p}_{i}({x}_{i}-\overline{x })({x}_{i-1}-\overline{x })= 0 \right\} (6) $$\end{document}Theorem:
Under regularity conditions the asymptotic null distribution of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-2\text{log R}\left(\phi \right)$$\end{document} is central chi-square with 1 degree of freedom.
Proof:
The Lagrange multiplier technique is used to solve this optimization problem.
Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G =\sum_{t=2}^{n}{\mathit{log}p}_{t} + \gamma \{{\sum }_{t=2}^{n}{p}_{t}-1 \}+\lambda \{\sum_{t=2}^{n}{p}_{t}({x}_{t}-\overline{x })({x}_{t-1}-\overline{x })- 0\}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text{Equating }\frac{\delta G}{ \delta {p}_{t}}=0,\text{ leads to }{p}_{t}={\left[-\gamma -\lambda ({x}_{t}-\overline{x })({x}_{t-1}-\overline{x })\right]}^{-1}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum_{t=2}^{n}{p}_{t}\frac{\delta G}{\delta {p}_{t}}=0, gives \gamma =-n$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Therfore, \quad{p}_{t}={\left[n-\lambda ({x}_{t}-\overline{x })({x}_{t-1}-\overline{x })\right]}^{-1}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$where\: \lambda\: is\: the\: unique\: solution\: of\: \sum_{\text{t}=2}^{n}\frac{({x}_{t}-\overline{x })({x}_{t-1}-\overline{x })}{[n-\lambda ({x}_{t}-\overline{x })({x}_{t-1}-\overline{x })]}=0$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Using\: Taylor \:expansion \:of\: \sum_{\text{t}=2}^{n}\frac{({x}_{t}-\overline{x })({x}_{t-1}-\overline{x })}{[n-\lambda ({x}_{t}-\overline{x })({x}_{t-1}-\overline{x })]} \:around\: \lambda\: =0\:\text{ results in}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda =- \frac{\sum_{t=2}^{n}({x}_{t}-\overline{x })({x}_{t-1}-\overline{x })}{\frac{1}{(n-1)}{\sum_{t=2}^{n}[({x}_{t}-\overline{x })({x}_{t-1}-\overline{x })]}^{2}}$$\end{document}Using the Taylor expansion of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathit{log}\left(1-x\right)$$\end{document} , omitting the term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(n-1)log (n-1)$$\end{document} which eventually gets cancelled,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & -2\sum_{\text{t}=2}^{\text{n}}\text{log}{p}_{t}=2\sum_{t=2}^{n }log\left[1-\frac{\lambda (({x}_{t}-\overline{x })({x}_{t-1}-\overline{x })) }{\left( n-1\right)}\right]\\ & =-2\frac{\lambda }{\left(n-1\right)}\sum_{t=2}^{n}({x}_{t}-\overline{x })({x}_{t-1}-\overline{x })-\frac{{\lambda }^{2}}{({n-1)}^{2}}{\sum_{t=2}^{n}[({x}_{t}-\overline{x })({x}_{t-1}-\overline{x })]}^{2}\\&= \frac{{[\sum_{t=2}^{n}({x}_{t}-\overline{x })({x}_{t-1}-\overline{x })]}^{2}}{\frac{1}{(n-1)} {\sum_{t=2}^{n}[({x}_{t}-\overline{x })({x}_{t-1}-\overline{x })]}^{2}}\end{aligned}$$\end{document}By LLN \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{1}{(\text{n}-1)}{\sum_{t=2}^{n}[({x}_{t}-\overline{x })({x}_{t-1}-\overline{x })]}^{2}\longrightarrow$$\end{document} Var \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(({x}_{t}-\overline{x })({x}_{t-1}-\overline{x }))$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text{Therefore }-2\sum\nolimits_{\text{t}=2}^{\text{n}}\text{log}{p}_{t}=\frac{{[\sum_{t=2}^{n}({x}_{t}-\overline{x })({x}_{t-1}-\overline{x })]}^{2}}{\text{Var }(({x}_{t}-\overline{x })({x}_{t-1}-\overline{x }))}$$\end{document}Thus, test statistic, - \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$2log R\left(\phi \right)$$\end{document} is asymptotically distributed as central \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\chi }^{2}$$\end{document} with 1 degree of freedom. The ELRT is robust to distributional assumptions, while the performance of the LB test is heavily dependent on the normality assumption, which may not always be valid. The LB test is commonly used to confirm whether a series follows an AR (1) model, but its accuracy is compromised when the normality assumption is not met. In such cases, the nonparametric ELRT offers a more reliable alternative for testing the AR (1) structure.
