Machine learning for microwave optimization using simplex surrogates, dual-resolution computational models and local tuning with sparse sensitivity updates
Slawomir Koziel, Anna Pietrenko-Dabrowska

TL;DR
This paper presents a fast and efficient machine learning method for optimizing microwave designs using advanced computational techniques.
Contribution
The novel approach combines simplex surrogates, dual-resolution models, and sparse sensitivity updates for microwave optimization.
Findings
The method achieves reliable optimization with fewer than fifty EM simulations on average.
It outperforms benchmark approaches in computational efficiency and ease of implementation.
The algorithm is demonstrated successfully on various microstrip components.
Abstract
Numerical optimization procedures are now an integral part of the microwave design process. Ensuring reliability requires conducting parameter tuning at the electromagnetic (EM) analysis level. This, however, entails considerable computational costs. Additionally, global optimization is often necessary (e.g., multimodal problems, large-scale operating frequency re-design, design of metasurfaces), which is incomparably more expensive when using conventional techniques. In this work, we introduce a novel approach to the fast globalized optimization of microwave structures. Our methodology is founded on processing the operating parameters of the circuit rather than its complete frequency characteristics, and the utilization of simplex-based regressors. Both permit regularizing the objective function, which facilitates and speeds up the identification of the optimum design. Further…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12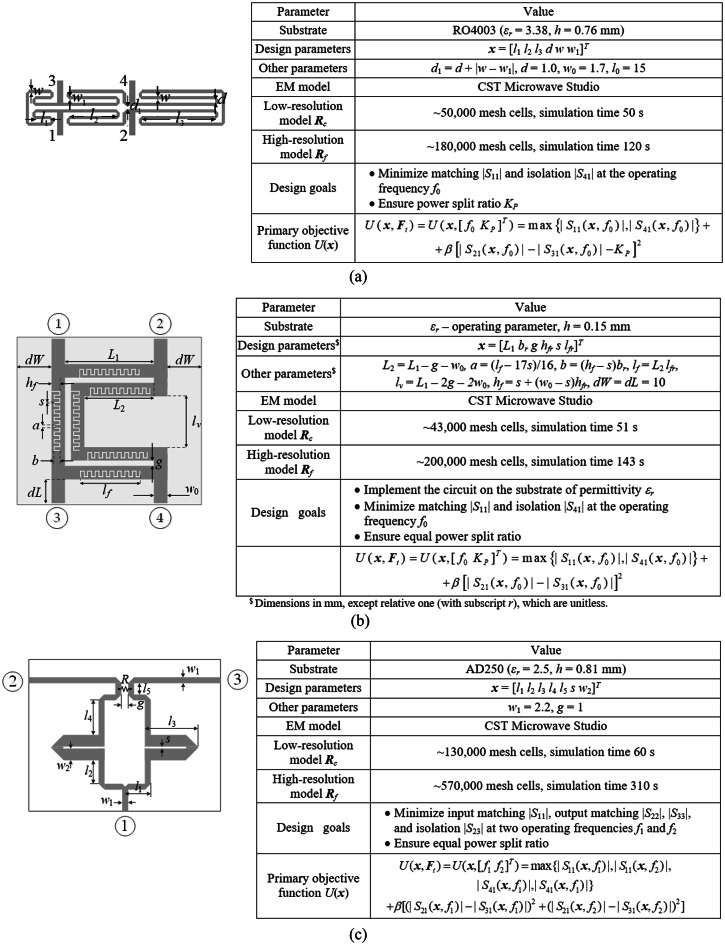 Figure 13
Figure 13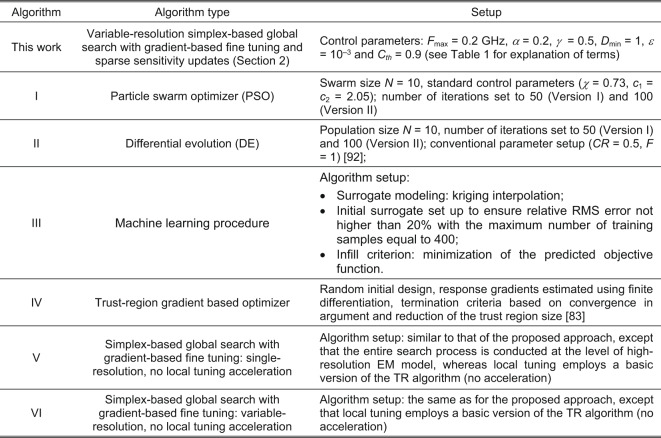 Figure 14
Figure 14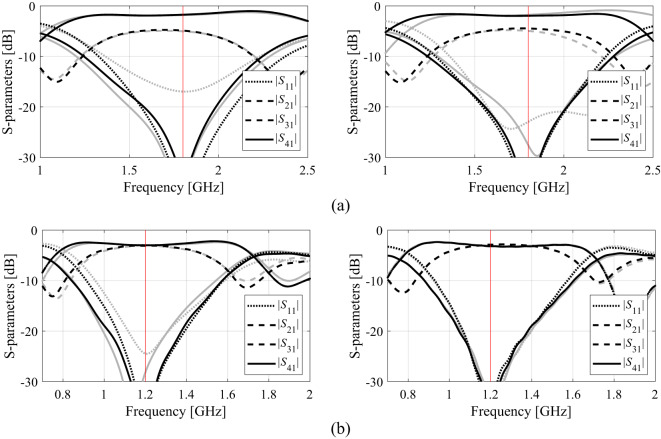 Figure 15
Figure 15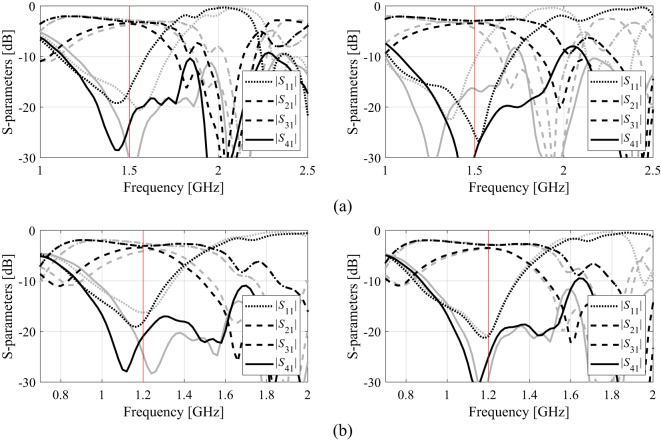 Figure 16
Figure 16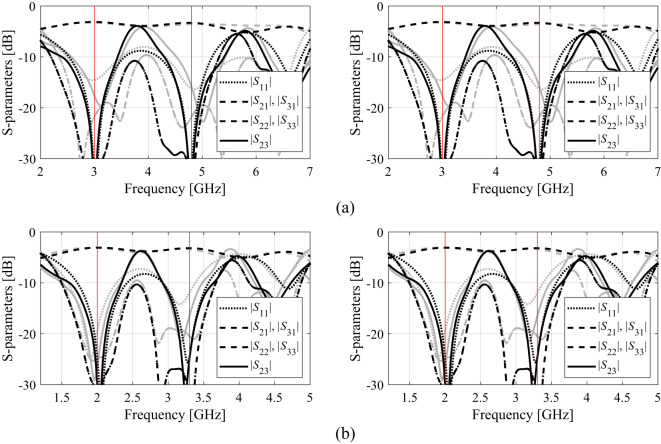 Figure 17
Figure 17 Figure 1
Figure 1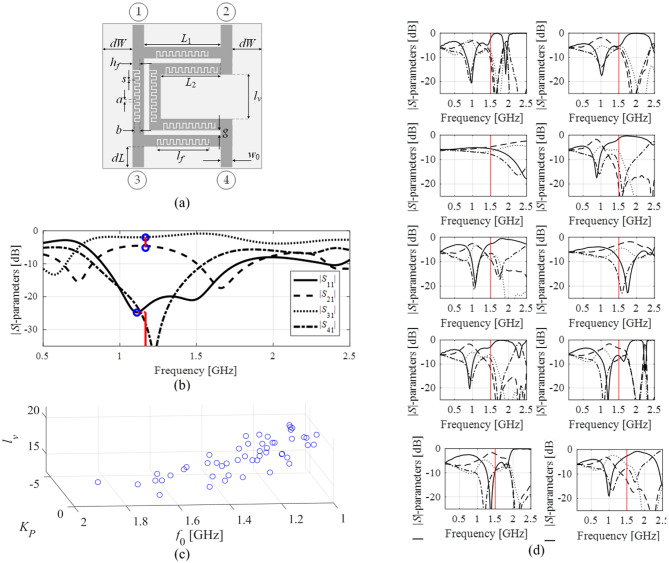 Figure 2
Figure 2 Figure 3
Figure 3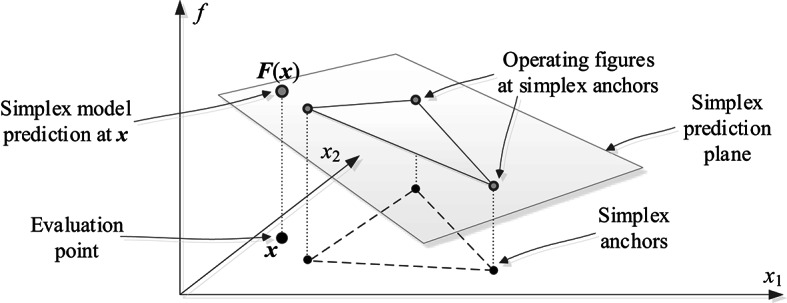 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9- —https://doi.org/10.13039/501100001840Icelandic Centre for Research
- —https://doi.org/10.13039/501100004281Narodowe Centrum Nauki
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMetamaterials and Metasurfaces Applications · Antenna Design and Optimization · Advanced Antenna and Metasurface Technologies
Introduction
Contemporary microwave passive components are designed to satisfy stringent performance and functionality requirements (reconfigurability, multi-band operation, limited physical size, harmonic suppression^1–8^. This makes their development process a difficult undertaking. For example, the design of compact circuits often involves meandering of transmission lines or the employment of slow-wave effect (e.g^9,10^.,, which increases the geometrical intricacy of the layout and the number of adjustable parameters^11–13^. Further, accounting for losses, cross-coupling effects, or the presence of connectors necessitates the utilization of electromagnetic (EM) analysis for reliable electrical characteristic evaluation. In particular, the tuning of circuit geometry parameters must be based on EM simulations. The latter is increasingly often realized using formal optimization methods, as they permit us to handle multiple variables and design goals simultaneously. Nevertheless, the computational efficacy of EM-driven optimization, even in the local case, remains far from satisfactory. The costs are significantly higher for global search, which is, however, recommended in many situations (e.g., optimization of metamaterials/metasurfaces^14,15^, radiation pattern synthesis^16^, multi-objective design^17^, simulation-based size reduction^18^, or operating frequency relocation^19^.
