Emergence of functionally differentiated structures via mutual information minimization in recurrent neural networks
Yuki Tomoda, Ichiro Tsuda, Yutaka Yamaguti

TL;DR
This paper shows how minimizing mutual information in recurrent neural networks leads to the emergence of functionally specialized modules, similar to how the brain develops.
Contribution
A novel method for inducing functional differentiation in recurrent neural networks by minimizing mutual information between subgroups.
Findings
Mutual information minimization leads to high task performance and functional modularity in neural networks.
Functional differentiation emerges before structural modularity in network development.
The method was successfully applied to working memory and chaotic signal separation tasks.
Abstract
Functional differentiation in the brain emerges as distinct regions specialize and is key to understanding brain function as a complex system. Previous research has modeled this process using artificial neural networks with specific constraints. Here, we propose a novel approach that induces functional differentiation in recurrent neural networks by minimizing mutual information between neural subgroups via mutual information neural estimation. We apply our method to a 2-bit working memory task and a chaotic signal separation task involving Lorenz and Rössler time series. Analysis of network performance, correlation patterns, and weight matrices reveals that mutual information minimization yields high task performance alongside clear functional modularity and moderate structural modularity. Importantly, our results show that functional differentiation, which is measured through…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
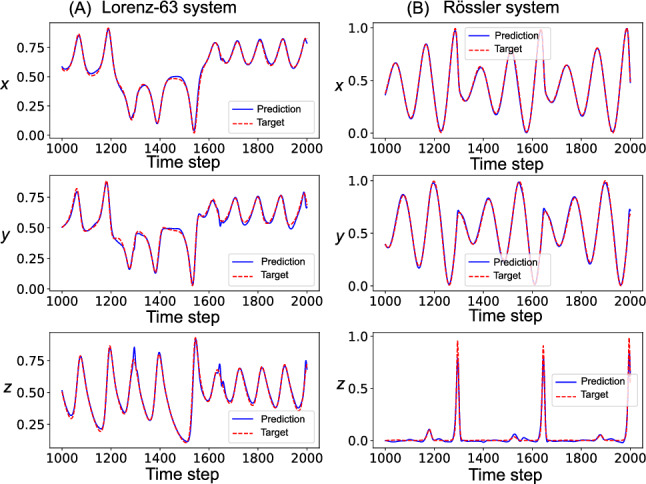 Figure 10
Figure 10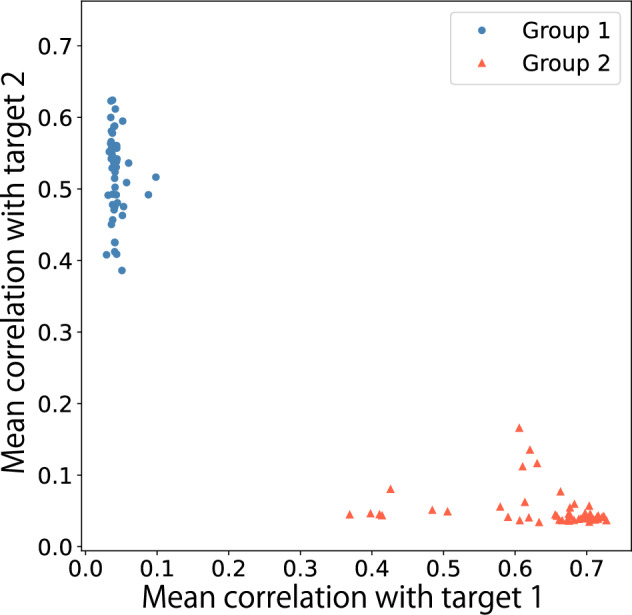 Figure 11
Figure 11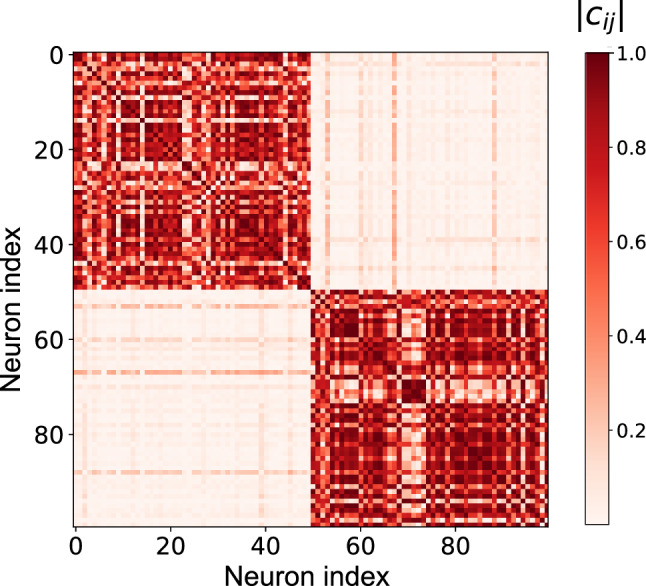 Figure 12
Figure 12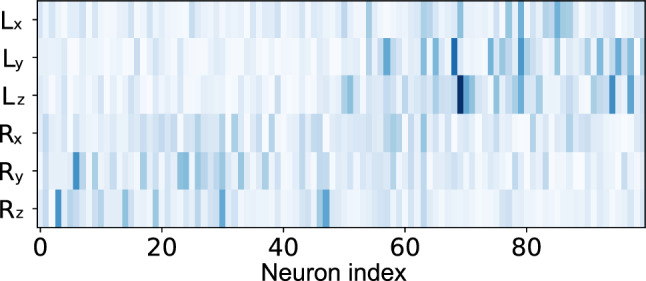 Figure 13
Figure 13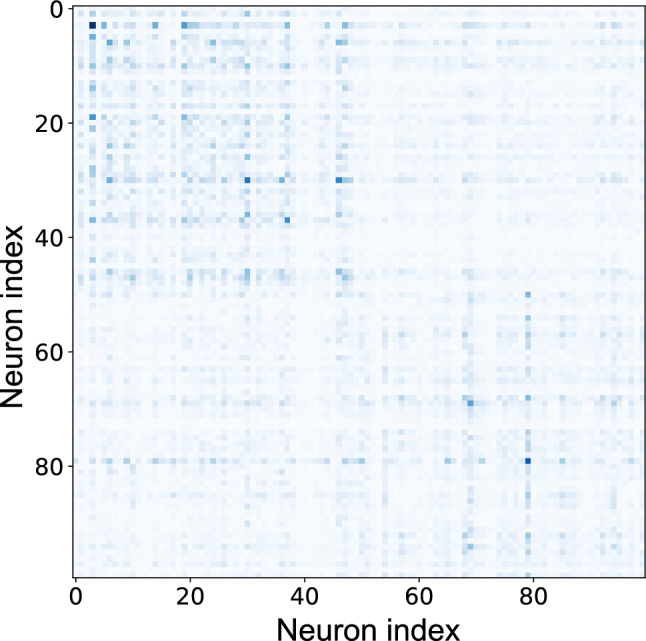 Figure 14
Figure 14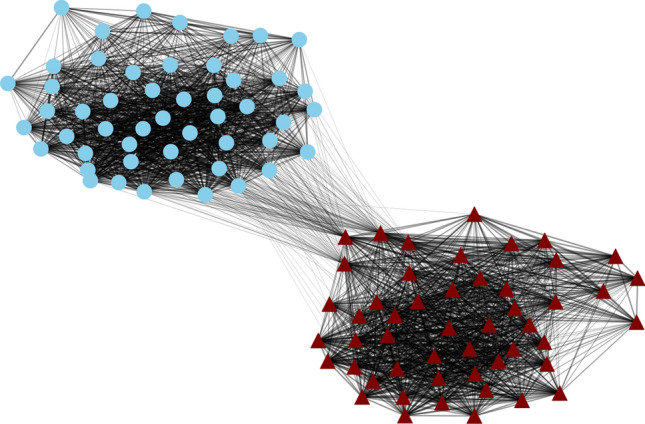 Figure 15
Figure 15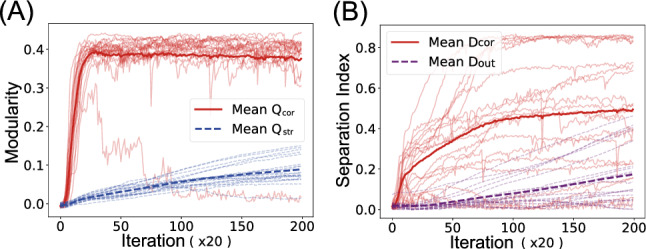 Figure 16
Figure 16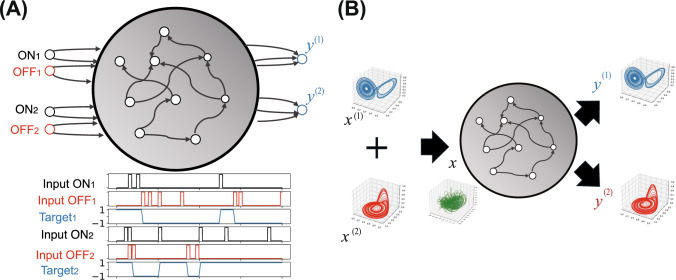 Figure 1
Figure 1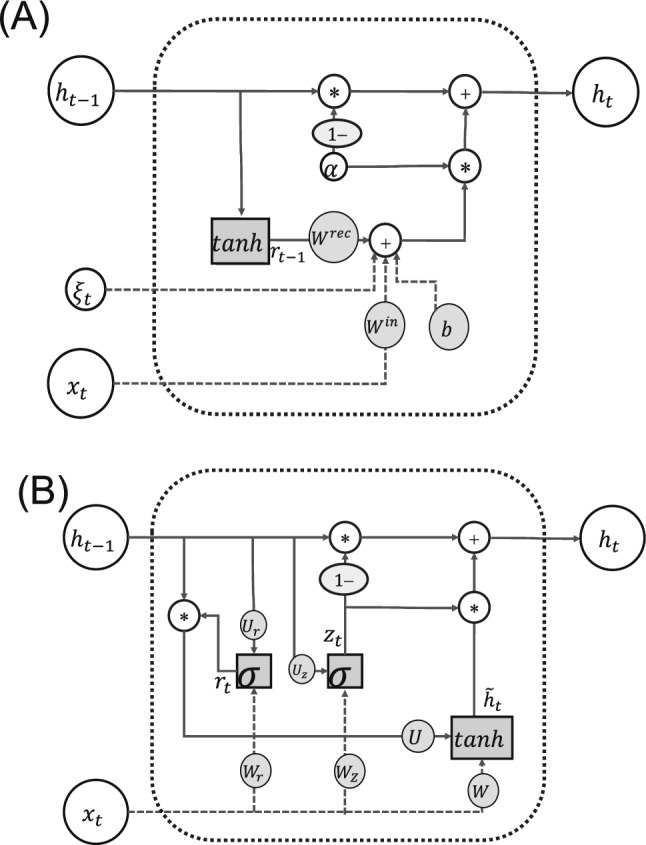 Figure 2
Figure 2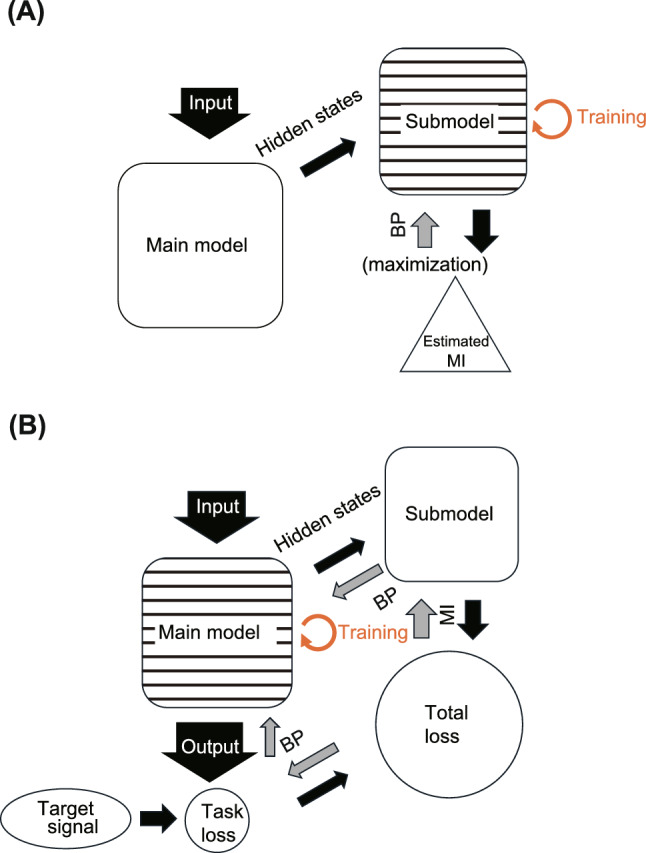 Figure 3
Figure 3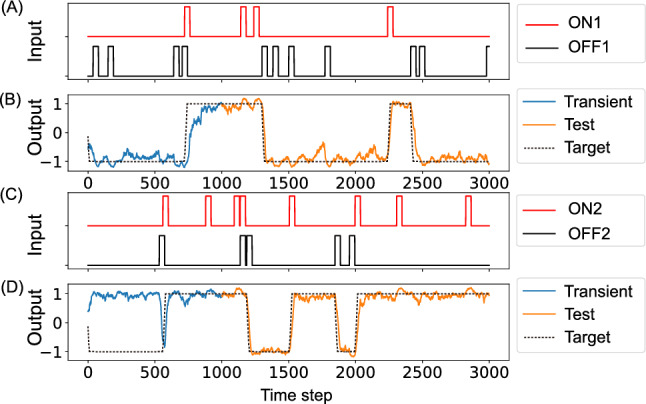 Figure 4
Figure 4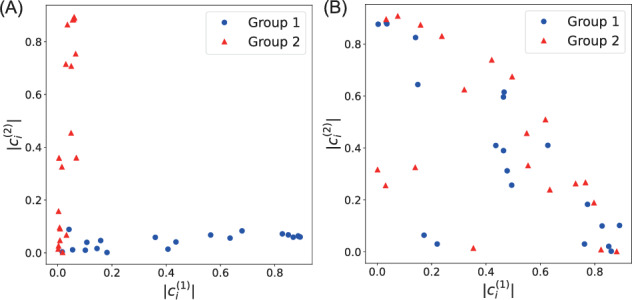 Figure 5
Figure 5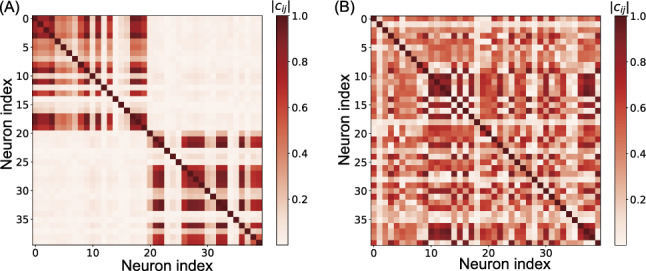 Figure 6
Figure 6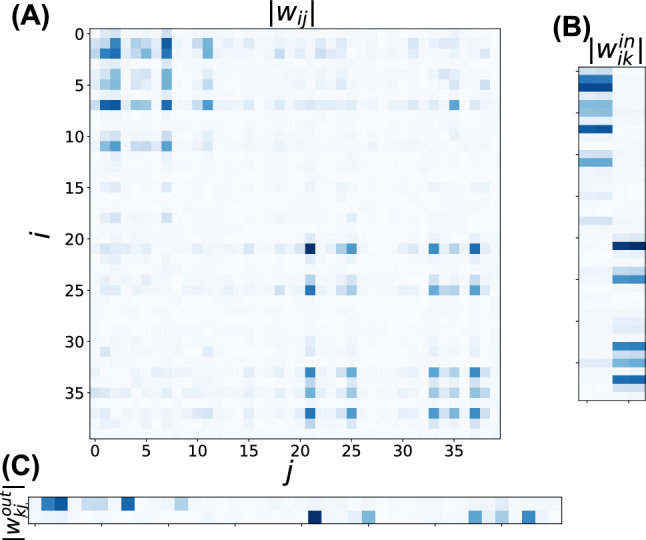 Figure 7
Figure 7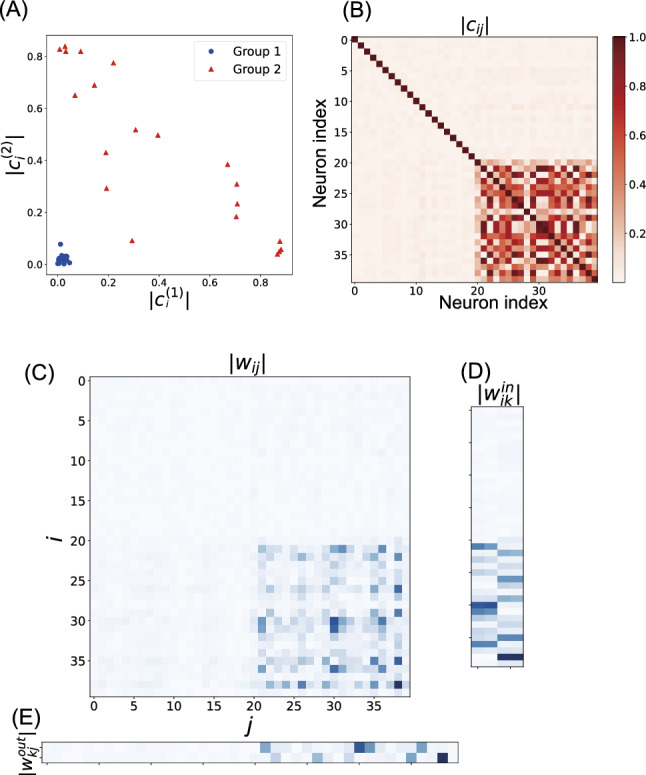 Figure 8
Figure 8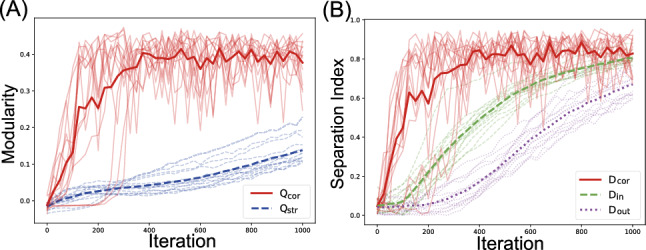 Figure 9
Figure 9- —JST CREST
- —JSPS KAKENHI
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNeural dynamics and brain function · Functional Brain Connectivity Studies · Neural Networks and Applications
Introduction