The proposed ELRT offers several advantages over the traditional LB test. Unlike LB test which relies on subjective interpretation of ACF and PACF plots, the ELRT provides a data-driven framework for evaluating the suitability of an AR(1) model. While the LB test assesses general autocorrelation without reference to a specific model, the ELRT is explicitly formulated to test the AR (1) hypothesis. The key assumption conditions under which the ELRT performs optimally include (a) correct specification of the moment conditions associated with the AR(1) process, (b) stationarity of the time series, (c) independence and identical distribution of the error terms with finite variance, and (d) absence of model misspecification. The empirical likelihood framework also assumes the existence of finite higher-order moments, which supports the asymptotic properties of the test under the Wilks theorem.
Although ELRT have been developed to detect the presence of autocorrelation, specifically AR(1) error structures in regression models^21^ and INAR processes, the focus of the present study is distinctly different. The proposed ELRT is specifically designed to assess whether the observed time series itself follows an AR (1) model, rather than testing for autocorrelation in regression residuals. Unlike previous approaches, the moment conditions in this ELRT are derived directly from the time series process, not from regression errors. This distinction highlights the novelty of the proposed method in the context of time series model validation.
Results
Simulation study
A Monte Carlo simulation study was conducted to assess the finite sample performance of the proposed ELRT in detecting the suitability of AR(1) time series model. The main objective of the simulation study was to compare the empirical size and power of the ELRT with the traditional Ljung-Box (LB) test under varying autocorrelation level and sample size.
Data generation process
The following autoregressive model of order 1 was used for data generation:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${X}_{t}= {{\phi }_{1} X}_{t-1} + {\varepsilon }_{t}, \text{t} =1,2,\ldots,\text{n}\: \text{where}\: X_t \sim AR(1).$$\end{document}Where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varepsilon }_{t}$$\end{document} are independent and identically distributed (i.i.d.) normal errors with mean zero and finite variance and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${X}_{t}$$\end{document} follows a stationary AR (1) process. Data were simulated using the arima.sim() function in the R programming environment, which is specifically designed for generating time series under ARIMA-type models. The autocorrelation parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\phi }_{1}$$\end{document} was varied across 10 values in the range [0,0.9] with increments of 0.1. This allowed evaluation of the test ability to detect serial dependence of varying strength. To evaluate finite sample performance, simulations were performed under multiple sample sizes combination : 30, 50, 80, 100, and 200. For each scenario, 5000 replications were generated and average values over 5000 replications are reported. The test are carried at a nominal significance level of 0.05.
Implementation of ELRT
A detailed R code is written for computing ELRT test statistics using Rsolnp package based on moment constraints derived from the AR(1) structure. This statistic asymptotically follows a chi-square distribution with 1 degree of freedom under the null hypothesis. For each simulated dataset, the ELRT statistic was calculated. If the statistic exceeded the critical value from the chi-square distribution with 1 degree of freedom at the 0.05 significance level (i.e., 3.84), the null hypothesis of no serial correlation was rejected.
Computation of empirical size and power
Empirical size
To compute the empirical size, data were generated under the null hypothesis with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\phi }_{1}$$\end{document} =0. Both the ELRT and the LB tests were applied, and the proportion of times the null hypothesis was incorrectly rejected over 5000 replications was recorded as the empirical size for each sample size.
Empirical power
To assess power, data were generated from an AR(1) time series model with varying levels of autocorrelation by changing the value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\phi }_{1}$$\end{document} . The proportion of times the null hypothesis was rejected across 5000 replications was recorded as the empirical power of the test to detect autocorrelation. Table 1 presents the empirical size results of the ELRT and the LB test across different sample sizes under the assumption of normally distributed errors.Table 1. Comparison of ELRT and LB test based on empirical size.Sample sizeTestEmpirical size20ELRT0.083LB0.0230ELRT0.076LB0.03950ELRT****0.055LB0.03380ELRT0.048LB0.042100ELRT****0.058LB0.034200ELRT0.054LB****0.046
From the simulation results, several important implications were drawn. For a sample size of 20, the ELRT test tends to be slightly liberal, exceeding the nominal size, while the LB test is notably conservative. Neither test maintains the nominal level with sample sizes as small as 30. However, for sample sizes of 50 and above, the ELRT test consistently adheres to the nominal size, and the LB test closely approximates the fixed nominal level. Given that a minimum of 50 observations^1^ is recommended for reliable time series modeling, it is noteworthy that the ELRT test effectively maintains the nominal size from this threshold onward. In summary, the ELRT test consistently maintains the nominal size more reliably than the LB test.