Nowadays, population-based metaheuristics^20–25^ prevail in the global search. There are numerous methods within this class. Some of the more traditional but still widely used are evolutionary optimization techniques^26^, particle swarm optimization algorithm (PSO)^27^, or differential evolution^28^. Notable examples of more recent techniques are the grey wolf optimization, firefly algorithm, and harmony search (e.g^29^., -^30^. The new routines are continuously piling up^31–37^. What enables the global search potential is the exchange of data between the candidate solutions processed by the algorithm^38–40^ as well as partial randomization (e.g., local alterations referred to as mutation^41^, design relocation biased towards the current best solution^42,43^, often imitating biological or social processes. The implementation of the aforementioned methods is relatively simple. However, they are costly in computational terms. Typically, the numbers of objective function evaluations are measured in thousands per algorithm run. Consequently, EM-based optimization using such methods is generally prohibitive, and their applications are limited to handling cheap models (e.g., analytical factor models in the case of antenna arrays^44^.
Alleviating the cost-related difficulties is possible using surrogate modeling methods (kriging^45^, artificial neural networks^46^, Gaussian process regression^47^. In surrogate-assisted frameworks, data-driven models act as fast predictors replacing expensive EM analysis^48–52^ and are gradually refined by incorporating EM simulation results acquired throughout the optimization process^53^. These schemes are frequently categorized as machine learning (ML) procedures^54,55^. Modern ML frameworks often exploit Bayesian optimization (BO)^56–58^, often in conjunction with population-based metaheuristics^59^, and multi-fidelity approaches^60^, as well as reinforcement learning^61,62^ (also in combination with deep neural networks^63,64^. BO has been applied to solve various design tasks such as global optimization, uncertainty quantification, and inverse design^65,66^, but also parameter determination of neural network models of high-frequency structures^67^. Other examples of applying ML in microwave design optimization can be found in^68–74^. Casting the numerical operations onto surrogates results in a considerable computational speedup. The bottleneck is the construction of accurate data-driven models, which is thwarted by dimensionality-related issues, large domains (extensive ranges of geometry parameters), and nonlinearity of frequency characteristics. As a result, most ML algorithms are showcased using rather simplistic examples^75,76^. Some of the mentioned issues can be mitigated using domain confinement (also known as performance-driven modeling)^77–80^. The surrogate is rendered only in a small region containing high-quality designs identified beforehand^77^, reducing the necessary training dataset size. Another possibility is employing the response feature approach^81^, i.e., expressing the design task with regard to so-called characteristic points of the circuit responses. This smoothens the objective function, expediting optimization procedures^82^ or facilitating the surrogate model setup^83^.