During brain development, populations of neurons with specific functions organize into different regions, forming a functional map, in a process called functional differentiation (Brodmann 1909). Studies analyzing finer structural division called parcellation have revealed that these functional areas are dynamically reorganized according to specific tasks (Glasser et al. 2016). Throughout these developmental processes, modular structures consistently emerge in the brain’s organization (Felleman and Van Essen 1991; Glasser et al. 2016; Sporns and Betzel 2016; Sporns 2016).
However, the underlying principles driving the formation of these differentiated structures remain largely unknown (Clune et al. 2013; Sporns and Betzel 2016). Thus, it is particularly valuable to study these problems to understand the mechanisms of emerging brain functions. Mathematical modeling offers a valuable approach to formulate these problems quantitatively and test hypotheses systematically (Kaneko and Tsuda 2001).
Functional differentiation in the brain is also believed to be fundamental to the emergence of intelligence (Kashtan and Alon 2005; Sporns and Betzel 2016; Yang et al. 2019). To investigate the underlying computational principles of this process, we need models that capture both the temporal dynamics of neural activity and the capacity for adaptive specialization. Therefore, insights from recent advances in machine learning can be particularly relevant (Sussillo 2014; Yang et al. 2019).
Recurrent neural networks (RNNs) provide an ideal framework for investigating functional differentiation. They exhibit temporal dynamics similar to biological circuits, have a long history in computational neuroscience (Caianiello 1961; Amari 1972; Hopfield 1982; Elman 1990), and recent developments enable modeling of complex neural dynamics (Sussillo 2014; Song et al. 2016; Yang et al. 2019; Yamaguti and Tsuda 2021). We use RNNs to examine how functional differentiation emerges under information-theoretic constraints.
Previous research has proposed that functional differentiation can be understood within the framework of self-organization with constraints, where system components emerge under constraints that act on the entire system (Tsuda et al. 2016, 2022). This framework suggests that the overall development may follow certain variational principles, and thus the differentiation process is not genetically predetermined. Instead, the components emerge dynamically as the system optimizes itself under global constraints. Considering that the brain’s primary information processing function is to acquire information from the environment to produce appropriate behaviors for survival, a compelling candidate for such a universal constraint is the optimization of information flow within neural networks. Mutual information (MI) provides a quantitative measure for analyzing this information flow because it captures the statistical dependencies among different neural populations. However, calculating MI in complex neural systems presents major challenges, particularly when assessing dependencies among multiple variables in high-dimensional spaces.
