Crosstalk Suppression in a Multi-Channel, Multi-Speaker System Using Acoustic Vector Sensors
Grzegorz Szwoch

TL;DR
This paper introduces a method to improve speech recognition in multi-speaker environments by suppressing crosstalk using acoustic vector sensors.
Contribution
A novel crosstalk suppression algorithm using acoustic vector sensors and source separation for multi-speaker speech recognition.
Findings
The algorithm achieved an SI-SDR improvement of 7.54 dB with source separation.
Without source separation, the SI-SDR improvement was 19.53 dB.
Abstract
Automatic speech recognition in a scenario with multiple speakers in a reverberant space, such as a small courtroom, often requires multiple sensors. This leads to a problem of crosstalk that must be removed before the speech-to-text transcription is performed. This paper presents an algorithm intended for application in multi-speaker scenarios requiring speech-to-text transcription, such as court sessions or conferences. The proposed method uses Acoustic Vector Sensors to acquire audio streams. Speaker detection is performed using statistical analysis of the direction of arrival. This information is then used to perform source separation. Next, speakers’ activity in each channel is analyzed, and signal fragments containing direct speech and crosstalk are identified. Crosstalk is then suppressed using a dynamic gain processor, and the resulting audio streams may be passed to a speech…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1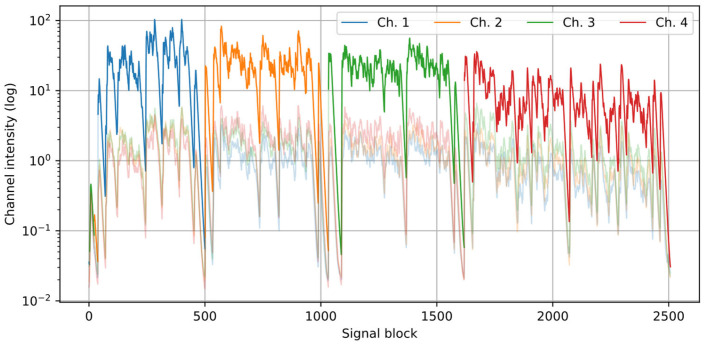 Figure 2
Figure 2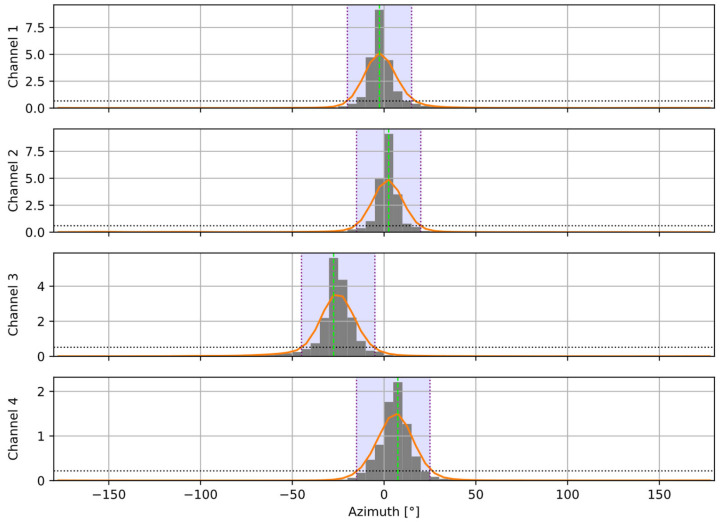 Figure 3
Figure 3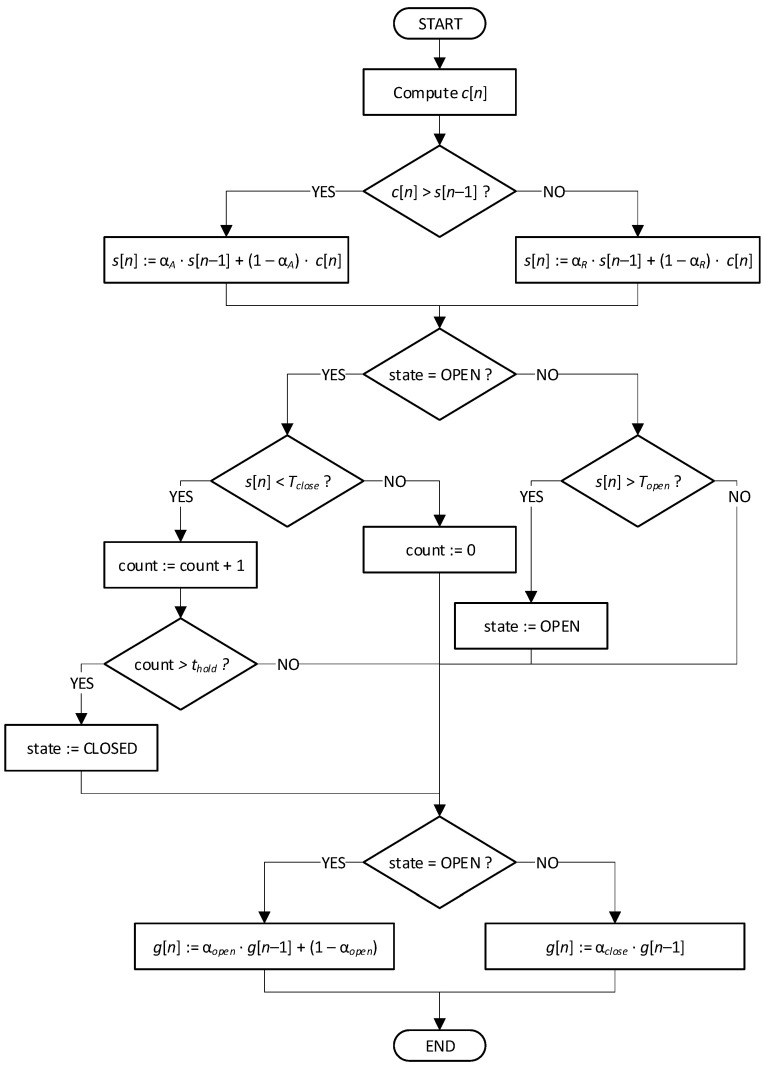 Figure 4
Figure 4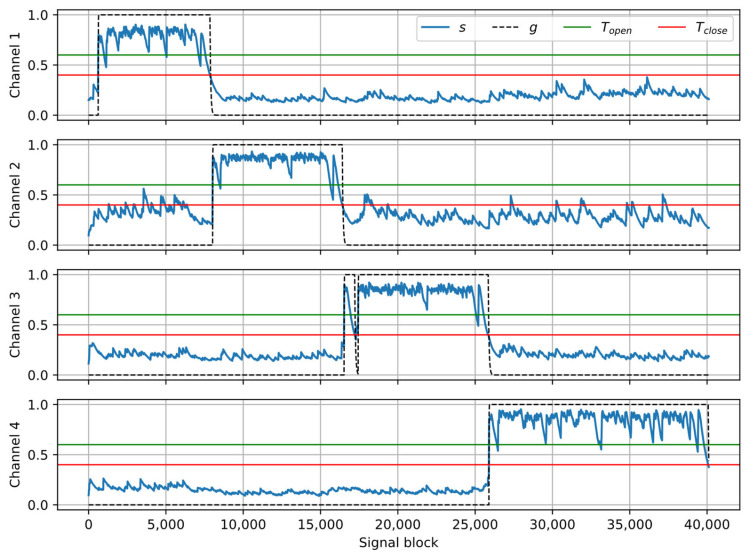 Figure 5
Figure 5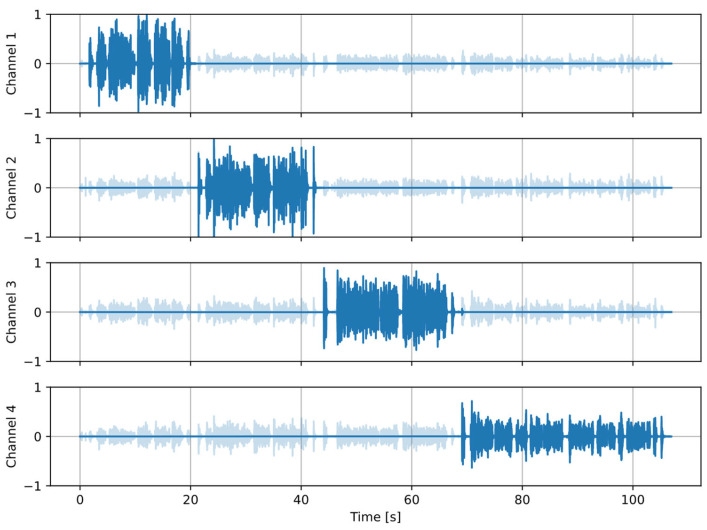 Figure 6
Figure 6 Figure 7
Figure 7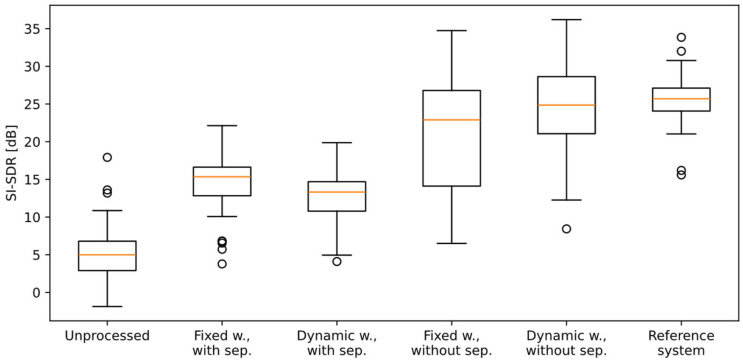 Figure 8
Figure 8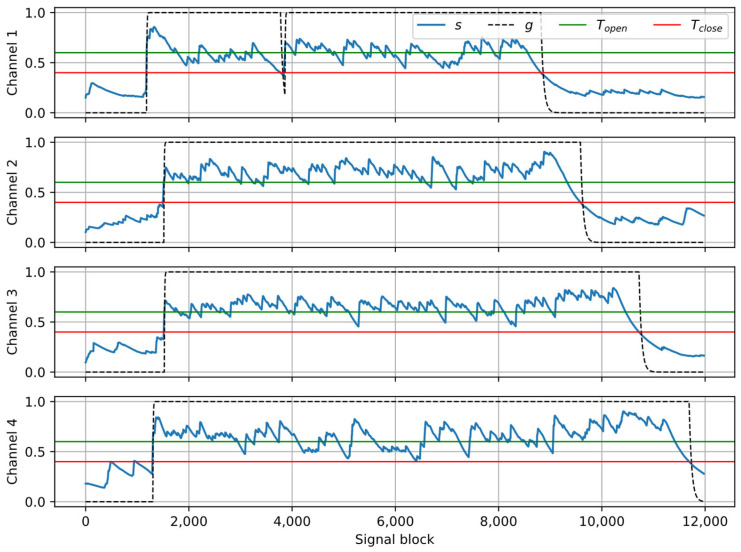 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSpeech and Audio Processing · Speech Recognition and Synthesis · Music and Audio Processing