This paper aims to introduce a novel methodology for the rapid globalized EM-driven optimization of passive microwave circuits. The proposed technique targets operating parameters of the considered circuit (e.g., center frequencies, power split ratios), which are inferred from the EM simulation data and predicted using structurally simple regression models. The latter dramatically improves the reliability of optimum identification and reduces the costs. Additional acceleration factors include the employment of dual-fidelity simulations and restricted sensitivity updates applied at the final (gradient-based) parameter tuning stage. The presented methodology has been verified with the use of several microstrip circuits optimized for different scenarios and compared to several benchmark methods: nature-inspired algorithms, random-start local search, and two machine-learning-based strategies. The results obtained corroborate our technique’s exceptional cost effectiveness (the average cost equals merely around 45 EM analyses of the structure at hand), global search potential, and the competitive quality of the designs produced. Excellent performance, supplemented by straightforward setup and handling, makes it a practical alternative to existing globalized search techniques for EM-driven microwave design.
This paper brings together several original components and technical contributions, which can be summarized as follows: (i) the development of a novel framework for global optimization of microwave components, (ii) the incorporation of algorithmic tools oriented towards low-cost global exploration of the parameter space such as low-resolution parameter pre-screening, feature-based simplex surrogates, and global search stage through simplex evolution, (iii) rapid final tuning involving variable-fidelity EM simulations and sparse sensitivity updating strategies based on principal directions, (iv) comprehensive demonstration of the algorithm’s efficacy and superiority over a range of bio-inspired, gradient-based, and machine learning methods. The main novelty of the work lies in meticulous integration of several mechanisms (as mentioned above) that work in synergy and contribute to both computational efficiency and reliability.
Globalized microwave optimization by operating parameter handling, dual-fidelity em simulations, and restricted sensitivity updates
In this section, we elaborate on the details of the introduced optimization methodology. The design task definition (Sect. 2.1), and comments on dual-fidelity EM models (Sect. 2.2), are followed by the definition of simplex-based surrogates in Sect. 2.3. The global and local search parts of the entire framework are discussed in Sect. 2.4 and 2.5, whereas Sect. 2.6 outlines the complete procedure.
EM-Driven optimization task definition
The notation relevant to simulation-based optimization of microwave components can be found in Fig. 1. The fundamental role is played by the scalar merit function U(x,Ft), which is defined with respect to the adjustable parameter vector x, and the target operating parameter vector Ft. The constraints or multiple objectives are treated using the penalty function approach^84^. The specific formulations of the objective functions employed in our work are listed in Sect. 3. It should be noted that other ways of handling multiple design goals are available as well, e.g., the weighted sum approach^85^ or genuine multi-objective optimization^86–88^.Fig. 1. Notation used in the context of EM-driven microwave design formulation.
With the notation introduced in Fig. 1, the microwave optimization problem can be stated as a nonlinear minimization task
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\bf{x}}^*} = \arg \mathop {\min }\limits_{\bf{x}} U({\bf{x}},{{\bf{F}}_t})$$\end{document}In (1), x^*^ is the optimum parameter vector to be found.
Dual-Fidelity EM simulations
Simplified representations, both analytical ones and equivalent network models, have been the primary tools of microwave design for decades^89^. Yet, the complexity of contemporary passive circuits makes such representations insufficient, leaving full-wave EM models the only means to capture cross-coupling effects, losses, dielectric anisotropy, etc. By controlling the discretization level of the considered (and other changes in the model^90^, one can alter the trade-offs between the evaluation speed and reliability, which is a convenient way of rendering less accurate but faster models. Due to sharing the same underlying physics, the simulation results of various fidelities are typically well-correlated, allowing for using lower-resolution models as reliable predictors upon suitable correction^91,92^. Normally, two resolution levels are utilized in practice^93^, although model management strategies involving a continuous spectrum of fidelities are also employed^94^.
We employ two models: low- and high-resolution ones, Rc(x) and Rf(x), respectively. To boost the computational efficiency of our algorithm, the model Rc will be used for sampling (pre-screening) and performing the global search stage of the optimization process. The simplex-based regression models in this stage will also be constructed using Rc. The model Rf will only be used for the final tuning of the circuit parameters (the last stage of the process), which is necessary to ensure reliability.
Surrogate modeling of circuit operating parameters
Global optimization is a computationally expensive endeavor, which can be facilitated using surrogate modeling methods^95–98^. The primary issue is the construction of reliable metamodels of highly nonlinear outputs of microwave components over large parameter spaces. This section discusses the proposed approach to this problem. It capitalizes on changing the focus of the modeling process from frequency responses to the system’s operating parameters.
Frequency responses versus operating parameters
As mentioned earlier, modeling of nonlinear characteristics of microwave components across extended ranges of frequency and geometry parameters is a daunting task. For example, consider a rat-race coupler of Fig. 2(a) and its EM-simulated S-parameters (Fig. 2(b)). Clearly, a successful optimization of the circuit through local search (here, for a target frequency of f0 = 1.5 GHz) is contingent upon the initial design quality. For most of the points shown in Fig. 2(d), local optimization would fail. Moreover, constructing a reliable surrogate model of circuit responses seems to be extremely difficult.Fig. 2S-parameter characteristics of a rat-race coupler: (a) circuit layout, (b) approximated operating parameters of the coupler: the power division is assessed for the frequency calculated as the mean value of the |S11| and |S41| minima (marked using thick vertical line), which is also used as the approximation of the circuit’s operating frequency f0; (c) relations between the operating parameters and selected circuit dimensions. The plots are created using a set of randomly generated designs. Clear patterns are visible even though the trial points were not optimized whatsoever; (d) S-parameters simulated for parameter vectors randomly allocated across the design space considered. The intended operating frequency of the circuit is marked with vertical line. Local optimization fails when starting from most of the designs shown: the misalignment between the target and the actual operating conditions is too severe.
However, the situation observed from the angle of the operating parameters renders an entirely different picture. As shown in Fig. 2(c), the geometry parameters are interrelated with the operating figures (here, the center frequency f0 and the power division ratio KP) in a considerably simpler manner. The said dependence can be described as monotonic, even though the plots have been generated using random samples (without any prior optimization). This type of relationship is common for high-frequency circuits, as proven both for optimization and modeling^81,82^-^83,99,100^.
Regression modeling using simplex-based design of experiments
We aim to explore the relationships illustrated in Fig. 2 for reduced-cost globalized optimization of microwave components. The simplicity of these dependencies fosters the utilization of structurally simple surrogate models to represent the operating conditions of the circuit. Here, we choose a simplex as a suitable geometrical object, which is spanned by n + 1 affinely independent vectors playing a role in the training dataset (with the parameter space dimensionality denoted as n). Below, we define the simplex-anchored surrogates and explain their employment in optimization. We refer to the notation gathered in Fig. 4. Therein, the fundamental concepts include the operating vectors f and performance vectors l. Let us explain these quantities using an exemplary microwave coupler. The frequencies f1 and f2 of the minima of |S11| and |S41| characteristics, respectively, are collected in the operating figure vector. While the levels of the said responses (i.e., l1 and l2) along with the power division at the frequency (f1 + f2)/2 are assembled in the performance figure vector. Thus, we have, f = [f1 f2]^T^ and l = [l1 l2 l3]^T^.