To implement this theoretical framework, we use mutual information neural estimation (MINE) (Belghazi et al. 2018), which enables efficient estimation of MI and gradient-based optimization in high-dimensional spaces. We propose inducing functional differentiation by minimizing MI between predefined neural subgroups. While previous studies maximized information-theoretic measures (Linsker 1988; Bell and Sejnowski 1995; Tanaka et al. 2009; Watanabe et al. 2020; Yamaguti and Tsuda 2021), we hypothesize that constraining subgroups to be statistically independent drives them to specialize in different task aspects without explicitly specifying their functions.
We test our approach on two complementary tasks (Fig. 1): (1) a 2-bit working memory task (Sussillo and Abbott 2009; Hoerzer et al. 2014) requiring independent maintenance of two binary states, and (2) separation of mixed chaotic time series from Lorenz and Rössler systems (Lorenz 1963; Rössler 1976). Both tasks require specialized neural functions analyzable through our information-theoretic framework.Fig. 1. Schematics of the two experimental tasks. A Working memory task. The network receives brief pulses on four input channels (ON \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_1$$\end{document} , OFF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_1$$\end{document} , ON \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_2$$\end{document} , OFF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_2$$\end{document} ) and must maintain two independent memory bits (output values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm 1.0$$\end{document} ) based on the most recent pulse received. B Chaotic signal separation task. The network receives a mixed 3-dimensional input signal from Lorenz and Rössler chaotic systems and must separate it into two distinct 3-dimensional output signals
Background
Driving forces for functional differentiation
Understanding the process through which cell populations differentiate into distinct groups with specific functions, as well as the evolutionary driving forces behind this process, is a key area in the study of complex systems (Kaneko and Tsuda 2001; Kaneko 2006). The question of how differentiation proceeds and why it is crucial for biological systems has been discussed extensively in neuroscience, evolutionary developmental biology, and artificial intelligence (Kashtan and Alon 2005; Espinosa-Soto and Wagner 2010; Clune et al. 2013; Ellefsen et al. 2015; Sporns 2016). Functional differentiation provides major advantages to biological systems, including greater robustness and higher connection efficiency, where modular organization enables effective communication with fewer and shorter connections (Latora and Marchiori 2001; Sporns 2016), better integration of information across different timescales (Ichikawa and Kaneko 2024), and facilitated information transfer (Yamaguti and Tsuda 2015, 2021). The crucial role of modular structure in neurodynamics has been investigated in several studies (Lord et al. 2017; Kawai et al. 2023).
We focus on information transfer as a key constraint for differentiation. Yamaguti and Tsuda (2015) demonstrated that coupled oscillator systems evolved to maximize the transfer entropy between subnetworks, which was accompanied by the emergence of asymmetric connections within these subnetworks, thus facilitating their differentiation. The precise mechanism underlying this relationship between inter-subnetwork information transfer and asymmetric connectivity remains unclear and may involve spontaneous symmetry breaking during the optimization process. These constraints that act as driving forces of differentiation are complementary rather than mutually exclusive, potentially working in concert to shape biological systems.
The approaches for investigating the emergence of functional differentiation in artificial neural networks can be broadly classified as bottom-up or top-down.
Bottom-up approaches either impose constraints only on local structures, such as synapses between neurons (Von der Malsburg 1973; Amari 1980; Kohonen 1982), or rely on the emergence of differentiation naturally through the requirements of the task itself (Yang et al. 2019). For example, Yang et al. (2019) demonstrated how functionally specialized neural clusters emerge through training a simple RNN on multiple cognitive tasks. By analyzing individual units and the effect of lesions, they revealed how complex cognitive abilities can arise from the interactions of neurons without explicitly imposing global organizational constraints.
In contrast, top-down approaches consider the existence of universal and global constraints that align with the general goals of biological systems (Tsuda et al. 2016). In our study, we adopt this top-down perspective through a variational principle that guides functional differentiation by imposing system-wide constraints (Tsuda et al. 2016, 2022; Watanabe et al. 2020).
Information-theoretic approaches to neural network optimization
In neural network learning, various optimization methods based on information-theoretic measures have been proposed. Linsker (1988) pioneered this approach with the InfoMax principle, which was applied to signal separation tasks by maximizing the MI between input and output (Bell and Sejnowski 1995). Building on this foundation, Tanaka et al. (2009) later developed the concept of Recurrent InfoMax, adapting these principles specifically for RNNs.
Several studies have employed evolutionary algorithms to optimize information flow in neural networks. Watanabe et al. (2020) evolved networks of dynamic elements by maximizing time-dependent MI between network elements and inputs, demonstrating that these elements evolved behaviors resembling spiking or oscillatory neurons. Similarly, Yamaguti and Tsuda (2015) used genetic algorithms to maximize bidirectional information transfer between subnetworks. Subsequently (Yamaguti and Tsuda 2021), they applied evolutionary adaptation to reservoir computing networks, enabling differentiation of output units into categories that respond specifically to corresponding input categories. This transformation from random to structured networks showed some similarities to evolutionary changes in vertebrate brains, particularly the development from the reptilian medial pallium to the mammalian hippocampus and neocortex. Kanemura and Kitano (2024) investigated reservoir computing models using genetic algorithms to simultaneously maximize information transfer and minimize network maintenance costs, revealing that sparse networks with a medullary structure emerge under these constraints.
These studies demonstrate that artificial neural networks can develop functional structures similar to those observed in biological systems when constrained by information-theoretic measures, such as MI or transfer entropy, highlighting the importance of information-theoretic principles in the self-organization of functionally differentiated neural structures.
However, estimating and optimizing MI between higher-dimensional variables has long been considered a difficult problem due to the curse of dimensionality. In response to this challenge, researchers have typically relied on either specialized models with tractable forms that allow gradient-based optimization of information-theoretic measures, or evolutionary approaches that avoid direct gradient computation altogether.
Belghazi et al. (2018) proposed MINE, a method that manages the estimation of MI for any differentiable model and enables the optimization of MI through backpropagation algorithms, harnessing the computational power of GPU-based deep learning frameworks.
In the present paper, we use MINE to estimate and minimize MI between neural subgroups in RNN models, investigating how functionally differentiated structures emerge under this information-theoretic constraint. Although most previous studies have focused on maximizing information metrics to enhance information transfer or representation quality (Linsker 1988; Bell and Sejnowski 1995; Tanaka et al. 2009; Yamaguti and Tsuda 2021), our approach uses the minimization of MI between neural subgroups as an organizing constraint. This constraint encourages subgroups to develop statistically independent activity patterns, thereby promoting functional specialization. To our knowledge, this is the first study to systematically investigate MI minimization as a mechanism for inducing functional differentiation in the context of computational neuroscience modeling. We acknowledge that alternative mechanisms–such as unsupervised learning rules, sparse connectivity constraints, or task structure alone (Yang et al. 2019)–can also lead to functional specialization, and comparative studies of these different approaches would be valuable for future research.
Models and Methods
Neural network architectures
We used two types of RNNs for the two experiments described in later sections: a simple leaky-integrator RNN and a gated recurrent unit (GRU) network (Chung et al. 2014). The leaky-integrator RNN (Fig. 2A) was used for the working memory task, whereas the GRU (Fig. 2B) was used for the chaotic signal separation task. In both experiments, we incorporated the MINE algorithm for both estimation and optimization of MI between neural subgroups. Using these distinct network architectures and task paradigms allows us to evaluate the generality and robustness of our approach; obtaining consistent patterns of functional differentiation across these different conditions would strengthen the validity of our hypothesized principles. In this section, we briefly describe these neural network architectures and the MINE algorithm used in our experiments.Fig. 2. Schematic of the hidden state update in the two RNN architectures used in this study. A Leaky-integrator RNN and B GRU. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma $$\end{document} is the sigmoid activation function and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tanh $$\end{document} is the hyperbolic tangent activation function. Weight parameters to be learned are represented by shaded circles
Simple leaky-integrator RNN
For the working memory task, we used a simple leaky-integrator RNN, which incorporates a mechanism that allows the network to maintain past information while letting the information gradually fade over time, a feature widely used in computational neuroscience models to approximate the firing rate dynamics of biological neurons better (Sussillo and Abbott 2009; Sussillo 2014; Song et al. 2016; Yang et al. 2019)
The dynamics of a leaky-integrator RNN with N units are given by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} h_t^{i}& = (1-\alpha )h_{t-1}^{i} + \alpha \Big (\sum _{j=1}^{N} w_{ij}^{\textrm{rec}}r_{t-1}^{j} \nonumber \\& + \sum _{k=1}^{N_{\text {in}}} w_{ik}^{\textrm{in}}x_t^k + b^i + \xi _{t}^{i}\Big ), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_t^i \in {\mathbb {R}}$$\end{document} is the state of neuron i at time t, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_t^i = \tanh (h_t^i) \in {\mathbb {R}}$$\end{document} is the firing rate of the neuron, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_t^k$$\end{document} is the k-th input signal at time t, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\xi _t^i \sim {\mathcal {N}}(0, 0.1)$$\end{document} is independent Gaussian noise for neuron i, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w^{\text {rec}}_{ij}$$\end{document} is the (i, j)-th element of recurrent weight matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W^{\text {rec}} \in {\mathbb {R}}^{N \times N}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w^{\text {in}}_{ik}$$\end{document} is the (i, k)-th element of input matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W^{\text {in}} \in {\mathbb {R}}^{N \times N_{\text {in}}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b^i$$\end{document} is the bias for neuron i, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha = 0.1$$\end{document} is the leakage parameter controlling the decay rate.
The model outputs are given by the weighted sum of the recurrent layer output as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} y_t^{j} = \sum _{i=1}^{N} w_{ji}^{\textrm{out}}a_t^{i} + b_j^{\textrm{out}}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_t^j \in {\mathbb {R}}$$\end{document} is the j-th output of the model at time t, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w_{ji}^{\textrm{out}}$$\end{document} is the (j, i)-th element of output weight matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W^{\textrm{out}} \in {\mathbb {R}}^{N_{\text {out}} \times N}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b_j^{\textrm{out}}$$\end{document} is the bias for output j, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_t^i$$\end{document} is the i-th element of the recurrent layer output (where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_t^i = r_t^i$$\end{document} for leaky-integrator RNNs), and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_{\text {out}}$$\end{document} is the number of output units.
