STCCA: Spatial–Temporal Coupled Cross-Attention Through Hierarchical Network for EEG-Based Speech Recognition
Liang Dong, Hengyi Shao, Lin Zhang, Lei Li

TL;DR
This paper introduces a new hierarchical network for EEG-based speech recognition that improves accuracy by better capturing spatial and temporal feature relationships.
Contribution
A novel spatial–temporal coupled cross-attention mechanism (STCCA) is proposed to enhance EEG-based speech recognition.
Findings
STCCA achieved 45.45% accuracy on one EEG speech dataset, outperforming existing models.
The model showed improvements of up to 3.98% on another dataset compared to baseline methods.
The hierarchical design with CCA fusion module effectively captures cross-feature interactions.
Abstract
Speech recognition based on Electroencephalogram (EEG) has attracted considerable attention due to its potential in communication and rehabilitation. Existing methods typically process spatial and temporal features with sequential, parallel, or constrained feature fusion strategies. However, the intricate cross-relationships between spatial and temporal features remain underexplored. To address these limitations, we propose a spatial–temporal coupled cross-attention mechanism through a hierarchical network, named STCCA. The proposed STCCA consists of three key components: local feature extraction module (LFEM), coupled cross-attention (CCA) fusion module, and global feature extraction module (GFEM). The LFEM employs CNNs to extract local temporal and spatial features, while the CCA fusion module leverages a dual-directional attention mechanism to establish deep interactions between…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
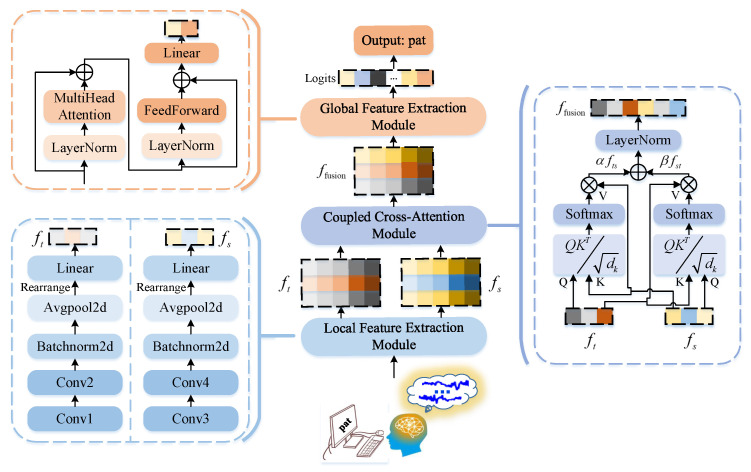 Figure 1
Figure 1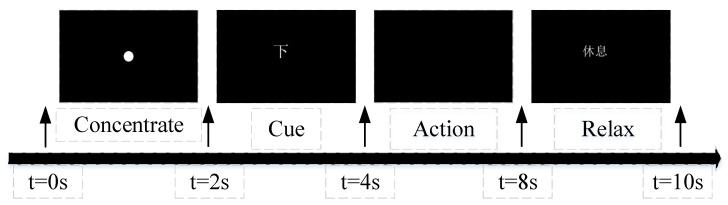 Figure 2
Figure 2 Figure 3
Figure 3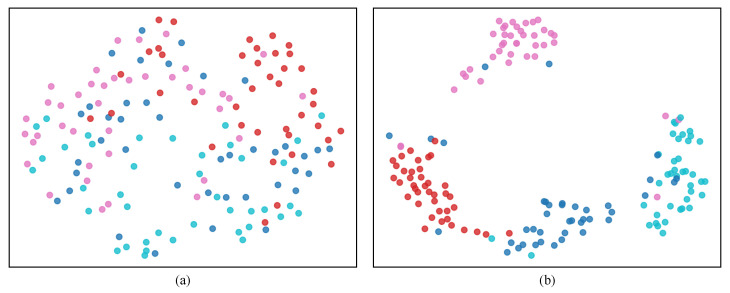 Figure 4
Figure 4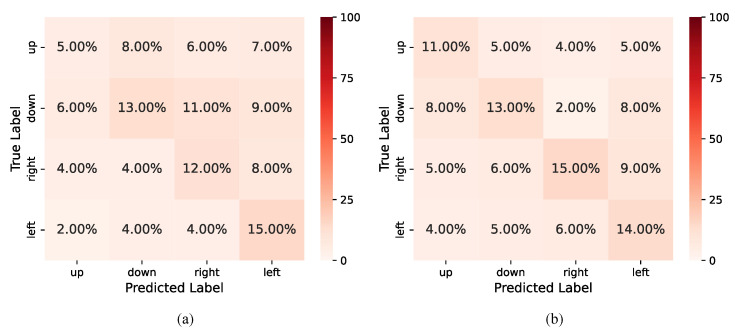 Figure 5
Figure 5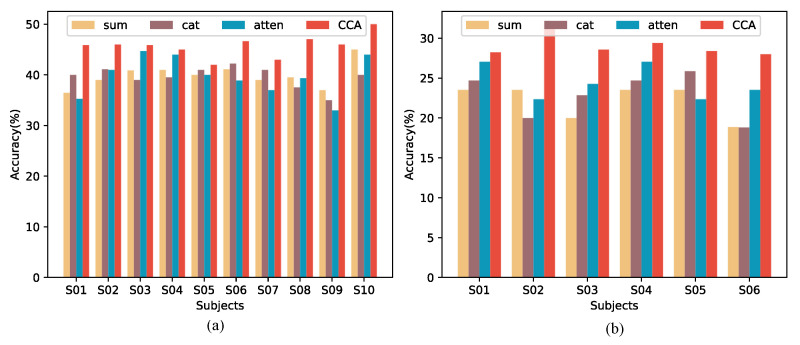 Figure 6
Figure 6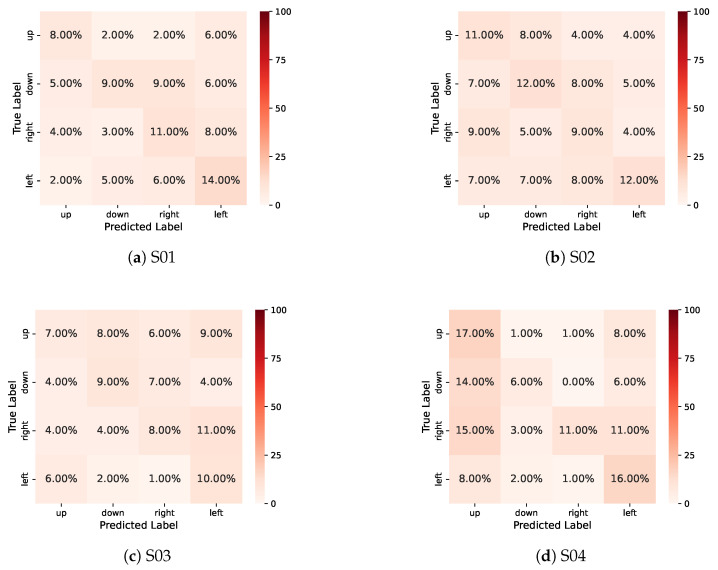 Figure 7
Figure 7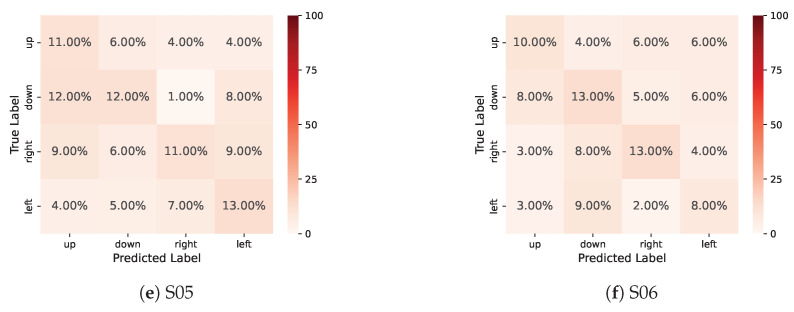 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSpeech and Audio Processing · Speech Recognition and Synthesis · Neural Networks and Applications