Consider n + 1 affinely independent x^(j)^ = [x1^(j)^ … xn^(j)^]^T^, j = 0, …, n, in the design space X (which is bounded by parameters’ lower and upper limits, i.e., circuit dimensions). The corresponding operating and performance vectors are f^(j)^ = f(x^(j)^) = [f1^(j)^ … fN^(j)^]^T^ and l^(j)^ = l(x^(j)^) = [l1^(j)^ … lM^(j)^]^T^, respectively. In practical implementation, the vectors x^(j)^ are randomly acquired until the required number of points satisfying the conditions.
provided in Fig. 3 have been identified. In other words, only the designs satisfying the said conditions form the basis for simplex-based regression model construction.Fig. 3. Simplex-based surrogate models: notation and terminology.
Surrogate model definition
Consider the affinely independent set {x^(j)^} introduced in Sect. 2.3.2. Since the vectors x^(j)^ – x^(0)^ are linearly independent, uniqueness of the expansion is ensured
where x is an arbitrary vector in the parameter space X, and
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\bf{X}} = \left[ {{{\bf{x}}^{(1)}} - {{\bf{x}}^{(0)}}\;\; \cdots \;\;\;{{\bf{x}}^{(n)}} - {{\bf{x}}^{(0)}}} \right]$$\end{document}X being an invertible n × n matrix. The coefficients a = [a1 … an]^T^ are identified as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\bf{a}}({\bf{x}}) = {{\bf{X}}^{ - 1}}({\bf{x}} - {{\bf{x}}^{(0)}})$$\end{document}We aim at defining the following surrogate models: (i) F(x) : X → F, which represents the operating parameters of the circuit, and (ii) L(x) : X → R^M^, predicting its performance parameters. The definitions involve the expansion (3), (4) as well as the vectors f(x^(j)^) and l(x^(j)^) associated with the anchor points x^(j)^. We have
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eqalign{ & {\bf{L}}({\bf{x}}) = {{\bf{l}}^{(0)}} + \sum\limits_{j = 1}^n {{a_j}} ({{\bf{l}}^{(j)}} - {{\bf{l}}^{(0)}}) = {{\bf{l}}^{(0)}} + {{\bf{X}}_l}{\bf{a}}({\bf{x}}) \cr & = {{\bf{l}}^{(0)}} + {{\bf{X}}_l}{{\bf{X}}^{ - 1}}({\bf{x}} - {{\bf{x}}^{(0)}}) \cr}$$\end{document}in which
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\bf{X}}_f} = \left[ {{{\bf{f}}^{(1)}} - {{\bf{f}}^{(0)}}\;\;\; \cdots \;\;\;{{\bf{f}}^{(n)}} - {{\bf{f}}^{(0)}}} \right]$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\bf{X}}_l} = \left[ {{{\bf{l}}^{(1)}} - {{\bf{l}}^{(0)}}\;\;\; \cdots \;\;\;{{\bf{l}}^{(n)}} - {{\bf{l}}^{(0)}}} \right]$$\end{document}Note that the models (5) and (6) interpolate the basis points, in particular, F(x^(j)^) = f^(j)^ and L(x^(j)^) = l^(j)^ for j = 0, …, n.
Figure 4. A graphical illustration of the simplex model construction and its application to predict the circuit’s operating figures F(x) at the evaluation point x.Fig. 4provides an illustration of simplex model construction and its use for predicting the circuit operating figures.
ML-Enabled global search
The global optimization part is executed using the surrogates F(x) and L(x) of Sect. 2.3.3. The underlying advantage is the aforementioned mildly nonlinear relationship of the operating parameters of the circuit with its geometrical dimensions, which “flattens” the objective function profile, making the identification of the optimal design faster and easier. The search process follows the machine learning principles, where the candidate design generated by optimizing the surrogates is employed to refine both F(x) and L(x). The criterion for infill selection is driven by the anticipated enhancement of the objective function.
Design assessment
The design quality x is assessed using the objective function UF being a function of the vectors f(x) and l(x) (i.e., operating and performance vectors). The goal is to align f(x) with the target ft as closely as possible. The latter is not the same as the target vector Ft. To explain this, consider the coupler of Fig. 2. If the device should operate at the center frequency f0 and yield a power split radio KP, we have Ft = [f0 KP]^T^. However, the operating parameter vector would be defined as f = [f1 f2]^T^. Consequently, for consistency, one needs to take ft = [f0 f0]^T^.
A formal definition of UF is as follows.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${U_F}({\bf{x}}) = U({\bf{f}}({\bf{x}}),{\bf{l}}({\bf{x}})) = {U_L}({\bf{l}}({\bf{x}})) + {\beta _F}||{\bf{f}}({\bf{x}}) - {{\bf{f}}_t}|{|^2}$$\end{document}The function UL is introduced to quantify the circuit performance based on the vector l(x). It can be defined as mimicking the original function U; see Fig. 5 for an example. However, it does not need to be the equivalent of U. At the global search phase, the aim is to push f(x) toward ft. For this purpose, the second factor of (9) is utilized, with βF being a penalty factor.Fig. 5. Example of the cost function UL (cf. (11).
Global search algorithm
Global search is the first part of the optimization process, which aims to pinpoint the parameter space’s most promising region. Therein, both F(x) and L(x) are used for prediction of the vectors f(x) and l(x), and to evaluate the quality of design x. The trial design xtmp is generated by minimizing the function UF of (9) as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\bf{x}}_{tmp}} = \arg \mathop {\min }\limits_{{\bf{x}} \in X} {U_F}({\bf{F}}({\bf{x}}),{\bf{L}}({\bf{x}}))$$\end{document}The task (10) is confined to the small neighborhood of the simplex {x^(j)^} by observing the following constraints
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum\limits_{j = 1}^n {{a_j} = 1}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$- \alpha \leqslant {a_j} \leqslant 1 + \alpha ,\;\;\;j = {\text{ }}1,{\text{ }} \ldots ,n\;\;$$\end{document}where α > 0 is a small number (here, we use α = 0.2), and a(x) = [a1 … an]^T^ are the expansion coefficients (5).
For the sake of implementing the search process, the vectors x^(j)^ are organized as follows: ||f^(0)^ – ft|| ≤ ||f^(1)^ – ft|| ≤ … ≤ ||f^(n)^ – ft||. As the norm corresponding to x^(0)^ assumes the lowest value, the said vector serves as an initial solution for (10). Having xtmp, the simplex is updated using the following rules:
1. Candidate acceptance: the vector xtmp is accepted only if
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left| {\left| {f\left( {{x_{tmp}}} \right){\text{ }}--{f_t}} \right|} \right|{\text{ }} < {\text{ }}max\{ j \in \left\{ {0,{\text{ }}1,{\text{ }} \ldots ,n} \right\}{\text{ }}:{\text{ }}\left| {\left| {{f^{(j)}}--{f_t}} \right|} \right|\}$$\end{document}i.e., it outperforms at least one vertex x^(j)^;
2. Vertex replacement: if xtmp has been accepted, it replaces the vertex x^(jworst)^, where
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${j_{worst}} = {\text{ }}argmax\{ {j\epsilon}\left\{ {0,{\text{ }}1,{\text{ }} \ldots ,n} \right\}{\text{ }}:{\text{ }}\left| {\left| {{f^{(j)}} - - {f_t}} \right|} \right|\}$$\end{document}3. Simplex reduction: if xtmp has been discarded, the simplex is scaled down toward x^(0)^ as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\bf{x}}^{(j)}} \leftarrow \gamma {{\bf{x}}^{(j)}} + (1 - \gamma ){{\bf{x}}^{(0)}}for\;\;\;\;j = {\text{ }}1,{\text{ }} \ldots ,n\;$$\end{document}The default value of the reduction factor is γ = 0.5. The reduction does not alter the best vertex x^(0)^.