GRU
GRUs (Chung et al. 2014) are an extension of the RNN and process sequential data with a long sequence dependency. Although GRUs were proposed as a simplified alternative to the more complex long short-term memory model (Hochreiter and Schmidhuber 1997), they show comparable performance for various tasks.
GRUs have update gates and reset gates, which adaptively control memorization and forgetting process, thereby enabling them to retain more past information than traditional RNNs. The dynamics of GRUs with N units are given by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} h_t^i& = \left( 1-z_t^i\right) h_{t-1}^i+z_t^i{{\widetilde{h}}}_t^i \\ z_t^i& = {\sigma (W_zx_t+U_zh_{t-1})}^i \\ {{\widetilde{h}}}_t^i& = \tanh {{(Wx_t+U\left( r_t\odot h_{t-1}\right) )}^i} \\ r_t^i& = {\sigma (W_r x_t+U_rh_{t-1})}^i, \end{aligned} \end{aligned}$$\end{document}where t is time, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma $$\end{document} is the sigmoid function, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\odot $$\end{document} is the Hadamard product of matrices, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_t\in \left[ 0,1\right] ^N$$\end{document} is an update gate that controls how much of the new information to incorporate, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_t\in \left[ 0,1\right] ^N$$\end{document} is a reset gate that determines which parts of the previous state to forget, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\widetilde{h}}}_t\in {\mathbb {R}}^N$$\end{document} is candidate activation that represents new information that could be stored, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_t\in {\mathbb {R}}^N$$\end{document} is the output of hidden states, hereafter simply called the hidden state. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_z$$\end{document} , W, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_{r}$$\end{document} are weight matrices that determine how input \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_t \in {\mathbb {R}}^{N_{\text {in}}}$$\end{document} affects variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_t$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widetilde{h}}_t$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_t$$\end{document} , respectively, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$U_{z}$$\end{document} , U, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$U_{r}$$\end{document} are matrices that determine how the previous internal state affects these variables. Upper right subscript i denotes the i-th element of the vector. The GRU output is also given by the weighted sum of the hidden states, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_t$$\end{document} , as in Eq. (2), where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_t^i = h_t^i$$\end{document} for GRU networks.
MINE
MINE is a method developed by Belghazi et al. (2018) that uses deep neural networks to construct a differentiable estimator for MI. The differentiable nature of this estimator enables the backpropagation of MI gradients, allowing for neural network parameters to be optimized with respect to information-theoretic objectives by incorporating the estimated MI value into the loss function for training the model. In our study, this capability is crucial because it allows the MI to be minimized between different neural subgroups while simultaneously optimizing task performance.
MI is an information-theoretic measure of the statistical dependence between two random variables, quantifying the amount of information shared between them. MI between random variables X and Y can be defined as the reduction in uncertainty about X when Y is known, as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} I\left( X;Y\right) =H\left( X\right) -H\left( X | Y\right) , \end{aligned}$$\end{document}where H is the Shannon entropy and H(X|Y) is the conditional Shannon entropy of variable X given knowledge of variable Y.
MI can be expressed equivalently in terms of the Kullback–Leibler (KL) divergence as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} I\left( X;Y\right) =D_{KL}\left( {\mathbb {P}}_{XY}\parallel {\mathbb {P}}_X\otimes {\mathbb {P}}_{Y}\right) , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbb {P}}_X$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbb {P}}_{Y}$$\end{document} are marginal distributions of X and Y, respectively, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbb {P}}_{XY}$$\end{document} is their joint distribution, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbb {P}}_X\otimes {\mathbb {P}}_{Y}$$\end{document} is the product of the marginal distributions. This product distribution has the same marginals as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbb {P}}_{XY}$$\end{document} but assumes that X and Y are statistically independent.
KL-divergence \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{KL}$$\end{document} between probability distributions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbb {P}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbb {Q}}$$\end{document} is defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} D_{KL}\left( {\mathbb {P}}\parallel {\mathbb {Q}}\right) ={\mathbb {E}}_{\mathbb {P}}\left[ \log {\frac{d{\mathbb {P}}}{d{\mathbb {Q}}}}\right] , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbb {P}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbb {Q}}$$\end{document} are distributions on compact domain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Omega $$\end{document} . The KL-divergence of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbb {P}}$$\end{document} relative to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbb {Q}}$$\end{document} can be defined when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbb {P}}$$\end{document} is absolutely continuous with respect to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbb {Q}}$$\end{document} .
Following Donsker and Varadhan (1983), the KL-divergence can be expressed as a dual representation,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} D_{KL}\left( {\mathbb {P}}\parallel {\mathbb {Q}}\right) =\sup _{T:\Omega \rightarrow {\mathbb {R}}}{{\mathbb {E}}_{\mathbb {P}}\left[ T\right] -\log ({\mathbb {E}}_{\mathbb {Q}}\left[ e^T\right] )}, \end{aligned}$$\end{document}where the supremum is taken over all functions T such that the two expectations are finite.
Applying this dual representation to MI by setting \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbb {P}} = {\mathbb {P}}_{XY}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbb {Q}} = {\mathbb {P}}_X \otimes {\mathbb {P}}_Y$$\end{document} from Eq. (5), we obtain
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} I(X;Y) = \sup _{T:\Omega \rightarrow {\mathbb {R}}}{{\mathbb {E}}_{{\mathbb {P}}_{XY}}\left[ T\right] -\log ({\mathbb {E}}_{{\mathbb {P}}_X \otimes {\mathbb {P}}_Y}\left[ e^T\right] )}. \end{aligned}$$\end{document}The key insight of MINE is to approximate this supremum using function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_\theta : \Omega \rightarrow {\mathbb {R}}$$\end{document} parameterized by a neural network with parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta \in \Theta $$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Theta $$\end{document} is the set of all possible parameters. The neural network is trained using gradient-based optimization to maximize this objective, effectively approximating the supremum. The resulting estimate of MI is given by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \widehat{{I(X;Y)}}={\sup }_{\theta \in \mathrm {\Theta }}{\mathbb {E}}_{{\mathbb {P}}_{XY}}\left[ T_\theta \right] -\log ({\mathbb {E}}_{{\mathbb {P}}_X\otimes {{\mathbb {P}}}_Y}\left[ e^{T_\theta }\right] ), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{{I(X;Y)}}$$\end{document} is the estimated MI, which provides a lower bound on the true MI.
Experimental setup
This subsection details our computational framework for investigating how functional differentiation emerges under information-theoretic constraints.
Our framework consists of two interconnected components: a main model (MM) and a submodel (SM). The MM is an RNN that develops functional differentiation under MI constraints and is trained to perform specific tasks while its internal structure evolves under constraints. The SM is a neural network estimator that quantifies the MI between designated neuronal subgroups within the MM. Crucially, the SM estimates MI and provides gradients that allow MI to be minimized between these subgroups during training, thereby encouraging functional specialization.
In the following subsections, we detail the specific architectures, training procedures, and analytical methods used to evaluate the emergence of structural and functional modules in the trained networks.
Main model
The main model (MM) implements the RNN architectures that perform our experimental tasks while developing functional differentiation under MI constraints. Different RNN architectures are used for the two tasks, as described below.
For the working memory task, we use the leaky-integrator RNN represented by Eqs. (1) and (2). For the chaotic signal separation task, we use a GRU network represented by Eqs. (3) and (2).
A key aspect of our approach is the division of recurrent layer neurons into two equal-sized groups, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(1)}=\{1,\ldots , N/2\}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(2)}=\{(1+N/2),\ldots , N\}$$\end{document} , with MI minimization between these groups driving functional differentiation during training.
In both tasks, the MM produces two output vectors, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y^{(1)}_t$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y^{(2)}_t$$\end{document} (Fig. 1). The dimension, M, of each output vector is 1 for the working memory task and 3 for the signal separation task. Thus, the total output dimension is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_{\text {out}} = 2M$$\end{document} , decomposed into two separate M-dimensional outputs.
These two outputs are calculated as weighted sums of the recurrent layer output,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} y^{(j)}_t = W^{(j)}_{y} a_t + b^{(j)}_{y}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j \in \{1,2\}$$\end{document} indexes the output vectors, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_t$$\end{document} is the output of the recurrent layer at time t, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W^{(j)}_{y}$$\end{document} is an \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(M \times N)$$\end{document} weight matrix connecting the recurrent layer to output j, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b^{(j)}_{y}$$\end{document} is the corresponding M-dimensional bias vector. The definition of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_t$$\end{document} depends on the network architecture of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_t = r_t$$\end{document} for the working memory task (leaky-integrator RNN) and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_t = h_t$$\end{document} for the chaotic signal separation task (GRU).
Working memory task
We use a 2-bit working memory task that requires the network to maintain two independent binary states simultaneously (Fig. 1A). The task structure is as follows.
- The network receives four distinct input channels: two ON channels (ON \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_1$$\end{document} , ON \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_2$$\end{document} ) and two OFF channels (OFF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_1$$\end{document} , OFF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_2$$\end{document} ), where the subscripts indicate which memory bit (1 or 2) the channel affects.
- When a brief pulse (of amplitude 1.0) is presented on the ON channel for a memory bit, the corresponding output should switch to and maintain the ON state (target value of 1.0).
- When a brief pulse is presented on the OFF channel for a memory bit, the corresponding output should switch to and maintain the OFF state (target value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-1.0$$\end{document} ).
- Between pulses, all input channels remain at zero, and the network must maintain the current state of both memory bits without additional input. The network has two output units ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_{\text {out}}=2$$\end{document} ) that correspond to the two memory bits. Each output is trained to maintain the appropriate state (1.0 for ON or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-1.0$$\end{document} for OFF) based on the most recent pulse received, with pulses affecting one memory bit not disturbing the other. The input pulses are generated randomly with a probability of 0.002 per time step per channel and width of 40 time steps. Training sequences are 2,000 time steps with an initial transient period of 1,000 time steps.
Task loss \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {task}}$$\end{document} is defined as the mean squared error between the network’s outputs and the target values,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L_{\text {task}} = \frac{1}{2L} \sum _{t=1}^{L} \sum _{j=1}^{2} (y_t^{(j)} - {\hat{y}}_t^{(j)})^2, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_t^{(j)}$$\end{document} is the network’s output for memory bit j at time t, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{y}}_t^{(j)}$$\end{document} is the corresponding target value, and L is the sequence length.
Chaotic signal separation task
In this task, the MM receives a mixed input signal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_t= x_t^{(1)}+x_t^{(2)}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{t}^{(1)}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{t}^{(2)}$$\end{document} are the 3-dimensional signals generated by the Lorenz and Rössler systems, respectively, as described in the Appendix. Thus, the input to MM is a single 3-dimensional time series representing the superposition of these two chaotic systems (Fig. 1B).
