Six complete genome sequences of a putative nitrogen-fixing bacteria from the genus Agarivorans sp. isolated from the seagrass, Zostera marina
Jackie Badillo, Diane Brache-Smith, E. Maggie Sogin

TL;DR
Six complete genomes of a potential nitrogen-fixing bacteria from seagrass roots are reported, aiding future research on their role in plant growth.
Contribution
The novelty lies in providing six complete genome sequences of Agarivorans sp. from seagrass, linked to nitrogen fixation.
Findings
Six complete genome sequences of Agarivorans sp. were obtained from Zostera marina.
The genomes may help study the bacteria's role in seagrass growth and nitrogen fixation.
The bacteria were isolated from the root endosphere and rhizoplane of seagrass.
Abstract
We report six complete genome sequences of Agarivorans sp. isolated from Zostera marina’s root endosphere and rhizoplane. The genomes will facilitate future studies investigating the role of these putative nitrogen-fixing bacteria in supporting seagrass growth and metabolism.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
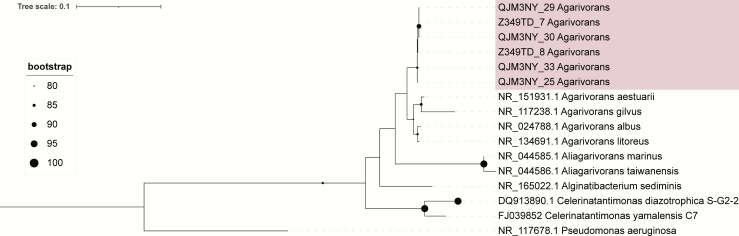 Fig 1
Fig 1| Isolate ID | Nr Reads | rN50 | ANI % | Genome size (mbp) | GC Content (%) | Genome Coverage | Completeness (%) | Contamination (%) | Nr. Genes | RNA | CDS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Z349TD_7 | 97,423 | 10,936 | 80 | 5.06 | 44.8 | 75.7 | 100 | 1.17 | 4614 | 118 | 4496 |
| QJM3NY_30 | 60,470 | 16,748 | 80 | 5.06 | 44.8 | 66.7 | 100 | 1.17 | 4613 | 118 | 4495 |
| QJM3NY_29 | 171,197 | 9,539 | 80.4 | 5.06 | 44.8 | 119.5 | 100 | 1.17 | 4612 | 118 | 4494 |
| QJM3NY_33 | 169,323 | 11,428 | 79.9 | 5.08 | 44.97 | 178.6 | 100 | 0.99 | 4605 | 118 | 4487 |
| QJM3NY_25 | 83,619 | 9,484 | 80 | 4.99 | 44.98 | 68.2 | 100 | 0.99 | 4578 | 119 | 4459 |
| Z349TD_8 | 115,399 | 12,086 | 79.9 | 5.03 | 44.91 | 129.4 | 100 | 0.99 | 4550 | 118 | 4432 |
- —National Science Foundation Graduate Research Fellowship Program
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMarine and coastal plant biology · Microbial Community Ecology and Physiology · Coastal wetland ecosystem dynamics
ANNOUNCEMENT
The seagrass, Zostera marina, occurs throughout coastal regions in the Northern Hemisphere and contributes to marine carbon sequestration (1). The microbial communities associated with Z. marina are thought to be crucial for supporting seagrass ecosystems and carbon burial. Here, we report on complete genome sequences of six strains of Agarivorans sp. isolated from Z. marina’s rhizoplane and endosphere. Agarivorans sp. is known to degrade complex polysaccharides and is predicted to play a role in nutrient cycling (2). These genomes will enable investigations into the potential role of Agarivorans sp. in biogeochemical cycling in Z. marina meadows.
Individual Z. marina plants were collected from Bodega Bay, CA (38.333446°N, 123.058785°W). The adhering sediments were removed from the roots. After which, we collected the rhizoplane inoculum by sonicating the roots in 10 mL of sterile filtered artificial seawater. The roots were then macerated and sonicated to collect inoculum from the endosphere. The slurries were serially diluted in sterile artificial seawater and plated onto agar plates supplemented with 5% v/v seagrass metabolite extract. Plates were incubated at 14°C for 30 days, after which single colonies were picked and subcultured three times on marine broth (MilliporeSigma) plates to ensure purity. Overnight cultures in marine broth were prepared prior to DNA extraction using Quick-DNA Miniprep Plus Kit (ZymoResearch). Extracted DNA was sent to Plasmidsaurus (Eugene, OR) for Nanopore sequencing using the ONT Ligation sequencing kit v.14 (SQK-LSK114) library preparation kit without size selection or fragmentation according to the manufacturer’s instructions. The library was sequenced on a PromethION 24 device using R10.4.1 flow cell chemistry.