In Sect. 2.4.3, it is shown that reducing the simplex size to a sufficient extent guarantees satisfying condition (13) by xtmp.
The updating procedure is continued until one of the termination criteria, listed in Fig. 6, has been satisfied. Note that termination does not ensure that a design produced by the search procedure satisfies (16); such a design may simply not exist. If this is the case, the procedure returns the best available solution.Fig. 6. Termination conditions for the global search stage.
Enhancement of the objective function
This section shows that reducing the simplex to a sufficient extent ensures that the vector xtmp generated by (10) reduces UF and ||f(x) – ft|| w.r.t. their values at x^(0)^, i.e., UF(f(xtmp),l(xtmp)) < UF(f(x^(0)^),l(x^(0)^)) and ||f(xtmp) – ft|| < ||f(x^(0)^) – ft||. We start by the following conjecture.
Conjecture 1: Assume (at least) a continuous differentiability of the functions f(x) and l(x) within X. Let D = max{j ∈ {1,2,…,n} : ||x^(j)^ – x^(0)^||} be the simplex size. Then, if D is sufficiently small, we have F(x) ≈ f(x) and L(x) ≈ l(x), which is understood as ||F(x) – f(x)|| → 0 and ||L(x) – l(x)|| → 0 as D → 0.
The proof of Conjecture 1 can be found in Fig. 7. The alignment of F and f (as well as L and l) implies that at x^(0)^ the matrices JF and JL (which correspond to the vectors F and L), are aligned with the sensitivity matrices Jf and Jl, which correspond to the vectors f and l. This is sufficient to demonstrate that the vector xtmp found by (10) enhances the merit function UF of (9). The formal proof is provided in Fig. 8.Fig. 7. Proof of Conjecture 1.Fig. 8. Necessary improvement of the objective function UF by xtmp for small-size simplexes.
Final parameter tuning
The final tuning of the circuit parameters is carried out once the global search stage of Sect. 2.4 has been concluded. This is necessary for two reasons: (i) global optimization was performed using the lower-fidelity EM model, which compromises the reliability, and (ii) global search terminates if the circuit’s operating parameters are aligned with the targets in a sufficient manner, which is not equivalent to minimizing the basic merit function U.
Trust-region (TR) gradient-based algorithm^101^ (utilizing the model Rf of higher accuracy) is employed for the final tuning. In this work, it is accelerated by employing the sparse sensitivity updating strategy of^102^, which is outlined below. The purpose thereof is to limit the number of gradient estimations using finite differentiation^103^, thereby lowering the overall computational cost (see also^104^ for alternative acceleration methods).
We begin by introducing the response variability metric Fv. Let. R(x) = [R(x,f1) … R(x,fm)]^T^, where fk are the evaluation frequencies. For microwave circuits, the response R would normally one of S-parameters. We define^102^
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${F_v}\left( {{{\bf{R}}_1}({{\bf{x}}_1}),{{\bf{R}}_2}({{\bf{x}}_2})} \right) = \sqrt {\sum\limits_{{f_k} \in F} {{{\left[ {{R_1}({{\bf{x}}_1},{f_k}) - {R_2}({{\bf{x}}_2},{f_k})} \right]}^2}} }$$\end{document}where F is a considered frequency interval, typically, pertinent to design specifications.
If several responses are considered, e.g., Sk1, k = 1, …, 4, for a coupler circuit, the metric Fv would be a mean of the metric computed for each characteristic separately^102^.
In the next step, an orthonormal basis of vectors {v^(j)^}j = 1, …, n, is found. The said vectors ordered with respect to their impact on the variability metric Fv. Let x^(i)^ be the ongoing iteration point, and JR(x^(i)^) be the corresponding sensitivity matrix (Jacobian) of the circuit responses. The first vector v^(1)^ is found by maximizing Fv as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\bf{v}}^{(1)}} = \arg \mathop {\max }\limits_{{\bf{v}};\;||{\bf{v}}|| = 1} {F_v}\left( {{{\bf{L}}^{(i)}}({{\bf{x}}^{(i)}} + {\bf{v}}),{\bf{R}}({{\bf{x}}^{(i)}})} \right)$$\end{document}In (28), L^(i)^ is the first-order Taylor expansion model. The remaining vectors v^(2)^, v^(3)^, …, are found as follows. Given v^(k)^, k = 1, …, j, we solve^102^
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\bf{v}}^{(j + 1)}} = \arg \mathop {\max }\limits_{{\bf{\bar v}}} {F_v}\left( {{{\bf{L}}^{(i)}}({{\bf{x}}^{(i)}} + {\bf{\bar v}}),{\bf{R}}({{\bf{x}}^{(i)}})} \right)$$\end{document}where. The projection P^(j)^ is defined as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${P^{(j)}}({\bf{v}}) = {\bf{v}} - \sum\nolimits_{k = 1}^j {{{\bf{v}}^{(k)}}\left[ {{{({{\bf{v}}^{(k)}})}^T}{\bf{v}}} \right]}$$\end{document} . Note that the above conditions ensure that v^(j+1)^ is of unity lengths and it is orthogonal to all v^(k)^, k = 1, …, j. Also, because v^(j+1)^ is searched for in the subspace orthogonal to the previously found directions, we have Fv(L^(i)^(x^(i)^ + v^(1)^),R(x^(i)^)) > Fv(L^(i)^(x^(i)^ + v^(2)^),R(x^(i)^)) > … > Fv(L^(i)^(x^(i)^ + v^(n)^),R(x^(i)^)).
Most of the circuit response variability is accounted for the first few directions. To quantify the response variability, we employ Cj factors
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${C_j} = \frac{{\sqrt {{{\sum\nolimits_{k = 1}^j {\left[ {{F_v}({{\bf{L}}^{(i)}}({{\bf{x}}^{(i)}} + {{\bf{v}}^{(k)}}),{\bf{R}}({{\bf{x}}^{(i)}}))} \right]} }^2}} }}{{\sqrt {{{\sum\nolimits_{k = 1}^n {\left[ {{F_v}({{\bf{L}}^{(i)}}({{\bf{x}}^{(i)}} + {{\bf{v}}^{(k)}}),{\bf{R}}({{\bf{x}}^{(i)}}))} \right]} }^2}} }}$$\end{document}Let Cth refer to a user-defined threshold (here, we use Cth = 0.9, cf^102^. The sensitivity updates are to be restrictive to Nupdate directions, where
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${N_{update}} = \arg \mathop {\min }\limits_{} \left\{ {j \in \{ 1,2,...,n\} :{C_j} \geqslant {C_{th}}} \right\}$$\end{document}The sensitivity updating procedure that employs {v^(j)^}j = 1, …, Nupdate, has been summarized in Fig. 9.Fig. 9. Sensitivity updating by means of principal directions^102,105^.