The MM generates two output time series, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_t^{(1)}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_t^{(2)}$$\end{document} , each of which is a 3-dimensional signal that should approximate the original Lorenz and Rössler signals, respectively.
As with the working memory task, the MM undergoes supervised training, where task loss \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {task}}$$\end{document} is the mean squared error between the outputs and their respective target signals,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L_{\text {task}} = \frac{1}{2L} \sum _{t=1}^{L} \left( \Vert y_t^{(1)} - x_t^{(1)}\Vert ^2 + \Vert y_t^{(2)} - x_t^{(2)}\Vert ^2 \right) , \end{aligned}$$\end{document}where L is the sequence length. During both training and evaluation, the input and target signals are generated by numerically solving differential equations Eqs. (24) and (25) with random initial values.
After training, the task performance is evaluated by calculating the coefficient of determination \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R^2$$\end{document} for each variable in each output signal as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} R^2 = 1-\frac{\sum _{t=1}^{L}\left( s_t-{\hat{s}}_t\right) ^2}{\sum _{t=1}^{L}\left( s_t-{\bar{s}}\right) ^2}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s_t$$\end{document} is a target signal component (either a component of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_t^{(1)}$$\end{document} or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_t^{(2)}$$\end{document} ), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{s}}_t$$\end{document} is the corresponding network output component from either \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_t^{(1)}$$\end{document} or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_t^{(2)}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\bar{s}}$$\end{document} is the mean of the target signal component. This metric quantifies the proportion of variance in the target signal that is captured by the network’s output, with values closer to 1.0 indicating better performance.
Sub model
The sub model (SM) is a feed-forward neural network represented by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_\theta $$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} is the network parameters. The SM serves two key functions: estimating the MI between two neuronal groups in the MM and providing gradients to minimize MI during training. The SM focuses on two neural subgroups from the recurrent layer in the MM, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_t^{(1)}= (h_1,\ldots , h_{N/2})$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_t^{(2)}= (h_{N/2+1},\ldots ,h_N)$$\end{document} , which correspond to the neuron index sets, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(1)}=\{1,\ldots , N/2\}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(2)}=\{(N/2+1),\ldots , N\}$$\end{document} , respectively. The input to the SM consists of these two vectors, each of length N/2. The SM architecture is a feed-forward neural network that produces a scalar value. Details of the SM architecture are provided in the Appendix.
To estimate the MI between the two neural groups indexed by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(1)}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(2)}$$\end{document} , we use the following steps.
- Input signals are fed into the MM to generate a time series of paired internal states \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(h_t^{(1)},h_t^{(2)})$$\end{document} .
- To improve the learning stability, Gaussian noise with zero mean and standard deviation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma _{\text {noise}}$$\end{document} is independently added to each element of these vectors.
- We collect these pairs across time steps and across samples in mini-batches, creating a dataset of sample size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(n_{\text {batch}} \times L)$$\end{document} for the SM, where L is the length of the input signal and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n_{\text {batch}}$$\end{document} is the batch size.
- Following the MINE approach (Eq. (9)), we compute the first term of the MI estimator by feeding the original paired samples, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(h_t^{(1)}, h_t^{(2)})$$\end{document} , to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_\theta $$\end{document} and calculating the average output as
where superscript b indicates the sample index in the mini-batch. 5. For the second term, we create independent samples by shuffling the pairs within the dataset, approximating samples from the product of marginal distributions. We then calculate
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \log \left( \frac{1}{n_{\text {batch}} L} \sum _{b=1}^{n_{\text {batch}}} \sum _{t=1}^{L} e^{T_\theta (h_t^{(1,b)}, h_{u(b,t)}^{(2,c(b,t))})}\right) \end{aligned}$$\end{document}where c(b, t) and u(b, t) are the indices of the randomly permuted samples and time steps, respectively. 6. The estimated MI is the difference between these two terms, following Eq. (9).
L2 regularization
L2 regularization is applied to encourage energetically economical network structures in our model. This method adds a penalty term to the loss function based on the squared magnitude of the weight parameters of
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L_{\text {reg}} = \frac{1}{2} \sum _{w \in {\mathcal {W}}} w^2, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal {W}}$$\end{document} is the set of all weight parameters in the MM.
The inclusion of L2 regularization is important for our study of functional differentiation, which is systematically investigated in the section on chaotic signal separation task results.
Adversarial training process
The training process involves alternating optimization between the SM and the MM (Fig. 3A and B). The process uses an adversarial relationship with respect to MI, where the SM learns to estimate MI better by maximizing it, as represented by Eq. (9), whereas the MM learns to perform the task and minimize the MI. This creates a minimax game similar to generative adversarial networks (Goodfellow et al. 2014), but focused on MI optimization rather than data generation.Fig. 3. Training process of the MM and SM. Training phases A and B are repeated alternately. BP indicates backpropagation. Horizontal hatching patterns indicate which network is being optimized. A SM training. Maximizes MI estimate between neural subgroups using MINE. B MM training. Minimizes total loss including task performance and MI between the two neural subgroups
To ensure stable training dynamics, we implement mini-batch training in which multiple input sequences are processed simultaneously. For the working memory task, each mini-batch contains \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n_{\text {batch}}$$\end{document} randomly generated pulse sequences. For the chaotic signal separation task, each mini-batch consists of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n_{\text {batch}}$$\end{document} pairs of Lorenz and Rössler time series with randomly sampled initial conditions.
Initially, the SM undergoes 100 training iterations to develop a reasonable MI estimator before beginning MM training. Subsequently, we adopt an alternating schedule where the MM is trained once for every 20 training iterations of the SM. This asymmetric schedule ensures that the SM maintains accurate MI estimation throughout training.
The training procedure implements an adversarial relationship between the SM and MM. First, the SM’s parameters, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} , are updated to maximize the estimated MI (Fig. 3A). Input signals from the current mini-batch are fed into the MM to generate sequences of paired internal states \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(h_t^{(1)}, h_t^{(2)})$$\end{document} for the two neural subgroups. Then, the SM processes these paired states to estimate the MI between the two groups using the MINE algorithm (Eq. (9)). Finally, the SM’s parameters are updated using a stochastic gradient descent optimizer to maximize the estimated MI.
Second, for training the MM (Fig. 3B), input signals were fed into by the RNN to produce sequences of paired internal states and task outputs. Then, the total loss for the MM is calculated as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L = L_{\text {task}} + \lambda _{\text {reg}} L_{\text {reg}} + \lambda _I {\hat{I}}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{I}}$$\end{document} is the MI estimated by the SM, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {reg}}$$\end{document} is the weight for the regularization term, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _I$$\end{document} is the weight for the MI minimization. The MM’s parameters are updated using the optimizer to minimize this total loss. The inclusion of the MI term in the MM’s loss function drives the formation of functionally differentiated modules because neural groups develop to minimize their statistical dependencies.
Modularity and separability
We use modularity as a quantitative measure of the extent to which a network can be divided into distinct modules or communities. A higher modularity value indicates that connections within modules are dense whereas connections between modules are sparse (Newman 2018). In our analysis, the group membership of each neuron is predetermined and remains fixed throughout training, as specified in Section MM. The modularity index Q measures how well the learned network structure aligns with this predefined partition into groups \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(1)}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(2)}$$\end{document} . Following the approach by Newman (2004) for weighted networks, we define modularity as follows. Consider a undirected, weighted, and connected network with N nodes divided into C different groups, where group membership of node i is denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s_i$$\end{document} . Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{ij} \ge 0$$\end{document} represent the weight of the connection between nodes i and j, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k_i = \sum _j A_{ij}$$\end{document} be the sum of all connection weights to node i, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{\text {total}} = \frac{1}{2}\sum _{ij} A_{ij}$$\end{document} be the total sum of all connection weights in the network. Modularity Q is then defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} Q = \frac{1}{2A_{\text {total}}}\sum _{ij}{(A_{ij}-\frac{k_{i}k_{j}}{2A_{\text {total}}})\delta (s_i,s_j)}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta (s_i,s_j)$$\end{document} is the Kronecker delta function, equal to 1 if nodes i and j belong to the same group and 0 otherwise. This measure quantifies how much the actual connection pattern deviates from what would be expected in a random network with the same node degrees.
In our analysis, we calculate modularity for two types of matrices to distinguish functional and structural organization as follows.
(1) Functional modularity ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {cor}}$$\end{document} ): Calculated from the correlation matrix between the activities of neurons in the recurrent layer, this measure quantifies the extent to which the dynamics of the network exhibit modular organization. This approach is analogous to functional connectivity analysis commonly used in neuroscience (Friston 2011).
(2) Structural modularity ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {str}}$$\end{document} ): Calculated from the recurrent weight matrix of the recurrent layer, this measure quantifies the extent to which the physical connections in the network form distinct modules.
To compare the two matrices, we first symmetrize the recurrent weight matrix by taking absolute values and adding it to its transpose, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A^{\text {sym}} = |W| + |W^T|$$\end{document} , where W is the original weight matrix. However, the correlation matrix is already symmetric by definition, only requiring the absolute value operation to ensure non-negativity. From both matrices, diagonal terms are removed to focus on the interactions among distinct nodes.
To quantify the degree of functional and structural separation among neural groups, we define three separability measures that assess how distinctly the two groups process inputs and generate outputs. These separability indices (D-measures) differ from modularity indices (Q-measures) in that they specifically evaluate the relationship among neural groups and their input/output connections, rather than measuring general community structure within the network.
Output separability \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {out}}$$\end{document} measures the degree to which each neural group preferentially connects to one of the two output channels. This metric quantifies the structural bias in output connections as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} D_{\text {out}} = \left| \frac{ \sum _{i=1}^{N}\sum _{k=1}^{M} (-1)^{s_{i}} \left( \left| w_{y,ki}^{(2)} \right| - \left| w_{y,ki}^{(1)} \right| \right) }{ \sum _{i=1}^{N}\sum _{k=1}^{M} \left( \left| w_{y,ki}^{(2)} \right| + \left| w_{y,ki}^{(1)} \right| \right) } \right| \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s_i \in \{1,2\}$$\end{document} denotes the group membership of neuron i and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w_{y,ki}^{(j)}$$\end{document} represents the (k, i)-th element of weight matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W^{(j)}_y$$\end{document} connecting the recurrent layer to output j (Eq. (10)). Values approaching 1 indicate strong output specialization, whereas values near 0 suggest equal contribution to both outputs.