Default parameters were used for all software described in this study unless otherwise specified. Base calling was completed using Guppy (v.6.1.5). Quality control was conducted with Filtlong (v.0.2.1) using the flags –min length 1000 –keep percent 90 to remove reads shorter than 1,000 bp and retain the top 90% of reads based on quality (3). Autocycler (v.0.2.1) (4) generated a consensus de novo assembly using CANU (v.2.4) (5), flye (v.2.9.5) (6), miniasm (v.0.3)(7), necat (v.0.0.1)(8), nextdenovo (v.2.5.2) (9), and raven (v.1.8.3) (10) and reported that all six genomes assembled into a single, circular contig. The circular assembly graph was manually inspected and subsequently reoriented to the origin of replication using Dnaapler (v.1.2.0) (11).
Genome analysis was conducted in Kbase (12). Using Quast (v.4.4), genome size was estimated to be between 4.99 and 5.08 Mb, average G+C content 44.8%, and an average of 106-fold genome coverage (Table 1) (13). The lineage_wf pipeline in CheckM (v.1.0.18) estimated each genome to be 100% complete with <1.2% contamination (14). GTDB-Tk (v.2.3.2) classified all isolates within the Agarivorans genus, with average nucleotide identity (ANI) values between 79.99 and 80.41% to the closest reference genome (GenBank GCF023238625.1) (15). A phylogenetic tree on the 16S rRNA gene confirmed that the isolates belonged to the Agarivorans genus (Fig. 1). Each genome was annotated using NCBI’s PGAP pipeline (v.6.10)(16), which resulted in 4,432–4,496 coding domain sequences per genome. All six genomes contained the genes needed for nitrogen fixation (i.e., nifHDK).
16S rRNA phylogenetic tree groups the isolates within the Agarivorans genus. The tree was calculated using extracted 16S rRNA sequences from each genome and NCBI sequences with >90% similarity to the query sequence. The tree was built from an MAFFT alignment in IQ-TREE (17, 18).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Fourqurean JW, Duarte CM, Kennedy H, Marbà N, Holmer M, Mateo MA, Apostolaki ET, Kendrick GA, Krause-Jensen D, Mc Glathery KJ, Serrano O. 2012. Seagrass ecosystems as a globally significant carbon stock. Nature Geosci 5:505–509. doi:10.1038/ngeo 1477 · doi ↗
- 2Liu N, Kivenson V, Peng X, Cui Z, Lankiewicz TS, Gosselin KM, English CJ, Blair EM, O’Malley MA, Valentine DL. 2024. Pontiella agarivorans sp. nov., a novel marine anaerobic bacterium capable of degrading macroalgal polysaccharides and fixing nitrogen. Appl Environ Microbiol 90:e 0091423. doi:10.1128/aem.00914-2338265213 PMC 10880615 · doi ↗ · pubmed ↗
- 3Wick RR. 2021. Filtlong. Available from: https://github.com/rrwick/Filtlong
- 4Wick RR, Howden BP, Stinear TP. 2025. Autocycler: long-read consensus assembly for bacterial genomes. bio Rxiv. doi:10.1093/bioinformatics/btaf 474PMC 1246005540875535 · doi ↗ · pubmed ↗
- 5Koren S, Walenz BP, Berlin K, Miller JR, Bergman NH, Phillippy AM. 2017. CANU: scalable and accurate long-read assembly via adaptive k-mer weighting and repeat separation. Genome Res 27:722–736. doi:10.1101/gr.215087.11628298431 PMC 5411767 · doi ↗ · pubmed ↗
- 6Kolmogorov M, Yuan J, Lin Y, Pevzner PA. 2019. Assembly of long, error-prone reads using repeat graphs. Nat Biotechnol 37:540–546. doi:10.1038/s 41587-019-0072-830936562 · doi ↗ · pubmed ↗
- 7Li H. 2016. Minimap and miniasm: fast mapping and de novo assembly for noisy long sequences. Bioinformatics 32:2103–2110. doi:10.1093/bioinformatics/btw 15227153593 PMC 4937194 · doi ↗ · pubmed ↗
- 8Chen Y, Nie F, Xie S-Q, Zheng Y-F, Dai Q, Bray T, Wang Y-X, Xing J-F, Huang Z-J, Wang D-P, He L-J, Luo F, Wang J-X, Liu Y-Z, Xiao C-L. 2021. Efficient assembly of nanopore reads via highly accurate and intact error correction. Nat Commun 12:60. doi:10.1038/s 41467-020-20236-733397900 PMC 7782737 · doi ↗ · pubmed ↗