Optimization framework
In this section, we put together the complete optimization framework using the components discussed so far (Sect. 2.1 through 2.5). Figure 10 summarizes the input variables of the algorithm. Figure 11 contains the list of control parameters along with their default values. Figure 12 presents the pseudocode of the optimization procedure.Fig. 10. Input parameters of the developed global optimization procedure.Fig. 11. Control parameters of the developed global optimization procedure.Fig. 12. Pseudocode of the global search procedure using simplex-based regressors, dual-resolution EM simulations, and sparse sensitivity updating strategy by means of principal directions.
The performance analysis of the framework presented will be carried out in Sect. 3. Here, we only emphasize that one of the attractive features of the method is easy setup and handling. Among the control parameters of Fig. 11, there is only one which is problem-dependent (cf. Section 2.4.2 for a discussion thereof). The role of the remaining parameters is to govern the search process resolution. Consequently, most of these parameters do not need to be tuned for the optimization task.
At this point, it should be emphasized that the algorithm proposed in this work utilizes mechanisms described earlier in the literature such as simplex-based regression models, response features^99^, variable-fidelity EM simulations^94^, or accelerated gradient-based tuning (here, using principal directions^102^, all these tools are incorporated into a unique algorithmic framework, which exhibits performance superior to methods reported in the literature thus far, as demonstrated in the next section.
It should also be clarified that the proposed algorithm has no connection with physics-based surrogate-assisted approaches such as space mapping (SM) (e.g.,^89,91,92^). Space mapping is normally used for local optimization and exploits an auxiliary low-fidelity (or coarse) model, which, in the case of microwave structures, is typically an equivalent network. The coarse model must undergo an appropriate correction, using auxiliary transformations referred to as input, implicit, or output SM.
The corrected model is then optimized in place of the high-fidelity (or fine) model, and the process is iterated until convergence. The main drawback of SM is that the coarse model is problem-specific and must be developed individually for each system. Also, ensuring its quality and the appropriate choice of SM transformations requires considerable user experience. The algorithm proposed in this work is of a completely different type. It does not rely on any extra models (nor their correction), utilizes simple data-driven models (here, based on simplexes) and is inherently developed to handle global optimization.
It is also important to emphasize the distinction between the proposed approach and conventional machine learning procedures, such as those using kriging, Gaussian process regression (GPR), or Bayesian optimization (which, in fact, is a GPR-based ML). The fundamental difference is the use of simple regressors, along with several other mechanisms combined into an automated design framework, such as pre-screening, dual-resolution EM analysis, and rapid final tuning (which does not only allow for a more precise allocation of the optimum, but also for keeping relaxed termination criteria for the global search stage). The sufficiency of simplex-based regressors is achieved by reformulating the design problem in terms of response features, which flattens the functional landscape to be handled by the algorithm. These features distinguish the proposed approach in a methodological sense from traditional machine learning paradigms and allow for achieving substantially better computational efficiency as illustrated in Sect. 3.
Validation and performance assessment
Here, the operation of the algorithm outlined in Sect. 2 is showcased using three microstrip circuits. Its performance is compared to five benchmark techniques that include nature-inspired optimization (specifically, the particle swarm optimizer, PSO^106^, and differential evolution, DE^41^, random-start gradient search, and also two machine learning procedures. The latter involve simplex-based predictors but lack acceleration mechanisms present in the proposed technique. The numerical experiments are arranged to verify the optimization process reliability, global search capability, and cost effectiveness of the considered procedures. Section 3.1 delineates the test cases. The setup of the numerical experiments is provided in Sect. 3.2. Section 3.3. provides the results and discusses them.
Verification test cases
The microstrip circuits utilized for verification of our approach are shown in Fig. 13, which also provides essential details concerning their substrates, designable parameters, parameter ranges, and EM models. The design scenarios (two per circuit) have been gathered in Table 1..
Experimental setup
The test circuits of Fig. 13 were optimized following the scenarios of Table 1. with the use of the proposed framework and six benchmark methods, the details of which can be found in Fig. 14. Identical setup has been employed in all experiments (Fmax = 0.2 GHz, α = 0.2, γ = 0.5, Dmin = 1, ε = 10^–3^, Cth = 0.9), to demonstrate that no tuning of the algorithm to a considered task is necessary. The choice of the benchmark procedures has explicitly been made to emphasize the essential aspects of the approach presented. For example, comparing PSO and DE allows illustrating the computational speedup over population-based metaheuristics, even though a low budget has been used for PSO and DE (only 1,000 objective function calls). Algorithm III is a standard efficient global optimization (EGO)-type machine learning procedure using kriging interpolation models. Comparison with random-start gradient search permits verification of the multimodality of the test problems. Algorithms V and VI, both machine learning routines involving simplex-based surrogates, permit investigating the benefits of incorporating dual-resolution models and restricted sensitivity updates. At the same time, it makes it possible to verify whether these mechanisms deteriorate the design quality.Fig. 13. Test circuits: (a) rat-race coupler with folder transmission lines^107^, (b) rat-race coupler coupler with defected microstrip structure^108^, (c) dual-band power divider, R denotes a lumped resistor^109^.Table 1.Circuits I through III: design goals and spaces.CircuitTarget operating parameters Parameter space X * (lower bounds l and upper bounds u)SymbolsSpecific values for numerical experimentsIF_t_ = [f0 K_P]^T^Case 1: f0 = 1.8 GHz, KP_ = − 3 dBl* = [0.5 5.0 5.0 0.2 0.2 0.2]^T^u = [15.0 30.0 50.0 2.0 2.0 2.0]^T^Case 2: f0 = 1.2 GHz, KP = 0 dBIIFt = [f0]^T^Case 1: f0 = 1.5 GHz, εr = 2.5l = [20.0 0.1 1.0 0.2 0.2 0.2]^T^u = [40.0 0.95 5.0 0.95 0.5 0.8]^T^Case 2: f0 = 1.2 GHz, εr = 4.4IIIFt = [f1 f2]^T^Case 1: f1 = 3.0 GHz, f2 = 4.8 GHzl = [10.0 1.0 10.0 0.5 1.0 0.1 1.5]^T^u = [40.0 20.0 40.0 15.0 6.0 1.5 8.0]^T^Case 2: f1 = 2.0 GHz, f2 = 3.3 GHz^$^The circuit is to be optimized for a specific substrate of given relative permittivity e_r_.Fig. 14. Setup of the introduced procedure and benchmark algorithms.