The input separability ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {in}}$$\end{document} ) is defined only for the working memory task, where input channels can be grouped naturally according to their target memory bits. This measure quantifies how distinctly each neural group responds to inputs associated with different memory bits as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} D_{\text {in}} = \left| \frac{ \sum _{i=1}^{N} \sum _{k=1}^{2} (-1)^{s_i} \left( \left| w^{\text {in}1}_{ik} \right| - \left| w^{\text {in}2}_{ik} \right| \right) }{ \sum _{i=1}^{N} \sum _{k=1}^{2} \left( \left| w^{\text {in}1}_{ik} \right| + \left| w^{\text {in}2}_{ik} \right| \right) } \right| , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w^{\text {in}j}_{ik}$$\end{document} is the input weight from the k-th channel of the j-th input group (corresponding to memory bit j) to neuron i. Indices \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k \in \{1,2\}$$\end{document} correspond to the ON and OFF channels, respectively, for each memory bit.
The correlation separability ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {cor}}$$\end{document} ) measures functional specialization by quantifying how differently each neural group correlates with the two output channels. Unlike the weight-based measures above, this metric captures the actual functional relationships during network operation as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} D_{\text {cor}} = \left| \frac{ \sum _{i=1}^{N} (-1)^{s_i} \left( \left| c_{i}^{(2)} \right| - \left| c_{i}^{(1)} \right| \right) }{ \sum _{i=1}^{N} \left( \left| c_{i}^{(2)} \right| + \left| c_{i}^{(1)} \right| \right) } \right| , \end{aligned}$$\end{document}where
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} c_i^{(j)} = \frac{1}{M}\sum _{k=1}^{M} \left| \text {corr}(h^i_t, y^{(j)}_{t,k})\right| \end{aligned}$$\end{document}represents the average correlation coefficient between the activity of neuron i and all elements of output vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y^{(j)}_t$$\end{document} .
Working memory task results
Task performance
The network learned to perform the 2-bit working memory task, exhibiting the ability to maintain two independent memory bits across prolonged time intervals and respond appropriately to ON and OFF pulses. Figure 4 illustrates a representative example of the network’s dynamics during the working memory task, showing the close alignment between the network’s output and the target signals for both memory bits. The first 1,000 time steps are a transient period during which the network stabilizes its internal dynamics, and outputs during this period were excluded from task loss calculation to ensure fair performance evaluation.
To quantify task performance systematically, we defined success as achieving correct output states for more than 90% of the time steps. Using this criterion, all 20 independent trials achieved successful performance when trained with MI minimization (100% success rate). Networks trained without MI minimization also achieved successful performance (20/20 trials, 100% success rate). These results indicate that the MI constraint does not impair task learning capability.Fig. 4. Dynamics of the working memory task. The four panels, from top to bottom, show: A input pulses for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {ON}_1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {OFF}_{1}$$\end{document} signals, B network output (solid) compared with target signal (dashed) for memory bit 1, C input pulses for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {ON}_{2}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {OFF}_2$$\end{document} signals, and D network output (solid) compared with target signal (dashed) for memory bit 2. In (B) and (D), the first 1,000 time steps are a transient period during which the outputs are not evaluated for the task loss calculation
Emergence of functional differentiation
Neuron–output correlation analysis
To analyze the emergence of functional differentiation in the network, we examined the correlation patterns between neural activities and output signals. Figure 5 shows scatter plots of correlation coefficients between each neuron’s activity and the two output signals, with coordinates determined by correlations with output signal 1 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c_i^{(1)}$$\end{document} ) and output signal 2 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c_i^{(2)}$$\end{document} ).Fig. 5. Correlation between neural activity and output signals in the working memory task. Each point represents a neuron, with coordinates determined by its absolute correlation with output signal 1 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$|c_i^{(1)}|$$\end{document} ) and output signal 2 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$|c_i^{(2)}|$$\end{document} ). A Results with MI minimization. B Results without MI minimization. Neurons in group 1 are represented by circles and those in group 2 by triangles
When trained with MI minimization (Fig. 5A), neurons in group 1 (circles) and group 2 (triangles) formed distinct clusters near their respective axes, demonstrating clear functional specialization where each neural subgroup primarily maintained one of the two memory bits.
In contrast, without MI minimization (Fig. 5B), both groups were intermixed throughout the correlation space and exhibited mixed selectivity where most neurons respond to both memory bits. This result is particularly notable because the four input channels (ON \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_1$$\end{document} , OFF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_1$$\end{document} , ON \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_2$$\end{document} , OFF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_2$$\end{document} ) are statistically identical, providing no explicit cues about which channels should control which memory bit. Without the MI constraint, the network has no pressure to align the two predefined neural subgroups with the two memory bits, resulting in both groups contributing to both outputs. The clear separation observed with MI minimization (Fig. 5A) therefore demonstrates that the information-theoretic constraint drives the network to discover an organization that aligns predefined groups with the task’s latent structure.
Importantly, both organizational strategies achieved comparable task performance. Networks trained with MI minimization showed mean squared error of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.146 \pm 0.0320$$\end{document} , while networks without MI minimization achieved \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.166 \pm 0.053$$\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p = 0.14$$\end{document} , two-sample t-test; all trials used independent random initializations), indicating no significant performance difference. Furthermore, among networks trained with MI minimization, we found no significant correlation between the final estimated MI values and task loss (Pearson \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r = 0.0046$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p = 0.98$$\end{document} ), suggesting that MI minimization primarily serves as an organizational constraint that shapes network structure rather than directly optimizing task performance.
To quantify this functional specialization pattern, we calculated the correlation separability index \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {cor}}$$\end{document} for both conditions. Networks trained with MI minimization achieved \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {cor}} = 0.623 \pm 0.316$$\end{document} (mean ± standard deviation across 20 independent trials), indicating strong functional differentiation, whereas networks without MI minimization showed significantly lower separability ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {cor}} = 0.072 \pm 0.057$$\end{document} ).
Correlation matrix analysis
We analyzed the functional organization further by examining the pairwise correlations between all neurons in the network. Figure 6 shows the correlation matrix of neural activities, with neurons from groups \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(1)}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(2)}$$\end{document} arranged along both axes. When trained with MI minimization (Fig. 6A), the correlation matrix revealed a striking block-diagonal structure, with high positive correlations between neurons within the same group (two darker blocks along the diagonal) and weak or negative correlations between neurons in different groups.Fig. 6. Correlation matrix of neural activities in the working memory task. Neurons from groups \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(1)}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(2)}$$\end{document} are arranged along both axes. A Results with MI minimization. B Results without MI minimization
This correlation structure indicates that neurons within each group exhibited similar activity patterns while functioning largely independently from neurons in the other group. Functional modularity index \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {cor}}$$\end{document} calculated from this correlation matrix reached a value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.299 \pm 0.153$$\end{document} (mean ± standard deviation over 20 trials), quantifying the strong functional segregation between the two neural subgroups. This high degree of functional modularity confirmed that MI minimization induced the network to develop functionally differentiated modules where each module specializes in processing different aspects of the task. In contrast, no clear block-diagonal structure was observed when the same network was trained without MI minimization (Fig. 6B). In this case, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {cor}}$$\end{document} was \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.0162 \pm 0.012$$\end{document} , indicating a lack of functional modularity.
Structural connectivity analysis
In addition to examining functional differentiation through correlation patterns, we analyzed how the structural connectivity of the network evolved during training with MI minimization. This analysis focused on three aspects of structural connectivity: the recurrent connection weights among neurons within the RNN, the input weights from input channels to RNN neurons, and the output weights connecting the RNN to the output units.
Recurrent weight differentiation
Figure 7A shows the absolute values of the recurrent weights after training, with neurons from both groups ordered along both axes. The recurrent weight matrix exhibited a modular structure, with stronger connections within groups (darker diagonal blocks) and weaker inter-group connections.Fig. 7. Weight matrix differentiation in the working memory task. A Recurrent weight matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W^{\text {rec}}$$\end{document} . B Input weight matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W^{\text {in}}$$\end{document} . C Output weight matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W^{\text {out}}$$\end{document} . In all panels, absolute values of weights are shown, with darker colors indicating stronger connections
Across 20 independent training runs, the structural modularity index showed \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {str}} = 0.114 \pm 0.049$$\end{document} (mean ± standard deviation). Although approximately half the trials developed a clear modular structure, the remainder failed to exhibit pronounced structural organization, resulting in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {str}} < 0.1$$\end{document} . These cases appeared to represent local minima where functional differentiation emerged without corresponding structural reorganization (detailed analysis in the Failure modes of structural differentiation section).
Despite this variability, the consistent emergence of functional modularity demonstrates that MI minimization effectively reduces information sharing between neural subgroups. Additionally, the modest \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {str}}$$\end{document} values compared with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {cor}}$$\end{document} suggest that complete structural segregation is not required for functional specialization.
Input weight differentiation
We analyzed input weight matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W^{\text {in}}$$\end{document} to determine whether the neural subgroups became specialized for processing specific input channels. Figure 7B depicts the input weight strengths, with neurons arranged along the vertical axis and the four input channels (ON \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_1$$\end{document} , OFF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_1$$\end{document} , ON \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_2$$\end{document} , and OFF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_2$$\end{document} ) along the horizontal axis.
Neurons in group \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(1)}$$\end{document} developed stronger connections from input channels related to the first memory bit (ON \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_1$$\end{document} and OFF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_1$$\end{document} ), whereas neurons in group \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(2)}$$\end{document} developed stronger connections from channels related to the second memory bit (ON \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_2$$\end{document} and OFF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$_2$$\end{document} ). Input separation index \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {in}}$$\end{document} reached a value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.623 \pm 0.31$$\end{document} , indicating strong specialization in input processing.
Output weight differentiation
Finally, we examined output weight matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W^{\text {out}}$$\end{document} to determine whether the functionally differentiated neural subgroups developed specialized output projections. Figure 7C shows the absolute values of output weights, with neurons from groups \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(1)}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(2)}$$\end{document} arranged along the horizontal axis and the two output units along the vertical axis.
A clear division of specialization emerged in the output connectivity: neurons in group \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(1)}$$\end{document} formed strong projections to output unit 1 (responsible for the first memory bit) and weak projections to output unit 2, whereas neurons in group \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(2)}$$\end{document} showed the opposite pattern. This structural specialization was quantified using output separation index \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {out}}$$\end{document} , which reached a value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.526 \pm 0.261$$\end{document} by the end of training, indicating a high degree of output weight specialization.