Figures 1,2,3,4,5,6 illustrate the empirical rejection rates across six different sample sizes. The vertical axis represents the rejection rate, while the horizontal axis displays varying values of the autocorrelation coefficient. Notably, the empirical power of the ELRT test surpasses that of the LB test, particularly with smaller sample sizes. For example, at a sample size of 20, the ELRT test shows a rejection rate of 0.896 for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\phi }_{1}=0.9$$\end{document} , whereas the LB test’s rejection rate is 0.428. Furthermore, as the sample size increases, the ELRT consistently maintains higher power than the LB test, regardless of the autocorrelation level. Overall, in all scenarios, the ELRT test demonstrates superior performance compared to the LB test.Fig. 1. Rejection rates for ELRT and LB test when n= 20.Fig. 2. Rejection rates for ELRT and LB test when n= 30.Fig. 3. Rejection rates for ELRT and LB test when n= 50.Fig. 4. Rejection rates for ELRT and LB test when n= 80.Fig. 5. Rejection rates for ELRT and LB test when n= 100.Fig. 6. Rejection rates for ELRT and LB test when n= 200.
Real life application
The Railway Colony station in Guwahati, Assam, is among the most polluted air quality stations in the city. For this study, monthly data on particulate matter 2.5(PM_2.5_) concentration data (measured in µg/m3) from the Railway Colony monitoring station, sourced from the Central Pollution Control Board (CPCB) of India, covering the period from 2022 to 2024. For the data analysis, the original monthly data was aggregated into weekly data. As part of the preprocessing, outlier analysis was conducted using box plots, which indicated the absence of significant outliers in the data. The dataset was also checked for missing observations, and the results indicated that approximately 2% of the data was missing. These missing values were imputed using the Last Observation Carried Forward (LOCF) method. Due to their small size, these particles can easily be inhaled, reaching deep into the lungs and potentially entering the bloodstream. This exposure can lead to serious health problems, including respiratory and heart diseases, as well as an increased risk of cancer. Longterm exposure to high concentrations of PM_2.5_ is associated with an elevated risk of premature death from these conditions. Given the severe health implications of fine particulate matter, the monitoring and forecasting of PM_2.5_ levels are essential for evidence-based environmental policymaking.
Based on the analysis, the estimated autocorrelation coefficient is 0.856. In the Figure 7, the PACF plot reveals a significant spike at lag 1, suggests that the series exhibits a first-order autoregressive structure. Additionally, the ACF plot given in figure 7 shows an exponential decay, which is a typical characteristic of autoregressive models. Further, this pattern in the ACF supports the conclusion that the data follows an AR (1) process. Therefore, the combination of the PACF and ACF patterns provides strong evidence for modeling the series using an AR (1) model. Following order selection, the AR(1) model was estimated using the method of maximum likelihood. To further evaluate the suitability of the AR(1) model, the LB test and ELRT were subsequently applied and results are provided in table 2.Fig. 7ACF and PACF plot of weekly PM_2.5_ level.Table 2. Results of ELRT and LB test for PM_2.5_ Level data.TestTest statisticp valueLjung -Box2.680.1016ELRT118.8332<0.001
The AR (1) model is fitted to the data, and the residuals are tested using the LB test. The Table 2 represents the results of ELRT and Ljung Box test for PM_2.5_ Level data. Since the p-value of LB test is greater than 0.05, suggests insignificant autocorrelation among the residuals, implying that the AR (1) model provides an adequate fit for the data.The ELRT of original series yielded a test statistic of 118.8332 with a p-value < 0.001, indicating significant autocorrelation at lag 1. These results imply that both LB test and ELRT identified significant autocorrelation of order 1, supporting the suitability of an AR (1) model. Therefore, the AR (1) model is fitted to obtain forecasts for the next 28 weeks (January to April 2025).
AR (1) model-based forecast of PM_2.5_ concentrations in Guwahati given in figure 8 provides critical implications for public health and environmental management. The initial forecasted values fall within the ‘Very Poor’ and ‘Poor’ air quality category for the first three months, indicating potentially hazardous conditions for the population. While there is a gradual improvement over time, with PM_2.5_ levels moving from ‘Very Poor’ to ‘Poor’ and eventually to ‘Moderately Polluted’, the overall air quality still remains below acceptable standards during the forecast period. The wider confidence bands observed in the forecast indicate increased variability and uncertainty, suggesting that while the AR(1) model captures the general trend, real-world fluctuations likely due to weather patterns, emissions, and seasonal changes remain difficult to predict precisely. Nevertheless, the model proves effective in identifying broad patterns of air quality deterioration and recovery.Fig. 8PM_2.5_ level forecast from AR (1) model for the next 28 weeks [Jan -April, 2025].