Results and discussion
The outcome of our procedure for Circuit I, II, and III has been presented in Tables 2 and 3, and Table 4. Table 5 provides the average CPU times (in hours) for the proposed algorithm and all benchmark methods. Figures 15 and 16, and 17 show the circuit responses obtained for certain runs of the proposed algorithm. For each test case and each design scenario, the procedure of Sect. 2 and all benchmark algorithms underwent ten runs.
The tables contain the average values of the objective function, the running cost (recalculated w.r.t. the number of high-fidelity EM analyses), and the success rate (i.e., the number of runs where the circuit operating parameters were placed to ensure ||f(x^^) – f_t*_) ≤ Fmax). Regarding the cost, Tables 2, 3 and 4 also provide the minimum and maximum expenses for all methods considered. In the following paragraphs, they analyze the performance of the proposed framework in comparison to the benchmark methods in terms of reliability, quality of the produced designs, and computational efficiency.
The first performance indicator that we investigate is reliability. As announced earlier, the metric utilized for this purpose is the success rate, defined as a relative number of optimization runs leading to a design meeting the condition ||f(x^^) – f_t*_)|| ≤ Fmax. A quick comparison with random-start gradient search corroborates the multimodality of all test problems: the success rate for this method is only 5/10 on average.
Table 2. Circuit I: optimization results and benchmarking.Optimization methodCase 1Case 2Average merit function [dB]Optimization cost^^Success rate^#^Average merit function [dB]Optimization cost^^Success rate^#^Dual-resolution simplex-based algorithm with sparse sensitivity updates (this work)–33.948.9–54.3–61.310/10–37.733.7–38.2–42.410/10Algorithm I (PSO)Version I (50 iterations)–24.8500–500–5009/10–23.7500–500–5009/10Version II (100 Iterations)–34.01000–1,000–100010/10–36.21000–1,000–100010/10Algorithm II (DE)Version I (50 iterations)–22.8500–500–5008/10–25.8500–500–5009/10Version II (100 Iterations)–33.21000–1000–100010/10–35.61000–1,000–100010/10Algorithm III (machine learning)–31.5435–468.3–50210/10–34.8473–485.3–51010/10Algorithm IV (Trust-region algorithm)–18.772–102.8–1236/1048.362–68.7–735/10Algorithm V (Simplex-based algorithm with high-fidelity model; no local tuning acceleration)–33.662–74.6–8310/10–38.348–55.7–6110/10Algorithm VI (Simplex-based algorithm with dual-resolution EM models, no local tuning acceleration)–32.954.2–60.2–65.810/10–37.540.2–43.1–46.310/10^$^The cost is represented by the number of higher-resolution EM simulations of the considered device. Shown are minimum, average, and maximum values.^#^Number of procedure executions for which satisfactory allocation of the operating frequencies has been accomplished.
Fig. 15. Circuit I: S-parameters at optimal designs (black): (a) Case 1, (b) Case 2; along with the responses at the designs found using the global search (gray). The intended operating frequencies are shown in red.
Table 3. Circuit II: optimization results and benchmarking.Optimization methodCase 1Case 2Average merit function [dB]Optimization cost^^Success rate^#^Average merit function [dB]Optimization cost^^Success rate^#^Dual-resolution simplex-based algorithm with sparse sensitivity updates (this work)–18.546.5–49.7–52.310/10–20.538.4–41.4–45.610/10Algorithm I (PSO)Version I (50 iterations)–17.6500–500–50010/10–19.4500–500–5009/10Version II (100 Iterations)–19.21000–1,000–100010/10–22.51000–1,000–100010/10Algorithm II (DE)Version I (50 iterations)–17.9500–500–5009/10–18.9500–500–5009/10Version II (100 Iterations)–18.31000–1,000–100010/10–21.51000–1,000–100010/10Algorithm III (machine learning)–18.1420–453.2–49010/10–19.5451–473.4–49910/10Algorithm III (Trust-region algorithm)1.872–77.0–835/107.678–83.8–915/10Algorithm IV (Simplex-based algorithm with high-fidelity model; no local tuning acceleration)–18.671–76.9–8410/10–19.461–69.8–7510/10Algorithm V (Simplex-based algorithm with dual-resolution EM models, no local tuning acceleration)–18.258.4–63.1–69.210/10–18.549.5–55.8–61.210/10$ The cost is represented by the number of higher-resolution EM simulations of the considered device. Shown are minimum, average, and maximum values.# Number of procedure executions for which satisfactory allocation of the operating frequencies has been accomplished.
Fig. 16. Circuit II: S-parameters at optimal designs (black): (a) Case 1, (b) Case 2; along with the responses at the designs found using the global search (gray). The intended operating frequencies are shown in red.
Table 4. Circuit III: optimization results and benchmarking.Optimization methodCase 1Case 2Average merit function [dB]Optimization cost^^Success rate^#^Average merit function [dB]Optimization cost^^Success rate^#^Dual-resolution simplex-based algorithm with sparse sensitivity updates (this work)–33.943.5–47.4–49.910/10–25.133.5–37.0–41.210/10Algorithm I (PSO)Version I (50 iterations)–19.6500–500–5008/10–18.8500–500–5008/10Version II (100 Iterations)–18.81000–1,000–10009/10–19.71000–1,000–10009/10Algorithm II (DE)Version I (50 iterations)–19.9500–500–5009/10–20.0500–500–5008/10Version II (100 Iterations)–21.51000–1,000–10009/10–20.01000–1,000–10009/10Algorithm III (machine learning)–29.5425–463.4–4999/10–24.3434–461.5–50510/10Algorithm IV (Trust-region algorithm)–12.389–95.1–1012/10–20.685–93.8–1007/10Algorithm V (Simplex-based algorithm with high-fidelity model; no local tuning acceleration)–33.875–82.0–9210/10–25.978–84.6–9310/10Algorithm VI (Simplex-based algorithm with dual-resolution EM models, no local tuning acceleration)–34.955.4–60.6–65.810/10–25.858.3–62.7–69.410/10$ The cost is represented by the number of higher-resolution EM simulations of the considered device. Shown are minimum, average, and maximum values.# Number of procedure executions for which satisfactory allocation of the operating frequencies has been accomplished.
Fig. 17. Circuit III: S-parameters at optimal designs (black): (a) Case 1, (b) Case 2; along with the responses at the designs found using the global search (gray). The intended operating frequencies are shown in red.