Failure modes of structural differentiation
Although MI minimization consistently induced functional differentiation, structural modularity emergence was more variable. In 10 out of 20 training runs, the recurrent weight matrix failed to develop a clear modular structure ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {str}} < 0.1$$\end{document} ), despite achieving functional specialization.
Figure 8 shows a representative failed case. The weight matrices (Fig. 8C–E) reveal an asymmetric solution where group 2 neurons dominated both input processing and output generation, whereas group 1 connections were largely eliminated. The neuron–output correlation analysis (Fig. 8A) shows that although group 2 neurons exhibited stronger correlations with both of the two output signals, group 1 neurons had weak or negligible correlations. Furthermore, the correlation matrix (Fig. 8B) shows that group 1 neurons were not well-correlated with each other, indicating that they were not functioning as a coherent module. Because of noise, group 1 neurons exhibited higher random activity, leading to reduced MI between the groups.Fig. 8. Analysis of a failed trial in the working memory task. A Correlation between neurons and output signals. B Correlation matrix. C–E Weight matrices
This asymmetric pattern suggests that MI minimization can be satisfied through functional silencing of one group rather than balanced specialization. These cases represent suboptimal local minima where the optimization constraints are satisfied without achieving the intended modular architecture.
Time course of modularity development
A key finding in our study is that functional differentiation precedes structural differentiation during training. We analyzed the 10 trials (50%) that achieved robust structural differentiation ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {cor}} > 0.1$$\end{document} ) to examine this temporal relationship.Fig. 9. Time course of modularity development in the working memory task. A Evolution of the functional modularity index ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {cor}}$$\end{document} , solid line) and structural modularity index ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {str}}$$\end{document} , dashed line). B Evolution of the correlation-based separation index ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {cor}}$$\end{document} , solid line), input weight separation index ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {in}}$$\end{document} , dashed line), and output weight separation index ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {out}}$$\end{document} , dotted line). Bold lines represent mean values across 10 successful trials
Figure 9 reveals distinct temporal dynamics. Functional modularity ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {cor}}$$\end{document} ) rises rapidly within the first 300 training steps, whereas structural modularity ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {str}}$$\end{document} ) increases more gradually. Similarly, correlation-based separation ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {cor}}$$\end{document} ) develops faster than both the input and output weight separation indices.
This temporal precedence was consistent across different initializations, indicating that neural activity patterns adapt first to task requirements, establishing functional specialization before significant synaptic reorganization occurs.
Chaotic signal separation task results
Task performance
The GRU network learned to separate the mixed chaotic signals, achieving high reconstruction accuracy for both the Lorenz and Rössler time series. Figure 10 shows representative examples of the network’s performance.Fig. 10. Signal separation performance for chaotic time series. A Separation of Lorenz system components (x, y, z). B Rössler system components. Network outputs are shown as solid blue lines and target signals are shown as dashed red lines
Quantitative evaluation using the coefficient of determination ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R^2$$\end{document} ) showed excellent performance across all variables. The average \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R^2$$\end{document} value across all six output variables (three for the Lorenz system and three for the Rössler system) was \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.973 \pm 0.013$$\end{document} (mean ± standard deviation over 20 trials). This high accuracy demonstrates that the network learned the complex nonlinear dynamics required for signal separation while maintaining the constraint of MI minimization.
Functional connectivity analysis
To evaluate whether MI minimization induced functional specialization in the network, we analyzed activity correlations following the same approach used for the working memory task.
Neuron–output correlation analysis
We examined the correlation patterns between individual neurons’ activities and the network outputs to characterize functional specialization. For each neuron i in the GRU layer, we calculated the mean absolute correlation coefficients with each output system following Eq. (22).
Figure 11 shows a scatter plot of these correlation values, with each point representing a single neuron. Neurons in group 1 (circles) cluster near the vertical axis, indicating strong correlation with the Rössler output and weak correlation with the Lorenz output. Conversely, neurons in group 2 (triangles) cluster near the horizontal axis, showing the opposite pattern.Fig. 11. Correlation between GRU neuron activities and output signals. Each point represents a neuron, with coordinates determined by its mean correlation with the Lorenz reconstruction output (horizontal axis) and Rössler reconstruction output (vertical axis). Circles represent neurons from group \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(1)}$$\end{document} , and triangles represent neurons from group \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(2)}$$\end{document}
This clear separation demonstrates functional specialization comparable to the working memory task, indicating strong functional differentiation between the neural subgroups. In this case, the average of the correlation separability index, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {cor}}$$\end{document} , reached \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.494 \pm 0.285$$\end{document} (mean ± standard deviation over 20 trials). The variance among trials is higher than in the working memory task because the network occasionally failed to develop clear specialization where each neural module corresponds perfectly to all three components (x, y, z) of either the Lorenz or Rössler systems. In some cases, the 3 + 3 dimensional output mapping did not align neatly with the 3/3 division between the two neural groups, leading to lower \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {cor}}$$\end{document} values.
Correlation matrix analysis
We analyzed the correlation structure between neural activities to assess functional modularity. Figure 12 displays the correlation matrix between all pairs of neurons in the GRU layer.Fig. 12. Correlation matrix of neural activities in the signal separation task. Neurons from groups \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(1)}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(2)}$$\end{document} are arranged along both axes
When trained with MI minimization, the correlation matrix exhibited a pronounced block-diagonal structure, with high positive correlations among neurons within the same group (two darker blocks along the diagonal) and weak or negative correlations among neurons in different groups. The functional modularity index calculated from this matrix was \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {cor}} = 0.375 \pm 0.090$$\end{document} , confirming that MI minimization effectively induced the emergence of functionally differentiated modules in the network.
Structural connectivity analysis
Output weight specialization
Figure 13 shows the absolute values of the output weight matrix, with neurons from groups \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(1)}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(2)}$$\end{document} arranged along the horizontal axis and the six output targets, consisting of Lorenz and Rössler components, along the vertical axis.
In this example, a visible pattern of specialization emerged: neurons in group \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(1)}$$\end{document} (left half) developed strong projections to the Rössler reconstruction output while maintaining weak projections to the Lorenz reconstruction output, with neurons in group \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(2)}$$\end{document} (right half) showing the opposite pattern.Fig. 13. Output weight specialization in the chaotic signal separation task. The heatmap shows the absolute values of output weights connecting the GRU neurons (horizontal axis) to the two output targets (vertical axis). A distinguishable specialization is evident with group \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(1)}$$\end{document} neurons (left) mainly connecting to the Rössler output and group \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(2)}$$\end{document} neurons (right) mainly connecting to the Lorenz output
This specialization was quantified using the output separation index, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {out}}$$\end{document} (Eq. (19)). The trained network achieved \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {out}} = 0.173 \pm 0.151$$\end{document} , compared with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {out}} = 0.021 \pm 0.015$$\end{document} for networks trained without MI minimization, indicating moderate but significant ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p<0.0001$$\end{document} , two-sample t-test; all trials used independent random initializations) output specialization. The variance in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {out}}$$\end{document} across trials is also higher than in the working memory task, reflecting incomplete specialization in some cases, as described in the Neuron–output correlation analysis section.
Recurrent weight modularity
Fig. 14 shows the symmetrized recurrent weight matrix, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$U_{\text {sym}} = |U| + |U|^T$$\end{document} , where U is the original recurrent weight matrix from the GRU (Eq. (3)).
The matrix revealed a modular structure with subtly stronger connections within groups (slightly darker blocks along the diagonal) compared with connections between groups.Fig. 14. Recurrent weight modularity in the chaotic signal separation task. The heatmap shows the symmetrized recurrent weight matrix with neurons from groups \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(1)}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(2)}$$\end{document} arranged along both axes. The block-diagonal structure indicates stronger connections within groups (darker diagonal blocks) compared with weaker connections among groups
The structural modularity was quantified using modularity index \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {str}}$$\end{document} , which achieved a value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.088 \pm 0.035$$\end{document} . Although this value was lower than the functional modularity observed in correlation patterns, it was significantly higher than that for the networks trained without MI minimization ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {str}} = -0.0048 \pm 0.0056$$\end{document} ; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p<0.0001$$\end{document} , t-test), demonstrating that MI minimization influences both the functional dynamics and the underlying structural connectivity of the network.
Community detection validation
To validate the correspondence of the observed modularity with the predefined groups, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{g^{(1)}, g^{(2)}\}$$\end{document} , we used community detection algorithms to identify the optimal partition that maximizes modularity without prior knowledge of group assignments.
Using the fast greedy algorithm (Clauset et al. 2004), we identified the community structure that maximizes modularity in the correlation matrix. The similarity between this data-driven partition and our predefined groups was evaluated using normalized MI as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} I_n = \frac{I(G; C)}{\frac{1}{2}[H(G) + H(C)]} \end{aligned}$$\end{document}where G is the predefined partition \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{g^{(1)}, g^{(2)}\}$$\end{document} , C is the community detection result, I(G; C) is the MI between the two partitions, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H(\cdot )$$\end{document} is entropy (Newman 2018).
Specifically, for each neuron i, we record its community membership in both partitions: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g_k$$\end{document} for the predefined partition ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k \in \{1,2\}$$\end{document} ) and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c_j$$\end{document} for the detected partition ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j \in \{1,2,\ldots \}$$\end{document} ). From the set of tuples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(i, c_j, g_k)$$\end{document} for all N neurons, we compute empirical probabilities by counting: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P(c_j) = n_{c_j}/N$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P(g_k) = n_{g_k}/N$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P(c_j, g_k) = n_{c_j,g_k}/N$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n_{c_j}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n_{g_k}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n_{c_j,g_k}$$\end{document} are the corresponding neuron counts. The entropy H(C), H(G), and mutual information I(G; C) are then calculated from these probabilities using their standard definitions for discrete variables. The normalized MI ranges from 0 (independent partitions) to 1 (identical partitions).
For networks trained with MINE, the normalized MI was \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$I_n = 0.926 \pm 0.224$$\end{document} , indicating almost perfect agreement between the optimal community structure and our predefined groups. In contrast, networks trained without MINE achieved only \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$I_n = 0.018 \pm 0.014$$\end{document} , demonstrating that MI minimization is crucial for establishing the modular organization.