These findings underscore the need for continuous air quality monitoring and proactive policy measures aimed at reducing emissions from key sources such as traffic, industry, and biomass burning. The wider confidence bands indicate greater variation and uncertainty in the forecasted PM_2.5_ levels, which also signals the need for closer attention and monitoring. Moreover, the persistent presence of unhealthy air quality levels reinforces the urgency of implementing evidence-based environmental interventions in Guwahati to protect public health and ensure sustainable urban development.
Limitations and future directions
The proposed ELRT is developed specifically for detecting AR(1) structures in time series data; however, its performance under model misspecification and non-normally distributed errors has not been evaluated. Future research could explore extending the ELRT framework to accommodate higher-order autoregressive structures such as AR(p) models, adapt it for multivariate time series settings, and develop robust versions capable of addressing model misspecification and non-normal error distributions.
Conclusion
Identifying a suitable time series model is crucial for obtaining reliable and accurate forecasts. In this study, a distribution-free method, the ELRT is proposed for detecting autoregressive models of order 1. The performance of ELRT is compared with the LB test. The results indicate that ELRT maintains the nominal size and outperforms the Ljung-Box test in terms of power. Real-life application also justifies the suitability of the proposed test for AR (1). The proposed ELRT method is a reliable tool for both researchers and practitioners, excelling in its ability to assess autocorrelation in AR (1) models. This effectiveness enhances the precision and reliability of time series modeling and forecasting, making it a significant contribution to the field. Also, the PM_2.5_ forecasting results underscore the persistent air pollution challenge in Guwahati and highlight the need for more robust strategies to protect public health.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Hu J, Zhou R, Ding R, Ye DW, Su Y: Effect of PM 2.5 air pollution on the global burden of lower respiratory infections, 1990–2019: A systematic analysis from the Global Burden of Disease Study 2019. J. Hazard. Mater. 2023, 459: 132215. 10.1016/j.jhazmat.2023.13221510.1016/j.jhazmat.2023.13221537557046 · doi ↗ · pubmed ↗
- 2World Health Organization (WHO): WHO global air quality guidelines: particulate matter (PM 2.5 and PM 10), ozone, nitrogen dioxide, sulfur dioxide and carbon monoxide: executive summary. 2021. Available at: https://apps.who.int/iris/handle/10665/34533434662007 · pubmed ↗
- 3Wang Y, Zhong Y, Liao J, Wang G: PM 2.5-related cell death patterns [Review]. International Journal of Medical Sciences. 2021, 18: 1024–1029. 10.7150/ijms.4642110.7150/ijms.46421 PMC 780718533456360 · doi ↗ · pubmed ↗
- 4Su R, Jin X, Li H, Huang L, Li Z: The mechanisms of PM 2.5 and its main components penetrate into HUVEC cells and effects on cell organelles. Chemosphere. 2020, 241: 125127. 10.1016/j.chemosphere.2019.12512710.1016/j.chemosphere.2019.12512731683440 · doi ↗ · pubmed ↗
- 5Pang Y, Huang W, Luo XS, Chen Q, Zhao Z, Tang M, Hong Y, Chen J, Li H: In-vitro human lung cell injuries induced by urban PM 2.5 during a severe air pollution episode: variations associated with particle components. Ecotoxicology and Environmental Safety. 2020, 206: 111406. 10.1016/j.ecoenv.2020.11140610.1016/j.ecoenv.2020.11140633007542 · doi ↗ · pubmed ↗
- 6Lin CH, Wan C, Liu WS, Wang HH: PM 2.5 induces early epithelial mesenchymal transition in human proximal tubular epithelial cells through activation of IL-6/STAT 3 pathway. International Journal of Molecular Sciences. 2021, 22: 12734. 10.3390/ijms 22231273410.3390/ijms 222312734 PMC 865785434884542 · doi ↗ · pubmed ↗
- 7Chen W, Lu X, Yuan D, Chen Y, Li Z, Huang Y, Fung T, Sun H, Fung JCH: Global PM 2.5 prediction and associated mortality to 2100 under different climate change scenarios. Environmental Science & Technology. 2023, 57: 10039–10052. 10.1021/acs.est.3c 0380410.1021/acs.est.3c 0380437377020 · doi ↗ · pubmed ↗
- 8Li J, Liang L, Lyu B, Cai YS, Zuo Y, Su J, Tong Z: Double trouble: The interaction of PM 2.5 and O 3 on respiratory hospital admissions. Environmental Pollution. 2023, 338: 122665.10.1016/j.envpol.2023.12266537806428 · doi ↗ · pubmed ↗