Table 5. Optimization costs for circuits I through III: average CPU times in hours and standard deviation of the objective function value in dB.Optimization methodCircuit ICircuit IICircuit IIICase 1Case 2Case 1Case 2Case 3Case 4Dual-resolution simplex-based algorithm with sparse sensitivity updates (this work)1.8 h[4.4 dB]1.3 h[5.5 dB]2.0 h[2.7 dB]1.6 h[2.9 dB]4.1 h[3.0 dB]3.2 h[3.5 dB]Algorithm I (PSO)Version I (50 iterations)16.7 h8.2 dB]16.7 h[8.5 dB]19.9 h[5.2 dB]19.9 h[6.2 dB]43.1 h[8.0 dB}43.1 h[6.9 dB]Version II (100 Iterations)33.3 h6.8 dB]33.3 h[7.8 dB]39.7 h[4.3 dB]39.7 h[5.5 dB]86.1 h[7.2 dB]86.1 h[6.1 dB]Algorithm II (DE)Version I (50 iterations)16.7 h[7.9 dB]16.7 h[7.5 dB]19.9 h[4.9 dB]19.9 h[6.0 dB]43.1 h[7.8 dB]43.1 h[7.0 dB]Version II (100 Iterations)33.3 h[7.5 dB]33.3 h[7.0 dB]39.7 h[4.5 dB]39.7 h[5.3 dB]86.1 h[6.9 dB]86.1 h[6.2 dB]Algorithm III15.6 h[10.2 dB]16.2 h[12.8 dB]18.0 h[3.3 dB]18.8 h[4.0 dB]41.9 h[6.1 dB]39.7 h[5.8 dB]Algorithm IV3.4 h[5.2 dB]2.3 h[6.0 dB]3.1 h[3.0 dB]3.3 h[3.5 dB]8.2 h[3.5 dB]8.1 h[3.9 dB]Algorithm V2.5 h[5.0 dB]1.9 h[5.6 dB]3.1 h[3.1 dB]2.8 h[3.3 dB]7.1 h[3.2 dB]7.3 h[3.5 dB]Algorithm VI2.0 h[5.0 dB]1.4 h[5.3 dB]2.5 h[2.8 dB]2.2 h[3.2 dB]5.2 h[3.6 dB]5.4 h[3.4 dB]
Population-based optimization turns out to be considerably better; however, for the budget of 500 function calls, it is still not perfect (8.7/10). For the budget of 1,000 it is closer to perfect, namely 9.7/10. On the other hand, both the proposed procedure and the machine learning techniques (Algorithms III, V and VI), exhibit 10/10 success rate. Recall, that all these methods except for Algorithm III share the same underlying principles in terms of the global search mechanism. Clearly, the technique introduced in this work is considerably faster, which will be elaborated below. The conventional EGO-based method (Algorithm III) yields the results of similar quality as the proposed approach; however, it is considerably slower due to the necessity of building a data-driven surrogate across parameter space.
As for the design quality, which is quantified using the average value of the merit function, the proposed method is comparable to all global optimization procedures in the benchmark set (Algorithms I, II, III, V, and VI), except Circuit III, where nature-inspired optimization produced noticeable inferior results. Also, significant differences between PSO results obtained for Version I and II (500 and 1,000 function calls, respectively) is indicative of insufficient computational budget. The latter was intentionally set to these numbers to avoid excessive running times, which are still up to three CPU days for some of the problems. Observe that differences of magnitude a few decibels are insignificant for function values below − 25 dB or so.
Perhaps the major advantage of the proposed optimization technique is its exceptional cost-efficiency. The overall cost (averaged across Circuits I through II and all considered design tasks) is only about 45 EM simulations (of higher resolution). This is almost 50% less than the cost of a direct gradient-based search at a high-fidelity level, which is unsurprising. Although the proposed technique contains gradient-based search as its last stage, it is executed from good starting points produced by the machine learning process and expedited by employing the sparse sensitivity updating scheme. The savings over Algorithm I (PSO) and Algorithm II (DE) equal 96%, meaning that our procedure is over twenty times faster than nature-inspired optimization. In addition, our approach is almost 90% faster than the EGO-based method. Moreover, the effects of including dual-fidelity simulations and sparse sensitivity updates lead to about 40% speedup (i.e., versus Algorithm IV), whereas the latter alone brings about 20% acceleration (i.e., versus Algorithm V). Meanwhile, the mentioned computational advantages are achieved without degrading the design quality.
Altogether, it can be concluded that all the algorithmic components integrated into the presented framework are relevant to ensure the desired properties of the optimization process: reliability and low running cost. These include conducting the search process from standpoint of the operating parameters of the circuits and using structurally simple surrogates, usage of dual-fidelity models, and lowering the number of FD-based sensitivity updates in the final tuning phase. Further, the number of control parameters is small, and they do not need to be tuned to a range of practical design tasks, which makes the procedure easy to handle.
Conclusion
This paper put forward a resource-efficient technique for global optimization of microwave passives. The search process targets the operating parameters of the considered circuit, which facilitates the identification of the conducive portions of the parameter space, and enables the utilization of structurally simple surrogate models. The machine learning procedure implemented using these tools is provably convergent and executed using a low-fidelity simulation model to achieve computational speedup. Reliability is ensured by a complementary gradient-based parameter tuning carried out using high-fidelity models but also involving a sparse sensitivity updating strategy to reduce the running costs even further.
Extensive verification experiments involving three microstrip structures and two design scenarios per circuit conclusively demonstrated the competitive performance of our algorithm. On the one hand, it ensured a perfect success rate with high-quality designs found in all optimization runs. On the other hand, the overall cost of our procedure is exceptionally low and equals less than fifty EM simulations at high-fidelity levels on average. This is considerably less than direct gradient-based search and corresponds to almost 96% savings over nature-inspired optimization. At the same time, the incorporation of dual-fidelity models and restricted sensitivity updates result in about 20% speedup each. The savings mentioned are not followed by any deterioration in the design quality.
Despite the merits discussed, the presented approach has a potential limitation, which may emerge in the case of excessively large search spaces. If the ranges of geometry parameters are very broad, most of the randomly sampled designs would be of poor quality, which impairs the pre-sampling procedure described in Sect. 2.3.2, the goal of which was to identify a set of affinely independent points to be used as the initial simplex vertices. Inferior designs would be repetitively rejected as their corresponding operating parameters are impossible to extract (e.g., may not exist, or be outside the range of interest), which inflates the overall computational cost. Still, the likelihood of this situation occurring is not so high if the definition of the parameter space has been cautious and/or initial parametric studies of the circuit at hand. Of course, large parameter spaces would be problematic for any global optimization algorithm just as well. A part of the future work will be further investigation of this issue. With this reservation, the findings of the paper indicate that our framework might be suitable as an alternative to the existing global search procedures, both nature-inspired routines and machine learning methods processing the complete frequency responses, although more extensive numerical studies involving a broader range of test cases are necessary to support this claim.
Future work will be focused on extending the applicability of the proposed algorithm to other types of high-frequency systems such as filters, metamaterial unit cells, and antennas. Another topic of further research will be investigating the properties of the algorithm for more complex problems, especially, higher-dimensionality parameter spaces.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Mandal, J. K. et al. (eds) Multi-Objective Optimization: Evolutionary to Hybrid Framework (Springer, 2018).
- 2Conn, A. R., Gould, N. I. M. & Toint, P. L. Trust Region Methods (MPS-SIAM Series on Optimization, 2000).
- 3Phani Kumar, K. V. & Karthikeyan, S. S. „A novel design of rat-race coupler using defected microstrip structure and folding technique, IEEE Applied Electromagnetics Conf. (AEMC), Bhubaneswar, India, pp. 1–2, (2013).