Figure 15 illustrates this validation graphically, showing that the network consisted of two strongly-connected modules. The network layout was generated using a spring-based force-directed algorithm, where nodes with stronger correlations were positioned closer together. This validation confirmed that MI minimization increased modularity values and specifically drove the formation of the intended functional architecture, rather than arbitrary clustering patterns.Fig. 15. Community structure validation for networks trained with MI minimization. Node shapes indicate which group the neuron belonged to (triangles: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(1)}$$\end{document} , circles: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(2)}$$\end{document} ), and the node color (light blue or dark red) indicates the community membership estimated by the community detection algorithm. In this case, the community detection algorithm identified the two groups, with all neurons in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(1)}$$\end{document} assigned to one community and all neurons in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g^{(2)}$$\end{document} assigned to another. Edges are drawn to indicate correlations, with only the top 50% strongest correlations shown for clarity
Effect of L2 regularization on network structure
Our analysis revealed that L2 regularization is crucial in determining whether functional differentiation translates into structural reorganization. We compared networks trained with and without L2 regularization to isolate its effects on modular structure formation.
With L2 regularization, networks achieved significant output separation ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {out}}=0.173 \pm 0.151$$\end{document} ) and structural modularity ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {str}}=0.088 \pm 0.035$$\end{document} ), as shown in the Structural connectivity analysis section. In contrast, networks trained without L2 regularization showed weaker structural organization ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {out}} = 0.041 \pm 0.032$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {str}} = 0.013 \pm 0.006$$\end{document} ). Notably, functional modularity and correlation separability remained relatively high, even without L2 regularization ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {cor}} = 0.380 \pm 0.075$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {cor}} = 0.460 \pm 0.285$$\end{document} ), suggesting that MI minimization alone is sufficient to induce functional specialization.
This pattern suggests that MI minimization drives functional organization through activity patterns, whereas the translation into structural reorganization requires additional sparsity constraints. L2 regularization encourages sparse connectivity patterns that reinforce the functionally established modules, bridging the gap between functional and structural differentiation.
Temporal development of modularity
Similar to the working memory task, functional differentiation preceded structural reorganization during training. Figure 16A tracks the evolution of both modularity indices. Functional modularity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {cor}}$$\end{document} rose rapidly in the earlier training iterations, whereas structural modularity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {str}}$$\end{document} exhibited a more gradual increase. The separation indices (Fig. 16B) showed similar temporal patterns, with correlation-based separation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {cor}}$$\end{document} developing earlier than output weight separation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {out}}$$\end{document} . However, the variance across trials was larger than for modularity indices, reflecting the occasional difficulty in achieving complete specialization in separating the Lorenz and Rössler components.Fig. 16. Time course of modularity and separability development in the chaotic signal separation task. A Development of functional modularity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {cor}}$$\end{document} (solid line) and structural modularity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{\text {str}}$$\end{document} (dashed line) over training iterations. B Development of correlation-based separation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {cor}}$$\end{document} (solid line) and output weight separation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {out}}$$\end{document} (dotted line). In both panels, bold lines represent mean values across 20 trials. The horizontal axis represents the number of training iterations, with one unit corresponding to 20 MM training cycles
Although the trial variance was larger than in the working memory task, the overall temporal pattern mirrored the working memory task findings, confirming that the precedence of functional over structural organization is a general principle in networks trained with MI minimization constraints. The consistency across different tasks strengthens the hypothesis that information-theoretic constraints first shape neural activity patterns, which subsequently influence synaptic connectivity reorganization. This finding has important implications for understanding how functional and structural brain networks might co-evolve during development and learning.
Discussion
This study demonstrates that minimizing MI among neural subgroups induces functionally differentiated structures in RNNs. Our key findings provide new insights into how information-theoretic constraints can drive neural organization.
Main findings
Networks trained with MI minimization achieved high task performance while developing distinct functional modules. Three key patterns emerged consistently. (1) Functional modularity exceeded structural modularity, indicating that activity-based organization is more pronounced than connectivity-based organization. (2) Functional modules emerged earlier than structural modules during training, with correlation patterns developing within earlier iterations compared with later iterations for weight reorganization. (3) L2 regularization increased robust structural modularity, suggesting that efficiency constraints are crucial in translating functional demands into structural organization.
It is important to clarify our use of the term "emergence" in describing functional differentiation. Our approach involves a top-down constraint (MI minimization) imposed at the system level, which might seem inconsistent with the notion of bottom-up emergence. However, we follow the framework of "self-organization with constraints" proposed by Tsuda et al. (Tsuda et al. 2016, 2022), where system-wide constraints guide the spontaneous organization of internal components. In this framework, emergence refers to the process by which functional modules and specialized connectivity patterns arise through local synaptic modifications under global constraints, rather than being explicitly predetermined. The specific pattern of functional differentiation–which neurons specialize for which functions–is not specified by the constraint itself but emerges through the optimization process. This perspective aligns with developmental neuroscience, where genetic and activity-dependent constraints shape neural organization without fully specifying the final functional architecture (Katz and Shatz 1996).
Biological relevance
The observation that functional modularity exceeds structural modularity is interesting in relation to neurodevelopmental research, where the relationship between functional and structural connectivity remains an area of active investigation (Friston 1994; Fujii et al. 1996; Bullmore and Sporns 2009; Hayashi et al. 2021). The temporal precedence of functional over structural modularity observed in our networks aligns with neurodevelopmental processes where spontaneous activity patterns emerge before synaptic maturation (Katz and Shatz 1996). Our results suggest that information-theoretic constraints could provide organizing principles that shape early activity patterns, which subsequently guide structural refinement through activity-dependent mechanisms.
The requirement for efficiency constraints (modeled by L2 regularization) also has biological parallels. Metabolic pressures in the brain favor sparse connectivity patterns (Laughlin and Sejnowski 2003), and developmental pruning eliminates unnecessary connections while strengthening functional ones (Huttenlocher and Dabholkar 1997). Our findings indicate that both information optimization and efficiency constraints are necessary for complete functional differentiation.
An important question is how MI minimization between neural subgroups might be implemented biologically. In our model, MI is estimated using an auxiliary network via MINE, which may not have a direct biological counterpart. However, biologically plausible approximations may exist. The computation of correlations between neural activities, which is central to MI estimation, is implemented through synaptic plasticity mechanisms such as anti-Hebbian learning (Hebb 1949) and spatio-temporal learning rule, which was proposed by Tsukada (Tsukada et al. 1996; Tsukada and Pan 2005). These local learning rules can detect and modify statistical dependencies without explicit MI computation. Second, the brain implements mechanisms for reducing statistical dependencies between representations, such as pattern separation (Rolls 2013) and sensory decorrelation (Barlow 1961). While no specific brain region is known to explicitly compute MI between neural subgroups, the existence of correlation-based plasticity mechanisms suggests that biologically plausible approximations may be feasible. Our approach can be viewed as implementing a top-down organizational constraint analogous to developmental signals that guide circuit formation (Katz and Shatz 1996).
Computational implications
From a machine-learning perspective, our method offers a principled approach for inducing modular architectures that maintain high task performance. The ability to develop functionally specialized modules suggests applications in continual learning (Veniat et al. 2021) and multi-task scenarios (Yang et al. 2019), where modules could be reused across related tasks or protected from catastrophic forgetting (Serra et al. 2018).
The temporal development pattern we observed of functional followed by structural specialization suggests training strategies where initial phases focus on establishing functional specialization through information-theoretic constraints, followed by structural optimization through sparsity regularization.
Limitations and future directions
Our analysis focused on predefined two-group divisions with relatively simple tasks. For the working memory task, while the task has two independent memory channels, our results demonstrate that MI minimization is necessary to drive functional differentiation: without this constraint, networks develop mixed selectivity despite the task structure (Fig. 5B). Nevertheless, investigating MI minimization on tasks requiring stronger inter-module cooperation would provide additional evidence for the generality of our approach.
An important consideration is the relationship between modular organization and mixed selectivity. Our results show that both strategies achieved comparable task performance, and the absence of significant correlation between MI values and task performance confirms that MI minimization primarily serves as an organizational principle rather than a direct performance optimizer. This aligns with growing recognition in neuroscience that mixed selectivity–where individual neurons encode multiple task variables–can be advantageous for flexible computation and generalization (Rigotti et al. 2013). The optimal balance between modular specialization and mixed selectivity likely depends on factors we did not systematically investigate, including robustness, generalization to novel task variants, and continual learning capabilities (Serra et al. 2018; Yang et al. 2019). Understanding when biological neural systems employ each organizational strategy, and how information-theoretic constraints interact with these principles, represents an important direction for future research.
Future research should investigate optimal group sizes using adaptive partitioning methods, test scalability on hierarchical tasks that are more complex, and systematically explore the relationship between MI minimization strength and differentiation degree. Additionally, extending our approach to spiking neural networks would strengthen biological relevance and enable direct comparisons with neuroscientific data. A particularly promising direction involves extending our approach to multiple modules ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$>2$$\end{document} ). Current pairwise MI minimization between two groups could be generalized to minimize MI among K neural subgroups simultaneously. This generalization would require developing efficient optimization algorithms that can handle the combinatorial complexity of multi-group MI estimation. These extensions would enable the modeling of more realistic neural architectures with multiple specialized functional areas, better reflecting the hierarchical organization observed in biological neural systems (Sporns 2016).
Conclusions
Our results demonstrate that information-theoretic constraints can serve as fundamental organizing principles in neural systems, driving the emergence of modular architectures that balance specialization with integration. The temporal precedence of functional over structural organization and the role of efficiency constraints provide insights into biological neural development and the design of artificial neural architectures.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Belghazi MI, Baratin A, Rajeshwar S et al (2018) Mutual information neural estimation. In: Dy J, Krause A (eds) Proceedings of the 35th International conference on machine learning. Proceedings of machine learning research vol 80.PMLR, pp 531–540, https://proceedings.mlr.press/v 80/belghazi 18a.html
- 2Goodfellow IJ, Pouget-Abadie J, Mirza M, et al (2014) Generative adversarial nets. In: Ghahramani Z, Welling M, Cortes C, et al (eds) Advances in neural information processing systems, vol 27. Curran Associates, Inc., https://proceedings.neurips.cc/paper_files/paper/2014/file/f 033ed 80deb 0234979 a 61f 95710 dbe 25-Paper.pdf
- 3Kashtan N, Alon U (2005) Spontaneous evolution of modularity and network motifs. Proc Natl Acad Sci USA 102:13773–10.1073/pnas.050361010210.1073/pnas.0503610102 PMC 123654116174729 · doi ↗ · pubmed ↗
- 4Serra J, Suris D, Miron M, et al (2018) Overcoming catastrophic forgetting with hard attention to the task. In: Dy J, Krause A (eds) Proceedings of the 35th International conference on machine learning, proceedings of machine learning research, vol 80. PMLR, pp 4548–4557, https://proceedings.mlr.press/v 80/serra 18a.html